Abstract
The rapid growth of digital journalism has heightened the need for reliable multi-document summarization (MDS) systems, particularly in underrepresented, low-resource, and culturally distinct contexts. However, current progress is hindered by a lack of large-scale, high-quality non-Western datasets. Existing benchmarks—such as CNN/DailyMail, XSum, and MultiNews—are limited by language, regional focus, or reliance on noisy, auto-generated summaries. We introduce NewsSumm, the largest human-annotated MDS dataset for Indian English, curated by over 14,000 expert annotators through the Suvidha Foundation. Spanning 36 Indian English newspapers from 2000 to 2025 and covering more than 20 topical categories, NewsSumm includes over 317,498 articles paired with factually accurate, professionally written abstractive summaries. We detail its robust collection, annotation, and quality control pipelines, and present extensive statistical, linguistic, and temporal analyses that underscore its scale and diversity. To establish benchmarks, we evaluate PEGASUS, BART, and T5 models on NewsSumm, reporting aggregate and category-specific ROUGE scores, as well as factual consistency metrics. All NewsSumm dataset materials are openly released via Zenodo. NewsSumm offers a foundational resource for advancing research in summarization, factuality, timeline synthesis, and domain adaptation for Indian English and other low-resource language settings.
1. Introduction
The explosive growth of digital news media has resulted in vast volumes of unstructured text, making efficient information synthesis a critical challenge in natural language processing (NLP) [1,2,3,4]. Text summarization, particularly in the news domain, condenses multiple sources into concise, coherent narratives, supporting faster and more informed decision-making. While existing summarization benchmarks reflect these limitations in distinct ways. Single-document datasets such as CNN/DailyMail [5] and XSum [6,7] excel at capturing individual article narratives but struggle with synthesis across multiple sources, a critical requirement for comprehensive news coverage [8]. Multi-document datasets like MultiNews [9] address scale but rely on automatically generated summaries from metadata or heuristics [10,11,12], introducing noise and factual inconsistencies that limit their reliability for high-stakes applications. Meanwhile, all major benchmarks, whether single or multi-document, predominantly feature Western English from North American or European sources, embedding cultural assumptions, editorial conventions, and entity distributions that diverge substantially from non-Western contexts. These three constraints (document scope, annotation quality, geographic bias) collectively restrict progress on factual, large-scale, multi-document summarization in diverse linguistic settings.
India represents one of the world’s largest and most complex news ecosystems, yet lacks a high-quality, large-scale, human-annotated [13] dataset for multi-document summarization in Indian English. This gap limits both practical applications and research on factual [14,15,16,17,18], scalable summarization in low-resource linguistic [19,20,21] settings. To address this gap, we introduce NewsSumm—the largest human-annotated multi-document news summarization dataset for Indian English. It comprises over 317,498 articles from 36 newspapers across 25 years (2000–2025) and 20+ topical domains, with professionally written summaries designed for coherence, factuality, and abstraction. NewsSumm uniquely combines (1) comprehensive temporal coverage enabling timeline-aware and diachronic summarization research; (2) human-curated, abstractive summaries avoiding noisy automatic extraction; (3) geographic and linguistic diversity reflecting Indian news ecosystem complexity; and (4) extensive quality control ensuring factual consistency across a 25-year span.
Our contributions include the following:
- Introducing NewsSumm, with detailed construction and annotation protocols ensuring reproducibility;
- Providing linguistic, statistical, and comparative analyses positioning NewsSumm relative to global benchmarks;
- Benchmarking state-of-the-art summarization models (BART, PEGASUS, T5) on NewsSumm with aggregate and category-specific evaluation;
- NewsSumm is fully accessible on Zenodo (https://zenodo.org/records/17670865 accessed on 21 November 2025), supporting open research and broad reproducibility.
Our experiments, described in Section 6.3 and Table 1, demonstrate that state-of-the-art summarization models trained exclusively on Western English datasets (CNN/DailyMail, XSum) perform substantially worse on Indian English news, quantitatively validating the need for culturally specific benchmark resources such as NewsSumm.

Table 1.
Comparison of PEGASUS model performance on the NewsSumm test set.
Section 2 reviews related work; Section 3 describes dataset construction and annotation methodology; Section 4 presents statistical and linguistic analyses of the dataset; Section 5 provides comparative insights with existing benchmarks; Section 6 details benchmarking experiments; Section 7 discusses emerging and potential applications; Section 8 outlines current limitations; and Section 9 suggests directions for future work.
2. Related Work
Automatic text summarization has progressed rapidly with the development of neural architectures [22,23,24,25] and large-scale benchmark datasets [5,6,7,9,13,21,26,27,28,29,30]. This section reviews foundational work in single-document summarization (SDS), multi-document summarization (MDS), and factual consistency evaluation, focusing on dataset evolution, scope, and limitations relevant to multilingual and regionally diverse contexts.
Early SDS efforts were shaped by datasets such as DUC 2002 [31], which introduced standardized tasks for abstractive summarization. Subsequent benchmarks like CNN/DailyMail, Gigaword [32] and XSum supported the rise of neural encoder-decoder [33] models and innovations in headline generation, pointer-generator networks, and single-sentence abstractive summaries. Domain-specific datasets extended SDS research: Newsroom [34] explored stylistic variety; Reddit TIFU [35] and SAMSum [13] targeted informal and conversational content; PubMed [36,37], arXiv [38], WikiHow [39], and BigPatent covered scientific, instructional, and legal domains. Despite this progress, most SDS datasets remain Western-centric and extractive, limiting their relevance for multi-source or culturally diverse summarization needs [40,41]. Because SDS corpora are largely Western-centric and often extractive, we turn to MDS resources that explicitly address multi-source synthesis.
2.1. Multi-Document Summarization Datasets
MDS tackles the challenge of synthesizing information from multiple related documents, with applications in news aggregation, legal analysis [42], and scientific discourse [43,44,45]. Foundational datasets like DUC and TAC [46] provided early benchmarks for multi-document synthesis and coherence [47].
Later, corpora scaled up MDS. MultiNews introduced 56k news clusters but relied on auto-generated summaries that used lead sections as references for aggregated source articles, and CCSUM [47] merged multilingual sources with mixed annotation quality. More recent datasets extend MDS beyond news—EventSum [48], CivilSum, and PeerSum [49] target legal, biomedical, and peer-review domains, respectively. Two collections sit in distinct subdomains: CRD focuses on opinion synthesis from conversational user/product or service reviews, while QMSum [50] addresses query-focused, multi-domain meeting summarization driven by information-seeking queries rather than standard article clusters. Unlike classic news/scientific MDS, CRD and QMSum are conversational or query-driven and use different annotation protocols and evaluation criteria, broadening MDS benchmarks beyond traditional narrative and event aggregation.
