
Interpretable Deep Learning for Diabetic Retinopathy: A Comparative Study of CNN, ViT, and Hybrid Architectures



Abstract
1. Introduction
- How do CNN, ViT, and hybrid models compare in their ability to classify the severity levels of diabetic retinopathy across multiple classes as defined by the ICDR scale?
- What do visualization techniques reveal about the decision-making processes of CNN, ViT, and hybrid models, and how can these insights help explain differences in their predictions and behavior?
2. Related Work
3. Dataset and Preprocessing
3.1. Training Corpus
3.2. Data Preprocessing
3.3. Data Augmentation
- Random scaling by ±10%: This slight variation in image size simulates differences in real-world image capture conditions.
- Random rotation between 0° and 360°: Rotating images by a random angle ensures that the model remains robust to variations in fundus orientation.
- Random distortion by ±20%: This simulates perspective distortions that may occur during image acquisition by shifting the image corners randomly along the x- or y-axis by up to ±20% of the image width or height.
4. Models and Training
4.1. Model Selection
4.2. Implementation and Training Setup
- Training Set: 70% of the data (20% per class)
- Validation Set: 15% of the data (20% per class)
- Test Set: 15% of the data (20% per class)
4.3. Evaluation Metrics
- Observed Frequencies (): Values extracted directly from the confusion matrix.
- Expected Frequencies (): Computed based on marginal distributions, representing expected values under random classification.
- Weight Matrix (): Defines the penalty for misclassification, increasing quadratically as the difference between the actual and predicted class increases.
4.4. Explainability Methods
- ResNet-50 and EfficientNet-B0: Well suited for Grad-CAM, as these models rely on convolutional layers that produce spatial feature maps.
- ViT-Small and DINO-v2: Compatible with Attention-Rollout, as they use multi-head self-attention (MHSA) layers of uniform structure, making attention visualization feasible.
- CvT-13: Since CvT-13 incorporates convolutional layers close to the output, Grad-CAM is applicable.
- SwinV2-Tiny: Although it includes a convolutional patch embedding layer, its hierarchical multi-head self-attention (MHSA) layers vary in structure, making Attention-Rollout unsuitable. Additionally, its convolutional layers are located far from the output, reducing the effectiveness of Grad-CAM.
- LeViT-256: While it incorporates elements of both CNNs and Transformers, it lacks uniform MHSA layers for Attention-Rollout and does not have convolutional layers positioned effectively for Grad-CAM.
5. Results
5.1. Overall Test Performance
5.2. Classwise Performance
5.3. Visual Analysis
6. Discussion
6.1. Main Findings
6.2. Comparison with Related Work
- First, class imbalance in the datasets used by other researchers may have affected performance. In particular, the APTOS-2019 dataset exhibits a highly imbalanced class distribution, which could lead to overfitting. Although other studies attempted to address this issue through data augmentation, the effectiveness of these strategies remains questionable. For instance, after augmentation in the study by Wu et al. [11], class distribution remained skewed: class 0 (no DR) 24.56%, class 1 (mild DR) 23.20%, class 2 (moderate DR) 25.18%, class 3 (severe DR) 14.94%, and class 4 (proliferative DR) 12.12%. The proportions for classes 3 and 4 remained significantly lower. In this research, the models generally performed worse on classes 3 and 4, indicating a need for more data in these categories.
- Second, the overall dataset size may have been too small to adequately train the more complex ViT models.
- Third, fine-tuning on a small training set with limited epochs may not have been sufficient to adapt the model effectively. Pretrained models learn general features from large, diverse datasets. However, fine-tuning on smaller, domain-specific datasets might not successfully align those general features with the task-specific patterns. This could explain the suboptimal adaptation observed in this study.
- Fourth, excessive augmentation techniques, especially random rotations of 0–360° and intensity distortions of ±20%, may have led to excessive complexity and impeded the learning process. Indeed, Kumar et al. [15] tested Transformer, CNN, and MLP models, achieving 86.4% accuracy with the Swin Transformer, notably without employing augmentation techniques to improve the performance. Bala et al.’s CTNet [18] for DR classification using residual connections, CNN, and ViT reported an AUC of 0.987 and a Kappa score of 0.972 on the APTOS-2019 dataset, also without using rotation or zoom-based augmentation.
