
Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Explaining Biases in Machine Learning

 ,
,  ,
,
Abstract
1. Introduction
- We have proposed a method to provide declarative explanations and descriptions using PRIDE of typical machine learning scenarios. Our approach guarantees a logical equivalent version to explain how the outputs are related with the inputs in a general machine learning setup.
- We have applied our proposal to two different domains to check the generality of our approach.
- –
- A multimodal machine learning test-bed around automatic recruitment including different biases (by gender and ethnicity) on synthetic datasets.
- –
- A real dataset about adult incomes taken from US census whose possible biases to get higher earnings are found and shown.
- We have updated the state of the art methods applicable to XAI.
- We have enriched the introduction to LFIT with examples for a more general audience.
- We have checked the expressiveness of our approach (based on LFIT) extending it to a dataset about adult income level from the 1994 US census. In this domain, we have not used any deep learning algorithms to compare, showing that the proposed approach is also applicable under this circumstance.
2. Related Works
2.1. Explainable AI (XAI): Declarative Approaches
- Statistical approaches need huge amounts of data to extract valid knowledge, while declarative ones are usually able to minimise the set of examples and counterexamples to get the same.
- Statistical approaches are usually compatible with noisy and poorly labelled data, while for declarative ones, this is a circumstance difficult to overcome.
- Statistical approaches do not offer, in the general case, clear explanations about the decisions they make (usually considered as weak machine learning algorithms), while declarative approaches (due to the declarative nature of the formal models that support them) are designed to be at least strong.
- Declarative approaches are supported by formal models like functional programming or formal logic. The theoretical properties of these models make it possible that the learned knowledge exhibits some characteristics (such as logical equivalence, minimisation, etc.)
- Hybrid approaches try to take advantage of both possibilities. Hybridisation can mix a declarative learning engine with numerical components or the opposite. The characteristics of the learned model depend on the type of hybridisation: equivalent noise-tolerant versions of the observed data can be learned by logical engines with numerical input components, and quasi-equivalent logical theories can be approximately induced by numerical/statistical machine learning algorithms that implement differentiable versions of logical operators and inference rules.
2.2. Inductive Programming for XAI
2.3. Learning from Interpretation Transition (LFIT)
3. Methods
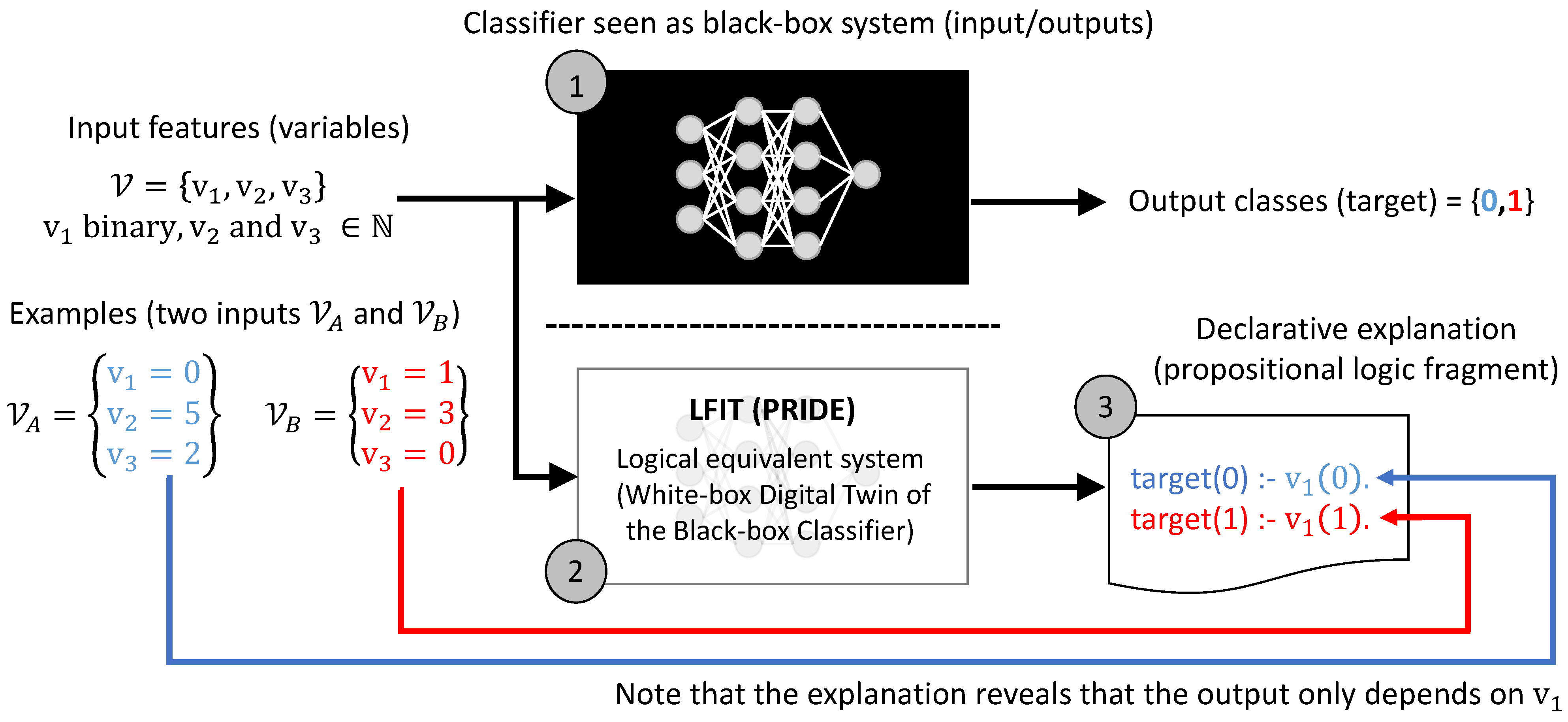
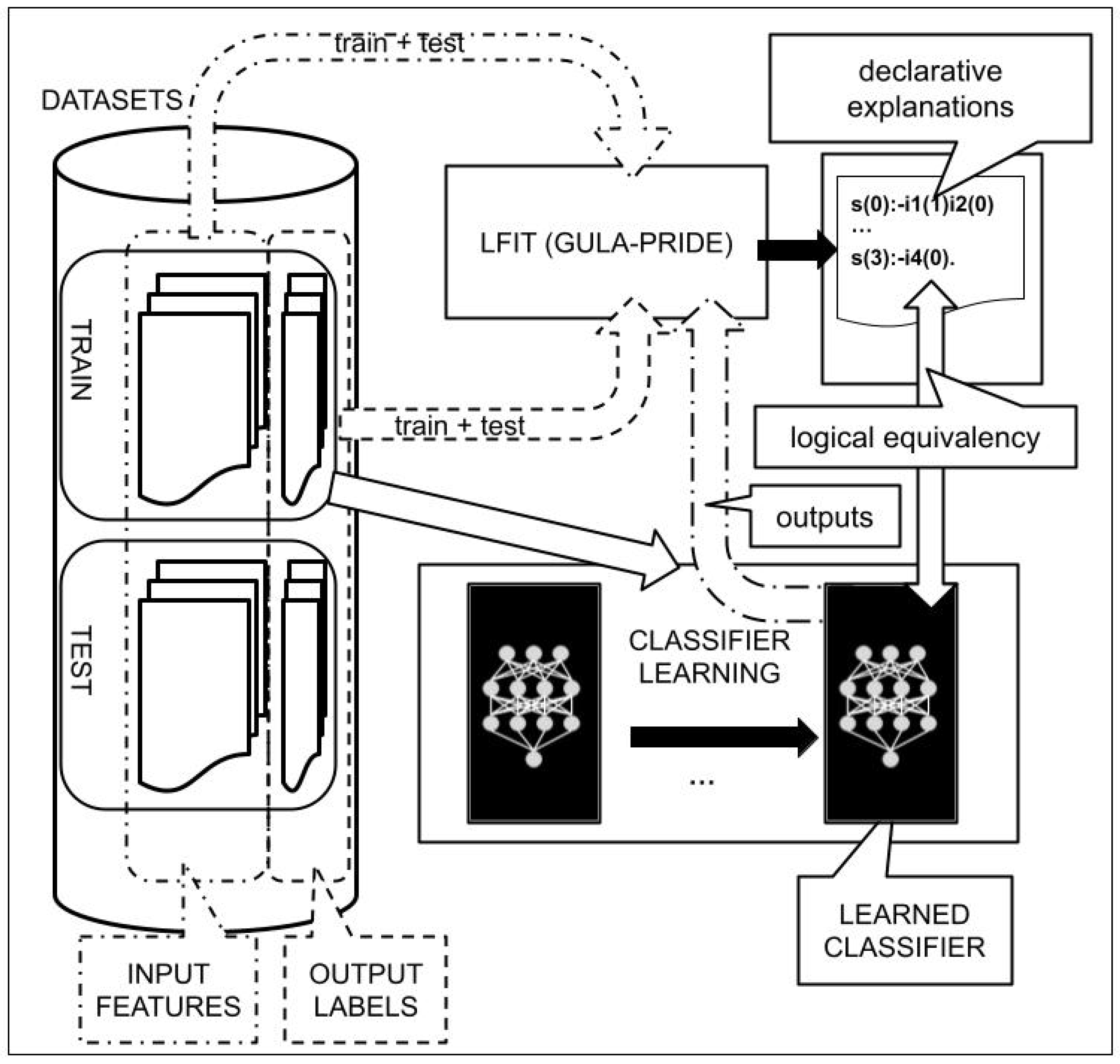
3.1. General Methodology
3.2. PRIDE Implementation of LFIT
3.2.1. Multi-Valued Logic
3.2.2. Rules

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| :- ,…, . |
| class(0) :- age(3), education(6), marital-status(0), occupation(0). |
| class(0) :- age(4), workclass(0), education(1), occupation(8), relationship(0), native-country(0). |
| class(1) :- education(7), marital-status(5). |
| class(1) :- age(2), education(8), occupation(10). |
| class(1) :- age(1), education(3), marital-status(2), occupation(9). |
3.2.3. Rule Domination
| : class(0) :- education(6), marital-status(0). |
| : class(0) :- age(3), education(6), marital-status(0), occupation(0). |
3.2.4. States and Rule-State Matching
| : age(3), education(6), marital-status(0), occupation(0) |
| : class(0) :- education(6), marital-status(0). |
- Match the observations in a complete (all observations are explained) and correct (no spurious explanation) way;
- Represent only minimally necessary interactions (according to Occam’s razor: no overly-complex bodies of rules).
