


A Ranking Learning Model by K-Means Clustering Technique for Web Scraped Movie Data

 , ,
, ,  , ,
, ,
Abstract
1. Introduction
1.1. Online Rating
1.2. Movie Rating and IMDB
- Research Scope: There is plenty of research on IMDB data analysis and the implementation of machine learning applications. Most of the works developed their own supervised models or applied clustering techniques, or performed a statistical analysis based on the repository data set (details in Section 2). The repository data set may consist of unnecessary fields at back dated information. Moreover, according to Quora [14], a good number of customers has no good experience when they select a movie only based on the scoring systems of Metascore or Rating because Metascore is biased by human error or business goals and Rating is biased by users’ influential factors (age, gender, race, and culture). On the other hand, an ordinary user has limited access on the IMDB movie information and most of the users follow Rating/Metascore, but it becomes ambiguous when a huge difference exists between these two scores of a movie.
1.3. Contribution
- (i)
- We extract up-to-date movie data (movie name, Metascore, Rating, year, votes, and gross income) from IMDB movie site. This is an ethical (grey area) data extraction process from the internet, which is more accurate and reliable than collected data from a third party.
- (ii)
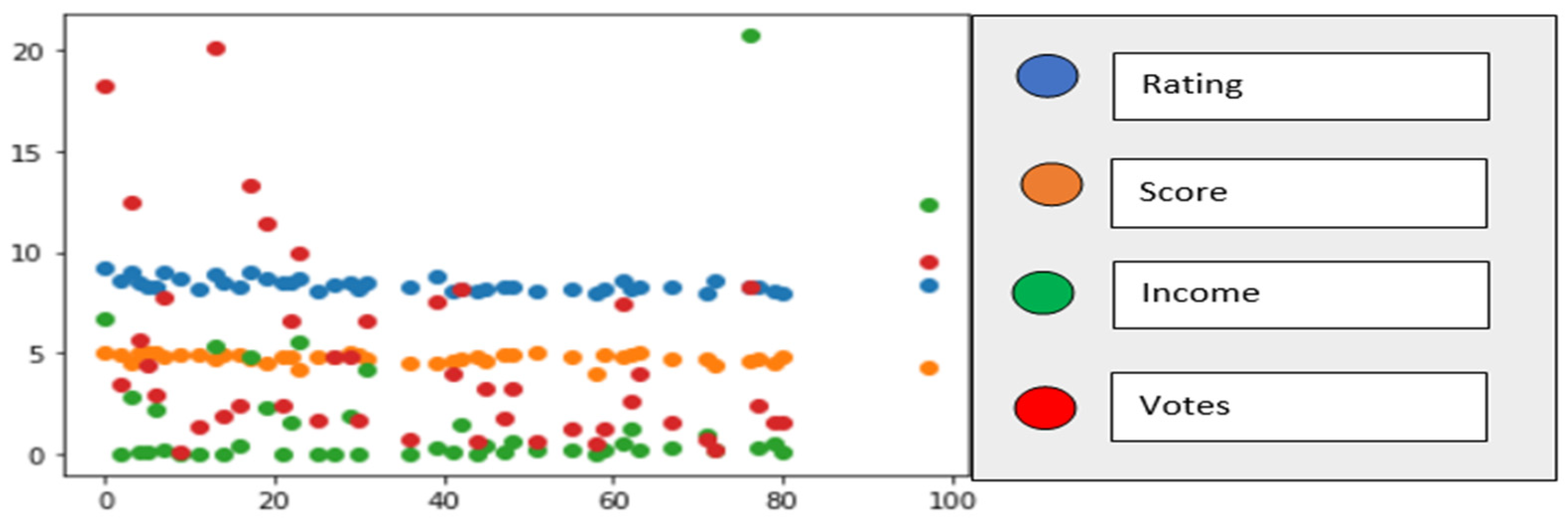
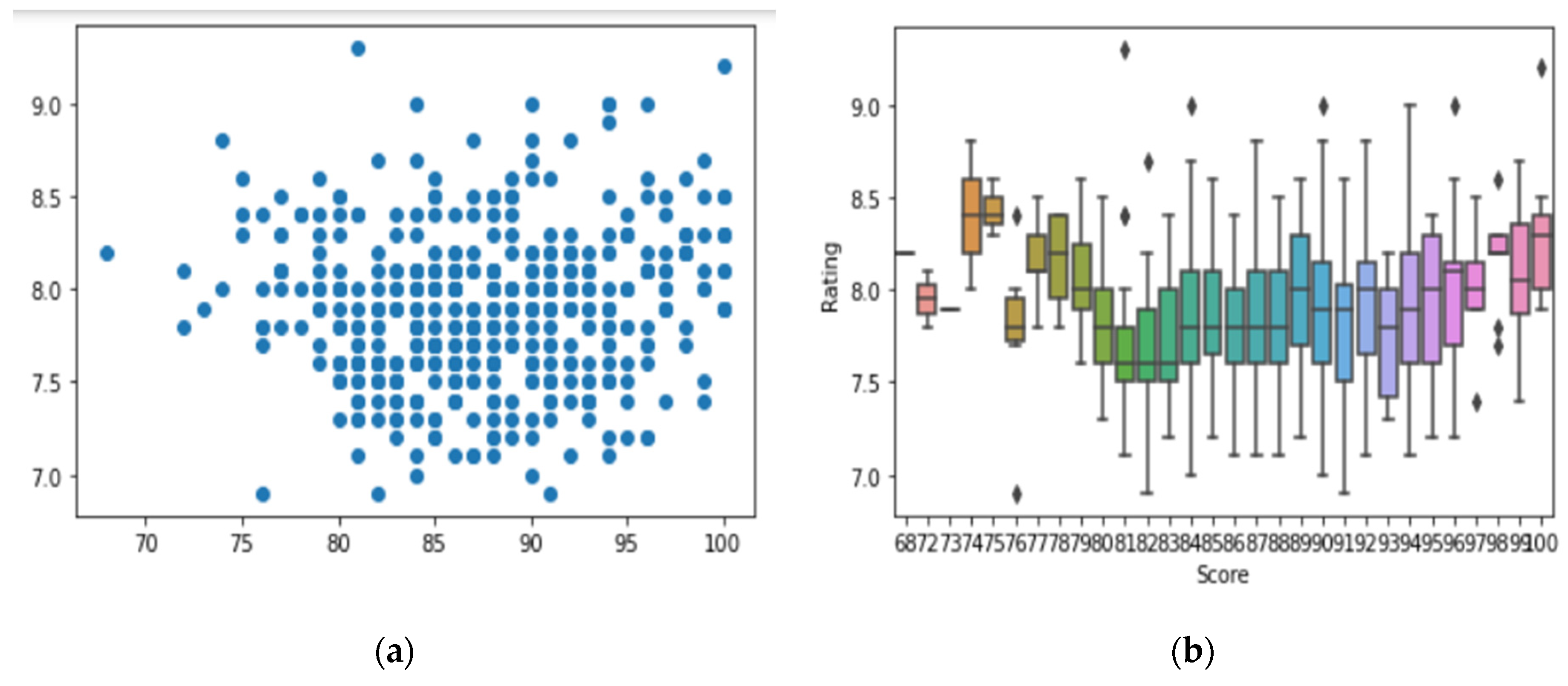
- Data cleansing and analysis is performed to show the correlation between rating, Metascore, votes, and gross income of the movies. The statistical analysis illustrates the relationship between Metascore and rating by scatter plot and boxplot for comparison between two different scoring systems. This supports data validation and feature selection for machine learning applications.
