
Error Classification and Static Detection Methods in Tri-Programming Models: MPI, OpenMP, and CUDA

 , , ,
, , ,  , and
, and
Abstract
1. Introduction
- Single-level, including independent models such as CUDA, MPI, or OpenMP.
- Two programming models, such as MPI + OpenMP or OpenMP + CUDA, are combined to generate dual-level (X + Y) systems that increase parallelism.
- Tri-level (MPI + X + Y) systems consist of three different programming models to improve parallelism.
2. Background
3. Challenges and Testing Techniques
4. Literature Review
Runtime Errors in MPI, OpenMP, and CUDA Programming Models
5. Static Testing Approach Implementation
5.1. Analysis Phase
- The MPI, OpenMP, and CUDA data are stored in vectors.
- These data include the start line number and the end line number of each model.
- The tool gathers information about the explicit barriers in the OpenMP model.
- The kernel definition, kernel launch, data transfer, and memory cleanup regions contain information about the start and end lines.
- The tool sets the start and end values of the variables in every parallel region in the two programming models.
- Finally, the tool records the ‘while’, ‘for’, and ‘do while’ loop data, the dependent variables, and the start and end values of these loops.
5.2. Detection Phase
| Algorithm 1: The MPI deadlock print error when there is a send without a receive or a receive without a send | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | SEARCH for mpi_send and mpi__recv which one happen first |
| 3: | if (mpi_send is found) |
| 4: | IDENTIFY receiver rank |
| 5: | SEARCH for matching mpi_recv at the receiver |
| 6: | if (mpi__recv is found) |
| 7: | MATCH tag, count, sender rank, communicator, datatype |
| 8: | if (there is any MISMATCH) |
| 9: | CONTINUE Search |
| 10: | else |
| 11: | Matching mpi__recv found |
| 12: | end if |
| 13: | if (no matching mpi__recv is found at the receiver rank) |
| 14: | “Print Error: Deadlock No corresponding RECV found” |
| 15: | end if |
| 16: | end if |
| 17: | if (mpi__recv is found) |
| 18: | IDENTIFY Sender rank |
| 19: | SEARCH for a matching mpi_send at the Sender |
| 20: | if (mpi_send is found) |
| 21: | MATCH tag, count, receiver rank, communicator, datatype |
| 22: | if (there is any MISMATCH) |
| 23: | CONTINUE Search |
| 24: | else |
| 25: | Matching mpi_send found |
| 26: | end if |
| 27: | if (no matching mpi_send is found at the sender rank) |
| 28: | “Print Error: Deadlock No corresponding SEND found” |
| 29: | end if |
| 30: | end if |
| Algorithm 2: The MPI livelock print error when an infinite loop develops | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | if (while(true) statement is found in any process) |
| 3: | SEARCH for a possible BREAK of the loop |
| 4: | if (loop BREAK statement is not found) |
| 5: | “Print Error: Livelock MPI process stuck in an infinite loop” |
| 6: | end if |
| 7: | end if |
| Algorithm 3: The MPI data race print error when an infinite loop develops | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | if (mpi_Isend is found) |
| 3: | IDENTIFY receiver rank |
| 4: | SEARCH for a matching mpi_Irecv at the receiver |
| 5: | if (mpi_Irecv is found) |
| 6: | MATCH tag, count, sender rank, communicator, datatype |
| 7: | if (there is any MISMATCH) |
| 8: | CONTINUE Search |
| 9: | else |
| 10: | Matching mpi_Irecv found |
| 11: | end if |
| 12: | if (matching mpi_Irecv is found) |
| 13: | SEARCH for mpi_wait statement after mpi_Isend |
| 14: | if (there is no mpi_wait statement) |
| 15: | “Print Error: Data Race Not waiting for messages to be received before sending again” |
| 16: | end if |
| 17: | else |
| 18: | “Print Error: Deadlock No corresponding mpi_Irecv found” |
| 19: | end if |
| Algorithm 4: The OpenMP deadlock print error when a lock is misused | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | if (OMPSetlock is found) |
| 3: | IDENTIFY lock variable |
| 4: | SEARCH for a corresponding OMPSetlock |
| 5: | if (OMPSetlock is not found) |
| 6: | “Print Error: Deadlock Lock is set but not unset” |
| 7: | end if |
| 8: | end if |
| Algorithm 5: The OpenMP deadlock print error when an infinite loop develops in a critical section | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | if (OMPcritical construct is found) |
| 3: | CHECK that there is no infinite while loop in the critical section |
| 4: | if (infinite while loop is found inside critical section) |
| 5: | “Print Error: Deadlock because One thread enters the critical section and the others keep on waiting” |
| 6: | end if |
| 7: | end if |
| Algorithm 6: The OpenMP livelock print error when an infinite loop develops in a #pragma construct | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | if (while(true) statement is found inside a #pragma construct) |
| 3: | SEARCH for a possible BREAK of the loop |
| 4: | else if (loop BREAK statement is not found) |
| 5: | “Print Error: Livelock occur because threads stuck in an infinite loop” |
| 6: | end If |
| 7: | end if |
| Algorithm 7: The CUDA print error when an atomicCAS operation is misused | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | SEARCH for cudakernel |
| 3: | IDENTIFY cudakernel name |
| 4: | if (atomicCAS statement if found inside cudakernel) |
| 5: | “Print Error: Deadlock Because Only one thread allowed to access critical section” |
| 6: | end if |
| Algorithm 8: The CUDA livelock print error when a kernel is called repeatedly in an infinite loop | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | IDENTIFY cudakernel name |
| 3: | FIND where cudakernel is being called |
| 4: | if (cudakernel is being called in an infinite loop) |
| 5: | “Print Error: Livelock: Kernel is being called repeatedly” |
| 6: | end if |
| Algorithm 9: The OpenMP data race print error | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | SEARCH for #PRAGMA construct |
| 3: | If (#PRAGMA construct is found) |
| 4: | FIND if it is OMP PARALLEL or OMP PARALLEL FOR |
| 5: | If (OMP PARALLEL is found || OMP PARALLEL FOR IS FOUND) |
| 6: | CHECK if there is a for loop in this section |
| 7: | If (for loop IS FOUND) |
| 8: | IDENTIFY the loop variable |
