
Feature Focus: Towards Explainable and Transparent Deep Face Morphing Attack Detectors †


Abstract
:1. Introduction
- Feature Focus: A more accurate and transparent face morphing attack detector based on a new loss function and modified architecture
- Quantitative analysis of FLRP and comparison with LRP using morphs that contain artifacts only in known predefined areas (partial morphs)
- Analysis of the features’ discrimination power learned by DNNs for face morphing attack detection and its relation to interpretability via FLRP and LRP
- Reliable and accurate explainability component for DNN-based face morphing attack detectors based on FLRP
2. Related Work
3. Focused Layer-Wise Relevance Propagation
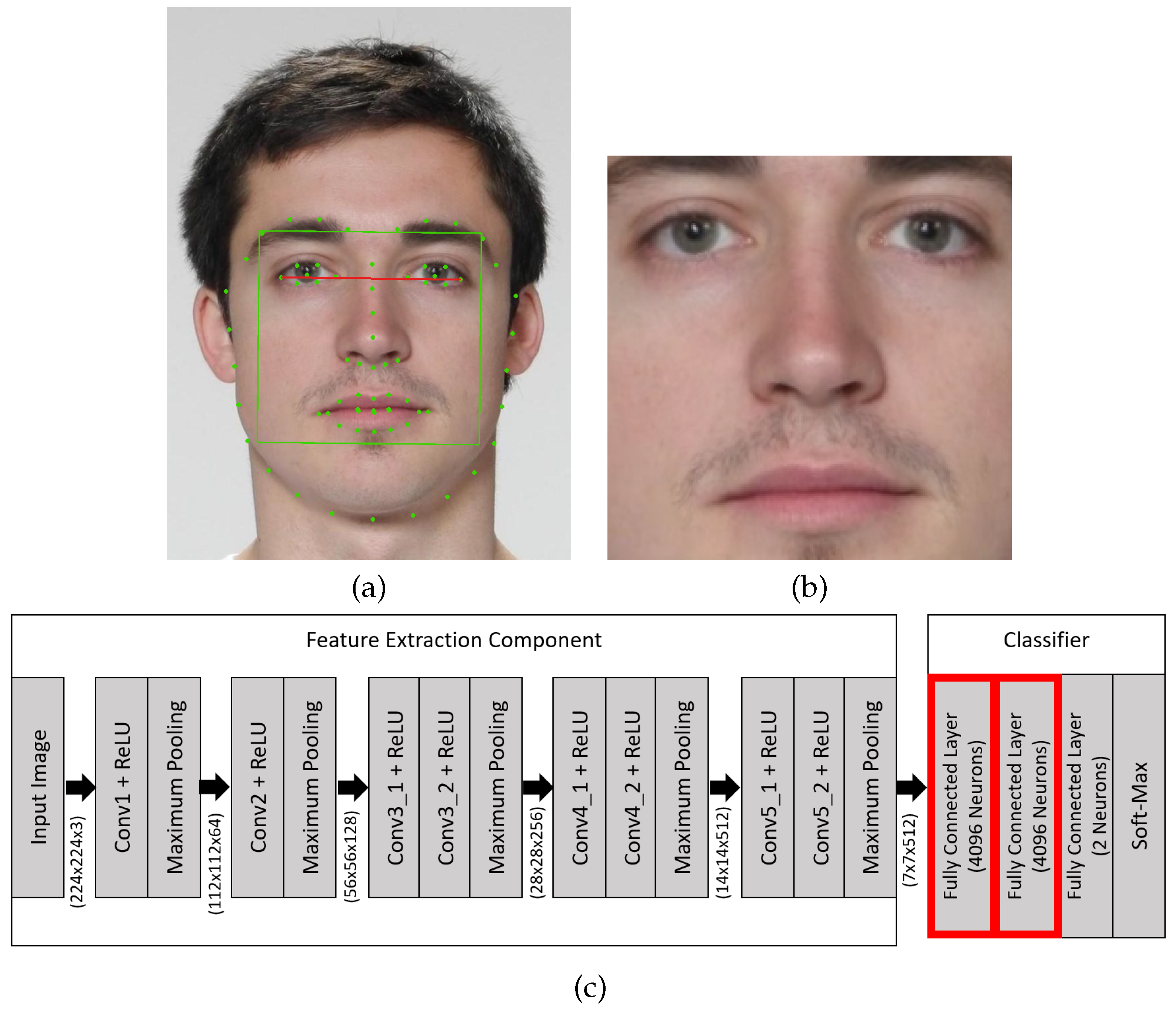
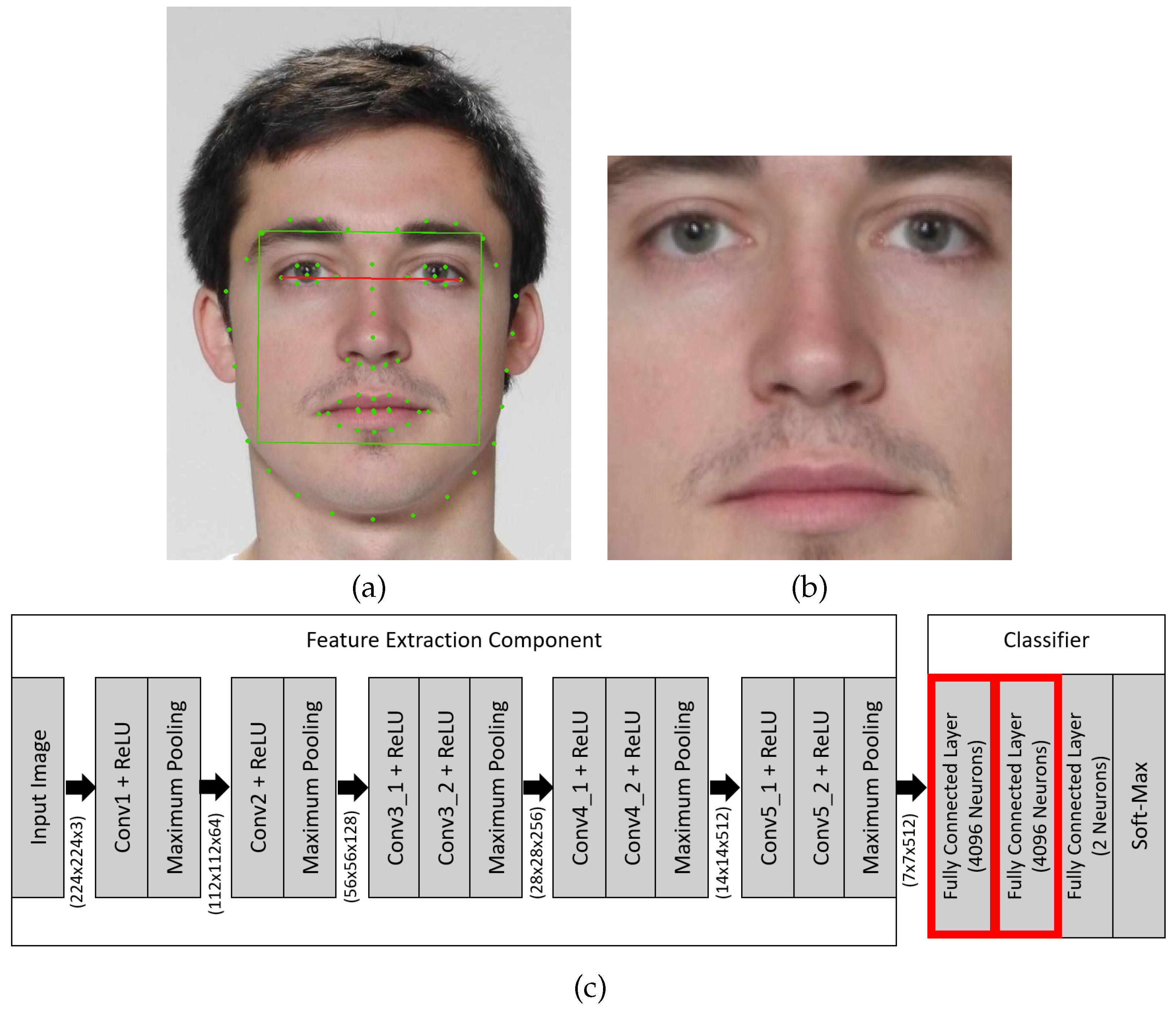
4. Feature Shaping Training
5. Training of the Detectors and Experimental Data
6. Evaluation Methods
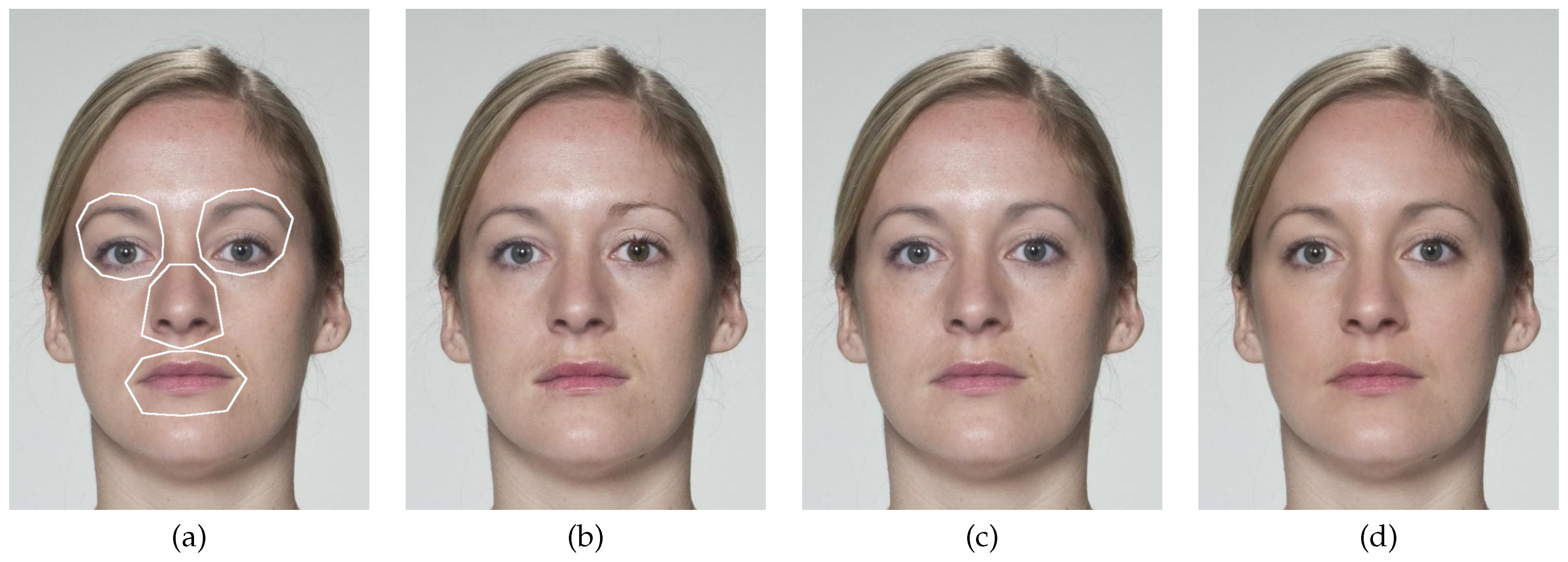
6.1. (F)LRP Evaluation with Partial Morphs
6.2. Evaluation of Features’ Discrimination Power
7. Results
7.1. Accuracy
7.2. Discrimination Power of Single Features
7.3. Relevance Distribution
7.4. Sample Results
8. Discussion
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| APCER | Attack Presentation Classification Error Rate |
| BPCER | Bona-fide Presentation Classification Error Rate |
| DNN | Deep Neural Networks |
| EER | Equal-Error-Rate |
| FLRP | Focused Layer-wise Relevance Propagation |
| LRP | Layer-wise Relevance Propagation |
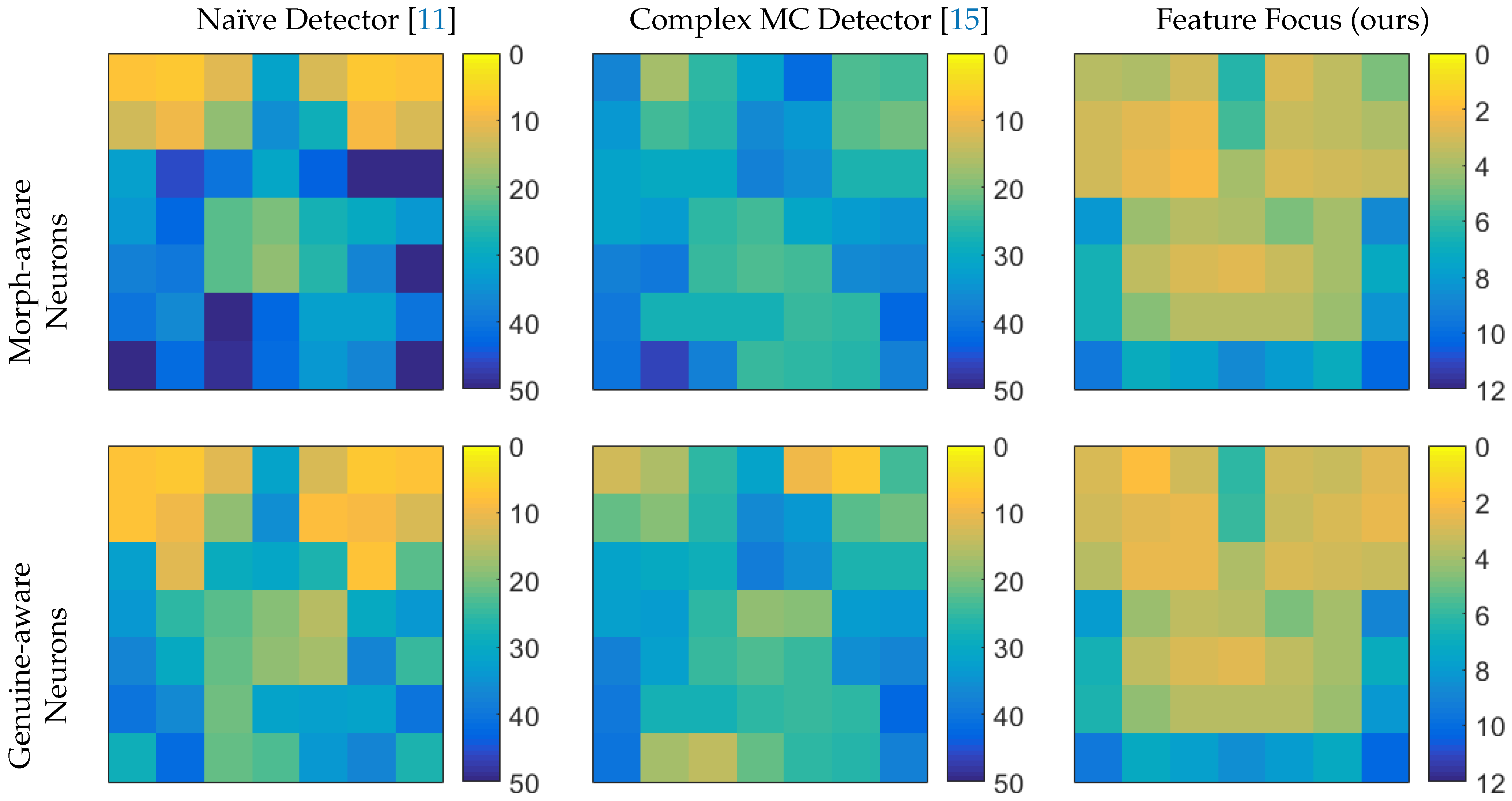
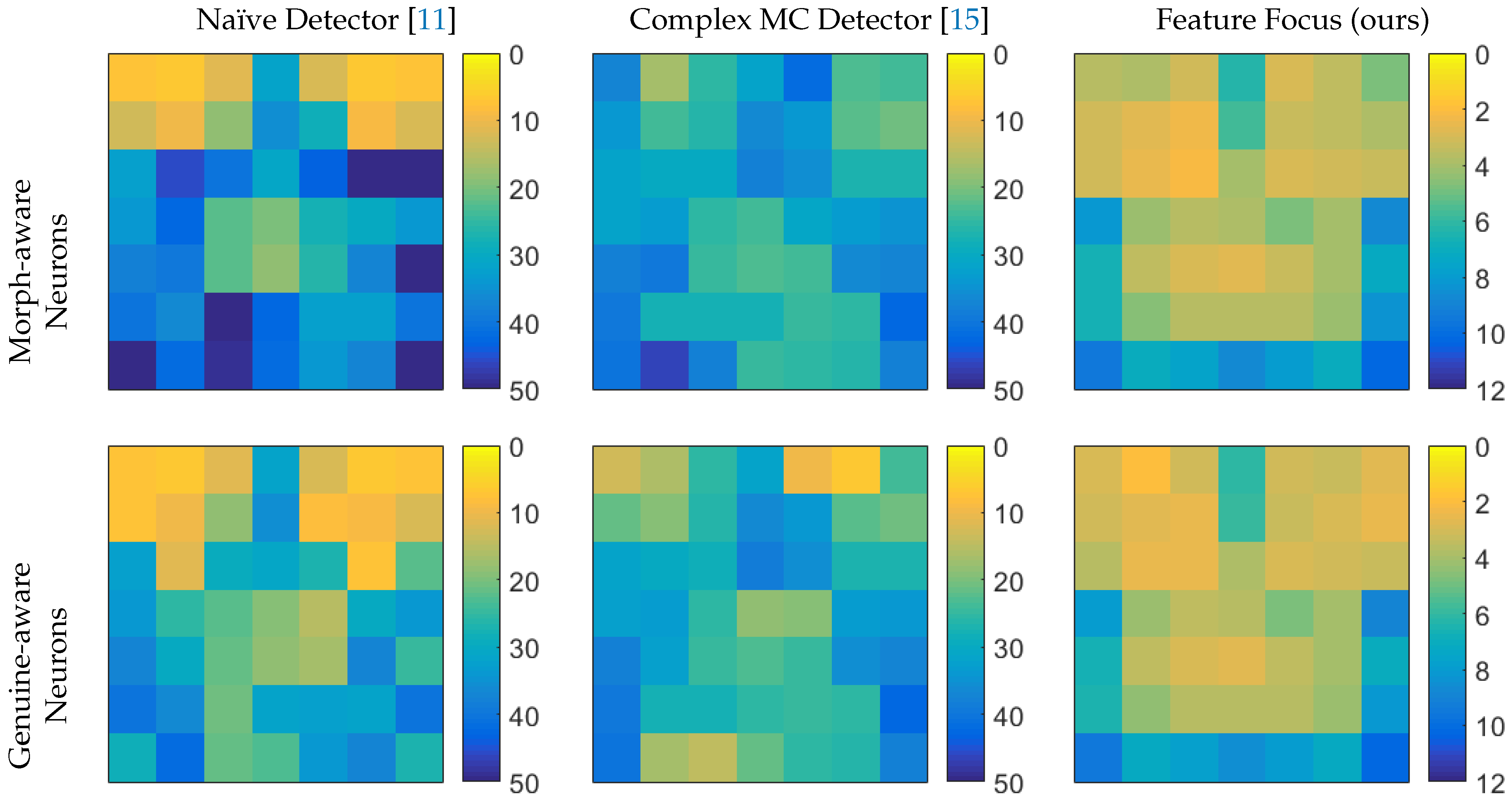
Appendix A. Discrimination Power of Single Features

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Morph-Aware Neurons | Genuine-Aware Neurons | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7.3% | 6.7% | 11.2% | 31.4% | 12.2% | 6.8% | 7.2% | 7.4% | 6.7% | 11.2% | 31.5% | 12.1% | 6.8% | 7.2% |
