
LAVID: A Lightweight and Autonomous Smart Camera System for Urban Violence Detection and Geolocation


Abstract
1. Introduction
2. Related Works
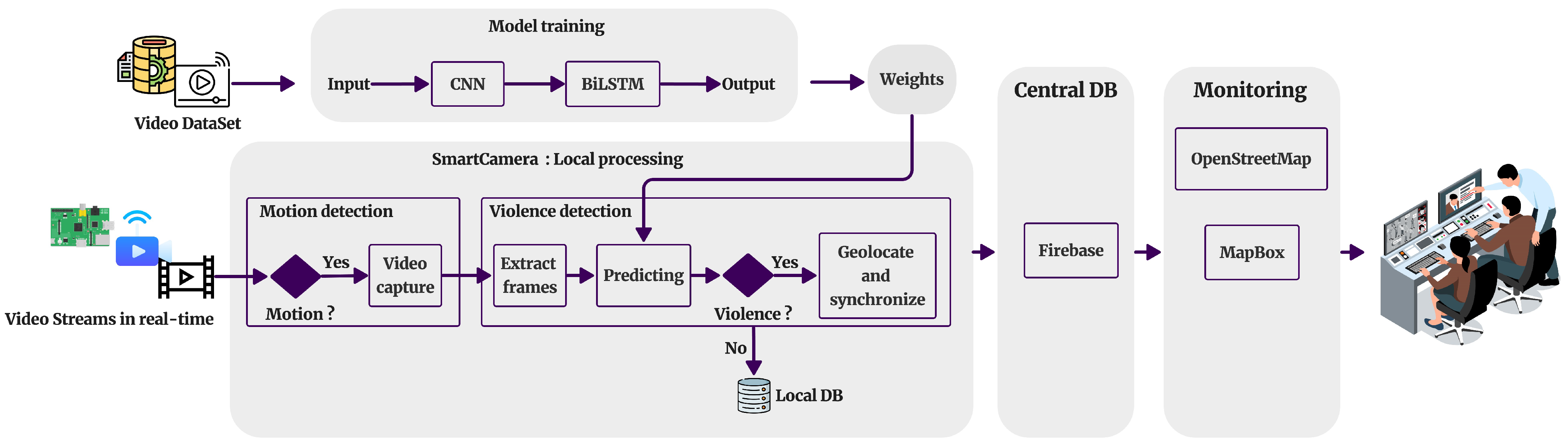
3. Proposed System
3.1. System Components
- Its low cost makes it the most affordable solution for implementing a distributed system.
- Its large community of users helps to increase knowledge and skills, and exchange technical solutions and publications.
- Its modularity allows it to support a variety of external peripherals and sensors, such as cameras, geolocation devices, edge AI hardware accelerators and Vision Processing Units (VPUs).
- Its versatility enables a wide variety of applications and solutions to be used, as it supports a wide range of operating systems and programming languages, including Python, which is used to implement deep learning algorithms.
3.2. System Architecture
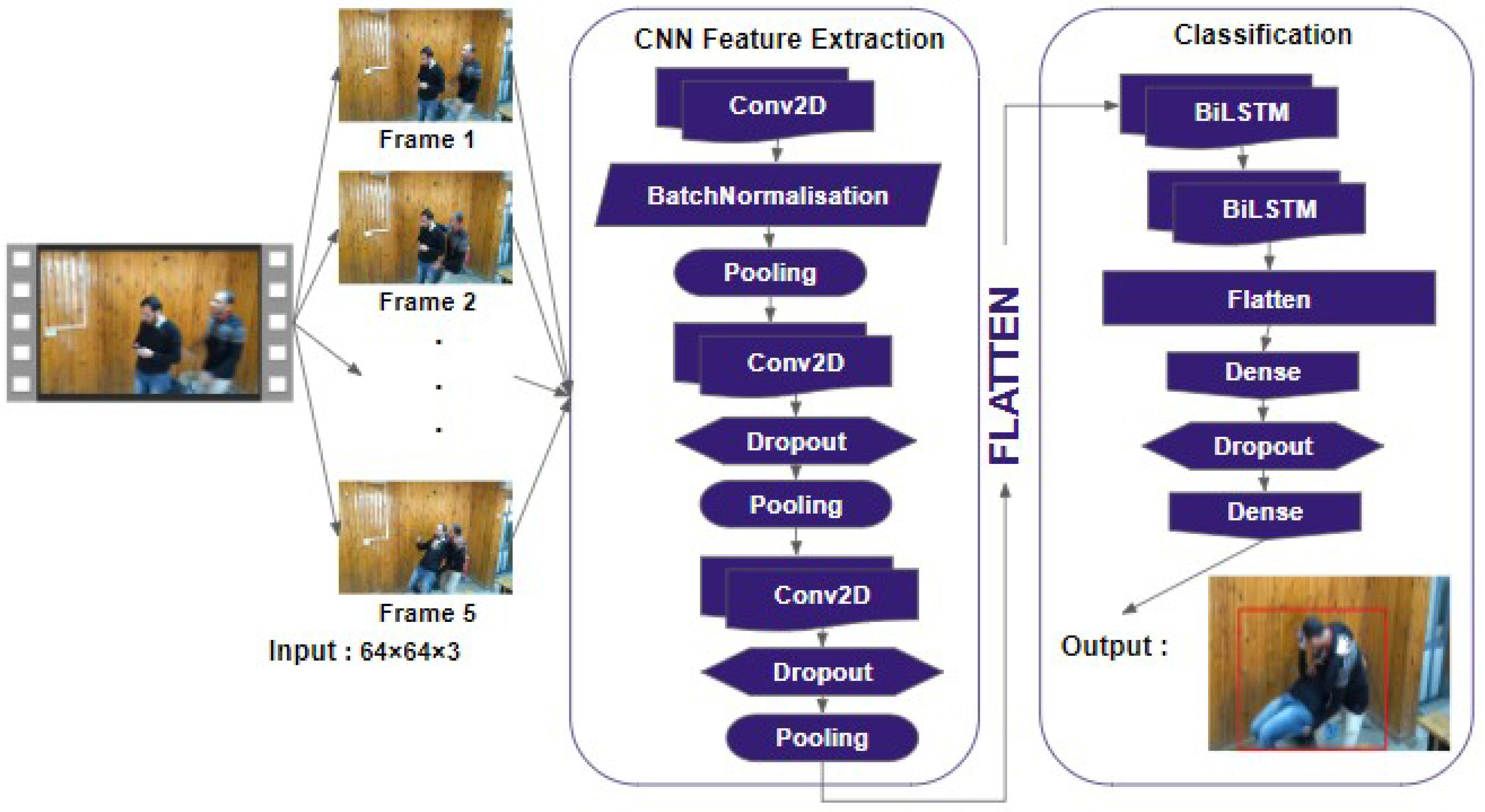
