1. Introduction
Cardiovascular disease is one of the leading causes of death worldwide, accounting for 17.9 million deaths per year due to undetected risk factors such as hypertension [
1]. Hypertension is a lethal risk factor for cardiovascular disease known as “the silent killer” since it exhibits no symptoms or complaints. However, hypertension may cause additional illnesses or problems such as organ damage [
2]. Measuring physiological factors such as blood pressure (BP) is critical for detecting and analyzing cardiovascular disorders. When BP measures are frequently acquired and evaluated using other physiological indicators, they can identify and be used to diagnose cardiac abnormalities and cardiovascular risk factors, such as hypertension, and they can even predict cardiovascular events [
3].
Traditionally, various invasive and noninvasive methods, such as catheterization, auscultation, and oscillometry, have been used to monitor BP. However, the current measurement techniques require expensive instruments with high precision and sensitivity, necessitating the expertise of specialized healthcare professionals. Furthermore, these methods involve physical contact, which increases the risk of COVID-19 exposure. In addition, the use of a cuff in a sphygmomanometer for continuous BP monitoring can be uncomfortable [
4]. Therefore, a convenient, remote, and accurate BP monitoring system is required.
COVID-19, caused by the SARS-CoV-2 virus [
5], has posed challenges to BP measurement as it is an infectious illness affecting the respiratory system. COVID-19 is highly contagious, spreading through droplets from the nose or mouth of an infected person while coughing, sneezing, talking, singing, or breathing. Since assessing physiological measures requires physical contact, the danger of COVID-19 exposure increases for healthcare personnel and patients, thereby aggravating health conditions and leading to difficulties [
5]. Therefore, reducing COVID-19 transmission by minimizing the physical contact between healthcare professionals and patients is crucial, thus prompting the need for remote measurements or monitoring solutions.
In recent years, there has been an ongoing evolution in BP measurement, especially in the realm of wireless or cuffless methods; such techniques address the limitations of other approaches, such as inconvenience and discomfort. Recently, researchers have used photoplethysmography (PPG) signals for wireless BP measurements. Multiple studies have focused on BP measurements by analyzing the critical features extracted from PPG signals. Subsequently, they have employed machine learning or deep learning to process the information from PPG signals, thereby aiming to generate accurate and reliable estimates.
Gaurav et al., in their BP measurement based on PPG using a Samsung Galaxy Note5, employed min-max scaling for preprocessing, successfully achieving mean absolute errors (MAEs) for the predictions of systolic BP (SBP) and diastolic BP (DBP), which were measured at 6.9 mmHg and 5 mmHg, respectively. They utilized a set of unique PPG features, which were specifically interpolated and normalized pulses with pulse lengths, in their artificial intelligence (AI) model, and they employed an artificial neural network to predict BP [
6].
Xie et al. proposed a real-time BP measurement method using PPG signals and feature extraction. They employed two PPG probes to extract the essential features for BP estimation, achieving a mean absolute difference (MAD) of 4.21 ± 7.59 mmHg for SBP and 3.24 ± 5.39 mmHg for DBP [
7]. Radha et al. introduced a wrist-worn PPG sensor-based method, and they complemented this approach with long short-term memory (LSTM) networks for BP trend tracking and SBP dip estimation [
8].
Furthermore, Slapničar et al. [
9], Attivissimo et al. [
10], Kachuee et al. [
11], Omer et al. [
12], Kachuee et al. [
13], and Liu et al. [
14] presented BP estimation systems utilizing PPG databases such as MIMIC II and MIMIC III. They employed various preprocessing and feature extraction techniques, including the use of first and second derivatives, maximal overlap discrete wavelet transform (MODWT), pulse transit time, and wavelet scattering transform (WST). Machine learning techniques such as artificial neural network, regression forest, secpro-temporal ResNet, XGBoost, support vector machine, LSTM, AdaBoost, and support vector regression have also been utilized.