| 13.3% | 9.8% | 18.3% | 35.7% | 28.9% | 9.3% | 11.9% | 7.0% | 9.7% | 18.1% | 35.6% | 8.3% | 9.2% | 11.8% |
| 32.6% | 46.0% | 40.3% | 30.7% | 43.0% | 53.1% | 51.0% | 32.6% | 11.0% | 29.2% | 30.5% | 27.2% | 7.7% | 21.9% |
| 34.3% | 42.5% | 22.6% | 19.7% | 27.6% | 30.3% | 33.8% | 34.2% | 25.6% | 22.4% | 19.4% | 15.1% | 30.4% | 33.7% |
| 37.5% | 39.4% | 22.0% | 18.7% | 26.3% | 36.9% | 51.8% | 37.4% | 30.1% | 21.8% | 18.7% | 16.5% | 36.8% | 24.2% |
| 40.1% | 36.5% | 62.8% | 42.8% | 32.2% | 32.1% | 40.3% | 40.1% | 36.4% | 21.0% | 31.9% | 32.2% | 31.8% | 40.4% |
| 58.9% | 41.6% | 49.1% | 41.5% | 34.0% | 37.0% | 67.4% | 28.7% | 41.7% | 21.1% | 23.3% | 34.1% | 36.9% | 27.3% |
| Morph-Aware Neurons | Genuine-Aware Neurons | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 37.4% | 16.5% | 25.1% | 32.0% | 42.1% | 22.8% | 24.1% | 13.2% | 16.0% | 25.0% | 31.9% | 9.7% | 6.5% | 24.0% |
| 33.8% | 24.1% | 26.6% | 36.5% | 33.8% | 22.2% | 20.6% | 21.7% | 19.5% | 26.5% | 36.1% | 34.0% | 22.2% | 20.6% |
| 31.7% | 30.0% | 30.0% | 38.3% | 35.6% | 26.8% | 27.1% | 31.9% | 30.1% | 28.9% | 38.3% | 35.5% | 26.8% | 27.1% |
| 32.0% | 33.3% | 25.5% | 23.6% | 30.5% | 33.0% | 34.5% | 32.2% | 33.2% | 25.5% | 18.5% | 19.5% | 33.1% | 34.2% |
| 38.1% | 39.3% | 24.2% | 22.9% | 24.1% | 36.1% | 37.1% | 38.2% | 32.0% | 24.4% | 22.8% | 24.5% | 35.8% | 37.3% |
| 39.4% | 28.0% | 28.0% | 27.6% | 24.7% | 25.0% | 42.6% | 39.5% | 27.8% | 27.9% | 25.8% | 24.6% | 25.0% | 42.7% |
| 40.5% | 46.8% | 38.1% | 24.4% | 25.3% | 26.2% | 38.3% | 40.4% | 16.5% | 14.6% | 21.5% | 25.0% | 26.1% | 38.0% |
| Morph-Aware Neurons | Genuine-Aware Neurons | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3.6% | 3.9% | 3.1% | 6.2% | 3.0% | 3.5% | 4.8% | 2.8% | 2.0% | 3.1% | 6.2% | 3.1% | 3.2% | 2.7% |
| 3.1% | 2.7% | 2.3% | 5.8% | 3.2% | 3.5% | 3.9% | 3.1% | 2.7% | 2.4% | 5.9% | 3.2% | 2.8% | 2.4% |
