
AI-Powered Software Development: A Systematic Review of Recommender Systems for Programmers


 ,
, 

Abstract
1. Introduction
2. Related Work
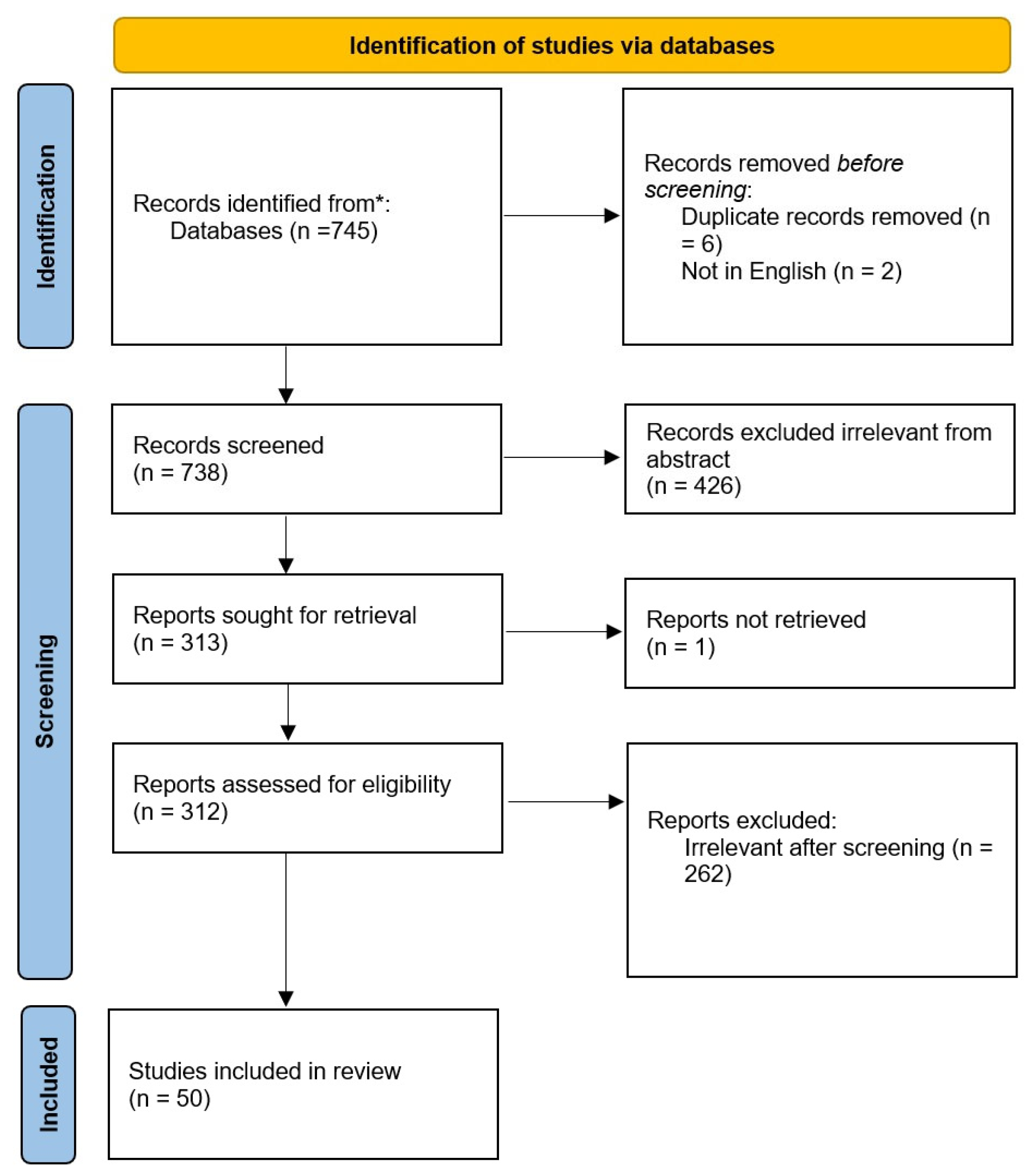
3. Research Methodology
- RQ1: What do RSSEs assist users with?
- RQ2: What user inputs do RSSEs require to make recommendations?
- RQ3: What output do RSSEs present to the user?
- RQ4: How are the recommendations generated?
- RQ5: Do they consider user context and personal information?
- RQ6: What topics are problematic and how are they covered?
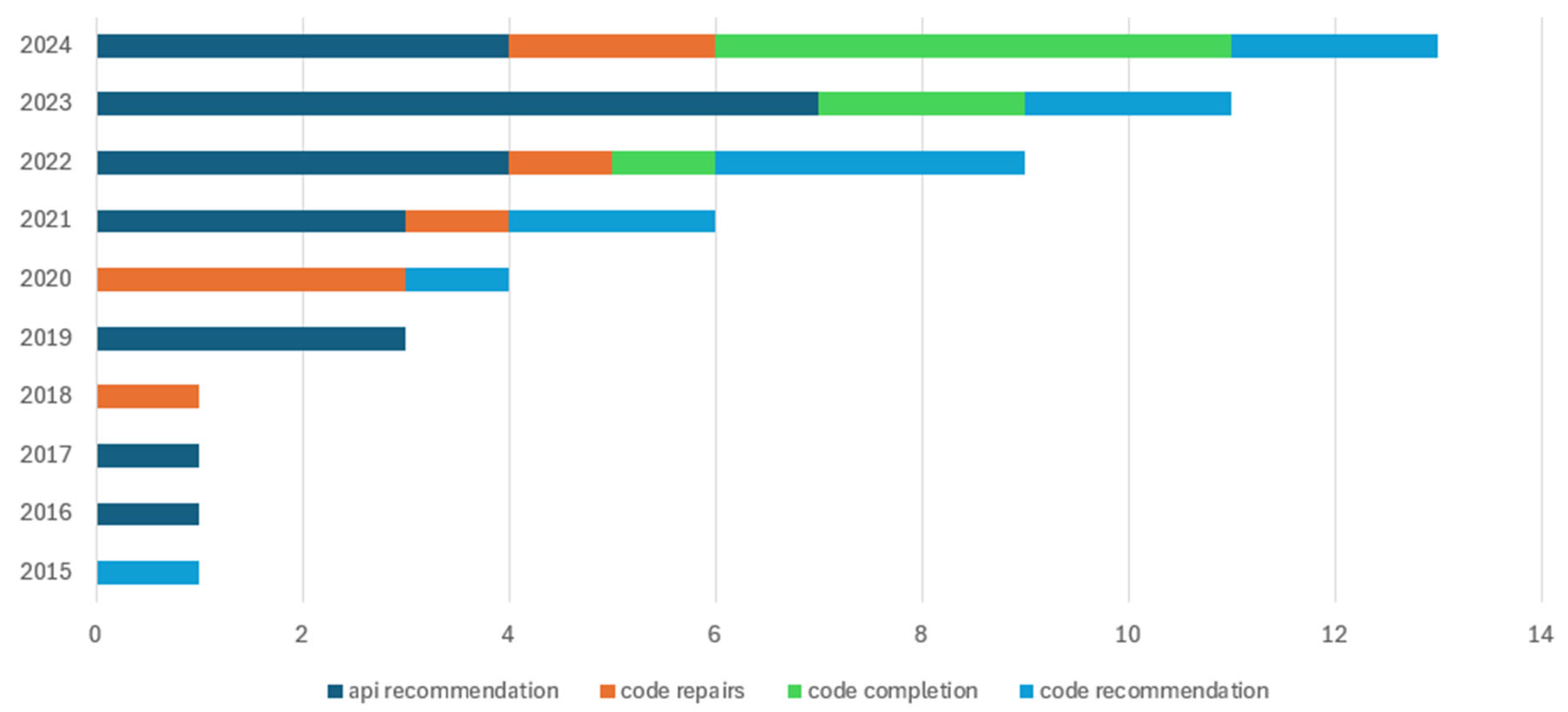
- RQ7: How do trends change in the coverage of certain issues?
