4.1. Dataset
In the data preparation phase, psychometric questions designed to measure an individual’s creditworthiness were obtained from Aktif Bank Company. A dataset was then prepared, consisting of the psychometric questionnaire results of known customers with credit risk.
The dataset contains 18 questions, and each question is mapped to a corresponding feature.
Figure 2 provides a detailed correlation matrix among various psychometric data features used in the analysis of credit risk prediction. Each cell in the matrix represents the correlation coefficient between a pair of features, with color intensities indicating the strength of the correlation—darker or brighter colors typically represent stronger correlations. Positive values denote a direct relationship, where an increase in one feature corresponds to an increase in the other, while negative values indicate an inverse relationship. This comprehensive visualization allows for immediate identification of features that are closely interrelated, as well as those that maintain independence, across the dataset.
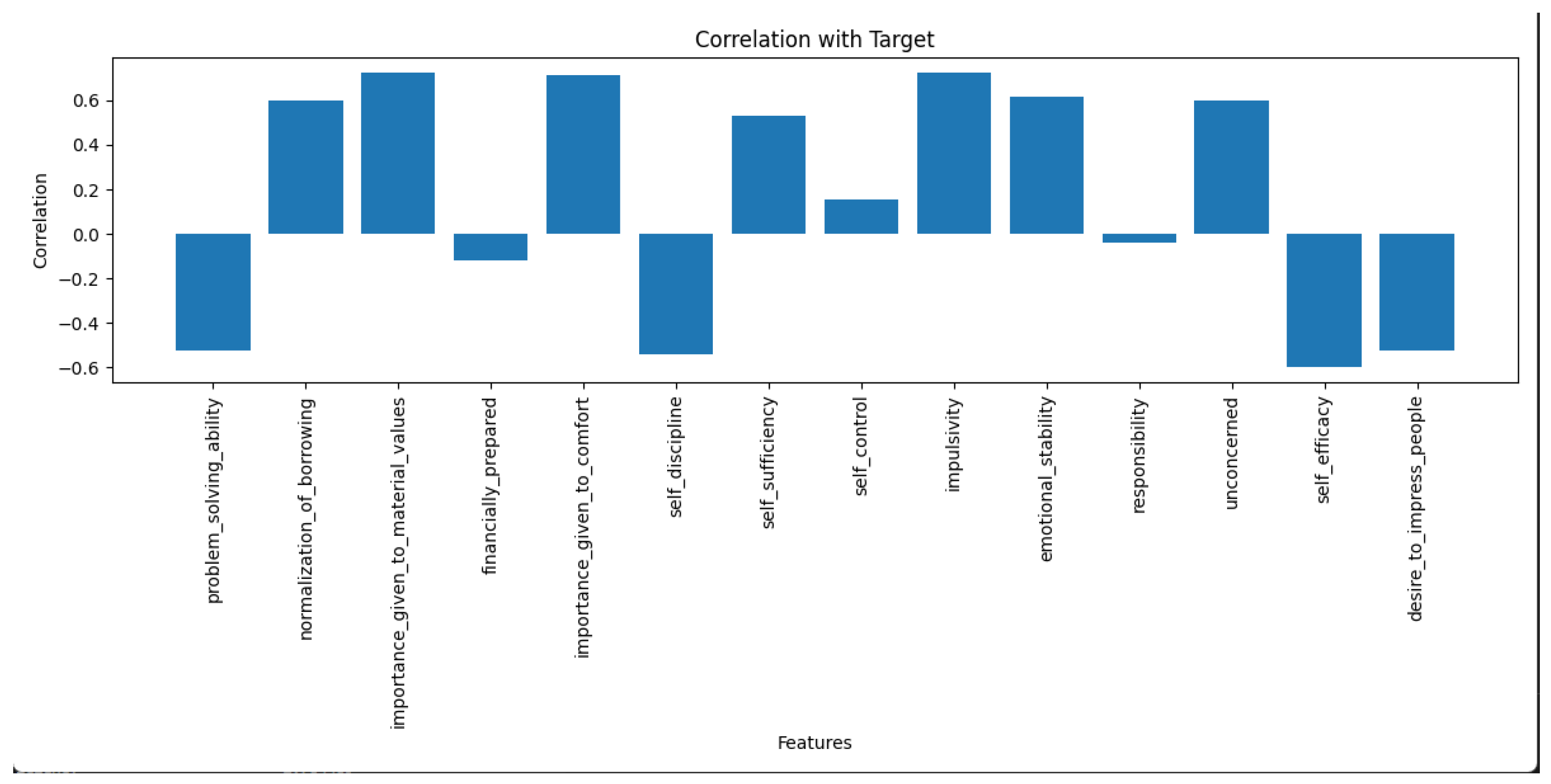
Figure 3 showcases the correlation coefficients between various psychometric data features and the target class labels indicative of credit risk (e.g., “high risk” vs. “low risk”). Each feature is assigned a correlation value, ranging from −1 to +1, representing the strength and direction of the relationship with the target variable. Features with values closer to +1 or −1 have a strong positive or negative correlation with credit risk, respectively, while those near 0 show little to no correlation. The graph is visually designed to allow quick discernment of the most influential features, highlighting them in larger size.