Figure 1 is the timeline matrix of major SDS and MDS summarization datasets (2002–2026). Each row corresponds to one dataset; columns mark the release year. Bubble area encodes dataset size (log scale); color encodes annotation strategy (green = extractive, cyan = human-abstractive, gold = auto/weakly supervised, purple = mixed). SDS appear in the upper block; MDS in the lower block. NewsSumm is highlighted with a bold black outline to indicate its position as the largest human-annotated MDS dataset for Indian English news.
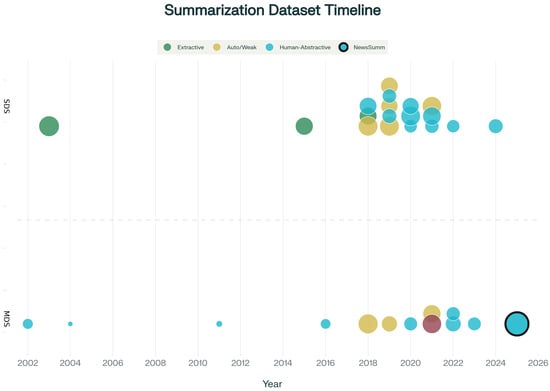
Figure 1.
Timeline matrix of major single-document (SDS) and multi-document (MDS) summarization datasets (2002–2026).
Yet, most of these corpora are either automatically labeled, domain-specific, or derived from Western media, limiting their applicability in multilingual, low-resource environments such as Indian English news. Figure 1 presents a taxonomy of major SDS and MDS datasets, highlighting the evolution of dataset scale, abstraction level, and domain coverage over time. This contextual overview underscores the growing need for regionally grounded, human-annotated resources that support factual, abstractive summarization across diverse editorial styles and languages.
2.2. Abstractive vs. Extractive Summarization Paradigms
A key methodological distinction in summarization is between extractive and abstractive approaches. Extractive summarization selects source sentences for output, preserving original phrasing and reducing hallucination risk but producing fragmentary, less coherent summaries. Abstractive summarization rephrases and compresses content, enabling fluency and conciseness but risking factual inconsistencies. Recent comparative reviews document key tradeoffs: extractive methods preserve factuality but sacrifice coherence and brevity; abstractive methods improve readability but require robust quality control [51,52].
For multi-document news summarization, abstractive approaches are strongly preferred when (i) source articles contain redundant phrasing across clusters, requiring paraphrasing to avoid verbatim duplication; (ii) compression from multi-source inputs demands synthesis and narrative coherence; (iii) readers expect fluent, contextualized narratives rather than sentence fragments. NewsSumm adopts abstractive annotation (50–250 word summaries, required rephrasing) to support these demands. While our primary focus is abstractive modeling, we establish extractive baselines (LexRank [51], TextRank [52]) for comparison in Section 6.4, Table 2. Preliminary results show extractive methods achieve ROUGE-L 20–22%, substantially lower than abstractive models (37–40%), validating our abstractive annotation choice for NewsSumm’s compression ratios and coherence requirements.
Table 2.
Extractive vs. abstractive model performance on NewsSumm.
2.3. Datasets for Factual Consistency and Evaluation
Factuality remains a key challenge in neural summarization, with models often generating hallucinations [53,54,55] or misrepresenting source content. FactCC [56] provides labeled pairs for factuality classification. SummEval [57] and FRANK offer human judgments and taxonomy-based annotations of hallucinations. QAGS [58] applies QA techniques to measure alignment between source and summary, while FactCheckSum focuses on verifying factual claims in generated summaries.
However, these resources are predominantly built from Western media and Wikipedia, limiting their reliability in evaluating summaries across different linguistic or cultural contexts, including Indian English news. Given that these tools are trained mostly on Western media/Wikipedia, reliability in Indian English news is limited, further promoting NewsSumm as both a benchmark and an evaluation platform.
Although more than 30 SDS and MDS datasets are publicly available—including CNN/DailyMail, XSum, MultiNews, WikiSum, EventSum, PubMed, and CivilSum—there remains a lack of large-scale, human-annotated corpora for multi-document summarization in linguistically diverse and underrepresented regions such as India. This limits research on inclusive and factually reliable summarization systems. We now turn from limitations in prior work to the resource itself, describing how NewsSumm is built and annotated in Section 3.
3. Dataset Construction and Annotation
NewsSumm is a large-scale, human-annotated multi-document summarization dataset curated from Indian English news sources. This section outlines the dataset’s construction, including source selection, annotation workflow, and quality assurance measures. The dataset comprises over 317,498 articles collected from 36 prominent Indian English newspapers, including national (e.g., The Hindu, Hindustan Times) and regional outlets (e.g., The Hitavada, The Assam Tribune). The articles span a 25-year period (2000–2025) and cover over 20 topical domains, such as politics, science, health, technology, crime, and the environment. To ground this overview, Section 3.1 details how articles were collected and summarized before we describe quality controls (Section 3.2), cleaning/normalization (Section 3.3), and alignment with global standards (Section 3.4).
3.1. Collection and Annotation Pipeline
A distributed team of over 14,000 trained volunteers collected and annotated the data using a standardized protocol. Annotators extracted metadata including headline, publication date, source, and URL, and composed 50–250-word abstractive summaries in their own words. Each article was tagged with one or more topical categories from a predefined taxonomy. The process involved manual article entry through structured forms, daily and archival collection, and summarization with emphasis on neutrality, coherence, and informativeness. Annotator metadata and timestamps were recorded to ensure reproducibility. Figure 2 illustrates the pipeline from source selection through annotation and quality control. Having described how entries are created, we next formalize the rules that guide annotators and the checks that enforce them in Section 3.2.
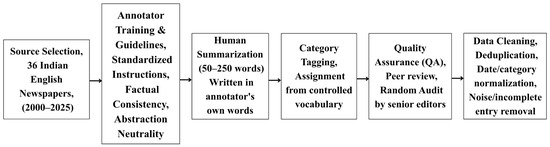
Figure 2.
Overview of the NewsSumm dataset collection and annotation process.
