
Microhooks: A Novel Framework to Streamline the Development of Microservices


Abstract
1. Introduction
2. Background
2.1. Microservices Architectural Style
2.2. Relevant Microservice Patterns
2.2.1. The Database-per-Service Pattern
2.2.2. The Data Replication/Materialized View Pattern
2.2.3. The Command Query Responsibility Segregation Pattern
3. Related Work
4. Microhooks from a User Perspective
4.1. Purpose, Scope, and Main Concepts Through Use Cases
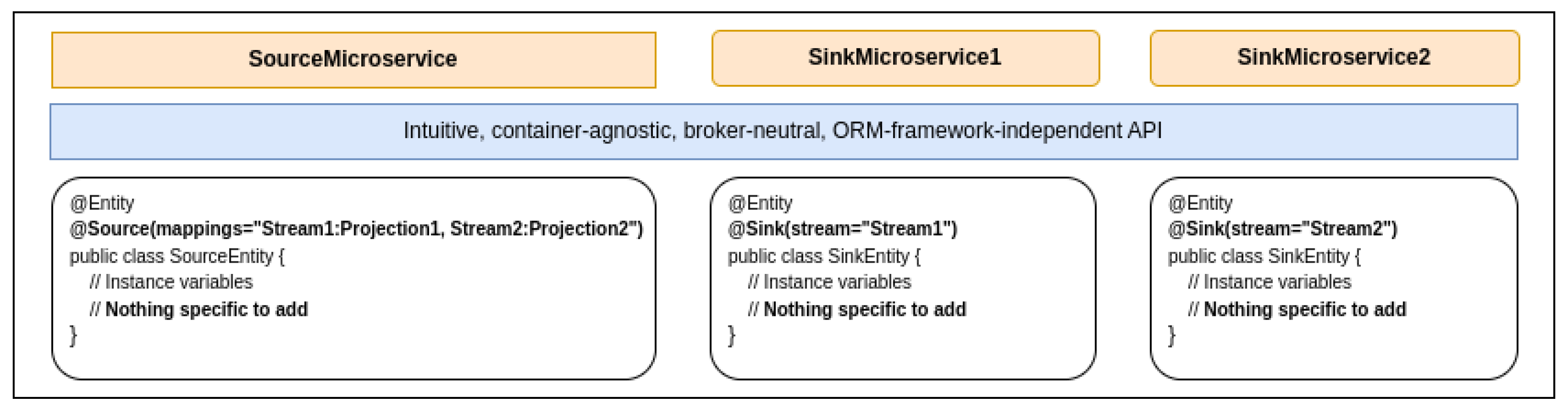
4.1.1. First Use Case
- Marking the entity as a source entity;
- Mapping at the level of that entity, each (output) stream to its corresponding projection.
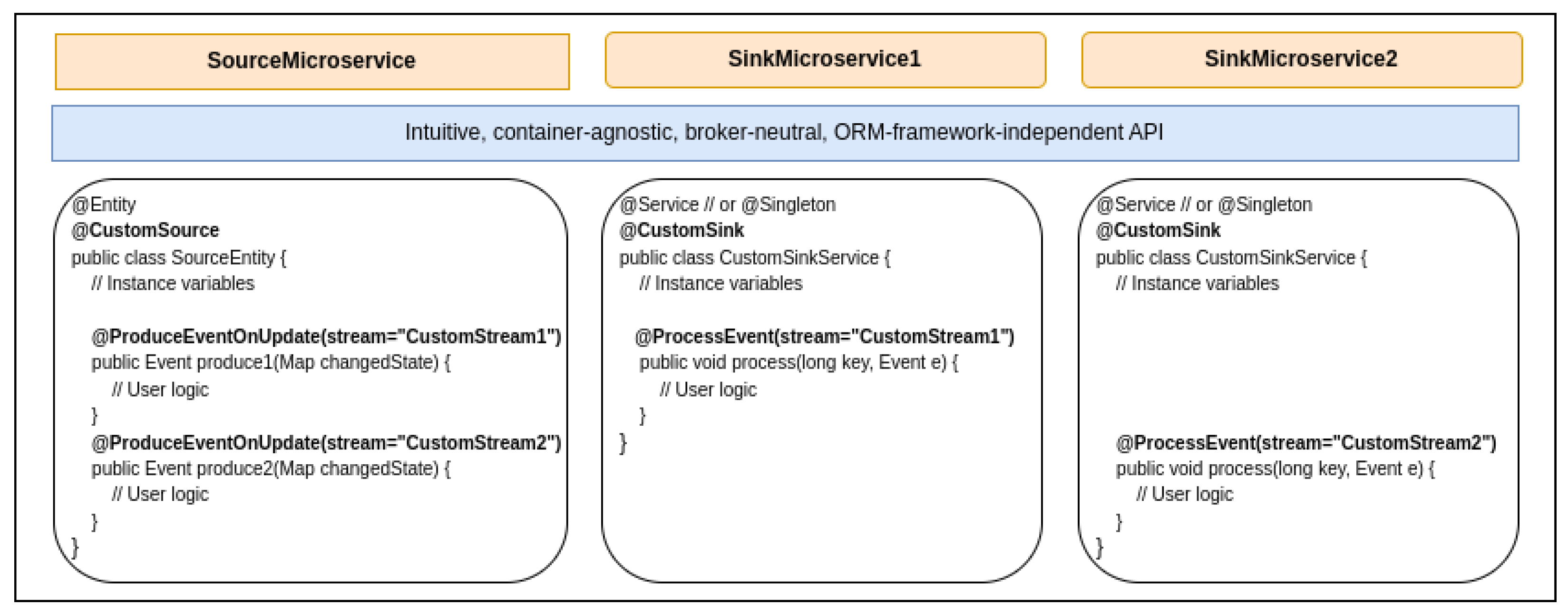
4.1.2. Second Use Case
- Marks the entity as a custom source;
- Exposes to Microhooks a callback that returns the event to be published. That callback encapsulates the logic to generate the event, including any precondition verification;
- Marks that callback with the appropriate annotation to specify the triggering operation, namely, the record creation, update, or deletion, as well as the stream or streams through which the event should be sent.
- Marks a class, a singleton service in practice, as a custom sink;
- Exposes to Microhooks a callback that expects an event as a parameter. That callback implements the event processing logic according to the business requirements;
- Maps that callback to a specific stream through a simple annotation.
