
Enhancing Automated Scoring of Math Self-Explanation Quality Using LLM-Generated Datasets: A Semi-Supervised Approach

 , , ,
, , ,
Abstract
:1. Introduction
- RQ1: To what extent can the integration of self-explanations generated by the LLM Japanese model and mathematical material be used to enhance the accuracy of the predictive regression model for self-explanation scores?
- RQ2: What is the optimal quantity of artificially generated pseudo-self-explanation data required to effectively improve the predictive performance of the model?
2. Related Work
2.1. Automated Scoring of Self-Explanations: The Imperative for Rich Data
2.2. Augmenting Mathematical Self -Explanations Using Large Language Models
3. Problem Setting: The Learning Task
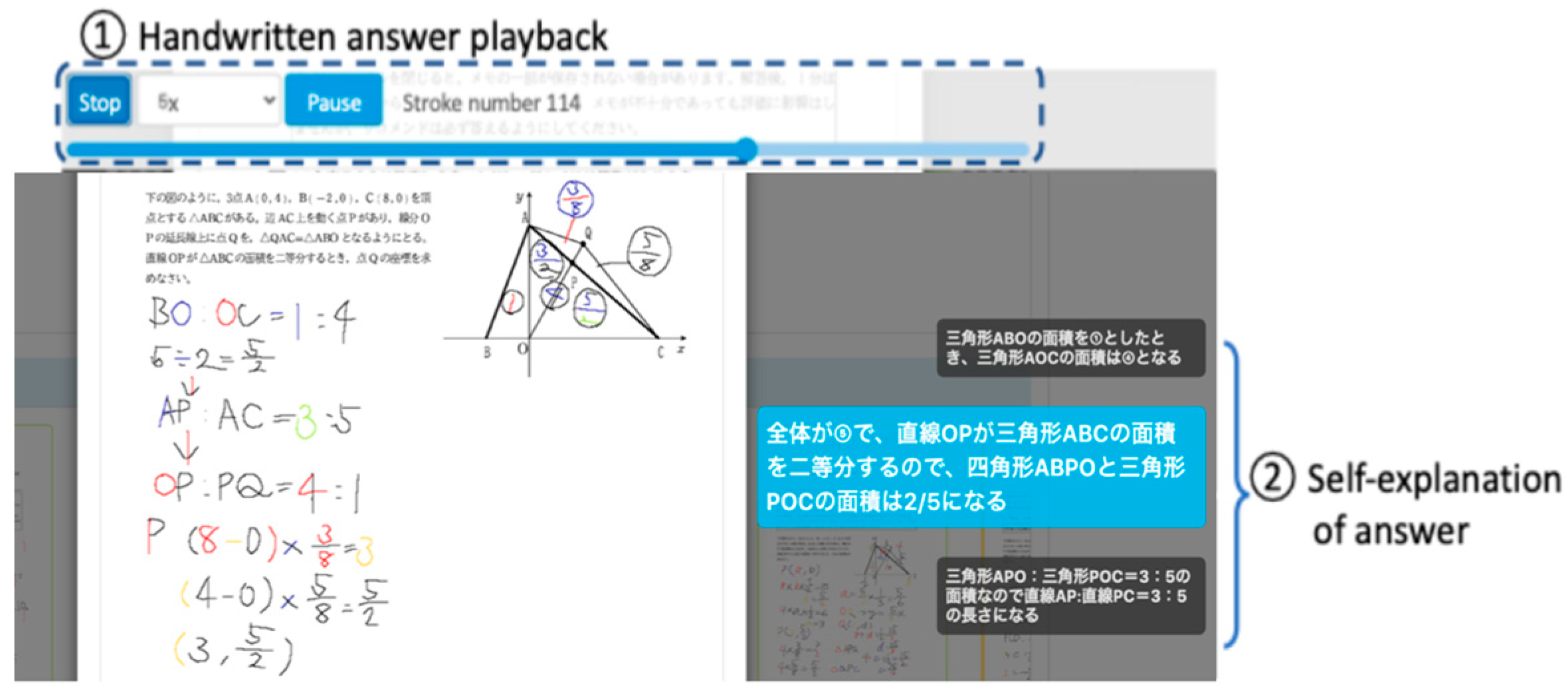
3.1. Collecting Self-Explanations
3.2. Assessment of Self-Explanation Quality
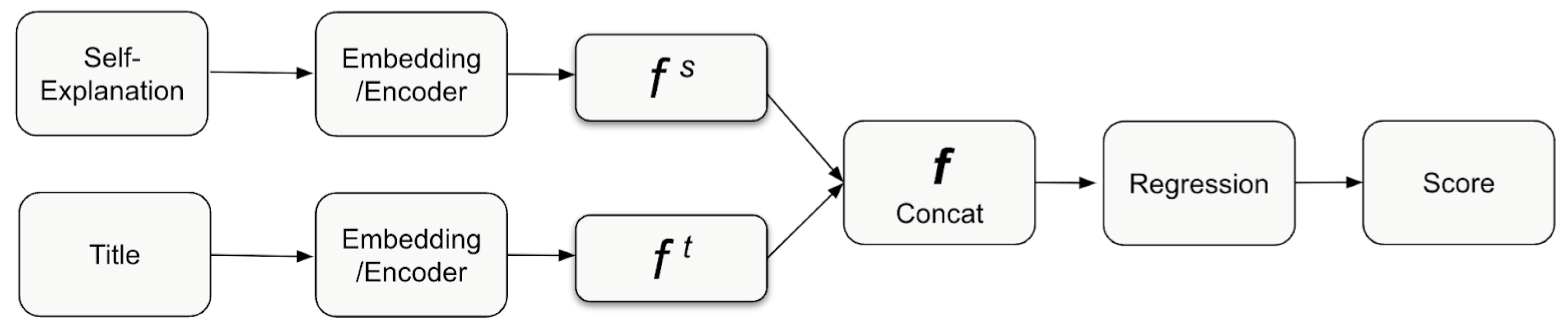
3.3. The Text Regression Model Description
4. The Proposed Method
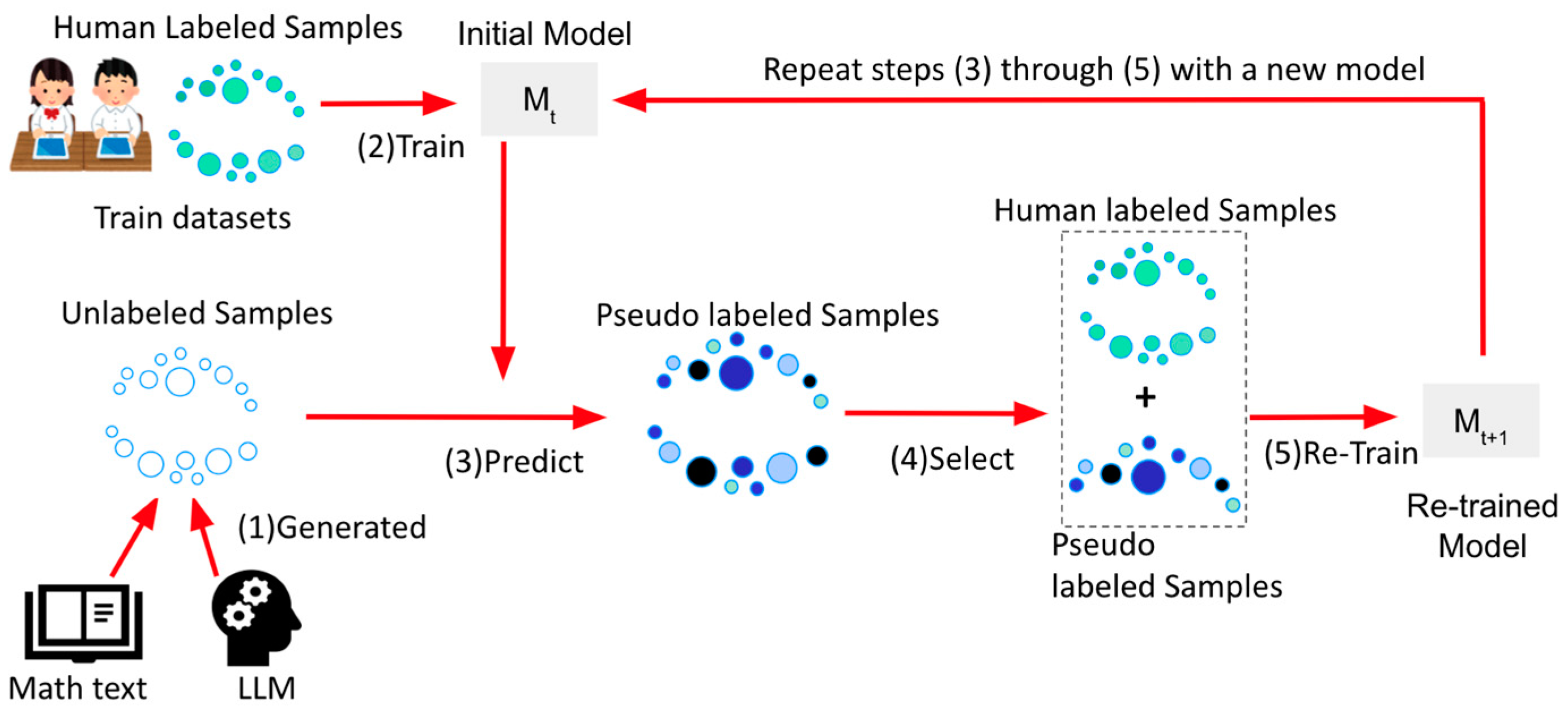
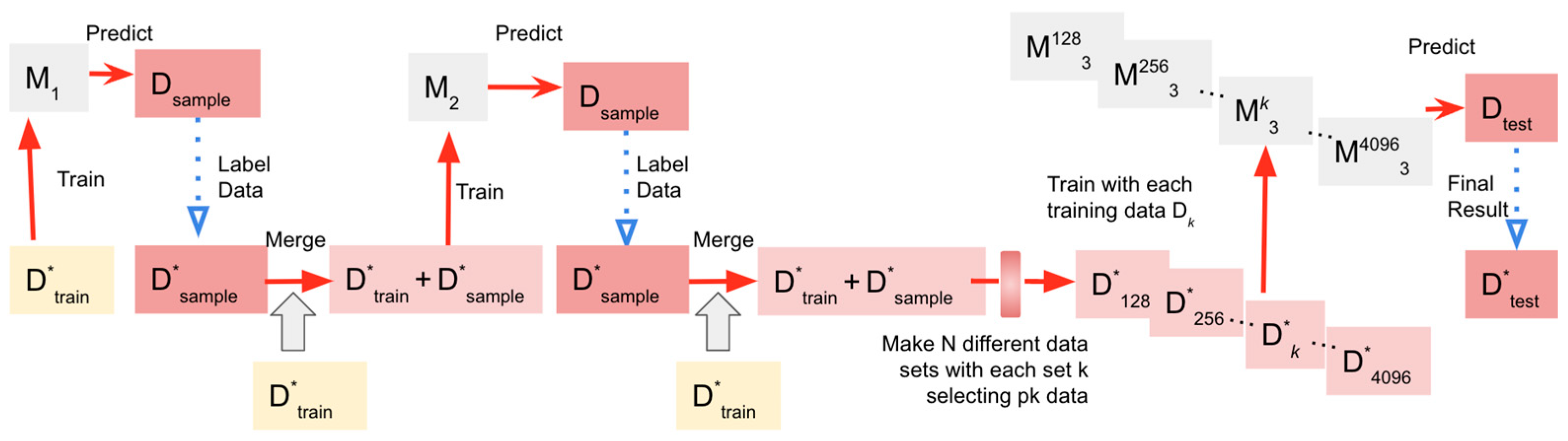
4.1. Overview or Pseudo-Labeling
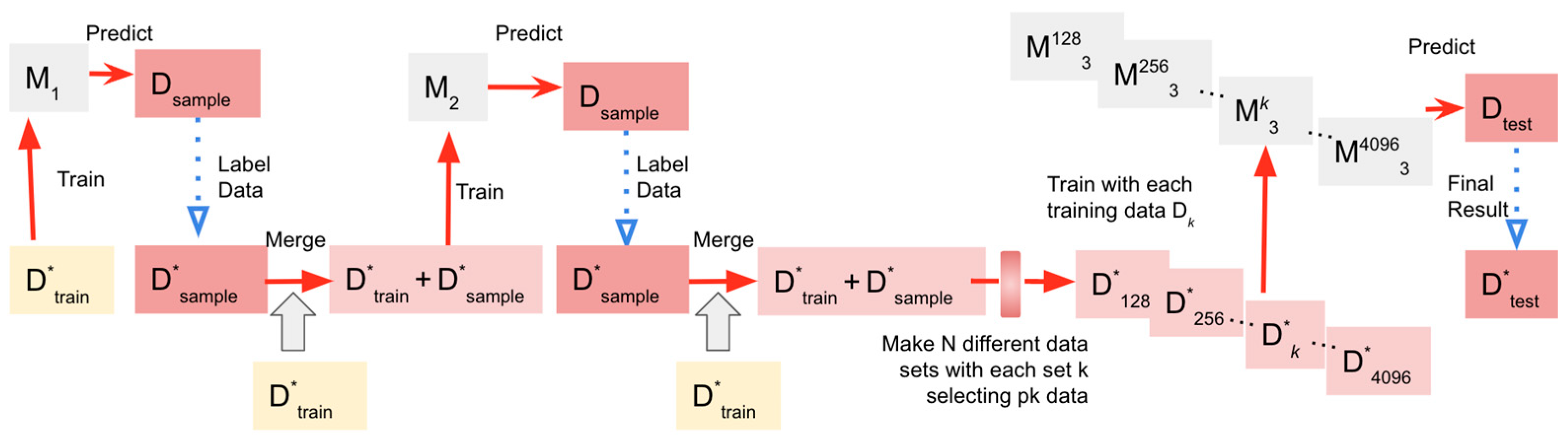
4.2. Pseudo-Labeling Training Algorithm: Dataset Categorization, Function Definitions, and Model Learning
- (1)
- Dataset categorization:
- (2)
- Function definitions:
- : A function that takes a set of parameters, denoted by , and a labeled dataset to yield a learned model .
