4.1. Prototype
The prototype comprises four screens, namely the context screen, detection screen, repairing screen, and analysis screen, each having a different functionality and a menu bar to navigate between the screens. The context screen is used to select the context in the streaming data as it is linked to the context phase in the proposed framework, and the detection screen is utilized to determine some of the detection rules from the rules controller. The repairing screen is designed to present a repairing technique and a recommended technique for each selected technique. The repairing screen is connected to the repairing rule in the rules controller and the recommendation unit in the analysis phase. The analysis screen shows a summary of each screen and visualizes the result of the streaming data to the user. Further explanation of these screens follows.
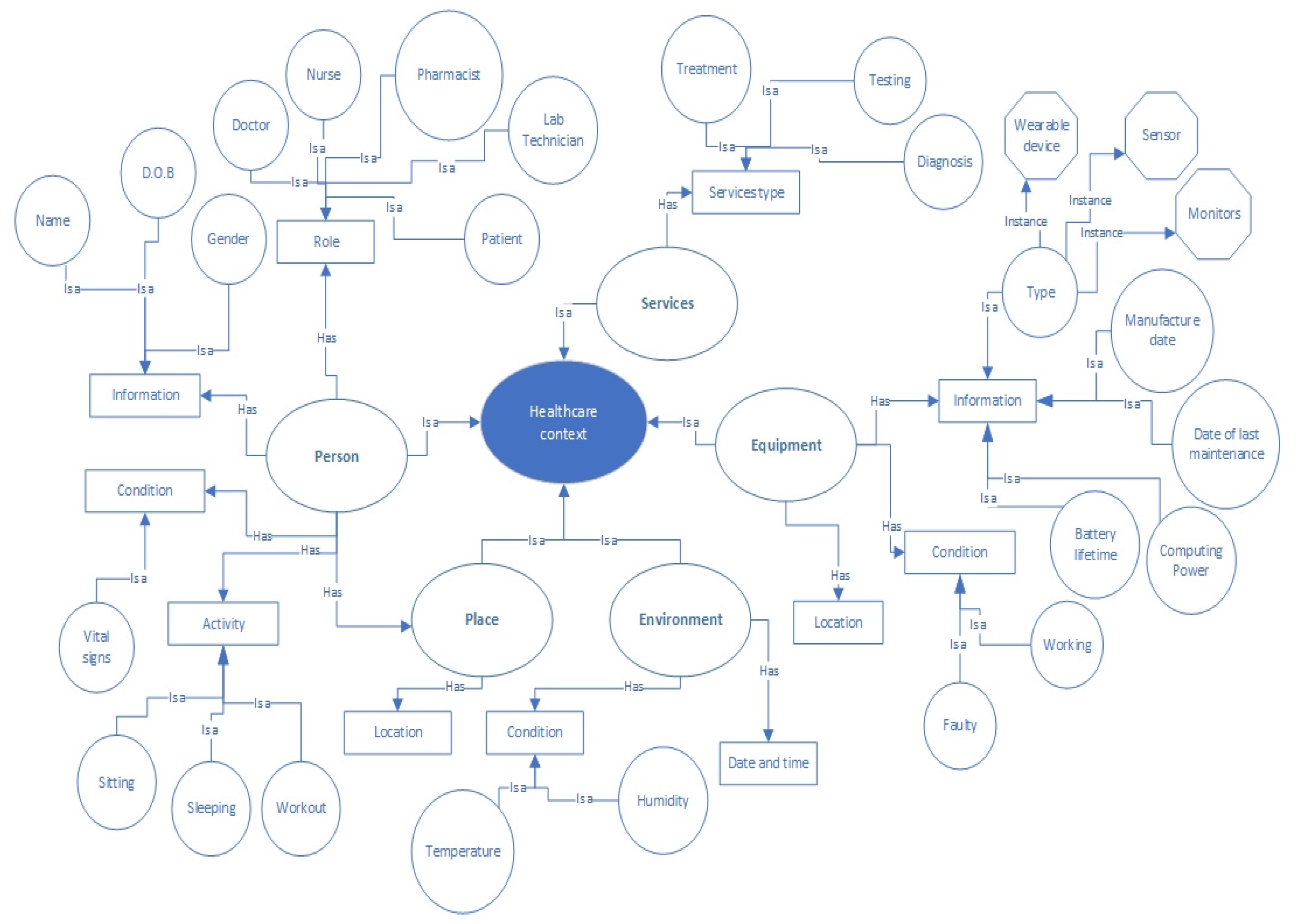
In the context screen, the user identifies the context, starting with choosing the domain from the drop-down menu, either healthcare, industry, business, weather, or education. When the user selects the domain, a description of using the system in this domain automatically appears next to the domain field to help the user understand what kind of analysis the user can perform based on the selected scenario and the data type. The description appears based on the information stored in the database, and after selecting the domain, the user selects a category from the category field, regardless whether the category is a person, place, environment, equipment, or services. After selecting the category, the user chooses one of the sub-categories that appear in the drop-down menu, which is a subset of the category, as shown in
Table 1. The sub-category automatically changes if the category changes.