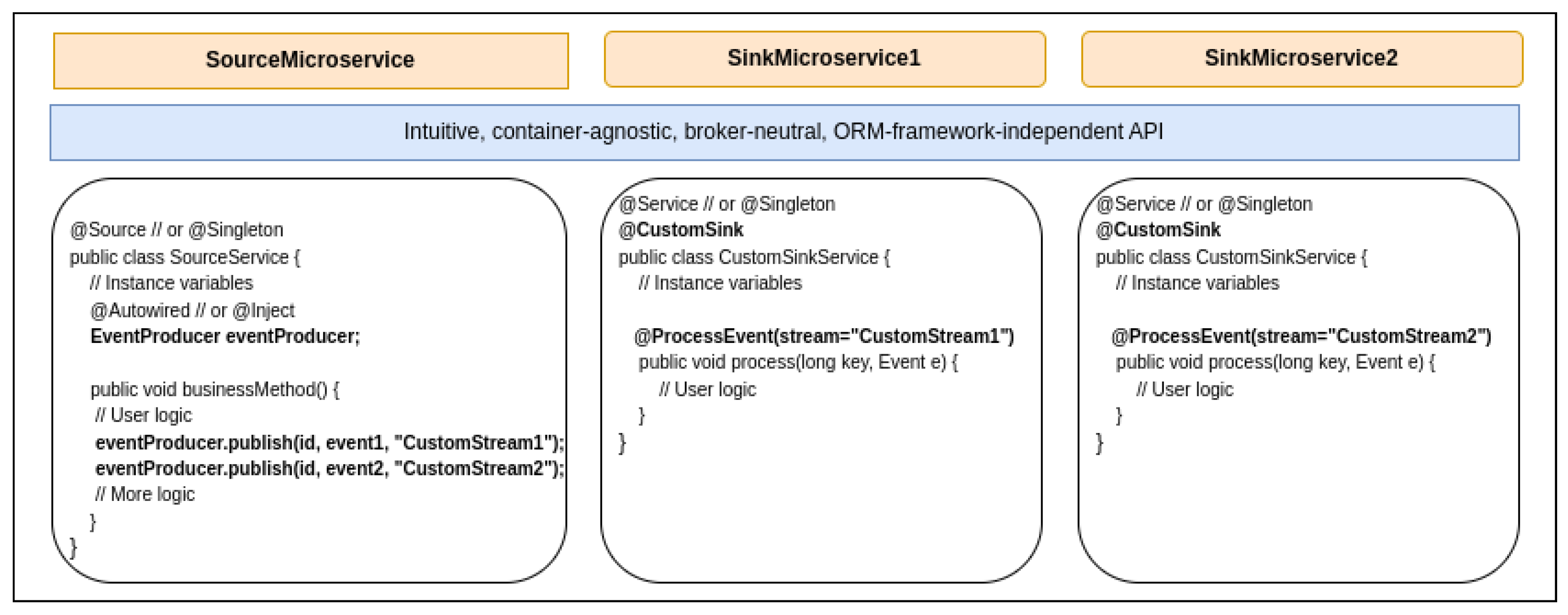
4.1.3. Third Use Case
- Inject an EventProducer instance in the service;
- Use it from within the business method to publish events through the appropriate streams, as needed.
4.2. Functional Requirements
4.2.1. The Source Microservice Developer
- Shall make any of his/her entities available as a source of truth, in a proactive manner, i.e., using push mode.
- Shall accommodate different sinks with different materialized views.
- Shall create custom events based on custom logic triggered by an entity record creation, update, or deletion.
- Shall create custom events based on custom logic triggered as part of the end-user request processing flow.
- Shall publish every custom event through one or more streams.
4.2.2. The Sink Microservice Developer
- Shall create materialized views (sink entities) and map each to exactly one (input) stream.
- Shall process custom events from input streams of interest.
4.3. Non-Functional Requirements
4.3.1. Usability
4.3.2. Performance
4.3.3. Security
4.3.4. Interoperability
4.3.5. Portability
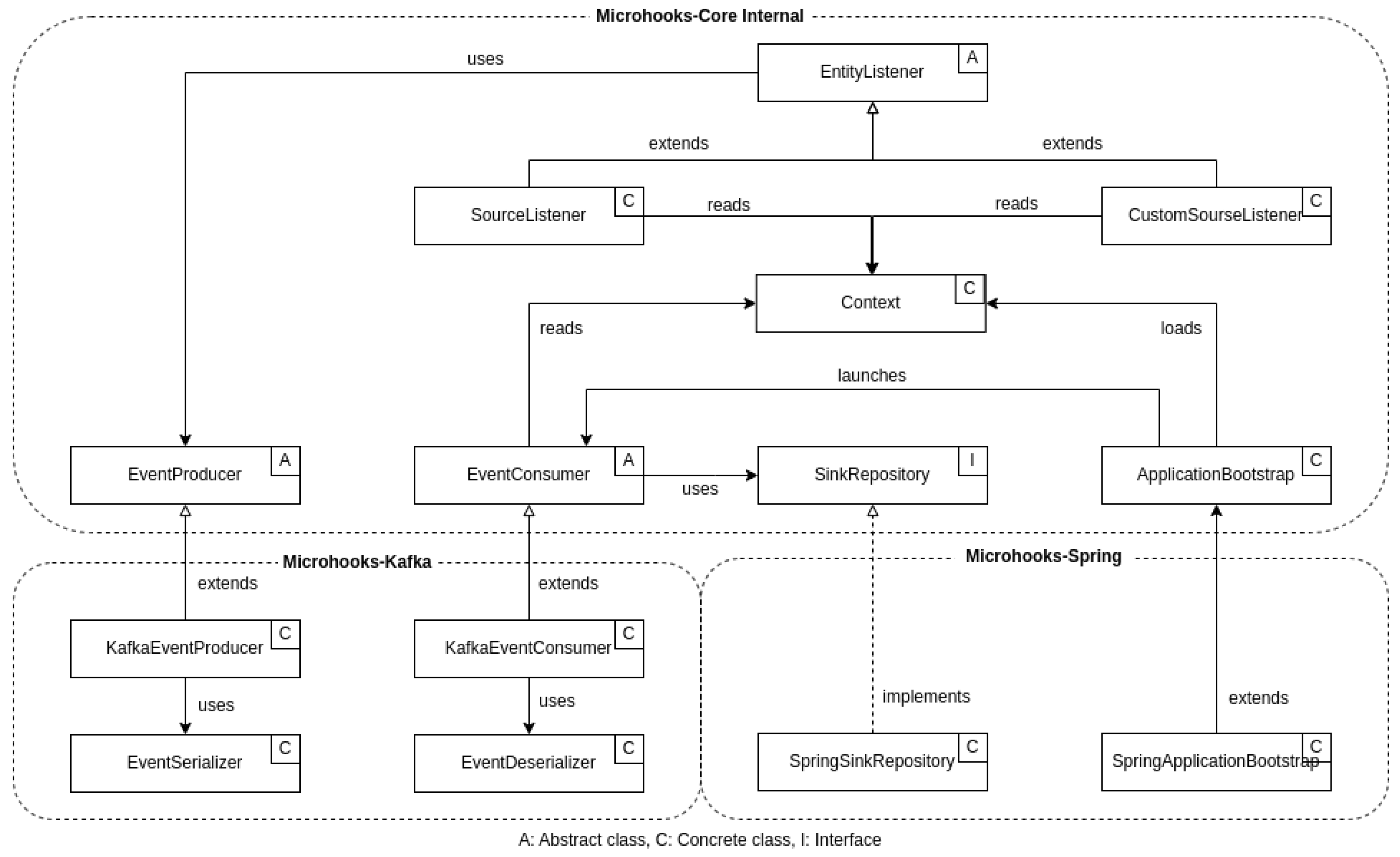
4.4. Application Programming Interface—API
4.4.1. io.microhooks.source
- Source: This annotation marks an entity as a source for the materialized view pattern. By doing so, Microhooks handles the propagation of record creation, update, and deletion events to the intended recipients (sinks). Instead of identifying those recipients, the user specifies the streams through which the events must be sent and the projection for each one. Therefore, the Source defines a required property, mappings, as an array of strings. Each string is in the following format: stream:projection, as shown in Listing 1.
