
Traditional vs. Modern Data Paths: A Comprehensive Survey

Abstract
:1. Introduction
2. Network Data Path
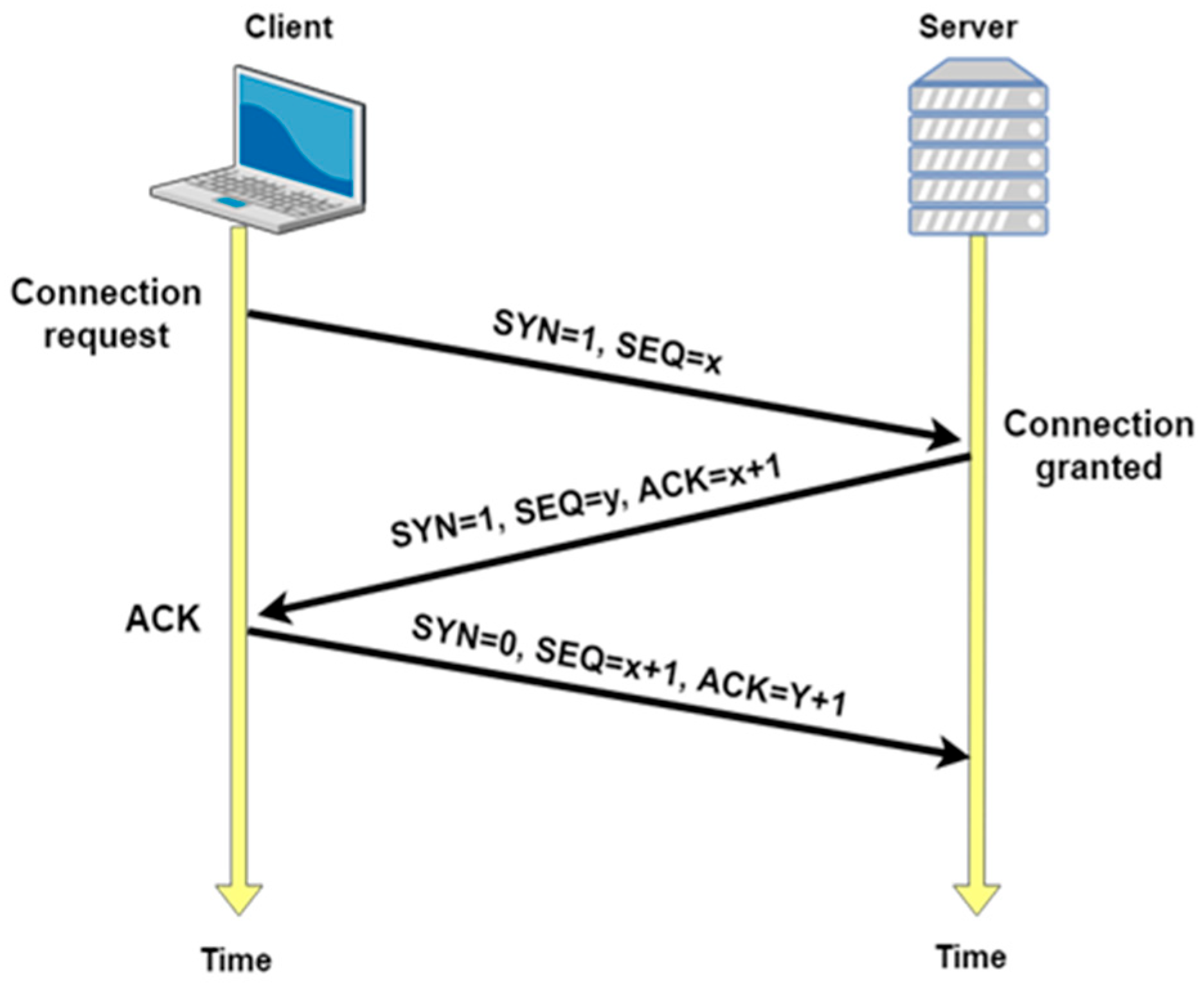
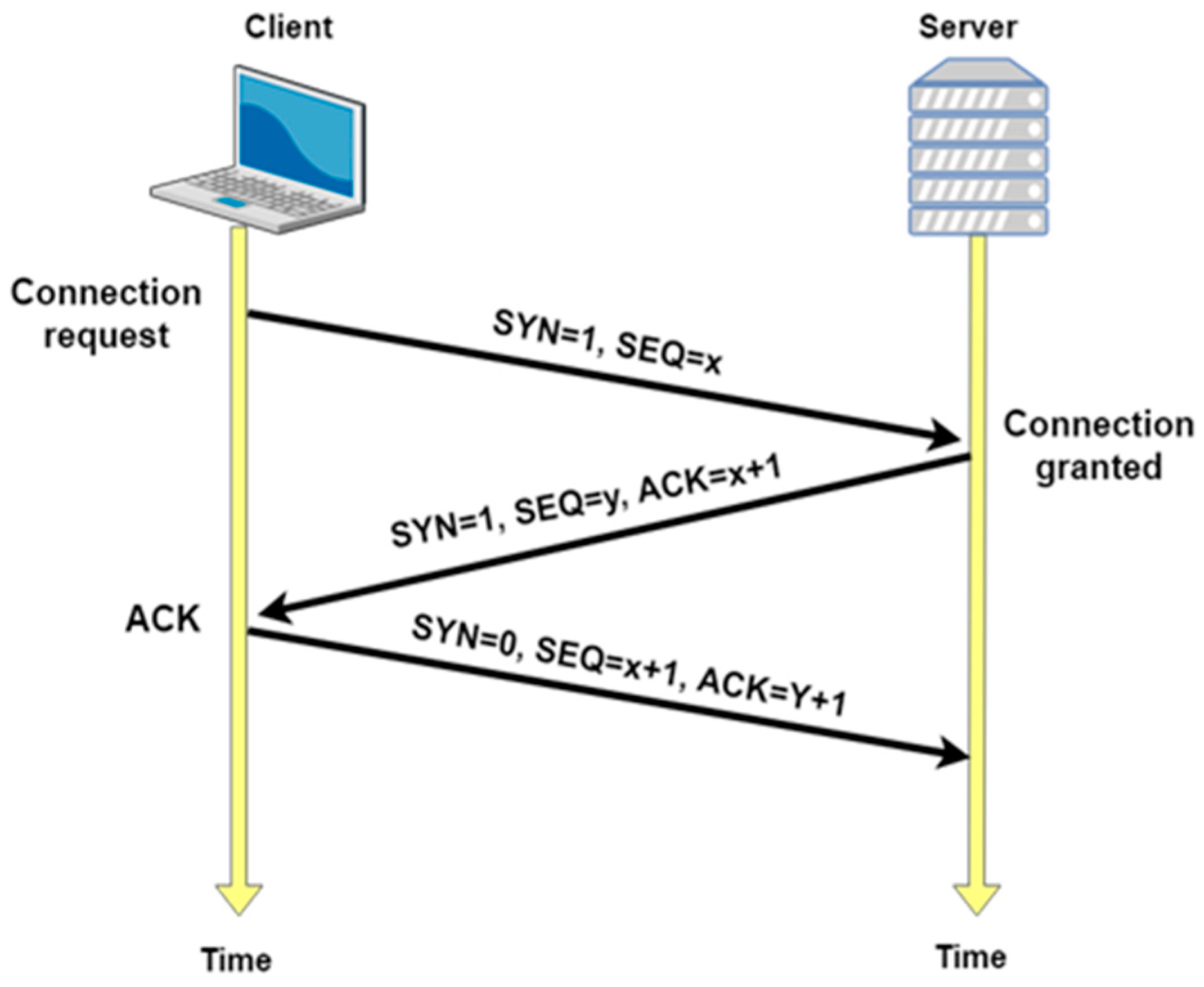
2.1. The Transmission Control Protocol (TCP)
2.2. User Datagram Protocol (UDP)
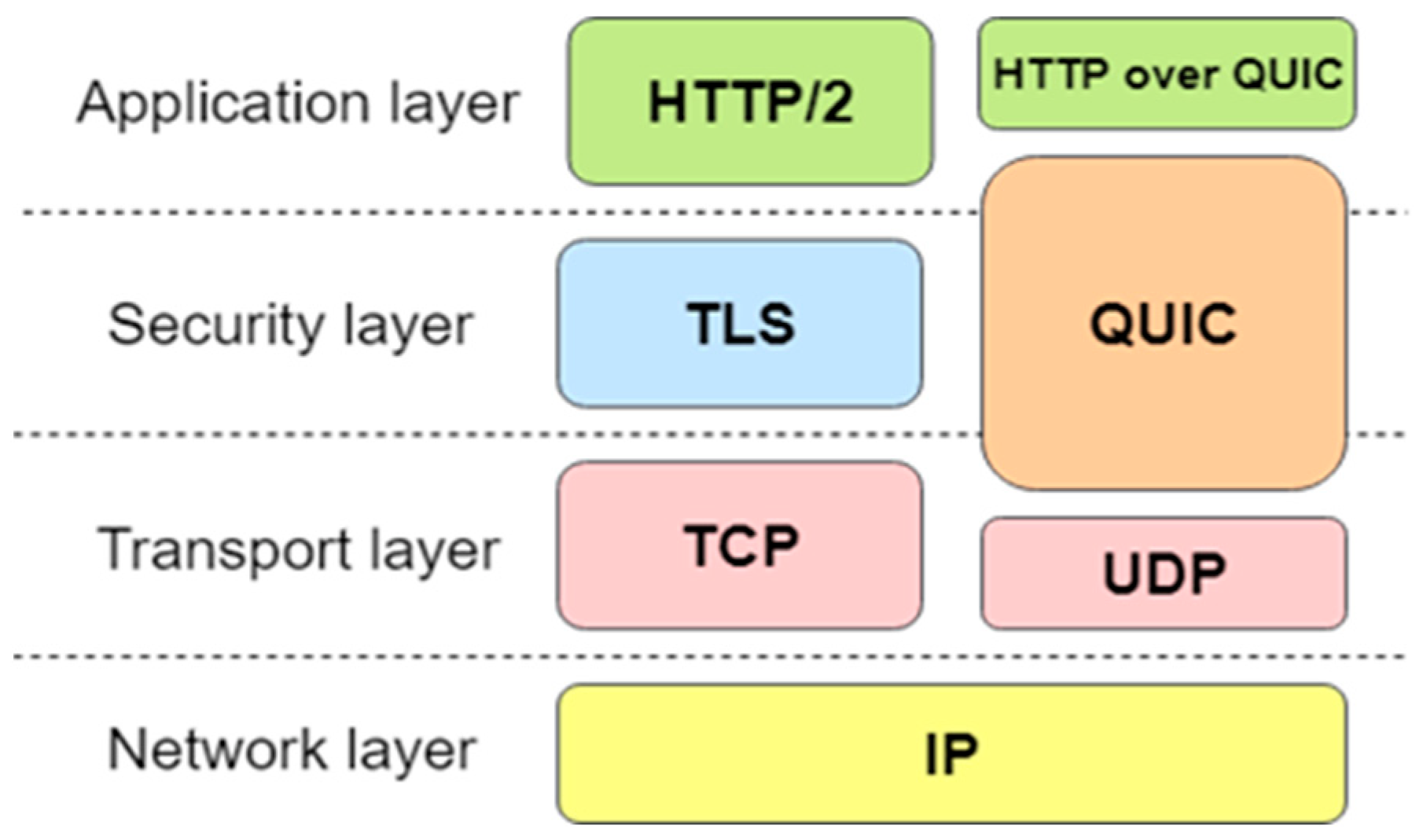
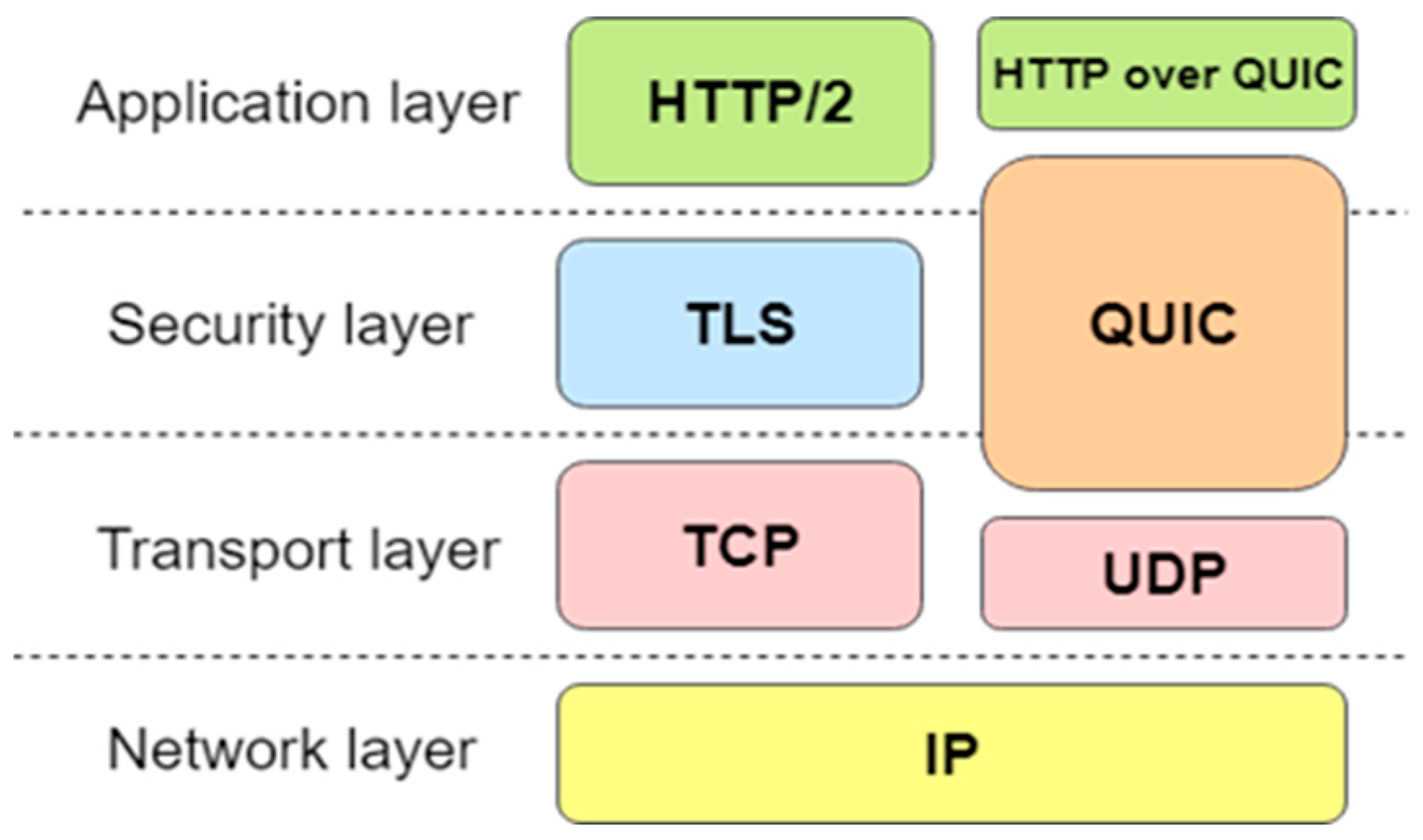
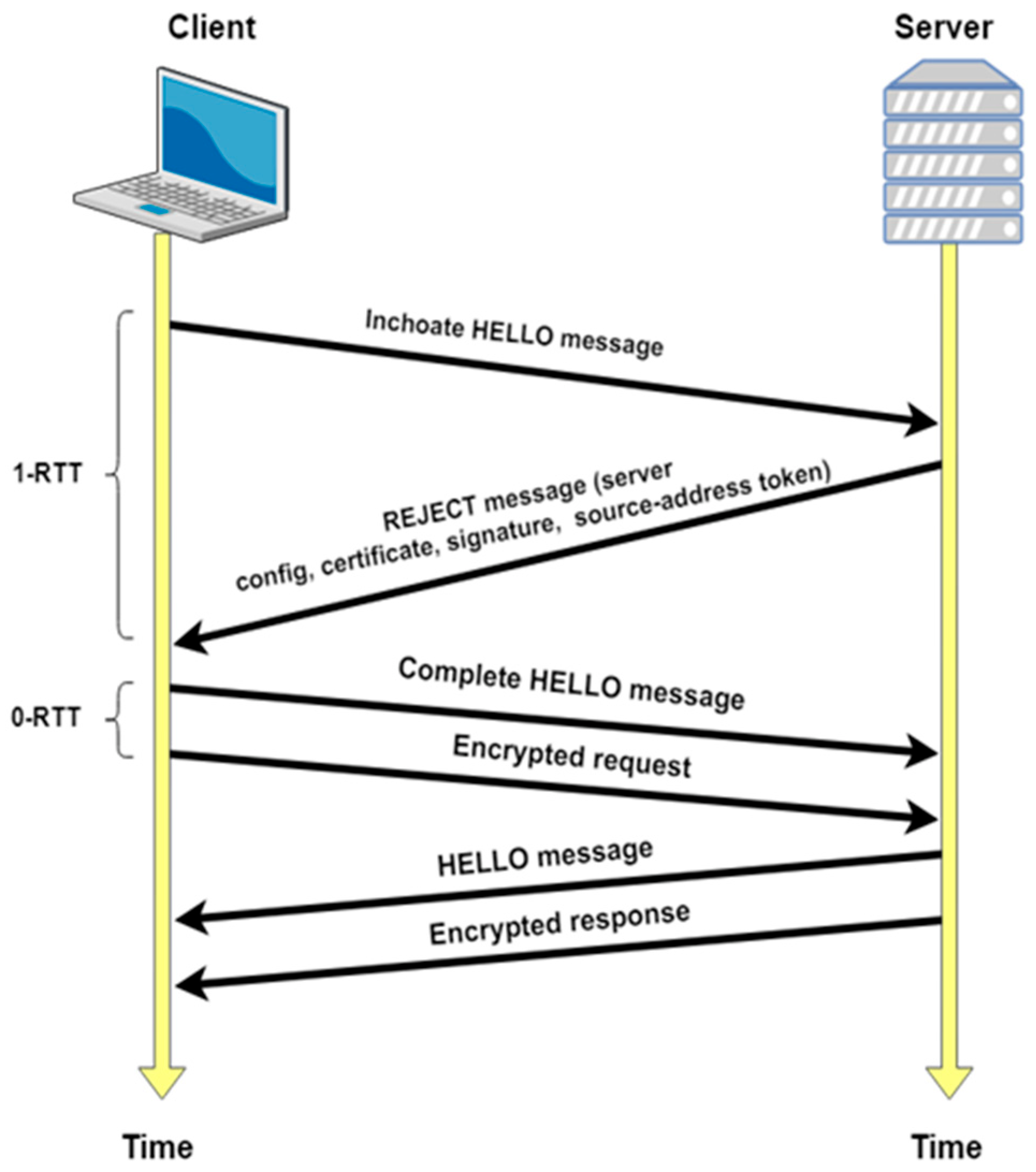
2.3. Quick UDP Internet Connection (QUIC) Protocol
2.4. Remote Dynamic Memory Access (RDMA) Technology
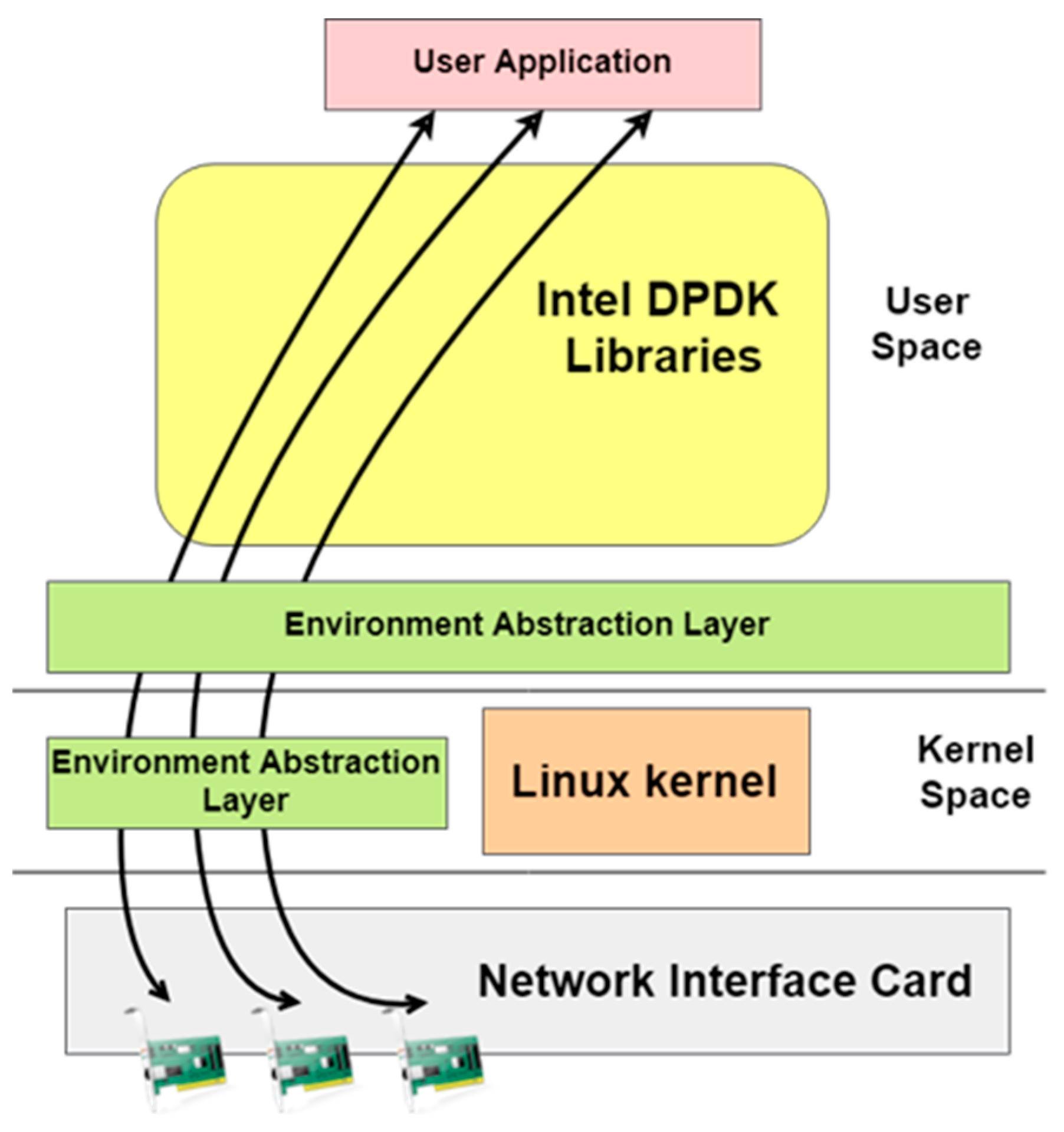
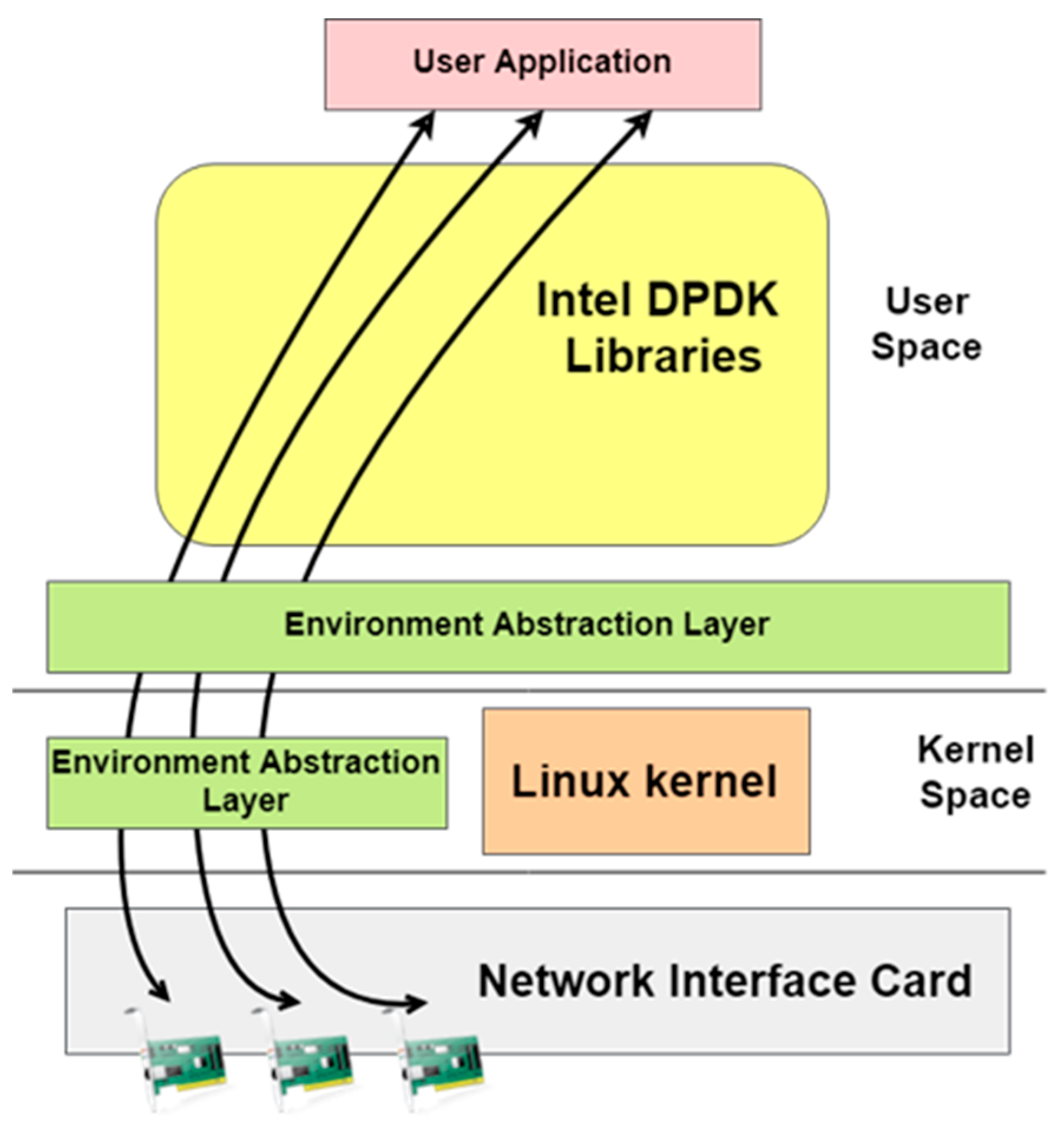
2.5. Data Plane Development Kit (DPDK)
3. Comparison of Data Paths
3.1. Techniques
3.1.1. TCP
3.1.2. UDP
3.1.3. QUIC
3.1.4. RDMA
3.1.5. DPDK
Queue Management
Memory Management
Buffer Management
3.2. Latency and Congestion Control
3.3. Head of Line Blocking
3.4. Throughput
3.5. Middleboxes
3.6. Loss Recovery and Retransmission Ambiguity
3.7. Developer Productivity
3.8. Host Resource Utilization
3.9. Target Applications
