1. Introduction
System complexity, sizes, and costs are all increasing as a result of the fast rise in demand and the adoption of advanced technologies in today’s society [
1]. Additionally, rivalries force many businesses to undertake rapid system updates while also ensuring that their systems remain fully operational. This necessitates the use of proper concepts, designs, and process models. These demands can be successfully addressed by several paradigms in software engineering, which break down traditional monolithic applications into a set of fine-grained services that can be developed, tested, and deployed independently [
2,
3].
Software maintenance is a critical stage in the software life cycle. Numerous companies nowadays invest large efforts in correcting, adapting, augmenting, and restructuring their existing programs, particularly in the presence of monolithic systems. This type of system is widely regarded as a key and critical component of many businesses (especially banks and insurance companies), particularly given that these systems—often legacy systems—have demonstrated a certain level of efficiency in executing complicated and significant business logic over a long period of time [
4]. On the other hand, monolithic systems have proven increasingly challenging to operate due to the tight connection between their internal components. Changing the functionality in one module frequently necessitates modifications in numerous other modules, increasing the work and attention necessary for development [
5,
6].
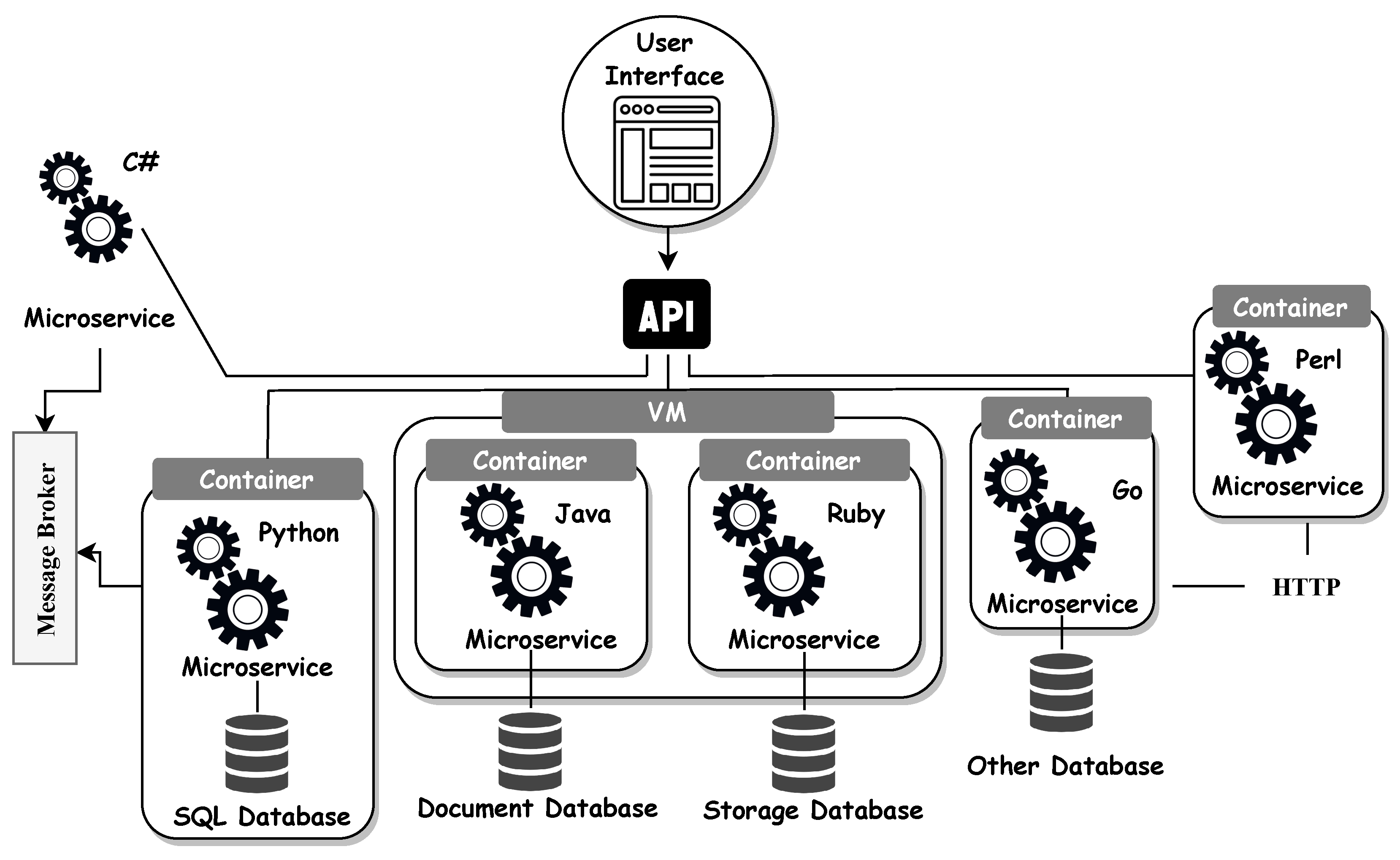
Microservice-based architectures are viewed as an excellent candidate for modernizing such systems, particularly because they enable the development of complex and inter-organizational applications through the integration of reusable, relatively autonomous, generally heterogeneous, and distributed microservices [
7,
8]. Recently, there has been a tremendous change in the approach used to develop and deliver applications or services. The MSA [
1] has gained a foothold in the software development industry and has become one of the latest architectural trends in software engineering, with more and more cloud computing applications starting to adopt microservices [
9,
10].
However, migrating monolithic applications to microservices is a complicated process that requires the consideration of a number of aspects, including the migration approach used, the method used to identify microservices, and the quality of the discovered services [
11]. The identification of microservices is regarded as the most significant and time-consuming stage in the process of migration, all the more so because the new architecture’s quality and resilience are contingent on the quality of the identified services. The identification of microservices entails finding modules of an existing system that may be encapsulated and represented as services [
5].
In this paper, we undertake a systematic mapping analysis to discover the migration processes from monolithic applications to determine the primary approaches for supporting the migration process, specifically the microservice identification phase. We thoroughly explore recent studies addressing the identification of microservices in the context of shifting from a monolithic design to one based on microservices. We use a detailed methodology to extract, analyze, and categorize the reported techniques to identify microservices. The following are the study’s main purposes:
Identify the most relevant challenges and levels of automation in microservice identification.
Point out the strategies, approaches, metrics, and inputs used for microservice identification.
Determine the set algorithms and tools employed, along with trends and emerging research directions.
End up with a middleweight ontology for microservice identification.
The remainder of this article is organized as follows: The second section presents an overview of the methodology and approaches utilized in this study, including the identification of microservices and the systematic mapping development procedure.
Section 3 provides an introduction to and discussion of related works, while
Section 4 describes our study approach.
Section 5 shows and examines the mapping findings;
Section 6 discusses the intended ontology for microservice identification;
Section 7 highlights potential research gaps; threats to validity are described in
Section 8; and
Section 9 wraps up the study.
