

Transformer-Based Student Engagement Recognition Using Few-Shot Learning


Abstract
1. Introduction
2. Literature Review
2.1. Student Engagement Recognition
2.2. Few-Shot Learning Technique
2.3. Vision Transformer
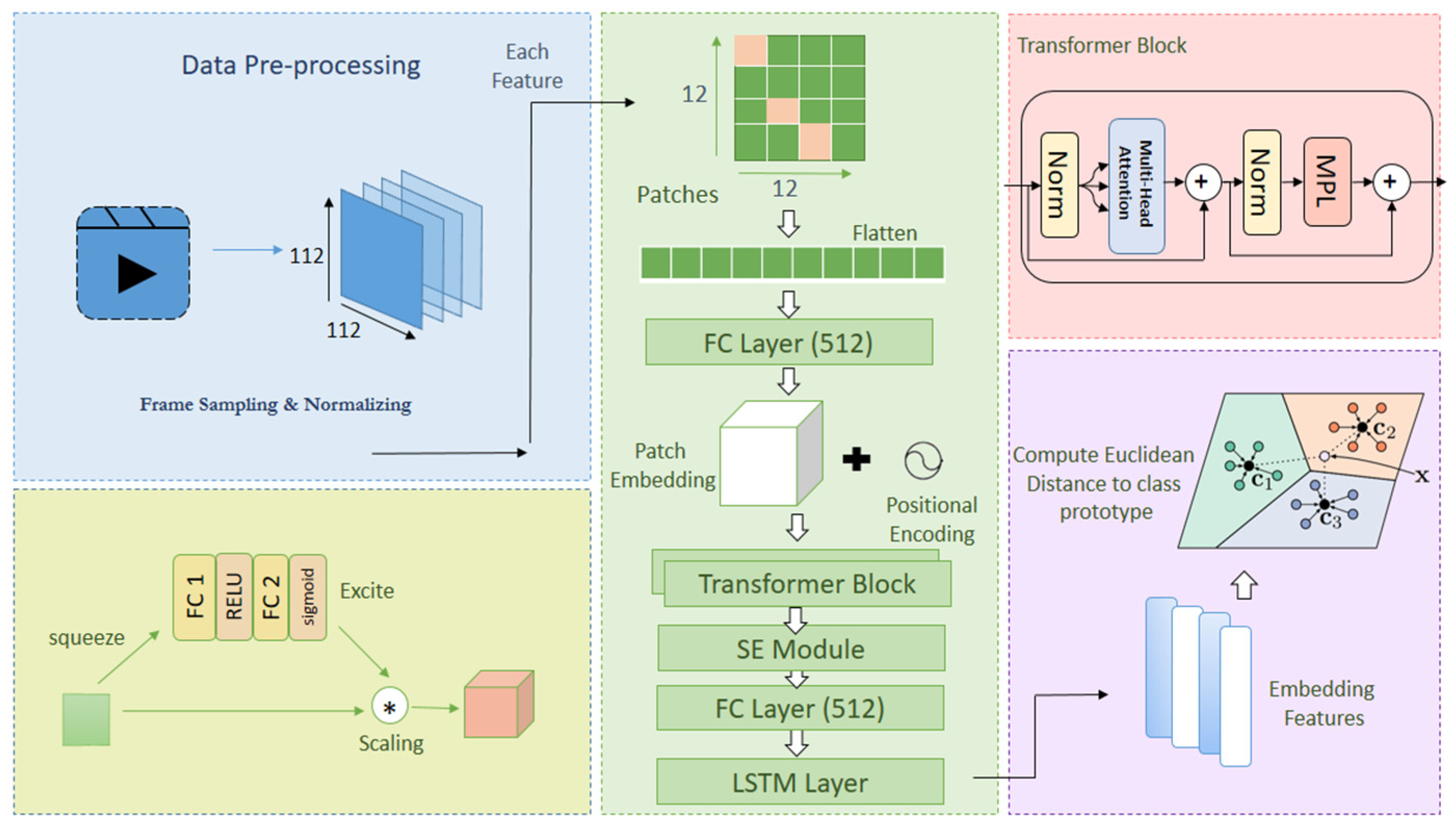
3. Proposed Architecture
Vision Transformer Backbone
4. Experimental Results
4.1. Dataset
4.2. Implementation Details
4.3. Evaluation Metrics
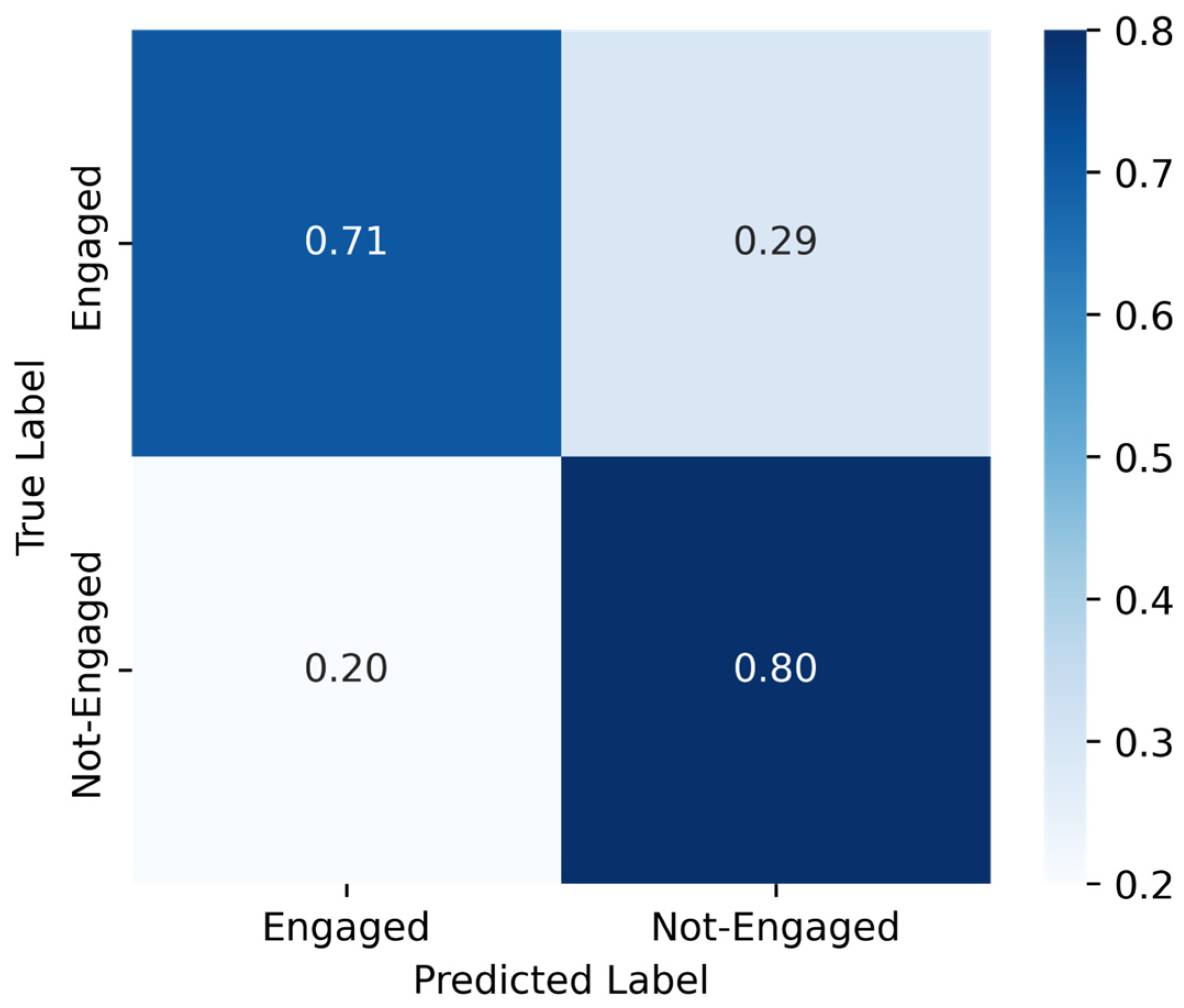
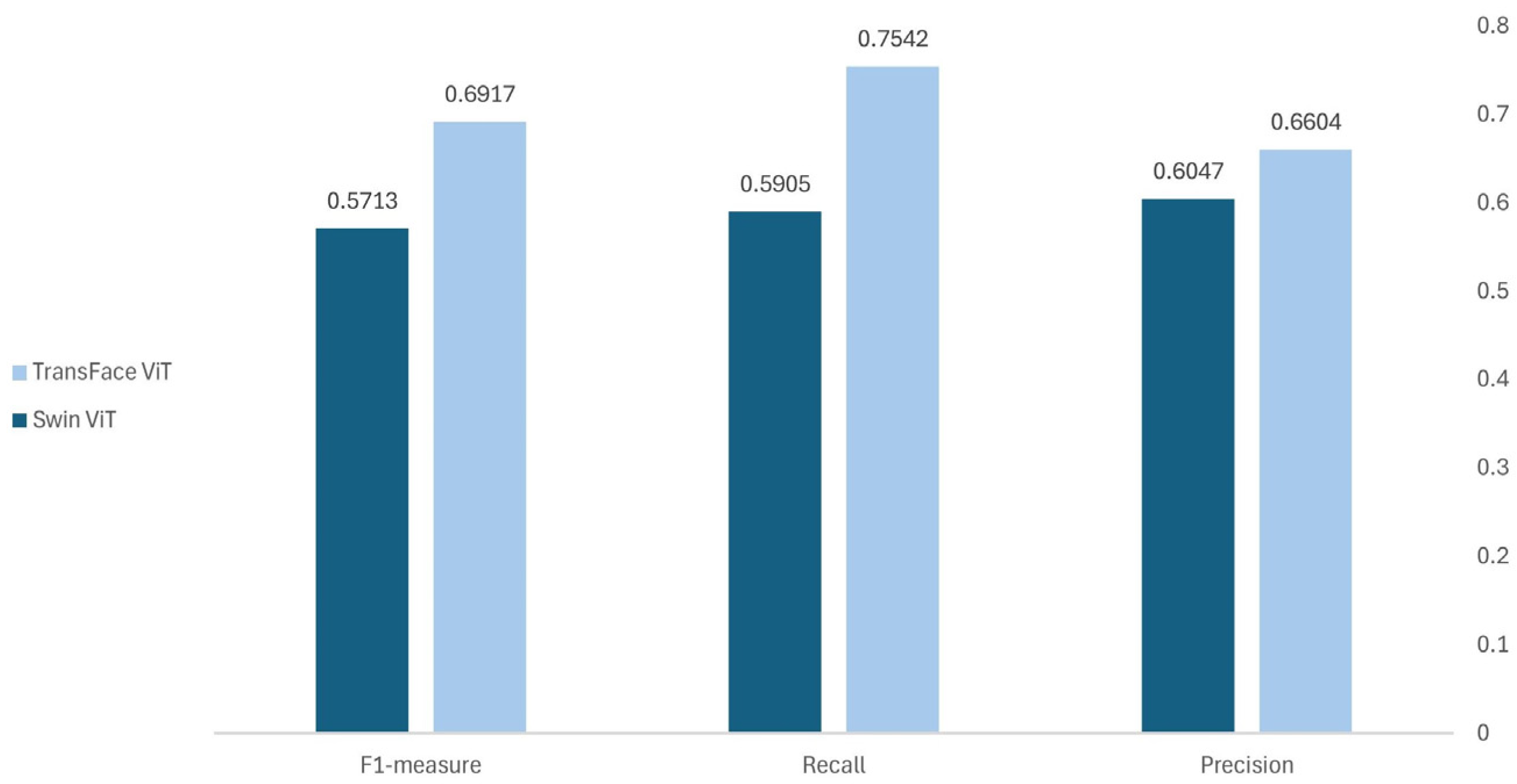
4.4. Results on the Unseen: EngageNet
4.5. Comparison Performance
5. Discussion
6. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, M.; Li, H. Student engagement in online learning: A review. In