



Toward Improved Machine Learning-Based Intrusion Detection for Internet of Things Traffic


Abstract
1. Introduction
- What are the main criteria relevant to preparing and selecting proper datasets that preserve the required quality for IDS performance in an IoT context?
- How would quality assurance factors, including both data and model perspectives, impact multi-class ML-based IDSs within an IoT context?
- How would quality assurance methods enhance the performance of ML-based IDSs?
- Can a lightweight framework designed based on model quality assurance methods enhance the IDS detection rate in an IoT context?
- Introducing dataset selection criteria to ensure high-quality data-driven modeling for IDSs within an IoT environment;
- A comprehensive investigation and analysis of the trade-offs regarding quality assurance challenges and solutions in ML-based IDSs considering an IoT environment;
- Improved generalization for the selected supervised ML techniques considering IoT resource-constrained devices;
- A lightweight framework for enhancing the IDS detection rate in an IoT context through employing selected data and model quality assurance methods.
2. Related Works
2.1. ML-Based Intrusion Detection Systems for IoT Networks
2.2. Quality Assurance Challenges of ML-Based IDSs
2.3. Data Collection, Pre-Processing, and Selection for IDSs Regarding the IoT
3. Best Practices for Efficient IDSs in IoT Networks
3.1. Data-Related Quality Assurance Solutions
3.1.1. Class Sampling
3.1.2. Feature Pre-Processing and Selection
3.2. Model-Related Quality Assurance Solutions
3.2.1. ML Technique Selection
3.2.2. Performance Evaluation
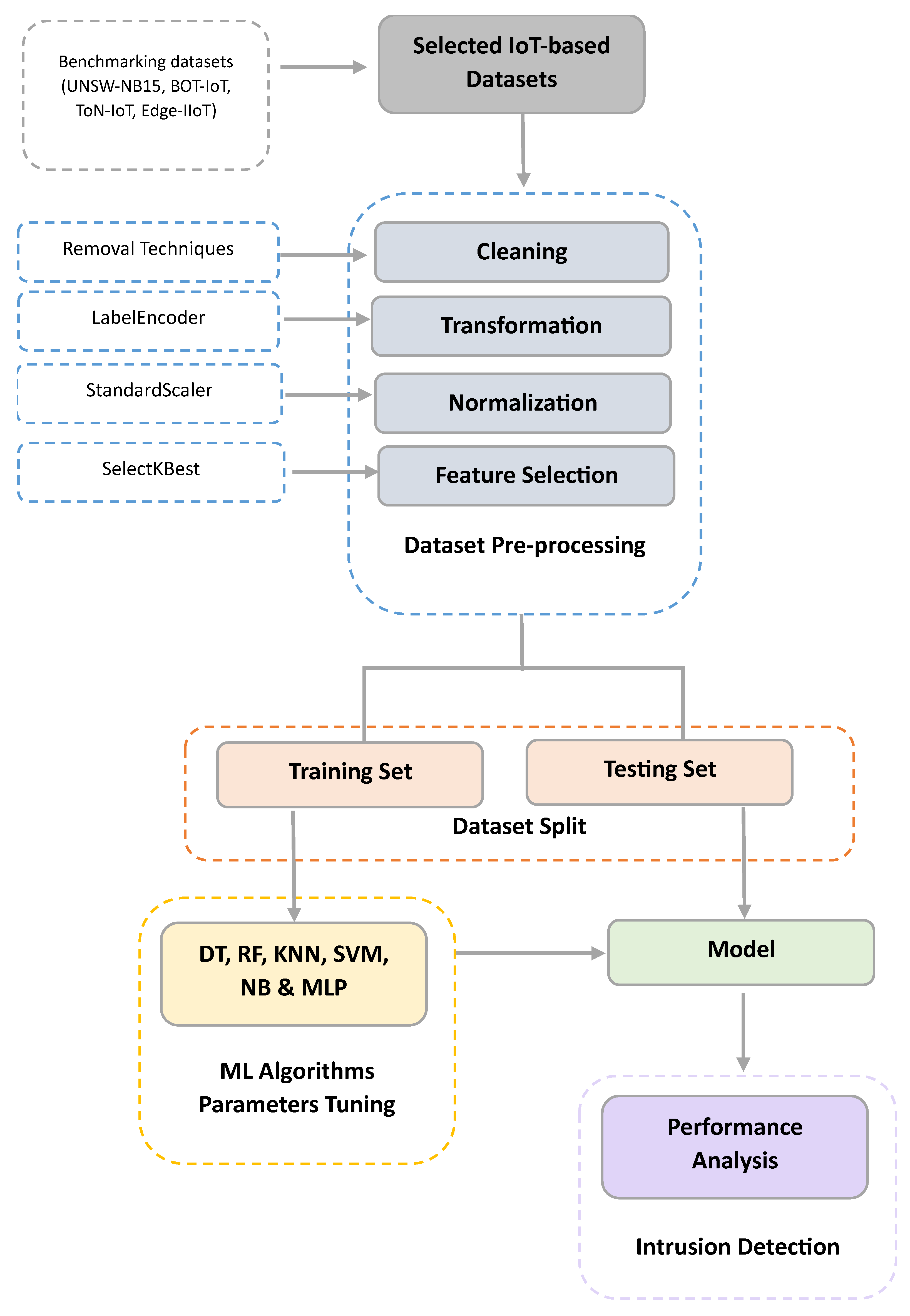
4. Proposed Approach
- Random forest (RF): A family of tree-based algorithms used for training an army of trees instead of one. These trees are built up randomly from different training subsets for both classification and regression tasks. They are scalable and can handle large datasets, minimizing the overall generalization error with high accuracy [1,61].
- Support vector machine (SVM): A family of non-probabilistic algorithms used for both classification and regression problems. It performs prediction by identifying the dividing hyper-plane that separates the inputs with the maximum margin. Both binary and multi-class systems can be handled and classified into a suitable dimensional space. SVM performs both linear and non-linear classification using a kernel trick [1,61].
- Naïve Bayes (NB): A family of probabilistic classification algorithms based on Bayes’ theorem for both binary and multi-class inputs. Naïve represents an oversimplified assumption so as to calculate the probabilities of attributes. They are assumed to be conditionally independent and can be high-dimensional attributes [1,61].
- K nearest neighbor (KNN): A family of clustering algorithms used for both classification and regression problems. It works on combining new unseen datapoints with similar given points by searching the closest neighbors in the feature space of the available dataset. A distance metric is used to find the K nearest neighbors, such as Euclidean distance, L∞ norm, and others [1,61].