6.3. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DR | Diabetic Retinopathy |
| NPDR | Non-Proliferative Diabetic Retinopathy |
| APTOS | Asia Pacific Tele-Ophthalmology Society |
| CNN | Convolutional Neural Network |
| ViT | Vision Transformer |
| CvT | Convolutional Vision Transformer |
| ResNet | Residual Network |
| LeViT | Light Vision Transformer |
| QWK | Quadratic Weighted Kappa |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| FLOPs | Floating Point Operations |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
Appendix A
Appendix A.1. Training and Validation Loss


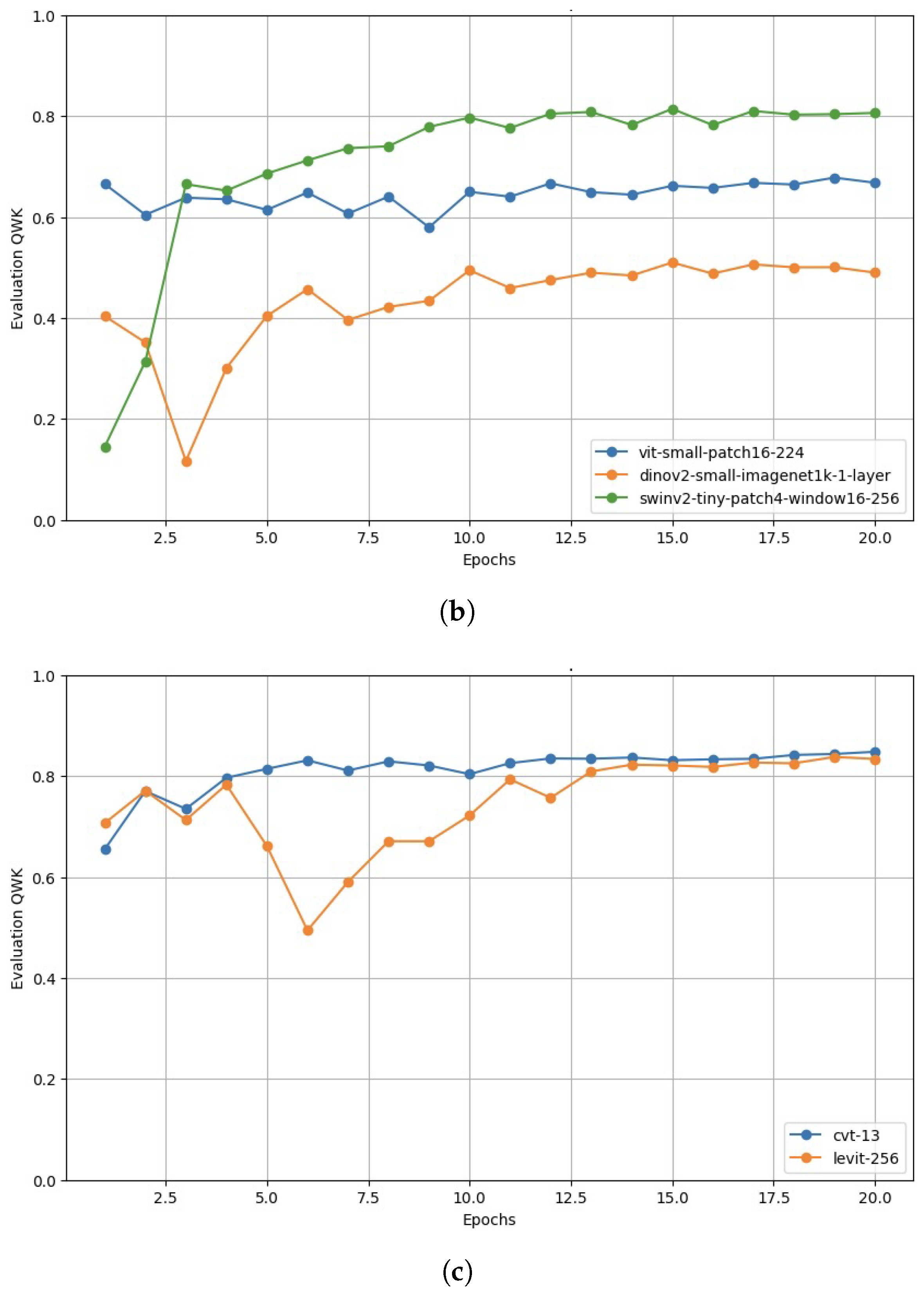
Appendix A.2. Validation Performance

References
- Leasher, J.L.; Bourne, R.R.; Flaxman, S.R.; Jonas, J.B.; Keeffe, J.; Naidoo, K.; Pesudovs, K.; Price, H.; White, R.A.; Wong, T.Y.; et al. Global Estimates on the Number of People Blind or Visually Impaired by Diabetic Retinopathy: A Meta-analysis From 1990 to 2010. Diabetes Care 2016, 39, 1643–1649. [Google Scholar] [CrossRef] [PubMed]
- Thomas, R.L.; Halim, S.; Gurudas, S.; Sivaprasad, S.; Owens, D.R. IDF Diabetes Atlas: A review of studies utilising retinal photography on the global prevalence of diabetes related retinopathy between 2015 and 2018. Diabetes Res. Clin. Pract. 2019, 157, 107840. [Google Scholar] [CrossRef]
- Thomas, R.L.; Luzio, S.D.; North, R.V.; Banerjee, S.; Zekite, A.; Bunce, C.; Owens, D.R. Retrospective analysis of newly recorded certifications of visual impairment due to diabetic retinopathy in Wales during 2007–2015. BMJ Open 2017, 7, e015024. [Google Scholar] [CrossRef] [PubMed]
- Laurik-Feuerstein, K.L.; Sapahia, R.; Cabrera DeBuc, D.; Somfai, G.M. The assessment of fundus image quality labeling reliability among graders with different backgrounds. PLoS ONE 2022, 17, e0271156. [Google Scholar] [CrossRef]
- Wong, T.Y.; Tan, T.E. The Diabetic Retinopathy “Pandemic” and Evolving Global Strategies: The 2023 Friedenwald Lecture. Investig. Opthalmology Vis. Sci. 2023, 64, 47. [Google Scholar] [CrossRef]
- Yagin, F.H.; Yasar, S.; Gormez, Y.; Yagin, B.; Pinar, A.; Alkhateeb, A.; Ardigò, L.P. Explainable Artificial Intelligence Paves the Way in Precision Diagnostics and Biomarker Discovery for the Subclass of Diabetic Retinopathy in Type 2 Diabetics. Metabolites 2023, 13, 1204. [Google Scholar] [CrossRef]
- Tao, Y.; Xiong, M.; Peng, Y.; Yao, L.; Zhu, H.; Zhou, Q.; Ouyang, J. Machine learning-based identification and validation of immune-related biomarkers for early diagnosis and targeted therapy in diabetic retinopathy. Gene 2025, 934, 149015. [Google Scholar] [CrossRef]