- (iii)
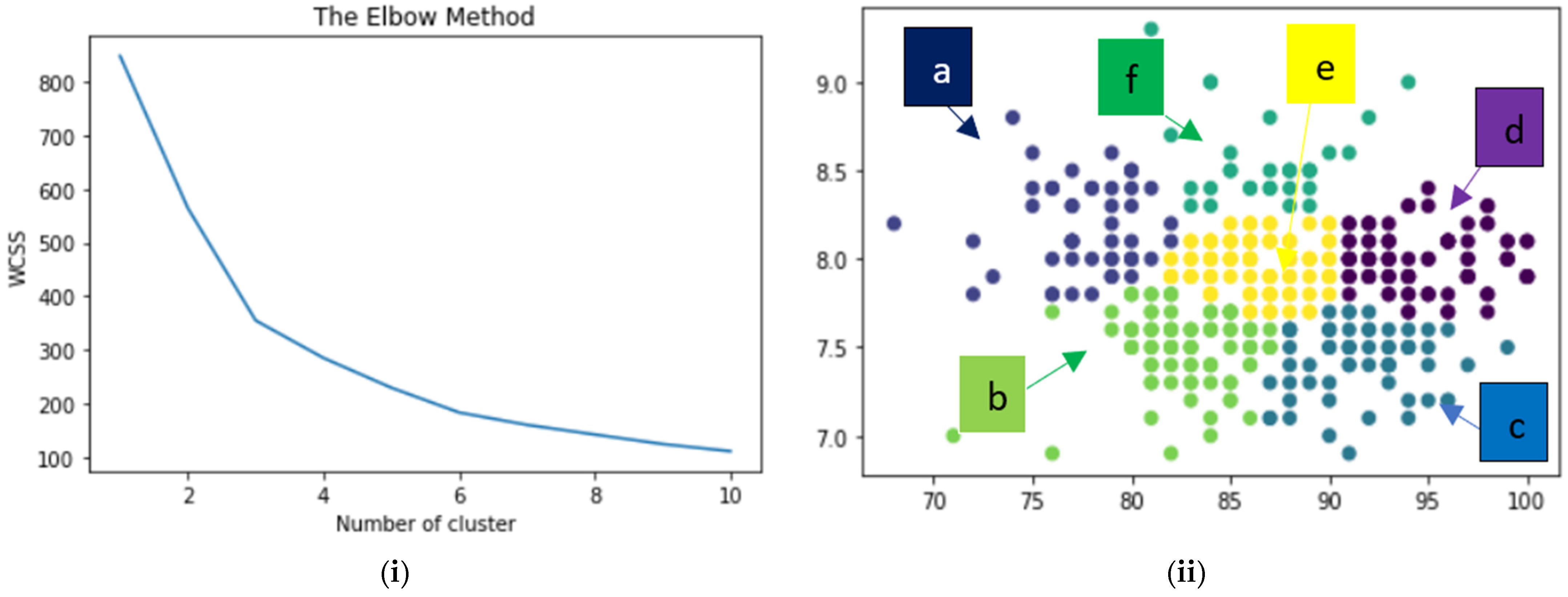
- Finally, the k-means clustering technique is applied after analyzing the machine learning approaches that will support a user to select a move from optimal clusters. The rest of the paper is organized as follows: Section 2 consists of recently completed research in data science and machine learning domains for the IMDB dataset. Section 3 illustrates the research methodology aided with a diagram. Web-scraping data extraction, data analysis (statistical), and implementation of k-Means clustering are executed with the required explanation and literature in the following three sections (Section 4, Section 5 and Section 6). Section 7 explains the result and application of the research. Concluding remarks with limitations and future work are mentioned in Section 8.
