
Multi-Project Multi-Environment Approach—An Enhancement to Existing DevOps and Continuous Integration and Continuous Deployment Tools


Abstract
:1. Introduction
- While it is technically feasible to manually insert steps into the pipeline for each desired environment using existing DevOps tools, this approach is suboptimal and inefficient. The reason is that manually expanding the pipeline in this manner results in an oversized, poorly structured, unorganized, and complex pipeline. Furthermore, it has adverse effects on the functionality and performance of the pipeline, as well as on its potential for future optimization.
- Within the context of continuous integration and continuous delivery (CI/CD), automation plays a pivotal role. Rather than manually adding specific environments to the pipeline, which creates obstacles that impede the smooth flow of the CI/CD pipeline, it becomes crucial to automate the environment provisioning process in a more efficient and advanced manner. Therefore, there is an urge to enhance existing DevOps and CI/CD automation processes to effectively address complex scenarios.
- To facilitate concurrent development across multiple projects, it was essential to find a robust solution. It was imperative to establish separate and isolated environments for each project within a shared Kubernetes cluster to mitigate the risk of conflicts. Therefore, the proposed solution needed to be dynamic and seamlessly manageable within the existing DevOps infrastructure.
- To effectively implement the creation process of multiple environments within the existing DevOps infrastructure, it is crucial to methodically tackle the challenges related to the integration of various DevOps toolchains. This requires a precise definition of requirements and a careful selection of compatible tools to streamline and optimize the integration process.
- In addition to implementing the MPME approach for simultaneous development, it is essential to adhere to best practices and stay current with advanced technologies. In light of this, the company’s existing DevOps implementation required more sophisticated deployment solutions, such as Helm deployment. The complex structures necessitated the incorporation of advanced deployment options.
2. Background
2.1. Tools for DevOps and CI/CD Practices
- Plan—The initial phase of the DevOps lifecycle focuses on gaining a deep understanding of the project’s requirements to ensure the development of a high-quality product. It provides essential inputs for the subsequent development and operations phases. Additionally, this phase helps organizations clarify their project development and management processes. There are various tools, such as Google Apps, Jira, Confluence, Slack, etc., available for this purpose; in our case, we used ClickUp for project planning, tracking, and collaboration.
- Code—In the development phase of the DevOps lifecycle, the project is constructed by creating the system infrastructure, writing code for features, and establishing test cases and automation procedures. Developers utilize a remote code repository, such as GitLab or Git, to facilitate code storage, collaboration, version control, and management. Development tools like IDEs such as Eclipse and IntelliJ, as well as project management tools like Jira, are commonly employed. In our case, we used Git as the version control system.
- Build—Applications are built by integrating various codes formed in the previous steps. Frequently utilized tools include Maven, Gradle, Sonatype Nexus, and others. In our case, we employed Maven for this task.
- Test—This represents a pivotal phase in the application development process. It involves thoroughly testing the application and, if needed, rebuilding it. We employed tools like Junit, Maven, and Sonarqube for testing purposes.
- Continuous integration—This phase automates code validation, building, and testing to verify that changes are implemented correctly and to detect errors at an initial stage. Tools like Jenkins, CircleCI, and BitBucket are employed for this purpose; we utilized Jenkins to establish our CI/CD pipeline.
- Deployment—DevOps streamlines the automation of deployment through the utilization of tools and scripts, ultimately aiming to automate the process by enabling feature activation. The code is deployed either in a cloud environment or on an on-premises cluster. The tools commonly used include Azure, AWS, Docker, Heroku, etc. For us, we used Docker-based Kubernetes clusters for deployment.
- Operations—This phase involves adapting to changing infrastructure dynamics, which offers opportunities to enhance availability, scalability, and product transformation. Some tools commonly used in this phase include Loggly, Chef, Ansible, Kubernetes, and others. Within our DevOps framework, we employed Kubernetes for container management and Ansible for automating infrastructure and application deployment.
- Monitor—Monitoring is an ongoing and integral phase within the DevOps methodology. Its purpose is to continuously monitor and analyze information to assess the status of software applications. The most common tools for this phase include Nagios, Splunk, DataDog etc. We used Prometheus and Grafana for this purpose.
2.1.1. Version Control
2.1.2. Branching Strategy
2.1.3. CI/CD Pipeline
2.2. Tools for Containerization
2.2.1. Container Runtime—Docker
2.2.2. Container Management System—Kubernetes
2.2.3. Package Manager—Helm
3. Related Work
3.1. Task Automation
3.2. Customizing Helm
3.3. Alternative Approach to MPME
3.4. Integrating Additional Tools
- A.
- Qovery [38]—It is an abstraction layer on top of some popular tools (Kubernetes, Terraform) and cloud service providers. The goal of Qovery is to provide a production-ready platform layer which will create preview environments for every pull request. These previews provide early feedback on the application changes before the changes are merged into production. Qovery currently supports multiple cloud service providers including AWS, DigitalOcean, Azure, GCP, and Scaleway. If a company plans to utilize cloud-based infrastructure, Qovery may be a good choice for managing multiple ephemeral environments throughout the software development cycle. However, it is important to note that Qovery is not suitable for private or self-managed DevOps infrastructure setups.
- B.
- Octopus Deploy [39,40]—It simplifies complex deployments and makes it easy to automate the deployment and operation runbooks from a single place, helping ship code faster, improve reliability, and break down DevOps silos. Even though Octopus Deploy can run on all kinds of infrastructure from on-premises to cloud-native, extra insights and understanding are required for using Octopus Deploy for an existing infrastructure. Some of the additional concepts, such as target, package, and packaging standard, can be a bit complicated if one tries to follow the regular ways. Furthermore, creating additional environments demands meticulous pipeline management, as Octopus Deploy is primarily tailored for predefined environments rather than the dynamic creation and administration of multiple environments.
- C.
- Humanitec [41]—It enables platform teams to build internal developer platforms (IDPs) on top of their existing stack. The additional configuration, pipeline maintenance, and the core architecture for environment provisioning in Humanitec are different from the ones in our approach. For instance, Humanitec employs two core components, ‘Score’ and the ‘Platform Orchestrator’, which are essential for environment creation. The Platform Orchestrator serves as the central component, generating configurations and deploying applications based on Score workload definitions. Developers use Score files to specify resource requirements in a platform-agnostic manner. The Platform Orchestrator interprets these definitions and provisions the necessary resources. Score itself consists of two components: the Score Specification, which outlines how to run a workload and the Score Implementation CLI, which serves as a conversion tool to generate platform-specific configurations. To integrate Humanitec into the development pipeline, one needs to configure pipelines with variables and secrets, set environment variables for new environment configuration in the Platform Orchestrator, install the score-humanitec binary into their pipeline runner, make a call to the Humanitec Platform Orchestrator API within the pipeline to create a new environment, and finally, configure the pipeline to execute the score-humanitec CLI to initiate the deployment. While this approach introduces additional concepts and configurations, it can be a valuable choice for organizations open to this extension in their DevOps toolchain.
- D.
- BunnyShell [42]—It supports on-demand or automatic creation of production, development, and staging environments. The process of creating an environment on Bunnyshell requires choosing between two methods: a Helm chart or a docker-compose. The Helm chart approach on Bunnyshell is conceptually similar to ours, as they employ a ‘bunnyshell.yaml’ file for environment definition. In contrast, their approach to docker-compose involves the implementation of environment variables at three levels: Project, Environment, and Component. These environment variables are inherited automatically by all applications, services, and databases within the Environment, which distinguishes it from our approach. BunnyShell offers seamless integration with Kubernetes clusters from major cloud service providers like AWS, Azure, and DigitalOcean, in addition to options for private Kubernetes clusters. They provide a range of solutions for automatic environment creation, including Helm chart, docker-compose, and terraform. Choosing BunnyShell might be advantageous for companies seeking a different approach to ephemeral environment provisioning.