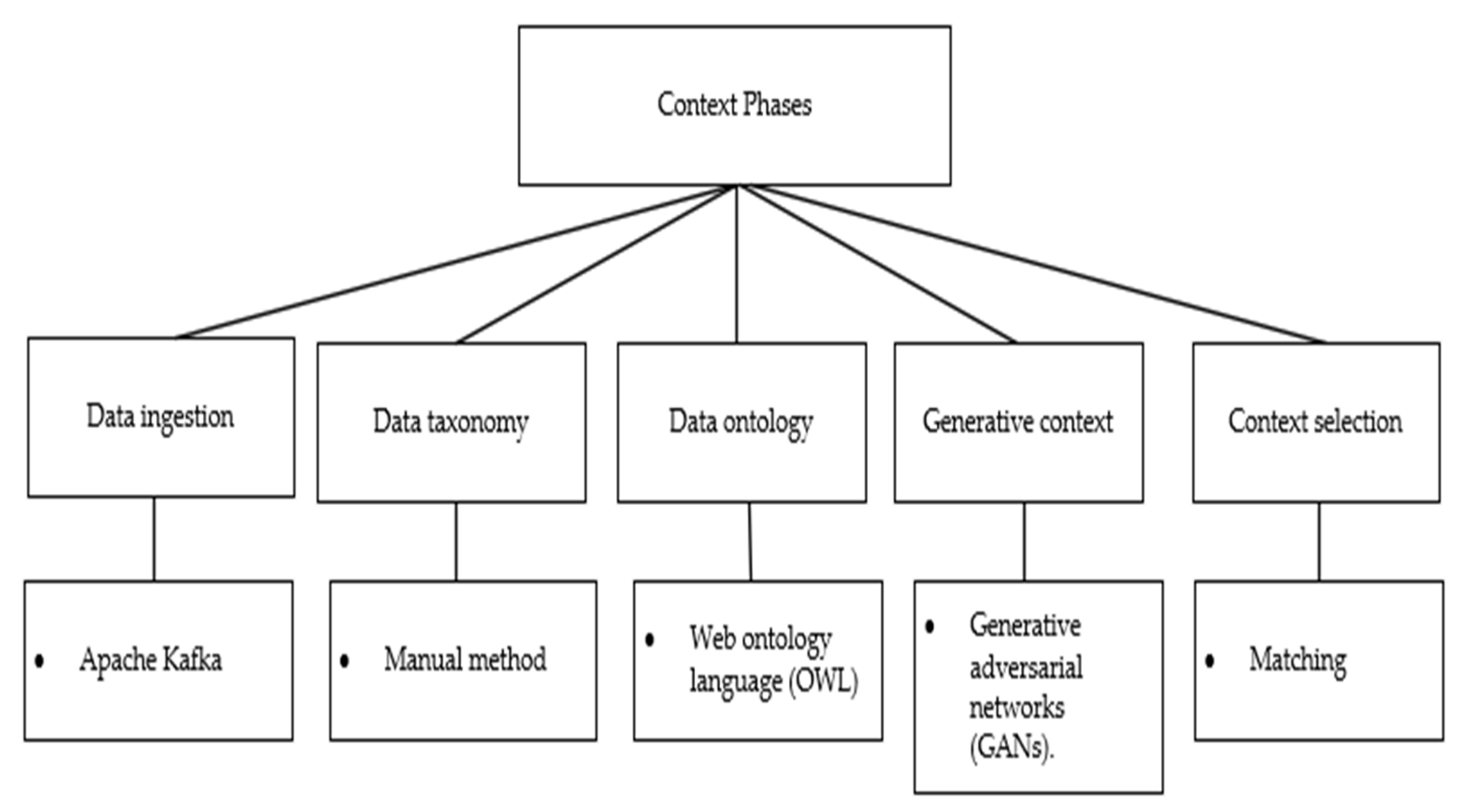
Next, the user chooses the sort of data from the sub-categories, then the type. Also, the sort of data is changed based on the sub-categories as well as the type. When the type of data is selected, the user sees the available variables as a list and the user selects the variables required to build the context. If the required variable does not appear in the list, the user adds the variable manually by typing the name and the type of data and presses the add button to add it to the context. The aforementioned fields are connected to the data ontology in the context phase. When the context is built, the user provides the data link where the data can be collected. Then, the user checks the context in the selected context section and when everything is ready, the user presses the next button to move to the detection screen. The context selected from the context screen is passed to the context selection unit in the context phase to match the user’s input with the context in the stream data and the matched context is considered as the selected context. It is then passed to the detection unit in the preprocessing phase.
Figure 7 illustrates the context screen.
