Abstract
Comprehensive highway scene understanding and robust traffic risk inference are vital for advancing Intelligent Transportation Systems (ITS) and autonomous driving. Traditional approaches often struggle with scalability and generalization, particularly under the complex and dynamic conditions of real-world environments. To address these challenges, we introduce a novel structured prompting and multi-agent collaborative knowledge distillation framework that enables automatic generation of high-quality traffic scene annotations and contextual risk assessments. Our framework orchestrates two large vision–language models (VLMs): GPT-4o and o3-mini, using a structured Chain-of-Thought (CoT) strategy to produce rich, multiperspective outputs. These outputs serve as knowledge-enriched pseudo-annotations for supervised fine-tuning of a much smaller student VLM. The resulting compact 3B-scale model, named VISTA (Vision for Intelligent Scene and Traffic Analysis), is capable of understanding low-resolution traffic videos and generating semantically faithful, risk-aware captions. Despite its significantly reduced parameter count, VISTA achieves strong performance across established captioning metrics (BLEU-4, METEOR, ROUGE-L, and CIDEr) when benchmarked against its teacher models. This demonstrates that effective knowledge distillation and structured role-aware supervision can empower lightweight VLMs to capture complex reasoning capabilities. The compact architecture of VISTA facilitates efficient deployment on edge devices, enabling real-time risk monitoring without requiring extensive infrastructure upgrades.
1. Introduction
The rapid advancement of Intelligent Transportation Systems (ITS) and autonomous driving technologies has created an urgent need for comprehensive road scene understanding and robust traffic risk inference [1,2,3]. These systems require real-time, reliable interpretation of complex, dynamic environments, where factors such as weather, pavement conditions, traffic congestion, and unexpected hazards interact in unpredictable ways. Numerous studies have shown that adverse environmental factors, such as rain, snow, fog, and poor visibility, substantially increase the likelihood and severity of traffic accidents [4]. Traditional approaches, largely dependent on manually annotated datasets and task-specific neural networks, struggle with scalability, adaptability, and generalization, particularly in real-world, high-variability conditions [1,2,3]. For traffic risk inference, traditional methods typically rely on single-image inputs and therefore lack the ability to capture multimodal and temporal dynamics that are critical for understanding evolving roadway conditions. Without temporal and contextual awareness, these approaches struggle to interpret complex traffic behaviors, such as vehicle interactions, congestion shockwaves, and the progression of weather-induced hazards. Incorporating sequential information is thus essential for accurate and reliable traffic risk assessment. As transportation systems become more interconnected and data-rich, the limitations of the traditional methods underscore the necessity for flexible, generalizable models capable of understanding nuanced environmental and traffic scenarios with minimal human intervention.
Vision–language models (VLMs) have recently emerged as a compelling solution to this challenge. By aligning visual and textual modalities, VLMs demonstrate strong zero-shot reasoning capabilities across diverse domains without requiring extensive task-specific retraining [5,6,7]. Built upon web-scale datasets, these models capture deep cross-modal correlations, enabling superior generalization and reduced reliance on manual labeling [5,6,7]. State-of-the-art large VLMs (LVLMs) have already outperformed conventional visual recognition models on tasks such as object detection, image classification, and semantic segmentation, proving effective not only in general computer vision benchmarks but also across downstream applications in scientific and industrial domains [5,6,7,8]. Moreover, recent innovations extend VLM capabilities to handle dynamic, time-varying data, enabling models to reason over video sequences and capture evolving scenes and behaviors. These capabilities are essential for real-world deployment [9].
Within the transportation domain, the application of VLMs has shown tremendous promise for semantic understanding of traffic environments. These models are increasingly being utilized to interpret complex scenes involving environmental context (e.g., fog, rain, or snow), road surface conditions (e.g., dry, wet, or flooded), vehicle behaviors, pedestrian interactions, and urban infrastructure [1,3,5,10]. For example, integrating scene graphs into VLM pipelines significantly improves the model’s ability to reason about causal relationships and event dynamics in traffic incidents, enabling deeper insights into accident events [11]. By leveraging multimodal inputs such as RGB imagery, thermal imaging, LiDAR point clouds, and high-definition map data, VLMs have demonstrated improved performance in understanding road scenes with greater accuracy and robustness [1,5,10,12]. Crucially, the ubiquity of traffic surveillance camera networks across metropolitan and highway systems provides an abundant source of real-time data, yet these streams remain under-exploited. Integrating VLMs with existing video infrastructure offers unprecedented opportunities for real-time scene understanding, anomaly detection, and traffic incident summarization and reporting at scale [1,5,9].
To further elevate the interpretive power of VLM-based systems, researchers have proposed multi-agent frameworks, wherein specialized agents collaboratively process different data modalities or subtasks [7,13,14]. These architectures foster robustness, compositional reasoning, and parallel perception, which are particularly beneficial in dense or ambiguous traffic scenarios [7,13]. Recent work in Multi-Agent Visual Question Answering (VQA), a benchmark task where the model interprets an image and answers free-form natural language questions about its content, as well as image captioning, retrieval, and risk interpretation demonstrates how foundation models distributed across agent roles can collectively outperform single-agent systems in zero-shot reasoning and question answering [15]. By decentralizing decision-making across cooperative agents, multi-agent VLMs improve generalization and robustness, which are critical for high-stakes applications such as autonomous driving, emergency response, and infrastructure safety monitoring [7,14]. These systems have also demonstrated proficiency in zero-shot detection of rare or hazardous events, offering scalable solutions for safety-critical deployments [3,13].