4. Experimental Framework
4.1. FairCVdb Dataset
Experimental Protocol: Towards Declarative Explanations
4.2. Adult Income Level Dataset
Experiments Design
- To prepare the dataset for PRIDE by preprocessing:
- Removing those entries with some unknown attribute. Only 45,222 entries remain after this step.
- Discretising continuous attributes (those marked as continuous in Table 1).
- To get a logical version equivalent to the data to analyse the effect of the attribute sex considering the income level as a function of the other attributes.
- To get a logical version equivalent to the data to analyse the effect of the attribute ethnicity considering the income level as a function of the other attributes.
5. Results
5.1. FairCVdb Dataset
5.1.1. Example of Declarative Explanation
| scores(3) :- gender(1), education(5), experience(3). |
| scores(3) :- education(4), experience(3). |
5.1.2. Quantitative Summary of the Results
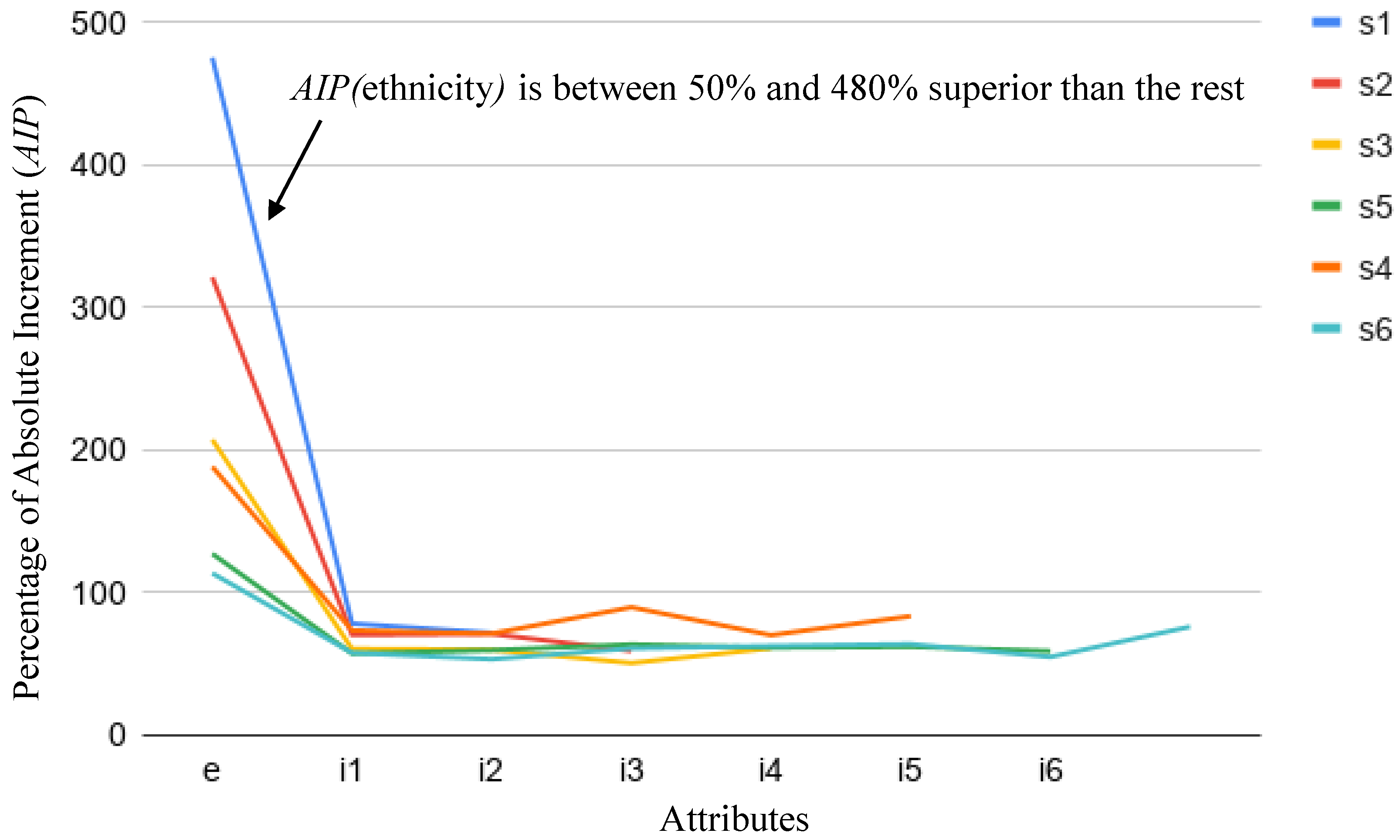
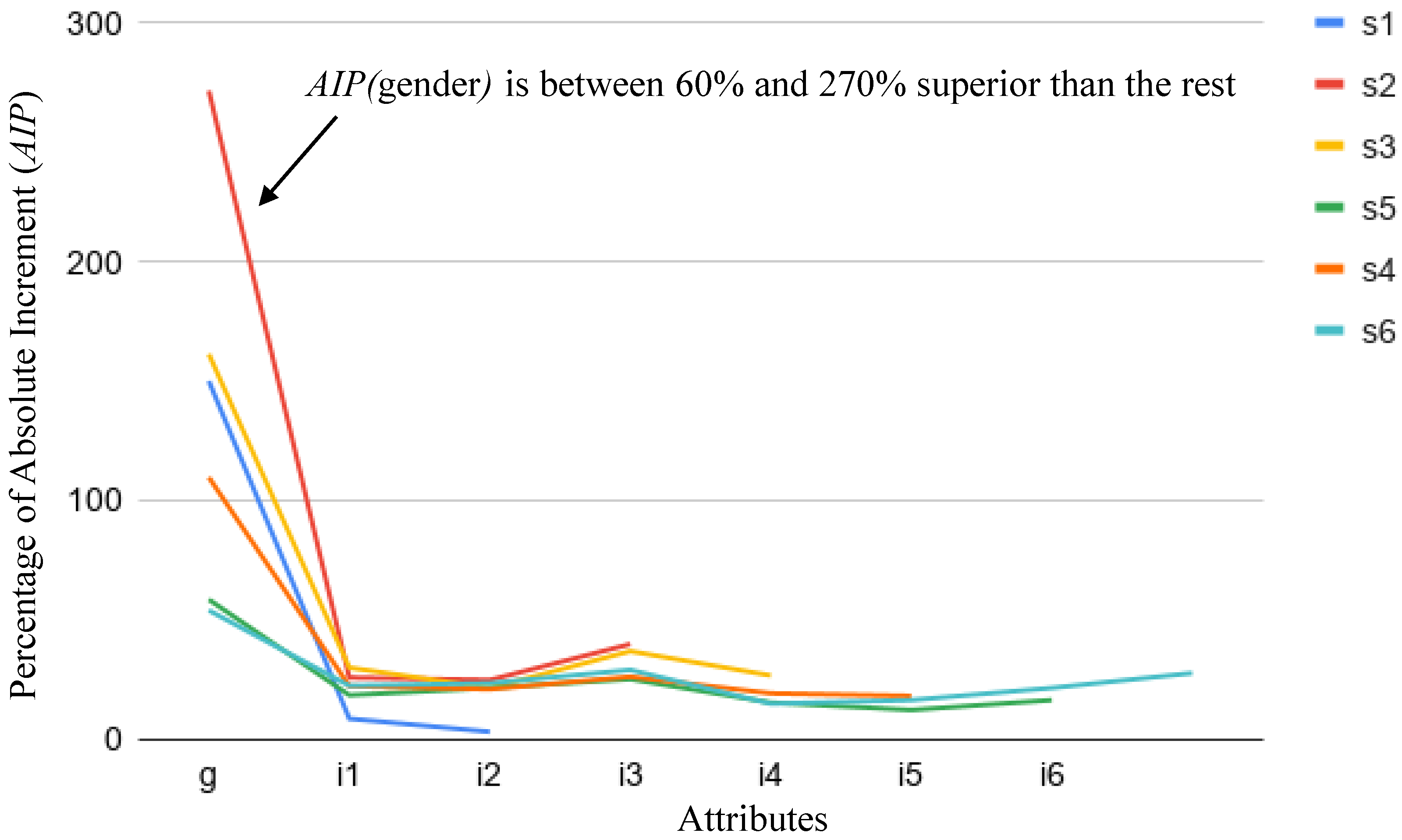
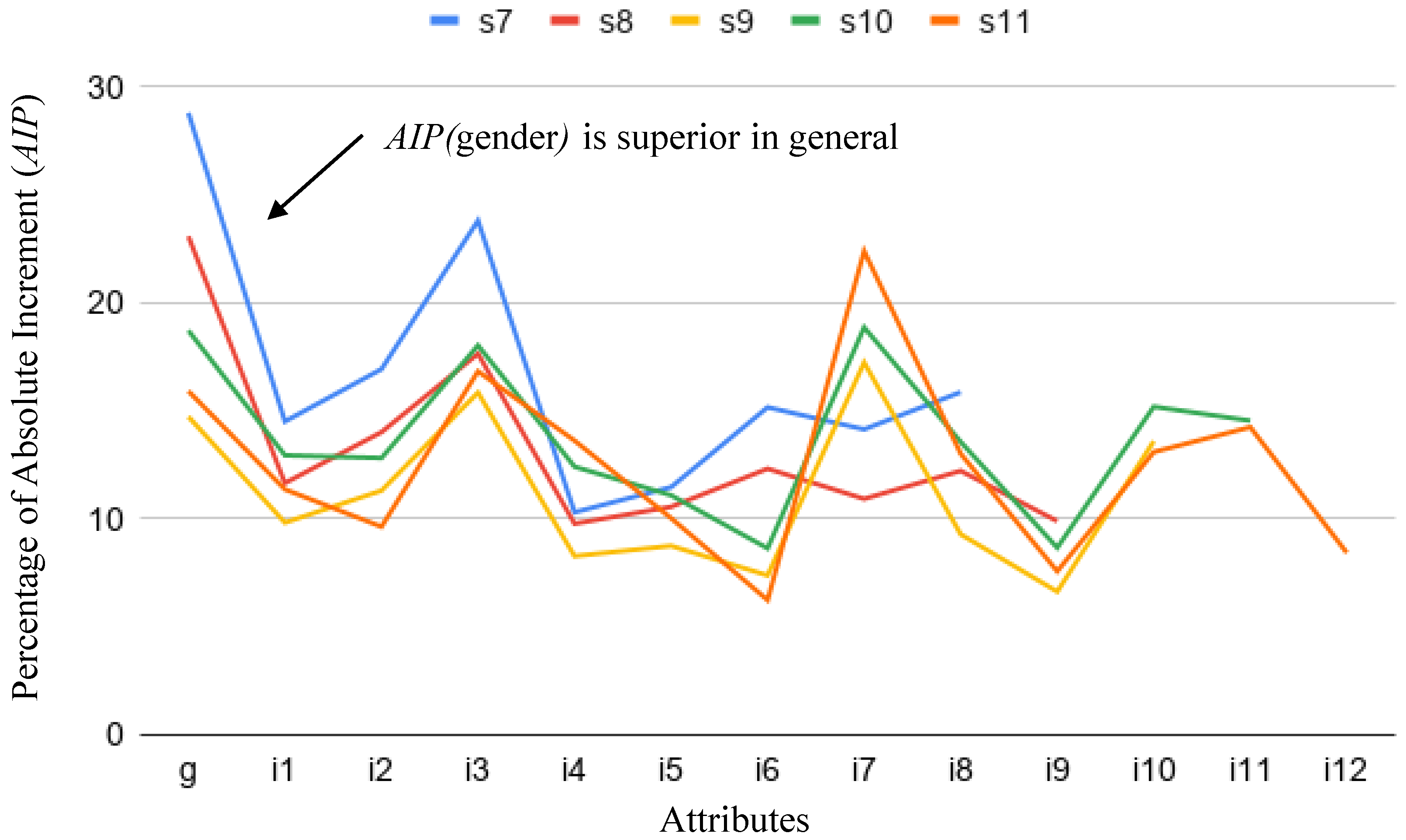
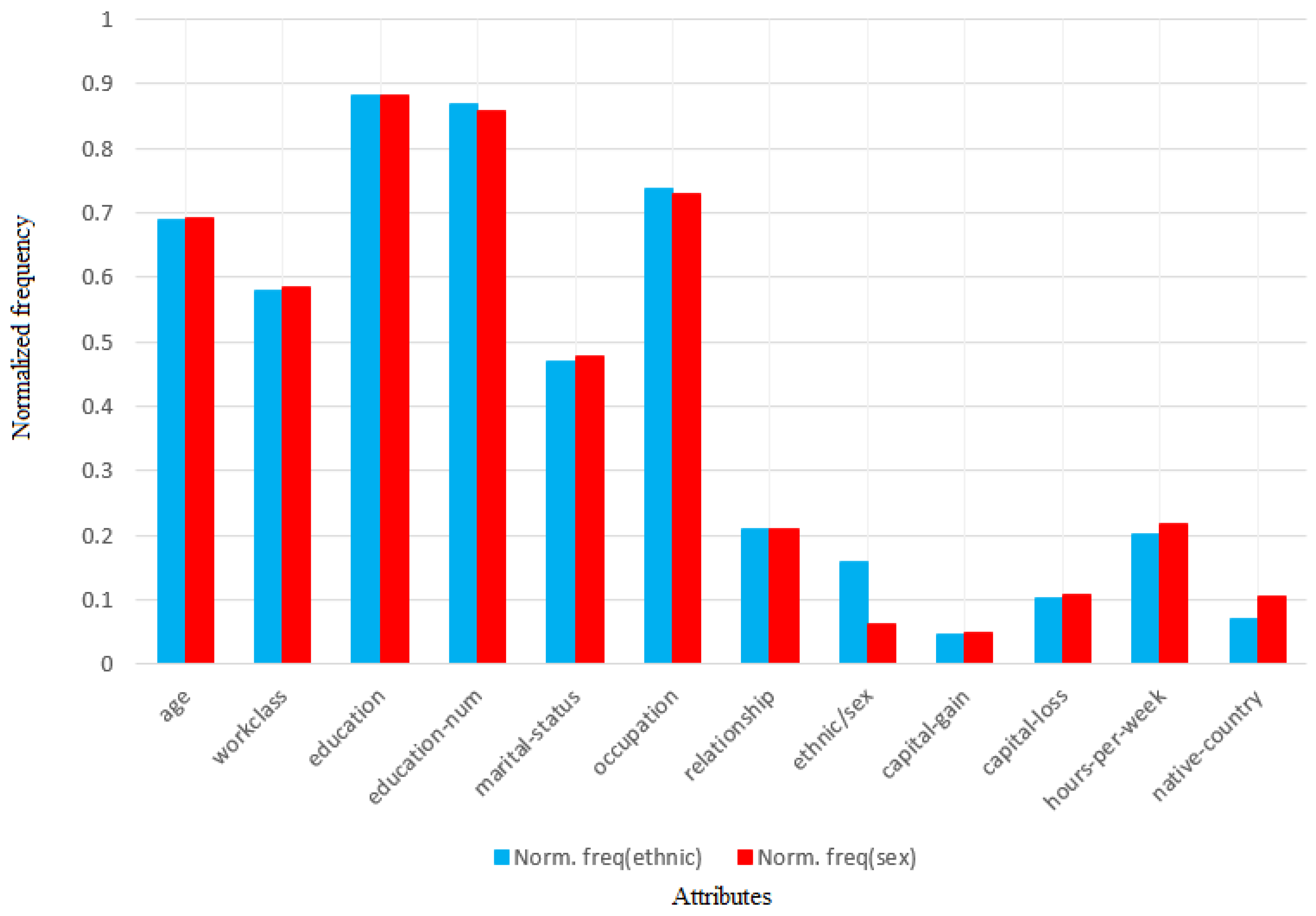
5.1.3. Quantitative Identification of Biased Attributes in Rules
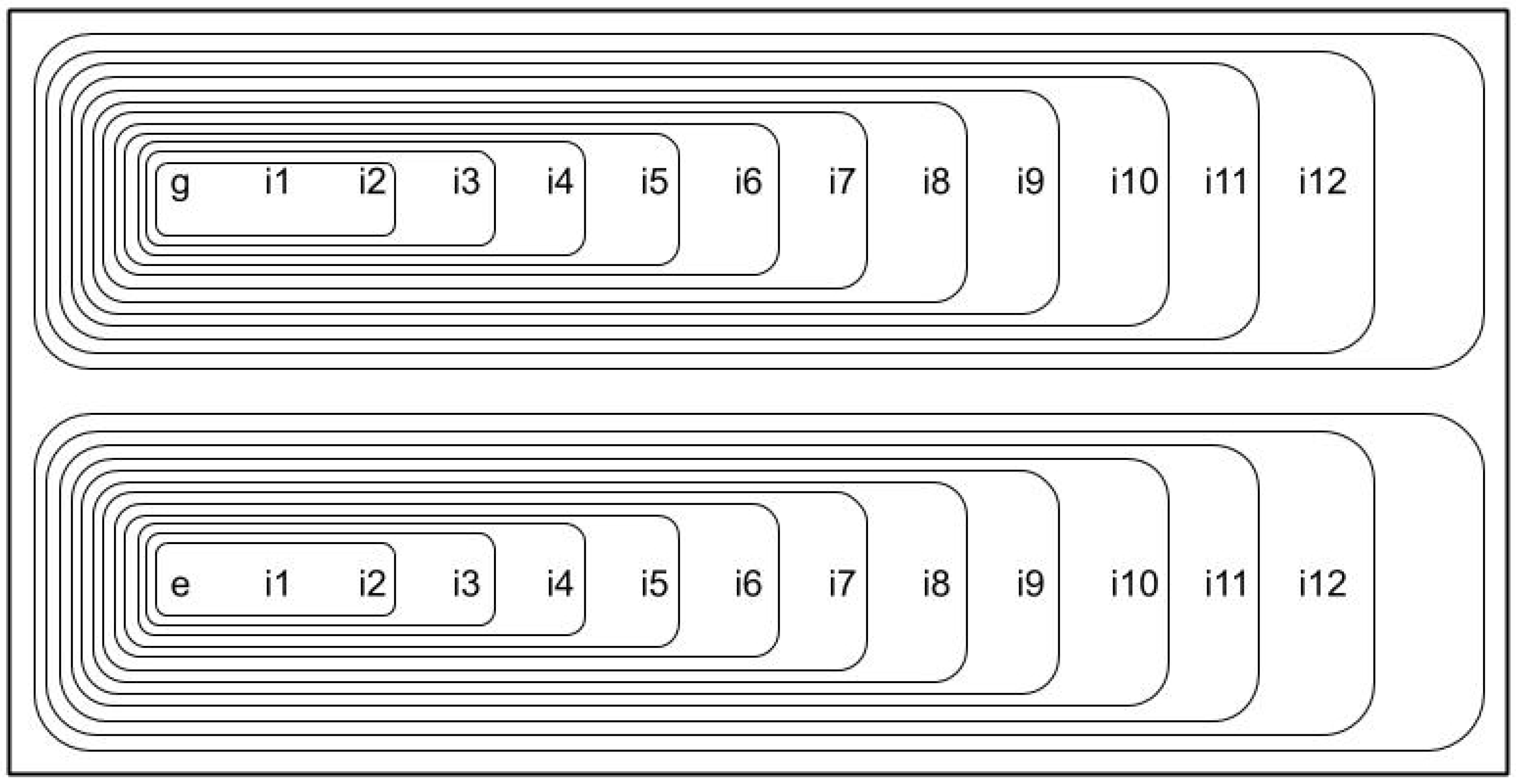
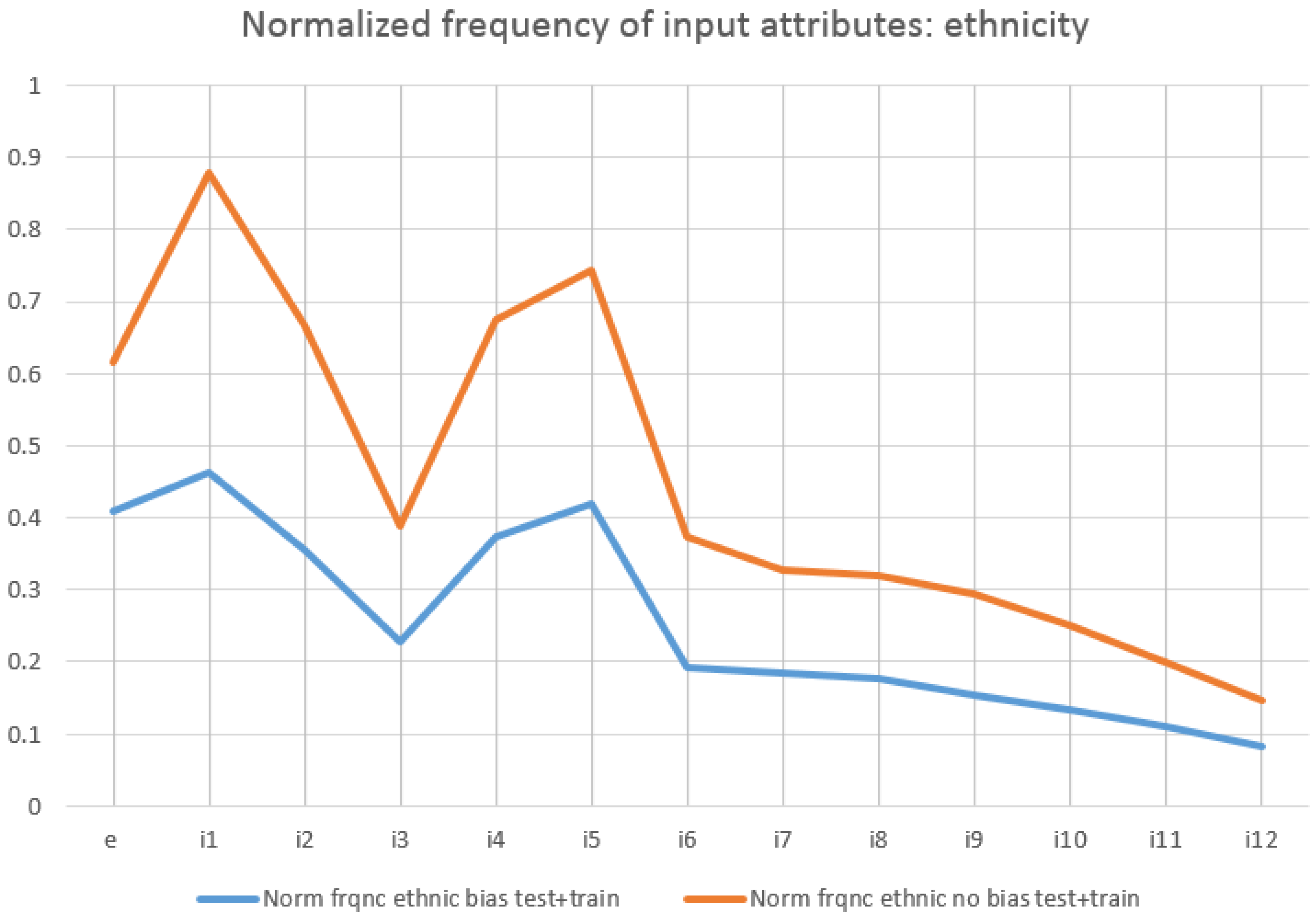
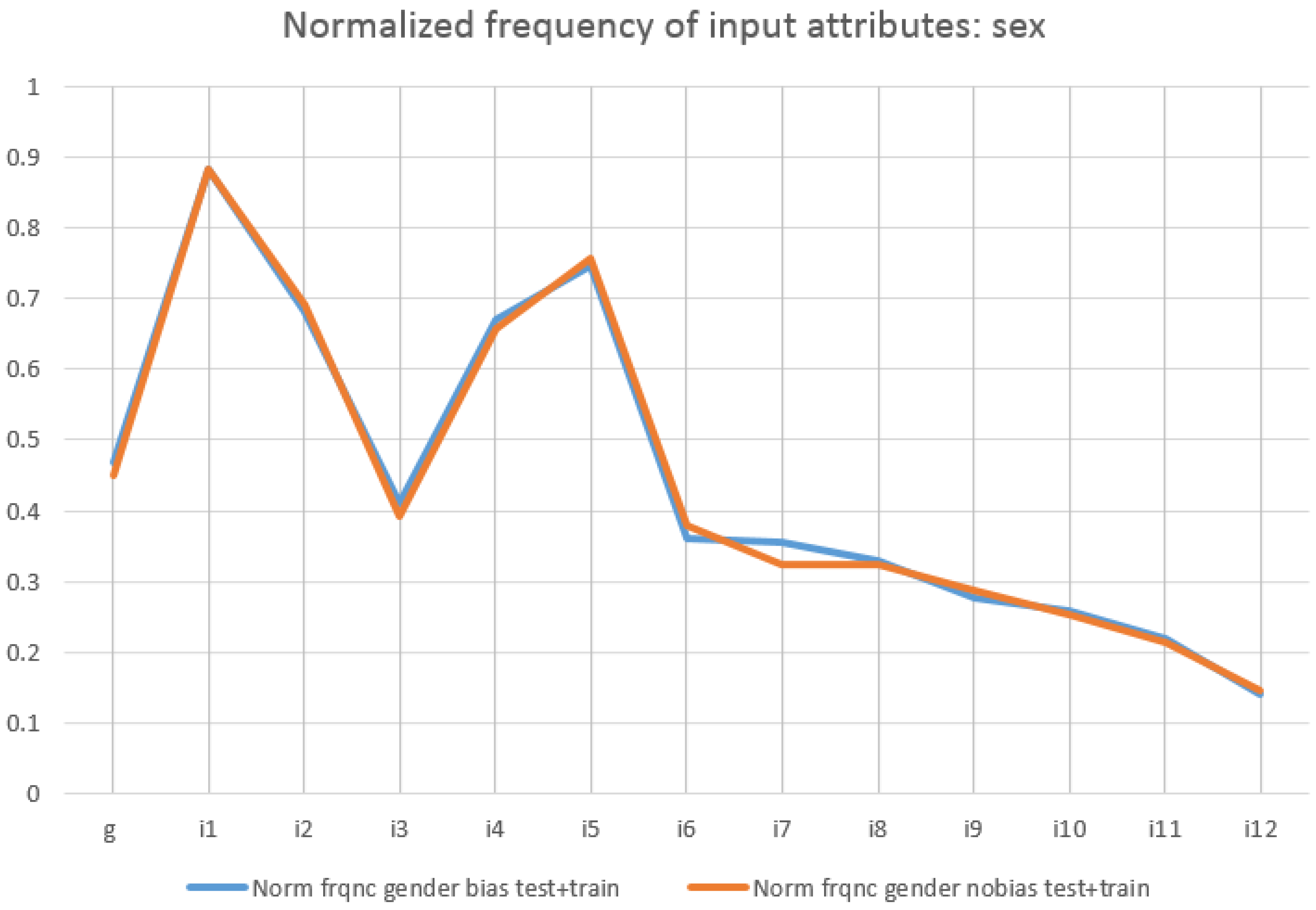
5.1.4. Quantitative Identification of the Distribution of Biased Attributes
5.2. Adult Income Level Dataset
6. Discussion
- PRIDE canexplainalgorithms learnt by neural networks. The theorems that support the characteristics of PRIDE allow a set of propositional clauses logically equivalent to the systems observed when facing the input data provided. In addition, each proposition has a set of conditions that is minimum. Thus, regarding the FairCVdb case, once the scorer is learnt, PRIDE translates it into a logical equivalent program. This program is a list of clauses like the one shown in Listing 5. Logical programs are declarative theories that explain the knowledge on a domain.
