
Click Fraud in Digital Advertising: A Comprehensive Survey



Abstract
:
1. Introduction
- First, we systematically look into the classification of different forms of click fraud as well as different types of click bots used to commit click fraud.
- We investigate the critical behavioral characteristics of bots versus humans in conducting click fraud within modern ad platforms.
- To date, several cutting-edge solutions have been proposed to address the problem of click fraud in online advertising. This article provides a thorough overview of the proposed methods and technologies in detecting and preventing click fraud discussed in the literature. We specifically categorize the surveyed techniques based on which particular actors within a digital advertising system are most likely to deploy them.
- We outline some of the most famous real-world click bots and their respective ad fraud campaigns observed to date.
- Finally, we conclude the article by highlighting some open challenges and future research directions in this field.
2. Background
2.1. Characteristics of Web-Bots
- Good Web-bots are legitimate bots whose activities might be beneficial to businesses as well as individuals. They crawl websites to help with search engine optimization (SEO) aggregation and market analysis. Some specific sub-categories of good Web-bots and the functions they perform are listed below:
- Web site monitoring bots monitor websites’ availability and system health. An example of a bot in this category is Pingdom.
- Aggregator bots collect information from websites and notify users or subscribers about news or events. An example of this type of bot is Feedly.
- Backlink checker bots confirm the inbound (referrer) URLs that a website receives so that marketers and SEOs can understand trends and optimize their pages accordingly. SEMRushBot is an example of this type of bot.
- Partner bots execute tasks and functions on transactional websites. An example being PayPal IPN.
- Social networking bots are deployed by social networking platforms, to add visibility to their webpages and drive the overall user engagement. Facebook bots are an example of this type of bot.
- Search engine bots, which are also known as Web crawlers or spiders, crawl through websites in order to index their pages and make them available/accessible on the respective search engine. Without them, most online businesses would struggle to define their brand value and attract new customers. Bots in this category include: GoogleBot, Bingbot, and Baidu Spider.
- Bad Web-bots are programmed to perform various malicious tasks on the WWW. They work evasively and are mainly used by scammers, cybercriminals, and other nefarious parties involved in a variety of illegal activities. Bad bots are automated programs that do not follow any rules. Mostly unregulated, they have a specific malicious objective which they are trying to accomplish. Some general sub-categories of bad Web-bots are [8,9]:
- Scraper bots collect/steal large amounts of information from websites. They are scripted to look for specific data, including product reviews, breaking news, prices, customer names, product catalogues, or even user-generated content on community forums. By scraping the content off a website and then posting it somewhere else, bots can negatively affect the search engine’s ranking of this websites and/or the products it advertises. By scraping and posting content elsewhere, bots can also have a negative impact on the companies that invest budget and resources into creating original digital content.
- Scalper bots are designed to automatically capture and purchase goods and have a high-speed checkout process. They make bulk purchases. For example, they buy hundreds of tickets immediately after opening of a booking and then sell them through reseller websites for a price considerably higher than the initial ticket price. It is very common for scalper bots to mimic human behavior in order to avoid detection.
- Spam bots (also known as content spammers) inject messages into the user-controlled areas of a website, such as forums, guestbooks, bulletin boards, and reviews or comments sections associated with news articles. They arrive in the middle of users’ conversation and insert messages with unwanted advertisements, links, and banners. This insertion frustrates real users who participate in forums and comment on blog posts. For example, spam bots may insert malicious links to direct users to phishing sites in order to trick them into revealing sensitive information such as bank account numbers and passwords.
2.2. An Overview of Different Generations of Web-Bots
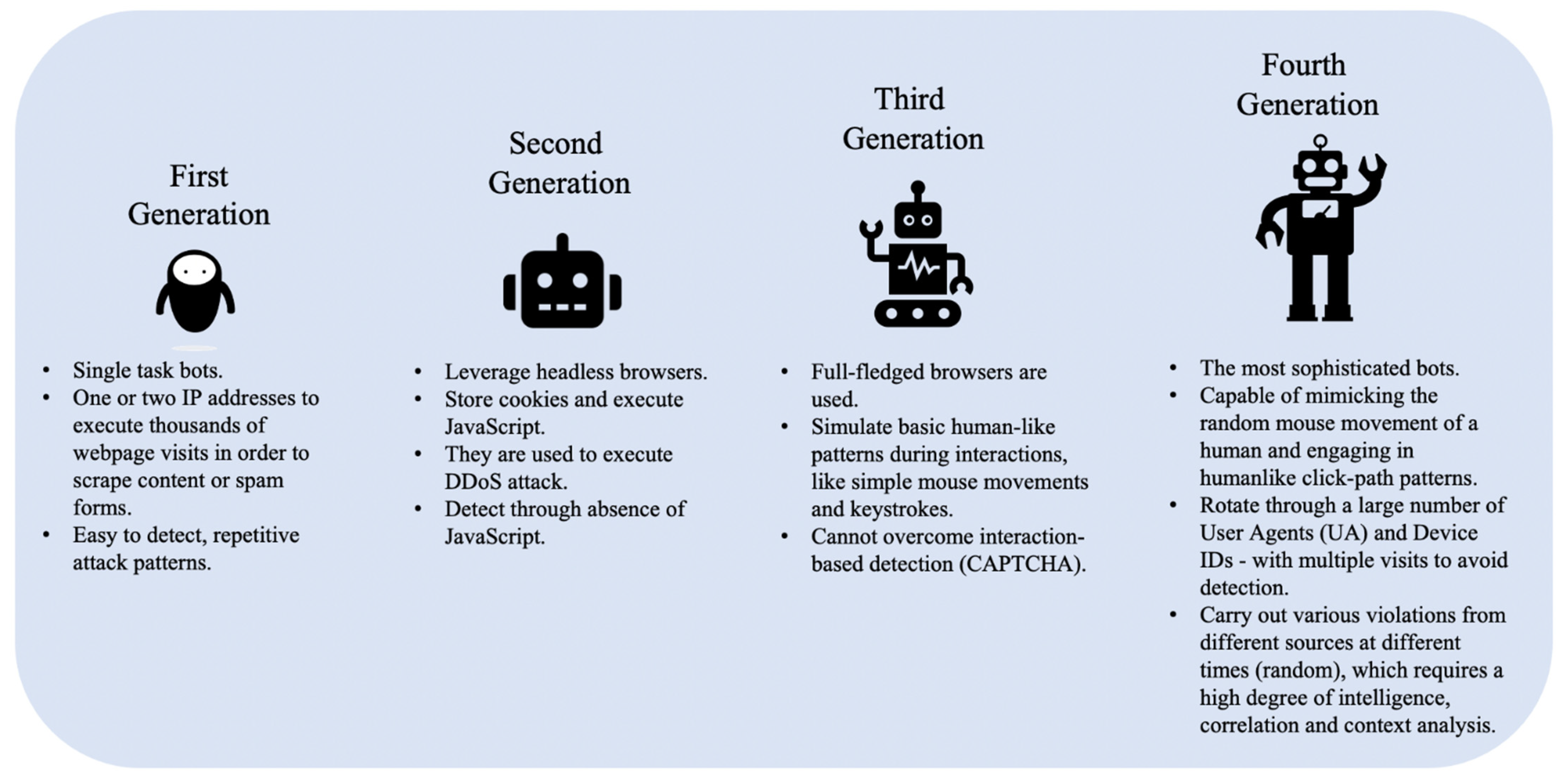
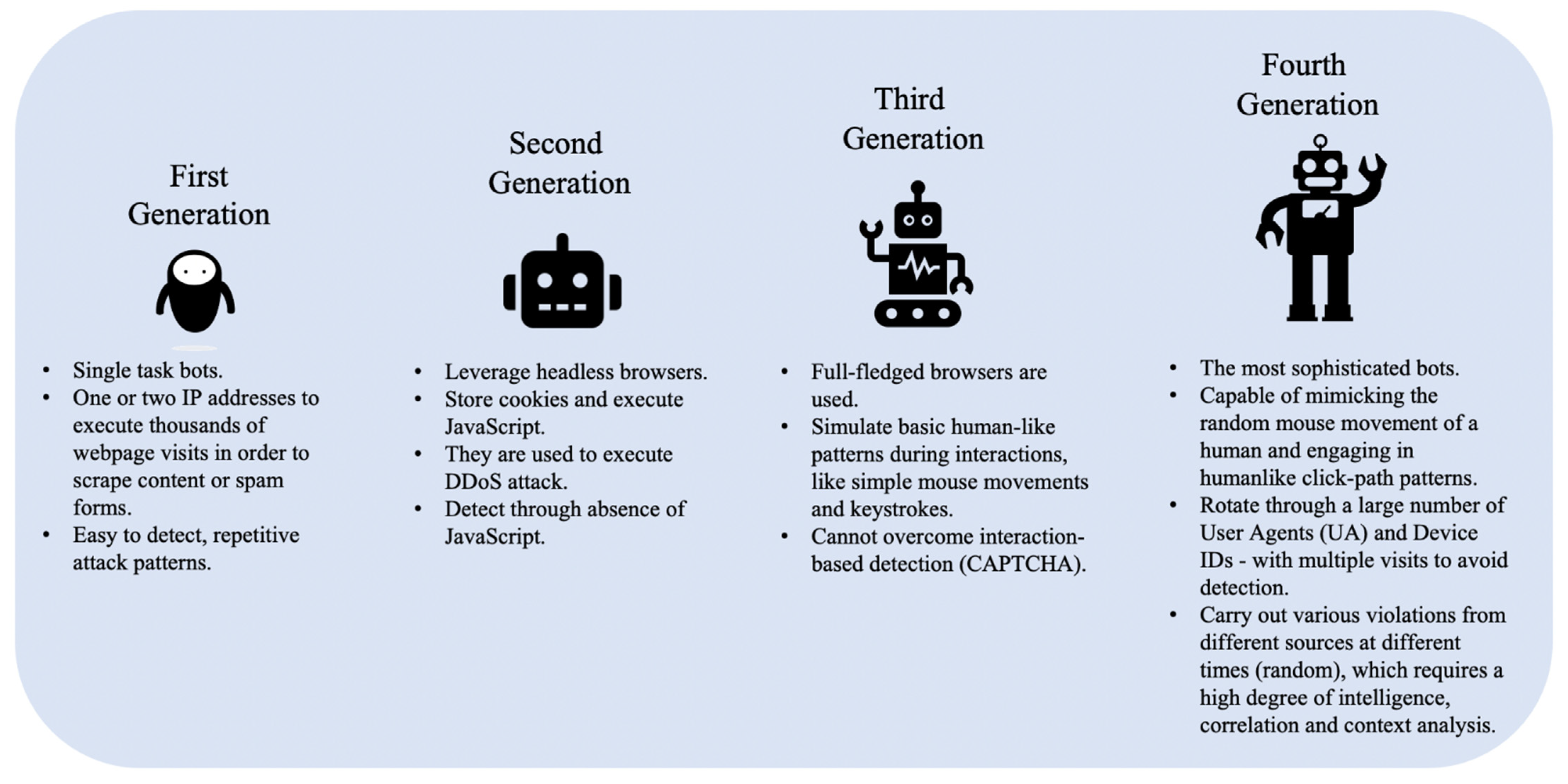
- First-Generation Bots are basic scripts that send requests such as cURL (Client for URLs (or cURL) is a command-line tool for getting or sending files using URL syntax.) from a small number of IP addresses. These bots cannot store cookies or run JavaScript code (i.e., they do not have real Web browser functionality) and can be easily detected and mitigated by blacklisting their IP addresses and UAs, as well as combinations of IPs and UAs. They are mostly used for scraping, carding, and spamming.
- Second-Generation Bots leverage headless browsers (such as PhantomJS), and unlike first-generation bots can store cookies and execute JavaScript code to automate control of a website. These bots are used to conduct DDoS attacks, scraping and spamming campaigns, as well as to skew Web analytics or conduct ad fraud. However, they can be effectively detected using their browser and device characteristics including the presence of certain JavaScript variables, frame forgery, sessions, and cookies. Once identified, these bots can subsequently be blocked based on their fingerprints. Another way of detecting these bots is by analyzing their click-path through the target website as they often exhibit significant discrepancies relative to the click-path of ordinary (human) users/visitors.
- Third-Generation Bots can operate in full browser mode and are capable of executing human-like interactions such as simple mouse movements and keystrokes. However, they are typically unable to exhibit human randomness in their behavior. They are commonly used to execute DDoS attacks, API abuse, ad fraud, and account takeover fraud. An interaction-based user behavioral analysis approach could help in identifying these bots as they generally follow a programmatic sequence of URL traversals.
- Fourth-Generation Bots, the most advanced category of bad bots, are capable of mimicking the mouse movements of a human and engaging in humanlike click-path patterns. These bots can change their UA as they cycle through thousands of IP addresses. The developers of this category of bots engage in behavioral hijacking (i.e., recording real users touching and swiping behaviors on hijacked mobile apps or websites) to fully simulate human behavior on websites or apps. This makes the process of detecting these bots challenging because their activity is not easily distinguished from real users, and they are usually distributed across tens of thousands of IP addresses. They are typically employed in ad fraud, account takeover, API abuse, and DDoS attacks. Figure 1 shows the key behaviors of bad bots by generation.
