
Enhancing CuFP Library with Self-Alignment Technique



Abstract
1. Introduction
2. Background
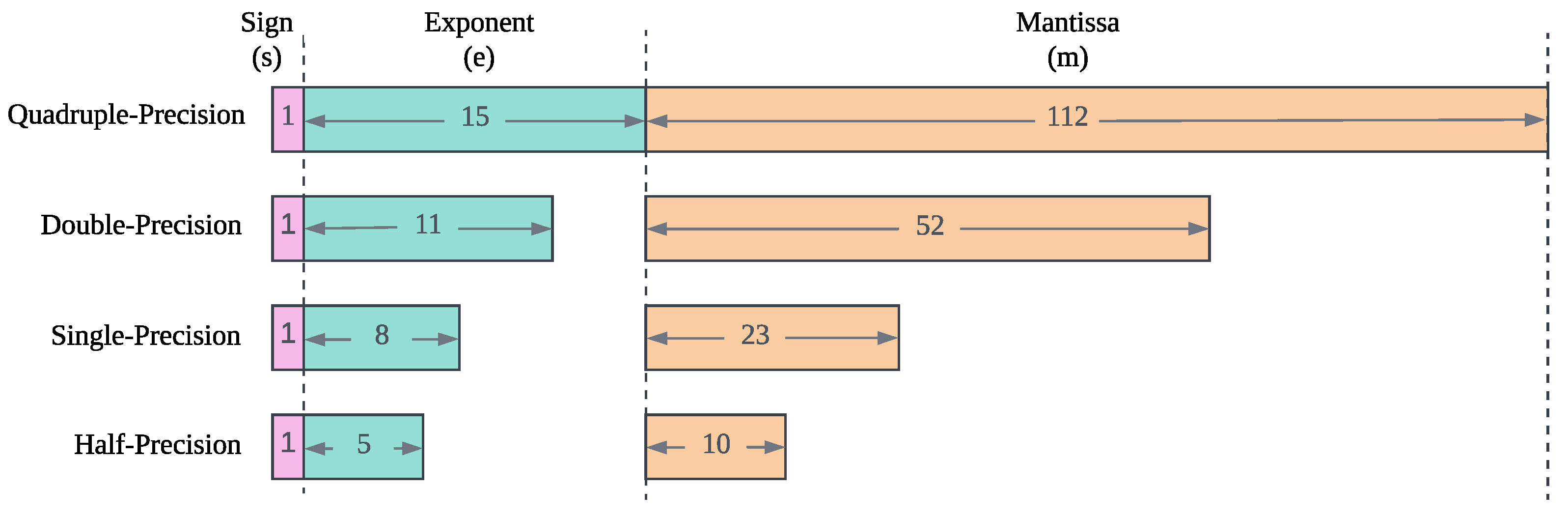
2.1. Floating-Point Format
2.2. Challenges in Floating-Point Operations
2.3. Role of High-Level Synthesis (HLS)
2.4. Overview of the CuFP Library
2.5. Self-Alignment Technique (SAT)
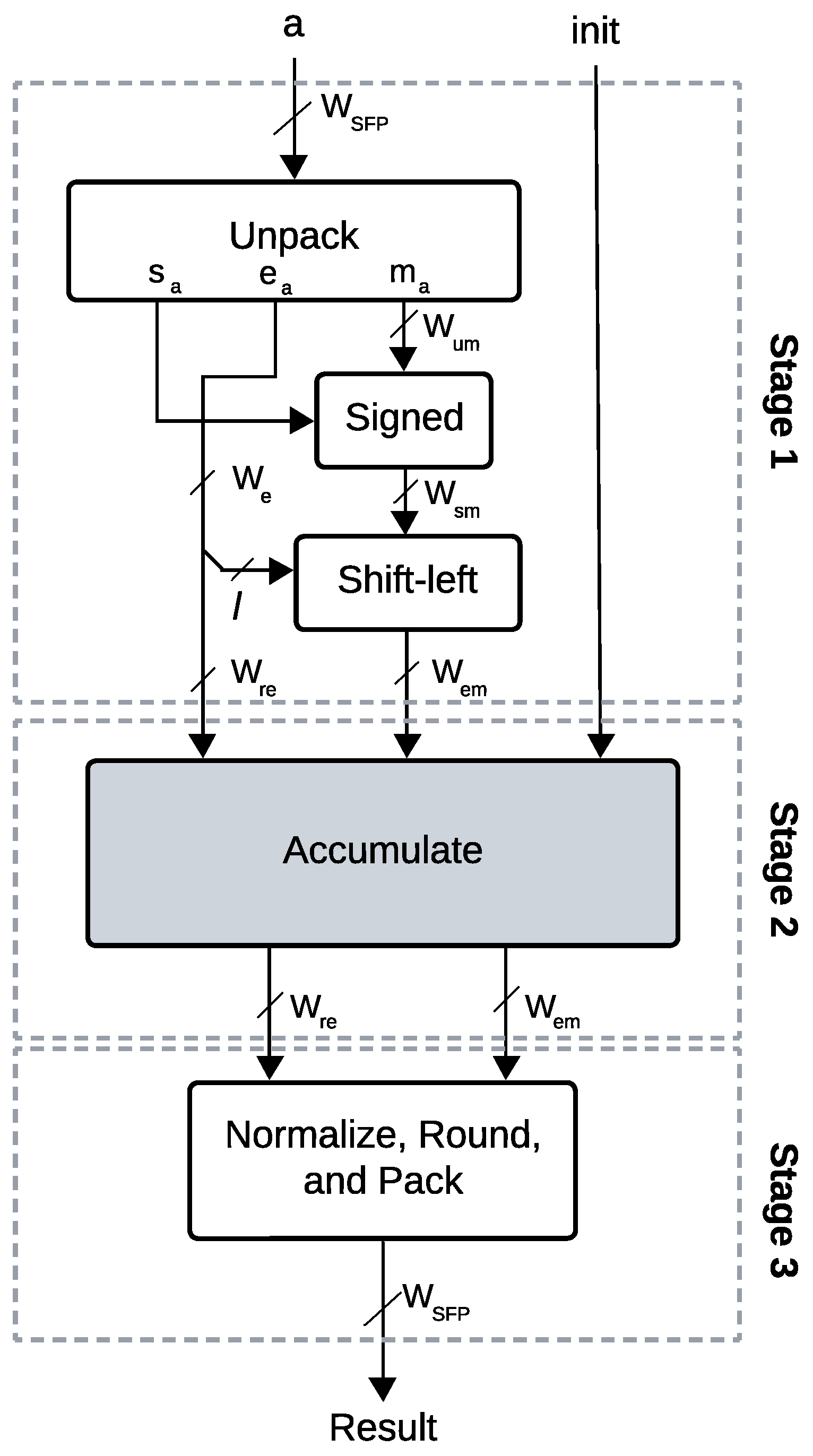
2.5.1. SAT-Based Addition
2.5.2. Self-Alignment Format (SAF)
3. Implementation Methodology
3.1. CuFPSAF Data Type
- WM: specifies the bit width of the mantissa.
- WE: specifies the bit width of the exponent.
- l: indicates the number of bits dropped in the exponent.
- b: represents the bias value, calculated based on the selected SAF format.