4. Recommender Systems for Programmers
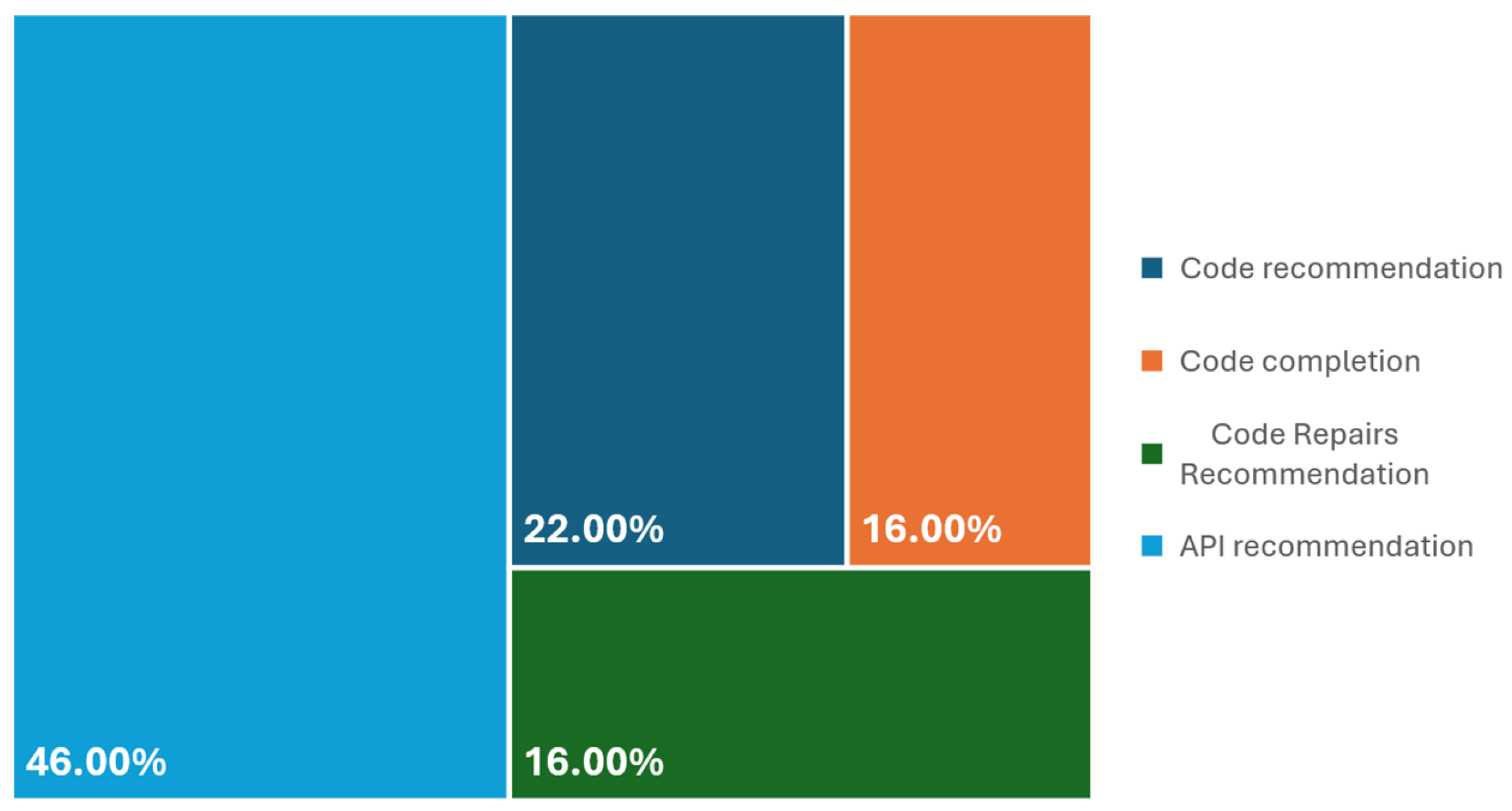
4.1. Code Recommendation
4.2. Code Completion
4.3. Code Repair Recommendation
4.4. API Recommendation
4.5. Evaluation of RSSEs for Programming
5. Discussion
Deep Learning Architectures
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Brandt, J.; Guo, P.J.; Lewenstein, J.; Dontcheva, M.; Klemmer, S.R. Two Studies of Opportunistic Programming. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 4 April 2009; ACM, pp. 1589–1598. [Google Scholar]
- Robillard, M.P.; Maalej, W.; Walker, R.J.; Zimmermann, T. Recommendation Systems in Software Engineering; Robillard, M.P., Maalej, W., Walker, R.J., Zimmermann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; ISBN 978-3-642-45134-8. [Google Scholar]
- Robillard, M.; Walker, R.; Zimmermann, T. Recommendation Systems for Software Engineering. IEEE Softw. 2010, 27, 80–86. [Google Scholar] [CrossRef]
- Mikić, V.; Ilić, M.; Kopanja, L.; Vesin, B. Personalisation Methods in E-learning-A Literature Review. Comput. Appl. Eng. Educ. 2022, 30, 1931–1958. [Google Scholar] [CrossRef]
- Sivapalan, S.; Sadeghian, A.; Rahnama, H.; Madni, A.M. Recommender Systems in E-Commerce. In Proceedings of the 2014 World Automation Congress (WAC), Waikoloa, HI, USA, 3–7 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 179–184. [Google Scholar]
- Pakdeetrakulwong, U.; Wongthongtham, P.; Siricharoen, W.V. Recommendation Systems for Software Engineering: A Survey from Software Development Life Cycle Phase Perspective. In Proceedings of the 9th International Conference for Internet Technology and Secured Transactions (ICITST-2014), London, UK, 8–10 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 137–142. [Google Scholar]
- Durrani, U.K.; Akpinar, M.; Fatih Adak, M.; Talha Kabakus, A.; Maruf Öztürk, M.; Saleh, M. A Decade of Progress: A Systematic Literature Review on the Integration of AI in Software Engineering Phases and Activities (2013–2023). IEEE Access 2024, 12, 171185–171204. [Google Scholar] [CrossRef]
- Wan, Y.; Bi, Z.; He, Y.; Zhang, J.; Zhang, H.; Sui, Y.; Xu, G.; Jin, H.; Yu, P. Deep Learning for Code Intelligence: Survey, Benchmark and Toolkit. ACM Comput. Surv. 2024, 56, 1–41. [Google Scholar] [CrossRef]
- Jin, H.; Zhou, Y.; Hussain, Y. Enhancing Code Completion with Implicit Feedback. In Proceedings of the 2023 IEEE 23rd International Conference on Software Quality, Reliability and, Security (QRS), Chiang Mai, Thailand, 22 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 218–227. [Google Scholar]
- Di Grazia, L.; Pradel, M. Code Search: A Survey of Techniques for Finding Code. ACM Comput. Surv. 2023, 55, 1–31. [Google Scholar] [CrossRef]
- Tao, C.; Lin, K.; Huang, Z.; Sun, X. CRAM: Code Recommendation With Programming Context Based on Self-Attention Mechanism. IEEE Trans. Reliab. 2023, 72, 302–316. [Google Scholar] [CrossRef]
- Silavong, F.; Moran, S.; Georgiadis, A.; Saphal, R.; Otter, R. Senatus: A Fast and Accurate Code-to-Code Recommendation Engine. In Proceedings of the 19th International Conference on Mining Software Repositories, Pittsburgh, PA, USA, 23 May 2022; ACM: New York, NY, USA, 2022; pp. 511–523. [Google Scholar]
- Hammad, M.; Babur, Ö.; Abdul Basit, H.; Brand, M. van den Clone-Advisor: Recommending Code Tokens and Clone Methods with Deep Learning and Information Retrieval. PeerJ Comput. Sci. 2021, 7, e737. [Google Scholar] [CrossRef]
- Sun, H.; Xu, Z.; Li, X. Code Recommendation Based on Deep Learning. In Proceedings of the 2023 12th International Conference of Information and Communication Technology (ICTech), Wuhan, China, 14–16 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 156–160. [Google Scholar]
- Wen, W.; Zhao, T.; Wang, S.; Chu, J.; Kumar Jain, D. Code Recommendation Based on Joint Embedded Attention Network. Soft Comput. 2022, 26, 8635–8645. [Google Scholar] [CrossRef]
- Islam, M.M.; Iqbal, R. SoCeR: A New Source Code Recommendation Technique for Code Reuse. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1552–1557. [Google Scholar]
- Abid, S.; Abdul Basit, H.; Shamail, S. Context-Aware Code Recommendation in Intellij IDEA. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–16 November 2022; ACM: New York, NY, USA, 2022; pp. 1647–1651. [Google Scholar]
- Jansen, S.; Brinkkemper, S.; Hunink, I.; Demir, C. Pragmatic and Opportunistic Reuse in Innovative Start-up Companies. IEEE Softw. 2008, 25, 42–49. [Google Scholar] [CrossRef]
- Abid, S.; Shamail, S.; Basit, H.A.; Nadi, S. FACER: An API Usage-Based Code-Example Recommender for Opportunistic Reuse. Empir. Softw. Eng. 2021, 26, 110. [Google Scholar] [CrossRef]
- Yu, Y.; Huang, Z.; Shen, G.; Li, W.; Shao, Y. ASTSDL: Predicting the Functionality of Incomplete Programming Code via an AST-Sequence-Based Deep Learning Model. Sci. China Inf. Sci. 2024, 67, 112105. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, T.T. PERSONA: A Personalized Model for Code Recommendation. PLoS ONE 2021, 16, e0259834. [Google Scholar] [CrossRef]
- Asaduzzaman, M.; Roy, C.K.; Monir, S.; Schneider, K.A. Exploring API Method Parameter Recommendations. In Proceedings of the 2015 IEEE 31st International Conference on Software Maintenance and Evolution (ICSME 2015), Bremen, Germany, 29 September–1 October 2015; pp. 271–280. [Google Scholar]
- Siddiq, M.L.; Casey, B.; Santos, J.C.S. Franc: A Lightweight Framework for High-Quality Code Generation. In Proceedings of the 2024 IEEE International Conference on Source Code Analysis and Manipulation (SCAM), Flagstaff, AZ, USA, 7–8 October 2024; pp. 106–117. [Google Scholar]
- Hussain, Y.; Huang, Z.; Zhou, Y.; Wang, S. Boosting Source Code Suggestion with Self-Supervised Transformer Gated Highway. J. Syst. Softw. 2023, 196, 111553. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; de Pinto, H.P.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Rozière, B.; Gehring, J.; Gloeckle, F.; Sootla, S.; Gat, I.; Tan, X.E.; Adi, Y.; Liu, J.; Sauvestre, R.; Remez, T.; et al. Code Llama: Open Foundation Models for Code. arXiv 2023, arXiv:2308.12950. [Google Scholar]