| 9: | If (an array is using an index other than the loop variable) |
| 10: | “Print Error: DATA RACE: Accessing values that may be |
| updated by other threads” | |
| 11: | end If |
| 12: | end If |
| 13: | end If |
| 14: | end If |
| Algorithm 10: The CUDA data race print error | |
| 1: | OPEN THE INPUT CODE FILE |
| 2: | SEARCH for CUDA Kernel |
| 3: | IDENTIFY CUDA Kernel name |
| 4: | “Print Error: DEADLOCK: Only one thread allowed to access critical section “ |
| 5: | end If |
| Algorithm 11: The dependency errors between the three models in the tri-programming model | |
| 1: | IF MPIDEADLOCK == TRUE |
| 2: | “Print Error: Deadlock in the whole system because there is a deadlock in MPI” |
| 3: | else if ompdeadlock == True |
| 4: | “Print Error: Deadlock in the whole system because there is deadlock in OpenMP” |
| 5: | else if cudadeadlock ==True |
| 6: | “Print Error: Deadlock in the whole system because there is deadlock inCUDA” |
| 7: | if mpiLivelock == True |
| 8: | “Print Error: Livelock in the whole system because there is livelock in MPI” |
| 9: | else if ompLivelock == True |
| 10: | “Print Error: Deadlock in the whole system because there is livelock in OpenMP” |
| 11: | else if CudaLivelock == True |
| 12: | “Print Error: Deadlock in the whole system because there is livelock inCUDA” |
| 13: | else if mpirace == True omprace == True |
| 14: | “Print Error: Race condition in the system because there is race condition in MPI and OpenMP” |
| 15: | else if mpirace == True AND cudarace == True |
| 16: | “Print Error: Race condition in the system because there is race condition in MPI and CUDA” |
| 17: | else if mpirace == True |
| 18: | “Print Error: Race condition and wrong result in the whole systembecause there is race condition in MPI” |
| 19: | else if omprace == True AND cudarace == True |
| 20: | “Print Error: Race condition the system because there is race condition in OpenMP and CUDA” |
| 21: | else if omprace == True |
| 22: | “Print Error: Race condition in the system because there is racecondition in OpenMP” |
| 23: | else if CudaRace == True |
| 24: | “Print Error: Race condition in the system because there is race condition. in CUDA” |
6. Testing and Evaluation
7. Conclusions and the Future Directions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
Appendix A
| Listing A1: The deadlock that occurs when lock_a is set twice in Lines 5 and 7 of the same thread without being unset between the lines. |
 |
| Listing A2: The deadlock that occurs when lock_a is set in each iteration of the loop in the parallel region of the OpenMP section. |
 |
| Listing A3: The deadlock that occurs when lock_a is set in the first section and then unset and destroyed in the second section. |
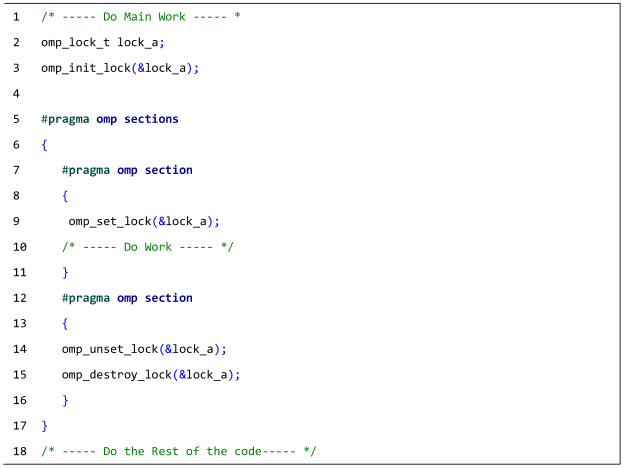 |
| Listing A4: The deadlock that occurs when a lock termination is conditionally executed with an if/else statement. The lock will be released when the condition is met. However, if the condition is not met, the lock remains in place, creating a deadlock. |
 |
| Listing A5: The deadlock that occurs when locks are incorrectly placed and ordered in two OpenMP sections. |
 |
| Listing A6: The deadlock that occurs when P2 arrives at the first receiver (recv), causing the second recv to wait forever. |
 |
| Listing A7: The deadlock that occurs when tags are mismatched or the order of operations has not been properly synchronized. |
 |
| Listing A8: The deadlock that occurs when the data types and tags of the MPI_Send and MPI_Recv operations are mismatched. |
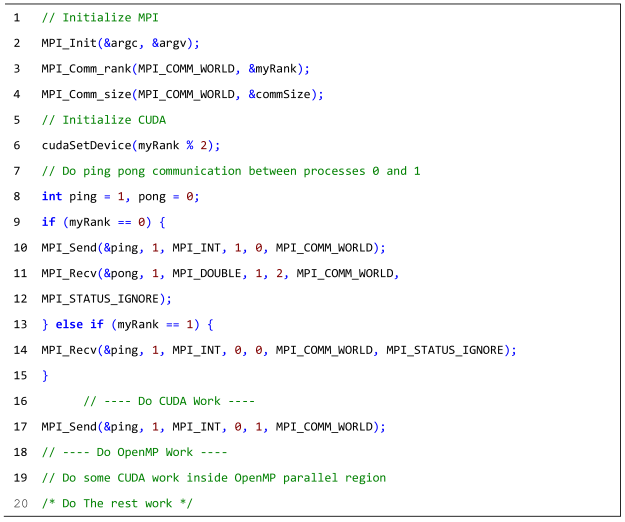 |
| Listing A9: The deadlock that occurs when tags are mismatched and the order of operations has not been properly synchronized. |
 |
| Listing A10: The deadlock that occurs when there are hidden resource leak issues that send without receiving, causing one of the processes to wait indefinitely for messages. |
 |
| Listing A11: The deadlock that occurs when an atomicCAS operation is improperly used in the CUDA kernel. |
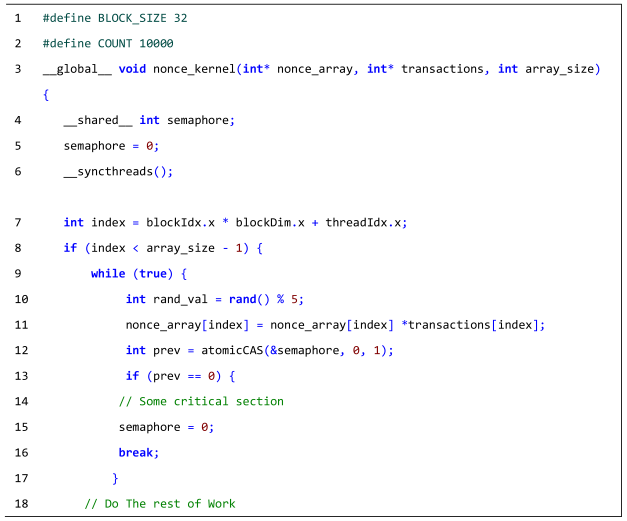 |
| Listing A12: The data race that occurs when the threads are not synchronized post-kernel execution. |
 |
| Listing A13: The livelock that occurs due to an infinite loop in the kernel. |
 |
References
- Miri Rostami, S.R.; Ghaffari-Miab, M. Finite Difference Generated Transient Potentials of Open-Layered Media by Parallel Computing Using OpenMP, MPI, OpenACC, and CUDA. IEEE Trans. Antennas Propag. 2019, 67, 6541–6550. [Google Scholar] [CrossRef]
- MPI Forum MPI Documents. Available online: https://www.mpi-forum.org/docs/ (accessed on 6 February 2023).
- Eassa, F.E.; Alghamdi, A.M.; Haridi, S.; Khemakhem, M.A.; Al-Ghamdi, A.S.A.-M.; Alsolami, E.A. ACC_TEST: Hybrid Testing Approach for OpenACC-Based Programs. IEEE Access 2020, 8, 80358–80368. [Google Scholar] [CrossRef]
- Chatarasi, P.; Shirako, J.; Kong, M.; Sarkar, V. An Extended Polyhedral Model for SPMD Programs and Its Use in Static Data Race Detection. In Lecture Notes in Computer Science; Including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer International Publishing: Cham, Switzerland, 2017; Volume 10136 LNCS, pp. 106–120. [Google Scholar]
- Norman, M.; Larkin, J.; Vose, A.; Evans, K. A Case Study of CUDA FORTRAN and OpenACC for an Atmospheric Climate Kernel. J. Comput. Sci. 2015, 9, 1–6. [Google Scholar] [CrossRef]
- Hoshino, T.; Maruyama, N.; Matsuoka, S.; Takaki, R. CUDA vs OpenACC: Performance Case Studies with Kernel Benchmarks and a Memory-Bound CFD Application. In Proceedings of the 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing, CCGrid 2013, Delft, The Netherlands, 13–16 May 2013; pp. 136–143. [Google Scholar] [CrossRef]
- Sunitha, N.V.; Raju, K.; Chiplunkar, N.N. Performance Improvement of CUDA Applications by Reducing CPU-GPU Data Transfer Overhead. In Proceedings of the 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 10–11 March 2017; IEEE: New York, NY, USA, 2017; pp. 211–215. [Google Scholar]
- NVIDIA About CUDA|NVIDIA Developer. Available online: https://developer.nvidia.com/about-cuda (accessed on 6 February 2023).
- OpenMP ARB About Us—OpenMP. Available online: https://www.openmp.org/about/about-us/ (accessed on 6 February 2023).
