
Combining the Strengths of LLMs and Persuasive Technology to Combat Cyberhate



Abstract
1. Introduction
2. Related Work
3. Methodology
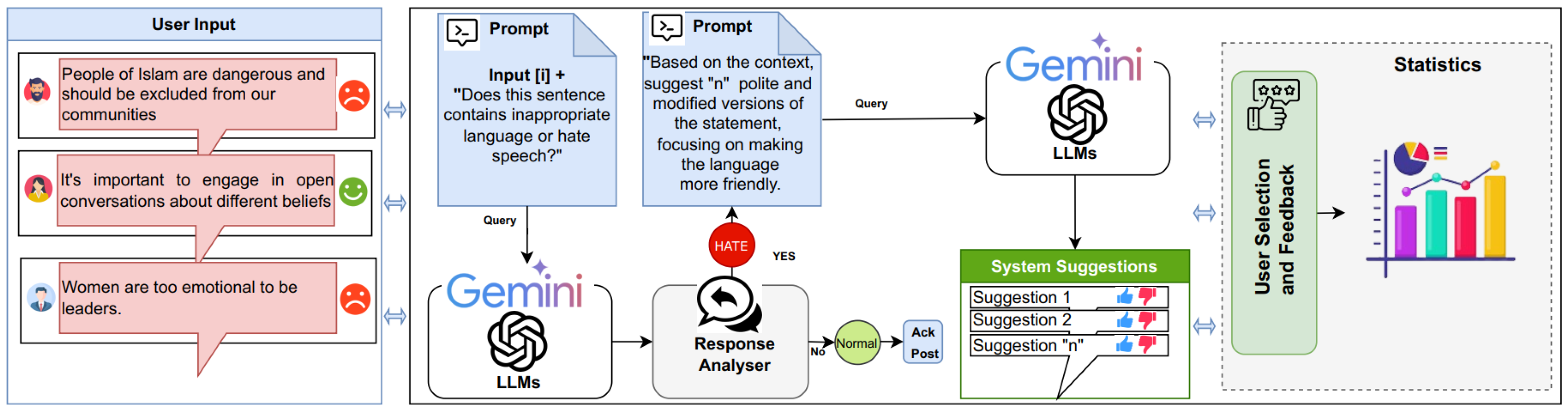
3.1. Comment Analysis Feature
- Max_output_tokens: This parameter controls the number of tokens (i.e., the length) generated by the model. We set it to maximum 100 tokens (words) to ensure concise responses, making it ideal for recommendations while avoiding long or irrelevant content.
- Temperature: This parameter defines the level of creativity and randomness in token selection. In this study, the temperature is set to 0.7, providing a balanced trade-off between logical coherence and creativity.
- Top_P and Top_K: These parameters determine how the model selects tokens during response generation. The Top_P parameter is set to 0.95, which means the model samples from the top 95% of the probability distribution. While, the Top_K parameter is set to 40, restricting selection to the top 40 most probable tokens within the Top_P range.
- 1.
- Input Analysis: The feature first receives user input i
- 2.
- Hate Speech Classification: The feature then evaluates user input i by concatenating it with the prompt :where LLM is a function that processes prompt template and user input i, returning a response , which indicates whether i contains inappropriate language or cyberhate (hateful) or normal (not hateful). The configuration parameters here govern the model’s response generation behavior.