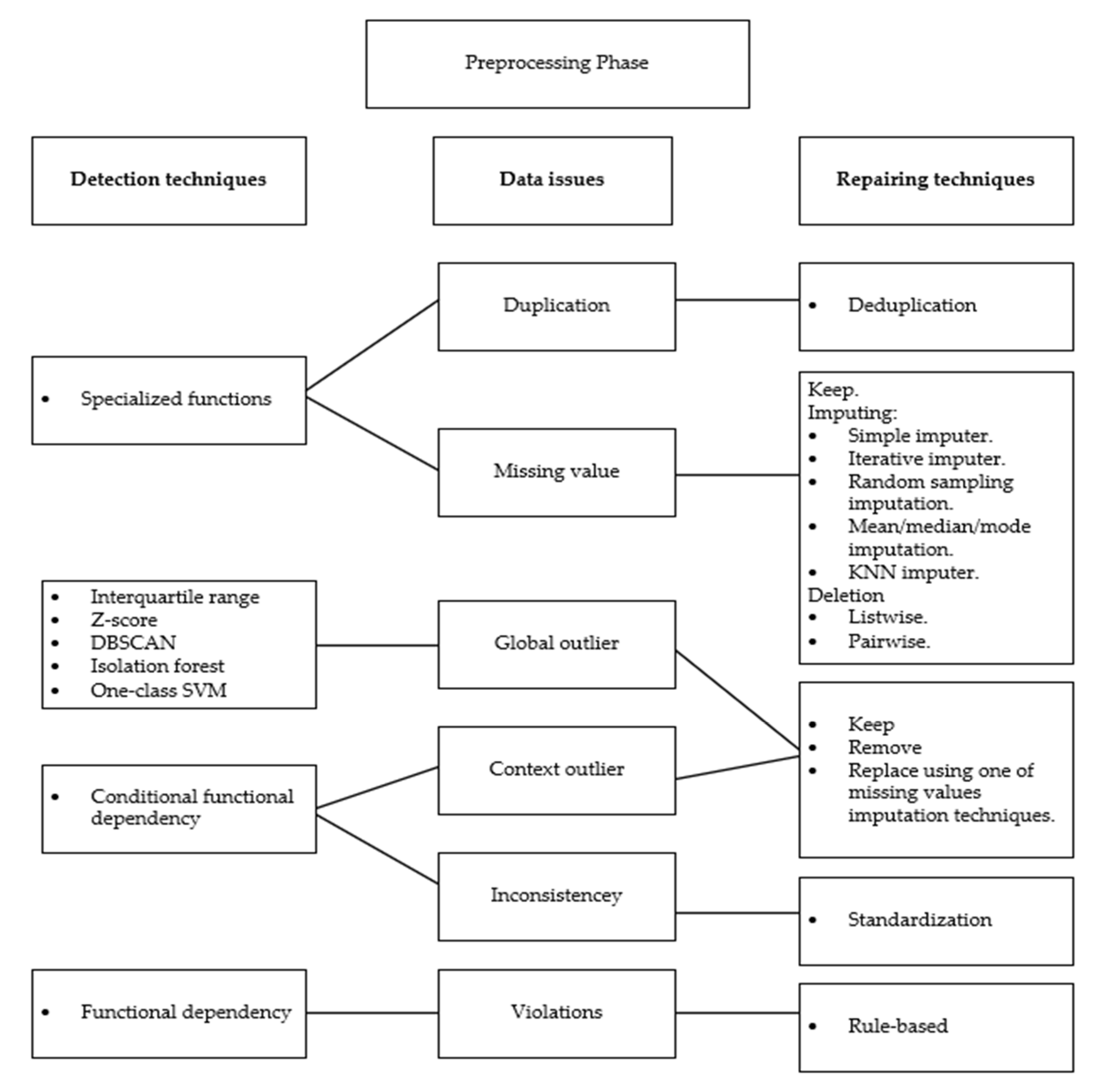
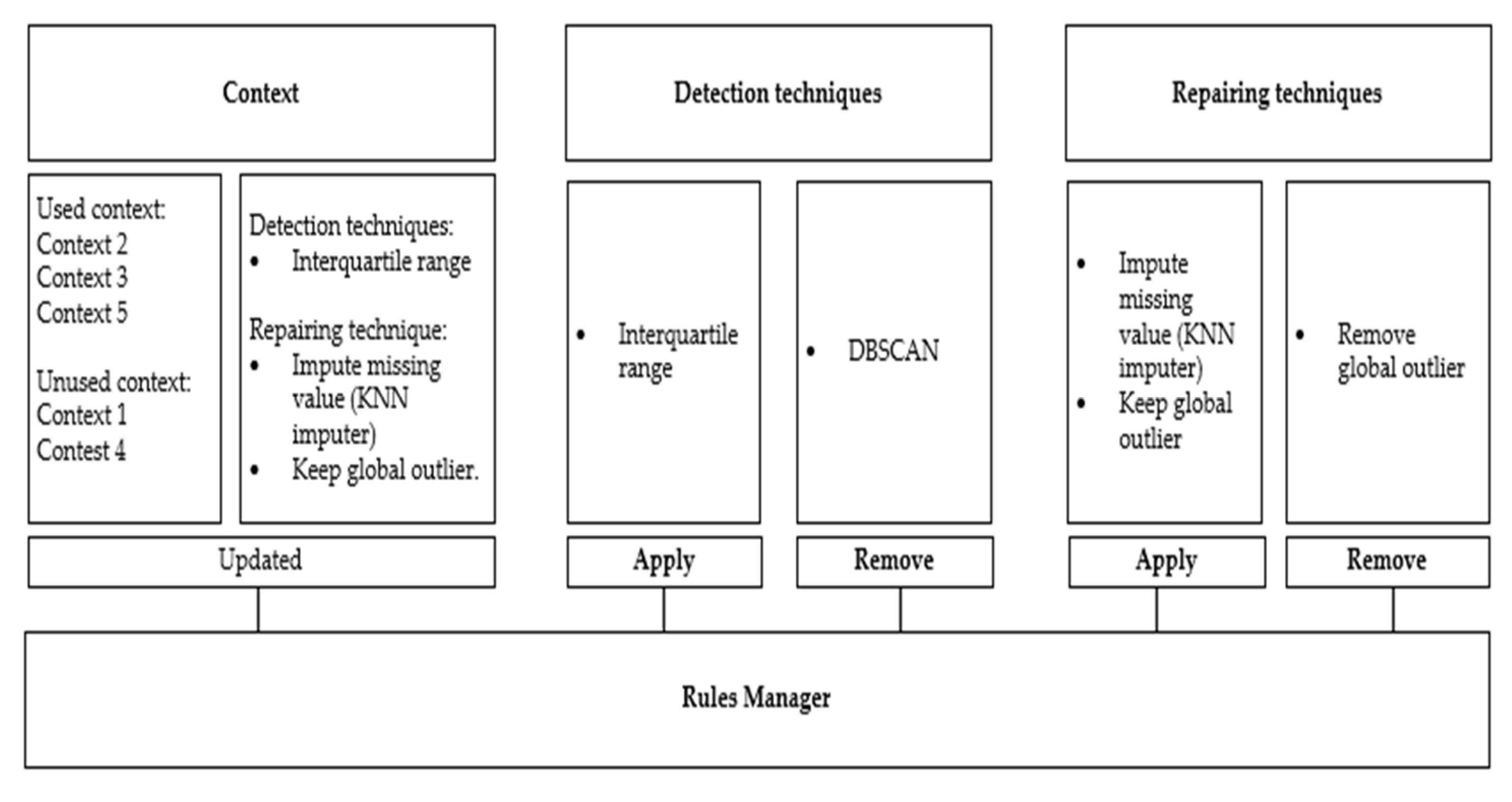
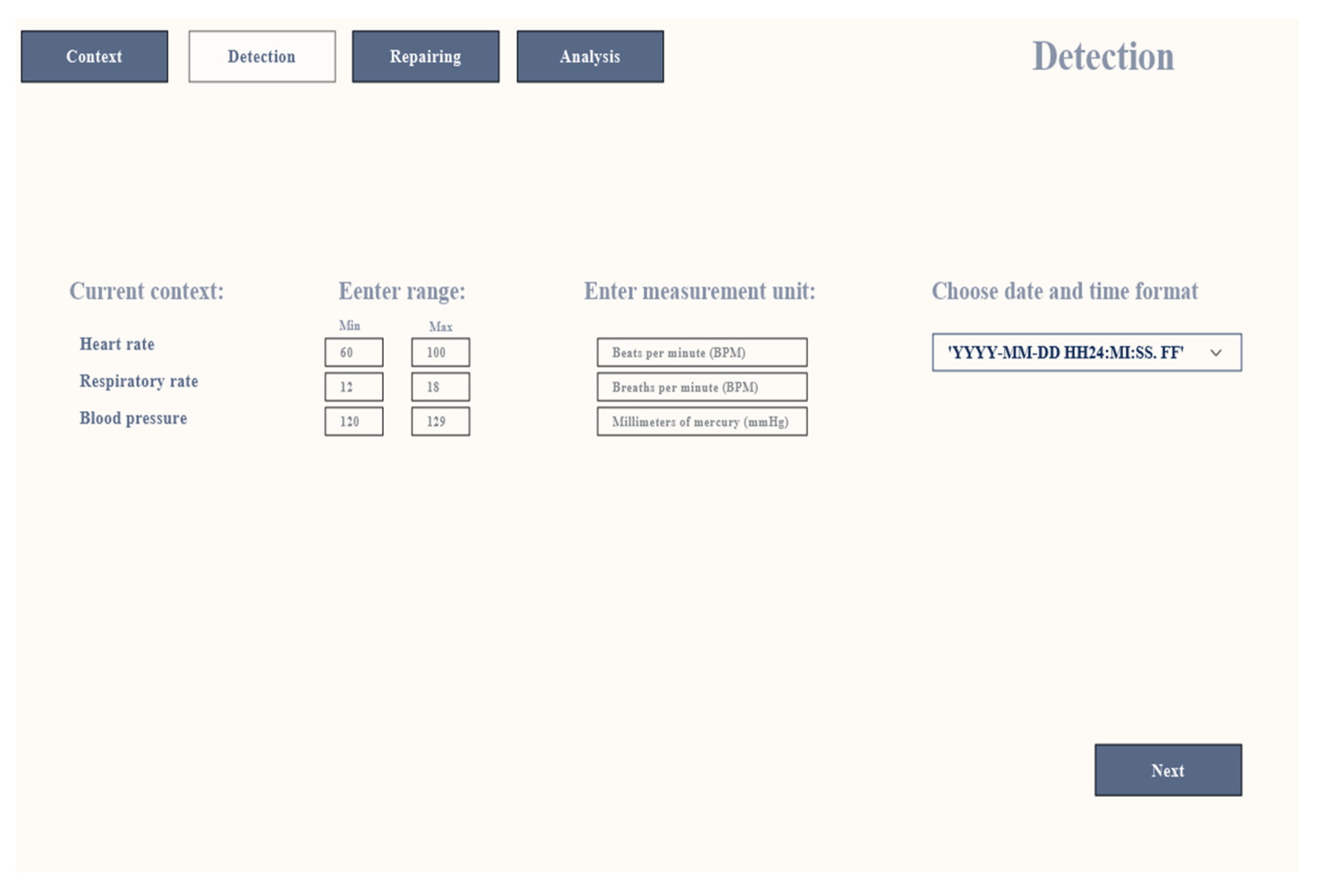
In the detection screen, the user sees the selected context from the context screen as the current context. Then the user determines the range of the data if the data type is numerical, which helps detect the outliers. The reason why the user defines the range of data values is that the range varies based on different factors, which is obvious to the user. The user needs to set the measurement unit of the context that has been selected to unify the measurement as it assists in detecting errors in the streaming data if they occur. Finally, the user defines the date and time format that is followed during the detection process if a different format appears. This screen is connected to the detection rules unit in the rules controller. Other issues, such as duplication and missing values, do not need any setup from the user side because there is only one approach to detect these issues. When the detection rules are finalized, the user clicks the next button to move to the repairing screen. The detection rules are sent to the detection unit in the preprocessing phase that is set by the user and other default detection rules (i.e., duplication, missing value issues).
Figure 8 shows the detection screen.
In the repairing screen, the user sees the context selected from the context screen as the current context. The user has multiple technique options to tackle the issues that appear in the selected context in the streaming data, as there are various methods to deal