- Zan, D.; Chen, B.; Zhang, F.; Lu, D.; Wu, B.; Guan, B.; Yongji, W.; Lou, J.-G. Large Language Models Meet NL2Code: A Survey. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 7443–7464. [Google Scholar]
- Wu, D.; Ahmad, W.U.; Zhang, D.; Ramanathan, M.K.; Ma, X. Repoformer: Selective Retrieval for Repository-Level Code Completion. arXiv 2024, arXiv:2403.10059. [Google Scholar]
- Liu, W.; Yu, A.; Zan, D.; Shen, B.; Zhang, W.; Zhao, H.; Jin, Z.; Wang, Q. GraphCoder: Enhancing Repository-Level Code Completion via Coarse-to-Fine Retrieval Based on Code Context Graph. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, Sacramento, CA, USA, 27 October–1 November 2024; ACM: New York, NY, USA, 2024; pp. 570–581. [Google Scholar]
- Xia, Y.; Liang, T.; Min, W.; Kuang, L. Improving AST-Level Code Completion with Graph Retrieval and Multi-Field Attention. In Proceedings of the 32nd IEEE/ACM International Conference on Program Comprehension, Lisbon, Portugal, 15–16 April 2024; ACM: New York, NY, USA, 2024; pp. 125–136. [Google Scholar]
- Liang, M.; Xie, X.; Zhang, G.; Zheng, X.; Di, P.; Jiang, W.; Chen, H.; Wang, C.; Fan, G. RepoGenix: Dual Context-Aided Repository-Level Code Completion with Language Models. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, Sacramento, CA, USA, 27 October–1 November 2024; ACM: New York, NY, USA, 2024; pp. 2466–2467. [Google Scholar]
- Ding, Y.; Wang, Z.; Ahmad, W.U.; Ramanathan, M.K.; Nallapati, R.; Bhatia, P.; Roth, D.; Xiang, B. CoCoMIC: Code Completion by Jointly Modeling In-File and Cross-File Context. arXiv 2022, arXiv:2212.10007. [Google Scholar]
- Bibaev, V.; Kalina, A.; Lomshakov, V.; Golubev, Y.; Bezzubov, A.; Povarov, N.; Bryksin, T. All You Need Is Logs: Improving Code Completion by Learning from Anonymous IDE Usage Logs. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–16 November 2022; ACM: New York, NY, USA, 2022; pp. 1269–1279. [Google Scholar]
- Böhme, M.; Soremekun, E.O.; Chattopadhyay, S.; Ugherughe, E.; Zeller, A. Where Is the Bug and How Is It Fixed? An Experiment with Practitioners. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017; ACM: New York, NY, USA, 2017; pp. 117–128. [Google Scholar]
- Winter, E.; Bowes, D.; Counsell, S.; Hall, T.; Haraldsson, S.; Nowack, V.; Woodward, J. How Do Developers Really Feel About Bug Fixing? Directions for Automatic Program Repair. IEEE Trans. Softw. Eng. 2023, 49, 1823–1841. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, C.; Li, A.; Wang, W.; Li, T.; Liu, Y. VulAdvisor: Natural Language Suggestion Generation for Software Vulnerability Repair. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, Sacramento, CA, USA, 27 October–1 November 2024; ACM: New York, NY, USA, 2024; pp. 1932–1944. [Google Scholar]
- Mahajan, S.; Abolhassani, N.; Prasad, M.R. Recommending Stack Overflow Posts for Fixing Runtime Exceptions Using Failure Scenario Matching. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual, 8–13 November 2020; ACM: New York, NY, USA, 2020; pp. 1052–1064. [Google Scholar]
- Nguyen, T.; Vu, P.; Nguyen, T. Code Recommendation for Exception Handling. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual, 8–13 November 2020; ACM: New York, NY, USA, 2020; pp. 1027–1038. [Google Scholar]
- Lee, S.; Lee, J.; Kang, S.; Ahn, J.; Cho, H. Code Edit Recommendation Using a Recurrent Neural Network. Appl. Sci. 2021, 11, 9286. [Google Scholar] [CrossRef]
- Dong, C.; Jiang, Y.; Niu, N.; Zhang, Y.; Liu, H. Context-Aware Name Recommendation for Field Renaming. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, Lisbon, Portugal, 14–20 April 2024; ACM: New York, NY, USA, 2024; pp. 1–13. [Google Scholar]
- Chakraborty, S.; Ding, Y.; Allamanis, M.; Ray, B. CODIT: Code Editing With Tree-Based Neural Models. IEEE Trans. Softw. Eng. 2022, 48, 1385–1399. [Google Scholar] [CrossRef]
- Nyamawe, A.S.; Liu, H.; Niu, N.; Umer, Q.; Niu, Z. Feature Requests-Based Recommendation of Software Refactorings. Empir. Softw. Eng. 2020, 25, 4315–4347. [Google Scholar] [CrossRef]
- Yu, H.; Jia, X.; Mine, T.; Zhao, J. Type Conversion Sequence Recommendation Based on Semantic Web Technology. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 7–11 October 2018; IEEE: Piscataway, NJ, USA, October, 2018; pp. 240–245. [Google Scholar]
- Zhou, Y.; Yang, X.; Chen, T.; Huang, Z.; Ma, X.; Gall, H. Boosting API Recommendation With Implicit Feedback. IEEE Trans. Softw. Eng. 2022, 48, 2157–2172. [Google Scholar] [CrossRef]
- Gao, S.; Liu, L.; Liu, Y.; Liu, H.; Wang, Y. API Recommendation for the Development of Android App Features Based on the Knowledge Mined from App Stores. Sci. Comput. Program. 2021, 202, 102556. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, C.; Wang, Y.; Han, T.; Chen, T. Context-Aware API Recommendation Using Tensor Factorization. Sci. China Inf. Sci. 2023, 66, 122101. [Google Scholar] [CrossRef]
- Li, X.; Liu, L.; Liu, Y.; Liu, H. A Lightweight API Recommendation Method for App Development Based on Multi-Objective Evolutionary Algorithm. Sci. Comput. Program. 2023, 226, 102927. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, L.; Gao, C.; Fang, Y.; Li, Y. Prompt Enhance API Recommendation: Visualize the User’s Real Intention behind This Query. Autom. Softw. Eng. 2024, 31, 27. [Google Scholar] [CrossRef]
- Wei, M.; Harzevili, N.S.; Huang, Y.; Wang, J.; Wang, S. Clear: Contrastive Learning for Api Recommendation. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; ACM: New York, NY, USA, 2022; pp. 376–387. [Google Scholar]
- Gao, S.; Zhang, L.; Liu, H.; Wang, Y. Which Animation API Should I Use Next? A Multimodal Real-Time Animation API Recommendation Model for Android Apps. IEEE Trans. Softw. Eng. 2024, 50, 106–122. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, H.; Gao, S.; Tang, X. Animation2API: API Recommendation for the Implementation of Android UI Animations. IEEE Trans. Softw. Eng. 2023, 49, 4411–4428. [Google Scholar] [CrossRef]