- : A function that accepts a model and a non-labeled test dataset , subsequently outputting a labeled test dataset .
- : A function that takes in a dataset and a numerical value where ( refers to the total number of data points in dataset ), outputting a selected subset .
- (3)
- Model learning and final test:
- (4)
- Parameter setting in our study:
| Algorithm 1: Semi-supervised learning with pseudo-labeling |
Input:
Output:
Procedure: Initialize model: Initialize values: While and not do a. Predict pseudo-labels: predicted labels of using threshold when labeling of using b. Filter high confidence predictions: in and c. Merge labeled and pseudo-labeled data: d. Retrain the model: trained with e. Evaluate current model performance: Evaluation metrics when labeling using f. Check for convergence: If g. Update iteration count: End Procedure |
4.3. Pseudo-Data Preparation: LLM Usage and Mathematical Material
- Random data selection: We began our process by randomly selecting 30% from our human-labeled training dataset to capitalize on the rich diversity of student-generated self-explanations.
- Keyword extraction: Ten keywords were extracted from each self-explanation, encapsulating its essence, guiding LLM to produce contextually relevant data.
- LLM generation: Armed with the extracted keywords, we then proceeded to prompt the LLM [47]. Specifically, each set of 10 keywords was used as seed input, directing the LLM to generate contextually coherent pseudo-self-explanation data. The model was given a directive to ‘elaborate based on the provided keywords’, ensuring the generated content-maintained relevance to the original self-explanation context.
4.4. Comparative Analysis of Original and LLM-Generated Dataset
5. Experiments and Evaluations
5.1. Exploring the Influence of Self-Explanation Augmentation on Model Efficiency
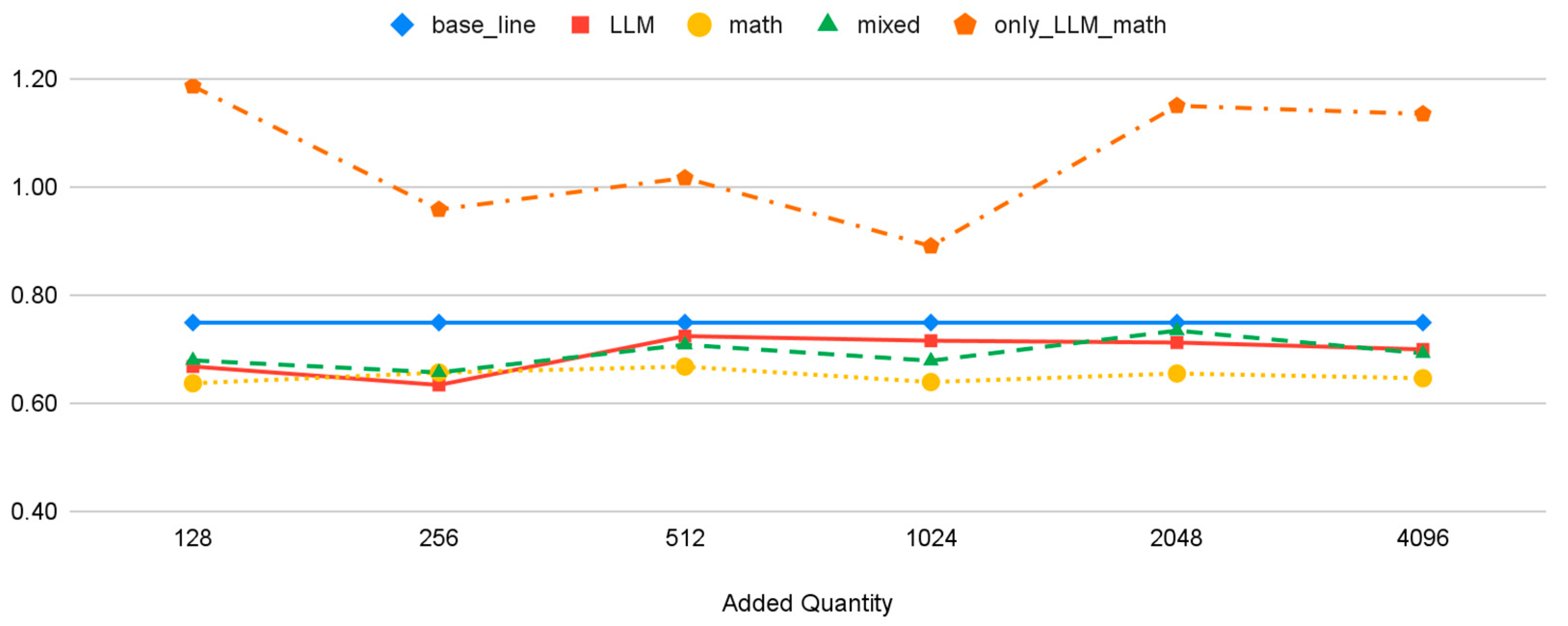
5.2. Evaluating Optimal Quantity of Pseudo-Self-Explanation Data
6. Discussion
6.1. Detailed Analysis of Results (RQ1)
6.2. Findings and Observations (RQ2)
6.3. Limitations and Future Research
- Subject scope: Our dataset is restricted to mathematics, potentially constraining the generalizability of our findings to other subjects.
