1. Introduction
Over the years, the production of data and the computing power of analytical tools have exponentially increased; this has enabled companies, on the one hand, to pursue better operational excellence and time-to-market orientation through more granular and real-time insights and, on the other hand, given birth to new business models that focus on leveraging the knowledge derived from this information.
One of the most promising fields of study that aims to extrapolate insights from data is Machine Learning (ML), which is a subfield of artificial intelligence (AI). ML methods involve the use of a set of algorithms and statistical methods to perform a specific task without explicit human development [
1]. These algorithms have been demonstrated to be very useful, especially in complex tasks that involve the analysis of large datasets, where usually the relation between variables is not clear to humans at first glance [
1]. Moreover, once the algorithm has learned how to handle data and perform assigned tasks, it can operate without human intervention, which realizes automation in business processes.
The aforementioned benefits make ML a very attractive technology from a business perspective because it contributes to achieving better outcomes and reducing the human effort needed to perform tasks [
2], which leads to reduced costs and better decision-making.
In this regard, accounting is a possible field in which ML can support the activities of business workers. The large production of documents and files in the industry, together with strict regulations and business rules to follow, makes accounting tasks a good option for applying these methodologies. However, the body of knowledge on the use of ML in accounting is still underdeveloped compared to other industries [
3].
An interesting accounting problem in which ML can be used is the classification of accounting entries related to bank transactions. In fact, banks’ transactions usually contain statements that can be exploited using suitable techniques, such as natural language processing (NLP), to train algorithms that can correctly match accounting records with bank transactions. Creating an algorithm that is able to do so would enable the automation of such processes, thereby allowing workers to save time and effort to get the job done.
In our study, we create a predictive model that can match bank transactions with appropriate accounting records. To realize this, NLP techniques and supervised learning methods are used to allow the model to learn how to recognize accounting records based on the words used in transaction statements. During the research process, the following research questions (RQ) will be answered:
RQ 1: What are the available NLP methods and ML algorithms in similar use cases?
RQ 2: What NLP methods and ML algorithms are suitable for creating the artifact?
RQ 3: How can NLP and ML algorithms be applied to a given dataset?
RQ 4: Do the created models achieve better accuracy than the previous models?
RQ 5: Is the model performance sufficient for deployment in practice?
In contrast to previous research, our study provides the following contributions:
The development of machine learning models tailored to the individual accounting practices of a company.
The prediction of individual ledgers instead of ledger groups.
An analysis of data-related reasons for the limited accuracy achieved.
The subsequent paper is structured as follows: In
Section 2, a review of related literature is provided. The research methodology is discussed in
Section 3.
Section 4 presents the results of the data analysis. The developed models are presented in
Section 5, whereas
Section 6 discusses the obtained results. Evaluation aspects of the models are treated in
Section 8. The article ends with the conclusions in
Section 8.
2. Literature Review: AI in Accounting and Common NLP Applications
AI is a disruptive technology in the accounting sector because it can increase process efficiency and improve the quality of information usage [
4]. It is expected to replace human workers operating in the field over the next few years, with an elimination rate of up to 96% [
5]. The need to use AI in this sector arises from the growing amount of data that must be handled within corporations. Nowadays, managing human resources is difficult and costly. In these situations, the support of electronic devices and suitable algorithms is essential to leverage knowledge and not risk losing valuable information [
6]. In fact, from a business perspective, the use of ML in accounting software can prevent personnel from making mistakes and help them to finish on schedule, thus enabling companies to provide timely and reliable information. In this regard, the so-called Big Four Accounting Firms (Deloitte, EY, PwC and KPMG) have already deployed robots capable of automatically generating financial reports [
7].
Currently, various studies on the usage of ML that involve both regression and classification tasks have been conducted in the field. For regression tasks, ML algorithms have been found to be useful to limit errors in cost estimation processes. Limiting errors is of the utmost importance to ensure the maximal reliability of reports built on top of these data [
8]. However, various classification tasks have also achieved interesting goals in the accounting field.
A very popular classification task in ML is fraud detection, which has been largely used in the financial industry. Moreover, with a focus on accounting, various studies have been conducted to detect accounting fraud in publicly traded firms. In the studies conducted first by Cecchini et al. [
9] and at a later stage by Bao et al. [
10], raw financial data were used as predictors for creating suitable models. These data were extrapolated from reports of publicly traded firms to predict fraud and allowed both studies to create algorithms that could outperform random classifiers. A similar application in accounting aiming to predict fraudulent financial reporting was provided by Salama and Omar [
11], who used an ANN for this purpose. Closely related use cases in accounting are the usage of AI for predicting bankruptcies, as analyzed by Ordia and Bhanawat [
12], or the usage of bank statement data for credit scoring [
13].
However, further studies in this field were proposed by Bertomeu et al. [
3], who suggested that the integration of different types of data, such as audit and market data, would increase the pattern recognition performance of accounting misstatements. In fact, thanks to the advent of the internet, the amount of data available for analysis that can be integrated to optimize predictions has grown considerably. Texts are a type of data that can be used to improve performance [
14], even though they are typically unstructured, which means that further preparation, usually by means of NLP methods, is required prior to analysis [
15].
Another popular classification task based on NLP is the analysis of e-mails due to the increasing importance of this communication method in business and private activities. In a recent study, Hamisu and Mansour [
16] created a decision tree that correctly classified all fraud events (accuracy of 100%) that occurred over the internet by analyzing a dataset containing ca. 4500 fraudulent e-mails.