| 3.1% | 2.6% | 2.2% | 4.1% | 3.0% | 3.1% | 3.4% | 3.7% | 2.6% | 2.4% | 3.9% | 2.8% | 3.1% | 3.3% |
| 8.1% | 4.3% | 3.7% | 3.9% | 4.8% | 4.0% | 8.8% | 8.0% | 4.2% | 3.5% | 3.7% | 4.7% | 4.0% | 8.8% |
| 6.6% | 3.5% | 3.0% | 2.7% | 3.4% | 4.0% | 7.2% | 6.7% | 3.5% | 3.0% | 2.7% | 3.5% | 4.0% | 7.0% |
| 6.6% | 4.5% | 3.6% | 3.6% | 3.6% | 4.3% | 8.3% | 6.5% | 4.4% | 3.6% | 3.6% | 3.7% | 4.2% | 8.2% |
| 9.5% | 7.1% | 7.6% | 8.8% | 8.0% | 7.1% | 10.2% | 9.5% | 7.2% | 7.8% | 8.6% | 8.0% | 7.2% | 10.1% |
References
- Ferrara, M.; Franco, A.; Maltoni, D. The magic passport. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014. [Google Scholar] [CrossRef]
- Ferrara, M.; Franco, A.; Maltoni, D. On the Effects of Image Alterations on Face Recognition Accuracy. In Face Recognition across the Imaging Spectrum; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Lewis, M.; Statham, P. CESG Biometric Security Capabilities Programme: Method, Results and Research challenges. In Proceedings of the Biometrics Consortium Conference (BCC), Arlington, VA, USA, 20–22 September 2004. [Google Scholar]
- Scherhag, U.; Rathgeb, C.; Merkle, J.; Breithaupt, R.; Busch, C. Face Recognition Systems Under Morphing Attacks: A Survey. IEEE Access 2019, 7, 23012–23026. [Google Scholar] [CrossRef]
- Makrushin, A.; Wolf, A. An Overview of Recent Advances in Assessing and Mitigating the Face Morphing Attack. In Proceedings of the EUSIPCO 2018: 26th European Signal Processing Conference, Roma, Italy, 3–7 September 2018. [Google Scholar]
- van der Hor, T. Developing harmonized automated border control (ABS) training capabilities. ICAO TRIP Mag. 2017, 12, 2. [Google Scholar]
- European Commission. Action Plan to Strengthen the European Response to Travel Document Fraud; Council of the European Union: Brussels, Belgium, 2016. [Google Scholar]