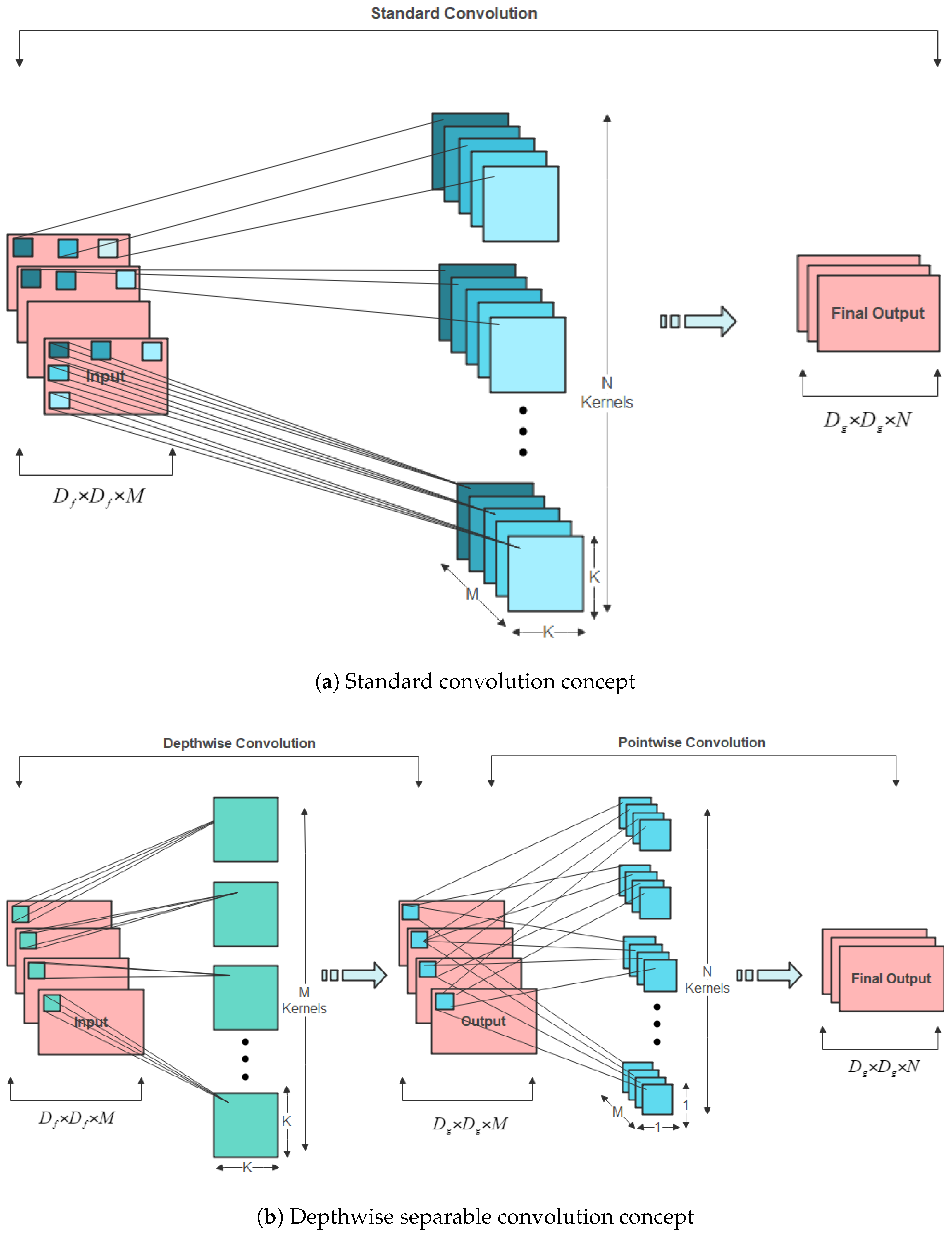
3.2.1. Model Training
3.2.2. Local Processing
Motion Detection
Violence Detection
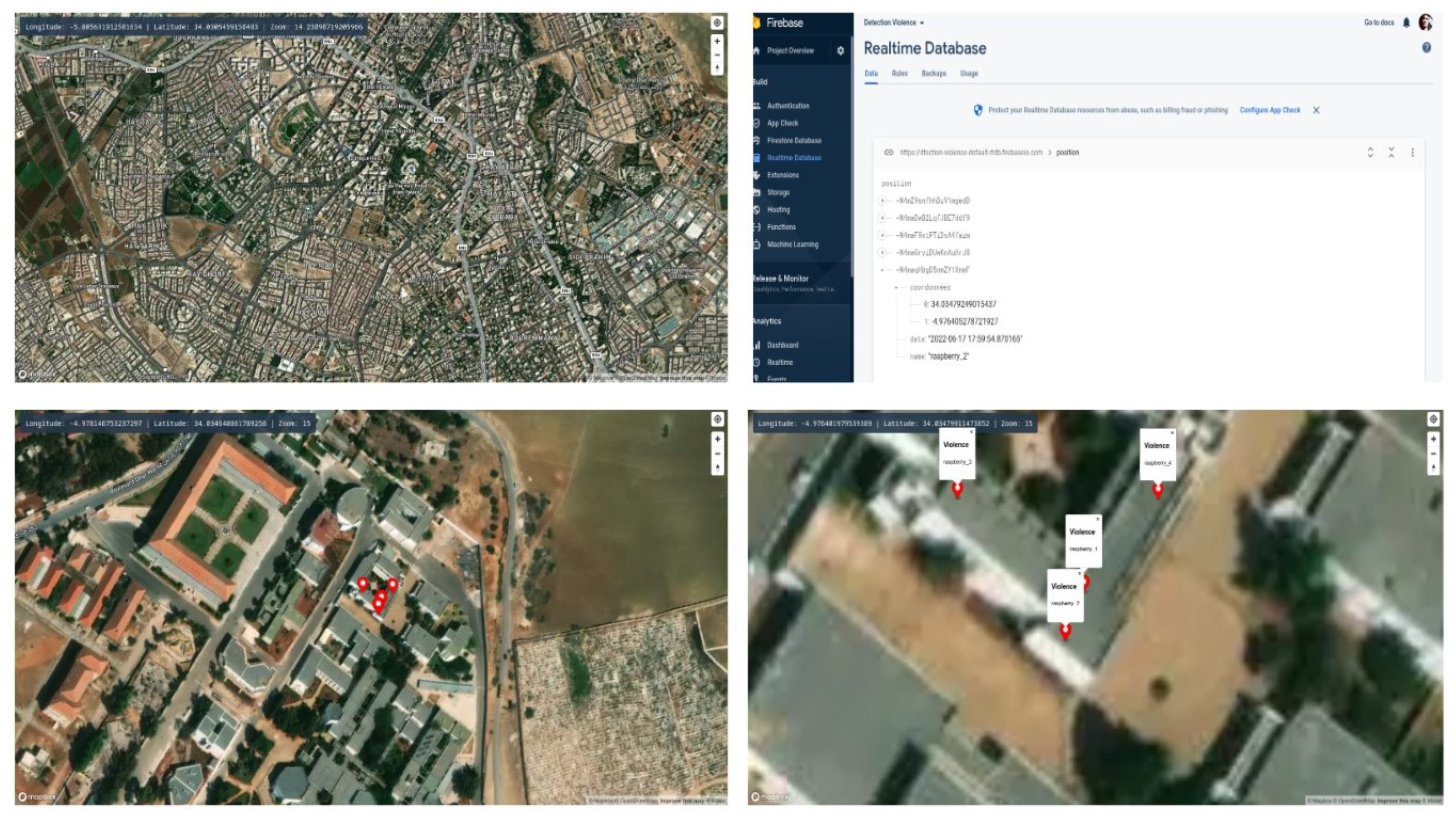
Geolocation and Mapping of Violence Coordinates
4. Experimental Setup and Results
4.1. Implementation Details
4.2. Dataset
- Nievas et al. presented two video datasets for violence detection, namely, Hockey Fights and Movies Fights [37]. The Hockey Fights dataset comprises 1000 short video clips captured from National Hockey League games. Each clip consists of approximately 50 frames with a resolution of 360 × 288 pixels. The clips primarily showcase close-up footage of fights between players. The dataset presents various challenges for detection models, including diverse viewpoints, camera movement, and the variety of individuals involved in each violence clip.The Movies Fights dataset includes 200 short video clips showcasing 100 person-on-person fights. This