Another study on e-mail detection was conducted by Egozi and Verma [
17], who extracted 26 features from e-mail texts by applying NLP to detect phishing. These features were then used to train a linear kernel Support Vector Machine (SVM) that could identify 80% of phishing emails. AbdulNabi and Yaseen [
18] were able to achieve a high accuracy (98.67%) on a similar task by utilizing Artificial Neural Networks (ANNs) based on the BERT transformer, which is a pretrained large language model that is used to consider the semantic context when executing word embeddings. This algorithm was able to outperform a bidirectional long short-term neural network that was used as a baseline model for this study.
As with e-mail detection, the accounting sector can also benefit from the combination of NLP and ML techniques to create value from small text data, enabling the improvement and automation of existing processes. A study in this direction was conducted by Ojala [
19], who analyzed short data from bank statements regarding their assignment. However, this work does not use specific information from text comments for assigning ledgers or other accounting-specific information. Another study that focusses on exactly these textual data for classification was conducted by Wong [
20] and Wong and Hanne [
21], who combined NLP and ML algorithms to classify booking items based on the statements of banks’ transactional data. The final goal of that study was the creation of a predictive model with very high accuracy to provide automatic suggestions on how to classify banking transactions. More specifically, both decision trees and ANN algorithms were trained and tested over a sample of more than 180,000 observations. The models had to predict labels belonging to three different class variables: account, contra account, and VAT code; these relate to the main account where the financial transactions are recorded, the contra account to ensure balance in bookkeeping, and the code related to the Value-Added Tax (VAT) category of that transaction. All codes conform to Swiss accounting principles.
However, in this study, accounting records were not predicted at a level of granularity that allowed automation because the account and contra account codes were rounded down to the nearest thousands (i.e., the main account groups), while booking ledgers need precise accounting labels to be considered compliant with Swiss law. From an algorithm development perspective, using rounded accounting records leads to a reduced set of categories for making predictions. For instance, in the account variable, after the rounding operation, there were only six potential outputs: 3000, 4000, 5000, 6000, 7000, and 8000.
The first digit of the of the 4-digit code corresponds to a macro category in accounting, which can be further divided into more specific categories. For example, the 3000 category covers transactions related to gross revenues (revenues from sales and services), 4000 deals with material, goods, and third-party services expenses, 5000 covers employee expenses, and 6000 includes other operational costs, such as depreciation, value adjustments, and financial outcomes. Additionally, 7000 represents revenues and expenses from non-operational activities, whereas 8000 indicates results of an exceptional, extraordinary, or unique nature or those related to different accounting periods. However, when considering the most detailed granularity level, the number of potential codes expands into the hundreds.
Among the rounded labels used, the 6000 group was the most popular. The combined popularity of the 3000, 4000, and 6000 groups accounted for over 90% of the account observations in the dataset. Out of the total 128,987 data items, 121,563 belonged to these three groups. Regarding the contra account, five groups were identified. The 1000 group emerged as the most popular, with a total of 101,519 inputs out of the 128,987 datasets. This represented approximately 78% of the contra account examples.
In the analysis, two ML methods were employed to develop the algorithm: ANN and Decision Trees. The dataset was divided into training and testing sets using different holdout splits. Various parameters were explored during the training and testing phases. For ANNs, the majority of trials focused on Feedforward Neural Network (FNN) architectures, with only one attempt using a Convolutional Neural Network (CNN).
Three weight initialization methods were tested: random uniform, He uniform, and Xavier. While the first method chooses initial weights randomly from a given interval, the latter two methods consider a normal distribution for the initial weights with expected values of zero and a variance inversely proportional to the number of input values (and output values in the case of Xavier) [
22]. In addition, two optimizers for determining the weights, Adam and RMSprop, were compared. Both methods apply a gradient-based approach for optimization and Adam extends RMSprop by considering the momentum from the previous search, which may increase the convergence speed [
23]. The results of Wong and Hanne [
21] demonstrate that Adam performed the best as an optimizer in the considered use case, whereas the selection of the weight initialization method did not have a significant impact on performance. Regarding the activation functions, the rectified linear unit activation function was used for the hidden layers, and the activation function used in the output layer was always SoftMax with a number of neurons equal to the number of classes to predict.
In addition to the ANN, Decision Trees were employed in the algorithm development process. Two different depths were experimented with 20 and 30 splits. The evaluation of these variations revealed that the Decision Tree with the highest depth achieved the best performance among the tested parameters. Overall, at the end of the research, 39 experiments were performed, in which highly variable results were found among the different types of labels. The best results were obtained on the contra account labels, where both neural networks and decision trees performed very well, achieving accuracies of 93.21% and 93.89%, respectively. On the other hand, the results on the account labels were not as good as the previous ones, achieving the best score of 75.11% with the FNN, while Decision Trees performed much worse, obtaining an accuracy of only 16.76%. The results for VAT codes with the FNN model were similar to the account labels, achieving a maximum accuracy of 76.68%, while an accuracy of 67.61% was achieved with the Decision Trees model. All in all, the studies [
20,
21] demonstrated that FNN models were the best models for the given task, and that very high accuracy on rounded accounting records was possible only on contra account labels, although fair performance was also obtained for the other two prediction tasks.
A similar study on predicting ledger groups based on a larger amount of proprietary bank statement data from different companies was conducted by Goldman [
24]. The study analyzed more traditional machine learning approaches such as logistic regression, random forest, and support vector machines, and a more complex pre-trained large language model (BERT and 2 variants of it). The accuracy values obtained were between 0.78 and 0.82, with random forest providing the best results. In a study by Wang et al. [
25], a large dataset from various companies in different industries was used for predicting rough ledger groups (16 groups). The suggested approach uses BERT as a large language model with different combinations of a text input approach and learning task. The accuracies achieved were in the range 0.8 to 0.9 for a not too large number of training samples (100), while more intensive training provided further improvements.