3. Related Work
The research community has shown significant interest in exploring microservice architectures in recent years. A comprehensive literature analysis by Francesco et al. [
7] examined emerging patterns in publications, key research directions, and the feasibility of implementing microservices in industrial settings. Building on this research foundation, Alshuqayran et al. [
19] conducted a systematic review investigating the primary architectural obstacles encountered when implementing microservice-based systems.
Numerous studies have explored the motivations, advantages, and disadvantages associated with microservice migration. Christoforou et al. [
20] conducted a systematic literature review to identify migration drivers, which were subsequently validated by domain experts, culminating in the development of a node-based decision support system to facilitate microservice migration. In parallel research, Kalske et al. [
21] investigated the rationale behind organizations’ decisions to transition from monolithic systems to microservices, categorizing the encountered challenges based on technical and organizational dimensions. Wolfart et al. [
22] analyzed the literature to determine organizational motivations for modernizing monolithic systems, documenting common activities and their associated inputs and outputs. Additionally, Soldani et al. [
14] examined gray literature to identify the technical and operational benefits and drawbacks of microservices, encompassing architectural design considerations, security measures, testing protocols, storage solutions, management practices, resource utilization, and monitoring requirements within microservice architectures.
Abgaz et al. [
10] introduced a comprehensive “Monolith to Microservices Decomposition Framework” that outlines the principal decomposition stages and components while evaluating current decomposition methodologies, the available tools, relevant metrics, and applicable datasets. In a similar vein, Oumoussa et al. [
8] conducted a literature analysis examining the progression of decomposition techniques, documenting methodologies and tools developed to address migration challenges, and identifying both promising approaches and their inherent limitations. While our previous work [
8] focused on the historical evolution of microservice identification techniques through a systematic literature review, it did not provide an ontological classification framework for practitioners to systematically select appropriate identification techniques based on their specific context and requirements. This limitation represents a significant gap that our current study addresses through a systematic mapping study approach.
Research examining migration to microservices has primarily concentrated on migration methodologies and the driving factors behind adopting microservice architectures. Razzaq et al. [
9] conducted a literature analysis examining publication trends, research contexts, focus areas, migration approaches, challenges, success factors, and the industrial adoption potential regarding transitioning from monolithic to microservice systems. Regarding the migration process itself, Fritzsch et al. [
5] explored the decomposition of a monolithic system into smaller services. Given its complexity and significance, this decomposition represents a critical migration milestone. Their systematic review identified ten primary techniques for microservice identification in the literature, culminating in a decision framework to guide migration efforts by selecting appropriate techniques for specific scenarios. Similarly, Ponce et al. [
23] performed a rapid review that categorized migration approaches into three groups: model-driven, static analysis, and dynamic code analysis. Kazanavičius et al. [
24] further evaluated various migration strategies, examining both advantages and limitations. Additionally, Saucedo et al. [
25] synthesized existing research on migration case studies, identification methods, the available tools, motivating elements, obstacles, advantages, and both migration processes and techniques.
Similarly, Fritzsch et al. [
26] examined industry-adopted migration processes, highlighting the absence of semi-automated migration support mechanisms. Their research revealed that organizations predominantly rely on unsystematic approaches or manual functional decomposition methods for migration implementation. Addressing this gap, Lapuz et al. [
27] compiled a collection of dynamic data collection instruments from the existing literature that were utilized in or could potentially support monolithic-to-microservice migration through dynamic analysis. Taking a different approach, Mparmpoutis et al. [
28] analyzed research utilizing data-driven artifacts from legacy systems to identify potential microservice candidates. Additionally, Di Francesco et al. [
29] conducted an industry-focused survey to characterize practitioners’ activities and challenges during microservice migration. Their findings revealed several prevalent pre-migration activities, including domain decomposition, service identification, the implementation of domain-driven design practices, and system decomposition.
Finally, Velepucha et al. [
30] concentrated their research on documenting migration-related issues and obstacles found in the academic literature. Building on this research foundation, Luz et al. [
31] documented the motivations, advantages, and challenges encountered during the transition from a monolithic enterprise architecture to microservice-based systems across three Brazilian Government Institutions.
Despite the valuable contributions of these studies, several critical research gaps remain unaddressed. First, existing studies lack a formal ontological framework that can be queried to match specific project requirements with appropriate identification techniques. Second, while previous studies have cataloged identification approaches, they have not provided a multi-dimensional evaluation framework that considers input types, data modeling approaches, identification algorithms, and performance metrics in an integrated manner. Third, the majority of existing studies focus on theoretical aspects without providing practical guidance for implementing identification techniques in real-world scenarios.
This research distinguishes itself by conducting a methodical analysis and synthesis of microservice identification methodologies, including evaluation metrics, tools, and implementation approaches. The analysis encompasses key inputs, procedural steps, and automation levels utilized during system decomposition, while also addressing associated challenges, benefits, and emerging developments highlighted in recent research. Through careful differentiation between identification methodologies, technical implementations, and their integration with domain expertise, this research delivers practical insights for practitioners developing novel approaches. Unlike previous studies that have primarily offered descriptive reviews, our work provides an actionable framework through the development of a middleweight ontology for microservice identification, which establishes formal definitions of core concepts, interconnections, and assessment criteria. This ontological approach enables developers to systematically query appropriate identification techniques based on their specific contexts, available inputs, and desired outcomes, addressing a significant gap in the current literature. Our systematic mapping study complements and extends our previous work [
8] by shifting the focus from historical evolution to practical implementation guidance, offering a structured methodology for evaluating and selecting identification approaches in real-world migration scenarios.
5. The Outcomes of the Mapping
In this section, we will elucidate and provide a comprehensive account of the findings from the mapping study, addressing the five research questions outlined in
Section 3.
5.1. Overview of Selected Research
The search process was carried out in August 2024, resulting in the identification of 45 unique papers that were published from 2016 onwards. The formulated query was employed across the chosen libraries, and
Table 5 illustrates the count of papers retrieved from each of these libraries.
