
Custom ASIC Design for SHA-256 Using Open-Source Tools

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
- A custom hardware implementation of the SHA-256 algorithm compatible with 32-bit microcontrollers is designed and presented with several details. The final description is openly available on the project’s GitHub page [20].
- An open-source approach to ASIC design is introduced. A complete integrated circuit is synthesized in a manufacturable open-source PDK utilizing exclusively non-proprietary EDA tools.
- Several configuration parameters in OpenLANE’s workflow are tested and analyzed. The findings are utilized to enhance the performance of the final ASIC design.
2. SHA-256 Algorithm
| Algorithm 1: Expansion function. |
 |
| Algorithm 2: Compression function. |
 |
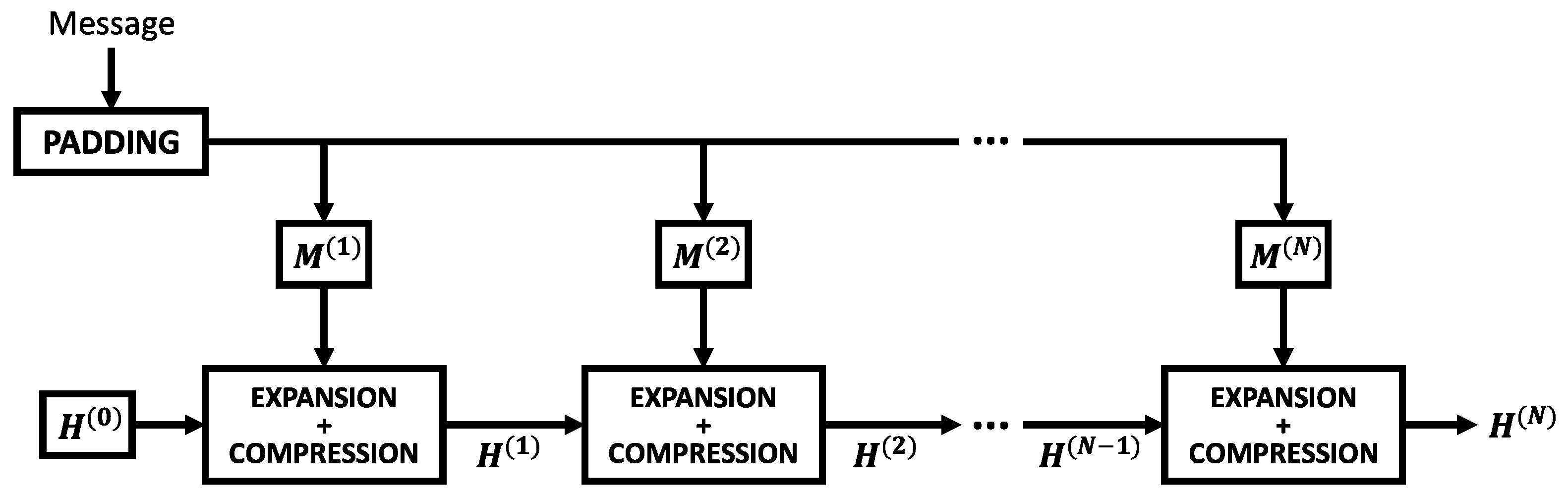
| Algorithm 3: Block hashing. |
 |
3. Hardware Design
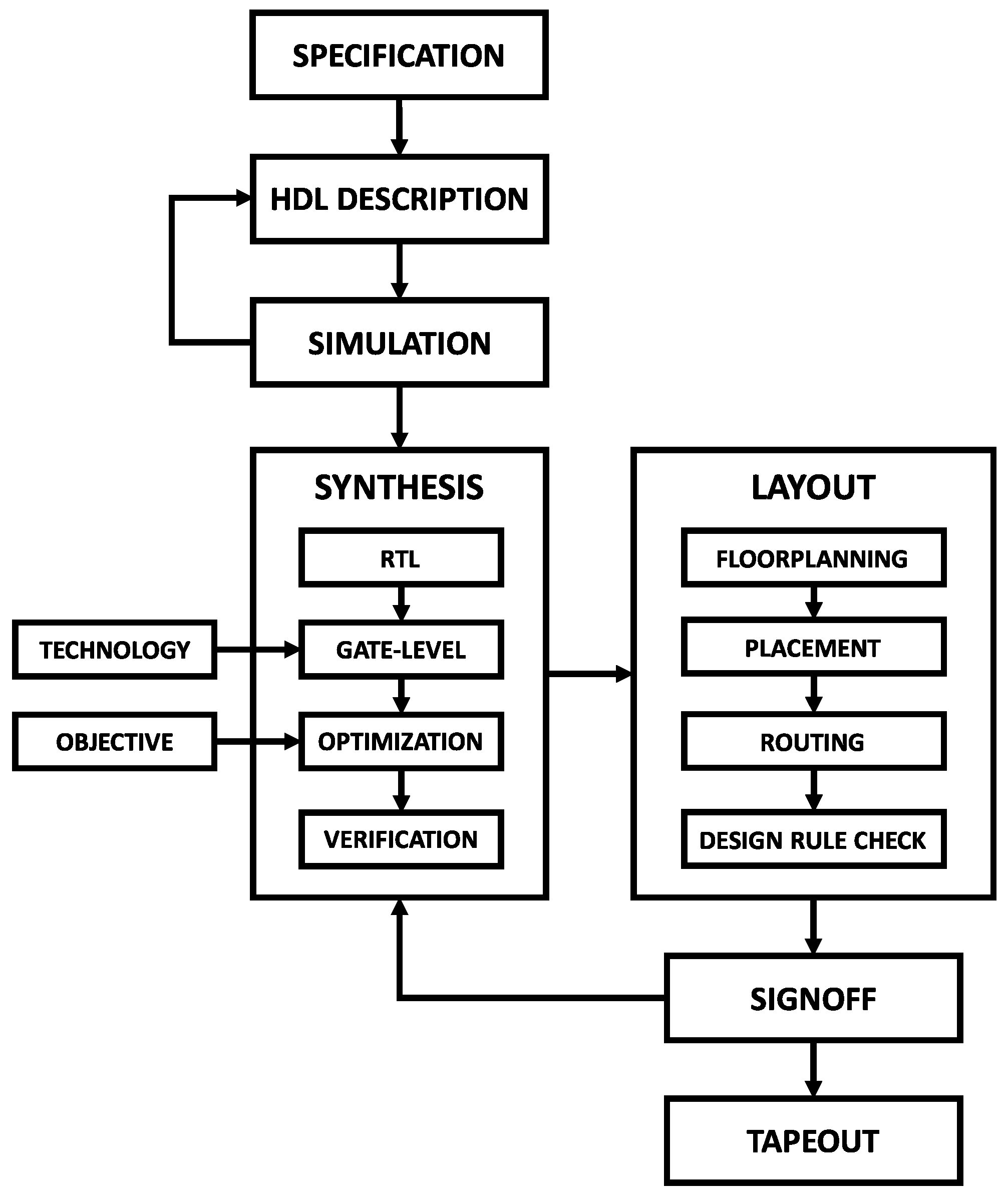
3.1. Digital ASIC Workflow
3.2. Open-Source EDA Tool and PDK