- Multi-layer perceptron (MLP): A family of basic artificial neural networks consisting of three layers: input, hidden, and output layers, which allows for solving both linearly separable and non-linearly separable problems. It is a feed-forward neural network that connects neurons in a forward manner without having loops. An activation function and a set of weights are employed, whereby the weights can be fine-tuned using a supervised learning technique called backpropagation [62].
5. Experiments
5.1. Datasets
5.1.1. UNSW-NB15 Dataset
5.1.2. BOT-IoT Dataset
5.1.3. ToN-IoT Dataset
5.1.4. Edge-IIoT Dataset
5.2. Performance Measures
5.3. Results
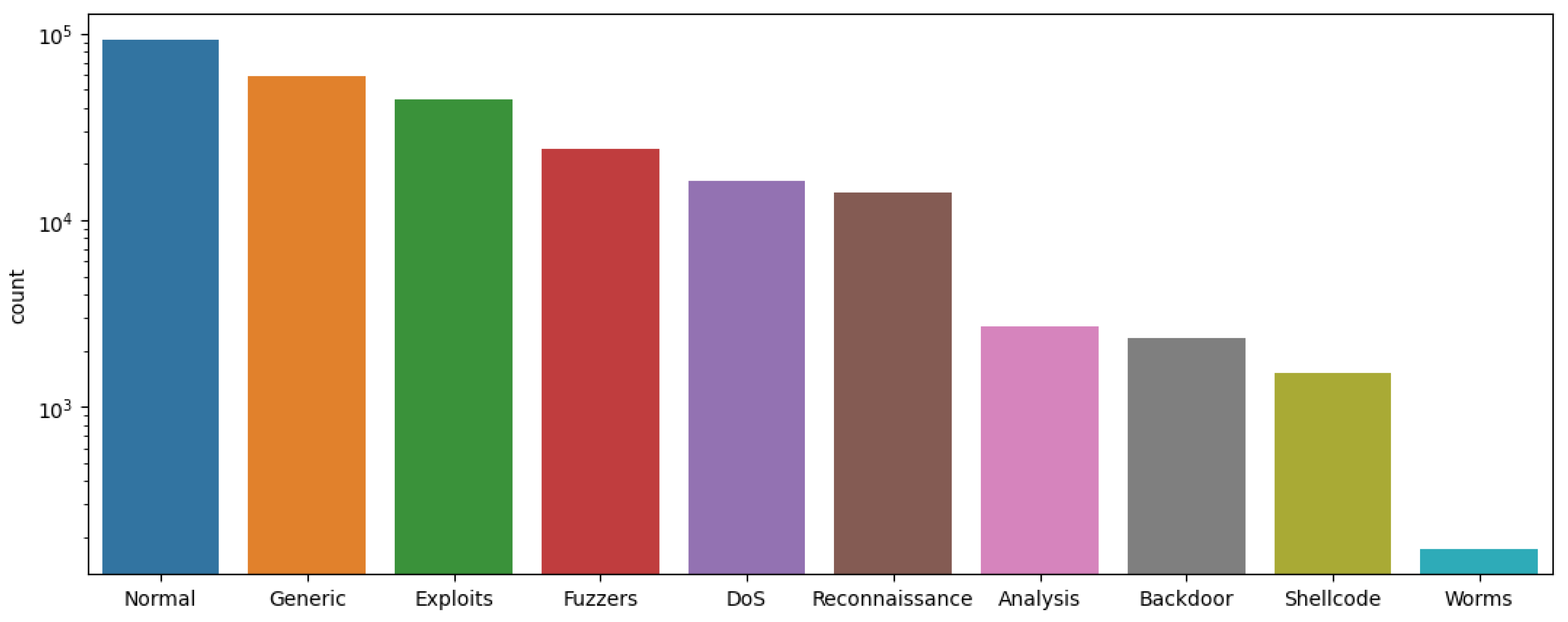
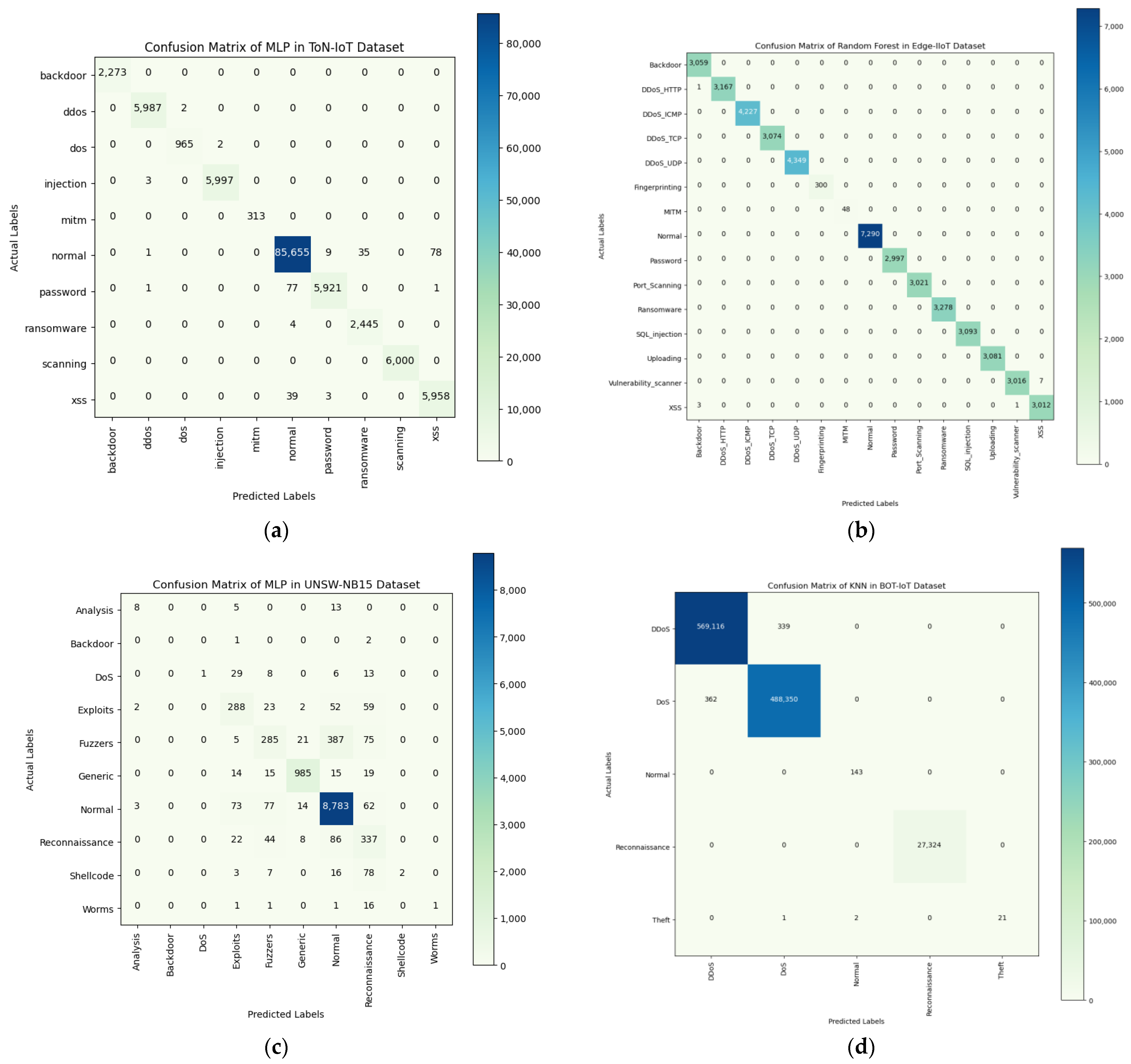
5.3.1. Classification Results Obtained Using Pre-Processed UNSW-NB15 Dataset
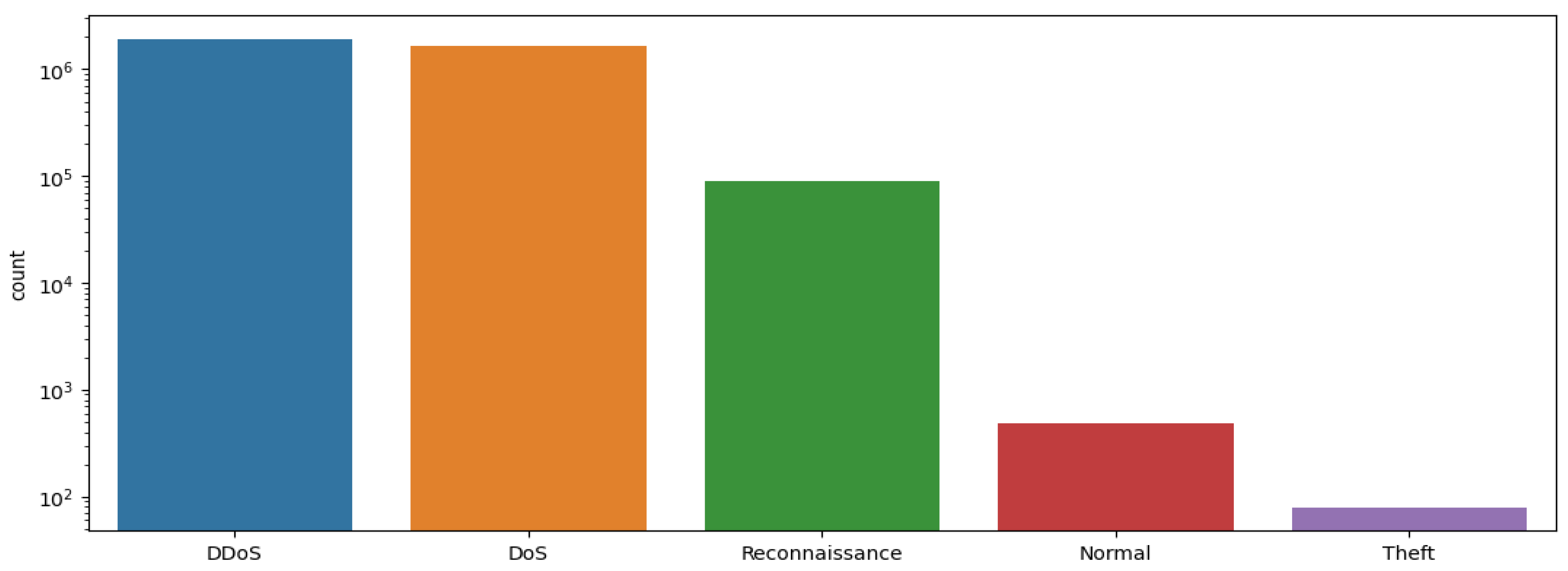
5.3.2. Classification Results Obtained Using the Pre-Processed BOT-IoT Dataset
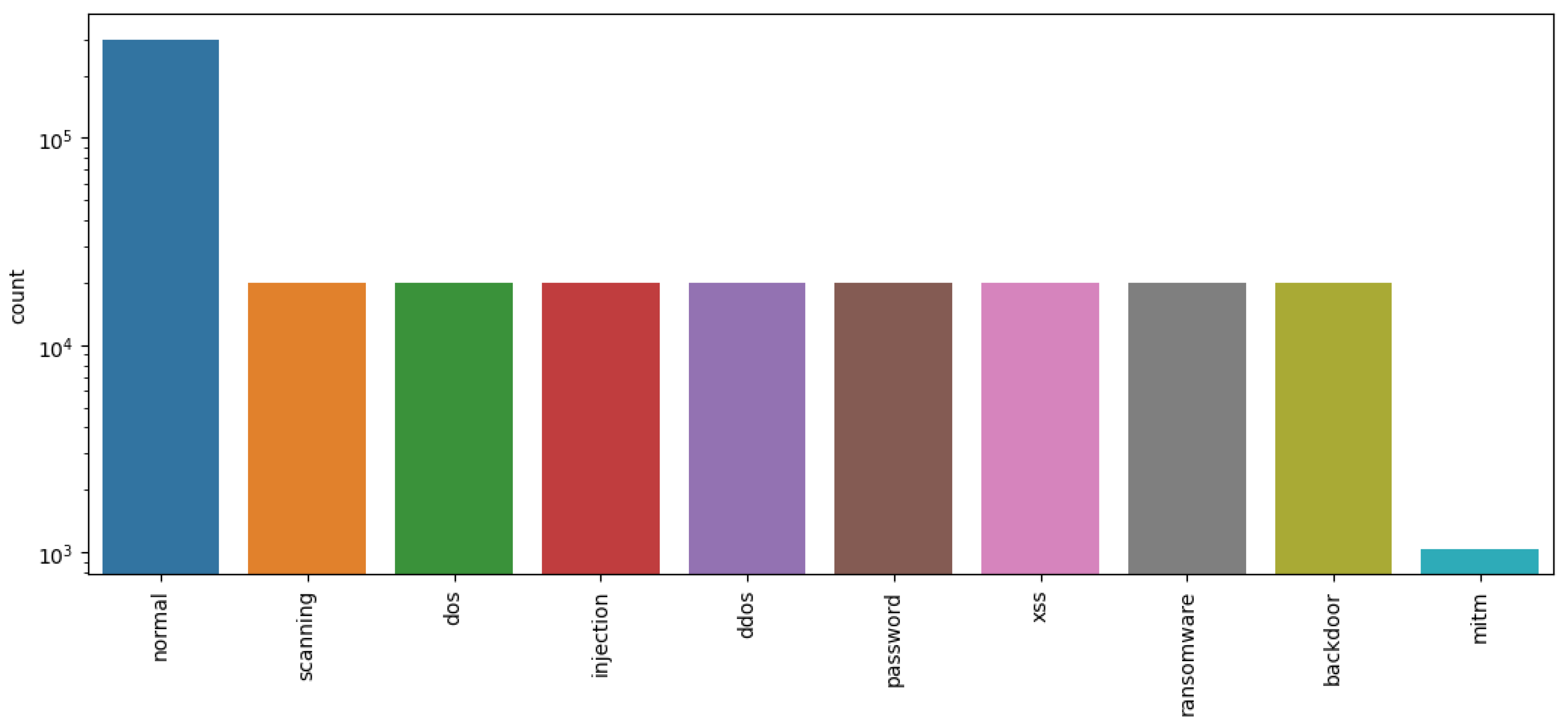
5.3.3. Classification Results Obtained Using the Pre-Processed ToN-IoT Dataset
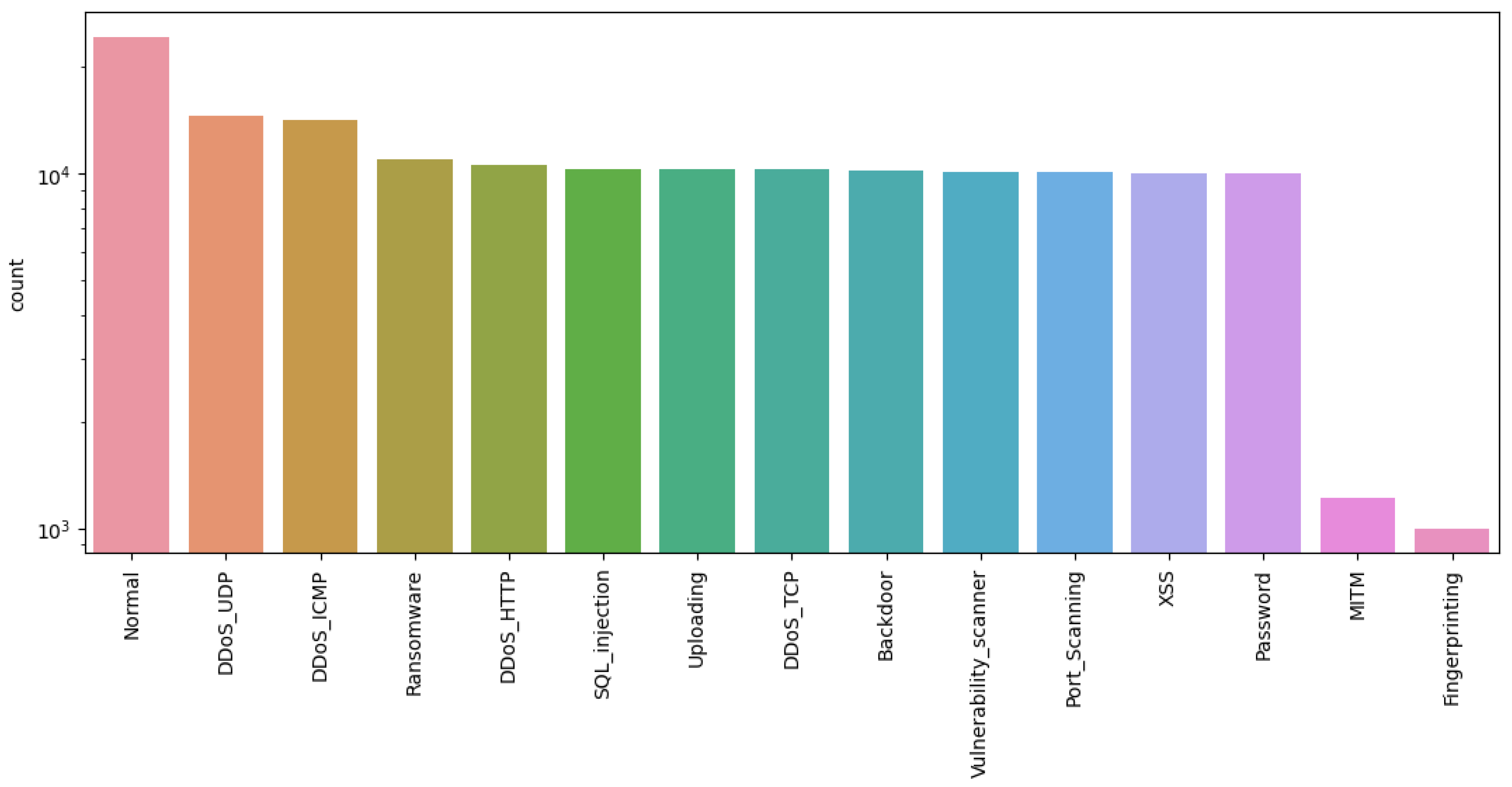
5.3.4. Classification Results Obtained Using the Pre-Processed Edge-IIoT Dataset