4. Simulation Findings
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
List of Abbreviations
| Transmission Control Protocol | TCP |
| User Datagram Protocol | UDP |
| network functions | NFs |
| Quality of Service | QoS |
| Deep packet inspection | DPI |
| Network Function Virtualization | NFV |
| Quick UDP Internet Connections | QUIC Protocol |
| Remote Dynamic Memory Access | RDMA |
| Data plane Development Kit | DPDK |
| Network Interface Card | NIC |
| Round Trip Time | RTT |
| Internet Protocol | IP |
| World Wide Web | WWW |
| The Retransmission timeout | RTO |
| IP Multimedia System | IMS |
| Real-time Transport Protocol | RTP |
| Internet Engineering Task Force | IETF |
| Network Address Translators | NATs |
| Domain Name System | DNS |
| Multipath QUIC | MPQUIC |
| Fast Remote Memory | FaRM |
| Environment Abstraction Layer | EAL |
| Non-Uniform Memory Access | NUMA |
| Advertised Window | AWND |
| Congestion Window | CWND |
| Diffie-Hellman | DH |
| Converged Ethernet | RoCE |
| Dynamic Random Access Memories | DRAMs |
| Longest Prefix Matching | LPM |
| Weighted Random Early Detection | WRED |
| Head of Line | HOL |
| Remote Procedure Calls | RPC |
References
- Khan, I.U.; Hassan, M.A. Transport Layer Protocols And Services. Int. J. Res. Comput. Commun. Technol. 2016, 5, 2320–5156. [Google Scholar]
- Rahmani, M.; Pettiti, A.; Biersack, E.; Steinbach, E.; Hillebrand, J. A comparative study of network transport protocols for in-vehicle media streaming. In Proceedings of the IEEE International Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2008; pp. 441–444. [Google Scholar]
- Andrew, T.; Wetherall, D. Computer Networks, 4th ed.; Prentice Hall: Hoboken, NJ, USA, 2003. [Google Scholar]
- Saima, Z.; Faisal, B. A survey of transport layer protocols for wireless sensor networks. Int. J. Comput. Appl. 2011, 33, 45–50. [Google Scholar]
- William, S. Business Data Communications; Prentice Hall PTR: Hoboken, NJ, USA, 1990. [Google Scholar]