with these issues. So, the user is allowed to apply any technique in the real-time data stream. For instance, there are several drop-down lists, and each drop-down list is allocated to a particular issue such as a missing value, global outlier, or context outlier. Each list contains multiple cleaning techniques that can be applied to tackle these issues in the real-time stream. When the user chooses a technique to handle missing values, the recommendation unit in the analysis phase recommends a technique from the list to the user that can help to improve data quality in the real-time data stream.
It is noteworthy that the detection screen displays issues that need to be a specified value from the user side, such as the range of outliers or date and time format, which will help in the detection process, whereas issues like missing values or duplicated data, which do not need a specified value from the user to be detected, will not appear on the detection screen, as these issues will be detected by the system. However, in the repairing screen, there is only one method to fix particular issues, such as the date format or removing duplicated data as this will be done by the system, whereas there are several methods to fix issues such as missing values like imputing, ignoring, or removing missing values and handling outliers, so the user has to select a technique to resolve these issues. After selecting a technique, the user needs to choose whether to apply this technique once the problems are detected, choose the Apply all option to apply the technique to all issues that appear in the data stream as long as the data pattern does not change, or choose to do nothing, so the detected issue will be ignored and no repair technique will be applied.
Since streaming data are affected by several issues that reduce data quality, the system asks the user if it should continue repairing the streaming data when the data quality falls below 60% because cleaning data with a data quality of 50% will adversely affect the outcome of the data analysis. For example, the data in the sliding window contain 50% missing values, so imputing missing values will lead to unreliable results because there will be a bias in the data. Removing these missing values will lead to the loss of valuable information. Therefore, the user needs to decide whether to remove, keep, or ignore the missing values based on the current situation because these missing values occur due to defects in devices or for other reasons that are obvious to the user.
The user sets the repairing techniques to fix any issues that appear in the context and presses the next button to navigate to the analysis screen. The repairing unit in the preprocessing phase receives these repair rules in two ways. If the user applies the recommendation technique, the repairing techniques are sent from the recommendation unit in the analysis phase and the repairing rules in the rules controller are updated. If the user chooses to apply a different technique to what the system recommends, the repairing rules are sent from the repairing rules to the repairing unit in the preprocessing phase.
Figure 9 presents the repairing screen.