2. Related Work
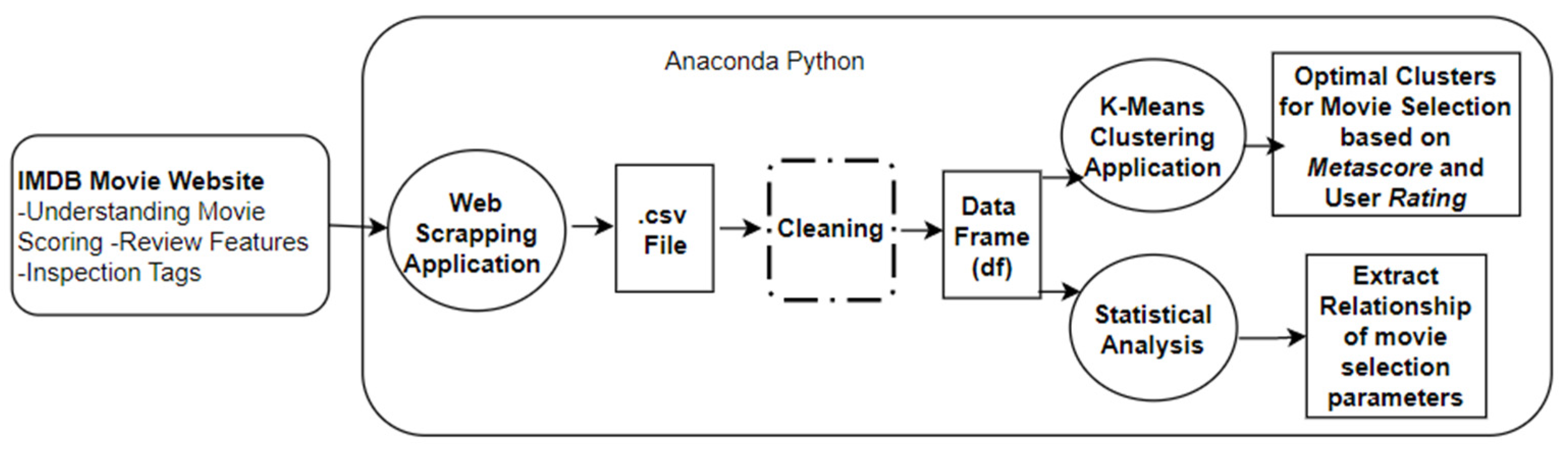
3. Methodology
4. Data Collection
4.1. Importance
4.2. Web Data Scraping
4.3. Scraping Technology
4.4. Web Scraping Legality
4.5. Movie Data Extraction
| Algorithm 1. Web Scraping |
| 1. BEGIN 2. ASSIGN array Variables 3. for pages !END 4. READ new URL for each page 5. PARSE each page 6. READ main DIV/CLASS/TAG of Data_Fields 7. for required_data_retrive !END if tag_of Data_Fields !SAME 8. Store_content ← Filter if Need to (READ text_of_tag) 9. Else 10. Store_content [i] ← Filter if Need to (READ text_of_tags) 11. Data_list←pandas_variable.DataFrame(Data_field1, .. ,data_fieldn) 12. Data_list.to_csv(Local_Data_File.csv) 13. END |
5. Data Analysis
6. Machine Learning
6.1. Classification Algorithm

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifications | Features/Characteristics and Applications |
|---|---|
| Naive Bayes (NB): | It is founded on Bayes’ theorem that is surprisingly good for independence assumption [88]. It is a supervised model that can implement robust prediction model construction and is effective for noisy instances of a dataset [88]. It can work with a small amount of training datasets compared to other sophisticated classification algorithms [84]. |
| Linear discriminant analysis (LDA): | It is generalized of Fisher’s linear discriminant that searches linear combinations of features to separate data into two or more classes. It is developed by Bayes’ rules and fitting class conditional data density [84,87]. Standard LDA is usually suited for Gaussian density and applied to analysis of variance, dimensionality reduction [84]. |
| Logistic regression (LR): | A statistical model used to solve classification issues by probabilistic theorem in machine learning applications [89]. It is also known as a sigmoid function in mathematics. High dimensional dataset could be over fitted by it, but it is effective when the dataset is linearly separable. L1 and L2 regularizations can be implemented to overcome over-fitting issues [84]. |
| K-nearest neighbors (KNN): | It is an instance-based learning that is also called lazy learning algorithm or non-generalizing learning technique [90]. Similarity measuring techniques (e.g., Euclidian distance calculation from a particular point) are used to classify new data [84]. The output is biased by data quality and noise. |
| Support vector machine (SVM) | It is a supervised learning model that can be used for classification and regression [91]. It creates a hyper plane for high or infinite dimension of data. It has distinguished applications based on the mathematical functions: sigmoid, radial bias function, kernel, polynomial, and linear, etc. [84]. |
| Decision tree (DT) | It is a non-parametric supervised learning approach [92] that can implement classifications and regression applications [84]. IntrudTree [93] and BehavDT [94] are two recently proposed DT algorithms for cyber security analysis and behavior analysis, respectively, while ID3, CS4.5, and CART [95,96] are commonly used DT algorithms. |
| Random forest (RF) | It is an ensemble classification technique in machine learning and data science [97] that can fit several parallel “ensemble trees” for simultaneous accessing [8], which is more effective than a single tree structure. Implementation of different sub-datasets on a tree of ensemble trees, minimize over-fitting problems [84]. It combines bootstrap aggregation [98] and random feature selection [99] to establish a series of trees (random forest tree) with several control variables. It is more accurate and efficient than a single decision tree structure [100]. |
| Adaptive Boosting (AdaBoost) | A serial ensemble classifier employed to reduce errors in classification that is developed by Freund Y [101]. It brings poor classifiers together and improves quality of classification; it is also called meta learning algorithms. It improves the performance of a base estimator [84] and a decision tree in binary classification but it is sensitive with outlier and noisy data. |
| Extreme gradient boosting (XGBoost) | It is like a random forest that creates a final ensemble model based on the series of individual models [97]. It uses gradient to reduce loss functions while neural networks use it for weight optimization [4]. Second order gradient is used to deduct loss function and over fitting by advanced regularization [4]. |
| Stochastic gradient descent (SGD) | It is an iterative process to optimize objective function (computational burden in high dimensional optimization problems) [4]. It is applied in text classification applications and natural language processing algorithms [84]. |
6.2. Regression
6.3. Reinforcement Learning
6.4. Clustering
7. Result Analysis
8. Conclusions and Future
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarker, I.H.; Kayes, A.S.M.; Badsha, S.; Alqahtani, H.; Watters, P.; Ng, A. Cybersecurity data science: An overview from machine learning perspective. J. Big Data 2020, 7, 41. [Google Scholar] [CrossRef]