While bank statement data are rarely used for further analysis, such as ledger assignment, invoice data have been considered more frequently. For instance, Bardelli et al. [
26] used semi-structured data from invoice-related xml files to predict general ledger entries and VAT codes. The authors used different machine learning algorithms, e.g., random forests, AdaBoost and multilayer perceptrons, together with preprocessing techniques. For ledger codes, random forest provided the best results whereas VAT codes were best classified by Adaboost. A similar focus on processing invoice data can be found in various other studies (e.g., [
27,
28,
29,
30]); this is instead of bank statements, as assumed in our use case. The difference is relevant from a methodological point of view, as invoice documents are affected by other characteristics and problems compared to short bank statement comments. For instance, invoice documents may need to address issues from OCR (Optical Character Recognition), which may lead to defective but comparably extensive data. In comparison, bank transfer comments are usually quite short and affected by other types of errors (e.g., from the frequent manual recording).
In summary, the existing literature suggests that AI is expected to impact the accounting sector in the coming years. Although various studies have demonstrated that the use of ML can produce good results in this field, there are still some areas in which their contribution has not yet been proven. An accounting process in which NLP and ML algorithms have been applied without achieving sufficient performance is the classification of accounting records based on bank transaction statements [
20,
21]. To investigate this further, a new study should be performed on non-rounded accounting records to explore the possibility of achieving high accuracy in all target classes, i.e., account, contra account, and VAT codes; this is a significant requirement for practical application. In addition, we focus on developing ML models specific to a single company, which has not been considered in previous studies such as that by Wong and Hanne [
21]. Therefore, our goal is to train new algorithms on new company-specific data to test whether ML can obtain sufficient performance in this process for practical deployment.
3. Methodology
3.1. Research Strategy
Our study follows the Design Science Research strategy proposed by Vaishnavi and Kuechler [
31], which consists of several phases contributing to solution development, such as the awareness, suggestion, implementation, and evaluation phases. The awareness phase corresponds to
Section 2, which summarizes the state-of-the-art regarding ML and NLP solutions deployed in the accounting field. The suggestion phase is considered in
Section 4, where insights from the literature review and preliminary data analysis are used to set the machine learning pipeline for the creation of a predictive model. More specifically, suggestions include aspects of data preparation, NLP operations, and the ML algorithms to be used.
Section 5 covers aspects of the development phase, i.e., the creation of the artifact for processing and analyzing the collected data, while
Section 6 presents some model results and their analysis. Finally,
Section 7 corresponds to the evaluation phase, during which the performance of the artifact is compared against the following:
- (1)
the performance of ML models on similar tasks in the literature.
- (2)
Contofox, a rule-based system that matches bank transactions with statements.
Moreover, an interview with the business owner of the Contofox service will be conducted to understand the business value of the artifact so that it is possible to understand whether the algorithm is sufficiently effective for deployment.
3.2. Datasets
The data used to create the artifact were collected by Sympag AG through a database connected to the Contofox software, one of the services offered by the aforementioned company. Contofox is a rule-based system that supports its customers in creating accounting records. Therefore, data on banks’ transactions and respective accounting records can be extracted from such databases.
The data collected consist of 3 different Excel files, each of which is related to an anonymous company. The number of observations in each file is distributed as follows: one of them has only 1630 instances, while the other two have 19,229 and 17,397. The variables included in each spreadsheet are similar and refer to the elements of which an accounting transaction is usually made up, as shown in
Table 1.
The aim of the artifact resulting from our research is to use the words included in the column “Text” to predict the accounting records involved in each line item, i.e., account, contra account, and, when available, the VAT code, since not all transactions are associated with a VAT code.
4. Data Analysis and Suggestions
The extracted data have issues that would hinder the algorithm from performing well. In general, activities for analyzing such issues and dealing with them (such as for data cleaning, e.g., identifying and eliminating duplicate or invalid data) could be conducted in a systematic way, such as by defining specific rules [
32,
33]. However, as we conduct an analysis of the data for the first time, respective rules are not yet available, and we need to better understand the specific nature of the data at hand. Thus, the data are explored and cleaned on a manual basis, considering the intended use case.
The data exploration revealed duplicate entries with interchanged values for the “contra account” and “account” values and monetary amounts in either the “Soll” or “Haben” column, which is considered incorrect. To address this issue, only entries with amounts in either the “debit” or “credit” columns are considered.
In the dataset, there were transactions labeled “div”, which stands for miscellaneous. This is not a label permitted by Swiss law and is therefore removed. In terms of missing data, there were no missing values for the contra account variable, while the account variable had two, the “Text” variable had seven, and the VAT Code had nearly two-thirds of its observations missing. The high number of missing values in the VAT code variable is normal because VAT is applied only to certain types of transactions.