- Cai, J.; Cai, Q.; Li, B.; Zhang, J.; Sun, X. Application Programming Interface Recommendation for Smart Contract Using Deep Learning from Augmented Code Representation. J. Softw. Evol. Process 2024, 36, e2658. [Google Scholar] [CrossRef]
- Gao, H.; Qin, X.; Barroso, R.J.D.; Hussain, W.; Xu, Y.; Yin, Y. Collaborative Learning-Based Industrial IoT API Recommendation for Software-Defined Devices: The Implicit Knowledge Discovery Perspective. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 66–76. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Y.; Chen, T.; Zhang, J.; Yang, W.; Huang, Z. Hybrid Collaborative Filtering-Based API Recommendation. In Proceedings of the 2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS), Hainan, China, 6–10 December 2022; pp. 906–914. [Google Scholar]
- Li, Z.; Li, C.; Tang, Z.; Huang, W.; Ge, J.; Luo, B.; Ng, V.; Wang, T.; Hu, Y.; Zhang, X. PTM-APIRec: Leveraging Pre-Trained Models of Source Code in API Recommendation. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–30. [Google Scholar] [CrossRef]
- Li, K.; Tang, X.; Li, F.; Zhou, H.; Ye, C.; Zhang, W. PyBartRec: Python API Recommendation with Semantic Information. In Proceedings of the 14th Asia-Pacific Symposium on Internetware, Hangzhou, China, 4–6 August 2023; ACM: New York, NY, USA, 2023; pp. 33–43. [Google Scholar]
- Chen, Z.; Zhang, T.; Peng, X. A Novel API Recommendation Approach By Using Graph Attention Network. In Proceedings of the 2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS), Hainan, China, 6–10 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 726–737. [Google Scholar]
- Svyatkovskiy, A.; Zhao, Y.; Fu, S.; Sundaresan, N. Pythia: AI-Assisted Code Completion System. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; ACM: New York, NY, USA, 2019; pp. 2727–2735. [Google Scholar]
- D’Souza, A.R.; Yang, D.; Lopes, C.V. Collective Intelligence for Smarter API Recommendations in Python. In Proceedings of the 2016 IEEE 16th International Working Conference on Source Code Analysis and Manipulation (SCAM), Raleigh, NC, USA, 2–3 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 51–60. [Google Scholar]
- Nguyen, P.T.; Di Rocco, J.; Di Sipio, C.; Di Ruscio, D.; Di Penta, M. Recommending API Function Calls and Code Snippets to Support Software Development. IEEE Trans. Softw. Eng. 2022, 48, 2417–2438. [Google Scholar] [CrossRef]
- Xie, R.; Kong, X.; Wang, L.; Zhou, Y.; Li, B. HiRec: API Recommendation Using Hierarchical Context. In Proceedings of the 2019 IEEE 30th International Symposium on Software Reliability Engineering (ISSRE), Berlin, Germany, 28–31 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 369–379. [Google Scholar]
- Zhao, Y.; Li, L.; Wang, H.; He, Q.; Grundy, J. APIMatchmaker: Matching the Right APIs for Supporting the Development of Android Apps. IEEE Trans. Softw. Eng. 2023, 49, 113–130. [Google Scholar] [CrossRef]
- Thung, F.; Oentaryo, R.J.; Lo, D.; Tian, Y. WebAPIRec: Recommending Web APIs to Software Projects via Personalized Ranking. IEEE Trans. Emerg. Top. Comput. Intell. 2017, 1, 145–156. [Google Scholar] [CrossRef]
- Chen, Y.; Gao, C.; Ren, X.; Peng, Y.; Xia, X.; Lyu, M.R. API Usage Recommendation Via Multi-View Heterogeneous Graph Representation Learning. IEEE Trans. Softw. Eng. 2023, 49, 3289–3304. [Google Scholar] [CrossRef]
- Nguyen, S.; Manh, C.T.; Tran, K.T.; Nguyen, T.M.; Nguyen, T.-T.; Ngo, K.-T.; Vo, H.D. ARist: An Effective API Argument Recommendation Approach. J. Syst. Softw. 2023, 204, 111786. [Google Scholar] [CrossRef]
- Nguyen, P.T.; Di Rocco, J.; Di Ruscio, D.; Ochoa, L.; Degueule, T.; Di Penta, M. FOCUS: A Recommender System for Mining API Function Calls and Usage Patterns. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1050–1060. [Google Scholar]
- Zhang, Y.; Chen, X. Explainable Recommendation: A Survey and New Perspectives. Found. Trends® Inf. Retr. 2020, 14, 1–101. [Google Scholar] [CrossRef]
- Ciniselli, M.; Pascarella, L.; Aghajani, E.; Scalabrino, S.; Oliveto, R.; Bavota, G. Source Code Recommender Systems: The Practitioners’ Perspective. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, 14–20 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2161–2172. [Google Scholar]
- McMillan, C.; Grechanik, M.; Poshyvanyk, D.; Fu, C.; Xie, Q. Exemplar: A Source Code Search Engine for Finding Highly Relevant Applications. IEEE Trans. Softw. Eng. 2012, 38, 1069–1087. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You”? In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Ying, R.; Bourgeois, D.; You, J.; Zitnik, M.; Leskovec, J. GNNExplainer: Generating Explanations for Graph Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Huang, Q.; Yamada, M.; Tian, Y.; Singh, D.; Chang, Y. GraphLIME: Local Interpretable Model Explanations for Graph Neural Networks. IEEE Trans. Knowl. Data Eng. 2023, 35, 6968–6972. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Input |
|---|---|
| [11,12,13,20,22] | Current code segment |
| [14,15,16,23] | Natural language query |
| [17] | Methods with API usages in a current active project |
| [21] | Developers’ coding history, project-specific and common code patterns |
| Ref. | Output |
|---|---|
| [11,12,13,14,15,16,23] | Ranked list of code snippets |
| [17] | Ranked list of related methods |
| [20] | A list of potential functionalities |
| [21] | Ranked list of code elements |
| [22] | Method parameters |
| Ref. | Method |
|---|---|
| [11] | Self-attention neural networks |
| [12] | AST-based feature scoring and De-Skew LSH |
| [13] | Pretrained GPT-2 and IR technique (TF-IDF) |
| [14] | SBERT model and similarity matching |
| [15] | GRU Network and JEAN model |
| [16] | Similarity matching |
| [17] | Similarity matching (cosine similarity) |