- E.
- GitLab CI [43]—It is a robust solution for automating software development and deployment tasks, providing features such as build automation, testing, version control, and collaboration. However, it has some limitations when it comes to handling multiple environments, especially dynamic ones. The primary challenge lies in maintaining distinct configurations for each environment, involving the setup of various pipelines, variables, and secrets. While GitLab CI does support dynamic environments through ‘review apps’, its design primarily focuses on managing individual applications rather than a collective group. To address this limitation, tools like Qovery and Bunnyshell, mentioned above, offer integration options with GitLab to simplify the management of multiple environments. These tools can be particularly valuable if developers find GitLab’s dynamic environment management too complex for their specific needs. Ultimately, the decision to use GitLab should be based on the company’s preferences and their intended approach to managing their development and deployment workflows.
4. Problem Statement
- Existing branching strategies and pipeline operations only allow us to deploy an application into a single environment, and limit our opportunities for simultaneous development and deployment.
- Well-defined automation is required for environment management to avoid manual labor for operations such as creating an environment and setting up basic configurations for it.
- The existing CI/CD process relies on static parameters designed for predefined environments, including development (DEV), system integration testing (SIT), and user acceptance testing (UAT). Our aim, however, is to implement a dynamic framework that can automatically provision and configure multiple environments (multiple DEV environments and multiple SIT environments) based on the active projects.
- Complex scenarios, like the implementation of the MPME approach for concurrent development, demand more advanced and meticulously organized deployment solutions. It is crucial to embrace best practices such as Helm for deployment and to stay current with cutting-edge technologies.
- To establish multiple environments efficiently within the current DevOps infrastructure, it is essential to methodically tackle the challenges posed by integrating various DevOps toolchains. This requires a precise definition of requirements and a careful selection of compatible tools to streamline and optimize the integration processes.
5. Multi-Project Multi-Environment Approach
- -
- Master node: n1-standard-1 (16 vCPU, 32 GB memory)
- -
