2.1. Animal Image Classification Using Convolutional Neural Networks
Ever since the pioneering work of LeCun et al. [
3] on handwritten zip code detection, Convolutional Neural Networks (CNNs) have been used for many image recognition problems. CNNs have also shown good results when applied to the animal classification problem, reporting accuracies of 90% and above. For example, Okafor et al. [
4] trained a fine-tuned InceptionV1 model to achieve a top-1 test classification accuracy of 99.93% on a Flicker-obtained dataset of 5000 images consisting of bears, elephants, leopards, lions, and wolves. Similarly, Zmudzinski [
5] trained GoogLeNet on a 1000-image dataset to distinguish between three species of guinea pig and obtained a classification accuracy of 99.31%. Yousif et al. [
6] trained AlexNet specifically for camera trap image classification and obtained an accuracy of 95.6%. Huang and Basanta [
7] proposed a novel CNN comprising of five convolution layers that classified a 27-species bird dataset of 3563 images with 95.37% accuracy. This proposed CNN contained skip connections, much like the ResNet architecture [
8], which obtained the highest training accuracy when compared to non-residual and Support Vector Machine (SVM) models. Allken et al. [
9] used a fish species classifier based on InceptionV3 using a synthetic 10,000-image dataset to obtain an accuracy of 94%. Hu and You [
10] used ResNet18 on the 19,465-image Animal-10 dataset to obtain an accuracy of 92%. Lai et al. [
11] trained Xception on the Stanford Dogs Dataset of 20,580 images and 120 breeds to achieve a species classification accuracy of 91.29%. Tabak et al. [
12] trained a ResNet-18 CNN on a 3.37 million-image dataset comprising of images from five U.S. states and achieved a multi-class classification accuracy of 97.6%. Whytock et al. [
13] trained ResNet-50 on a 300,000-image dataset comprising of 26 different species and attained 77.63% accuracy. Schneider et al. [
14] also trained DenseNet201 and Xception on the Parks Canada dataset that contained 47,279 images of 55 classes and achieved 95.6% and 95.4% classification accuracy and 0.794 and 0.786 F1-scores, respectively. However, Schneider et al. [
14] observed a 26.9% drop in accuracy in both models and a 0.096 and 0.14 drop in F1-scores, respectively, when applying the trained models to animals in unseen locations, raising questions about overfitting of the models. This issue was also highlighted by Tabak et al. [
15], who proposed to solve this issue by training ResNet-18 on a mixed dataset comprising of animal images from ten different states in the U.S., achieving a classification accuracy of 96.8% and packaging these trained models into an R package named Machine Learning for Wildlife Image Classification (MLWIC) [
16].
Mixed approaches have also been used in animal classification. For example, rather than using individual images for image classification, Shashidhara et al. [
17] took a different approach of capturing animal images in “burst”, wherein each instance of animal movement was captured not by a single image but by a series of three to five images. These images were then concatenated and represent a single data point whose temporal information could be leveraged to aid in classification. Using this technique, they trained ResNet-152 to achieve an ROC AUC of 0.857. Finally, Norouzzadeh et al. [
18] proposed a hybrid approach of combining manual image labelling with CNN image classification. This active learning approach involved training a model to not only classify images, but to determine which images, from a dataset of mostly unlabeled data, were the best candidates for manual labelling in order to aid the model in labelling the rest by itself. Using this approach, they trained ResNet-50 to achieve 91.37% accuracy.