6. Discussion
7. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for Internet of Things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Almseidin, M.; Alzubi, M.; Kovacs, S.; Alkasassbeh, M. Evaluation of machine learning algorithms for intrusion detection system. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; pp. 277–282. [Google Scholar]
- Zarpelão, B.B.; Miani, R.S.; Kawakani, C.T.; de Alvarenga, S.C. A survey of intrusion detection in Internet of Things. J. Netw. Comput. Appl. 2017, 84, 25–37. [Google Scholar] [CrossRef]
- Capra, M.; Peloso, R.; Masera, G.; Ruo Roch, M.; Martina, M. Edge computing: A survey on the hardware requirements in the internet of things world. Future Internet 2019, 11, 100. [Google Scholar] [CrossRef]
- Shukla, P. ML-IDS: A machine learning approach to detect wormhole attacks in Internet of Things. In Proceedings of the 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 234–240. [Google Scholar]
- Viegas, E.; Santin, A.; Oliveira, L.; Franca, A.; Jasinski, R.; Pedroni, V. A reliable and energy-efficient classifier combination scheme for intrusion detection in embedded systems. Comput. Secur. 2018, 78, 16–32. [Google Scholar] [CrossRef]
- Canedo, J.; Skjellum, A. Using machine learning to secure IoT systems. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 219–222. [Google Scholar]
- Kim, J.; Kim, J.; Thu HL, T.; Kim, H. Long short term memory recurrent neural network classifier for intrusion detection. In Proceedings of the 2016 International Conference on Platform Technology and Service (PlatCon), Jeju, Republic of Korea, 15–17 February 2016; pp. 1–5. [Google Scholar]
- Saeed, A.; Ahmadinia, A.; Javed, A.; Larijani, H. Intelligent intrusion detection in low-power IoTs. ACM Trans. Internet Technol. (TOIT) 2016, 16, 1–25. [Google Scholar] [CrossRef]
- Zhang, J.; Qin, Z.; Yin, H.; Ou, L.; Zhang, K. A feature-hybrid malware variants detection using CNN based opcode embedding and BPNN based API embedding. Comput. Secur. 2019, 84, 376–392. [Google Scholar] [CrossRef]
- Agarap, A.F. Towards Building an Intelligent Anti-Malware System: A Deep Learning Approach Using Support Vector Machine (SVM) for Malware Classification, No. 1. 2017. Available online: http://arxiv.org/abs/1801.00318 (accessed on 13 April 2022).