Figure 4 presents the information gain values associated with each psychometric data feature used in predicting credit risk. Note that the feature importance values are derived from information gain metrics calculated through decision-tree-based models. While we employed decision-tree-based methodologies, we observed consistency in the ranking of feature importance across different individual decision-tree0based models. This consistency reaffirms the robustness of our selected features and the reliability of our methodology.
Figure 4 illustrates a descending order of features, starting with the most impactful, based on the amount of information gain each contributes. Information gain is crucial as it quantifies how much each feature improves our ability to make accurate predictions, essentially indicating the reduction in entropy or uncertainty. In the context of credit risk, it highlights which aspects of a borrower’s psychometric profile most significantly influence their likelihood of default or creditworthiness.
The features used in this study include attributes related to creditworthiness such as self-discipline, impulsivity, importance given to comfort, responsibility, and normalization of borrowing. An attribute vector is created by calculating the average of the answers given to the questions representing each feature.
The target variable for this dataset represents the customer’s credit risk, which ranges from 0 to 1. A value of 0 indicates low credit risk, while a value of 1 indicates high credit risk. Practitioners of data mining and machine learning have long observed that the imbalance of classes in a dataset negatively impacts the quality of classifiers trained on that data [
54]. To mitigate this concern, we applied a stratified sampling technique during the data collection process. The ratio of positive (high credit risk, labeled as 1) to negative (low credit risk, labeled as 0) labels was maintained at approximately 45:55. This ensures that both classes are adequately represented in the dataset, allowing our models to better generalize and make more accurate predictions.
Table 1 provides a view of the descriptive statistics for the dependent feature, the credit risk score, across the dataset used in this study. It lists the average (mean), variance, and standard deviation, key metrics that together offer a snapshot of the distribution characteristics of the credit risk scores among the participants. The mean value indicates the average credit risk score, offering a central point around which the dataset is distributed. The variance and standard deviation provide insights into the dispersion of the scores, indicating the variability and consistency in the credit risk levels among the individuals assessed.
Table 2 delineates the methodology used for categorizing credit risk into discrete classes based on quantitative scores. It explicitly states the threshold values applied to the continuous credit risk scores, transforming them into binary outcomes: “high risk” and “low risk”. According to the table, a pivotal point of 0.5 has been established as the benchmark—scores exceeding this value are classified as “high risk”, indicating a less favorable credit assessment, while those falling below this threshold are deemed “low risk”, suggesting a more favorable creditworthiness. This categorical approach simplifies the subsequent analysis and decision-making processes, providing actionable classifications based on quantifiable data.
Table 3 presents a detailed breakdown of the dataset in terms of the number of instances classified under each category of the dependent feature, specifically the “high risk” and “low risk” credit scores. The table quantifies the exact number of occurrences or individuals falling into each group, thereby providing a depiction of the dataset’s distribution.
Table 4 compiles key descriptive statistics—namely, the average, variance, and standard deviation—for each independent feature in the dataset. These statistics offer foundational insights into the dataset’s nature before any further modeling. The mean provides a central value for each feature, highlighting the average outcome that can be expected. Simultaneously, the variance and standard deviation deliver information about the spread of the data, indicating how much variability exists and how far data points tend to deviate from the mean, respectively.
4.3. Results
Various metrics, such as accuracy, precision, recall, and f1 score, have been used to evaluate the performance of trained models.
The evaluation results shown in
Table 5.
Table 5 encapsulates the prediction performance results of the credit risk assessment models implemented in the study. It outlines key performance metrics, accuracy, precision, recall, FP rate, F1-score, and the area under the receiver operating characteristic curve (ROC). Each metric is important in evaluating the models’ performance, providing insights into their reliability in correctly classifying instances into “high risk” and “low risk”.
Table 6 enumerates the results of the
t-test analysis conducted on several key psychometric variables: self sufficiency, self-discipline, impulsivity, and self-control. Each of these attributes represents a dimension of behavior that could significantly influence an individual’s financial decisions and credit risk.
Table 7 provides a comprehensive evaluation of the prediction performance of the machine learning models used for assessing credit risk scores. This assessment is uniquely characterized by the prediction of continuous credit risk probabilities, a different approach compared to binary classifications. The table details critical metrics—including mean absolute error (MAE), root mean squared error (RMSE), and Matthew’s correlation coefficient (MCC)—each reflecting different aspect of the model’s accuracy and predictive power. The MAE quantifies the average magnitude of errors in the predictions, without considering their direction, offering a clear measure of accuracy on the continuous scale. The RMSE calculates the difference by squaring the errors before averaging them, thus placing more weight on large errors and indicating the presence of extreme variances in predictions. The MCC provides a balanced measure of the model’s true positive and negative rates, indicating its ability to distinguish between different levels of risk accurately, even on a continuous scale. This table helps us to understand the model’s effectiveness and reliability in predicting nuanced probabilities of credit risk, rather than just discrete categories.