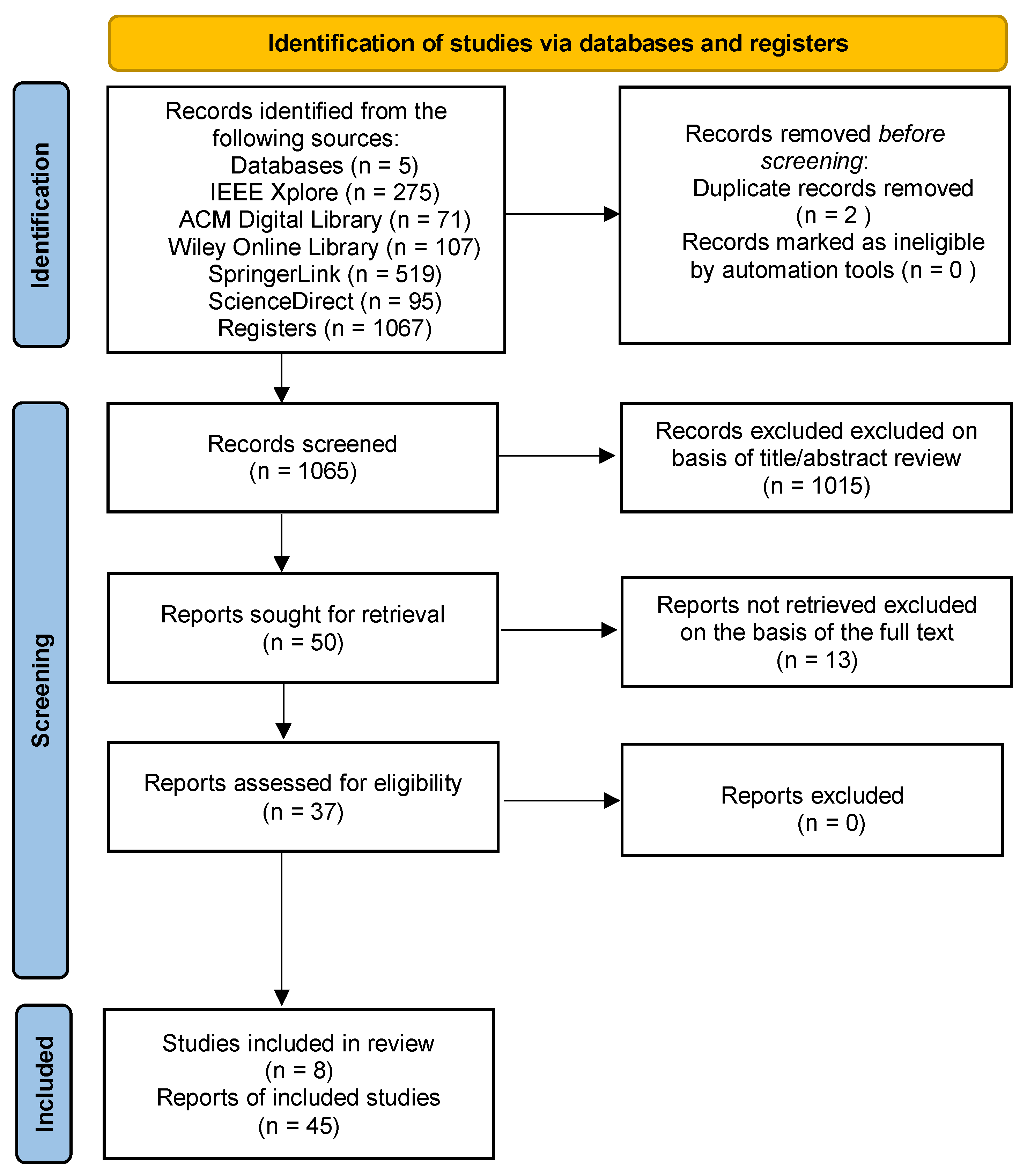
After gathering the 1067 papers retrieved from various search engines, duplicates were eliminated, reducing the number to 1065. Upon screening the titles and abstracts of the remaining papers, 1015 were deemed irrelevant and excluded. Following a thorough review against the inclusion and exclusion criteria, only 37 papers were deemed suitable for inclusion. An additional eight papers were identified using recursive backward and forward snowballing techniques. Two rounds of snowballing were conducted to reach a state of stability. In the first round, five new papers were incorporated, while three more were added in the second round. The number of included and excluded papers for each phase is presented in
Figure 3 using a PRISMA flowchart.
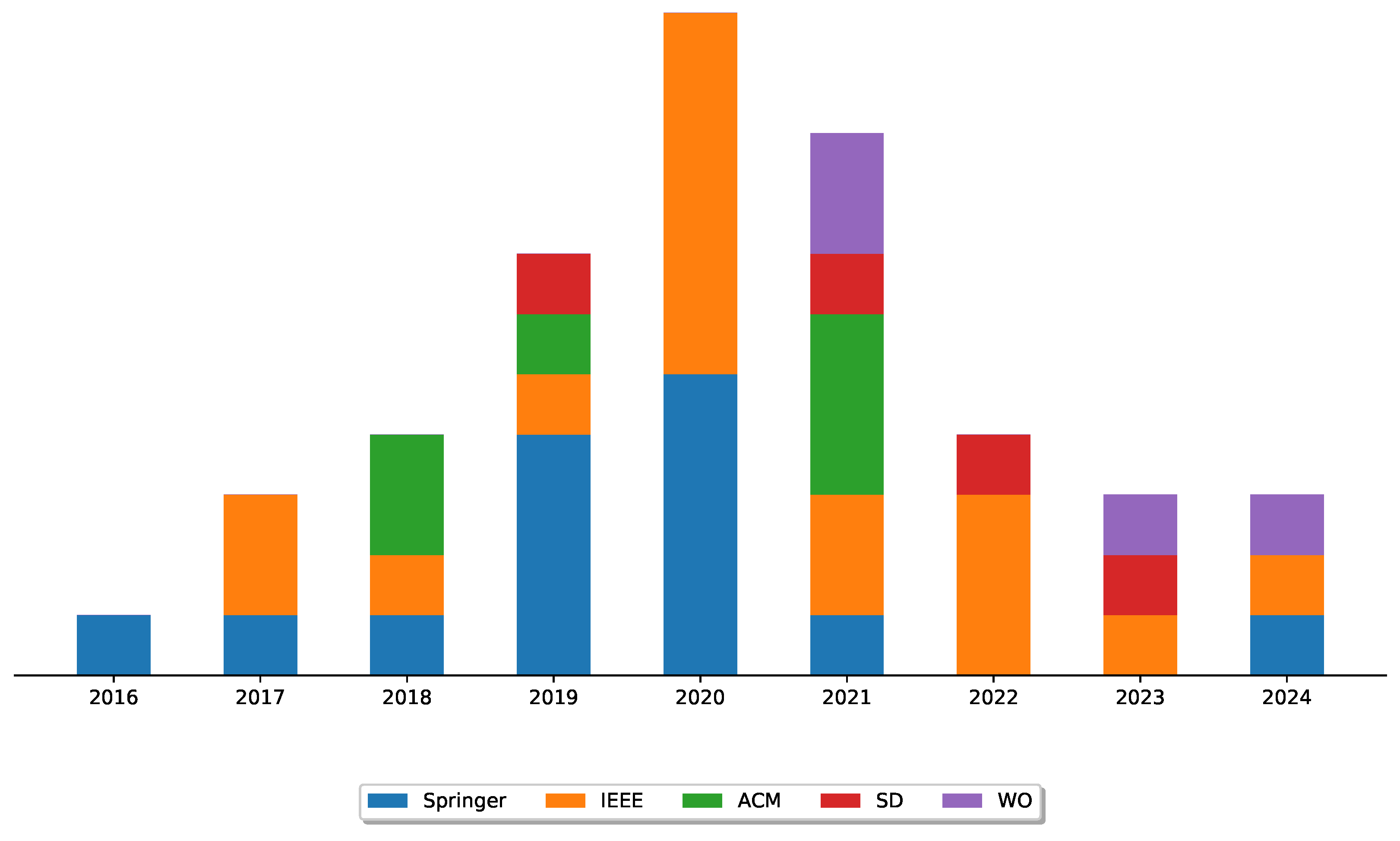
Figure 4 illustrates the distribution of the selected studies based on their publication year and source. Notably, despite the initial introduction of the MSA in 2016, interest in microservice identification and microservice architectures gained significant traction in 2020 and beyond. Furthermore,
Figure 4 reveals that IEEE Xplorer and Springer were the primary sources for publications in this domain.