Building on the advancements highlighted above, this paper describes a novel, cost-effective, and cuffless BP measuring system that capitalizes on precise BP estimation. Using a simple optical method, PPG can effectively capture changes in arterial volume [
4]. Our method for translating PPG signals into BP readings involves extracting key features from PPG signal components [
4]. We introduced a unique feature extraction algorithm to identify the amplitudes of the foot, notch, systolic, and diastolic components. By emphasizing the affordable and innovative feature extraction techniques, our work lays the groundwork for advancing cuffless, wireless, noninvasive, and real-time BP monitoring. Additionally, this system enables the remote monitoring of patients’ BP, thus facilitating measurements from a distance.
2. Materials and Methods
BP measurements provide SBPs and DBPs [
15]. SBP is the arterial pressure while the heart beats, whereas the BP in the arteries when the heart is at rest between beats is referred to as the DBP [
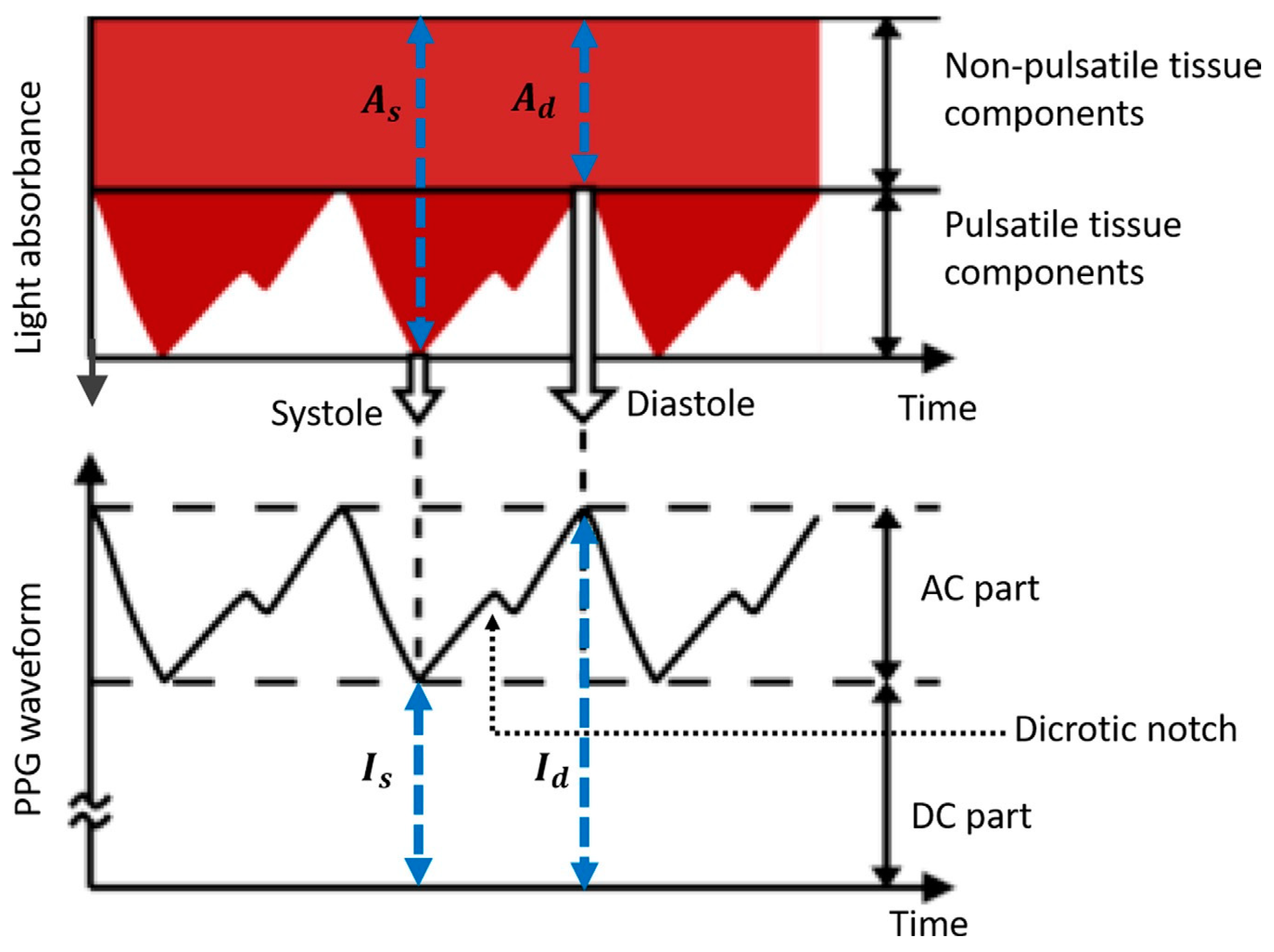
15]. PPG utilizes the variations in light absorption caused by changes in tissue characteristics during the cardiac cycle. This cycle comprises the systole and diastole parts, and the resulting changes in light absorption generate a PPG waveform that is synchronized with each heartbeat. Light is directed at the tissue to capture a PPG signal, with a portion absorbed and the remainder reflected or transmitted. The modulated light intensity is measured using a photodetector. The intensities of the reflected and scattered light reaching the photodetector are measured, and variations in the photodetector current are associated with the changes in blood volume [
16]. A schematic of the PPG waveform is shown in
Figure 1.