- Worker nodes: n1-standard-2 (32 vCPUs, 125 GB memory—for each)
- -
- Networking: calico-3.19.1
- -
- Kubernetes Version: 1.21.3
- -
- Docker Version: 20.10.4
- -
- Helm Version: v3.8.0
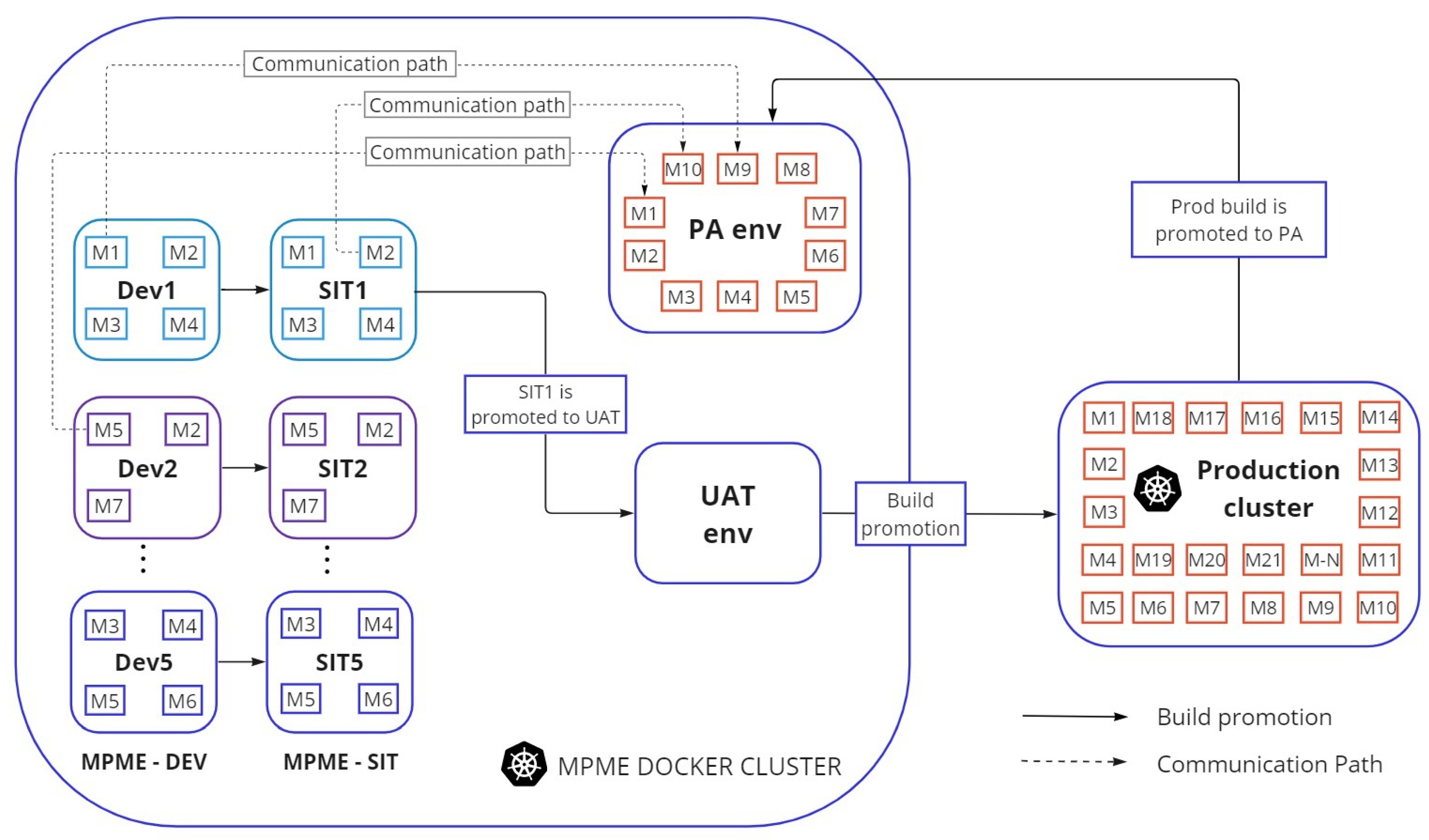
5.1. Architecture in the MPME Approach
- –
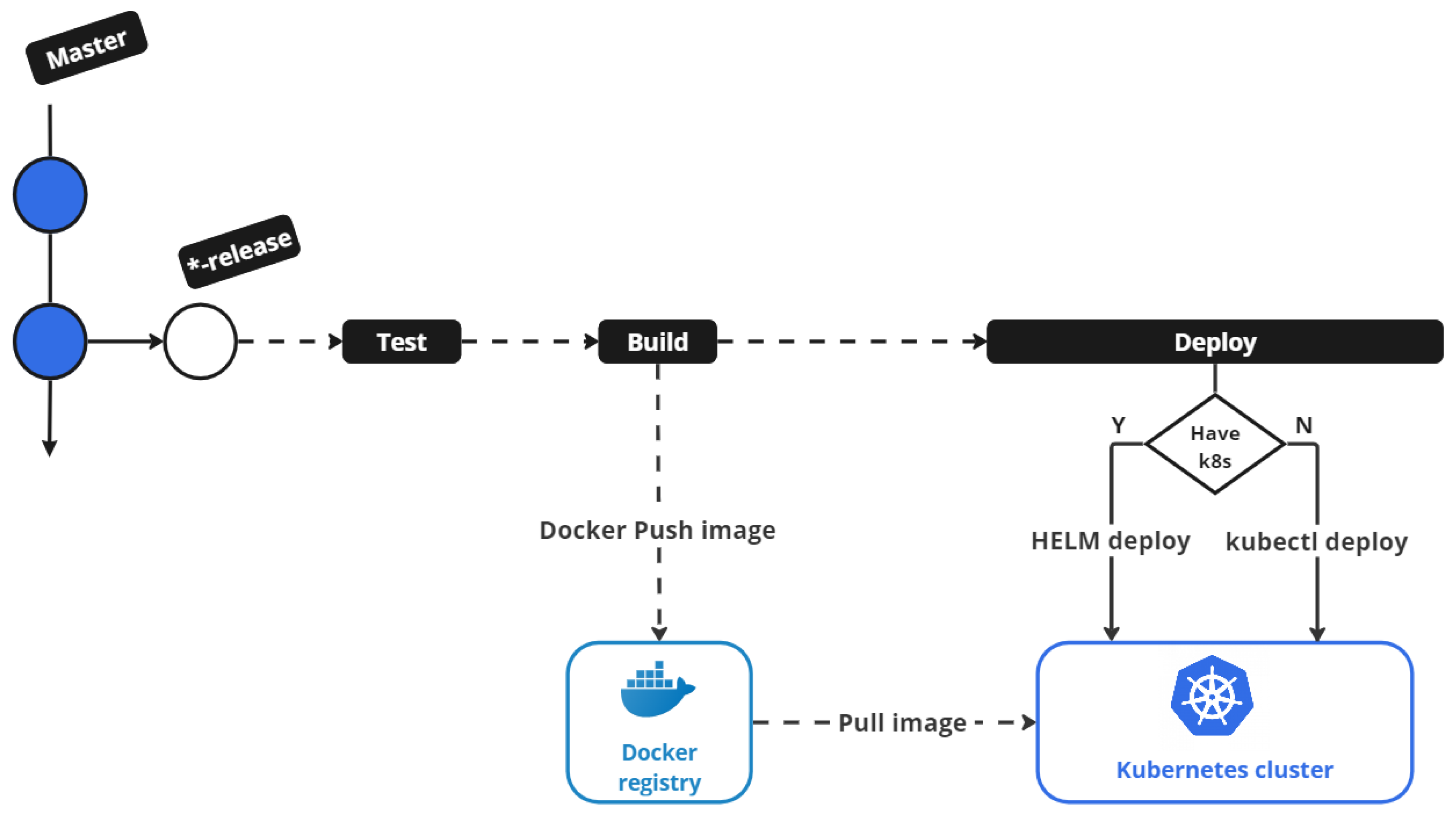
- The feature branch is utilized in the development of new features involving specific microservices. Any Jenkins build originating from a feature branch should be directed into a DEV environment of the cluster.
- –
- Once all changes are finalized within a feature branch, they are merged into the corresponding develop branch, thus forming the pre-production code.
- –
- The release branch is strategically designated for the upcoming release cycle, exclusively accommodating bug fixes or configuration adjustments. Derived from the develop branch, these release branches enable the quality assurance (QA) team to rigorously assess the current release. After confirming its readiness, the release branch is merged into the master branch and distinctly tagged with a version number.
- –
- The master branch serves as the main branch intended for all the production code. Once the code in a release branch is ready to be released, the changes are merged with the master branch and used in the production deployment.
- Initialize Parameters: To create environments for active projects, the first step is to define crucial parameters. These parameters include the project name, branch name, environment type (e.g., development, testing, production), and the necessary configuration values. To implement the MPME approach, it is essential to create a feature branch that incorporates the project name component, such as ‘dev-pi-login-enhancement’.
- Development: The next step focuses on necessary code modifications and development activities for the microservice. Developers must monitor vigilantly the changes in the version control repository, such as Git, where the code is hosted.
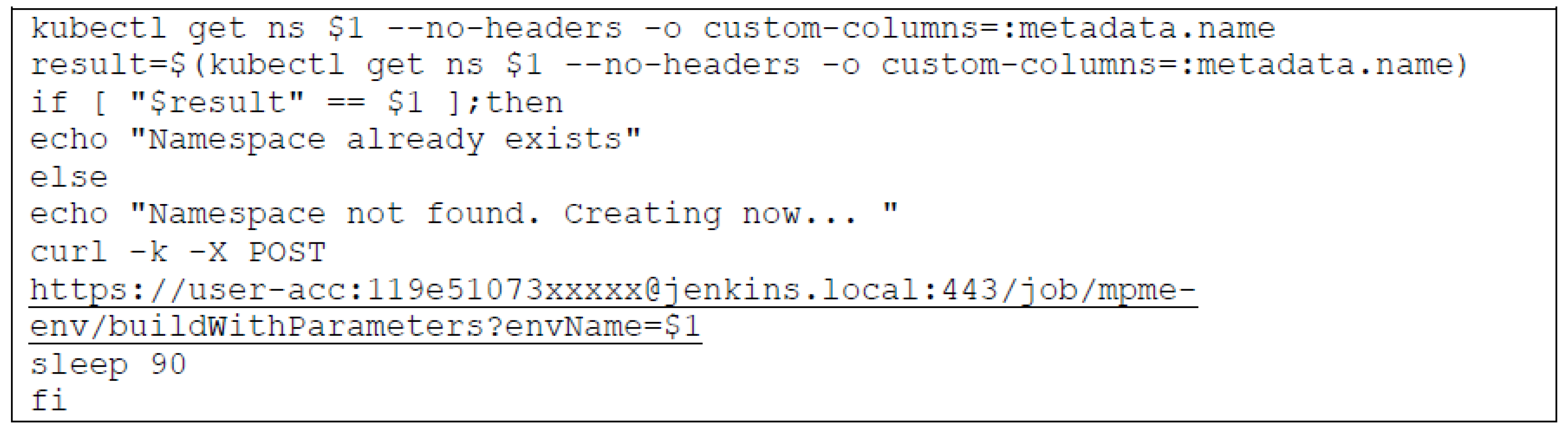
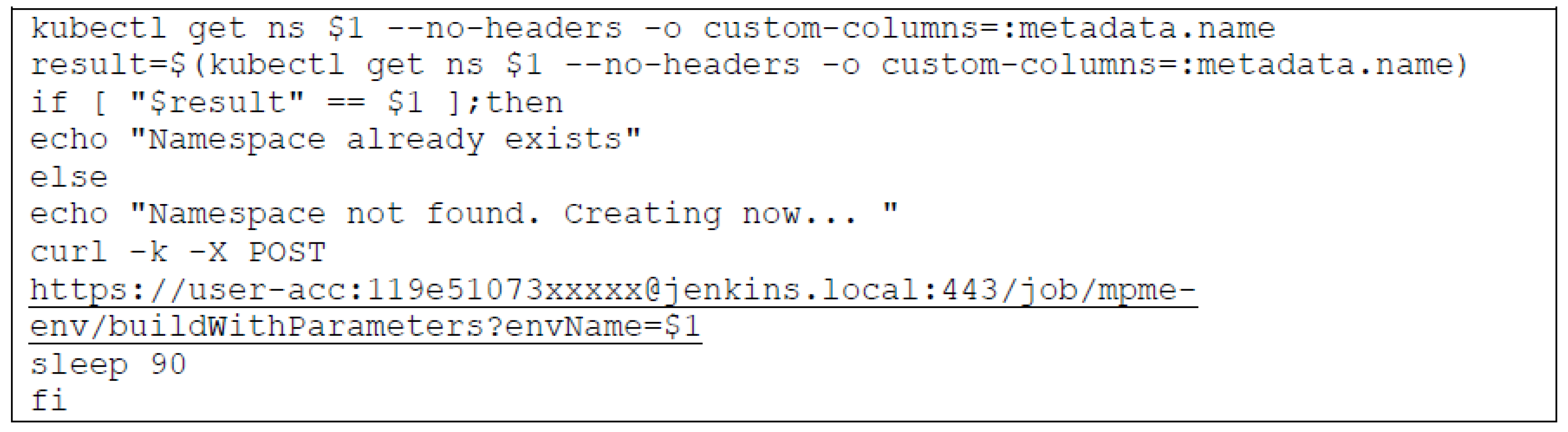
- Creating environment with MPME: Developers need to initiate the build command, which in turn triggers a Jenkins job to verify the presence of the environment based on the specified ‘project-naming component’. If the target environment is not found within the cluster, this job takes over provisioning the necessary resources. This provisioning encompasses tasks such as configuring networking, security policies, and essential environment-specific settings. Moreover, the job applies the relevant configuration values and secrets to ensure the environment is appropriately configured.