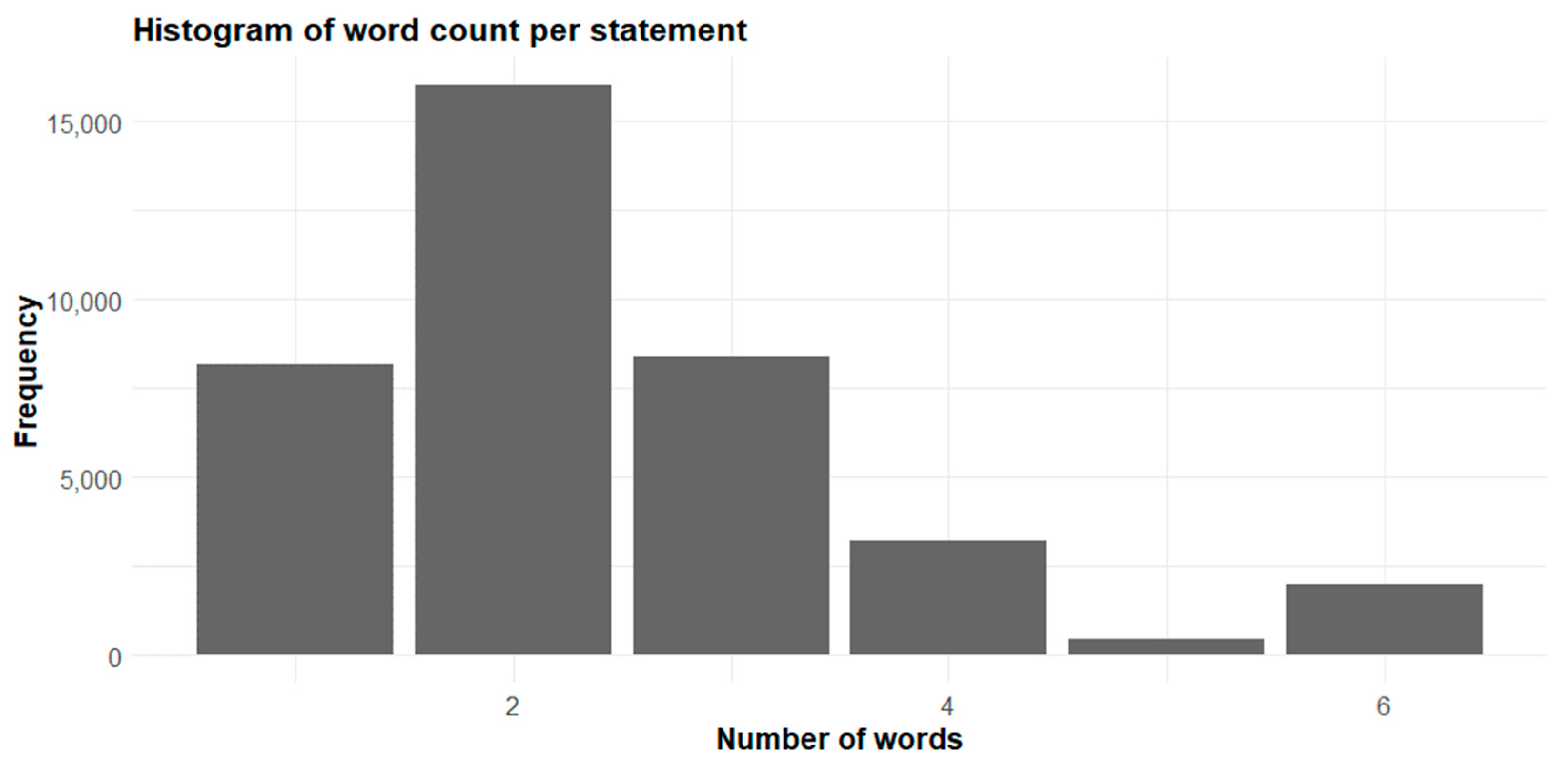
Regarding the “Text” variable, which is also the unique predictor considered in our study, the number of words in the statements ranged from 1 to 6, with a mode of 2, as shown in
Figure 1.
The reason for the low number of words included in the statements comes from the logic of how Contofox works and how a company usually runs its business. More precisely, as the software allows customers to manually set rules to automatically match statements with labels and, from a business-like perspective, companies often have the same suppliers and partners with whom they interact repeatedly, it is often enough for Contofox users to simply set the name of the supplier/partner company as a rule for the identification of accounting records to obtain good results in terms of accuracy. However, a typical set of approximately 200 user-specified rules usually does not allow us to classify all data correctly, especially in the case of “contradictory” entries.
Moreover, a dataset built upon these conditions has, as a consequence, statements that are likely to be generalizable only for companies that share similar partners and suppliers for the same reasons, which can be a reasonable assumption depending on factors such as industry, location, and size. Since the datasets used to create the algorithm belong to companies operating in different industries (or just applying different accounting practices), to obtain high accuracy, it is important to create an algorithm by keeping the Excel files separated by company, i.e., by training and testing an ML algorithm for each company separately. Other issues regarding the “Text” column included abbreviations, inconsistent capitalization, inconsistent whitespace, and typing errors. Therefore, all these factors should be managed during data preparation.
In the context of correcting typing errors, we used the Levenshtein distance, which is a well-established measure of similarity between strings, to correct misspellings [
34]. Following a systematic trial-and-error approach, a decision was made to restrict replacements exclusively to statements with a length exceeding 3 characters. This choice was made because the risk of introducing incorrect corrections for shorter statements is unacceptably high, making the effort to rectify misspellings a less worthwhile endeavor.
To execute the correction process, groups of strings with a Levenshtein distance of 1 are identified, and the strings with fewer associated values are replaced by those with the strongest associations. This strategy was adopted to optimize the consistency of statements within the datasets.
Class imbalances were found in all the 3 class variables. In this study, we decided to handle this by setting a threshold with a minimum frequency of 10 observations, i.e., all the labels with lower frequencies were removed. In addition, due to the small amount of observation available, oversampling is preferred to undersampling [
35].
