1. Introduction
Fifth-generation (5G) and beyond networks are planned to enable a wide range of new applications like industry v4, automobiles, and smart cities, which have substantially higher performance and cost requirements than traditional mobile broadband services [
1]. Therefore, these networks should have flexible and scalable structures for meeting these different constraints, including performance, security, availability, and cost minimization. To achieve these goals, network slicing has been proposed by researchers and industry as a key enabler to offering customized 5G network services using the same physical network infrastructure [
2]. Thanks to Network Functions Virtualization (NFV) and Software Defined Networking (SDN) technologies, which paved the way to creating network slices that enable many logical networks to operate independently over shared physical infrastructure [
3], each logical network can offer personalized services for a certain application scenario [
4].
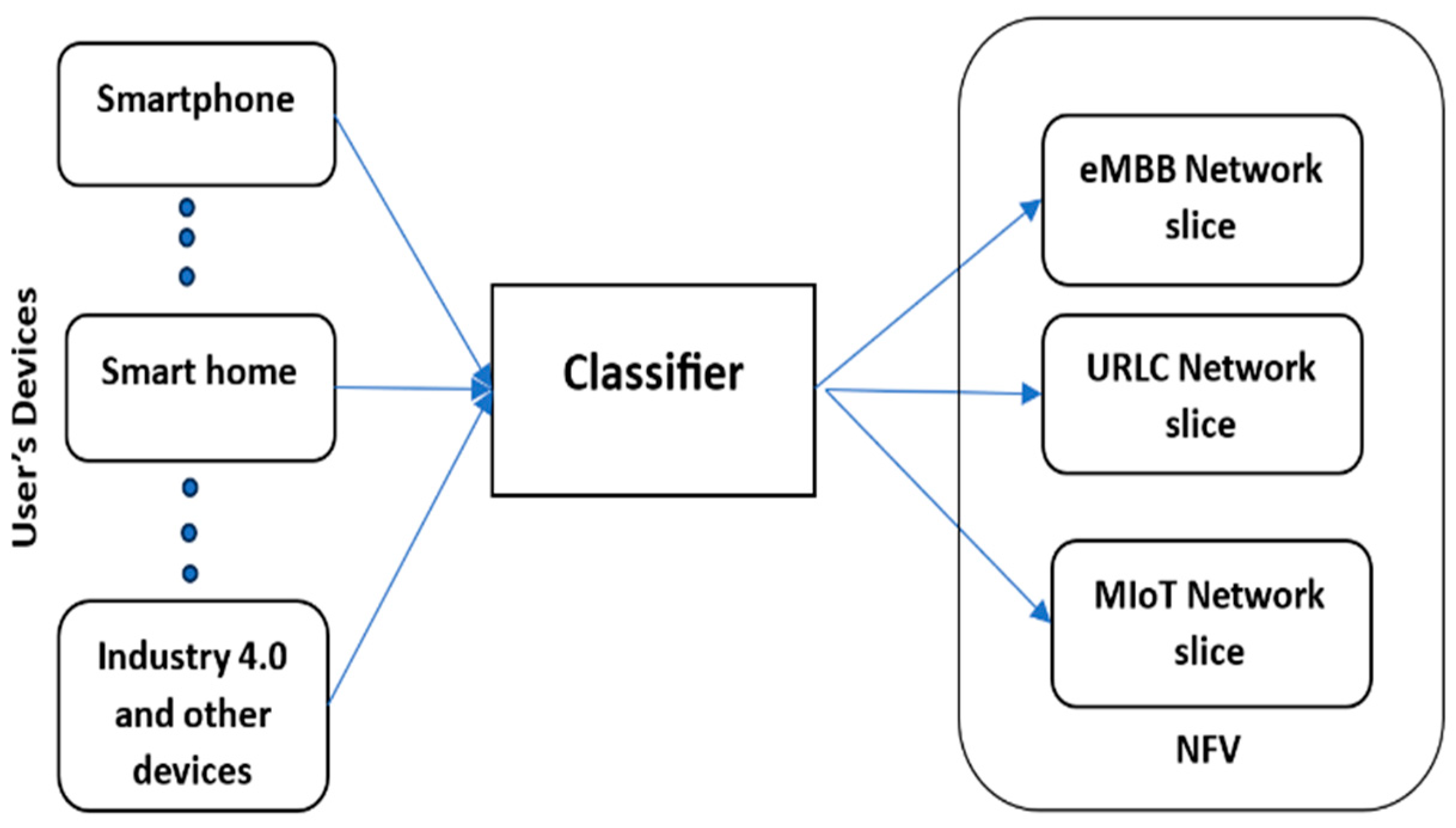
Network slicing creates multiple virtual networks in a single physical infrastructure, where each virtual network meets the requirements for a specific service.
In 5G networks, large amounts of data should be analyzed before decisions are made to select network slices to ensure that the network can adequately meet QoS requirements [
4]. Therefore, machine and deep learning models can be used to analyze large amounts of data and make the most accurate predictions of network slices in 5G networks. Additionally, these models should be optimized in terms of complexity to provide fast decisions for network slicing [
5].
