
Performance Comparison of CFD Microbenchmarks on Diverse HPC Architectures

 , , , , , , ,
, , , , , , ,  , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. MB1 Cavity 3D
2.2. MB2 Compressible Starting Square Jet
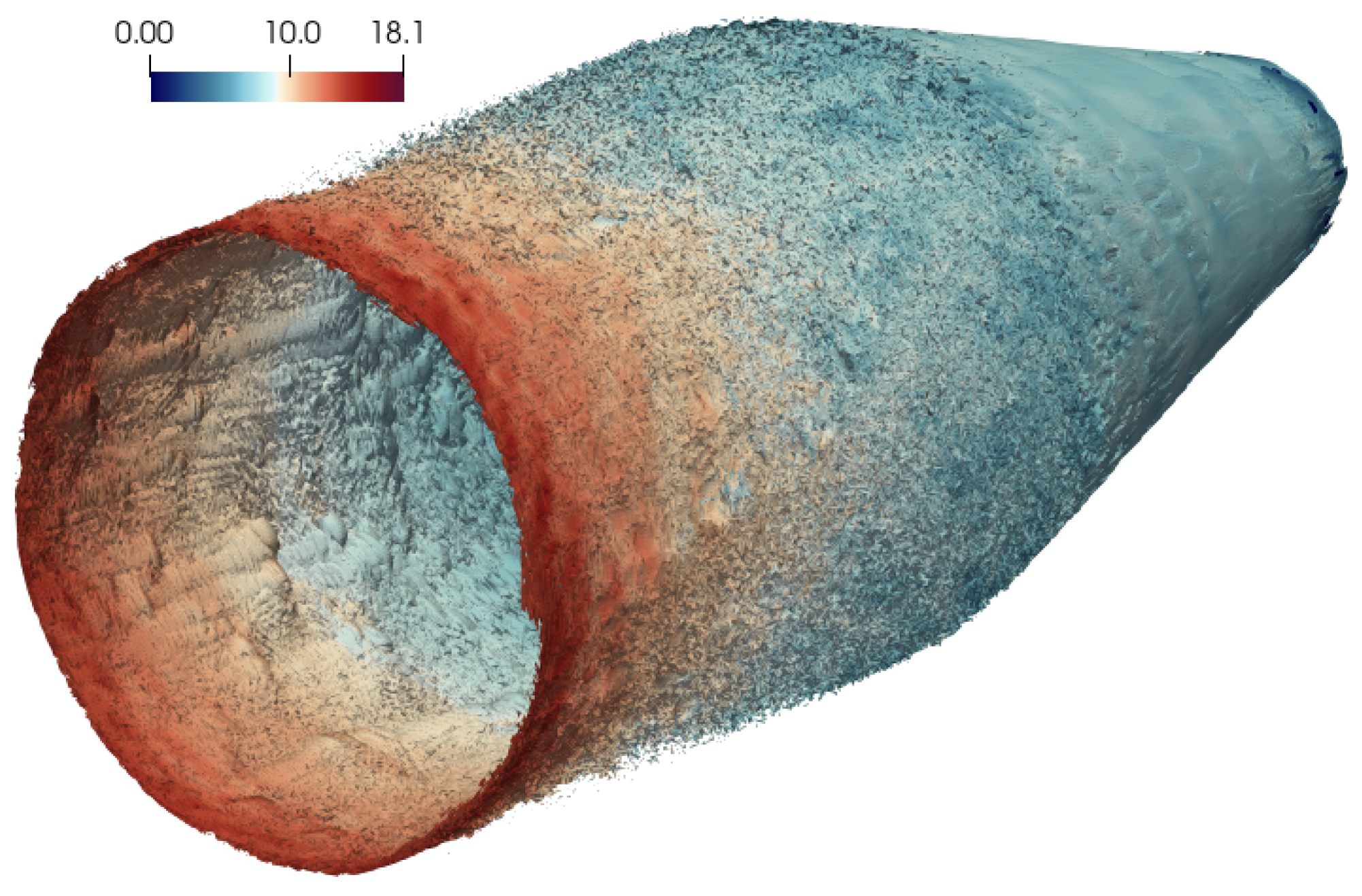
2.3. MB4 DLR-JHC Burner
2.4. MB5 ERCOFTAC Conical Diffuser
2.5. Mb6 Two Cylinders in Line
2.6. MB8 Rotating Wheel
2.7. MB9 High-Lift Airfoil
2.8. MB11 Pitz&Daily Combustor
2.9. MB12 Model Wind Farm
2.10. MB17 1D Aeroacoustic Wave Train
2.11. MB19 Viscoelastic Polymer Melt Flow
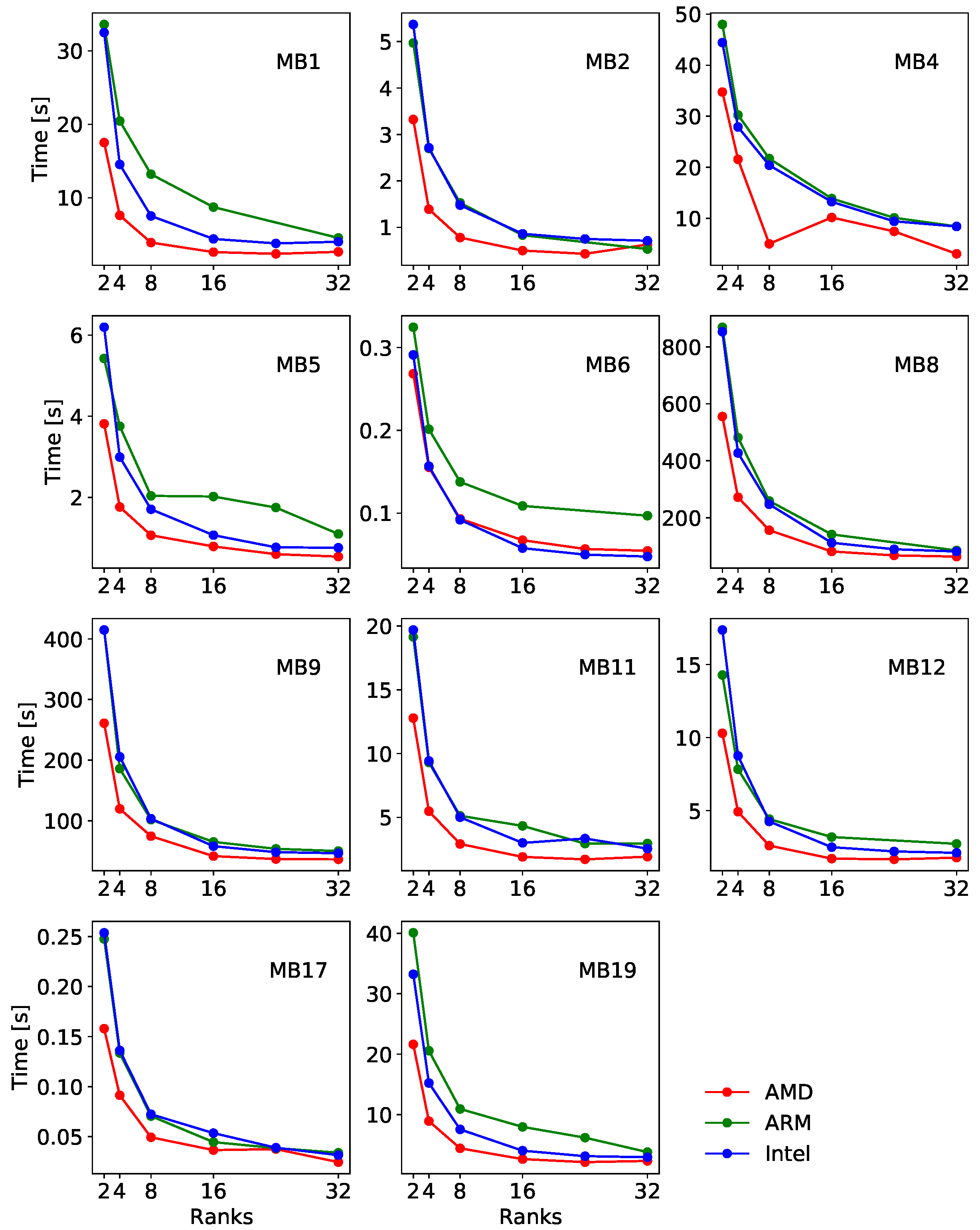
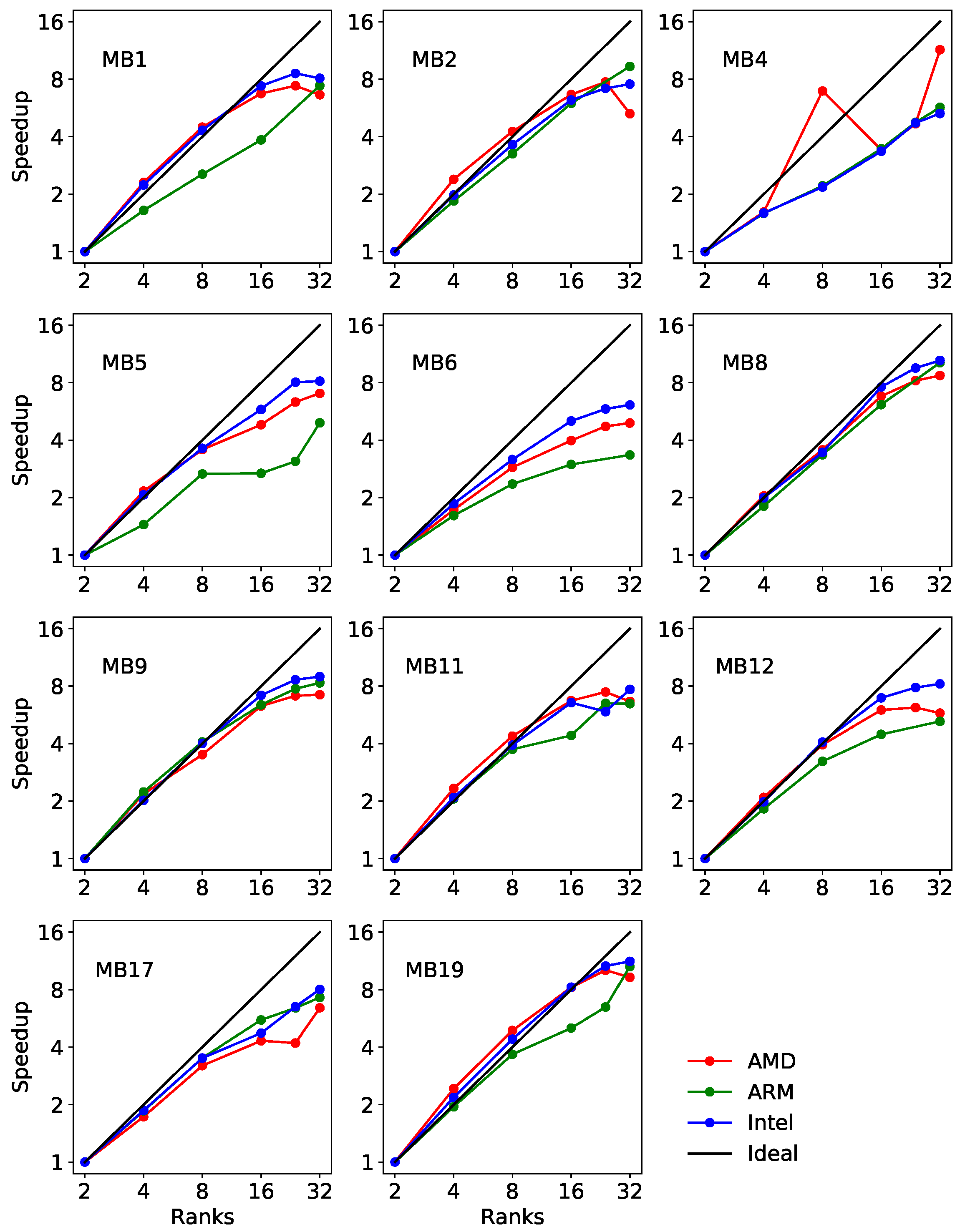
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACMI | Arbitrarily Coupled Mesh Interface |
| ADM | Actuator Disk Model |
| BM | blockMesh |
| CAD | Computer Aided Design |
| CFD | Computational Fluid Dynamics |
| CFM | cfMesh |
| DLR | Deutsches Zentrum für Luft- und Raumfahrt |
| ERCOFTAC | European Research Community on Flow, Turbulence and Combustion |