Proceedings of the 2017 International Symposium on Educational Technology, ISET 2017, Hong Kong, China, 27–29 June 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 39–43. [Google Scholar] [CrossRef]
- Altuwairqi, K.; Jarraya, S.K.; Allinjawi, A.; Hammami, M. A new emotion–based affective model to detect student’s engagement. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 99–109. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Z.; Liu, H.; Cao, T.; Liu, S. Data-driven Online Learning Engagement Detection via Facial Expression and Mouse Behavior Recognition Technology. J. Educ. Comput. Res. 2020, 58, 63–86. [Google Scholar] [CrossRef]
- Mohamad Nezami, O.; Dras, M.; Hamey, L.; Richards, D.; Wan, S.; Paris, C. Automatic Recognition of Student Engagement Using Deep Learning and Facial Expression. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2020; pp. 273–289. [Google Scholar] [CrossRef]
- Khenkar, S.; Jarraya, S.K. Engagement detection based on analyzing micro body gestures using 3D CNN. Comput. Mater. Contin. 2022, 70, 2655–2677. [Google Scholar] [CrossRef]
- Kaur, A.; Mustafa, A.; Mehta, L.; Dhall, A. Prediction and Localization of Student Engagement in the Wild. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, ACT, Australia, 10–13 December 2018; Available online: http://arxiv.org/abs/1804.00858 (accessed on 26 June 2018).
