1. Introduction
Concrete surface crack detection is a crucial component of road maintenance and infrastructure safety management. Early and accurate identification of surface cracks helps prevent potential structural damage and traffic accidents [
1,
2]. Among various approaches, vision-based automatic crack detection has attracted increasing attention due to its potential for high efficiency, scalability, and cost-effectiveness [
3,
4].
Recent crack detection models are predominantly based on supervised deep learning techniques, often adopting encoder–decoder architectures [
5]. These models, such as UNet [
6], BiSeNetV2 [
7], and DeeplabV3+ [
8], typically rely on convolutional backbones to extract local features, followed by upsampling strategies to produce dense segmentation results. With the development of attention mechanisms, models like PCNet have improved the continuity of detection by integrating spatial and channel attention [
2], while high-resolution segmentation network (HrSegNet) leverages multi-resolution branches to address the scale imbalance of slender cracks [
9]. Additionally, loss functions such as Focal Loss [
10] enhance model focus on hard-to-detect crack features. Some studies have further explored the use of generative adversarial networks (GANs) for image reconstruction to improve feature extraction indirectly [
11,
12,
13].
Despite these advancements, existing models still face key challenges under real-world road conditions. First, fine cracks with elongated and irregular shapes are easily lost during downsampling, resulting in low recall and incomplete segmentation [
1,
14]. Second, models often require large parameter sizes to achieve high accuracy, which limits their deployment in resource-constrained scenarios. Lastly, diverse road textures, occlusions such as stains and shadows, and inconsistent manual annotations introduce noise into training, reducing model robustness and generalization [
3,
4]. In addition, although post-processing algorithms have been developed to refine segmentation results based on surrounding pixel predictions [
15,
16,
17], they often lack robustness across datasets and require manual parameter tuning.
To address these challenges, this paper proposes a novel crack detection model based on adaptive feature quantization. The model comprises three main components: (1) a maximum soft pooling module to preserve the continuity and completeness of crack structures; (2) an adaptive feature quantization module that highlights key crack features through enhanced spatial fusion; and (3) a trainable, edge-guided post-processing module that corrects prediction errors and refines segmentation boundaries. Experimental results on the Crack500 Road Crack Dataset demonstrate that our model achieves higher accuracy and precision over baseline methods, and significantly reduces computational cost, fewer parameters and faster inference.
The contributions of this article are as follows:
We propose an adaptive feature quantization network for instance-level surface crack segmentation (AFQSeg), a surface crack detection model based on adaptive feature quantization. It integrates three key modules—SMP for downsampling, AFQ for feature enhancement, and CR for refined segmentation—to improve robustness and accuracy in crack detection.
We design the SoftMax Pooling (SMP) module to enhance the continuity of fine crack detection. By preserving all pixel information within pooling windows and adaptively adjusting weights based on pixel distributions, the module reduces feature loss during downsampling while achieving efficient information compression.
We introduce the AFQ (Adaptive Feature Quantization) module, which enhances feature representation by leveraging a pre-trained vector quantized generative adversarial network (VQGAN) codebook and a spatial feature fusion strategy. This combination allows the model to extract more representative crack prototypes and adaptively integrate them with current feature maps, improving detection performance across different domains.
We propose the crack refinement (CR) module, which fuses edge information with high-level features and introduces an edge-aware loss function to enhance the accuracy of boundary segmentation.
We significantly reduce model complexity, achieving up to 88.7% fewer parameters and 96.8% faster inference compared to baseline models, making AFQSeg more suitable for real-world deployment.
The rest of this paper is organized as follows.
Section 2 reviews related work.
Section 3 describes the proposed method.
Section 4 outlines the experimental setup.
Section 5 presents the results and analysis.
Section 6 discusses the method’s strengths and limitations. Finally,
Section 7 concludes the paper and suggests future work.
2. Related Works
2.1. Crack Detection Under Challenging Conditions
Recent studies have addressed the challenges of crack detection under complex environmental conditions, such as varying illumination and underwater settings. For instance, Fan et al. proposed a shadow-removal-oriented crack detection approach that effectively mitigates the interference of shadows in pavement crack images, enhancing detection accuracy [
18]. Similarly, Pal et al. provided an overview of the difficulties associated with automatic detection of concrete cracks in the presence of shadows, highlighting the limitations of models trained on ideal conditions [
19].