- 3.
- Contextual Recommendation: According to the output of :
- If : The feature generates n alternative sentences (suggestions) using template for user offensive input i:where , and each is an alternative suggestions for i. These suggestions aim to preserve the meaning while removing offensive or harmful words from user input.
- If : The feature acknowledges and posts the conversation:
3.2. Study Design
3.2.1. News Website Development
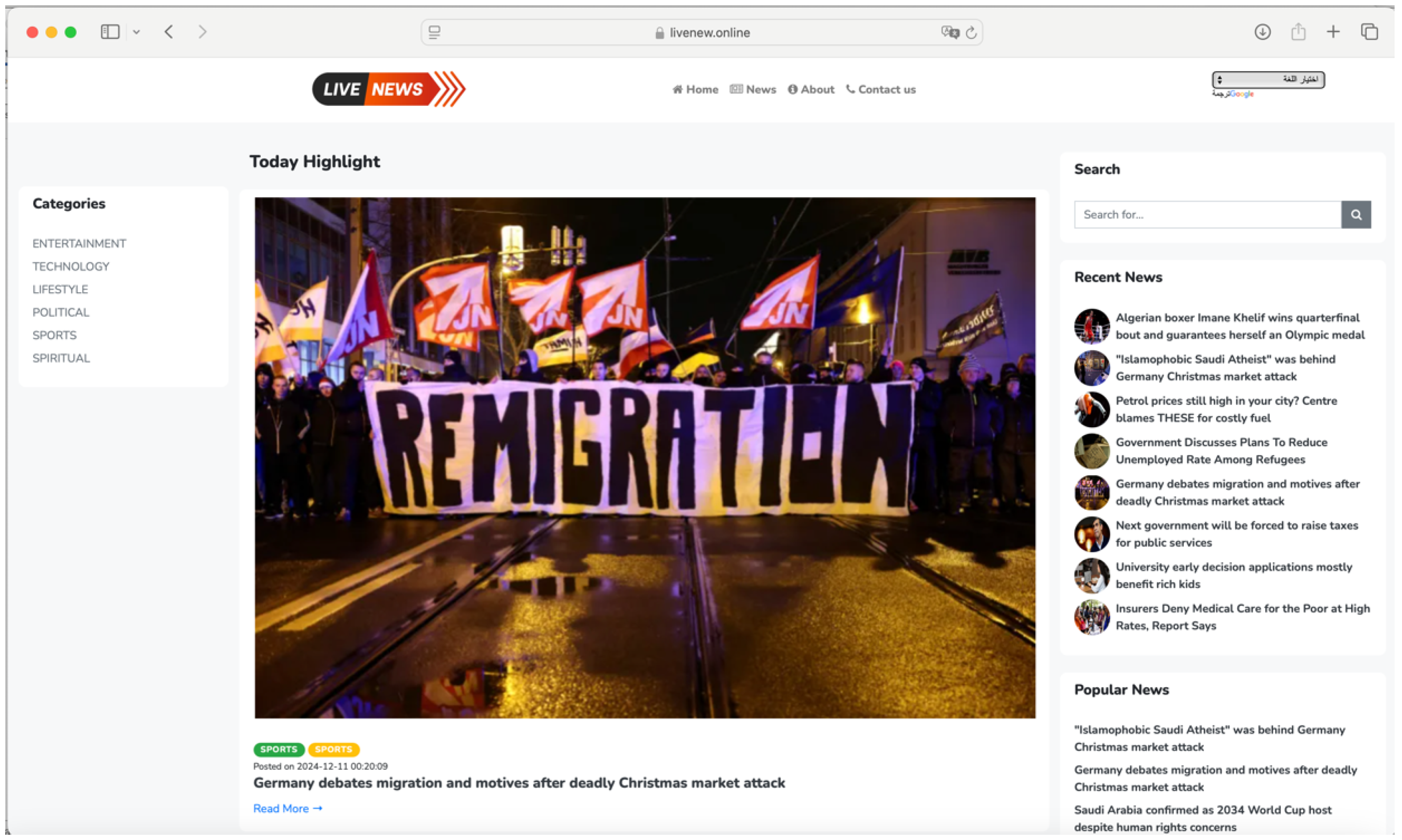
- Website Content:The website included news articles collected from trusted news sources, covering a wide range of tones and topics, from neutral subjects to more controversial and emotionally charged topics. The participants can post comments, reply to others, and engage in discussions related to news articles. Figure 3 shows the home page of the news website.
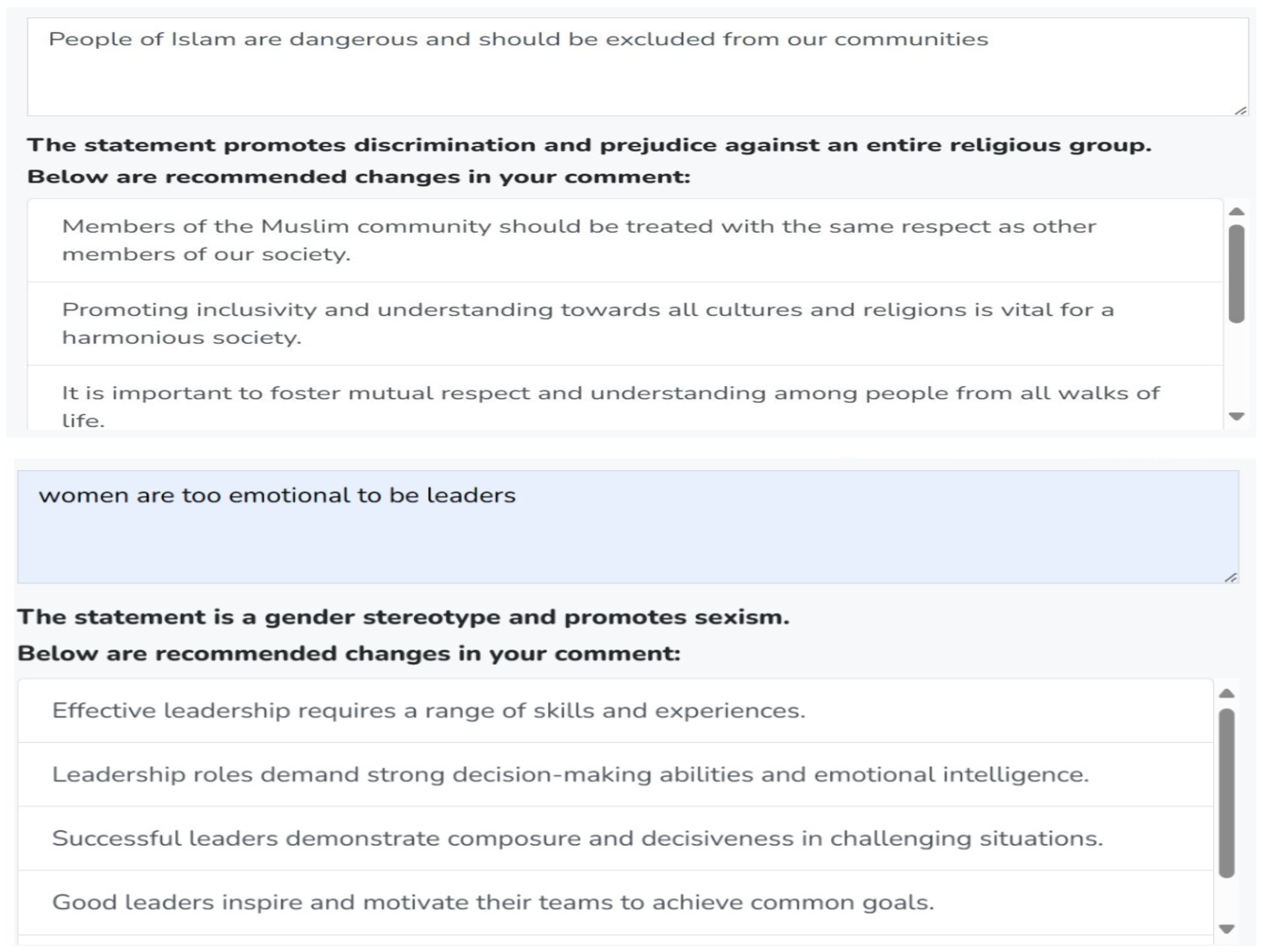
- LLM-Based Comment Analysis Feature:The website employs a comment analysis feature powered by Google Gemini AI model to analyze the participants’ comments before they post them to detect any cyberhate instances. Figure 4 presents examples of how LLM-Based Comment Analyzer detects and categorizes different types of hateful content in user comments.