collection also contains 100 non-fight scenarios showcasing various sports footage and samples from the Weizmann action recognition dataset. Each sequence consists of around 50 frames with a resolution of 720 × 480, although some have a resolution of 720 × 576. Movies Fights offers a wider variety of scenes but may be impacted by interlacing artifacts.
- Hassner et al. introduced the Violent Crowd [38] dataset, which comprises 246 short video sequences from YouTube depicting various settings like football stadiums, bars, and demonstrations. The videos capture indoor and outdoor areas using both stationary and mobile cameras, with an image resolution of 320 × 240 and varying video lengths ranging from 50 to 150 frames. Challenges in this dataset include image quality issues such as compression artifacts, motion blur, text overlay, flashlights, and differing temporal resolutions, which make accurate extraction of motion information challenging.
- Soliman et al. presented the RLVS-2000 [5] dataset, which includes 1000 violence and 1000 non-violence videos depicting real-life situations sourced from YouTube videos and other sources. The dataset features various real street fight scenarios in different environments and conditions, while the non-violence videos encompass diverse human actions, such as sports, eating, walking, and more.
- Cheng et al. developed a new dataset called the RWF-2000 [39], comprising 2000 videos recorded by surveillance cameras in real-world settings. Each video has a duration of 5 s, with half of the videos depicting violent behaviors and the remaining videos showcasing non-violent actions. A few samples from each dataset were visually displayed in Figure 10, Figure 11, Figure 12 and Figure 13, while Table 2 presents a statistical overview of each dataset used in the evaluation of our proposed model.