| [20] | Deep learning model |
| [21] | Fuzzy sets |
| [23] | Heuristics and ranking based on quality criteria applied for the output of transformer-based code generation model |
| [22] | Similarity matching (cosine similarity and locality sensitive hashing) |
| Ref. | Input |
|---|---|
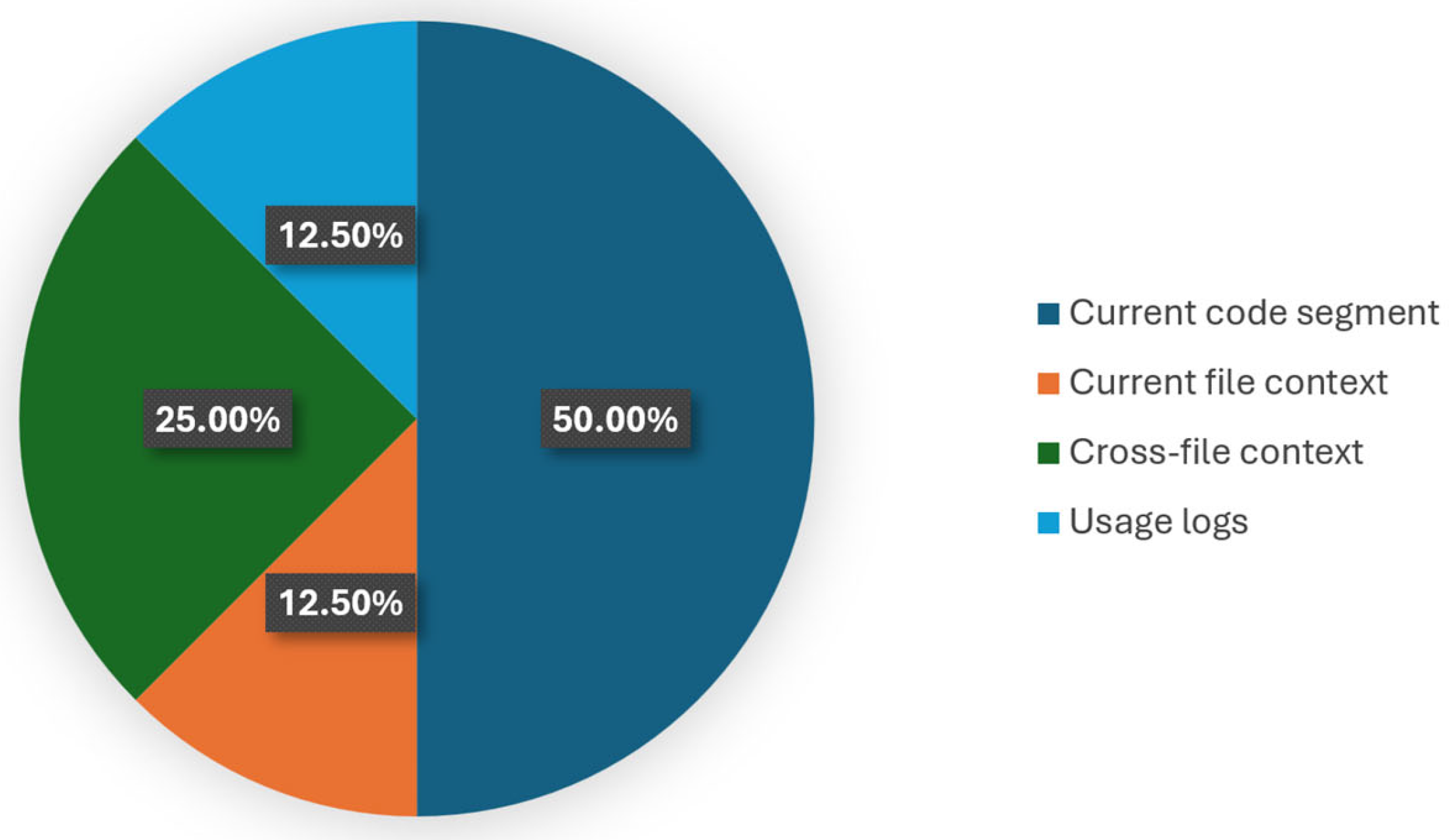
| [9,24] | Current code segment (token-based representation) |
| [28] | Current file context |
| [29,30] | Current code segment (graph representation) |
| [31,32] | Cross file context |
| [33] | Current code segment and usage logs |
| Ref. | Output |
|---|---|
| [9,24,32,33] | Next code token |
| [29] | Next code statement |
| [28,30,31] | Next code snippets |
| Ref. | Method |
|---|---|
| [9] | LSTM and pre-trained model BERT |
| [24] | Transformer-based model |
| [28] | Selective RAG |
| [29] | Coarse-to-fine retrieval process and LLM |
| [30] | Graph matching and Multi-field Graph Attention Block |
| [31] | Retrieval Augmented-Generation (RAG) solution |
| [32] | Pretrained Code LMs |
| [33] | Decision tree |
| Ref. | Input |
|---|---|
| [36,37,38,41] | Current code segment |
| [39] | Developer’s history of interactions |
| [40] | Field name to be renamed |
| [42] | Feature requests |
| [43] | Code and libraries of the current project |
| Ref. | Output |
|---|---|
| [36] | Natural language suggestions |
| [37] | Stack Overflow (SO) post |
| [38,41] | Code snippets |
| [39] | Files to edit |
| [40] | Field renaming |
| [42] | Refactoring types |
| [43] | Type conversion sequence |
| Ref. | Method |
|---|---|
| [36] | Similarity matching |
| [37] | Graph matching |
| [38] | Fuzzy logic |
| [39] | Recurrent neural network |
| [40] | Sequence of context-aware heuristics |
| [41] | Tree-based neural network |
| [42] | MNB classifier |
| [43] | Semantic ontology reasoning rules |
| Ref. | Input |
|---|---|
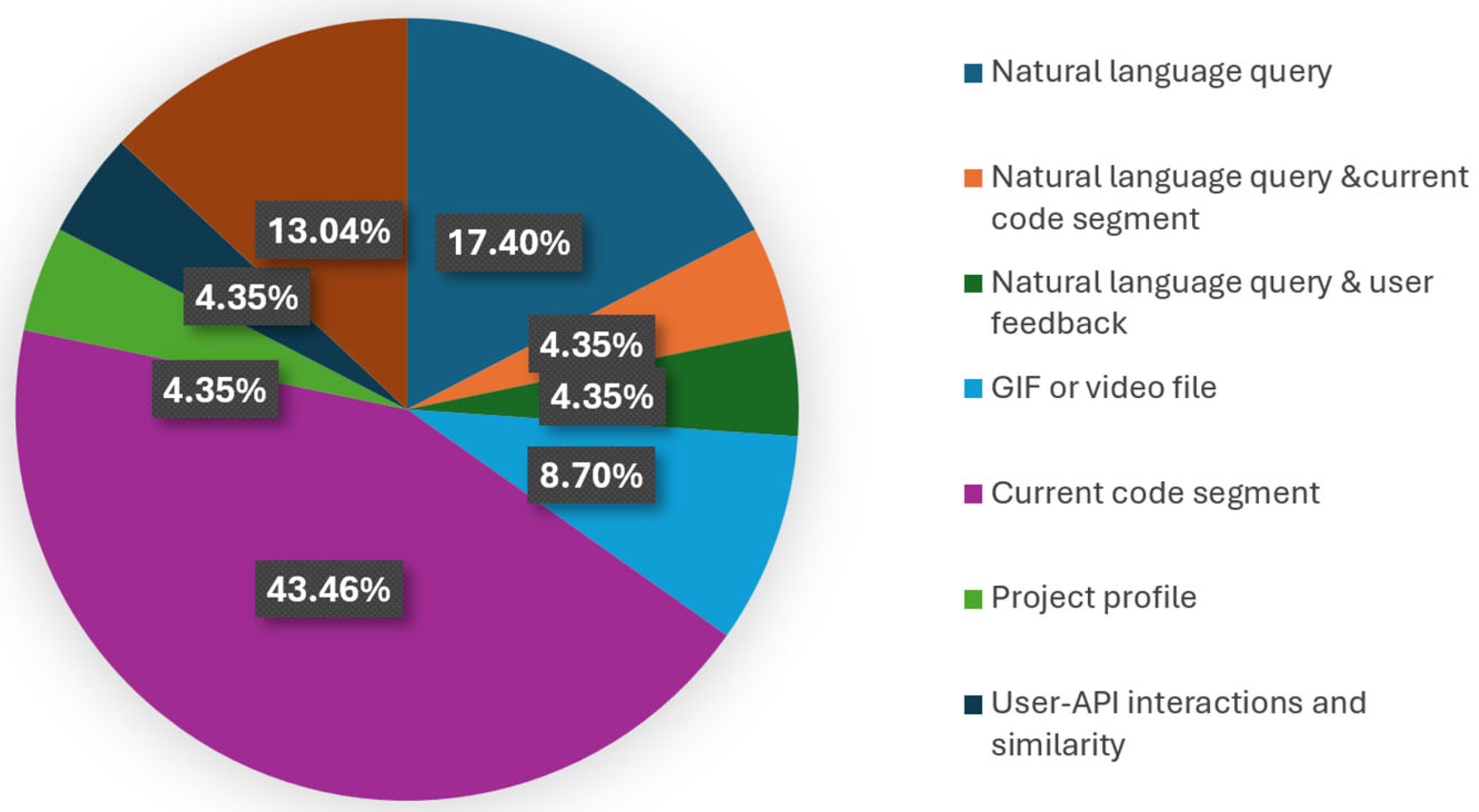
| [44] | Natural language query and user feedback |
| [45,47,48,49] | Natural language query |
| [46] | Natural language query and current code segment |
| [50,51] | GIF or video file |
| [52,55,56,57,58,59,61,64,65,66] | Current code segment |
| [53] | User–API interactions, user–user similarity, item–item similarity |
| [54,60,62] | Current code segment and project |
| [63] | Project profile (description and keywords) |
| Ref. | Output |
|---|---|
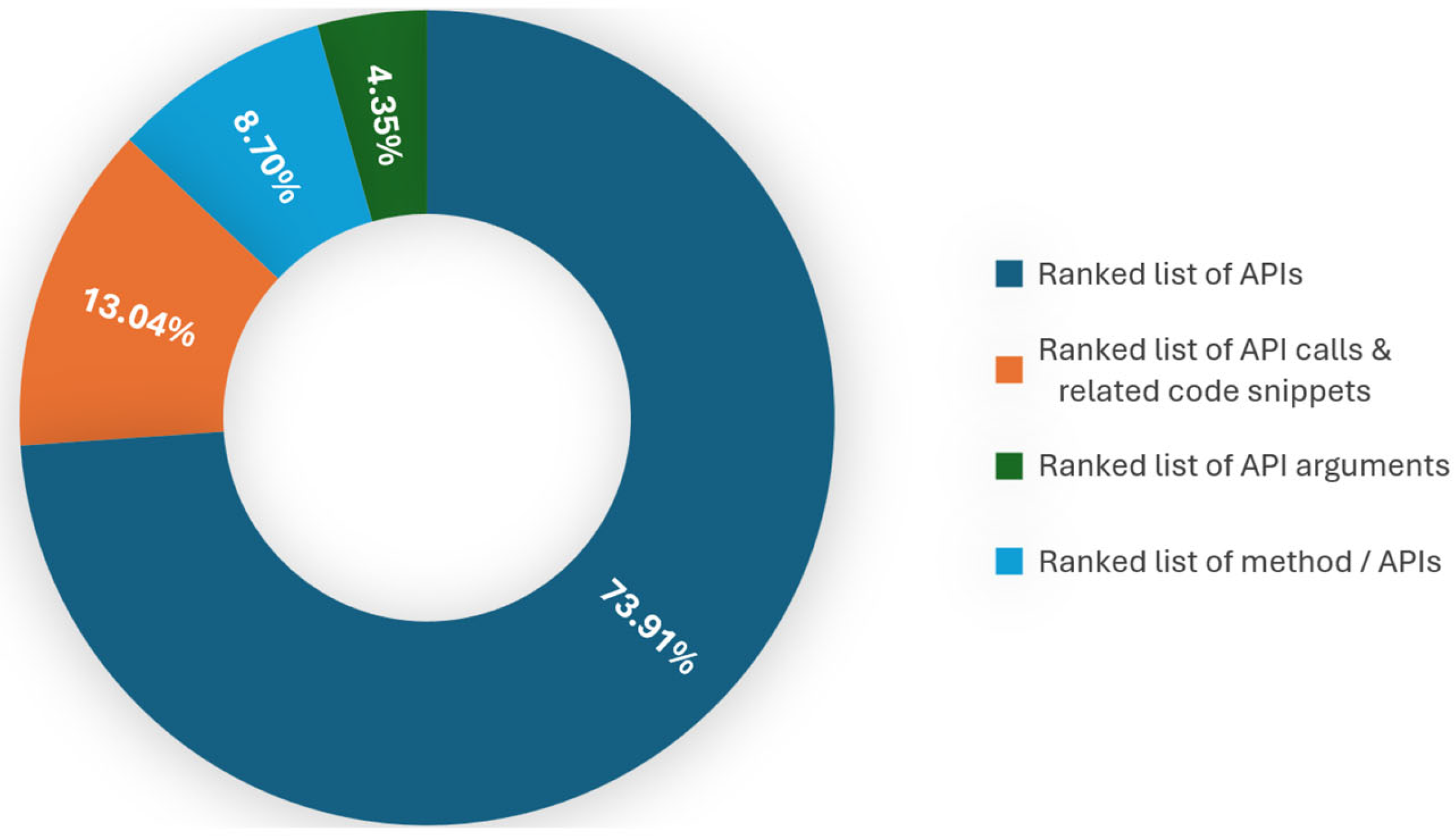
| [44,45,46,47,48,49,50,51,52,53,54,55,56,57,61,63,64] | Ranked list of APIs |
| [60,62,66] | Ranked list of API calls and related code snippets |
| [65] | Ranked list of API arguments |
| [58,59] | Ranked list of methods/APIs |
| Ref. | Method |
|---|---|
| [44] | Learning-to-rank and active learning techniques |
| [45,51,62] | Similarity matching |
| [46] | Similarity matching with tensor factorization |
| [47] | Optimization using a genetic algorithm for structural and semantic similarity |
| [48] | Similarity matching with Stack Overflow posts and API documentation |
| [49] | Contrastive learning with BERT embeddings and similarity matching |
| [50] | Multimodal deep learning |
| [52] | Graph Attention Networks and Multilayer Perceptron |
| [53] | Matrix Factorization combined with user and API similarity matching |
| [54] | Memory and model-based CF |
| [55] | Pretrained models and similarity matching |
| [56] | Transformer-based pre-trained model for feature extraction and deep neural network |
| [57] | Graph Attention Network, LSTM and deep neural network |
| [58] | LSTM based on AST representation |
| [59] | Nearest neighbor based on usage data |
| [60] | Context-aware CF (similarity matching) |
| [61] | Hierarchical context extraction and inference |
| [63] | Personalized ranking model |
| [64] | Heterogenous graph-based representation and attention networks |
| [65] | Ensemble ranking based on program analysis and language models |
| [66] | Context-aware CF |
| Ref. | Evaluation Metrics | Datasets | Results/Comparative Results | Remarks/Benchmarking |
|---|---|---|---|---|
| [11] | Recall@K (K = 1, 3, 5, 10), Precision@K (K = 5, 10), NDCG@K (K = 5, 10) | BigCloneBench, 743 open-source Java projects from GitHub (741,148 code snippets) | Recall@10 of 88.7% and Recall@1 of 37.3% | Outperformed all compared methods |
| [12] | Precision@100, Recall@100, F1@100, Query Time (s), Usefulness (Likert 1–5) | CodeSearchNet and Neural Code Search | P@100 of 92.50% and F@100 of 42.95 at CodeSearchNet. P@100 of 68.83% and F1@100 of 56.42% at Neural Code Search. 147.9× faster than Aroma on CodeSearchNet and 224× faster on Neural Code Search. MinHash is faster on Neural Code Search but Senatus has comparable time and 10x Precision, Recall and F-measure | Outperformed compared methods |
| [13] | Perplexity (PPL), MRR, Top-K Accuracy (K = 1, 3, 5, 10) | BigCloneBench, IJaDataset | MRR of 29%, Accuracy Top-1 of 23.8%, Top-3 of 32.5%, Top-5 of 36.2% and Top-10 of 40.5% for Exact Match and MRR of 74%, Accuracy Top-1 69.4%, Accuracy Top-3 77%, Accuracy Top-5 of 80.1% and Accuracy Top-10 of 84.5% | Comparing perplexities for Deep Clone and Clone advisor, where Clone advisor showed lower perplexities in top-10 retrieved snippets |
| [14] | MRR, Hit@K (K = 1, 3, 5) | CodeSearchNet | MRR 0.44, Hit@1 of 36.75%, and Hit@5 of 57.35% | Outperformed compared methods |
| [15] | SuccessRate@K (K = 1, 5, 10), MRR | Stack Overflow (Top 100 questions), GitHub Java projects | SuccessRate@1 of 32%, SuccessRate@10 of 57% and MRR 0.44 | Outperformed baselines |
| [16] | Precision | Tested only with three sample queries | Precision 70–86.67% for 3 sample queries | - |
| [17] | Precision@K (P@5), Success Rate, Wilcoxon Test | 120 Android Java projects from GitHub (Music Player, Bluetooth Chat, Weather, File Management) | P@5 of 94% and success rate of 90–95% | Outperformed FACER |
| [20] | Accuracy@K (K = 1, 10) for incomplete code, Classification Accuracy for complete code | Online Judge (OJ) System dataset (52,000 files from 104 programming problems) | Accuracy@10 of 97.49% | Outperformed compared methods |
