3. Data Set Creation and Preprocessing
The data set which was used in the authors’ conference paper [
19] was created by scraping 57 articles written in English from Wikipedia’s API (
https://pypi.org/project/wikipedia/, accessed on 5 June 2022) with Python (BeautifulSoup4 (
https://pypi.org/project/beautifulsoup4/, accessed on 5 June 2022) and Requests (
https://pypi.org/project/requests/, accessed on 5 June 2022)). The criterion for selecting these specific articles was their relevance to five vocational domains considered to be the most common for refugee and migrant employment in Europe, Canada, and the United States of America [
1,
2,
6,
7,
8].
The initial textual data set comprised of 6827 sentences extracted from the 57 Wikipedia articles. The data set was preprocessed in four stages, namely:
Initial preprocessing and tokenization;
Numbers and punctuation mark removal;
Stopwords removal;
Lemmatization and duplicate removal.
The data set was initially tokenized to 6827 sentences and to 69,062 words; the sentences were used as training–testing examples, and the words were used as unigram features. Numbers, punctuation marks, and special characters were removed. Stopwords (conjunctions, articles, adverbs, pronouns, auxiliary verbs, etc.) were also removed. Finally, lemmatization was performed to normalize the data without reducing the semantic information, and 912 duplicate sentences and 58,393 duplicate words were removed. For more details on these stages of preprocessing, refer to [
19].
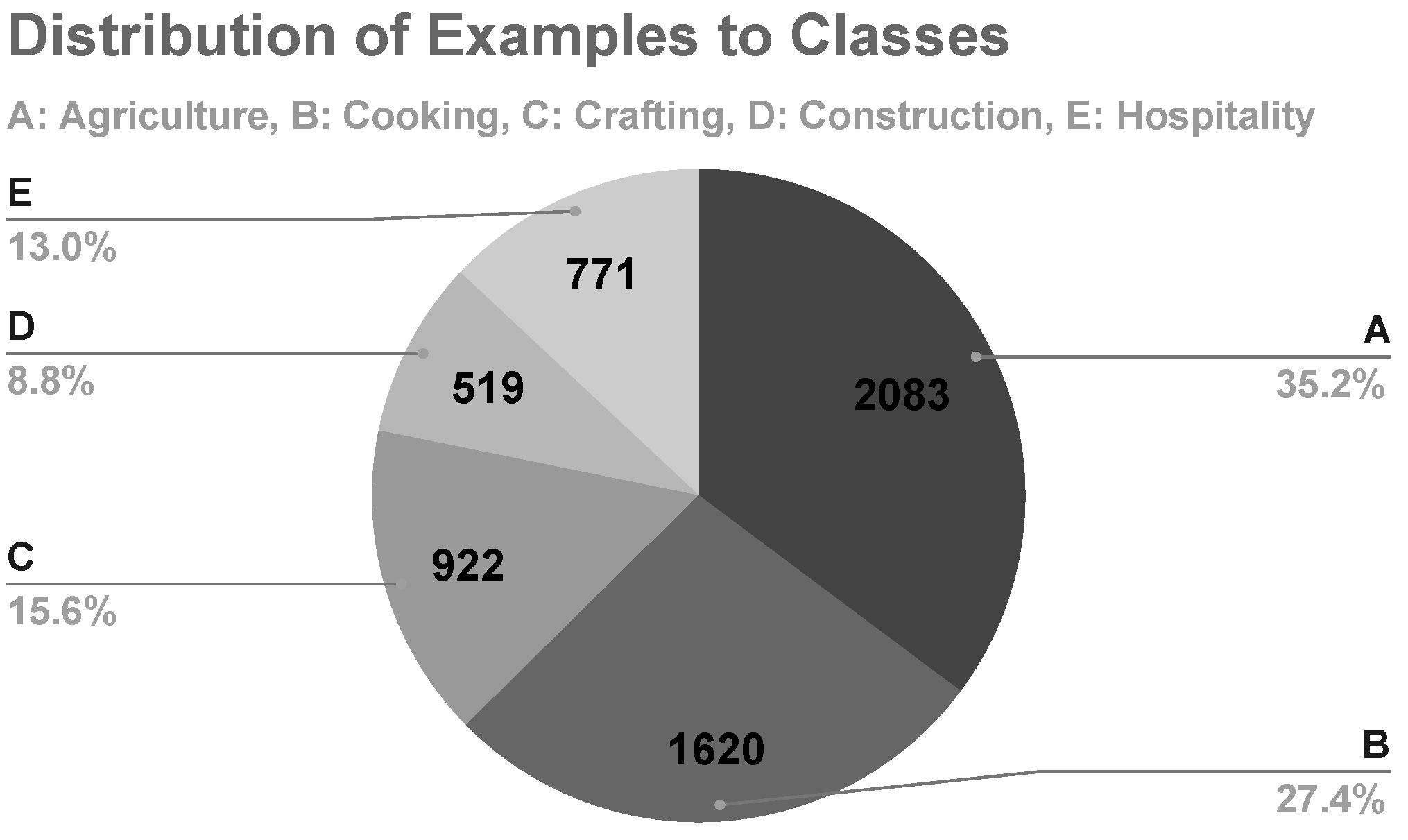
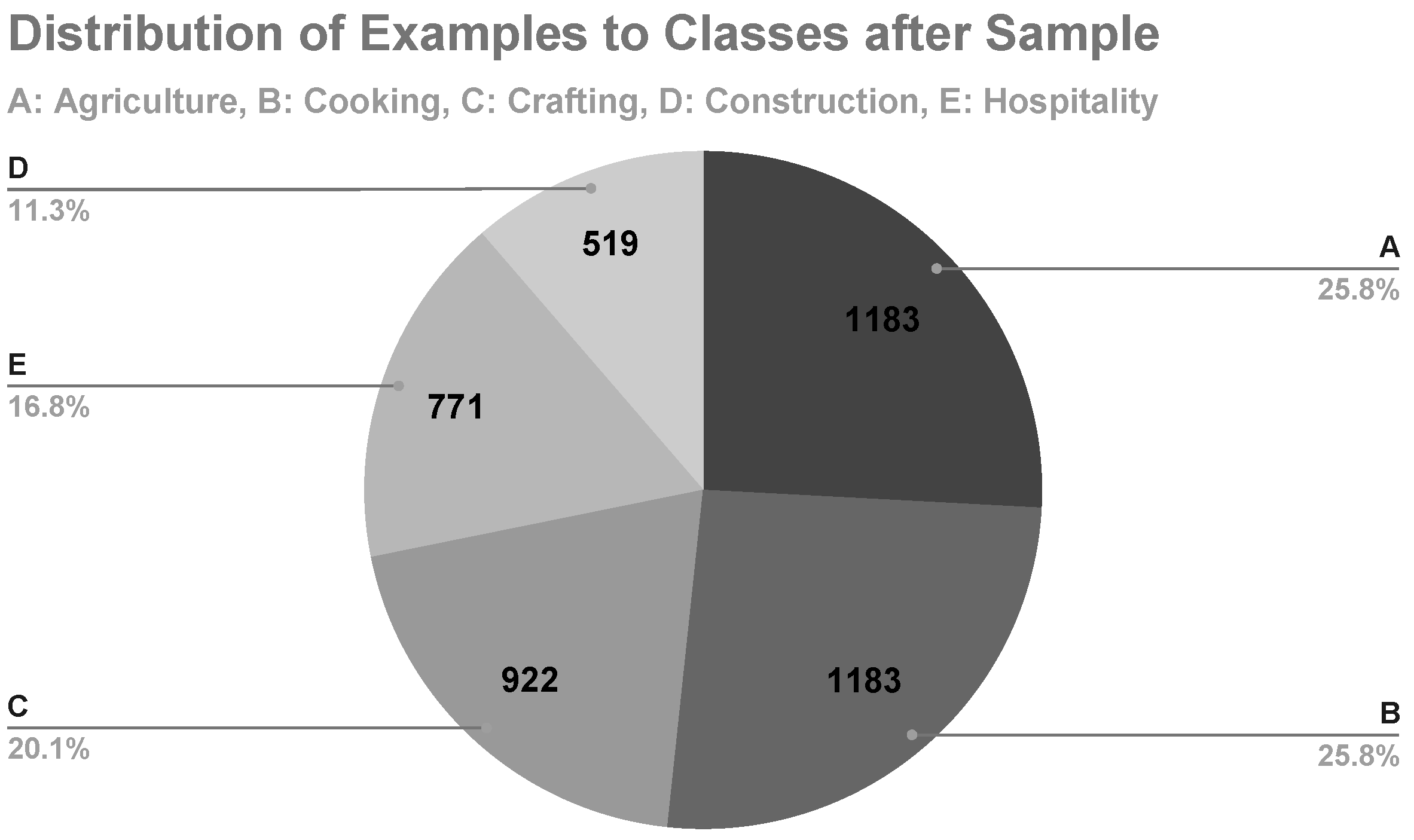
Resulting from the preprocessing stages, the text data set comprised 5915 sentences (examples) and five classes to be used in machine learning experiments. For each sentence, the domain that was most relevant to each article’s topic, as shown in
Table 2, was considered as its class, thus resulting in five distinct classes, namely: A. Agriculture, B. Cooking, C. Crafting, D. Construction, and E. Hospitality. The distribution of the sentences to these five classes is shown in
Figure 1.