- Awasthi, P.; Kosta, A. Comparative Study and Simulation of TCP and UDP Traffic over Hybrid Network with Mobile IP. Int. J. Comput. Appl. 2013, 83, 9–13. [Google Scholar] [CrossRef]
- Bhargavi, G. Experimental Based Performance Testing of Different TCP Protocol Variants in comparison of RCP+ over Hybrid Network Scenario. Int. J. Innov. Adv. Comput. Sci. IJIACS ISSN 2014, 3, 2347–8616. [Google Scholar]
- Li, Z. HPSRouter: A high performance software router based on DPDK. In Proceedings of the 2018 20th International Conference, Chuncheon-si, Korea, 11–14 February 2018. [Google Scholar]
- Luigi, R. Netmap: A novel framework for fast packet I/O. In Proceedings of the 21st USENIX Security Symposium (USENIX Security 12), Bellevue, WA, USA, 8–10 August 2012; pp. 101–112. [Google Scholar]
- Wu, W.; Crawford, M.; Bowden, M. The performance analysis of Linux networking–packet receiving. Comput. Commun. 2007, 30, 1044–1057. [Google Scholar] [CrossRef]
- Bolla, R.; Bruschi, R. Linux software router: Data plane optimization and performance evaluation. J. Netw. 2007, 2, 6–17. [Google Scholar] [CrossRef]
- Intel DPDK, Data Plane Development Kit Project. Intel. 2014. Available online: http://www.dpdk.org (accessed on 1 July 2022).
- Intel DPDK, Programmers Guide. 2014. Available online: https://doc.dpdk.org/guides/prog_guide/ (accessed on 1 July 2022).
- Kurose, J.; Ross, K. Computer Networking: A Top Down Approach; Addision Wesley: Boston, MA, USA, 2013. [Google Scholar]
- Moura, G.; Heidemann, J.; Hardaker, W.; Bulten, J.; Ceron, J.; Hesselman, C. Old but Gold: Prospecting TCP to Engineer DNS Anycast (Extended). 2020. Available online: https://www.sidnlabs.nl/downloads/5OtgdbyQ9LK0ELbuegno38/38748ecbcabcb32e1fbc885dee3938cf/Old_but_Gold_Prospecting_TCP_to_Engineer_DNS_Anycast.pdf (accessed on 1 July 2022).
- Paxson, V.; Allman, M.; Chu, J.; Sargent, M. Computing TCP’s Retransmission Timer. 2011. Available online: https://www.rfc-editor.org/rfc/rfc6298 (accessed on 1 July 2022).