4.3. Results
4.4. Cost Analysis
4.5. Discussion
5. Conclusions
6. Patents
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Singh, V.; Singh, S.; Gupta, P. Real-Time Anomaly Recognition Through CCTV Using Neural Networks. Procedia Comput. Sci. 2020, 173, 254–263. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Obaidat, M.S.; Ullah, A.; Muhammad, K.; Hijji, M.; Baik, S.W. A Comprehensive Review on Vision-Based Violence Detection in Surveillance Videos. ACM Comput. Surv. 2023, 55, 200:1–200:44. [Google Scholar] [CrossRef]
- Mumtaz, N.; Ejaz, N.; Habib, S.; Mohsin, S.M.; Tiwari, P.; Band, S.S.; Kumar, N. An overview of violence detection techniques: Current challenges and future directions. Artif. Intell. Rev. 2023, 56, 4641–4666. [Google Scholar] [CrossRef]
- Zahrawi, M.; Shaalan, K. Improving video surveillance systems in banks using deep learning techniques. Sci. Rep. 2023, 13, 7911. [Google Scholar] [CrossRef]
- Soliman, M.M.; Kamal, M.H.; El-Massih Nashed, M.A.; Mostafa, Y.M.; Chawky, B.S.; Khattab, D. Violence Recognition from Videos using Deep Learning Techniques. In Proceedings of the 2019 Ninth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 8–10 December 2019; pp. 80–85. [Google Scholar] [CrossRef]
- Khan, S.U.; Haq, I.U.; Rho, S.; Baik, S.W.; Lee, M.Y. Cover the Violence: A Novel Deep-Learning-Based Approach Towards Violence-Detection in Movies. Appl. Sci. 2019, 9, 4963. [Google Scholar] [CrossRef]
- Leroux, S.; Li, B.; Simoens, P. Multi-branch Neural Networks for Video Anomaly Detection in Adverse Lighting and Weather Conditions. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3027–3035, ISSN: 2642-9381. [Google Scholar] [CrossRef]
- Shuang, K.; Lyu, Z.; Loo, J.; Zhang, W. Scale-balanced loss for object detection. Pattern Recognit. 2021, 117, 107997. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255, ISSN: 1063-6919. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Lejmi, W.; Khalifa, A.B.; Mahjoub, M.A. Challenges and Methods of Violence Detection in Surveillance Video: A Survey. In Proceedings of the Computer Analysis of Images and Patterns; Vento, M., Percannella, G., Eds.; Springer: Cham, Switzerland, 2019; pp. 62–73. [Google Scholar] [CrossRef]
- Kaur, G.; Singh, S. Violence Detection in Videos Using Deep Learning: A Survey. In Advances in Information Communication Technology and Computing, Proceedings of the Advances in Information Communication Technology and Computing; Goar, V., Kuri, M., Kumar, R., Senjyu, T., Eds.; Springer: Singapore, 2022; pp. 165–173. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Violence Detection Using Spatiotemporal Features with 3D Convolutional Neural Network. Sensors 2019, 19, 2472. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017. [Google Scholar] [CrossRef]
- Kang, M.S.; Park, R.H.; Park, H.M. Efficient Spatio-Temporal Modeling Methods for Real-Time Violence Recognition. IEEE Access 2021, 9, 76270–76285. [Google Scholar] [CrossRef]
- Sahay, K.B.; Balachander, B.; Jagadeesh, B.; Anand Kumar, G.; Kumar, R.; Rama Parvathy, L. A real time crime scene intelligent video surveillance systems in violence detection framework using deep learning techniques. Comput. Electr. Eng. 2022, 103, 108319. [Google Scholar] [CrossRef]
- Gracia, I.S.; Suarez, O.D.; Garcia, G.B.; Kim, T.K. Fast Fight Detection. PLoS ONE 2015, 10, e0120448. [Google Scholar] [CrossRef]
- Wang, G.; Ding, H.; Duan, M.; Pu, Y.; Yang, Z.; Li, H. Fighting against terrorism: A real-time CCTV autonomous weapons detection based on improved YOLO v4. Digit. Signal Process. 2023, 132, 103790. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788, ISSN: 1063-6919. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525, ISSN: 1063-6919. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018. [Google Scholar] [CrossRef]
- Elhanashi, A.; Saponara, S.; Dini, P.; Qinghe, Z.; Morita, D.; Raytchev, B. An integrated and real-time social distancing, mask detection, and facial temperature video measurement system for pandemic monitoring. J. Real-Time Image Process. 2023, 20, 95. [Google Scholar] [CrossRef]