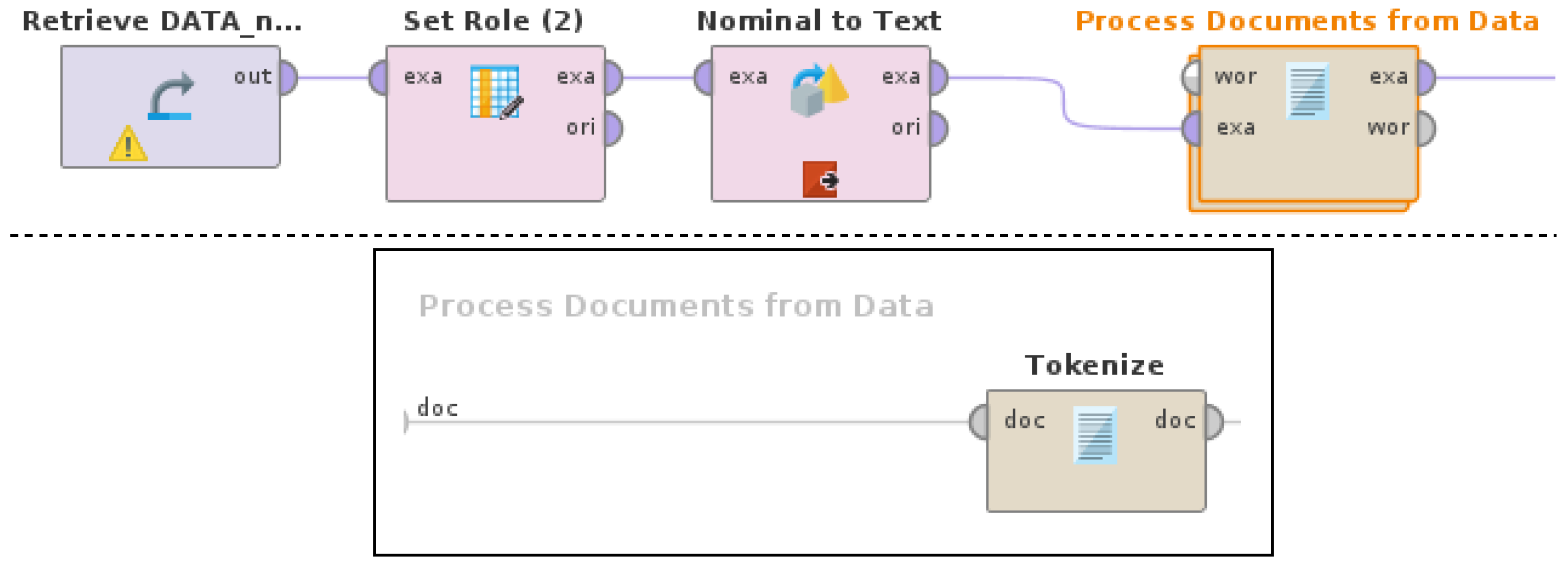
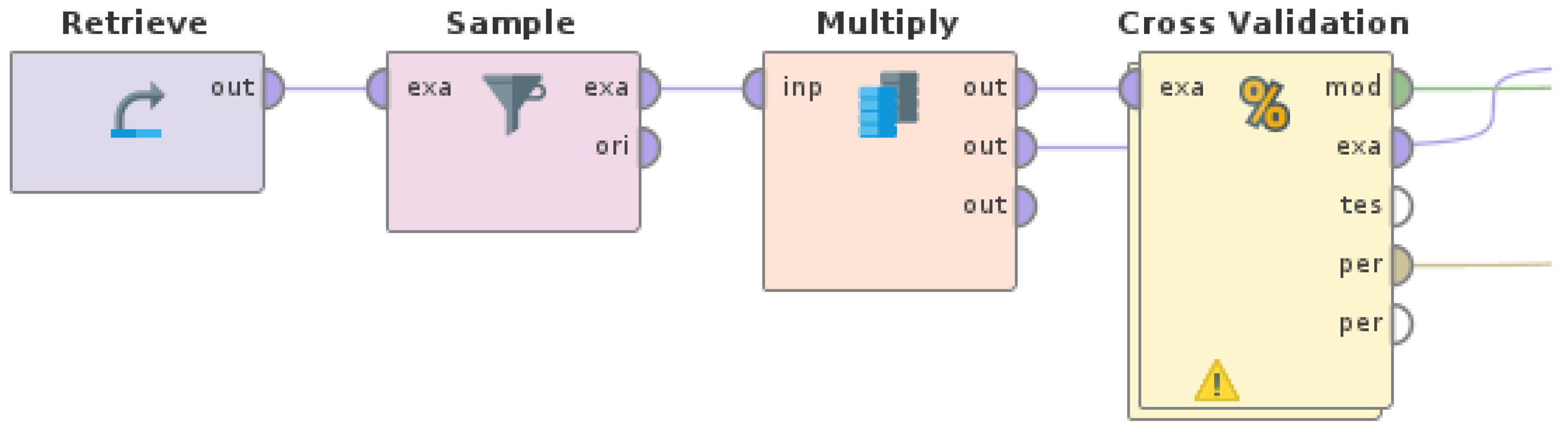
A RapidMiner Studio (version 9.10) process, as shown in
Figure 2, was used to extract the feature set with TF-IDF values and taking into consideration the feature occurrences by pruning features, which rarely occur (below 1%) or very often occur (above 30%); this resulted in 109 unigram features. For more details on the operators and parameters of the feature extraction process, refer to [
19] and RapidMiner documentation (
https://docs.rapidminer.com/, accessed on 20 October 2022). It is important to note that the extracted features that were used as inputs for the machine learning experiments in this paper were terms in the form of single words—also known as unigrams. Unigrams are the most simple and generic linguistic features that can be used in NLP tasks. Consequently, the methodology described in this paper is not overspecified, meaning that it can be generalized and applied in any corpus, and these features can be used as inputs for any machine learning model.
Resulting from the feature extraction process, the final data set comprised 5915 examples, 109 features, and a class as label.
4. Predictions Analysis
Gradient Boosted Trees is a forward-learning ensemble of either regression or classification models that depends on the task. It uses steadily improved estimations, thus resulting in better predictions in terms of accuracy. More specifically, a sequence of weak prediction models, in this case Decision Trees, creates an ensemble that steadily improves its predictions based on the changes in data after each round of classification. This boosting method and the parallel execution running on a H2O 3.30.0.1 cluster, along with the variety of refined parameters for tuning, enable Gradient Boosted Trees to be a robust and highly effective model that can overcome issues that are typical for other tree models (e.g., Decision Trees and Random Forest), such as data imbalance and overfitting. Additionally, it has to be noted that, despite the fact that other methods of tree boosting tend to decrease the speed of the model and human interpretability of its results, the gradient boosting method generalizes the boosting process and, thus, mitigates these problems while maintaining high accuracy.
Regarding the parameters for
Gradient Boosted Trees, the
number of trees was set to 50, the
maximal depth of trees was set to 5,
min rows was set to 10,
min split improvement was left at the default,
number of bins was set to 20,
learning rate was set to 0.01,
sample rate was set to 1, and the
distribution function of the training data was selected automatically as multinomial, since the
label was nominal for the specific task and data set. For more information on the operators and parameters of the RapidMiner Studio (version 9.10) experiment with
Gradient Boosted Trees, as shown in
Figure 3, refer to [
19] and the RapidMiner documentation.
With regard to the high performance of this machine learning model, it is of interest to examine which examples were classified wrongly for each class, as well as which distinct features contributed to their misclassification. In the same line of thought, regarding the correctly classified examples, the examination of the features that were the most dominant and led to correct predictions would contribute to the identification of a primary set of terms that highlighted the terminology of the vocational domains.