Table 6 provides a comprehensive overview of the selected studies, including their publication year, publication type, and acquisition method.
To assess the significance of our primary investigations on microservice identification, we employed word clouds as recommended in [
35].
Figure 5 displays the most prevalent terms in titles and abstracts, such as microservice, architecture, and service. Terms related to identification methods like clustering, classification, and similarity were also common. The word cloud underscores the importance of the breakdown process in identifying microservices and the need for effective extraction and classification procedures.
5.2. Challenges in Microservice Identification (RQ1)
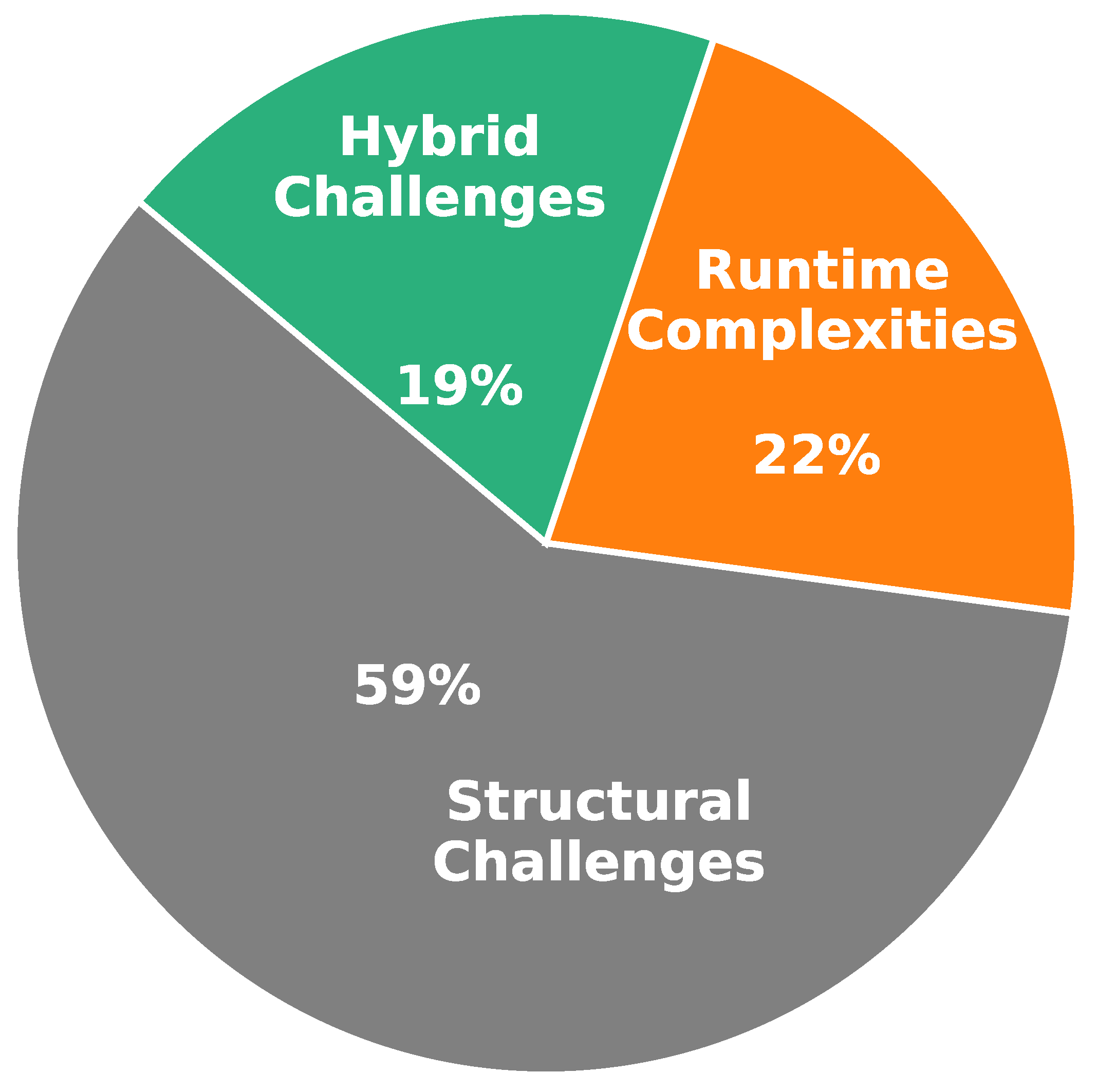
Microservice identification, as a pivotal phase in migrating from monolithic to microservice architectures, brings unique challenges that threaten the quality, scalability, and maintainability of the resulting system. These challenges may stem from structural issues within the monolith, runtime complexities, or the inherent trade-offs in service design. To achieve effective decomposition, all challenges, regardless of their origin, need to be identified and addressed. In this study, we explored the focus of existing research with respect to the source of challenges (structural, runtime, or hybrid).
Figure 6 depicts the distribution of the selected studies regarding the identified sources of challenges. The results indicate that 59% (27 studies) of primary studies focused on structural challenges, 22% (10 studies) addressed runtime complexities, and 19% (8 studies) considered hybrid challenges. This highlights a predominant focus on static structural issues, with less emphasis on runtime or combined approaches.
Given the diverse perspectives on microservice identification challenges and the lack of a unified taxonomy, we adopted a classification based on the targets of these challenges. Accordingly, challenges in microservice identification can be classified into the following:
Granularity Challenges: Issues related to defining service boundaries that balance granularity with maintainability and operational efficiency. Overly fine-grained services may lead to a high communication overhead, while coarse-grained services risk reintroducing monolithic dependencies.
Dependency Challenges: Addressing tight coupling and interdependencies within monolithic systems that make it difficult to isolate functionalities for effective service decomposition.
Domain Modeling Challenges: Ensuring semantic cohesion and domain alignment in the identified services, which requires comprehensive domain knowledge and precise business process understanding.
Data Distribution Challenges: Managing the decomposition of centralized monolithic databases into distributed microservices while preserving data integrity and consistency.
Table 7 shows the categorization of microservice identification challenges addressed by the primary studies. The results reveal that granularity and dependency challenges are the most treated and studied issues, while domain modeling and data distribution challenges receive comparatively less attention. Furthermore, hybrid approaches that combine structural and runtime perspectives are emerging but remain underexplored.