In underwater environments, where visibility is often compromised, Orinaitė et al. developed a deep learning-based approach for detecting concrete cracks below the waterline, demonstrating the feasibility of machine learning techniques in such challenging conditions [
20]. Additionally, a study introduced an improved YOLOv8 network tailored for underwater crack detection, incorporating image enhancement methods to address issues like low contrast and blurriness [
21].
2.2. Encoder–Decoder Architectures
Research on concrete surface crack detection has progressed significantly in recent years, particularly with the adoption of deep learning-based approaches. Most existing methods follow an encoder–decoder architecture, where convolutional layers extract features and upsampling layers restore spatial resolution for pixel-wise segmentation [
6,
22,
23]. Among them, UNet remains a foundational baseline due to its simplicity and effectiveness [
6].
2.3. Attention Mechanisms
To improve performance, many researchers have explored attention mechanisms. For instance, channel and spatial attention modules have been integrated to enhance the model’s capacity to focus on critical regions. PCNet introduces both types of attention to address crack continuity issues [
2], while HrSegNet incorporates multi-resolution branches to capture detailed crack structures and mitigate scale imbalance [
9]. Further improvements have been achieved using transformer-based designs and more advanced attention configurations [
24,
25,
26].
2.4. Post-Processing Techniques
Loss function optimization is another area of focus. The Focal Loss has been shown to help models pay more attention to hard-to-detect crack features, thereby improving accuracy in imbalanced scenarios [
10]. Additionally, some researchers have introduced generative adversarial networks (GANs) for image-level reconstruction before detection, which indirectly enhances the quality of feature representations [
11,
12,
13].
To further refine results, post-processing methods have been adopted to improve segmentation accuracy. These techniques often rely on the contextual consistency of predicted pixels, adjusting outputs based on neighboring information [
15,
16,
17]. However, such methods can be sensitive to parameter settings and lack robustness across datasets.
2.5. Existing Challenges
While the incorporation of attention mechanisms, advanced loss functions, and post-processing steps has led to notable performance improvements, existing methods still face limitations in robustness, parameter efficiency, and their ability to handle challenging real-world conditions.
3. Method
In light of the aforementioned challenges, this paper proposes a targeted AFQSeg surface crack detection model based on adaptive feature quantization. This model is primarily composed of three key modules: the maximum soft pooling module (SMP), the adaptive crack feature quantization module (AFQ), and the trainable crack post-processing module (CR). The SMP module is designed to address the limitations of continuous recognition of small cracks caused by feature information loss during dimensionality reduction in traditional max pooling operations. SMP efficiently preserves high-resolution features, minimizing information loss during down-sampling and enhancing the capture of fine crack details. The AFQ module is designed to extract more representative crack prototype features through VQGAN [
27,
28,
29,
30]. It dynamically adjusts the fusion strategy to ensure optimal alignment and complementarity between features, which in turn improves the model’s detection accuracy and robustness across various domains. The CR module is designed to solve the common problems of inaccurate segmentation and misjudgment caused by annotation errors in practical applications. By accurately locating edge pixels and guiding the segmentation pixels to diffuse towards the target edge, it effectively compensates for the segmentation deviation caused by inaccurate annotation, ensuring the accuracy and reliability of detection results.