- Olmos, R.; Tabik, S.; Herrera, F. Automatic handgun detection alarm in videos using deep learning. Neurocomputing 2018, 275, 66–72. [Google Scholar] [CrossRef]
- Hosang, J.; Benenson, R.; Dollár, P.; Schiele, B. What Makes for Effective Detection Proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 814–830. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Durham, R.; Wilkinson, P. Joker: How ‘entertaining’ films may affect public attitudes towards mental illness—Psychiatry in movies. Br. J. Psychiatry 2020, 216, 307. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Zhang, S. Shot Boundary Detection based on Multilevel Difference of Colour Histograms. In Proceedings of the 2016 First International Conference on Multimedia and Image Processing (ICMIP), Bandar Seri Begawan, Brunei, 1–3 June 2016; pp. 15–22. [Google Scholar] [CrossRef]
- Rezazadegan Tavakoli, H.; Rahtu, E.; Heikkilä, J. Fast and Efficient Saliency Detection Using Sparse Sampling and Kernel Density Estimation. In Image Analysis; Heyden, A., Kahl, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 666–675. [Google Scholar] [CrossRef]
- Imah, E.M.; Laksono, I.K.; Karisma, K.; Wintarti, A. Detecting violent scenes in movies using Gated Recurrent Units and Discrete Wavelet Transform. Regist. J. Ilm. Teknol. Sist. Inf. 2022, 8, 94–103. [Google Scholar] [CrossRef]
- Zhang, D. Wavelet Transform. In Fundamentals of Image Data Mining: Analysis, Features, Classification and Retrieval; Zhang, D., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 35–44. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807, ISSN: 1063-6919. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, ICML’15, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Youssef, K.; Woo, P.Y. Difference of the Absolute Differences—A New Method for Motion Detection. Int. J. Intell. Syst. Appl. 2012, 4, 1–14. [Google Scholar] [CrossRef]
- Rakesh, S.; Hegde, N.P.; Venu Gopalachari, M.; Jayaram, D.; Madhu, B.; Hameed, M.A.; Vankdothu, R.; Suresh Kumar, L. Moving object detection using modified GMM based background subtraction. Meas. Sensors 2023, 30, 100898. [Google Scholar] [CrossRef]
- Odunlade, E. Raspberry Pi GPS Module Interfacing Tutorial. 2017. Available online: https://circuitdigest.com/microcontroller-projects/raspberry-pi-3-gps-module-interfacing (accessed on 15 March 2025).
- Bermejo Nievas, E.; Deniz Suarez, O.; Bueno García, G.; Sukthankar, R. Violence Detection in Video Using Computer Vision Techniques. In Proceedings of the Computer Analysis of Images and Patterns; Real, P., Diaz-Pernil, D., Molina-Abril, H., Berciano, A., Kropatsch, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 332–339. [Google Scholar] [CrossRef]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. ISSN: 2160-7516. [Google Scholar] [CrossRef]
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An Open Large Scale Video Database for Violence Detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4183–4190, ISSN: 1051-4651. [Google Scholar] [CrossRef]
- Gedel, I.A.; Nwulu, N.I. Low Latency 5G Distributed Wireless Network Architecture: A Techno-Economic Comparison. Inventions 2021, 6, 11. [Google Scholar] [CrossRef]
- Shariati, B.; Velasco, L.; Pedreno-Manresa, J.J.; Dochhan, A.; Casellas, R.; Muqaddas, A.; Gonzalez de Dios, O.; Luque Canto, L.; Lent, B.; Lopez de Vergara, J.E.; et al. Demonstration of latency-aware 5G network slicing on optical metro networks. J. Opt. Commun. Netw. 2022, 14, A81–A90. [Google Scholar] [CrossRef]
- Safe and Sound Security. CCTV Camera Installation Cost: 2024 Price Guide. 2024. Available online: https://getsafeandsound.com/blog/surveillance-camera-installation-cost/ (accessed on 15 March 2025).
- Cisco Networking, Security, Collaboration, and Cloud Solutions. 2025. Available online: https://www.cisco.com/ (accessed on 15 March 2025).
- Axis Communications Security Cameras and Video Surveillance Solutions. 2025. Available online: https://www.axis.com/ (accessed on 15 March 2025).