- Deploying microservices: Once the environment has been successfully created, the workflow advances to deploy microservices within that specific environment. The MPME approach utilizes either Helm deployment or the traditional kubectl deployment, depending on the presence of Helm folders. This deployment process ensures that microservices are effectively deployed into the newly created environment, complete with the required Kubernetes resources and configurations.
- Running tests: Once the microservices are up and running, commence an extensive testing phase to validate the proper functioning of both the environment and microservices. They evaluate functionality and perform testing of code changes with client microservices located in the stable environment of MPME. This testing phase includes a range of test types, such as unit tests, integration tests, and end-to-end tests, as necessary.
- Monitoring and Validation: It is essential to maintain continuous monitoring of the health and performance of microservices within the designated environment. This includes verifying smooth communication among microservices and ensuring the overall stability of the environment through ongoing validation.
- Cleaning up the environment with MPME: Upon successful project completion, or in alignment with project lifecycle or policy guidelines, developers must trigger an automated cleanup process. This process, which includes the systematic removal of the project’s host environment, along with all associated Kubernetes resources and configurations, is effectively managed through an automated Jenkins job within the MPME approach.
5.2. Environment Creation Based on Project
- Secrets—These contain sensitive information/data that the microservice needs to run, such as passwords, tokens for connecting to other pods, and certificate keys. Using a Secret means that one do not need to include confidential data in the application code. Because Secrets can be created independently of the Pods that use them, there is less risk of the Secret (and its data) being exposed during the workflow of creating, viewing, and editing Pods [48]. We must provide the following custom secrets for an environment:
- (a)
- PFX Certificate Files: These files encapsulate certificates, public and private keys tailored for the microservice;
- (b)
- Java Key Store (JKS) Files: These files contain a collection of encrypted keys and certificates that ensure the proper operation of the microservice.
- Configuration service—In the microservice world, managing configurations of each service separately is a tedious and time-consuming task [49]. Within our Kubernetes cluster and microservices ecosystem, we have implemented centralized configuration servers, effectively streamlining the configuration management process. Each microservice is empowered to retrieve their specific configuration from these dedicated servers. Notably, we have established two distinct configuration servers: one exclusively for mobile-oriented microservices, and the other catering to web-based ones. Consequently, the following configuration services are indispensable for each environment:
- (a)
- config-service-1: Tailored to accommodate web-based microservices, this service assumes a modified form to align with the MPME approach;