- Projection: This annotation is used to mark projection classes. It defines no properties. Its purpose is to facilitate the copying of an entity’s fields that have matching ones in the projection while ignoring the rest.
- CustomSource: This annotation marks an entity to define custom logic that is executed upon the creation, update, or deletion of its records. It defines no property.
- Track: This annotation goes hand in hand with the CustomSource annotation, especially when reacting to updates. It allows for marking fields whose changes must be tracked. Without such an annotation, Microhooks would need to track all entity fields for changes, which is sub-optimal.
- ProduceEventOnCreate: This annotation marks a CustomSource entity’s method as a callback defining custom logic, to be executed whenever a record is created. It defines one required streams property that allows specifying the array of streams through which the produced event must be sent. The method decorated by this annotation shall take no parameters and must return an event.
- ProduceEventsOnCreate: As opposed to ProduceEventOnCreate, this annotation marks a CustomSource entity’s method as a callback that returns several events upon record creation, each of which is to be sent through several streams. It defines no property. The callback method decorated by this annotation shall take no parameters and shall return a map whose key is an event to be sent and whose value is the list of corresponding streams.
- ProduceEventOnUpdate: This annotation marks a CustomSource entity’s method as a callback defining custom logic, to be executed whenever a record is updated, and at least one of its fields marked with Track has changed. It defines one required streams property that allows specifying the array of streams through which the produced event must be sent. The callback method decorated by this annotation shall take a map of fields that have changed along with their corresponding old values and return an event. The map of changed fields is constructed by Microhooks and passed to the user code as a parameter. This is convenient to implement custom logic based on specific changes of specific fields and their combinations. The user has access to previous values of tracked fields through the passed map, as well as to the current values through the entity’s instance variables.
- ProduceEventsOnUpdate: The same as ProduceEventOnUpdate, except that it defines no property, and it marks methods that are to return a map of events and the respective streams through which they must be sent.
- ProduceEventOnDelete: This annotation marks a CustomSource entity’s method as a callback defining custom logic, to be executed whenever a record is deleted. It defines one required streams property that allows specifying the array of streams through which the produced event must be sent. The method decorated by this annotation shall take no parameters and shall return an event.
- ProduceEventsOnDelete: As opposed to ProduceEventOnDelete, this annotation marks a CustomSource entity’s method as a callback that returns several events upon record deletion, each of which is to be sent through several streams. It defines no property. The callback method decorated by this annotation shall take no parameters and shall return a map whose key is an event to be sent and whose value is the list of corresponding streams.
- EventProducer: Microhooks publishes events returned from callbacks, on behalf of the user. However, if the user wants to explicitly publish events without concerning themselves with low-level details related to the broker and its API, the EventProducer is at the rescue. It is designed as a wrapper class around an underlying implementation that is dynamically loaded depending on the broker used.
| Listing 1. Source—Usage Example. |
 |
| Listing 2. CustomSource—Usage Example. |
 |
4.4.2. io.microhooks.sink
- Sink: This annotation marks an entity as a sink for the materialized view pattern. By doing so, Microhooks handles listening to related incoming events for record creation, update, and deletion. Sink defines a required property, a stream, as a string specifying the stream from which such events must be received.
- CustomSink: This annotation allows marking a sink-side class, in practice, a singleton service, as a component exposing custom logic to process incoming events from the source side. It defines no property.
- ProcessEvent: This annotation goes hand in hand with CustomSink. It allows marking on a CustomSink class, the methods that must be called back based on incoming events. It defines two properties. The first one is the input stream that shall be listened to, and the second is the label of received events for filtering purposes. The annotated method shall define two parameters—the first representing the event ID or a key of type ‘long’, and the second representing the event itself. The method is not supposed to return anything.
4.4.3. io.microhooks.common
- Payload: This is of a generic type, specialized by the user.
- Label: This is a string used to characterize the event. Several events can have the same label value.
- Timestamp: This is a long value representing the number of milliseconds since 1 January 1970, 00:00:00 GMT. It is automatically generated upon the event creation.