- Mali, J.; Atigui, F.; Azough, A.; Travers, N.; Ahvar, S. How to Optimize the Environmental Impact of Transformed NoSQL Schemas through a Multidimensional Cost Model? arXiv 2023. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, H.; Sun, X.; Wang, C.; Liu, Y. Violence detection using Oriented VIolent Flows. Image Vis. Comput. 2016, 48–49, 37–41. [Google Scholar] [CrossRef]
- Sharma, M.; Baghel, R. Video Surveillance for Violence Detection Using Deep Learning. In Proceedings of the Advances in Data Science and Management; Borah, S., Emilia Balas, V., Polkowski, Z., Eds.; Springer: Singapore, 2020; pp. 411–420. [Google Scholar] [CrossRef]
- Moaaz, M.M.; Mohamed, E.H. Violence Detection In Surveillance Videos Using Deep Learning. FCI-H Inform. Bull. 2020, 2, 1–6. [Google Scholar] [CrossRef]
- Dong, Z.; Qin, J.; Wang, Y. Multi-stream Deep Networks for Person to Person Violence Detection in Videos. In Proceedings of the Pattern Recognition; Tan, T., Li, X., Chen, X., Zhou, J., Yang, J., Cheng, H., Eds.; Springer: Singapore, 2016; pp. 517–531. [Google Scholar] [CrossRef]
- Serrano, I.; Deniz, O.; Espinosa-Aranda, J.L.; Bueno, G. Fight Recognition in Video Using Hough Forests and 2D Convolutional Neural Network. IEEE Trans. Image Process. 2018, 27, 4787–4797. [Google Scholar] [CrossRef]
- Akti, S.; Tataroglu, G.A.; Ekenel, H.K. Vision-based Fight Detection from Surveillance Cameras. In Proceedings of the 2019 Ninth International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 6–9 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Sudhakaran, S.; Lanz, O. Learning to detect violent videos using convolutional long short-term memory. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Song, W.; Zhang, D.; Zhao, X.; Yu, J.; Zheng, R.; Wang, A. A Novel Violent Video Detection Scheme Based on Modified 3D Convolutional Neural Networks. IEEE Access 2019, 7, 39172–39179. [Google Scholar] [CrossRef]
- Su, Y.; Lin, G.; Zhu, J.; Wu, Q. Human Interaction Learning on 3D Skeleton Point Clouds for Video Violence Recognition. In Proceedings of the Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 74–90. [Google Scholar] [CrossRef]
- Jain, A.; Vishwakarma, D.K. Deep NeuralNet For Violence Detection Using Motion Features From Dynamic Images. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 826–831. [Google Scholar] [CrossRef]
- Elkhashab, Y.R.; H. El-Behaidy, W. Violence Detection Enhancement in Video Sequences Based on Pre-trained Deep Models. FCI-H Inform. Bull. 2023, 5, 23–28. [Google Scholar] [CrossRef]
- AlDahoul, N.; Karim, H.A.; Datta, R.; Gupta, S.; Agrawal, K.; Albunni, A. Convolutional Neural Network—Long Short Term Memory based IOT Node for Violence Detection. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Malaysia, 13–15 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Vijeikis, R.; Raudonis, V.; Dervinis, G. Efficient Violence Detection in Surveillance. Sensors 2022, 22, 2216. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Muhammad, K.; Haq, I.U.; Khan, N.; Heidari, A.A.; Baik, S.W.; de Albuquerque, V.H.C. AI-Assisted Edge Vision for Violence Detection in IoT-Based Industrial Surveillance Networks. IEEE Trans. Ind. Inform. 2022, 18, 5359–5370. [Google Scholar] [CrossRef]
- Choqueluque-Roman, D.; Camara-Chavez, G. Weakly Supervised Violence Detection in Surveillance Video. Sensors 2022, 22, 4502. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Identifier | Description |
|---|---|
| $GPGGA | Global Positioning System Fix Data |
| HHMMSS.SSS | Time in Hour Minute |
| Latitude | Latitude (Coordinate) |
| N | Direction N = North, S = South |
| Longitude | Longitude (Coordinate) |
| E | Direction E = East, W = West |
