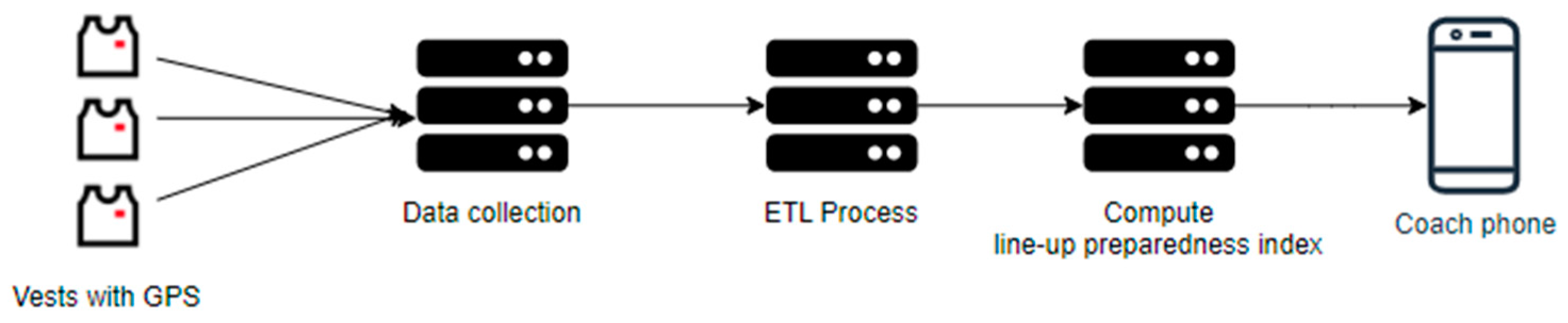
The aim of the present work is to develop an information system, using artificial intelligence, to identify potentially football match line-ups, which architecture is presented in
Figure 1. The system collects the physiological variables from the GPS vests of the players. These variables are imported into a database, to which some transformations are performed. The ML model is used for calculating the line-up preparedness index of each player, which then the soccer coach can consult and use in his decision making.
For the ML process the Cross Industry Standard Process for Data Mining (CRISP-DM) [
17] process was selected, as in [
18] but in sport result prediction. The CRISP-DM framework has six phases: business understanding, data understanding, data preparation, modelling, evaluation, and deployment. Apart from the deploy stage, which was not performed since the model has not yet been put into production, all the others were performed and are presented in the following subsections.
3.1. Business Understanding
The purpose of this work is to construct a player fitness index to help football coaches choose the players who should be starters, i.e., those who should participate in the starting line-up.
To create this index, all the physiological variables of each player were collected by GPS both in games and in training. In addition to this data, the results of the team in the games (target variable) and the initial line-up of the players in the games were also recorded.
To build the index several steps were followed: first, the physiological variables of the players, by field position (Central Defender (CD), Full Back (FB), Centre Midfielder (CM), Offensive Midfielder (OM), Winger (W) and Forward (F)), that most contribute to victory were identified using Recursive Feature Elimination (RFE) [
19,
20] (already carried out in a previous study [
8]. Then ML algorithms were trained to determine if the variables selected by the RFE algorithm produced better results than using all variables. Finally, a logistic regression was performed on the most appropriate set of variables to create the fitness index of the players to be part of the team taking the field.
As a result, it is expected that this predictive index can have an influence on the training analysis, because the coaching staff can understand where they should apply more focus in the training sessions to perform better on game day.
3.2. Data Understanding
For this study, a dataset was compiled with the physiological variables of football players recorded by a GPS during the training sessions and football games of a Portuguese team from the 2nd Regional Division of AF Santarém in the 2018/2019 season (see
Table 1).
In addition to the physiological variables, the dataset regarding the football matches also contains the line-up selection for the games, contextual variables such as the type of field where the training session/match was played (Pitch) and definition of home or away game (Home or Away) and the games result variable (Final Score), which will be, after its transformation, our target variable (win), that will hold the indication whether the game was won or not (binary).