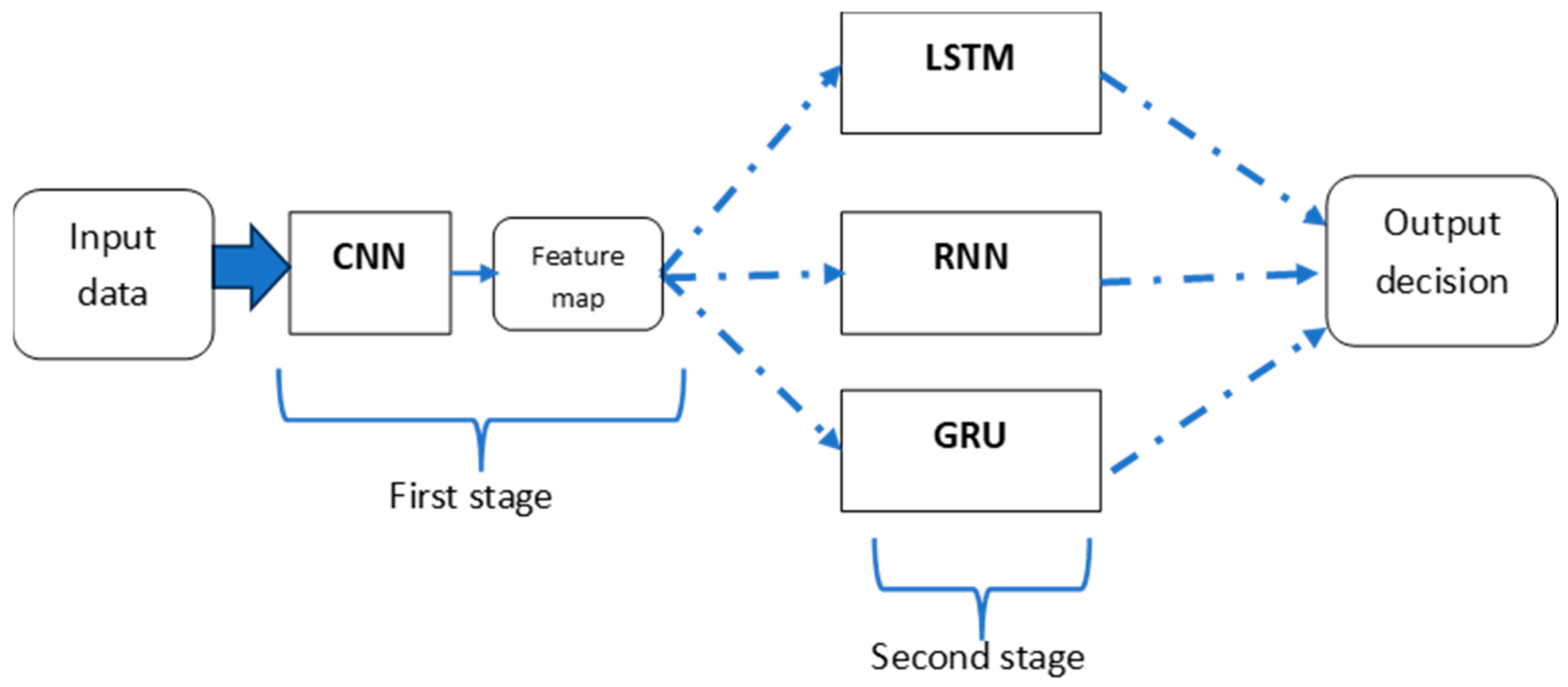
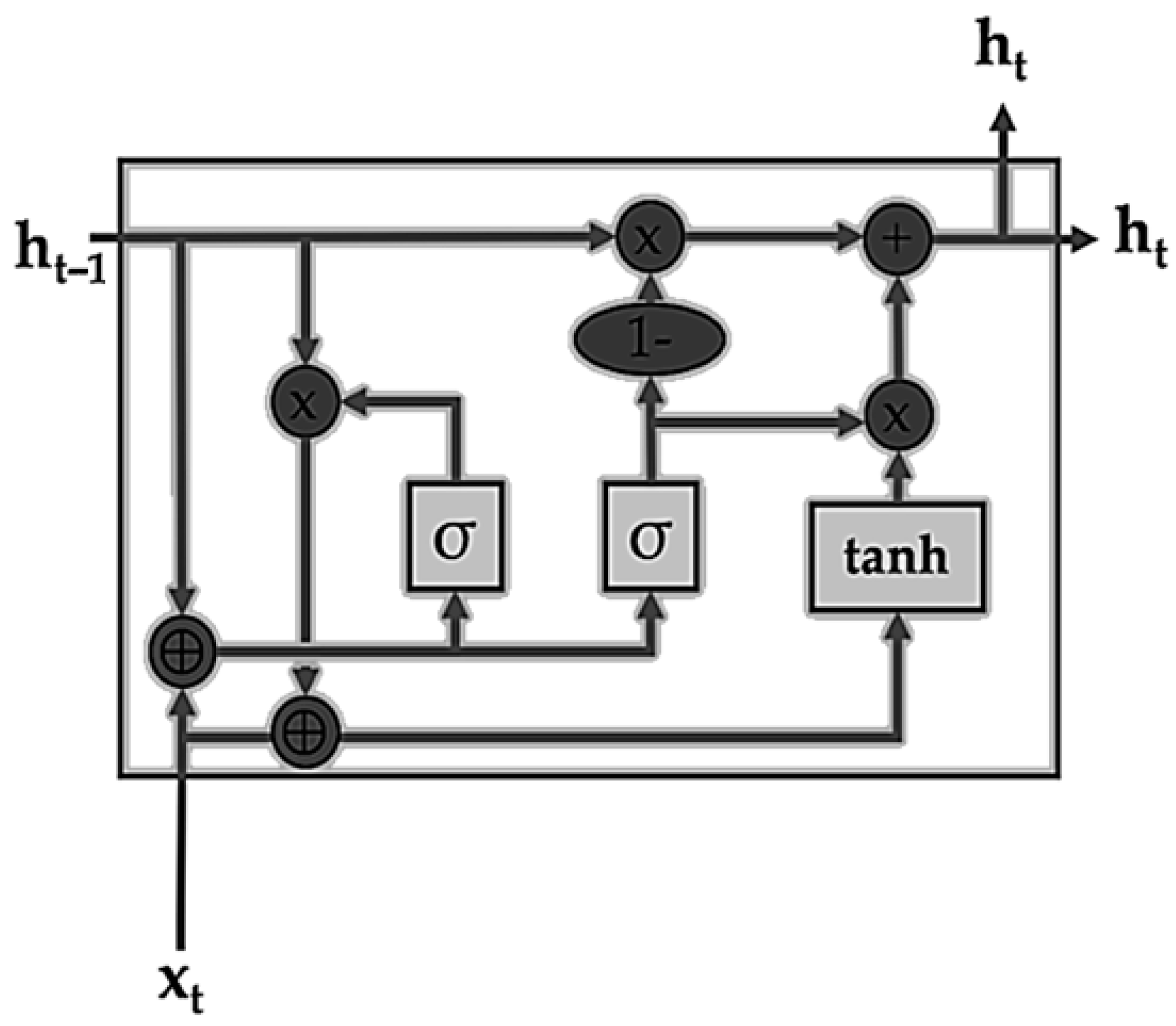
The hybridization of different deep learning methods can leverage the complementary strengths of each model and improve generalization, therefore leading to better performance, robustness, or adaptability.
Convolutional neural networks have the advantage of extracting and reducing spatial features, whereas recurrent neural networks are superior at modeling sequential or temporal dependencies. Therefore, combining convolutional neural networks with recurrent neural network variations can lead to better accuracy when used for network slicing. Although combining different deep learning methods can result in relatively complex models, optimization techniques can be beneficial for reducing the model complexity by selecting the best hyperparameters while assuring the best model performance.
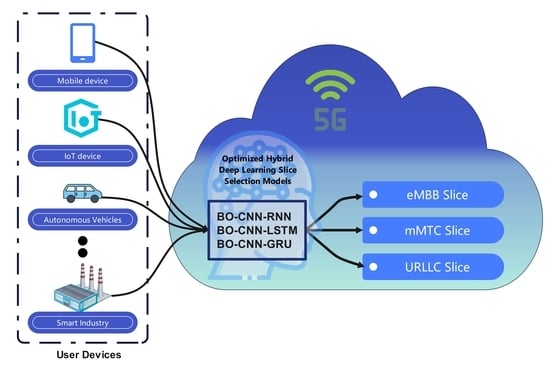
In this paper, an optimized hybrid deep learning-based wireless network slicing model for 5G networks is proposed to accurately select the appropriate network slices with less complexity.
The main contributions of this work are summarized as follows:
Multiple hybridizations of DL models, including CNN-LSTM, CNN-RNN, and CNN-GRU, are investigated for building an accurate 5G network slicing model.