| FQ | Fix Quality Data |
| NOS | No. of Satellites being Used |
| HPD | Horizontal Dilution of Precision |
| Altitude | Altitude from Sea Level |
| M | Meter |
| Height | Height |
| * | Start-of-checksum delimiter |
| Checksum | Checksum Data |
| Dataset | Total Samples | Frame Resolution | Clip Length (Seconds) | Violent Samples | Non-violent Samples |
|---|---|---|---|---|---|
| Hockey Fights | 1000 | Variable | Variable | 500 | 500 |
| Violent Crowd | 246 | Variable | 5 | 123 | 123 |
| RLVS | 2000 | Variable | 5 | 1000 | 1000 |
| RWF-2000 | 2000 | Variable | 5 | 1000 | 1000 |
| Dataset | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Hockey Fights [37] | 95.33% | 95.97% | 94.70% | 95.33% |
| Violent Crowd [38] | 96.59% | 97.61% | 96.47% | 97.04% |
| RLVS [5] | 92.73% | 93.53% | 92.95% | 93.24% |
| RWF [39] | 91.06% | 89.58% | 93.42% | 91.46% |
| Parameter | Value |
|---|---|
| Number of monitored zones | 50 |
| People per zone every 5 min | 100 |
| Data size per detection | 10 KB |
| Video clip for violence detection | MB |
| Video stream bandwidth | 5 Mbps |
| Violence detection latency | 32 ms |
| Violence detection time | 160 ms |
| Streaming latency for centralized system | 2 s |
| Criterion | Distributed System | Centralized System |
|---|---|---|
| Total Hardware Cost (€) | 12,500€ | 10,500€ |
| Total Bandwidth (Mbps) | 1.33 Mbps | 254.17 Mbps |
| Processing Time (ms) | 160 ms | 170 ms |
| Latency (s) | 0.032 s | 2 s (streaming delay) |
| Model | Hockey Fight | Violent Crowd | RLVS | RWF-2000 | Nbr of Params |
|---|---|---|---|---|---|
| ViF [38] | 82.90% | 81.30% | - | - | - |
| ViF + OViF [46] | 87.50% | 88.00% | - | - | - |
| MobileNet + LSTM [6] | 87.00% | - | - | - | - |
| ResNet50 + ConvLSTM [47] | 87.50% | 80.00% | - | - | - |
| CNN + LSTM [48] | 94.00% | - | 92.00% | - | 4.69 M |
| Three streams + LSTM [49] | 93.90% | - | - | - | - |
| Hough Forests + 2D CNN [50] | 94.60% | - | - | - | - |
| FightCNN + BiLSTM + attention [51] | 95.00% | - | - | - | 9 M |
| Flow Gated Network [39] | - | 88.87% | - | 87.25% | 0.27 M |
| ConvLSTM [52] | - | 94.57% | - | - | 9.6 M |
| 3D ConvNet [53] | - | 94.30% | - | - | - |
| SPIL Convolution [54] | - | 94.50% | - | 89.30% | - |
| VGG16 + LSTM [5] | - | - | 82.20% | - | - |
| Inception-Resnet-V2 [55] | - | - | 86.79% | - | - |
| DenseNet121 + LSTM [56] | - | - | 92.05% | - | - |
| End-to-end CNN-LSTM [57] | - | - | - | 73.35% | 1.266 M |
| MobileNetV2 + LSTM [58] | - | - | - | 82.00% | 4.074 M |
| VD-Net [59] | - | - | - | 88.20% | 4.4 M |
| Fast-RCNN-style [60] | - | - | - | 88.71% | >30 M |
| LAVID (Our Model) | 95.33% | 96.59% | 92.73% | 91.06% | 0.57 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azzakhnini, M.; Saidi, H.; Azough, A.; Tairi, H.; Qjidaa, H. LAVID: A Lightweight and Autonomous Smart Camera System for Urban Violence Detection and Geolocation. Computers 2025, 14, 140. https://doi.org/10.3390/computers14040140
Azzakhnini M, Saidi H, Azough A, Tairi H, Qjidaa H. LAVID: A Lightweight and Autonomous Smart Camera System for Urban Violence Detection and Geolocation. Computers. 2025; 14(4):140. https://doi.org/10.3390/computers14040140
Chicago/Turabian StyleAzzakhnini, Mohammed, Houda Saidi, Ahmed Azough, Hamid Tairi, and Hassan Qjidaa. 2025. "LAVID: A Lightweight and Autonomous Smart Camera System for Urban Violence Detection and Geolocation" Computers 14, no. 4: 140. https://doi.org/10.3390/computers14040140
APA StyleAzzakhnini, M., Saidi, H., Azough, A., Tairi, H., & Qjidaa, H. (2025). LAVID: A Lightweight and Autonomous Smart Camera System for Urban Violence Detection and Geolocation. Computers, 14(4), 140. https://doi.org/10.3390/computers14040140