- Lorincz, J.; Klarin, Z.; Ožegović, J. A Comprehensive Overview of TCP Congestion Control in 5G Networks: Research Challenges and Future Perspectives. Sensors 2021, 21, 4510. [Google Scholar] [CrossRef] [PubMed]
- Addagatla, S.; Goddanakoppalu, B.; Kumar, K.; Oyj, N. System and Method of Network Congestion Control by UDP Source Throttling. U.S. Patent 10/758,854, 21 July 2005. [Google Scholar]
- Wirges, J.; Dettmar, U. Performance of TCP and UDP over Narrowband Internet of Things (NB-IoT). In Proceedings of the 2019 IEEE International Conference on Internet of Things and Intelligence System (IoTaIS), Bali, Indonesia, 5–7 November 2019. [Google Scholar]
- Chai, L.; Reine, R. Performance of UDP-Lite for IoT network. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Sarawak, Malaysia, 26–28 November 2019; IOP Publishing: Bristol, UK, 2019; Volume 495. [Google Scholar]
- Eggert, L.; Fairhurst, G.; Shepherd, G. UDP Usage Guidelines. 2017. Available online: https://tools.ietf.org/html/rfc8085 (accessed on 1 July 2022).
- Alós, A.; Morán, F.; Carballeira, P.; Berjón, D.; García, N. Congestion control for cloud gaming over udp based on round-trip video latency. IEEE Access 2019, 7, 78882–78897. [Google Scholar] [CrossRef]
- Gu, Y.; Grossman, R.L. UDT: UDP-based data transfer for high-speed wide area networks. Comput. Netw. 2007, 51, 1777–1799. [Google Scholar] [CrossRef]
- QUIC Working Group. IETF. Available online: https://quicwg.org/ (accessed on 4 May 2019).
- Carlucci, G.; Cicco, L.D.; Mascolo, S. HTTP over UDP: An Experimental Investigation of QUIC. In Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain, 13–17 April 2015. [Google Scholar]
- Viernickel, T.; Frommgen, A.; Rizk, A.; Koldehofe, B.; Steinmetz, R. Multipath quic: A deployable multipath transport protocol. In Proceedings of the IEEE International Conference on Communications, Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Langley, A.; Riddoch, A.; Wilk, A.; Vicente, A.; Vicente, A.; Krasic, C.; Zhang, D.; Yang, F.; Kouranov, F.; Swett, I.; et al. The QUIC transport protocol: Design and Internet-scale deployment. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017. [Google Scholar]
- QUIC, a Multiplexed Stream Transport over UDP. Available online: https://www.chromium.org/quic (accessed on 4 May 2019).
- Sandvine. Global Internet Phenomena Report—Latin America and North America. 2016. Available online: https://www.sandvine.com/hubfs/Sandvine_Redesign_2019/Downloads/Internet%20Phenomena/2016-global-internet-phenomena-report-latin-america-and-north-america.pdf (accessed on 1 July 2022).
- Huang, S.; Cuadrado, F.; Uhlig, S. Middleboxes in the Internet: A HTTP perspective. In Proceedings of the 2017 Network Traffic Measurement and Analysis Conference (TMA), Dublin, Ireland, 21–23 June 2017. [Google Scholar]
- Roy, F.; Reschke, J. RFC 7230: Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing. 2014. Available online: https://datatracker.ietf.org/doc/rfc7230/ (accessed on 1 July 2022).
- Mike, B.; Peon, R.; Thomson, M. RFC 7540: Hypertext Transfer Protocol Version 2 (HTTP/2). 2015. Available online: https://www.rfc-editor.org/rfc/rfc7540 (accessed on 1 July 2022).
- Clark, D.; Tennenhouse, D.L. Architectural considerations for a new generation of protocols. ACM SIGCOMM Comput. Commun. Rev. 1990, 20, 200–208. [Google Scholar] [CrossRef]
- Christopher, M.; Geng, Y.; Li, J. Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store. In Proceedings of the 2013 USENIX Annual Technical Conference, San Jose, CA, USA, 26–28 June 2013. [Google Scholar]
- Berk, A.; Xu, Y.; Frachtenberg, E.; Jiang, S.; Paleczny, M. Workload analysis of a large-scale key-value store. In ACM SIGMETRICS Performance Evaluation Review; Association for Computing Machinery: New York, NY, USA, 2012; pp. 53–64. [Google Scholar]
- Kalia, A.; Mellon, C.; Kaminsky, D.G.A.M. FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) OSD; USENIX Association: Savannah, GA, USA, 2016; pp. 185–201. [Google Scholar]
- Aleksandar, D.; Narayanan, D.; Castro, M.; Hodson, O. FaRM: Fast remote memory. In {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 14); USENIX Association: Seattle, WA, USA, 2014; pp. 401–414. [Google Scholar]
- Anuj, K.; Kaminsky, M.; Andersen, D. Using RDMA efficiently for key-value services. In Proceedings of the ACM SIGCOMM Computer Communication Review, Chicago, IL, USA, 17–22 August 2014; pp. 295–306. [Google Scholar]
- Gunnar, G.E.; Eimot, M.; Reinemo, S.-A.; Skeie, T.; Lysne, O.; Huse, L.P.; Shainer, G. First experiences with congestion control in InfiniBand hardware. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), Atlanta, GA, USA, 19–23 April 2010. [Google Scholar]
- Jaichen, X.; Chaudhry, M.U.; Vamanan, B.; Vijaykumar, T.N.; Thottethodi, M. Fast Congestion Control in RDMA-based Datacenter Networks. In Proceedings of the ACM SIGCOMM 2018 Conference on Posters and Demos, Budapest, Hungary, 20–25 August 2018; pp. 24–26. [Google Scholar]
- Mohammad, A.; Greenberg, A.; Maltz, D.; Padhye, J.; Patel, P.; Prabhakar, B.; Sengupta, S.; Sridharan, M. Data center tcp (dctcp). In Proceedings of the ACM SIGCOMM Computer Communication Review, New York, NY, USA, 5 September 2011. [Google Scholar]
- Charles, L. Fat-trees: Universal networks for hardware-efficient supercomputing. IEEE Trans. Comput. 1985, C34, 892–901. [Google Scholar]
- Kulkarni, H.; Agrawal, S.; Pore, R.; Andhale, P.; Patil, N. A survey on TCP/IP API stacks based on DPDK. Int. J. Adv. Res. Innov. Ideas Educ. 2017, 3, 1205–1208. [Google Scholar]
- Mihai, D.; Egi, N.; Argyraki, K.; Chun, B.-G.; Fall, K.; Iannaccone, G.; Knies, A.; Manesh, M.; Ratnasamy, S. RouteBricks: Exploiting Parallelism to Scale Software Routers. In Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, Big Sky, MT, USA, 11–14 October 2009; pp. 15–28. [Google Scholar]
- Dominik, S. A Look at Intel’s Dataplane Development Kit. In Proceedings of the Seminars FI/IITM SS, Network Architectures and Services, Munich, Germany, 30 April–3 August 2014. [Google Scholar] [CrossRef]
- Sangjin, H.; Jang, K.; Park, K.; Moon, S. PacketShader: A GPU-Accelerated Software Router. ACM SIGCOMM Comput. Commun. Rev. 2011, 40, 195–206. [Google Scholar]
- Francesco, L.D.F. High speed network traffic analysis with commodity multi-core systems. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement, Melbourne, Australia, 1–30 November 2010; pp. 218–224. [Google Scholar]
- Nicola, B.; Pietro, A.D.; Giordano, S.; Procissi, G. On multi–gigabit packet capturing with multi–core commodity hardware. In International Conference on Passive and Active Network Measurement; Springer: Berlin/Heidelberg, Germany, 2012; pp. 64–73. [Google Scholar]
- Miguel, R.; Goutelle, M.; Kelly, T.; Hughes-Jones, R.; Martin-Flatin, J.-P.; Li, Y.-T. A map of the Networking Code in Linux Kernel 2.4. 20. Technical Report DataTAG. Available online: http://files.securitydate.it/misc/draft12.pdf (accessed on 31 March 2004).