- LLM-Based Feedback Feature:As shown in Figure 4, the comment analyzer not only identifies hateful instances in user comments but also suggests alternative, non-hateful revisions. If a comment includes hateful or aggressive input, the comment analyzer will provide the participants with suggestions of a none-hateful and more friendly form of their comments. It will offer textual recommendations to help the participants modify their input to sound more positive. For example, if a comment is detected as potentially harmful, the comment analyzer can suggest a rephrasing to make it less hateful and less aggressive. The participants will then have the option to accept or reject these suggestions. Figure 5 shows examples of some LLM-based suggestions to help the participants modify their comments.
- Flagging on Comments: Three different flag indicators were assigned to the participants’ comments to measure their interactions with the proposed self-monitoring strategy (comment analysis feature) and the LLM-based suggestions. These flags were as follow: The Blue Flag was assigned to standard comments, where the participants posted their comment without requiring intervention from LLM. The Green Flag was used for comments that were detected by the comment analyzer as cyberhate and the participants accepted the suggested revisions by the LLM. Lastly, the Red Flag was assigned to hateful comments where the participants declined to adopt the LLM-based suggestions for modification. This classification enabled a structured analysis of user engagement with the proposed features and their willingness to adjust their language accordingly. Figure 6 presents examples of flagged comments.
3.2.2. Study Procedure
3.2.3. Study Evaluation
3.2.4. Survey Design
3.2.5. Sampling
3.2.6. Analysis
4. Findings
4.1. LLM Intervention Clarity and Acceptance
- The suggestion was not relevant to their opinions (51%)
- The suggestion was too different from what they wanted to express (38%)
- They did not think their comments were hateful (23%)
- They did not agree with the tone of the LLM suggestion (20%)