- Tareq, I.; Elbagoury, B.M.; El-Regaily, S.; El-Horbaty, E.-S.M. Analysis of ToN-IoT, UNW-NB15, and Edge-IIoT Datasets Using DL in Cybersecurity for IoT. Appl. Sci. 2022, 12, 9572. [Google Scholar] [CrossRef]
- Nesa, N.; Ghosh, T.; Banerjee, I. Non-parametric sequence-based learning approach for outlier detection in IoT. Future Gener. Comput. Syst. 2018, 82, 412–421. [Google Scholar] [CrossRef]
- Khan, H.U.; Sohail, M.; Ali, F.; Nazir, S.; Ghadi, Y.Y.; Ullah, I. Prioritizing the Multi-criterial Features based on Comparative Approaches for Enhancing Security of IoT devices. Phys. Commun. 2023, 59, 102084. [Google Scholar] [CrossRef]
- Mazhar, T.; Talpur, D.B.; Shloul, T.A.; Ghadi, Y.Y.; Haq, I.; Ullah, I.; Ouahada, K.; Hamam, H. Analysis of IoT Security Challenges and Its Solutions Using Artificial Intelligence. Brain Sci. 2023, 13, 683. [Google Scholar] [CrossRef] [PubMed]
- Tran, N.; Chen, H.; Bhuyan, J.; Ding, J. Data Curation and Quality Evaluation for Machine Learning-Based Cyber Intrusion Detection. IEEE Access 2022, 10, 121900–121923. [Google Scholar] [CrossRef]
- Si-Ahmed, A.; Al-Garadi, M.A.; Boustia, N. Survey of Machine Learning Based Intrusion Detection Methods for Internet of Medical Things. arXiv 2022, arXiv:2202.09657. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-IoT dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Kanimozhi, V. Jacob PUNSW-NB15 dataset feature selection network intrusion detection using deep learning. Int. J. Recent Technol. Eng. 2019, 7, 443–446. [Google Scholar]
- Nawir, M.; Amir, A.; Yaakob, N.; Lynn, O.B. Effective and efficient network anomaly detection system using machine learning algorithm. Bull. Electr. Eng. Inform. 2019, 8, 46–51. [Google Scholar] [CrossRef]
- Alsaedi, A.; Moustafa, N.; Tari, Z.; Mahmood, A.; Anwar, A. TON_IoT telemetry dataset: A new generation dataset of IoT and IIoT for data-driven intrusion detection systems. IEEE Access 2020, 8, 165130–165150. [Google Scholar] [CrossRef]
- Kasongo, S.M.; Sun, Y. Performance analysis of intrusion detection systems using a feature selection method on the UNSW-NB15 dataset. J. Big Data 2020, 7, 105. [Google Scholar] [CrossRef]
- Thaseen, I.S.; Mohanraj, V.; Ramachandran, S.; Sanapala, K.; Yeo, S.S. A hadoop based framework integrating machine learning classifiers for anomaly detection in the internet of things. Electronics 2021, 10, 1955. [Google Scholar] [CrossRef]
- Sugi, S.S.S.; Ratna, S.R. Investigation of machine learning techniques in intrusion detection system for IoT network. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3–5 December 2020; pp. 1164–1167. [Google Scholar]
- Sarhan, M.; Layeghy, S.; Portmann, M. Feature Analysis for Machine Learning-based IoT Intrusion Detection. arXiv 2021, arXiv:2108.12732. [Google Scholar]
- Ferrag, M.A.; Friha, O.; Hamouda, D.; Maglaras, L.; Janicke, H. Edge-IIoTset: A new comprehensive realistic cyber security dataset of IoT and IIoT applications for centralized and federated learning. IEEE Access 2022, 10, 40281–40306. [Google Scholar] [CrossRef]
- Fatani, A.; Abd Elaziz, M.; Dahou, A.; Al-Qaness, M.A.; Lu, S. IoT intrusion detection system using deep learning and enhanced transient search optimization. IEEE Access 2021, 9, 123448–123464. [Google Scholar] [CrossRef]
- Yin, Y.; Jang-Jaccard, J.; Xu, W.; Singh, A.; Zhu, J.; Sabrina, F.; Kwak, J. IGRF-RFE: A hybrid feature selection method for MLP-based network intrusion detection on UNSW-NB15 Dataset. J. Big Data 2023, 10, 15. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Inf. Secur. J. A Glob. Perspect. 2016, 25, 18–31. [Google Scholar] [CrossRef]
- Gad, A.R.; Nashat, A.A.; Barkat, T.M. Intrusion detection system using machine learning for vehicular ad hoc networks based on ToN-IoT dataset. IEEE Access 2021, 9, 142206–142217. [Google Scholar] [CrossRef]
- KDD Cup 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 1 February 2023).