| HPC | High-performance computing |
| MBs | Microbenchmarks |
| SHM | snappyHexMesh |
References
- Weller, H.G.; Tabor, G.; Jasak, H.; Fureby, C. A tensorial approach to computational continuum mechanics using object orientated techniques. Comput. Phys. 1998, 12, 620–631. [Google Scholar] [CrossRef]
- Jasak, H. OpenFOAM: Open source CFD in research and industry. Int. J. Nav. Archit. Ocean. Eng. 2009, 1, 89–94. [Google Scholar]
- Segui, M.; Abel, F.R.; Botez, R.M.; Botez, R.M.; Ceruti, A. High-fidelity aerodynamic modeling of an aircraft using OpenFoam: Application on the CRJ700. Aeronaut. J. 2021, 126, 585–606. [Google Scholar] [CrossRef]
- Pedro, R.; Gamez-Montero, J.; Raush, G.; Codina, E. Method for Fluid Flow Simulation of a Gerotor Pump Using OpenFOAM. J. Fluids Eng. 2017, 139, 111101. [Google Scholar]
- Serdeczny, M.P.; Comminal, R.; Mollah, M.T.; Pedersen, D.B.; Spangenberg, J. Numerical modeling of the polymer flow through the hot-end in filament-based material extrusion additive manufacturing. Addit. Manuf. 2020, 36, 101454. [Google Scholar] [CrossRef]