Accuracy is a common metric used to assess the overall correctness of a classification model’s predictions. It measures the proportion of correctly classified instances (both true positives and true negatives) out of all instances. The random forest, KNN, SVM, and logistic regression algorithms achieved the same level of accuracy at 96.15%. The decision tree algorithm achieved a slightly lower accuracy of 92.30%. Therefore, based on these results, we conclude that the evaluated machine learning algorithms are suitable for predicting a customer’s credit risk via psychometric tests with high accuracy. These values reflect the models’ overall classification capabilities and are indicative of their quality in correctly classifying instances in our binary classification task.
Precision is a metric that measures the proportion of true positive predictions (correctly identified positive cases) out of all instances predicted as positive. It provides insight into the model’s ability to make accurate positive predictions without producing many false positives. In summary, in this study, the precision values suggest that all of the supervised learning models perform well in terms of making accurate positive predictions while minimizing false positives, with the logistic regression, random forest, KNN, and SVM models achieving the highest precision scores.
Recall, also known as sensitivity or true positive rate (TP Rate), measures the proportion of true positive predictions (correctly identified positive cases) out of all actual positive cases. It provides insight into the model’s ability to correctly identify positive instances. In summary, the recall values suggest that all of the models, used in this study, perform well in terms of capturing and correctly identifying positive instances, with the SVM model achieving the highest recall score, while the logistic regression and decision tree models achieved slightly lower but still high scores.
The F1 Score is a metric that combines precision and recall into a single value, providing a balanced measure of a model’s overall performance in binary classification tasks. In summary, in this study, the F1 Score values suggest that all of the supervised learning models provide a balanced and effective performance in terms of correctly identifying positive cases while minimizing both false positives and false negatives.
The false positive rate (FP Rate), measures the proportion of false positive predictions (incorrectly identified positive cases) out of all actual negative cases. It reflects a model’s tendency to make false positive errors. Based on the results, the FP Rate values indicate that the random forest and KNN models are particularly effective at avoiding false positive errors, with the SVM model having a slightly higher rate of false positives.
The area under the receiver operating characteristic curve (ROC Area) is a metric used to evaluate the overall performance of a binary classification model. It measures the model’s ability to distinguish between positive and negative cases across different probability thresholds. In this study, The ROC area metric values suggest that all of the supervised learning models perform well in terms of their ability to discriminate between positive and negative cases, with the KNN and SVM models achieving the highest scores.
The notable high performance of these algorithms underscores the effectiveness of the selected features in capturing credit risk accurately. This suggests that the features used in this study successfully capture the relevant information needed to assess credit risk. Based on these results, the developed system holds promise as a supportive tool for credit risk prediction.
Based on the results shown in
Table 6, it can be observed that the
p-values are significantly smaller than 0.05, indicating that these features have an effect on the dependent variable.
To ensure the selection of relevant attributes, it is important to test whether these attributes have an impact on the dependent variable (high or low credit risk), and having attributes that do not reflect the customer’s credit risk would complicate the survey. For this purpose, the statistical analysis method “t-test” has been applied. If the p-value is smaller than the predetermined level of significance (usually accepted as 0.05), then a significant difference between the two groups is accepted. An example of the results for self-discipline has a p-value of . Additionally, the p-value for the impulsivity attribute was found to be , and the p-value for the self-control attribute was 0.00738. Thus, the appropriateness of the attributes has been confirmed.
Note that the results of our model are probabilistic estimates. To turn them into binary classifications, the error in these continuous forecasts had to be measured. To this end, in our experimental study, we went beyond the usual level of classification accuracy and looked into how wrong the predictions were. With this analysis, we could see more details about how well the model worked with this method, which helped us figure out not only if an estimate was wrong, but also by how much.
In this study, we investigate the effectiveness of our approach from the perspective of mean absolute error (MAE), root mean squared error (RMSE), and Matthew’s correlation coefficient (MCC) values for each model. The results are listed in
Table 7.
Based on the results, it appears for the MAE metric, all of our machine learning models are performing quite well. MAE measures the average absolute difference between the predicted values and the actual values. Hence, on average, these models’ predictions are negligible units away from the actual values.
RMSE measures the average magnitude of the errors between predicted values and actual values, with a focus on larger errors. Based the results, an RMSE indicates that, on average, the models’ predictions deviate negligible units from the actual values. This also indicates that these models perform well on the dataset.
MCC is a metric used primarily for binary classification tasks and assesses the overall quality of binary classification predictions. It takes into account true positives, true negatives, false positives, and false negatives. Higher MCC values indicate better model performance, specifically in terms of correctly classifying data points into the correct binary classes. Based on the results, the MCC values are relatively high across all models, suggesting that these models are performing well in terms of classification accuracy.









{kind=link}
{kind=link}
{kind=link}
{kind=link}