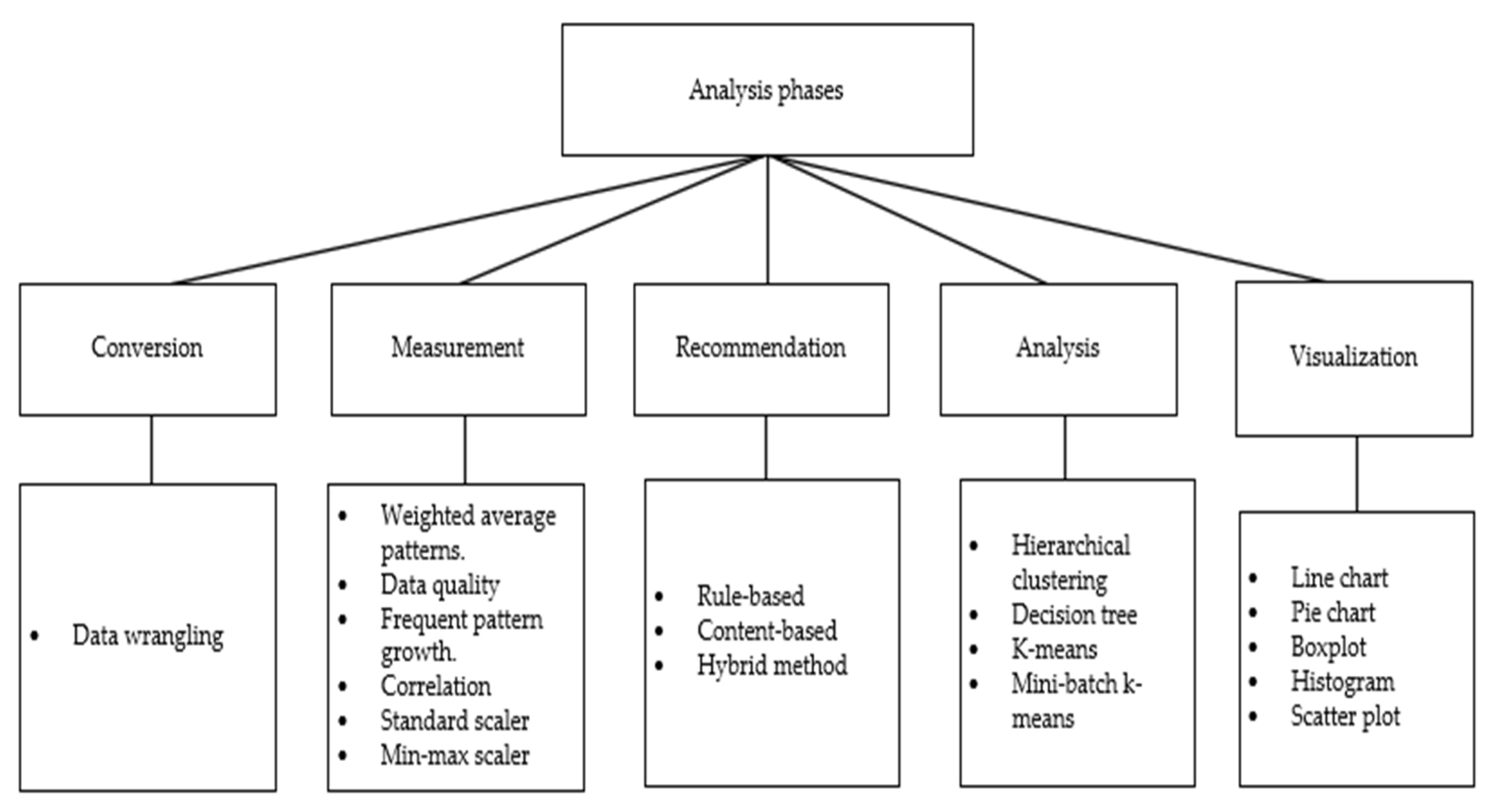
In the analysis screen, the user sees four subsections, namely summary of context, summary of data detection, summary of data repairing, and visualization. The context area is in the upper left screen. The user sees the summary of the current context that was selected from the context screen and sees the normal range of the selected context, average range, current value, and the equipment age. The equipment’s age is considered in the data quality. Also, the user sees if a new context is added or removed from the context area by the context generative unit in the context phase. These amendments are sent from the context rule to the context generative unit and are updated by the rules manager in the rules controller. On the lower left of the analysis screen is the detection area, which presents a statistical table as a summary of the number of detected issues in the streaming data. The detection table is linked to the detection unit in the preprocessing phase.