- Nieves-Remacha, M.J.; Kulkarni, A.A.; Jensen, K.F. OpenFOAM Computational Fluid Dynamic Simulations of Single-Phase Flows in an Advanced-Flow Reactor. Ind. Eng. Chem. Res. 2015, 54, 7543–7553. [Google Scholar] [CrossRef]
- exaFOAM Project Website. Available online: https://exafoam.eu/ (accessed on 28 February 2024).
- OpenFOAM HPC Committee Code Repository. Available online: https://develop.openfoam.com/committees/hpc/-/tree/develop/ (accessed on 28 February 2024).
- AbdelMigid, T.A.; Saqr, K.M.; Kotb, M.A.; Aboelfarag, A.A. Revisiting the lid-driven cavity flow problem: Review and new steady state benchmarking results using GPU accelerated code. Alex. Eng. J. 2017, 56, 123–135. [Google Scholar] [CrossRef]
- Ghia, U.; Ghia, K.N.; Shin, C.T. High-Re solutions for incompressible flow using the Navier–Stokes equations and a multigrid method. J. Comput. Phys. 1982, 48, 387–411. [Google Scholar] [CrossRef]
- Koseff, J.R.; Street, R.L. Erratum: The Lid-Driven Cavity Flow: A Synthesis of Qualitative and Quantitative Observations. J. Fluids Eng. 1984, 106, 390–398. [Google Scholar] [CrossRef]
- Bna, S.; Spisso, I.; Olesen, M.; Rossi, G. PETSc4FOAM: A Library to Plug-in PETSc into the OpenFOAM Framework. Zenodo. Available online: https://zenodo.org/records/3923780 (accessed on 28 February 2024).
- Brogi, F.; Bnà, S.; Boga, G.; Amati, G.; Esposti Ongaro, T.; Cerminara, M. On floating point precision in computational fluid dynamics using OpenFOAM. Future Gener. Comput. Syst. 2024, 152, 1–16. [Google Scholar] [CrossRef]
- Fiolitakis, A.; Arndt, C.M. Transported PDF simulation of auto-ignition of a turbulent methane jet in a hot, vitiated coflow. Combust. Theory Model. 2020, 24, 326–361. [Google Scholar] [CrossRef]
- ERCOFTAC. Swirling Diffuser Flow. Available online: https://www.kbwiki.ercoftac.org/w/index.php?title=UFR_4-06_Description (accessed on 28 February 2024).