3.1. Framework
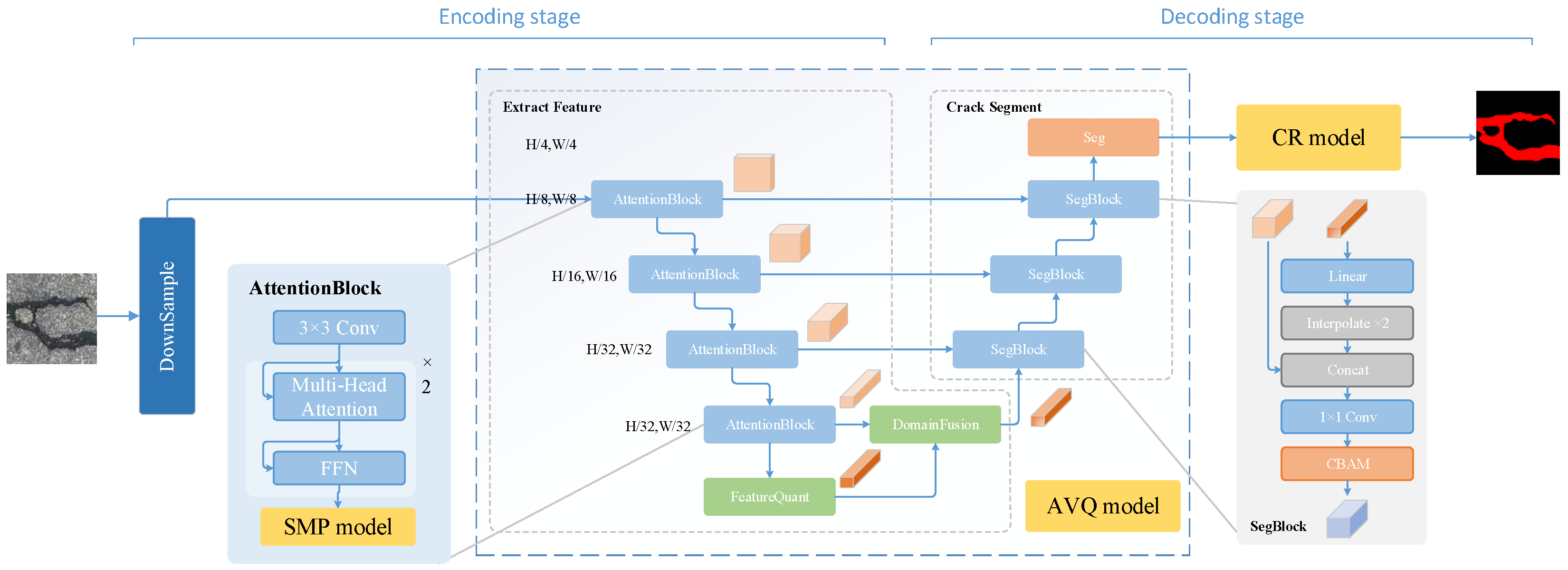
The proposed AFQSeg surface crack detection model, which is based on adaptive feature quantization, introduces three key modules: the SMP (Soft Max Pooling), AFQ (Adaptive Crack Feature Quantization), and CR (Crack Post-processing) modules. These modules are integrated into the conventional encoder-decoder architecture for image defect detection, enabling efficient recognition and precise localization of crack areas in road images, as illustrated in
Figure 1.
3.2. AFQSeg Surface Crack Detection Model
In the encoding stage, the model first processes the input crack image through a feature extraction module, reducing the size of the feature map to reduce computational complexity. It then employs a four-layer Attention Block module to extract features. This module merges traditional convolutional layers with attention mechanisms, encoding block features first and then enhancing the focus on global contextual information through self-attention mechanisms. This design enhances the model’s understanding of complex textures and structures, especially suitable for capturing slender and complex targets such as cracks. To mitigate computational complexity while retaining crucial information, the model introduces the SMP module with a probabilistic down-sampling method, effectively avoiding key information loss and enhancing the model’s robustness.
In the encoding-decoding stage, the AFQ module is extensively utilized, employing pre-trained codebooks for feature enhancement during the encoding phase. The vectors in these codebooks represent the key visual features in the image library. By calculating the feature distance and quantifying it, the model learns more abstract and generalized crack features, thereby enhancing the quality of feature representation and fortifying the model’s crack identification capabilities. To integrate quantitative and extracted features, the model uses the DF (Dynamic Fusion) module, which dynamically adjusts fusion weights based on various feature map positions, achieving efficient consolidation of features across different scales and types. This mechanism enhances the model’s ability to discern cracks against complex backgrounds, thereby improving the precision and robustness of its predictions. During the decoding process, multiple SegBlocks are used to fuse and segment the features of each layer. SegBlock consists of multiple convolutional layers, each containing multiple CBAM (Convolutional Block Attention Module) and MLP (Multi-Layer Perceptron) modules. These modules further extract and enhance crack features to ensure that the model can accurately identify and locate crack areas. The model uses the CBAM module to fuse and enhance the features of skip layer concatenation. Then, linear interpolation is used to up-sample the segmentation features.
In the decoding stage, in order to further improve the precision of prediction, especially in the definition of crack edges, a CR module is integrated for crack refinement. In this stage, multi-scale separable convolution modules are used to enhance feature extraction, and a reprediction module is employed to perform secondary segmentation on the edge regions in the preliminary prediction results. This strategy significantly reduces false positives and false negatives, and improves the accuracy of crack detection.