- Sarker, I.H.; Kayes, A.S.M. Abc-ruleminer: User behavioral rule based machine learning method for context-aware intelligent services. J. Netw. Comput. Appl. 2020, 168, 102762. [Google Scholar] [CrossRef]
- Cao, L. Data science: A comprehensive overview. ACM Comput. Surv. (CSUR) 2017, 50, 43. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Sarker, I.H.; Hoque, M.M.; Kafil Uddin, M.; Tawfeeq, A. Mobile data science and intelligent apps: Concepts, ai-based modeling and research directions. Mob. Netw. Appl. 2021, 26, 285–303. [Google Scholar] [CrossRef]
- Marchand, A.; Marx, P. Automated product recommendations with preference-based explanations. J. Retail. 2020, 96, 328–343. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, NJ, USA, 2005. [Google Scholar]
- Sarker, I.H.; Watters, P.; Kayes, A.S.M. Effectiveness analisis of machine learning classification models for predicting personalized context-aware smartphone usage. J. Big Data 2019, 6, 57. [Google Scholar] [CrossRef]
- Harmon, S.A.; Sanford, T.H.; Sheng, X.; Turkbey, E.B.; Roth, H.; Ziyue, X.; Yang, D.; Myronenko, A.; Anderson, V.; Amalou, A.; et al. Artifcial intelligence for the detection of COVID-19 pneumonia on chest ct using multinational datasets. Nat. Commun. 2020, 11, 4080. [Google Scholar] [CrossRef]
- Chen, J.; Kou, G.; Peng, Y. The dynamic effects of online product reviews on purchase decisions. Technol. Econ. Dev. Econ. 2018, 24, 2045–2064. [Google Scholar] [CrossRef]
- Park, D.; Lee, J. eWOM overload and its effect on consumer behavioral intention depending on consumer involvement. Electron. Commer. Res. Appl. 2008, 7, 386–398. [Google Scholar] [CrossRef]
- Schneider, F.; Domahidi, E.; Dietrich, F. What Is Important When We Evaluate Movies? Insights from Computational Analysis of Online Reviews. Media Commun. 2020, 8, 153–163. [Google Scholar] [CrossRef]
- Raney, A.A.; Bryant, J. Entertainment and enjoyment as media effect. In Media Effects: Advances in Theory and Research, 4th ed.; Oliver, M.B., Raney, A.A., Bryant, J., Eds.; Routledge: New York, NY, USA, 2020; pp. 324–341. [Google Scholar]
- Quora, How Trustworthy Is IMDB with Its Ratings? Available online: https://www.quora.com/How-trustworthy-is-IMDB-with-its-ratings (accessed on 10 October 2022).
- Hsieh, J. Final Project: IMDB Data Analysis. 2015. Available online: http://mercury.webster.edu/aleshunas/Support%20Materials/Analysis/Hsieh-Final%20Project%20imdb.pdf (accessed on 10 October 2022).
- Qaisar, S.M. Sentiment Analysis of IMDb Movie Reviews Using Long Short-Term Memory. In Proceedings of the 2020 2nd International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 13–15 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Topal, K.; Ozsoyoglu, G. In Proceedings of the Movie review analysis: Emotion analysis of IMDb movie reviews. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Davis, CA, USA, 18–21 August 2016; pp. 1170–1176. [Google Scholar] [CrossRef]
- Nithin, V.; Pranav, M.; Babu, P.S.; Lijiya, A. Predicting Movie Success Based on IMDB Data. Int. J. Bus. Intell. 2014, 3, 34–36. [Google Scholar] [CrossRef]
- Naeem, M.Z.; Rustam, F.; Mehmood, A.; Din, M.Z.; Ashraf, I.; Choi, G.S. Classification of movie reviews using term frequency-inverse document frequency and optimized machine learning algorithms. PeerJ Comput. Sci. 2022, 8, e914. [Google Scholar] [CrossRef] [PubMed]
- Mehra, S.; Choudhary, T. Sentiment Analysis of User Entered Text. In Proceedings of the International Conference of Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belgaum, India, 21–22 December 2018; ISBN 978-1-5386-7709-4. [Google Scholar]
- Bulut, H.; Korukoglu, S. Analysis and Clustering of Movie Genres. J. Comput. 2011, 3, 16–23. [Google Scholar]
- Aditya, T.S.; Rajaraman, K.; Subashini, M.M. Comparative Analysis of Clustering Techniques for Movie Recommendation. In Proceedings of the MATEC Web of Conferences 225, Nadu, India, 18–19 September 2018; p. 02004. [Google Scholar]
- Lawson, R. Web Scraping with Python; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Gheorghe, M.; Mihai, F.-C.; Dârdală, M. Modern techniques of web scraping for data scientists. Int. J. User-Syst. Interact. 2018, 11, 63–75. [Google Scholar]
- Rahman, R.U.; Tomar, D.S. Threats of price scraping on e-commerce websites: Attack model and its detection using neural network. J. Comput. Virol. Hacking Tech. 2020, 17, 75–89. [Google Scholar] [CrossRef]
- Watson, H.J. Tutorial: Big Data Analytics: Concepts, Technologies, and Applications. Commun. Assoc. Inf. Syst. 2014, 34, 1247–1268. [Google Scholar] [CrossRef]
- Sarker, K.U.; Deraman, A.B.; Hasan, R.; Abbas, A. Ontological Practice for Big Data Management. Int. J. Comput. Digit. Syst. 2019, 8, 265–273. Available online: https://journal.uob.edu.bh/handle/123456789/3485 (accessed on 24 July 2022). [CrossRef]
- Almaqbali, I.S.; Al Khufairi, F.M.; Khan, M.S.; Bhat, A.Z.; Ahmed, I. Web Scrapping: Data Extraction from Websites. J. Stud. Res. 2019, 12. [Google Scholar] [CrossRef]