Another essential component in VLM-powered transportation analysis is detailed and temporally aligned video captioning. High-quality captions enable the transformation of continuous visual input into structured, interpretable semantic representations, forming the basis for downstream tasks such as risk detection, abnormal behavior analysis, and driver assistance [6,9,16]. Techniques such as differential captioning and multimodal prompting with models like GPT-4V allow for granular descriptions that reflect intra-frame changes, temporal dependencies, and contextual interactions within traffic videos [6,9]. These capabilities are especially important for automated monitoring systems that must parse fleeting events (e.g., abrupt lane changes, sudden stops, or near-collisions) with both accuracy and timeliness.
Despite their exceptional performance, large-scale VLMs pose significant computational demands, making them impractical for many real-world deployments, especially in embedded or resource-constrained systems. To bridge this gap, knowledge distillation (KD) has emerged as a vital strategy. KD techniques aim to transfer the reasoning and generalization power of a large, complex “teacher” model to a smaller, more efficient “student” model [7,8]. While knowledge distillation focuses on transferring abstract reasoning abilities, skill distillation emphasizes replicating specific task-oriented behaviors, both are highly relevant to transportation applications where timely and accurate decisions are paramount [7,8]. Recent surveys underscore the role of KD in enabling lightweight VLMs that maintain high interpretability and performance, even under stringent latency or energy constraints [8].
Fine-tuned and distilled VLMs are increasingly being deployed in real-time traffic risk analysis pipelines. By generating automatic, semantically rich descriptions of road events, these models support rapid response, proactive management, and long-term planning by transportation authorities [1,3,9]. Furthermore, automated risk reporting systems powered by VLMs can serve as intelligent roadside agents, continuously assessing road safety conditions and issuing timely alerts to prevent accidents. Such systems not only represent a significant leap toward Vision Zero goals but also enhance equity by enabling advanced traffic monitoring in resource-limited regions.
While current VLMs have showed notable capability to address traffic scene understanding tasks, most existing approaches primarily emphasize single-agent captioning or perception subtasks, with lacking the exploration of explicit reasoning structures or collaborative multi-agent designs. To bridge this gap, we present a novel collaborative prompting and distillation framework designed to automatically generate high-fidelity traffic scene annotations and contextual risk assessments in this study. This is achieved by orchestrating two popular VLMs (GPT-4o and o3-mini) using a structured Chain-of-Thought (CoT) strategy. The multiperspective outputs from these expert agents serve as a knowledge-enriched supervision signals for supervised fine-tuning of a compact student VLM. Through this framework, we introduce VISTA (Vision for Intelligent Scene and Traffic Analysis), a lightweight 3B model specifically engineered for understanding low-resolution traffic videos from existing traffic cameras and generating semantically faithful, risk-aware captions. Despite its substantially reduced parameter count, VISTA demonstrates strong competitive performance across commonly used metrics: BLEU-4, METEOR, ROUGE-L, and CIDEr, when quantitatively benchmarked against its larger teacher models. Importantly, its lightweight architecture enables efficient deployment on edge devices, thereby facilitating proactive risk monitoring without necessitating costly infrastructure upgrades. Our full training pipeline and model checkpoints can be found in [17].
2. Data Description
We collected a large-scale, multimodal dataset comprising synchronized video streams and road weather sensor data sourced from publicly accessible traffic monitoring platforms. The videos were primarily collected from state-operated traffic camera networks in Virginia, Georgia, and California, states chosen to ensure geographic diversity and a wide range of environmental conditions. Several of these camera sites are co-located with Road Weather Information System (RWIS) sensors, which provide measurements such as air and pavement condition, precipitation type, and wind speed. These RWIS sensor readings serve as ground-truth references during dataset curation and annotation generation process for validating the environmental contexts inferred from visual data, ensuring that visual perception outputs (e.g., rain, snow, fog, or wet pavement) are consistent with co-located sensor readings.
The data collection process spanned from February 2025 to July 2025, capturing real-world traffic scenes across varying lighting, weather, and congestion scenarios. In total, we collected over 21,000 short video clips, each 3 to 7 s long, depending on the source camera’s configuration. Because the roadside cameras are fixed and capture consistent views most of time, many clips contain highly repetitive or nearly identical scenes. To reduce redundancy while preserving informative learning signals, we carefully sampled 500 video clips representing diverse weather, traffic, and pavement conditions. These video clips vary in resolution, including 366 at 320 × 240, 32 at 640 × 480, 92 at 852 × 480, and 10 at 1280 × 720, depending on camera models and settings. This curated subset provides a compact, balanced dataset suitable for fine-tuning pretrained models, guiding them toward traffic-specific contexts while leveraging the generalization strengths of large-scale pretraining and maintaining training efficiency. The distribution of this dataset is visualized in Figure 1.
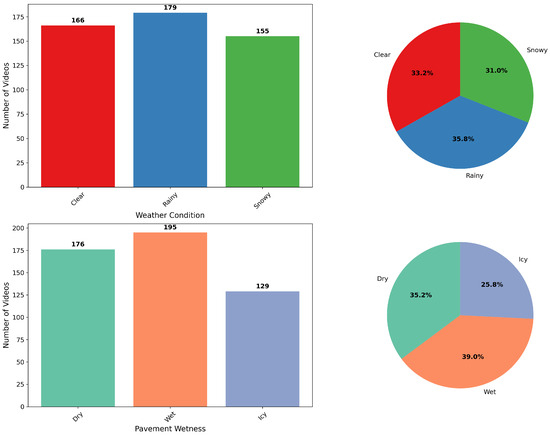
Figure 1.
Distribution of the sampled training dataset.