In order to deal with the “non-animal” or ghost images problem prevalent in camera traps, prior classification or object-detection techniques have been used. For example, Vargas-Felipe et al. [
19] used SVM and achieved a 99.95% accuracy in classifying between empty images and those with Ovis canadensis. Similarly, Willi et al. [
20] trained ResNet18 on the Camera CATalogue dataset to distinguish between animals (“non-empty”), vehicles (under “empty”), and other “empty” objects using randomly initialized weights and achieving an accuracy of 98.0%. They also trained a fine-tuned ResNet18, initialized on weights based on other unspecified camera trap projects, on the Elephant Expedition dataset and achieved up to 96.6% accuracy. Similarly, Chen et al. [
21] proposed an AlexNet-based CNN with five convolution layers initialized on AlexNet weights, which achieved a binary (badger vs. no-badger) classification accuracy of 98.05% and a multi-class (six classes: badger, bird, cat, fox, rat, and rabbit) accuracy of 90.32% when trained on an 8368-image dataset. Using drone imagery, Sahu [
22] trained U-Net to detect and classify lizards from other background objects using a slightly different two-step approach. The approach included training the model on a dataset with only lizards (positive class) and then training it on the full dataset of background images that contained multiple, single, or no lizards. Using this approach, the model was able to achieve 98.63% accuracy. Similarly, Nguyen et al. [
23] used a binary classifier based on VGG-16 and a multi-species classifier ResNet-50 to attain 96.6% and 84.39% accuracies, respectively. Gomez et al. [
24] used ResNet101 to achieve a binary (birds vs. no birds) accuracy of 97.5% and multi-class (bird species) accuracy of 90.23%. Others, like Beery et al. [
25] and Shepley et al. [
26], used object detection techniques to eliminate non-animal images before classification. An object detection approach proposed by Wei et al. [
27] outperformed MLWIC [
16]. Finally, Cunha et al. [
28] compared the performance of the classification and object detection approaches to the empty-image identification problem and showed that object-detection approaches, like EfficientNet-D0 and SSDLite + MobileNet-V2, outperformed classifier-only approaches, like MobileNet-V2, EfficientNet-B0, and EfficientNet-B3.
Besides using state-of-the-art CNNs such as GoogLeNet, AlexNet, ResNet, U-Net, and VGG, many have proposed novel CNN architectures for the animal classification problem (e.g., [
7,
21]). For example, Teto and Xie [
29] proposed a capsule network that achieved a 79% accuracy compared to VGG-16 (96.4%) and InceptionV3 (95%) after being trained on a 500,000-image subset of the Snapshot Serengeti dataset. Rathi et al. [
30] proposed a novel three-layer CNN trained on the 27,142-image Fish4Knowledge dataset with a 96.29% classification accuracy. Zuluaga et al. [
31] proposed a novel CNN called MixtureNet that is comprised of the concatenated features and last pooling layers from GoogLeNet, ResNet50, ResNet101, and ResNet152, all of which were trained on the 9208-image Alexander von Humboldt database. MixtureNet obtained an accuracy of 92.65% when classifying between ten classes. Tariq et al. [
32] proposed a binary classifier comprised of five convolution layers to classify between snow leopards and other animals. In their work, the CNN was trained on an unspecified local dataset of 1500 images and achieved an accuracy of 91%. Jiang et al. [
33] proposed a Bilateral Convolution Network (BCNet) comprised of two parallel networks and designed to achieve a trade-off between the classification accuracy and model size in order to be feasible on mobile and edge computing devices. BCNet4 contained two convolution layers and two fully connected layers that performed with 83.9% classification accuracy on a 50-species, 37,322-image dataset with a model size of 16.80 MB and a computational complexity of 0.62 GFlops. This is comparable to another lightweight CNN architecture, EfficientNetB0 (of the EfficientNet series), that has a size of 29.00 MB [
34], a complexity of 0.4 GFlops [
35], and a macro-F1-score of 0.225 according to the top seven (out of 336) entry on the iWildCam 2019 animal image recognition competition [
36]. Finally, an aquatic species classifier based on a CNN with two convolution layers obtained an accuracy of 85.59% [
37].
Table 1 shows a summary of applying CNNs for animal image classification.