2.3. Impact of Bad Bots on Various Business Functions and Industries
2.3.1. Impact on Different Business Functions
- Web scraping (Scraping of pricing, content and inventory information): This is a technique of extracting different types of information from websites, such as product prices and news content, which can be costly if extracted without consent. For example, nefarious competitors scrape prices and product lists to attract the other business’ customers. They effortlessly steal whatever pieces of content they are programmed to find in order to sabotage the (victim) retailer’s sources of income. Attackers also scrape unique content (and duplicate exclusive content) of an online business to negatively impact their search engine optimization (SEO) efforts.
- Cart Abandonment and Inventory Exhaustion: Merchants usually leave items in the shopping cart for about 10 to 15 min before concluding that the buyer has abandoned the purchase. After this period, the items are released and placed back into the available inventory. Competitors’ bots put hundreds of items in shopping carts and abandon them later to limit real consumers from buying products. That sets the grounds for a decline in sales, distorted conversion rates, and ultimately a damaged brand reputation.
- Application DDoS: These types of attacks look for functionality areas that are ‘weak points’ of the target application. This can be an area that involves high CPU usage, integration with third-party systems, or complex database activity such as search, registration, availability checking, or real-time booking requests. The bots automate their requests to those areas of the website until the website reaches its limit and fails or is unable to carry out normal transactions with legitimate customers. These attacks specialize in utilizing rotating IP addresses and legitimate user agents (to conceal the bots’ identities) and are usually launched via large botnets.
- Scalping Products and Tickets: Malicious bots can be programmed to actively buy valuables goods such as consumer electronics and resell them for a considerably higher price. Bots can pick up tickets for popular events as soon as they go on sale.
- Card Cracking: Fraudsters use bots to test thousands of stolen credit card numbers against merchant payment processing. Since the stolen card owner can report a fraudulent transaction and request a repayment, the sites targeted with card cracking attacks will ultimately suffer financial losses (due to issued refunds), legal penalties, and lousy trading history. In extreme cases, frequent carding activities and too many refunds may force the merchant to disable credit card payments altogether.