Figure 2 shows sample frames from the training dataset, illustrating a range of weather and pavement surface conditions. Notably, the majority of traffic cameras used for traffic monitoring are in relatively low resolutions. To evaluate model performance under realistic deployment conditions, we curated a test set comprising 200 video clips in low resolution (199 at 320 × 240 and 1 at 240 × 180).

Figure 2.
Sample frames illustrating different weather and pavement wetness conditions. Left column: (top) clear with no precipitation, (bottom) dry pavement. Middle column: (top) rainy, (bottom) wet pavement. Right column: (top) snowy, (bottom) icy pavement.
3. Methodology
3.1. Overview
To capture temporal dynamics while preserving computational efficiency, we extract multiple frames from each short traffic video clip at fixed intervals (typically 0.5 s). Given that all video clips have durations of 3–7 s, the resulting frame count per clip ranges from 6 to 14 frames. This fixed-interval sampling is to ensure temporal consistency across clips while preserving sufficient motion cues for event reasoning.
These frames are first processed by the GPT-4o model [18], which serves as Agent 1 in our collaborative agentic framework. Guided by a tailored CoT prompt [19], the model performs structured scene interpretation across six semantic dimensions: time of day (daytime or nighttime), road weather condition (clear, rainy, foggy, or snowy), pavement surface wetness (dry, wet, flooded, or snowy), vehicle behavior, traffic flow and speed, and congestion level. The output is a step-by-step, semantically rich caption that provides a comprehensive summary of the visual input.
Subsequently, both the selected video frames and the structured scene analysis from Agent 1 are passed to the o3-mini model [20], which functions as Agent 2 for reasoning. This agent employs a dedicated CoT prompt to perform traffic risk interpretation across multiple safety-critical dimensions, including environmental risk factors, vehicle behavior risk, traffic flow risk, and overall safety level, alongside actionable insights such as driver alerts and recommended safe speeds.
The combined output from both agents, consisting of detailed scene understanding and structured risk assessment, serves as high-quality, knowledge-enriched pseudo-annotations. These annotations are then used to perform supervised fine-tuning (SFT) on a compact 3B Qwen2.5-VL model [21], leading to our distilled student model, VISTA, which can be deployed for real-time traffic safety applications. An overview of the training and inference pipeline is illustrated in Figure 3.
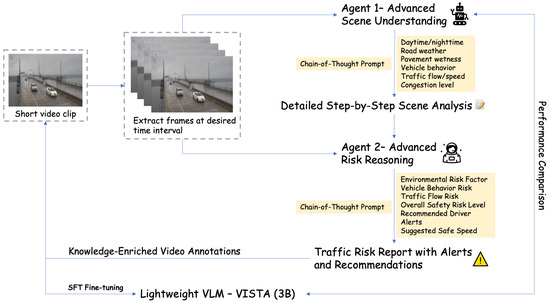
Figure 3.
Overview of the proposed framework.
3.2. CoT Prompt Design for Role-Aware Video Analysis
To elicit structured and context-rich outputs from VLMs, we design two customized CoT prompts tailored to each expert agent’s specific capabilities. These prompts guide the reasoning steps for interpreting visual scenes and assessing traffic risks, resulting in coherent, interpretable outputs usable for downstream supervision.
3.2.1. Road Scene Understanding
Agent 1 (GPT-4o) is responsible for extracting high-level semantic information from short video clips by following a multi-step CoT prompt (see Figure 4). This prompt breaks down the video interpretation into six semantic dimensions:

Figure 4.
CoT prompt design for Agent 1 (GPT-4o): structured scene understanding.
- Time of Day: Distinguishing between daytime and nighttime based on ambient light and sky conditions.
- Road Weather Conditions: Classifying the environment as clear, foggy, rainy, or snowy.
- Pavement Wetness Condition: Assessing the road surface as dry, wet (shiny or moist), flooded (pooled water), or snowy (slush/coverage).
- Vehicle Behavior: Identifying maneuvers such as lane changes, braking, acceleration, turns, or unusual/hazardous actions.
- Traffic Flow and Speed: Estimating traffic smoothness and the general speed level (high, medium, or low).
- Congestion Level: Categorizing congestion as light, moderate, or heavy.
By decomposing the analysis in this manner, the prompt encourages the VLM to produce a logically ordered and granular description. The output is not a generic caption but a semantically annotated scene summary, concluding with a synthesized paragraph summarizing the overall traffic conditions. A sample output is shown in Figure 5.

Figure 5.
Sample output from Agent 1 (GPT-4o): multi-step scene analysis based on visual cues and traffic dynamics.
3.2.2. Risk Reasoning
Building upon the structured scene analysis from Agent 1, the second agent (o3-mini) performs risk interpretation using a dedicated CoT prompt (see Figure 6). The prompt positions the model as a traffic safety expert and requests a comprehensive report in four dimensions:

Figure 6.
CoT prompt design for Agent 2 (o3-mini): structured traffic risk reasoning.
- Environmental Risk Factors: This component focuses on analyzing the interplay between visibility, weather, and pavement surface conditions—three critical elements in assessing traffic safety. Time of day plays a decisive role in determining visibility, with nighttime or low-light conditions significantly impairing a driver’s ability to detect road hazards, pedestrians, or surface anomalies such as standing water or debris. Weather factors such as rain, fog, or snow further compound these risks by introducing glare, reduced contrast, or obscured features. Pavement wetness, in particular, poses substantial safety concerns by affecting vehicle traction, braking distance, and hydroplaning likelihood. For example, a reflective road surface under overcast skies may suggest recent precipitation, while visible pooling indicates potential flooding. Distinguishing between partially wet and deeply saturated pavement is therefore crucial for anticipating vehicle instability and enabling downstream risk prediction. The CoT prompt guides the model to reason across these dimensions collectively, enabling a comprehensive assessment of how environmental conditions influence roadway safety.