5. Microhooks Design
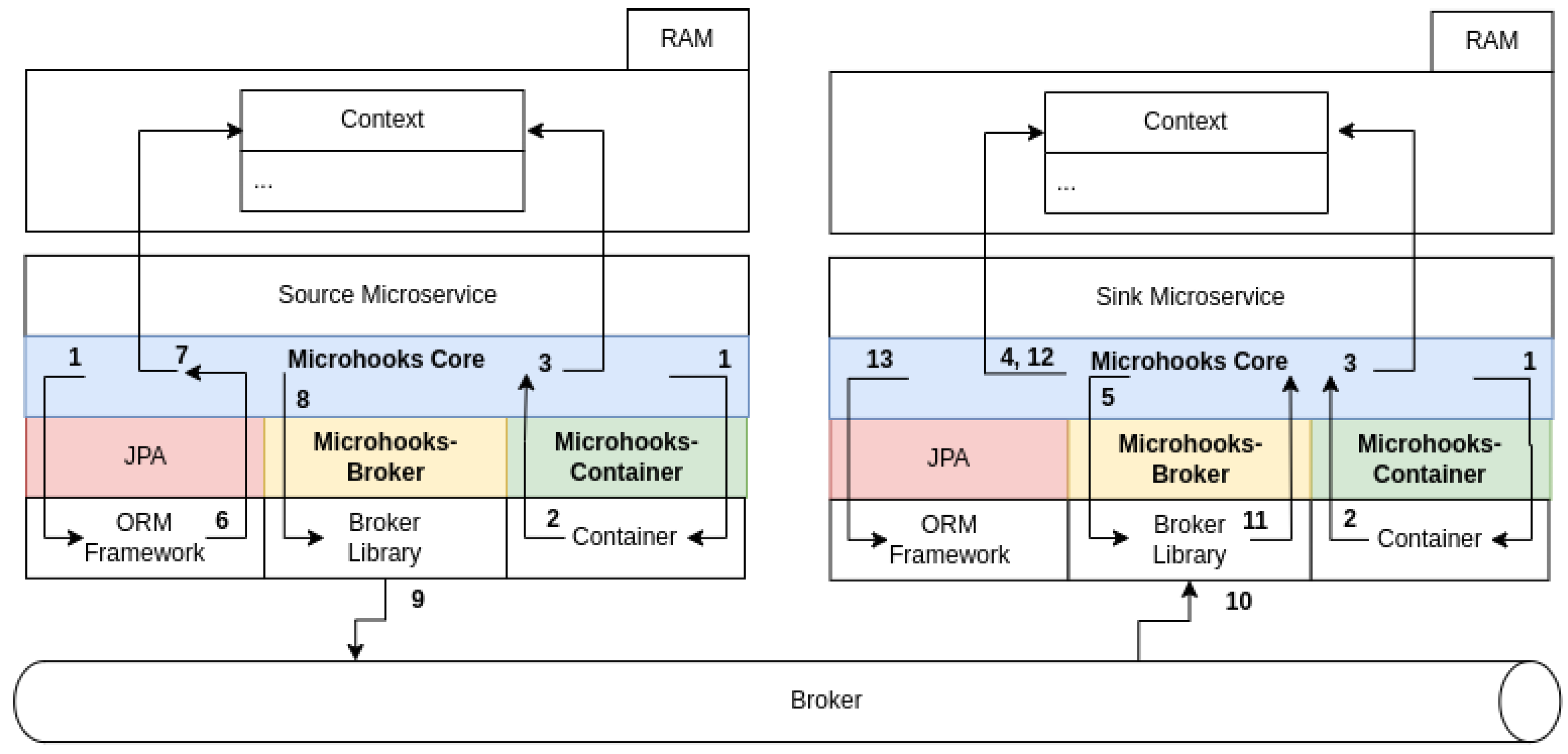
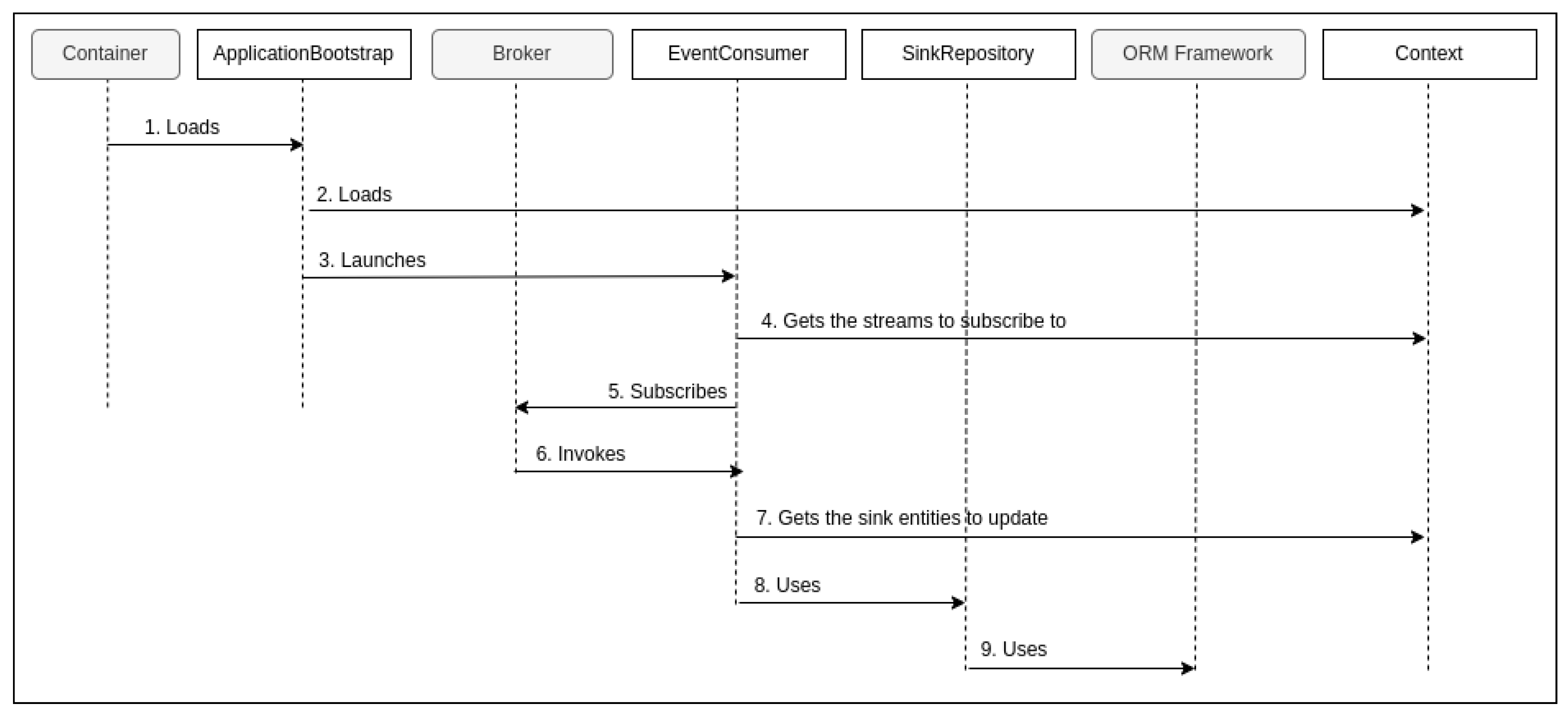
5.1. High-Level Design
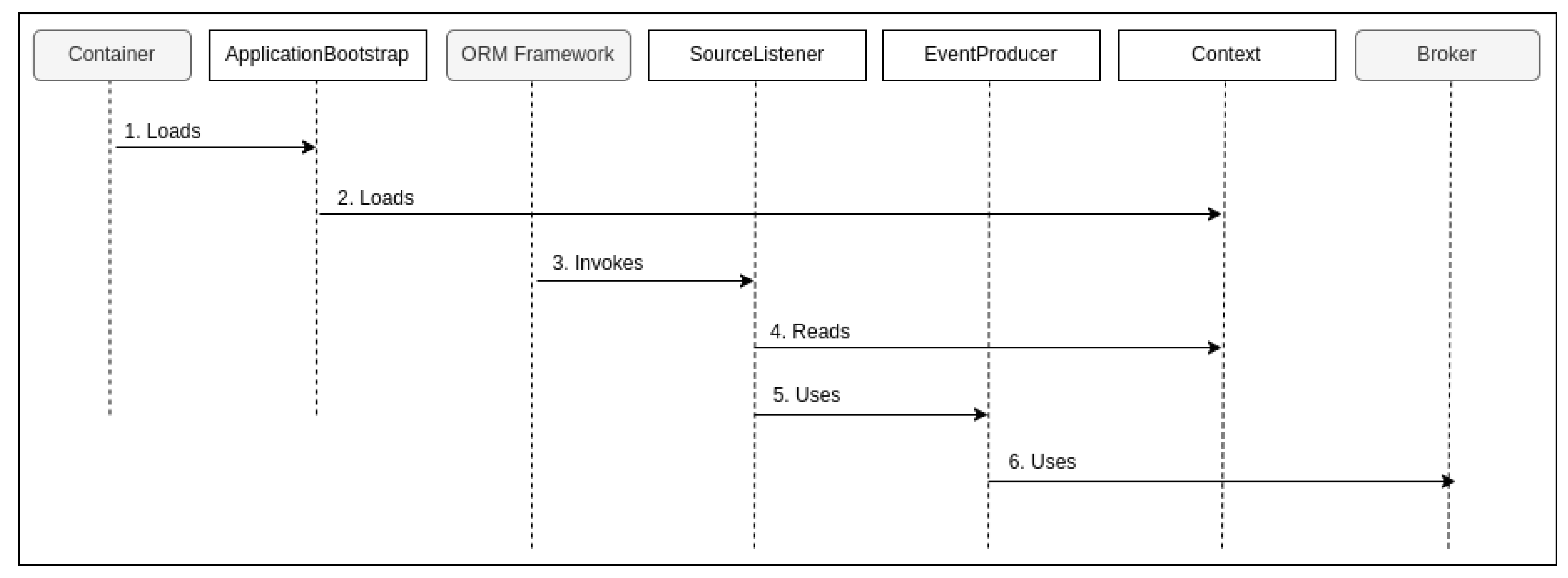
- Step 1: On both sides, Microhooks hooks itself with the container during startup. Moreover, on the source side, Microhooks hooks itself with the ORM framework. This hooking is detailed in the design and implementation.
- Step 2: Once the startup finishes, the container calls Microhooks back (as it was already hooked).
- Step 3: This gives it the opportunity to load the pre-built context from disk to memory on both sides. Indeed, the context is constructed at build time. This will be elaborated on in the implementation subsection.
- Steps 4, 5: At the sink side, Microhooks retrieves all input streams from the context, and subscribes to them with the broker via the corresponding extension and library.