| [21] | Top-1 Accuracy, Top-3 Accuracy | 14,807 Java projects (350 M lines of code, 2 M files), evaluated on 10 large Java projects with 23,000 to 400,000 commits | Top-1 Accuracy of 66% and Top-3 Accuracy of 74% | Outperformed baselines |
| [22] | Precision@K (K = 1, 3, 10), Recall@K (K = 1, 3, 10) | JEdit, ArgoUML, JHotDraw (method parameter recommendations) | Precision@10 of 72.06% in Eclipse and 78.38% in NetBeans | Outperformed compared methods |
| [23] | NDCG@10, Quality Improvement Score | Java and Python code generated from 5 LLMs | Improved NDCG@10 score | Improved NDCG@10 score for all compared methods |
| [9] | Hit@K (K = 1, 3, 5, 10), MRR | Dataset provided by CodeGRU (https://github.com/yaxirhuxxain/Source-Code-Suggestion accessed on 21 March 2025), built from open-source Java Github project | Hit@1 0.4998, Hit@3 0.6319, Hit@5 0.6759, Hit@10 0.7191 and MRR 0.5764 when compared to N-gram and Hit@3 0.5986, Hit@5 0.7576, Hit@5 0.8056, Hit@10 0.8425 and MRR 0.6867 when compared with CodeGRU | EHOPE outperformed the baselines |
| [24] | Accuracy@K (K = 1, 3, 5, 10), MRR@K (K = 1, 3, 5, 10), Precision, Recall, F1-Score | Java and C# datasets collected from GitHub | Accuracy@10 of 90.10% (Java) and 86.05% (C#), MRR@10 is 75.13% (Java) and 68.66% (C#) | Outperforming all baselines. Precision and Recall surpass previous models. |
| [28] | Exact Match (EM), Edit Similarity (ES), Unit Test Pass Rate (UT) | RepoEval, CrossCodeEval, CrossCodeLongEval | EM 54.40 and ES 76.00 at line level, EM 46.10 and 72.70 ES at API-level and UT 28.79 and ES 57.30 at function level for RepoEval dataset | Outperformed methods compared in terms of EM, ES, UT in various experimentation settings. |
| [29] | Exact Match (EM), Identifier Match (IM) | 8000 repository-level completion tasks from 20 repositories | Achieved higher EM | Achieved higher EM improved by +6.06 and IM by +6.23 over baselines |
| [30] | Accuracy (Value and Type), Precision, Recall, F1-Score | PY150K (Python), JS150K (JavaScript), PY1K, PY10K, PY50K, JS1K, JS10K, JS50K (Filtered vocabulary versions) | Achieved accuracy of 80.8% (JS1K) and 75.1% (PY1K) | Outperformed baselines. |
| [31] | Edit Similarity (ES), Identifier F1-Score (ID-F1), SpeedUp (%) | CrossCodeEval benchmark Python dataset | ES 80.82 and ID-F1 77.31 | Outperformed compared variations achieving an improved speed of 33.29% and 48.41% for prompt Length of 2048 and 1024 |
| [32] | Exact Match (EM), BLEU-4 for code match, EM, Precision and Recall for Identifier Match, Perplexity (PPL) | 60891 projects from Python Package Index | +33.94% improvement in Exact Match (EM), +28.69% improvement | COCOMIC outperformed in ID Match over in-file-only baselines |
| [33] | Recall@K (K = 1, 5) for offline evaluation and for online evaluation with user-defined session-based metrics (i.e., Explicit Select Rate, Typed Select Rate, Typing Actions, Prefix Length, Manual Start Rate) | Usage logs collected from Python projects in PyCharm for 2 weeks | Improved Recall@1 from 0.761 to 0.870, Recall@5 from 0.957 to 0.981 | Outperformed baseline in all metrics and settings |
| [36] | BLEU, ROUGE-L, BERTScore, RAS | Dataset of 18,517 pairs of vulnerabilities and suggestions from open-source projects | BLEU 21, ROUGE-L 34.7, BERTSCORE 67.7 AND RAS 12.5 | Outperformed all compared methods |
| [37] | I-score (percentage of perfect SO posts, IH-score (percentage of relevant SO posts) and M-score (percentage of irrelevant posts) | Dataset based on Stack Overflow dump and top 500 open-source Java repositories in Github | 0.40 I-score, 0.71 IH-score and 0.26 M-score | Outperformed compared methods |
| [38] | Top-K Accuracy (K = 1, 3), percentage of fixes of developers/recommendations | Dataset constructed by crawling apps and collecting exception bugs from open-source repositories resulting in 1000-exception bug dataset | Top-1 accuracy 73–75% for correct warning on exceptions (different setting of risk level). Similarly, Top-3 accuracy 79–81% | 65% of the recommendations were applied by developers, where 21% were higher than CAR-Miner and 37% higher than heuristic-based recommendation |
| [39] | Precision, Recall, F1-Score | Interaction traces data collected by Eclipse Bugzilla with Mylyn plugin | Average F-1 score 0.64 vs. 0.59 | Performed slightly better than MI-EA when recommendations stop after the first incorrect edit |
| [40] | Precision, Recall, F1-Score | 11,085 real-world field renamings collected from 388 open-source Java projects with RefactoringMiner | 49.44% F1 score while IDEA scored 6.3%, Incoder 13.41% and Zhang’s test 20.17% | Outperformed compared methods for all metrics. |
| [41] | Top-K Accuracy (K = 1, 2, 5) | Code-Change-Data, Pull-Request-Data, Defects4J-data | 15.94% Top-5 Accuracy for Code-Change-Data and 28.87% for Pull-Request-Data | Outperformed compared methods. |
| [42] | Accuracy, Precision, Recall, F1-score, Hamming Loss, Hamming Score | Dataset from 55 open-source Java repositories and 18,899 feature requests from JIRA issue tracker | Precision 76% vs. 20%, Recall 54% vs. 34% and F-measure 61% vs. 25% | Significantly outperformed the compared method for all the evaluation metrics |
| [43] | Hit Rate @ K (K = 3, 10), | Tomcat 7.0.47 source code, 1338 code snippets requiring type conversion sequences containing 145 static method entry points | 72.2% top-3 hit rate vs. 60.7% and 90.3% top-10 hit rates vs. 78.4% | Outperformed Eclipse Code recommenders |
| [44] | Hit@k (Top-k Accuracy), MAP (Mean Average Precision), MRR (Mean Reciprocal Rank) | BIKER, RACK, and NLP2API datasets | For 100% accumulation of repository Hit-1, values improved by 9.44% for BIKER (method level), 6.79% for BIKER (class level), 18% for RACK, and 18.39% for NLP2API | Improved baseline methods for all metrics as accumulation of the feedback repository increased. |