- Jin, Z.; Finkel, H. Performance-Oriented Optimizations for OpenCL Streaming Kernels on the FPGA. In Proceedings of the IWOCL’18: International Workshop on OpenCL, Oxford, UK, 14–16 May 2018; ACM: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Barreales, G.N.; Novalbos, M.; Otaduy, M.A.; Sanchez, A. MDScale: Scalable Multi-GPU Bonded and Short-Range Molecular Dynamics. J. Parallel Distrib. Comput. 2021, 157, 243–255. [Google Scholar] [CrossRef]
- Kondratyuk, N.; Nikolskiy, V.; Pavlov, D.; Stegailov, V. GPU-Accelerated Molecular Dynamics: State-of-Art Software Performance and Porting from Nvidia CUDA to AMD HIP. Int. J. High Perform. Comput. Appl. 2021, 35, 312–324. [Google Scholar] [CrossRef]
- Strout, M.M.; De Supinski, B.R.; Scogland, T.R.W.; Davis, E.C.; Olschanowsky, C. Evolving OpenMP for Evolving Architectures. In Proceedings of the 14th International Workshop on OpenMP, IWOMP 2018, Barcelona, Spain, 26–28 September 2018; Proceedings. Volume 11128, ISBN 978-3-319-98520-6. [Google Scholar]
- Münchhalfen, J.F.; Hilbrich, T.; Protze, J.; Terboven, C.; Müller, M.S. Classification of Common Errors in OpenMP Applications. In Lecture Notes in Computer Science; Including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in, Bioinformatics); DeRose, L., de Supinski, B.R., Olivier, S.L., Chapman, B.M., Müller, M.S., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8766, pp. 58–72. [Google Scholar]
- Supinski, B.R.D.; Scogland, T.R.W.; Duran, A.; Klemm, M.; Bellido, S.M.; Olivier, S.L.; Terboven, C.; Mattson, T.G. The Ongoing Evolution of OpenMP. Proc. IEEE 2018, 106, 2004–2019. [Google Scholar] [CrossRef]
- Bertolacci, I.; Strout, M.M.; de Supinski, B.R.; Scogland, T.R.W.; Davis, E.C.; Olschanowsky, C.; de Supinski, B.R.; Labarta, J.; Valero-Lara, P.; Martorell, X.; et al. Extending OpenMP to Facilitate Loop Optimization. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11128, pp. 53–65. ISBN 0302-9743. [Google Scholar]
- Sato, M.; Hanawa, T.; Müller, M.S.; Chapman, B.M.; de Supinski, B.R. (Eds.) Beyond Loop Level Parallelism in OpenMP: Accelerators, Tasking and More; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6132, ISBN 978-3-642-13216-2. [Google Scholar]
- Harakal, M. Compute Unified Device Architecture (CUDA) GPU Programming Model and Possible Integration to the Parallel Environment. Sci. Mil. J. 2008, 3, 64–68. [Google Scholar]
- Saillard, E. Static/Dynamic Analyses for Validation and Improvements of Multi-Model HPC Applications. Ph.D. Thesis, Université de Bordeaux, Bordeaux, France, 2015. Volume 1228. [Google Scholar]
- Basloom, H.S.; Dahab, M.Y.; Alghamdi, A.M.; Eassa, F.E.; Al-Ghamdi, A.S.A.-M.; Haridi, S. Errors Classification and Static Detection Techniques for Dual-Programming Model (OpenMP and OpenACC). IEEE Access 2022, 10, 117808–117826. [Google Scholar] [CrossRef]
- Cai, Y.; Lu, Q. Dynamic Testing for Deadlocks via Constraints. IEEE Trans. Softw. Eng. 2016, 42, 825–842. [Google Scholar] [CrossRef]
- Saillard, E.; Carribault, P.; Barthou, D. Static/Dynamic Validation of MPI Collective Communications in Multi-Threaded Context. In Proceedings of the ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPOPP, San Francisco, CA, USA, 7–11 February 2015; ACM: New York, NY, USA, 2015; Volume 2015, pp. 279–280. [Google Scholar]
- Intel® Trace Analyzer and Collector Available. Available online: https://www.intel.com/content/www/us/en/docs/trace-analyzer-collector/user-guide-reference/2023-1/correctness-checking-of-mpi-applications.html (accessed on 18 June 2023).
- Droste, A.; Kuhn, M.; Ludwig, T.M.-C. MPI-Checker-Static Analysis for MPI. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, Austin, TX, USA, 15 November 2015; ACM: New York, NY, USA, 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Fan, S.; Keller, R.; Resch, M. Enhanced Memory Debugging of MPI-Parallel Applications in Open MPI. In Tools for High Performance Computing; Resch, M., Keller, R., Himmler, V., Krammer, B., Schulz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 49–60. [Google Scholar]
- Vetter, J.S.; de Supinski, B.R. Dynamic Software Testing of MPI Applications with Umpire. In Proceedings of SC ‘00: Proceedings of the 2000 ACM/IEEE Conference on Supercomputing, Dallas, TX, USA, 4–10 November 2000; IEEE: Dallas, TX, USA, 2000; pp. 4–10. [Google Scholar] [CrossRef]
- Hilbrich, T.; Schulz, M.; de Supinski, B.R.; Müller, M.S. MUST: A Scalable Approach to Runtime Error Detection in MPI Programs. In Tools for High Performance Computing 2009; Springer: Berlin/Heidelberg, Germany, 2010; pp. 53–66. ISBN 978-3-642-11260-7. [Google Scholar]
- Kranzlmueller, D.; Schaubschlaeger, C.; Volkert, J. A Brief Overview of the MAD Debugging Activities. In Proceedings of the AADEBUG 2000, 4th International Workshop on Automated Testing, Munich, Germany, 28–30 August 2000; pp. 1–6. [Google Scholar]
- MUST—RWTH AACHEN UNIVERSITY Lehrstuhl Für Informatik 12—Deutsch. Available online: https://www.i12.rwth-aachen.de/cms/Lehrstuhl-fuer-Informatik/Forschung/Forschungsschwerpunkte/Lehrstuhl-fuer-Hochleistungsrechnen/~nrbe/MUST/ (accessed on 19 February 2023).
- Hilbrich, T.; Protze, J.; Schulz, M.; de Supinski, B.R.; Muller, M.S. MPI Runtime Error Detection with MUST: Advances in Deadlock Detection. In Proceedings of the 2012 International Conference for High Performance Computing, Networking, Storage and Analysis, Washington, DC, USA, 10–16 November 2012; IEEE: New York, NY, USA, 2012; Volume 21, pp. 1–10. [Google Scholar]
- Forejt, V.; Joshi, S.; Kroening, D.; Narayanaswamy, G.; Sharma, S. Precise Predictive Analysis for Discovering Communication Deadlocks in MPI Programs. ACM Trans. Program. 2017, 39, 1–27. [Google Scholar] [CrossRef]
- Luecke, G.R.; Coyle, J.; Hoekstra, J.; Kraeva, M.; Xu, Y.; Park, M.-Y.; Kleiman, E.; Weiss, O.; Wehe, A.; Yahya, M. The Importance of Run-Time Error Detection. In Tools for High Performance Computing 2009; Müller, M.S., Resch, M.M., Schulz, A., Nagel, W.E., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 145–155. ISBN 978-3-642-11261-4. [Google Scholar]
- Saillard, E.; Carribault, P.; Barthou, D. Combining Static and Dynamic Validation of MPI Collective Communications. In Proceedings of the 20th European MPI Users’ Group Meeting, Madrid, Spain, 15–18 September 2013; ACM: New York, NY, USA, 2013; pp. 117–122. [Google Scholar]
- Alghamdi, A.S.A.A.M.; Alghamdi, A.S.A.A.M.; Eassa, F.E.; Khemakhem, M.A.A. ACC_TEST: Hybrid Testing Techniques for MPI-Based Programs. IEEE Access 2020, 8, 91488–91500. [Google Scholar] [CrossRef]
- Basupalli, V.; Yuki, T.; Rajopadhye, S.; Morvan, A.; Derrien, S.; Quinton, P.; Wonnacott, D. OmpVerify: Polyhedral Analysis for the OpenMP Programmer. In OpenMP in the Petascale Era; IWOMP 2011 Lecture Notes in Computer Science; Chapman, B.M., Gropp, W.D., Kumaran, K., Müller, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6665. [Google Scholar] [CrossRef]
- Ye, F.; Schordan, M.; Liao, C.; Lin, P.-H.; Karlin, I.; Sarkar, V. Using Polyhedral Analysis to Verify OpenMP Applications Are Data Race Free. In Proceedings of the 2018 IEEE/ACM 2nd International Workshop on Software Correctness for HPC Applications (Correctness), Dallas, TX, USA, 12 November 2018; IEEE: New York, NY, USA, 2018; pp. 42–50. [Google Scholar]
- Jannesari, A.; Bao, K.; Pankratius, V.; Tichy, W.F. Helgrind+: An Efficient Dynamic Race Detector. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome Italy, 23–29 May 2009; IEEE: New York, NY, USA, 2009; pp. 1–13. [Google Scholar]
- Valgrind: Tool Suite. Available online: https://valgrind.org/info/tools.html#memcheck (accessed on 8 March 2023).
- Nethercote, N.; Seward, J. Valgrind. ACM Sigplan Not. 2007, 42, 89–100. [Google Scholar] [CrossRef]
- Terboven, C. Comparing Intel Thread Checker and Sun Thread Analyzer. Adv. Parallel Comput. 2008, 15, 669–676. [Google Scholar]
- Intel(R) Thread Checker 3.1 Release Notes. Available online: https://registrationcenter-download.intel.com/akdlm/irc_nas/1366/ReleaseNotes.htm (accessed on 8 March 2023).
- Sun Studio 12: Thread Analyzer User’s Guide. Available online: https://docs.oracle.com/cd/E19205-01/820-0619/820-0619.pdf (accessed on 8 March 2023).