During the 2018/2019 the team with 28 players with an average age of 22 years old played 14 games in the first phase of the championship, 10 games in the second phase and 2 extra games in Ribatejo Cup, regarding the training session, 39 training sessions were recorded through 13 microcycles. A total of 33,748 different episodes were registered, regarding the different players, and games they played. In addition, the dataset regarding the training sessions had a total of 24,360 different episodes, regarding the different players. ML algorithms were applied to these records, which results are presented in
Section 3.4.1 and
Section 3.4.2.
Table 2 presents the description of the variables used in this study.
3.3. Data Preparation
At this stage the selected data was processed to be later used by the ML models. Firstly, null or inconsistent information was removed from the dataset. After cleaning the data two transformations were performed. The first was to create a
Win variable (data labelling) since the objective of this study are the victories and therefore the distinction between draw and defeat was not considered relevant in the scope of this work. In this case, the variable
Win contains the information about the victory in the game (1—victory; 0—other). This variable was computed from the variable with the game result, “Final Score” (see
Table 1 and
Table 2). The second one was to merge the different datasets, associating the variables
win and
line-up of the games with the training sessions, as this dataset does not contain these two variables. In order to do so, two new variables were created in the training sessions dataset namely,
win and
line-up. These new variables are used for the identification within the training dataset which players were in the starting 11 of each game and its outcome. To create this new variable in the training sessions dataset a query (join) that related the two datasets using the variables
athlete and
game was built resulting in a new dataset with 16,996 episodes (see
Table 3 and
Table 4). During the model and evaluation phases, the episodes were grouped by player position to run the different ML algorithms. The episodes regarding the Goalkeeper position were excluded because of the specific physiological demands regarding this position.
3.4. Modelling
The modelling stage was divided into two phases: one where the most important physiological variables of the players in determining the victory in the game are identified, and a second in where an index of the players best suited for the game from the point-of-view of physiological variables is generated—the so-called the line-up preparedness index—using logistic regression.
3.4.1. Selection of the Best Set of Variables
At this stage, two models were used to select the variables: one with all the variables available in the game dataset (see
Table 1) and another where the RFE algorithm was used to determine the most important variables for determining the victory, for each player position. The variables selected by RFE allow the understanding of the different effects of a football game in the different positions, and how these variables affect winning the game. These variables are dependent on the player’s position, displaying differences depending on the position as they are related to specific demands of the player function and team strategy. The results are presented in
Table 5 and were obtained in a previous study conducted by the authors [
8].
The use of the model presented in
Table 5 in the training session dataset faced/encountered two difficulties associated with missing values: the inexistence of data for the OM, which forced it to be removed from the model; and the inexistence of values regarding the variables associated with Heart Rate (
HR, %HR, <60%HR, 60–74.9%HR, 75–89,9%HR and >90%HR), which mainly affected the position W that was left with only one variable to perform the logistic regression, so the literature was used to select a second variable and it was selected a variable defended by Altavilla [
22] where it affirms that total distance during the game (
‘Distance_m/min’) is a very important variable for analysing the performance. The model resulting from these changes is shown in
Table 6.
Then the two models, with and without RFE selected variables, were trained using ML algorithms (Decision Tree Classifier (DT) and Naïve Bayes Classifier (NB)), which results are presented in
Table 7. The classification algorithms were selected with a purpose of analysing the possibility of predicting the win, because our target variable (win), is a binary variable (win or not win).
To analyse the results, the previous table was divided for the two classification algorithms and each model. The present results of the ML algorithms for the 2 models were achieved with Cross-Validation (CV). 5-fold Cross Validation was used.
With the DT classification algorithm, the first model had better results for the CM (achieved 83% accuracy) and the same result for CD (with 83% accuracy) and F (with 70% accuracy). Regarding the other two positions, FB and W, performed better with the second model, achieving 71% and 73% for each position, in terms of accuracy.
Regarding the NB classification algorithm, the first model only achieved better results to one position, FB, with 77% accuracy. It achieved the same results for both models for the W position, with 68% accuracy. In addition, performed better with the second model, for the remaining positions, CD (73%), CM (65%) and F (57%).