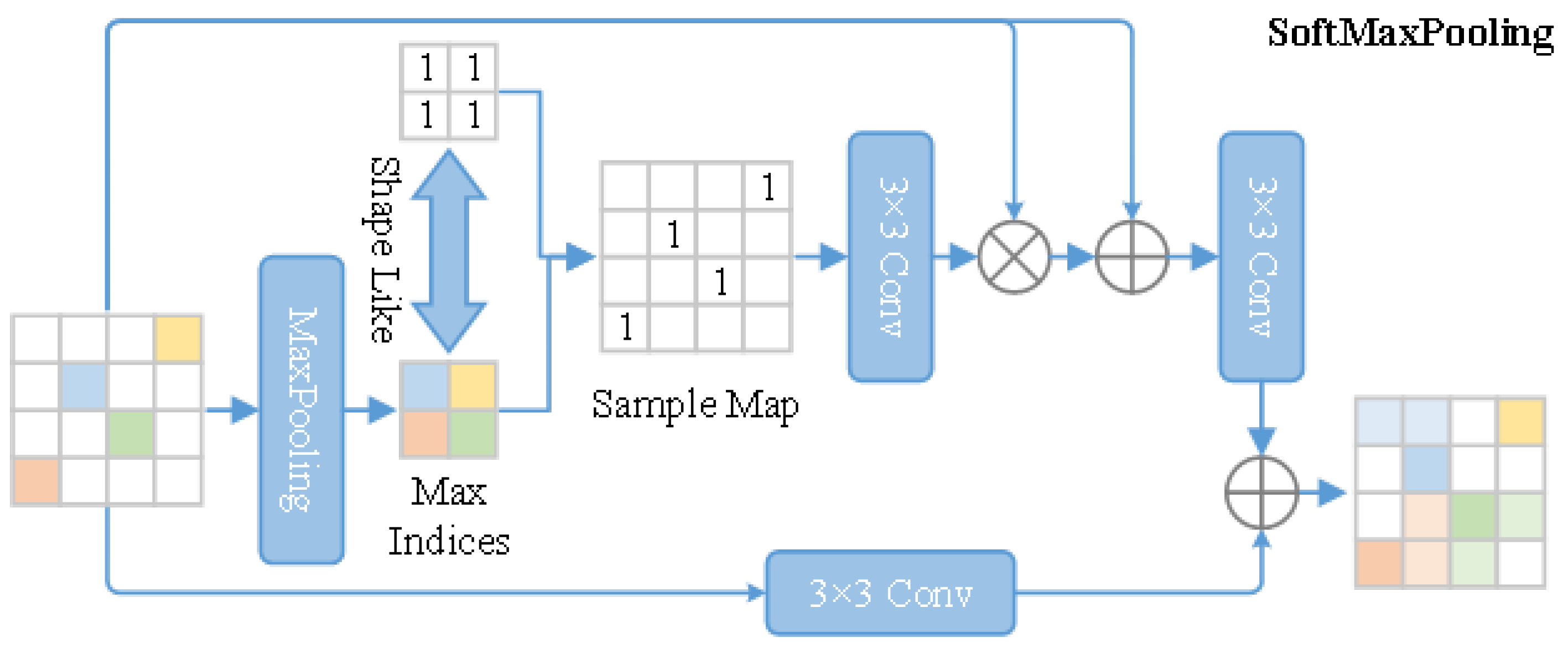
3.3. SoftMax Pooling Module
Max Pooling is a common downsampling operation in convolutional neural networks, which reduces the feature scale by preserving the maximum value within a specified window size. However, this method is prone to losing feature details because it directly ignores non maximum elements in the window [
31]. To counteract this issue, this paper proposes the Soft Max Pooling method, aimed at preserving the information of all pixels in the window, not just the maximum value, as depicted in
Figure 2. The main steps of Soft Max Pooling are as follows:
Conduct traditional max pooling to identify the index of the maximum value within each window.
Utilize tensors, where all elements are set to 1, along with the recorded index of the maximum value, to reconstruct a weight map equivalent to the current feature scale.
In this weight map, assign a weight of 1 to the position of the maximum value and 0 to all other positions.
To ensure a smoother transition and to retain more information, fine-tune the weight map.
Input the adjusted weight map into a 3 × 3 convolutional layer to calculate new pooling weights via convolution.
Assign a weight to each pixel based on the distribution of pixel values within the window, instead of selecting only the maximum value.