- Gu, Y.; Mellor-Crummey, J. Dynamic Data Race Detection for OpenMP Programs. In Proceedings of the SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 11–16 November 2018; IEEE: New York, NY, USA, 2018; pp. 767–778. [Google Scholar]
- Serebryany, K.; Bruening, D.; Potapenko, A.; Vyukov, D. AddressSanitizer: A Fast Address Sanity Checker. In Proceedings of the 2012 USENIX Annual Technical Conference (USENIX ATC 12), Boston, MA, USA, 13–15 June 2012; USENIX Association: Boston, MA, USA, 2012; pp. 309–318. [Google Scholar]
- Serebryany, K.; Potapenko, A.; Iskhodzhanov, T.; Vyukov, D. Dynamic Race Detection with LLVM Compiler: Compile-Time Instrumentation for ThreadSanitizer. In Proceedings of the International Conference on Runtime Verification, Istanbul, Turkey, 25–28 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7186 LNCS, pp. 110–114. [Google Scholar]
- Atzeni, S.; Gopalakrishnan, G.; Rakamaric, Z.; Ahn, D.H.; Laguna, I.; Schulz, M.; Lee, G.L.; Protze, J.; Muller, M.S. ARCHER: Effectively Spotting Data Races in Large OpenMP Applications. In Proceedings of the 2016 IEEE 30th International Parallel and Distributed Processing Symposium, IPDPS 2016, Chicago, IL, USA, 23–27 May 2016; pp. 53–62. [Google Scholar] [CrossRef]
- Hilbrich, T.; Müller, M.S.; Krammer, B. Detection of Violations to the Mpi Standard in Hybrid Openmp/Mpi Applications. In Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5004 LNCS, pp. 26–35. ISBN 354079560X. [Google Scholar]
- Krammer, B.; Bidmon, K.; Müller, M.S.; Resch, M.M. MARMOT: An MPI Analysis and Checking Tool. Adv. Parallel Comput. 2004, 13, 493–500. [Google Scholar] [CrossRef]
- Betts, A.; Chong, N.; Donaldson, A.F.; Qadeer, S.; Thomson, P. GPU Verify: A Verifier for GPU Kernels. In Proceedings of the Conference on Object-Oriented Programming Systems, Languages, and Applications, OOPSLA, New York, NY, USA, 19–26 October 2012; pp. 113–131. [Google Scholar]
- Bardsley, E.; Betts, A.; Chong, N.; Collingbourne, P.; Deligiannis, P.; Donaldson, A.F.; Ketema, J.; Liew, D.; Qadeer, S. Engineering a Static Verification Tool for GPU Kernels. In Lecture Notes in Computer Science; Including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer International Publishing: Cham, Switzerland, 2014; Volume 8559 LNCS, pp. 226–242. ISBN 9783319088662. [Google Scholar]
- Gupta, S.; Sultan, F.; Cadambi, S.; Ivancić, F.; Rotteler, M. Using Hardware Transactional Memory for Data Race Detection. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–11. [Google Scholar] [CrossRef]
- Mekkat, V.; Holey, A.; Zhai, A. Accelerating Data Race Detection Utilizing On-Chip Data-Parallel Cores. In Runtime Verification: 4th International Conference, RV 2013, Rennes, France, 24–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8174, pp. 201–218. [Google Scholar]
- Bekar, C.; Elmas, T.; Okur, S.; Tasiran, S. KUDA: GPU Accelerated Split Race Checker. In Proceedings of the Workshop on Determinism and Correctness in Parallel Programming (WoDet), London, UK, 3 March 2012; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Zheng, M.; Ravi, V.T.; Qin, F.; Agrawal, G. GMRace: Detecting Data Races in GPU Programs via a Low-Overhead Scheme. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 104–115. [Google Scholar] [CrossRef]
- Zheng, M.; Ravi, V.T.; Qin, F.; Agrawal, G. GRace: A Low-Overhead Mechanism for Detecting Data Races in GPU Programs. In Proceedings of the ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPOPP, San Antonio, TX USA, 12–16 February 2011; pp. 135–145. [Google Scholar] [CrossRef]
- Dai, Z.; Zhang, Z.; Wang, H.; Li, Y.; Zhang, W. Parallelized Race Detection Based on GPU Architecture. Commun. Comput. Inf. Sci. 2014, 451 CCIS, 113–127. [Google Scholar] [CrossRef]
- Boyer, M.; Skadron, K.; Weimer, W. Automated Dynamic Analysis of CUDA Programs. In Proceedings of the Third Workshop on Software Tools for MultiCore Systems, Amsterdam Netherlands, 1 November 2016. [Google Scholar]
- Li, P.; Li, G.; Gopalakrishnan, G. Practical Symbolic Race Checking of GPU Programs. In Proceedings of the SC’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, New Orleans, LA, USA, 16–21 November 2014; Volume 14. pp. 179–190. [Google Scholar]
- Clemencon, C.; Fritscher, J.; Ruhl, R. Visualization, Execution Control and Replay of Massively Parallel Programs within Annai’s Debugging Tool. In Proceedings of the High-Performance Computing Symposium (HPCS’95), Raleigh, NC, USA, 22–25 January 1995; pp. 393–404. [Google Scholar]
- Bronevetsky, G.; Laguna, I.; Bagchi, S.; De Supinski, B.R.; Ahn, D.H.; Schulz, M. AutomaDeD: Automata-Based Debugging for Dissimilar Parallel Tasks. In Proceedings of the International Conference on Dependable Systems and Networks, Chicago, IL, USA, 28 June–1 July 2010; IEEE: New York, NY, USA, 2010; pp. 231–240. [Google Scholar]
- Linaro DDT. Available online: https://www.linaroforge.com/linaro-ddt (accessed on 31 October 2023).
- Allinea DDT|HPC@LLNL. Available online: https://hpc.llnl.gov/software/development-environment-software/allinea-ddt (accessed on 31 October 2023).
- Totalview Technologies: Totalview—Parallel and Thread Debugger. Available online: https://help.totalview.io/ (accessed on 14 July 2023).
- TotalView Debugger|HPC@LLNL. Available online: https://hpc.llnl.gov/software/development-environment-software/totalview-debugger (accessed on 31 October 2023).
- Claudio, A.P.; Cunha, J.D.; Carmo, M.B. Monitoring and Debugging Message Passing Applications with MPVisualizer. In Proceedings of the 8th Euromicro Workshop on Parallel and Distributed Processing, Rhodes, Greece, 19–21 January 2000; pp. 376–382. [Google Scholar] [CrossRef]
- Intel Inspector|HPC@LLNL. Available online: https://hpc.llnl.gov/software/development-environment-software/intel-inspector (accessed on 8 March 2023).
- Documentation—Arm DDT. Available online: https://www.alcf.anl.gov/support-center/training/debugging-arm (accessed on 31 October 2023).
- Saad, S.; Fadel, E.; Alzamzami, O.; Eassa, F.; Alghamdi, A.M. Temporal-Logic-Based Testing Tool Architecture for Dual-Programming Model Systems. Computers 2024, 13, 86. [Google Scholar] [CrossRef]
- Alghamdi, A.M.; Eassa, F.E. Openacc Errors Classification and Static Detection Techniques. IEEE Access 2019, 7, 113235–113253. [Google Scholar] [CrossRef]
- Checkaraou, A.W.M.; Rousset, A.; Besseron, X.; Varrette, S.; Peters, B. Hybrid MPI+openMP Implementation of EXtended Discrete Element Method. In Proceedings of the 2018 30th International Symposium on Computer Architecture and High Performance Computing, SBAC-PAD, Lyon, France, 24–27 September 2018; pp. 450–457. [Google Scholar] [CrossRef]
- Garcia-Gasulla, M.; Houzeaux, G.; Ferrer, R.; Artigues, A.; López, V.; Labarta, J.; Vázquez, M. MPI+X: Task-Based Parallelisation and Dynamic Load Balance of Finite Element Assembly. Int. J. Comput Fluid Dyn. 2019, 33, 115–136. [Google Scholar] [CrossRef]
- Altalhi, S.M.; Eassa, F.E.; Al-Ghamdi, A.S.A.M.; Sharaf, S.A.; Alghamdi, A.M.; Almarhabi, K.A.; Khemakhem, M.A. An Architecture for a Tri-Programming Model-Based Parallel Hybrid Testing Tool. Appl. Sci. 2023, 13, 1960. [Google Scholar] [CrossRef]
- Freire, Y.N.; Senger, H. Integrating CUDA Memory Management Mechanisms for Domain Decomposition of an Acoustic Wave Kernel Implemented in OpenMP. In Escola Regional de Alto Desempenho de São Paulo (ERAD-SP); SBC: Bento Gonçalves, Brazil, 2023; pp. 21–24. [Google Scholar] [CrossRef]
- Lai, J.; Yu, H.; Tian, Z.; Li, H. Hybrid MPI and CUDA Parallelization for CFD Applications on Multi-GPU HPC Clusters. Sci. Program. 2020, 2020, 8862123. [Google Scholar] [CrossRef]
- Haque, W. Concurrent Deadlock Detection in Parallel Programs. Int. J. Comput. Appl. 2006, 28, 19–25. [Google Scholar] [CrossRef]
- Eslamimehr, M.; Palsberg, J. Sherlock: Scalable Deadlock Detection for Concurrent Programs. In Proceedings of the ACM SIGSOFT Symposium on the Foundations of Software Engineering, (FSE 2014). Association for Computing Machinery, Hong Kong China, 16–21 November 2014; pp. 353–365. [Google Scholar] [CrossRef]
- Agarwal, R.; Bensalem, S.; Farchi, E.; Havelund, K.; Nir-Buchbinder, Y.; Stoller, S.D.; Ur, S.; Wang, L. Detection of Deadlock Potentials in Multithreaded Programs. IBM J. Res. Dev. 2010, 54, 1–15. [Google Scholar] [CrossRef]
- OpenMP Application Programming Interface. Available online: https://www.openmp.org/wp-content/uploads/OpenMP-API-Specification-5-2.pdf (accessed on 16 April 2025).