- Ngan, M.; Grother, P.; Hanaoka, K.; Kuo, J. Face Recognition Vendor Test (FRVT) Part 4: MORPH—Performance of Automated Face Morph Detection; NIST Interagency/Internal Report (NISTIR); National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Minaee, S.; Luo, P.; Lin, Z.L.; Bowyer, K. Going Deeper Into Face Detection: A Survey. arXiv 2021, arXiv:2103.14983. [Google Scholar]
- Seibold, C.; Samek, W.; Hilsmann, A.; Eisert, P. Detection of Face Morphing Attacks by Deep Learning. In Proceedings of the 16th International Workshop, IWDW 2017, Magdeburg, Germany, 23–25 August 2017. [Google Scholar] [CrossRef]
- Debiasi, L.; Rathgeb, C.; Scherhag, U.; Uhl, A.; Busch, C. PRNU Variance Analysis for Morphed Face Image Detection. In Proceedings of the 9th IEEE International Conference on Biometrics Theory, Applications and Systems, Redondo Beach, CA, USA, 22–25 October 2018. [Google Scholar]
- Scherhag, U.; Debiasi, L.; Rathgeb, C.; Busch, C.; Uhl, A. Detection of Face Morphing Attacks Based on PRNU Analysis. IEEE Trans. Biom. Behav. Identity Sci. 2019, 1, 302–317. [Google Scholar] [CrossRef]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.R. Unmasking Clever Hans Predictors and Assessing What Machines Really Learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seibold, C.; Samek, W.; Hilsmann, A.; Eisert, P. Accurate and robust neural networks for face morphing attack detection. J. Inf. Secur. Appl. 2020, 53, 102526. [Google Scholar] [CrossRef]
- Seibold, C.; Hilsmann, A.; Eisert, P. Focused LRP: Explainable AI for Face Morphing Attack Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, Waikola, HI, USA, 5–9 January 2021; pp. 88–96. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-wise Explanations for Non-Linear Classifier Decisions by Layer-wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Seibold, C.; Hilsmann, A.; Eisert, P. Style Your Face Morph and Improve Your Face Morphing Attack Detector. In Proceedings of the International Conference of the Biometrics Special Interest Group, Darmstadt, Germany, 18–20 September 2019. [Google Scholar]