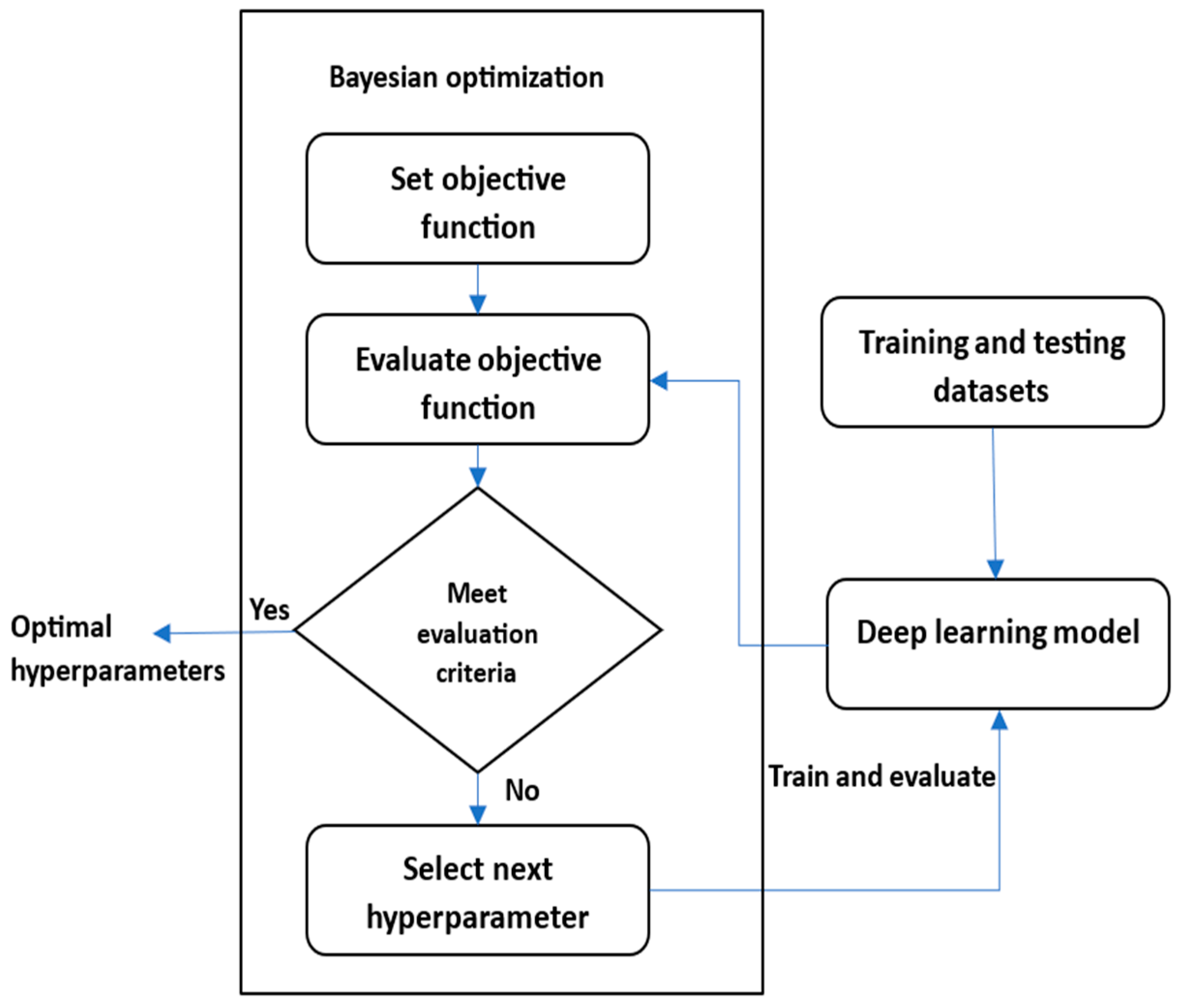
A Bayesian-based algorithm is utilized for hyperparameter and model structure optimization to improve the accuracy and reduce the complexity of the proposed models.
Two types of datasets from different repositories are utilized to analyze and evaluate the performance of the suggested model.
The proposed approach is tested and evaluated using simulated network scenarios.
The rest of the paper is structured as follows. In
Section 2, the most related works are discussed. The theoretical background of the main components of this work is described in
Section 3.
Section 4 illustrates the proposed methods. The evaluation of the proposed methods is described in
Section 5. Finally, the conclusions are presented in
Section 6.
2. Related Work
There are several research studies which focused on designing efficient decision making to select accurate slicing in a network environment. A concise review of the most relevant literature is illustrated below.
In [
6], based on a device’s important attributes, a hybrid network slicing mechanism based on CNN-LSTM was presented for the best prediction of the most suitable network slice for all incoming network traffic. The CNN is responsible for resource allocation and slice selection, and the LSTM manages network slice load balancing. The necessity for efficient network slicing in 5G is critical in terms of lowering network operator costs and energy usage while maintaining service quality. The authors of [
7] used application-specific radio spectrum scheduling to apply deep learning models to the radio access network (RAN) slicing architecture. In [
8], the authors applied an auto-encoded neural network architecture which is known as the deep auto-encoded dense neural network algorithm for network slicing. The authors of [
9,
10,
11] forecasted future traffic demand patterns using deep neural networks (DNNs) based on either the spatiotemporal linkages between stations or the real-time network traffic load. The research studies in [
12,
13,
14] applied the recurrent neural network (RNN) for network slicing along with mobility prediction and management in wireless 5G networks. Additionally, in [
15,
16,
17,
18], the authors used a slicing strategy based on reinforcement learning (RL), where for network slicing, RL revises resource allocation choices. In [
19], the authors proposed a framework for maximizing device application performance using optimized network slice resources. To solve network load balancing issues more effectively, a machine learning-based network sub-slicing framework in a sustainable 5G environment was designed, where each logical slice was separated into a resource-virtualized sub-slice. In [
20,
21], the authors utilized the Support Vector Machine (SVM) algorithm to automate network functions for the creation, construction, deployment, operation, control, and management of network slices. Likewise, the authors of [
22] used various machine learning methods such as Extra Tree, AdaBoost, SVM, extreme gradient boosting (xGB), Light Gradient Boosting Machine (LGBM), k-nearest neighbors (k-NN), and multi-layer perceptrons (MLPs) for slice-type classification. In [
23], different deep learning models such as the attention-based encoder decoder, MLP, LSTM, and GRU are used to predict network slice segmentation (streaming, messaging, search, and cloud).