- Chaulagain, R.S.; Pandey, S.; Basnet, S.R.; Shakya, S. Cloud based web scraping for big data applications. In Proceedings of the 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017; pp. 138–143. [Google Scholar]
- Sirisuriya, D.S. A comparative study on web scraping. In Proceedings of the 8th International Research Conference, KDU, Palisades, NY, USA, 7–10 October 2015. [Google Scholar]
- Milev, P. Conceptual approach for development of web scraping application for tracking information. Econ. Altern. 2017, 3, 475–485. [Google Scholar]
- Hillen, J. Web scraping for food price research. Br. Food J. 2019, 121, 3350–3361. [Google Scholar] [CrossRef]
- Shaukat, K.; Alam, T.M.; Ahmed, M.; Luo, S.; Hameed, I.A.; Iqbal, M.S.; Li, J. A Model to Enhance Governance Issues through Opinion Extraction. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 0511–0516. [Google Scholar] [CrossRef]
- Mitchell, R. Web Scraping with Python: Collecting More Data from the Modern Web; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Broucke, S.V.; Baesens, B. Practical Web Scraping for Data Science: Best Practices and Examples with Python, 1st ed.; Apress: New York, NY, USA, 2018. [Google Scholar]
- Black, M.L. The World Wide Web as Complex Data Set: Expanding the Digital Humanities into the Twentieth Century and Beyond through Internet Research. Int. J. Humanit. Arts Comput. 2016, 10, 95–109. [Google Scholar] [CrossRef]
- Zhao, B. Web scraping. In Encyclopedia of Big Data; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 1–3. [Google Scholar]
- Tarannum, T. Cleaning of Web Scraped Data with Python. Doctoral Dissertation, Brac University, Dhaka, Bangladesh, 1 April 2019. [Google Scholar]
- Manjushree, B.S.; Sharvani, G.S. Survey on Web scraping technology. Wutan Huatan Jisuan Jishu 2020, XVI(VI), 1–8. [Google Scholar]
- Yannikos, Y.; Heeger, J.; Brockmeyer, M. An Analysis Framework for Product Prices and Supplies in Darknet Marketplaces. In Proceedings of the 14th International Conference on Availability, Reliability and Security, New York, NY, USA, 26 August 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Kurniawati, D.; Triawan, D. Increased information retrieval capabilities on e-commerce websites using scraping techniques. In Proceedings of the 2017 International Conference on Sustainable Information Engineering and Technology (SIET), Malang, Indonesia, 24–25 November 2017; pp. 226–229. [Google Scholar]
- Raicu, I. Financial Banking Dataset for Supervised Machine Learning Classification. Inform. Econ. 2019, 23, 37–49. [Google Scholar] [CrossRef]
- Mbah, R.B.; Rege, M.; Misra, B. Discovering Job Market Trends with Text Analytics. In Proceedings of the 2017 International Conference on Information Technology (ICIT), Singapore, 27–29 December 2017; pp. 137–142. [Google Scholar] [CrossRef]
- Farooq, B.; Husain, M.S.; Suaib, M. New Insights into Rental Housing Markets across the United States: Web Scraping and Analyzing Craigslist Rental Listings. Int. J. Adv. Res. Comput. Sci. 2018, 9, 64–67. [Google Scholar]
- Lunn, S.; Zhu, J.; Ross, M. Utilizing Web Scraping and Natural Language Processing to Better Inform Pedagogical Practice. In Proceedings of the 2020 IEEE Frontiers in Education Conference (FIE), Uppsala, Sweden, 21–24 October 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Andersson, P. Developing a Python Based Web Scraper: A Study on the Development of a Web Scraper for TimeEdit. Master’s. Thesis, Mid Sweden University, Holmgatan, Sweden, 1 July 2021. Available online: https://www.diva-portal.org/smash/get/diva2:1596457/FULLTEXT01.pdf (accessed on 8 August 2022).
- Uzun, E.; Yerlikaya, T.; Kirat, O. Comparison of Python Libraries used for Web Data Extraction. J. Tech. Univ.–Sofia Plovdiv Branch Bulg. “Fundam. Sci. Appl.” 2018, 24, 87–92. [Google Scholar]
- Uzun, E.; Buluş, H.N.; Doruk, A.; Özhan, E. Evaluation of Hap, Angle Sharp and HTML Document in web content extraction. In Proceedings of the International Scientific Conference’2017 (UNITECH’17), Gabrovo, Bulgaria, 17–18 November 2017; Volume II, pp. 275–278. [Google Scholar]
- Ferrara, E.; De Meo, P.; Fiumara, G.; Baumgartner, R. Web data extraction, applications and techniques: A survey. Knowl.-Based Syst. 2014, 70, 301–323. [Google Scholar] [CrossRef]
- Munzert, S.; Rubba, C.; Meißner, P.; Nyhuis, D. Automated Data Collection with R: A Practical Guide to Web Scraping and Text Mining; John Wiley & Sons, Ltd.: Chichester, UK, 2015. [Google Scholar]
- Krotov, V.; Tennyson, M. Scraping Financial Data from the Web Using the R Language. J. Emerg. Technol. Account. 2018, 15, 169–181. [Google Scholar] [CrossRef]
- Ives, B.; Palese, B.; Rodriguez, J.A. Enhancing Customer Service through the Internet of Things and Digital Data Streams. MIS Q. Exec. 2016, 15, 4. [Google Scholar]
- Constantiou, I.D.; Kallinikos, J. New Games, New Rules: Big Data and the Changing Context of Strategy. J. Inf. Technol. 2015, 30, 44–57. [Google Scholar] [CrossRef]
- Snell, J.; Menaldo, N. Web Scraping in an Era of Big Data 2.0. Bloomberg BNA. 2016. Available online: https://www.bna.com/web-scraping-era-n57982073780/ (accessed on 13 September 2022).