- (b)
- config-service-2: Designed to cater to mobile-based microservices;
- (c)
- Logging configuration: A configuration that governs the logging of the microservices.
- Routing external traffic to environments—Upon establishing a designated environment within the cluster, it becomes imperative to activate and inject Istio [50] into the environment. This step empowers us to precisely direct external traffic to the intended Pod or microservice housed within the target environment.
- RBAC (role-based access control) policy implementation—In the context of establishing multiple environments within a single cluster, the security boundary is defined by a namespace. A service account [51] has access to only that particular namespace with restricted RBAC [52] policy. The namespace then represents the environment, and the limited scope (access control) of the service account prevents modifications of the Kubernetes resources/objects of any other environment while it allows deployments only to that specific environment. The service account and RBAC policy will be automatically applied to the target environment. So, the following three Kubernetes resources must be created:
- (a)
- A service account—This allows us to manage the deployment of microservices and their resources on the cluster through a defined role and role binding;
- (b)
- A role—This entity defines permissions within a specific environment. While creating a role, it is necessary to specify the environment to which it pertains [53]; and
- (c)
- A role binding—A role binding grants the permissions defined in a role to a user or a set of users; it holds a list of subjects (users, groups, or service accounts), and a reference to the role being granted [53].
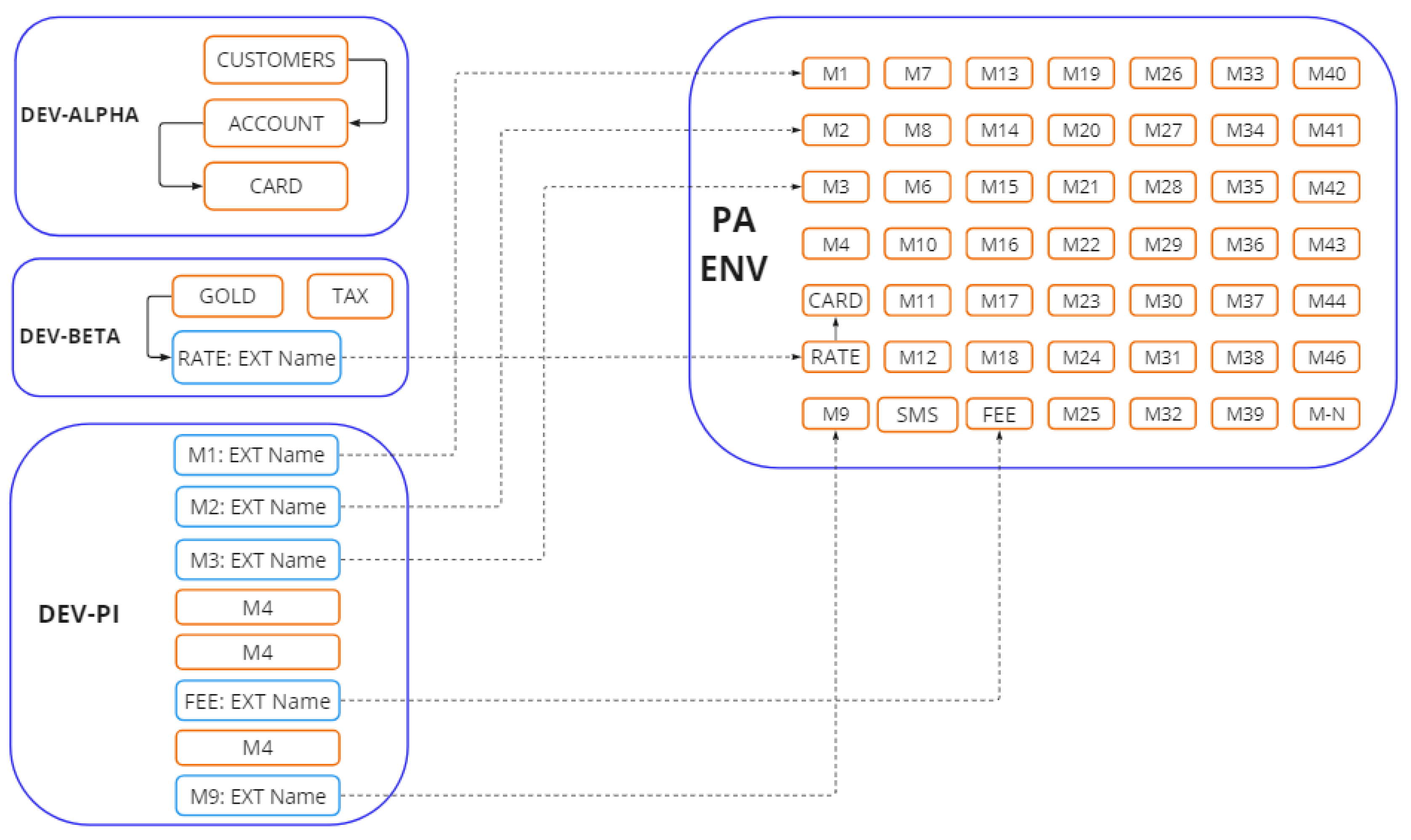
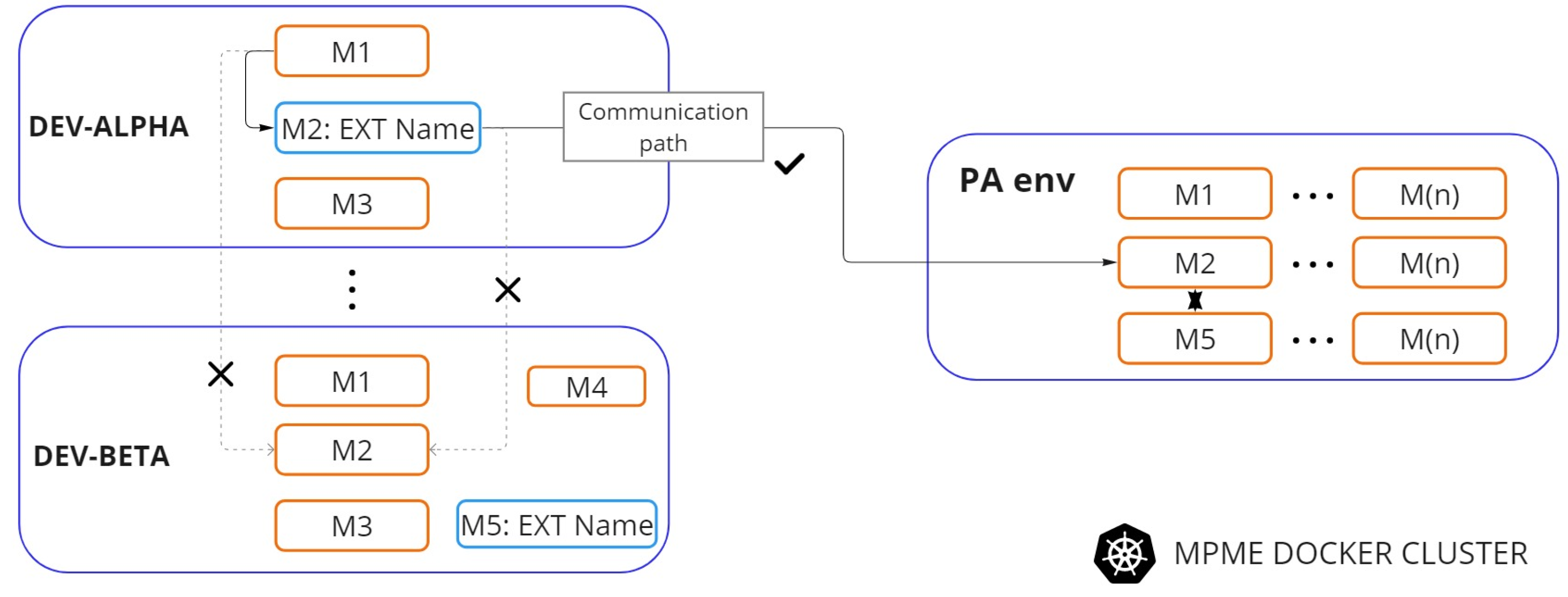
5.3. Facilitating Communication Paths across the Environments
5.4. Isolating the Environments in a Shared Cluster
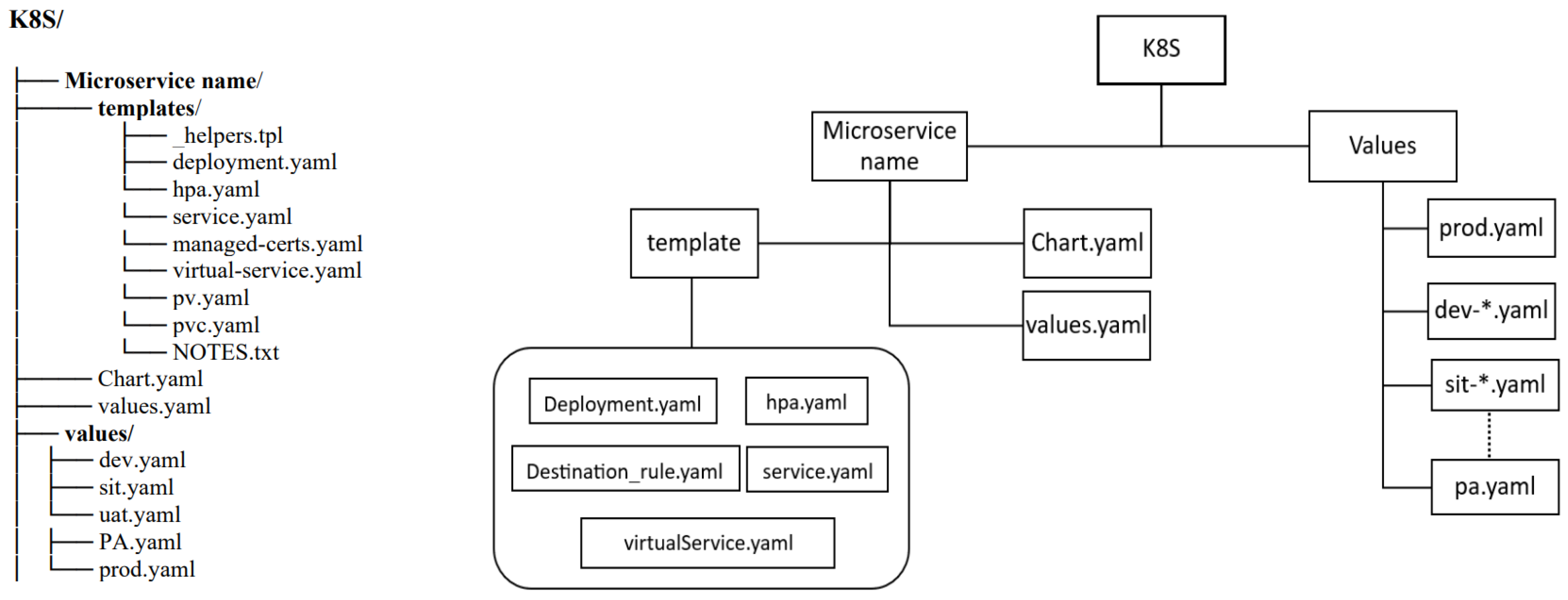
6. Customized Helm Deployment Strategy for MPME
7. Pipeline Optimization
- A clone step that fetches the code from Git when a commit is pushed.
- A test step in which smoke, unit, and integration tests are executed.
- A build step that creates a docker image and pushes it into a private registry.
- A deploy step that deploys to production if the branch is “master”. If the branch is not “master”, then it deploys to a pre-production environment such as “DEV”,“SIT”, or “UAT”.
- Deploying an environment;
- Destroying an environment;
- Starting an environment;
- Configuring an environment.
- Integration—The branch-naming strategy of the MPME approach should be seamlessly integrated into the pipeline operations. This integration ensures the creation of environments without any naming conflicts, thereby enabling unified and easy-to-parameterize access across the pipeline.
- Creation of MPME environments—A dedicated job (e.g., Jenkins job) has been defined exclusively for environment creation. This job will be automatically triggered by the CI/CD pipeline, which allows us to apply the required configuration, bind Kubernetes resources, and provisioning of default secrets within the environment.