- Fake Account Creation: Criminals use bots to create fake accounts and commit various forms of cybercrime. Some of the activities that can be carried out after creating such accounts include: misusing the ‘first-time-buyer’ bonus, using a free product trial awarded to a new account, using multiple accounts to attack the inventory of websites that only allow logged-in users to store items, content spamming, money laundering, malware distribution, and skewed research and SEO.
- Account takeover (ATO): Account takeover bots focus on gaining control over user accounts within a system and accessing people’s personal data for use elsewhere. Credential stuffing and card cracking/credential cracking are amongst the commonly used ATO techniques, and each uses automated bots to gain brute force entry to an account. In the credential cracking attack model, multiple username and password combinations are attempted until a successful combination is discovered. Credential stuffing as an alternative approach involves taking known lists of email and password combinations and determining if they are further valid for alternative sites. After the credentials are authenticated, attackers can extract money or other financially valuable items (e.g., loyalty rewards) from within that account. They can also harvest personal data for use/sale elsewhere.
2.3.2. Impact on Different Industries
- Threat in Finance: Banks, financial service providers, and insurance companies are counted as high-value targets for fraudsters. In recent years, botnet attacks have progressively ramped up the rate and extent of fraud in these industries. The types of botnet attacks on financial institutions include: account takeover, DDoS attacks, and content scraping. However, credential stuffing and card cracking are the two most common techniques used by attackers in the financial services domain [8].
- Threat in Education: Malicious bots can be employed to look for research papers, class availability, and access user accounts in educational institutions. Recently, educational institutions have become a major target of DDoS attacks as more schools rely on distance learning to stop the spread of COVID-19. Researchers also reported an increase in phishing pages and emails, as well as threats that are posing as online learning platforms and apps. According to the recent study in [11], the number of DdoS attacks on educational resources increased 550% in January 2020 compared with January 2019.