- Vehicle Behavior Risk: This dimension evaluates whether the observed driving patterns suggest cautious or erratic behavior, offering insight into potential latent hazards. Behavioral responses such as sudden braking, abrupt acceleration, or frequent lane changes often reflect driver reactions to perceived risks—such as reduced visibility, surface irregularities, or obstructions not directly captured in the visual field. Importantly, clusters of such evasive maneuvers across multiple vehicles may signal the presence of high-risk zones ahead, including flooded pavement, debris fields, or stalled traffic. By analyzing both the frequency and distribution of these maneuvers, the model can infer emergent risk factors and support preemptive safety reasoning that extends beyond the immediate visual context.
- Traffic Flow Risk: This component assesses the stability and efficiency of traffic flow to identify dynamic risk patterns. Consistent, smooth flow typically indicates low interaction risk, whereas abrupt fluctuations in vehicle speed or spacing may signal unexpected environmental disturbances—such as roadway obstructions, water accumulation, or sudden visibility drops. Such disruptions not only degrade flow efficiency but also elevate the probability of rear-end collisions, particularly under conditions of limited traction or poor visual perception. The CoT prompt enables the model to reason temporally, detecting irregularities in flow continuity and interpreting them as early indicators of potential hazards ahead. This temporal perspective is critical for proactive traffic risk evaluation.
- Overall Safety Risk Level: Providing a low/moderate/high-risk classification with justification.
Additionally, the prompt requests actionable driver guidance in the form of
- Alerts: Warnings or advisories relevant to current road conditions.
- Suggested Safety Speed: A recommended driving speed that reflects current visibility, pavement, and flow characteristics.
This structured reasoning output represents an interpretable risk abstraction over raw video frames. A representative sample response generated by o3-mini is visualized in Figure 7.

Figure 7.
Sample output from Agent 2 (o3-mini): structured risk analysis and advisory reasoning based on scene context.
Prompt Structure for General-Purpose Fine-Tuning
While the previous sections describe the two structured prompts used during knowledge-enriched label generation, our general-purpose training requires a unified prompt format to supervise the student model directly. This ensures that the model learns not only how to reason but also to structure its outputs in an interpretable, standardized format compatible with downstream risk assessment tasks.
Figure 8 presents the full training-time instruction used for the training of VISTA. The prompt integrates the elements from the structured prompts of the two teacher agents and explicitly positions the student model as an intelligent traffic safety assistant tasked with generating a two-part response: (1) a structured scene analysis, and (2) a traffic risk report. This format blends descriptive grounding (scene perception) with high-level reasoning (risk abstraction), thereby encouraging the model to encode both factual observations and safety-critical interpretations.

Figure 8.
Unified training-time prompt used to supervise the student model during supervised fine-tuning.
3.3. Collaborative Role-Aware Knowledge Distillation via Caption and Risk Label Generation
To enable a lightweight VLM to perform high-quality road scene interpretation and traffic risk inference, we propose a novel collaborative, role-aware knowledge distillation framework. Unlike conventional approaches that distill feature representations or logits from a single teacher model, our method orchestrates multiple expert agents, i.e., GPT-4o and o3-mini, to generate rich, semantically structured supervision signals in the form of captions and risk reports. These outputs are subsequently used to supervise a smaller VLM via supervised fine-tuning (SFT).
3.3.1. Distillation Setup
Let denote a collection of N short traffic video clips. For each video , we extract a sequence of frames denoted by at uniform temporal intervals (e.g., 0.5 s).
The extracted are first processed by Agent 1 (GPT-4o) with a CoT prompt, resulting in a structured scene description:
where is designed to infer attributes such as daytime/nighttime, weather condition, pavement wetness, traffic flow, vehicle behavior, and congestion level.
The scene caption is then combined with the original frames and passed to Agent 2 (o3-mini) for advanced risk reasoning:
where targets traffic risk interpretation, including environmental risk, behavior risk, traffic flow-related risk, an overall safety assessment, and actionable driving recommendations (alerts and safe speed).
3.3.2. Unified Label Construction
For each video , the outputs from Agent 1 (scene-level description) and Agent 2 (risk-level reasoning) are concatenated at the text level to form a unified annotation:
where and are the raw natural language outputs from the two expert agents. This unified text sequence encapsulates both perceptual understanding and prescriptive reasoning about the traffic scene.
Before training, is tokenized into a sequence of discrete token IDs:
where is the tokenized sequence length.
3.3.3. Distillation Objective
Let the student model be a lightweight VLM, i.e., our VISTA model, denoted as , where are the model parameters. In practice, both teacher agents output discrete text rather than token-level probability distributions. Thus, our distillation reduces to supervised fine-tuning on tokenized pseudo-labels, where the student is trained to maximize the likelihood of reproducing the teacher-generated annotations.
Formally, given the input frame sequence , the model generates a sequence of logits:
where denotes the tokens preceding position t. The logits (with V being the vocabulary size) are transformed into probability distributions via the softmax:
The sequence-level cross-entropy loss for SFT is
where denotes the predicted probability assigned to the ground-truth token at step t.
The overall fine-tuning objective over the dataset is
This knowledge distillation strategy enables the transfer of rich, structured knowledge from large-scale VLMs to a compact student model. GPT-4o contributes detailed visual understanding, while o3-mini provides contextual and risk-aware reasoning. Their distinct, yet complementary expertise allows the student model to learn and generalize beyond descriptive captioning to safety-critical reasoning and interpretation.