- Dependency on LLM: Our methodology hinges on the LLM’s ability to generate pseudo-self-explanation data. This dependence may introduce noise and errors into our system.
- Data quality and representativeness: The performance of our approach is contingent on the quality and representativeness of labeled data. Poor or biased data could compromise model efficacy.
- Model performance variability: We identified noticeable disparities in our model’s performance across various mathematical categories. For instance, it predicted the ‘property of a circle’ (0.242) more accurately than ‘quadratic functions’ (0.419) within the validation datasets. These results indicate that self-explanation augmentation’s effectiveness may be influenced by the inherent complexity of a topic and the linguistic nuances present within the self-explanations.
- Evaluation dataset categories and size: The evaluation dataset for some categories is comparatively small, which poses challenges in drawing definitive conclusions. It is essential to consider the ease of inference as it pertains to various mathematical concepts, including linear functions, shapes, equations, and square roots. Certain subjects may be inherently more challenging for machine training due to their linguistic or conceptual intricacies.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rittle-Johnson, B.; Loehr, A.M.; Durkin, K. Promoting self-explanation to improve mathematics learning: A meta-analysis and instructional design principles. ZDM 2017, 49, 599–611. [Google Scholar] [CrossRef]
- Rittle-Johnson, B. Developing Mathematics Knowledge. Child Dev. Perspect. 2017, 11, 184–190. [Google Scholar] [CrossRef]
- Renkl, A. Learning from worked-examples in mathematics: Students relate procedures to principles. ZDM 2017, 49, 571–584. [Google Scholar] [CrossRef]
- Chi, M.T.; Leeuw, N.D.; Chiu, M.; LaVancher, C. Eliciting Self-Explanations Improves Understanding. Cogn. Sci. 1994, 18, 439–477. [Google Scholar]
- Rittle-Johnson, B. Promoting transfer: Effects of self-explanation and direct instruction. Child Dev. 2006, 77, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Conati, C.; VanLehn, K. Toward Computer-Based Support of Meta-Cognitive Skills: A Computational Framework to Coach Self-Explanation. Int. J. Artif. Intell. Educ. 2000, 11, 389–415. [Google Scholar]
- Bisra, K.; Liu, Q.; Nesbit, J.C.; Salimi, F.; Winne, P.H. Inducing Self-Explanation: A Meta-Analysis. Educ. Psychol. Rev. 2018, 30, 703–725. [Google Scholar] [CrossRef]
- Crippen, K.J.; Earl, B.L. The impact of web-based worked examples and self-explanation on performance, problem solving, and self-efficacy. Comput. Educ. 2007, 49, 809–821. [Google Scholar] [CrossRef]
- Nakamoto, R.; Flanagan, B.; Takami, K.; Dai, Y.; Ogata, H. Identifying Students’ Stuck Points Using Self-Explanations and Pen Stroke Data in a Mathematics Quiz. In Proceedings of the 29th International Conference on Computers in Education, Online, 22–26 November 2021; Volume 2021, pp. 22–26. [Google Scholar]
- Nakamoto, R.; Flanagan, B.; Dai, Y.; Takami, K.; Ogata, H. Unsupervised techniques for generating a standard sample self-explanation answer with knowledge components in a math quiz. Res. Pract. Technol. Enhanc. Learn. 2024, 19, 016. [Google Scholar] [CrossRef]
- Berthold, K.; Eysink, T.H.; Renkl, A. Assisting self-explanation prompts are more effective than open prompts when learning with multiple representations. Instr. Sci. 2009, 37, 345–363. [Google Scholar] [CrossRef]
- Berthold, K.; Renkl, A. Instructional Aids to Support a Conceptual Understanding of Multiple Representations. J. Educ. Psychol. 2009, 101, 70–87. [Google Scholar] [CrossRef]
- McEldoon, K.L.; Durkin, K.L.; Rittle-Johnson, B. Is self-explanation worth the time? A comparison to additional practice. Br. J. Educ. Psychol. 2013, 83, 615–632. [Google Scholar] [CrossRef] [PubMed]
- Panaite, M.; Dascalu, M.; Johnson, A.M.; Balyan, R.; Dai, J.; McNamara, D.S.; Trausan-Matu, S. Bring It on! Challenges Encountered While Building a Comprehensive Tutoring System Using ReaderBench. In Proceedings of the International Conference on Artificial Intelligence in Education, London, UK, 27–30 June 2018. [Google Scholar]
- Hodds, M.; Alcock, L.; Inglis, M. Self-explanation training improves proof comprehension. J. Res. Math. Educ. 2014, 45, 62–101. [Google Scholar] [CrossRef]
- CyberAgent. Open-Calm-7B [Software]. Hugging Face. 2023. Available online: https://huggingface.co/cyberagent/open-calm-7b (accessed on 1 June 2023).