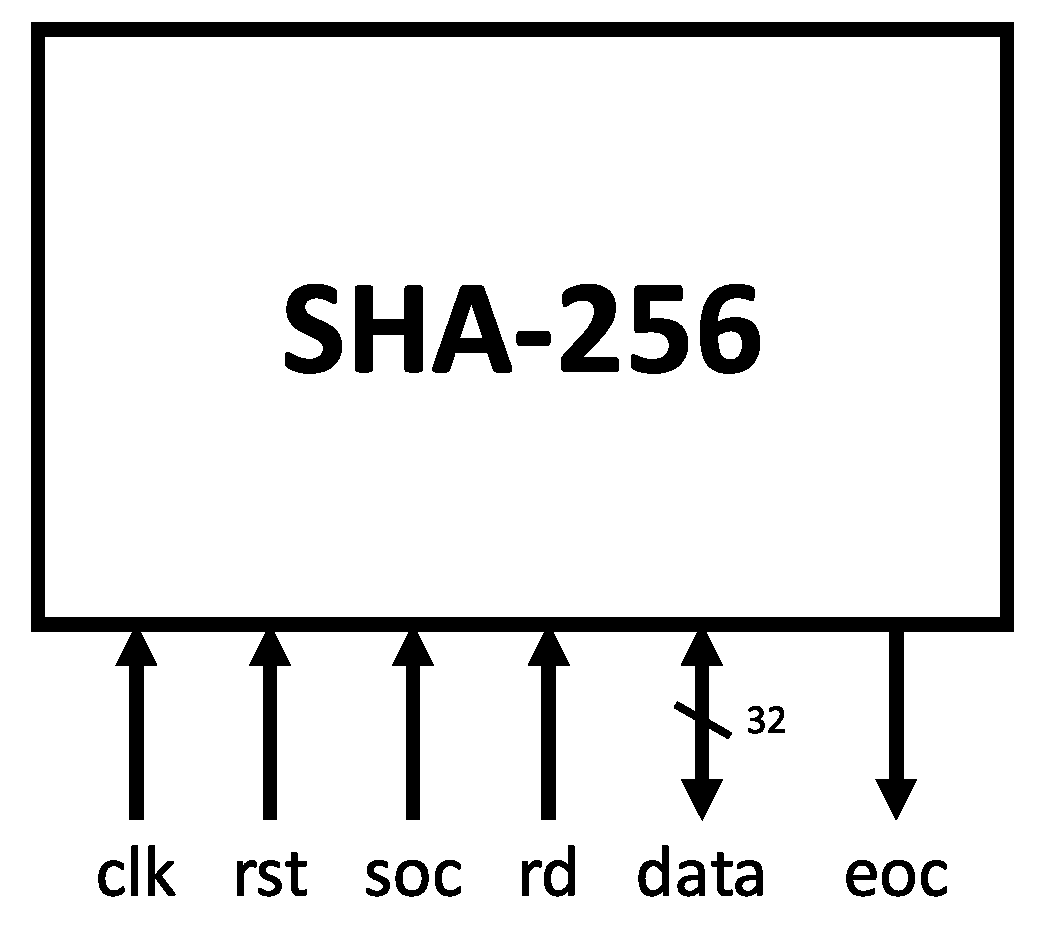
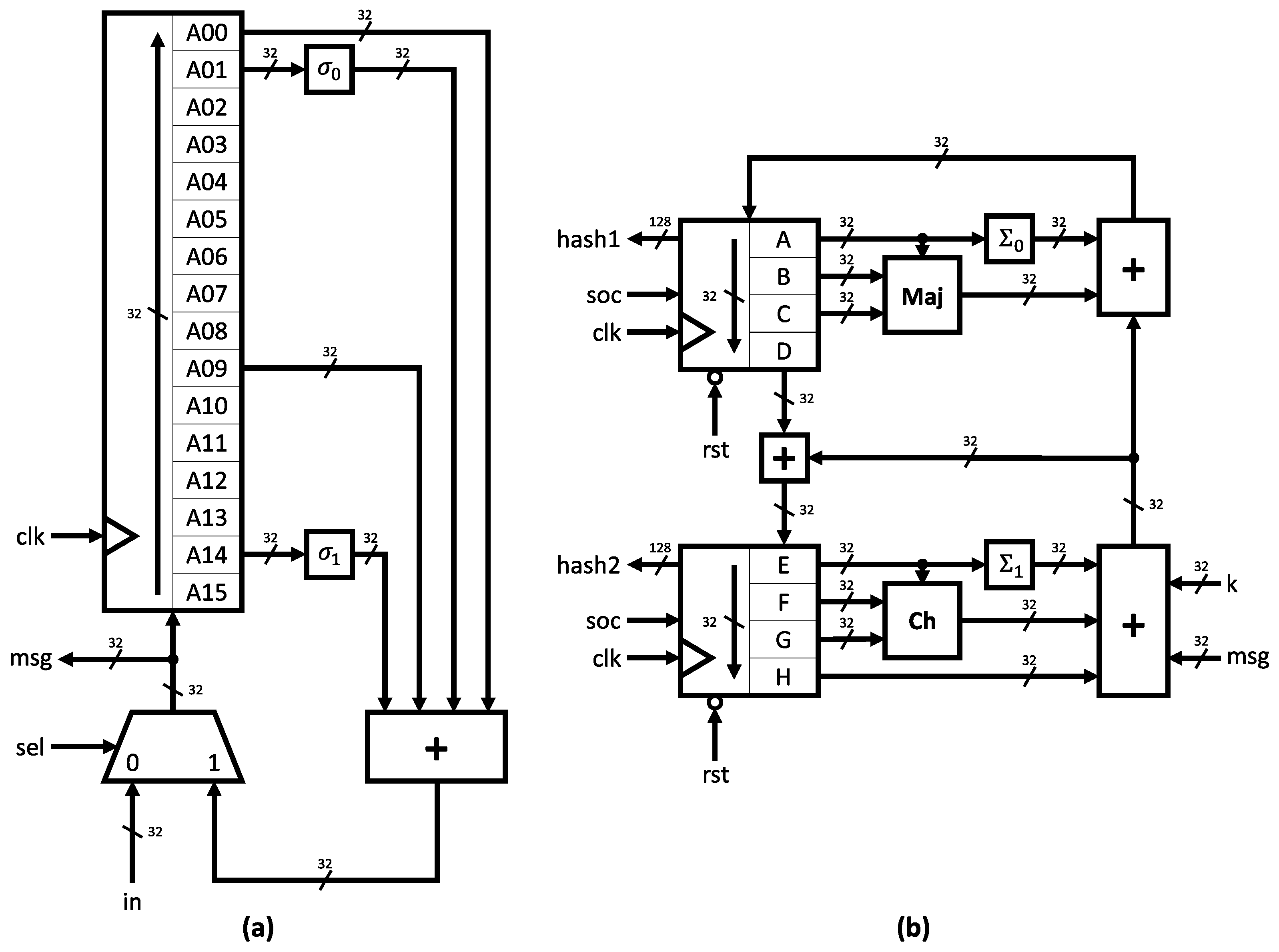
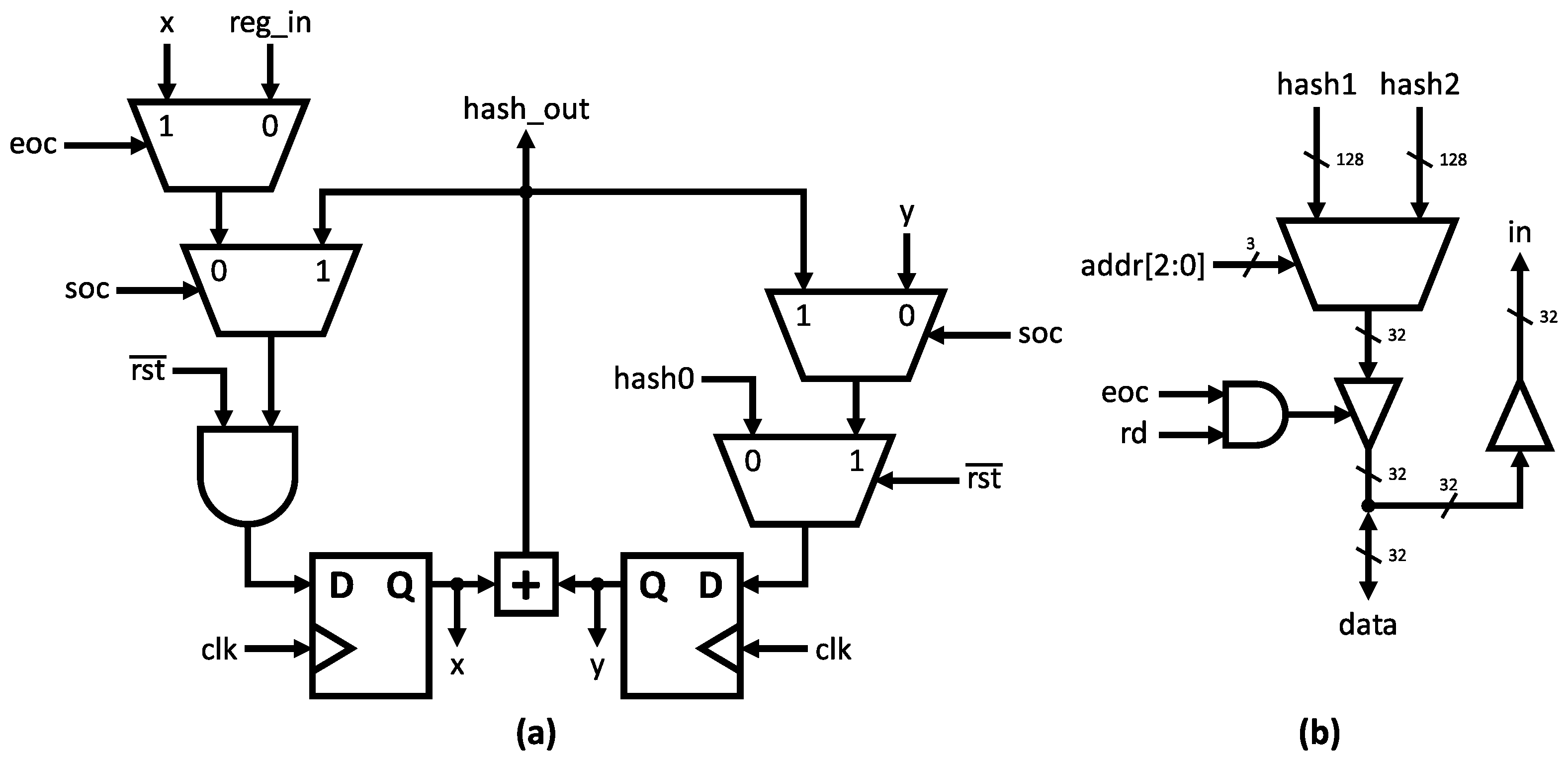
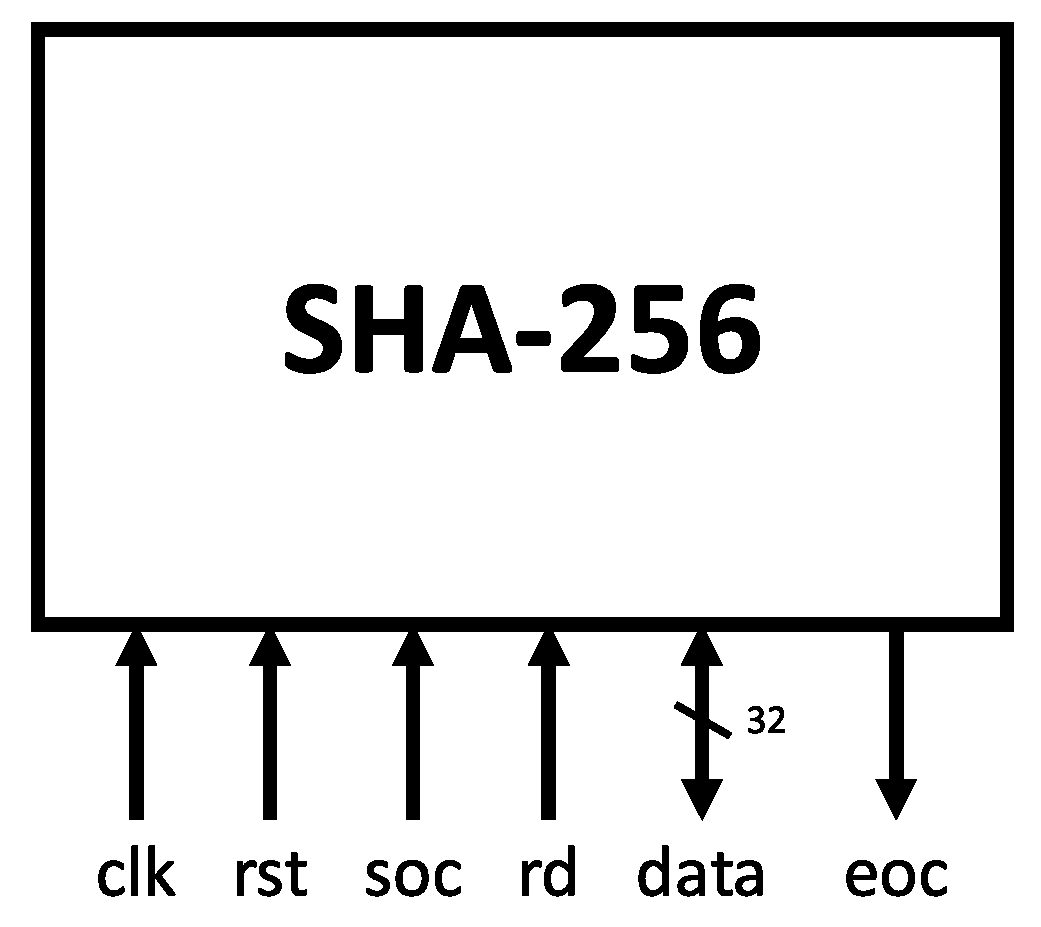
3.3. Hardware Architecture
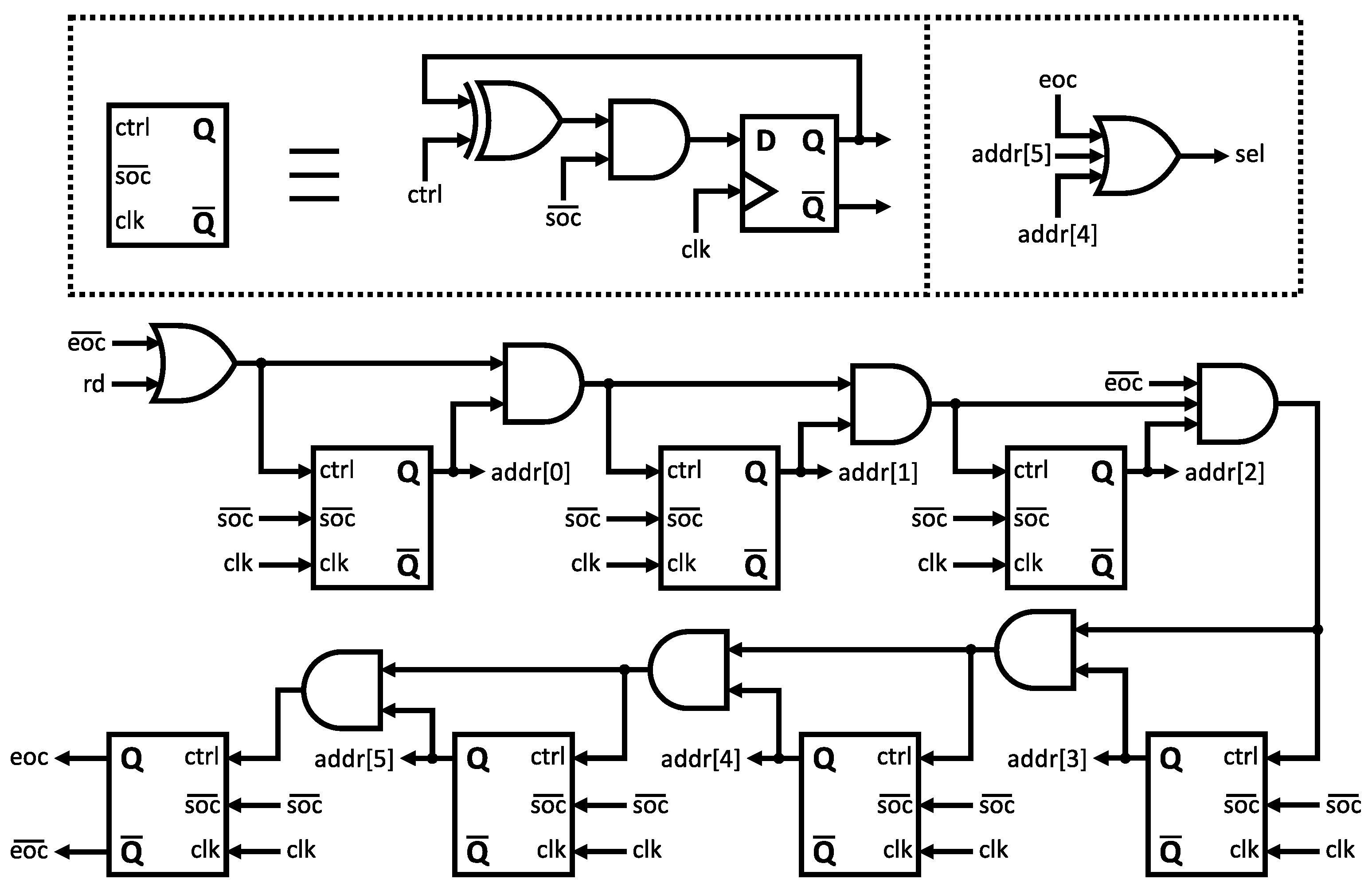
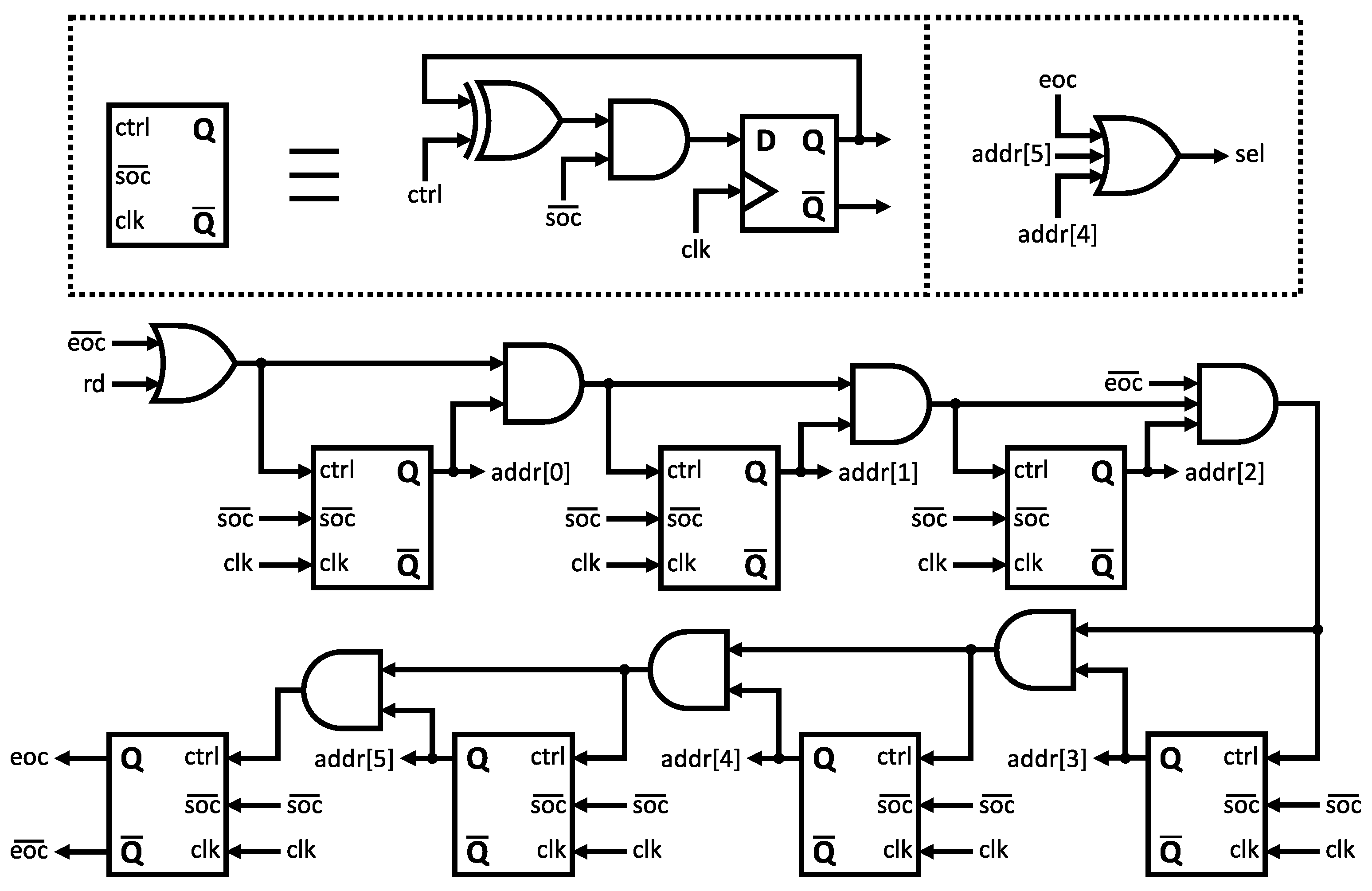
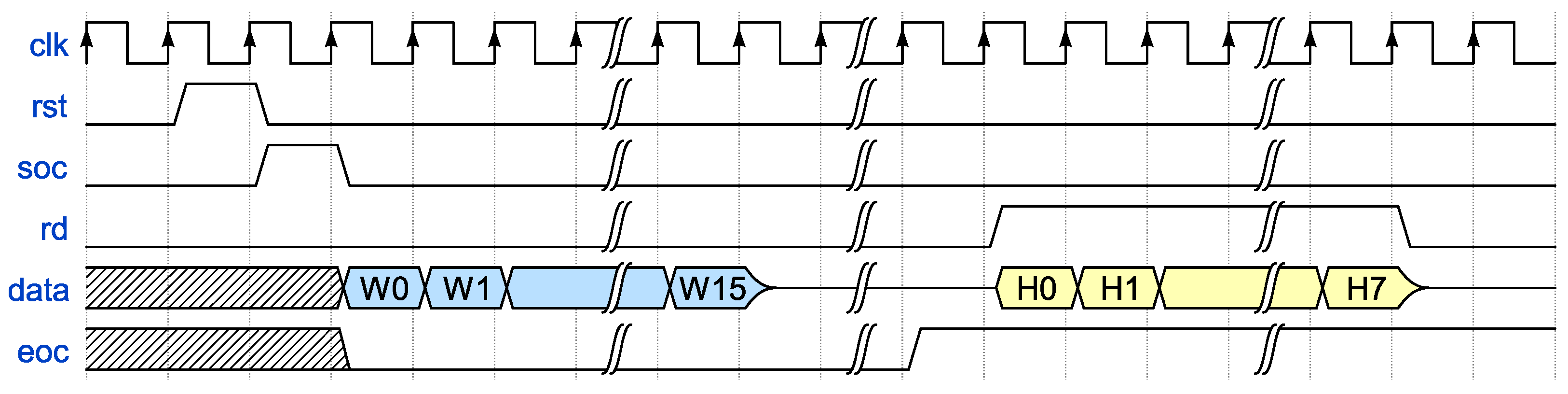
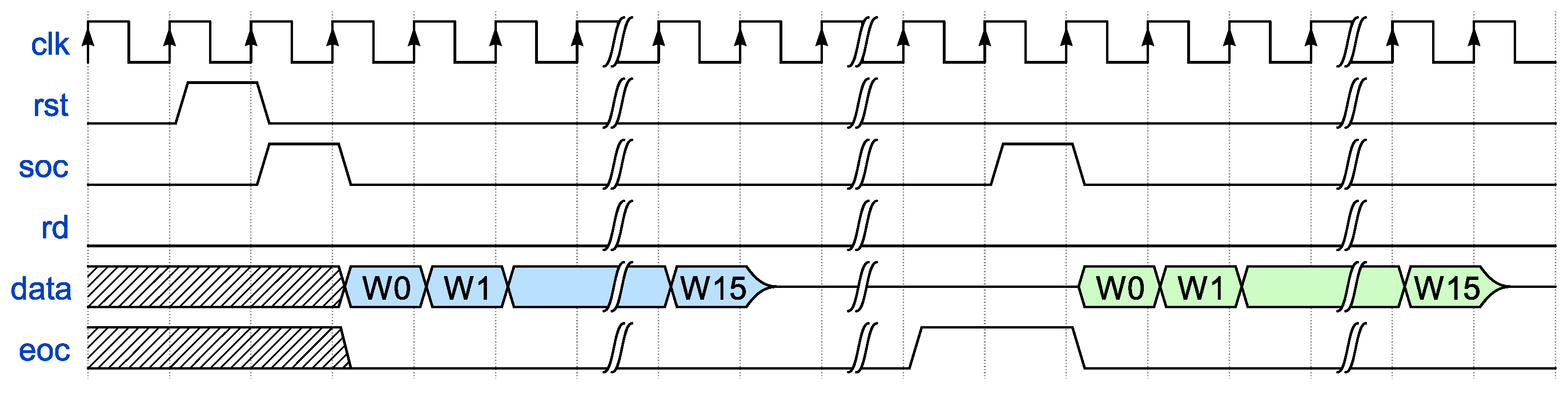
3.4. Design Control Sequence
4. Results and Discussion
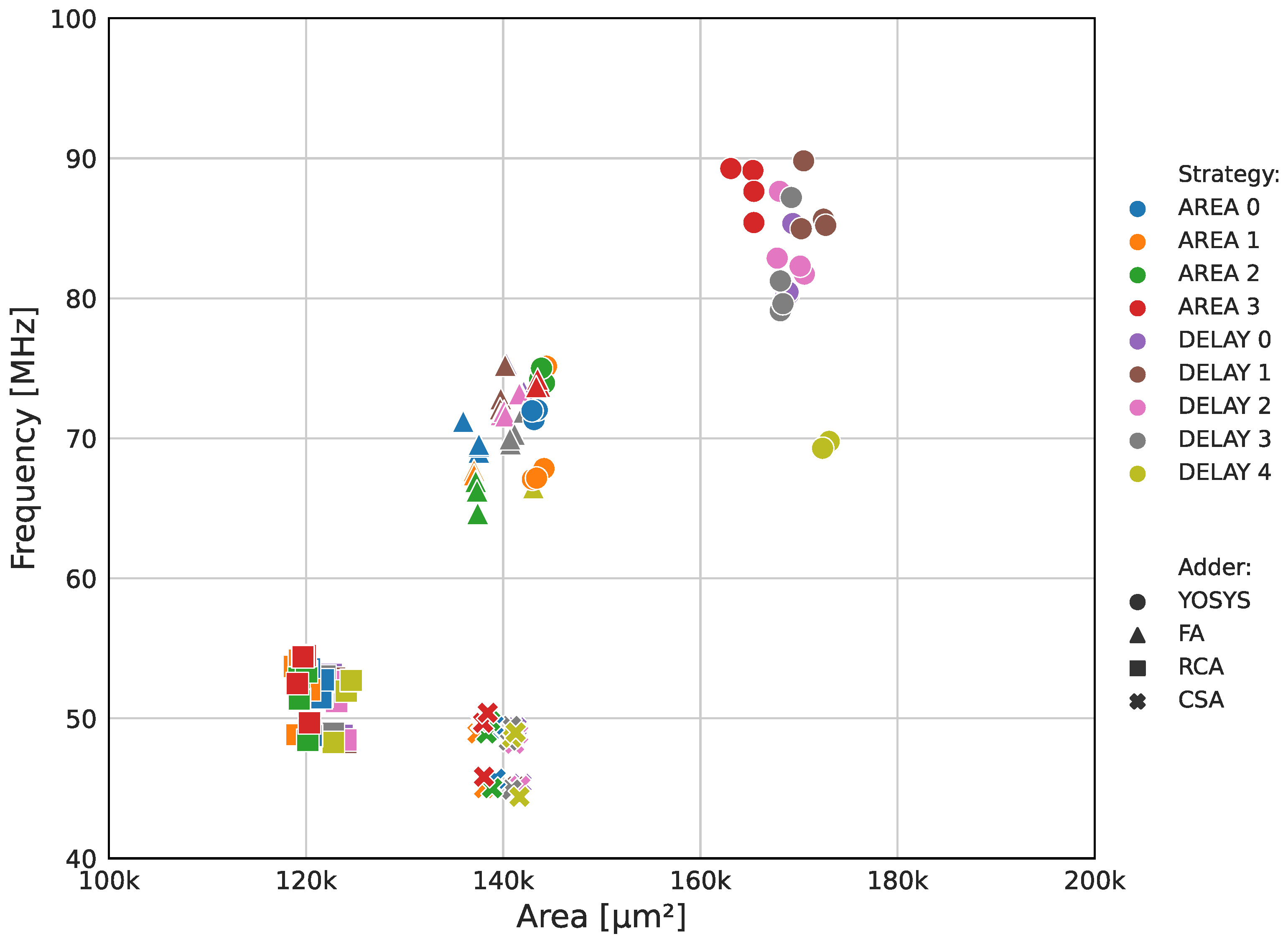
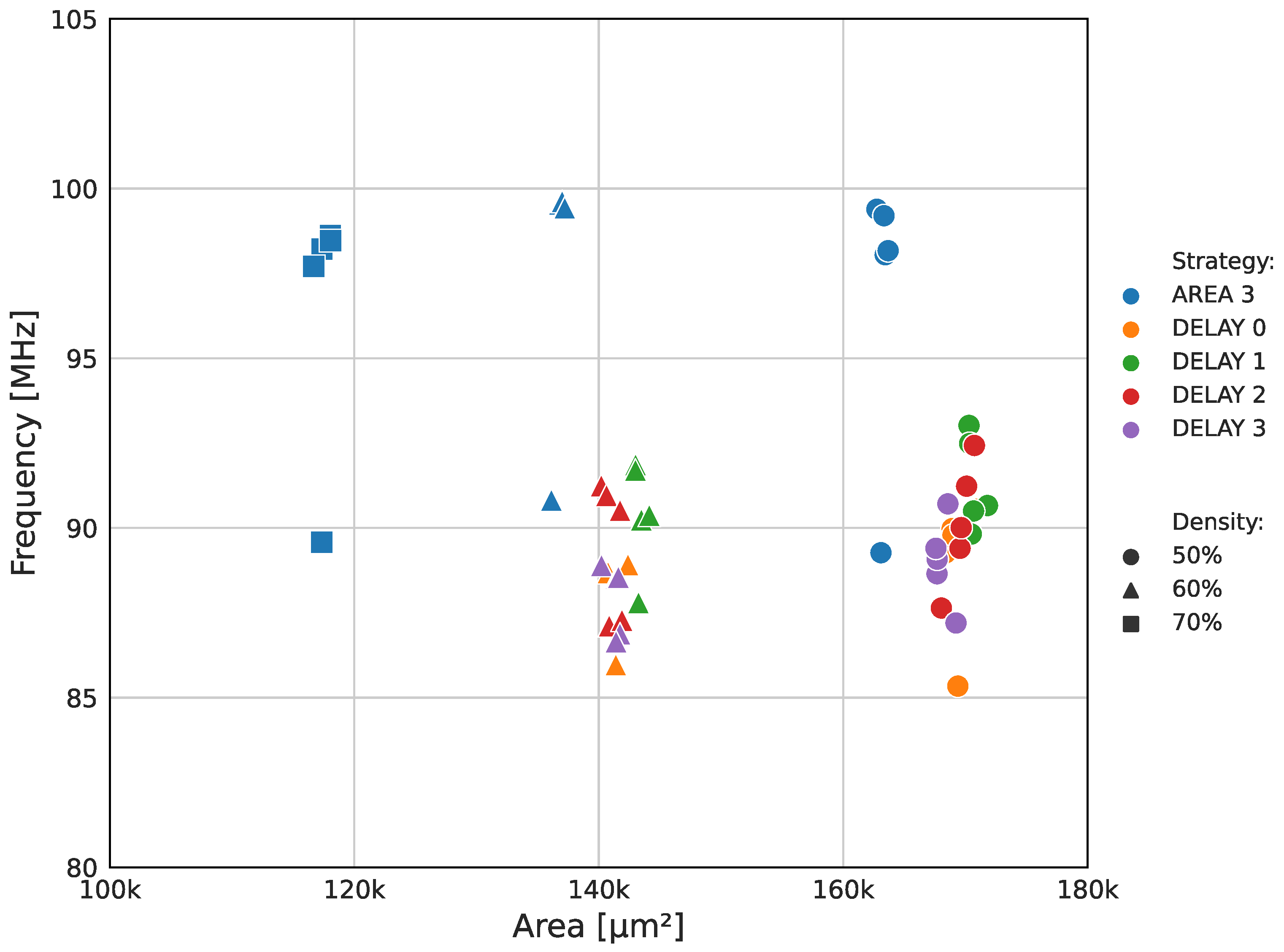