- Workflow Segregation—To maintain pipeline clarity and prevent unwieldy complexity, a dedicated workflow should be established for Helm deployment. This approach ensures that the pipeline remains organized and manageable, even as deployment processes evolve.
- Modifications—The CI/CD pipeline should be adapted to accommodate specific scenarios, such as the multi-version deployment of a microservice with different configurations, as well as options for the deployment using Helm or kubectl, and so on. We have provided a script that determines the number of versions requiring deployment for each specific case.
- Automatic Deletion—As part of resource optimization, the MPME approach integrates an automated mechanism for environment cleanup and removal. Upon the successful completion of a project, the related environments and branches are automatically eradicated. This process involves the comprehensive purging of associated Kubernetes objects, ensuring the systematic removal of the environment from the cluster.
8. Results and Discussion
- Automated Environment Provisioning: To streamline the creation of environments within the existing DevOps infrastructure, we proposed project-based name components for the MPME approach. This concept integrates project-naming components into the branching strategy within the CI/CD pipeline. It helps to enable the automatic creation of multiple development and testing environments simultaneously for each project within a shared cluster.
- Efficient Resource Allocation: To optimize resource allocation across multiple projects and microservices, we have proposed the concept of a stable environment called ‘PA’. This environment holds the latest post-production releases of the microservices. Rather than each project maintaining its own set of client microservices for testing purposes, a centralized stable ‘PA’ environment serves as a comprehensive repository. This stable environment enhances resource efficiency by eliminating the necessity to run multiple client microservices within each development environment.
- Enabling Communication Path: To establish a communication path between the stable environment (PA) and other development environments, we have adopted the Kubernetes concept of “ExternalName” service. This allows smooth communication between environments, promoting efficient intercommunication and testing.
- Customized Helm Deployment: To mitigate the complexities associated with managing and provisioning multiple environments, we introduce a customized Helm chart for the MPME approach. This custom Helm is designed to seamlessly align with our objective of enabling dynamic environment provisioning and configuration. Our refinement of Helm charts involves storing configuration values at two different levels, thus supporting the creation of multiple environments without the need for redundant adjustments to configuration values in multiple places. When a project includes a Helm chart folder, Helm is utilized for packaging, deploying, and managing microservices and Kubernetes resources.
- Streamlining CI/CD Pipeline: Throughout the implementation phase of the MPME approach, we ensured the incorporation and refinement of the CI/CD pipeline in alignment with the principles outlined above. This extensive work was focused on optimizing the pipeline to effectively manage the dynamic processes of multiple environments such as their creation, configuration, and decommissioning.
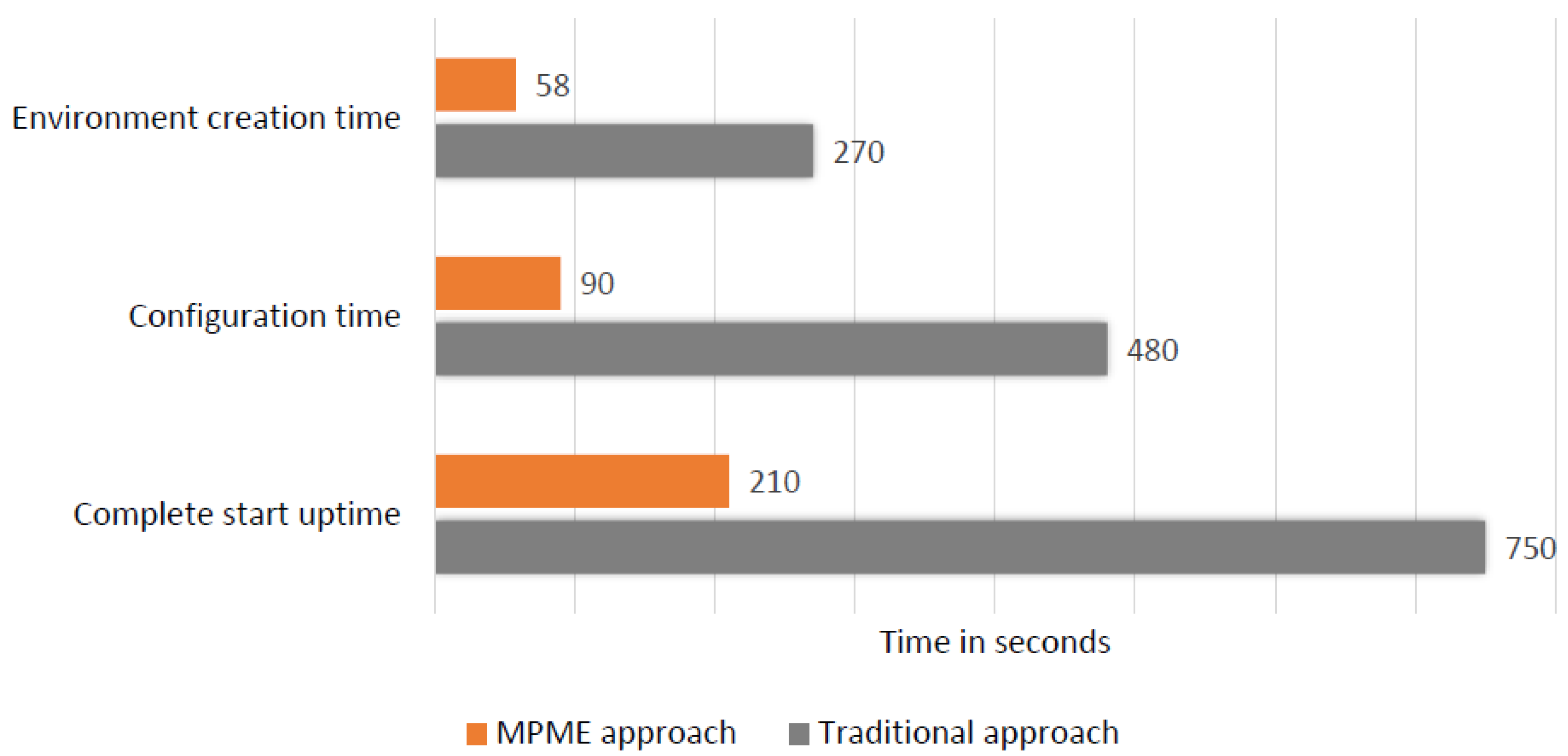
8.1. Performance Evaluation
8.1.1. Measurement on Environment Management
8.1.2. Resource Consumption
8.2. Scalability of Multi-Environments and Applications
8.3. Practical Implementation Challenges
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bass, L.; Weber, I.; Zhu, L. DevOps: A Software Architect’s Perspective, 1st ed.; Addison-Wesley Professional: Boston, MA, USA, 2015. [Google Scholar]
- Zhu, L.; Bass, L.; Champlin-Scharff, G. DevOps and Its Practices. IEEE Softw. 2016, 33, 32–34. [Google Scholar] [CrossRef]
- Humble, J.; Farley, D. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation, 1st ed.; Addison-Wesley Professiona: Boston, MA, USA, 2010. [Google Scholar]
- Microsoft Azure. DevOps Definition. Available online: https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-devops/ (accessed on 3 May 2023).