- Scherhag, U.; Rathgeb, C.; Merkle, J.; Busch, C. Deep Face Representations for Differential Morphing Attack Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3625–3639. [Google Scholar] [CrossRef]
- Banerjee, S.; Ross, A. Conditional Identity Disentanglement for Differential Face Morph Detection. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Ferrara, M.; Franco, A.; Maltoni, D. Face Demorphing. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1008–1017. [Google Scholar] [CrossRef]
- Peng, F.; Zhang, L.; Long, M. FD-GAN: Face De-Morphing Generative Adversarial Network for Restoring Accomplice’s Facial Image. IEEE Access 2019, 7, 75122–75131. [Google Scholar] [CrossRef]
- Seibold, C.; Hilsmann, A.; Eisert, P. Reflection Analysis for Face Morphing Attack Detection. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO), Roma, Italy, 3–7 September 2018. [Google Scholar]
- Makrushin, A.; Neubert, T.; Dittmann, J. Automatic Generation and Detection of Visually Faultless Facial Morphs. In Proceedings of the VISIGRAPP—Volume 6: VISAPP, Porto, Portugal, 27 February–1 March 2017; pp. 39–50. [Google Scholar]
- Neubert, T. Face Morphing Detection: An Approach Based on Image Degradation Analysis. In Proceedings of the 16th International Workshop on Digital-forensics and Watermarking (IWDW 2017), Magdeburg, Germany, 23–25 August 2017; pp. 93–106. [Google Scholar]
- Neubert, T.; Kraetzer, C.; Dittmann, J. A Face Morphing Detection Concept with a Frequency and a Spatial Domain Feature Space for Images on eMRTD. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2019. [Google Scholar]