4.1. Wrong Predictions
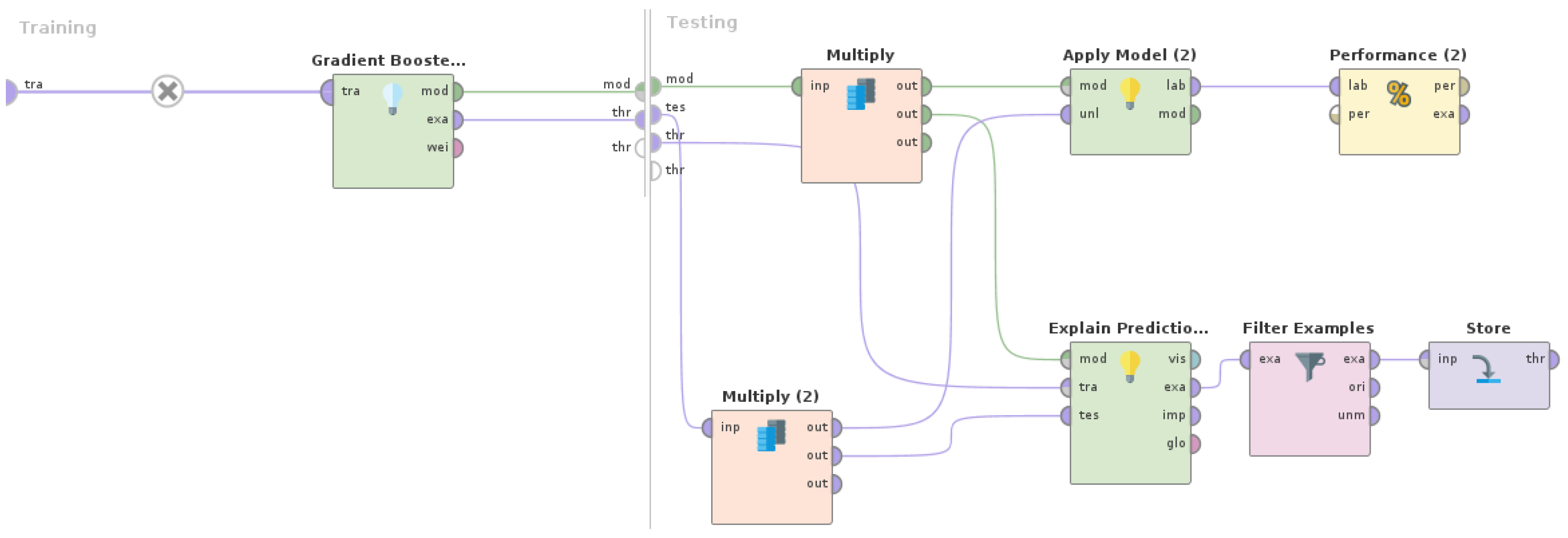
The
Gradient Boosted Trees model showed high performance regarding all classes (
Table 3), with a precision ranging from 99.78% to 100%, a recall ranging from 99.61% to 100%, and an F1 score ranging from 99.70% to 100%, and it misclassified a total of four examples. In order to identify the misclassified examples, a RapidMiner Studio (version 9.10) process, as shown in
Figure 4, was designed and executed.
The
Explain Predictions (
https://docs.rapidminer.com/10.1/studio/operators/scoring/explain_predictions.html, accessed on 20 March 2023) operator was used to identify which features were the most dominant in forming predictions. A model and a set of examples, along with the feature set, were considered as inputs in order to produce a table highlighting the features that most strongly supported or contradicted each prediction, while also containing numeric details. For each example, a neighboring set of data points was generated by using correlation to define the local feature weights in that neighborhood. The operator can calculate model-specific weights though model-agnostic global feature weights that derive directly from the explanations.
Explain Predictions is able to work with all data types and data sizes and can be applied for both classification and regression problems.
In this case, in which the machine learning model (Gradient Boosted Trees) used supervised learning, all supporting local explanations added positively to the weights for correct predictions, while all contradicting local explanations added positively to the weights for wrong predictions. Regarding the parameters for this operator, the maximal explaining attributes were set to 3 and the local sample size was left at the default (500). The sort weights parameter was set to true, along with the descending sort direction of the weight values, in order to apply sorting to the resulting feature weights supporting and contradicting the predictions.
The
Filter Examples (
https://docs.rapidminer.com/10.1/studio/operators/blending/examples/filter/filter_examples.html, accessed on 20 March 2023) operator selects which examples are kept and which are removed. In this case, only the misclassified examples (wrong predictions) were kept. Regarding the
condition class parameter for this operator, it was set to wrong_predictions in order to only keep those examples where the class and prediction were different, which meant that the prediction was wrong.
The four misclassified examples included the following:
WP1: building edifice structure roof wall standing permanently house factory;
WP2: typically whitesmiths product required decorative finish fire grate coldworking screw lathed machine;
WP3: organic food;
WP4: traditional vernacular building method suit local condition climate dispensed favour generic cookie cutter housing type.
In
Table 4, detailed information is provided for these wrong predictions. Class is the real class of the example, while Prediction is the wrongly predicted class for the example. Confidence, with values ranging from 0 to 1, is derived from feature weights regarding both Class and Prediction.
The features that contributed to the wrong predictions for each class are shown in
Table 5. The effect of the value for each feature was denoted in consideration of whether it supported, contradicted, or was neutral to the prediction. The typical value for the specific feature for each class is also provided.
4.2. Correct Predictions
The Gradient Boosted Trees model managed to correctly classify most of the examples. Regarding class A, it is of particular interest that all of its examples were classified correctly, while none of the examples of the other classes were classified wrongly to class A. Consequently, it is of significance to identify and examine which features were the most dominant and led to the correct predictions for each class, thus contributing to the identification of a primary set of terms for the vocational domains.
In order to identify the correctly classified examples, the same RapidMiner Studio (version 9.10) process, as was used for wrong predictions (
Figure 4), was used. The only difference was that the
Condition Class parameter for the
Filter Examples operator was set to correct_predictions in order to only keep those examples where the class and prediction were the same, which meant that the prediction was correct.
The Confidence parameter, with values that can be from 0 to 1, was derived from feature weights for each class: for class A, it ranged from 0.49 to 0.55; for class B, it ranged from 0.37 to 0.55; for class C, it ranged from 0.48 to 0.55; for class D, it ranged from 0.47 to 0.55; and, for class E, it ranged from 0.54 to 0.55. The features that were the most dominant and led to the correct predictions are shown in
Table 6 in a descending order, along with the global weights that were calculated for each one of them.
4.3. Discussion
Regarding the wrong prediction analysis, the four misclassified examples were successfully identified (WP1–WP4), as shown in
Table 4. More specifically, two examples of class D, namely, WP1 and WP4, were wrongly classified to classes C and E, respectively, while one example of class C, WP2, was misclassified to class D, and one example of class B, WP3, was misclassified to class C. It was observed that, for all wrong predictions, the Confidence for the Class, which is the real class of the examples, ranged from 0.11 to 0.17 and was significantly lower than the Confidence for Prediction, which is the wrongly predicted class of the examples and ranged from 0.31 to 0.55. This indicates that these examples diverged significantly from the other examples of their class. By examining
Table 5 and
Table 6, this observation can be explained as described below.
For WP1, the value for the building feature was 1, while, typically for examples of D (class), the values were 0 and, of C (prediction), they were mostly 0 and sometimes 1. Considering that building was the only most dominant feature of WP1, with an assigned feature weight of 0.013, its overall impact on the prediction being neutral was expected.
For WP2, the value for the typically feature was 1, for the fire feature was 0.66, and for the product feature was 0.54, while, typically, the values of all these features for examples of both C (class) and D (prediction) were mostly 0 and sometimes 1. Considering that typically was the most dominant feature of WP2, with an assigned feature weight of 0.025, which is high, its overall impact on the prediction being neutral was expected. The fire and product features contradicted the prediction, though, due to their quite low feature weights of 0.01 and 0.015, respectively, their effects on the prediction were insignificant.
For WP3, the value for the food feature was 0.50 and for the organic feature was 0.86, while, typically, for examples of B (class), the values were 0 for both features and, of C (prediction), the value was 1 for the food feature and mostly 0 and sometimes 1 for the organic feature. Considering that food was the most dominant feature of WP3, with an assigned feature weight of 0.029, which is high, its overall impact on the prediction being positive (support) was expected. The organic feature also supported the prediction, though, due to its quite low feature weight (0.012), its effect on the prediction was insignificant.
For WP4, the value for the local feature was 0.56, for the method feature it was 0.47, and for the type feature it was 0.46, while, typically, the values of all these features for examples of D (class) were 0 and, for E (prediction), were mostly 0 and sometimes 1. Considering that local was the most dominant feature of WP4, with an assigned feature weight of 0.025, which is high, its overall impact on the prediction being positive (support) was expected. The method and type features also supported the prediction, with quite high feature weights of 0.02 for both, and they had a significant effect on the prediction.
Overall, it became evident that the main factor that led the Gradient Boosted Trees model to misclassify the examples was the lack of dominant features supporting the real class more than the prediction in terms of feature weight.
Regarding the correct prediction analysis, it was observed that the confidence for the correct predictions for all classes was considerably high, with the lowest being for class B in a range from 0.37 to 0.55 and the highest for class E in a range from 0.54 to 0.55. This means that the model could classify the examples of class E more confidently compared to the examples of the other classes.
Additionally, the most dominant features, in terms of feature weights, which led to the correct predictions for each class, were identified successfully and sorted in descending order, as shown in
Table 6. Features with higher weights were more dominant for the correct predictions of this model than features with lower weights. A total of 51 features, which were about half of the 109 features of the extracted feature set, had the highest feature weights, which ranged from 0.02 up to 0.037. This indicates that the feature extraction process, as described in
Section 3 and [
19], performed quite well, thus producing a robust feature set with great impact on the correct predictions. Finally, it was also observed that, among these features, terms that were relevant to all of the vocational domains were included, thus yielding a primary set of terms for the vocational domains.
