


Feature Encoding and Selection for Iris Recognition Based on Variable Length Black Hole Optimization


Abstract
1. Introduction
- To the best of our knowledge, it is the first article that presents the problem of iris recognition from a feature selection perspective. Mainly, it presents a variable length of the number of features to be selected for optimizing the iris recognition performance instead of traditional methods that use a fixed-length number of features. This provides two benefits, namely, reducing the size of feature space needed for training and prediction which means memory reduction, and improving the accuracy considering the non-relevant features are removed.
- It uses existing variable length black hole optimization for the purpose of feature selection in the context of iris recognition. This algorithm is selected due to the competing performance it provides compared with other similar methods such as variable length particle swarm optimization VLPSO [21].
- It compares the performance of variable length black hole optimization for feature selection in iris recognition using two feature spaces, namely, Gabor and LBP and using two classifiers, namely, support vector machine SVM and logistic regression model which shows the superiority of VLBHO over VLPSO.
2. Background of the Iris Coding
2.1. Gabor
2.2. Local Binary Pattern
2.3. Iris Coding
3. Literature Survey
3.1. Feature Extraction
3.2. Feature Selection and Iris Coding
3.3. Iris Classification
4. Methodology
4.1. Pre-Processing
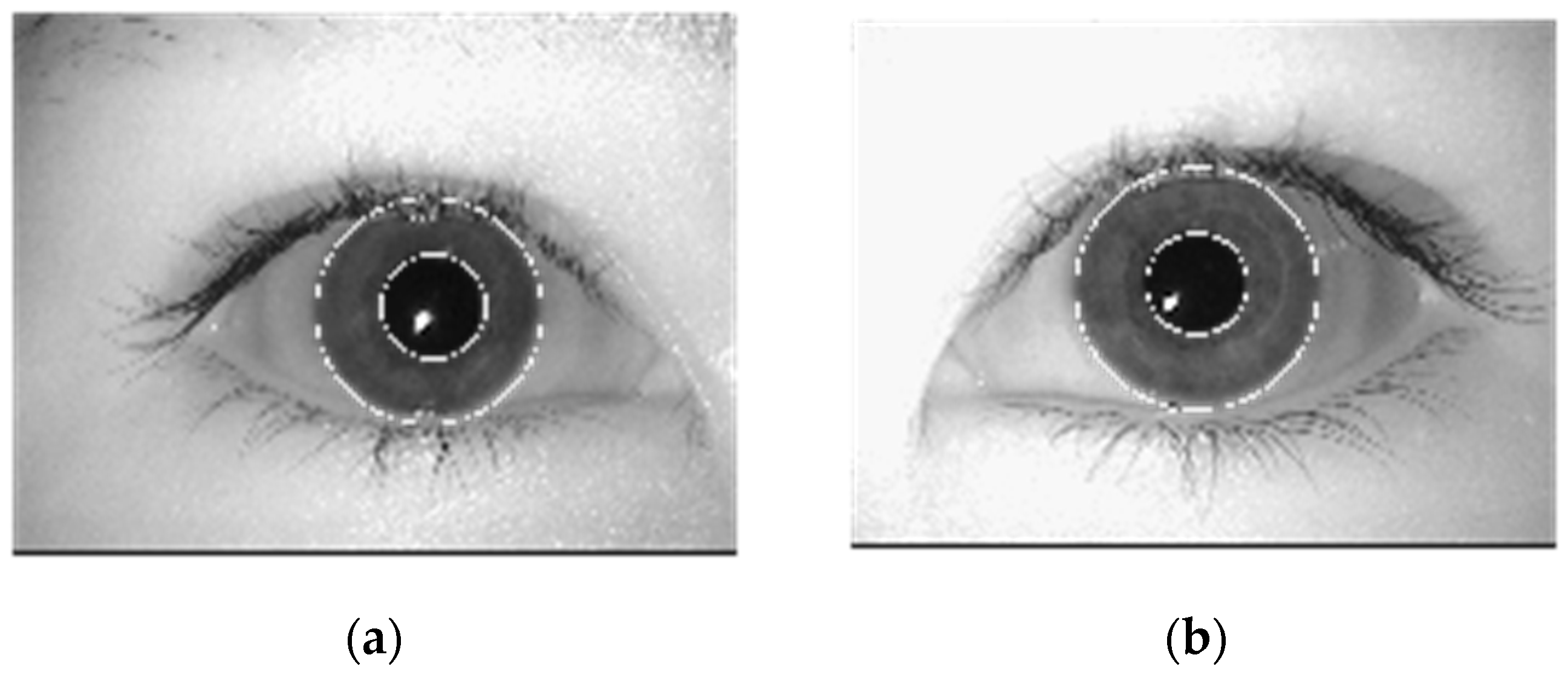
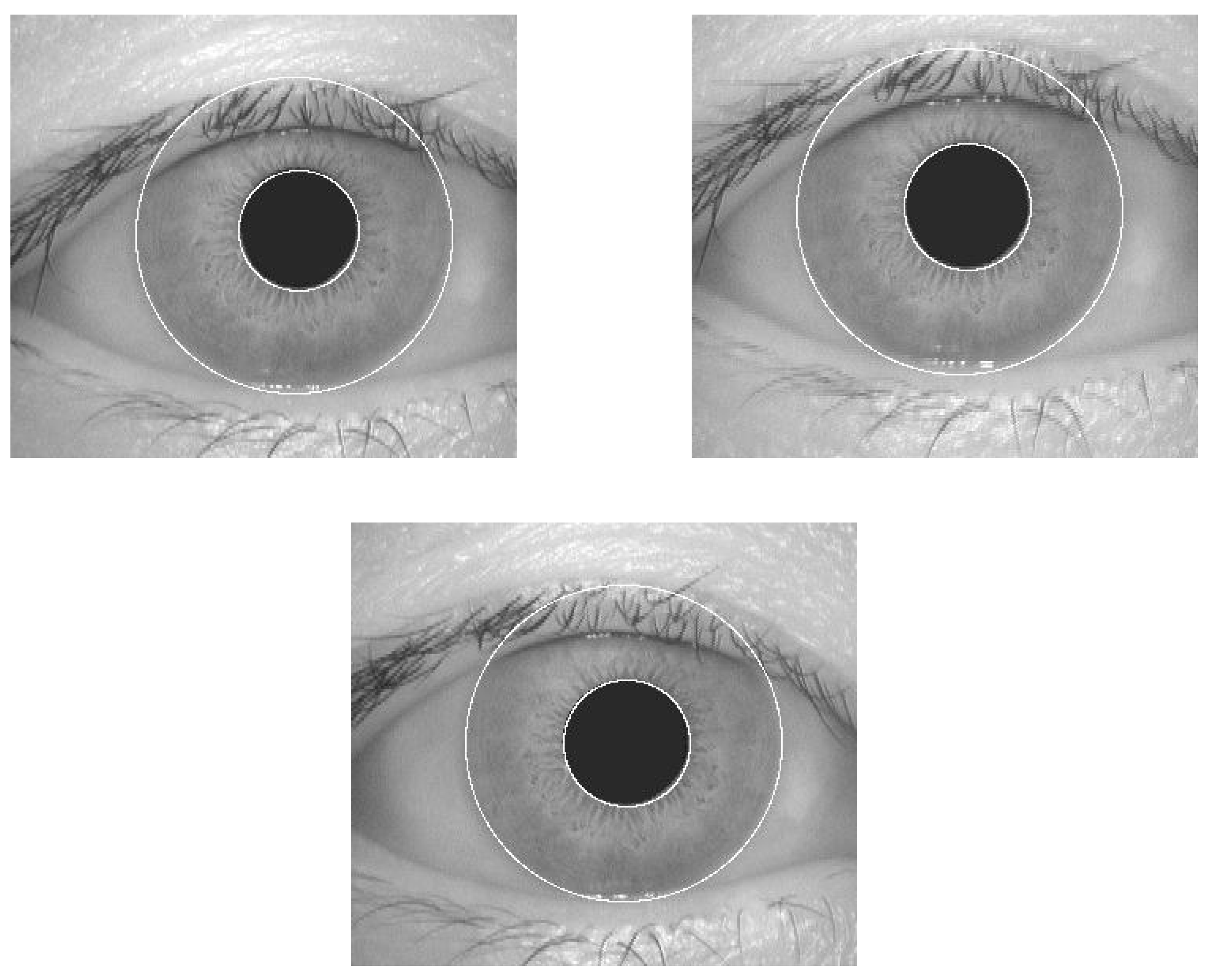
4.2. Segmentation
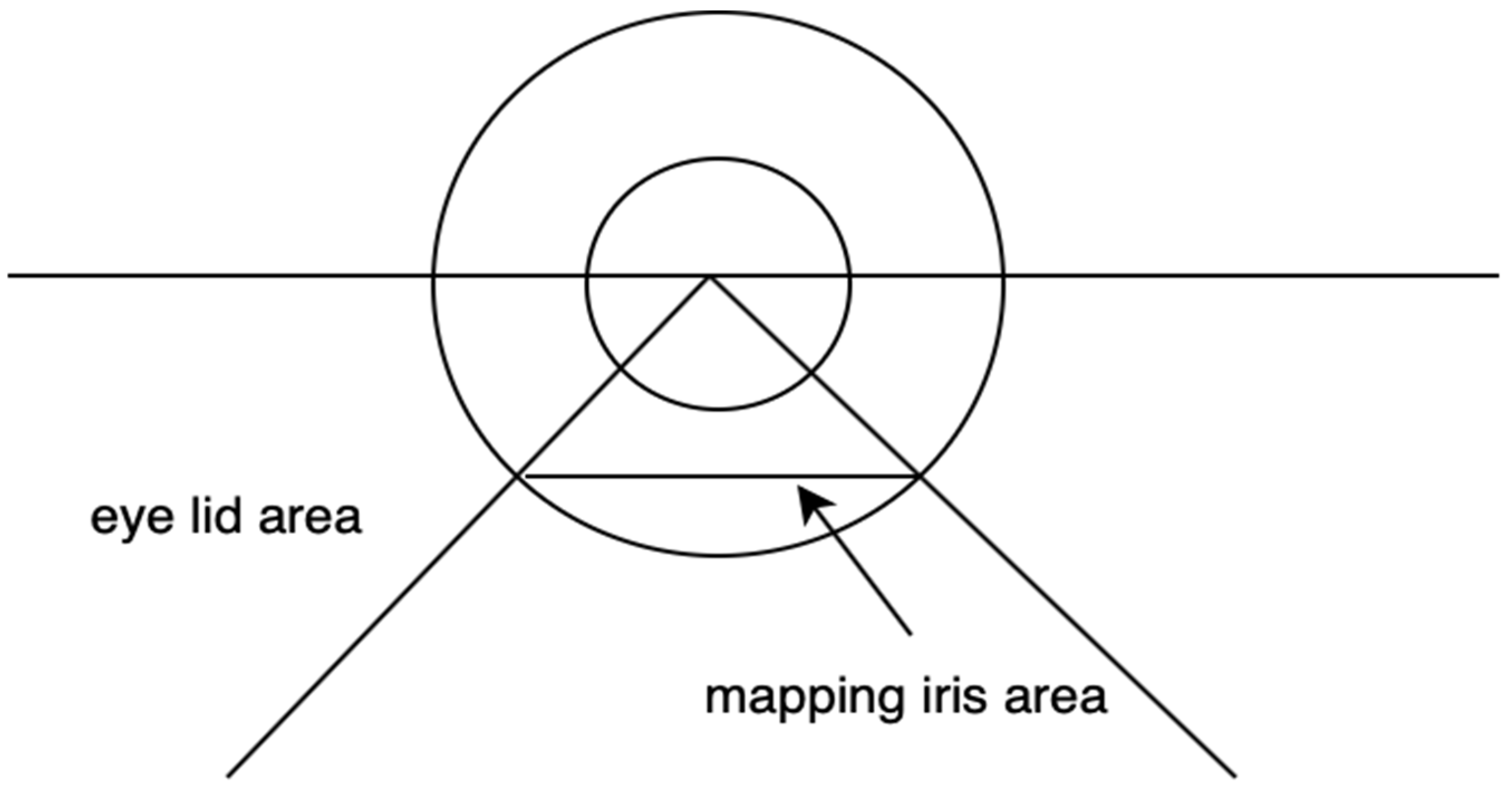
4.3. Iris Normalization
- Considering the lower half iris
- Consider only percentage of the lower half circle
- Now take the trapezoid form and change it to a rectangle by taking away the triangle shapes from both of its sides.