- Ramachandra, R.; Raja, K.B.; Busch, C. Detecting morphed face images. In Proceedings of the 8th IEEE International Conference on Biometrics Theory, Applications and Systems, Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–7. [Google Scholar]
- Damer, N.; Zienert, S.; Wainakh, Y.; Saladié, A.M.; Kirchbuchner, F.; Kuijper, A. A Multi-detector Solution Towards an Accurate and Generalized Detection of Face Morphing Attacks. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Makrushin, A.; Kraetzer, C.; Dittmann, J.; Seibold, C.; Hilsmann, A.; Eisert, P. Dempster-Shafer Theory for Fusing Face Morphing Detectors. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Chen, C.; Li, O.; Barnett, A.; Su, J.; Rudin, C. This looks like that: Deep learning for interpretable image recognition. arXiv 2018, arXiv:1806.10574. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the ICCV IEEE Computer Society, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Kohlbrenner, M.; Bauer, A.; Nakajima, S.; Binder, A.; Samek, W.; Lapuschkin, S. Towards best practice in explaining neural network decisions with LRP. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ouahabi, A.; Taleb-Ahmed, A. Deep learning for real-time semantic segmentation: Application in ultrasound imaging. Pattern Recognit. Lett. 2021, 144, 27–34. [Google Scholar] [CrossRef]
- Yin, L.; Chen, X.; Sun, Y.; Worm, T.; Reale, M. A high-resolution 3D dynamic facial expression database. In Proceedings of the 8th IEEE International Conference on Automatic Face Gesture Recognition, Amsterdam, The Netherland, 17–19 September 2008; pp. 1–6. [Google Scholar] [CrossRef]
- Ma, D.; Correll, J.; Wittenbrink, B. The Chicago face database: A free stimulus set of faces and norming data. Behav. Res. Methods 2015, 47, 1122–1135. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Phillips, P.J. Color FERET Database; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2003.