Table 1 shows the model used, its size in MB, size of the dataset used, and the accuracy achieved. As the table shows, it was possible to use pre-trained models like Inception and ResNet to obtain high accuracies. In addition, the model sizes varied between 28 MB to 528 MB.
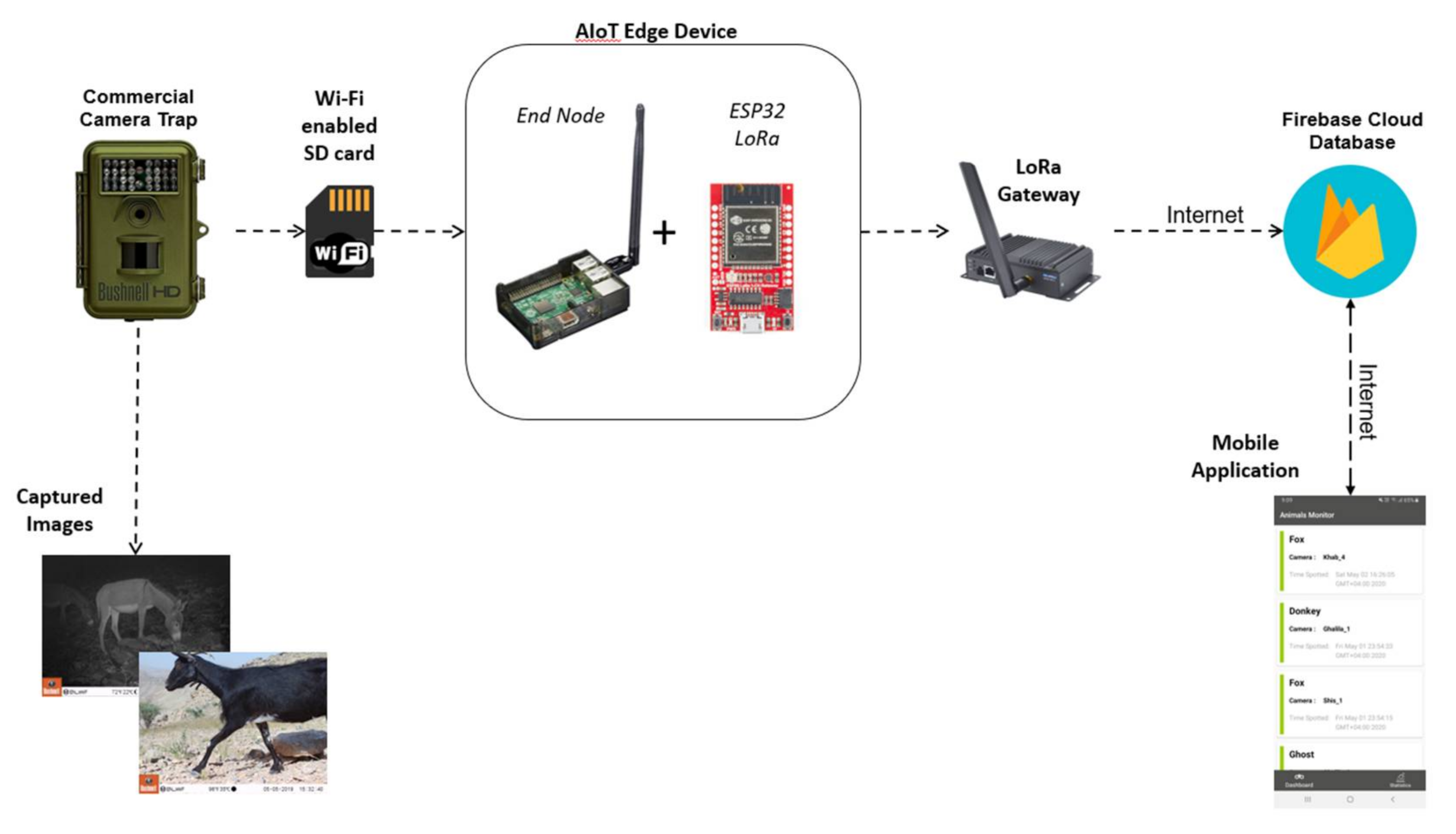
2.2. Using Edge Devices for Camera Trap Animal Classification
Using machine learning and deep learning approaches to process large amounts of data requires considerable computational resources, and therefore, many such resource-intensive programs run on the cloud. However, deploying a deep learning model on the edge could be a better solution and more cost-effective for applications where the network bandwidth is scarce, low latency is required, and/or security is an issue. For example, camera traps are usually deployed in remote areas where the network bandwidth and speed are limited, and therefore, sending all images captured by the camera trap to the cloud is potentially slow and expensive. This is especially relevant because many captured images are empty or contain ghosts and do not provide any interesting or important information. Being able to classify the animal images captured by camera traps on the edge will help eliminate empty images and identify animals on the spot without the need to send anything to the cloud for processing or to collect data manually from the camera traps. IoT cameras, including dash mounted cameras, drone cameras, Google glass, and phone cameras, are already prevalent in our lives and have several applications in law enforcement and traffic monitoring. Such edge cameras allow for the crowdsourcing of videos that are used to find a variety of targets [
44]. Camera traps can similarly be incorporated within an IoT ecosystem to help identify animals.
Edge devices like Raspberry Pi [
45,