5. Data Balancing
Random Forest is an ensemble of random trees that are created and trained on bootstrapped subsets of the data set. For a random tree, each node constitutes a splitting rule for one particular feature, while a subset of the features, according to a subset ratio criterion (e.g., information gain), is considered for selecting the splitting rules. In classification tasks, the rules are splitting values that belong to different classes. New nodes are created repeatedly until the stopping criteria are met. Then, each random tree provides a prediction for each example by following the tree branches according to the splitting rules and by evaluating the leaf. Class predictions are based on the majority of the examples, and estimations are procured through the average of values reaching a leaf, thus resulting in a voting model of all created random trees. The final prediction of the voting model usually varies less than the single predictions, since all single predictions are considered equally significant and are based on subsets of the data set.
AdaBoost, aka Adaptive Boosting, is a meta-algorithm that can be used in combination with various learning algorithms in order to improve their performance. Its adaptiveness is due to the fact that any subsequent classifiers built are adapted in favor of the examples that were misclassified by previous classifiers. AdaBoost is sensitive to noisy data and outliers; however, in some tasks, it may be less susceptible to overfitting than most learning algorithms. It is important to note that, even with weak classifiers (e.g in terms of error rate), the final model is improved when its performance is not random. AdaBoost generates and calls a new weak classifier in each of a series of rounds . For each call, a distribution of weights is updated. This distribution denotes the significance of examples in the data set for the classification task. During each round, the weights of each misclassified example are increased, while the weights of each correctly classified example are decreased, in order for the new classifier to focus on the misclassified examples.
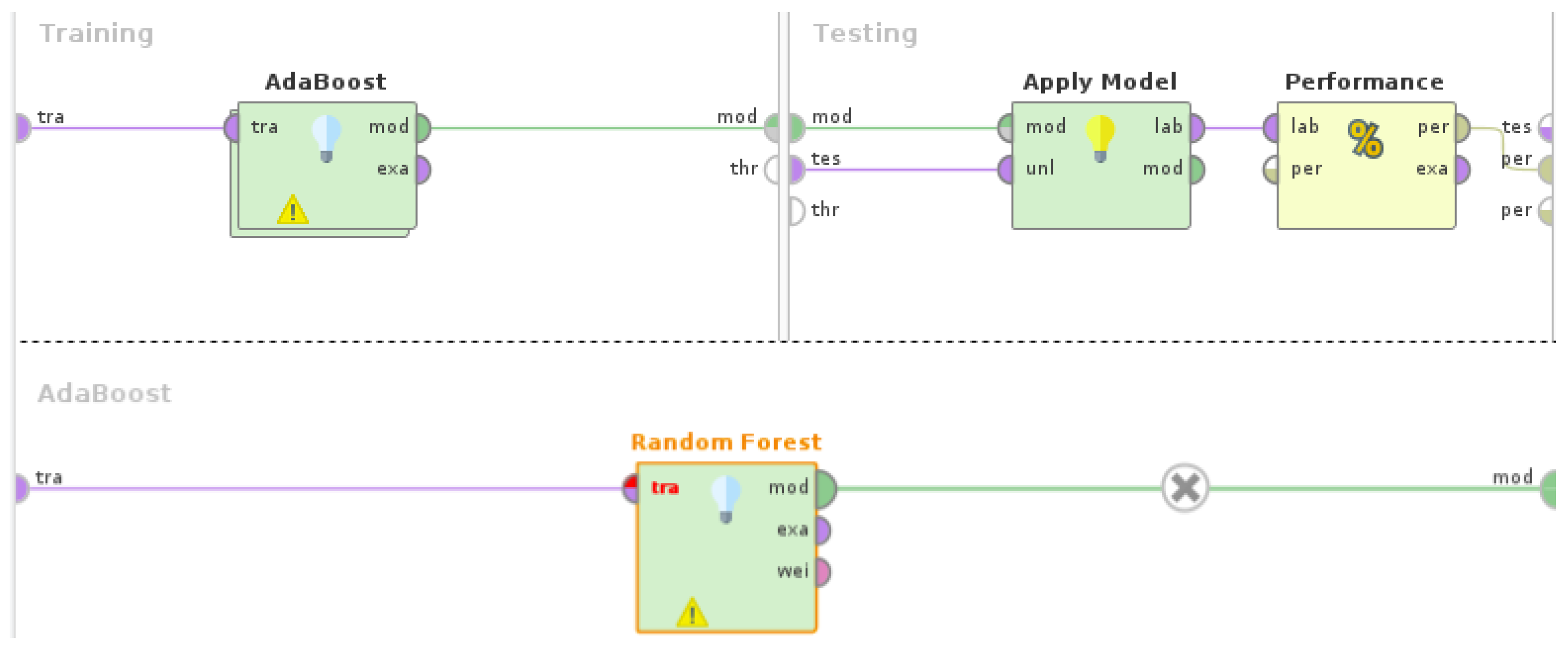
Regarding the parameters for
Random Forest, the
number of trees was set to 100, the
maximal depth of trees was set to 10,
information gain was selected as the criterion for feature splitting, and
confidence vote was selected as the voting strategy. Neither pruning nor prepruning were selected, since it was observed that they did not improve the performance of the model for this task. The maximum
iterations for
AdaBoost were set to 10. For more information on the operators and parameters of the RapidMiner Studio (version 9.10) experiment with
Random Forest and
AdaBoost, as shown in
Figure 5, refer to [
19] and the RapidMiner documentation (
https://docs.rapidminer.com/, accessed on 20 October 2022).
Regarding the model’s accuracy of 62.33%, it is important to bear in mind that, despite being considerably lower than the accuracy of the Gradient Boosted Trees model (99.93%), it was significantly above the randomness baseline by 42.33%, considering that the randomness for a five-class problem was at 20%.
Examining the model’s results (
Table 7) more closely, it was noted that, despite its precision for classes B, C, D, and E being high, which ranged from 91.52% to 98.21%, the recall for these classes was low, which ranged from 31.79% to 51.30%. Also, considering its low precision (49.06%) and high recall (97.60%) for class A, this examination highlighted that a lot of the examples were classified wrongly to class A. As a result, it became evident that the
Random Forest and
AdaBoost model tended to classify most of the examples to class A. Due to the fact that the examples of class A consisted of the majority of the examples in the data set (35.20%,
Figure 1), this tendency could be attributed to the imbalance of data.
Consequently, it is of interest to examine whether applying data balancing techniques on the data set (oversampling and undersampling), has any impact, whether positive or negative, on the performance of the Random Forest and AdaBoost model.
5.1. Data Oversampling
As a first step towards addressing data imbalance, SMOTE oversampling [
17] was applied in a successive manner on the data set in order to balance the data using oversampling, which pertained to the minority class each time. Consequently, a RapidMiner Studio (version 9.10) process, as shown in
Figure 6, was designed and executed four times. The four derived oversampled data sets were then used as inputs for the machine learning experiments with
Random Forest and
AdaBoost.
The
SMOTE Upsampling (
https://docs.rapidminer.com/10.1/studio/operators/extensions/Operator%20Toolbox/blending/smote.html, accessed on 20 March 2023) operator practically applies the Synthetic Minority Oversampling Technique, as defined in the paper by Chawla et al. [
17]. More specifically, the algorithm considers only the examples of the minority class, and the k nearest neighbors for each example are searched. Then, a random example and a random nearest neighbor for this example are selected, thus resulting in the creation of a new example on the line between the two examples.
Regarding the parameters for this operator, the number of neighbors was left at the default (5), while normalize and round integers were set to true, and nominal change rate was set to 0.5 in order to make the distance calculation solid. The equalize classes parameter was set to true to draw the necessary amount of examples for class balance, and the auto detect minority class was set to true to automatically upsample the class with the least amount of occurrences.
The set of machine learning experiments with successive applications of SMOTE oversampling, as described below, follows a novel and original methodology, since it was defined and used for the specific task for the first time, to the best of the authors’ knowledge. The methodology steps were the following:
Detect the minority class;
Resample the minority class with SMOTE oversampling;
Run the machine learning experiment;
Repeat steps 1–3 until the data set is balanced (no minority class exists).
By running the experiments following this methodology, the impact of every class distribution, from completely imbalanced to completely balanced data, on the performance of the machine learning model could be examined thoroughly. Consequently, this four-step methodology was an important contribution of this paper.