- Dryer, A.J.; Stockton, J. Internet ‘Data Scraping’: A Primer for Counseling Clients. New York Law Journal. 2013. Available online: https://www.law.com/newyorklawjournal/almID/1202610687621 (accessed on 13 September 2022).
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Khan, W.A.; Sarwar, M.U.; Iqbal, F.; Luo, S. A novel framework for prognostic factors identification of malignant mesothelioma through association rule mining. Biomed. Signal Process. Control. 2021, 68, 102726. [Google Scholar] [CrossRef]
- Sulong, G.; Mohammedali, A. Recognition of human activities from still image using novel classifier. J. Theor. Appl. Inf. Technol. 2015, 71, 59103531. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing: The Sparse Way; Academic Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Gutiérrez-Gómez, L.; Petry, F.; Khadraoui, D. A comparison framework of machine learning algorithms for mixed-type variables datasets: A case study on tire-performances prediction. IEEE Access 2020, 8, 214902–214914. [Google Scholar] [CrossRef]
- Starck, J.; Murtagh, F.; Fadili, J. Sparse Image and Signal Processing: Wavelets and Related Geometric Multiscale Analysis; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Mohammed, M.; Khan, M.B.; Bashier Mohammed, B.E. Machine Learning: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Paltrinieri, N.; Comfort, L.; Reniers, G. Learning about risk: Machine learning for risk assessment. Saf. Sci. 2019, 118, 475–486. [Google Scholar] [CrossRef]
- Shaukat, K.; Iqbal, F.; Alam, T.M.; Aujla, G.K.; Devnath, L.; Khan, A.G.; Iqbal, R.; Shahzadi, I.; Rubab, A. The Impact of Artificial intelligence and Robotics on the Future Employment Opportunities. Trends Comput. Sci. Inf. Technol. 2020, 5, 050–054. [Google Scholar]
- Yu, S.; Chen, Y.; Zaidi, H. AVA: A financial service chatbot based on deep bidirectional transformers. Front. Appl. Math. Stat. 2021, 7, 604842. [Google Scholar] [CrossRef]
- Eling, M.; Nuessl, D.; Staubli, J. The impact of artificial intelligence along the insurance value chain and on the insurability of risks. In Geneva Paper on Risk and Insurance-Issues and Practices; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Dornadula, V.N.; Geetha, S. Credit card fraud detection using machine learning algorithms. Procedia Comput. Sci. 2019, 165, 631–641. [Google Scholar] [CrossRef]
- Leo, M.; Sharma, S.; Maddulety, K. Machine learning in banking risk management: A literature review. Risks 2019, 7, 29. [Google Scholar] [CrossRef]
- Zand, A.; Orwell, J.; Pfluegel, E. A secure framework for anti-money laundering using machine learning and secret sharing. In Proceedings of the International Conference on Cyber Security and Protection of Digital Services, Dublin, Ireland, 15–19 June 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Gu, S.; Kelly, B.; Xiu, D. Empirical asset pricing via machine learning. Rev. Financ. Stud. 2020, 33, 2233–2273. [Google Scholar] [CrossRef]
- Ye, T.; Zhang, L. Derivatives pricing via machine learning. J. Math. Financ. 2019, 9, 561–589. [Google Scholar] [CrossRef]
- Javed, U.; Shaukat, K.; AHameed, I.; Iqbal, F.; Mahboob Alam, T.; Luo, S. A Review of Content-Based and Context-Based Recommendation Systems. Int. J. Emerg. Technol. Learn. (iJET) 2021, 16, 274–306. [Google Scholar] [CrossRef]
- Ramzan, B.; Bajwa, I.S.; Jamil, N.; Amin, R.U.; Ramzan, S.; Mirza, F.; Sarwar, N. An Intelligent Data Analysis for Recommendation Systems Using Machine Learning. Sci. Program. 2019, 2019, 5941096. [Google Scholar] [CrossRef]
- Zhou, Y.; Mao, H.; Yi, Z. Cell mitosis detection using deep neural networks. Knowl.-Based Syst. 2017, 137, 19–28. [Google Scholar] [CrossRef]
- Yang, S.; Korayem, M.; AlJadda, K.; Grainger, T.; Natarajan, S. Combining content-based and collaborative filtering for job recommendation system: A cost-sensitive statistical relational learning approach. Knowl.-Based Syst. 2017, 136 (Suppl. C), 37–45. [Google Scholar] [CrossRef]
- Cohen, Y.; Hendler, D.; Rubin, A. Detection of malicious webmail attachments based on propagation patterns. Knowl.-Based Syst. 2018, 141, 67–79. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance Comparison and Current Challenges of Using Machine Learning Techniques in Cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Xu, M. A Survey on Machine Learning Techniques for Cyber Security in the Last Decade. IEEE Access 2020, 8, 222310–222354. [Google Scholar] [CrossRef]
- Rodr’ıguez, C.; Florian, D.; Casati, F. Mining and quality assessment of mashup model patterns with the crowd: A feasibility study. ACM Trans. Internet Technol. 2016, 16, 17. [Google Scholar] [CrossRef]
- Xu, K.; Zheng, X.; Cai, Y.; Min, H.; Gao, Z.; Zhu, B.; Xie, H.; Wong, T. Improving user recommendation by extracting social topics and interest topics of users in uni-directional social networks. Knowl.-Based Syst. 2018, 140 (Suppl. C), 120–133. [Google Scholar] [CrossRef]