- Acquire a tiny, rectangular, normalized picture of the iris for which the characteristics have been computed.
4.4. Feature Extraction
4.5. Feature Selection and Coding
| Algorithm 1. Pseudocode of features extraction and coding using VLBHO. |
| Input D//combined of set of labelled image with an iris part s for the purpose of training SS//segment size OF//objective function Output F//extracted features from the image Start Algorithm For each image in D ProssessedImage=pre-processing (image) IrisRegion=localization(ProssessedImage) IrisRegion=denoising (IrisRegion) Iris=Segmentation(IrisRegion) [Gabor,LBP] =Extract(Iris) Features=Concatenate(Gabor,LBP) End [smallSegments] =Segment(Gabor,LBP,SS) Call VLBHO using OF Return best solution that contains the coding threshold and the selected features End Algorithm |
4.6. Classification
4.6.1. Logistic Regression
4.6.2. Support Vector Machine
4.7. Datasets
4.7.1. CASIA.v4 Thousand
4.7.2. IIT Delhi Iris Database
4.8. Classification Metrics
- Predictive accuracy is defined as positive values and is given in Equation (12)where FDR stands for false discovery
- Recall or sensitivity (true positive rate)
- F-measure
- G-mean
- Accuracy
5. Experimental Works and Evaluation
6. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Malarvizhi, N.; Selvarani, P.; Raj, P. Adaptive fuzzy genetic algorithm for multi biometric authentication. Multimed. Tools Appl. 2020, 79, 9131–9144. [Google Scholar] [CrossRef]
- Duarte, T.; Pimentão, J.P.; Sousa, P.; Onofre, S. Biometric access control systems: A review on technologies to improve their efficiency. In Proceedings of the 2016 IEEE International Power Electronics and Motion Control Conference (PEMC), Varna, Bulgaria, 25–28 September 2016; pp. 795–800. [Google Scholar]
- Labati, R.D.; Genovese, A.; Muñoz, E.; Piuri, V.; Scotti, F.; Sforza, G. Biometric recognition in automated border control: A survey. ACM Comput. Surv. 2016, 49, 1–39. [Google Scholar] [CrossRef]
- Goode, A. Biometrics for banking: Best practices and barriers to adoption. Biom. Technol. Today 2018, 2018, 5–7. [Google Scholar] [CrossRef]
- Rajput, P.; Mahajan, K. Dental biometric in human forensic identification. In Proceedings of the 2016 International Conference on Global Trends in Signal Processing, Information Computing and Communication (ICGTSPICC), Jalgaon, India, 22–24 December 2016; pp. 409–413. [Google Scholar]
- Linsangan, N.B.; Panganiban, A.G.; Flores, P.R.; Poligratis, H.A.T.; Victa, A.S.; Torres, J.L.; Villaverde, J. Real-time Iris Recognition System for Non-Ideal Iris Images. In Proceedings of the 2019 11th International Conference on Computer and Automation Engineering, Perth, Australia, 23–25 February 2019; pp. 32–36. [Google Scholar]
- Indrawal, D.; Waykole, S.; Sharma, A. Development of Efficient and Secured Face Recognition using Biometrics. Int. J. Electron. Commun. Comput. Eng. 2019, 10, 183–189. [Google Scholar]
- Jain, A.K.; Prabhakar, S.; Pankanti, S. On the similarity of identical twin fingerprints. Pattern Recognit. 2002, 35, 2653–2663. [Google Scholar] [CrossRef]
- Raut, S.D.; Humbe, V.T. Biometric palm prints feature matching for person identification. Int. J. Mod. Educ. Comput. Sci. 2012, 4, 61. [Google Scholar] [CrossRef][Green Version]
- Al-Kateeb, Z.N.; Mohammed, S.J. Encrypting an audio file based on integer wavelet transform and hand geometry. TELKOMNIKA Indones. J. Electr. Eng. 2020, 18, 2012–2017. [Google Scholar] [CrossRef]
- Seong, J.-w.; Lee, H.-j.; Cho, S.-h. A Study on the Voice Security System Using Sensor Technology. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Korea, 19–22 February 2020; pp. 520–525. [Google Scholar]
- Pathan, M.; Singh, G.; Yelane, A. Vein Pattern Recognition and Authentication Based on Gradient Feature Algorithm. Available online: http://shabdbooks.com/gallery/spl-175.pdf (accessed on 1 June 2022).