| Listing 1. The body of CustomFloat template class. |
 |
3.2. Primary Operations
3.2.1. CuFPSAF Addition
| Algorithm 1: CuFPSAF Addition (inspired from [5]) |
1 Parameters: 2 Inputs: , 3 Outputs: 4 Local Variables: 5 6 ; 7 // Compare x and y based on and 8 9 10 11 12 13 Return z |
3.2.2. CuFPSAF Multiplication
| Algorithm 2: CuFPSAF Multiplication |
1 Parameters: 2 Inputs: , 3 Outputs: 4 Local Variables: e 5 Constant: 6 ; 7 8 9 10 Return z |
3.3. Vector-Based Operations
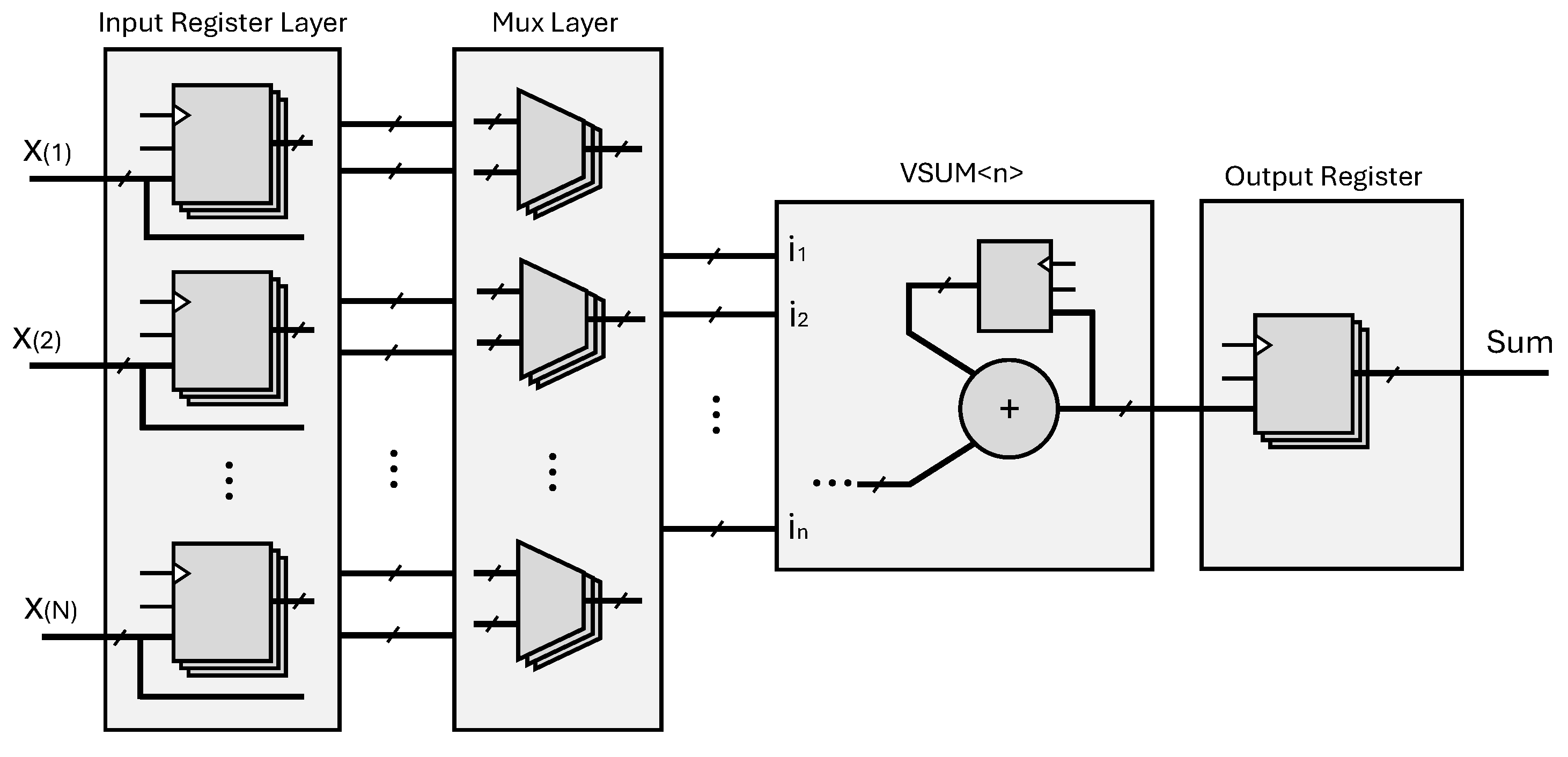
3.3.1. CuFPSAF Vector Summation
| Algorithm 3: CuFPSAF Vector Summation |
1 Parameters: 2 Inputs: 3 Outputs: 4 Local Variables: 5 Constant: 6 7 8 9 10 11 12 Return z; |
3.3.2. CuFPSAF Dot Product
| Listing 2. A pseudo-code of SAFCuFP dot product operation. |