3.2. Annotation Guidelines and Quality Assurance
Annotators received detailed instructions and participated in hands-on training sessions. Each summary was expected to be written using abstraction rather than direct extraction, maintain strict factual consistency with the source content, and follow a logical structure while remaining neutral and free of personal opinions or bias. Quality control involved multiple stages, including independent peer review of each summary, random audits by senior editors, and iterative feedback and revision cycles to ensure adherence to guidelines and high annotation quality. Summaries that failed to meet standards were excluded. Table 3 outlines the roles and outcomes at each stage of the QA process. In this manuscript, the terms “annotators” and “volunteers” refer to the same group—over 14,000 trained individuals coordinated by the Suvidha Foundation. Each participant completed a structured 7–11 h training program that included an orientation session, detailed annotation manuals, and 10–15 practice tasks. Only those achieving at least 90% accuracy on gold-standard references proceeded to live annotation. Weekly recalibration sessions were conducted to minimize drift and maintain consistency. Valid summaries were required to range between 50 and 250 words and demonstrate non-trivial abstraction, comprehensive coverage, factual correctness, neutrality, and at least 90% reviewer agreement. The annotators represented a strong and diverse demographic: 61% held university degrees, 34% had journalism experience, 91% possessed C1-level or higher English proficiency, and 80% were fluent in Hindi (refer to Table 4). With guidelines and multi-stage QA in place, we then standardized and validated the corpus through data cleaning procedures in Section 3.3.
Table 3.
Roles and outcomes at each QA stage.
Table 4.
Annotator Demographics and Attributes.
To address temporal validity across the 25-year span (2000–2025), NewsSumm employed a date-stamped fact-verification protocol. Annotators were instructed to ground all summaries exclusively in source article content and to flag claims that could be disputed or time-sensitive. When factual status was uncertain, summaries were escalated to senior editors, who documented decisions with timestamps for auditability. No summary was approved without all claims being verifiable in sources contemporary with the original publication date. Annotators were explicitly prohibited from applying hindsight or present-day knowledge to “correct” past events. A 5% year-by-year random QA audit verified absence of retrospective bias. This protocol ensures that summaries faithfully represent facts as understood at publication time, maintaining temporal consistency and reproducibility.
3.3. Data Cleaning
Post-annotation, the dataset underwent cleaning to ensure consistency and integrity. Duplicate entries were identified and removed through a combination of automated similarity checks and manual review. Dates and category labels were standardized for uniformity across the corpus. Incomplete or noisy records—such as those with missing headlines or summaries below the minimum length—were flagged and either corrected or excluded. Finally, all records were validated against a predefined schema to ensure field completeness and correct formatting (see Figure 3a,b). Each record contains eight core fields: source (newspaper), publication date, headline, article text, human summary, category/tags, URL (for source traceability), and annotator ID (for quality auditing and reproducibility). After normalization and schema validation, we situate NewsSumm relative to established practices to facilitate comparability and reuse.
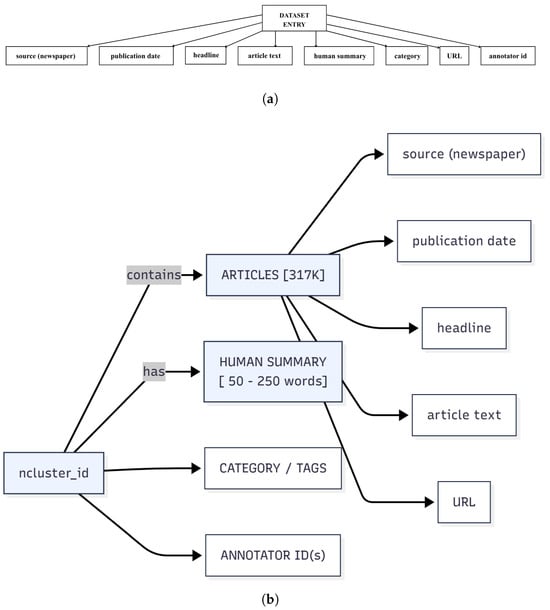
Figure 3.
NewsSumm Dataset Schema: (a) NewsSumm dataset entry schema showing the eight core fields associated with each article. Each dataset entry includes: source (newspaper name), publication date, headline, article text, human-written summary, category/tags, URL, and annotator ID. (b) Structured annotation workflow and data schema for NewsSumm. The figure illustrates how each article cluster (containing a total of 317K articles) connects to its associated metadata fields: source newspaper, publication date, headline, article text, human summary (50–250 words), topical category/tags, URL, and annotator ID(s).
3.4. Alignment with Global Standards
NewsSumm follows practices established by CNN/DailyMail, XSum, and MultiNews, adapted for Indian-English news and multi-document synthesis. Emphasis on human annotation, rigorous QA, and linguistic diversity makes it globally interoperable while uniquely valuable for low-resource, culturally specific NLP. Figure 3a,b show the structured schema with eight core fields centered on the main article, ensuring completeness, traceability, and consistency. The URL field enables source verification and reproducibility; the annotator ID supports quality auditing and longitudinal analysis of annotation patterns. This alignment preserves compatibility with existing evaluation workflows and enables downstream analyses and benchmarking described next.
4. Dataset Statistics and Analysis
NewsSumm is the largest human-annotated multi-document summarization resource for Indian English news, distinguished by its scale, linguistic richness, and high-quality human-written summaries. The corpus comprises 317,498 articles spanning from 2000 to 2025, covering 5121 unique categories. Articles and their corresponding summaries collectively contain over 123.67 million tokens and exhibit consistent editorial standards with summaries ranging between 50–250 words. Table 5 provides comprehensive dataset statistics, including total counts of articles, sentences, words, and tokens, along with averages per article and summary. Section roadmap: Section 4.1 examines temporal coverage; Section 4.2 profiles topical composition; Section 4.3 reports tokenization statistics; Section 4.4 quantifies compression ratios; Section 4.5 grounds these with a concrete example entry, and Section 4.6 shows analytical insights of NewsSumm.
Table 5.
Overall statistics of the NewsSumm dataset.
To better characterize the scale and structure of the NewsSumm dataset, we analyzed distributions of article and summary lengths. Figure 4 presents a histogram of article lengths in words, capturing the wide spectrum from short news briefs to long-form investigative reports. Figure 5 similarly illustrates the distribution of summary lengths, demonstrating consistency in human annotation and a balance between conciseness and informativeness. Together, Figure 4 and Figure 5 establish the basic length profiles, setting up a closer look at how coverage evolves over time in Section 4.1.
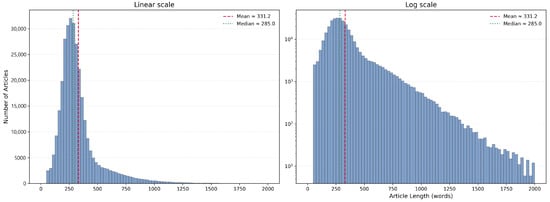
Figure 4.
Distribution of article lengths in words with a logarithmic y-axis. The log scale reveals the long-tail region (≥1250 words) that is not visible under a linear scale. Dashed and dotted lines mark the mean and median, respectively.