- Intel DPDK, Packet Processing on Intel Architecture, Presentation Slides. 2012. Available online: https://www.dpdk.org/wp-content/uploads/sites/35/2018/03/Updated-India-DPDK-Summit-2018-MJay-NIC-Perfo.pptx (accessed on 4 May 2015).
- Intel DPDK, Getting Started Guide. 2014. Available online: https://doc.dpdk.org/guides-16.04/linux_gsg/index.html (accessed on 4 May 2019).
- Intel Open Source Organization, Intel Open Source Technology Center: Packet Processing. 2014. Available online: https://01.org/packet-processing (accessed on 1 July 2022).
- Chen, T.; Liu, A.X.; Munir, A.; Yang, J.; Zhao, Y. OpenFunction: Data Plane Abstraction for Software-Defined Middleboxes. arXiv 2016. [Google Scholar] [CrossRef]
- Paul, R. Selective-TCP for Wired/Wireless Networks. 2006. Available online: https://www.sfu.ca/~ljilja/cnl/pdf/rajashree_thesis.pdf (accessed on 1 July 2022).
- Mohammad, R.; Norwawi, N.; Ghazali, O.; Faaeq, M. Detection algorithm for internet worms scanning that used user datagram protocol. Int. J. Inf. Comput. Secur. 2019, 11, 17–32. [Google Scholar]
- Bonczkowski, J.L.; Hansen, N.A.; Hart, S.R.; Ancelot, P. Computer Implemented System and Method and Computer Program Product for Testing a Software Component by Simulating a Computing Component Using Captured Network Packet Information. U.S. Patent US-9916225-B1, 12 March 2018. [Google Scholar]
- Alexander, S.; Zahavi, E.; Dahley, O.; Barnea, A.; Damsker, R.; Yekelis, G.; Zus, M.; Kuta, E.; Baram, D. Roce rocks without pfc: Detailed evaluation. In Proceedings of the Workshop on Kernel-Bypass Networks, Los Angeles, CA, USA, 20–25 August 2017. [Google Scholar]
- IEEE, 802.1Qau–Congestion Notification. 2010. Available online: https://www.ietf.org/proceedings/67/slides/tsvarea-2.pdf (accessed on 1 July 2022).
- IEEE, 802.1Qbb–Priority-Based Flow Control. 2011. Available online: https://1.ieee802.org/dcb/802-1qbb/ (accessed on 1 July 2022).
- Aleksandar, D.N.M.C.D. RDMA Reads: To Use or Not to Use? IEEE Data Eng. Bull 2017, 40, 3–14. [Google Scholar]
- Redis: An Advanced Key-Value Store. Available online: http://redis.io (accessed on 1 July 2022).
- Memcached: A Distributed Memory Object Caching System. Available online: https://memcached.org/ (accessed on 1 July 2022).
- Renato, R.; Metzle, B.; Culley, P.; Hilland, J.; Garcia, D. A Remote Direct Memory Access Protocol Specification. 2007. Available online: https://tools.ietf.org/html/rfc5040 (accessed on 1 July 2022).
- Lwn.Net. A Lockless Ring-Buffer. 2014. Available online: https://lwn.net/Articles/340400/ (accessed on 1 July 2022).
- Christian, B. Understanding Linux Network Internals; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2006. [Google Scholar]
- Badach, A.; Hoffmann, E. Technik der IP-Netze -TCP/IP incl. IPv6, Hanser. 2007. Available online: https://www.hanser-elibrary.com/doi/book/10.3139/9783446410893 (accessed on 1 July 2022).
- Alexander, A.; Tilley, N.; Reiher, P.; Kleinrock, L. Host-to-host congestion control for TCP. IEEE Commun. Surv. Tutor. 2010, 12, 304–342. [Google Scholar]
- Lopes, K.; Augusto, D.; Monteiro, S.; Florissi, D. Traffic Management in Isochronets Networks. In Managing QoS in Multimedia Networks and Services; Springer: Boston, MA, USA, 2000; pp. 131–146. [Google Scholar]
- Chen-Nien, M.; Huang, M.-H.; Padhy, S.; Wang, S.-T.; Chung, W.-C.; Chung, Y.-C.; Hsu, C.-H. Minimizing latency of real-time container cloud for software radio access networks. In Proceedings of the 2015 IEEE 7th International Conference on Cloud Computing Technology and Science (CloudCom), Vancouver, BC, Canada, 30 November–3 December 2015. [Google Scholar]
- Organization DPDK, Documentation. 2019. Available online: https://doc.dpdk.org/guides/index.html (accessed on 9 April 2019).
- Michael, S.; Kiesel, S. Head-of-line Blocking in TCP and SCTP: Analysis and Measurements. In Proceedings of the IEEE GLOBECOM Technical Conference, San Francisco, CA, USA, 27 November–1 December 2006. [Google Scholar]
- Hamilton, R.; Iyengar, J.; Swett, I.; Wilk, A. QUIC: A Udp-Based Secure and Reliable Transport for HTTP/2. 2016. Available online: https://datatracker.ietf.org/doc/html/draft-tsvwg-quic-protocol-02 (accessed on 1 July 2022).