- Adak, C.; Karkera, T.; Chattopadhyay, S.; Saqib, M. Detecting Severity of Diabetic Retinopathy from Fundus Images using Ensembled Transformers. arXiv 2023, arXiv:2301.00973. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Wu, J.; Hu, R.; Xiao, Z.; Chen, J.; Liu, J. Vision Transformer-based recognition of diabetic retinopathy grade. Med. Phys. 2021, 48, 7850–7863. [Google Scholar] [CrossRef] [PubMed]
- Chetoui, M.; Akhloufi, M.A. Federated Learning for Diabetic Retinopathy Detection Using Vision Transformers. BioMedInformatics 2023, 3, 948–961. [Google Scholar] [CrossRef]
- Mohan, N.J.; Murugan, R.; Goel, T.; Roy, P. ViT-DR: Vision Transformers in Diabetic Retinopathy Grading Using Fundus Images. In Proceedings of the 2022 IEEE 10th Region 10 Humanitarian Technology Conference (R10-HTC), Hyderabad, India, 16–18 September 2022; pp. 167–172. [Google Scholar] [CrossRef]
- Nazih, W.; Aseeri, A.; Youssef Atallah, O.; El-Sappagh, S. Vision Transformer Model for Predicting the Severity of Diabetic Retinopathy in Fundus Photography-Based Retina Images. IEEE Access 2023, 11, 117546–117561. [Google Scholar] [CrossRef]
- Kumar, N.S.; Ramaswamy Karthikeyan, B. Diabetic Retinopathy Detection using CNN, Transformer and MLP based Architectures. In Proceedings of the 2021 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hualien City, Taiwan, 16–19 November 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Sun, R.; Li, Y.; Zhang, T.; Mao, Z.; Wu, F.; Zhang, Y. Lesion-Aware Transformers for Diabetic Retinopathy Grading. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10933–10942. [Google Scholar] [CrossRef]
- Yang, Y.; Cai, Z.; Qiu, S.; Xu, P. Vision transformer with masked autoencoders for referable diabetic retinopathy classification based on large-size retina image. PLoS ONE 2024, 19, e0299265. [Google Scholar] [CrossRef]
- Bala, R.; Sharma, A.; Goel, N. CTNet: Convolutional Transformer Network for Diabetic Retinopathy Classification. Neural Comput. Appl. 2024, 36, 4787–4809. [Google Scholar] [CrossRef]
- Wang, Z.; Lu, H.; Yan, H.; Kan, H.; Jin, L. Vison Transformer Adapter-Based Hyperbolic Embeddings for Multi-Lesion Segmentation in Diabetic Retinopathy. Sci. Rep. 2023, 13, 11178. [Google Scholar] [CrossRef]
- Zang, F.; Ma, H. CRA-Net: Transformer guided category-relation attention network for diabetic retinopathy grading. Comput. Biol. Med. 2024, 170, 107993. [Google Scholar] [CrossRef]