4.2. LLM Frequency of Intervention
4.3. LLM Impact on Awareness and Behavior
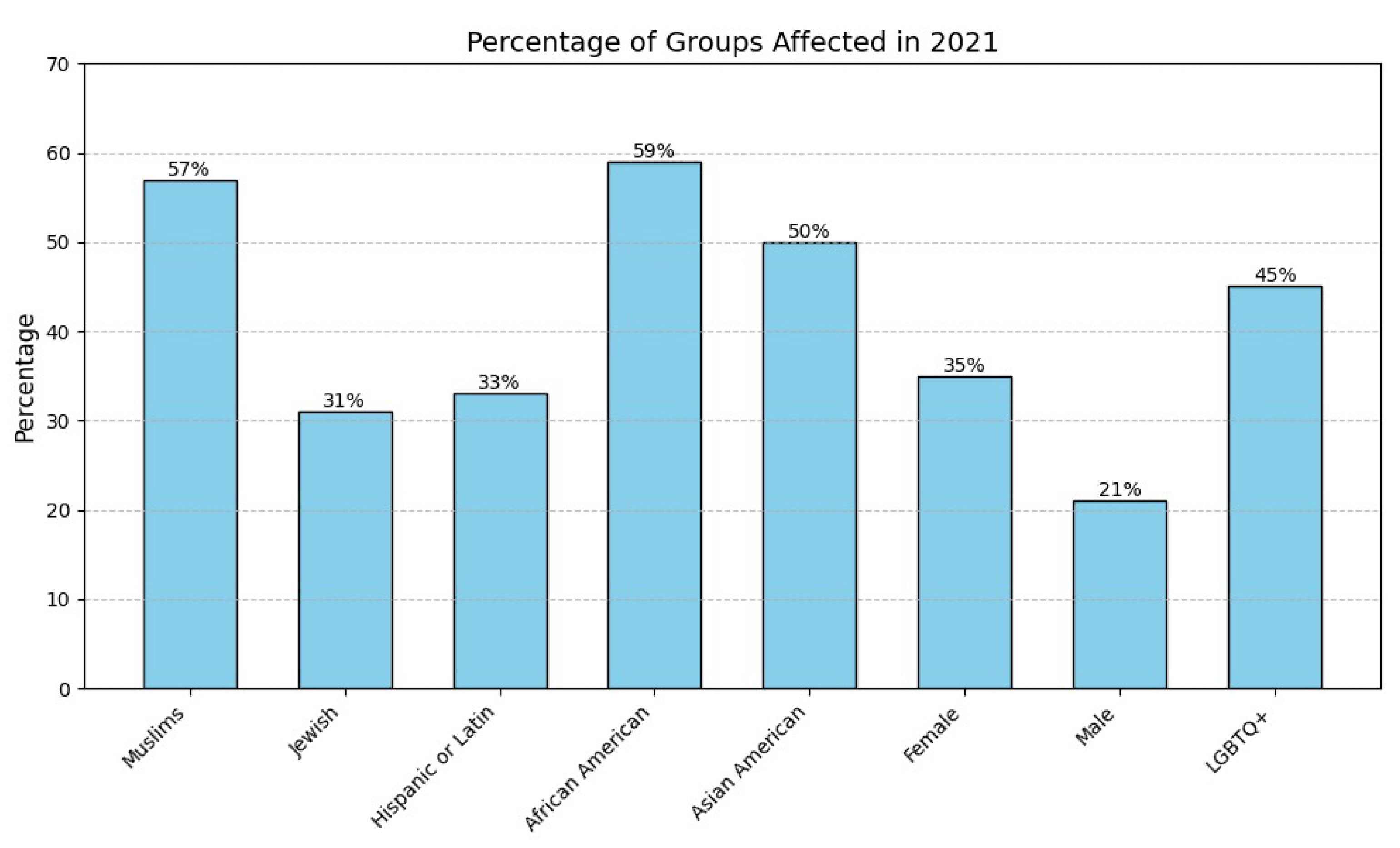
4.4. Long-Term Impact on Cyberhate and Freedom of Speech
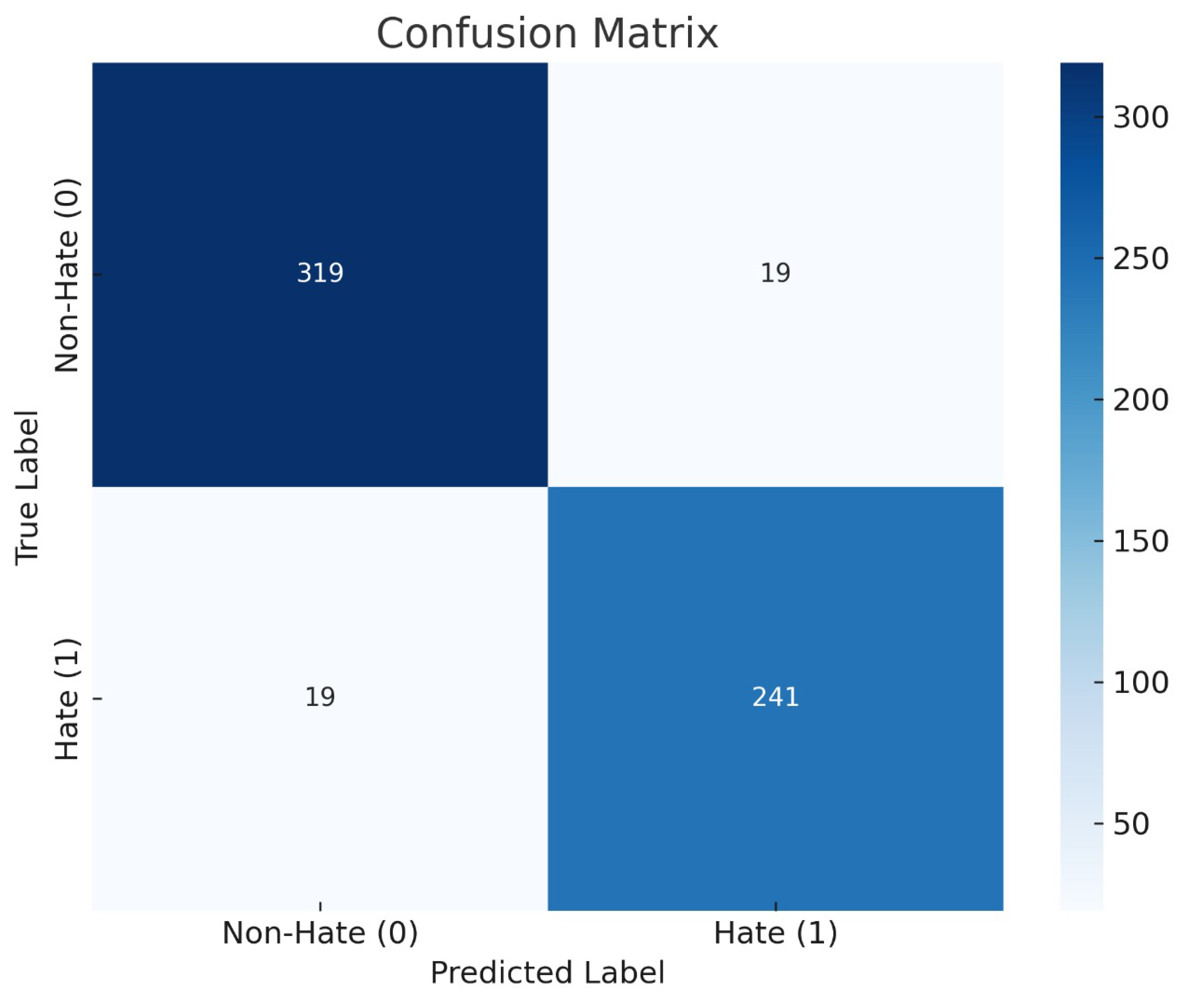
4.5. LLM Classification Performance
5. Discussion
6. Validity Threats
- The persuasive suggestions generated by the LLM may implicitly assume a universal standard of politeness, potentially overlooking cultural, contextual, and rhetorical variations in communication. As a result, individual participants may interpret these suggestions differently based on their personal beliefs, language proficiency, or communication norms. Future work should prioritize fairness by incorporating diverse datasets, multi-perspective evaluations, and explainability features to ensure that interventions are culturally sensitive and do not disproportionately moderate marginalized voices. To improve interpretability and reduce unintended variation in user responses, future studies will also include standardized participant training and calibration sessions prior to interaction, along with behavioral analytics (e.g., tracking changes in commenting patterns) to supplement self-reported perceptions with objective measures of intervention impact.
- Participants may have provided socially desirable responses rather than their true opinions, particularly regarding sensitive topics like cyberhate. To minimize this threat, the author ensured anonymity in responses and emphasized that there were no right or wrong answers, encouraging honesty.
- While the news website allowed for testing of the LLM-based intervention, we acknowledge that it does not fully replicate real-world social media dynamics. Key features such as user networks, content algorithms, and evolving community standards were beyond the scope of this study. However, this study environment enabled a focused evaluation of user responses to self-monitoring strategies. Future research will explore integration with real-world social platforms to validate and extend these findings in more dynamic and socially nuanced contexts.