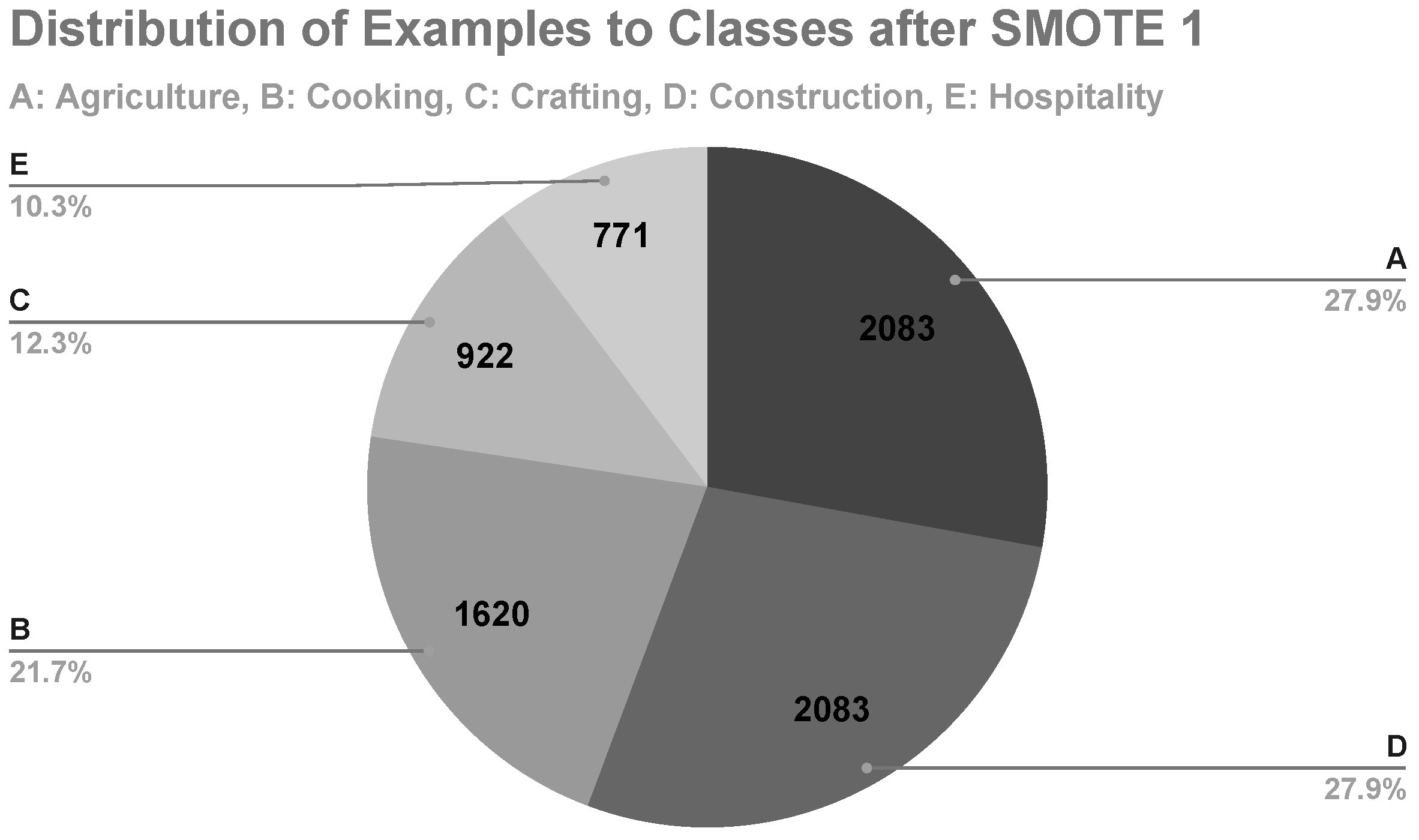
In the first machine learning experiment, class D was the minority class, with its examples representing merely 8.8% of the data set (
Figure 1). After applying SMOTE, class D represented 27.9% of the data set with 2083 examples (
Figure 7). The results of the
Random Forest and
AdaBoost with
SMOTE are shown in
Table 8.
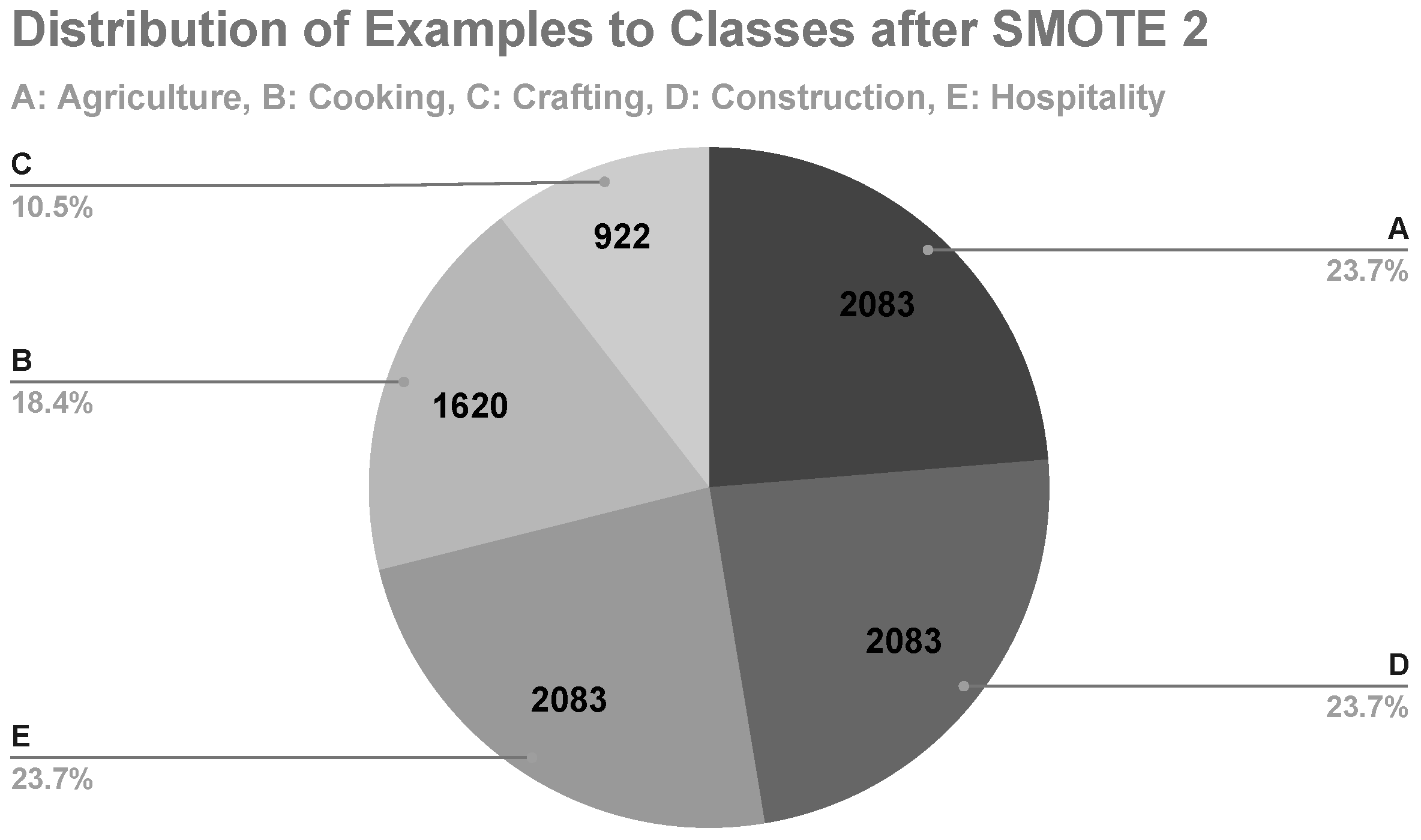
In the second machine learning experiment, class E was the minority class, with its examples representing 10.3% of the data set (
Figure 7). After applying SMOTE, class E represented 23.7% of the data set with 2083 examples (
Figure 8). The results of the
Random Forest and
AdaBoost with
SMOTE (two times) are shown in
Table 9.