| [45] | Precision@N(P@N) and Mean Average Precision@N(MAP@N) | Dataset made by crawling Google Play Store apps from 4 categories (rating ≥4.5) | Precision@4 of 0.49, Precision@5 of 0.53, Precision@10 of 0.69 and MAP@1 of 0.31, MAP@5 of 0.34 and MAP@10 of 0.34 | Showed higher results than compared method, but they are not comparable since they were not based on the same dataset |
| [46] | SuccessRate@N, Precision@N, Recall@N, Mean Average Precision (MAP@N), Mean Reciprocal Rank (MRR@N), Normalized Discounted Cumulative Gain (NDCG@N) | Official data dump of StackOverflow, 125,847 Java questions, 62,067 (query, API, context) triplets extracted, 458 test queries manually constructed. Test dataset used in BIKER [16] | Outperformed BIKER, SuccessRate@1 of 39.5% vs. 30.0% | Outperformed significantly RACK, higher values for all metrics (10–45% improvements) |
| [47] | Precision@N (P@N), Mean Average Precision@N (MAP@N), Mean Reciprocal Rank (MRR) | Google Play apps in 5 categories: Android API descriptions and Q&A from Stack Overflow (for ground truth) | Outperformed LibraryGuru in all metrics improvements for 19.4% to 91.7%. Similarly, outperformed GAPI improving metrics ranging from 106.3% to 1050% | Outperformed LibraryGuru and GAPI |
| [48] | MRR (Mean Reciprocal Rank) and MAP (Mean Average Precision), Success Rate (S @ K) | Stack Overflow Data, 413 manually labeled test queries | Improved S@1 by 27.2% over BIKER and by 22.3 over BRAID at method level. Similarly, improved S@1 by 22.3% over BIKER and by 24 over BRAID at class level | Outperformed compared methods |
| [49] | MRR (Mean Reciprocal Rank), MAP (Mean Average Precision), Precision@N, Recall@N | Stack Overflow data from BIKER dataset | Improved Precision@1 by 314.94% to 732.24% and Recall@1 by 133.18% to 326.29% | Outperformed compared methods at method and class level |
| [50] | Accuracy@N (for N = 1, 3, 5, 10), Average Completion Time in user study | 960 apps from Google Play apps from 4 categories, resulting in 5329 mappings between UI animations and API sequences | Average Accuracy@1: 45.13% and Accuracy@10: 81.85% | Outperformed LUPE; however they are not exactly comparable methods |
| [51] | Success Rate@N, MAP@N (Mean Average Precision), Precision@N, Recall@N | Top- 20 free Android apps from 32 categories of Google Play, resulting in 3200 animation-API mappings. Rico dataset | Precision@20 230.77% and Recall@20 improvement by 184.95% | Outperformed Guru |
| [52] | Accuracy@N (Top-1, Top-2, Top-3, Top-5, Top-10), MRR (Mean Reciprocal Rank) | Collected 25,000 Solidity smart contract projects from Etherscan | Top-1 Accuracy of 64.85% (214.19% higher than best baseline). Top-5 Accuracy: 71.65% (81.43% higher than best baseline). MRR: 68.02% (106.4% higher than best baseline) | Outperformed baselines |
| [53] | MAE (Mean Absolute Error), RMSE (Root Mean Square Error) | Crawled 17,412 APIs from ProgrammableWeb | Best MAE = 0.151, RMSE = 0.204 for 90% training set density | Outperformed all compared methods |
| [54] | Success Rate@N, Precision@N, Recall@N, MRR (Mean Reciprocal Rank), NDCG (Normalized Discounted Cumulative Gain) (N = 1, 3, 5) | SHL (610 Java projects from GitHub), SHS (200 Java projects from SHL), MVL (3600 JAR archives from Maven Central Repository), MVS (1600 selected unique projects from MVL) | - | Outperformed FOCUS in most cases; it performed better in small and sparse datasets. FOCUS performed slightly better in large datasets |
| [55] | Top-K Accuracy (Top-1, Top-5, Top-10), MRR (Mean Reciprocal Rank) | APIBench dataset, Java and Android APIs | Top-1 Accuracy 77.37%, Top-5 94.79%, Top-10 98.15% and MRR 0.851 in Java dataset and Accuracy Top-1 71.60%, Top-5 90.21%, Top-10 94.46% and MRR 0.798 in Android | Outperformed all baseline approaches |
| [56] | Top-K Accuracy (k = 1, 2, 3, 4, 5, 10), MRR (Mean Reciprocal Rank) | Intra-Project Edition (constructed using 8 Python open-source projects from GitHub) | Average Top-1 Accuracy 40.27%, Top-2 Accuracy 45.15, Top-3 Accuracy 49.44, Top-4 Accuracy 52.83, Top-5 Accuracy 54.18, Top-10 Accuracy 60.38 and MRR 47.30% | Outperformed compared methods. |
| [57] | Top-K Accuracy (Top-1, Top-5, Top-10) | 625 Java projects from GitHub, over 1000 stars and datasets used by the compared approaches | Top-1 Accuracy 67.3–70.1%, Accuracy Top-5 85.1–90.8%, Top-10 91.3–95.8%. | Outperformed the compared methods in most of the datasets. However, the compared methods were not reproduced and their results were taken directly from their papers. |
| [58] | Top-K Accuracy (Top-1, Top-5), MRR (Mean Reciprocal Rank) | 2700 Python open-source GitHub projects, 15.8 million method calls | Top-1 Accuracy 0.71, Top-5 Accuracy 0.92 and MRR 0.814 | Outperformed all compared methods. |
| [59] | MRR (Mean Reciprocal Rank), Recall | 20 Python libraries | Achieved average MRR 0.5 and recall 0.84 | Outperformed significantly compared methods. |
| [60] | Success Rate@N, Precision@N, Recall@N, Levenshtein Distance, Time, User-Perceived Usefulness | 26,854 API functions extracted from 2600 open-source Android apps (from Google Play and GitHub) | Success rate of 92.10% vs. 58.40% of PAM and 40.66% UP-Miner. UP-Miner is the fastest (regarding recommendation time). FOCUS is faster than PAM | FOCUS outperformed significantly compared methods in all experiments. Majority of users evaluated positively (69%) that recommendations are relevant |
| [61] | Top-K Accuracy (Top-1, Top-5, Top-10), Execution Time | Datasets used by compared methods, galaxy, log4j, spring, antlr, jGit, froyo-email, grid-sphere and itext | - | HiRec outperformed methods compared with top-5 and top-10 accuracy rates. APIREC is close to HiRec regarding top-1 accuracy. |
| [62] | Success Rate@N, Precision@N, Recall@N | 12000 Android apps | - | APIMatchmaker outperformed both FOCUS and statistics baseline in terms of success rate, precision, and recall. |