- Classic Collection Database. Available online: http://cfd.mace.manchester.ac.uk/ercoftac/doku.php?id=cases:case060&s[]=conical (accessed on 28 February 2024).
- Dehkordi, B.; Moghaddam, H.; Jafari, H. Numerical Simulation of Flow Over Two Circular Cylinders in Tandem Arrangement. J. Hydrodyn. Ser. B 2011, 23, 114–126. [Google Scholar] [CrossRef]
- Mittal, S.; Kumar, V.; Raghuvanshi, A. Unsteady incompressible flows past two cylinders in tandem and staggered arrangements. Int. J. Numer. Methods Fluids 1997, 25, 1315–1344. [Google Scholar] [CrossRef]
- Griewank, A.; Walther, A. Algorithm 799: Revolve: An implementation of checkpointing for the reverse or adjoint mode of computational differentiation. ACM Trans. Math. Softw. 2000, 26, 19–45. [Google Scholar] [CrossRef]
- Hupertz, B.; Chalupa, K.; Krueger, L.; Howard, K.; Glueck, H.-D.; Lewington, N.; Chang, J.-I.; Shin, Y.-S. On the Aerodynamics of the Notchback Open Cooling DrivAer: A Detailed Investigation of Wind Tunnel Data for Improved Correlation and Reference. SAE Int. J. Adv. Curr. Prac. Mobil. 2021, 3, 1726–1747. [Google Scholar] [CrossRef]
- 4th Automotive CFD Prediction Workshop. Available online: https://autocfd.eng.ox.ac.uk/#test-cases (accessed on 28 February 2024).
- Lacy, D.; Clark, A. Definition of Initial Landing and Takeoff Reference Configurations for the High Lift Common Research Model (CRM-HL). In Proceedings of the AIAA Aviation 2020 Forum, Virtual, 15–19 June 2020. AIAA Paper 2020–2771. [Google Scholar] [CrossRef]
- Shur, M.; Spalart, P.; Strelets, M.; Travin, A. A hybrid RANS-LES approach with delayed-DES and wall-modelled LES capabilities. Int. J. Heat Fluid Flow 2008, 29, 1638–1649. [Google Scholar] [CrossRef]
- Chin, V.; Peters, D.; Spaid, F.; McGhee, R. Flowfield measurements about a multi-element airfoil at high Reynolds numbers. In Proceedings of the 23rd Fluid Dynamics, Plasmadynamics, and Lasers Conference, Orlando, FL, USA, 6–9 July 1993. AIAA Paper 1993–3137. [Google Scholar] [CrossRef]
- Pitz, R.W.; Daily, J.W. Combustion in a turbulent mixing layer formed at a rearward-facing step. AIAA J. 1983, 21, 1565–1570. [Google Scholar] [CrossRef]
- Chamorro, L.P.; Porté-Agel, F. Effects of thermal stability and incoming boundary-layer flow characteristics on wind turbine wakes: A wind-tunnel study. Bound. Layer Meteorol. 2010, 136, 515. [Google Scholar] [CrossRef]
- Wu, Y.T.; Porté-Agel, F. Large-Eddy Simulation of Wind-Turbine Wakes: Evaluation of Turbine Parametrisations. Bound. Layer Meteorol. 2011, 138, 345–366. [Google Scholar] [CrossRef]
- Chamorro, L.P.; Porté-Agel, F. Turbulent flow inside and above a wind farm: A wind-tunnel study. Energies 2011, 4, 1916. [Google Scholar] [CrossRef]
- Wu, Y.-T.; Porté-Agel, F. Simulation of Turbulent Flow Inside and Above Wind Farms: Model Validation and Layout Effects. Bound. Layer Meteorol. 2013, 146, 181–205. [Google Scholar] [CrossRef]
- Galeazzo, F.C.C.; Weiß, R.G.; Lesnik, S.; Rusche, H.; Ruopp, A. Understanding Superlinear Speedup in Current HPC Architectures. Preprints 2024, 2024040219. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | CPU Model | Frequency | Cores/Node | Memory/Node | L3 Cache/Node |