3.4. Training and Evaluation Pipeline
Figure 9 illustrates the end-to-end training and evaluation framework of VISTA. To fully leverage the strengths of LVLMs while enabling lightweight deployment, our pipeline consists of two supervision paths:
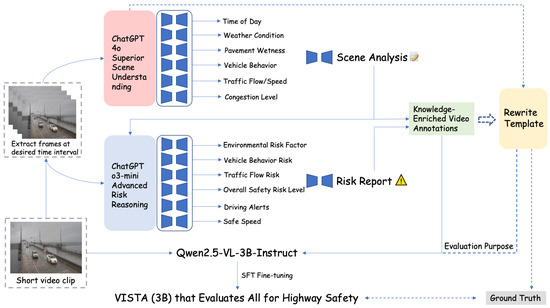
Figure 9.
Overall pipeline of collaborative supervision, fine-tuning, and evaluation for VISTA.
- (1)
- Role-Aware Knowledge-Enriched Supervision.The first path generates rich, semantically grounded annotations from a pair of expert LVLMs: GPT-4o and o3-mini. Specifically, we sample frames from short video clips and pass them along with two specialized prompting branches: (i) GPT-4o for fine-grained scene analysis and captioning, and (ii) o3-mini for contextual risk reasoning. Their outputs are merged and organized into structured, knowledge-enriched video annotations which are used as pseudo-labels to supervise the fine-tuning of a 3B student model (Qwen2.5-VL-3B-Instruct), leading to our VISTA model, suitable for deployment in real-world highway safety monitoring.
- (2)
- Template-Based Evaluation.To rigorously assess the semantic fidelity of VISTA against its LVLM teachers, we construct another parallel supervision path. The outputs are reformatted into a unified evaluation template (refer to Figure 10) that reflects the exact linguistic structure expected during inference. We then further fine-tune the same 3B model under this template supervision using identical hyperparameters. This guarantees structural alignment between model outputs and GPT-4o reference generations, enabling precise metric-based comparison.
 Figure 10. Rewritten template for unified evaluation.
Figure 10. Rewritten template for unified evaluation.
For evaluation, we apply the same rewritten template to all test video clips using GPT-4o to produce ground-truth reference outputs. In parallel, our fine-tuned VISTA is evaluated on the same video clips. Performance is assessed over 200 samples using BLEU-4, METEOR, ROUGE-L, and CIDEr, as detailed in the Section 4.1. The resulting scores (Table 1) quantify the alignment between the distilled lightweight model and its large-scale teacher ensemble.
4. Experiments and Results
In this section, we evaluate the performance of our lightweight VLM model, VISTA, under different fine-tuning schemes that target distinct model components, with all fine-tuned variants compared against the pretrained model as a baseline. All model variants are evaluated against GPT-4o outputs as reference on a held-out test set comprising 200 traffic video clips. These videos are curated to be representative of diverse real-world scenarios involving different weather conditions, pavement wetness levels, traffic flow conditions, and dynamics.
4.1. Evaluation Metrics
Our goal is to assess both local n-gram fidelity and global semantic alignment. For this purpose, we employ four widely adopted evaluation metrics from the captioning literature: BLEU-4, METEOR, ROUGE-L, and CIDEr. Each metric captures a different facet of linguistic similarity, enabling a holistic comparison.
- BLEU-4 [22] evaluates n-gram precision, focusing on exact phrase-level overlap between the predicted caption and the reference. Specifically, BLEU-4 computes the modified precision of 4-g aswhere denotes the modified precision for n-grams (up to 4), , and is the brevity penalty to discourage overly short predictions. In our case, we compute BLEU-4 between each VISTA-generated caption and the corresponding GPT-4o reference over all 200 samples and report the average.
- METEOR [23] balances unigram precision and recall, incorporating stemming, synonymy, and word order through alignment. It is defined aswhere is the harmonic mean of unigram precision and recall, and P is a penalty based on the fragmentation of matched chunks. This metric tends to correlate better with human judgment, especially for short descriptive text such as video captions.
- ROUGE-L [24] measures sentence-level structural similarity based on the longest common subsequence (LCS) between the predicted and reference token sequences. Let denote the prediction and the reference. Define
Following the official rouge_score implementation, we report the F1-based ROUGE-L score (), which harmonically combines LCS-based precision and recall:
The final metric is obtained by averaging over all test clips.
- CIDEr [25] evaluates consensus across multiple references by computing TF-IDF-weighted n-gram similarity. For each caption, it is defined aswhere is the weight for n-gram n (typically uniform), and is the cosine similarity between TF-IDF vectors of the n-grams. Since we use single-reference evaluation (GPT-4o output), CIDEr provides insight into descriptive richness and term relevance.
- To facilitate unified comparison, we compute a composite score from all four metrics, defined aswhere CIDEr is scaled by 0.1 to normalize its value range. This aggregate formulation captures both structural accuracy and semantic fidelity while accounting for redundancy and term frequency. A similar multi-metric strategy has been adopted in the recent literature such as CityLLaVA [26], where BLEU, METEOR, and ROUGE are combined to evaluate semantic grounding and coherence in urban scene descriptions. In our case, the composite score enables a holistic assessment of model performance, integrating both exact n-gram matches (BLEU), semantic fluency and recall (METEOR), sentence-level structure (ROUGE-L), and consensus with human-like outputs (CIDEr).
4.2. Implementation Details
We implement our full pipeline using the Qwen2.5-VL-3B architecture, a compact yet capable instruction-tuned vision–language model All training is conducted on a high-performance server equipped with four NVIDIA A6000 GPUs (each with 48 GB memory). We adopt mixed-precision training using bfloat16 for memory efficiency and enable DeepSpeed ZeRO Stage 3 parallelism and gradient checkpointing to scale training across longer input contexts without exceeding GPU memory constraints.