Although the differences were not very significant, it was possible to confirm from the results the advantage of using the model with the most important variables for each position using the RFE algorithm compared to the model with all variables (see
Table 7). The use of fewer variables makes it easier for the football coach to monitor them, focusing on the physiological variables that are most relevant to each player’s position on the field. Thus, the variables from the second model were used in the logistic regression, the second part of the study.
3.4.2. Predicting the Starting Line-Up and Chose the Better Prepare Players
To predict the starting line-up a logistic regression was initially used. A logistic regression is a useful way to create a model of probability of a certain class or event to exist, resulting in an index. To create this, it was important to understand if the logistic regression could be applied to all the positions regarding the model created. So, the logistic regression was only applied to the positions where the variables achieved a
p value < 0.05. For that reason, only the results for FB (
Table 8), CM (
Table 9) and W (
Table 10) are presented.
3.5. Evaluation
As for the players’ initial line-up forecast for the match, as mentioned in the modelling section, a logistic regression was used initially to construct an index to create a model of probability.
Based on logistic regression, an index was created to help select the players for the matches, based on the values of the physical variables of the week of training prior to the match, and understand if the player chosen for a particular match was the best prepared one. Using this index, the tables with the index values per player per microcycle (which includes the training sessions of the week) were created for the positions of the players where the regression was considered valid: FB (
Table 11), W (
Table 12) and CM (
Table 13).
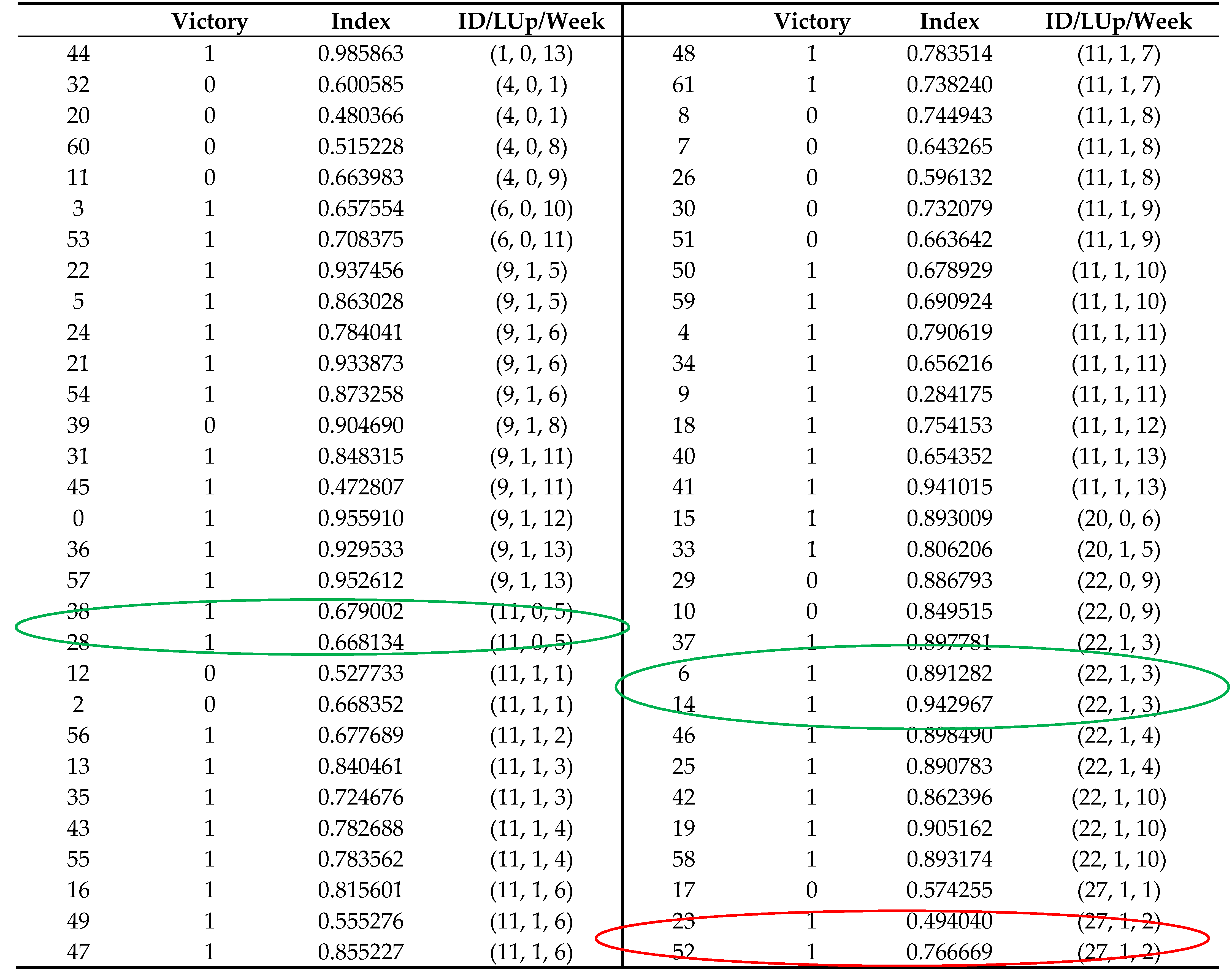
The tables presented were divided into four columns and all are important for understanding the data and the proposed analysis. The first column displays the index in the training session dataset. The second column shows whether the match outcome in which the player participated was a win or not. The third column is the value of the logistic regression index. Finally, the fourth column displays three values: “ID” that represents the identity of the player; “LUp” that indicates if this player was in the line-up; and “Week” that represents the number of the microcycle. To better understand the information associated with each table, two examples of correct decisions (circled in green) and one incorrect decision (red circled) will be identified for each table.