As we were dealing with a prediction task, black-box models such as FNN and SVM, were considered a suitable algorithm choice due to their focus on accuracy. Based on insights from both the data analysis and problem understanding, the following suggestions were made for the research design:
- (1)
Maintain data divided by company;
- (2)
Handle duplicated rows by removing observations with missing values in the debit column (data preparation);
- (3)
Remove rows with “div” values from the selected label (data preparation);
- (4)
Remove observations with missing values in the text and labels (data preparation);
- (5)
Remove labels with frequencies below a certain threshold (data preparation);
- (6)
Remove capitalization, numbers, punctuation, corporate legal forms and whitespace (data preparation);
- (7)
Correct misspellings for words with more than 3 letters and an edit distance equal to 1 (data preparation);
- (8)
Tokenize the text column (data preparation);
- (9)
Train Feedforward Neural Networks and Support Vector Machines (machine learning algorithms);
- (10)
Evaluate model performance using accuracy as a metric (evaluation).
5. Model Development
During data preparation, all steps described in
Section 4 were performed. This resulted in 8 scenarios, i.e., combinations of company datasets and labels to predict. Each scenario was simulated using both the normal and oversampled datasets. Oversampling was performed to ensure that when dividing the class with the minimum frequency by the majority class, the resulting ratio was no less than 0.8. Moreover, two types of tokenization were used: one with the whole statement and one using single words as predictors. The results for these two approaches were quite similar to the statement-based tokenization, leading to slightly better results. The results, presented in terms of data structures, following this data preparation, are shown in
Table 2:
With regard to the algorithms applied to the scenarios, the FNN and SVM algorithms are supposed to be suitable choices as they frequently provide sufficiently accurate results for prediction tasks for applications in finance and accounting [
21,
36]. Other more complex model choices such as CNN or transformer networks may certainly be interesting but have so far not shown significantly better results in related scenarios [
21]. Regarding the FNN, the choice of depth in terms of the number of layers was decided using a trial-and-error approach, in which it emerged that a deep FNN structure composed of 5 hidden layers allows a slightly better accuracy to be achieved. For the size of the hidden layers, a changing number of neurons was tested while maintaining the aforementioned depth. The strategy behind selecting the number of neurons follows the suggestions stated by Heaton [
37], who identified that it is best practice to have a number of hidden neurons between the size of the input layer and the output layer. Based on these considerations, the following 7 hidden layer sizes are used for all scenarios:
- (1)
Number of labels
- (2)
(Number of labels + Number of inputs) × 0.15
- (3)
(Number of labels + Number of inputs) × 0.30
- (4)
(Number of labels + Number of inputs) × 0.50
- (5)
(Number of labels + Number of inputs) × 0.70
- (6)
(Number of labels + Number of inputs) × 0.85
- (7)
Number of inputs
With the above strategy, it is possible to assume that at least one of the settings is rather close to the optimum architecture. However, one of the main drawbacks of the proposed development method is that it can be time-consuming, and the number of simulations would increase significantly with the number of different parameters used; therefore, the pre-selection of other settings is performed beforehand. More precisely, regarding the activation function in the hidden layers, the Rectified Linear unit (ReLu) should be used, which is a very common choice for classification tasks with deep FNN trained with backpropagation because it allows us to effectively handle the vanishing gradient problem [
38]. ReLu is a nonlinear function that can be mathematically defined as follows: f(x) = max(0,x). Hence, if the value of the neuron is below 0, the activation function returns 0; otherwise, it returns the input value. In the output layer, the SoftMax activation function is instead applied. Softmax is a popular activation function in the output layer for multiclass classification problems. This function allows us to assign probabilities to each class such that the sum of the probabilities of all possible classes for each example is equal to 1. The predicted class is the one with the highest assigned probability. With regard to the optimizer, the search in the loss function space was guided by using two methods: adaptive moment estimation (Adam) and root mean square propagation (RMSprop). Let us note that more refined choices regarding the settings for FNN and SVM (e.g., choice of initial weights, different activation functions, or regarding kernel specification) may lead to improved results, which we leave for potential future research.
Considering the combination of the 4 dataset types with the 7 proposed architectures and the 2 optimizers, each scenario was simulated 56 times using the FNN. Since the number of observations varies widely among the datasets, a batch size of 1 is used for dataset 1, while a batch size of 8 is used for dataset 2 and 3 to accelerate training. With regard to the stop criteria, a predefined number of epochs is used, i.e., 30, because it became apparent after some experiments that the FNN could learn the patterns and fit the data within this timeframe. In addition, for all datasets, a holdout split was used, with 80% of the data used for training and 20% used for testing. Let us note that this proportion is not true for the oversampled dataset because the split is performed before oversampling, and only the training set is oversampled through a simple replication of the variables.
Therefore, the size of the training set compared to the test set will be much higher than 80%. For SVM application, different penalty terms (C) and kernels are used. Three values for C were tested for each scenario: 0.01, 0.5 and 1. For these values, how the models perform is observed, with varying emphases on bias and variance because higher C values tend to focus more on capturing the signal of the training data, which can result in a model with low bias but potentially high variance, while smaller C values tend to focus less on capturing the signal of the training data but prioritize the maximization of the soft margin hyperplane, which usually results in a slightly higher bias but lower variance.
In the analysis, three types of kernels were employed, i.e., linear, polynomial, and sigmoidal kernels [
39]. The linear kernel assumes linearity between the input and output, whereas the polynomial and sigmoidal kernels capture nonlinear relationships using polynomials and sigmoidal functions, respectively. Hence, each scenario was tested 36 times, which is the combination of the four data preparation approaches, the three penalty terms, and the three different kernels. Let us note that further types of kernel functions could be used, possibly with some refinement depending on the specific data (see, e.g., [
40]), which we suggest exploring in future research.
Finally, according to the research objectives, accuracy was used as a performance metric to evaluate the model. To select the best candidate, the maximum accuracy achieved by the algorithm was considered.