- PRIDE canexplainwhat happens in a specific domain. Our experimental results discover these characteristics of the domain:
- –
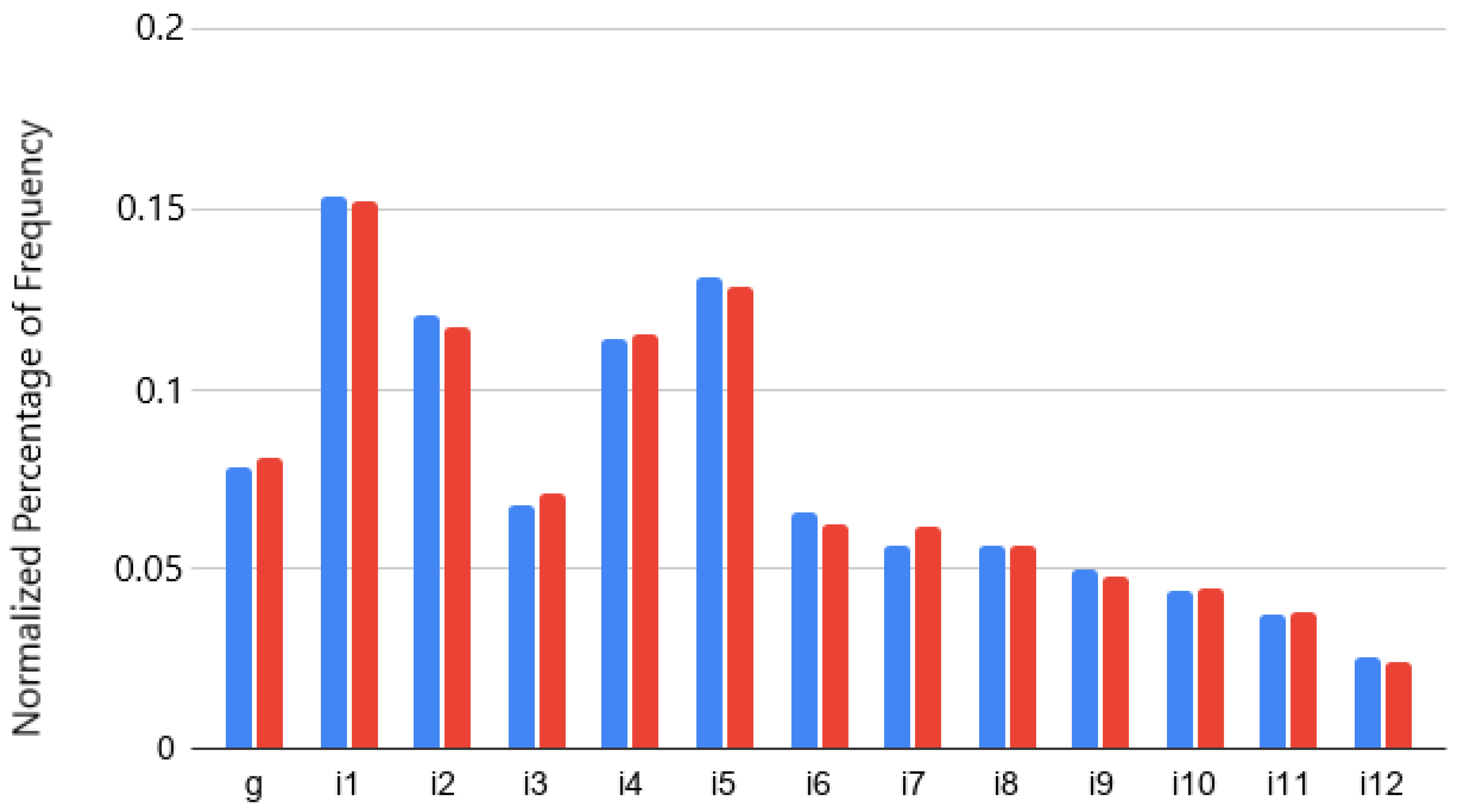
- Insights into the structure of the FairCVd dataset. We have seen (and further confirmed with the authors of the datasets) characteristics of the datasets, e.g., (1) All attributes are needed for the score. We have learnt the logical version of the system starting from only two input attributes and including one additional attribute at a time and only reached an accuracy of 100% when taking into account all of them. This is because removing some attributes generates indistinguishable CVs (all the remainder attributes have the same value) with different scores (that correspond to different values in some of the removed attributes). (2) Gender and ethnicity are not the most relevant attributes for scoring: The number of occurrences of these attributes is much smaller than others in the conditions of the clauses of the learnt logical program. (3) While trying to catch the biases we have discovered that some attributes seem to increase their relevance when the score is biased. For example, the competence in some specific languages (attribute i7) seems to be more relevant when the score has gender bias. After discussing with the authors of the datasets, they confirmed a random perturbation of these languages into the biases, that explained our observations.
- –
- Biases in the training FairCVdb datasets were detected. We have analysed the relationship between the scores and the specific values of the attributes used to generate the biased data. We have proposed a simple mathematical model based on the effective weights of the attributes that concludes that higher values of the scores correspond to the same specific values of gender (for gender bias) and ethnic group (for ethnicity bias). On the other hand, we have performed an exhaustive series of experiments to analyse the increase of the presence of the gender and ethnicity in the conditions of the clauses of the learnt logical program (comparing the unbiased and biased versions).
- –
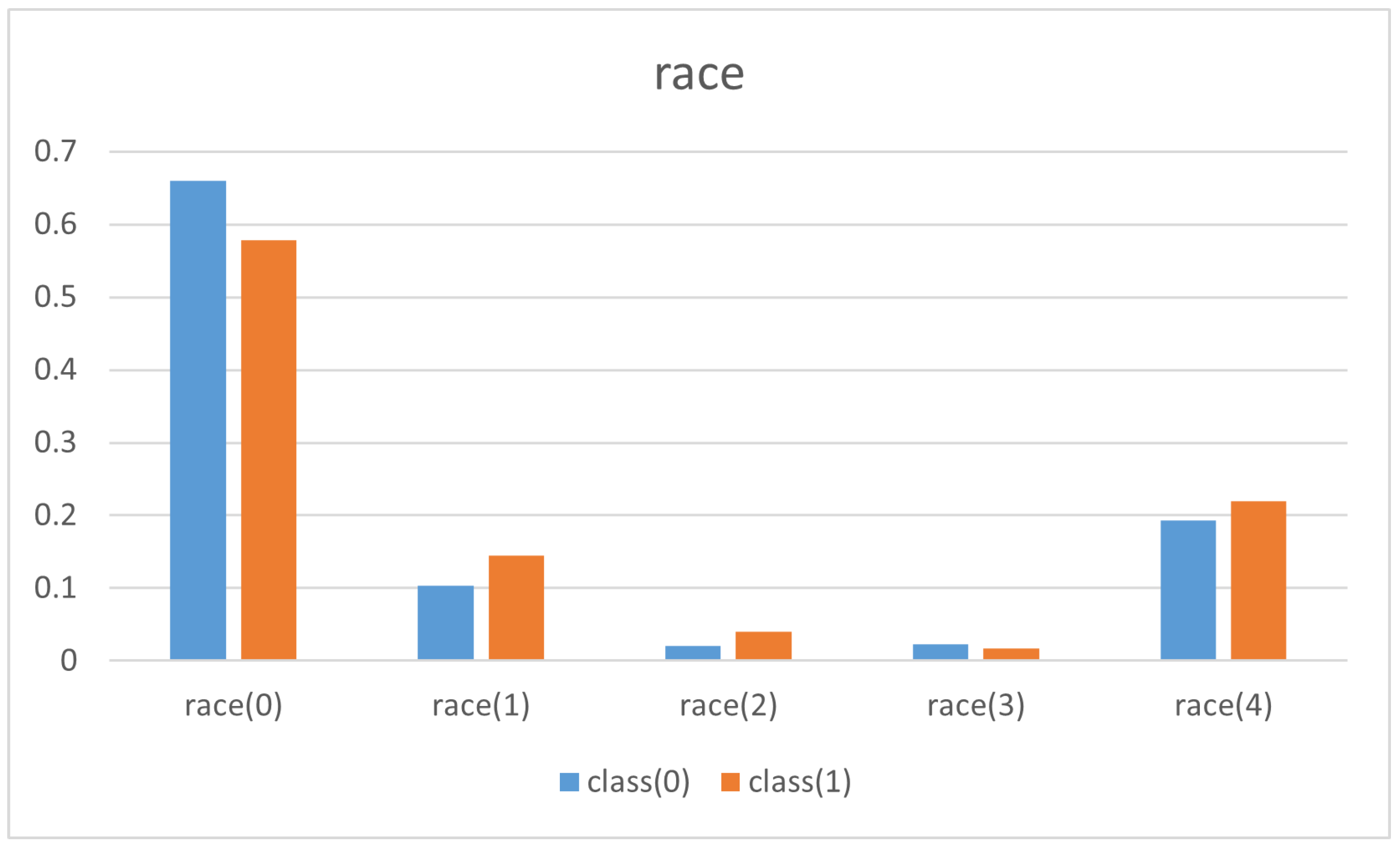
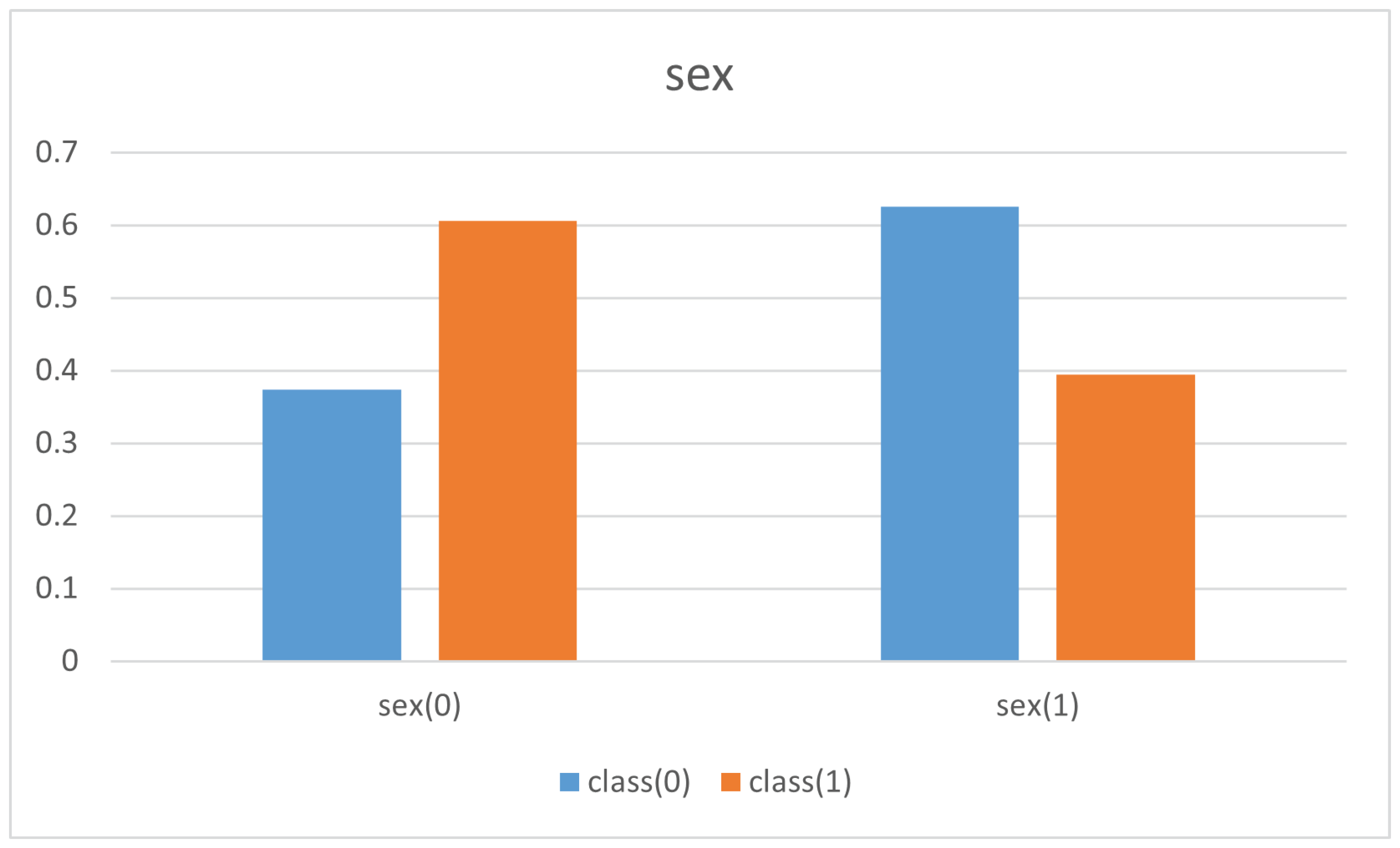
- Insights into the structure of dataset about the adult income from the US census. In this case, there is no unbiased version to compare with, as in the FairCVdb dataset. In addition, we do not have any machine learning approach to be considered for the black-box explanation. Nevertheless, there exists a common belief about the presence of biases (gender and ethnicity) in the income level. PRIDE has been used considering the dataset itself as a black-box, understanding the income level as a function of the other attributes. We have obtained a logic theory that supports this common belief.
7. Further Research Lines
- Increasing understandability. Two possibilities could be considered in the future: (1) to ad hoc post-process the learned program for translating it into a more abstract form, or (2) to increase the expressive power of the formal model that supports the learning engine using, for example, ILP based on first-order logic.
- Adding predictive capability. PRIDE is actually not aimed to predict but to explain (declaratively) by means of a digital twin of the observed systems. Nevertheless, it is not really complicated to extend PRIDE functionality to predict. It should be necessary to change the way in which the result is interpreted as a logical program: mainly by adding mechanisms to chose the most promising rule when more than one is applicable.Our plan is to test an extended-to-predict PRIDE version to this same domain and compare the result with the classifier generated by deep learning algorithms.
- Handling numerical inputs. [8] included as input the images of the faces of the owners of the CVs. Although some variants to PRIDE are able to cope with numerical signals, the huge amount of information associated with images implies performance problems. Images are a typical input format in real deep learning domains. We would like to add some automatic pre-processing steps for extracting discrete information (such as semantic labels) from input images. We are motivated by the success of systems with similar approaches but different structure like [65].
- Generating and combining multiple explanations. The present work has explored a way to provide a single human-readable explanation of the behavior of an AI model. An extension we have in mind is generating multiple explanations by different complementary methods and parameters of those methods and then generating a combined explanation [66,67].
- Measuring the accuracy and performance of the explanations. As far as the authors know, there is no standard procedure to evaluate and compare different explainability approaches. We will incorporate in future versions some formal metric.
- Analysing other significant problems where non-explainable AI is now the common practice for good explanations. The scenario studied here (automatic tools for screening in recruitment and estimating the income level based on demographic information) are only two of the many application areas where explanations of the action of AI systems are really needed. Other areas that will significantly benefit from this kind of approaches are e-learning [70], e-health [71,72], and other human-computer interaction applications [73,74].