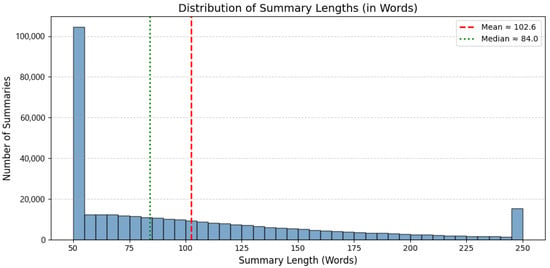
Figure 5.
Distribution of summary lengths (in words).
4.1. Temporal Distribution
NewsSumm spans articles published from 2000 to 2025, enabling longitudinal analyses of media trends across a 25-year period. As shown in Figure 6, the dataset exhibits steady growth over time, with marked surges during major national events, reflecting both evolving news volume and collection dynamics. Having established temporal coverage, we next examine topical breadth and category balance in Section 4.2.
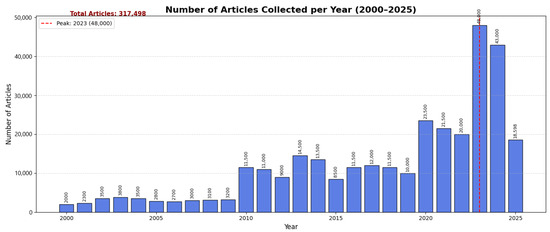
Figure 6.
Number of articles per year from 2000 to 2025.
4.2. Category Distribution
The dataset covers a diverse topical space with over 5000 unique sub-categories across more than 20 major domains. Figure 7 highlights the top 10 most frequent categories, demonstrating the dataset’s wide thematic range, from politics and economy to health and education. Given this thematic diversity, we turn to token-level characteristics relevant for model design and sequence handling in Section 4.3.
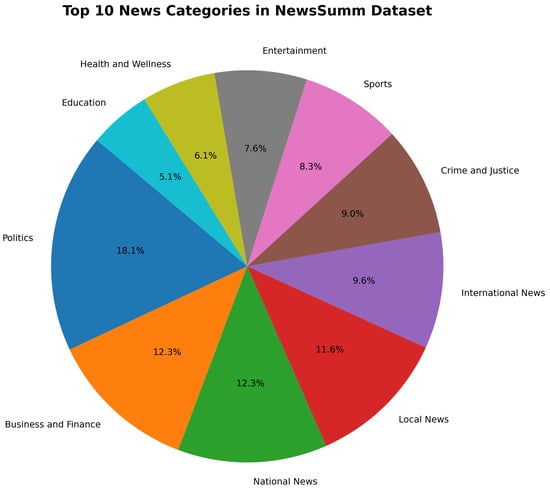
Figure 7.
Top 10 most frequent news categories in the NewsSumm dataset. The figure illustrates category distribution across major domains, highlighting prevalent topics such as politics, business, and sports.
4.3. Number of Articles per Year from 2000 to 2025
To support downstream model design, we examined token-level distributions using HuggingFace’s AutoTokenizer. Figure 8 shows boxplots of token counts in both articles and summaries, capturing central tendencies and variance, along with the presence of long-tailed outliers. Building on these sequence length statistics, Section 4.4 quantifies summarization difficulty via article-to-summary compression ratios.
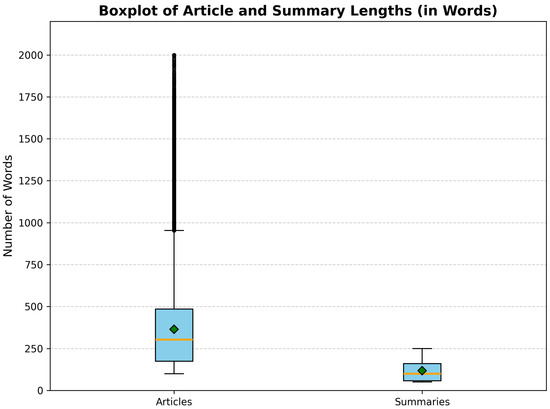
Figure 8.
Boxplots of token counts for articles and summaries. The figure captures central tendencies and variance, along with long-tailed outliers, illustrating token-level distribution relevant for summarization difficulty.
4.4. Compression Ratios
We calculated the compression ratio (article length divided by summary length) to evaluate the summarization challenge presented by NewsSumm. With a mean ratio of 3.58:1 (words) and 3.55:1 (tokens), the summaries are concise yet content-rich, attesting to the annotation quality. Figure 9 displays the distribution of these ratios, highlighting typical and extreme cases. To contextualize the statistics above, Section 4.5 presents a concrete example entry that reflects the schema and annotation style.
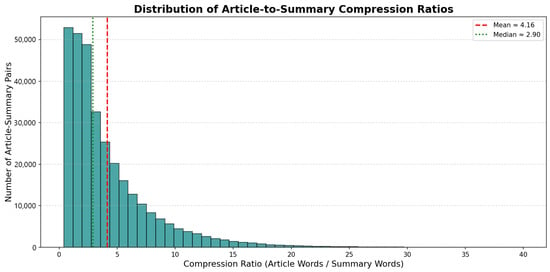
Figure 9.
Histogram of article-to-summary compression ratios. The figure illustrates the distribution of compression ratios across the dataset, highlighting the balance between article length and summary length, and indicating summarization difficulty levels.
4.5. Example Entry
To illustrate the annotation schema, Table 6 presents a representative NewsSumm entry. This includes metadata such as source, publication date, category, and URL, along with the full article text and its corresponding human-written summary. The example showcases the depth of curation and fidelity to content. These analyses collectively establish NewsSumm’s scale, diversity, and modeling characteristics; the next section situates NewsSumm alongside existing datasets to contextualize its contributions.
Table 6.
Example entry from the NewsSumm dataset with full metadata and human-written summary.
4.6. Analytical Insights of NewsSumm
While Table 5 establishes scale, the true value of NewsSumm emerges through comparative analysis. NewsSumm achieves the rare combination of 300k articles, , years, and 100% human-generated summaries, a feature set unattained by any existing MDS benchmark (see Section 5.1, Table 7). Furthermore, the compression ratio of 3.58 (words) and 3.55 (tokens) positions NewsSumm between extractive datasets like CNN/DM (lower compression) and abstractive resources like XSum (higher demands for rephrasing). Linguistic analysis (Table 8) quantifies the gap between Indian and Western English—vocabulary divergence (crore vs. million, ration card vs. welfare), code-switching frequency (8–12% Hindi/Urdu terms), and political-administrative references (Lok Sabha, MLA vs. Congress, Senator)—which Western-trained models struggle with, as demonstrated empirically in Section 6.3 (PEGASUS Western-trained: ROUGE-L 29.4 vs. fine-tuned: 39.6). These insights establish NewsSumm not as “just another dataset,” but as a methodologically grounded, comparative contribution addressing gaps in culturally-specific, large-scale abstractive summarization.