- Step 6: Once there is a record creation, update, or deletion of a source (or a custom source) entity, the ORM framework calls Microhooks back through JPA.
- Step 7: This gives it the opportunity to look up, in the context, the method(s) marked with the ProduceEventOnUpdate annotation, invoke them in the case of a custom source, and determine the output stream(s) to use.
- Step 8: Microhooks uses the dynamically loaded broker extension and underlying library to send the generated event(s) through the identified streams.
- Steps 9 and 10: The library at the source actually sends the event(s), and its peer at the sink receives them.
- Step 11: It delivers them to Microhooks (remember, it has already subscribed with the broker in step 5).
- Step 12: Depending on the nature of the event (CRUD or custom), Microhooks looks up in the context of the concerned sink entity(ies) or custom sink object(s).
- Step 13: Finally, it uses the ORM framework through JPA to perform the necessary data operation, or it invokes the appropriate method(s), marked with ProcessEvent annotation, on the identified sink object(s).
5.2. Detailed Design
6. Microhooks Implementation
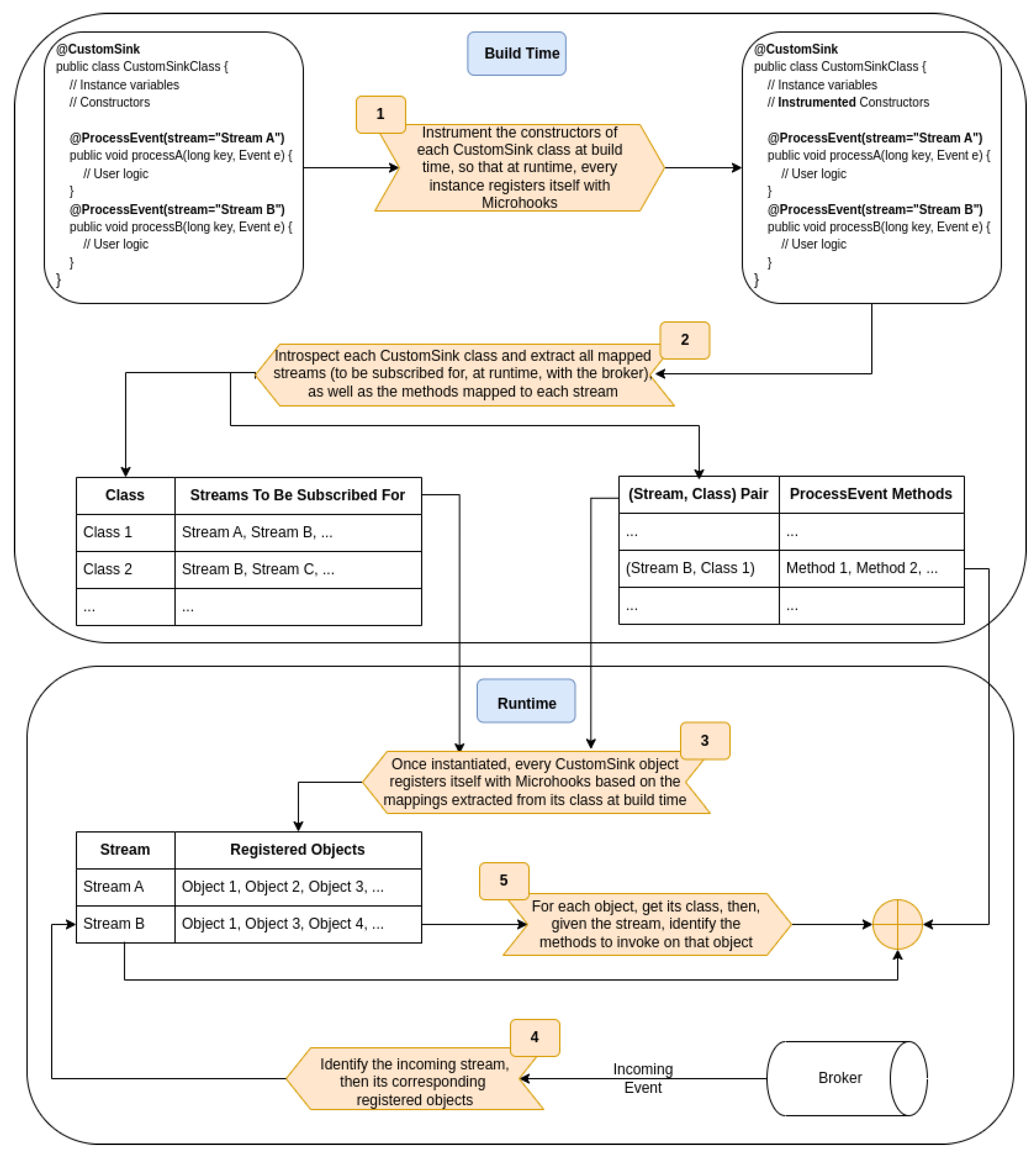
6.1. Leveraging the Build Time
6.2. Code Instrumentation and Context Building
6.2.1. Source-Annotated Class
| Listing 3. Source Entity—Before Instrumentation. |
 |
| Listing 4. Source Entity—After Instrumentation. |
 |
6.2.2. CustomSource-Annotated Class
6.2.3. Sink-Annotated Class
| Listing 5. Sink Entity—Before Instrumentation. |
 |
| Listing 6. Sink Entity—After Instrumentation. |
 |
6.2.4. CustomSink-Annotated Class
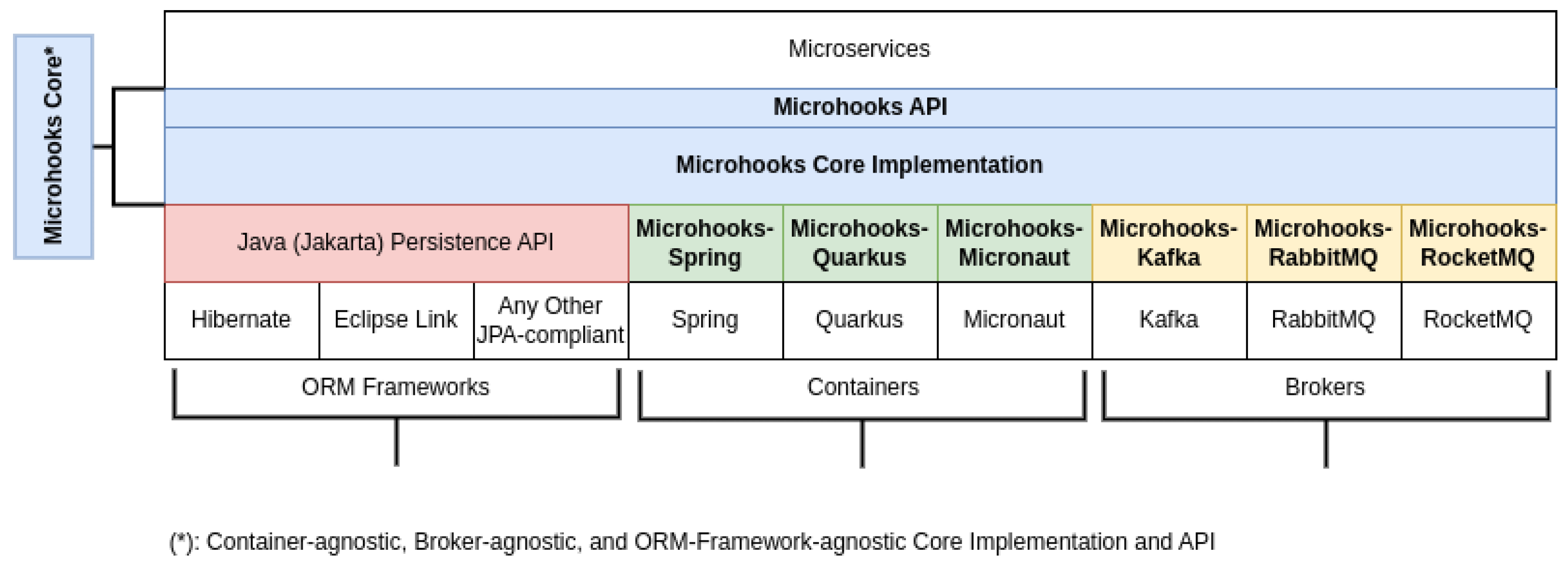
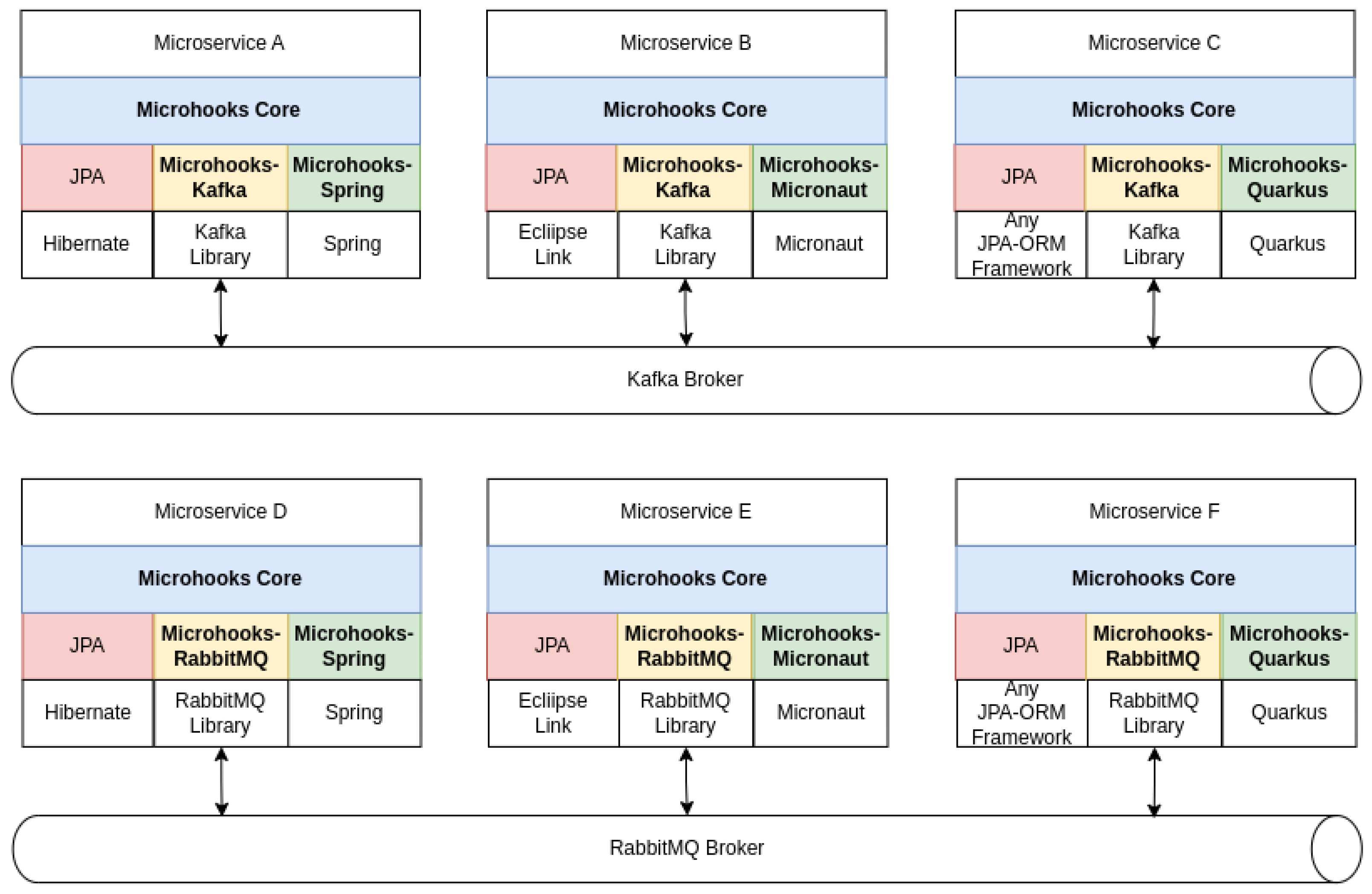
6.3. Project Organization and How to
- Three container-specific Gradle projects: Microhooks-Spring, Microhooks-Micronaut, and Microhooks-Quarkus.