6. Model Results and Analysis
Table 3 presents the best results obtained by the two chosen algorithms during the simulation sessions. As can be seen, FNNs performed better in all scenarios compared to SVMs. Moreover, it is possible to note that both algorithms were able to predict contra account labels and VAT codes with much higher accuracy compared to the account labels in both datasets 2 and 3.
A possible explanation of such results derives from the way accounting records are registered, because when VAT is applied to a certain transaction, the transaction is usually split into two data objects (two rows) with the same statement text and two different account labels, one referring to the VAT to pay and the other to the net amount of the transaction.
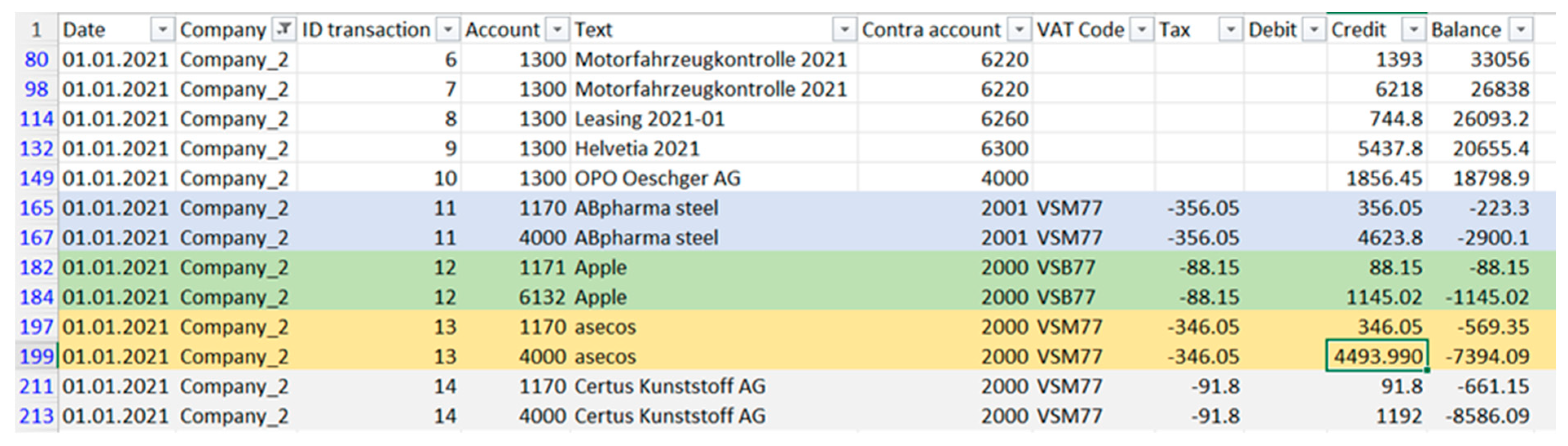
In
Figure 2, pairs of line items that refer to the same transaction are highlighted in different colors because they have the same ID transaction and Date values. To this end, it is possible to see that the account labels are different within the selected pairs of transactions even when the same statement is used. This situation inevitably increases the unavoidable bias for such labels because the algorithm tends to classify labels with the same accounting number. In contrast, it can be seen that the contra account is not affected by this problem because the labels are the same.
However, this problem can be overcome easily by specifying in the statements whether it refers to the net amount or the VAT amount to pay. Despite this, by using the existing data, it would be possible to increase the overall accuracy by, for instance, using other features, such as the values in the VAT and credit columns, as predictors to enable the ML model to differentiate between pairs of transactions.
Regarding the prediction logic, it is possible to better understand it by analyzing the predicted labels with statements as tokens. To do so, a data frame was created in R, in which the probability assigned to different labels and the final classification are shown.
Table 4 shows the prediction with statement tokens on the contra account labels of dataset 1 and ordered by incorrect predictions. The statements are shown in the first column, while from columns 2 to 5, it is possible to see the probability, for each label assigned by the FNN, that such a statement is associated with such a label, while columns 6, 7, and 8 represent the true label, the predicted label, and whether they match. Comparing these results with the observations in the training set reveals how the model behaves with such data. For example, in the line corresponding to the “ut” statement, it is possible to see that a probability of 1 is assigned to the wrong label, namely 3400 instead of 1100; this occurred because the training set had only 1 observation with this statement that was associated with 1100. More borderline was the incorrect prediction with the statement “mobiliar”, where both labels 1020 and 3400 had almost the same probability of 0.507 and 0.481. In this case, the training set was composed of two observations with such a statement, one associated with label 3400 and one associated with label 1020. The reason why the model decided to use two different probabilities, although very similar, is not clear. However, in such datasets, it is possible to notice a prediction in which the model had one statement associated with several labels on the training dataset, like the “dufour treuhand” text, where 11 observations in the training set were split as follows: seven related to the 3400 code, two with label 1020, and one related to the other two labels. In this case, it is possible to notice that the probability of predicting 3400 is much higher than that of the other labels. Thus, it is possible to observe that for each statement in the test set, the model predicts the class with the highest frequency associated with the text predictors found in the training set.
Delving into the results obtained from different data preparation procedures, it is possible to notice that both words and token statements performed very similarly with both algorithms. However, these results indicate that the entire statements were composed of words with poor semantics when considered alone. For example, from
Figure 2, it is possible to notice that most statements simply comprise the name of the company providing a service or buying one. In these cases, using words instead of statements does not provide any advantage because words considered as a single unit provide no additional meaning that can be generalized to other types of transactions.