- Andonian, A.; Anthony, Q.; Biderman, S.; Black, S.; Gali, P.; Gao, L.; Hallahan, E.; Levy-Kramer, J.; Leahy, C.; Nestler, L.; et al. GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch (Version 0.0.1) [Computer Software]. 2021. Available online: https://zenodo.org/record/7714278 (accessed on 1 June 2023).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- McNamara, D.S.; Levinstein, I.B.; Boonthum, C. iSTART: Interactive strategy training for active reading and thinking. Behavior Research Methods. Instrum. Comput. 2004, 36, 222–233. [Google Scholar] [CrossRef]
- Funayama, H.; Asazuma, Y.; Matsubayashi, Y.; Mizumoto, T.; Inui, K. Reducing the Cost: Cross-Prompt Pre-finetuning for Short Answer Scoring. In Proceedings of the International Conference on Artificial Intelligence in Education, Tokyo, Japan, 3–7 July 2023. [Google Scholar]
- Crossley, S.A.; Kim, M.; Allen, L.K.; McNamara, D.S. Automated Summarization Evaluation (ASE) Using Natural Language Processing Tools. In Proceedings of the International Conference on Artificial Intelligence in Education, Chicago, IL, USA, 25–29 June 2019. [Google Scholar]
- Özsoy, M.G.; Alpaslan, F.N.; Çiçekli, I. Text summarization using Latent Semantic Analysis. J. Inf. Sci. 2011, 37, 405–417. [Google Scholar] [CrossRef]
- León, J.A.; Olmos, R.; Escudero, I.; Cañas, J.J.; Salmerón, L. Assessing short summaries with human judgments procedure and latent semantic analysis in narrative and expository texts. Behav. Res. Methods 2006, 38, 616–627. [Google Scholar] [CrossRef]
- Panaite, M.; Ruseti, S.; Dascalu, M.; Balyan, R.; McNamara, D.S.; Trausan-Matu, S. Automated Scoring of Self-explanations Using Recurrent Neural Networks. In Proceedings of the European Conference on Technology Enhanced Learning, Delft, The Netherlands, 16–19 September 2019. [Google Scholar]
- Cascante-Bonilla, P.; Tan, F.; Qi, Y.; Ordonez, V. Curriculum Labeling: Revisiting Pseudo-Labeling for Semi-Supervised Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Chawla, N.; Bowyer, K.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. arXiv 2002, arXiv:1106.1813. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Salazar, A.; Vergara, L.; Safont, G. Generative Adversarial Networks and Markov Random Fields for oversampling very small training sets. Expert Syst. Appl. 2021, 163, 113819. [Google Scholar] [CrossRef]
- Rubin, D.B. Statistical disclosure limitation. J. Off. Stat. 1993, 9, 461–468. [Google Scholar]
- Antulov-Fantulin, N.; Bošnjak, M.; Zlatić, V.; Grčar, M.; Šmuc, T. Synthetic Sequence Generator for Recommender Systems–Memory Biased Random Walk on a Sequence Multilayer Network. In Discovery Science. DS 2014. Lecture Notes in Computer Science; Džeroski, S., Panov, P., Kocev, D., Todorovski, L., Eds.; Springer: Cham, Switerland, 2014; Volume 8777. [Google Scholar] [CrossRef]
- El Emam, K. Seven Ways to Evaluate the Utility of Synthetic Data. IEEE Secur. Priv. 2020, 18, 56–59. [Google Scholar] [CrossRef]
- Ping, H.; Stoyanovich, J.; Howe, B. DataSynthesizer: Privacy-Preserving Synthetic Datasets. In Proceedings of the 29th International Conference on Scientific and Statistical Database Management, Chicago, IL, USA, 27–29 June 2017. [Google Scholar]
- Dahmen, J.; Cook, D.J. SynSys: A Synthetic Data Generation System for Healthcare Applcations. Sensors 2019, 19, 1181. [Google Scholar] [CrossRef] [PubMed]
- Berg, A.; Mol, S.T.; Kismihók, G.; Sclater, N. The Role of a Reference Synthetic Data Generator within the Field of Learning Analytics. J. Learn. Anal. 2016, 3, 107–128. [Google Scholar] [CrossRef]