The table for the FB position is shown in
Table 11, where correct decisions are highlighted in green and the wrong ones in red.
For example, the first correct decision according to the model is related to player ID 8 (in the records 21, 95 and 56) since in the three training sessions of the third week, the player’s index reached 91% in the first two and 84% in the last training session. These results indicate that the player in question should be selected for the line-up, which in fact happened, resulting in a positive outcome for the match (win). In the same group, looking at player ID 20 (in the records 88, 71 and 6), it is possible to see that the player in question obtained two training sessions with a low index value (60% and 56%) and a good last training session (with 87%). According to the coaching staff, the player was not selected for the starting line-up, which according to the model is correct. The third player analysed in this example was the same player, player with the ID 20 (in the records 57, 35 and 25) regarding the second week. In this case, the player was selected for the starting line-up by the coaching staff, presenting an index of 67% in the first training session, 60% in the second training session and 59% in the third session. According to the proposed model, this decision did not reflect an adequate evaluation of the readiness/fitness of the player to be in the starting line-up.
Table 12 presents the table regarding the Winger position.
For the Winger position, let us start by analysing the player with the ID 11 (in the records 38 and 28) in the fifth week of training. In this training week, the player only took part of the first and last session of the week with a reported index of 67% and 66%, respectively. In this case, the coaching staff did not select the player for the starting line-up, which according to the model was a correct decision. Another choice of the coaching staff aligned with the model proposed, is related to the player with the ID number 22 (in the records 37, 6 and 14). In this example, the player displayed good index values in week three, achieving 89%, 89% and 94%. In this case, the player in question was selected for the starting line-up, with the team having a positive outcome for the same week match (win). Another example chosen was the player with ID number 27 (in the records 23 and 52), for the second week. In this case, the player was selected for the starting line-up, but only achieved 49% in the first training session and 76% in the last one. These are considered low index values and for that reason and regarding the model is considered a poor choice, as it did not optimise the overall performance of the team.