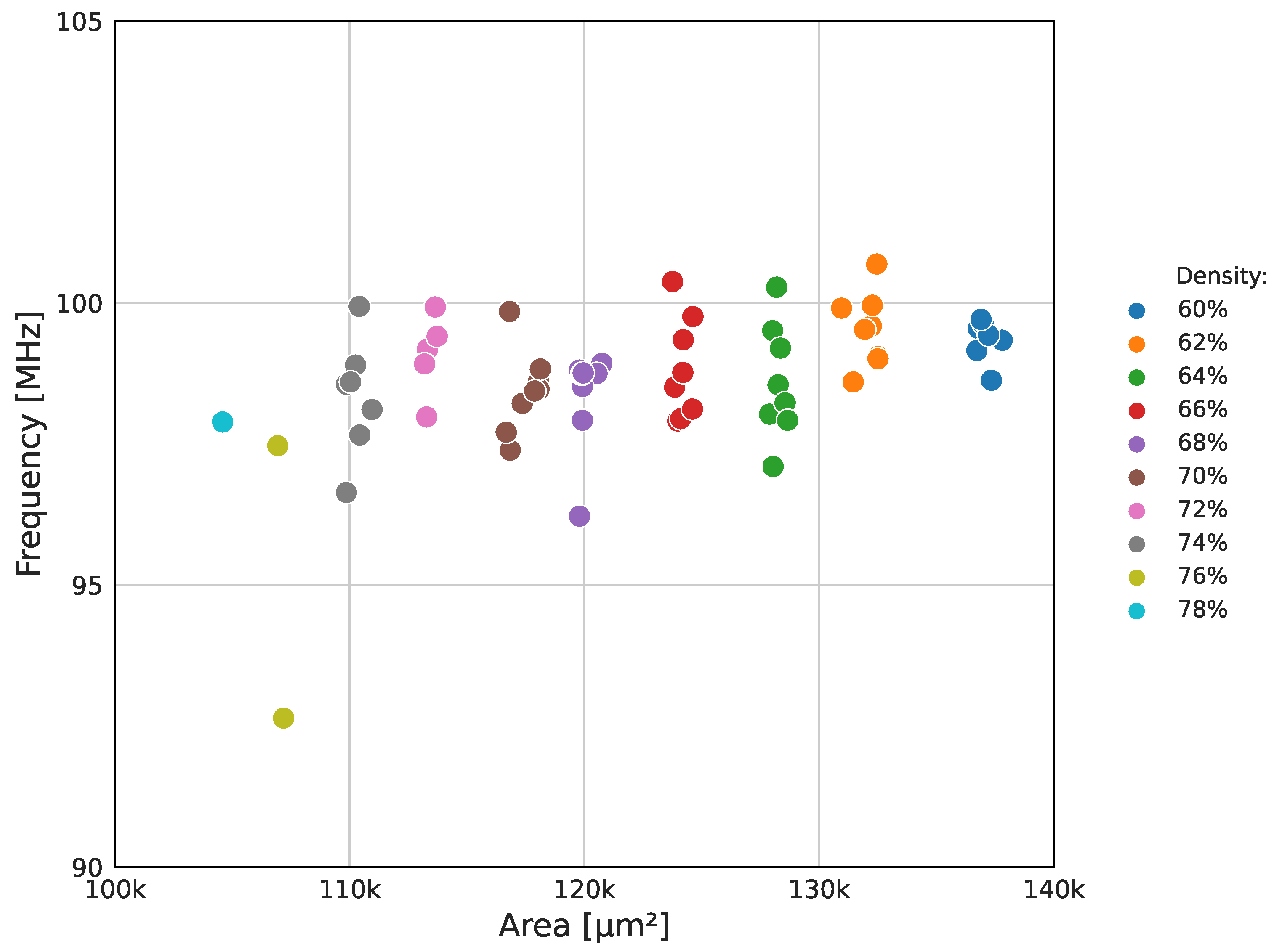
4.1. Performance Metrics
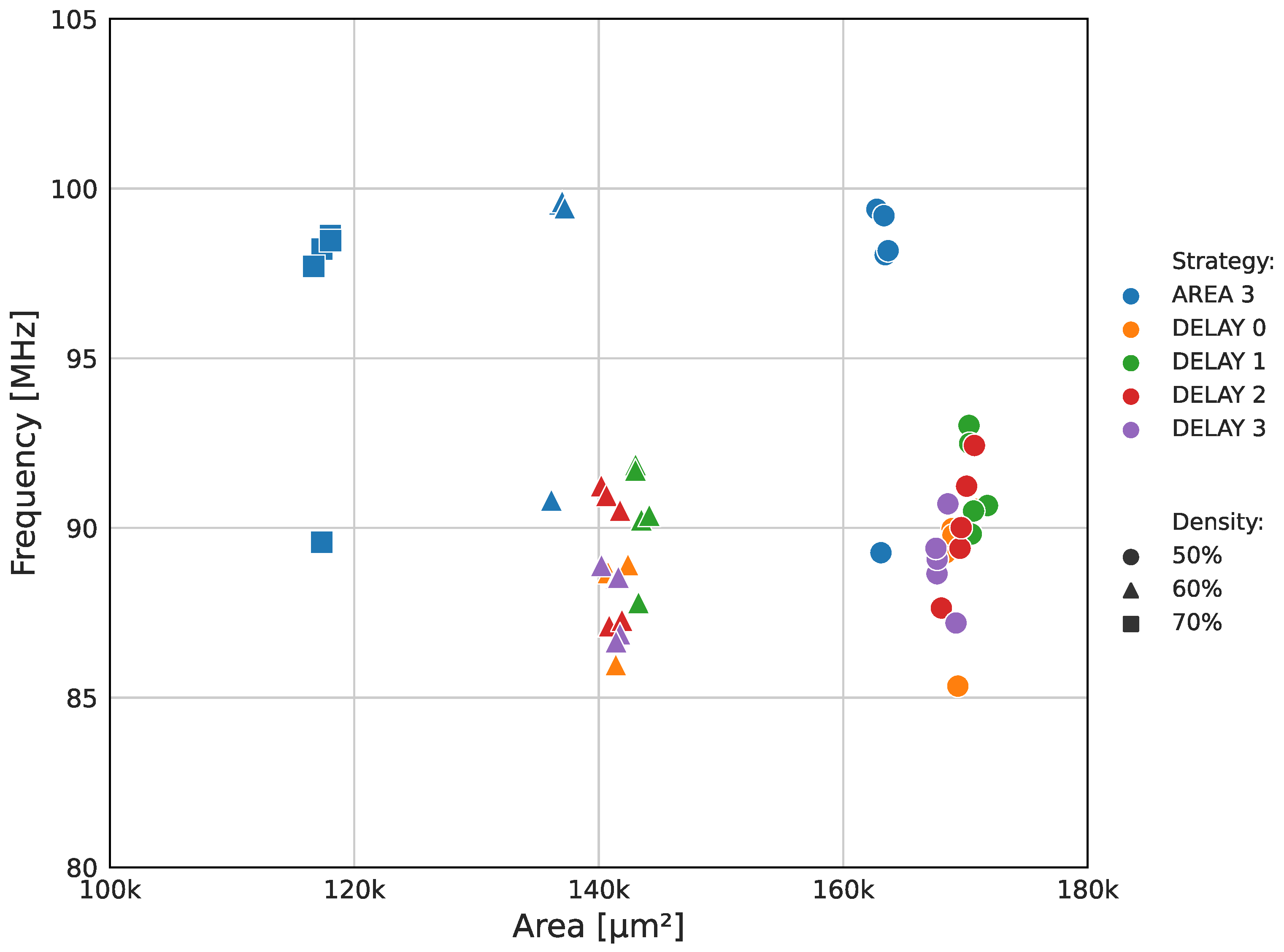
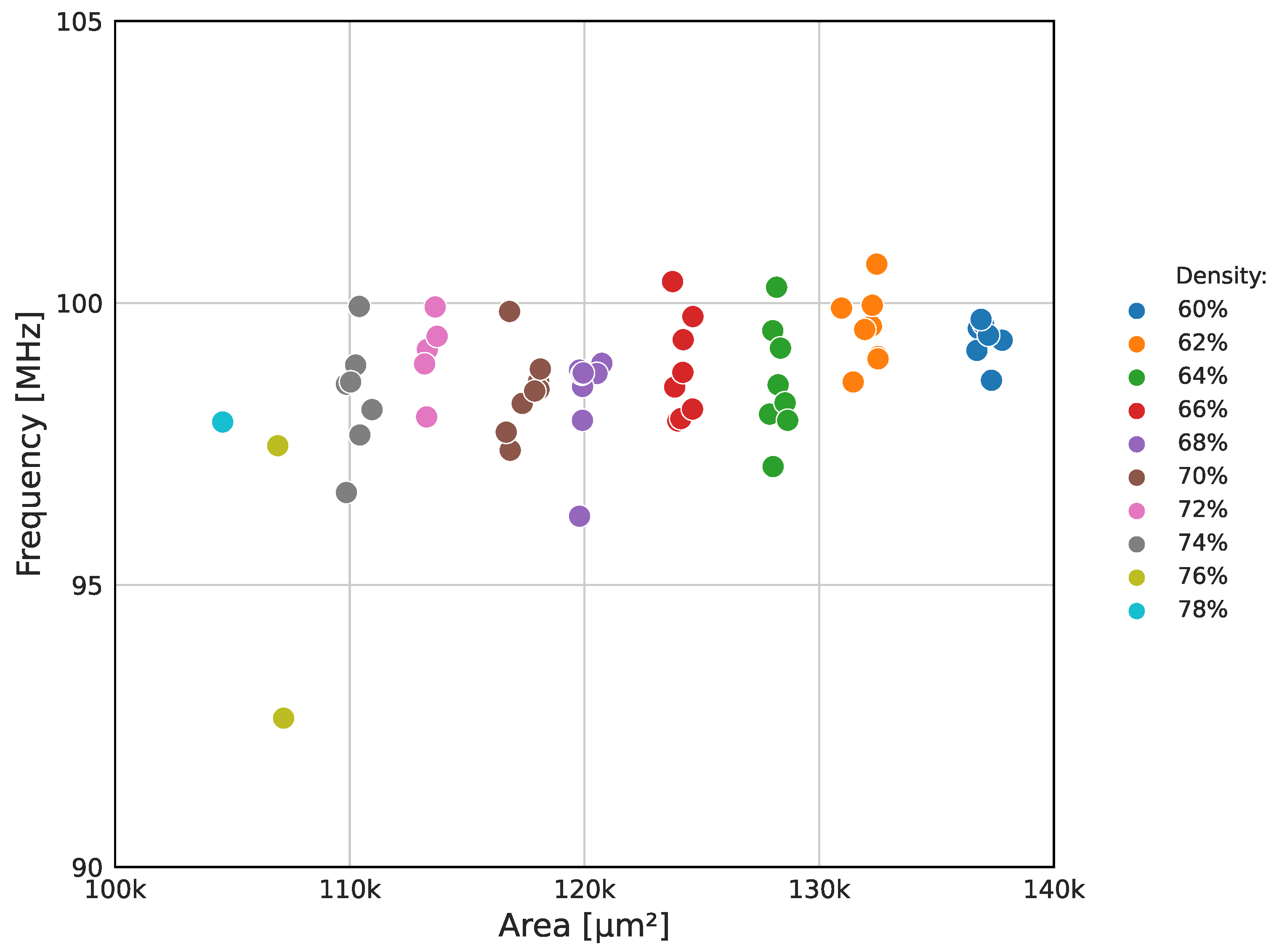
4.2. Synthesis Results
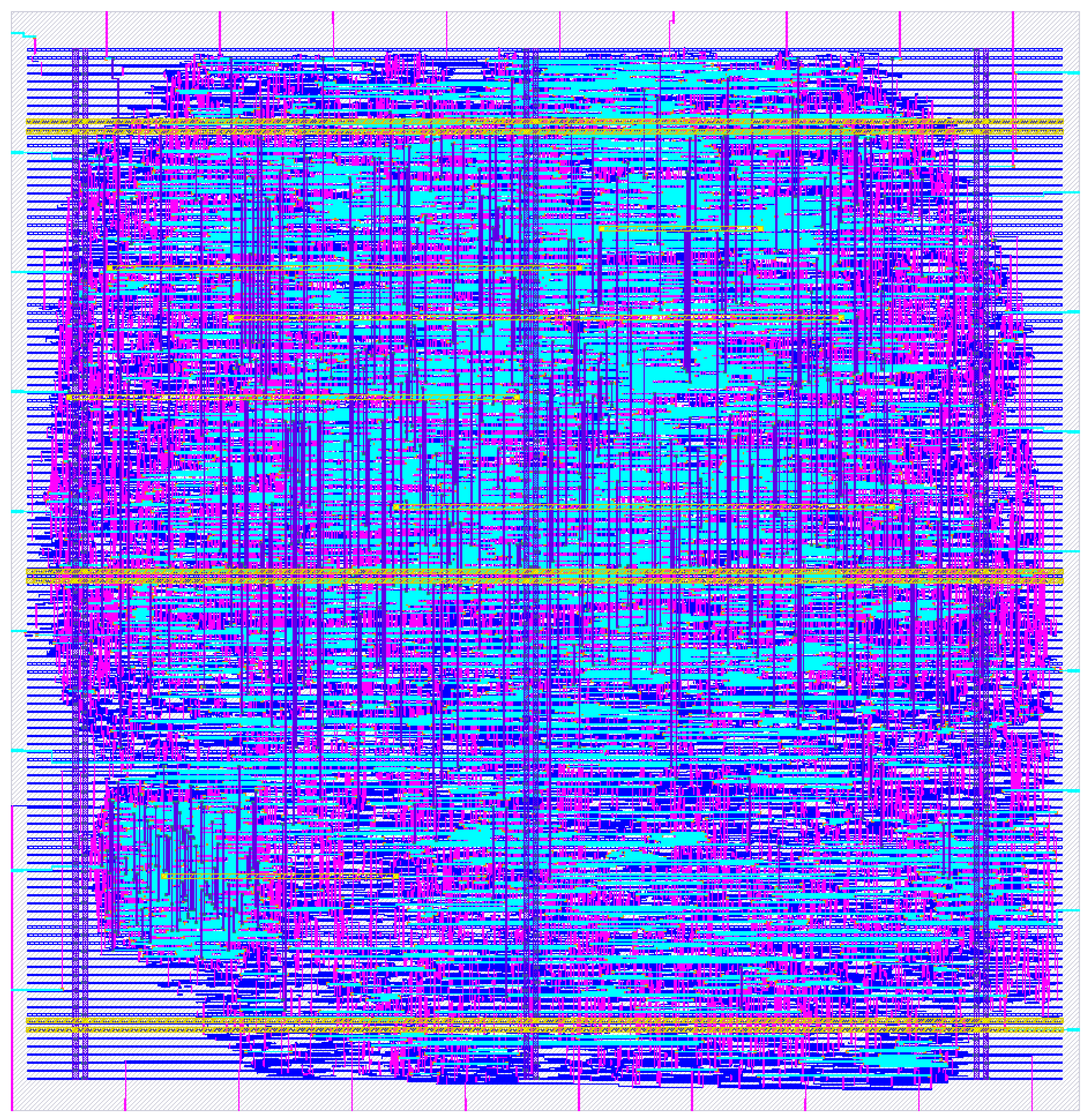
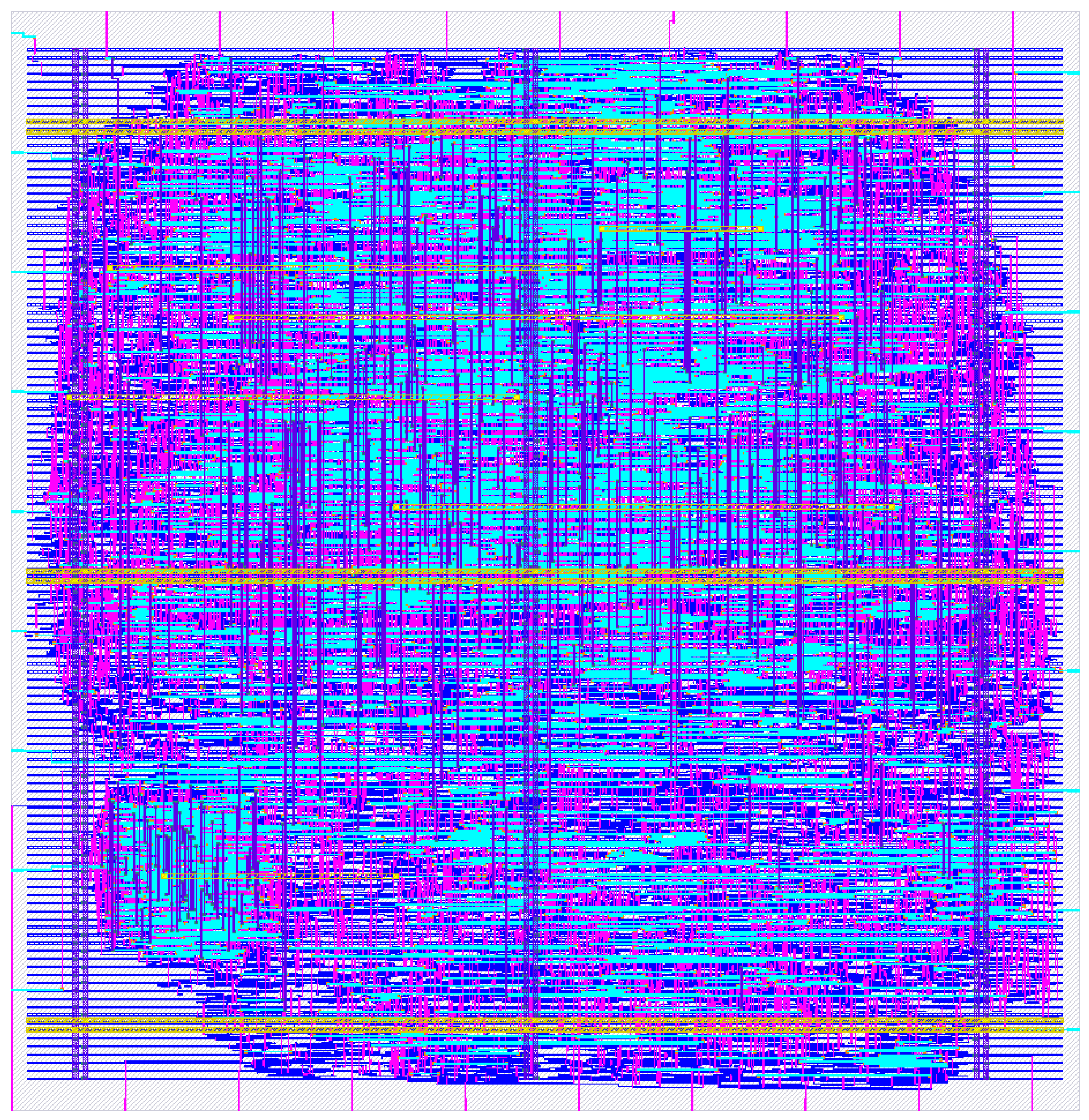
4.3. Final Layout
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASIC | Application-Specific Integrated Circuit |
| CMOS | Complementary Metal-Oxide Semiconductor |
| CPU | Central Processing Unit |