- Proposing metrics for the complexity of the datasets. Due to the formal properties that the general LFIT model gives to the learned theories, the complexity of the original data could be estimated from the complexity of the propositional logic equivalent theory. This approach is inspired by some implementations of Kolmogorov’s complexity by means of file compressors [64].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Klingner, J. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Rahwan, I.; Cebrian, M.; Obradovich, N.; Bongard, J.; Bonnefon, J.F.; Breazeal, C.; Crandall, J.W.; Christakis, N.A.; Couzin, I.D.; Jackson, M.O.; et al. Machine behaviour. Nature 2019, 568, 477–486. [Google Scholar] [CrossRef] [PubMed]
- Serna, I.; Morales, A.; Fierrez, J.; Cebrian, M.; Obradovich, N.; Rahwan, I. Algorithmic Discrimination: Formulation and Exploration in Deep Learning-based Face Biometrics. In Proceedings of the AAAI Workshop on Artificial Intelligence Safety (SafeAI), New York, NY, USA, 7 February 2020. [Google Scholar]
- Tome, P.; Vera-Rodriguez, R.; Fierrez, J.; Ortega-Garcia, J. Facial Soft Biometric Features for Forensic Face Recognition. Forensic Sci. Int. 2015, 257, 171–284. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Loyola-Gonzalez, O.; Ferreira, E.F.; Morales, A.; Fierrez, J.; Medina-Perez, M.A.; Monroy, R. Impact of Minutiae Errors in Latent Fingerprint Identification: Assessment and Prediction. Appl. Sci. 2021, 11, 4187. [Google Scholar] [CrossRef]
- Peña, A.; Serna, I.; Morales, A.; Fierrez, J. Bias in Multimodal AI: Testbed for Fair Automatic Recruitment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 129–137. [Google Scholar] [CrossRef]
- Terhorst, P.; Kolf, J.N.; Huber, M.; Kirchbuchner, F.; Damer, N.; Morales, A.; Fierrez, J.; Kuijper, A. A Comprehensive Study on Face Recognition Biases Beyond Demographics. arXiv 2021, arXiv:2103.01592. [Google Scholar] [CrossRef]
- Serna, I.; Peña, A.; Morales, A.; Fierrez, J. InsideBias: Measuring Bias in Deep Networks and Application to Face Gender Biometrics. In Proceedings of the IAPR International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Serna, I.; Morales, A.; Fierrez, J.; Ortega-Garcia, J. IFBiD: Inference-Free Bias Detection. arXiv 2021, arXiv:2109.04374. [Google Scholar]
- Michie, D. Machine Learning in the Next Five Years. In Proceedings of the Third European Working Session on Learning, EWSL 1988, Glasgow, UK, 3–5 October 1988; Sleeman, D.H., Ed.; Pitman Publishing: London, UK, 1988; pp. 107–122. [Google Scholar]
- Schmid, U.; Zeller, C.; Besold, T.R.; Tamaddoni-Nezhad, A.; Muggleton, S. How Does Predicate Invention Affect Human Comprehensibility? In Proceedings of the Inductive Logic Programming—26th International Conference (ILP 2016), London, UK, 4–6 September 2016; Revised Selected Papers, Lecture Notes in Computer Science. Cussens, J., Russo, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 10326, pp. 52–67. [Google Scholar] [CrossRef]
- Muggleton, S.H.; Schmid, U.; Zeller, C.; Tamaddoni-Nezhad, A.; Besold, T.R. Ultra-Strong Machine Learning: Comprehensibility of programs learned with ILP. Mach. Learn. 2018, 107, 1119–1140. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Rodríguez, N.D.; Ser, J.D.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Muggleton, S. Inductive Logic Programming. New Gener. Comput. 1991, 8, 295–318. [Google Scholar] [CrossRef]
- Muggleton, S.H.; Lin, D.; Pahlavi, N.; Tamaddoni-Nezhad, A. Meta-interpretive learning: Application to grammatical inference. Mach. Learn. 1994, 94, 25–49. [Google Scholar] [CrossRef]
- Cropper, A.; Muggleton, S.H. Learning efficient logic programs. Mach. Learn. 2019, 108, 1063–1083. [Google Scholar] [CrossRef]
- Dai, W.Z.; Muggleton, S.H.; Zhou, Z.H. Logical Vision: Meta-Interpretive Learning for Simple Geometrical Concepts. In Proceedings of the 25th International Conference on Inductive Logic Programming, Kyoto, Japan, 20–22 August 2015. [Google Scholar]
- Muggleton, S.; Dai, W.; Sammut, C.; Tamaddoni-Nezhad, A.; Wen, J.; Zhou, Z. Meta-Interpretive Learning from noisy images. Mach. Learn. 2018, 107, 1097–1118. [Google Scholar] [CrossRef]
- Ribeiro, T. Studies on Learning Dynamics of Systems from State Transitions. Ph.D. Thesis, The Graduate University for Advanced Studies, Tokyo, Japan, 2015. [Google Scholar]
- Ortega, A.; Fierrez, J.; Morales, A.; Wang, Z.; Ribeiro, T. Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Fair and Explainable Automatic Recruitment. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision Workshops, WACV Workshops 2021, Waikola, HI, USA, 5–9 January 2021; pp. 78–87. [Google Scholar] [CrossRef]
- Eiben, A.; Smith, J. Introduction To Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2003; Volume 45. [Google Scholar] [CrossRef]
- O’Neill, M.; Conor, R. Grammatical Evolution—Evolutionary Automatic Programming in an Arbitrary Language; Genetic Programming; Kluwer: Boston, MA, USA, 2003; Volume 4. [Google Scholar]
- de la Cruz, M.; de la Puente, A.O.; Alfonseca, M. Attribute Grammar Evolution. In Artificial Intelligence and Knowledge Engineering Applications: A Bioinspired Approach: First International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2005, Las Palmas, Canary Islands, Spain, 15–18 June 2005, Proceedings, Part II; Lecture Notes in Computer, Science; Mira, J., Álvarez, J.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3562, pp. 182–191. [Google Scholar] [CrossRef]
- Ortega, A.; de la Cruz, M.; Alfonseca, M. Christiansen Grammar Evolution: Grammatical Evolution With Semantics. IEEE Trans. Evol. Comput. 2007, 11, 77–90. [Google Scholar] [CrossRef]
- Alonso, C.L.; Montaña, J.L.; Puente, J.; Borges, C.E. A New Linear Genetic Programming Approach Based on Straight Line Programs: Some Theoretical and Experimental Aspects. Int. J. Artif. Intell. Tools 2009, 18, 757–781. [Google Scholar] [CrossRef]