- DeBruine, L.; Jones, B. Face Research Lab London Set. figshare 2017. [Google Scholar] [CrossRef]
- Kasiński, A.; Florek, A.; Schmidt, A. The PUT face database. Image Process. Commun. 2008, 13, 59–64. [Google Scholar]
- Grgic, M.; Delac, K.; Grgic, S. SCface—Surveillance Cameras Face Database. Multimed. Tools Appl. 2011, 51, 863–879. [Google Scholar] [CrossRef]
- Hancock, P. Utrecht ECVP Face Dataset; School of Natural Sciences, University of Stirling: Stirling, UK, 2008; Available online: http://pics.stir.ac.uk/ (accessed on 13 April 2017).
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Malolan, B.; Parekh, A.; Kazi, F. Explainable Deep-Fake Detection Using Visual Interpretability Methods. In Proceedings of the 2020 3rd International Conference on Information and Computer Technologies (ICICT), San Jose, CA, USA, 9–12 March 2020; pp. 289–293. [Google Scholar]
- Pérez, P.; Gangnet, M.; Blake, A. Poisson Image Editing. ACM Trans. Graph. 2003, 22, 313–318. [Google Scholar] [CrossRef]
- Fraunhofer HHI and TU Berlin. Available online: http://heatmapping.org (accessed on 20 July 2021).
- Lapuschkin, S. Opening the Machine Learning Black Box with Layer-Wise Relevance Propagation. Ph.D. Thesis, Technische Universität Berlin, Berlin, Germany, 2019. [Google Scholar] [CrossRef]
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. LayerCAM: Exploring Hierarchical Class Activation Maps. IEEE Trans. Image Process. 2021. [Google Scholar] [CrossRef] [PubMed]
- Seibold, C.; Hilsmann, A.; Makrushin, A.; Kraetzer, C.; Neubert, T.; Dittmann, J.; Eisert, P. Visual Feature Space Analyses of Face Morphing Detectors. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- International Organization for Standardization. Information Technology—Biometric Presentation Attack Detection—Part 3: Testing and Reporting; ISO Standard No. 30107-3:2017; International Organization for Standardization: Geneva, Switzerland, 2017; Available online: https://www.iso.org/standard/67381.html (accessed on 20 July 2021).