- Playout, C.; Duval, R.; Boucher, M.C.; Cheriet, F. Focused Attention in Transformers for interpretable classification of retinal images. Med. Image Anal. 2022, 82, 102608. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Abnar, S.; Zuidema, W. Quantifying Attention Flow in Transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Band, N.; Rudner, T.G.J.; Feng, Q.; Filos, A.; Nado, Z.; Dusenberry, M.W.; Jerfel, G.; Tran, D.; Gal, Y. Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks. arXiv 2022, arXiv:2211.12717. [Google Scholar]
- Lee, C.H.; Ke, Y.H. Fundus images classification for Diabetic Retinopathy using Deep Learning. In Proceedings of the 13th International Conference on Computer Modeling and Simulation, ICCMS ’21, New York, NY, USA, 25–27 June 2021; pp. 264–270. [Google Scholar] [CrossRef]
- Halder, A.; Gharami, S.; Sadhu, P.; Singh, P.K.; Woźniak, M.; Ijaz, M.F. Implementing vision transformer for classifying 2D biomedical images. Sci. Rep. 2024, 14, 12567. [Google Scholar] [CrossRef]
- Philippi, D.; Rothaus, K.; Castelli, M. A vision transformer architecture for the automated segmentation of retinal lesions in spectral domain optical coherence tomography images. Sci. Rep. 2023, 13, 517. [Google Scholar] [CrossRef]
- He, J.; Wang, J.; Han, Z.; Ma, J.; Wang, C.; Qi, M. An interpretable transformer network for the retinal disease classification using optical coherence tomography. Sci. Rep. 2023, 13, 3637. [Google Scholar] [CrossRef]
- Goh, J.H.L.; Ang, E.; Srinivasan, S.; Lei, X.; Loh, J.; Quek, T.C.; Xue, C.; Xu, X.; Liu, Y.; Cheng, C.Y.; et al. Comparative Analysis of Vision Transformers and Conventional Convolutional Neural Networks in Detecting Referable Diabetic Retinopathy. Ophthalmol. Sci. 2024, 4, 100552. [Google Scholar] [CrossRef]
- Touati, M.; Touati, R.; Nana, L.; Benzarti, F.; Ben Yahia, S. DRCCT: Enhancing Diabetic Retinopathy Classification with a Compact Convolutional Transformer. Big Data Cogn. Comput. 2025, 9, 9. [Google Scholar] [CrossRef]
- Sassi Hidri, M.; Hidri, A.; Alsaif, S.A.; Alahmari, M.; AlShehri, E. Optimal Convolutional Networks for Staging and Detecting of Diabetic Retinopathy. Information 2025, 16, 221. [Google Scholar] [CrossRef]
- Asia, A.O.; Zhu, C.Z.; Althubiti, S.A.; Al-Alimi, D.; Xiao, Y.L.; Ouyang, P.B.; Al-Qaness, M.A.A. Detection of Diabetic Retinopathy in Retinal Fundus Images Using CNN Classification Models. Electronics 2022, 11, 2740. [Google Scholar] [CrossRef]