 |
| Listing 3. A pseudo-code of CuFPSAF dot product operation, considering two different approaches: Latency-Constrained and Resource-Constrained. |
 |
3.3.3. CuFPSAF Matrix-Vector Multiplication
| Listing 4. A pseudo-code of CuFPSAF matrix-vector multiplication, considering RC approach. |
 |
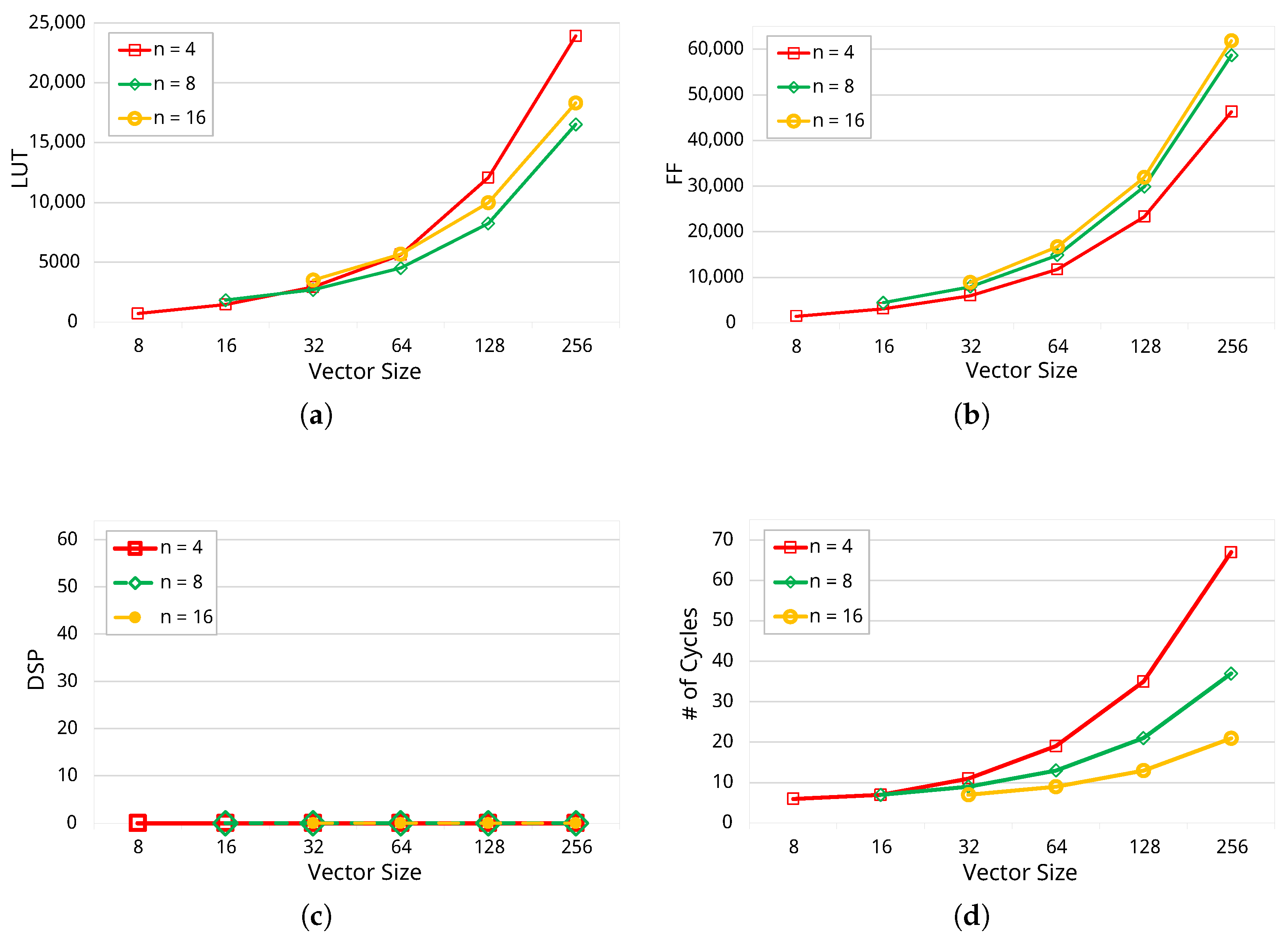
4. Experimental Results
Error Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xie, K.; Lu, Q.; Jiang, H.; Wang, H. Accurate Sum and Dot Product with New Instruction for High-Precision Computing on ARMv8 Processor. Mathematics 2025, 13, 270. [Google Scholar] [CrossRef]
- Xilinx. UG1399: Vitis High-Level Synthesis User Guide; Xilinx: San Jose, CA, USA, 2023. [Google Scholar]
- Hajizadeh, F.; Ould-Bachir, T.; David, J.P. CuFP: An HLS Library for Customized Floating-Point Operators. Electronics 2024, 13, 2838. [Google Scholar] [CrossRef]
- Sohn, J.; Swartzlander, E.E. Improved Architectures for a Floating-Point Fused Dot Product Unit. In Proceedings of the 2013 IEEE 21st Symposium on Computer Arithmetic, Austin, TX, USA, 7–10 April 2013; pp. 41–48. [Google Scholar]
- Ould-Bachir, T.; David, J.P. Self-Alignment Schemes for the Implementation of Addition-Related Floating-Point Operators. Acm Trans. Reconfigurable Technol. Syst. 2013, 6, 1–21. [Google Scholar] [CrossRef]
- Std 754-2008; IEEE Standard for Floating-Point Arithmetic. IEEE: New York, NY, USA,, 2008; pp. 1–70.