| CSA | Carry-Save Adder |
| DRC | Design Rule Checking |
| EDA | Electronic Design Automation |
| FA | Full Adder |
| FPGA | Field-Programmable Gate Arrays |
| GE | Gate Equivalent |
| HDL | Hardware Description Language |
| IC | Integrated Circuit |
| IR | Voltage |
| IoT | Internet of Things |
| LVS | Layout Versus Schematic |
| NIST | National Institute of Standards and Technology |
| NSA | National Security Agency |
| P&R | Place and Route |
| PDK | Process Design Kit |
| RCA | Ripple-Carry Adder |
| ROM | Read-Only Memory |
| RTL | Register Transfer Level |
| SHA | Secure Hash Algorithm |
| SMIC | Semiconductor Manufacturing International Corporation |
| STA | Static Timing Analysis |
| TSMC | Taiwan Semiconductor Manufacturing Company |
| VHDL | VHSIC Hardware Description Language |
| VHSIC | Very High Speed Integrated Circuit |
References
- Andrews, W.; Lindeman, T. The Black Budget. The Washington Post. 29 August 2013. Available online: https://www.washingtonpost.com/wp-srv/special/national/black-budget/ (accessed on 23 February 2023).
- Rawal, B.S.; Kumar, L.S.; Maganti, S.; Godha, V. Comparative Study of Sha-256 Optimization Techniques. In Proceedings of the 2022 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 6–9 June 2022; pp. 387–392. [Google Scholar]
- FIPS 180-4; Secure Hash Standard (SHS). Federal Information Processing Standards Publication, National Institute of Standards and Technology: Gaithersburg, MD, USA, August 2015.