Unlike the previous research studies, which focused on a standalone or single approach in network slicing classification, there is another research route that focuses on using hybrid deep learning methods in the context of network slicing. The work that used hybridization of deep learning methods for network slicing is summarized as follows.
The authors of [
24] used a 5G network slicing dataset to build a hybrid learning technique that included three phases: data collection, Optimal Weighted Feature Extraction (OWFE), and slicing classification. To improve network slicing effectiveness and accuracy, the author used glowworm swarm optimization and deer hunting optimization algorithms with neural networks and deep belief network-based network slicing. For efficient network slicing in 5G networks, the authors of [
25] suggested a three-phase process that consists of loading the dataset, optimizing using Harris Hawk Optimization (HHO), and a hybrid deep learning model for network slice classification. Initially, they imported the datasets and optimized the hyperparameters using HHO. After that, a hybrid deep learning model based on LSTM and a CNN is employed.
Although different deep learning techniques, including hybrid models, have been employed for 5G network slicing, more improvements are still required due to the continuous increase in the number of applications and user devices in 5G and beyond networks. This can be achieved through the investigation of different combinations of hybrid deep learning models and optimization techniques to achieve higher accuracy with consideration of complexity reduction. In addition, using different datasets for evaluating the model ensures the generalization and robustness of the final model.
5. Results and Discussion
The performance of the proposed hybrid models is examined in this section. The evaluation process is divided into two parts. The first part involves the proposed hybrid models’ evaluation, while the second part of the evaluation focuses on the network performance with a selected slicing model. The applicability of the proposed model was investigated individually using the DeepSlice dataset and the 5G Network Slicing dataset. Ten-fold cross-validation was used with a ratio of 70:30 for training and testing, respectively. The evaluation parameters described in
Section 4.2 were considered. The proposed models were initially evaluated without using hyperparameter optimization, and then evaluation was achieved with the presence of the BO optimization algorithm. Initially, the hyperparameters illustrated in
Table 3 were manually selected for each hybrid model using trial experiments.
The evaluation results for each model using the DeepSlice dataset and the 5G Network Slicing dataset are shown in
Table 4 and
Table 5, respectively.
It can be noticed that for both datasets, the CNN-GRU model achieved the highest accuracy. The CNN-LSTM model achieved comparable performance to the CNN-GRU model. On the other hand, the CNN-RNN model achieved the worst performance compared with the CNN-LSTM and CNN-GRU models. This is because these two models (CNN-GRU and CNN-LSTM) are better at capturing the long-term dependencies from the data compared with the CNN-RNN model. It is worth mentioning that the models trained using a larger DeepSlice dataset obtained better accuracy, as shown in