- Three broker-specific Gradle projects: Microhooks-Kafka, Microhooks-RabbitMQ, and Microhooks-RocketMQ.
- Microhooks-Builder as a Gradle buildscript dependency.
- Byte Buddy Gradle plugin, with a configured transformation pointing to Microhooks-Builder entry class.
- Microhooks-Core as an implementation dependency.
- The two specific extensions for their adopted container and broker, respectively, as implementation dependencies.
7. Microhooks Evaluation
7.1. Code Enhancement Quantification
7.2. Qualitative Comparison with Other Frameworks
7.3. Performance Evaluation
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | application programming interface |
| CAP | consistency, availability, and partitioning |
| CRUD | create, retrieve, update, delete |
| DDD | domain-driven design |
| JPA | Java/Jakarta Persistence API |
| ORM | object-relational mapping |
References
- Chen, L. Microservices: Architecting for Continuous Delivery and DevOps. In Proceedings of the ICSA. IEEE Computer Society, Seattle, WA, USA, 30 April–4 May 2018; pp. 39–46. Available online: http://dblp.uni-trier.de/db/conf/icsa/icsa2018.html (accessed on 1 February 2025).
- Waseem, M.; Liang, P.; Shahin, M. A Systematic Mapping Study on Microservices Architecture in DevOps. J. Syst. Softw. 2020, 170, 110798. [Google Scholar] [CrossRef]
- Ponce, F.; Márquez, G.; Astudillo, H. Migrating from monolithic architecture to microservices: A Rapid Review. In Proceedings of the 2019 38th International Conference of the Chilean Computer Science Society (SCCC), Concepcion, Chile, 4–9 November 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Lauretis, L.D. From Monolithic Architecture to Microservices Architecture. In Proceedings of the ISSRE Workshops; Wolter, K., Schieferdecker, I., Gallina, B., Cukier, M., Natella, R., Ivaki, N., Laranjeiro, N., Eds.; IEEE: Piscataway, NJ, USA, 2019; pp. 93–96. Available online: http://dblp.uni-trier.de/db/conf/issre/issre2019w.html (accessed on 1 February 2025).
- Abgaz, Y.; McCarren, A.; Elger, P.; Solan, D.; Lapuz, N.; Bivol, M.; Jackson, G.; Yilmaz, M.; Buckley, J.; Clarke, P. Decomposition of Monolith Applications Into Microservices Architectures: A Systematic Review. IEEE Trans. Softw. Eng. 2023, 49, 4213–4242. [Google Scholar] [CrossRef]
- Al-Debagy, O.; Martinek, P. A Comparative Review of Microservices and Monolithic Architectures. In Proceedings of the 2018 IEEE 18th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 21–22 November 2018; pp. 000149–000154. [Google Scholar] [CrossRef]
- Ramírez, F.; Mera-Gómez, C.; Bahsoon, R.; Zhang, Y. An Empirical Study on Microservice Software Development. In Proceedings of the 2021 IEEE/ACM Joint 9th International Workshop on Software Engineering for Systems-of-Systems and 15th Workshop on Distributed Software Development, Software Ecosystems and Systems-of-Systems (SESoS/WDES), Madrid, Spain, 3 June 2021; pp. 16–23. [Google Scholar] [CrossRef]
- Li, S.; Zhang, H.; Jia, Z.; Zhong, C.; Zhang, C.; Shan, Z.; Shen, J.; Babar, M.A. Understanding and addressing quality attributes of microservices architecture: A Systematic literature review. Inf. Softw. Technol. 2021, 131, 106449. [Google Scholar] [CrossRef]
- Zhou, X.; Peng, X.; Xie, T.; Sun, J.; Ji, C.; Li, W.; Ding, D. Fault Analysis and Debugging of Microservice Systems: Industrial Survey, Benchmark System, and Empirical Study. IEEE Trans. Softw. Eng. 2021, 47, 243–260. [Google Scholar] [CrossRef]
- Spring Cloud. Available online: https://spring.io/projects/spring-cloud (accessed on 1 February 2025).
- Why You Can’t Talk About Microservices Without Mentioning Netflix. 2015. Available online: https://smartbear.com/blog/develop/why-you-cant-talkabout-microservices-without-ment/ (accessed on 1 February 2025).
- Netflix Open Source Software Center. Available online: https://netflix.github.io/ (accessed on 1 February 2025).
- Microhooks: Code and Examples. Available online: https://github.com/oiraqi/microhooks (accessed on 1 February 2025).
- Vernon, V. Domain-Driven Design Distilled; Addison-Wesley: Boston, MA, USA, 2016. [Google Scholar]
- Evans, E. Domain-Driven Design Reference; Dog Ear Publishing: Indianapolis, IN, USA, 2014; Available online: http://domainlanguage.com/ddd/reference/ (accessed on 1 February 2025).
- Database-per-Service Pattern. Available online: https://docs.aws.amazon.com/prescriptive-guidance/latest/modernization-data-persistence/database-per-service.html (accessed on 1 February 2025).