- Akhtar, S.; Aftab, S.; Ali, O.; Ahmad, M.; Khan, M.A.; Abbas, S.; Ghazal, T.M. A deep learning based model for diabetic retinopathy grading. Sci. Rep. 2025, 15, 3763. [Google Scholar] [CrossRef]
- Xue, J.; Wu, J.; Bian, Y.; Zhang, S.; Du, Q. Classification of Diabetic Retinopathy Based on Efficient Computational Modeling. Appl. Sci. 2024, 14, 11327. [Google Scholar] [CrossRef]
- Dugas, E.; Jared, J.; Cukierski, W. Diabetic Retinopathy Detection. 2015. Available online: https://kaggle.com/competitions/diabetic-retinopathy-detection (accessed on 21 May 2024).
- Maggie, K.; Dane, S. APTOS 2019 Blindness Detection. 2019. Available online: https://kaggle.com/competitions/aptos2019-blindness-detection (accessed on 21 May 2024).
- Cleland, C. Comparing the International Clinical Diabetic Retinopathy (ICDR) severity scale. Community Eye Health 2023, 36, 10. [Google Scholar]
- Graham, B. Diabetic Retinopathy Detection Competition Report. 2015. Available online: https://storage.googleapis.com/kaggle-forum-message-attachments/88655/2795/competitionreport.pdf (accessed on 21 May 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv 2024, arXiv:2304.07193. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11999–12009. [Google Scholar] [CrossRef]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jegou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Los Alamitos, CA, USA, 11–17 October 2021; pp. 12239–12249. [Google Scholar] [CrossRef]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar] [CrossRef]
- Microsoft. ResNet-50. Available online: https://huggingface.co/microsoft/resnet-50 (accessed on 3 June 2024).
- Google. EfficientNet-B0. Available online: https://huggingface.co/google/efficientnet-b0. (accessed on 3 June 2024).
- WinKawaks. vit-small-patch16-224. 2023. Available online: https://huggingface.co/WinKawaks/vit-small-patch16-224 (accessed on 3 June 2024).
- Facebook. DINOv2-Small-ImageNet1K-1-Layer. Available online: https://huggingface.co/facebook/dinov2-small-imagenet1k-1-layer. (accessed on 3 June 2024).
- Microsoft. SwinV2-Tiny-Patch4-Window16-256. Available online: https://huggingface.co/microsoft/swinv2-tiny-patch4-window16-256 (accessed on 3 June 2024).
- Facebook. LeViT-256. Available online: https://huggingface.co/facebook/levit-256 (accessed on 3 June 2024).
- Microsoft. CvT-13. Available online: https://huggingface.co/microsoft/cvt-13 (accessed on 3 June 2024).