- Peña-Ayala, A. Learning analytics: A glance of evolution, status, and trends according to a proposed taxonomy. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1243. [Google Scholar] [CrossRef]
- Flanagan, B.; Majumdar, R.; Ogata, H. Fine Grain Synthetic Educational Data: Challenges and Limitations of Collaborative Learning Analytics. IEEE Access 2022, 10, 26230–26241. [Google Scholar] [CrossRef]
- Dai, H.; Liu, Z.; Liao, W.; Huang, X.; Cao, Y.; Wu, Z.; Zhao, L.; Xu, S.; Liu, W.; Liu, N.; et al. AugGPT: Leveraging ChatGPT for Text Data Augmentation. arXiv 2023, arXiv:2302.13007. [Google Scholar]
- Lightman, H.; Kosaraju, V.; Burda, Y.; Edwards, H.; Baker, B.; Lee, T.; Leike, J.; Schulman, J.; Sutskever, I.; Cobbe, K. Let’s Verify Step by Step. arXiv 2023, arXiv:2305.20050. [Google Scholar]
- Flanagan, B.; Ogata, H. Learning analytics platform in higher education in Japan. Knowl. Manag. E-Learn. Int. J. 2018, 10, 469–484. [Google Scholar]
- Thompson, D.R.; Senk, S.L. Using rubrics in high school mathematics courses. Math. Teach. Learn. Teach. PK–12 1998, 91, 786–793. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Wang, T.; Inoue, N.; Ouchi, H.; Mizumoto, T.; Inui, K. Inject Rubrics into Short Answer Grading System. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; NIPS’17, 6000-6010. Curran Associates Inc.: Red Hook, NY, USA, 2017. ISBN 9781510860964. [Google Scholar]
- Suzuki, M. Pretrained Japanese BERT Models, GitHub Repository. 2019. Available online: https://github.com/cl-tohoku/bert-japanese (accessed on 1 April 2021).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2021, 55, 1–35. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geoscientific Model Development. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Numbers | Rubric | Sample Answer of Self-Explanations |
|---|---|---|
| Step 1 | Be able to find the equation of a linear function from two points. | Substituting the y-coordinate of p into the equation of the line AC. |
| Step 2 | Be able to find the equation of the line that bisects the area of a triangle. | Find the area of triangle ABC, then find the area of triangle OPC. |
| Step 3 | Be able to represent a point on a straight-line using letters (P-coordinates). | With the line OC as the base, find the y-coordinate of p, which is the height. P’s coordinate is (t, −1/2t + 4). |
| Step 4 | Be able to represent a point on a straight-line using letters (Q-coordinate). | Since the coordinates of P are (3,5/2), the line OP is y = ⅚x, and the coordinates of Q are (t,5/6). |
| Graded Score | Description |
|---|---|
| 1 (Unacceptable) | The number of steps for which self-explanation is filled in for the steps required for the solution is minimal, and there were problematic expressions in the students’ self-explanation (e.g., mistaken patterns, boredom). |
| 2 (Poor) | Self-explanation is mainly provided for the steps required for the solution. Still, they are more like bullet points than explanations. |
| 3 (Fair) | Self-explanation is mainly provided for the steps required for the answer—the average self-explanation level among all respondents. |
| 4 (Very Good) | Self-explanation is provided for most of the steps required for the answer, but there is room for improvement as an explanation (logic, expressions). |
| 5 (Excellent) | Self-explanation is mainly provided for the steps required for the answer, and the explanation is logical and well-written. |
| Data Type | Num of Quiz | Variations in Math Units | Total Answers | Sentence Length (Character Count) | Quality Score | ||