Apply the calculated pooling weights to perform weighted down-sampling on the original feature map, resulting in an output where each position is the weighted sum of all pixels in the window.
Integrate this process with a branch that employs adaptive down-sampling through convolution, merging its output with that of the Soft Max Pooling branch to achieve the final Soft Max Pooling result.
SoftMax Pooling retains the information of all pixels in the window, not just the maximum value, thereby reducing the loss of feature details. By calculating pooling weights through convolution, the weights can be adaptively adjusted based on the distribution of pixel values, making the down-sampling results more reasonable. Combining direct convolution down-sampling branches increases the flexibility and adaptability of the model.
3.4. Adaptive Feature Quantization Module
The core components of this module include a feature space conversion module and a quantized feature encoder [
32]. This module is designed to effectively utilize the fourth layer features as input, and achieve nonlinear mapping of the feature space through a 1 × 1 convolutional layer to accurately match the feature space of the current codebook. Then, the features are quantized using a pre-training codebook. The quantized features are then mapped to the feature space through 1 × 1 convolution to obtain effective quantized features, as shown in
Figure 3a.
The initialization of the codebook is completed through a pre-training process to ensure that its parameters can adapt to different task requirements. Primarily, the codebook is mainly responsible for quantifying the features extracted by the model. These quantified features can accurately reflect the characteristics of the pixel’s category, thereby enhancing the model’s ability to restore image details. To further optimize the effects of style reconstruction and local detail reconstruction, this module introduces a local discriminator based on the global discriminator, as shown in
Figure 3b. This discriminator can classify both local and global features of an image simultaneously, ensuring consistency between overall style and local details during the reconstruction process. Through this mechanism, the codebook not only achieves image feature extraction and clustering optimization, but also plays an important role in feature enhancement.
During the feature quantization process, the model uses a codebook to quantize the extracted features. This quantization process aims to improve the processing efficiency and accuracy of the model by reducing the complexity of the feature space and encoding the image with a limited number of features. Concurrently, the quantified features can more effectively express the category information of pixels, providing valuable references for subsequent crack segmentation. Upon completing the spatial mapping of the fourth layer features, an efficient algorithm based on the cosine similarity formula is used to calculate the feature with the smallest distance between each pixel feature in the codebook. This calculation process is based on the cosine similarity formula, which can accurately reflect the similarity between pixel features and features in the codebook. Through this calculation process, the most matching feature representation can be selected for each pixel, providing a quantization target.
After completing the feature mapping, in order to further improve the generalization ability and robustness of the model, this study performed an additional spatial transformation on the obtained features. This conversion process aims to weaken the model’s excessive dependence on feature encoding, allowing the model to adapt more flexibly to different input data. Through this mechanism, the model can reduce its dependence on specific codebooks while maintaining high performance, improving its generality and scalability.
In order to effectively integrate quantitative features with extracted features, this paper proposes an adaptive spatial fusion module, as shown in
Figure 4. This module first evaluates the importance of each pixel by calculating the channel accumulation value and performing convolution operations. Then, the softmax function is used to normalize these importance levels and obtain the weight of each pixel in the feature fusion process. Finally, based on these weights, the features are accumulated and calculated to achieve the fusion of quantized features and extracted features. This fusion process can fully utilize the advantages of both features, improving the model’s expressive power and reconstruction quality. Meanwhile, due to its adaptability, this module can automatically adjust the fusion strategy based on different input data, thus possessing high flexibility and generalization ability.