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Cohen, J. Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit. Psychol. Bull. 1968, 70, 213–220. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Peng, Y.; Yin, H. Markov Random Field Based Convolutional Neural Networks for Image Classification. In Intelligent Data Engineering and Automated Learning—IDEAL 2017; Yin, H., Gao, Y., Chen, S., Wen, Y., Cai, G., Gu, T., Du, J., Tallón-Ballesteros, A.J., Zhang, M., Eds.; Springer: Cham, Switzerland, 2017; pp. 387–396. [Google Scholar]
- Park, C.; Park, S.Y.; Kim, H.J.; Shin, H.J. Statistical Methods for Comparing Predictive Values in Medical Diagnosis. Korean J. Radiol. 2024, 25, 656. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ICDR Severity Scale | Grade | Symptoms |
|---|---|---|
| No diabetic retinopathy | R0 | Normal retina. |
| Mild non-proliferative diabetic retinopathy (NPDR) | R1 | Microaneurysms (small blood vessel bulges) or hemorrhages (bleeding) with or without hard exudates (inflammatory fluid deposits). |
| Moderate NPDR | R2 | Microaneurysms, retinal dot or blot hemorrhages, hard exudates or cotton wool spots (nerve fiber swelling). |
| Severe NPDR | R3 | Multiple intraretinal hemorrhages, definite venous beading (venous pearl formation), and intraretinal microvascular abnormalities. |
| Proliferative diabetic retinopathy (PDR) | R4 | Neovascularization (new blood vessels), and vitreous or pre-retinal hemorrhage. |
| Model | Type | Architecture | Explainability Method |
|---|---|---|---|
| ResNet [39] Residual Network | CNN | Stacked residual blocks with skip connections | Grad-CAM |
| EfficientNet [40] Efficient Network | Compound scaling + depthwise separable convolutions | Grad-CAM | |
| ViT Standard Vision Transformer | ViT | Patch embeddings + global self-attention | Attention-Rollout |
| DINO-v2 [41] Self-Distillation with no Labels v2 | Self-supervised learning with teacher-student distillation | Attention-Rollout | |
| Swin-v2 [42] Shifted Window Transformer v2 | Shifted window self-attention with hierarchical feature learning | Not applicable | |
| LeViT [43] Lightweight Vision Transformer | Hybrid | Hybrid CNN-Transformer with efficient self-attention | Grad-CAM and Not applicable |
| CvT [44] Convolutional Vision Transformer | CNN-based tokenization with Transformer backbone | Grad-CAM and Attention-Rollout |
| Model | Params (M) | FLOPs (G) | Dataset | Resolution |
|---|---|---|---|---|
| CNN | ||||
| microsoft/resnet-50 [45] | 25.6 | 4.10 | ImageNet-1k | 224 × 224 |
| google/efficientnet-b0 [46] | 5.3 | 0.39 | ImageNet-1k | 224 × 224 |
| ViT | ||||
| winkawaks/vit-small-patch16-224 [47] | 22.1 | 4.60 | ImageNet-1k | 224 × 224 |
| facebook/dinov2-small-imagenet1k-1-layer [48] | 22.0 | 6.10 | ImageNet-1k | 224 × 224 |
| microsoft/swinv2-tiny-patch4-window16-256 [49] | 28.0 | 6.60 | ImageNet-1k | 256 × 256 |
| Hybrid | ||||