Table 4, compared with the models trained using the 5G Network Slicing dataset. Generally, a large dataset provides more information, which leads to more generalization in the model. Alternatively, the 5G Network Slicing dataset has additional features that could introduce noise or might be nonrelevant, therefore providing models with lower accuracy.
Regarding the complexity analysis of the proposed CNN-RNN, CNN-LSTM, and CNN-GRU methods, it is worth stating that the complexity difference mainly depends on the RNN, LSTM, and GRU parts of the method, since the CNN is common.
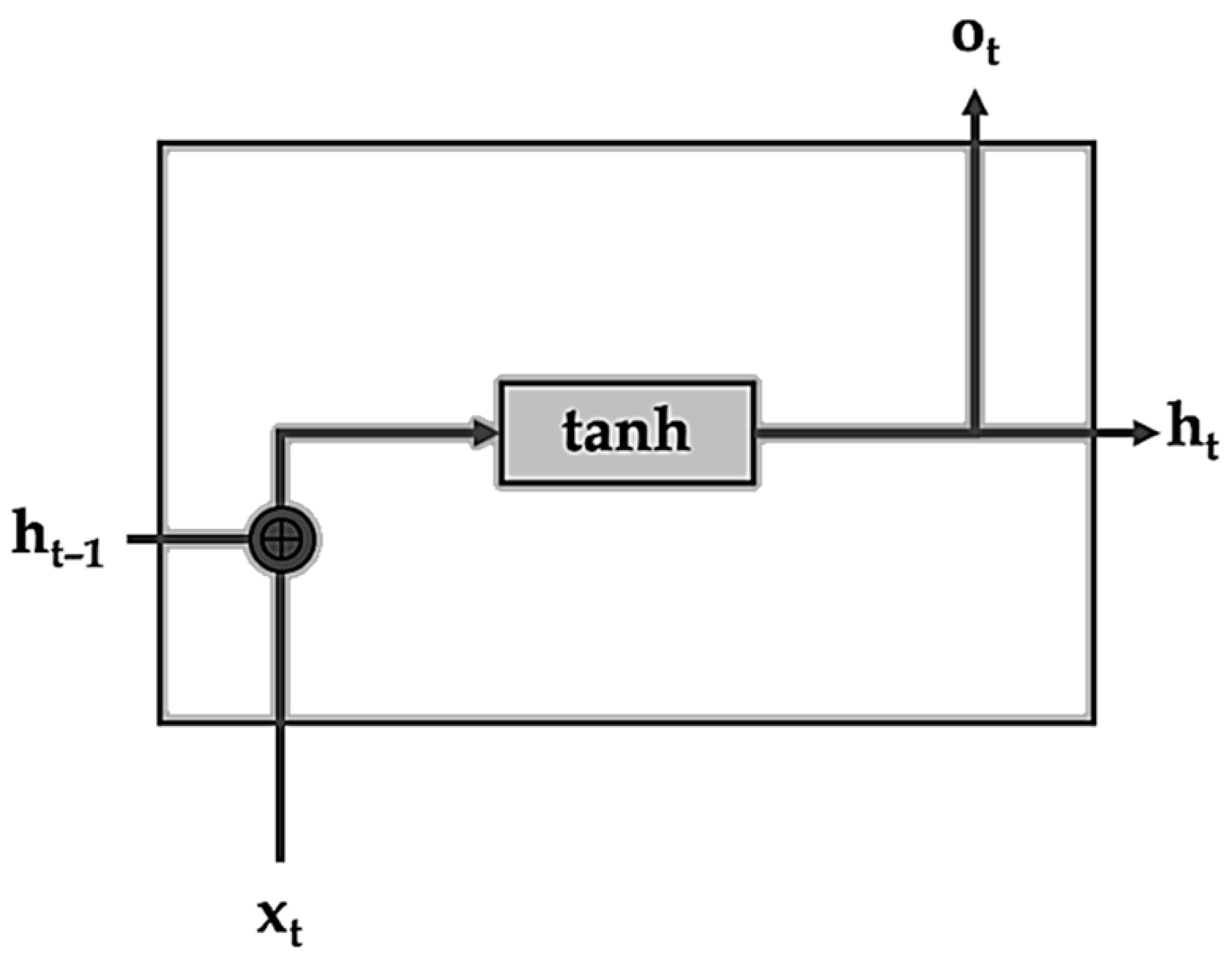
The complexity of the CNN algorithm depends on the input size, number of filters, filter size, and depth. The complexity of the RNN unit depends on the weights for the input and the hidden state only. The complexity of the GRU unit depends on the weights for the input and the hidden state, with additional update gate and reset gate weights. On the other hand, the complexity of LSTM units depends on four sets of weights for each gate or cell update. Therefore, the CNN-LSTM model is considered the most complex model, the CNN-GRU is the moderate model, and the CNN-RNN is the least complex model.
It is worth mentioning that the model complexity had an inverse proportion with the scalability of the model and a direct proportion with the training time when using larger data and model sizes.
Then, the BO optimization technique was used to tune the hyperparameters to improve the accuracy and reduce the complexity of the proposed models by reducing the number of model units.
Based on the constraints mentioned in
Section 3.3, both the search range for the selected parameter and the optimal value were obtained using BO for the proposed models trained with the DeepSlice dataset and for the same models trained with the 5G Network Slicing dataset, as shown in
Table 6 and
Table 7, respectively.
It can be observed that after using the best optimized hyperparameters, the evaluation results for the optimized models using the DeepSlice dataset are shown in
Table 8, and the results while using the 5G Network Slicing dataset are shown in
Table 9.
It can be noticed that, based on the results for both datasets in
Table 8 and
Table 9, the BO-CNN-GRU model with optimized hyperparameters obtained the highest accuracy, followed by the BO-CNN-LSTM and BO-CNN-RNN models. The optimized BO-CNN-LSTM model achieved highly comparable results to the BO-CNN-GRU model. However, it is worth stating that the number of units (layers) in the BO-CNN-GRU model (two units) was smaller than the number of units in the BO-CNN-LSTM (four and five units) model. Therefore, the optimized BO-CNN-GRU model had less complexity.
To investigate the impact of hyperparameter optimization, a comparison between the performance of the proposed hybrid deep learning models with and without using hyperparameter optimization was achieved as shown in
Figure 11 for both datasets.