|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | ||||
| Train | 40 | 8 | 1420 | 67.8 | 56.8 | 2.94 | 1.34 |
| Valid | 37 | 8 | 355 | 67.3 | 59.3 | 2.92 | 1.31 |
| Test | 8 | 3 | 431 | 63.7 | 53.2 | 2.81 | 1.25 |
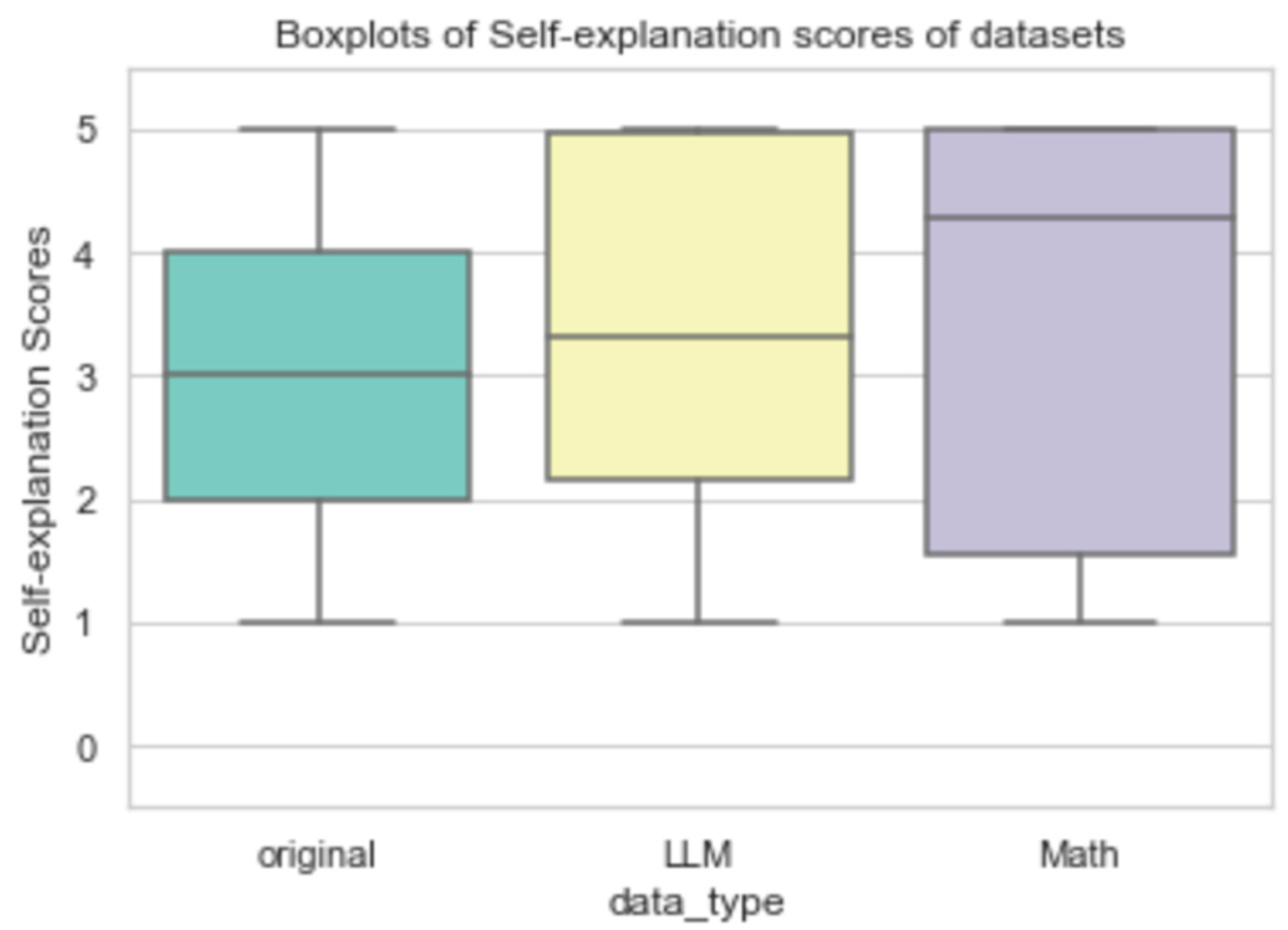
| Data Type | Counts | Mean Score | Std |
|---|---|---|---|
| Original | 2205 | 2.91 | 1.33 |
| LLM | 4096 | 3.39 | 1.44 |
| Math | 4096 | 3.87 | 1.77 |
| LLM-Generated Samples (Original) | LLM-Generated Samples (English Translation) | Predicted Self-Explanation Score |
|---|---|---|
| その後、α + β = −a−2とαβ = 2aの関係から解と係数の関係が分かる。次に、問題で言及されたαとβを用いて式を展開し整理し、右辺を0にする。さらに式を工夫して代入が可能な形にする。そして、関係式α + β = −a−2とαβ = 2aを式に代入して簡略化し、a^2 + a−6 = 0となる。これを因数分解してaの解を求めると、a = −3とa = 2が得られる。その後、a = 2を代入すると解が重解になり、解が一つしかなくなるため問題に合わない。したがって、正しい答えはa = −3である。その後、重積算や累乗などいろいろな計算が解に出てきて混乱するだろうから丁寧に説明していく。 | After that, α + β = −a−2 and αβ = 2a can be understood from the relationship between the solutions and coefficients. Next, expand and organize the expressions using the α and β mentioned in the problem, and set the right side to 0. Further manipulate the equation to transform it into a form that allows for substitution. Then, substitute the relationship α + β = −a−2 and αβ = 2a into the equation and simplify it, resulting in a2 + a−6 = 0. Factorize this to find the solutions for a, which are a = −3 and a = 2. Afterward, when a = 2 is substituted, the answer becomes a repeated root, which means there is only one solution, making it inconsistent with the problem. Therefore, the correct answer is a = −3. Afterward, various calculations such as product of roots and exponentiation may appear in the solution, and it may be confusing, so I will explain it carefully. | 5.00 |
| 代入してみたら、平方根の中が計算できた。αとβを求めた。αに−2を代入した。解を吟味して、答えは−3だった。その後、a = −4.7x^5 + 7として計算したが誤差があった。そこで右側の5を左側の4に変形すると正しい値が求められた(ただし小数点以下を切り捨て)。この問題は高校数学の範囲外であるが、中学・高校で習った知識で解くことができたので紹介したい。 | Substituted it into the formula for solutions. Calculated the value inside the square root. Found α and β. Substituted α = −2. Examined the solution, and the answer was −3. Afterward, calculated it as a = −4.7x^5 + 7, but there was an error. So I rearranged the 5 on the right side to 4, and the correct value was obtained (with the decimal part truncated). This problem is beyond the scope of high school mathematics, but it could be solved using knowledge learned in middle and high school, so I want to introduce it. | 4.08 |
| グラフを書いた傾きがー4のy = x^2の接線を求めた。その後、接点を原点とし両辺に点a,bを代入すると「sin-cos」と出たので、「COS(1)」で求めた。これで式の意味が分かったと思う。−5は角度が変化しないからゼロでないといけないのだ! | Used the slope obtained from graphing to find the tangent of y = x^2 with slope −4. Took the point of tangency as the origin and substituted points a and b on both sides. ‘Sin-cos’ was obtained, so I calculated it using ‘COS(1)’. I think I understood the meaning of the equation now. −5 does not change the angle, so it must be nonzero! | 3.02 |
| x = 3を代入する。方程式を解き進める。解の吟味を書く。間違いに気づき、修正する。最終的な答えを書く。その後、再帰的に解く。 | Substituted x = 3. Proceeded to solve the equation. Wrote the examination of the solutions. Noticed the mistake and corrected it. Wrote the final answer. Afterward, solve it recursively. | 2.18 |
| 前のは間違えたため、全部消した。その後、通分してみた。 | Since the previous one was incorrect, I deleted everything and then performed the common denominator. Afterwards, something like this. | 1.23 |
| Math Texts Samples | Predicted Self-Explanation Score |
|---|---|