| facebook/levit-256 [50] | 19.0 | 1.10 | ImageNet-1k | 224 × 224 |
| microsoft/cvt-13 [51] | 20.0 | 4.50 | ImageNet-1k | 224 × 224 |
| Parameter | Value |
|---|---|
| Training Batch Size | 64 |
| Evaluation Batch Size | 64 |
| Number of Epochs | 20 |
| Best Model Metric | QWK |
| Optimizer | AdamW |
| Learning Rate | |
| Weight Decay |
| Component | Specification |
|---|---|
| GPU | NVIDIA RTX 4090 (24GB) |
| CPU | 12 vCPUs, Intel Xeon Platinum 8352V @ 2.10GHz |
| PyTorch Version | 2.0.0 |
| Python Version | 3.8 |
| CUDA Version | 11.8 |
| Operating System | Ubuntu 20.04 |
| Model | QWK | Accuracy | Recall | Precision | F1 | ROC-AUC |
|---|---|---|---|---|---|---|
| CNN | ||||||
| ResNet-50 | 0.81 | 0.73 | 0.73 | 0.74 | 0.72 | 0.91 |
| EfficientNet-B0 | 0.84 | 0.73 | 0.73 | 0.74 | 0.73 | 0.92 |
| ViT | ||||||
| ViT-Small | 0.62 | 0.54 | 0.54 | 0.54 | 0.53 | 0.80 |
| DINOv2-Small | 0.51 | 0.51 | 0.51 | 0.50 | 0.49 | 0.80 |
| SwinV2-Tiny | 0.80 | 0.71 | 0.71 | 0.71 | 0.70 | 0.92 |
| Hybrid | ||||||
| LeViT-256 | 0.83 | 0.74 | 0.74 | 0.74 | 0.74 | 0.92 |
| CvT-13 | 0.84 | 0.74 | 0.74 | 0.74 | 0.74 | 0.93 |
| Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|
| CNN | ||||
| ResNet-50 | 0.99 | 0.99 | 1.00 | 1.00 |
| EfficientNet-B0 | 0.97 | 0.97 | 1.00 | 0.99 |
| ViT | ||||
| ViT-Small-Patch16-224 | 0.89 | 0.89 | 1.00 | 0.94 |
| DINOv2-Small | 0.88 | 0.88 | 1.00 | 0.94 |
| SwinV2-Tiny | 1.00 | 1.00 | 1.00 | 1.00 |
| Hybrid | ||||
| LeViT-256 | 0.99 | 0.99 | 1.00 | 1.00 |
| CvT-13 | 1.00 | 1.00 | 1.00 | 1.00 |
| Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|
| CNN | ||||
| ResNet-50 | 0.85 | 0.85 | 1.00 | 0.92 |
| EfficientNet-B0 | 0.21 | 0.21 | 1.00 | 0.34 |
| ViT | ||||
| ViT-Small-Patch16-224 | 0.50 | 0.50 | 1.00 | 0.67 |
| DINOv2-Small | 0.17 | 0.17 | 1.00 | 0.29 |
| SwinV2-Tiny | 0.77 | 0.77 | 1.00 | 0.87 |
| Hybrid | ||||
| LeViT-256 | 0.88 | 0.88 | 1.00 | 0.94 |
| CvT-13 | 0.85 | 0.85 | 1.00 | 0.92 |
| Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|
| CNN | ||||
| ResNet-50 | 0.95 | 0.95 | 1.00 | 0.98 |
| EfficientNet-B0 | 0.99 | 0.99 | 1.00 | 0.99 |
| ViT | ||||
| ViT-Small-Patch16-224 | 0.59 | 0.59 | 1.00 | 0.74 |
| DINOv2-Small | 0.65 | 0.65 | 1.00 | 0.79 |
| SwinV2-Tiny | 0.88 | 0.88 | 1.00 | 0.94 |
| Hybrid | ||||
| LeViT-256 | 0.94 | 0.94 | 1.00 | 0.97 |
| CvT-13 | 0.94 | 0.94 | 1.00 | 0.97 |
| Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|
| CNN | ||||
| ResNet-50 | 0.84 | 0.84 | 1.00 | 0.91 |
| EfficientNet-B0 | 0.13 | 0.13 | 1.00 | 0.24 |
| ViT | ||||
| ViT-Small-Patch16-224 | 0.49 | 0.49 | 1.00 | 0.66 |
| DINOv2-Small | 0.37 | 0.37 | 1.00 | 0.54 |
| SwinV2-Tiny | 0.46 | 0.46 | 1.00 | 0.63 |
| Hybrid | ||||
| LeViT-256 | 0.85 | 0.85 | 1.00 | 0.92 |
| CvT-13 | 0.88 | 0.88 | 1.00 | 0.94 |
| Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|
| CNN | ||||
| ResNet-50 | 0.84 | 0.84 | 1.00 | 0.91 |
| EfficientNet-B0 | 0.50 | 0.50 | 1.00 | 0.67 |