5.3. Categorization and Performance of Microservice Identification Approaches (RQ2)
Given the variety of proposed solutions in the field of microservice identification, we classified the microservice identification approaches addressed in the primary studies according to the nature of their methodologies and classification strategies as follows:
General identification strategies: Approaches using conventional methods to identify microservices, such as heuristic-based techniques or guidelines for selecting appropriate tools, languages, or technologies for microservice identification.
Framework-based solutions: Architectural frameworks for microservices that incorporate predefined modules or patterns for identifying and managing microservices, including service decomposition, interface identification, and microservice dependencies.
Technique-based solutions: New techniques or adaptations of existing methods from other domains applied specifically for the identification of microservices. These include machine learning and artificial intelligence approaches, such as clustering, classification, and deep learning models used to identify service boundaries and dependencies.
Tool-based solutions: Tools specifically designed for the identification of microservices in existing systems or for guiding the design of microservice architectures.
Algorithm-based solutions: New algorithms proposed for the automatic or semi-automatic identification of microservices, utilizing data analysis, clustering, or other optimization techniques to define microservice boundaries.
Protocol-based solutions: New communication protocols or methods for identifying interactions between microservices, ensuring efficient integration and service identification.
Analysis-based solutions: Studies focusing on the comparison, evaluation, or experimentation of existing microservice identification methodologies, highlighting their benefits, limitations, and performance in different contexts.
Our investigation (see
Figure 7) revealed that 34% of the studies focused on new techniques for identifying microservices, while 31% proposed framework-based solutions and 13% emphasized general identification strategies. A smaller proportion of studies developed new tools (10%), algorithms (5%), or protocols (4%). Notably, 3% of the studies focused on the analysis of existing identification approaches. The authors of P20 analyzed existing identification approaches and proposed a refined framework based on insights derived from their analysis. The proposed solutions for identifying microservices can be classified into the following key categories based on their focus:
Service Decomposition: Techniques for breaking down monolithic applications into distinct, manageable microservices based on business logic or domain-driven design.
Interface Identification: Approaches aimed at identifying the interactions and communication patterns between services, which are crucial for defining microservice boundaries.
Dependency Mapping: Methods that focus on identifying service dependencies and interactions, often visualized through dependency graphs or matrices to clearly delineate service boundaries.
Performance Evaluation: Techniques that assess the effectiveness and performance of microservice identification approaches, ensuring that the identified services align with the performance goals of the architecture.
Adaptation and Refinement: Approaches that allow for the ongoing refinement of microservice identification as the system evolves or as new requirements emerge.
Table 8 presents a classification of the proposed microservice identification solutions, showing the proportion of studies in each category. The results indicate that a significant emphasis is placed on service decomposition (40%), interface identification (24.9%), and dependency mapping (15.5%), with less attention given to performance evaluation (13.4%) and adaptation and refinement (11.1%).
5.4. Key Inputs, Data Modeling, and Evaluation Metrics in Microservice Identification (RQ3)
Microservices identification relies on diverse inputs, sophisticated data modeling techniques, and precise evaluation metrics to ensure the effective and accurate decomposition of monolithic systems. The selection of inputs and the chosen modeling approach significantly influence the quality of the identified microservices, while evaluation metrics provide a means to measure the success of these efforts. In this study, we examined the focus of existing approaches with respect to the types of inputs, data modeling methods, and evaluation metrics employed.
The inputs used in microservice identification are varied and include both business and technical artifacts. Business-oriented inputs, such as process models, user stories, and functional or non-functional requirements, provide high-level guidance for defining microservices that align with organizational goals. Technical inputs, including the source code, execution logs, database schemas, and OpenAPI specifications, offer detailed insights into system operations and interactions. These inputs are critical for capturing the structural and behavioral aspects of the system under consideration.
Data modeling in microservice identification is predominantly based on graph or relational data representations. Graph-based approaches represent systems as nodes and edges, where nodes correspond to entities like classes, modules, or functions and edges depict their interactions or dependencies. Partitioning algorithms are then applied to identify cohesive clusters that can serve as microservices. Examples include semantic clustering, syntactic clustering, and knowledge graphs. Relational models, on the other hand, such as data flow matrices, focus on quantifying relationships between components, employing matrices to quantify the relationships between system components, with matrix factorization techniques employed to deduce independent service boundaries. Both approaches aim to balance granularity, cohesion, and independence in the identified services.
Evaluation metrics play an essential role in validating the effectiveness of microservice identification techniques. Metrics such as cohesion and coupling assess the internal consistency of services and their independence from one another. The precision and recall measure the alignment of the identified services with a predefined ground truth, while modularity indices evaluate the overall quality of the decomposition. Performance metrics, including the execution time and resource usage, are particularly relevant for approaches applied to large-scale systems. These metrics collectively provide a robust framework for assessing the feasibility and reliability of proposed identification methods.
Table 9 shows the distribution of approaches proposed by the primary studies across the different input types, data modeling techniques, and evaluation metrics. This study revealed that much emphasis is placed on graph-based and relational modeling techniques, which dominate data representation approaches, and on technical inputs such as the source code, execution traces, and API specifications. In contrast, less attention is given to business-oriented inputs, including BPMN diagrams, user stories, and transactional contexts, or to hybrid evaluation metrics that combine functional and non-functional assessments.
5.5. Automation in Microservice Identification Approaches (RQ4)
The reviewed studies indicate significant advancements in automation for microservice identification, with approaches varying in their degree of automation. These methods can be broadly categorized into manual, semi-automated, and fully automated techniques. As shown in
Table 10, semi-automated techniques dominate the landscape, accounting for 62.22% of the proposed methods. These approaches leverage a combination of automated tools and expert validation to achieve accurate service decomposition. Examples include tools that generate dependency graphs or runtime logs, requiring human intervention to refine the resulting service candidates.
Fully automated techniques, constituting 33.33% of the studies, rely on advanced algorithms such as clustering, graph-based partitioning, machine learning models, or Natural Language Processing (NLP) to identify microservices with minimal human intervention. These methods are particularly effective for large-scale systems where manual processing is infeasible. However, challenges remain in ensuring the interpretability and trustworthiness of the results.
Manual approaches, which represented 4.44% of the studies, are rarely employed in niche contexts or when the data availability is limited. These techniques rely heavily on expert judgment and domain knowledge to identify microservices through processes such as domain-driven design or functional analysis.
5.6. Trends and Emerging Research Directions in Microservice Identification (RQ5)
The reviewed studies reveal key trends and emerging research directions in the field of microservice identification. Automation continues to dominate as a critical focus area, with significant efforts directed toward fully automating the identification process. Researchers are also exploring diverse methodologies to address the complexities of modern software systems and to adapt microservice architectures to meet evolving demands. We determined the trends and research directions:
Automation: Studies like P5 and P38 emphasized the application of advanced algorithms, including the semantic analysis of application specifications and machine learning techniques, to streamline microservice identification and ensure loose coupling and high cohesion.
Service Mesh Technologies: Tools such as Istio and Linkerd are increasingly being adopted to manage communication between microservices. Studies such as P13 and P39 highlighted their role in providing advanced routing, monitoring, and security features essential for scaling complex microservice architectures.