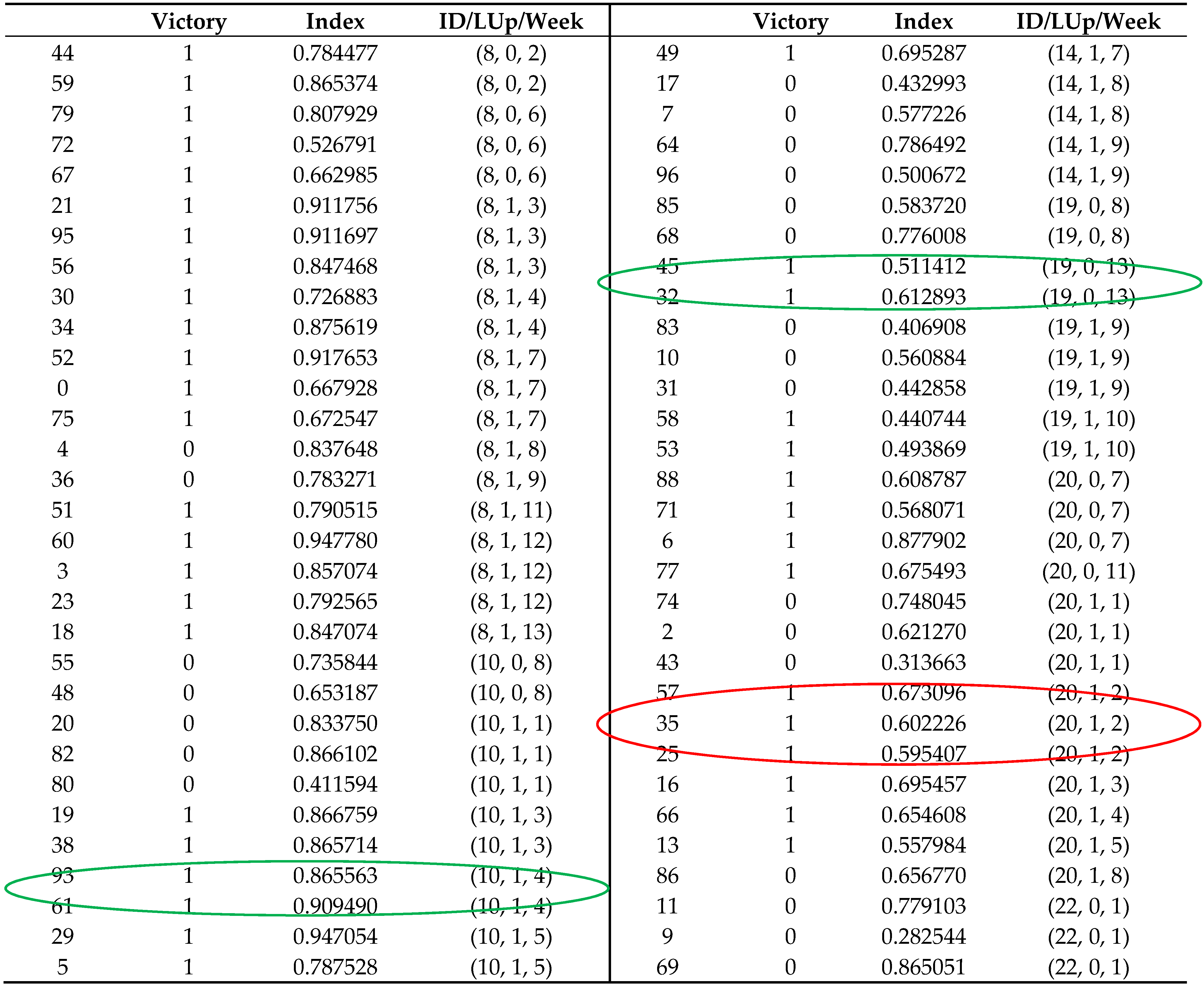
Finally, the table regarding the CM is presented in
Table 13.
Finally, in the case of Central Midfielders, the first example is related with player with the ID number 10 (in the records 93 and 61). The player performance was analysed in the two training sessions regarding the fourth week, where this player achieved 86% in the first training session and 90% in the last training session. In this training week, the player was selected for the starting line-up, with the team having won the match. Considering the model proposed, the option made by the coaching staff was good, since the index values are high (above 85%). The second player analysed in this example was the player with the ID number 19 (in the records 45 and 32). Considering the player performance index (51% and 61%) during the training sessions of week 13, the player should not be selected for the starting line-up, which is in agreement with the decision made by the coaching staff. The last example presented in this work refers to the player with the ID number 20 (in the records 57, 35 and 25) whose performance was analysed for the second week. In this example the player was selected for the line-up, and achieved 67% in the first training, 60% in the second training session, and 59% in the last training session. Considering the proposed model, this player did not display a good performance (low index values), even though the team won the week match.






{kind=link}