| ViT | ||||
| ViT-Small-Patch16-224 | 0.22 | 0.22 | 1.00 | 0.36 |
| DINOv2-Small | 0.40 | 0.40 | 1.00 | 0.57 |
| SwinV2-Tiny | 0.55 | 0.55 | 1.00 | 0.71 |
| Hybrid | ||||
| LeViT-256 | 0.72 | 0.72 | 1.00 | 0.84 |
| CvT-13 | 0.80 | 0.80 | 1.00 | 0.89 |
| Grad-CAM | Attention-Rollout | ||||
|---|---|---|---|---|---|
| Augmentiert | ResNet | EfficientNet | CvT | ViT | DINOv2 |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
| Study | Model Type | Datasets | Best Metrics |
|---|---|---|---|
| Adak et al. [8] | Ensemble of ViTs | APTOS-2019 | 94.63% (Accuracy) |
| Wu et al. [11] | ViT-Base ViT-Large | EyePACS APTOS-2019 | 91.4% (Accuracy) |
| Chetoui et al. [12] | ViT DenseNet (Federated) | APTOS-2019 EyePACS Others | 95% (Accuracy) |
| Sun et al. [16] | Lesion-Aware Transformer (LAT) | EyePACS Messidor-1/2 | 0.893 (Validation QWK) |
| Kumar et al. [15] | Swin Transformer | APTOS-2019 | 86.4% (Accuracy) |
| Bala et al. [18] | CTNet (CNN + ViT Hybrid) | APTOS-2019 IDRiD | 0.972 (QWK) 0.987 (AUC) |
| Goh et al. [29] | VGG19 ResNet50 InceptionV3 DenseNet201 EfficientNetV2S VAN_small Cross-ViT_small ViT_small [SWIN]_tiny | Kaggle dataset SEED Messidor-1 | 0.973 (AUC) |
| Hidri et al. [31] | Xception Inception-Resnetv2 DenseNet | Kaggle dataset | 0.92 (AUC) |
| Touati et al. [30] | DRCCT (CNN + ViT Hybrid) | APTOS-2019 | 95% (Validation Accuracy) |
| Asia et al. [32] | ResNet-101 ResNet-50 VggNet-16 | XHO (HRF STARE DIARETDB0 MESSIDOR) | 98.8% (XHO Accuracy) 100% (STARE Accuracy) |
| Akhtar et al. [33] | RSG-Net (CNN) | Messidor-1 | 99.36% (Accuracy 4 grades) 99.37% (Accuracy 2 grades) |
| Xue et al. [34] | VMamba-m (ViT) | APTOS-2019 | 94.3% (Accuracy) 0.951 (AUC) |
| Yang et al. [17] | ViT + MAE Pretraining | APTOS-2019 EyePACS Messidor-2 OIA-DDR | 93.42% (Accuracy) 0.985 (AUC) |
| This study | CNN ViT Hybrid | EyePACS + APTOS-2019 (balanced) | 0.841 (QWK) 72.93% (Accuracy) 0.93 (AUC) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Belcheva, V.; Ermakova, T. Interpretable Deep Learning for Diabetic Retinopathy: A Comparative Study of CNN, ViT, and Hybrid Architectures. Computers 2025, 14, 187. https://doi.org/10.3390/computers14050187
Zhang W, Belcheva V, Ermakova T. Interpretable Deep Learning for Diabetic Retinopathy: A Comparative Study of CNN, ViT, and Hybrid Architectures. Computers. 2025; 14(5):187. https://doi.org/10.3390/computers14050187
Chicago/Turabian StyleZhang, Weijie, Veronika Belcheva, and Tatiana Ermakova. 2025. "Interpretable Deep Learning for Diabetic Retinopathy: A Comparative Study of CNN, ViT, and Hybrid Architectures" Computers 14, no. 5: 187. https://doi.org/10.3390/computers14050187
APA StyleZhang, W., Belcheva, V., & Ermakova, T. (2025). Interpretable Deep Learning for Diabetic Retinopathy: A Comparative Study of CNN, ViT, and Hybrid Architectures. Computers, 14(5), 187. https://doi.org/10.3390/computers14050187