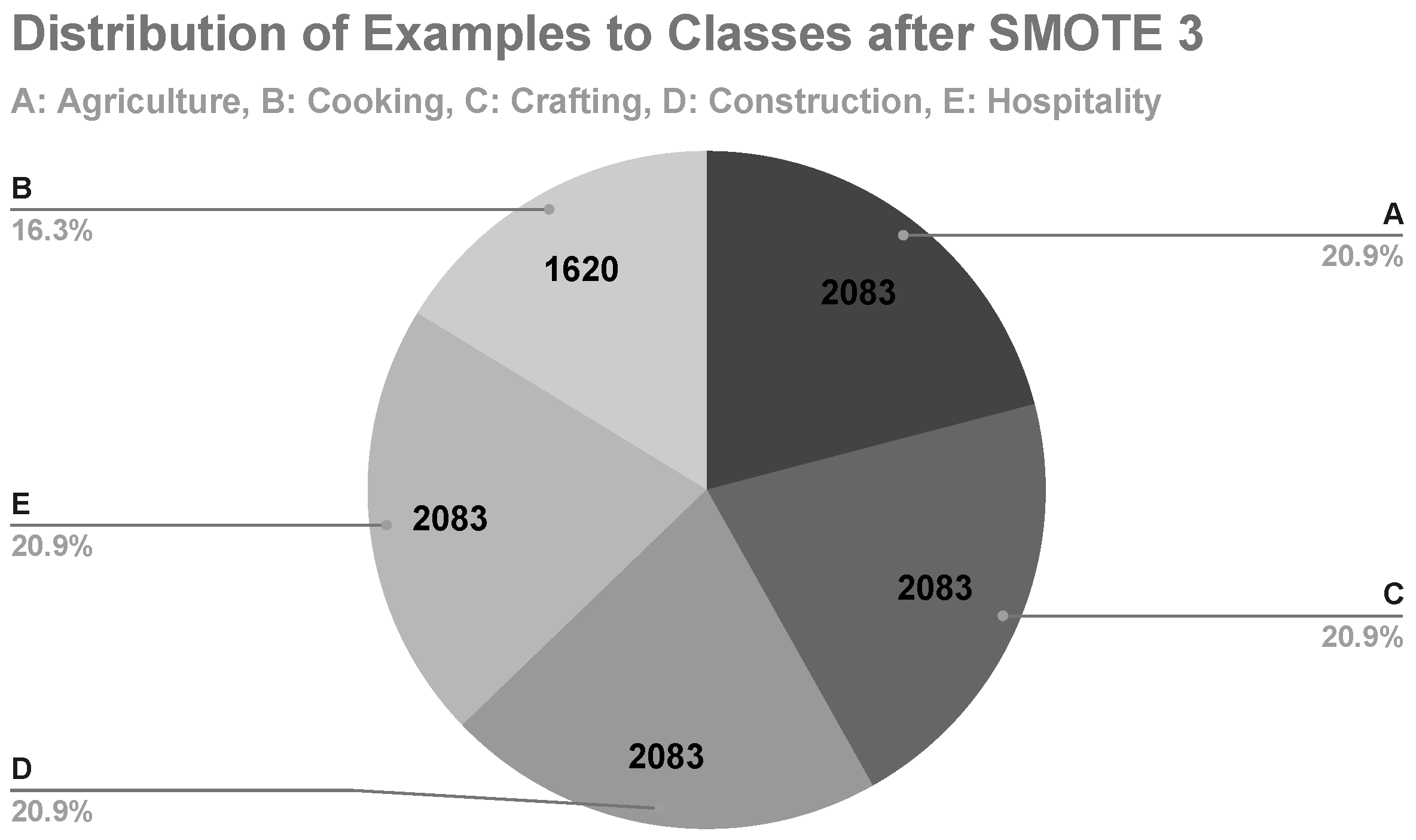
In the third machine learning experiment, class C was the minority class, with its examples representing 10.5% of the data set (
Figure 8). After applying SMOTE, class C represented 20.9% of the data set with 2083 examples (
Figure 9). The results of the
Random Forest and
AdaBoost with
SMOTE (three times) are shown in
Table 10.
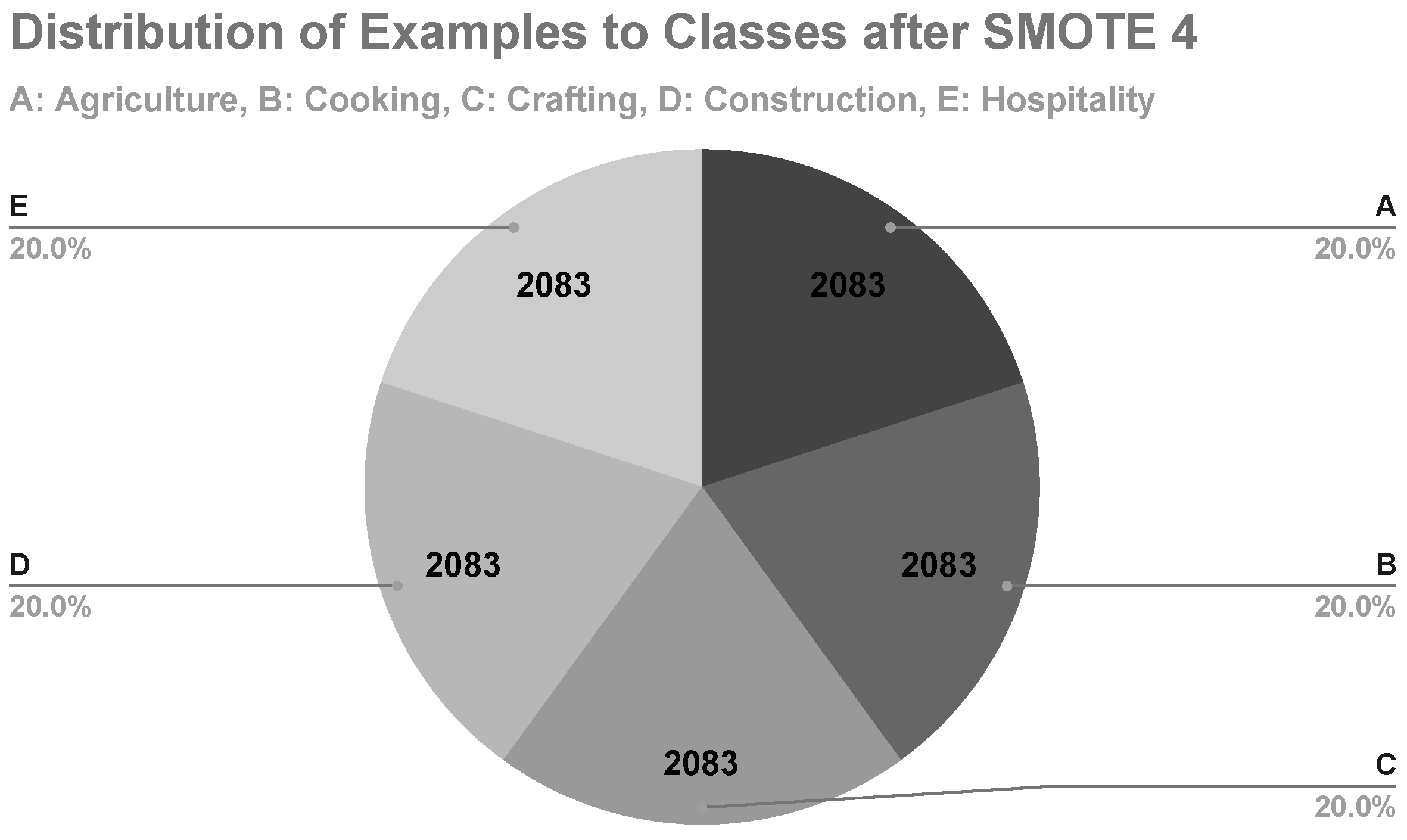
In the fourth machine learning experiment, class B was the minority class, with its examples representing 16.3% of the data set (
Figure 9). After applying SMOTE, class B represented 20% of the data set with 2083 examples (
Figure 10). The results of the
Random Forest and
AdaBoost with
SMOTE (four times) are shown in
Table 11.
5.2. Data Undersampling
In another set of experiments, undersampling was applied to the data set, thereby balancing the data by undersampling the classes represented by the most examples. Consequently, a RapidMiner Studio (version 9.10) process, as shown in
Figure 11, was designed and executed. The derived undersampled data set was then used as the input for the machine learning experiments with
Random Forest and
AdaBoost.
The
Sample (
https://docs.rapidminer.com/10.1/studio/operators/blending/examples/sampling/sample.html, accessed on 20 March 2023) operator has basic principles that are common to the
Filter Examples operator, wherein it takes a set of examples as the input and procures a subset of it as output. However, while
Filter Examples follows previously specified conditions,
Sample is centered on the number of examples and the class distribution in the resulting subset, thus producing samples in a random manner.
Regarding the parameters for this operator,
Sample was set to absolute in order for it to be created to consist of an exact number of examples. The
Balance Data parameter was set to true in order to define different sample sizes (by number of examples) for each class, while the class distribution of the sample was set with
Sample Size Per Class. Examples of classes A and B were reduced to 1183 for each one, which is the mean of the number of all examples in the data set. The sample sizes for each class are shown in
Figure 12. The results of this experiment are shown in
Table 12.