46,
47,
48,
49,
50,
51,
52] and Nvidia Jetson [
45,
53,
54,
55,
56,
57] have been previously used for edge-based detection of animals. Raspberry Pi 4 Model B is a single-board computer (SBC) with a Broadcom BCM2711 System-on-a-Chip (SoC) comprising of a Quad-core Cortex-A72 (ARM v8) 64-bit 1.5 GHz CPU and a VideoCore VI 3D 500 MHz GPU. Pi can support up to 8 GB of LPDDR4-3200 SDRAM and uses a microSD for storage. Pi has a two-lane MIPI CSI camera port, HDMI and Display Port for the display output, and 4 USB ports. The Pi also supports Gigabit Ethernet, Bluetooth 5.0, BLE, and 2.4/5 GHz Wi-Fi for connectivity [
58]. Similarly, NVIDIA Jetson Nano is another small, low-power computer specifically designed for AI and neural network applications. Nano uses a Quad-core Cortex A-57 CPU clocked at 1.43 GHz and an NVIDIA 128-core GPU. Nano allows the GPU to run neural networks in the TensorRT format. Nano contains a 64-bit, 4 GB LPDDR4 memory with a RAM speed of 25.6 GB/s and a microSD for storage. Nano also has a 2-lane MIPI CSI-2 DPHY camera port, HDMI and Display Port for display output, and 5 USB ports [
59]. Google Coral is another potential candidate edge device specially designed for machine learning applications. Coral contains an on-board Edge TPU, which performs up to 4 trillion operations per second. The Coral has a Quad-core Cortex A-53 CPU clocked at 1.5 GHz and an integrated GC7000 Lite Graphics card. Coral has 1 GB of LPDDR4 RAM and uses a microSD for storage. Coral has a 4-lane MIPI-CSI-2 camera port, HDMI and MIPI-DSI for display output, and 4 USB ports. Coral supports Gigabit Ethernet, Bluetooth 4.2, and 2.4/5.0 GHz Wi-Fi for connectivity [
60]. Any of the above-mentioned devices can be used to process images on the edge because they support camera, native neural network processing, and microSD image storage capabilities.