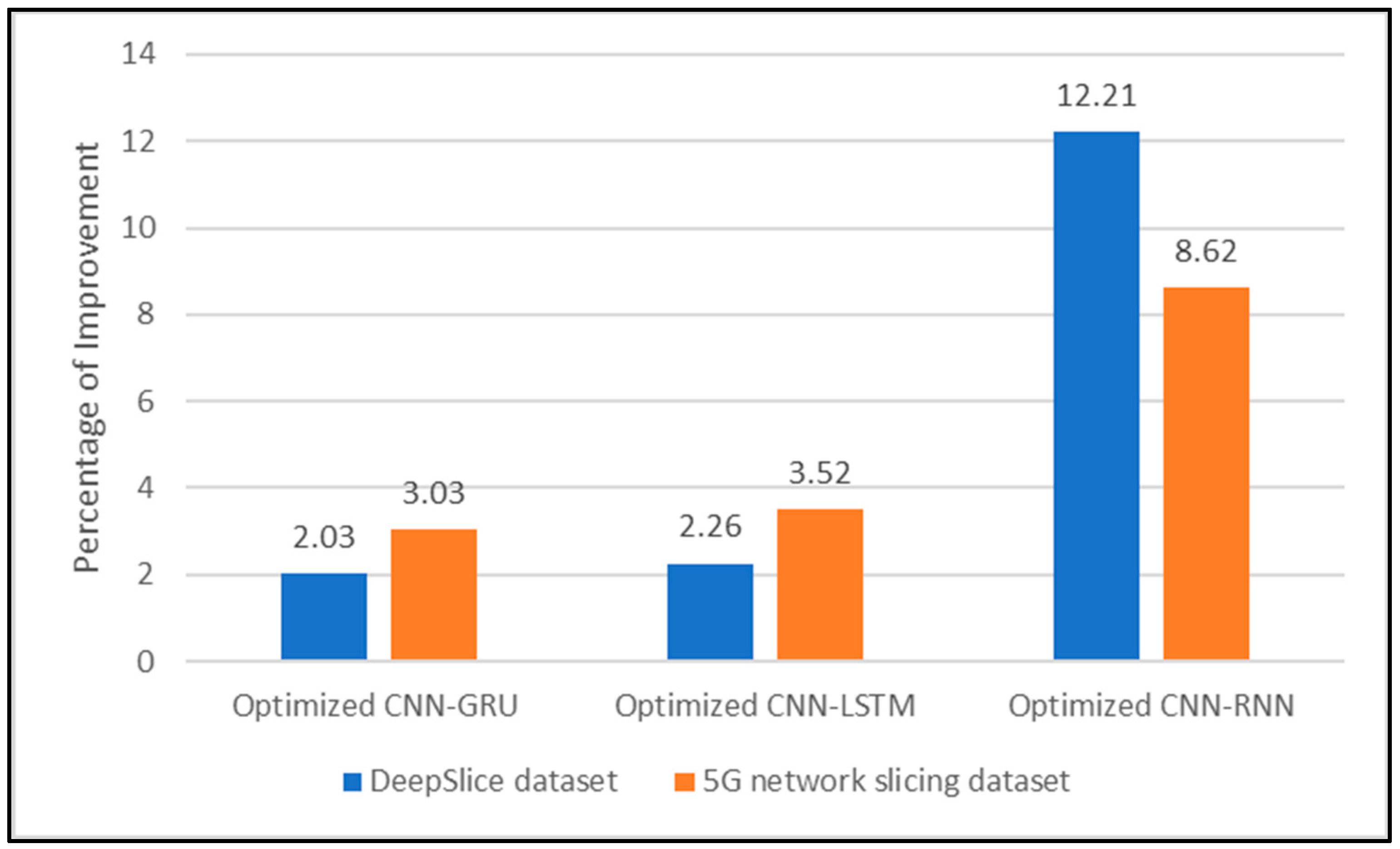
The results in
Figure 11 show that using hyperparameter optimization had a positive impact on increasing the model’s performance. The percentage of improvement in the proposed models in terms of accuracy with hyperparameter optimization is summarized in
Figure 12.
Although the CNN-RNN did not achieve the highest results in terms of accuracy, the use of hyperparameter optimization resulted in significant improvement in the model’s performance.
Based on the evaluation results of the proposed hybrid deep learning models for 5G mobile network slicing, it was found that the hybrid BO-CNN-GRU model with optimized hyperparameters using the BO algorithm stratified the required aim of this research in terms of accuracy and complexity (accuracy of 99.31% and two GRU units). Therefore, it was selected as a slice prediction model.
Table 10 provides a comparison between the performance of the proposed best BO-CNN-GRU model in terms of accuracy and the state-of-the-art methods using similar datasets.
The comparison shown in
Table 10 shows that the proposed optimized BO-CNN- GRU and BO-CNN-LSTM hybrid models outperformed the other similar, state-of-the-art methods in terms of accuracy. Based on the results presented in
Table 10, the hybrid deep learning models [
6,
24,
25] and the proposed BO-CNN-GRU model achieved higher accuracy when compared with the standalone deep learning models in [
2,
25,
32]. This is due fact that the hybrid model can gain the best merit of the combined methods.
When comparing the proposed BO-CNN-GRU model to the GS-DHOA-NN+DBN [
24] model, the proposed model can provide greater accuracy, since the CNN-GRU model is better in some aspects, such as learning spatial and temporal features, compared with neural networks and deep belief networks, which aim to learn unsupervised features only. Comparing the HHO-CNN-LSTM [
25] model with the proposed BO-CNN-GRU model shows that our model provided greater accuracy because the GRU has a simpler structure, which reduces the risk of overfitting. Additionally, it was fine-tuned better by the proposed BO optimization.
The obtained results show that the Deepslice dataset provided the models with better accuracy compared with the 5G Network Slicing dataset, as the larger dataset presented numerous examples, enhancing the model’s potential to generalize and reduce overfitting.
The next evaluation stage will focus on comparing the network performance using the best obtained BO-CNN-GRU slicing model and the less accurate BO-CNN-RNN model.