- Wettinger, J.; Andrikopoulos, V.; Leymann, F. Enabling DevOps Collaboration and Continuous Delivery Using Diverse Application Environments. In On the Move to Meaningful Internet Systems: OTM 2015 Conferences, Proceedings of the OTM 2015, Rhodes, Greece, 26–30 October 2015; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9415. [Google Scholar] [CrossRef]
- Yu, Y.; Silveira, H.; Sundaram, M. A microservice based reference architecture model in the context of enterprise architecture. In Proceedings of the 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 3–5 October 2016; pp. 1856–1860. [Google Scholar] [CrossRef]
- Villamizar, M.; Garcés, O.; Castro, H.; Verano, M.; Salamanca, L.; Casallas, R.; Gil, S. Evaluating the monolithic and the microservice architecture pattern to deploy web applications in the cloud. In Proceedings of the 2015 10th Computing Colombian Conference (10CCC), Bogota, Colombia, 21–25 September 2015; pp. 583–590. [Google Scholar] [CrossRef]
- Kalske, M.; Mäkitalo, N.; Mikkonen, T. Challenges When Moving from Monolith to Microservice Architecture. In Current Trends in Web Engineering. ICWE 2017; Garrigós, I., Wimmer, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10544. [Google Scholar] [CrossRef]
- Bernstein, D. Containers and Cloud: From LXC to Docker to Kubernetes. IEEE Cloud Comput. 2014, 1, 81–84. [Google Scholar] [CrossRef]
- Wan, X.; Guan, X.; Wang, T.; Bai, G.; Choi, B.-Y. Application deployment using Microservice and Docker containers: Framework and optimization. J. Netw. Comput. Appl. 2018, 119, 97–109. [Google Scholar] [CrossRef]
- RedHat. Understanding DevOps Automation. Available online: https://www.redhat.com/en/topics/automation/what-is-devops-automation (accessed on 3 May 2023).
- Armenise, V. Continuous Delivery with Jenkins: Jenkins Solutions to Implement Continuous Delivery. In Proceedings of the 2015 IEEE/ACM 3rd International Workshop on Release Engineering, Florence, Italy, 19 May 2015; pp. 24–27. [Google Scholar] [CrossRef]
- Bass, L.; Clements, P.; Kazman, R. Software Architecture in Practice, 3rd ed.; Addison-Wesley: Westford, MA, USA, 2012. [Google Scholar]
- Saito, H.; Lee, H.-C.; Wu, C.-Y. DevOps with Kubernetes; Packt Publishing: Birmingham, UK, 2017; ISBN 978-1-78839-664-6. [Google Scholar]
- Jenkins, D.; Arnaud, J.; Thompson, S.; Yau, M.; Wright, J. Version Control and Patch Management of Protection and Automation Systems. In Proceedings of the 12th IET International Conference on Developments in Power System Protection, Copenhagen, Denmark, 31 March–3 April 2014. [Google Scholar]
- Spinellis, D. Git. IEEE Softw. 2012, 29, 100–101. [Google Scholar] [CrossRef]
- Chandrasekara, C.; Herath, P. Branching with Azure Git Repos. In Hands-On Azure Repos; Apress: Berkeley, CA, USA, 2020. [Google Scholar] [CrossRef]
- Chen, L. Microservices: Architecting for Continuous Delivery and DevOps. In Proceedings of the 2018 IEEE International Conference on Software Architecture (ICSA), Seattle, WA, USA, 30 April–4 May 2018; pp. 39–397. [Google Scholar] [CrossRef]
- Shahin, M.; Babar, M.A.; Zhu, L. Continuous Integration, Delivery and Deployment: A Systematic Review on Approaches, Tools, Challenges and Practices. IEEE Access 2017, 5, 3909–3943. [Google Scholar] [CrossRef]
- Anderson, C. Docker [Software engineering]. IEEE Softw. 2015, 32, 102-c3. [Google Scholar] [CrossRef]
- Rad, B.B.; Bhatti, H.J.; Ahmadi, M. An Introduction to Docker and Analysis of its Performance. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2017, 17, 228–235. [Google Scholar]
- Sayfan, G. Mastering Kubernetes, 2nd ed.; Packt Publishing: Birmingham, UK, 2018; ISBN 978-1788999786. [Google Scholar]
- The Kubernetes Authors. Kubernetes Offcial Website. Available online: https://Kubernetes.io/ (accessed on 5 May 2023).
- Burns, B.; Vohra, A. Kubernetes: Up and Running: Dive into the Future of Infrastructure; O’Reilly Media, Incorporated: Sebastopol, CA, USA, 2016. [Google Scholar]
- Buchanan, S.; Rangama, J.; Bellavance, N. Helm Charts for Azure Kubernetes Service. In Introducing Azure Kubernetes Service; Apress: Berkeley, CA, USA, 2020. [Google Scholar] [CrossRef]
- Helm. Charting Our Future—Helm3 Preview. Available online: https://Helm.sh/blog/Helm-3-preview-pt1/ (accessed on 3 May 2023).
- Duffy, M. DevOps Automation Cookbook; Packt Publishing: Birmingham, UK, 2015. [Google Scholar]
- Been, H.; Keiholz, E.; Staal, E. Azure Infrastructure as Code: With ARM Templates and Bicep; Manning: Henley-on-Thames, UK, 2022; pp. 239–251. [Google Scholar]
- Brikman, Y. Terraform: Up and Running; O’Reilly Media: Sebastopol, CA, USA, 2022. [Google Scholar]
- Jourdan, S.; Pomes, P. Infrastructure as Code (IAC) Cookbook; Packt Publishing: Birmingham, UK, 2017; pp. 217–230. [Google Scholar]
- Omofoyewa, Y.; Grebe, A.; Leusmann, P. IaC reusability for Hybrid Cloud Environment. Available online: https://www.researchgate.net/publication/357281177_IaC_reusability_for_Hybrid_Cloud_Environment (accessed on 20 October 2023).
- Sayfan, G.; Ibryam, B. Mastering Kubernetes: Dive into Kubernetes and Learn How to Create and Operate World-Class Cloud-Native Systems; Packt Publishing: Birmingham, UK, 2023; pp. 297–311. [Google Scholar]
- Helm Chart Template Guideline. Available online: https://helm.sh/docs/chart_template_guide/ (accessed on 5 May 2023).
- Butcher, M.; Farina, M.; Dolitsky, J. Learning Helm: Managing Apps on Kubernetes; O’Reilly Media, Incorporated: Sebastopol, CA, USA, 2021. [Google Scholar]
- Authors of Tarka Labs: Handling Multiple Environments with Helm. Available online: https://blog.tarkalabs.com/handling-multiple-environments-with-helm-kubernetes-f214192f8f7b (accessed on 20 October 2023).
- Performing a Rolling Update. Available online: https://kubernetes.io/docs/tutorials/kubernetes-basics/update/update-intro/ (accessed on 20 October 2023).
- Sayfan, G. Hands-On Microservices with Kubernetes: Build, Deploy, and Manage Scalable Microservices on Kubernetes; Packt Publishing: Birmingham, UK, 2019; pp. 317–338. [Google Scholar]
- Qovery. Basic Concepts and Preview Environments. Available online: https://www.qovery.com/docs/getting-started (accessed on 3 May 2023).
- Octopus. Overview. Available online: https://octopus.com/features (accessed on 3 May 2023).
- Machiraju, S.; Gaurav, S. Deployment via TeamCity and Octopus Deploy. In DevOps for Azure Applications; Apress: Berkeley, CA, USA, 2018. [Google Scholar] [CrossRef]
- Humanitec. Introduction. Available online: https://developer.humanitec.com/getting-started/pe/introduction/ (accessed on 3 May 2023).
- BunnyShell. Documents. Available online: https://documentation.bunnyshell.com/docs (accessed on 3 May 2023).
- GitLab CI. Documents. Available online: https://docs.gitlab.com/ee/ci/environments/#create-a-dynamic-environment (accessed on 20 October 2023).