Neural network models are typically optimized to run on an edge device. Tensorflow Lite and Tensor RT are two common target edge-optimized frameworks for mobile and embedded devices [
61]. However, optimizing a neural network for the edge may have an impact on the speed of inference, power consumption, and performance. For example, Mathur and Khattar [
46] compared TensorFlow and TensorFlow Lite versions of their model and noticed that the ResNet-50 took about ¼ of the time to classify a single image while drawing twice the amount of power. Similarly, Ramos-Arredondo et al. [
53] compared MobileNetV2 against a quantized version and a TensorFlow Lite version. They noticed that the quantized and TensorFlow Lite versions had more frequent false detections. In addition to using the standardized optimization frameworks, custom optimizations can also be utilized. For example, a pruned CNN architecture that resulted in a smaller, less complex network that had the same performance as the original network was proposed by Rohilla et al. [
56]. In doing so, they were able to reduce the number of parameters of a five-layer CNN model by 94% (from 40,000 to 2400 parameters).
An earlier work using machine learning methods using edge devices to classify and detect animals automatically was proposed by Matuska et al. [
62]. They proposed an Automatic System for Animal Recognition (ASFAR). The system detected and classified animals through the use of distributed watching devices that consisted of a video camera, computation unit, control unit, communication unit, and a supply unit, which could detect an animal presence and send back information to a main computing unit (MCU) for evaluation. The MCU classified unknown objects using a bag of visual points method with an SVM classifier. The model was trained on 300 images from 6 different animals and was tested on 50 images and achieved a classification score of 94%. Similarly, Ramos-Arredondo et al. [
53] developed autonomous and portable photo identification by optimizing the image classification algorithms that were based on Scale Invariant Feature Transform (SIFT). The system classified dorsal fin images of the blue whale through offline information processing on a mobile platform. The system was deployed in a Jetson Tegra TK1 GPU platform with 192 cores. The model was trained on 300 images and tested on 1172 images from the CICIMAR-IPN blue whale database. Tests were performed on segmented images and unsegmented images of the blue whale dorsal fin. Results showed that the accuracy of classifying six classes using unsegmented ROIs ranged between 66.27% and 95.36%, while the segmented ROIs showed better accuracy ranging between 79% and 93%.
More recently, Elias et al. [
57] proposed an end-to-end distributed data acquisition and analytics system that implemented an IoT architecture consisting of sensors (cameras), edge cloud, and a back-end public or private cloud. This system was implemented for wildlife monitoring and integrated with remote motion-triggered camera traps. The proposed methodology included a novel deep learning training technique where the model was trained using synthetic images constructed using freely available labelled images from Google Images. Those images were combined with empty images captured by camera traps at different times of the day. The trained model, based on InceptionV3, was then transferred to the edge cloud where the classification was performed. Only the classified animals of interest were transmitted to scientists as requested. This approach avoided transferring large training sets to a private or public cloud to train a model, hence reducing the time and bandwidth requirements for image transfer, as well as saving end-user analysis time. Transferring only the classified images required approximately one-third of the time of transferring all the images.
Raspberry Pi is a popular choice for running animal classification on edge. For example, Curtin and Mathews [
50] used a Raspberry Pi-based camera system augmented with a deep learning image recognition model for detecting wildlife. The system had a total estimated cost of
$50, as compared to the trail cameras which cost upwards of
$100. The system used a simple CNN with two convolutional layers to classify images into one of three classes: snow leopard, human, and other. The model was trained on 3600 images, of which 1262 pictures were of human pedestrians from the VIPeR database, 1568 pictures were of snow leopards, and 768 pictures were of natural background environments (for the “other” category) obtained from the ImageNet database. The model was designed to run on the edge so that only pictures of the desired animals were transferred to the user. The system was tested in different settings, one in which the images were pre-downloaded on the Raspberry Pi, and another in which the images were captured and classified in real-time. The Raspberry Pi model was able to classify 347 pre-downloaded images in 29.2 s. However, in the live capture experiment, classification and image capture took 0.12 s per image. The accuracy achieved through the live testing was only 74% for snow leopards, 77% for humans, and 72% for the “other” category which was much lower than the pre-downloaded image results of 96%, 85%, and 99%, respectively. This difference could be because of the lower resolution of the onboard camera. The system consumed 0.10 amperes in the live testing mode with an up time of 10 h using four Alkaline AA batteries. Similarly, Thomassen [
47] deployed MobileNet on a Raspberry Pi. The best model achieved an accuracy of 81.1% on the COAT dataset with a model size of 17 MB. The Raspberry Pi had a classification speed of 1.17 frames per second (fps) and could analyze 2.1 million images using a car battery. Liu et al. [
63] deployed several image classification models on a Raspberry Pi that could be connected to camera traps to perform image classification. They got the best results from a mean-per-class accuracy of 86.7% using the ResNet-50 224 × 224 model. Monburinon et al. [
49] proposed a hierarchical edge computing solution to detect the intrusion of wild animals in agricultural fields using a CNN based on MobileNet. Their system had more than two times faster evaluation time, consumed less than 6% of the network bandwidth, and was more energy efficient. Finally, Ramos-Arredondo [
53] also used a Raspberry Pi as an edge device and selected the MobileNetV2 model, despite not having the highest accuracy nor the fastest inference time because of its low false positive rate, higher precision, and its small size.