- Castillo, P.A.; Mora, A.M.; Faris, H.; Merelo, J.J.; García-Sanchez, P.; Fernandez-Ares, A.J.; de las Cuevas, P.; Garcıa-Arenas, M.I. Applying computational intelligence methods for predicting the sales of newly published books in a real editorial business management environment. Knowl.-Based Syst. 2017, 115 (Suppl. C), 133–151. [Google Scholar] [CrossRef]
- Hajek, P.; Henriques, R. Mining corporate annual reports for intelligent detection of financial statement fraud–Comparative study of machine learning methods. Knowl.-Based Syst. 2017, 128, 139–152. [Google Scholar] [CrossRef]
- Lee, W.; Chen, C.; Huang, J.; Liang, J. A smartphone-based activity aware system for music streaming recommendation. Knowl.-Based Syst. 2017, 131 (Suppl. C), 70–82. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the kdd cup 99 data set. In. IEEE symposium on computational intelligence for security and defense applications. IEEE 2009, 2009, 1–6. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wu, C.-C.; Yen-Liang, C.; Yi-Hung, L.; Xiang-Yu, Y. Decision tree induction with a constrained number of leaf nodes. Appl. Intell. 2016, 45, 673–685. [Google Scholar] [CrossRef]
- Holte, R.C. Very simple classification rules perform well on most commonly used datasets. Mach. Learn. 1993, 11, 63–90. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating continuous distributions in Bayesian classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence; Morgan Kaufmann Publishers Inc.: Burlington, NJ, USA, 1995; pp. 338–345. [Google Scholar]
- Sarker, I.H. A machine learning based robust prediction model for real-life mobile phone data. Internet Things 2019, 5, 180–193. [Google Scholar] [CrossRef]
- LeCessie, S.; Van Houwelingen, J.C. Ridge estimators in logistic regression. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1992, 41, 191–201. [Google Scholar]
- Kibler, D.; Albert, M. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar]
- Keerthi, S.S.; Shevade, S.K.; Bhattacharyya, C.; Radha Krishna, M.K. Improvements to platt’s smo algorithm for svm classifer design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for machine learning. Mach. Learn. 1993, 16, 235–240. [Google Scholar]
- Sarker, I.H.; Abushark, Y.B.; Alsolami, F.; Khan, A. Intrudtree: A machine learning based cyber security intrusion detection model. Symmetry 2020, 12, 754. [Google Scholar] [CrossRef]
- Sarker, I.H.; Alan, C.; Jun, H.; Khan, A.I.; Abushark, Y.B.; Khaled, S. Behavdtee: A behavioral decision tree learning to build user-centric context-aware predictive model. Mob. Netw. Appl. 2019, 25, 1151–1161. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classifcation and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Amit, Y.; Geman, D. Shape quantization and recognition with randomized trees. Neural Comput. 1997, 9, 1545–1588. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. Icml Citeseer 1996, 96, 148–156. [Google Scholar]
- Iqbal, M.A. Application of Regression Techniques with their Advantages and Disadvantages. Elektron. Mag. 2021, 4, 11–17. [Google Scholar]
- Ciulla, G.; Amico, A.D. Building energy performance forecasting: A multiple linear regression approach. Appl. Energy 2019, 253, 113500. [Google Scholar] [CrossRef]
- Maio, F.D.; Tsui, K.L.; Zio, E. Combining relevance vector machines and exponential regression for bearing residual life estimation. Mech. Syst. Signal Process. 2012, 31, 405–427. [Google Scholar] [CrossRef]
- Kim, S.J.; Kim, C.H.; Jung, S.Y.; Kim, Y.J. Optimal design of novel pole piece for power density improvement of magnetic gear using polynomial regression analysis. IEEE Trans. Energy Convers. 2015, 30, 1171–1179. [Google Scholar] [CrossRef]
- Wi, Y.M.; Joo, S.K.; Song, K.B. Holiday load forecasting using fuzzy polynomial regression with weather feature selection and adjustment. IEEE Trans. Power Syst. 2011, 27, 596–603. [Google Scholar] [CrossRef]
- Wiering, M.A.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 729. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Dar, K.S.; Javed, I.; Amjad, W.; Aslam, S.; Shamim, A. A Survey of clustering applications. J. Netw. Commun. Emerg. Technol. (JNCET) 2015, 4, 10–15. [Google Scholar]
- Dagli, Y. Partitional Clustering using CLARANS Method with Python Example. 2019. Available online: https://medium.com/analytics-vidhya/partitional-clustering-using-clarans-method-with-python-example-545dd84e58b4 (accessed on 29 August 2022).
- Shaukat, K.; Masood, N.; Shafaat, A.B.; Jabbar, K.; Shabbir, H.; Shabbir, S. Dengue Fever in Perspective of Clustering Algorithms. arXiv 2015, arXiv:abs/1511.07353. [Google Scholar]
- Chauhan, N.S. DBSCAN Clustering Algorithm in Machine Learning. An Introduction to the DBSCAN Algorithm and Its Implementation in Python. KDnuggets. 2022. Available online: https://www.kdnuggets.com/2020/04/dbscan-clustering-algorithm-machine-learning.html (accessed on 30 August 2022).