Edge Computing: The integration of microservices with edge computing, as explored in P16 and P27, enhances responsiveness by processing data closer to their source. This trend is particularly significant for IoT systems and real-time applications where latency reduction is critical.
AI-Driven Solutions: Artificial intelligence plays an essential role in microservice management. Studies such as P8 and P14 highlighted the use of AI algorithms for tasks such as anomaly detection, resource allocation, predictive monitoring, and intelligent fault recovery.
Low-Code/No-Code Platforms: P18 demonstrated how these platforms are enabling rapid application development within microservice frameworks, empowering non-technical users and reducing the time to market for new solutions.
Enhanced Observability: Distributed systems require robust observability tools. Studies like 11 and P13 emphasized the development of AI-powered observability solutions that provide real-time insights into the system performance and offer end-to-end tracing for addressing bottlenecks.
Decomposition Techniques: Research on defining optimal service boundaries is ongoing. Studies such as P31 and P45 explored approaches like graph-based partitioning and domain-driven design to ensure microservices were cohesive and independent.
Migration Strategies: Frameworks for transitioning from monolithic systems to microservices, as seen in P3 and P10, address challenges in software re-engineering and offer systematic methods for decomposition.
Performance Analysis: Techniques for evaluating the latency, throughput, and resource utilization are becoming increasingly important. Studies like P20 and P26 focused on understanding the performance trade-offs associated with different microservice configurations.
Standardized Metrics: Despite the variety of proposed metrics, a unified framework for evaluating microservice identification techniques is still lacking. Studies such as P20 and P24 proposed cohesion, coupling, and modularity metrics, but further standardization is needed.
Industry Benchmarks: Establishing benchmarks using real-world datasets and open-source systems is critical for validating microservice identification approaches. P12 and P35 advocated for these efforts to ensure practical applicability and foster collaboration across the community.
Based on the analysis of research directions in microservice identification,
Table 11 shows that automation emerged as the predominant focus of the reviewed studies, closely followed by decomposition techniques. The significant attention to AI-driven solutions demonstrates the field’s increasing emphasis on artificial intelligence applications. Migration strategies and performance analysis are also widely explored, which indicates a focus on optimizing and improving the migration and performance aspects of microservices. Conversely, service mesh technologies and standardized metrics are among the least-addressed areas, demonstrating a moderate but consistent research interest. The data reveal balanced attention across several areas, with edge computing, enhanced observability, low-code/no-code platforms, and industry benchmarks each comprising 9% of the research landscape. This distribution suggests a comprehensive approach to microservice identification rather than significant research gaps.
A notable pattern emerged in the interconnected nature of these research directions, with many studies incorporating multiple approaches. For instance, several papers appeared across different categories, such as combining AI-driven solutions with decomposition techniques. This integration suggests a holistic approach to addressing the complexities of microservice identification. While studies like P2 and P20 focused on automation, they also contributed to other areas such as low-code platforms and standardized metrics, indicating a broader scope than initially suggested. It is important to note that the studies listed in the table may span multiple research directions, leading to some duplication. As a result, the total number of unique studies (45) is not fully represented in the distribution percentages of each category. This reflects the multidisciplinary nature of the field and the tendency for research to address overlapping challenges in microservice identification.
6. An Ontology for Microservice Identification
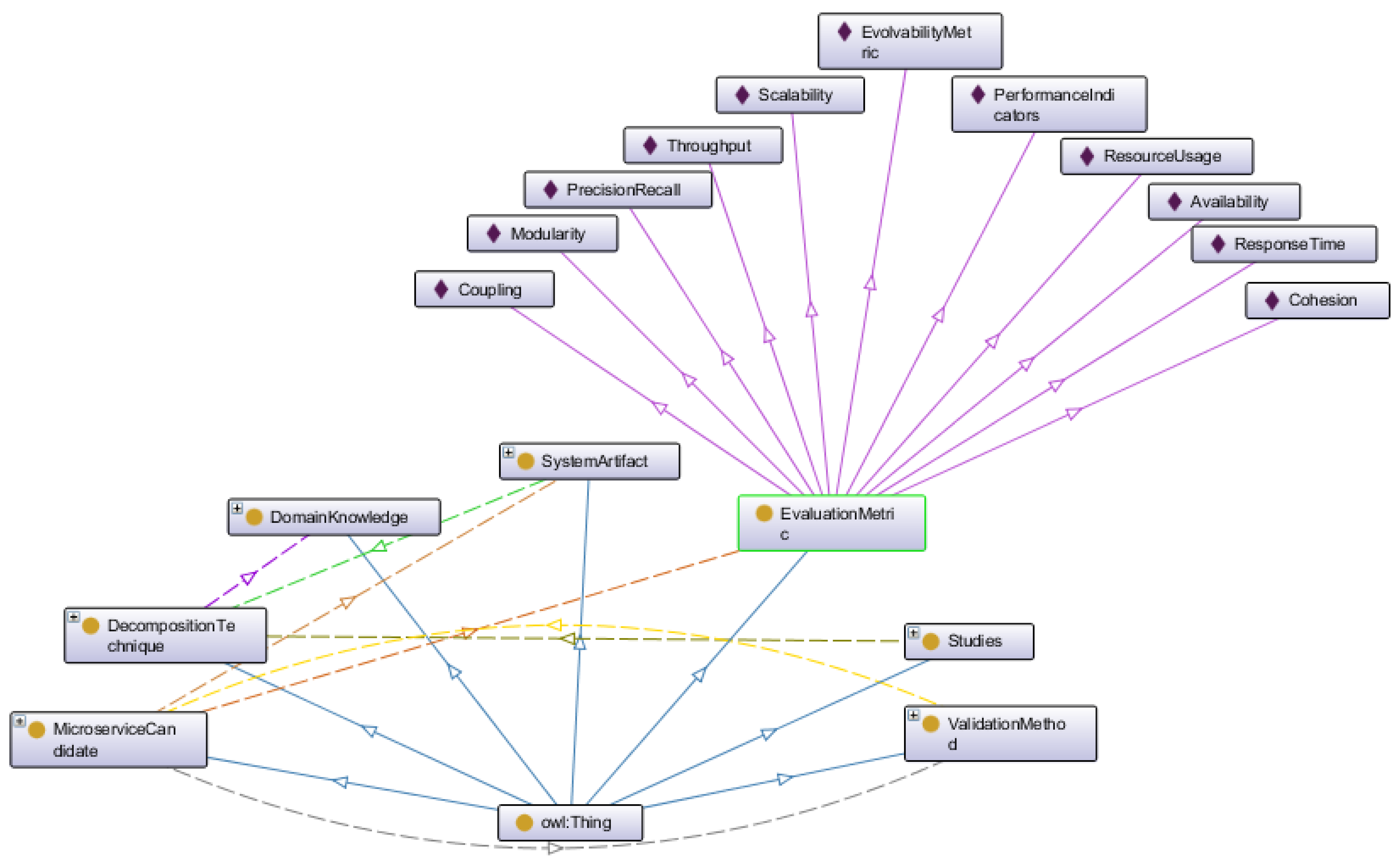
Making the results of our study practical and extendable, and considering the static nature of taxonomies, we propose an ontology-based representation of our findings. To the best of our knowledge, this work is the first to propose an ontology for microservice identification. This approach formalizes the relationships among key concepts and entities within the microservice identification domain, enabling the creation of a reusable, extensible framework for researchers and practitioners. The ontology models the relationships between system artifacts, decomposition techniques, evaluation metrics, microservice candidates, domain knowledge, and validation methods.