- Evans, R.; Grefenstette, E. Learning Explanatory Rules from Noisy Data. J. Artif. Intell. Res. 2017, 61, 1–64. [Google Scholar] [CrossRef]
- Manhaeve, R.; Dumancic, S.; Kimmig, A.; Demeester, T.; De Raedt, L. DeepProbLog: Neural Probabilistic Logic Programming. arXiv 2019, arXiv:1805.10872v2. [Google Scholar] [CrossRef]
- Doran, D.; Schulz, S.; Besold, T. What Does Explainable AI Really Mean? A New Conceptualization of Perspectives. arXiv 2017, arXiv:1710.00794. [Google Scholar]
- Hailesilassie, T. Rule Extraction Algorithm for Deep Neural Networks: A Review. arXiv 2016, arXiv:1610.05267. [Google Scholar]
- Zilke, J.R. Extracting Rules from Deep Neural Networks. arXiv 2016, arXiv:1610.05267. [Google Scholar]
- Donadello, I.; Serafini, L. Integration of numeric and symbolic information for semantic image interpretation. Intell. Artif. 2016, 10, 33–47. [Google Scholar] [CrossRef]
- Donadello, I.; Dragoni, M. SeXAI: Introducing Concepts into Black Boxes for Explainable Artificial Intelligence. In Proceedings of the XAI.it@AI*IA 2020 Italian Workshop on Explainable Artificial Intelligence, Online, 25–26 November 2020. [Google Scholar]
- Yuan, H.; Yu, H.; Gui, S.; Ji, S. Explainability in Graph Neural Networks: A Taxonomic Survey. arXiv 2020, arXiv:2012.15445. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.A.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Guidotti, R.; Monreale, A.; Turini, F.; Pedreschi, D.; Giannotti, F. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. (CSUR) 2019, 51, 1–42. [Google Scholar] [CrossRef]
- Koza, J. Genetic Programming; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Steele, G. Common LISP: The Language, 2nd ed.; Digital Pr.: Woburn, MA, USA, 1990. [Google Scholar]
- Bratko, I. Prolog Programming for Artificial Intelligence, 4th ed.; Addison-Wesley: Boston, MA, USA, 2012. [Google Scholar]
- Huang, S.S.; Green, T.J.; Loo, B.T. Datalog and emerging applications: An interactive tutorial. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; Sellis, T.K., Miller, R.J., Kementsietsidis, A., Velegrakis, Y., Eds.; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1213–1216. [Google Scholar] [CrossRef]
- Thompson, S.J. Haskell—The Craft of Functional Programming, 3rd ed.; Addison-Wesley: London, UK, 2011. [Google Scholar]
- Gebser, M.; Kaminski, R.; Kaufmann, B.; Schaub, T. Answer Set Solving in Practice; Synthesis Lectures on Artificial Intelligence and Machine Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2012. [Google Scholar] [CrossRef]
- Lloyd, J.W. Foundations of Logic Programming, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1987. [Google Scholar] [CrossRef]
- Muggleton, S. Inductive Logic Programming. In Proceedings of the First International Workshop on Algorithmic Learning Theory, Tokyo, Japan, 8–10 October 1990; Arikawa, S., Goto, S., Ohsuga, S., Yokomori, T., Eds.; Springer: Berlin/Heidelberg, Germany, 1990; pp. 42–62. [Google Scholar]
- Katayama, S. Systematic search for lambda expressions. In Revised Selected Papers from the Sixth Symposium on Trends in Functional Programming; Trends in Functional Programming; van Eekelen, M.C.J.D., Ed.; Intellect: Bristol, UK, 2005; Volume 6, pp. 111–126. [Google Scholar]
- Law, M. Inductive Learning of Answer Set Programs. Ph.D. Thesis, Imperial College London, London, UK, 2018. [Google Scholar]
- Nezhad, A.T. Logic-Based Machine Learning Using a Bounded Hypothesis Space: The Lattice Structure, Refinement Operators and a Genetic Algorithm Approach. Ph.D. Thesis, Imperial College London, London, UK, 2013. [Google Scholar]
- Inoue, K.; Ribeiro, T.; Sakama, C. Learning from interpretation transition. Mach. Learn. 2014, 94, 51–79. [Google Scholar] [CrossRef]
- Ribeiro, T.; Magnin, M.; Inoue, K.; Sakama, C. Learning Delayed Influences of Biological Systems. Front. Bioeng. Biotechnol. 2015, 2, 81. [Google Scholar] [CrossRef] [PubMed]
- Martínez Martínez, D.; Ribeiro, T.; Inoue, K.; Alenyà Ribas, G.; Torras, C. Learning probabilistic action models from interpretation transitions. In Proceedings of the Technical Communications of the 31st International Conference on Logic Programming (ICLP 2015), Cork, Ireland, 31 August–4 September 2015; pp. 1–14. [Google Scholar]
- Ribeiro, T.; Magnin, M.; Inoue, K.; Sakama, C. Learning Multi-valued Biological Models with Delayed Influence from Time-Series Observations. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 25–31. [Google Scholar] [CrossRef]
- Martınez, D.; Alenya, G.; Torras, C.; Ribeiro, T.; Inoue, K. Learning relational dynamics of stochastic domains for planning. In Proceedings of the 26th International Conference on Automated Planning and Scheduling, London, UK, 12–17 June 2016. [Google Scholar]
- Ribeiro, T.; Tourret, S.; Folschette, M.; Magnin, M.; Borzacchiello, D.; Chinesta, F.; Roux, O.; Inoue, K. Inductive Learning from State Transitions over Continuous Domains. In Inductive Logic Programming; Lachiche, N., Vrain, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 124–139. [Google Scholar]
- Ribeiro, T.; Folschette, M.; Magnin, M.; Roux, O.; Inoue, K. Learning dynamics with synchronous, asynchronous and general semantics. In Proceedings of the International Conference on Inductive Logic Programming, Ferrara, Italy, 2–4 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 118–140. [Google Scholar]
- Ribeiro, T.; Folschette, M.; Magnin, M.; Inoue, K. Learning any Semantics for Dynamical Systems Represented by Logic Programs. 2020. Available online: https://hal.archives-ouvertes.fr/hal-02925942/ (accessed on 3 November 2021).