As illustrated in
Figure 1, an inverse relationship exists between the recorded PPG intensity (I) and the light absorbance (A). The intensity of PPG is categorized into two sets depending on its impact on light absorption in both pulsating and non-pulsating tissue segments. The initial nonpulsatile classification entails a relatively steady direct current (DC) component generated through light absorption in nonpulsating tissues such as muscle and bone. The second type, referred to as pulsatile, comprises a pulsatile alternating current (AC) component generated by light absorption in the pulsating arterial blood, with variations corresponding to the pulse. The AC PPG is segmented into two phases: the rising edge of the pulse, known as the anacrotic phase, which is linked to the systole; and the falling edge of the pulse, termed the catacrotic phase, which is associated with the diastole. Furthermore, the dicrotic notch indicates the end of the aortic systole and the beginning of the diastole [
4].
A linear solid viscoelastic model establishes a direct relationship between the AC components of PPG and BP waveforms in the frequency domain (∆V(ω) and ∆P(ω)) according to the following equation:
Here,
represents the low-frequency elastic modulus (the inverse of compliance),
denotes the high-frequency elastic modulus, and
stands for the viscosity of the arterial wall. This model shows that the PPG waveform acts as a low-pass filtered version of the BP waveform at the same arterial site, indicating that PPG waveform characteristics may contain information regarding BP [
4].
PPG can be used to measure BP, as shown in the equation above. Designing a PPG-based blood measurement system involves acquiring relevant equipment, such as datasets and devices, and executing experiments using the appropriate models. The objective is to establish a wireless connection between the sensor and the microcontroller to generate PPG signals from the subjects, thus enabling a more accessible and convenient approach for monitoring BP.
2.1. PPG BP Measurement Systematic Flow
BP measurement begins by connecting the ESP-WROOM-32 to the available Wi-Fi by uploading a code from the Arduino IDE to the microcontroller, which contains the IP address of the computer, Wi-Fi name, Wi-Fi password, and the code responsible for measuring the PPG signal from the finger. Suppose that the ESP-WROOM-32 and MAX30102 sensor are successfully connected to the internet. In this case, the index finger is attached to the PPG measurement device consisting of the ESP-WROOM-32 and MAX30102 sensor, and the infrared amplitude forms the PPG signal obtained from the sensor, which is sent to the cloud database using the Wi-Fi protocol available on the ESP-WROOM-32.
In this study, the data were initially stored in a cloud database on various platforms, including the ThingSpeak library, which is accessible on the Arduino IDE, Antares, which is integrated with the ESP-WROOM-32 and a MySQL database. Thirteen data points per second were sent to the MySQL Database from the MAX30102 sensor. In comparison, other database types can only receive one data point every 2 s for Antares and every 18 s for ThingSpeak. Therefore, the MySQL Database (MySQL 8.0.28, Oracle, TX, USA) used as the storage medium in this study is superior to the other two platforms.