- Threat in IT and Services: Malicious bot attacks are capable of freezing inventory, crashing customer service, suspending orders, and crippling the operation of IT systems. They may not only stop businesses from generating revenue but also cause their complete closure.
- Threat in E-commerce (Web shops, Marketplaces, Classified portals, Aggregators): Web shop: A company has a product that it sells to customers through its own website. Marketplaces: They do not sell the product or service themselves but rather provide a platform for sellers and buyers to make online transactions. Classifieds portals: In this method, sellers list their products or services on a portal, and potential buyers contract the sellers through the portal. Aggregators: they are portals that crawl the Web and collect information on the same products and compare prices across Web shops; in fact, they aggregate information [12]. E-commerce companies receive a wide range of bad bot attacks. Malicious bots sent to third parties by competitors can crawl/collect information from these websites to post them elsewhere or even (re)sell them. Malicious bots can not only steal new listings, they can also fill Web forms with bogus details. In general, their activities include price and content scraping, account takeovers, credit card fraud, and gift card abuse [13].
- Threat in Government: When it comes to bad bot attacks, Governments are generally concerned with protecting company registration lists from being deleted by bots and eliminating election bots from tampering with voter registration accounts.
- Threat in Travel: Card cracking in the travel industry results in the theft of valuable and monetizable frequent flyer miles that are subsequently sold for a profit. Bad aggregators plague travel sites for travel lists, prices, and trends that can be used to inform and offer competitive package deals. Furthermore, inventory denials are frequently practiced at airlines, though this method is used throughout the tourism industry. In the airline sector, bots are employed to reserve seats on flights for up to 20 min (until they are paid for). During this time, genuine customers are shown that there is no availability on flights. The perpetrators then try to sell these seats for a profit.