- Yang, C.T.; Huang, C.L.; Lin, C.F. Hybrid CUDA, OpenMP, and MPI Parallel Programming on Multicore GPU Clusters. Comput. Phys. Commun. 2011, 182, 266–269. [Google Scholar] [CrossRef]
- Diener, M.; Kale, L.V.; Bodony, D.J. Heterogeneous Computing with OpenMP and Hydra. Concurr. Comput. 2020, 32, e5728. [Google Scholar] [CrossRef]
- Akhmetova, D.; Iakymchuk, R.; Ekeberg, O.; Laure, E. Performance Study of Multithreaded MPI and Openmp Tasking in a Large Scientific Code. In Proceedings of the 2017 IEEE 31st International Parallel and Distributed Processing Symposium Workshops, IPDPSW 2017, Orlando, FL, USA, 29 May–2 June 2017; pp. 756–765. [Google Scholar] [CrossRef]
- Gonzalez Tallada, M.; Morancho, E. Heterogeneous Programming Using OpenMP and CUDA/HIP for Hybrid CPU-GPU Scientific Applications. Int. J. High. Perform. Comput. Appl. 2023, 37, 626–646. [Google Scholar] [CrossRef]
- Gil-Costa, V.; Senger, H. High-Performance Computing for Computational Science. Concurr. Comput. 2020, 32, 18–19. [Google Scholar] [CrossRef]
- Aji, A.M.; Panwar, L.S.; Ji, F.; Chabbi, M.; Murthy, K.; Balaji, P.; Bisset, K.R.; Dinan, J.; Feng, W.C.; Mellor-Crummey, J.; et al. On the Efficacy of GPU-Integrated MPI for Scientific Applications. In Proceedings of the 22nd ACM International Symposium on High-Performance Parallel and Distributed Computing—HPDC, Minneapolis, MN, USA, 27 June–1 July 2022; pp. 191–202. [Google Scholar] [CrossRef]
- Gottschlich, J.; Boehm, H. Generic Programming Needs Transactional Memory. In Proceedings of the Transact 2013: 8th ACM SIGPLAN Workshop on Transactional Computing, Houston, TX, USA, 17 March 2013. [Google Scholar]
- Suess, M.; Leopold, C. Generic Locking and Deadlock-Prevention with C++. Adv. Parallel Comput. 2008, 15, 211–218. [Google Scholar]
- NAS Parallel Benchmarks Version 3.4.3. Available online: https://www.nas.nasa.gov/software/npb.html (accessed on 14 October 2024).
- Bull, J.M.; Enright, J.; Guo, X.; Maynard, C.; Reid, F. Performance Evaluation of Mixed-Mode OpenMP/MPI Implementations. Int. J. Parallel Program. 2010, 38, 396–417. [Google Scholar] [CrossRef]
- Grove, D.A.; Coddington, P.D. Precise MPI Performance Measurement Using MPIBench. In Proceedings of the HPC Asia, Nagoya, Japan, 25–27 January 2024. [Google Scholar]
- GitHub—LLNL/MpiBench: MPI Benchmark to Test and Measure Collective Performance. Available online: https://github.com/LLNL/mpiBench (accessed on 14 October 2024).
- Liao, C.; Lin, P.H.; Asplund, J.; Schordan, M.; Karlin, I. DataRaceBench: A Benchmark Suite for Systematic Evaluation of Data Race Detection Tools. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 9–19 November 2020. [Google Scholar] [CrossRef]
- GitHub—LLNL/Dataracebench: Data Race Benchmark Suite for Evaluating OpenMP Correctness Tools Aimed to Detect Data Races. Available online: https://github.com/LLNL/dataracebench (accessed on 14 October 2024).
- Griebler, D.; Loff, J.; Mencagli, G.; Danelutto, M.; Fernandes, L.G. Efficient NAS Benchmark Kernels with C++ Parallel Programming. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 733–740. [Google Scholar]