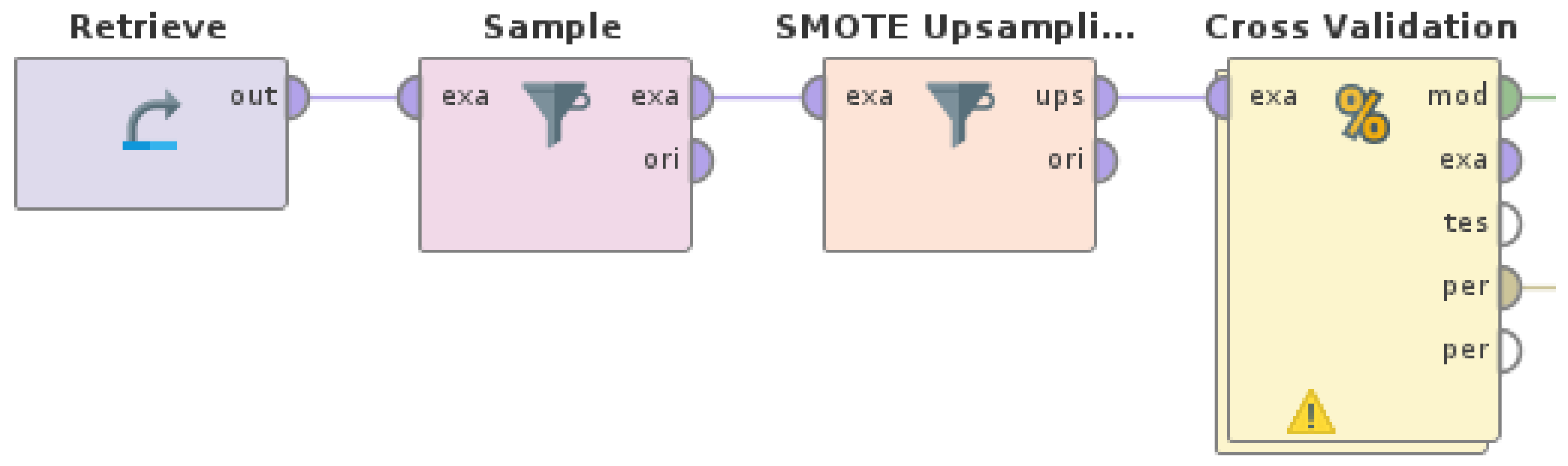
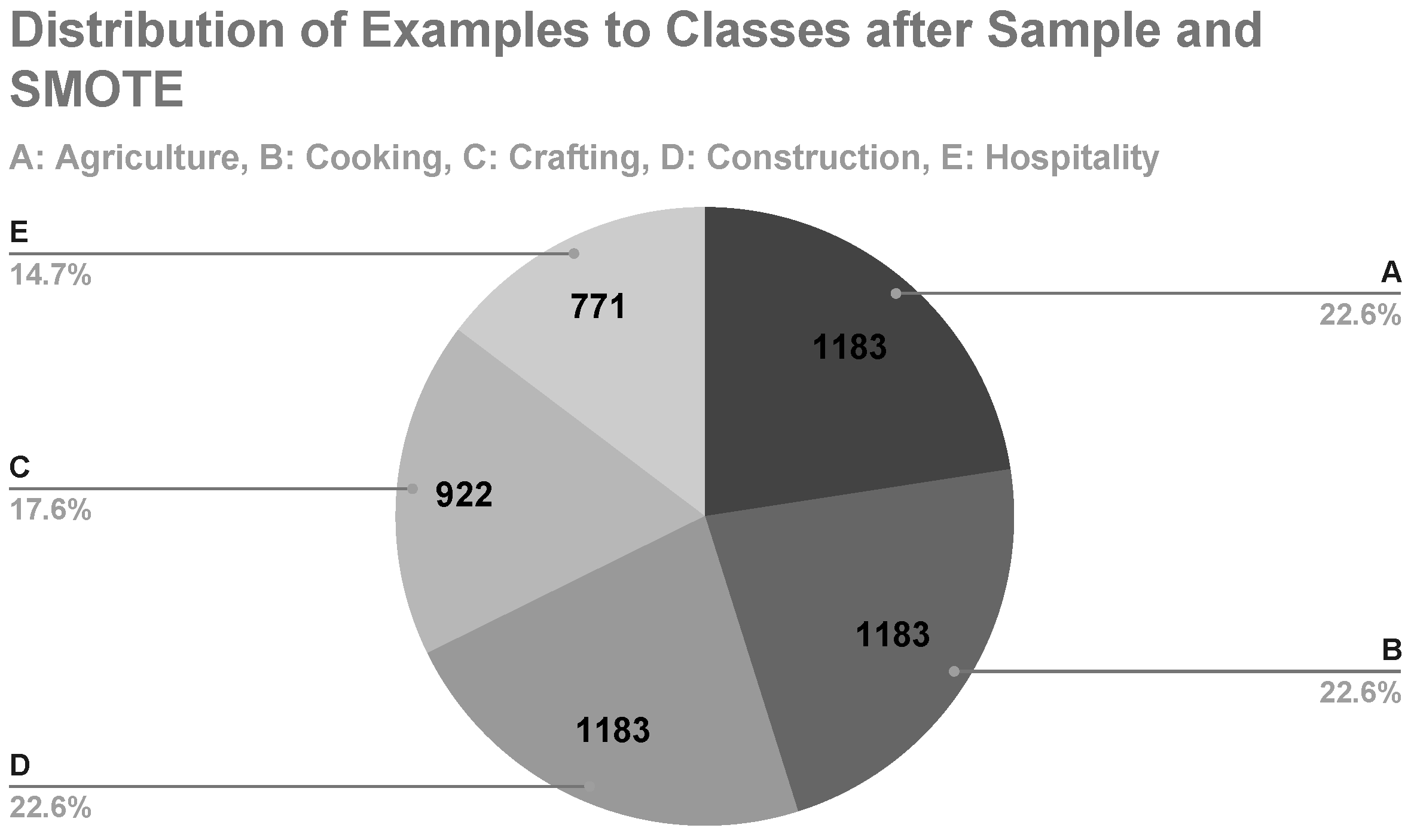
A hybrid approach combining data oversampling and undersampling was also tested. In this experiment, both the
SMOTE Upsampling operator and the
Sample operator were applied on the data set to balance the data by undersampling the classes represented by the most examples and oversampling the classes represented by the least examples, respectively. Consequently, a RapidMiner Studio (version 9.10) process, as shown in
Figure 13, was designed and executed. The derived undersampled data set was then used as the input for the machine learning experiments with
Random Forest and
AdaBoost.
Regarding the parameters for
Sample and
SMOTE Upsampling, they were set in the same way as in the previous experiments. After applying them, examples of classes A and B were reduced to 1183 for each one, which is the mean of the number of all examples in the data set, while examples of class D were added to also result in 1183 for this class. The sample sizes for each class are shown in
Figure 14. The results of this experiment are shown in
Table 13.
5.3. Discussion
Regarding the machine learning experiments’ results with
Random Forest and
AdaBoost with
SMOTE oversampling, it was observed that the accuracy and overall performance, as shown in
Table 8,
Table 9,
Table 10 and
Table 11, improved compared to those of
Random Forest and
AdaBoost with imbalanced data, as shown in
Table 7. More specifically, the accuracy increased from 62.33% up to 66.01%, and the F1 score increased from 65.29% up to 79.77% for class A, maintained up to 65.74% for class B, maintained up to 57.92% for class C, increased from 47.20% up to 70.72% for class D, and increased from 52.19% up to 65.32% for class E. It is also noteworthy that, despite the overall performance of the model becoming slightly worse with each iteration (each added SMOTE oversampling), it was still significantly better than the performance of the experiment with completely imbalanced data; even the lowest accuracy (64.09%), which was that of the fourth machine learning experiment with SMOTE, was quite higher than the accuracy (62.33%) of the experiment with completely imbalanced data. Additionally, the values of precision, recall, and F1 score seemed to be distributed more evenly among the classes with each iteration, thus mitigating any emerging bias of the model towards one particular class. Another important observation from these experiments is that, in a classification task where one of the five vocational domains may be considered as the class of interest, e.g., for trying to exclusively detect articles of a specific vocational domain from a corpus to filter relevant content, the application of SMOTE oversampling for the class of interest had a positive effect on the results of this classification task.
Regarding the machine learning experiments’ results with
Random Forest and
AdaBoost with
Sample, it was observed that the accuracy and overall performance, as shown in
Table 12, improved slightly compared to those of
Random Forest and
AdaBoost with imbalanced data, as shown in
Table 7. More specifically, accuracy increased from 62.33% to 62.84%, and the F1 score increased from 65.29% to 77.85% for class A, reduced from 65.74% to 58.30% for class B, increased from 57.92% to 60.86% for class C, increased from 47.20% to 56.80% for class D, and increased from 52.19% to 58.14% for class E. Compared to the results obtained with SMOTE oversampling (
Table 8,
Table 9,
Table 10 and
Table 11), undersampling had worse performance in terms of accuracy, class precision, recall, and F1 score.
Regarding the machine learning experiments’ results with
Random Forest and
AdaBoost with
Sample and
SMOTE oversampling (hybrid approach), it was observed that the accuracy and overall performance, as shown in
Table 13, marginally improved compared to those of
Random Forest and
AdaBoost with
Sample only (
Table 12). More specifically, the accuracy increased from 62.84% to 63.35%, and the F1 score increased from 77.85% to 78.46% for class A, reduced from 58.30% to 56.17% for class B, reduced from 60.86% to 60.39% for class C, increased from 56.80% to 67.83% for class D, and reduced from 58.14% to 57.46% for class E. In any case, the performance of this experiment was better than that of the experiment with completely imbalanced data. Overall, these experiments indicate that, when applying both data undersampling and oversampling in a hybrid approach, the results were better than only applying undersampling but were worse than only applying oversampling for this data set.