- Conducting the study on a custom-built news website may limit the generalizability of findings to other social media platforms with different dynamics and policies. To mitigate this, future experiments will replicate the study across multiple platforms with varying user interfaces and community guidelines. Cross-platform comparisons will help determine the consistency of LLM-based intervention effects.
- While the adopted methodology successfully identified and described users’ perceptions regarding our proposed approach, it is possible that certain significant aspects that could impact their behaviors in this context were not fully captured.
- A common concern when using questionnaires is whether respondents interpreted and understood the questions as intended. To address this, a pilot study was conducted with 10 participants who met the study’s inclusion criteria. Based on their feedback, some questions were reviewed and improved to ensure a shared understanding among all respondents.
- The sample size of the study, consisting of 122 respondents, can be considered medium-sized. A larger sample would enable the findings to be more generalizable to larger population groups. Further investigation of the study’s results on a larger population will be conducted in future research.
- The study utilized a convenience sampling method, which may not fully represent the broader population. To mitigate this issue, the author recruited participants from diverse cultural backgrounds and demographics to enhance the generalizability of the findings.
- The exact number of comments posted per participant was not recorded, limiting our ability to fully decouple the effects of the comments volume. In future work will track this precisely.
- Resource constraints prevented human labeling of all suggestions, though our sample analysis (92% true-positive) provides an initial estimate.
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Almars, A.M.; Almaliki, M.; Noor, T.H.; Alwateer, M.M.; Atlam, E. Hann: Hybrid attention neural network for detecting COVID-19 related rumors. IEEE Access 2022, 10, 12334–12344. [Google Scholar] [CrossRef]
- Müller, K.; Schwarz, C. Fanning the flames of hate: Social media and hate crime. J. Eur. Econ. Assoc. 2021, 19, 2131–2167. [Google Scholar] [CrossRef]
- Nobata, C.; Tetreault, J.; Thomas, A.; Mehdad, Y.; Chang, Y. Abusive language detection in online user content. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 145–153. [Google Scholar]
- Noor, T.H.; Almars, A.M.; Alwateer, M.; Almaliki, M.; Gad, I.; Atlam, E.S. Sarima: A seasonal autoregressive integrated moving average model for crime analysis in Saudi Arabia. Electronics 2022, 11, 3986. [Google Scholar] [CrossRef]
- Blaya, C. Cyberhaine: Les Jeunes et la Violence sur Internet; Nouveau Monde: Paris, France, 2019. [Google Scholar]
- Machackova, H.; Blaya, C.; Bedrosova, M.; Smahel, D.; Staksrud, E. Children’s Experiences with Cyberhate. 2020. Available online: https://eprints.lse.ac.uk/106730/1/EUkidsonline_childrens_experiences_wth_cyberhate.pdf (accessed on 30 December 2024).
- Wachs, S.; Wright, M.F. Associations between bystanders and perpetrators of online hate: The moderating role of toxic online disinhibition. Int. J. Environ. Res. Public Health 2018, 15, 2030. [Google Scholar] [CrossRef]
- League, A.D. Online Hate and Harassment. The American Experience 2021; Center for Technology and Society: New York, NY, USA, 2021; pp. 10–23. [Google Scholar]
- Almaliki, M.; Almars, A.M.; Gad, I.; Atlam, E.S. Abmm: Arabic bert-mini model for hate-speech detection on social media. Electronics 2023, 12, 1048. [Google Scholar] [CrossRef]
- Ponte, C.; Batista, S. EU kids online Portugal. Usos, competências, riscos e mediações da internet reportados por crianças e jovens (9-17 anos). EU Kids Online e NOVA FCSH. 2019. Available online: https://fabricadesites.fcsh.unl.pt/eukidsonline/wp-content/uploads/sites/36/2019/03/RELATO%CC%81RIO-FINAL-EU-KIDS-ONLINE.docx.pdf (accessed on 30 December 2024).
- Elmezain, M.; Malki, A.; Gad, I.; Atlam, E.S. Hybrid deep learning model-based prediction of images related to cyberbullying. Int. J. Appl. Math. Comput. Sci. 2022, 32, 323–334. [Google Scholar] [CrossRef]
- Costa, S.; Mendes da Silva, B.; Tavares, M. Video games and gamification against online hate speech? In Proceedings of the 10th International Conference on Digital and Interactive Arts, Aveiro, Portugal, 13–15 October 2021; pp. 1–7. [Google Scholar]
- Citron, D.K.; Norton, H. Intermediaries and hate speech: Fostering digital citizenship for our information age. BUL Rev. 2011, 91, 1435. [Google Scholar]
- Cao, R.; Lee, R.K.W.; Hoang, T.A. DeepHate: Hate speech detection via multi-faceted text representations. In Proceedings of the 12th ACM Conference on Web Science, Southampton, UK, 6–10 July 2020; pp. 11–20. [Google Scholar]
- Almars, A.M.; Atlam, E.S.; Noor, T.H.; ELmarhomy, G.; Alagamy, R.; Gad, I. Users opinion and emotion understanding in social media regarding COVID-19 vaccine. Computing 2022, 104, 1481–1496. [Google Scholar] [CrossRef]
- Nugroho, K.; Noersasongko, E.; Fanani, A.Z.; Basuki, R.S. Improving random forest method to detect hatespeech and offensive word. In Proceedings of the 2019 International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 July 2019; pp. 514–518. [Google Scholar]
- Arango, A.; Pérez, J.; Poblete, B. Hate speech detection is not as easy as you may think: A closer look at model validation. In Proceedings of the 42nd International ACM Sigir Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 45–54. [Google Scholar]