Table 7.
Comparative overview of major summarization datasets, including scale, annotation type, temporal range, and document structure.
Table 8.
Linguistic comparison between NewsSumm (Indian English) and Western news.
5. Comparison with Existing Datasets
To contextualize NewsSumm within the existing summarization landscape, we compare it with prominent datasets across both single-document (SDS) and multi-document summarization (MDS) paradigms. Key axes of comparison include dataset scale, annotation quality, document structure, domain and linguistic diversity, and temporal coverage. Section roadmap: Section 5.1 maps the dataset landscape; Section 5.2 focuses on linguistic specificity; Section 5.3 examines domain/temporal breadth and event modeling; Section 5.4 discusses annotation quality and ethics.
5.1. Dataset Landscape
Table 7 presents a comparative overview of major summarization datasets, highlighting NewsSumm’s distinctiveness in its large-scale (317,498 documents), full human abstraction, multi-document structure, and 25-year temporal span. Unlike CNN/DailyMail (extractive), MultiNews (auto-generated), or WikiSum (Wikipedia-based), NewsSumm provides manually written summaries with rich metadata and factual verification across 20+ domains in Indian English. In short, NewsSumm uniquely combines large-scale, full human abstraction, and multi-document structure over two-and-a-half decades—setting the stage to examine its linguistic distinctiveness in Section 5.2.
NewsSumm uniquely fulfills the combination of N > 300k articles, C > 20 categories, Y > 20 years, and 100% human-generated summaries—features not simultaneously present in any other benchmark. Having situated the broader landscape, we next compare linguistic and cultural properties in Section 5.2.
5.2. Linguistic and Cultural Specificity
Unlike datasets built on US or UK news (e.g., CNN/DailyMail, XSum), NewsSumm captures the nuances of Indian English. Table 8 compares key linguistic traits between NewsSumm and Western datasets, highlighting divergences in vocabulary, sentence structure, idiomatic expressions, and political references. These contrasts underscore why Indian English requires dedicated benchmarks; we now turn to breadth across domains and time in Section 5.3. These features support research into model generalization across underrepresented linguistic varieties.
5.3. Domain, Temporal Breadth, and Event Modeling
NewsSumm spans a 25-year period (2000–2025) and includes 5000+ fine-grained topical categories ranging from legislative proceedings and rural governance to caste-based social issues and cultural events. The dataset is structured as multi-document clusters, enabling modeling of evolving events and discourse-level coherence as shown in Figure 10. A mathematical summary of NewsSumm’s distinctive attributes:
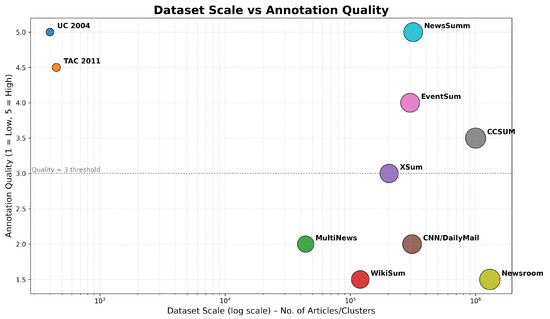
Figure 10.
Scatter plot of summarization datasets by size and annotation quality. NewsSumm is uniquely positioned in the top-right quadrant, combining large-scale and high-quality human-written multi-document summaries, demonstrating its strength as a benchmark for future research.
- (articles);
- (topical categories);
- (years).
No other human-annotated MDS resource simultaneously satisfies all three criteria: N > 100,000, C > 10, and Y > 10.
5.4. Annotation Quality and Ethical Construction
All summaries are manually authored, peer-reviewed, and audited for factual accuracy and neutrality. The dataset was constructed through a transparent and ethical process, employing over 14,000 trained annotators under fair-labor guidelines via the Suvidha Foundation. This contrasts with many Western benchmarks, which rely on web-scraped or weakly supervised sources. Taken together, Section 5 shows that NewsSumm uniquely integrates scale, linguistic specificity, temporal breadth, and rigorous human annotation—context that motivates the downstream benchmarks and analyses that follow.
6. Benchmarking Experiments
To evaluate the utility of NewsSumm as a benchmark, we conducted experiments with three state-of-the-art transformer models: PEGASUS, BART, and T5. These models were selected for their strong performance on existing abstractive summarization tasks. Section roadmap. Section 6.1 describes the experimental setup; Section 6.2 reports overall and category-wise results, including factuality; we conclude with takeaways that motivate the next section.
6.1. Experimental Setup
The dataset was split into training (80%), validation (10%), and testing (10%) sets with mutually exclusive document clusters to avoid data leakage. Inputs comprised concatenated articles from each cluster, truncated to model-specific token limits (512–1024), and tokenized using Hugging Face’s AutoTokenizer. Fine-tuning was performed using official model checkpoints with the AdamW optimizer and early stopping based on validation ROUGE-L. Training was conducted on NVIDIA A100 GPUs.
We evaluated performance using ROUGE-1, ROUGE-2, and ROUGE-L metrics, and assessed factual consistency on a representative subset using FactCC. Additionally, we performed category-wise evaluations across the top 10 news domains to explore domain-specific challenges. All code, splits, and checkpoints are available via the NewsSumm repository for reproducibility. With the setup established, we now present aggregate model performance in Section 6.2 and then drill down by domain and factuality.
6.2. Results
Table 9 shows the ROUGE scores for each model on the test set. PEGASUS [60] consistently outperformed BART [61] and T5 [24], particularly in ROUGE-L.
Table 9.
ROUGE scores on the NewsSumm test set.
Category-wise analysis (Figure 11) revealed higher scores in domains such as Business and Sports, which tend to have more structured narratives. Lower performance in Politics and International News reflects the increased difficulty of summarizing multi-perspective, event-rich content.
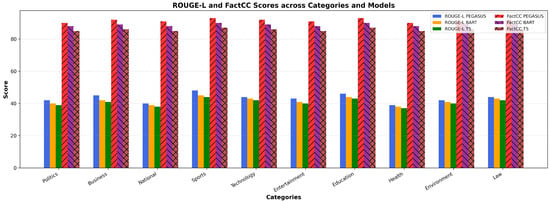
Figure 11.
ROUGE-L and FactCC scores across news domains for PEGASUS, BART, and T5. The figure compares summarization quality and factual consistency across categories, highlighting domain-wise performance variations for each model.