The findings derived from the machine learning experiments of this paper are in accordance with those of the relevant literature [
12,
17], with the results that data oversampling obtained better results than data undersampling in imbalanced data sets, while hybrid approaches performed reasonably well. The performance of all the machine learning experiments performed in this research is shown in
Table 14.
6. Conclusions
Displaced communities, such as migrants and refugees, face multiple challenges in seeking and finding employment in high-skill vocations in their host countries, which derive from discrimination. Unemployment and overworking phenomena usually affect the displaced communities more than the natives. A deciding factor for their prospects of employment is the knowledge of not the language of their host country in general, but specifically of the sublanguage of the vocational domain they are interested in working. Consequently, more and more highly skilled migrants and refugees worldwide are finding employment in low-skill vocations, despite their professional qualifications and educational backgrounds, with the language barrier being one of the most important factors. Both high-skill and low-skill vocations in agriculture, cooking, crafting, construction, and hospitality, among others, consist of the most common vocational domains in which migrants and refugees seek and find employment according to the findings of the recent research.
In the last decade, due to the expansion of the user base of wikis and social networks, user-generated content has increased exponentially, thereby providing a valuable source of data for various tasks and applications in data mining, natural language processing, and machine learning. However, minority class examples are the most difficult to obtain from real data, especially from user-generated content from wikis and social networks, thereby creating a class imbalance problem that affects various aspects of real-world applications that are based on classification. Especially for multi-class problems, such as the one addressed in this paper, they are more challenging to solve.
This paper extends the contribution of the authors’ previous research [
19] on automatic vocational domain identification by further processing and analyzing the results of machine learning experiments with a domain-specific textual data set, wherein we considered two research directions: a. prediction analysis and b. data balancing.
Regarding the prediction analysis direction, important conclusions were drawn from successfully identifying and examining the four misclassified examples (WP1–WP4) for each class (wrong predictions) using the Gradient Boosted Trees model, which managed to correctly classify most of the examples, as well as identify which distinct features contributed to their misclassification. An important finding is that the misclassified examples diverged significantly from the other examples of their class, since, for all wrong predictions, the confidence values for class, which is the real class of the examples, were significantly lower (from 0.11 to 0.17) than the confidence values for prediction (from 0.31 to 0.55), which indicates the wrongly predicted class of the examples. More specifically, the feature values of WP1–WP4 were the main factors for their misclassification, by either being neutral or by supporting the wrong over the correct prediction. Even when they contradicted the wrong prediction, such as the features of WP2 and WP3, they did not have a significant effect due to their feature weights being quite low. In conclusion, the main factor that led the Gradient Boosted Trees model to misclassify the examples was the lack of dominant features supporting the real class more than the prediction in terms of feature weight.
In the same line of thought, the examination of the correctly classified examples (correct predictions) resulted in several findings. The confidence values for the correct predictions for all classes were considerably high, with the lowest being from class B (from 0.37 to 0.55) and the highest being from class E (from 0.54 to 0.55), which means that the model could classify the examples of class E more confidently compared to the examples of the other classes. Additionally, the most dominant features, in terms of feature weight, led to the correct predictions for each class being identified successfully and sorted in a descending order; features with higher weights were more dominant for the correct predictions of this model than features with lower weights. Another important finding concerning the most dominant features is the fact that about half of the features of the extracted feature set had the highest feature weights (from 0.02 up to 0.037), therefore indicating that the feature extraction process, as described in
Section 3 and [
19], performed quite well and produced a robust feature set with great impact on the correct predictions. It is important to note that, among these features, terms relevant to all of the vocational domains were included, thus yielding a primary set of terms for the vocational domains.
Regarding the data balancing direction, oversampling and undersampling techniques, both separately and in combination as a hybrid approach, were applied to the data set in order to observe their impacts (positive or negative) on the performance of the
Random Forest and
AdaBoost model. A novel and original four-step methodology was proposed in this paper and used for data balancing for the first time, to the best of the authors’ knowledge. It consisted of successive applications of SMOTE oversampling on imbalanced data in order to balance them while considering which class was the minority class in each iteration. By running the experiments while following this methodology, the impact of every class distribution, from completely imbalanced to completely balanced data, on the performance of the machine learning model could be examined thoroughly. This process of data balancing enabled the comparison of the performance of this model with balanced data to the performance of the same model with imbalanced data from the previous research [
19].
More specifically, the machine learning experiments’ results with Random Forest and AdaBoost with SMOTE oversampling obtained significantly improved overall performance and accuracy values (up to 66.01%) compared to those of Random Forest and AdaBoost with imbalanced data, all while maintaining or surpassing the achieved F1 scores per class. A major finding is that, despite the overall performance of the model becoming slightly worse with each iteration (each added SMOTE oversampling), it was still significantly better than the performance of the experiment with completely imbalanced data; even the lowest accuracy (64.09%), which was that of the fourth machine learning experiment with SMOTE, was quite higher than the accuracy (62.33%) of the experiment with completely imbalanced data. Moreover, the values of precision, recall, and F1 score seemed to be distributed more evenly among the classes with each iteration, thus mitigating any emerging bias of the model towards one particular class. Another important finding is that, in a classification task where one of the five vocational domains was considered as the class of interest, e.g., for trying to exclusively detect articles of a specific vocational domain from a corpus to filter relevant content, the application of SMOTE oversampling for the class of interest had a positive effect on the results of this classification task.
The machine learning experiments’ results with
Random Forest and
AdaBoost with
Sample showed slightly improved overall performance and accuracy values (62.84%) compared to those of
Random Forest and
AdaBoost with imbalanced data, all while surpassing the achieved F1 scores per class, except for from class B. Compared to the results obtained with SMOTE oversampling, undersampling had worse performance in terms of accuracy, class precision, recall, and F1 score. The machine learning experiments’ results with
Random Forest and
AdaBoost with
Sample and
SMOTE oversampling (hybrid approach) showed marginally improved overall performance and accuracy values (63.35%) compared to those of
Random Forest and
AdaBoost with
Sample only, all while surpassing the achieved F1 scores for classes A and D. However, the performance of this experiment was better than that of the experiment with completely imbalanced data. In conclusion, these experiments indicate that, when applying both data undersampling and oversampling in a hybrid approach, the results were better than only applying undersampling but were worse than only applying oversampling for this data set. The findings derived from the machine learning experiments of this paper are in accordance with those of the relevant literature [
12,
17] regarding the conclusion that data oversampling obtains better results than data undersampling in imbalanced data sets, while hybrid approaches perform reasonably well.
In
Table 15, the performance of related work (
Section 2 and
Table 1) is compared to the performance of this paper in terms of accuracy and F1 score, which considers the data sets and models that obtained the best results for each research. The performance of the
Gradient Boosted Trees model was quite high when compared to the performance of the models applied in related work. It is important to note that Hamza et al. [
20] and Balouchzahi et al. [
21] worked with data sets consisting of news articles. Hande et al. [
22] used scientific articles, and Dowlagar & Mamidi [
23] and Gundapu & Mamidi [
24] used sentences from technical reports and papers. As a result, their data sets consist of more structured text compared to the social text of the data set created in this paper, which consists of sentences from Wikipedia. Consequently, the fact that the performance of the models of this paper was the same or higher than the performance of the models of the aforementioned papers is noteworthy. Stoica et al. [
28], on the other hand, used Wikipedia articles as the input for their models, while sole sentences were used as the input for the models in this paper. Consequently, the fact that the performance of the models of this paper was higher than their performance is also noteworthy. Regarding
Random Forest, they combined it with XGBoost and obtained much better results (90% F1 score) compared to the results (79.77% F1 score) of the combination with
AdaBoost used in this paper, thus indicating that the boosting algorithm is crucial to the performance of the models. Another observation is that the performance of
Random Forest and
AdaBoost was improved with SMOTE oversampling compared to the authors’ previous research [
19]. More specifically, the accuracy increased from 62.33% to 66.01%, and the F1 score increased from 65.74% to 79.77%, thus indicating that oversampling had a positive effect on the performance of the model.
Potential directions for future work include the automatic extraction of domain-specific terminology to be used as a component of an educational tool for sublanguage learning regarding specific vocational domains in host countries with the aim to help displaced communities, such as migrants and refugees, overcome language barriers. This terminology extraction task could use the terms (features) that were identified in this paper as the most dominant for vocational domain identification in terms of feature weight. Moreover, a more vocational domain-specific data set could be created to perform a more specialized domain identification task in vocational subdomains, especially considering the set of dominant terms identified in this paper. Another direction for future work could be performing experiments with a larger data set, wherein they consist of either more Wikipedia articles or even textual data from other wikis and social networks as data sources, in order to examine the impact of more data on the performance of the models. Using a different feature sets, e.g., with n-grams and term collocations, or using features that are more social-text-specific could also be attempted to improve performance. Additionally, machine learning experiments with more intricate boosting algorithms and sophisticated machine learning models could be performed. Finally, another potential direction could be the application of the novel methodology of successive SMOTE oversampling proposed in this paper in combination with undersampling techniques on other imbalanced data sets in order to test its performance in different class imbalance problems.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}