|---|---|---|---|---|---|
| x86_64 | Intel(R) Xeon(R) Gold 6226R (Cascade Lake) | 2.9 GHz | 32 | 192 GB | 44 MB |
| x86_64 | AMD EPYC 7313 16-Core Processor (Milan) | 3.3 GHz | 32 | 256 GB | 256 MB |
| aarch64 | Arm Neoverse-N1 | 3.0 GHz | 256 | 512 GB | 32 MB |
| Microbenchmarks | Top-Level Solver | Mesh Generation—Cell Count—Cell Type | |
|---|---|---|---|
| MB1 | Cavity 3D | icoFoam | BM—8 M—Hexahedra |
| - incompressible laminar flow | |||
| MB2 | Compressible starting square jet | rhoPimpleFoam | BM—2 M—Hexahedra |
| - compressible flow, LES turbulence modeling | |||
| MB4 | DLR-JHC burner | reactingFoam | BM—400 k—Hexahedra |
| - turbulent combustion with detailed chemistry and LES turbulence modeling | |||
| MB5 | ERCOFTAC Conical diffuser | simpleFoam | BM—3 M—Hexahedra |
| - incompressible flow, RANS turbulence modeling | |||
| MB6 | Two cylinders in line | adjointOptimisationFoam | BM—24,500—Hexahedra |
| - unsteady adjoint optimization, 2D laminar flow | |||
| MB8 | Rotating Wheel | pimpleFoam | SHM—20 M—Polyhedra |
| - incompressible, external flow with rotating wheels, DDES turbulence modeling | |||
| MB9 | High-lift airfoil | rhoPimpleFoam | SHM—20 M—Polyhedra |
| - 2D compressible flow, DDES turbulence modeling | |||
| MB11 | Pitz&Daily Combustor | XiFoam | BM—200 k—Hexahedra |
| - turbulent combustion, LES turbulence modeling | |||
| MB12 | Model Wind Farm | pimpleFoam | BM—8 M—Hexahedra |
| - incompressible flow, wind turbines using actuator disc model, LES turbulence modeling | |||
| MB17 | 1D Aeroacoustic Wave Train | rhoPimpleFoam 1D | BM—0.05 M—Hexahedra |
| - 1D compressible laminar flow | |||
| MB19 | Viscoelastic polymer melt flow | viscoelasticFluidFoam | CFM—1 M—Polyhedra |
| - 3D laminar, viscoelastic flow | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galeazzo, F.C.C.; Garcia-Gasulla, M.; Boella, E.; Pocurull, J.; Lesnik, S.; Rusche, H.; Bnà, S.; Cerminara, M.; Brogi, F.; Marchetti, F.; et al. Performance Comparison of CFD Microbenchmarks on Diverse HPC Architectures. Computers 2024, 13, 115. https://doi.org/10.3390/computers13050115
Galeazzo FCC, Garcia-Gasulla M, Boella E, Pocurull J, Lesnik S, Rusche H, Bnà S, Cerminara M, Brogi F, Marchetti F, et al. Performance Comparison of CFD Microbenchmarks on Diverse HPC Architectures. Computers. 2024; 13(5):115. https://doi.org/10.3390/computers13050115
Chicago/Turabian StyleGaleazzo, Flavio C. C., Marta Garcia-Gasulla, Elisabetta Boella, Josep Pocurull, Sergey Lesnik, Henrik Rusche, Simone Bnà, Matteo Cerminara, Federico Brogi, Filippo Marchetti, and et al. 2024. "Performance Comparison of CFD Microbenchmarks on Diverse HPC Architectures" Computers 13, no. 5: 115. https://doi.org/10.3390/computers13050115
APA StyleGaleazzo, F. C. C., Garcia-Gasulla, M., Boella, E., Pocurull, J., Lesnik, S., Rusche, H., Bnà, S., Cerminara, M., Brogi, F., Marchetti, F., Gregori, D., Weiß, R. G., & Ruopp, A. (2024). Performance Comparison of CFD Microbenchmarks on Diverse HPC Architectures. Computers, 13(5), 115. https://doi.org/10.3390/computers13050115