FactCC revealed persistent factual inconsistencies, including incorrect attributions and hallucinations, particularly in complex or ambiguous stories. While PEGASUS led overall, the margin of difference narrowed in challenging categories. Detailed category-wise scores are provided in Table 10.
Table 10.
Category-wise ROUGE-L and FactCC scores for PEGASUS, BART, and T5 on the NewsSumm test set.
These results highlight the limitations of current summarization models when applied to a large, diverse, multi-document dataset like NewsSumm. Although the models generate fluent summaries, maintaining factual accuracy remains a key challenge. NewsSumm thus offers a realistic, high-quality benchmark for advancing research in factual consistency, cross-document synthesis, and domain adaptation in abstractive summarization.
6.3. Cross-Lingual Generalization of Western-Trained Models on NewsSumm
To empirically assess the impact of language/cultural adaptation, we evaluated PEGASUS, BART, and T5 models trained solely on Western English corpora (CNN/DailyMail + XSum) directly on the NewsSumm test split—without any Indian in-domain fine-tuning. These “zero-shot” models yielded a marked drop in performance, with PEGASUS (Western-trained) achieving a ROUGE-L of just 29.4, versus 39.6 for the same architecture fine-tuned on NewsSumm. We analyzed a sample of outputs and found frequent failures on Indian idioms (“ration card” misinterpreted as ”welfare form”), misattributed legal/policy contexts, and loss of crucial local detail. These findings underline the real gap between general English and Indian English news summarization, and reinforce the critical benchmarking potential of NewsSumm.
6.4. Extractive Baseline Comparison
To ensure robust and transparent benchmarking, we evaluate both abstractive and extractive models on NewsSumm. While our dataset annotations are designed for abstractive summarization—requiring paraphrasing and deep information compression—extractive techniques provide important baselines. We implemented two classical extractive methods: LexRank (graph-based sentence ranking) and TextRank (eigenvector centrality). As shown in Table 2, extractive baselines underperform abstractive models by 15–19 ROUGE-L points, confirming that NewsSumm’s compressed, paraphrased summaries are better suited to abstractive approaches. These results validate both our annotation strategy and the necessity of neural abstractive models for high-quality multi-document news summarization in the Indian English context. In sum, Section 6 demonstrates strong baselines but persistent factual deficits; the next section discusses implications, ablations, and avenues for improving cross-document faithfulness.
7. Applications
NewsSumm’s scale, human-verified abstractive summaries, and diverse multi-document structure make it a valuable resource for developing and evaluating advanced summarization models. Its extensive temporal coverage enables timeline-aware modeling for historical and policy-related narratives, while the inclusion of headlines supports tasks like headline generation and news compression. As an Indian English corpus, NewsSumm facilitates research in domain adaptation and cross-lingual transfer, helping models generalize to low-resource, culturally distinct settings. Its professionally curated summaries also serve as a reliable benchmark for evaluating factual consistency in both standard and large language models. Finally, NewsSumm’s open access, standardized splits, and supporting code foster reproducibility and fair benchmarking in summarization research. Together, these applications motivate careful reflection on scope and biases, which we address next in Section 8 (Limitations).
8. Limitations
NewsSumm exclusively represents English-language Indian news, which may reflect regional or urban biases typical of mainstream media. Its evolving annotation pipeline across a long temporal span could introduce slight inconsistencies in style or coverage. These challenges are mitigated through versioning, clear documentation, and continuous quality monitoring.
9. Future Work
To further enhance the utility and research impact of NewsSumm, future developments will focus on three key areas. First, the dataset will incorporate event-centric clustering and fine-grained topical categorization to support narrative modeling and event timeline summarization. Multilingual versions in major Indian languages such as Hindi, Marathi, and Tamil are also planned to facilitate cross-lingual and comparative summarization research. Second, structured human evaluation protocols will be introduced to complement automated metrics like ROUGE and FactCC, enabling a more nuanced assessment of model coherence, informativeness, and factual accuracy. Finally, NewsSumm is openly released via Zenodo, complete with detailed dataset documentation and standardized metadata to ensure accessibility, transparency, and alignment with open science best practices.
10. Conclusions
We present NewsSumm, the largest human-annotated, multi-document summarization dataset curated from Indian English news sources. Spanning 317,000+ articles across 36 newspapers and 25 years, NewsSumm fills a critical gap in culturally diverse, low-resource NLP benchmarking. Its abstractive, fact-checked summaries—produced by over 14,000 trained annotators—offer high-quality supervision for modeling real-world summarization challenges. Through extensive benchmarking with PEGASUS, BART, and T5, we provide reproducible baselines and highlight performance trends across domains. NewsSumm uniquely supports tasks such as timeline summarization, factual consistency evaluation, and cross-domain modeling. Its ethical construction, linguistic uniqueness, and scale make it an essential resource for advancing summarization technologies in global, multilingual settings.
We invite the community to build on NewsSumm for research in factuality, domain adaptation, and inclusive NLP. Its public availability, comprehensive metadata, and reproducible benchmarks ensure wide accessibility and continued relevance.
Author Contributions
All authors have contributed equally to this work. M.M., M.A. and A.A. jointly contributed to the conceptualization and methodology of the study. M.M. developed the software and handled data curation, resources, and visualization. Validation and formal analysis were carried out collaboratively by M.M., M.A. and A.A. The investigation and overall research design were conducted collectively by all three authors. M.M. prepared the original draft, while M.A. and A.A. contributed to the review and editing process. A.A. supervised the project. M.M. managed project administration. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The complete NewsSumm dataset, including all associated preprocessing scripts, model configurations, training routines, evaluation metrics, and supporting documentation, has been publicly released via Zenodo and is freely accessible at https://zenodo.org/records/17670865. All resources are available for direct download, with no access request required. Comprehensive documentation, annotation protocols, dataset schema, and user instructions are included to ensure ease of use, transparency, and reproducibility. Users are requested to cite the following paper in any publications or research utilizing NewsSumm: Motghare, M.; Agarwal, M.; Agrawal, A. NewsSumm: The World’s Largest Human-Annotated Multi-Document News Summarization Dataset for Indian English. Computers 2025. Contributions and feedback are welcomed to further advance research in Indian English and multilingual NLP.