- Löff, J.; Griebler, D.; Mencagli, G.; Araujo, G.; Torquati, M.; Danelutto, M.; Fernandes, L.G. The NAS Parallel Benchmarks for Evaluating C++ Parallel Programming Frameworks on Shared-Memory Architectures. Future Gener. Comput. Syst. 2021, 125, 743–757. [Google Scholar] [CrossRef]
- GitHub—RWTH-HPC/DRACC: Benchmarks for Data Race Detection on Accelerators. Available online: https://github.com/RWTH-HPC/DRACC (accessed on 14 October 2024).
- Altalhi, S.M.; Eassa, F.E.; Alghamdi, A.M.; Khalid, R.A.B. Static-Tools-for-Detecting-Tri-Level-Programming-Models-MPI-OpenMP-CUDA-MOC-: Static Analysis Components for Tri-Level-Programming Model Using MPI, OpenMP, and CUDA (MOC). Available online: https://github.com/saeedaltalhi/Static-Tools-for-Detecting-Tri-Level-Programming-Models-MPI-OpenMP-CUDA-MOC- (accessed on 22 April 2025).
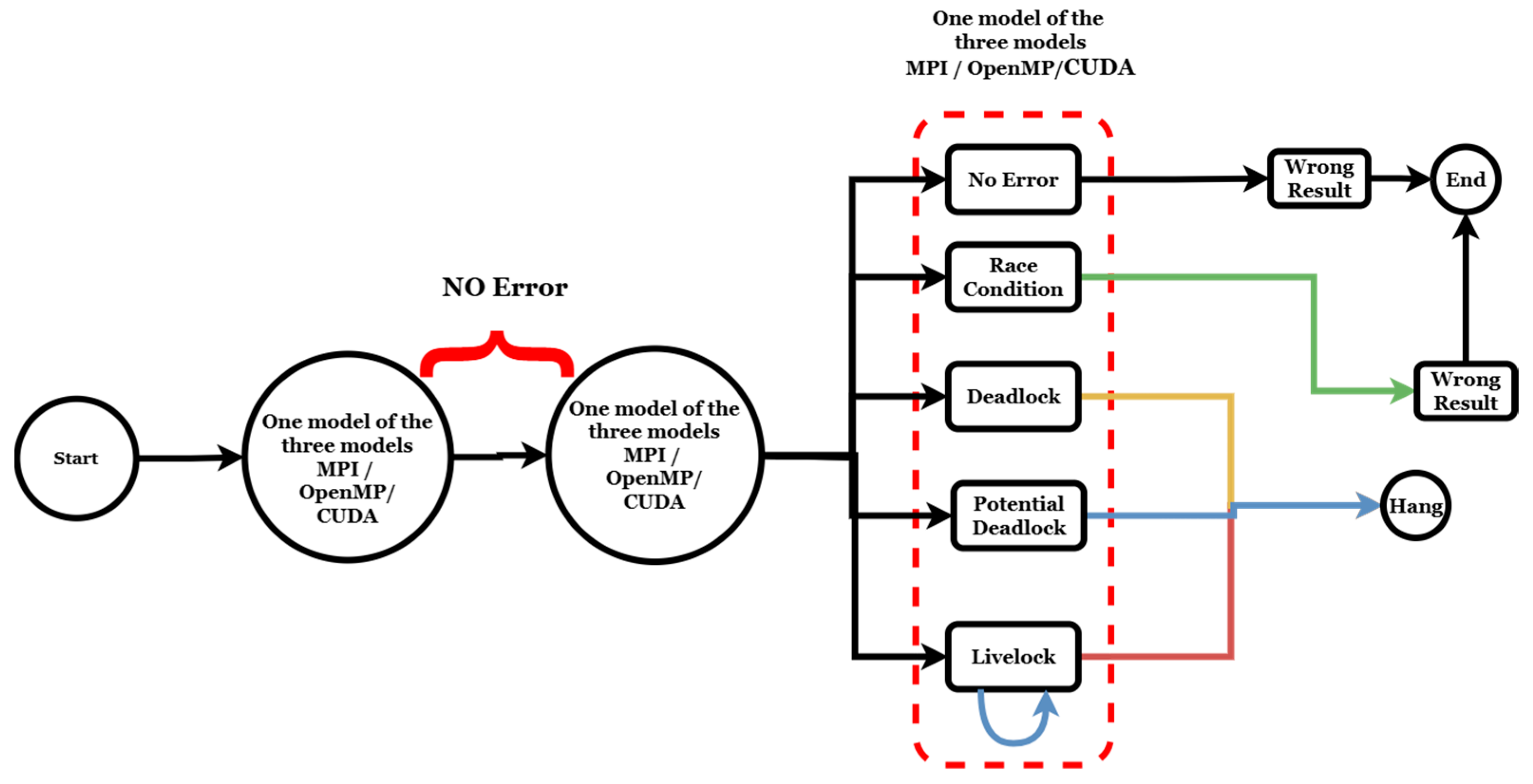






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
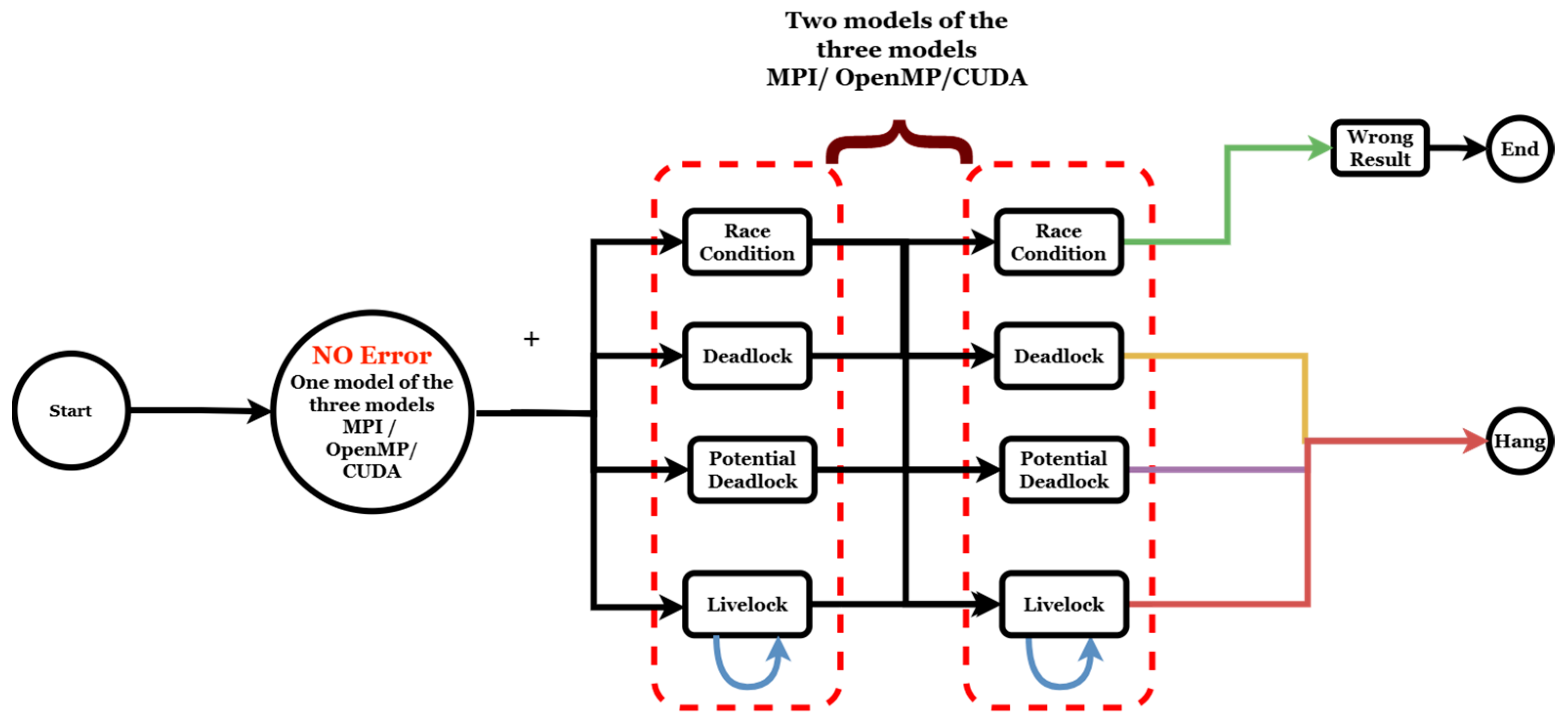
| CUDA | MPI | OpenMP | Tri-Programming Model |
|---|---|---|---|
| Error-free | Error-free | Error-free | No error |
| Data race | Error-free | Error-free | Data race |
| Deadlock | Error-free | Error-free | Deadlock |
| Potential deadlock | Error-free | Error-free | Potential deadlock |
| Livelock | Error-free | Error-free | Livelock |
| Potential livelock | Error-free | Error-free | Potential livelock |
| Error-free | Deadlock | Error-free | Deadlock |
| Error-free | Potential deadlock | Error-free | Potential deadlock |
| Error-free | Data race | Error-free | Data race |
| Error-free | Potential data race | Error-free | Potential data race |
| Error-free | Error-free | Deadlock | Deadlock |
| Error-free | Error-free | Potential deadlock | Potential deadlock |
| Error-free | Error-free | Data race | Data race |
| Error-free | Error-free | Potential data race | Potential data race |
| Error-free | Error-free | Livelock | Livelock |
| Error-free | Error-free | Potential livelock | Potential livelock |
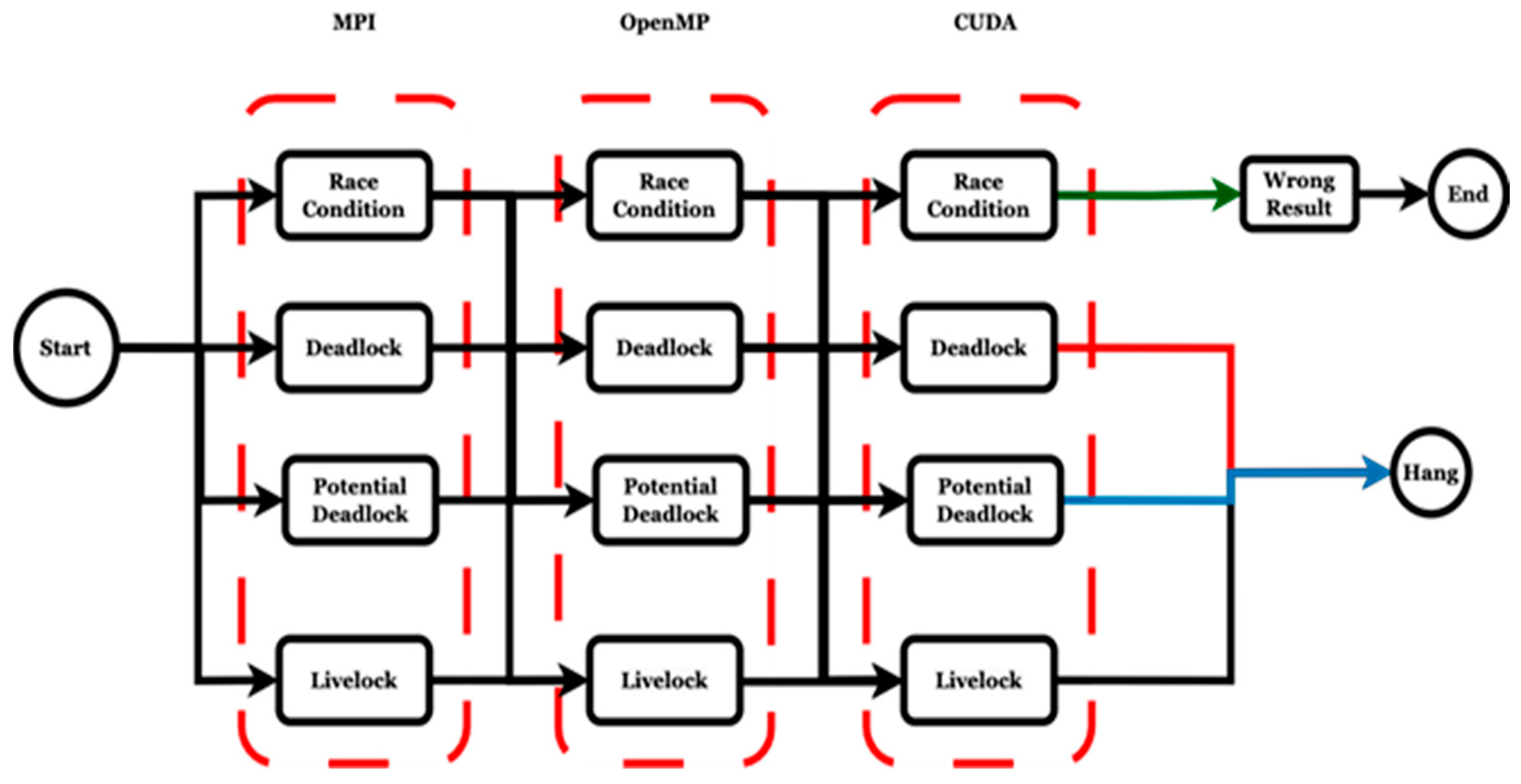
| CUDA | MPI | OpenMP | Tri-Programming Model |
|---|---|---|---|
| Data race | Deadlock | Error-free | Deadlock |
| Data race | Race condition | Error-free | Data race, with possibly incorrect results |
| Deadlock | Deadlock | Error-free | Deadlock |
| Deadlock | Race condition | Error-free | Deadlock |
| Livelock | Deadlock | Error-free | Stuck, depending on which error occurs first |
| Livelock | Data race | Error-free | Livelock |
| Data race | Error-free | Deadlock | Deadlock |
| Data race | Error-free | Data race | Data race, with possibly incorrect results |
| Data race | Error-free | Livelock | Livelock |
| Deadlock | Error-free | Deadlock | Deadlock |
| Deadlock | Error-free | Data race | Deadlock |
| Deadlock | Error-free | Livelock | Deadlock |
| Livelock | Error-free | Deadlock | Stuck, depending on which error occurs first |
| Livelock | Error-free | Data race | Livelock |
| Livelock | Error-free | Livelock | Livelock |
| Error-free | Deadlock | Deadlock | Stuck, depending on which deadlock occurs first |
| Error-free | Deadlock | Data race | Deadlock |