- Zhou, Y.; Yang, Y.; Liu, H.; Liu, X.; Savage, N. Deep learning based fusion approach for hate speech detection. IEEE Access 2020, 8, 128923–128929. [Google Scholar] [CrossRef]
- Swamy, S.D.; Jamatia, A.; Gambäck, B. Studying generalisability across abusive language detection datasets. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 November 2019; pp. 940–950. [Google Scholar]
- Yin, W.; Zubiaga, A. Towards generalisable hate speech detection: A review on obstacles and solutions. PeerJ Comput. Sci. 2021, 7, e598. [Google Scholar] [CrossRef]
- Mathew, B.; Dutt, R.; Goyal, P.; Mukherjee, A. Spread of hate speech in online social media. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 173–182. [Google Scholar]
- Bedrosova, M.; Machackova, H.; Šerek, J.; Smahel, D.; Blaya, C. The relation between the cyberhate and cyberbullying experiences of adolescents in the Czech Republic, Poland, and Slovakia. Comput. Hum. Behav. 2022, 126, 107013. [Google Scholar] [CrossRef]
- Mathew, B.; Illendula, A.; Saha, P.; Sarkar, S.; Goyal, P.; Mukherjee, A. Hate begets hate: A temporal study of hate speech. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–24. [Google Scholar] [CrossRef]
- Almaliki, M. Cyberhate Dissemination: A Systematic Literature Map. IEEE Access 2023, 11, 117385–117392. [Google Scholar] [CrossRef]
- Leonhard, L.; Rueß, C.; Obermaier, M.; Reinemann, C. Perceiving threat and feeling responsible. How severity of hate speech, number of bystanders, and prior reactions of others affect bystanders’ intention to counterargue against hate speech on Facebook. SCM Stud. Commun. Media 2018, 7, 555–579. [Google Scholar] [CrossRef]
- Schieb, C.; Preuss, M. Governing hate speech by means of counterspeech on Facebook. In Proceedings of the 66th ICA Annual Conference, Fukuoka, Japan, 9–13 June 2016; pp. 1–23. [Google Scholar]
- Preuß, M.; Tetzlaff, F.; Zick, A. Publizieren wird zur Mutprobe. In Studie zur Wahrnehmung von und Erfahrungen mit Angriffen unter JournalistInnen [Publishing Is Becoming a Test of Courage: A Study on Perceptions and Experiences Concerning Aggression Among Journalists]. Report; Mediendienst Integration: Berlin, Germany, 2017. [Google Scholar]
- Bartlett, J.; Krasodomski-Jones, A. Counter-Speech Examining Content That Challenges Extremism Online. DEMOS. October 2015. Available online: https://demos.co.uk/wp-content/uploads/2015/10/Counter-speech.pdf (accessed on 30 December 2024).
- Delgado, R.; Stefancic, J. Hate speech in cyberspace. Wake Forest L. Rev. 2014, 49, 319. [Google Scholar]
- Darley, J.M. The Unresponsive Bystander: Why Doesn’t He Help? Appleton-Century Crofts: New York, NY, USA, 1970. [Google Scholar]
- Oinas-Kukkonen, H. A foundation for the study of behavior change support systems. Pers. Ubiquitous Comput. 2013, 17, 1223–1235. [Google Scholar] [CrossRef]
- Oinas-Kukkonen, H.; Harjumaa, M. Towards deeper understanding of persuasion in software and information systems. In Proceedings of the First International Conference on Advances in Computer-Human Interaction, Sainte Luce, France, 10–15 February 2008; pp. 200–205. [Google Scholar]
- Fogg, B.J. Creating persuasive technologies: An eight-step design process. In Proceedings of the 4th International Conference on Persuasive Technology, Claremont, CA, USA, 26–29 April 2009; pp. 1–6. [Google Scholar]
- Alhasani, M.; Mulchandani, D.; Oyebode, O.; Orji, R. A Systematic Review of Persuasive Strategies in Stress Management Apps. BCSS@ PERSUASIVE 2020. Available online: https://ceur-ws.org/Vol-2662/BCSS2020_paper4.pdf (accessed on 30 December 2024).
- Orji, R.; Moffatt, K. Persuasive technology for health and wellness: State-of-the-art and emerging trends. Health Inform. J. 2018, 24, 66–91. [Google Scholar] [CrossRef]
- Widyasari, Y.D.L.; Nugroho, L.E.; Permanasari, A.E. Persuasive technology for enhanced learning behavior in higher education. Int. J. Educ. Technol. High. Educ. 2019, 16, 1–16. [Google Scholar] [CrossRef]
- Win, K.T.; Mullan, J.; Howard, S.K.; Oinas-Kukkonen, H. Persuasive Systems Design Features in Promoting Medication Management for Consumers. 2017. Available online: https://scholarspace.manoa.hawaii.edu/server/api/core/bitstreams/e876d59d-2ae4-4089-a482-40881f39d75d/content (accessed on 4 January 2025).
- Atlam, E.S.; Ewis, A.; Abd El-Raouf, M.; Ghoneim, O.; Gad, I. A new approach in identifying the psychological impact of COVID-19 on university student’s academic performance. Alex. Eng. J. 2022, 61, 5223–5233. [Google Scholar] [CrossRef]
- Mohammed, Z.; Arafa, A.; Atlam, E.S.; El-Qerafi, N.; El-Shazly, M.; Al-Hazazi, O.; Ewis, A. Psychological problems among the university students in Saudi Arabia during the COVID-19 pandemic. Int. J. Clin. Pract. 2021, 75, e14853. [Google Scholar] [CrossRef]
- Elaheebocus, S.M.R.A.; Weal, M.; Morrison, L.; Yardley, L. Peer-based social media features in behavior change interventions: Systematic review. J. Med. Internet Res. 2018, 20, e8342. [Google Scholar] [CrossRef] [PubMed]
- Wiafe, I.; Koranteng, F.N.; Owusu, E.; Ekpezu, A.O.; Gyamfi, S.A. Persuasive social features that promote knowledge sharing among tertiary students on social networking sites: An empirical study. J. Comput. Assist. Learn. 2020, 36, 636–645. [Google Scholar] [CrossRef]
- Introducing ChatGPT. Available online: https://openai.com/index/chatgpt/ (accessed on 30 December 2024).
- Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Lovenia, H.; Ji, Z.; Yu, T.; Chung, W.; et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv 2023, arXiv:2302.04023. [Google Scholar]
- Guo, B.; Zhang, X.; Wang, Z.; Jiang, M.; Nie, J.; Ding, Y.; Yue, J.; Wu, Y. How close is chatgpt to human experts? comparison corpus, evaluation, and detection. arXiv 2023, arXiv:2301.07597. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Chiu, K.L.; Collins, A.; Alexander, R. Detecting hate speech with gpt-3. arXiv 2021, arXiv:2103.12407. [Google Scholar]
- Li, L.; Fan, L.; Atreja, S.; Hemphill, L. “HOT” ChatGPT: The promise of ChatGPT in detecting and discriminating hateful, offensive, and toxic comments on social media. ACM Trans. Web 2024, 18, 1–36. [Google Scholar] [CrossRef]
- He, X.; Zannettou, S.; Shen, Y.; Zhang, Y. You only prompt once: On the capabilities of prompt learning on large language models to tackle toxic content. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2024; pp. 770–787. [Google Scholar]
- Zannettou, S.; Finkelstein, J.; Bradlyn, B.; Blackburn, J. A quantitative approach to understanding online antisemitism. In Proceedings of the International AAAI Conference on Web and Social Media, Buffalo, NY, USA, 3–6 June 2020; Volume 14, pp. 786–797. [Google Scholar]
- Warner, W.; Hirschberg, J. Detecting hate speech on the world wide web. In Proceedings of the Second Workshop on Language in Social Media, Montreal, QC, Canada, 7 June 2012; pp. 19–26. [Google Scholar]
- Sambasivan, N.; Batool, A.; Ahmed, N.; Matthews, T.; Thomas, K.; Gaytán-Lugo, L.S.; Nemer, D.; Bursztein, E.; Churchill, E.; Consolvo, S. “They Don’t Leave Us Alone Anywhere We Go” Gender and Digital Abuse in South Asia. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–14. [Google Scholar]
- Kwak, H.; Blackburn, J.; Han, S. Exploring cyberbullying and other toxic behavior in team competition online games. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 3739–3748. [Google Scholar]
- Cheng, J.; Danescu-Niculescu-Mizil, C.; Leskovec, J. Antisocial behavior in online discussion communities. In Proceedings of the International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015; Volume 9, pp. 61–70. [Google Scholar]
- Thomas, K.; Akhawe, D.; Bailey, M.; Boneh, D.; Bursztein, E.; Consolvo, S.; Dell, N.; Durumeric, Z.; Kelley, P.G.; Kumar, D.; et al. Sok: Hate, harassment, and the changing landscape of online abuse. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 247–267. [Google Scholar]
- Citron, D.K. Addressing cyber harassment: An overview of hate crimes in cyberspace. Case W. Res. JL Tech. Internet 2014, 6, 1. [Google Scholar]
- Khali, L. Identifying cyber hate: Overview of online hate speech policies &finding possible measures to counter hate speech on internet. J. Media Stud. 2019, 31. Available online: http://111.68.103.26//journals/index.php/jms/article/view/1925 (accessed on 30 December 2024).
- Alorainy, W.; Burnap, P.; Liu, H.; Williams, M.L. “The enemy among us” detecting cyber hate speech with threats-based othering language embeddings. ACM Trans. Web (TWEB) 2019, 13, 1–26. [Google Scholar] [CrossRef]
- Casula, C.; Tonelli, S. Generation-Based Data Augmentation for Offensive Language Detection: Is It Worth It? In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023; pp. 3359–3377. [Google Scholar]
- Liu, Q.; Wu, X.; Zhao, X.; Zhu, Y.; Xu, D.; Tian, F.; Zheng, Y. When MOE Meets LLMs: Parameter Efficient Fine-tuning for Multi-task Medical Applications. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 1104–1114. [Google Scholar]
- Adaji, I.; Adisa, M. A review of the use of persuasive technologies to influence sustainable behaviour. In Proceedings of the Adjunct Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization, Barcelona, Spain, 4–7 July 2022; pp. 317–325. [Google Scholar]
- Oinas-Kukkonen, H.; Harjumaa, M. Persuasive systems design: Key issues, process model and system features 1. In Routledge Handbook of Policy Design; Routledge: New York, NY, USA, 2018; pp. 87–105. [Google Scholar]
- Jain, A. Impact of Digitalization and Artificial Intelligence as Causes and Enablers of Organizational Change; Nottingham University Business School: Nottingham, UK, 2021. [Google Scholar]
- Ahmad, W.N.W.; Salim, M.H.M.; Rodzuan, A.R.A. An Inspection of Learning Management Systems on Persuasiveness of Interfaces and Persuasive Design: A Case in a Higher Learning Institution. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 684–692. [Google Scholar] [CrossRef]
- Bergram, K.; Djokovic, M.; Bezençon, V.; Holzer, A. The digital landscape of nudging: A systematic literature review of empirical research on digital nudges. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–16. [Google Scholar]
- Chen, C.; Shu, K. Combating misinformation in the age of llms: Opportunities and challenges. AI Mag. 2023, 45, 354–368. [Google Scholar] [CrossRef]
- Oyebode, O.; Alqahtani, F.; Orji, R. Exploring for possible effect of persuasive strategy implementation choices: Towards tailoring persuasive technologies. In Proceedings of the International Conference on Persuasive Technology, Virtual Event, 29–31 March 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 145–163. [Google Scholar]