Acknowledgments
We gratefully acknowledge the Suvidha Foundation for its foundational support, strategic guidance, and leadership throughout the creation of NewsSumm. This work would not have been possible without the tireless contributions of over 14,000 trained annotators and volunteers, whose dedication and expertise ensured the dataset’s quality and consistency. We thank the editorial and quality assurance teams for their critical role in validating and refining the annotations. We also extend special appreciation to Shobha Motghare, Payal Badhe, and the core technical team at Suvidha Foundation for their exceptional project management and coordination.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MDS | Multi-Document Summarization |
| NLP | Natural Language Processing |
| AI | Artificial Intelligence |
| ML | Machine Learning |
| LLM | Large Language Model |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| BLEU | Bilingual Evaluation Understudy |
| BERTScore | Bidirectional Encoder Representations from Transformers Score |
| CNN | Convolutional Neural Network |
| PEGASUS | Pre-training with Extracted Gap-sentences for Abstractive Summarization |
| T5 | Text-To-Text Transfer Transformer |
References
- DeYoung, J.; Martinez, S.C.; Marshall, I.J.; Wallace, B.C. Do Multi-Document Summarization Models Synthesize? Trans. Assoc. Comput. Linguist. 2024, 12, 1043–1062. [Google Scholar] [CrossRef]
- Ahuja, O.; Xu, J.; Gupta, A.; Horecka, K.; Durrett, G. ASPECTNEWS: Aspect-Oriented Summarization of News Documents. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 6494–6506. [Google Scholar]
- Alambo, A.; Lohstroh, C.; Madaus, E.; Padhee, S.; Foster, B.; Banerjee, T.; Thirunarayan, K.; Raymer, M. Topic-Centric Unsupervised Multi-Document Summarization of Scientific and News Articles. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020. [Google Scholar]
- Benedetto, I.; Cagliero, L.; Ferro, M.; Tarasconi, F.; Bernini, C.; Giacalone, G. Leveraging large language models for abstractive summarization of Italian legal news. Artif. Intell. Law 2025. [Google Scholar] [CrossRef]
- See, A.; Liu, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Rao, A.; Aithal, S.; Singh, S. Single-Document Abstractive Text Summarization: A Systematic Literature Review. ACM Comput. Surv. 2025, 57, 1–37. [Google Scholar] [CrossRef]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1797–1807. [Google Scholar]
- Li, H.; Zhang, Y.; Zhang, R.; Chaturvedi, S. Coverage-Based Fairness in Multi-Document Summarization. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Albuquerque, NM, USA, 29 April–4 May 2025. [Google Scholar]
- Fabbri, A.; Li, I.; She, T.; Li, S.; Radev, D. Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Langston, O.; Ashford, B. Automated Summarization of Multiple Document Abstracts and Contents Using Large Language Models. TechRxiv 2024. [Google Scholar] [CrossRef]
- Wang, M.; Wang, M.; Yu, F.; Yang, Y.; Walker, J.; Mostafa, J. A Systematic Review of Automatic Text Summarization for Biomedical Literature and EHRs. J. Am. Med. Inform. Assoc. 2021, 28, 2287–2297. [Google Scholar] [CrossRef]
- Yu, Z.; Sun, N.; Wu, S.; Wang, Y. Research on Automatic Text Summarization Using Transformer and Pointer-Generator Networks. In Proceedings of the 2025 4th International Symposium on Computer Applications and Information Technology (ISCAIT), Xi’an, China, 21 March 2025; pp. 1601–1604. [Google Scholar]
- Gliwa, B.; Mochol, I.; Biesek, M.; Wawer, A. SAMSum Corpus: A Human-Annotated Dialogue Dataset for Abstractive Summarization. In Proceedings of the 2nd Workshop on New Frontiers in Summarization, Hong Kong, China, 4 November 2019; pp. 70–79. [Google Scholar]
- Cao, M.; Dong, Y.; Wu, J.; Cheung, J.C.K. Factual Error Correction for Abstractive Summarization Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6251–6258. [Google Scholar]
- Kryscinski, W.; McCann, B.; Xiong, C.; Socher, R. Evaluating the Factual Consistency of Abstractive Text Summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 9332–9346. [Google Scholar]
- Luo, Z.; Xie, Q.; Ananiadou, S. Factual Consistency Evaluation of Summarization in the Era of Large Language Models. Expert Syst. Appl. 2024, 254, 124456. [Google Scholar] [CrossRef]
- Pagnoni, A.; Balachandran, V.; Tsvetkov, Y. Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4812–4829. [Google Scholar]
- Wang, A.; Cho, K.; Lewis, M. Asking and Answering Questions to Evaluate the Factual Consistency of Summaries. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5008–5020. [Google Scholar]
- Tulajiang, P.; Sun, Y.; Zhang, Y.; Le, Y.; Xiao, K.; Lin, H. A Bilingual Legal NER Dataset and Semantics-Aware Cross-Lingual Label Transfer Method for Low-Resource Languages. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2025, 24, 1–21. [Google Scholar] [CrossRef]
- Mi, C.; Xie, S.; Li, Y.; He, Z. Loanword Identification in Social Media Texts with Extended Code-Switching Datasets. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2025, 24, 1–19. [Google Scholar] [CrossRef]
- Mohammadalizadeh, P.; Safari, L. A Novel Benchmark for Persian Table-to-Text Generation: A New Dataset and Baseline Experiments. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2025, 24, 1–17. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar] [CrossRef]
- Fodor, J.; Deyne, S.D.; Suzuki, S. Compositionality and Sentence Meaning: Comparing Semantic Parsing and Transformers on a Challenging Sentence Similarity Dataset. Comput. Linguist. 2025, 51, 139–190. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Zandie, R.; Mahoor, M.H. Topical Language Generation Using Transformers. Nat. Lang. Eng. 2023, 29, 337–359. [Google Scholar] [CrossRef]
- Al-Thubaity, A. A Novel Dataset for Arabic Domain Specific Term Extraction and Comparative Evaluation of BERT-Based Models for Arabic Term Extraction. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2025, 24, 1–12. [Google Scholar] [CrossRef]
- Kurniawan, K.; Louvan, S. IndoSum: A New Benchmark Dataset for Indonesian Text Summarization. In Proceedings of the 2018 International Conference on Asian Language Processing (IALP), Bandung, Indonesia, 15–17 November 2018. [Google Scholar]
- Sharma, E.; Li, C.; Wang, L. BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2204–2213. [Google Scholar]