Figure 8 illustrates an excerpt of the ontology structure derived from this study. While the complete ontology is too extensive to display in its entirety, the figure shows its core structural organization while still capturing the key structural elements.
The ontology was developed using Protégé (
https://protege.stanford.edu/, accessed on 5 February 2025), and its consistency and coherence were validated using the Protégé Debugger option. The ontology organizes domain knowledge into key concepts that collectively represent the microservice identification process. The main concepts of the ontology are as follows:
Studies: Encompass the 45 selected research studies (P1 to P45). Each study in this class contains essential information, including its title, DOI, automation degree, challenges, and other relevant attributes.
SystemArtifact: Represents the primary inputs required for microservice identification, including runtime logs, the source code, architectural models, and business process descriptions.
DecompositionTechnique: Defines the techniques used for service decomposition, such as static analysis, dynamic analysis, and clustering algorithms.
EvaluationMetric: Captures the metrics used to evaluate the quality of the identified microservices, including the cohesion, coupling, modularity, and granularity.
MicroserviceCandidate: Describes the potential microservices identified during decomposition, characterized by their boundaries, dependencies, and functional roles.
DomainKnowledge: Represents business processes, workflows, and other domain-specific data that inform the decomposition process and ensure alignment with organizational objectives.
ValidationMethod: Details the techniques used to validate the identified microservices, including case studies, simulation environments, and proof-of-concept implementations.
Relationships between these classes are represented using Protégé object properties, as outlined in
Table 12. For instance, the relationship isEvaluatedBy links MicroserviceCandidate to EvaluationMetric, while isDecomposedBy connects SystemArtifact to DecompositionTechnique.
For usability, the ontology supports OWL-DL queries to explore its structure and retrieve actionable insights.
Table 13 describes several useful queries. For example, Q1 retrieves a list of decomposition techniques applied to business processes, while Q2 identifies evaluation metrics most commonly associated with clustering algorithms. Q3 lists all system artifacts used in studies that employed graph-based partitioning, and Q4 retrieves the evaluation metrics used to evaluate microservice candidates.
The proposed ontology is available in OWL format at
https://github.com/Ioumoussa/MicroservicesIdentification (accessed on 20 February 2025), allowing researchers and practitioners to extend and adapt it for various contexts. By formalizing the microservice identification process, this ontology provides a foundational framework for advancing research and developing standardized tools in this domain.
7. Discussion
This study sought to comprehensively characterize the migration of monolithic systems to microservices by analyzing microservice identification techniques, presenting key findings, identifying research gaps, and outlining future research directions. The insights derived from the systematic mapping study establish a robust foundation for understanding the challenges, methodologies, and emerging trends within this domain.
7.1. Principal Findings and Lessons Acquired
This investigation extended beyond the taxonomic framework proposed by Fritzsch et al. [
5], introducing a more comprehensive classification methodology for microservice identification techniques. While previous research has primarily focused on monolithic system attributes that facilitate identification, our analysis encompassed multiple dimensions: the automation sophistication, auxiliary methodologies, granularity considerations, and evaluation frameworks. To systematically codify this knowledge domain, we developed and implemented a middleweight ontological framework for identification methodologies. This ontological structure enables the systematic querying of essential components, including input parameters, data modeling paradigms, identification algorithms, and performance evaluation metrics.
The implementation of this ontological framework addresses a significant lacuna in the field by establishing a standardized methodology for the comparative analysis of identification approaches. This structured knowledge representation enables practitioners and researchers to conduct systematic analyses of methodological interrelationships and make empirically informed decisions regarding approach selection based on specific contextual requirements.
Our empirical analysis revealed significant heterogeneity in the proposed methodologies, each presenting distinct trade-offs between technological constraints and requisite manual intervention. A noteworthy finding indicates that semi-automated methodologies maintain a substantial dependence on domain expertise, potentially creating operational bottlenecks in large-scale identification initiatives. This dependency is particularly pronounced in organizations attempting to identify microservices within complex, enterprise-scale systems.
The establishment of uniform quality assessment metrics for microservice identification necessitates the development of industry-standard and academically validated evaluation criteria. The current absence of comprehensive boundary evaluation metrics and standardized validation frameworks significantly impedes the comparative analysis of different approaches. This limitation is particularly evident in industrial applications, where the lack of standardized benchmarks complicates the evaluation of identification strategy efficacy. In this context, Aderaldo et al. [
83] have proposed essential criteria for architectural benchmark selection to enhance research reproducibility. Similarly, Santos et al. [
84] have introduced metrics for quantifying the identification complexity and implementation costs.
The analysis of the motivating factors for microservice identification revealed predominant themes of scalability enhancement, maintainability improvement, technological independence, and implementation efficiency. Empirical evidence suggests that the anticipated benefits of microservice adoption align closely with these primary drivers. However, it is noteworthy that a minority of studies proposing identification techniques have conducted post-implementation evaluations to verify the realization of these expected benefits.
Our research findings align with those of Saucedo et al. [
25] regarding the significant complexities inherent in service boundary identification during microservice adoption. While our investigation did not specifically address database integration, incorporating database components into the identification methodology presents a promising direction for enhancing service boundary delineation. Current methodologies generally demonstrate an insufficient consideration of database elements during the identification phase. The incorporation of database schemas, data flow relationships, and quantitative decomposition metrics could substantially improve the efficacy of microservice identification methodologies.
Furthermore, an emerging consideration in this domain pertains to retroactive optimization capabilities, specifically the potential requirement to reassess or modify previously identified services due to technical or organizational constraints. With the exception of the methodology proposed by Freire et al. [
56], the reviewed approaches do not explicitly incorporate provisions for such retroactive modifications. Although a comprehensive evaluation of microservice architectures’ suitability should be conducted during the initial identification phase, unanticipated challenges may manifest subsequent to the completion of service identification. The implementation of semi-automated refinement methodologies or service boundary adjustment mechanisms could potentially reduce the manual effort associated with such modifications, thereby enhancing the adaptability and sustainability of microservice identification processes.
7.2. Practical Implications for Practitioners
This investigation yields several significant implications for practitioners engaged in microservice identification initiatives. The following empirically derived insights merit particular consideration.
Systematic Service Identification for Enhanced Scalability. The methodological identification of microservices demonstrates substantial potential for improving system scalability characteristics. Through the precise identification of autonomous services, organizations can implement granular scaling mechanisms, enabling independent resource allocation based on service-specific demand patterns. This granular approach to scalability optimization facilitates enhanced performance metrics while simultaneously reducing operational resource consumption.