- Ribeiro, T.; Inoue, K. Learning prime implicant conditions from interpretation transition. In Inductive Logic Programming; Springer: Berlin/Heidelberg, Germany, 2015; pp. 108–125. [Google Scholar]
- Blair, H.A.; Subrahmanian, V. Paraconsistent logic programming. Theor. Comput. Sci. 1989, 68, 135–154. [Google Scholar] [CrossRef]
- Blair, H.A.; Subrahmanian, V. Paraconsistent foundations for logic programming. J. Non-Class. Log. 1988, 5, 45–73. [Google Scholar]
- Ribeiro, T.; Folschette, M.; Trilling, L.; Glade, N.; Inoue, K.; Magnin, M.; Roux, O. Les enjeux de l’inférence de modèles dynamiques des systèmes biologiques à partir de séries temporelles. In Approches Symboliques de la Modélisation et de L’analyse des Systèmes Biologiques; Lhoussaine, C., Remy, E., Eds.; ISTE Editions: London, UK, 2020. [Google Scholar]
- Ribeiro, T.; Folschette, M.; Magnin, M.; Inoue, K. Learning Any Memory-Less Discrete Semantics for Dynamical Systems Represented by Logic Programs. Mach. Learn. 2021. Available online: http://lr2020.iit.demokritos.gr/online/ribeiro.pdf (accessed on 3 November 2021).
- Iken, O.; Folschette, M.; Ribeiro, T. Automatic Modeling of Dynamical Interactions Within Marine Ecosystems. In Proceedings of the International Conference on Inductive Logic Programming, Online, 25–27 October 2021. [Google Scholar]
- Kohavi, R. Scaling Up the Accuracy of Naive-Bayes Classifiers: A Decision-Tree Hybrid. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996. [Google Scholar]
- Fenner, S.; Fortnow, L. Compression Complexity. arXiv 2017, arXiv:1702.04779. [Google Scholar]
- Varghese, D.; Tamaddoni-Nezhad, A. One-Shot Rule Learning for Challenging Character Recognition. In Proceedings of the 14th International Rule Challenge, Oslo, Norway, 29 June–1 July 2020; Volume 2644, pp. 10–27. [Google Scholar]
- Fierrez, J. Adapted Fusion Schemes for Multimodal Biometric Authentication. Ph.D. Thesis, Universidad Politecnica de Madrid, Madrid, Spain, 2006. [Google Scholar]
- Fierrez, J.; Morales, A.; Vera-Rodriguez, R.; Camacho, D. Multiple classifiers in biometrics. Part 1: Fundamentals and review. Inf. Fusion 2018, 44, 57–64. [Google Scholar] [CrossRef]
- Fierrez, J.; Morales, A.; Ortega-Garcia, J. Biometrics Security. In Encyclopedia of Cryptography, Security and Privacy; Chapter Biometrics, Security; Jajodia, S., Samarati, P., Yung, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Neves, J.C.; Tolosana, R.; Vera-Rodriguez, R.; Lopes, V.; Proenca, H.; Fierrez, J. GANprintR: Improved Fakes and Evaluation of the State of the Art in Face Manipulation Detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1038–1048. [Google Scholar] [CrossRef]
- Hernandez-Ortega, J.; Daza, R.; Morales, A.; Fierrez, J.; Ortega-Garcia, J. edBB: Biometrics and Behavior for Assessing Remote Education. In Proceedings of the AAAI Workshop on Artificial Intelligence for Education (AI4EDU), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Gomez, L.F.; Morales, A.; Orozco-Arroyave, J.R.; Daza, R.; Fierrez, J. Improving Parkinson Detection using Dynamic Features from Evoked Expressions in Video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRw), Nashville, TN, USA, 19–25 June 2021; pp. 1562–1570. [Google Scholar]
- Faundez-Zanuy, M.; Fierrez, J.; Ferrer, M.A.; Diaz, M.; Tolosana, R.; Plamondon, R. Handwriting Biometrics: Applications and Future Trends in e-Security and e-Health. Cogn. Comput. 2020, 12, 940–953. [Google Scholar] [CrossRef]
- Acien, A.; Morales, A.; Vera-Rodriguez, R.; Fierrez, J.; Delgado, O. Smartphone Sensors For Modeling Human-Computer Interaction: General Outlook And Research Datasets For User Authentication. In Proceedings of the IEEE Conference on Computers, Software, and Applications (COMPSAC), Madrid, Spain, 13–17 July 2020. [Google Scholar] [CrossRef]
- Tolosana, R.; Ruiz-Garcia, J.C.; Vera-Rodriguez, R.; Herreros-Rodriguez, J.; Romero-Tapiador, S.; Morales, A.; Fierrez, J. Child-Computer Interaction: Recent Works, New Dataset, and Age Detection. arXiv 2021, arXiv:2102.01405. [Google Scholar]













| Attribute | Meaning | Type | Codification |
|---|---|---|---|
| Age | Age of the individual (years) | C | |
| Workclass | Work type (self employment, private, …) | D | |
| Fnlwgt | Demographic weight (row) from census | D | |
| Education | Highest academic degree | D | |
| Marital status | Civil status | D | |
| Occupation | Individual’s job sector | D | |
| Relationship | Present individual’s relationship | D | |
| Ethnicity | Ethnic group | D | |
| Sex | D | ||
| Capital gain | Increase in individual’s capital asset | C | |
| Capital loss | Decrease in individual’s capital asset | C | |
| Hours per week | Spent on work (average) | D | |
| Native country | Country of origin | D | |
| Income level | Individual’s class of income (≤50, >50) | D |
| Attribute | Meaning | Type | Codification |
|---|---|---|---|
| Ethnicity | Ethnic group | D | |
| Gender | D | ||
| Education | Education level | D | |
| Experience | Work experience | C | |
| Availability | Time for being ready to start | D | |
| Foreign languages | Level of 8 possible languages | D | |
| Score | Unbiased value assigned | C | |
| Gender biased score | (Gender) biased value assigned | C | |
| Ethnicity biased score | (Ethnicity) biased value assigned | C |
| e | i1 | i2 | i3 | i4 | i5 | i6 | |
|---|---|---|---|---|---|---|---|
| Ethnic bias | 3221 | 3648 | 2802 | 1789 | 2951 | 3300 | 1520 |
| No ethnic bias | 1682 | 2398 | 1822 | 1065 | 1846 | 2032 | 1023 |
| i7 | i8 | i9 | i10 | i11 | i12 | #Rules | |
|---|---|---|---|---|---|---|---|
| Ethnic bias | 1449 | 1404 | 1214 | 1044 | 870 | 652 | 7886 |
| No ethnic bias | 892 | 875 | 805 | 683 | 544 | 397 | 2732 |
| g | i1 | i2 | i3 | i4 | i5 | i6 | |
|---|---|---|---|---|---|---|---|
| Gender bias | 1150 | 2164 | 1671 | 1006 | 1642 | 1830 | 884 |
| No gender bias | 992 | 1943 | 1524 | 861 | 1445 | 1663 | 832 |
| i7 | i8 | i9 | i10 | i11 | i12 | #Rules | |
|---|---|---|---|---|---|---|---|
| Gender bias | 874 | 807 | 681 | 630 | 537 | 347 | 2449 |
| No gender bias | 714 | 714 | 633 | 557 | 470 | 320 | 2200 |
| #Rules | Age | Workclass | Education | ed.# | Civil-Status | Occu. | |
|---|---|---|---|---|---|---|---|
| ethnc. | 7948 | 5478 | 4612 | 7007 | 6902 | 3737 | 5860 |
| Relationship | Ethnc/Sex | Cap-Gain | Cap-Loss | h/Week | Country | |
|---|---|---|---|---|---|---|
| ethnc. | 1656 | 1263 | 374 | 813 | 1605 | 554 |
| #Rules | Age | Workclass | Education | ed.# | Civil-Status | Occu. | |
|---|---|---|---|---|---|---|---|
| gender | 7735 | 5353 | 4522 | 6821 | 6633 | 3696 | 5634 |
| Relationship | Ethnc/Sex | Cap-Gain | Cap-Loss | h/Week | Country | |
|---|---|---|---|---|---|---|
| gender | 1620 | 478 | 374 | 832 | 1685 | 810 |
| ethnc(0) | ethnc(1) | ethnc(2) | ethnc(3) | ethnc(4) | |
|---|---|---|---|---|---|
| class(0) | 452 | 71 | 14 | 16 | 132 |
| class(1) | 334 | 84 | 23 | 10 | 127 |
| Sex(0) | Sex(1) | |
|---|---|---|
| class(0) | 101 | 169 |
| class(1) | 126 | 82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortega, A.; Fierrez, J.; Morales, A.; Wang, Z.; de la Cruz, M.; Alonso, C.L.; Ribeiro, T. Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Explaining Biases in Machine Learning. Computers 2021, 10, 154. https://doi.org/10.3390/computers10110154
Ortega A, Fierrez J, Morales A, Wang Z, de la Cruz M, Alonso CL, Ribeiro T. Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Explaining Biases in Machine Learning. Computers. 2021; 10(11):154. https://doi.org/10.3390/computers10110154
Chicago/Turabian StyleOrtega, Alfonso, Julian Fierrez, Aythami Morales, Zilong Wang, Marina de la Cruz, César Luis Alonso, and Tony Ribeiro. 2021. "Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Explaining Biases in Machine Learning" Computers 10, no. 11: 154. https://doi.org/10.3390/computers10110154
APA StyleOrtega, A., Fierrez, J., Morales, A., Wang, Z., de la Cruz, M., Alonso, C. L., & Ribeiro, T. (2021). Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Explaining Biases in Machine Learning. Computers, 10(11), 154. https://doi.org/10.3390/computers10110154