Regarding the results obtained with SVM, in all cases, the best results were obtained with the highest penalty term because in no case did a lower C value outperform the largest values. Achieving the best results with the highest penalty term values means that the patterns are highly generalizable; thus, it is more convenient to focus more on minimizing misclassification rather than the variance. A possible explanation for this is that very limited implicit patterns can be learned during training, thus providing insufficient leeway for generalization. In fact, by using only statements as predictors, the only pattern that the algorithm can learn is whether the statements of a transaction in the training and test sets are identical, giving the same label to them. The same conditions can also be applied to word tokens in this specific study because, as mentioned previously, words in statements have poor semantics. Hence, under these circumstances, word tokens do not allow the algorithm to learn better patterns than statement tokens. However, these results should be tested with other types of statements with words that have more semantic expressiveness, to see whether these results hold true.
7. Artifact Evaluation
In this section, an evaluation of the artifact is carried out using the strategy described in
Section 3.1.
7.1. Comparison with Previous Studies
As mentioned above, there are only a few publications on the prediction of accounting records. However, similar research was reported by Wong [
20] and Wong and Hanne [
21], in which the same predictors, i.e., banking statements, were used to classify rounded labels. Therefore, a thorough comparison of the results is provided.
Data preparation was similar between our approach and the mentioned studies because statements were first handled with different pre-processing steps, such as removing missing values and miscellaneous labels, eliminating low-frequency label groups (rounded accounting records), and so on. However, there are two main differences. In the current research dataset, different companies were kept separate to create the artifact, and an additional step based on the Levenstein distance was used to handle misspellings, which resulted in the correction of several statements.
Comparing the results of the studies, it is possible to notice that there are some similarities. For instance, there were high variances between the accuracy obtained for the account and contra account labels because, in both previous studies and this one, the predictive model was much better at predicting the contra account data. Comparing the results, the previous studies achieved a maximum score of 75.11% and 92.71%, respectively, on account and contra account; meanwhile, in this study, the accuracy achieved for the contra account labels was slightly lower in all three datasets, while the performance on the other labels was higher for dataset 1 and lower for the other two scenarios. By examining the challenges that impede the effective performance of the account label in
Section 6, it can be assumed that similar circumstances were likely present in the previous study as well. This assumption arises because rounded accounting records encounter the same underlying issues.
Regarding the different results obtained in the two studies, predicting rounded accounting records and predicting detailed numbers are different tasks; therefore, a direct comparison cannot be performed.
In contrast, the classification of VAT codes was conducted on labels with the same granularity, although different strategies for handling the labels were used, enabling a more accurate comparison. In the previous study, the highest accuracy achieved was 76.68%. In this study, a slightly lower accuracy was obtained on dataset 3 (76.51%), but a significantly higher accuracy was obtained on dataset 2 (98.38%). Considering that similar algorithms, specifically FNN, yielded the best performance in both studies, it is reasonable to attribute the difference in results to a different bias in the dataset and in the different preprocessing of the labels. In fact, while different labels were merged in the previous study, i.e., some codes were mutated into a different one that represented a more superficial class, in this study, VAT codes with low frequency were removed.
7.2. Comparison with the Baseline Model
To assess the results, we compared the accuracy of the model with that of the Contofox software. In this regard, statistics concerning the accuracy of the rule generator system are available only for complete-case predictions, i.e., when all the details of the transactions are imported correctly from the bank to the accounting system.
To this end, the results of the software were, on average, 89.5% on the datasets given. However, the results obtained in the artifact development phase do not allow a fair comparison with the baseline because the Contofox scores consider the prediction of all labels simultaneously. Therefore, a new algorithm that encodes the account, contra account, and VAT codes in a single string is created to be able to perform the comparison.
Overall, the results for the encoded labels were quite similar to the predictions for the single accounting records (see
Table 5). In fact, the FNNs outperformed the SVM in all presented scenarios. In addition, the results obtained on datasets 2 and 3 were inferior to those obtained on dataset 1. The main reason for these differences is again as discussed above; this is the problem of splitting a transaction into one with the net amount and one with the VAT amount, as shown in
Figure 2. Comparing the results with the baseline model, none of the datasets surpassed the performance of Contofox software (89.5%). However, when the problem of transactions with splitting statements for the net amount and VAT amount is not present, the results are very close to the baseline model performance, as indicated for dataset 1. Moreover, there are several ways in which it is possible to handle this problem and improve the overall performance of the ML algorithm for the prediction of accounting records. This includes the following:
- (1)
Data enrichment: the data used to train the model provide a small amount of information. Thus, having statements comprising more information, such as the object of the transaction (renting car, purchasing materials, selling products), can increase the overall performance on the datasets.
- (2)
Include different predictors: including other predictors besides statements, such as the transaction amount and tax amount, can also enable the ML algorithm to differentiate between transaction pairs and provide relevant information regarding label classification.
7.3. Business Value of the Artifact
Sympag AG currently uses a rule generator included in the Contofox software to predict accounting records. Such software allows us to predict records very accurately but, on the other hand, takes time for customers to produce all the rules required to classify the accounting records. However, customers of Contofox already can save ca. 50% of their time compared to traditional manual processes. An alternative approach that could be used to handle the same task is using ML algorithms, where a model is trained on the historical data of the customer and deployed to predict new labels. Such characteristics make this methodology potentially better from a customer’s perspective because it allows a higher degree of automation in the accounting process. The potential benefits of the proposed artifact are then investigated during an interview with Mr. Laeuchli, an owner of Sympag AG. In the interview, the ease of communicating the value of the product for marketing purposes was identified as the main benefit of implementing a ML-based system. In this regard, an automated accounting system would be, in his opinion, very appreciated by the market because people trust AI and products based on such technology. Regarding its implementation, Mr. Laeuchli expressed doubts about the possibility of using a fully automated approach based on ML due to the achieved accuracy. In fact, even obtaining a 90% rate of correct label prediction is not considered sufficient for him since 10% misclassification would be too high for accountants who are concerned about the reliability of bookkeeping. Despite that, Mr. Laeuchli thinks that the created artifact could be of great value when inserted into a hybrid solution, in which ML is used to make proposals about accounting record classification, and the accountant can easily check if the proposal is correct and handle misclassified transactions. In this way, customers can save time and insert only correct labels into the accounting system. Reducing errors at the preliminary stage is very important because correcting errors at the beginning of the accounting process can save time and additional costs.