- Murshed, M.; Dewan, M.A.A.; Lin, F.; Wen, D. Engagement Detection in e-Learning Environments using Convolutional Neural Networks. In Proceedings of the 2019 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 80–86. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 63. [Google Scholar] [CrossRef]
- Singh, M.; Hoque, X.; Zeng, D.; Wang, Y.; Ikeda, K.; Dhall, A. Do I Have Your Attention: A Large Scale Engagement Prediction Dataset and Baselines. In Proceedings of the 25th International Conference on Multimodal Interaction, Paris, France, 9–13 October 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 174–182. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Zhang, W.; Lu, G.; Tian, Q.; Ling, N. Few-Shot Image Classification: Current Status and Research Trends. Electronics 2022, 11, 1752. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dan, J.; Liu, Y.; Xie, H.; Deng, J.; Xie, H.; Xie, X.; Sun, B. TransFace: Calibrating Transformer Training for Face Recognition from a Data-Centric Perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Mandia, S.; Singh, K.; Mitharwal, R. Vision Transformer for Automatic Student Engagement Estimation. In Proceedings of the 2022 IEEE 5th International Conference on Image Processing Applications and Systems (IPAS), Genova, Italy, 5–7 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Hasnine, M.N.; Bui, H.T.T.; Tran, T.T.T.; Nguyen, H.T.; Akçapõnar, G.; Ueda, H. Students’ emotion extraction and visualization for engagement detection in online learning. In Procedia Computer Science; Elsevier B.V.: Amsterdam, The Netherlands, 2021; pp. 3423–3431. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, T.R. Prototypical Networks for Few-shot Learning. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, H.; Fu, Y.; Meng, J. Engagement Detection in Online Learning Based on Pre-trained Vision Transformer and Temporal Convolutional Network. In Proceedings of the 2024 36th Chinese Control and Decision Conference (CCDC), Xi’an, China, 25–27 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1310–1317. [Google Scholar] [CrossRef]
- Maddula, N.V.S.S.; Nair, L.R.; Addepalli, H.; Palaniswamy, S. Emotion Recognition from Facial Expressions Using Siamese Network. In Communications in Computer and Information Science; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2021; pp. 63–72. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2290–2304. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Su, R.; He, L.; Luo, M. Leveraging part-and-sensitive attention network and transformer for learner engagement detection. Alex. Eng. J. 2024, 107, 198–204. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.; Schölkopf, B.; Smola, A.J. A Kernel Method for the Two-Sample-Problem. In Advances in Neural Information Processing Systems; Schölkopf, B., Platt, J., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2006; Volume 19. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Selim, T.; Elkabani, I.; Abdou, M.A. Students Engagement Level Detection in Online e-Learning Using Hybrid EfficientNetB7 Together With TCN, LSTM, and Bi-LSTM. IEEE Access 2022, 10, 99573–99583. [Google Scholar] [CrossRef]
- Mandia, S.; Singh, K.; Mitharwal, R.; Mushtaq, F.; Janu, D. Transformer-Driven Modeling of Variable Frequency Features for Classifying Student Engagement in Online Learning. arXiv 2025, arXiv:2502.10813. [Google Scholar]