PPG signals stored in the database were visualized on a graph displayed on the web using a local server approach. The graphical user interface (GUI) display in this study comprised several components, including the title of the webpage, a description of the webpage contents, and a graph illustrating the PPG measurements. The x-axis represented the time of the measurement, and the y-axis represented the amplitude of the infrared light intensity absorbed as the light passed through the finger. A prediction button was placed at the bottom of each page. When pressed, this button processed the PPG signal graph by preprocessing the signal and making estimations using the AI model, which was trained using the collected dataset. The processed PPG signal was recorded for the minute preceding the button press. The BP estimation results from the PPG signal appeared in the text box below the prediction button as SBPs and DBPs. The overall systematic flow of the PPG BP measurements is shown in
Figure 2.
2.2. Components
The proposed BP measurement system was designed using two electronic components: a MAX30102 PPG sensor (Maxim Integrated, CA, USA) and an ESP-WROOM-32 microcontroller (Espressif Systems, Shanghai, China). The MAX30102 is a module with integrated pulse oximetry and heart rate monitoring capabilities [
17]. The ESP-WROOM-32 is another module with integrated Wi-Fi, Bluetooth, and Bluetooth LE capabilities, and it is suitable for various applications ranging from low-power sensors to heavy-duty tasks such as voice encoding, music streaming, and MP3 decoding [
18].
The MAX30102 and ESP-WROOM-32 devices were linked using a female-to-female jumper cable to connect the pins on the sensor and microcontroller. The connections were as follows: V
in to V
in, which function as power pins for the boards; SDA to SDA, serving as serial data pins used to send and receive data for I2C communication; SCL to SCL, which function as serial clock pins for clock signals; and GND to GND, which serve as ground pins. The device assembly is shown in
Figure 3.
The MAX30102 light-emitting diode emitted an infrared light that was absorbed, reflected, and dispersed by the subject’s tissue and blood. The photodetector measured the modulated light intensity and generated a PPG signal. The sensor retrieved data from the measurement program code in the Arduino IDE, which was uploaded to the microcontroller linked to the PPG sensor.
2.3. AI Model: Random Forest Algorithm
The BP measurement AI model started by collecting data from a dataset. Subsequently, the collected data were preprocessed to eliminate undesired noise and artifacts. Once the preprocessing was complete, the proposed model proceeded with feature extraction, and the resulting data were used as the training dataset for the AI model. A comprehensive flow of the AI model is shown in
Figure 4.
Machine learning empowers computers to learn without being programmed directly. It involves the use of computers with the ability to learn. There are three categories of machine learning methods: supervised, unsupervised, and reinforcement learning [
19]. A supervised learning method was used to develop the BP measurement system. In the development of this system, a regression approach was chosen because the output variable represents BP, which is a continuous real value (whereas classification is used to categorize variables into different categories [
19]). The supervised learning algorithm that was used with the regression category utilized in designing this system was random forest.
Random forest is a popular machine learning algorithm patented by Leo Breiman and Adele Cutler that aggregates predictions from numerous decision trees to produce a unified outcome. The random forest algorithm utilizes tree-based models by splitting a dataset into groups based on specific criteria until a predefined stopping condition is reached. At the end of each decision tree, the leaf nodes are known as leaves. Its widespread acceptance is attributed to its simplicity and adaptability, which make it suitable for classification and regression tasks [
20,
21].
2.3.1. Data Acquisition
The data were retrieved by holding a finger on the sensor for 1 min, thereby ensuring that the PPG graphic data obtained were PPG graphs. The data gathering subjects were six healthy individuals, between 21–24 years old, with the BP measurements falling into the categories of normal and elevated. The distributions of the SBP and DBP in the raw dataset before cleaning are shown in
Figure 5. Data were collected from all participants when they were seated. Every subject was assessed using a PPG BP measuring system and an OMRON HEM-8712 BP measurement device to collect the actual measurements. The PPG signal data were then retrieved by the sensor and sent to the server using the Wi-Fi protocol. Subsequently, the data received were stored in a MySQL Database. The database collected sensor data, which were then evaluated and displayed.
The data collection process resulted in a unified dataset that included comprehensive measurement data from six subjects, totaling 114 BP measurements and comprising 2856 rows of extracted features representing the unique pairs of systolic and diastolic values from each measurement. Each row corresponded to a signal representing various physiological parameters, including foot, notch, diastolic, and systolic values. Note that each measurement may have a different number of rows of extracted features. This dataset provides a detailed perspective on these physiological parameters, which require further analysis.