- Fekete, A. CAP Theorem. In Encyclopedia of Database Systems, 2nd ed.; Liu, L., Özsu, M.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Available online: http://dblp.uni-trier.de/db/reference/db/c2.html (accessed on 1 February 2025).
- Challenges and Solutions for Distributed Data Management. Available online: https://learn.microsoft.com/en-us/dotnet/architecture/microservices/architect-microservice-container-applications/distributed-data-management (accessed on 1 February 2025).
- Maddodi, G.; Jansen, S. Responsive Software Architecture Patterns for Workload Variations: A Case-study in a CQRS-based Enterprise Application. In Proceedings of the BENEVOL; CEUR Workshop Proceedings; Demeyer, S., Parsai, A., Laghari, G., van Bladel, B., Eds.; CEUR-WS.org: Aachen, Germany, 2017; Volume 2047, p. 30. Available online: http://dblp.uni-trier.de/db/conf/benevol/benevol2017.html (accessed on 1 February 2025).
- Laigner, R.; Zhou, Y.; Salles, M.A.V. A Distributed Database System for Event-Based Microservices. In Proceedings of the 15th ACM International Conference on Distributed and Event-Based Systems, DEBS ’21, New York, NY, USA, 11–15 July 2021; pp. 25–30. [Google Scholar] [CrossRef]
- Soldani, J.; Tamburri, D.A.; van den Heuvel, W.J. The pains and gains of microservices: A Systematic grey literature review. J. Syst. Softw. 2018, 146, 215–232. Available online: http://dblp.uni-trier.de/db/journals/jss/jss146.html (accessed on 1 February 2025). [CrossRef]
- Laigner, R.; Zhou, Y.; Salles, M.A.V.; Liu, Y.; Kalinowski, M. Data Management in Microservices: State of the Practice, Challenges, and Research Directions. Proc. VLDB Endow. 2021, 14, 3348–3361. [Google Scholar] [CrossRef]
- Eventuate Tram. Available online: https://eventuate.io/docs/manual/eventuate-tram/latest/about-eventuate-tram.html (accessed on 1 February 2025).
- Jakarta Persistence. Available online: https://jakarta.ee/specifications/persistence/3.0/jakarta-persistence-spec-3.0.pdf (accessed on 1 February 2025).
- Spring Framework. Available online: https://spring.io (accessed on 1 February 2025).
- Micronaut Framework. Available online: https://micronaut.io (accessed on 1 February 2025).
- Quarkus Framework. Available online: https://quarkus.io (accessed on 1 February 2025).
- Hibernate ORM Framework. Available online: https://hibernate.org (accessed on 1 February 2025).
- EclipseLink ORM Framework. Available online: https://projects.eclipse.org/projects/ee4j.eclipselink (accessed on 1 February 2025).
- Byte Buddy: Code Generation and Manipulation Library for Java. Available online: https://bytebuddy.net (accessed on 1 February 2025).
- SonarQube: Code Quality and Security Analysis Tool. Available online: https://www.sonarsource.com/products/sonarqube/ (accessed on 1 February 2025).
- JMeter: Functional Behavior and Performance Metering Tool. Available online: https://jmeter.apache.org/ (accessed on 1 February 2025).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Applicability | Source Side | Sink Side |
|---|---|---|
| Package | io.microhooks.source | io.microhooks.sink |
| Fully-Automated CRUD Events | ||
| Class Annotations | Source | Sink |
| Projection | – | |
| User-Defined Custom Events | ||
| Class Annotations | CustomSource | CustomSink |
| Field Annotations | Track | – |
| Method Annotations | ProduceEventOnCreate | ProcessEvent |
| ProduceEventsOnCreate | ||
| ProduceEventOnUpdate | ||
| ProduceEventsOnUpdate | ||
| ProduceEventOnDelete | ||
| ProduceEventsDelete | ||
| Class | EventProducer | |
| Applicability | Common | |
| Package | io.microhooks.common | |
| Class | Event | |
| Source Side | |||
| Metric | Raw | Using Microhooks | Enhancement |
| Number of Lines | 230 | 95 | 58% |
| Number of Classes | 12 | 5 | 58% |
| Cyclomatic Complexity | 22 | 9 | 59% |
| Cognitive Complexity | 11 | 3 | 73% |
| Sink Side | |||
| Metric | Raw | Using Microhooks | Enhancement |
| Number of Lines | 388 | 86 | 78% |
| Number of Classes | 13 | 4 | 69% |
| Cyclomatic Complexity | 54 | 6 | 89% |
| Cognitive Complexity | 33 | 1 | 97% |
| Source Side | ||||
| Users | Reqs/User | Average Handling Time (µs) | Overhead | |
| Raw | Using Microhooks | |||
| 25 | 20,000 | [20–23] | [20–23] | <0.5% |
| 50 | 10,000 | [21–24] | [21–24] | <0.5% |
| 100 | 5000 | [21–24] | [21–24] | <0.5% |
| 200 | 2500 | [22–25] | [22–25] | <0.5% |
| Sink Side | ||||
| Processed Events | Average Handling Time (µs) | Overhead | ||
| Raw | Using Microhooks | |||
| 500,000 | [235–385] | [235–385] | <0.5% | |
| Source Side | ||||
| Users | Reqs/User | Average Handling Time (µs) | Overhead | |
| Raw | Using Microhooks | |||
| 25 | 20,000 | [19–23] | [19–23] | <0.5% |
| 50 | 10,000 | [21–27] | [21–27] | <0.5% |
| 100 | 5000 | [21–27] | [21–27] | <0.5% |
| 200 | 2500 | [21–27] | [21–27] | <0.5% |
| Sink Side | ||||
| Processed Events | Average Handling Time (µs) | Overhead | ||
| Raw | Using Microhooks | |||
| 500,000 | [14–19] | [14–19] | <0.5% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iraqi, O.; El Kadiri El Hassani, M.; Zouine, A. Microhooks: A Novel Framework to Streamline the Development of Microservices. Computers 2025, 14, 139. https://doi.org/10.3390/computers14040139
Iraqi O, El Kadiri El Hassani M, Zouine A. Microhooks: A Novel Framework to Streamline the Development of Microservices. Computers. 2025; 14(4):139. https://doi.org/10.3390/computers14040139
Chicago/Turabian StyleIraqi, Omar, Mohamed El Kadiri El Hassani, and Anass Zouine. 2025. "Microhooks: A Novel Framework to Streamline the Development of Microservices" Computers 14, no. 4: 139. https://doi.org/10.3390/computers14040139
APA StyleIraqi, O., El Kadiri El Hassani, M., & Zouine, A. (2025). Microhooks: A Novel Framework to Streamline the Development of Microservices. Computers, 14(4), 139. https://doi.org/10.3390/computers14040139