By looking at future possibilities, a fully automated approach can be considered feasible when the algorithm achieves an accuracy very close to 100%. A solution based on such performance, according to Mr. Laeuchli, could be very interesting for the market and be perceived as having huge value, especially for SMEs, which usually cannot afford internal investments to create automated accounting systems. In addition, during the interview, the possibility of applying ML methodologies to other data sources, such as E-bills or QR codes, was also thought to enable more comprehensive and effective accounting systems. In addition, in this case, an ML approach based on NLP can be used. However, according to Mr. Laeuchli, even if it is possible to extend the prediction of accounting records by also using other data sources, integrating data would be very challenging because of possible consistency and redundancy problems, since most of bills are currently on paper.
Overall, applying ML in accounting processes can generate business value because it reduces costs and improves customers’ experience. The market seems ready to embrace the benefits of this new technology. Due to the nature of accounting tasks, which require high precision, a fully automated process is perceived as valuable only when high accuracy is achieved. However, an intermediate step in which ML is used to support accounting operations and limit human intervention can be used and would provide benefits to accounting operators. The created artifact could be employed in such a use case, in which accounting records are proposed by ML and checked by accountants.
8. Conclusions
Accounting is an essential task that companies are compelled to carry out by law. At the foundation of such a discipline is the data entry related to accounting records, which is usually performed manually, especially in SMEs. The automation of such tasks can bring significant benefits to companies, enabling them to save both time and costs.
This research would facilitate this by analyzing the predictive power of statements in accounting records at a granular level, i.e., the exact code that should be recorded in bookkeeping, as the basis for automating data entry processes in the field.
Three different datasets and four types of data preparation were used to perform a total of 448 simulations with FNN and 288 with SVM on account, contra account, and VAT codes. The results obtained exhibited good accuracy for the contra account and VAT codes, whereas account labels achieved inferior results on both datasets 2 and 3. More precisely, the best results were obtained for the VAT codes of dataset 2, with an accuracy of 98.39% for the test set. The prediction of the same label on dataset 3 was less accurate, achieving a maximum accuracy of 76.51%, while dataset 1 did not include such a label. For contra account labels, more similar results among the datasets were obtained, with the best accuracy being 89.54% in dataset 1, 86.89% in dataset 2, and 81.19% in dataset 3. Regarding the account label, the results obtained on dataset 1 remained high at 87.07%, whereas the performance dropped for the other two datasets, achieving an overall result of 52.92% and 55.62% on datasets 2 and 3, respectively. The reason for the low accuracy is the way the transactions were recorded in the dataset, where the VAT amount is divided by the net amount in two rows with the same statement but different account labels; this prevents the algorithm from differentiating them. However, there are several ways to handle this problem, such as using new predictors like the transaction amount and the VAT amount, or using more precise statements in which it is specified whether one line item refers to the VAT or the net amount.
Regarding the different performance results obtained by the algorithms, the best results were always obtained by the FNNs, which outperformed the SVMs in all simulated scenarios even though the difference was often small. However, analyzing the results of SVMs allowed us to better understand the nature of the data, which provided some evidence that they are highly generalizable. Therefore, it is more useful to try to handle misclassification by setting high penalty term values because they have always achieved better performances than lower ones. Further insights were obtained by analyzing how the FNN classified labels with statements as tokens. In fact, it was demonstrated that in the selected examples, the FNN always matched the statement with the most frequent label assigned to it.
During the evaluation, the ML algorithms were compared to a baseline model provided by Contofox. For the comparison, we considered the results obtained from the rule generator system and provided by the company for the research project. However, since the results were related to the prediction of a complete row, the three aforementioned labels were encoded in a way that facilitated a fair comparison. In this regard, the results obtained using all encoded labels were inferior to the baseline, which had an average score of ca. 89.50%. However, for dataset 1, for which the account label did not show problems regarding transactions split into VAT and net transaction amount, the results were quite close, i.e., 87.02%. In addition, with the simultaneous prediction of all labels, the FNNs outperformed the SVMs.
Thereafter, the business value of the solution was assessed through an interview with the owner of Sympag AG, Mr. Laeuchli, in which it was pointed out that, from a business perspective, ML is a prominent technology that can be easily accepted by the market. Therefore, creating products based on such a methodology could make the product easier to communicate. From a technical perspective, the results obtained do not seem suitable for a fully automated approach; however, it seems possible to benefit from such an algorithm by implementing it in a hybrid form, in which the algorithm classifies transactions by making proposals to the human accounting operator, who will still be in charge of checking the results.
Finally, after this research, there is still room to improve the obtained results by testing whether using other predictors, in addition to the statements, could enhance the overall accuracy, especially on the account labels. Moreover, the provided data had very short statements in which the words usually did not have a semantic value that could be used by the algorithm for prediction when splitting it into words tokens. Thus, the creation of algorithms for more precise statements could also be tested to determine whether the accuracy can be increased.





{kind=link}
{kind=link}