The training follows a consistent hyperparameter configuration across all model variants. We use a cosine learning rate scheduler with an initial learning rate of and a warm-up ratio of 0.03. The per-device batch size is set to 1, with gradient accumulation steps of 1. Inputs are truncated at a maximum sequence length of 8192 tokens, while image resolution is fixed at , bounded by a total pixel limit of 50,176 to avoid memory overflow. Each training run is conducted for five epochs, and checkpoints are saved every 1000 steps, with only the latest checkpoint retained.
We perform end-to-end fine-tuning of all key components in the Qwen2.5-VL-3B architecture:
- Visual Encoder: The CLIP-style backbone is updated to specialize in low-resolution traffic footage under diverse environmental conditions.
- Language Decoder: Tuning the LLM decoder enables the model to emulate expert-style reasoning and reporting formats derived from large teacher models (GPT-4o and o3-mini).
- Cross-Modal MLP Fusion: This module aligns vision and language representations. Fine-tuning it improves grounding of visual semantics into structured CoT outputs.
While parameter-efficient fine-tuning (PEFT) strategies [27] such as LoRA [28] and adapter modules are effective in general-purpose scenarios, we deliberately opt for full-model fine-tuning. This decision is driven by the significant domain gap between pretraining corpora and our targeted deployment setting: rural traffic environments with complex road/weather dynamics and low-visibility conditions. In our empirical assessment, adapter-based methods struggled to adapt cross-modal dependencies and preserve fine-grained semantics under such domain shift. Full fine-tuning ensures holistic adaptation of the vision–language model, which is essential for capturing subtle visual cues (e.g., glare from wet pavement, and faint lane markings) and delivering high-fidelity safety reasoning required in real-world ITS applications.
4.3. Results
All evaluation metrics were computed using widely adopted open-source packages. Specifically, BLEU-4 and METEOR were computed using nltk.translate from the Natural Language Toolkit (NLTK). ROUGE-L was computed using the rouge-score package (https://pypi.org/project/rouge-score, accessed on 22 July 2025), and CIDEr followed the official implementation from the AI City Challenge’s WTS dataset repository (https://github.com/woven-visionai/wts-dataset/blob/main/evaluation/eval-metrics-AIC-Track2/cider/cider_scorer.py, accessed on 15 July 2025).
Table 1 reports the performance of the original pretrained model and four fine-tuned model variants on the same test set of 200 traffic video clips. Evaluation is conducted against reference outputs produced by GPT-4o using four standard captioning metrics (BLEU-4, METEOR, ROUGE-L, and CIDEr), along with a composite score as defined in Section 4.1.

Table 1.
Comparison of model performance under different fine-tuning schemes.
Table 1.
Comparison of model performance under different fine-tuning schemes.
| Model | BLEU-4 | METEOR | ROUGE-L | CIDEr | Score |
|---|---|---|---|---|---|
| 3B original | 0.2517 | 0.5396 | 0.3902 | 0.2984 | 30.28 |
| 3B mlp | 0.2581 | 0.5287 | 0.4040 | 0.3363 | 30.61 |
| 3B mlp + vision | 0.2722 | 0.5281 | 0.4346 | 0.2413 | 31.48 |
| 3B mlp + llm | 0.3269 | 0.5691 | 0.4862 | 0.6712 | 36.23 |
| 3B mlp + llm + vision (VISTA) | 0.3289 | 0.5634 | 0.4895 | 0.7014 | 36.30 |
Notes: 3B original: Pretrained Qwen2.5-VL-3B-Instruct without fine-tuning. 3B mlp: Fine-tunes only the multimodal fusion MLP. 3B mlp + vision: Fine-tunes the fusion MLP and the vision encoder. 3B mlp + llm: Fine-tunes the fusion MLP and the LLM backbone. 3B llm + mlp + vision (VISTA): Fine-tunes all three components: vision encoder, fusion MLP, and LLM backbone.
As shown in Table 1, the pretrained model (3B original) model performs the worst across most metrics, underscoring the necessity of task-specific adaptation. Fine-tuning the MLP projector alone (3B mlp) marginally improves structural alignment (BLEU, ROUGE), yet its semantic richness (METEOR, CIDEr) remains limited due to a frozen decoder incapable of adapting to downstream reasoning patterns.
The 3B mlp + vision variant introduces visual context but still retains a frozen language model. While visual features enhance structural grounding, the lack of LLM tuning hinders its capacity to interpret and articulate complex scene semantics. This gap is particularly evident in METEOR and CIDEr, both of which emphasize contextual fluency and consensus relevance.
Substantial performance gains are observed when the LLM backbone is unfrozen and tuned, as seen in 3B mlp + llm. Compared to the vision-tuning baseline, The model achieves notable improvements in CIDEr (+0.43) and METEOR (+0.04), suggesting that decoder tuning plays a pivotal role in aligning outputs with the narrative structure and reasoning patterns embedded in expert references. This observation is consistent with the findings in the recent instruction-tuned LLM literature, highlighting decoder adaptation is central to cross-domain generalization.
Finally, our VISTA (3B llm + mlp + vision) achieves the highest scores across nearly all metrics, demonstrating that joint optimizing vision, fusion, and language components yields synergistic improvements. The model leverage grounded visual cues, adaptive semantic decoding, and a well-aligned cross-modal embedding space. Its superior CIDEr and BLEU-4 scores suggest not only enhanced fluency but also precise alignment with human-level multi-step descriptions.