- Huo, G.; Guo, H.; Zhang, Y.; Zhang, Q.; Li, W.; Li, B. An effective feature descriptor with Gabor filter and uniform local binary pattern transcoding for Iris recognition. Pattern Recognit. Image Anal. 2019, 29, 688–694. [Google Scholar] [CrossRef]
- Daugman, J. Statistical richness of visual phase information: Update on recognizing persons by iris patterns. Int. J. Comput. Vis. 2001, 45, 25–38. [Google Scholar] [CrossRef]
- Quinn, G.W.; Quinn, G.W.; Grother, P.; Matey, J. IREX IX Part One: Performance of Iris Recognition Algorithms; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018.
- Kaur, B.; Singh, S.; Kumar, J. Robust iris recognition using moment invariants. Wirel. Pers. Commun. 2018, 99, 799–828. [Google Scholar] [CrossRef]
- Hancer, E.; Xue, B.; Zhang, M. Differential evolution for filter feature selection based on information theory and feature ranking. Knowl.-Based Syst. 2018, 140, 103–119. [Google Scholar] [CrossRef]
- Daugman, J. Information theory and the iriscode. IEEE Trans. Inf. Forensics Secur. 2015, 11, 400–409. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Astorga, G.; García, J.; Castro, C.; Paredes, F. Putting continuous metaheuristics to work in binary search spaces. Complexity 2017, 2017, 8404231. [Google Scholar] [CrossRef]
- Rodríguez-Molina, A.; Mezura-Montes, E.; Villarreal-Cervantes, M.G.; Aldape-Pérez, M. Multi-objective meta-heuristic optimization in intelligent control: A survey on the controller tuning problem. Appl. Soft Comput. 2020, 93, 106342. [Google Scholar] [CrossRef]
- Tran, B.; Xue, B.; Zhang, M. Variable-length particle swarm optimization for feature selection on high-dimensional classification. IEEE Trans. Evol. Comput. 2018, 23, 473–487. [Google Scholar] [CrossRef]
- Wong, W.; Ming, C.I. A review on metaheuristic algorithms: Recent trends, benchmarking and applications. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; pp. 1–5. [Google Scholar]
- Zhang, B.; Gao, Y.; Zhao, S.; Liu, J.Z. Local Derivative Pattern Versus Local Binary Pattern: Face Recognition with High-Order Local Pattern Descriptor. IEEE Trans. Image Process. 2009, 19, 533–544. Available online: https://ieeexplore.ieee.org/document/5308376/ (accessed on 1 June 2022). [CrossRef]
- Hu, Y.; Sirlantzis, K.; Howells, G.; Security. Optimal generation of iris codes for iris recognition. IEEE Trans. Inf. Forensics 2016, 12, 157–171. [Google Scholar] [CrossRef]
- He, F.; Han, Y.; Wang, H.; Ji, J.; Liu, Y.; Ma, Z. Deep learning architecture for iris recognition based on optimal Gabor filters and deep belief network. J. Electron. Imaging 2017, 26, 023005. [Google Scholar] [CrossRef]
- Lim, S.; Lee, K.; Byeon, O.; Kim, T. Efficient iris recognition through improvement of feature vector and classifier. ETRI J. 2001, 23, 61–70. [Google Scholar] [CrossRef]
- Daugman, J. High Conf Visual Recog of Persons by a test of statistical significance. IEEE Trans. Pattern Anal. Mach. Intell 1993, 15, 1148–1161. [Google Scholar] [CrossRef]
- Boles, W.; Boashash, B. Iris Recognition for Biometric Identification using dyadic wavelet transform zero-crossing. IEEE Trans. Signal Process. 1998, 46, 1185–1188. [Google Scholar] [CrossRef]
- Adamović, S.; Miškovic, V.; Maček, N.; Milosavljević, M.; Šarac, M.; Saračević, M.; Gnjatović, M. An efficient novel approach for iris recognition based on stylometric features and machine learning techniques. Future Gener. Comput. Syst. 2020, 107, 144–157. [Google Scholar] [CrossRef]
- Xiao, L.; Sun, Z.; He, R.; Tan, T. Coupled feature selection for cross-sensor iris recognition. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar]