The Optimization of Development and Deployment Methodologies. The identification of well-defined service boundaries significantly enhances the efficiency of deployment and development processes. The implementation of continuous integration and continuous deployment (CI/CD) methodologies becomes more systematic when founded upon properly identified service boundaries. This enhancement enables accelerated release cycles and reduced time-to-market metrics. Furthermore, organizations can leverage precisely identified microservices to implement sophisticated automated testing frameworks, streamlined deployment processes, and efficient rollback mechanisms.
The Implementation of Domain-Driven Design Paradigms. The identification of microservices necessitates the adoption of a methodologically rigorous approach founded upon domain-driven design principles. This approach encompasses the comprehensive analysis of business domains, systematic identification of bounded contexts, and precise alignment of service boundaries with fundamental business capabilities. The integration of hybrid evaluation metrics, incorporating both quantitative performance indicators and qualitative domain expertise, substantially enhances the precision of service identification outcomes.
Architectural Decision Support Framework. Our findings provide a structured approach for evaluating competing microservice identification methodologies. The ontological framework enables architects to systematically compare the available techniques based on system-specific characteristics, including the codebase complexity, business domain nature, and existing architectural constraints. This methodological comparison facilitates evidence-based decision-making when selecting identification approaches aligned with architectural quality attributes prioritized by the organization.
Implementation Guidance for Development Teams. This research offers practical guidance on implementing the identified microservice boundaries. The analysis of automation sophistication levels helps development teams anticipate the required technical expertise and manual intervention during the identification process. Our findings regarding communication patterns provide developers with insights for implementing loose coupling between services, reducing system instability risks, and facilitating independent deployment capabilities.
Business–Technical Alignment Methodology. Our research bridges technical and business perspectives by emphasizing domain-driven design principles in service identification. This study highlights the importance of aligning service boundaries with business capabilities, enabling analysts to effectively communicate technical decomposition decisions using business domain terminology. This alignment enhances collaboration between technical and business teams, ensuring that the identified microservices support both technical objectives and business agility.
7.3. Emerging Research Trajectories
The analysis of primary research studies revealed several critical trajectories requiring further investigation within the domain of microservice identification. The following areas present significant opportunities for advancement in both theoretical frameworks and practical methodologies:
Data-Intensive Systems and Technological Evolution. Contemporary data-intensive systems present unique methodological challenges for microservice identification, primarily due to complex data processing requirements. The emergence of advanced technologies, including 5G infrastructure and edge computing paradigms, introduces additional complexity dimensions, particularly regarding latency-sensitive service identification and dynamic reconfiguration requirements. These evolutionary paradigms necessitate innovative identification methodologies capable of accommodating both performance requirements and architectural flexibility considerations.
Business Logic Integration and Data Dependency Analysis. Legacy system architectures frequently incorporate business rules directly within database structures, introducing significant complexity in service boundary identification. This historical architectural pattern necessitates sophisticated approaches to service identification that consider both application logic and data dependency patterns. Further research is required to develop methodological frameworks for identifying service boundaries while maintaining data integrity and business rule coherence.
Security Integration in Service Identification Methodology. The integration of security considerations must be fundamental to the service identification process rather than treated as a supplementary concern. Contemporary approaches, including Moving Target Defense (MTD) and artificial intelligence-based anomaly detection systems, present promising frameworks for securing the identified microservices. These advanced security paradigms require integration within core identification methodologies, particularly concerning inter-service communication protocols and dependency structures.
Communication Pattern Analysis in Service Identification. The identification of microservices must incorporate the sophisticated analysis of communication patterns and service dependencies. Contemporary best practices emphasize the minimization of synchronous communication patterns, as tightly coupled services can propagate system instability. Future research should focus on identification methodologies that promote loose coupling architectures and support asynchronous communication patterns.
Organizational Alignment and Conway’s Law’s Implications. The influence of Conway’s Law on microservice identification presents significant implications for organizational structure consideration. The efficacy of microservice identification demonstrates a strong correlation with organizational structural alignment. This necessitates the development of identification strategies that incorporate both technical and organizational dimensions. An alignment between organizational team structures and service boundaries facilitates enhanced development efficiency and long-term maintainability characteristics.
The synthesis of these emerging perspectives, supported by our ontological framework, establishes a comprehensive foundation for future research initiatives in microservice identification. Subsequent investigations should focus on the development of sophisticated identification methodologies that address these emerging challenges while maintaining practical applicability in industrial contexts. The integration of our findings with established theoretical frameworks suggests several trajectories for future research, particularly in the development of standardized evaluation metrics and the enhancement of automated identification tools. These research directions, coupled with our ontological framework, provide a robust foundation for advancing the field of microservice identification.
9. Conclusions
This systematic mapping study presents a comprehensive analysis of the current research landscape regarding microservice identification methodologies in the context of monolithic-to-microservice migration. The investigation encompassed identification techniques, supporting tools, decision criteria, and the determination of optimal service boundaries. Furthermore, this research provides a methodical examination of the identification process, with particular emphasis on its inherent challenges, quantitative metrics, and degrees of automation.
The findings indicate that no singular microservice identification methodology demonstrates universal efficacy across all scenarios. The heterogeneity in automation capabilities, granularity specifications, input prerequisites, and technological support mechanisms presents substantial obstacles in formulating a generalized identification framework applicable across diverse systems and domains. Moreover, the analyzed literature reveals significant disparities regarding essential aspects such as input requirements, granularity determinations, supporting methodologies, and evaluation metrics for microservice identification. These inconsistencies significantly impede both the comparative analysis of different approaches and the development of standardized methodologies.
This systematic mapping study further contributes by offering an analytical perspective on the specific challenges and advantages associated with microservice identification, thereby establishing a foundation for the development of standardized tools and evaluation frameworks. The proposed middleweight ontology serves as a taxonomic framework for organizing and categorizing microservice identification techniques, facilitating the establishment of a standardized vocabulary and enhancing collaboration among stakeholders involved in the identification process.
Given the current absence of standardized and extensively validated identification frameworks, future research directions will prioritize the integration of industrial insights to enhance the ontological framework and improve the practical applicability of identification techniques. Additionally, the expansion of this research to include gray literature—encompassing industry reports, professional blogs, and practitioner experiences—will facilitate a multivocal analysis, thereby strengthening the bridge between academic research and industrial implementation practices.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 35.56%
35.56% 15.56%
15.56%
 6.67%
6.67%
 13.33%
13.33%
 31.11%
31.11% 8.89%
8.89%
 20%
20% 4.44%
4.44%
 13.8%
13.8%
 11.1%
11.1%
 6.7%
6.7%
 4.4%
4.4%
 8.9%
8.9%
 11%
11%
 60%
60%
 29%
29%
 32%
32%
 51%
51%
 17%
17%
 42%
42%
 33%
33%
 16%
16%
 9%
9%
 62.22%
62.22%
 33.33%
33.33%
 22%
22%
 18%
18%