Overall, the results demonstrate that compact VLMs, when supervised using signals generated by collaborative, role-aware agents, can rival or even surpass the performance of much larger single-agent models, offering a scalable, cost-efficient, and interpretable solution for video-based traffic risk assessment.
These findings further support the emerging perspective in multimodal learning that the quality of supervision data, prompt design, and alignment mechanisms can be more crtical than sheer model size, particularly for deploying lightweight VLMs for real-time applications.
5. Practical Implications
The resulting lightweight VISTA model can be deployed on edge-computing devices to process live image feeds from existing traffic cameras and generate real-time, risk-aware captions. These outputs provide actionable insights, including environmental descriptors (e.g., fog, rain, or snow), pavement condition indicators, and behavioral risk signals, that can be directly integrated into Advanced Traffic Management Systems (ATMS) and Advanced Traveler Information Systems (ATIS). By enabling continuous visual monitoring and interpretation of roadway conditions, VISTA supports a range of operational applications such as low-visibility advisories, variable speed limit control, congestion notifications, and incident alerts. In addition, its outputs can be aggregated into spatial–temporal risk heatmaps to inform infrastructure planning, incident analysis, and data-driven maintenance prioritization.
Furthermore, VISTA’s visual perception outputs can augment or substitute traditional roadway sensors by providing localized, image-derived environmental and pavement condition data. This capability offers a resilient and cost-effective alternative, particularly valuable when conventional road weather sensors are unavailable or compromised under extreme or adversarial conditions.
In summary, while model training and distillation are conducted offline, VISTA supports online inference, providing scalable, cost-effective, and resilient safety intelligence that effectively bridges the gap between multimodal perception research and real-world Intelligent Transportation Systems.
6. Conclusions
This work introduces a scalable, modular framework for traffic scene understanding and safety risk assessment by leveraging multiple distinct VLM agents with structured prompting for knowledge distillation. Specifically, we orchestrate two complementary VLMs: GPT-4o for semantic scene interpretation and o3-mini for safety-centric reasoning, to generate high-quality, structured annotations from low-resolution traffic videos. These annotations, enriched through CoT prompting, serve as effective knowledge-enriched labels for fine-tuning a compact student model.
Quantitative assessment demonstrates that the proposed VISTA model, a 3 billion-parameter lightweight VLM, achieves BLEU-4 = 0.329, METEOR = 0.563, ROUGE-L = 0.490, and CIDEr = 0.701, yielding a composite score of 36.3, which outperforms all partially fine-tuned baselines. These results highlight the critical role of prompt design, collaborative agent supervision, and domain-specific grounding in developing efficient and interpretable VLMs for domain-targeted applications.
VISTA’s compactness and effectiveness make it well suited for real-time deployment on edge devices within existing transportation infrastructure. By augmenting the analytical capability of legacy traffic cameras without hardware upgrades, our framework offers a cost-effective solution for enhancing incident detection and roadway safety at scale.
To promote reproducibility and foster community-driven adaptation, we publicly released both the model and the training pipeline. Practitioners can fine-tune VISTA on region-specific data to enable localized intelligence across diverse deployment contexts.
This work demonstrates the feasibility of collaborative, role-aware prompting, structured knowledge distillation, and lightweight multimodal AI for enhancing the existing Intelligent Transportation Systems. Looking ahead, VISTA can be further improved in several directions. First, the model architecture can be further optimized to reduce computational footprint and improve deployment efficiency on edge devices. Second, multi-sensor fusion should be pursued to integrate video streams with complementary Internet-of-Things data, thereby enhancing robustness under conditions of poor visibility or visual occlusion. Finally, a federated learning framework can be developed to enable continuous large-scale fine-tuning of VISTA while preserving data privacy and minimizing communication overhead. Collectively, these advancements will evolve VISTA from a high-fidelity perception engine into an intelligent decision-support module, capable of assisting human operators and autonomous systems in achieving safer, more resilient, and adaptive traffic and roadway operations.
Author Contributions
Conception and design: J.J.Y. and Y.Y.; data processing: Y.Y. and N.X.; analysis and interpretation of results: Y.Y., N.X. and J.J.Y.; draft manuscript preparation: Y.Y. and N.X.; review and editing: J.J.Y.; visualization, Y.Y.; supervision, J.J.Y.; project administration, J.J.Y.; funding acquisition, J.J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the U.S. Department of Transportation, Office of the Assistant Secretary for Research and Technology (OST-R), University Transportation Centers Program, through the Center for Regional and Rural Connected Communities (CR2C2) under Grant No. 69A3552348304.