- Malik, M.; Zhao, Z.; Fonseca, M.; Rao, S.; Cohen, S.B. CivilSum: A Dataset for Abstractive Summarization of Indian Court Decisions. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC USA, 10 July 2024; pp. 2241–2250. [Google Scholar]
- Wang, H.; Li, T.; Du, S.; Wei, X. Mixed Information Bottleneck for Location Metonymy Resolution Using Pre-trained Language Models. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2025. [Google Scholar] [CrossRef]
- Gutiérrez-Hinojosa, S.J.; Calvo, H.; Moreno-Armendáriz, M.A.; Duchanoy, C.A. Sentence Embeddings for Document Sets in DUC 2002 Summarization Task; IEEE Dataport: Piscataway, NJ, USA, 2018. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Fatima, W.; Rizvi, S.S.R.; Ghazal, T.M.; Kharma, Q.M.; Ahmad, M.; Abbas, S.; Furqan, M.; Adnan, K.M. Abstractive Text Summarization in Arabic-Like Script Using Multi-Encoder Architecture and Semantic Extraction Techniques. IEEE Access 2025, 13, 104977–104991. [Google Scholar] [CrossRef]
- Grusky, M.; Naaman, M.; Artzi, Y. Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 708–719. [Google Scholar]
- Kim, B.; Kim, H.; Kim, G. Abstractive Summarization of Reddit Posts with Multi-level Memory Networks. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 2519–2531. [Google Scholar]
- Gupta, V.; Bharti, P.; Nokhiz, P.; Karnick, H. SumPubMed: Summarization Dataset of PubMed Scientific Articles. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: Student Research, Online, 1–6 August 2021; pp. 292–303. [Google Scholar]
- Xia, T.C.; Bertini, F.; Montesi, D. Large Language Models Evaluation for PubMed Extractive Summarisation. ACM Trans. Comput. Healthc. 2025, 3766905. [Google Scholar] [CrossRef]
- Cohan, A.; Dernoncourt, F.; Kim, D.S.; Bui, T.; Kim, S.; Chang, W.; Goharian, N. A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 615–621. [Google Scholar]
- Koupaee, M.; Wang, W.Y. WikiHow: A Large Scale Text Summarization Dataset. arXiv 2018, arXiv:1810.09305. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, N.; Liu, Y.; Fabbri, A.; Liu, J.; Kamoi, R.; Lu, X.; Xiong, C.; Zhao, J.; Radev, D.; et al. Fair Abstractive Summarization of Diverse Perspectives. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024. [Google Scholar]
- Huang, K.-H.; Laban, P.; Fabbri, A.; Choubey, P.K.; Joty, S.; Xiong, C.; Wu, C.-S. Embrace Divergence for Richer Insights: A Multi-Document Summarization Benchmark and a Case Study on Summarizing Diverse Information from News Articles. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024; pp. 570–593. [Google Scholar]
- Datta, D.; Soni, S.; Mukherjee, R.; Ghosh, S. MILDSum: A Novel Benchmark Dataset for Multilingual Summarization of Indian Legal Case Judgments. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 5291–5302. [Google Scholar]
- Zhao, C.; Zhou, X.; Xie, X.; Zhang, Y. Hierarchical Attention Graph for Scientific Document Summarization in Global and Local Level. arXiv 2024, arXiv:2405.10202. [Google Scholar] [CrossRef]
- To, H.Q.; Liu, M.; Huang, G.; Tran, H.-N.; Greiner-Petter, A.; Beierle, F.; Aizawa, A. SKT5SciSumm—Revisiting Extractive-Generative Approach for Multi-Document Scientific Summarization. arXiv 2024, arXiv:2402.17311. [Google Scholar]
- Lu, Y.; Dong, Y.; Charlin, L. Multi-XScience: A Large-Scale Dataset for Extreme Multi-Document Summarization of Scientific Articles. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 8068–8074. [Google Scholar]
- Deutsch, D.; Dror, R.; Roth, D. A Statistical Analysis of Summarization Evaluation Metrics Using Resampling Methods. Trans. Assoc. Comput. Linguist. 2021, 9, 1132–1146. [Google Scholar] [CrossRef]
- Jiang, X.; Dreyer, M. CCSum: A Large-Scale and High-Quality Dataset for Abstractive News Summarization. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024; pp. 7306–7336. [Google Scholar]
- Zhu, M.; Zeng, K.; Wang, M.; Xiao, K.; Hou, L.; Huang, H.; Li, J. EventSum: A Large-Scale Event-Centric Summarization Dataset for Chinese Multi-News Documents. Proc. AAAI Conf. Artif. Intell. 2025, 39, 26138–26147. [Google Scholar] [CrossRef]
- Li, M.; Qi, J.; Lau, J.H. PeerSum: A Peer Review Dataset for Abstractive Multi-Document Summarization. arXiv 2022, arXiv:2203.01769. [Google Scholar]
- Zhong, M.; Yin, D.; Yu, T.; Zaidi, A.; Mutuma, M.; Jha, R.; Awadallah, A.H.; Celikyilmaz, A.; Liu, Y.; Qiu, X.; et al. QMSum: A New Benchmark for Query-Based Multi-Domain Meeting Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5905–5921. [Google Scholar]
- Giarelis, N.; Mastrokostas, C.; Karacapilidis, N. Abstractive vs. Extractive Summarization: An Experimental Review. Appl. Sci. 2023, 13, 7620. [Google Scholar] [CrossRef]
- Shakil, H.; Farooq, A.; Kalita, J. Abstractive Text Summarization: State of the Art, Challenges, and Improvements. Neurocomputing 2024, 603, 128255. [Google Scholar] [CrossRef]
- Farquhar, S.; Kossen, J.; Kuhn, L.; Gal, Y. Detecting Hallucinations in Large Language Models Using Semantic Entropy. Nature 2024, 630, 625–630. [Google Scholar] [CrossRef] [PubMed]
- Chrysostomou, G.; Zhao, Z.; Williams, M.; Aletras, N. Investigating Hallucinations in Pruned Large Language Models for Abstractive Summarization. Trans. Assoc. Comput. Linguist. 2024, 12, 1163–1181. [Google Scholar] [CrossRef]
- Alansari, A.; Luqman, H. Large Language Models Hallucination: A Comprehensive Survey. arXiv 2025, arXiv:2510.06265. [Google Scholar] [CrossRef]
- Gang, L.; Yang, W.; Wang, T.; He, Z. Corpus Fusion and Text Summarization Extraction for Multi-Feature Enhanced Entity Alignment. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2025, 24, 89. [Google Scholar] [CrossRef]
- Fabbri, A.R.; Kryściński, W.; McCann, B.; Xiong, C.; Socher, R.; Radev, D. SummEval: Re-Evaluating Summarization Evaluation. Trans. Assoc. Comput. Linguist. 2021, 9, 391–409. [Google Scholar] [CrossRef]
- Shi, H.; Xu, Z.; Wang, H.; Qin, W.; Wang, W.; Wang, Y.; Wang, Z.; Ebrahimi, S.; Wang, H. Continual Learning of Large Language Models: A Comprehensive Survey. ACM Comput. Surv. 2025, 58, 120. [Google Scholar] [CrossRef]
- Hindustan Times. Available online: https://www.hindustantimes.com/ (accessed on 5 November 2025).
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. PEGASUS: Pre-Training with Extracted Gap-Sentences for Abstractive Summarization. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2019. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).