- Jamro, E.; Dąbrowska-Boruch, A.; Russek, P.; Wielgosz, M.; Wiatr, K. Novel architecture for floating point accumulator with cancelation error detection. Bull. Pol. Acad. Sci. Tech. Sci. 2023, 66, 579–587. [Google Scholar] [CrossRef]
- Perera, A.; Nilsen, R.; Haugan, T.; Ljokelsoy, K. A Design Method of an Embedded Real-Time Simulator for Electric Drives using Low-Cost System-on-Chip Platform. In Proceedings of the PCIM Europe Digital Days 2021; International Exhibition and Conference for Power Electronics, Intelligent Motion, Renewable Energy and Energy Management, Virtual Event, 3–7 May 2021; pp. 1–8. [Google Scholar]
- Zamiri, E.; Sanchez, A.; Yushkova, M.; Martínez-García, M.S.; de Castro, A. Comparison of Different Design Alternatives for Hardware-in-the-Loop of Power Converters. Electronics 2021, 10, 926. [Google Scholar] [CrossRef]
- Sanchez, A.; Todorovich, E.; De Castro, A. Exploring the Limits of Floating-Point Resolution for Hardware-In-the-Loop Implemented with FPGAs. Electronics 2018, 7, 219. [Google Scholar] [CrossRef]
- Martínez-García, M.S.; de Castro, A.; Sanchez, A.; Garrido, J. Analysis of Resolution in Feedback Signals for Hardware-in-the-Loop Models of Power Converters. Electronics 2019, 8, 1527. [Google Scholar] [CrossRef]
- Fiorito, M.; Curzel, S.; Ferrandi, F. TrueFloat: A Templatized Arithmetic Library for HLS Floating-Point Operators. In Proceedings of the Embedded Computer Systems: Architectures, Modeling, and Simulation, Samos, Greece, 2–6 July 2023; Silvano, C., Pilato, C., Reichenbach, M., Eds.; pp. 486–493. [Google Scholar]
- Thomas, D.B. Templatised Soft Floating-Point for High-Level Synthesis. In Proceedings of the IEEE Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; pp. 227–235. [Google Scholar]
- Gao, J.; Shen, J.; Zhang, Y.; Ji, W.; Huang, H. Precision-Aware Iterative Algorithms Based on Group-Shared Exponents of Floating-Point Numbers. arXiv 2024, arXiv:cs.DC/2411.04686. [Google Scholar]
- Filippas, D.; Nicopoulos, C.; Dimitrakopoulos, G. Templatized Fused Vector Floating-Point Dot Product for High-Level Synthesis. J. Low Power Electron. Appl. 2022, 12, 56. [Google Scholar] [CrossRef]
- de Dinechin, F.; Pasca, B. Designing Custom Arithmetic Data Paths with FloPoCo. IEEE Des. Test Comput. 2011, 28, 18–27. [Google Scholar] [CrossRef]
- Wang, X.; Leeser, M. VFloat: A Variable Precision Fixed- and Floating-Point Library for Reconfigurable Hardware. ACM Trans. Reconfigurable Technol. Syst. 2010, 3, 1–34. [Google Scholar]
- Swartzlander, E.E.; Saleh, H.H. FFT Implementation with Fused Floating-Point Operations. IEEE Trans. Comput. 2012, 61, 284–288. [Google Scholar]
- Ferrandi, F.; Castellana, V.G.; Curzel, S.; Fezzardi, P.; Fiorito, M.; Lattuada, M.; Minutoli, M.; Pilato, C.; Tumeo, A. Invited: Bambu: An Open-Source Research Framework for the High-Level Synthesis of Complex Applications. In Proceedings of the ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 1327–1330. [Google Scholar]
- Uguen, Y.; Dinechin, F.D.; Lezaud, V.; Derrien, S. Application-Specific Arithmetic in High-Level Synthesis Tools. ACM Trans. Archit. Code Optim. 2020, 17, 1–23. [Google Scholar]