- Sureshchandra, K.; Shrinivasavadhani, J. Moving from Waterfall to Agile. In Proceedings of the Agile 2008 Conference, Toronto, ON, Canada, 4–8 August 2008; pp. 97–101. [Google Scholar] [CrossRef]
- Kim, G.; Humble, J.; Debois, P.; Willis, J.; Forsgren, N. The DevOps Handbook: How to Create World-Class Agility, Reliability, & Security in Technology Organizations; IT Revolution Press: Portland, OR, USA, 2021; Available online: https://books.google.hu/books?id=8kRDEAAAQBAJ (accessed on 15 March 2012).
- Chacon, S.; Straub, B. Git Branching. In Pro Git; Apress: Berkeley, CA, USA, 2014. [Google Scholar] [CrossRef]
- Balalaie, A.; Heydarnoori, A.; Jamshidi, P. Microservices Architecture Enables DevOps: Migration to a Cloud-Native Architecture. IEEE Softw. 2016, 33, 42–52. [Google Scholar] [CrossRef]
- The Kubernetes Authors. Secrets. Available online: https://Kubernetes.io/docs/concepts/configuration/secret/ (accessed on 5 May 2023).
- Jayakantha, I. Microservices—Centralized Configuration with Spring Cloud. Available online: https://medium.com/@ijayakantha/f2a1f7b78cc2 (accessed on 5 May 2023).
- Sharma, R.; Singh, A. Getting Started with Istio Service Mesh: Manage Microservices in Kubernetes., 1st ed.; Apress: Berkeley, CA, USA, 2020. [Google Scholar] [CrossRef]
- The Kubernetes Authors. Service Accounts. Available online: https://kubernetes.io/docs/concepts/security/service-accounts/ (accessed on 5 May 2023).
- The Kubernetes Authors. RBAC Good Practices. Available online: https://kubernetes.io/docs/concepts/security/rbac-good-practices/ (accessed on 8 May 2023).
- The Kubernetes Authors. Using RBAC Authorization. Available online: https://Kubernetes.io/docs/reference/access-authn-authz/rbac/ (accessed on 5 May 2023).
- The Kubernetes Authors. Services. Available online: https://kubernetes.io/docs/concepts/services-networking/service/ (accessed on 5 May 2023).
- Brewer, E. Kubernetes and the Path to Cloud Native. In Proceedings of the SoCC ’15: Proceedings of the Sixth ACM Symposium on Cloud Computing, Kohala Coast, HI, USA, 27–29 August 2015; p. 167. [Google Scholar] [CrossRef]
- Google Kubernetes Engine (GKE). Types of Kubernetes Services. Available online: https://cloud.google.com/kubernetes-engine/docs/concepts/service#types-of-services (accessed on 5 May 2023).
- The Kubernetes Authors. Services-ExternalName. Available online: https://kubernetes.io/docs/concepts/services-networking/service/#externalname (accessed on 5 May 2023).
- The Kubernetes Authors. Services-ClusterIP. Available online: https://kubernetes.io/docs/concepts/services-networking/service/#type-clusterip (accessed on 5 May 2023).
- Wang, K.; Wu, S.; Suo, K.; Liu, Y.; Huang, H.; Huang, Z.; Jin, H. Characterizing and optimizing Kernel resource isolation for containers. Future Gener. Comput. Syst. 2023, 141, 218–229. [Google Scholar] [CrossRef]
- Mallett, A. Writing YAML and Basic Playbooks. In Red Hat Certified Engineer (RHCE) Study Guide; Apress: Berkeley, CA, USA, 2021; pp. 63–77. [Google Scholar] [CrossRef]
- The Helm Authors. Using Helm. Available online: https://helm.sh/docs/intro/using_helm/ (accessed on 5 May 2023).
- Mike Treadway—FAUN Publication. Helm Charts for More Complex Projects and How to Secure Them. Available online: https://faun.pub/a1dfde804226 (accessed on 5 May 2023).
- The Helm Authors. Values Files. Available online: https://helm.sh/docs/chart_template_guide/values_files/ (accessed on 5 May 2023).
- Nocentino, A.E.; Weissman, B. Storing Persistent Data in Kubernetes. In SQL Server on Kubernetes; Apress: Berkeley, CA, USA, 2021. [Google Scholar] [CrossRef]
- The Kubernetes Authors. Persistent Volumes. Available online: https://kubernetes.io/docs/concepts/storage/ (accessed on 5 May 2023).
- Martin, P. Kubernetes: Preparing for the CKA and CKAD Certifications, 1st ed.; Apress: Berkeley, CA, USA, 2021. [Google Scholar] [CrossRef]
- Shahin, M.; Zahedi, M.; Babar, M.A.; Zhu, L. An Empirical Study of Architecting for Continuous Delivery and Deployment. Empir. Softw. Eng. 2019, 24, 1061–1108. [Google Scholar] [CrossRef]
- Uphill, T. DevOps: Puppet, Docker and Kubernetes; Packt Publishing: Birmingham, UK, 2017; ISBN 978-1788297615. [Google Scholar]
- Arundel, J.; Domingus, J. Cloud Native DevOps with Kubernetes: Building, Deploying, and Scaling Modern Applications in the Cloud; O’Reilly Media: Newton, MA, USA, 2019; ISBN 978-1492040767. [Google Scholar]
- Arachchi, S.; Perera, I. Continuous Integration and Continuous Delivery Pipeline Automation for Agile Software Project Management. In Proceedings of the 2018 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 30 May–1 June 2018; pp. 156–161. [Google Scholar] [CrossRef]
- Rajput, D.; Rajesh, R.V. Building Microservices with Spring: Master Design Patterns of the Spring Framework to Build Smart, Efficient Microservices; Packt Publishing: Birmingham, UK, 2018; pp. 434–437. [Google Scholar]
- Nguyen, T.-T.; Yeom, Y.-J.; Kim, T.; Park, D.-H.; Kim, S. Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration. Sensors 2020, 20, 4621. [Google Scholar] [CrossRef] [PubMed]
- CoreDNS: DNS and Service Discovery. Available online: https://coredns.io/ (accessed on 20 October 2023).
- Erdenebat, B.; Bud, B.; Kozsik, T. Challenges in service discovery for microservices deployed in a Kubernetes cluster—A case study. Infocommun. J. 2023, 15, 69–75. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traditional Approach | MPME Approach | |
|---|---|---|
| Environment isolation | Yes | Yes |
| Simultaneous deployment to single cluster | No | Yes |
| Availability for parallel testing | No | Yes |
| Process automation | Yes | Yes |
| Real-time monitoring | Yes | Yes |
| Automated environment creation and configuration | No | Yes |
| Integration with existing DevOps tools | Yes | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Erdenebat, B.; Bud, B.; Batsuren, T.; Kozsik, T. Multi-Project Multi-Environment Approach—An Enhancement to Existing DevOps and Continuous Integration and Continuous Deployment Tools. Computers 2023, 12, 254. https://doi.org/10.3390/computers12120254
Erdenebat B, Bud B, Batsuren T, Kozsik T. Multi-Project Multi-Environment Approach—An Enhancement to Existing DevOps and Continuous Integration and Continuous Deployment Tools. Computers. 2023; 12(12):254. https://doi.org/10.3390/computers12120254
Chicago/Turabian StyleErdenebat, Baasanjargal, Bayarjargal Bud, Temuulen Batsuren, and Tamás Kozsik. 2023. "Multi-Project Multi-Environment Approach—An Enhancement to Existing DevOps and Continuous Integration and Continuous Deployment Tools" Computers 12, no. 12: 254. https://doi.org/10.3390/computers12120254
APA StyleErdenebat, B., Bud, B., Batsuren, T., & Kozsik, T. (2023). Multi-Project Multi-Environment Approach—An Enhancement to Existing DevOps and Continuous Integration and Continuous Deployment Tools. Computers, 12(12), 254. https://doi.org/10.3390/computers12120254