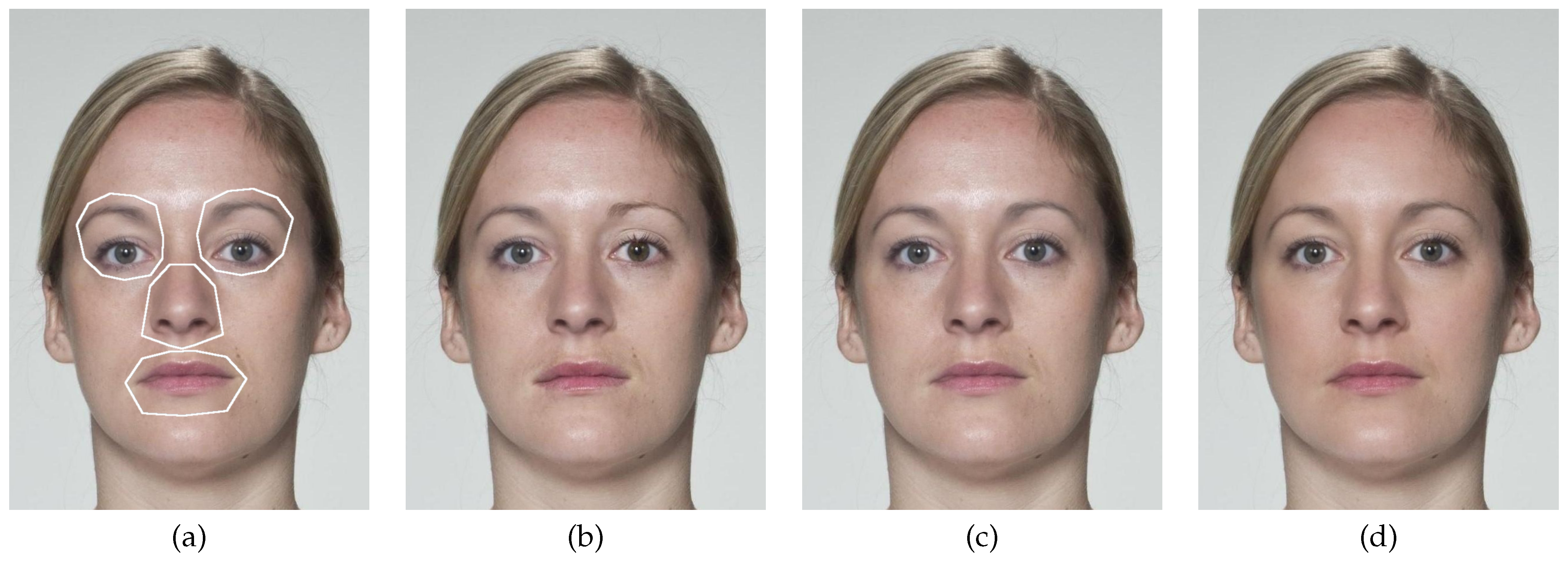



| Training Type | BPCER | APCER | EER |
|---|---|---|---|
| Naïve [11] | 0.8% | 2.2% | 1.4% |
| Complex MC [15] | 1.8% | 1.8% | 1.8% |
| Xception [43] | 1.7% | 1.2% | 1.5% |
| Feature Focus (ours) | 0.5% | 1.2% | 0.6% |
| Morphed Regions | Naïve | Complex MC | Feature Focus | Xception | |||
|---|---|---|---|---|---|---|---|
| [11] | [15] | (Ours) | [43] | ||||
| LRP | FLRP | LRP | FLRP | LRP | FLRP | LRP | |
| left eye | 74.1% | 76.7% | 8.8% | 53.6% | 80.0% | 89.0% | 21.7% |
| right eye | 78.9% | 86.1% | 25.7% | 45.4% | 72.1% | 87.7% | 29.2% |
| nose | 36.7% | 71.4% | 5.3% | 40.5% | 57.4% | 85.2% | 13.6% |
| mouth | 18.2% | 43.2% | 22.3% | 48.2% | 16.6% | 83.3% | 3.8% |
| both eyes | 91.8% | 92.9% | 44.9% | 68.6% | 91.2% | 94.7% | 72.2% |
| left eye, nose | 84.8% | 92.0% | 18.7% | 68.9% | 89.6% | 95.2% | 36.6% |
| right eye, nose | 87.1% | 95.2% | 32.5% | 63.3% | 87.6% | 95.9% | 54.2% |
| left eye, mouth | 77.5% | 84.1% | 11.4% | 71.4% | 83.7% | 96.7% | 30.9% |
| right eye, mouth | 82.5% | 90.6% | 61.3% | 66.8% | 78.9% | 95.8% | 39.9% |
| mouth and nose | 48.8% | 85.1% | 38.2% | 63.2% | 57.0% | 94.2% | 19.6% |
| all but left eye | 89.5% | 97.4% | 73.0% | 75.8% | 87.9% | 98.4% | 62.4% |
| all but right eye | 86.7% | 95.1% | 34.1% | 79.1% | 90.2% | 98.0% | 45.0% |
| all but nose | 92.7% | 95.0% | 33.5% | 79.6% | 94.2% | 97.8% | 83.2% |
| all but mouth | 95.0% | 97.6% | 76.4% | 79.0% | 96.1% | 97.0% | 86.7% |
| all | 95.9% | 98.9% | 89.4% | 85.5% | 97.2% | 98.9% | 91.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seibold, C.; Hilsmann, A.; Eisert, P. Feature Focus: Towards Explainable and Transparent Deep Face Morphing Attack Detectors. Computers 2021, 10, 117. https://doi.org/10.3390/computers10090117
Seibold C, Hilsmann A, Eisert P. Feature Focus: Towards Explainable and Transparent Deep Face Morphing Attack Detectors. Computers. 2021; 10(9):117. https://doi.org/10.3390/computers10090117
Chicago/Turabian StyleSeibold, Clemens, Anna Hilsmann, and Peter Eisert. 2021. "Feature Focus: Towards Explainable and Transparent Deep Face Morphing Attack Detectors" Computers 10, no. 9: 117. https://doi.org/10.3390/computers10090117
APA StyleSeibold, C., Hilsmann, A., & Eisert, P. (2021). Feature Focus: Towards Explainable and Transparent Deep Face Morphing Attack Detectors. Computers, 10(9), 117. https://doi.org/10.3390/computers10090117