Nvidia Jetson represents another candidate edge computing device for animal classification. For example, Liu et al. [
63] used MobileNetV2 deployed on a Jetson TX2. MobileNetV2 outperformed MobileNetV1 and InceptionV3 with a validation set accuracy of 92.89%. MobileNetV2 also provided a suitable model size of 40 MB. Rohilla et al. [
56] used the Nvidia Jetson TX1 to process images captured by camera traps. They trained a five-layer CNN on 27,370 fish images captured from a live video feed and pruned the trained model by removing all of the zero activation neurons. Arshad et al. [
54] used an Nvidia Jetson TX2 as the edge device with a CNN-based YOLOv3 object detector coupled with a discriminative correlation filter-based tracker. The system was used to identify and count deer in the wild, where the deer count was transmitted to a remote server through 4G connectivity. In a 14-day trial, this system was able to process 170 videos that needed 18.5 h of manual processing in 0.3 h, resulting in a 98% reduction in effort. The system was able to identify 17 deer out of the 20 deer present in the trial. Finally, Islam and Valles [
55] used NVIDIA Jetson Nano along with a camera module to run a CNN network that could detect snakes, lizards, and toads/frogs from the camera trap images. A commercial camera trap was used in an experiment where the data was captured and saved in a microSD card and was transferred using a portable adapter.
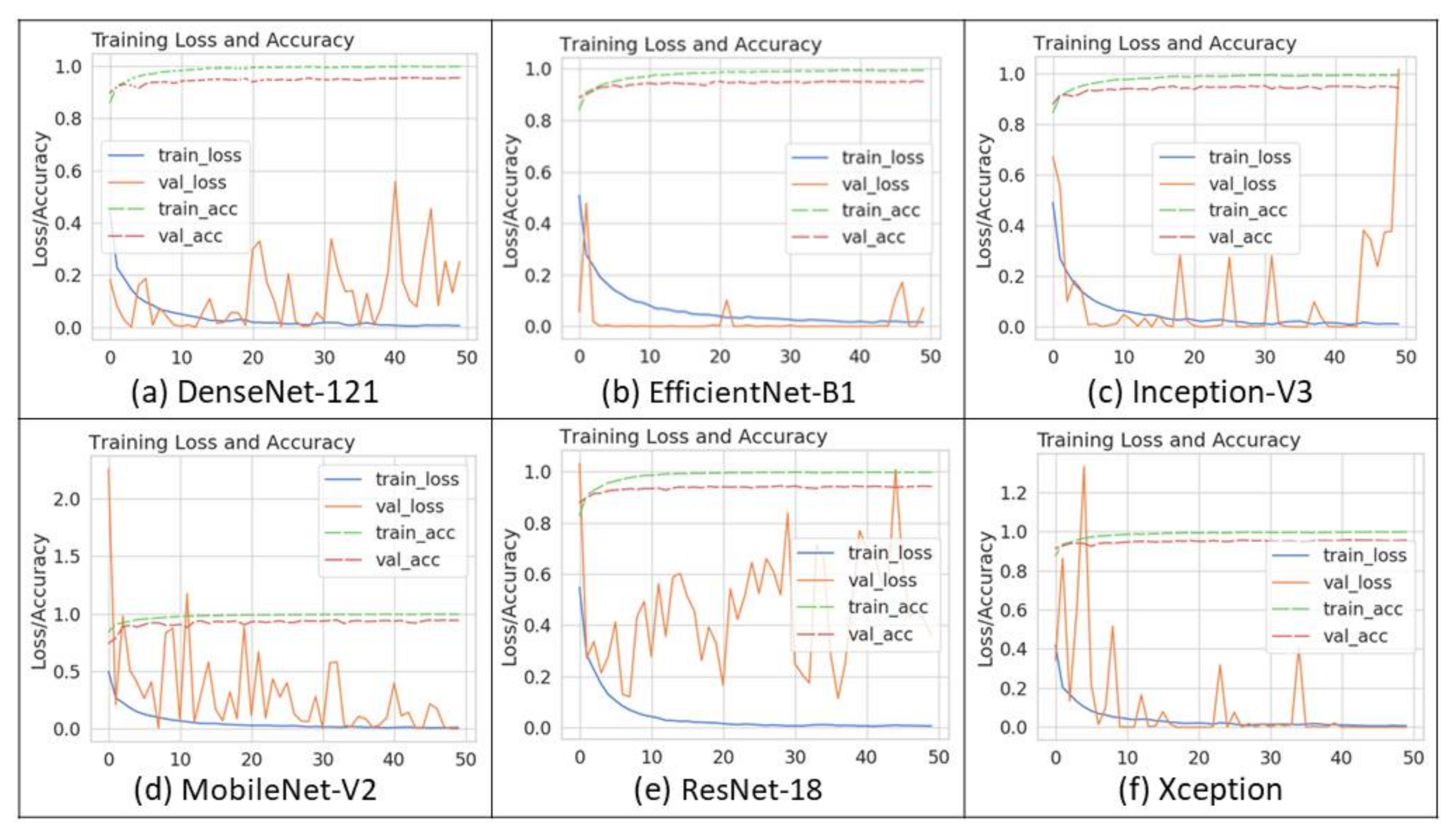
Table 2 summarizes the performance obtained by prior CNN models. As the table shows, mostly the Tensor Flow Lite versions of known models, like Inception V3 or MobileNet-V2, have been deployed. The accuracies range between 70 to 90%.
Table 2 also shows that the size of the models varies between 15 to 87 MB. The size is generally proportional to the number of weights, and hence, the number of operations required for inference. Therefore, this will have an impact on the inference time as well.