2.3.2. Preprocessing
Preprocessing is an important step that must be completed before data processing. This step aims to eliminate noise or artifacts from the data. Motion artifacts are the most common issues observed when assessing physiological data using PPG sensors. Baseline wander correction was employed in this phase to address the baseline drift that may have been caused by motion artifacts [
22]. The result of applying the baseline wander correction to our signal can be observed in
Figure 6.
2.3.3. Feature Extraction
The preprocessed data underwent a 2-step process: peak detection and feature extraction. Feature extraction is the latest method for converting PPG into BP. This method measured the PPG signals based on their morphological features and the characteristics of the PPG signal [
4]. BP measurement from the PPG signal can be achieved by extracting four points from the PPG signal, as shown in
Figure 7, which indicate the beginning of the systolic phase, the systolic peak representing the maximum peak of the systolic phase, the dicrotic notch marking the end of the systole and the beginning of the diastole, and the diastolic peak representing the maximum peak of the diastolic phase.
This study utilized peak detection to identify the foot, notch, diastolic, and systolic peaks in the PPG signal, and this was conducted because these peaks contain information that is crucial for BP measurement. These peaks were categorized into two types: maximum peaks and minimum peaks. The maximum peak contains the systolic and diastolic peak values, whereas the minimum peak encompasses the foot and dicrotic notch values of the PPG signal. Hence, the peak detection process generates two lists: the maximum and minimum peaks.
Our proposed feature extraction method separates the foot and notch peaks from the maximum peak values which can be seen as purple circles on
Figure 8, as well as the systolic and diastolic notches from the minimum peak which can be seen as red crosses on
Figure 8. Features that were combined in both lists had to be separated. Therefore, feature extraction was performed in four steps. The first step was to input the amplitude values of the foot and notch peaks into separate lists, namely the foot list for the amplitude of the foot peak and the notch list for the amplitude of the notch peak. Next, the index of the notch peak was stored in a new list by determining its index from the baseline variable (a variable containing y-axis values in the PPG signal or amplitude values). This notch list index was used to determine the diastolic index from the minimum peak list. The last step was to extract, while equalizing the total sum of all data in each feature, the systolic index from the minimum peaks and the foot peak index from the peaks.
The results of the feature extraction comprised four columns: foot, notch, diastolic, and systolic. These columns were in addition to two other columns representing the actual BP measurements, namely SBP and DBP. The extraction results were saved in a comma-separated values (.csv) file format. Each measurement may have a different number of lines of extracted features depending on the number of PPG signals present in each measurement.
Furthermore, owing to the difference in the number of extracted features in each BP measurement, a reduction in the number of feature extraction rows was performed to achieve balance in the data, specifically to 20 rows as the highest average number of extracted features was found in 20 rows. Thus, a total of 1540 feature extraction rows were obtained, representing 77 BP measurements, each representing unique pairs of systolic and diastolic values from each measurement. The dataset was then divided into 90% training data, which consisted of 1400 rows representing 70 BP measurements, and 10% testing data, which consisted of 140 rows representing 7 BP measurements. The training and testing datasets were divided by stratified sampling. This method involves a probability sampling of the elements from the target population, where the elements are grouped into distinct strata. Within each stratum, the elements shared characteristics that were important for the survey [
23]. The results of the feature extraction process are presented in
Figure 8.
2.4. Model Evaluation
The training dataset was then used to train the AI model, thereby resulting in a model, which was saved as a pickle (.pkl) file. The proposed model was subsequently assessed to determine which of the models provided the best predictions. The proposed model was evaluated using various metrics, including the MAE, which measures the average difference between the predicted and actual values. A low MAE value indicates high accuracy. In the below formula,
represents the number of samples,
is the actual sphygmomanometer value for sample, and
is the predicted data for sample
i. The MAE was calculated using the following formula:
The coefficient of determination (R
2) measures how well the proposed model predicts the measurement value, with an evaluation value ranging from 0 to 1; if the R
2 is close to 1, the model is very accurate. The evaluation results of the tested models were compared, and the model with the highest accuracy was obtained. In this context,
represents the actual sphygmomanometer value for sample
i,
represents the predicted data for sample
i, and
represents the average of all response values. This equation takes the following form:
2.5. Model Deployment
The model with the highest accuracy can reliably predict the physiological parameter readings. Subsequently, the best model was deployed in the GUI development stage. This stage was conducted so that users can utilize the product and find it easier to apply the research results. The GUI displayed the PPG signal graphs and conducted peak identification and feature extraction. The prediction model to estimate the BP values was published locally on the web, as shown in
Figure 9.