| Angle bisector and ratio, using Ceva’s theorem: Revised version succeed math A problem 349 Δ (Triangle), let Δ have the angle bisector of ∠ and the point where it intersects the side, and the point that divides the side in the ratio. When the line intersects at point, find the length of the side. | 5.00 |
| Using Menelaus’s theorem: Segment ratio and area ratio, revised version succeed math A problem 350 Δ, let be the point where it divides the side in the ratio, and the point where the segment is divided in the ratio, and the point where the extension of the segment intersects the side. Find the following segment ratios and area ratios Δ : Δ | 4.93 |
| Using the relationship between sides and angles: Range of values for side length in a triangle, revised version succeed math A problem 355, determine the range of values for so that a triangle with the following side lengths exists. | 3.84 |
| Using the relationship between the sizes of three sides: Proving inequalities related to segment lengths, revised version succeed math A important example 66, take point inside Δ, and join and prove that . Abbreviated. | 3.13 |
| Examining the sizes of the three angles of a triangle, revised version succeed math A important example 64, examine the sizes of the three interior angles of Δ. | 2.66 |
| Dataset | Base_Line | LLM | Math | Mixed | Only_LLM_Math |
|---|---|---|---|---|---|
| Original (N = 1420) | ● | ● | ● | ● | |
| LLM- generated (N = 4096) | ● | ● | ● | ||
| Math texts (N = 4096) | ● | ● | ● | ||
| Total Number of Data | 1420 | 5516 | 5516 | 9612 | 8192 |
| Data Type | Base_Line | LLM | Math | Mixed | Only_LLM_Math |
|---|---|---|---|---|---|
| Test | 0.749 | 0.699 | 0.646 | 0.692 | 1.135 |
| Val | 0.602 | 0.341 | 0.358 | 0.336 | 1.033 |
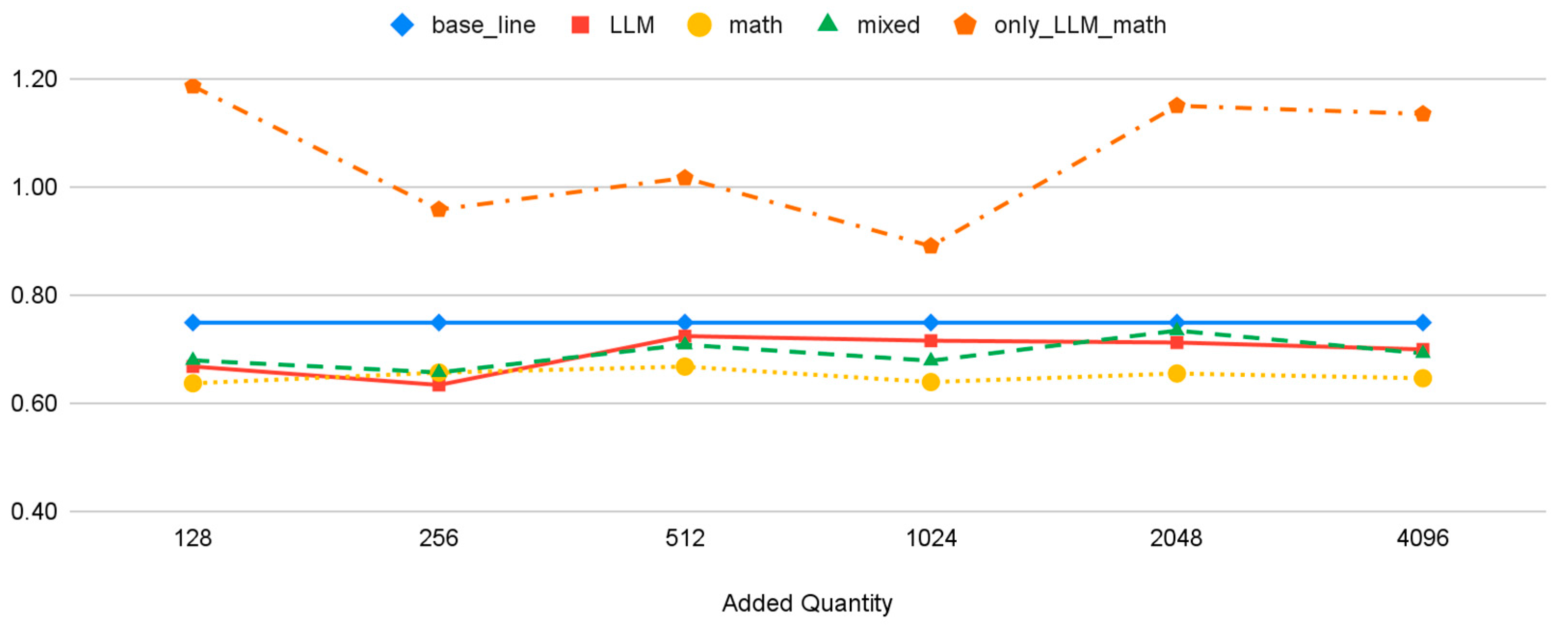
| Dataset | Number of Datasets Added | |||||
|---|---|---|---|---|---|---|
| 128 | 256 | 512 | 1024 | 2048 | 4096 | |
| base_line | 0.75 | |||||
| LLM | 0.67 | 0.63 | 0.72 | 0.72 | 0.71 | 0.7 |
| math | 0.64 | 0.66 | 0.67 | 0.64 | 0.65 | 0.65 |
| mixed | 0.68 | 0.66 | 0.71 | 0.68 | 0.73 | 0.69 |
| only_LLM_math | 1.19 | 0.96 | 1.02 | 0.89 | 1.15 | 1.14 |
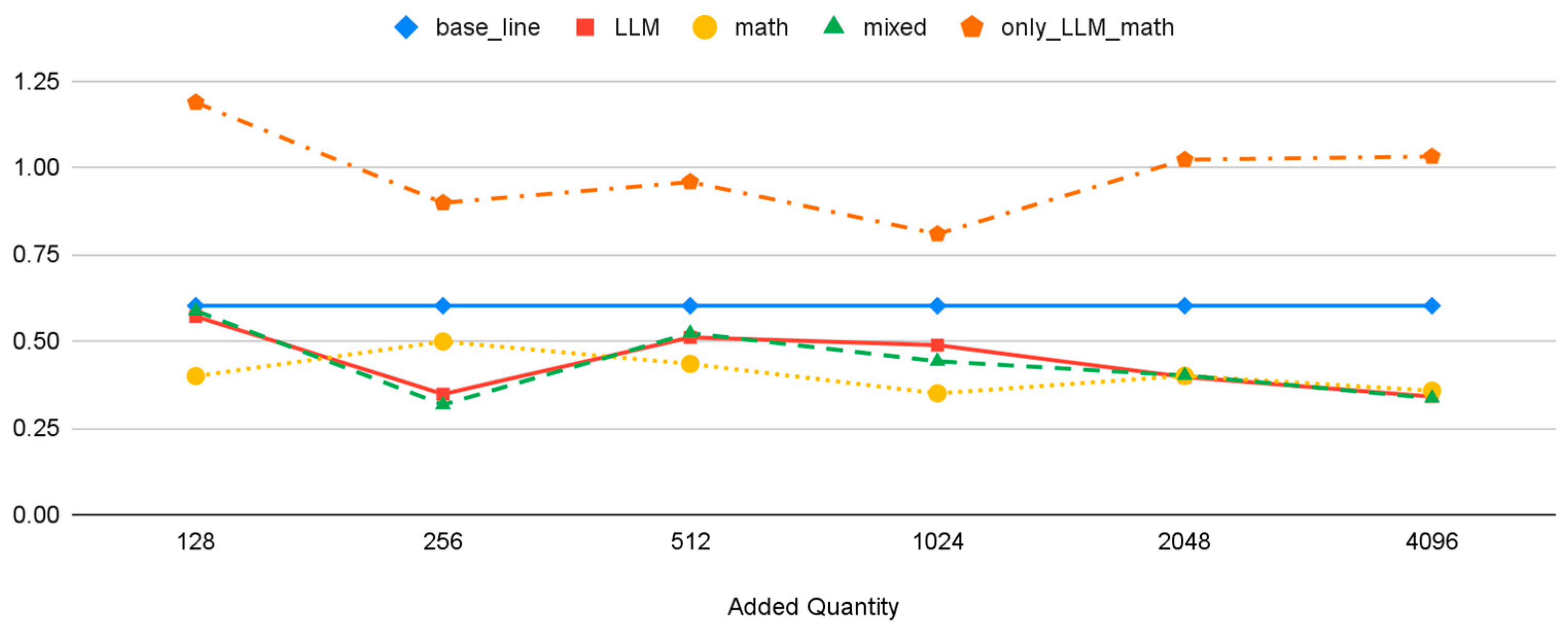
| Dataset | Number of Datasets Added | |||||
|---|---|---|---|---|---|---|
| 128 | 256 | 512 | 1024 | 2048 | 4096 | |
| base_line | 0.60 | |||||
| LLM | 0.57 | 0.35 | 0.51 | 0.49 | 0.40 | 0.34 |
| math | 0.40 | 0.50 | 0.43 | 0.35 | 0.40 | 0.36 |
| mixed | 0.59 | 0.32 | 0.52 | 0.44 | 0.40 | 0.34 |
| only_LLM_math | 1.19 | 0.90 | 0.96 | 0.81 | 1.02 | 1.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nakamoto, R.; Flanagan, B.; Yamauchi, T.; Dai, Y.; Takami, K.; Ogata, H. Enhancing Automated Scoring of Math Self-Explanation Quality Using LLM-Generated Datasets: A Semi-Supervised Approach. Computers 2023, 12, 217. https://doi.org/10.3390/computers12110217
Nakamoto R, Flanagan B, Yamauchi T, Dai Y, Takami K, Ogata H. Enhancing Automated Scoring of Math Self-Explanation Quality Using LLM-Generated Datasets: A Semi-Supervised Approach. Computers. 2023; 12(11):217. https://doi.org/10.3390/computers12110217
Chicago/Turabian StyleNakamoto, Ryosuke, Brendan Flanagan, Taisei Yamauchi, Yiling Dai, Kyosuke Takami, and Hiroaki Ogata. 2023. "Enhancing Automated Scoring of Math Self-Explanation Quality Using LLM-Generated Datasets: A Semi-Supervised Approach" Computers 12, no. 11: 217. https://doi.org/10.3390/computers12110217
APA StyleNakamoto, R., Flanagan, B., Yamauchi, T., Dai, Y., Takami, K., & Ogata, H. (2023). Enhancing Automated Scoring of Math Self-Explanation Quality Using LLM-Generated Datasets: A Semi-Supervised Approach. Computers, 12(11), 217. https://doi.org/10.3390/computers12110217