- Zhang, X.; Liu, B.; Zhao, Y.; Hu, X.; Shen, Z.; Zheng, Z.; Liu, Z.; Chong, K.-S.; Yu, G.; Wang, C.; et al. Design and Analysis of Area and Energy Efficient Reconfigurable Cryptographic Accelerator for Securing IoT Devices. Sensors 2022, 22, 9160. [Google Scholar] [CrossRef] [PubMed]
- Sghaier, A.; Zeghid, M.; Massoud, C.; Mahchout, M. Design And Implementation of Low Area/Power Elliptic Curve Digital Signature Hardware Core. Electronics 2017, 6, 46. [Google Scholar] [CrossRef]
- Diehl, W.; Abdulgadir, A.; Kaps, J.-P.; Gaj, K. Comparing the Cost of Protecting Selected Lightweight Block Ciphers against Differential Power Analysis in Low-Cost FPGAs. Computers 2018, 7, 28. [Google Scholar] [CrossRef]
- Nam, H.; Lysecky, R. Mixed Cryptography Constrained Optimization for Heterogeneous, Multicore, and Distributed Embedded Systems. Computers 2018, 7, 29. [Google Scholar] [CrossRef]
- Baldanzi, L.; Crocetti, L.; Falaschi, F.; Bertolucci, M.; Belli, J.; Fanucci, L.; Saponara, S. Cryptographically Secure Pseudo-Random Number Generator IP-Core Based on SHA2 Algorithm. Sensors 2020, 20, 1869. [Google Scholar] [CrossRef] [PubMed]
- Zhu, S.; Zhu, C.; Wang, W. A New Image Encryption Algorithm Based on Chaos and Secure Hash SHA-256. Entropy 2018, 20, 716. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Xu, Y.; Huo, G.; Yang, Y.; Jin, Y. Optimized Dual-mode Security Encryption Chip Design Based on Hash Algorithm. In Proceedings of the 2022 IEEE 11th International Conference on Communication Systems and Network Technologies (CSNT), Indore, India, 23–24 April 2022; pp. 566–570. [Google Scholar]
- Dadda, L.; Macchetti, M.; Owen, J. The design of a high speed ASIC unit for the hash function SHA-256 (384, 512). In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition, Paris, France, 16–20 February 2004; Volume 3, pp. 70–75. [Google Scholar]
- Bai, L.; Li, S. VLSI implementation of high-speed SHA-256. In Proceedings of the 2009 IEEE 8th International Conference on ASIC, Changsha, China, 20–23 October 2009; pp. 131–134. [Google Scholar]
- Wu, R.; Zhang, X.; Wang, M.; Wang, L. A High-Performance Parallel Hardware Architecture of SHA-256 Hash in ASIC. In Proceedings of the 2020 22nd International Conference on Advanced Communication Technology (ICACT), Phoenix Park, Republic of Korea, 16–19 February 2020; pp. 1242–1247. [Google Scholar]
- Li, J.; He, Z.; Qin, Y. Design of Asynchronous High Throughput SHA-256 Hardware Accelerator in 40nm CMOS. In Proceedings of the 2019 IEEE 13th International Conference on ASIC (ASICON), Chongqing, China, 30 October–1 November 2019; pp. 1–4. [Google Scholar]
- Zhang, Y.; He, Z.; Wan, M.; Zhan, M.; Zhang, M.; Peng, K.; Song, M.; Gu, H. A New Message Expansion Structure for Full Pipeline SHA-2. IEEE Trans. Circuits Syst. Regul. Pap. 2021, 68, 1553–1566. [Google Scholar] [CrossRef]
- Nannipieri, P.; Bertolucci, M.; Baldanzi, L.; Crocetti, L.; Di Matteo, S.; Falaschi, F.; Fanucci, L.; Saponara, S. SHA2 and SHA-3 accelerator design in a 7 nm technology within the European Processor Initiative. Microprocess Microsyst. 2020, 87, 103444. [Google Scholar] [CrossRef]
- Le, V.T.D.; Pham, H.L.; Duong, T.S.; Tran, T.H.; Nguyen, Q.D.N.; Nakashima, Y. RHCP: A Reconfigurable High-efficient Cryptographic Processor for Decentralized IoT Platforms. In Proceedings of the 2023 15th International Conference on Knowledge and Systems Engineering (KSE), Hanoi, Vietnam, 18–20 October 2023; pp. 1–6. [Google Scholar]
- Michail, H.E.; Athanasiou, G.S.; Theodoridis, G.; Gregoriades, A.; Goutis, C.E. Design and implementation of totally-self checking SHA-1 and SHA-256 hash functions’ architectures. Microprocess Microsyst. 2016, 45, 227–240. [Google Scholar] [CrossRef]
- Shalan, M.; Edwards, T. Building OpenLANE: A 130nm OpenROAD-based Tapeout- Proven Flow: Invited Paper. In Proceedings of the 2020 IEEE/ACM International Conference On Computer Aided Design (ICCAD), San Diego, CA, USA, 2–5 November 2020; pp. 1–6. [Google Scholar]
- LDFranck. Custom ASIC Design for SHA-256 GitHub. 2023. Available online: https://github.com/LDFranck/SHA-256 (accessed on 1 November 2023).
- D’Amore, R. VHDL Descrição e Síntese de Circuitos Digitais, 2nd ed.; LTC: Rio de Janeiro, Brazil, 2005; p. 308. [Google Scholar]
- Balaji, S. Digital Design Flow Techniques and Circuit Design for Thin-Film Transistors. Master’s Thesis, Lund University, Lund, Sweden, 18 June 2020. [Google Scholar]
- The OpenROAD Project. Available online: https://theopenroadproject.org/ (accessed on 1 November 2023).
- YosysHQ. Yosys Open Synthesis Suite GitHub. 2023. Available online: https://github.com/YosysHQ/yosys (accessed on 1 November 2023).
- RTimothyEdwards. Magic GitHub. 2023. Available online: https://github.com/RTimothyEdwards/magic (accessed on 1 November 2023).
- RTimothyEdwards. Netgen GitHub. 2023. Available online: https://github.com/RTimothyEdwards/netgen (accessed on 1 November 2023).
- KLayout EDA Tool. Available online: https://www.klayout.de/ (accessed on 1 November 2023).
- SkyWater Foundries. FOSS 130 nm Production PDK. 2020. Available online: https://skywater-pdk.readthedocs.io/ (accessed on 6 August 2023).
- Efabless Corporation. OpenLANE Project GitHub. 2023. Available online: https://github.com/The-OpenROAD-Project/OpenLane (accessed on 6 August 2023).
- Martin, D. SHA-256 Algorithm Explained. 2022. Available online: https://sha256algorithm.com/ (accessed on 2 March 2023).
- Efabless Corporation. The OpenLANE Documentation. 2022. Available online: https://openlane.readthedocs.io/ (accessed on 6 August 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design | Year | Technology | Frequency (MHz) | Area | Cycles * | Power (mW) | |
|---|---|---|---|---|---|---|---|
| (µm2) | GE | ||||||
| [10] | 2022 | SMIC 65 nm | 472 | - | 35,600 | - | 4.97 |
| [11] | 2004 | ST 180 nm | 819 | 164,856 | - | 67 | - |
| [12] | 2009 | SMIC 180 nm | 208 | 211,955 | - | 65 | - |
| [13] | 2019 | Intel 14 nm | 1530 | 14,273 | - | - | 6.86 |
| [14] | 2019 | SMIC 40 nm | 227 | 38,885 | - | 32 | - |
| [15] | 2021 | 28 nm CMOS | 446 | 209,773 | - | 1 | 252 |
| [16] | 2021 | TSMC 7 nm | 5150 | - | 31,550 | 67 | 13.5 |
| [17] | 2023 | FreePDK 45 nm | 254 | - | - | 16 | 1850 |
| [18] | 2016 | TSMC 90 nm | 503 | 209,624 | - | 8 | 128 |
| Symbol | Operation |
|---|---|
| ∧ | Bitwise AND |
| ∨ | Bitwise OR |
| ⊕ | Bitwise XOR |
| ¬ | Bitwise NOT |
| + | Addition modulo |
| Concatenation | |
| Right-shift by n bits | |
| Rotate-right by n bits |
| Input Message | Hexadecimal Hash |
|---|---|
| abc | BA7816BF 8F01CFEA 414140DE 5DAE2223 B00361A3 96177A9C B410FF61 F20015AD |
| abcdbcdecdefdefgefghfghighij hijkijkljklmklmnlmnomnopnopq | 248D6A61 D20638B8 E5C02693 0C3E6039 A33CE459 64FF2167 F6ECEDD4 19DB06C1 |
| Signal | Function |
|---|---|
| clk | Clock signal |
| sel | Data selection |
| in | External data input |
| msg | Expander module output |
| soc | Start of computation |
| eoc | End of computation |
| rst | Master reset |
| k | Constants () |
| hash1+hash2 | Hash output |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Franck, L.D.; Ginja, G.A.; Carmo, J.P.; Afonso, J.A.; Luppe, M. Custom ASIC Design for SHA-256 Using Open-Source Tools. Computers 2024, 13, 9. https://doi.org/10.3390/computers13010009
Franck LD, Ginja GA, Carmo JP, Afonso JA, Luppe M. Custom ASIC Design for SHA-256 Using Open-Source Tools. Computers. 2024; 13(1):9. https://doi.org/10.3390/computers13010009
Chicago/Turabian StyleFranck, Lucas Daudt, Gabriel Augusto Ginja, João Paulo Carmo, José A. Afonso, and Maximiliam Luppe. 2024. "Custom ASIC Design for SHA-256 Using Open-Source Tools" Computers 13, no. 1: 9. https://doi.org/10.3390/computers13010009
APA StyleFranck, L. D., Ginja, G. A., Carmo, J. P., Afonso, J. A., & Luppe, M. (2024). Custom ASIC Design for SHA-256 Using Open-Source Tools. Computers, 13(1), 9. https://doi.org/10.3390/computers13010009