4. Discussion
We present a cuffless BP measurement system that estimates SBP and DBP values based on PPG signal features, including the amplitudes of the foot, notch, and the systolic and diastolic components. Based on the model results from the previous section, the random forest model achieved an MAE of 4.38 for the SBP and 4.49 for the DBP. However, notable discrepancies existed in the R2s between the training and testing datasets. This discrepancy may be attributed to the very small amount of measurement data, which could limit the proposed model’s ability to learn and generalize patterns effectively, causing it to struggle to capture variability in the data.
Considering the results of the random forest model, further analysis was conducted and is described below. This includes a comparison with other algorithms and studies to assess the performance of the cuffless BP measurement system comprehensively.
4.1. Comparison with Another Algorithm
In addition, we employed the XGBoost algorithm to develop a BP prediction model based on the PPG signal extraction findings. XGBoost is an AI algorithm derived from ensemble learning techniques. Ensemble learning, also known as committee-based learning or the learning of multiple classifier systems, trains multiple learners to solve the same problem [
26]. The working principle of ensemble learning is similar to that of decision making in the real world, wherein it seeks different opinions from different experts to help determine the best choice, thus increasing confidence in the decision made [
27]. The most commonly used algorithms for ensemble learning are bagging, stacking, and boosting. The boosting method, which is capable of converting weak learners into strong ones, was employed in the design of this system [
27]. The key to boosting the ensemble is to rectify errors in the predictions. Models are added to the ensemble sequentially, with the second model attempting to correct the predictions of the first model, and the third model improving upon the second [
28]. In this method, the training dataset remains unchanged; only the learning algorithm is modified to focus on the details of the data rows based on what has been correctly or incorrectly predicted by the previous ensemble members.
The hyperparameters used in this algorithm were the learning_rate, gamma, max_depth, n_estimators, alpha, and lambda. Learning_rate was used to prevent overfitting. This was chosen because, after every boosting step, it directly obtains the weights of new features; learning_rate shrinks the feature weights to make the boosting process more conservative. The default learning_rate was 0.3. Gamma was used to minimize the loss reduction and further partition the leaf node of the tree. Max_depth is the maximum depth of a tree, and its default value is six. N_estimators represents the number of trees in the XGBoost model, with a default value of 100. Alpha and lambda are hyperparameters for regularization.
Regularization is employed to reduce errors in learning algorithms by modifying their behaviors. L1 regularization (lasso) and L2 regularization (ridge) are common techniques used for this purpose. Lasso regression methods are often utilized to prioritize efficiency in fields that deal with large datasets. However, they encounter challenges with highly correlated predictors, often arbitrarily selecting one while disregarding the others. Moreover, the lasso may encounter issues when the predictors are identical. The penalty associated with the lasso is that numerous coefficients are expected to be close to zero, with only a small subset being larger and non-zero. Ridge regression is ideal for datasets with many predictors, all of which have non-zero coefficients drawn from a normal distribution. This performs well when predictors have small effects, and it prevents high variance in models with correlated variables by equally shrinking their coefficients toward zero [
29]. The L1 parameter in the XGBoost method is alpha, and the L2 parameter is lambda [
30,
31]. A grid search was used to identify hyperparameter values. The hyperparameter values are listed in
Table 4.
Based on the results of the hyperparameter values, it can be seen that the configuration indicated a conservative approach to prevent overfitting, as indicated by the low learning_rate and max_depth values. In addition, it can also be seen that both alpha and lambda had values based on the grid search, which means that elastic net (ENET) regularization was implemented. The ENET serves as an extension of the lasso, thereby offering robustness against the extreme correlations among predictors. This addresses the instability encountered in lasso solutions when the predictors are highly correlated by introducing a combination of L1 (lasso) and L2 (ridge) penalties. Proposed for analyzing high-dimensional data, ENET provides a solution to the challenges posed by highly correlated predictors [
29]. The training evaluation results for XGBoost and random forest are compared in
Table 5, with the superior value between XGBoost and random forest highlighted in bold.