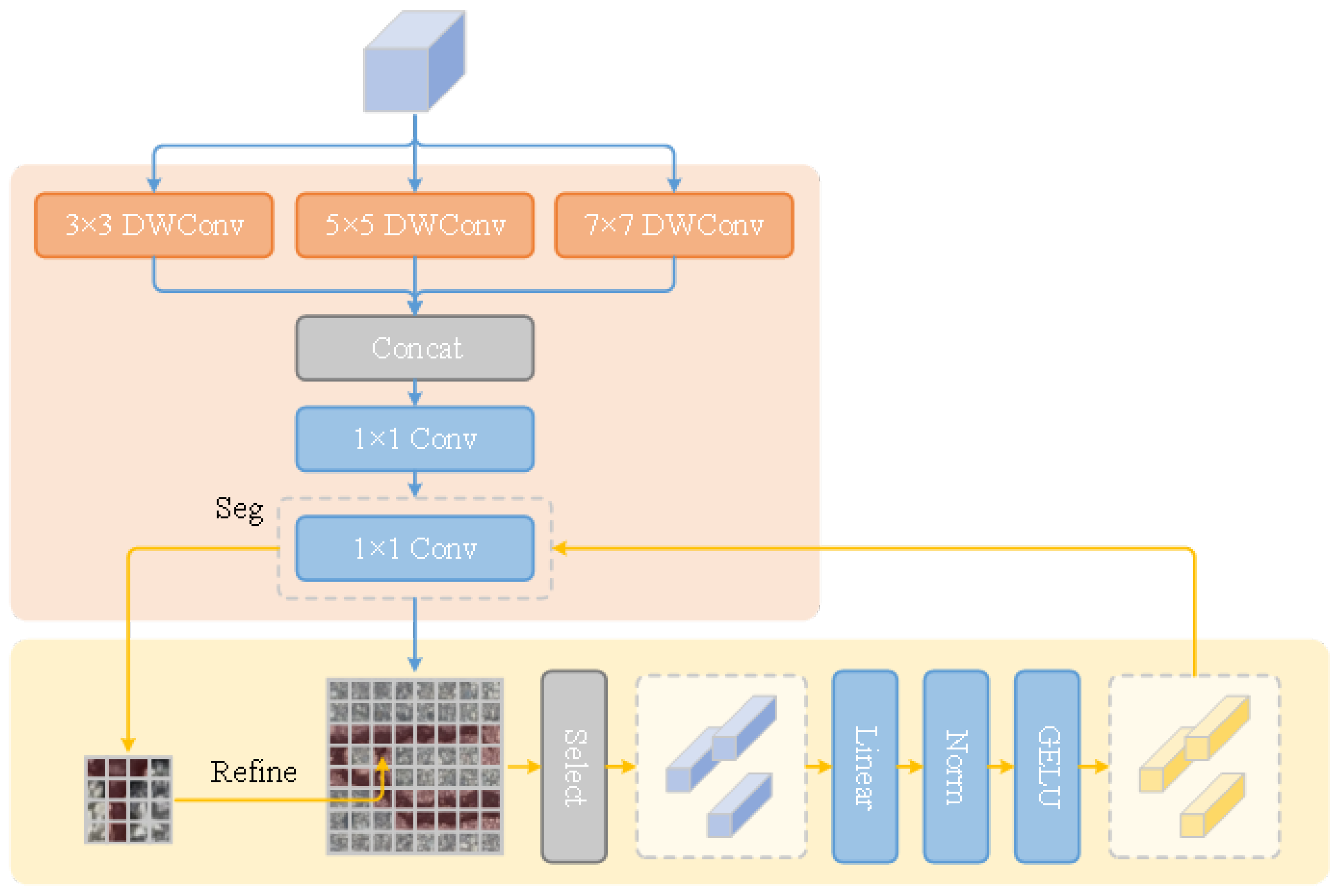
3.5. Post Processing Module
In crack detection tasks, there is often a high degree of similarity between the apparent and background features of cracks, which leads to uncertainty in predicting classification at the probability level. In addition, during the model training process, the prediction of segmentation results at the original resolution is achieved by up-sampling the segmentation results. However, this up-sampling method may not accurately capture the details of cracks, especially when the proportion of pixels in the image is small, thereby reducing the accuracy of segmentation [
33]. To overcome this challenge, we incorporate the re-segmentation strategy from PointRend into our model, combining it with edge-aware optimization to refine the final crack segmentation outputs. Specifically, it is to use the extracted second layer features and the current prediction result as inputs for re-segmentation, and train a specialized re-segmentation module, as shown in
Figure 5.
Firstly, multiple points are randomly oversampled on the feature map, and linear interpolation is applied to each input feature independently to obtain features upsampled to their original spatial positions. This method ensures that the model can fully utilize the information in the original image during the re-segmentation process, improving the accuracy of crack detection. However, due to the small pixel proportion of cracks in the image and the crucial importance of predicting crack edges for overall detection accuracy [
34]. Therefore, this article further introduces edge detection operators, focusing on re-segmentation of edge pixels. The model concatenates the second layer features and classification features corresponding to the pixel, and inputs them into a multi-layer perceptron (MLP) network to predict the classification of the features. In this way, the model can more accurately identify the edges of cracks and further improve the accuracy of crack detection.