- Threat in Gambling and Gaming: Account take over and credential stuffing are the two most common techniques that gambling and gaming companies suffer from because each account contains cash or loyalty points that can easily be transferred to other users and emptied if compromised.
- Threat in Digital Advertising: Ad fraud is known as a multi-billion dollar industry that uses very sophisticated methods to ensure that the maximum value is extracted. Fraudsters use botnets to generate fake clicks and obtain fraudulent digital ad impressions. Fake traffic artificially increases advertising costs. Malicious automated traffic also performs retargeting fraud to illegally generate revenue from invalid traffic to publishing sites. Such attacks sabotage the advertising network’s efforts to connect them to quality inventory. It also prevents marketers from reaching a wider audience. Bad bots generate invalid traffic, which negatively affects the brand reputation of an advertising network and undermines its claim to provide reliable media for a media buying environment. Over and above that, skewing of analytics and other metrics by bad bots would result in invalid business decisions and a large amount of marketing and advertising expenditure being squandered, often in a matter of hours [5].
2.3.3. Terminology
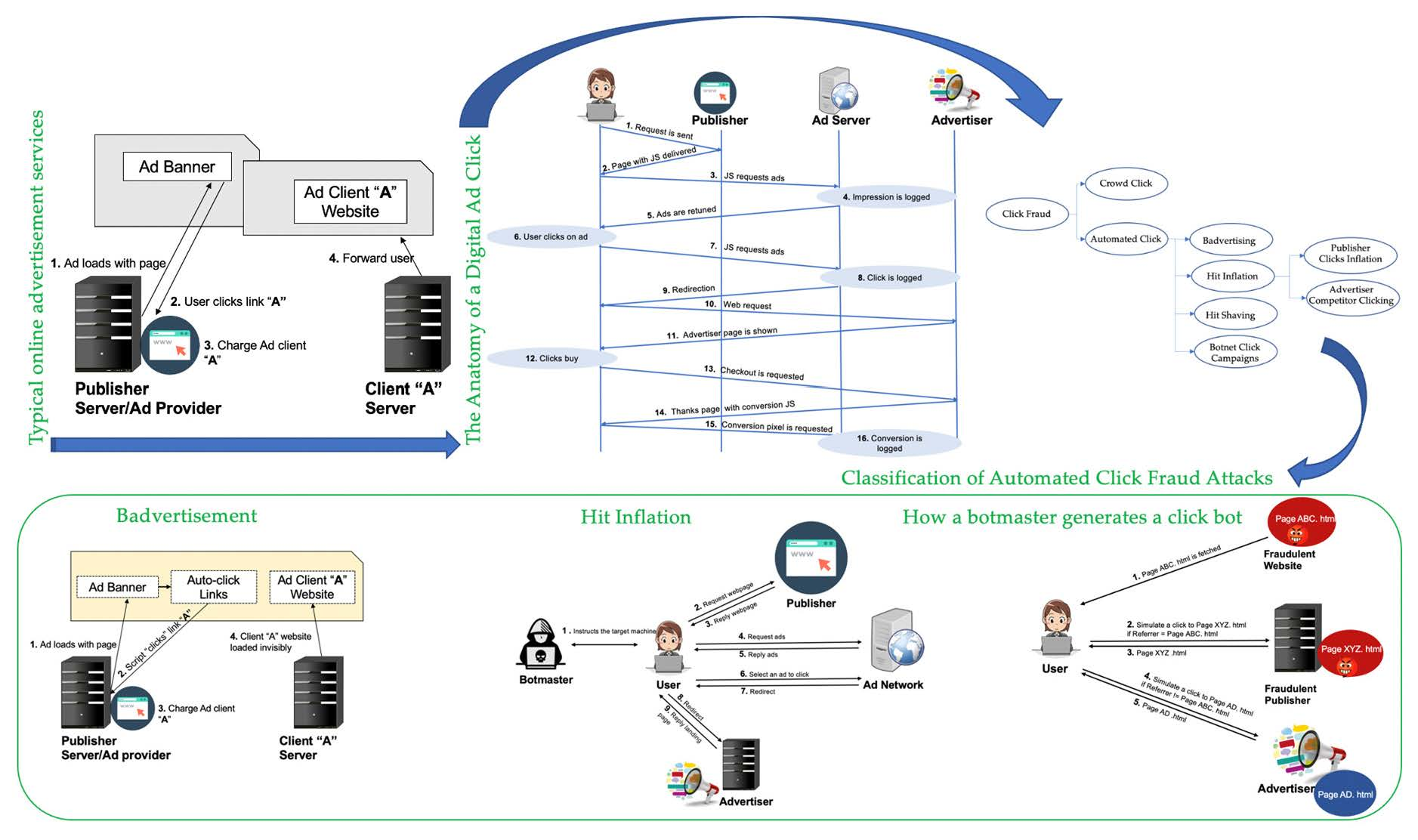
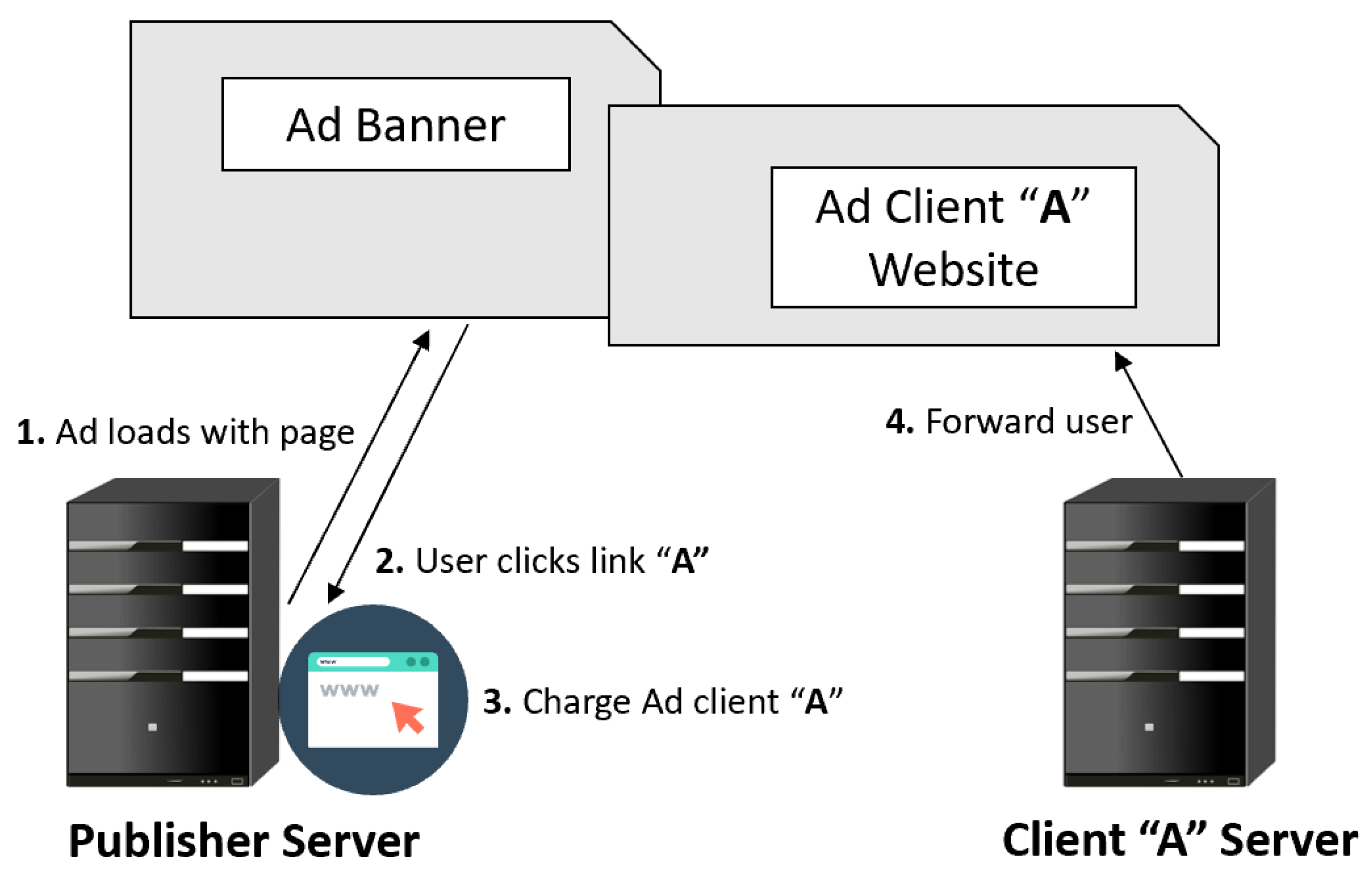
2.3.4. Typical Online Advertisement Services
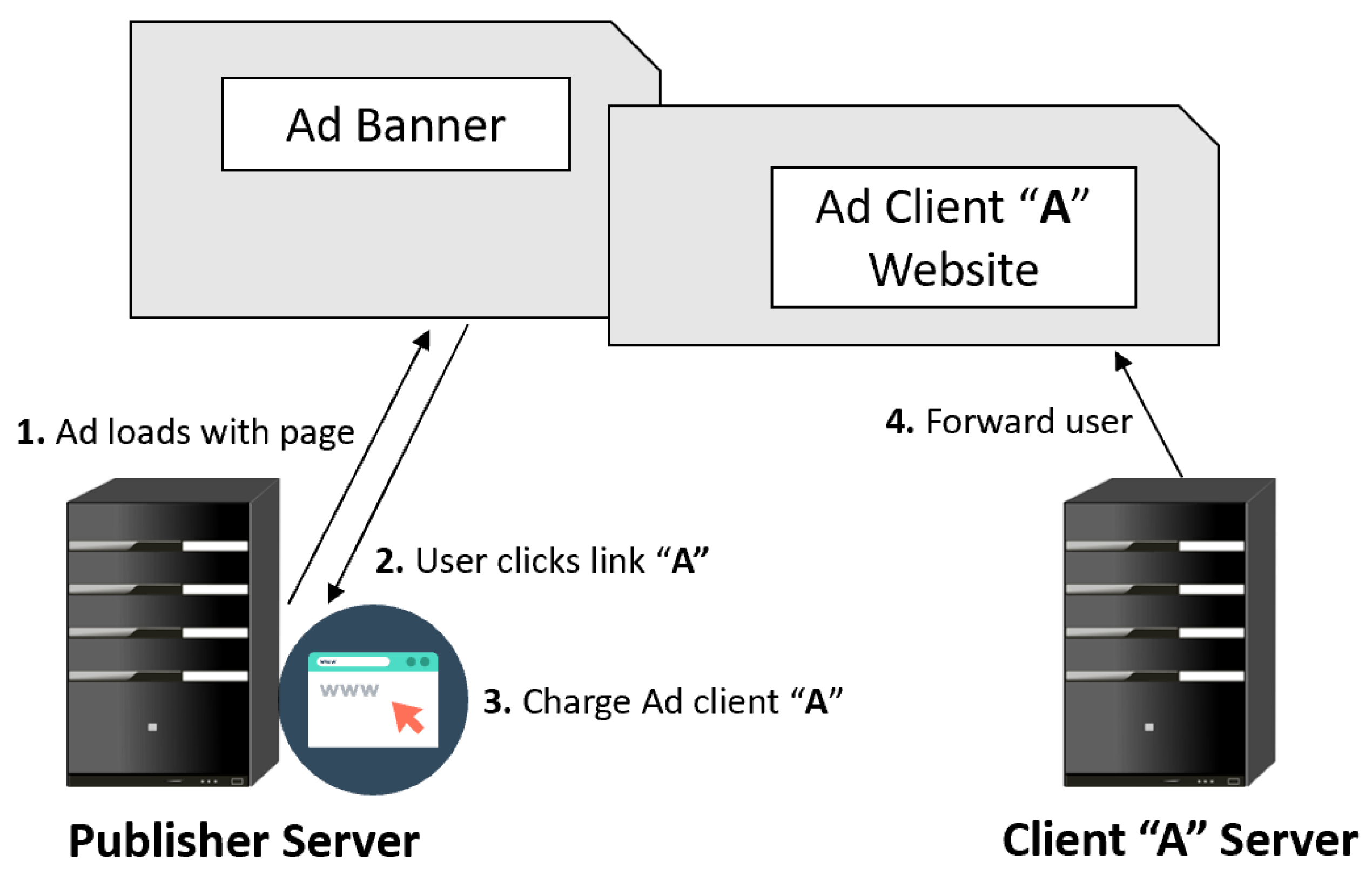
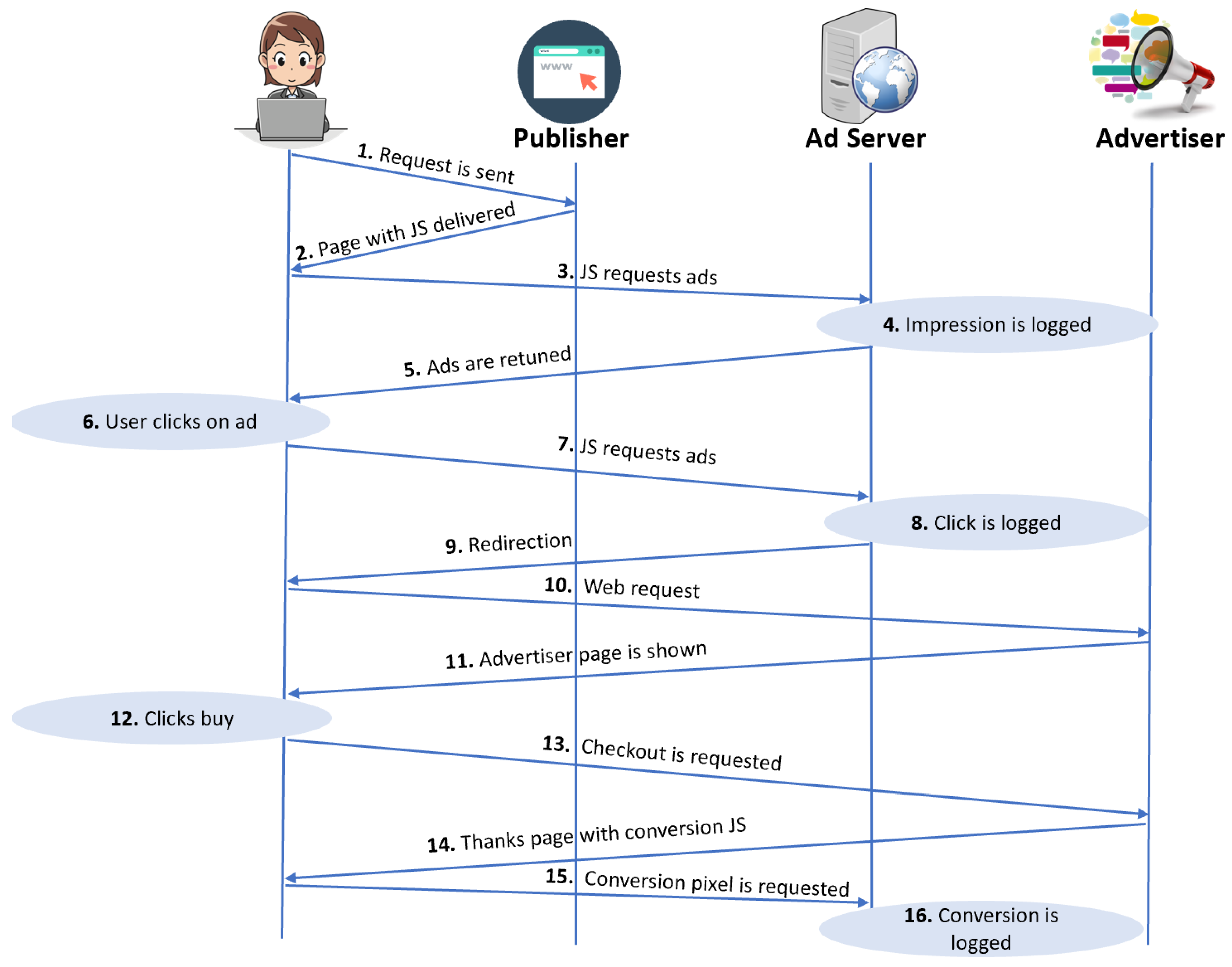
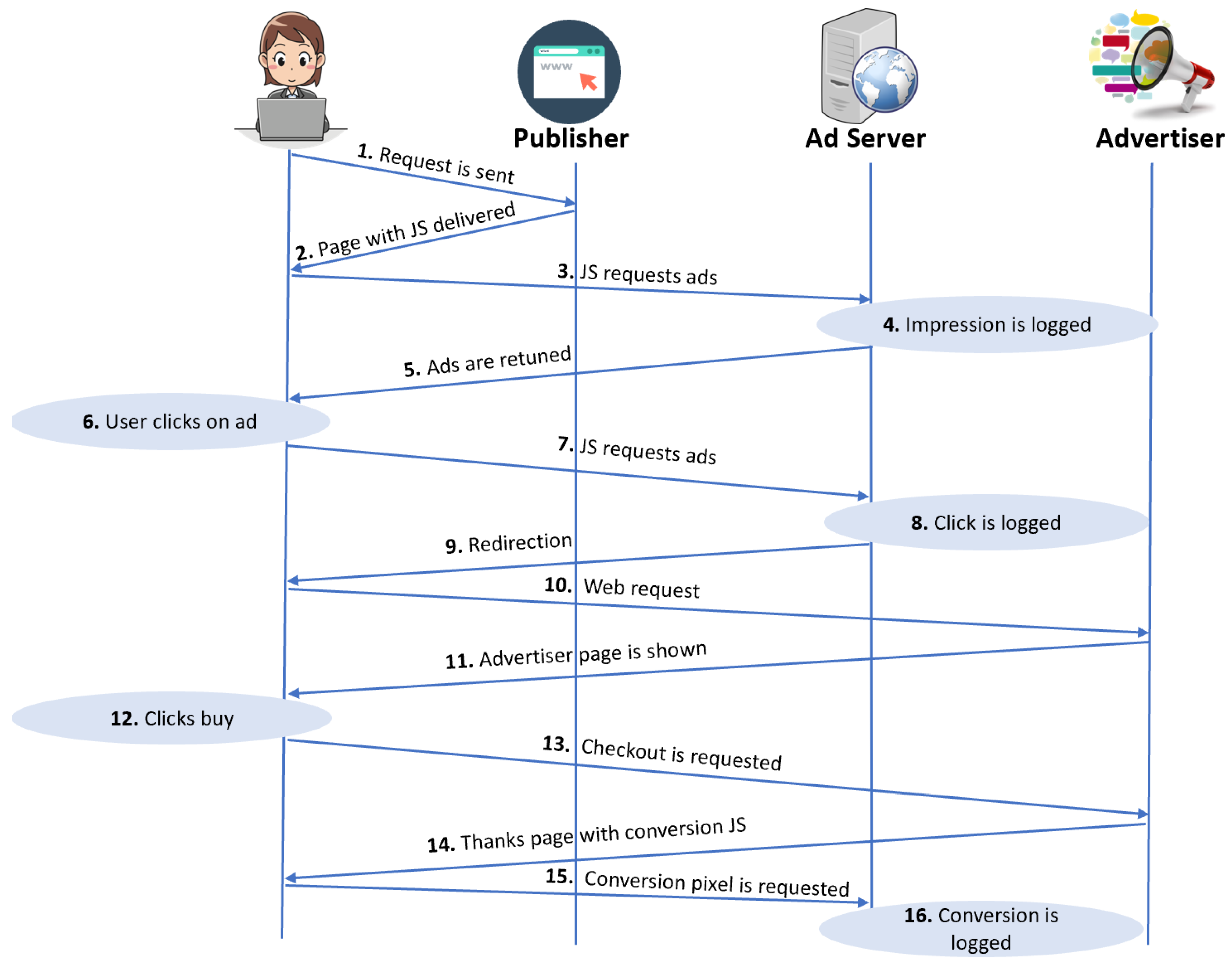
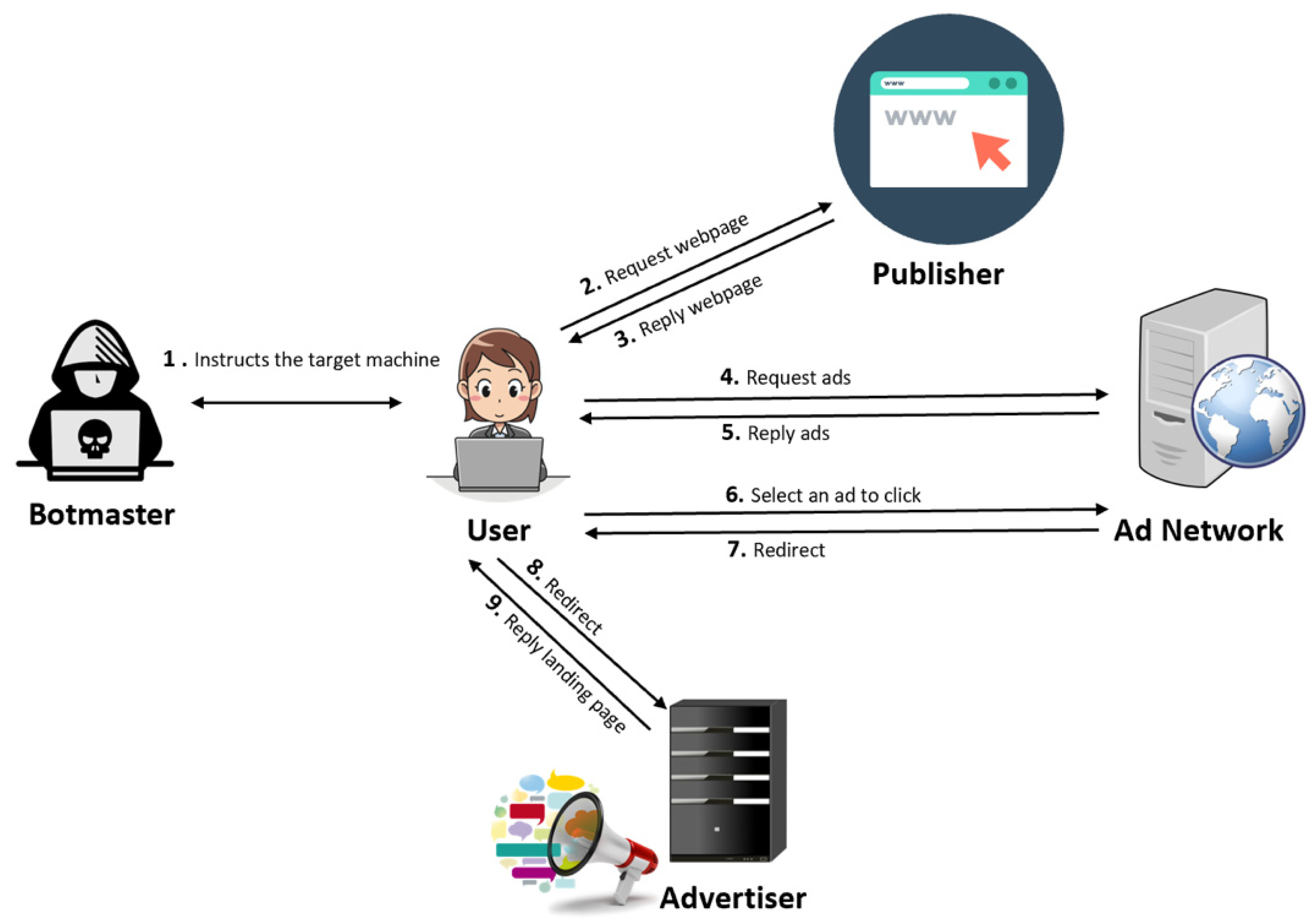
2.3.5. The Anatomy of a Digital Ad Click
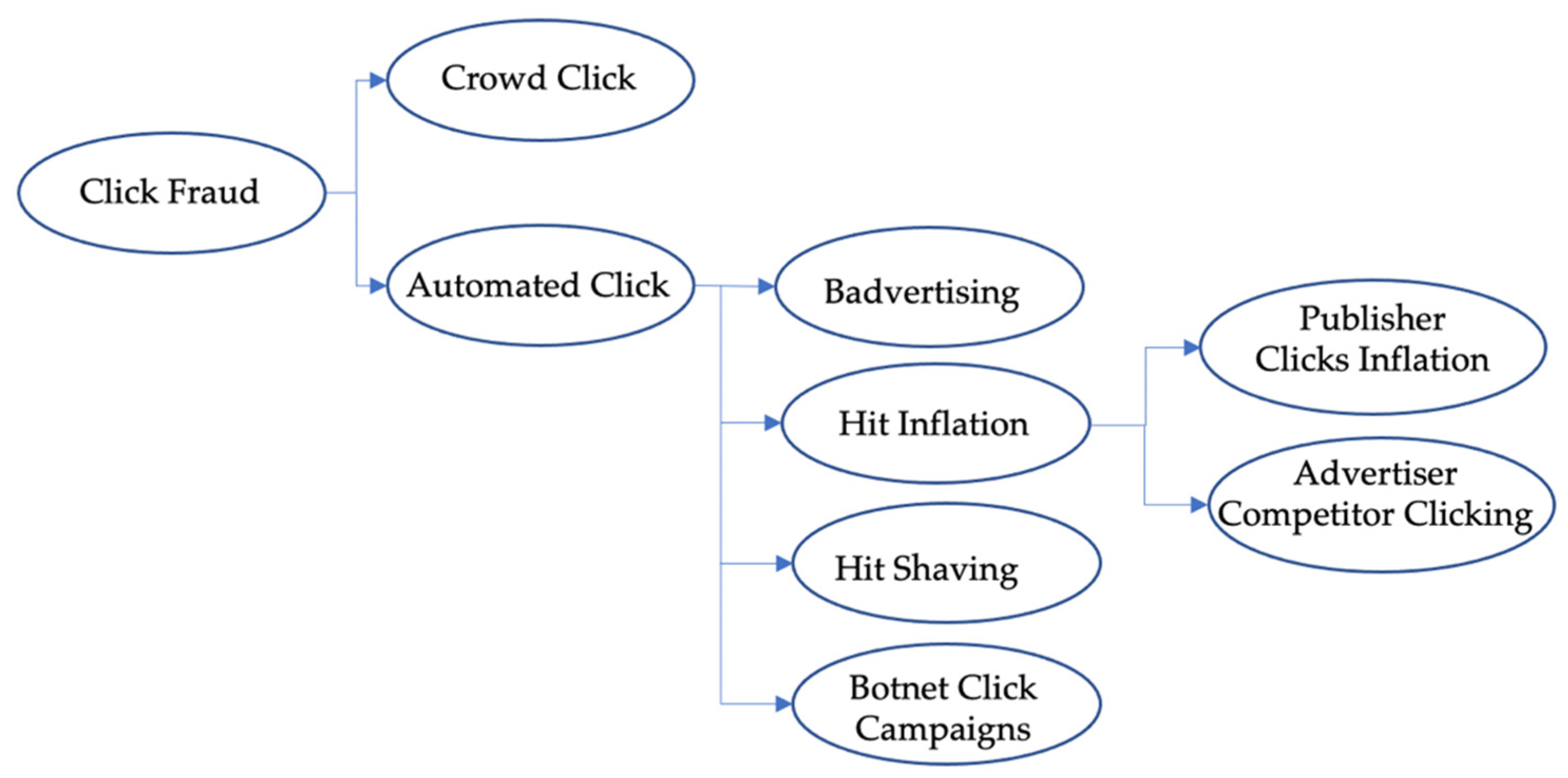
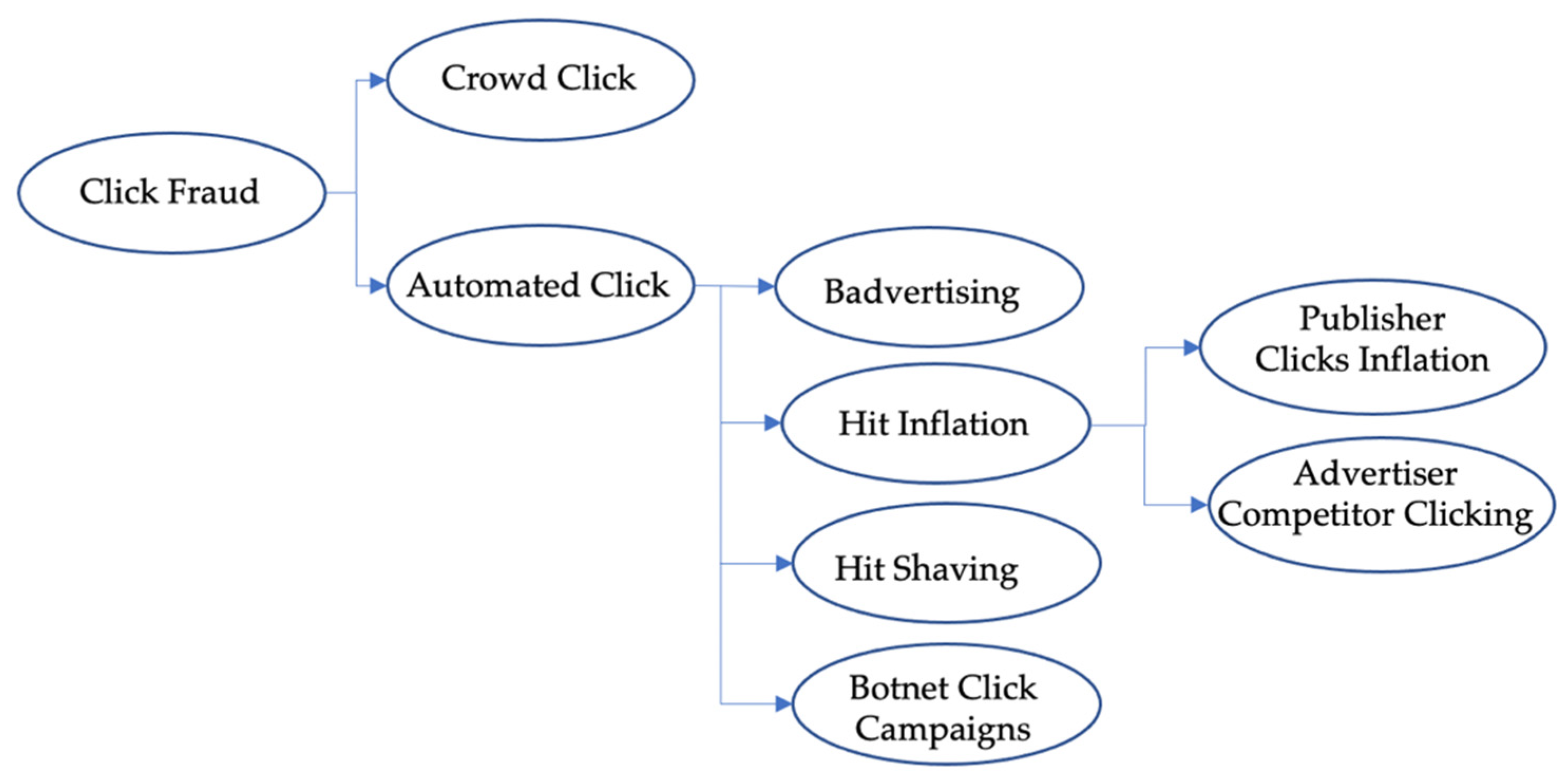
3. Taxonomy of Click-Based Fraud
3.1. Click Fraud—What We Know
3.2. Classification of Automated Click Fraud Attacks
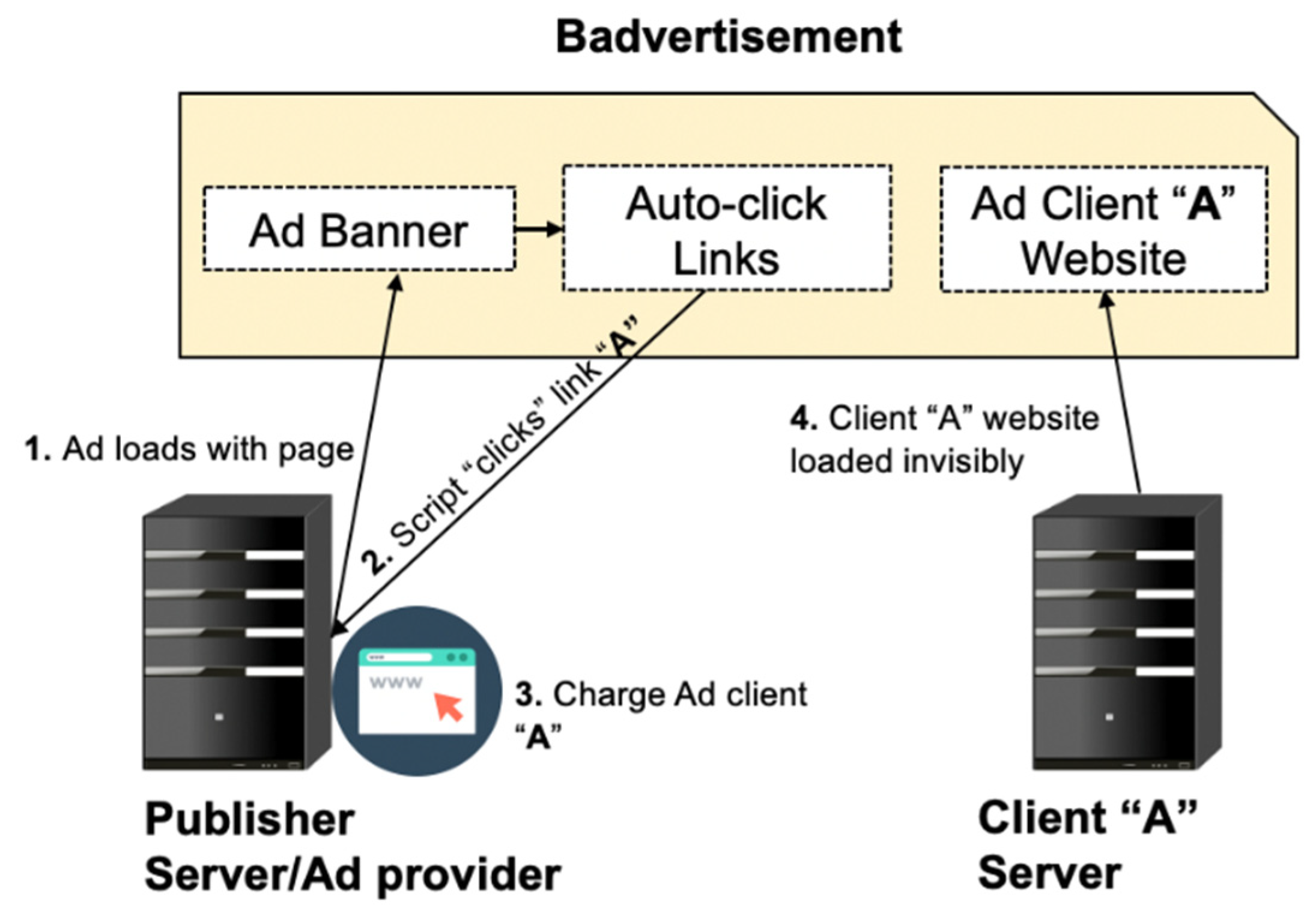
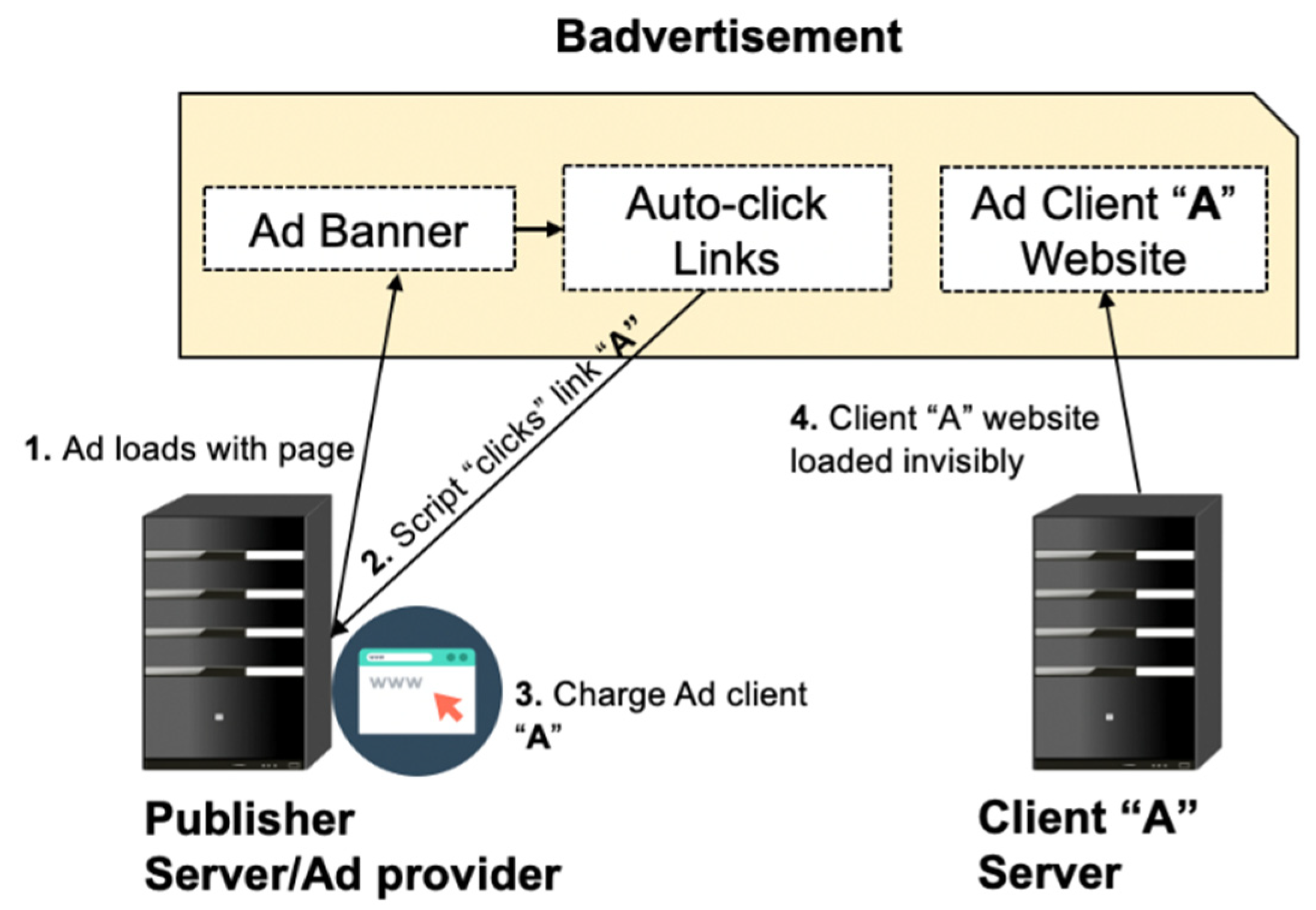
3.2.1. Badvertising
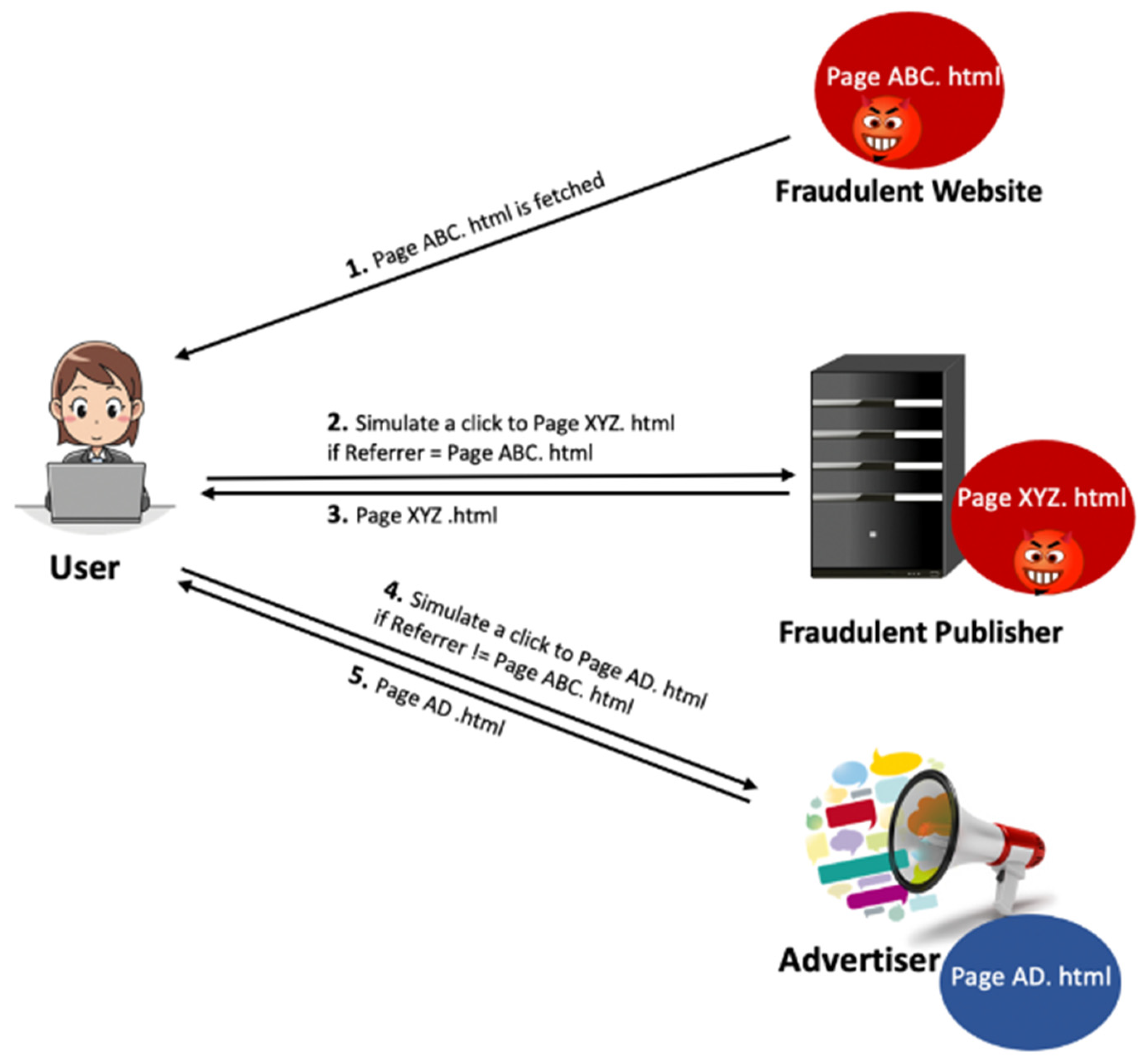
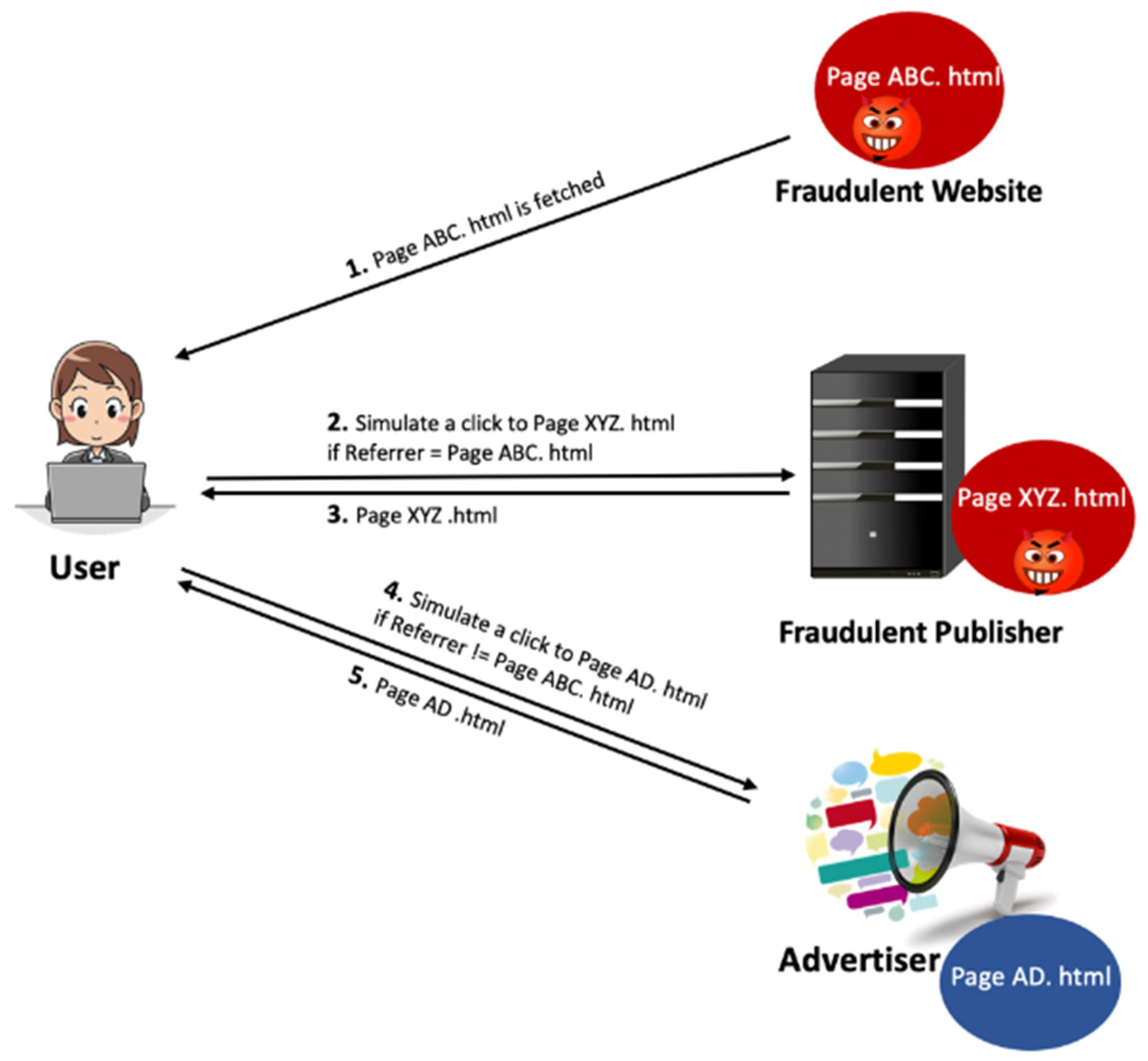
3.2.2. Hit Inflation
- Cookieless Attacks. Dishonest publishers employ two techniques to launch cookieless attacks. They either disable the cookies on the machine(s) they use to attack or utilize network anonymization services that are commercially available and generally used to protect users’ privacy. Network anonymization is designed to protect users’ privacy, and therefore, they block third-party cookies. As a result, such publishers will have a high percentage of cookieless traffic. This can be detected by tracking the percentage of cookieless traffic for each publisher and examining publishers that deviate from the norm.