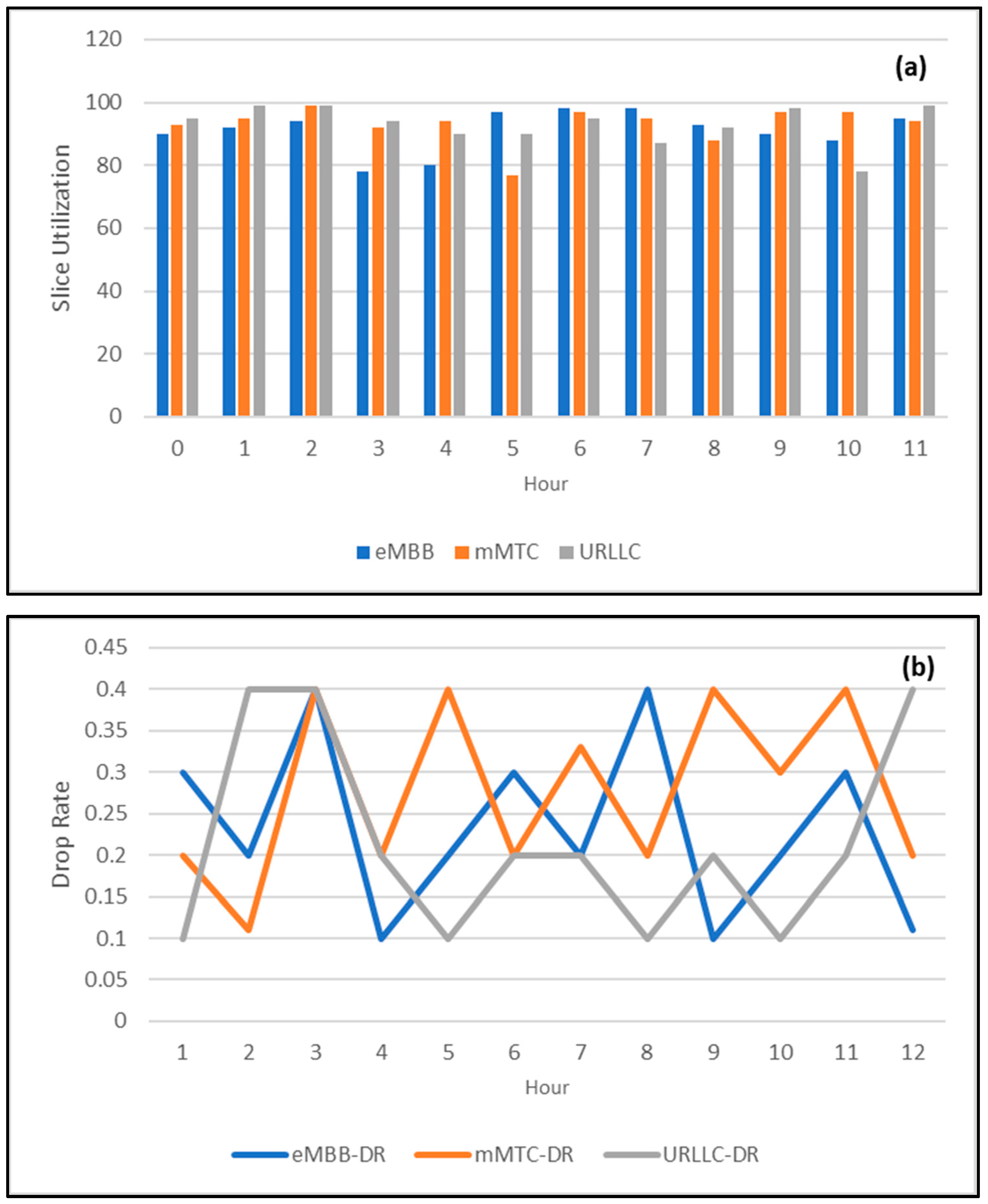
In the first scenario, to verify the effectiveness of the optimized BO-CNN-GRU slicing model, a 12-h network simulation was carried out. Over 250,000 user connection requests were generated, which consisted of 50% eMBB, 20% mMTC, and 30% URLLC.
Figure 13 shows the simulation results in terms of the slice utilization (which is the ratio between used resources and the available resources in a specific network slice) and user drop rate (which refers to the percentage of users within a specific network slice who were disconnected due to slice overutilization) for the network simulation.
Similarly, in the second scenario, a network simulation was carried out using the less accurate BO-CNN-RNN slicing model. The simulation results in terms of the slice utilization and user drop rate for the second scenario are shown in
Figure 14.
To clarify the difference between the network performance using the accurate BO-CNN-GRU slicing model and the low-accuracy BO-CNN-RNN model, the average enhancement in slice utilization and the reduction in the user drop rate were calculated, as shown in
Table 11.
Based on the results in
Table 11, the average improvement in the network’s slice utilization was 13.53%, and the reduction in the drop rate was 58% when the BO-CNN-GRU slicing model was used compared with the less accurate BO-CNN-RNN slicing model.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}