- Tieu, B.H.; Nguyen, T.T.; Nguyen, T.T. Detecting Student Engagement in Classrooms for Intelligent Tutoring Systems. In Proceedings of the 2019 6th NAFOSTED Conference on Information and Computer Science (NICS), Hanoi, Vietnam, 12–13 December 2019; pp. 145–149. [Google Scholar] [CrossRef]
- Abedi, A.; Khan, S.S. Detecting Disengagement in Virtual Learning as an Anomaly using Temporal Convolutional Network Autoencoder. Signal Image Video Process. 2023, 17, 3535–3543. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Engagement Level | # of Samples |
|---|---|
| High engagement | 2936 |
| Medium engagement | 2199 |
| Low engagement | 1890 |
| Disengagement | 1090 |
| Before | After | # of Samples |
|---|---|---|
| Highly-Engaged | Engaged | |
| Engaged | 130 | |
| Barely-Engaged | ||
| Not-Engaged | Not-Engaged | 130 |
| Model | |
|---|---|
| # of Frames/clip | 16 |
| Learning Rate | 0.0001 |
| Weight Decay | 0.001 |
| Epochs | 100 |
| Iterations/Episodes | 20 |
| Batch-Size | 40 |
| Transformer Blocks | 12 each with 512 dim |
| Attention Heads | 8 |
| Optimizer | ReduceLROnPlateau |
| Loss | Prototypical Loss |
| Similarity Measure | Euclidean Distance |
| Metric | 2-Way 5-Shot | |||||
|---|---|---|---|---|---|---|
| TransFace ViT | Swin ViT | |||||
| Engaged | Not-Engaged | Avg. | Engaged | Not-Engaged | Avg. | |
| Precision | 0.7495 ± 0.1153 | 0.7597 ± 0.1244 | 0.7546 | 0.5758 ± 0.15033 | 0.57615 ± 0.1412 | 0.5759 |
| Recall | 0.7251 ± 0.1527 | 0.7348 ± 0.1467 | 0.7299 | 0.5552 ± 0.1743 | 0.5819 ± 0.1740 | 0.5686 |
| F1-Measure | 0.7158 ± 0.1094 | 0.7235 ± 0.1077 | 0.7197 | 0.5445 ± 0.1385 | 0.5560 ± 0.1350 | 0.5503 |
| Accuracy | 0.7362 ± 0.0266 | 0.5686 ± 0.0231 | ||||
| Ref | Feature Extraction | Method | Task Type | Accuracy |
|---|---|---|---|---|
| Mandia et al. [25] | Detect faces using the Multi-task Cascaded Convolutional Network (MTCNN) | Video Vision Transformer (ViViT) based architecture named Transformer Encoder with Low Complexity (TELC) | Multi-class | 63.9% |
| Zhang et al. [16] | Facial features | Vision transformer + Temporal convolutional network | Multi-class | 65.58 |
| Selim et al. [24] | CNN | EfficientNet B7 + LSTM | Multi-class | 67.48% |
| Abedi et al. [27] | Time-series data sequences extracted from both the behavioral feature and emotional states | Temporal convolutional network with autoencoder TCN-AE | Binary | (AUC ROC) 0.7489 |
| Tieu et al. [26] | CNN | Fine-tune the VGG16 | Binary | 74.9% |
| (Proposed model) | Vision transformer | Proposed Model (ViT + LSTM + FSL) | Binary | 74% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alarefah, W.; Jarraya, S.K.; Abuzinadah, N. Transformer-Based Student Engagement Recognition Using Few-Shot Learning. Computers 2025, 14, 109. https://doi.org/10.3390/computers14030109
Alarefah W, Jarraya SK, Abuzinadah N. Transformer-Based Student Engagement Recognition Using Few-Shot Learning. Computers. 2025; 14(3):109. https://doi.org/10.3390/computers14030109
Chicago/Turabian StyleAlarefah, Wejdan, Salma Kammoun Jarraya, and Nihal Abuzinadah. 2025. "Transformer-Based Student Engagement Recognition Using Few-Shot Learning" Computers 14, no. 3: 109. https://doi.org/10.3390/computers14030109
APA StyleAlarefah, W., Jarraya, S. K., & Abuzinadah, N. (2025). Transformer-Based Student Engagement Recognition Using Few-Shot Learning. Computers, 14(3), 109. https://doi.org/10.3390/computers14030109