- Garg, M.; Arora, A.; Gupta, S. An Efficient Human Identification Through Iris Recognition System. J. Signal Process. Syst. 2021, 93, 701–708. [Google Scholar] [CrossRef]
- Raghavendra, C.; Kumaravel, A.; Sivasuramanyan, S. Features subset selection using improved teaching learning based optimisation (ITLBO) algorithms for IRIS recognition. Indian J. Sci. Technol. 2017, 10, 1–12. [Google Scholar] [CrossRef]
- Ma, J.; Gao, X. A filter-based feature construction and feature selection approach for classification using Genetic Programming. Knowl.-Based Syst. 2020, 196, 105806. [Google Scholar] [CrossRef]
- Vatsa, M.; Singh, R.; Noore, A. Improving iris recognition performance using segmentation, quality enhancement, match score fusion, and indexing. IEEE Trans. Syst. Man Cybern. Part B 2008, 38, 1021–1035. [Google Scholar] [CrossRef]
- Choudhary, M.; Tiwari, V.; Venkanna, U. An approach for iris contact lens detection and classification using ensemble of customized DenseNet and SVM. Future Gener. Comput. Syst. 2019, 101, 1259–1270. [Google Scholar] [CrossRef]
- Raghavendra, R.; Raja, K.B.; Busch, C. Contlensnet: Robust iris contact lens detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1160–1167. [Google Scholar]
- Zhang, H.; Sun, Z.; Tan, T. Contact lens detection based on weighted LBP. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 4279–4282. [Google Scholar]
- Yadav, D.; Kohli, N.; Doyle, J.S.; Singh, R.; Vatsa, M.; Bowyer, K.W. Unraveling the effect of textured contact lenses on iris recognition. IEEE Trans. Inf. Forensics Secur. 2014, 9, 851–862. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, C.; Wang, Y. T-center: A novel feature extraction approach towards large-scale iris recognition. IEEE Access 2020, 8, 32365–32375. [Google Scholar] [CrossRef]
- Bastys, A.; Kranauskas, J.; Masiulis, R. Iris recognition by local extremum points of multiscale Taylor expansion. Pattern Recognit. 2009, 42, 1869–1877. [Google Scholar] [CrossRef]
- Cheng, Y.; Liu, Y.; Zhu, X.; Li, S. A multiclassification method for iris data based on the hadamard error correction output code and a convolutional network. IEEE Access 2019, 7, 145235–145245. [Google Scholar] [CrossRef]
- Hatamlou, A. Black hole: A new heuristic optimization approach for data clustering. Inf. Sci. 2013, 222, 175–184. [Google Scholar] [CrossRef]
- Hameed, I.M.; Abdulhussain, S.H.; Mahmmod, B.M. Content-based image retrieval: A review of recent trends. Cogent Eng. 2021, 8, 1927469. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Solution Pace | Formula 1 | Formula 2 | Formula 3 | Formula 4 |
|---|---|---|---|---|
| Role | Binary coding of features values | Exploiting the vertical neighbour adjacency of the iris codes | Enhancing the stability or reduce bits flops | Jointly Exploiting the vertical neighbour adjacency and Enhancing the stability |
| Article | Category | Approach | Strength | Limitations |
|---|---|---|---|---|
| [26] | Filter based | Gabor, 2D Haar Wavelet Transform | Good immunity to illumination | The size of features is long |
| [27] | Filter based | quadrature 2-D Gabor wavelet coefficients with most-significant bits | Good immunity to illumination | Information loss |
| [28] | Filter based | wavelet transform (WT) zero crossings | Good discriminative performance | Requires feature selection |
| Article | Feature Selection | Optimization | Dataset |
|---|---|---|---|
| [30] | Coupled feature selection | Objective function of misclassification errors and norm regularization | CASIA |
| [31] | GA (Genetic Algorithm) | Reducing the dimensionality of the feature space | |