- Halttu, K.; Oinas-Kukkonen, H. Need for cognition among users of self-monitoring systems for physical activity: Survey study. JMIR Form. Res. 2021, 5, e23968. [Google Scholar] [CrossRef] [PubMed]
- Bandura, A. Social Cognitive Theory of Self-Regulation. Organ. Behav. Hum. Decis. Processes 1991, 50, 248–287. [Google Scholar] [CrossRef]
- Kitchenham, B.; Pickard, L.; Pfleeger, S.L. Case studies for method and tool evaluation. IEEE Softw. 1995, 12, 52–62. [Google Scholar] [CrossRef]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer: Berlin, Germany, 2012; Volume 236. [Google Scholar]
- Peng, J.; Yang, W.; Wei, F.; He, L. Prompt for extraction: Multiple templates choice model for event extraction. Knowl.-Based Syst. 2024, 289, 111544. [Google Scholar] [CrossRef]
- Ziegler, A.; Berryman, J. A developer’s guide to prompt engineering and LLMs. GitHub Blog. 2023, 17. Available online: https://github.blog/ai-and-ml/generative-ai/prompt-engineering-guide-generative-ai-llms/ (accessed on 10 January 2025).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Li, Y. A practical survey on zero-shot prompt design for in-context learning. arXiv 2023, arXiv:2309.13205. [Google Scholar]
- MacNeil, S.; Tran, A.; Kim, J.; Huang, Z.; Bernstein, S.; Mogil, D. Prompt middleware: Mapping prompts for large language models to UI affordances. arXiv 2023, arXiv:2307.01142. [Google Scholar]
- Feng, Y.; Li, L.; Xiang, Y.; Qin, X. PromptCL: Improving event representation via prompt template and contrastive learning. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Foshan, China, 12–15 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 261–272. [Google Scholar]
- Williams, A. How to… Write and analyse a questionnaire. J. Orthod. 2003, 30, 245–252. [Google Scholar] [CrossRef] [PubMed]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 512–515. [Google Scholar]
- Sandvig, C.; Hamilton, K.; Karahalios, K.; Langbort, C. Auditing algorithms: Research methods for detecting discrimination on internet platforms. Data Discrim. Convert. Crit. Concerns Into Product. Inq. 2014, 22, 4349–4357. [Google Scholar]
- Gillespie, T. Custodians of the Internet: Platforms, Content Moder Ation, and the Hidden Decisions That Shape Social Media; Yale University Press: Dunmore, PA, USA, 2018. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Chandrasekharan, E.; Pavalanathan, U.; Srinivasan, A.; Glynn, A.; Eisenstein, J.; Gilbert, E. You can’t stay here: The efficacy of reddit’s 2015 ban examined through hate speech. Proc. ACM Hum.-Comput. Interact. 2017, 1, 1–22. [Google Scholar] [CrossRef]
- Suler, J. The online disinhibition effect. Cyberpsychol. Behav. 2004, 7, 321–326. [Google Scholar] [CrossRef]
- Schmidt, A.; Wiegand, M. A survey on hate speech detection using natural language processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media, Valencia, Spain, 3–4 April 2017; pp. 1–10. [Google Scholar]
- Crawford, K.; Paglen, T. Excavating AI: The politics of images in machine learning training sets. Ai Soc. 2021, 36, 1105–1116. [Google Scholar] [CrossRef]
- Roberts, S.T. Behind the Screen: Content Moderation in the Shadows of Social Media; Yale University Press: Dunmore, PA, USA, 2019. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age Groups | Gender | Cultural Background | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 18–25 | 26–34 | 35–54 | 55 or Above | Total | Male | Female | Total | European | Middle Eastern | Total | ||
| level of education | No Schooling | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 |
| High school | 12 | 0 | 1 | 3 | 16 | 13 | 3 | 16 | 9 | 7 | 16 | |
| Associate degree | 4 | 10 | 5 | 0 | 19 | 13 | 6 | 19 | 13 | 6 | 19 | |
| Bachelor’s degree | 24 | 20 | 13 | 8 | 65 | 35 | 30 | 65 | 24 | 41 | 65 | |
| Master’s degree | 0 | 3 | 8 | 3 | 14 | 5 | 9 | 14 | 11 | 3 | 14 | |
| Doctorate degree | 0 | 0 | 2 | 0 | 2 | 0 | 2 | 2 | 2 | 0 | 2 | |
| Others | 2 | 1 | 0 | 2 | 5 | 3 | 2 | 5 | 3 | 2 | 5 | |
| Total | 42 | 34 | 30 | 16 | 122 | 70 | 52 | 122 | 63 | 59 | 122 | |
| Class | Tweet Count |
|---|---|
| Non-Hate (0) | 338 |
| Hate (1) | 260 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almaliki, M.; Almars, A.M.; Aljuhani, K.O.; Atlam, E.-S. Combining the Strengths of LLMs and Persuasive Technology to Combat Cyberhate. Computers 2025, 14, 173. https://doi.org/10.3390/computers14050173
Almaliki M, Almars AM, Aljuhani KO, Atlam E-S. Combining the Strengths of LLMs and Persuasive Technology to Combat Cyberhate. Computers. 2025; 14(5):173. https://doi.org/10.3390/computers14050173
Chicago/Turabian StyleAlmaliki, Malik, Abdulqader M. Almars, Khulood O. Aljuhani, and El-Sayed Atlam. 2025. "Combining the Strengths of LLMs and Persuasive Technology to Combat Cyberhate" Computers 14, no. 5: 173. https://doi.org/10.3390/computers14050173
APA StyleAlmaliki, M., Almars, A. M., Aljuhani, K. O., & Atlam, E.-S. (2025). Combining the Strengths of LLMs and Persuasive Technology to Combat Cyberhate. Computers, 14(5), 173. https://doi.org/10.3390/computers14050173