In the inference stage, the selection of sampling points is mainly based on the uncertainty of classification. Priority should be given to selecting points with low classification probability and high uncertainty for further segmentation, to ensure that the model can focus on difficulty to distinguish regions and further improve the accuracy and robustness of crack detection.
4. Experiment
4.1. Dataset Description
To verify the effectiveness of the proposed method, we adopt the Crack500 Road Crack Dataset, a widely used benchmark in the field of computer vision and deep learning for road crack detection. This dataset is of significant value for applications such as intelligent transportation systems, urban infrastructure maintenance, and predictive maintenance. Owing to its reliability and generality, Crack500 has been adopted in numerous prior studies.
The dataset consists of 250 training images, 50 validation images, and 200 test images, covering various types of cracks including horizontal, vertical, and irregular patterns—each presenting different levels of detection difficulty. Although the dataset primarily features road surface images, the proposed AFQSeg model is designed to generalize across different concrete structures. With minimal domain-specific adaptation, it can be extended to other scenarios such as bridges, walls, and building foundations.
4.2. Experimental Environment
To evaluate the performance of the proposed method, experiments were implemented using the PyTorch (
https://pytorch.org/) deep learning framework, with code developed in Python 3.6. All input images were uniformly resized to a fixed resolution to reduce computational cost and maintain consistency. Batch normalization was applied after each convolutional layer to accelerate convergence during training. Xavier initialization was used to initialize the model weights, and parameters were updated using stochastic gradient descent (SGD).
Training and testing were conducted on a server equipped with an Intel(R) Xeon(R) Silver 4214 CPU (4 cores) and an NVIDIA Tesla A100-SXM4-40GB GPU.
4.3. Evaluation Indicators
This article uses four key evaluation metrics: Intersection over Union (IoU), Recall (R
ec), Precision (P
re), and F
1 Score, which are also evaluation metrics used by many machine learning methods. The calculation formula is as follows:
In the formula, Tp is the number of positive samples correctly classified, Fp is the number of negative samples misclassified as positive samples, Fn is the number of positive samples misclassified as negative samples, C is the candidate box, and G is the original marked box. Intersection over Union (IoU) is the overlap rate between the candidate bound generated by object detection and the ground truth bound, which is the ratio of their intersection to the union. The ideal situation is complete overlap, with a ratio of 1.
5. Results and Analyze
To better validate the accuracy, efficiency, and experimental feasibility of the proposed method, comparisons were made with five commonly used reference algorithms, including UNet [
25], BiSeNetV2 [
35], DeeplabV3+ [
36], HRNet [
13], and SwinUNet [
37]. In addition to evaluation metrics such as Intersection over Union (IoU), Recall, Precision, and Score, Params and GFLOPs were also calculated to better verify the practicality and efficiency of the method. The specific experimental results are shown in the
Table 1:
The method proposed in this article has been experimentally verified to have good detection performance, with an Intersection over Union (IoU) of 75.93%, a recall rate of 88.49%, an precision of 82.81%, and a score of 84.45%. Compared with five reference algorithms, UNet, BiSeNetV2, DeeplabV3+, HRNet, SwinUNet, etc., all four evaluation indicators have been improved. Among them, the precision can reflect the precision of the method in crack detection. Compared with the reference algorithm, the maximum improvement is 6.67%, and the minimum improvement is 0.62%; The intersection to union ratio can reflect the degree of overlap between the target and the candidate, and can also effectively reflect the crack detection effect.
Compared with the reference algorithm, it has a maximum improvement of 6.13% and a minimum improvement of 1.14%; The recall rate can reflect the comprehensiveness of the detection effect, especially in the field of transportation. In order to prevent traffic accidents, sometimes even subtle cracks need to be detected in a timely manner, and the improvement of the recall rate of the detection algorithm is quite important. The maximum increase in recall rate is 6.6%, and the minimum increase is 0.96%; The F1 value can reflect the degree of recognition of positive and negative examples, with a maximum increase of 6.95% and a minimum increase of 0.96%. In summary, the application of the method can comprehensively improve the precision, efficiency, and practicality of crack detection.
This method can effectively detect cracks in various scene images. After detecting cracks in scenes of the same type as the experimental images, the specific effect is shown in
Figure 6, where rows represent a type of scene, columns represent each detection model, green represents the defect itself, and red represents the predicted result. It can be seen that our proposed method has good detection performance.