| Error-free | Deadlock | Livelock | Stuck, depending on which error occurs first |
| Error-free | Data race | Deadlock | Deadlock |
| Error-free | Data race | Data race | Data race, with possibly incorrect results |
| Error-free | Data race | Livelock | Livelock |
| CUDA | MPI | OpenMP | Tri-Programming Model |
|---|---|---|---|
| Data race | Deadlock | Deadlock | Stuck, depending on which deadlock occurs first |
| Data race | Deadlock | Data race | Deadlock |
| Data race | Deadlock | Livelock | Stuck, depending on which error occurs first |
| Data race | Data race | Deadlock | Deadlock |
| Data race | Data race | Data race | Data race, with possibly incorrect results |
| Data race | Data race | Livelock | Livelock |
| Deadlock | Deadlock | Deadlock | Stuck, depending on which deadlock occurs first |
| Deadlock | Data race | Data race | Deadlock |
| Deadlock | Deadlock | Livelock | Stuck, depending on which error occurs first |
| Deadlock | Data race | Deadlock | Stuck, depending on which deadlock occurs first |
| Deadlock | Deadlock | Data race | Stuck, depending on which deadlock occurs first |
| Deadlock | Data race | Livelock | Stuck, depending on which error occurs first |
| Livelock | Deadlock | Deadlock | Stuck, depending on which error occurs first |
| Livelock | Data race | Data race | Livelock |
| Livelock | Deadlock | Livelock | Stuck, depending on which livelock occurs first |
| Livelock | Data race | Deadlock | Stuck, depending on which error occurs first |
| Livelock | Deadlock | Data race | Stuck, depending on which error occurs first |
| Livelock | Data race | Livelock | Stuck, depending on which livelock occurs first |
| Model | Benchmark Program | Lines | |
|---|---|---|---|
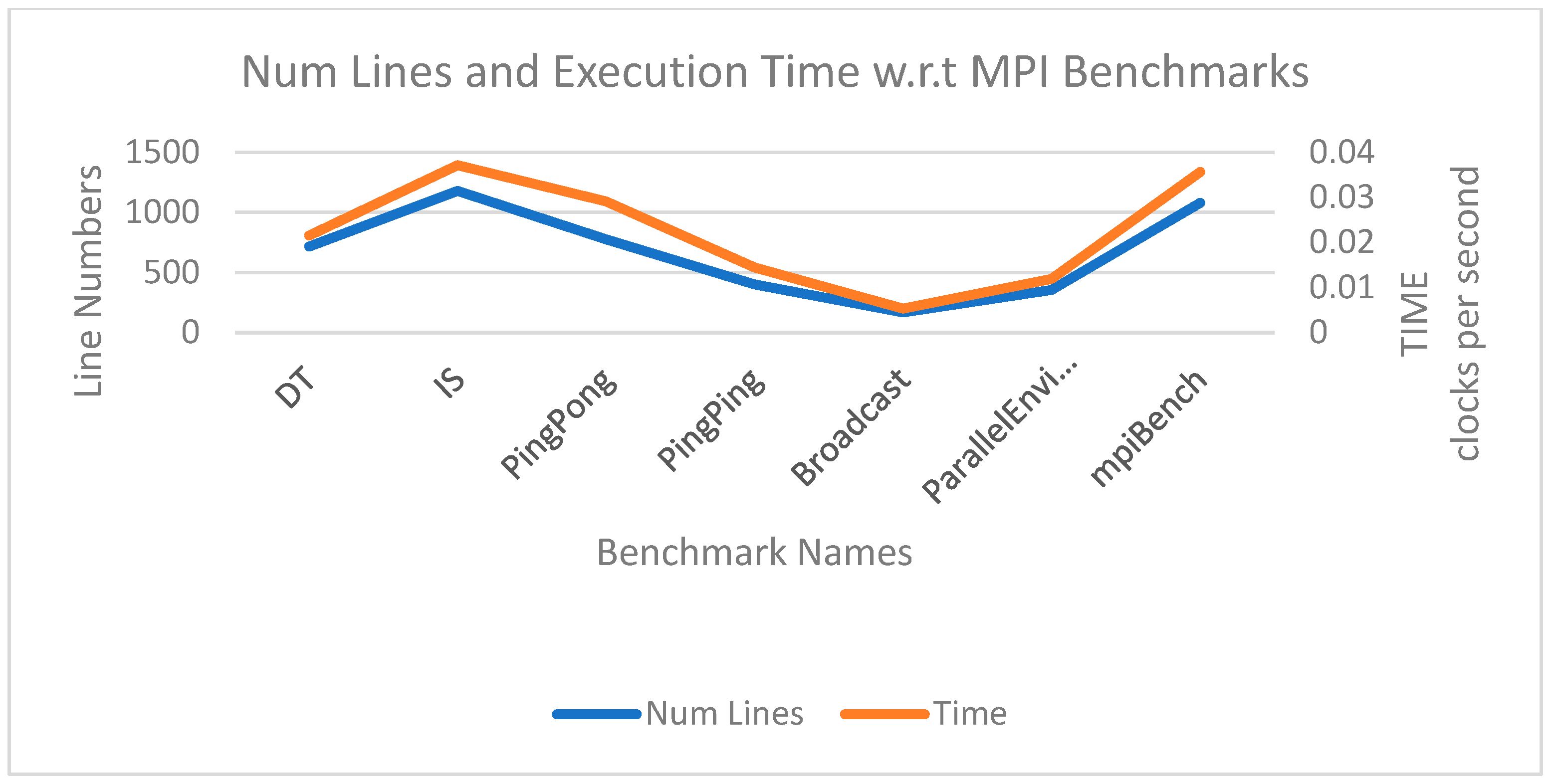
| MPI | NAS | DT | 714 |
| IS | 1179 | ||
| EPCC | PingPong | 774 | |
| PingPing | 400 | ||
| Broadcast | 169 | ||
| ParallelEnvironment | 353 | ||
| mpiBench | mpiBench | 1077 | |
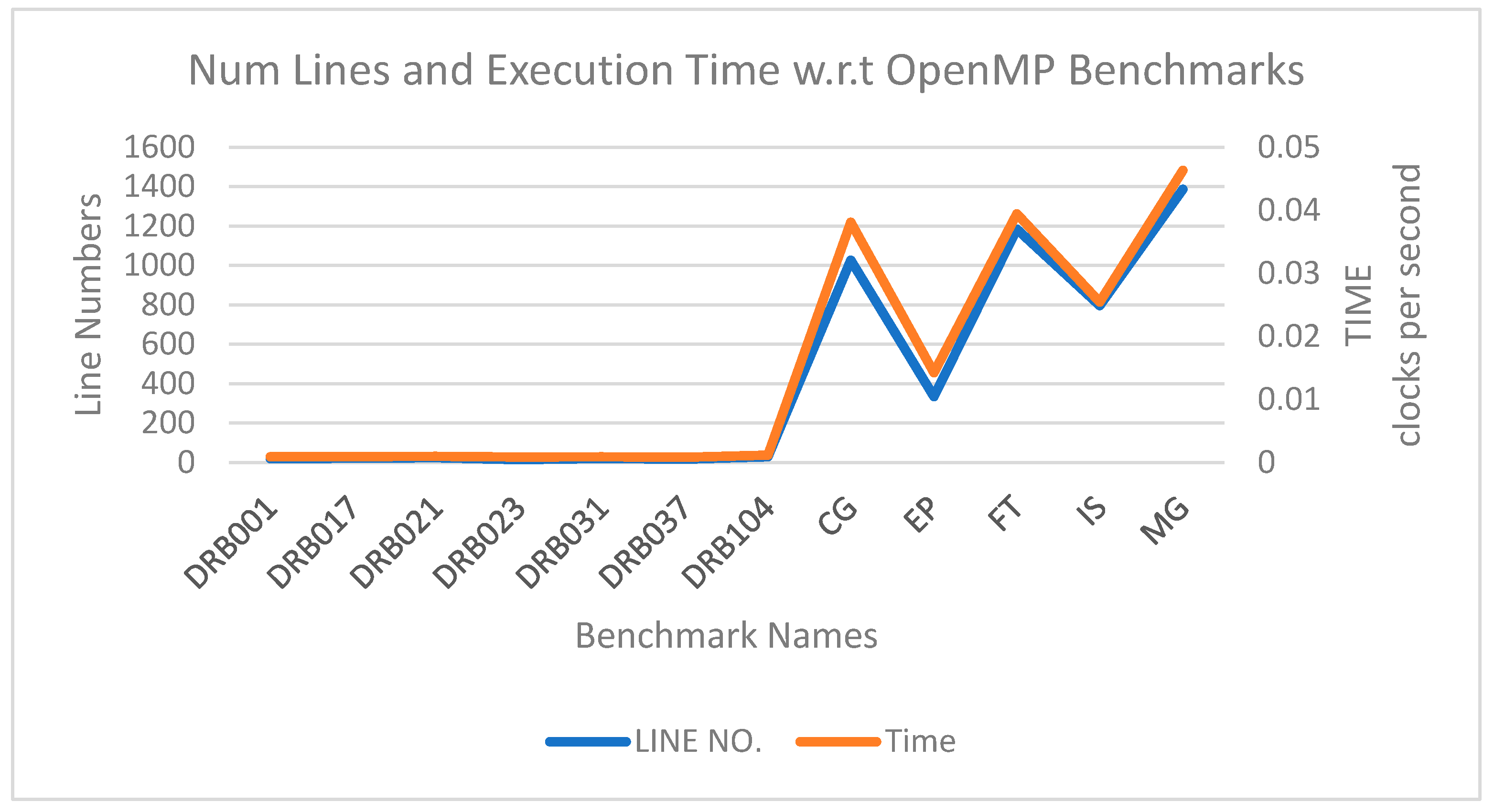
| OpenMP | RWTH-HPC/DRACC | DRB001 | 19 |
| DRB017 | 22 | ||
| DRB021 | 24 | ||
| DRB023 | 15 | ||
| DRB031 | 21 | ||
| DRB037 | 17 | ||
| DRB104 | 29 | ||
| NPB-CPP/NPB-OMP | CG | 1027 | |
| EP | 334 | ||
| FT | 1184 | ||
| IS | 796 | ||
| MG | 1388 | ||
| CUDA | RWTH-HPC/DRACC | DRAAC_CUDA_001 | 66 |
| DRAAC_CUDA_004 | 93 | ||
| DRAAC_CUDA_007 | 85 | ||
| DRAAC_CUDA_020 | 120 | ||
| DRAAC_CUDA_023 | 75 | ||
| DRAAC_CUDA_027 | 67 | ||
| Programming Model | Runtime Error | Our Tool (Static Approach) * | ACC_TEST * | ROMP * | LLOV * | ARCHER * | MPR ACER * | GPUVerify |
|---|---|---|---|---|---|---|---|---|
| OpenMP | Race Condition | |||||||
| Loop Parallelization Race | ✓ | ✕ | ✓ | ✓ | ✓ | ✓ | ✕ | |
| NowaitClause | ✓ | ✕ | ✓ | ✕ | ✓ | ✓ | ✕ | |
| Shared Clause | ✓ | ✕ | ✓ | ✓ | ✓ | ✓ | ✕ | |
| Barrier Construct | ✓ | ✕ | ✓ | ✕ | ✓ | ✓ | ✕ | |
| Atomic Construct | ✓ | ✕ | ✓ | ✓ | ✓ | ✓ | ✕ | |
| Critical Construct | ✓ | ✕ | ✓ | ✓ | ✓ | ✓ | ✕ | |
| Master Construct | P | ✕ | ✓ | ✓ | ✓ | ✓ | ✕ | |
| Single Construct | P | ✕ | ✕ | ✓ | ✕ | ✓ | ✕ | |
| SIMD Directives | ✕ | ✕ | ✕ | ✓ | ✕ | ✓ | ✕ | |