Data Availability Statement
The dataset utilized in this study were obtained from publicly accessible traffic camera feeds maintained by the respective state Departments of Transportation (DOTs). The data is available through the official DOT websites subject to the access policies of the corresponding agencies.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ATIS | Advanced Traveler Information System |
| ATMS | Advanced Traffic Management System |
| BLEU | Bilingual Evaluation Understudy |
| CIDEr | Consensus-based Image Description Evaluation |
| CoT | Chain-of-Thought |
| FPS | Frames Per Second |
| ITS | Intelligent Transportation Systems |
| LCS | Longest Common Subsequence |
| LLM | Large Language Model |
| MLP | Multilayer Perceptron |
| RWIS | Road Weather Information System |
| SFT | Supervised Fine-Tuning |
| VISTA | Vision-Informed Safety and Transportation Assessment |
| VLM | Vision–Language Model |
| VQA | Visual Question Answering |
References
- Rivera, J.; Lin, K.; Adeli, E. Scenario Understanding of Traffic Scenes Through Large Visual Language Models. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 26 February–6 March 2025. [Google Scholar]
- Zhang, Y.; Liu, L.; Zhang, H.; Wang, X.; Li, M. Semantic Understanding of Traffic Scenes with Large Vision-Language Models. arXiv 2024, arXiv:2406.20092. [Google Scholar]
- Zheng, O.; Abdel-Aty, M.; Wang, D.; Wang, Z.; Ding, S. ChatGPT Is on the Horizon: Could a Large Language Model Be All We Need for Intelligent Transportation? arXiv 2023, arXiv:2303.05382. [Google Scholar]
- Theofilatos, A.; Yannis, G. A review of the effect of traffic and weather characteristics on road safety. Accid. Anal. Prev. 2014, 72, 244–256. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Huang, J.; Jin, S.; Lu, S. Vision-Language Models for Vision Tasks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5625–5645. [Google Scholar] [CrossRef]
- Li, Z.; Wu, X.; Du, H.; Nghiem, H.; Shi, G. Benchmark Evaluations, Applications, and Challenges of Large Vision Language Models: A Survey. arXiv 2025, arXiv:2501.02189. [Google Scholar] [CrossRef]
- Xu, H.; Jin, L.; Wang, X.; Wang, L.; Liu, C. A Survey on Multi-Agent Foundation Models: Progress and Challenges. arXiv 2024, arXiv:2404.20061. [Google Scholar]
- Yang, C.; Zhu, Y.; Lu, W.; Wang, Y.; Chen, Q.; Gao, C.; Yan, B.; Chen, Y. Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application. ACM Trans. Intell. Syst. Technol. 2024. [Google Scholar] [CrossRef]
- Chen, L.; Wei, X.; Li, J.; Dong, X.; Zhang, P.; Zang, Y.; Chen, Z.; Duan, H.; Tang, Z.; Yuan, L.; et al. ShareGPT4Video: Improving Video Understanding and Generation with Better Captions. Adv. Neural Inf. Process. Syst. 2024, 37, 19472–19495. [Google Scholar]
- Cao, X.; Zhou, T.; Ma, Y.; Ye, W.; Cui, C.; Tang, K.; Cao, Z.; Liang, K.; Wang, Z.; Rehg, J.M.; et al. MAPLM: A Real-World Large-Scale Vision-Language Benchmark for Map and Traffic Scene Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Lohner, A.; Compagno, F.; Francis, J.; Oltramari, A. Enhancing Vision-Language Models with Scene Graphs for Traffic Accident Understanding. In Proceedings of the 2024 IEEE International Automated Vehicle Validation Conference (IAVVC), Pittsburgh, PA, USA, 22–23 October 2024. [Google Scholar]
- Ashqar, H.I.; Alhadidi, T.I.; Elhenawy, M.; Khanfar, N.O. Leveraging Multimodal Large Language Models (MLLMs) for Enhanced Object Detection and Scene Understanding in Thermal Images for Autonomous Driving Systems. Automation 2024, 5, 508–526. [Google Scholar] [CrossRef]
- Shriram, S.; Perisetla, S.; Keskar, A.; Krishnaswamy, H.; Westerhof Bossen, T.E.; Møgelmose, A.; Greer, R. Towards a Multi-Agent Vision-Language System for Zero-Shot Novel Hazardous Object Detection for Autonomous Driving Safety. In Proceedings of the 2025 IEEE 21st International Conference on Automation Science and Engineering (CASE), Los Angeles, CA, USA, 17–21 August 2025. [Google Scholar]
- Kugo, N.; Li, X.; Li, Z.; Gupta, A.; Khatua, A.; Jain, N.; Patel, C.; Kyuragi, Y.; Ishii, Y.; Tanabiki, M.; et al. VideoMultiAgents: A Multi-Agent Framework for Video Question Answering. arXiv 2025, arXiv:2504.20091. [Google Scholar]
- Jiang, B.; Zhuang, Z.; Shivakumar, S.S.; Roth, D.; Taylor, C.J. Multi-Agent VQA: Exploring Multi-Agent Foundation Models in Zero-Shot Visual Question Answering. arXiv 2024, arXiv:2403.1478. [Google Scholar]
- Bhooshan, R.S.; Suresh, K. A Multimodal Framework for Video Caption Generation. IEEE Access 2022, 10, 92166–92176. [Google Scholar] [CrossRef]
- Yang, Y. Vision-Informed Safety and Transportation Assessment (VISTA). 2025. Available online: https://github.com/winstonyang117/Vision-informed-Safety-and-Transportation-Assessment (accessed on 8 August 2025).
- OpenAI. GPT-4 Technical Report; Technical Report; OpenAI: San Francisco, CA, USA, 2023. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- OpenAI. ChatGPT (o3-mini). 31 January 2025. Available online: https://openai.com/index/openai-o3-mini/ (accessed on 4 November 2025).
- Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J.; et al. Qwen2.5-VL Technical Report. arXiv 2025, arXiv:2502.13923. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL), Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Association for Computational Linguistics, Ann Arbor, MI, USA, 23 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out (WAS), Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. CIDEr: Consensus-Based Image Description Evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Deng, C.; Li, Y.; Jiang, H.; Li, W.; Zhang, Y.; Zhao, H.; Zhou, P. CityLLaVA: Efficient Fine-Tuning for Vision-Language Models in City Scenario. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Wang, L.; Chen, S.; Jiang, L.; Pan, S.; Cai, R.; Yang, S.; Yang, F. Parameter-efficient fine-tuning in large language models: A survey of methodologies. Artif. Intell. Rev. 2025, 58, 227. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the Tenth International Conference on Learning Representations (ICLR), Virtual Conference, 25–29 April 2022. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).