Table 3 shows the hardware metrics when reported. As the table shows, the inference speeds vary widely between 0.09 frames per second to 17.5 frames per second when an edge GPU like the Jetson TX2 was used. Capturing an image on a camera trap depends on the trigger speed, which is how long it takes a motion detector to detect and capture and image followed by the inference speed that determines how long it takes to classify the image as one of the known animals. For example, most commercial camera traps have a trigger delay of between 0.3 and 0.7 s. Therefore, a Pi that can do an inference at 0.09 frames/s or 11 s per frame (Mathur & Khattar [
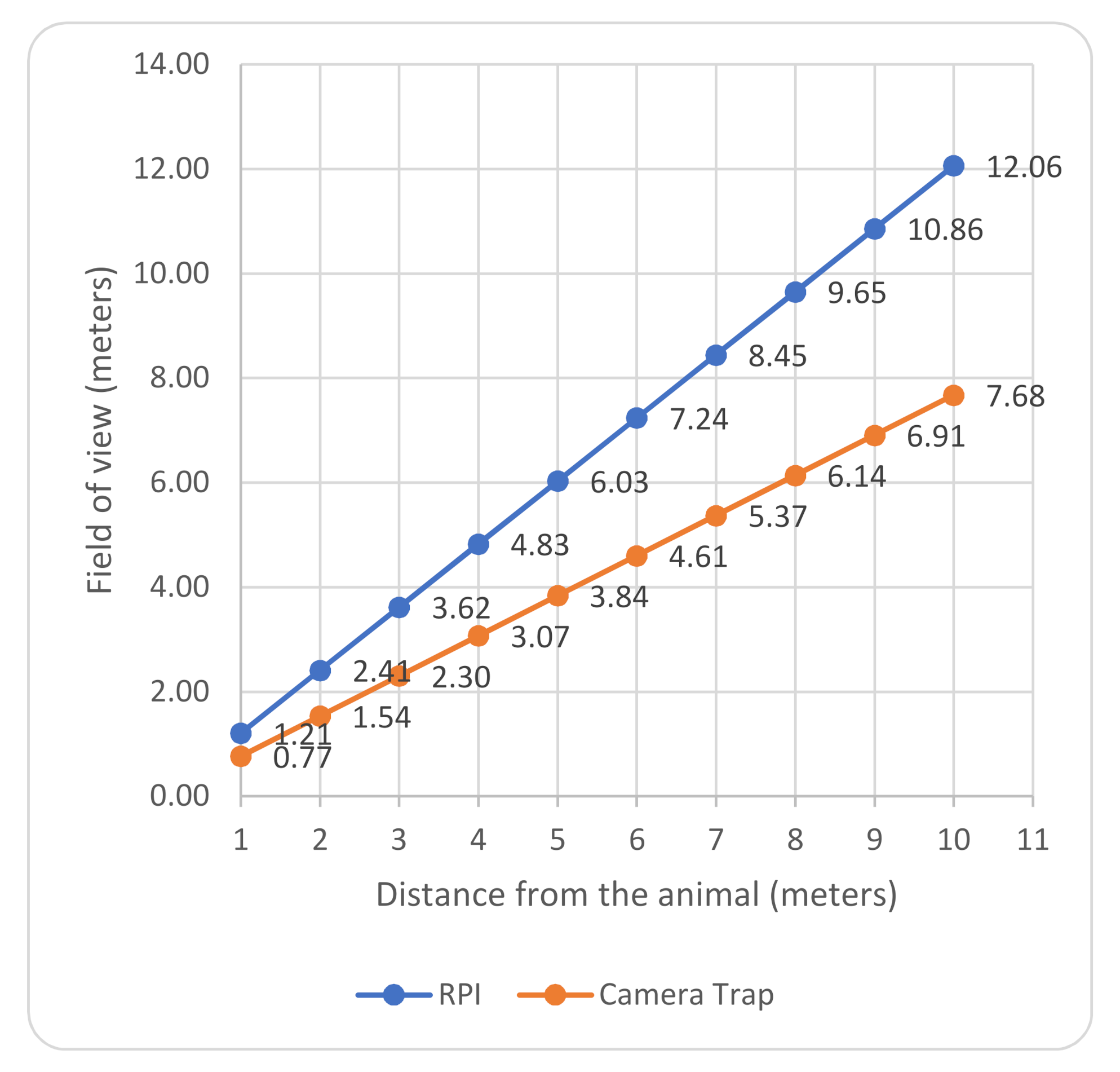
46]) will effectively take about 11.3 s to process a single image. While this delay may be acceptable for slow moving or far away animals, it may not be feasible to capture running animals such as a goat, which can achieve speeds of up to 80 km/h. In general, the ability to capture an image will depend on many other factors, like the camera’s sensor size, focal length, and, eventually, the angle and field of view. These are discussed in more detail in the results section of this paper.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}