- Amit, I.; Matherly, J.; Hewlett, W.; Xu, Z.; Meshi, Y.; Weinberger, Y. Machine learning in cyber-security-problems, challenges and data sets. arXiv 2018, arXiv:1812.07858. [Google Scholar]
- Kayacik, H.G.; Zincir-Heywood, A.N.; Heywood, M.I. Selecting features for intrusion detection: A feature relevance analysis on KDD 99 intrusion detection datasets. In Proceedings of the Third Annual Conference on Privacy, Security and Trust, Saint Andrews, NB, Canada, 12–14 October 2005; Volume 94, pp. 1722–1723. [Google Scholar]
- Sahu, A.; Mao, Z.; Davis, K.; Goulart, A.E. Data processing and model selection for machine learning-based network intrusion detection. In Proceedings of the 2020 IEEE International Workshop Technical Committee on Communications Quality and Reliability (CQR), Stevenson, WA, USA, 14 May 2020; pp. 1–6. [Google Scholar]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Yang, X.; Peng, G.; Zhang, D.; Lv, Y. An Enhanced Intrusion Detection System for IoT Networks Based on Deep Learning and Knowledge Graph. Secur. Commun. Netw. 2022, 2022, 4748528. [Google Scholar] [CrossRef]
- Gudivada, V.; Apon, A.; Ding, J. Data quality considerations for big data and machine learning: Going beyond data cleaning and transformations. Int. J. Adv. Softw. 2017, 10, 1–20. [Google Scholar]
- Cawley, G.C.; Talbot, N.L. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Alkadi, S.; Al-Ahmadi, S.; Ismail MM, B. Better Safe Than Never: A Survey on Adversarial Machine Learning Applications towards IoT Environment. Appl. Sci. 2023, 13, 6001. [Google Scholar] [CrossRef]
- Paleyes, A.; Urma, R.G.; Lawrence, N.D. Challenges in deploying machine learning: A survey of case studies. ACM Comput. Surv. 2022, 55, 1–29. [Google Scholar] [CrossRef]
- Hansson, K.; Yella, S.; Dougherty, M.; Fleyeh, H. Machine learning algorithms in heavy process manufacturing. Am. J. Intell. Syst. 2016, 6, 1–13. [Google Scholar]
- Monasterios, Y.D.P. Adversarial Machine Learning: A Comparative Study on Contemporary Intrusion Detection Datasets; The University of Toledo: Toledo, OH, USA, 2020. [Google Scholar]
- Khraisat, A.; Alazab, A. A critical review of intrusion detection systems in the internet of things: Techniques, deployment strategy, validation strategy, attacks, public datasets and challenges. Cybersecurity 2021, 4, 18. [Google Scholar] [CrossRef]
- Luo, Z.; Zhao, S.; Lu, Z.; Sagduyu, Y.E.; Xu, J. Adversarial machine learning based partial-model attack in IoT. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, Linz, Austria, 13 July 2020; pp. 13–18. [Google Scholar]
- Arp, D.; Quiring, E.; Pendlebury, F.; Warnecke, A.; Pierazzi, F.; Wressnegger, C.; Cavallaro, L.; Rieck, K. Dos and Don’ts of Machine Learning in Computer Security. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 3971–3988. [Google Scholar]
- Garc´ıa, S.; Zunino, A.; Campo, M. Survey on network-based botnet detection methods. Secur. Commun. Netw. 2014, 7, 878–903. [Google Scholar] [CrossRef]
- Ge, M.; Syed, N.F.; Fu, X.; Baig, Z.; Robles-Kelly, A. Towards a deep learning-driven intrusion detection approach for Internet of Things. Comput. Netw. 2021, 186, 107784. [Google Scholar] [CrossRef]
- Małowidzki, M.; Berezinski, P.; Mazur, M. Network intrusion detection: Half a kingdom for a good dataset. In Proceedings of the NATO STO SAS-139 Workshop, Lisbon, Portugal, 23 April 2015. [Google Scholar]
- Ring, M.; Wunderlich, S.; Scheuring, D.; Landes, D.; Hotho, A. A survey of network-based intrusion detection data sets. Comput. Secur. 2019, 86, 147–167. [Google Scholar] [CrossRef]
- Gharib, A.; Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. An evaluation framework for intrusion detection dataset. In Proceedings of the 2016 International Conference on Information Science and Security (ICISS), Pattaya, Thailand, 19–22 December 2016; IEEE: Pattaya, Thailand, 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Bulavas, V.; Marcinkevičius, V.; Rumiński, J. Study of multi-class classification algorithms’ performance on highly imbalanced network intrusion datasets. Informatica 2021, 32, 441–475. [Google Scholar] [CrossRef]
- Fan, W. Data quality: From theory to practice. Acm Sigmod Rec. 2015, 44, 7–18. [Google Scholar]
- Lemaitre, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2016, 18, 1–5. [Google Scholar]
- Pears, R.; Finlay, J.; Connor, A.M. Synthetic Minority Over-sampling TEchnique (SMOTE) for Predicting Software Build Outcomes. arXiv 2014, arXiv:1407.2330. [Google Scholar]
- Daza, L.; Acuna, E. Feature selection based on a data quality measure. In Proceedings of the World Congress on Engineering, London, UK, 2–4 July 2008; Volume 2, pp. 1095–1099. [Google Scholar]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 20. [Google Scholar] [CrossRef]
- Shetye, A. Feature Selection with Sklearn and Pandas. 2019. Available online: https://towardsdatascience.com/featureselection-with-pandas-e3690ad8504b (accessed on 20 January 2023).
- Pilnenskiy, N.; Smetannikov, I. Modern Implementations of Feature Selection Algorithms and Their Perspectives. In Proceedings of the 2019 25th Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 5–8 November 2019; pp. 250–256. [Google Scholar]
- Studer, S.; Bui, T.B.; Drescher, C.; Hanuschkin, A.; Winkler, L.; Peters, S.; Müller, K.R. Towards CRISP-ML (Q): A machine learning process model with quality assurance methodology. Mach. Learn. Knowl. Extr. 2021, 3, 392–413. [Google Scholar] [CrossRef]
- Banaamah, A.M.; Ahmad, I. Intrusion Detection in IoT Using Deep Learning. Sensors 2022, 22, 8417. [Google Scholar] [CrossRef]
- Hussain, F.; Hussain, R.; Hassan, S.A.; Hossain, E. Machine learning in IoT security: Current solutions and future challenges. IEEE Commun. Surv. Tutor. 2020, 22, 1686–1721. [Google Scholar] [CrossRef]
- Qayyum, A.; Usama, M.; Qadir, J.; Al-Fuqaha, A. Securing connected & autonomous vehicles: Challenges posed by adversarial machine learning and the way forward. IEEE Commun. Surv. Tutor. 2020, 22, 998–1026. [Google Scholar]
- Liashchynskyi, P.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. arXiv 2019, arXiv:1912.06059. [Google Scholar]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (unsw-nb15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015. [Google Scholar] [CrossRef]
- Papadopoulos, P.; Thornewill von Essen, O.; Pitropakis, N.; Chrysoulas, C.; Mylonas, A.; Buchanan, W.J. Launching adversarial attacks against network intrusion detection systems for iot. J. Cybersecur. Priv. 2021, 1, 252–273. [Google Scholar] [CrossRef]
- Peterson, J.M.; Leevy, J.L.; Khoshgoftaar, T.M. A review and analysis of the bot-iot dataset. In Proceedings of the 2021 IEEE International Conference on Service-Oriented System Engineering (SOSE), Oxford, UK, 23–26 August 2021; pp. 20–27. [Google Scholar]
- Moustafa, N. Ton-Iot Datasets 2019. Available online: https://ieee-dataport.org/documents/toniot-datasets (accessed on 15 January 2023).
- Ferrag, M.A. EdgeIIoT Dataset 2022. Available online: https://www.kaggle.com/datasets/mohamedamineferrag/edgeiiotset-cybersecurity-dataset-of-iot-iiot (accessed on 15 January 2023).