- Nane, R.; Sima, V.M.; Pilato, C.; Choi, J.; Fort, B.; Canis, A.; Chen, Y.T.; Hsiao, H.; Brown, S.; Ferrandi, F.; et al. A Survey and Evaluation of FPGA High-Level Synthesis Tools. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2016, 35, 1591–1604. [Google Scholar]
- Lahti, S.; Rintala, M.; Hämäläinen, T.D. Leveraging Modern C++ in High-Level Synthesis. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2023, 42, 1123–1132. [Google Scholar]
- Luo, Z.; Martonosi, M. Accelerating pipelined integer and floating-point accumulations in configurable hardware with delayed addition techniques. IEEE Trans. Comput. 2000, 49, 208–218. [Google Scholar] [CrossRef]
- Vangal, S.; Hoskote, Y.; Borkar, N.; Alvandpour, A. A 6.2-GFlops Floating-Point Multiply-Accumulator With Conditional Normalization. IEEE J. Solid-State Circuits 2006, 41, 2314–2323. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | Variant | (%) |
|---|---|---|
| Sum | Vendor IP | 2.02 × |
| CuFP [3] | 2.68 × | |
| CuFPSAF | 2.63 × | |
| Mul | Vendor IP | 6.03 × |
| CuFP [3] | 6.35 × | |
| CuFPSAF | 6.31 × |
| Variant | Vector Size | Interval | # of Cycles | Resource Utilization | ||
|---|---|---|---|---|---|---|
| DSP | LUT | FF | ||||
| Vendor IP | 8 | 1 | 12 | 14 | 1564 | 1887 |
| 16 | 1 | 16 | 30 | 3324 | 4007 | |
| 32 | 1 | 20 | 62 | 6844 | 8247 | |
| 64 | 1 | 24 | 126 | 15,364 | 16,727 | |
| CuFP [3] | 8 | 1 | 5 | 0 | 2010 | 722 |
| 16 | 1 | 6 | 0 | 3662 | 1424 | |
| 32 | 1 | 6 | 0 | 7032 | 3891 | |
| 64 | 1 | 7 | 0 | 15,387 | 6999 | |
| CuFPSAF | 8 | 1 | 3 | 0 | 990 | 1197 |
| 16 | 1 | 4 | 0 | 1659 | 2640 | |
| 32 | 1 | 4 | 0 | 3644 | 6046 | |
| 64 | 1 | 5 | 0 | 7075 | 13,757 | |
| Variant | Vector Size | Interval | # of Cycles | Resource Utilization | ||
|---|---|---|---|---|---|---|
| DSP | LUT | FF | ||||
| Vendor IP | 8 | 1 | 15 | 38 | 2204 | 3175 |
| 16 | 1 | 19 | 78 | 4604 | 6583 | |
| 32 | 1 | 23 | 158 | 10,028 | 13,399 | |
| 64 | 1 | 27 | 318 | 20,300 | 27,031 | |
| Fused Vector FP [15] | 8 | 1 | 8 | 16 | 6160 | 2409 |
| 16 | 1 | 9 | 32 | 12,254 | 5290 | |
| 32 | 1 | 13 | 64 | 26,094 | 10,409 | |
| 64 | 1 | 19 | 128 | 51,761 | 24,977 | |
| CuFP [3] | 8 | 1 | 6 | 16 | 2330 | 1515 |
| 16 | 1 | 7 | 32 | 4219 | 2929 | |
| 32 | 1 | 7 | 64 | 8151 | 5731 | |
| 64 | 1 | 7 | 128 | 16,634 | 13,796 | |
| CuFPSAF | 8 | 1 | 5 | 16 | 3989 | 2030 |
| 16 | 1 | 5 | 32 | 8353 | 3975 | |
| 32 | 1 | 5 | 64 | 16,249 | 7871 | |
| 64 | 1 | 5 | 128 | 28,208 | 14,859 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hajizadeh, F.; Ould-Bachir, T.; David, J.P. Enhancing CuFP Library with Self-Alignment Technique. Computers 2025, 14, 118. https://doi.org/10.3390/computers14040118
Hajizadeh F, Ould-Bachir T, David JP. Enhancing CuFP Library with Self-Alignment Technique. Computers. 2025; 14(4):118. https://doi.org/10.3390/computers14040118
Chicago/Turabian StyleHajizadeh, Fahimeh, Tarek Ould-Bachir, and Jean Pierre David. 2025. "Enhancing CuFP Library with Self-Alignment Technique" Computers 14, no. 4: 118. https://doi.org/10.3390/computers14040118
APA StyleHajizadeh, F., Ould-Bachir, T., & David, J. P. (2025). Enhancing CuFP Library with Self-Alignment Technique. Computers, 14(4), 118. https://doi.org/10.3390/computers14040118