| Teams Construct | ✕ | ✕ | ✓ | ✓ | ✕ | ✓ | ✕ | |
| Deadlock | ||||||||
| LockRoutines | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ||
| Section Construct | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ||
| Barrier Construct | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ||
| NowaitClause | P | ✕ | ✕ | ✕ | ✕ | ✕ | ||
| Livelock | P | ✕ | ✕ | ✕ | ✕ | ✕ | ||
| Device Directives | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ||
| CUDA | Race Condition | ✕ | ✕ | ✕ | ||||
| Host/Device Synchronization Race | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ | |
| Asynchronous Directive Race | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ | |
| Deadlock | ||||||||
| Device Deadlock | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | |
| Host Deadlock | P | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | |
| Livelock | P | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | |
| MPI | Point-to-Point Blocking/ Nonblocking Communications | |||||||
| Illegal MPI Calls | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ||
| Data Type Mismatching | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ||
| Data Size Mismatching | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ||
| Resource Leaks | ✓ | ✓ | ✕ | ✕ | ✕ | ✕ | ||
| Inconsistence Send/Recv Pairs Wildcard Receive | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ||
| Race Condition | P | P | ✕ | ✕ | ✕ | ✓ | ||
| Deadlock | P | P | ✕ | ✕ | ✕ | ✓ | ||
| Collective Blocking/ Nonblocking Communications | ✕ | |||||||
| Illegal MPI Calls | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ||
| Data Type Mismatching | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ||
| Data Size Mismatching | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ||
| Inconsistent Send/Recv Pairs—Wildcard Receive | P | P | ✕ | ✕ | ✕ | ✓ | ||
| Race Condition | P | P | ✕ | ✕ | ✕ | ✓ | ||
| Deadlock | P | P | ✕ | ✕ | ✕ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altalhi, S.M.; Eassa, F.E.; Sharaf, S.A.; Alghamdi, A.M.; Almarhabi, K.A.; Khalid, R.A.B. Error Classification and Static Detection Methods in Tri-Programming Models: MPI, OpenMP, and CUDA. Computers 2025, 14, 164. https://doi.org/10.3390/computers14050164
Altalhi SM, Eassa FE, Sharaf SA, Alghamdi AM, Almarhabi KA, Khalid RAB. Error Classification and Static Detection Methods in Tri-Programming Models: MPI, OpenMP, and CUDA. Computers. 2025; 14(5):164. https://doi.org/10.3390/computers14050164
Chicago/Turabian StyleAltalhi, Saeed Musaad, Fathy Elbouraey Eassa, Sanaa Abdullah Sharaf, Ahmed Mohammed Alghamdi, Khalid Ali Almarhabi, and Rana Ahmad Bilal Khalid. 2025. "Error Classification and Static Detection Methods in Tri-Programming Models: MPI, OpenMP, and CUDA" Computers 14, no. 5: 164. https://doi.org/10.3390/computers14050164
APA StyleAltalhi, S. M., Eassa, F. E., Sharaf, S. A., Alghamdi, A. M., Almarhabi, K. A., & Khalid, R. A. B. (2025). Error Classification and Static Detection Methods in Tri-Programming Models: MPI, OpenMP, and CUDA. Computers, 14(5), 164. https://doi.org/10.3390/computers14050164