| [63] | Hit@N, MAP@N, MRR (Mean Reciprocal Rank) | 9883 web APIs and 4315 projects from ProgrammableWeb | Hit@5, Hit@10, MAP@5, MAP@10, MAP, and MRR scores of 0.840, 0.880, 0.697, 0.687, 0.626, and 0.750, respectively. | Outperformed compared methods |
| [64] | Success Rate@K, Precision@K and Recall@K (K = 1, 5, 10, 20). User study (6 developers): Relevance and preference | SHS (200 Java projects), SHL (610 Java projects), MV (868 JAR archives) | SR@1 0.439, SR@5 0.672, SR@10 0.794 and SR@20 0.836 for MV dataset, while the best results of comparisons were for GAPI SR@1 0.195, SR@5 0.363, SR@10 0.479 and SR@20 0.600 | Outperformed compared methods in all datasets and for all evaluation metrics |
| [65] | Top-K Accuracy (K = 1, 3, 5, 10), Precision, Recall, MRR (Mean Reciprocal Rank) | Small corpus: 2 large projects, Eclipse and Netbeans Large corpus: 9271 projects | The NetBeans dataset achieved MRR 0.72 while GPT-2’s MRR was 0.55, CodeT5 MRRS was 0.63 and SLP’s MRR was 0.44 | Outperformed all baselines for all metrics and datasets |
| [66] | Success Rate@N, Precision@N, Recall@N, Recommendation Time | 610 Java projects from GitHub, 200 small Java projects, 3600 JAR archives from Maven Central | SuccessRate@1 24.59% for a small dataset vs. SuccessRate@1 72.30 a larger dataset. FOCUS is about 100× faster than PAM (average recommendation time 0.095 s vs. 9 s) | Outperformed compared method. Achieved better evaluation metrics in large datasets |
| Aim (RQ1) | Input (RQ2) | Output (RQ3) | Method (RQ4) | Ref. |
|---|---|---|---|---|
| Code Recommendation | Current code segment, natural language query, methods with API usages in current active project, developers’ coding history, project-specific and common code patterns | Ranked list of code snippets, ranked list of related methods, a list of potential functionalities, ranked list of code elements, method parameters | Self-attention neural networks, AST-based feature scoring and De-Skew LSH, pretrained GPT-2 and IR technique (TF-IDF), SBERT model and similarity matching, GRU Network and JEAN model, similarity matching, deep learning model Fuzzy sets, heuristics and ranking based on quality criteria applied in the output of transformer-based code generation model, similarity matching (cosine) | [11,12,13,14,15,16,17,20,21,22,23] |
| Code Completion | Current code segment (token-based representation), current file context, current code segment (graph representation), cross file context, current code segment and usage logs | Next code token, predicted statement, next code snippets | LSTM and pre-trained model BERT, transformer-based model Selective RAG, coarse-to-fine retrieval process and LLM, Graph Matching and Multi-field Graph Attention Block, Retrieval Augmented-Generation (RAG) solution | [9,24,28,29,30,31,32,33] |
| Recommending Code Repairs | Current code segment, current code segment and associated Java, runtime exception, developer’s history of interactions, field name to be renamed, feature requests, code and libraries of the current project | Natural language suggestions, Stack Overflow (SO) post, code snippets, files to edit, field renaming, refactoring types, type conversion sequence | Similarity matching, graph matching, fuzzy logic, recurrent neural network, sequence of context-aware heuristics, Tree-based neural network, MNB classifier, semantic ontology reasoning rules | [36,37,38,39,40,41,42,43] |
| API Recommendation | Natural language query and user feedback, natural language query, natural language query and current code segment, GIF or video file, current code segment, user–API interactions, user–user similarity, item–item similarity, current code segment and project, project profile (description and keywords) | Ranked list of APIs, ranked list of API calls and related code snippets, ranked list of API arguments, ranked list of methods/APIs | Learning-to-rank and active learning techniques, similarity matching, similarity matching with tensor factorization, optimization using a genetic algorithm for structural and semantic similarity, similarity matching with Stack Overflow posts and API documentation, contrastive learning with BERT embeddings and similarity matching, multimodal deep learning, Graph Attention Networks and multilayer perceptron, matrix factorization combined with user and API similarity matching, memory and model-based CF, pretrained models and similarity matching, transformer-based pre-trained model for feature extraction and deep neural network, Graph Attention Network, LSTM and deep neural network, LSTM based on AST representation, nearest neighbor based on usage data, context-aware CF (similarity matching), hierarchical context extraction and inference, personalized ranking model, heterogenous graph-based representation and attention networks, ensemble ranking based on program analysis and language models, context-aware CF | [44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mavridou, E.; Vrochidou, E.; Kalampokas, T.; Kanakaris, V.; Papakostas, G.A. AI-Powered Software Development: A Systematic Review of Recommender Systems for Programmers. Computers 2025, 14, 119. https://doi.org/10.3390/computers14040119
Mavridou E, Vrochidou E, Kalampokas T, Kanakaris V, Papakostas GA. AI-Powered Software Development: A Systematic Review of Recommender Systems for Programmers. Computers. 2025; 14(4):119. https://doi.org/10.3390/computers14040119
Chicago/Turabian StyleMavridou, Efthimia, Eleni Vrochidou, Theofanis Kalampokas, Venetis Kanakaris, and George A. Papakostas. 2025. "AI-Powered Software Development: A Systematic Review of Recommender Systems for Programmers" Computers 14, no. 4: 119. https://doi.org/10.3390/computers14040119
APA StyleMavridou, E., Vrochidou, E., Kalampokas, T., Kanakaris, V., & Papakostas, G. A. (2025). AI-Powered Software Development: A Systematic Review of Recommender Systems for Programmers. Computers, 14(4), 119. https://doi.org/10.3390/computers14040119