- Iqbal, H. Sarker, Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Stroudsburg, PA, USA, 19–24 June 2011; Volume 1, pp. 142–150. [Google Scholar]
- Shaukat, K.; Luo, S.; Varadharajan, V. A novel method for improving the robustness of deep learning-based malware detectors against adversarial attacks. Eng. Appl. Artif. Intell. 2022, 116, 105461. [Google Scholar] [CrossRef]





| Libraries | Description |
|---|---|
| Requests | It is the most basic and essential library for web-scraping that is used for various HTTP requests like GET and POST to extract information from HTML server pages [48]. It is simple, support HTTP(s) proxy and it is easy to get chunk amount data from static web pages, but it cannot parse data from retrieved HTML files or collet information from Java script pages [47]. |
| Beautiful Soup | Perhaps it is the most used Python library that creates parse tree for parsing HTML and XML document. It is comparatively easier and suitable for beginners to extract information and combine with lxml. It is commonly used with Requests in industries though it is slower than pure lxml [47,49]. |
| lxml | This is a blazingly fast HTML and XML parsing library of Python that shows high performance for large amount dataset scraping [49]. It also works with Requests in industries. It supports data extraction by CSS and XPath selectors but is not good for poorly designed HTML webpages [48]. |
| Selenium | It was developed for automatic webpage testing and pretty quickly it has turned into a data science for web-scraping. It supports web-scraping dynamically populated pages. It is not suitable for large application but can be applied if time and speed is not a concern. |
| Scrapy | It is a web-scraping framework that can crawl multiple web sites by spider bots. It is asynchronous to send multiple HTTP requests simultaneously. It can extract data from dynamic websites using the Splash library [49]. |
| Specification | Remarks |
|---|---|
| Web-scraping is explicitly prohibited by terms and conditions. | No |
| The extracted data are confidential for the organization. | No |
| Information of the website is copyrighted. | No |
| Are data going to be used for illegal, fraudulent, or commercial purposes? | No |
| Scraping causes information or system damage. | No |
| Web-scraping diminishes the service. | No |
| Collected data are going to compromise individuals’ privacy. | No |
| Collected information will be shared. | No |
| Unnamed:0 | Name_of_Movie | Release_Year | Duration_of_Flim | Rating | Score | Votes | Income | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Cameraperson | 2016 | 102 | 7.4 | 86 | 2900 | 0 |
| 1 | 2 | Goldfinger | 1964 | 110 | 7.7 | 87 | 189,661 | 51.08 |
| 2 | 6 | True Grit | 2010 | 110 | 7.6 | 80 | 337,113 | 171.24 |
| 3 | 7 | Nebraska | 2013 | 115 | 7.7 | 87 | 118,215 | 17.65 |
| 4 | 9 | Paterson | 2016 | 118 | 7.3 | 90 | 81,270 | 2.14 |
| … | … | … | … | … | … | … | … | … |
| 419 | 78 | Pan’s Labyrinth | 2006 | 118 | 8.2 | 98 | 662,747 | 37.63 |
| 420 | 85 | The Best Years of Our Lives | 1946 | 170 | 8.1 | 93 | 64,310 | 23.65 |
| 421 | 88 | Tampopo | 1985 | 114 | 7.9 | 87 | 19,097 | 0.22 |
| 422 | 89 | Werckmeister harm6niak | 2000 | 145 | 8.0 | 92 | 14,231 | 0.03 |
| 423 | 98 | Rio Bravo | 1959 | 141 | 8.0 | 93 | 62,485 | 12.54 |
| 424 rows × 8 columns | ||||||||
| Comparing Factors | K-Means | K-Medoids | CLARA | CLARANS |
|---|---|---|---|---|
| Implementation on practical dataset of application users’ opinions. | Easier | Acceptable | Complicated | Complicated |
| Appropriateness of the algorithm based on the size of the dataset. | Smaller | Smaller | Larger | Larger |
| Time complexity for n points, k is clusters, s is the sample size, and i is iterations. | O(ink) | O(k(n − k)2) | O(k(s2 + n − k)) | O(n2) |
| Accuracy of the clustering sensitive for outliers. | Yes | No | No | No |
| Research on IMDB Movie Information | Objective of the Research | Data Extraction | Outcomes |
|---|---|---|---|
| S. M. Qaisar [16] | Classification: Sentiment analysis based on the text of the review comments. | Used data repository: created by Andrew Maas [114] | The comments are classified into positive and negative classification by the Long Short-Term Memory (LSTM) classifier and showed that the classification accuracy is 89.9%. |
| Sourav M. and Tanupriya C. [20] | Classification: Sentiment analysis based on the text of the review comments. | Used data repository: the “IMDB Large Movie Review Dataset” | Compared and analyzed SVM machine with Naïve Bayes and showed that SVM is more accurate than Naïve Bayes. |
| Naeem et al. [19] | Classification: Sentiment analysis based on the text of the review comments. | Used data repository: Kaggle.com | Compared gradient boosting classifiers, support vector machines (SVM), Naïve Bayes classifier, and random forest and showed that SVM is better than any other methods. |
| Aditya TS et al. [22] | Clustering: Based on the on rating with respect to years, Facebook likes, and budget. | Used data repository: the Movie Database on kaggle.com | Created different clusters based on the rating of the movies with respect to release year, Facebook likes, etc., that support the user to select a popular movie from a particular domain. |
| Hasan B. and Serdar K. [21] | Clustering: Based on the genre of the movies. | Used data repository: the “IMDB Large Movie Review Dataset” | Created different clusters based on the genre of the movies that supports the user to select a popular movie from a particular genre. |
| Our study | Clustering: Based on the Metascore and Rating. | Web-scraped up-to-date data | Our study validates the scoring systems and supports the user to make faster decision based on the outcome of both scoring systems. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarker, K.U.; Saqib, M.; Hasan, R.; Mahmood, S.; Hussain, S.; Abbas, A.; Deraman, A. A Ranking Learning Model by K-Means Clustering Technique for Web Scraped Movie Data. Computers 2022, 11, 158. https://doi.org/10.3390/computers11110158
Sarker KU, Saqib M, Hasan R, Mahmood S, Hussain S, Abbas A, Deraman A. A Ranking Learning Model by K-Means Clustering Technique for Web Scraped Movie Data. Computers. 2022; 11(11):158. https://doi.org/10.3390/computers11110158
Chicago/Turabian StyleSarker, Kamal Uddin, Mohammed Saqib, Raza Hasan, Salman Mahmood, Saqib Hussain, Ali Abbas, and Aziz Deraman. 2022. "A Ranking Learning Model by K-Means Clustering Technique for Web Scraped Movie Data" Computers 11, no. 11: 158. https://doi.org/10.3390/computers11110158
APA StyleSarker, K. U., Saqib, M., Hasan, R., Mahmood, S., Hussain, S., Abbas, A., & Deraman, A. (2022). A Ranking Learning Model by K-Means Clustering Technique for Web Scraped Movie Data. Computers, 11(11), 158. https://doi.org/10.3390/computers11110158