The training evaluation results indicate that the random forest approach achieved a lower MAE and a higher R2 for both systolic and diastolic BPs. This may be attributed to random forest being easier to tune than XGBoost as it has only two main parameters: the number of features and the number of decision trees. Consequently, random forest is less prone to overfitting than XGBoost, which is more sensitive to overfitting and more difficult to tune.
4.2. Comparison with Other Studies
We also compared our study with some related studies on BP estimation using PPG, as shown in
Table 6. However, a comparison with other studies poses challenges owing to differences in data acquisition methods, evaluation metrics, and datasets. In this study, the selection and identification of other studies for comparison were based on the types of data acquisition methods, features employed, and algorithms used. Specifically, the criterion for comparison was the training of the machine learning algorithms using the features extracted from the PPG signal, which constituted the research methodology.
A direct comparison between our method and the approaches of Xie et al. [
7] and Radha et al. [
8] is not feasible, as shown in
Table 6. This is because of the use of different measurement systems, specifically the MAD, standard deviation, and root mean square error (RMSE). As mentioned previously, comparing our findings with those of other studies is challenging.
Table 6 illustrates this difficulty as the studies utilized different datasets and various machine learning algorithms. For example, Attivissimo et al. [
10] achieved a smaller MAE for both SBP and DBP. This disparity could be attributed to differences in the datasets and the inclusion of demographic features that were potentially influenced by the sensors used to measure the PPG signals. In our study, optimal results were obtained using random forest instead of XGBoost. This approach appears to outperform other AI algorithms, as indicated in
Table 6.
4.3. Sources of Error and Limitations, Clinical Significance, and Future Advancements
The findings of this study offer promising indications for estimating BP using PPG signals. However, several limitations should be addressed in future studies to enhance the effectiveness of this model. One probable limitation may arise from the small sample size (six participants) with a specific waveform shape, all of whom were healthy young individuals under seated conditions. This limitation may hinder the ability of the proposed model to learn and generalize patterns effectively, thereby impeding its capacity to capture data variability. Additionally, the proposed model might only be able to predict within the range of BPs that were trained in the model, and it was only trained with one condition, which was seated. The struggle to capture variability in the BP data can have far-reaching consequences in clinical practice, thus affecting diagnostic accuracy, treatment decision making, risk stratification, patient monitoring, and overall trust in predictive models. A possible solution to this limitation is to increase the number of participants with a broader age range and use different medical histories to enhance the proposed model’s accuracy.
Despite these limitations, this cost-effective, cuffless, wireless, and noninvasive system is capable of real-time monitoring and can be set for long-term BP changes at 1 min intervals, thereby allowing the system to measure the patient’s BP every minute. As this system is also wireless, it can perform a remote monitoring of patients’ BP, thus enabling measurements from a distance. Moreover, calibration is not required to implement this system in the future.
5. Conclusions
The development of a cuffless, noninvasive, wireless, and real-time BP measurement system was successful. The system comprises a MAX30102 PPG sensor and an ESP-WROOM-32 microcontroller integrated with a GUI. The random forest algorithm was selected as the optimal model with a 90:10 training:validation split, which was achieved by utilizing a preprocessed dataset that underwent baseline wander correction and data filtering. The performance evaluation yielded an MAE value of 4.38 for the SBP and 4.49 for the DBP, with an R2 of 0.37 for the SBP and 0.46 for the DBP. One limitation was the small sample size (six participants) of a specific waveform form. This included all healthy young people in the seated position configuration, which may impair the model’s capacity to learn and generalize patterns successfully. This limitation may affect diagnostic accuracy, treatment decision making, risk stratification, patient monitoring, and overall trust in predictive models. Considering these results, our future work will focus on incorporating additional data by increasing the number of participants of various ages and medical histories, which could improve the proposed model’s accuracy to enable the measurement device to capture all possible combinations of systolic and diastolic BP values.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}