While improving the evaluation indicators, the model parameters and computational complexity of the method have also been greatly improved. The model parameters of this method are 6.683 MB, and the computational speed is 7.081 GFLOPs. Compared with the reference algorithm, this method can greatly reduce the model parameters and improve the computational speed. The specific experimental results are shown in the
Table 2.
Among them, the model parameters have been reduced by 49.7–88.7%, with the highest improvement in DeeplabV3+ algorithm and 49.7% improvement in BiSeNetV2 algorithm with only 13.294 parameters. It can be seen that this method has been greatly optimized at the parameter level. The method has good computational performance, with an improvement range of 0.92–96.8%. Especially compared with the UNet method, it has the highest improvement rate.
The model integrates the SMP, AFQ, and CR modules into the encoding-decoding architecture, endowing the method with good accuracy, recall, and practicality. To better ensure the stability and simplicity of the model, one or more modules were removed for ablation experiments, and then the prediction performance compared and analyzed. The experimental results show that the fusion of the three modules can complement each other and has better effects than using them separately. The specific experimental results are shown in the
Table 3.
6. Discussion
The proposed AFQSeg model demonstrates several notable advantages over existing crack detection methods. First, it achieves consistent improvements across all key evaluation metrics—IoU, Recall, Precision, and F1-score—when compared to five representative deep learning models (UNet, BiSeNetV2, DeeplabV3+, HRNet, and SwinUNet). Notably, AFQSeg achieves an F1-score of 84.45%, outperforming the best baseline (SwinUNet) by 1.75%, and yields a Recall improvement of up to 6.6%, which is particularly critical in safety-sensitive applications such as road maintenance, where even subtle cracks must be identified reliably.
Another significant strength lies in the model’s lightweight architecture. AFQSeg achieves these accuracy gains while using only 6.683 MB of parameters, with a parameter reduction of up to 88.7% compared to heavier models like DeeplabV3+, and up to 96.8% improvement in inference speed over UNet. These improvements make the model highly practical for real-time or resource-constrained scenarios such as UAV-based inspections or mobile deployment.
From a design perspective, AFQSeg integrates three complementary modules—SMP for feature-preserving downsampling, AFQ for semantic feature quantization and fusion, and CR for post-refinement guided by edge information. Ablation studies confirm that these modules contribute synergistically to the final performance, with the full integration yielding superior results over any partial configuration.
However, the method also has certain limitations. Unlike some recent approaches that report extremely high accuracy (up to 99%), the performance metrics reported here are relatively modest. This discrepancy is primarily due to the choice of dataset. The Crack500 dataset used in our experiments contains more diverse, complex, and challenging real-world images than many previously used datasets, making it a more rigorous testbed. In addition, no extensive pretraining or domain-specific tuning was applied to artificially boost performance. Thus, while the numerical performance may appear lower than some previous works, the evaluation here reflects realistic robustness and generalization.
Furthermore, the current model is validated mainly on road surface cracks. While the design is generic and potentially applicable to other types of concrete surfaces (e.g., bridges, tunnels, walls), additional optimization may be needed to handle drastically different image characteristics or environmental conditions such as underwater imagery.
In summary, AFQSeg offers a strong balance between detection accuracy, computational efficiency, and architectural simplicity. The proposed method demonstrates strong potential for real-world applications and future adaptation to a wider range of surface types or more challenging detection environments.
7. Conclusions
This paper addresses the challenge of detecting fine surface cracks, which are often difficult to identify due to their narrow width, irregular shapes, and susceptibility to visual interference. To tackle this problem, we propose a novel crack detection model based on adaptive feature quantization. The model integrates a feature-preserving pooling module, a prototype-driven quantization mechanism, and an edge-aware refinement component. Experimental results on the Crack500 dataset demonstrate that the proposed method outperforms several baselines in terms of IoU, precision, recall, and F1-score, while also significantly reducing model parameters and computational cost. By enhancing the contrast between cracks and background features and preserving high-resolution details, the model effectively improves the detection of subtle and elongated cracks. Moreover, the adaptive fusion strategy enhances the model’s robustness across complex scenarios.
In future work, we plan to explore the application of AFQSeg to more diverse concrete surfaces beyond roads, such as bridge decks and structural walls. Given the model’s adaptability and modular design, we expect that, with appropriate domain-specific fine-tuning, AFQSeg can be effectively extended to a broader range of crack detection scenarios.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}