- Zhu, Y.; Eran, H.; Firestone, D.; Guo, C.; Lipshteyn, M.; Liron, Y.; Padhye, J.; Raindel, S.; Yahia, M.H.; Zhang, M. Congestion control for large-scale RDMA deployments. ACM SIGCOMM Comput. Commun. Rev. 2015, 45, 523–536. [Google Scholar] [CrossRef]
- Radisys. Radisys Leads with DPDK Performance-Benchmark Study. 2014. Available online: https://www.radisys.com/benchmark-study-radisys-leads-dpdk-performance-feature (accessed on 5 April 2019).
- Giannoulis, S.; Antonopoulos, C.P.; Topalis, E.; Athanasopoulos, A.; Prayati, A.; Koubias, S.A. TCP vs. UDP Performance Evaluation for CBR Traffic on Wireless Multihop Networks. Simulation 2009, 14, 43. [Google Scholar]
- Brian, T. TCP Tuning Guide for Distributed Applications on Wide Area Networks. Usenix SAGE Login 2001, 26, 33–39. [Google Scholar]
- Eric, W.; Feng, W.-c. Dynamic right-sizing: A simulation study. In Proceedings of the Tenth International Conference on Computer Communications and Networks, Scottsdale, AZ, USA, 15–17 October 2001; pp. 152–158. [Google Scholar]
- Amit, C.; Cohen, R. A dynamic approach for efficient TCP buffer allocation. IEEE Trans. Comput. 2002, 51, 303–312. [Google Scholar]
- Lockwood, J.W. Scalable Key/Value Search in Datacenters. In Proceedings of the 2015 IEEE 23rd Annual International Symposium on Field-Programmable Custom Computing Machines, Vancouver, BC, Canada, 2–6 May 2007. [Google Scholar]
- Gandhi, R. Improving Cloud Middlebox Infrastructure for Online Services. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2016. [Google Scholar]
- Phil, K.; Partridge, C. Improving round-trip time estimates in reliable transport protocols. ACM SIGCOMM Comput. Commun. Rev. USA 1987, 17, 2–7. [Google Scholar]
- Lixia, Z. Why TCP timers don’t work well. ACM SIGCOMM Comput. Commun. Rev. USA 1986, 16, 397–405. [Google Scholar]
- Wu, X.; Li, P.; Ran, Y.; Luo, Y. Network Measurement for 100Gbps Links Using Multicore Processors. In Proceedings of the 3rd Innovating the Network for Data-Intensive Science (INDIS2016), Salt Lake City, UT, USA, 13–16 November 2016. [Google Scholar]
- Hendrickson, S.; Sturdevant, S.; Harter, T. Serverless Computation with Openlambda. In 8th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 16); USENIX Association: Denver, CO, USA, 2016; p. 80. [Google Scholar]
- Carol, D.; Johnston, A.; Singh, K.; Sinnreich, H.; Wimmreuter, W. SIP APIs for voice and video communications on the web. In Proceedings of the 5th International Conference on Principles, Systems and Applications of IP Telecommunications, Chicago, IL, USA, 1–2 August 2011. [Google Scholar]
- Ken, B.; Behrens, J.; Jha, S.; Milano, M.; Tremel, E.; Renesse, R.V. Groups, Subgroups and Auto-Sharding in Derecho: A Customizable RDMA Framework for Highly Available Cloud Services. 2016. Available online: http://www.cs.cornell.edu/projects/Quicksilver/public_pdfs/Derecho-API-v9.5.pdf (accessed on 1 July 2022).
- Shinae, W.; Park, K. Scalable TCP Session Monitoring with Symmetric Receive-Side Scaling. 2012. Available online: https://www.ndsl.kaist.edu/~kyoungsoo/papers/TR-symRSS.pdf (accessed on 1 July 2022).
- Kyratzis, A.; Cottis, P. QUIC vs. TCP: A Performance Evaluation over LTE with NS-3. Commun. Netw. 2022, 4, 12–22. [Google Scholar] [CrossRef]
- Lai, L.; Ara, G.; Cucinotta, T.; Kondepu, K.; Valcarenghi, L. Ultra-Low Latency NFV Services Using DPDK. In Proceedings of the 2021 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Virtual Conference, 9–11 November 2021. [Google Scholar]
- Pm-04-Dublin-Urdma-Presentation. Available online: https://www.dpdk.org/wp-content/uploads/sites/35/2018/10/pm-04-dublin-urdma-presentation.pdf (accessed on 1 July 2022).
- Dugan, J.; Estabrook, J.; Ferbuson, J.; Gallatin, A.; Gates, M.; Gibbs, K.; Hemminger, S.; Jones, N.; Qin, F.; Renker, G.; et al. iPerf: TCP/UDP Bandwidth Measurement Tool. Available online: https://iperf.fr/v (accessed on 4 May 2019).
- Kakhki, A.M. Measuring QUIC vs. TCP on Mobile and Desktop. 2018. Available online: https://blog.apnic.net/2018/01/29/measuring-quic-vs-tcp-mobile-desktop/ (accessed on 5 May 2019).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Latency Type | Users | Percentage |
|---|---|---|
| Latency reduction in Google search responses | Desktop users | 8% |
| Mobile users | 3.8% | |
| YouTube playback re-buffer rate reduction | Desktop users | 18% |
| Mobile users | 15.3% |
| Reliability | Congestion Control | HOL | Throughput | Middleboxes Effect | Recovery of Lost Packets | Example of Target Applications | |
|---|---|---|---|---|---|---|---|
| TCP | Reliable | Available | Prone to | Not Important | Low | Recovered | Emails and Web browsing |
| UDP | Unreliable | Not Available | No HOL | High | Low | Not recovered | VoIP |
| QUIC | Contains unreliable component | At the application layer | No HOL | High | High | Recovered | Streaming |
| RDMA | Reliable | Available | Prone to | Top | Low | Lossless links | Datacenters |
| DPDK | Unreliable | Not Available | Not reported | High | Low | - | Intel processors |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barghash, A.; Hammad, L.; Gharaibeh, A. Traditional vs. Modern Data Paths: A Comprehensive Survey. Computers 2022, 11, 132. https://doi.org/10.3390/computers11090132
Barghash A, Hammad L, Gharaibeh A. Traditional vs. Modern Data Paths: A Comprehensive Survey. Computers. 2022; 11(9):132. https://doi.org/10.3390/computers11090132
Chicago/Turabian StyleBarghash, Ahmad, Lina Hammad, and Ammar Gharaibeh. 2022. "Traditional vs. Modern Data Paths: A Comprehensive Survey" Computers 11, no. 9: 132. https://doi.org/10.3390/computers11090132
APA StyleBarghash, A., Hammad, L., & Gharaibeh, A. (2022). Traditional vs. Modern Data Paths: A Comprehensive Survey. Computers, 11(9), 132. https://doi.org/10.3390/computers11090132