- Single Cookie and Single IP Address Attacks. The fraudster (i.e., fraudulent publisher) can run a simple script to launch an attack from one machine with a fixed IP and one cookie ID.
- Single Cookie and Multiple IP Addresses Attacks. It is generally easier for a fraudulent publisher to manipulate the cookie than to change the IP address of the attacking machine; therefore, this class of attack is not prevalent among attacking publishers but advertisers. Formally, in this attack, fraud investigators need to discover cookies that appear with more than p IPs in a specified period t to detect this type of attack.
- Multiple Cookies and Single IP Address Attacks. This category of attacks can be performed in many ways. For example, one simple although not the most economical way would be to utilize many scripts running on many machines connected to the Internet through one router. As such, this attack may resemble a normal traffic scenario, where many users with different cookie IDs are connected to the Internet with a single IP through a Network Address Translation (NAT) or ISP. In a more comprehensive and sophisticated way, the attacker can connect several machines to the Internet via an ISP with a similar IP. By combining fraudulent traffic with normal traffic, the fraudulent publisher can reduce the impact of the attack and confuse the fraud detection mechanisms.
- Multiple Cookies and Multiple IP Addresses Attacks. This attack is the most complicated type of attack in terms of execution and detection. Fraudsters must access several valid cookies and IPs to launch the attack. The simplest but not economically viable way is when fraudsters obtain access to various machines with multiple accounts residing on different ISPs. Another possibility is to acquire cookies and IP addresses of legitimate users via spyware and Trojans [28]. The traffic generated in this way is most likely to resemble normal/real traffic.
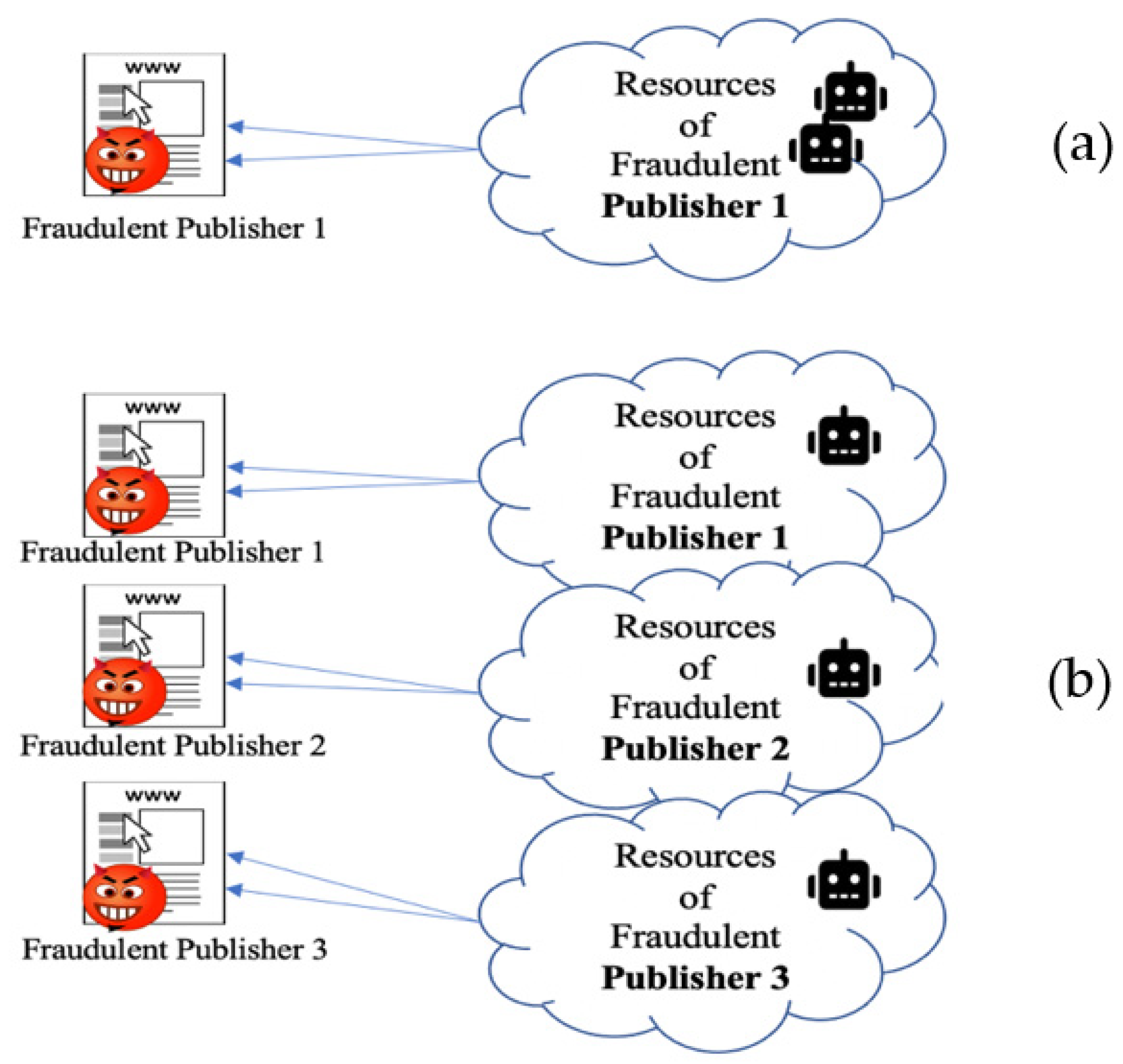
3.2.3. Hit Shaving
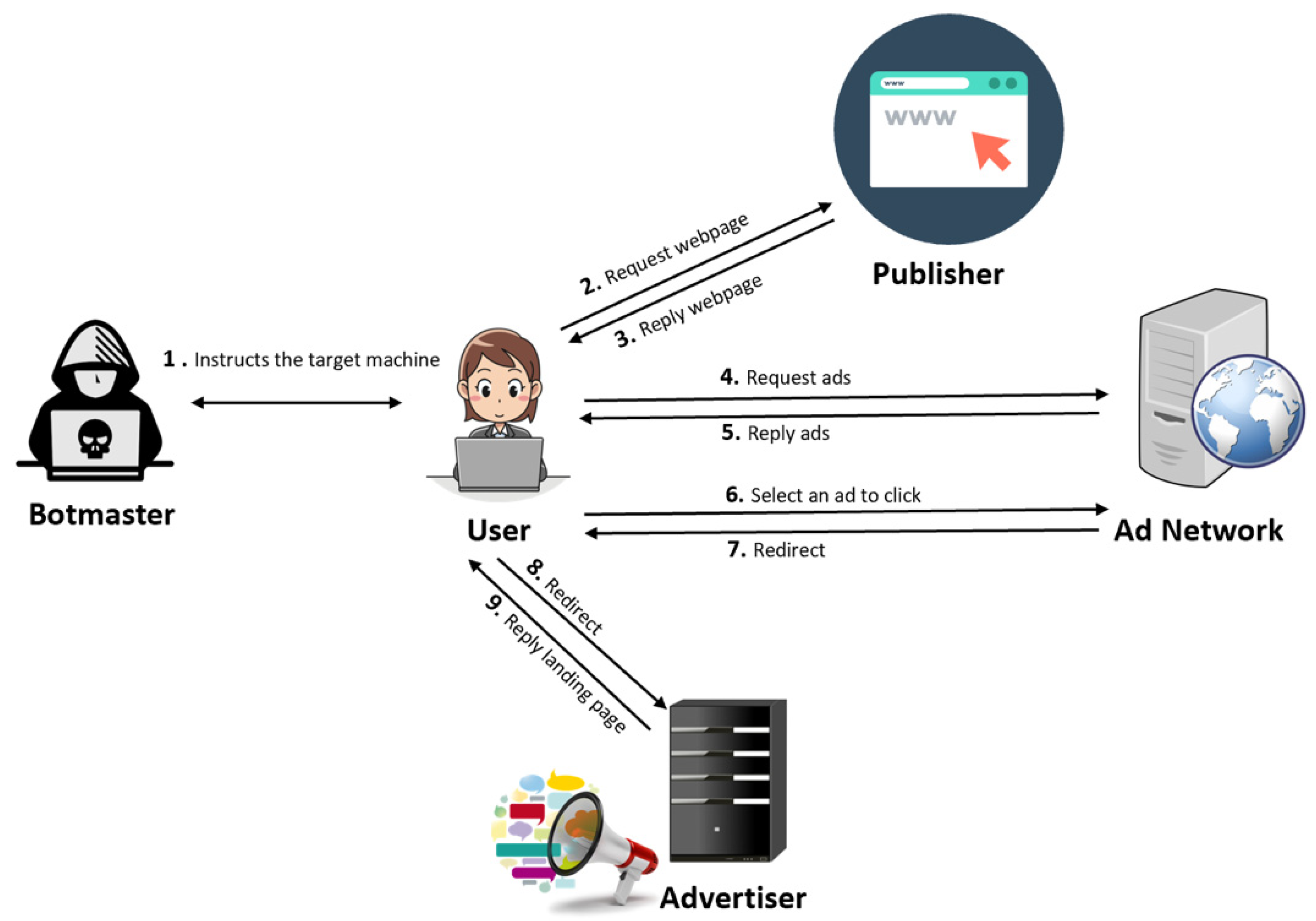
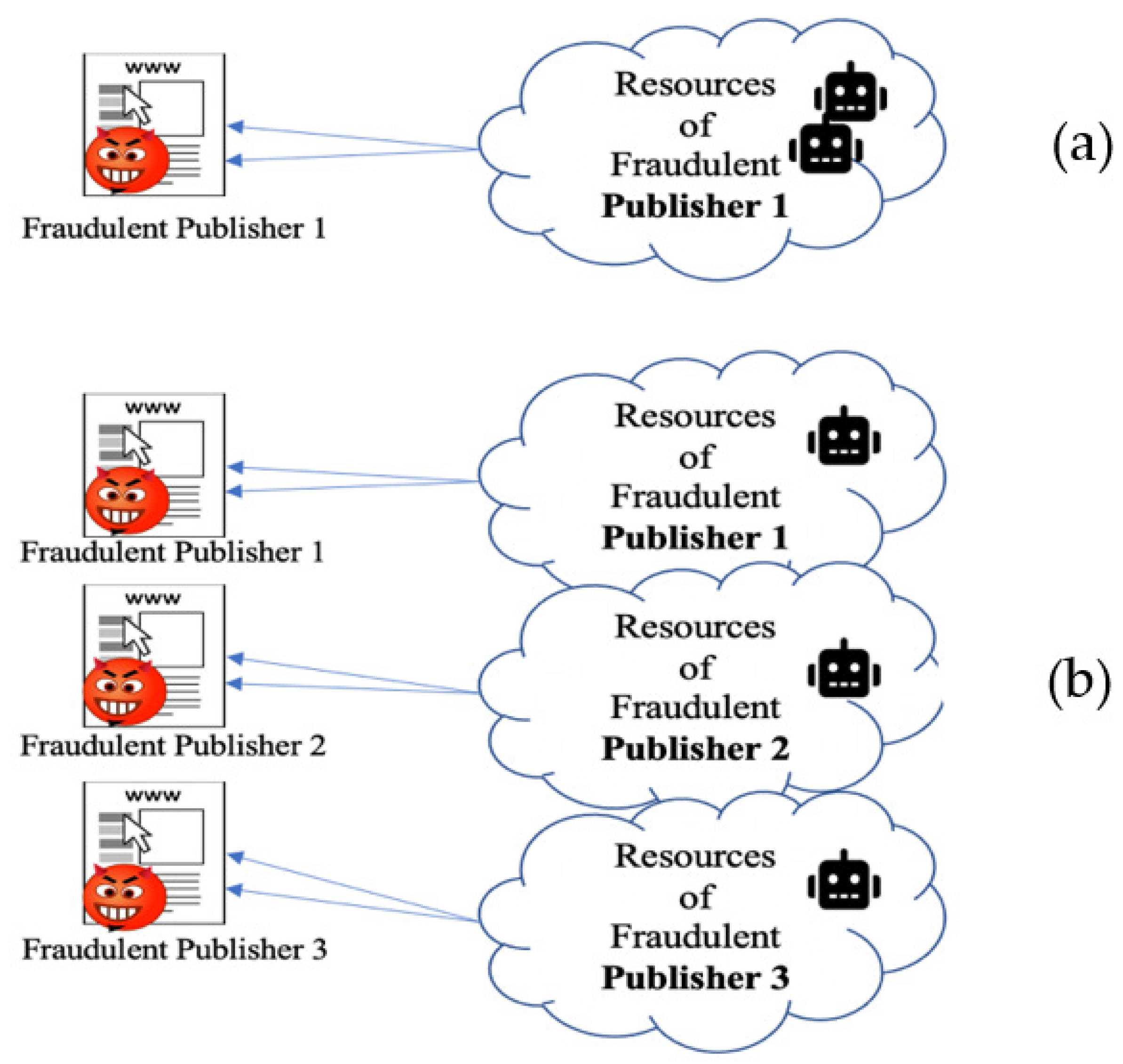
3.2.4. Botnet Click Campaigns
4. Comparison of Existing Detection Methods for Click Fraud
- Some participants used spatial features and click traffic grouped by country, referral URL, channel, etc. Simple normalization was also often used to increase the effectiveness of the deployed classifiers. Feature transformation and scaling techniques (such as principal component analysis, PCA) were rarely practiced as they could not bring performance improvements, according to the participants’ reports.