- Rodríguez, M.; Alesanco, Á.; Mehavilla, L.; García, J. Evaluation of Machine Learning Techniques for Traffic Flow-Based Intrusion Detection. Sensors 2022, 22, 9326. [Google Scholar] [CrossRef] [PubMed]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.K.; Du, X.; Ali, I.; Guizani, M. A survey of machine and deep learning methods for internet of things (IoT) security. IEEE Commun. Surv. Tutor. 2020, 22, 1646–1685. [Google Scholar] [CrossRef]
- Martins, N.; Cruz, J.M.; Cruz, T.; Abreu, P.H. Adversarial machine learning applied to intrusion and malware scenarios: A systematic review. IEEE Access 2020, 8, 35403–35419. [Google Scholar] [CrossRef]
- Deshmukh, J.V.; Sankaranarayanan, S. Formal techniques for verification and testing of cyber-physical systems. In Design Automation of Cyber-Physical Systems; Springer: Cham, Switzerland, 2019; pp. 69–105. [Google Scholar] [CrossRef]
- Seshia, S.A.; Sadigh, D.; Sastry, S.S. Toward verified artificial intelligence. Commun. ACM 2022, 65, 46–55. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | ML Technique | Dataset | Evaluation Metric | Classification |
|---|---|---|---|---|---|
| Tareq et al. [12] | 2022 | DenseNet Inception Time | ToN-IoT Edge-IIoT UNSW-NB15 | Accuracy, Precision, Recall, F1-measure | Multi-class |
| Koroniotis et al. [18] | 2019 | RNN, SVM LSTM | BOT-IoT | Accuracy, Precision, Recall | Multi-class |
| Kanimozhi et al. [19] | 2019 | ANN, RF-DT | UNSW-NB15 | Accuracy, Precision, Recall, F1-measure | Multi-class |
| Nawir et al. [20] | 2019 | NB, MLP DT | UNSW-NB15 | Accuracy | Binary |
| Alsaedi et al. [21] | 2020 | LR, LDA KNN, RF CART, NB SVM, LSTM | ToN-IoT | Accuracy, Precision, Recall, F1-measure | Multi-class |
| Kasongo et al. [22] | 2020 | ANN, LR KNN, SVM DT | UNSW-NB15 | Accuracy, Precision, Recall, F1-measure | Multi-class |
| Thaseen et al. [23] | 2020 | C4.5, NB RF, MLP SVM, CART KNN, ANN Ensemble Learning | BOT-IoT | Accuracy, Precision, Recall, F1-measure, Specificity, AUC. | Multi-class |
| Sugi et al. [24] | 2020 | LSTM, KNN | BOT-IoT | Accuracy | Multi-class |
| Sarhan et al. [25] | 2021 | DFF, RF | ToN-IoT | Accuracy, AUC F1-measure, Detection Rate, False Alarm Rate, Prediction Time | Multi-class |
| Ferrag et al. [26] | 2021 | DT, RF SVM, KNN DNN, | Edge-IIoT | Accuracy, Precision, Recall, F1-measure | Multi-class |
| Fatani et al. [27] | 2021 | CNN | BOT-IoT | Accuracy, Precision, Recall | Multi-class |
| Yin et al. [28] | 2023 | MLP | UNSW-NB15 | Accuracy, Precision, Recall, F1-measure, AUC, FPR | Multi-class |
| Moustafa et al. [29] | 2016 | ANN | UNSW-NB15 | Accuracy, Precision, Recall | Multi-class |
| Gad et al. [30] | 2021 | LR, NB, DT, RF, AdaBoost, KNN, SVM, XGBoost | ToN-IoT | Accuracy, Precision, Recall | Multi-class |
| No. | Criteria | Brief |
|---|---|---|
| 1 | Complete Network Configuration | Realistic network configuration with all essential equipment such as PCs, servers, routers, and firewalls. |
| 2 | Complete Traffic | Contains a sequence of packets that originate from a source (to a destination) and can be realistic or pseudo-realistic with both real and simulated world traffic. |
| 3 | Labeled Dataset | All dataset instances are tagged with correct labels for a valid and reliable analysis. |
| 4 | Complete Interaction | All network interactions, such as within or between internal LANs, are recorded for better interpretation and evaluation of the prediction results. |
| 5 | Complete Capture | All network traffic without removing any non-functional or not labeled parts is captured to better calculate the false-positive rate of an IDS. |
| 6 | Available Protocols | All protocols of network traffic are recorded and traced, such as HTTP, FTP, VOIP, and other protocols. |
| 7 | Attack Diversity | Different attacks and threat scenarios are supported by the offline dataset, including a variety of categories. |
| 8 | Anonymity | Datasets without payload information for privacy concerns that affect the usefulness of the dataset. |
| 9 | Heterogeneity | Building datasets from different sources such as network traffic, operating systems logs, or network equipment logs. |
| 10 | Feature set | A group of related features from several data sources, such as traffic or logs. |
| 11 | Metadata | A complete documentation of the network configuration, operating systems, attack scenarios, and others. |
| Dataset | Year | Attacks | Features | Total Records | IoT Devices |
|---|---|---|---|---|---|
| UNSW-NB15 [38] | 2015 | 10 attacks | 45 | 2 million | NA |
| BOT-IoT [18] | 2019 | 5 attacks | 43 | 72 million | Simulated |
| ToN-IoT [35] | 2020 | 9 attacks | 31 | 22 million | Simulated |
| Edge-IIoT [36] | 2022 | 14 attacks | 61 | 20 million | More than 10 devices |
| Criteria | Complied | Criteria | Complied |
|---|---|---|---|
| Complete Network Configuration | Yes | Attack Diversity | 10 |
| Complete Traffic | Yes | Anonymity | No |
| Labeled Dataset | Yes | Heterogeneity | Yes |
| Complete Interaction | Yes | Feature set | 45 |
| Complete Capture | Yes | Metadata | No |
| Available Protocols | TCP, UDP, ICMP and others |
| Method | Examples of Results | |
|---|---|---|
| Before | After | |
| Combining training and test datasets | Training dataset = 82,331 records Test dataset = 175,340 records | Combined dataset = 257,673 records |
| Removal of NaN values | Rows = 257,673 | Rows= 257,673 |