| [32] | Teaching learning based optimization | Similarity between sub-component | CASIA |
| [33] | Genetic programming | correlation-based evaluation | Freebase and YAGO |
| [24] | Solving objective function equation by using numerical approach | two objective terms. The first objective term exploits the spatial relationships of the bits in different positions of an iris code. The second objective term mitigates the influence of less reliable bits in iris codes. | CASIAT ND0405 CASIAD UBIRS2 |
| Attribute | Value |
|---|---|
| Number of images | 1120 |
| Number of people | 224 |
| Number of male | 176 |
| Number of female | 48 |
| Resolution | 320 by 240 pixels |
| Position Based, S Shape | Position Based, V Shape | Fitness Based, S Shape | Fitness Based, V Shape |
|---|---|---|---|
| PS | PV | FS | FV |
| LBP | Gabor | ||
|---|---|---|---|
| Parameter | Value | Value | Value |
| Radius | 2 | No. of scales | 5 |
| neighbors | 8 | No. of or entaions | 8 |
| Block size | 16 16 | filter bank s ze | size of image |
| Feature Name | Segment Size |
|---|---|
| Gabor | 8 |
| LBP | 1 |
| Feature Type | Classification Algorithm | Feature Selection Algorithm | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|---|
| Gabor | SVM | PS | 0.93750 | 0.94107 | 0.94866 | 0.93750 |
| PV | 0.95982 | 0.96339 | 0.96875 | 0.95982 | ||
| FS | 0.94196 | 0.94628 | 0.95759 | 0.94196 | ||
| FV | 0.93750 | 0.94286 | 0.95089 | 0.93750 | ||
| VLPSO | 0.92857 | 0.93289 | 0.94420 | 0.92857 | ||
| LR | PS | 0.99554 | 0.99583 | 0.99777 | 0.99554 | |
| PV | 0.99554 | 0.99583 | 0.99777 | 0.99554 | ||
| FS | 0.99554 | 0.99583 | 0.99777 | 0.99554 | ||
| FV | 0.99554 | 0.99583 | 0.99777 | 0.99554 | ||
| VLPSO | 0.99554 | 0.99583 | 0.99777 | 0.99554 | ||
| LBP | SVM | PS | 0.95982 | 0.95685 | 0.95848 | 0.95982 |
| PV | 0.92411 | 0.92217 | 0.93095 | 0.92411 | ||
| FS | 0.92411 | 0.92381 | 0.93973 | 0.92411 | ||
| FV | 0.91964 | 0.92054 | 0.93192 | 0.91964 | ||
| VLPSO | 0.80804 | 0.80045 | 0.81920 | 0.80804 | ||
| LR | PS | 0.99107 | 0.99137 | 0.99330 | 0.99107 | |
| PV | 0.95982 | 0.95714 | 0.95848 | 0.95982 | ||
| FS | 0.98661 | 0.98869 | 0.99554 | 0.98661 | ||
| FV | 0.94196 | 0.94449 | 0.95238 | 0.94196 | ||
| VLPSO | 0.81696 | 0.81101 | 0.82813 | 0.81696 |
| Feature Type | Classification Algorithm | Feature Selection Algorithm | Accuracy | IP |
|---|---|---|---|---|
| Gabor | SVM | VLBHO-PS | 0.95982 | 3% |
| VLPSO | 0.92857 | |||
| LR | VLBHO-FV | 0.99554 | 0% | |
| VLOPSO | 0.99554 | |||
| LBP | SVM | VLBHO-PS | 0.95982 | 18% |
| VLPSO | 0.80804 | |||
| LR | VLBHO-PS | 0.99107 | 21% | |
| VLOPSO | 0.81696 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saraf, T.O.Q.; Fuad, N.; Taujuddin, N.S.A.M. Feature Encoding and Selection for Iris Recognition Based on Variable Length Black Hole Optimization. Computers 2022, 11, 140. https://doi.org/10.3390/computers11090140
Saraf TOQ, Fuad N, Taujuddin NSAM. Feature Encoding and Selection for Iris Recognition Based on Variable Length Black Hole Optimization. Computers. 2022; 11(9):140. https://doi.org/10.3390/computers11090140
Chicago/Turabian StyleSaraf, Tara Othman Qadir, N. Fuad, and N. S. A. M. Taujuddin. 2022. "Feature Encoding and Selection for Iris Recognition Based on Variable Length Black Hole Optimization" Computers 11, no. 9: 140. https://doi.org/10.3390/computers11090140
APA StyleSaraf, T. O. Q., Fuad, N., & Taujuddin, N. S. A. M. (2022). Feature Encoding and Selection for Iris Recognition Based on Variable Length Black Hole Optimization. Computers, 11(9), 140. https://doi.org/10.3390/computers11090140