- Some participants applied feature selection methods and reported that the wrapper methods (A wrapper algorithm provides a subset of features intended to improve the results of the specific predictors.) performed better than the filter methods. (A filtering method is a feature selecting function that is independent of predictors and filters the features that may not be useful in data analysis [46].)
- Over and above that, ensembles of decision trees were the most widely used classification algorithms. The algorithms provided reasonably fast learning, and they were well suited to highly skewed class distribution and noisy nonlinear patterns.
5. Case Study
5.1. Clickbot.A—2006
5.2. TDL-4—2008–2012
5.3. Bamital—2009–2013
5.4. Fiesta Click Bot—2011
5.5. 7cy Click Bot—2011
5.6. Stantinko—2012
5.7. ZeroAccess—2013
5.8. MIUREF—2013
5.9. Ramdo—2013
5.10. Boaxxe—2013
- User-initiated click fraud: users who entered keywords in search engines could be rerouted to related ad websites. This form of click fraud had already been seen in various malware families, such as Win32/TrojanDownloader.Tracur or Win32/Goblin.
- Automated click fraud: Boaxxe could browse ad websites silently, without the user’s knowledge.
5.11. Chameleon—2013
5.12. Kovter—2014–Present
5.13. Methbot—2015–2017
5.14. 3ve—2017–2018
5.15. HyphBot—2017
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fourberg, N.; Serpil, T.; Wiewiorra, L.; Godlovitch, I.; De Streel, A.; Jacquemin, H.; Jordan, H.; Madalina, N.; Jacques, F.; Ledger, M. Online Advertising: The Impact of Targeted Advertising on Advertisers, Market Access and Consumer Choice. 2021. Available online: https://www.europarl.europa.eu/thinktank/en/document.html?reference=IPOL_STU%282021%29662913 (accessed on 27 October 2021).
- Pooranian, Z.; Conti, M.; Haddadi, H.; Tafazolli, R. Online Advertising Security: Issues, Taxonomy, and Future Directions. IEEE Commun. Surv. Tutor. 2021, 23, 2494–2524. [Google Scholar] [CrossRef]
- Cavazos, P.R. The Economic Cost of Invalid Clicks in Paid Search and Paid Social Campaigns. 9. 2020. Available online: https://cdn2.hubspot.net/hubfs/5228455/UniBaltimore%20PPC%20Fraud-1.pdf (accessed on 27 October 2021).
- Mirtaheri, S.M.; Dinçktürk, M.E.; Hooshmand, S.; Bochmann, G.V.; Jourdan, G.-V.; Onut, I.V. A Brief History of Web Crawlers. arXiv 2014, arXiv:1405.0749. [Google Scholar]
- Managing and Mitigating Bots: The Automated Threat Guide—Netacea. 2018. Available online: https://www.netacea.com/managing-and-mitigating-bots-guide/ (accessed on 27 October 2021).
- Bot Attacks: Top Threats and Trends. Barracuda. 2021. Available online: https://assets.barracuda.com/assets/docs/dms/Bot_Attacks_report_vol1_EN.pdf (accessed on 27 October 2021).
- Bad Bot Report 2020: Bad Bots Strike Back | Imperva. 2020. Available online: https://www.imperva.com/blog/bad-bot-report-2020-bad-bots-strike-back/ (accessed on 27 October 2021).
- Ultimate Guide to Bot Management. [E-book] Radware. 2019. Available online: https://blog.radware.com/wp-content/uploads/2019/09/Radware_UltimateGuideBotManagement_Final.pdf (accessed on 27 October 2021).
- Everything You Need to Know about Bots in 2020. Netacea. 2020. Available online: https://www.netacea.com/evolving-threat-guide-2020/ (accessed on 27 October 2021).
- What’s the Difference between a Bot and a Botnet? 2020. Available online: https://www.radwarebotmanager.com/bots-vs-botnets/ (accessed on 27 October 2021).
- Digital Education: The Cyberrisks of the Online Classroom. 2020. Available online: https://securelist.com/digital-education-the-cyberrisks-of-the-online-classroom/98380/ (accessed on 27 October 2021).
- Differences between Marketplaces and Classifieds Portals. MarketplaceGuru. 2017. Available online: http://marketplaceguru.de/differences-marketplaces-classifieds/ (accessed on 27 October 2021).
- Industry Report: Bad Bot Landscape 2019—The Bot Arms Race Continues. 2019. Available online: https://www.globaldots.com/resources/blog/industry-report-bad-bot-landscape-2019-the-bot-arms-race-continues/ (accessed on 27 October 2021).
- Dave, V.; Guha, S.; Zhang, Y. Viceroi: Catching Click-Spam in Search Ad Networks. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 765–776. [Google Scholar]
- What Is an Ad Tag and How to Generate It [Examples Inside]. 2020. Available online: https://epom.com/blog/ad-server/what-is-an-ad-tag (accessed on 27 October 2021).
- About Bidding Features in Display Campaigns–Google Ads Help. Available online: https://support.google.com/google-ads/answer/2947304?visit_id=637427097783271992-4033346762&rd=1 (accessed on 27 October 2021).
- Gilani, Z.; Farahbakhsh, R.; Tyson, G.; Crowcroft, J. A Large-Scale Behavioural Analysis of Bots and Humans on Twitter. ACM Trans. Web 2019, 13, 1–23. [Google Scholar] [CrossRef]
- Xu, H.; Liu, D.; Koehl, A.; Wang, H.; Stavrou, A. Click Fraud Detection on the Advertiser Side. In European Symposium on Research in Computer Security; Springer: Berlin/Heidelberg, Germany, 2014; pp. 419–438. [Google Scholar]
- Thejas, G.S.; Dheeshjith, S.; Iyengar, S.S.; Sunitha, N.R.; Badrinath, P. A Hybrid and Effective Learning Approach for Click Fraud Detection. Mach. Learn. Appl. 2021, 3, 100016. [Google Scholar]
- Gandhi, M.; Jakobsson, M.; Ratkiewicz, J. Badvertisements: Stealthy Click-Fraud with Unwitting Accessories. J. Digit. Forensic Pract. 2006, 1, 131–142. [Google Scholar] [CrossRef]
- Metwally, A.; Agrawal, D.; El Abbad, A.; Zheng, Q. On Hit Inflation Techniques and Detection in Streams of Web Advertising Networks. In Proceedings of the 27th International Conference on Distributed Computing Systems (ICDCS’07), Toronto, ON, Canada, 22–29 June 2007; p. 52. [Google Scholar]
- Kim, C.; Miao, H.; Shim, K. CATCH: A Detecting Algorithm for Coalition Attacks of Hit Inflation in Internet Advertising. Inf. Syst. 2011, 36, 1105–1123. [Google Scholar] [CrossRef]
- Mayer, V.A.A.; Pinkas, K.N.B.; Reiter, M.K. On the Security of Pay-Per-Click and Other Web Advertising Schemes. Comput. Netw. 1999, 31, 1091–1100. [Google Scholar]
- Neal, A.; Kouwenhoven, S.; Sa, O. Quantifying Online Advertising Fraud: Ad-Click Bots vs Humans. In Techincal Report; Oxford Bio Chronometrics: London, UK, 2015. [Google Scholar]
- Chellapilla, K.; Maykov, A. A Taxonomy of JavaScript Redirection Spam. In Proceedings of the 3rd International Workshop on Adversarial Information Retrieval on the Web, Banff, AB, Canada, 8 May 2007; pp. 81–88. [Google Scholar]
- How to Simulate a Click by Using x, y Coordinates in JavaScript? The Web Dev. 2021. Available online: https://thewebdev.info/2021/05/02/how-to-simulate-a-mouse-click-using-javascript/ (accessed on 27 October 2021).
- Metwally, A.; Emekçi, F.; Agrawal, D.; El Abbadi, A. Sleuth: Single-Publisher Attack Detection Using Correlation Hunting. Proc. VLDB Endow. 2008, 1, 1217–1228. [Google Scholar] [CrossRef]
- Shaw, G. Spyware & Adware: The Risks Facing Businesses. Netw. Secur. 2003, 2003, 12–14. [Google Scholar] [CrossRef]
- Ding, X. A Hybrid Method to Detect Deflation Fraud in Cost-per-Action Online Advertising. In International Conference on Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2010; pp. 545–562. [Google Scholar]
- Reiter, M.K.; Anupam, V.; Mayer, A.J. Detecting Hit Shaving in Click-Through Payment Schemes. In Proceedings of the USENIX Workshop on Electronic Commerce, Boston, MA, USA, 31 August–3 September 1998. [Google Scholar]
- Ge, L.; King, D.; Kantardzic, M. Collaborative Click Fraud Detection and Prevention System (Ccfdp) Improves Monitoring of Software-Based Click Fraud. E-COMMERCE 2005, 2005, 34. [Google Scholar]
- Juels, A.; Stamm, S.; Jakobsson, M. Combating Click Fraud via Premium Clicks. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 6–10 August 2007. [Google Scholar]
- Zhang, L.; Guan, Y. Detecting Click Fraud in Pay-per-Click Streams of Online Advertising Networks. In Proceedings of the 2008 the 28th International Conference on Distributed Computing Systems, Beijing, China, 17–20 June 2008; pp. 77–84. [Google Scholar]
- Haddadi, H. Fighting Online Click-Fraud Using Bluff Ads. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 21–25. [Google Scholar] [CrossRef] [Green Version]
- Kantardzic, M.; Walgampaya, C.; Yampolskiy, R.; Woo, R.J. Click Fraud Prevention via Multimodal Evidence Fusion by Dempster-Shafer Theory. In Proceedings of the 2010 IEEE Conference on Multisensor Fusion and Integration, Salt Lake City, UT, USA, 5–7 September 2010; pp. 26–31. [Google Scholar]
- Dave, V.; Guha, S.; Zhang, Y. Measuring and Fingerprinting Click-Spam in Ad Networks. In Proceedings of the ACM SIGCOMM 2012 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Helsinki, Finland, 13–17 August 2012; pp. 175–186. [Google Scholar]
- Kitts, B.; Zhang, J.Y.; Roux, A.; Mills, R. Click Fraud Detection with Bot Signatures. In Proceedings of the 2013 IEEE International Conference on Intelligence and Security Informatics, Seattle, WA, USA, 4–7 June 2013; pp. 146–150. [Google Scholar]
- Iqbal, M.S.; Zulkernine, M.; Jaafar, F.; Gu, Y. Fcfraud: Fighting Click-Fraud from the User Side. In Proceedings of the 2016 IEEE 17th International Symposium on High Assurance Systems Engineering (HASE), Washington, DC, USA, 7–9 January 2016; pp. 157–164. [Google Scholar]
- Almeida, P.S.; Gondim, J.J. Click Fraud Detection and Prevention System for Ad Networks. J. Inf. Secur. Cryptogr. 2018, 5, 27–39. [Google Scholar] [CrossRef]
- Thejas, G.S.; Soni, J.; Boroojeni, K.G.; Iyengar, S.S.; Srivastava, K.; Badrinath, P.; Sunitha, N.R.; Prabakar, N.; Upadhyay, H.A. Multi-Time-Scale Time Series Analysis for Click Fraud Forecasting Using Binary Labeled Imbalanced Dataset. In Proceedings of the 2019 4th International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS), Bengaluru, India, 20–21 December 2019; Volume 4, pp. 1–8. [Google Scholar]
- Kar, K. A Study on Machine Learning Approach using Ensemble Learners for Click Fraud Detection in Online Advertisement. J. Gujarat Res. Soc. 2019, 21, 693–705. [Google Scholar]
- Pan, L.; Mu, S.; Wang, Y. User Click Fraud Detection Method Based on Top-Rank-k Frequent Pattern Mining. Int. J. Mod. Phys. B 2019, 33, 1950150. [Google Scholar] [CrossRef]
- Minastireanu, E.-A.; Mesnita, G. Light Gbm Machine Learning Algorithm to Online Click Fraud Detection. J. Inform. Assur. Cybersecur. 2019. Available online: https://www.researchgate.net/profile/Gabriela-Mesnita/publication/332268924_Light_GBM_Machine_Learning_Algorithm_to_Online_Click_Fraud_Detection/links/5cab2156299bf118c4ba99c4/Light-GBM-Machine-Learning-Algorithm-to-Online-Click-Fraud-Detection.pdf (accessed on 27 October 2021).