| Columns = 45 | Columns = 43 | |
| Transformation of categorical features (Ex: Attack category values) | ‘Analysis’, | 0 |
| ‘Backdoor’, | 1 | |
| ‘DoS’, | 2 | |
| ‘Exploits’, | 3 | |
| ‘Fuzzers’, | 4 | |
| ‘Generic’, | 5 | |
| ‘Normal’, | 6 | |
| ‘Reconnaissance’, | 7 | |
| ‘Shellcode’, | 8 | |
| ‘Worms’ | 9 | |
| Selection of best features | All | SelectKBest K = 30 |
| Removal of duplicate values | Class 0 len: 2031 | Class 0 len: 450 |
| Class 1 len: 1879 | Class 1 len: 350 | |
| Class 2 len: 5499 | Class 2 len: 3623 | |
| Class 3 len: 27,433 | Class 3 len: 25,548 | |
| Class 4 len: 20,954 | Class 4 len: 19,044 | |
| Class 5 len: 7599 | Class 5 len: 7324 | |
| Class 6 len: 85,027 | Class 6 len: 85,024 | |
| Class 7 len: 9991 | Class 7 len: 9991 | |
| Class 8 len: 1456 | Class 8 len: 1456 | |
| Class 9 len: 171 | Class 9 len: 171 | |
| Criteria | Complied | Criteria | Complied |
|---|---|---|---|
| Complete Network Configuration | Yes | Attack Diversity | 5 |
| Complete Traffic | Yes | Anonymity | Yes |
| Labeled Dataset | Yes | Heterogeneity | Yes |
| Complete Interaction | Yes | Feature set | 43 |
| Complete Capture | Yes | Metadata | No |
| Available Protocols | TCP, MQTT, ARP, IGMP, and others |
| Criteria | Complied | Criteria | Complied |
|---|---|---|---|
| Complete Network Configuration | Yes | Attack Diversity | 9 |
| Complete Traffic | Yes | Anonymity | Yes |
| Labeled Dataset | Yes | Heterogeneity | Yes |
| Complete Interaction | No | Feature set | IoT: 44 Linux: 36 Windows 7: 135 Windows 10: 127 Network: 46 |
| Complete Capture | Yes | Metadata | Yes |
| Available Protocols | TCP, UDP, DNS, HTTP, SSL, and others |
| Criteria | Complied | Criteria | Complied |
|---|---|---|---|
| Complete Network Configuration | Yes | Attack Diversity | 14 |
| Complete Traffic | Yes | Anonymity | Yes |
| Labeled Dataset | Yes | Heterogeneity | Yes |
| Complete Interaction | No | Feature set | 61 |
| Complete Capture | Yes | Metadata | Yes |
| Available Protocols | TCP, ARP, DNS, ICMP, HTTP, and others |
| Research | Year | ML Technique | Accuracy | Feature Selection | Class |
|---|---|---|---|---|---|
| Kanimozhi et al. [19] | 2019 | ANN RF-DT | 89.00% 75.62% | Recursive Feature Elimination (RFE) | Multi |
| Kasongo et al. [22] | 2020 | ANN LR KNN SVM DT | 77.51% 65.29% 72.30% 61.53% 67.57% | XGBoost-based feature selection | Multi |
| Yin et al. [28] | 2023 | MLP | 84.24% | Information Gain (IG) and Random Forest (RF) | Multi |
| Moustafa et al. [29] | 2016 | ANN | 81.34% | Chi-square | Multi |
| The proposed method | 2023 | DT RF KNN SVM NB MLP | 77.44% 79.50% 86.16% 84.02% 26.08% 89.00% | ANOVA F-value | Multi |
| Research | Year | ML Technique | Accuracy | Feature Selection | Class |
|---|---|---|---|---|---|
| Koroniotis et al. [18] | 2019 | SVM | 88.3% | Correlation Coefficient | Multi |
| RNN | 99.7% | ||||
| LSTM | 99.7% | ||||
| Thaseen et al. [23] | 2020 | C4.5 NB RF MLP SVM CART KNN ANN Ensemble Learning | 92.0% 87.6% 92.7% 87.4% 89.5% 80.3% 88.4% 97.0% 99.0% | Correlation Coefficient | Multi |
| Sugi et al. [24] | 2020 | LSTM KNN | 77.51% | Information Gain (IG) | Multi |
| 92.29% | |||||
| Fatani et al. [27] | 2021 | CNN | 99.47% | Transient Search Optimization (TSO) | Multi |
| The proposed method | 2023 | DT RF KNN SVM NB MLP | 99.88% 99.89% 99.94% 89.00% 71.00% 98.00% | ANOVA F-value | Multi |
| Research | Year | ML Technique | Accuracy | Feature Selection | Class |
|---|---|---|---|---|---|
| Tareq et al. [12] | 2022 | DenseNet Inception Time | 98.57% 99.65% | - | Multi |
| Sarhan et al. [20] | 2021 | DFF RF | 96.58% 97.49% | Chi-square | Multi |
| Alsaedi et al. [21] | 2020 | LR LDA KNN RF CART NB SVM LSTM | 61% 62% 72% 71% 77% 54% 60% 68% | - | Multi |
| Gad et al. [30] | 2021 | LR NB DT RF AdaBoost KNN SVM XGBoost | 85.9% 69.2% 97.2% 97.2% 90.6% 98.2% 86.0% 98.3% | Chi-square | Multi |
| The proposed method | 2023 | DT RF KNN SVM NB MLP | 98.06% 99.95% 99.87% 87.22% 99.39% 99.97% | ANOVA F-value | Multi |
| Research | Year | ML Technique | Accuracy | Feature Selection | Class |
|---|---|---|---|---|---|
| Ferrag et al. [26] | 2021 | DT | 67.11% | Generic Model (RF) | Multi |
| RF | 80.83% | ||||
| SVM | 77.61% | ||||
| KNN | 79.18% | ||||
| DNN | 94.67% | ||||
| Tareq et al. [12] | 2022 | Inception Time | 94.94% | - | Multi |
| The proposed method | 2023 | DT | 99.87% | ANOVA F-value | Multi |
| RF | 99.97% | ||||
| KNN | 99.65% | ||||
| SVM | 97.00% | ||||
| NB | 95.01% | ||||
| MLP | 99.87% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkadi, S.; Al-Ahmadi, S.; Ben Ismail, M.M. Toward Improved Machine Learning-Based Intrusion Detection for Internet of Things Traffic. Computers 2023, 12, 148. https://doi.org/10.3390/computers12080148
Alkadi S, Al-Ahmadi S, Ben Ismail MM. Toward Improved Machine Learning-Based Intrusion Detection for Internet of Things Traffic. Computers. 2023; 12(8):148. https://doi.org/10.3390/computers12080148
Chicago/Turabian StyleAlkadi, Sarah, Saad Al-Ahmadi, and Mohamed Maher Ben Ismail. 2023. "Toward Improved Machine Learning-Based Intrusion Detection for Internet of Things Traffic" Computers 12, no. 8: 148. https://doi.org/10.3390/computers12080148
APA StyleAlkadi, S., Al-Ahmadi, S., & Ben Ismail, M. M. (2023). Toward Improved Machine Learning-Based Intrusion Detection for Internet of Things Traffic. Computers, 12(8), 148. https://doi.org/10.3390/computers12080148