The repair area in the lower right of the screen shows a summary table of the number of repaired issues based on the selected cleaning techniques from the repair screen. The repair table is connected to the repair unit in the preprocessing phase. In the visualization area (top right), the results are visualized to the user based on the result of the descriptive analysis unit in the analysis phase. The data quality percentage is displayed to the user next to the visualization chart. We initially propose the following formula to measure the data quality in the stream data:
The equation is used in the detection unit and when the data come to the analysis stage. Then we take the average of these measurements as follows:
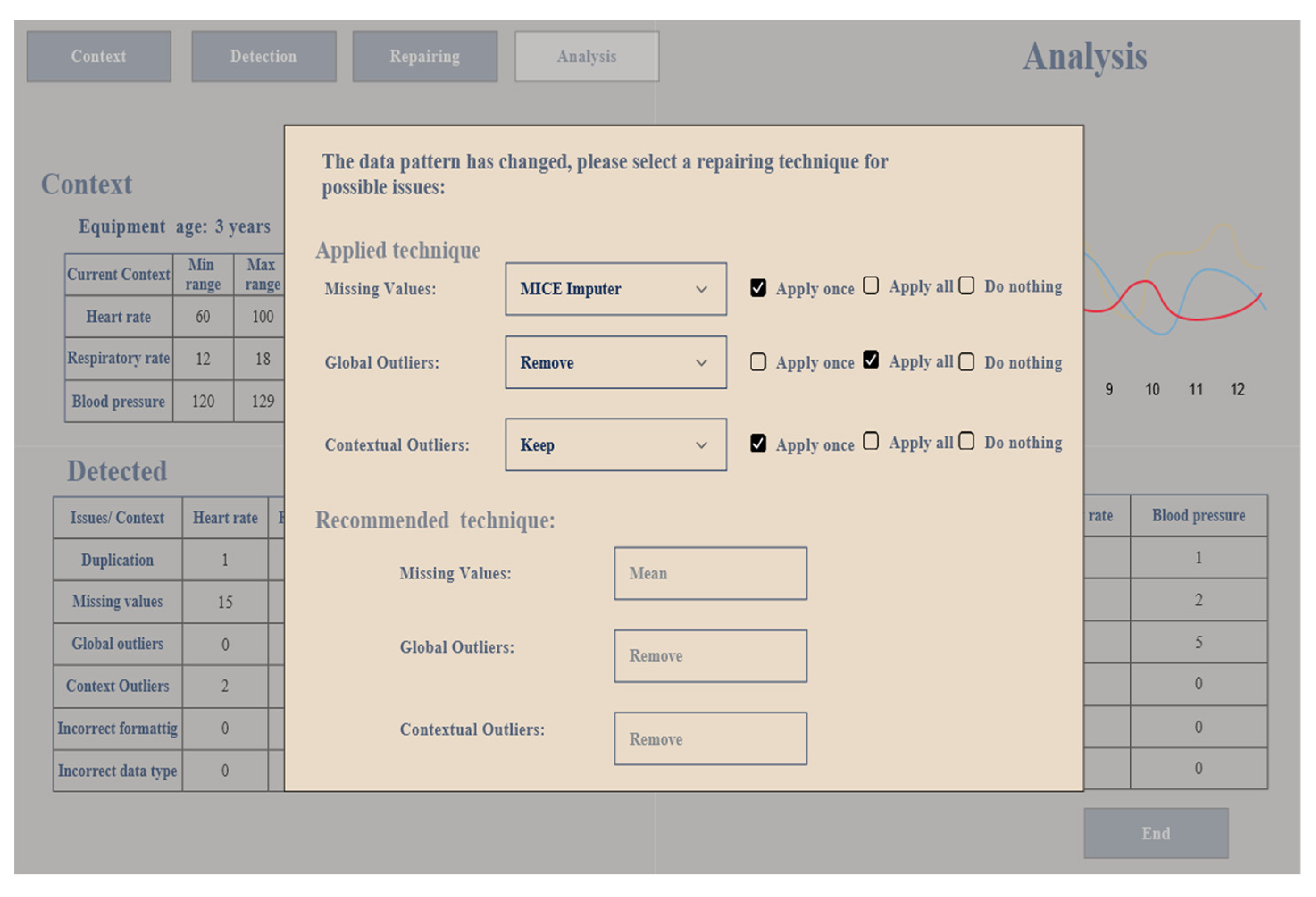
The reason for using average data quality is that repairing data is based on assumptions, especially imputing missing values or replacing outliers. Therefore, the data quality percentage and the charts can assist the user in making better decisions in real time. If the data pattern in the stream data has changed, a popup window appears on the analysis screen that asks the user to select the repair techniques based on the current situation. Finally, the user clicks on a button to end the session.
Figure 10 shows the analysis screen and
Figure 11 shows the popup window.
It is noteworthy that there is a default setting for each section on every screen. If the user has left some section of the screen empty, this setting is applied to these sections. For example, if the user does not specify the date and time format in the detection screen, there is a default date and time format that is applied to the date and time format section, and so for the other screens.
4.2. Use Case
We use a vital signs dataset that was collected at the Royal Adelaide Hospital by [
22], which contains a wide range of patient vital signs monitoring data. The dataset parameter description is given in [
23].
Let us say an expert wants to see a patient’s vital signs because some patients have reactions to particular types of drugs that change heart rate, breathing, and blood pressure. Thus, the expert wants to monitor these vital signs so they can react to any changes in these vital signs, if they occur.