- Nagaraja, S.; Shah, R. Clicktok: Click Fraud Detection Using Traffic Analysis. In Proceedings of the 12th Conference on Security and Privacy in Wireless and Mobile Networks, Miami, FL, USA, 17–19 May 2019; pp. 105–116. [Google Scholar]
- Oentaryo, R.; Lim, E.-P.; Finegold, M.; Lo, D.; Zhu, F.; Phua, C.; Cheu, E.-Y.; Yap, G.-E.; Sim, K.; Nguyen, M.N. Detecting Click Fraud in Online Advertising: A Data Mining Approach. J. Mach. Learn. Res. 2014, 15, 99–140. [Google Scholar]
- Gabryel, M. Data Analysis Algorithm for Click Fraud Recognition. In Information and Software Technologies; Communications in Computer and Information Science; Damaševičius, R., Vasiljevienė, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 920, pp. 437–446. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, 1–6 June 2006; pp. 1322–1328. [Google Scholar]
- Fuller, W.A. Introduction to Statistical Time Series; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 428. [Google Scholar]
- Kwiatkowski, D.; Phillips, P.C.; Schmidt, P.; Shin, Y. Testing the Null Hypothesis of Stationarity against the Alternative of a Unit Root: How Sure Are We That Economic Time Series Have a Unit Root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Franciso, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Oli. A Short History of Ad Click Bots & PPC Fraud. 2020. Available online: https://www.clickcease.com/blog/a-short-history-of-ad-click-bots-ppc-fraud/ (accessed on 27 October 2021).
- Daswani, N.; Stoppelman, M. The Anatomy of Clickbot. A. In Proceedings of the First Workshop on Hot Topics in Understanding Botnets, Cambridge, MA, USA, 10 April 2007. [Google Scholar]
- Staff, S.C. TDL-4 Variant Spreads Click-Fraud Campaign. 2021. Available online: https://www.scmagazine.com/news/security-news/tdl-4-variant-spreads-click-fraud-campaign (accessed on 27 October 2021).
- Rent-a-Bot Networks Tied to TDSS Botnet—Krebs on Security. 2011. Available online: https://krebsonsecurity.com/2011/09/rent-a-bot-networks-tied-to-tdss-botnet/ (accessed on 27 October 2021).
- Microsoft, Symantec Hijack ‘Bamital’ Botnet—Krebs on Security. 2013. Available online: https://krebsonsecurity.com/2013/02/microsoft-symantec-hijack-bamital-botnet/ (accessed on 27 October 2021).
- Miller, B.; Pearce, P.; Grier, C.; Kreibich, C.; Paxson, V. What’s Clicking What? Techniques and Innovations of Today’s Clickbots. In Detection of Intrusions and Malware, and Vulnerability Assessment; Lecture Notes in Computer Science; Holz, T., Bos, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 164–183. [Google Scholar] [CrossRef] [Green Version]
- Stantinko Botnet Was Undetected for at Least 5 Years While Infecting Half a Million Systems. 2017. Available online: https://securityaffairs.co/wordpress/61250/malware/stantinko-botnet.html (accessed on 27 October 2021).
- StantinkoTeddy Bear Surfing Out of Sight. 2017. Available online: https://www.welivesecurity.com/wp-content/uploads/2017/07/Stantinko.pdf (accessed on 27 October 2021).
- How Stantiko Click-Fraud Bot Butchers CPA’s. C3 Metrics. 2017. Available online: https://c3metrics.com/stantiko-click-fraud-bot-butchers-cpas/ (accessed on 27 October 2021).
- Pearce, P.; Dave, V.; Grier, C.; Levchenko, K.; Guha, S.; McCoy, D.; Paxson, V.; Savage, S.; Voelker, G.M. Characterizing Large-Scale Click Fraud in ZeroAccess. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 141–152. [Google Scholar] [CrossRef]
- The Click Fraud Malware: How MIUREF Turns Users into Cybercriminal Accomplices–Threat Encyclopedia. 2014. Available online: https://www.trendmicro.com/vinfo/us/threat-encyclopedia/web-attack/133/the-click-fraud-malware-how-miuref-turns-users-into-cybercriminal-accomplices (accessed on 27 October 2021).
- Malware Spotlight: What Is Click Fraud?-Infosec Resources. 2019. Available online: https://resources.infosecinstitute.com/topic/malware-spotlight-what-is-click-fraud/#gref (accessed on 27 October 2021).
- Ramdo Click-Fraud Malware Continues to Evolve | SecurityWeek.Com. 2016. Available online: https://www.securityweek.com/ramdo-click-fraud-malware-continues-evolve (accessed on 27 October 2021).
- Boaxxe Adware: ‘A Good ad Sells the Product without Drawing Attention to Itself’—Pt 1. 2014. Available online: https://www.welivesecurity.com/2014/01/14/boaxxe-adware-a-good-ad-sells-the-product-without-drawing-attention-to-itself-pt-1/ (accessed on 27 October 2021).
- spider.io—Discovered: Botnet Costing Display Advertisers over Six Million Dollars per Month. 2013. Available online: http://www.spider.io/blog/2013/03/chameleon-botnet/ (accessed on 27 October 2021).
- White Ops. The Methbot Operation. White Ops. 2016. Available online: https://cdn2.hubspot.net/hubfs/3400937/WO_Methbot_Operation_WP_01.pdf (accessed on 27 October 2021).
- Digital Video Ad Serving Template (VAST). Available online: https://www.iab.com/guidelines/vast/ (accessed on 27 October 2021).
- “Biggest Ad Fraud Ever”: Hackers Make $5M A Day by Faking 300M Video Views. 2016. Available online: https://www.forbes.com/sites/thomasbrewster/2016/12/20/methbot-biggest-ad-fraud-busted/?sh=50a126324899 (accessed on 27 October 2021).
- Eight People Are Facing Charges as A Result of The FBI’s Biggest-Ever Ad Fraud Investigation. 2018. Available online: https://www.buzzfeednews.com/article/craigsilverman/3ve-botnet-ad-fraud-fbi-takedown (accessed on 27 October 2021).
- How AdformDiscovered HyphBot. 2017. Available online: https://site.adform.com/media/85132/hyphbot_whitepaper_.pdf (accessed on 27 October 2021).
- What Is Ads.txt and How Does It Work? 2020. Available online: https://clearcode.cc/blog/ads-txt/ (accessed on 27 October 2021).
- Oli. Click Fraud Hall of Fame: HyphBot. 2020. Available online: https://www.clickcease.com/blog/click-fraud-hall-of-fame-hyphbot/ (accessed on 27 October 2021).
- Intent-Based Deep Behavioral Analysis: A Proprietary Bot Detection Technology. 2019. Available online: https://www.radwarebotmanager.com/web/wp-content/uploads/IDBA_WP.pdf (accessed on 27 October 2021).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Threat | Mitigation Strategy | Key Points | To Be Deployed By | Ref. |
|---|---|---|---|---|
| Competitors click fraud/Click farm/ Software click fraud/Background click fraud | CCFDP (Collaborative click fraud detection and prevention system), Log Analysis, Filtering-based Approach, |
| Publisher and Advertiser | [31] 2005 |
| Click fraud | Badvertisment detection model using active and passive schemes |
| Advertiser | [20] 2006 |
| Click fraud /hit shaving | Cryptographic authentication |
| Advertiser | [32] 2007 |
| Duplicate clicks pay-per-clickstreams | Decaying Window models including jumping Windows and sliding Windows |
| Advertisers | [33] 2008 |
| Click bot | Bluff ads |
| Publisher and Advertiser | [34] 2010 |
| Click fraud | Multimodal Evidence Fusion by Dempster-Shafer Theory |
| Advertiser | [35] 2010 |
| Click fraud /deflation fraud | A hybrid of cryptography and probability tools |
| Publisher | [29] 2010 |
| Click spam | Bayesian Approach |
| Advertiser and Ad network | [36] 2012 |
| Click bot | Bot signature |
| Ad industry | [37] 2013 |
| Click spam | ViceROI: Filtering-based approach |
| Ad network | [14] 2013 |
| Crowd click and click bot | JavaScript support and mouse event test, Browser functionality test, Browser behavior examination |
| Advertiser | [18] 2014 |
| Click bots | FCFraud—Random Forest classifier |
| User | [38] 2016 |
| Click bot | Rule-based model |
| Ad network | [39] 2018 |
| Click fraud | Multi-time-scale Time Series Analysis |
| Ad network | [40] 2019 |
| Click fraud | Ensemble Learner |
| Advertiser | [41] 2019 |
| Click fraud | Top-Rank-k frequent pattern mining |
| Ad industry | [42] 2019 |
| Click fraud | LightGBM—a Gradient Boosting Decision Tree-type method |
| Advertiser | [43] 2019 |
| Click fraud | Traffic analysis |
| Ad network | [44] 2019 |
| Click fraud | CFXGB (Cascaded Forest and XGBoost), Feature transformation and classification. |
| Ad industry | [19] 2020 |
| Type of Click Bot | Number of Infected Devices | Years Active | Target | Botmaster/Operator | Inflicted Damages |
|---|---|---|---|---|---|
| Clickbot.A—Botnet | 100,000 | 2006 | Advertisers on syndicated search engines | Unknown | USD 50,000 |
| TDL-4—the fourth generation of TDSS botnet | 4 million | 2008–2012 | Government agencies, 46 companies within the Fortune 500, and ISPs in the U.S., Germany and U.K. | Cybercrime group Known as GangstaBucks | USD 340,000 lost daily loss for advertisers |
| Bamital—A search hijacking and click fraud botnet | 1 million | 2009–2013 | Advertisers (through major search engines and browsers, including those of Microsoft, Yahoo and Google | Unknown | USD 700,000 per year |
| Stantinko—A multi-use botnet | More than 500,000 | 2012–present | Joomla and WordPress administrative login pages in Russia and Ukraine | Unknown | Not known |
| Chameleon—humanlike botnet | More than 120,000 | 2013 | Advertisers (through infecting Microsoft Windows machines in the U.S.) | Unknown | USD 6 million per month |
| ZeroAccess—botnet | 1.9 million | 2013 | Advertisers (through major search engines) | Unknown | USD 100,000 per day |
| MIUREF—Trojan | Unknown | 2013–2014 | Advertisers in the United States, Japan, France and Australia. | Unknown | Not known |
| Kovter—botnet | 700,000 | 2014–present | Advertisers (through major Windows Web browser in the US, Canada, the UK, and Australia) | KovCoreG group | Not known |
| Methbot—botnet | 852,992 dedicated IPs, many falsely registered as US ISPs, 800–1200 dedicated servers operating from data centers in the U.S. and the Netherlands | 2015–2017 | Over 6000 premium domain names were targeted, then cloned, and made to serve up video ads. | A group of Russian criminals | USD 3 million to USD 5 million per day |
| 3ve (Eve)—botnet | 1.7 million | 2017–2018 | Advertisers (through 250,000 fake domains, spoofed from genuine websites including the Wall Street Journal, CNN, BBC.com and ESPN | A team of Russian and Kazakh nationals | USD 29 million |
| HyphBot)—botnet | 500,000 computers in the US, UK, Netherlands and Canada | 2017 | Advertisers and a huge selection of premium inventory websites, including some of the most visited sites on the web | Unknown | USD 1.2 million per day |
| 404Bot—botnet | Not known | 2018–present | Advertisers and sites with a large inventory of ads.txt vendors | Unknown | USD 15 million |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadeghpour, S.; Vlajic, N. Click Fraud in Digital Advertising: A Comprehensive Survey. Computers 2021, 10, 164. https://doi.org/10.3390/computers10120164
Sadeghpour S, Vlajic N. Click Fraud in Digital Advertising: A Comprehensive Survey. Computers. 2021; 10(12):164. https://doi.org/10.3390/computers10120164
Chicago/Turabian StyleSadeghpour, Shadi, and Natalija Vlajic. 2021. "Click Fraud in Digital Advertising: A Comprehensive Survey" Computers 10, no. 12: 164. https://doi.org/10.3390/computers10120164
APA StyleSadeghpour, S., & Vlajic, N. (2021). Click Fraud in Digital Advertising: A Comprehensive Survey. Computers, 10(12), 164. https://doi.org/10.3390/computers10120164