The expert starts by selecting healthcare as a domain from the context screen. Improving patient safety, healthcare services, and quality of care are the benefits that the expert expects when selecting the healthcare domain as a sector. The expert continues selecting a person as a category, then selects a condition as a sub-category of the person, and finally, vital signs as a type of the condition. Then, the vital signs automatically appear on the screen and the expert selects the heart rate (HR), the mean blood pressure (NBP (Mean)), and the breathing rate (RR) to be monitored and provides the data link because sensors are used to collect data during surgery. When the context is ready and the data link is provided, the expert presses the next button to move to the next screen, as shown in
Figure 7.
In the detection screen, the expert determines the upper limit and lower limit of the selected vital signs considering the patient’s age, gender, and medical history. The expert assigns 60 as the lower limit and 100 as the upper limit for the HR, 12 as the lower limit 18 as the upper limit for the RR, and 120 as the minimum limit and 129 as the maximum limit for the NBP (Mean). These ranges are normal for healthy adults (the patient is an adult and has not previously suffered from any medical issues). After the upper and lower limits have been assigned to the vital signs, the expert defines the measurement units for the selected context as follows: beats per minute for the HR, breaths per minute for the RR, and millimeters of mercury (mmHg) for the NBP(Mean). The expert chooses the format of date and time to be as follows ‘YYYY:MM: DD HH24:MI: SS.FF’. If the values of the selected context exceed the determined limit, they are considered an outlier. Also, the data measurement units are standardized based on the user selection so, if the data appears with different measurement units, it is fixed. When the detection rules are set, as presented in
Figure 8, the expert moves to the repairing screen.
In the repairing screen, the expert chooses a proper technique to deal with the issues in the streaming data. For the missing values, the expert assigns a median method to replace the missing values with the median and chooses this technique to be applied to all missing values as long as the data pattern has not changed. For the global outliers, the expert chooses to keep the outlier and applies this technique only once when the global outlier is detected. For the contextual outlier, the expert decides to remove any detecting contextual outlier and implement the removing approach once. When the technique has been allocated to the data issue, the expert sees the recommended technique for the same issue and the expert prefers not to apply this technique. The expert prefers not to repair the streaming data if the data quality is under 60%, as depicted in
Figure 9. Since the context, detection techniques, and repair techniques have been defined, the expert moves to the analysis screen by pressing the next button and sees the visualization of the selected context in the real-time data stream.
The expert monitors the analysis screen and the streaming data starts to arrive from different sources to the context phase in the proposed framework, and it is ingested by the data ingestion unit in the context phase. Then, the ingested data are passed to the taxonomy unit in the context phase. In the taxonomy unit, the stream data are classified into five categories, namely person, equipment, environment, place, and services; each category has types, as presented in
Table 3. After categorizing the streaming data, they are mapped to the data ontology in the context selection unit, and the expert input in the context screen is also passed to the context selection unit. In the context selection unit, the streaming data are already categorized and mapped to the data ontology. The patient’s vital signs are selected based on the expert input from the context screen, then the selected context is sent to the preprocessing phase to check if the selected context contains any issues such as missing data, outliers, wrong unit measurements, etc.
In the preprocessing phase, the detection unit checks the selected context when it comes to the preprocessing phase based on the rules that have been received from the detection rules unit in the rules controller. When the selected context comes to the detection unit, the context values are as follows: the NBP (Mean) is 87 mmHg, the RR is 0 breaths per minute at the beginning and it increases when the breathing device is used, and the HR is 80 beats per minute for patient’s vital signs. If the selected context is in the normal range and does not have any issues, it is considered to be clean data and is passed to the analysis phase; otherwise, it is considered to be uncleaned data and is sent to the repairing unit.
The analysis screen presents to the expert a summary table of the currently selected context, a summary of the detected issues and repairing issues, and the chart with the data quality percentage of the stream data. The detection unit captures issues regarding the values of the HR, RR, and NBP (Mean) and the number of the detected issues for each issue is presented in the detection table to the expert. These issues pass to the repair unit and the selected techniques are applied to repair these issues. The repairing table shows the number of repaired data for each issue, as shown in
Figure 10. The expert noted from the detection table that the selected context contains missing values, and the RR has eight global outliers because the breathing device was not used at the beginning (the RR values were 0 breaths per minute and the lower limit for RR was 12 breaths per minute); however, the breathing rate is now in the normal range, so the expert ignores the outliers in the RR. The expert sees any detection issues that appear in the detected table. The repair table shows the number of repaired issues to the expert, so the expert has insight into the functionality of the system in terms of detecting issues and repairing the issues in the streaming data based on the selected cleaning techniques.
The data continue to arrive and the system continues to ensure that the incoming data are cleaned. The system repairs the streaming data if they have issues in improving data quality in a real-time stream. Also, the system visualizes the result and assesses the data quality based on our proposed metrics. With the high-quality data that the system provides, difficult decisions can be made with confidence.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}