
A Cognitive Diagnostic Module Based on the Repair Theory for a Personalized User Experience in E-Learning Software




Abstract
:1. Introduction
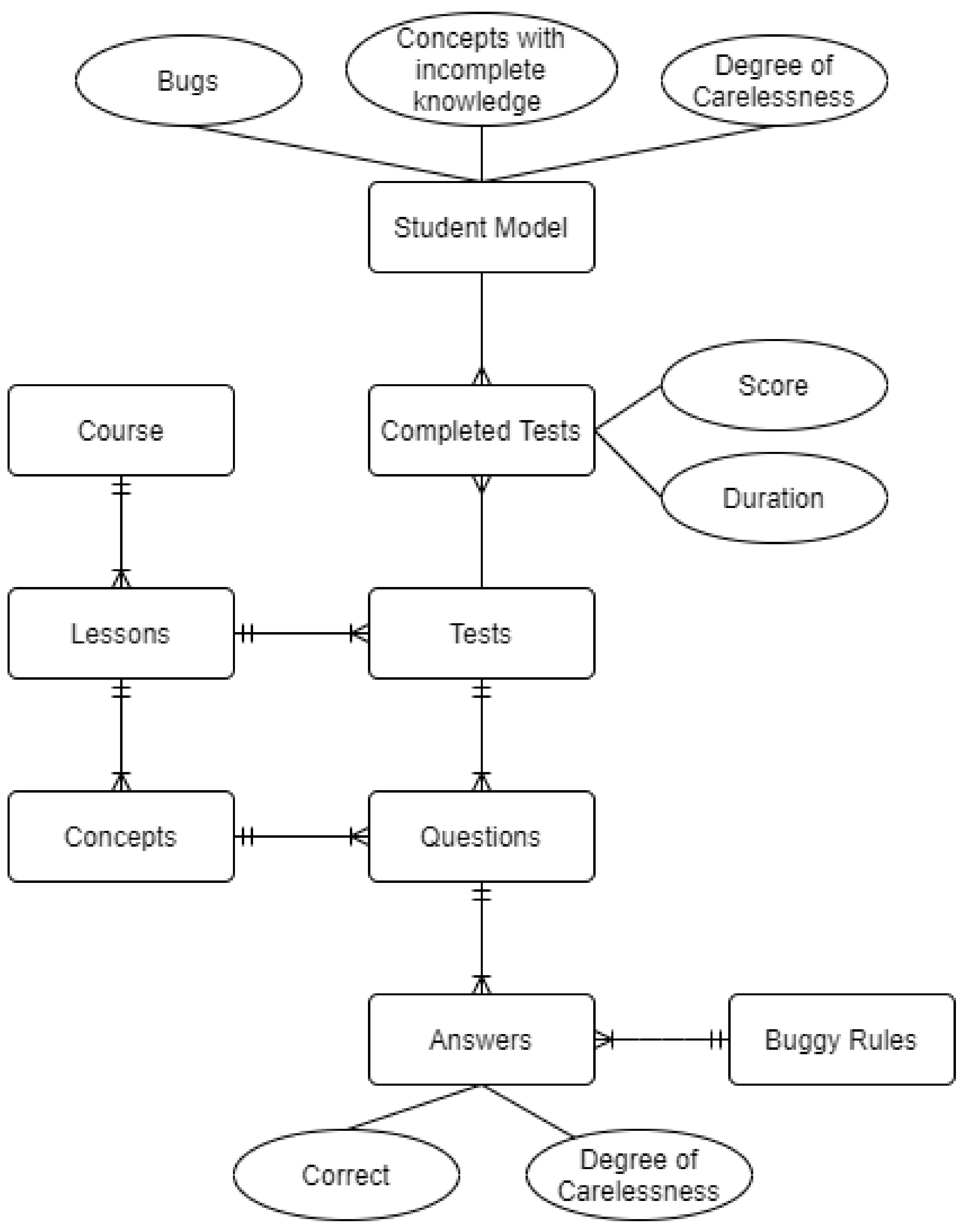
2. Diagnosis of Student Cognitive Bugs and Personalized Guidance
| Algorithm 1 Diagnostic Mechanism |
| 1: student test time = 0 2: mistakes = 0 3: start time = time 4: do 5: Display question(test) 6: Get answer 7: if is in correct(answer) AND degree of carelessness (answer) < 0.5 then 8: Display alternative question in same concept(test, question) 9: if is correct (answer) then 10: Print “Be careful with your answers!” 11: else 12: Get concept, buggy rule related to answer 13: Store concept, buggy rule in student profile 14: mistakes + = 1 15: endif 16: endif 17: if last question (test) then 18: Student test time = time—start time 19: endif 20: until student test time <> 0 21: student test score = Calculate score (mistakes) 22: Print report on score (student test score) 23: Print report on test duration(student test time) 24: Print report on concepts(student profile) 25: Print report on bugs(student profile) |
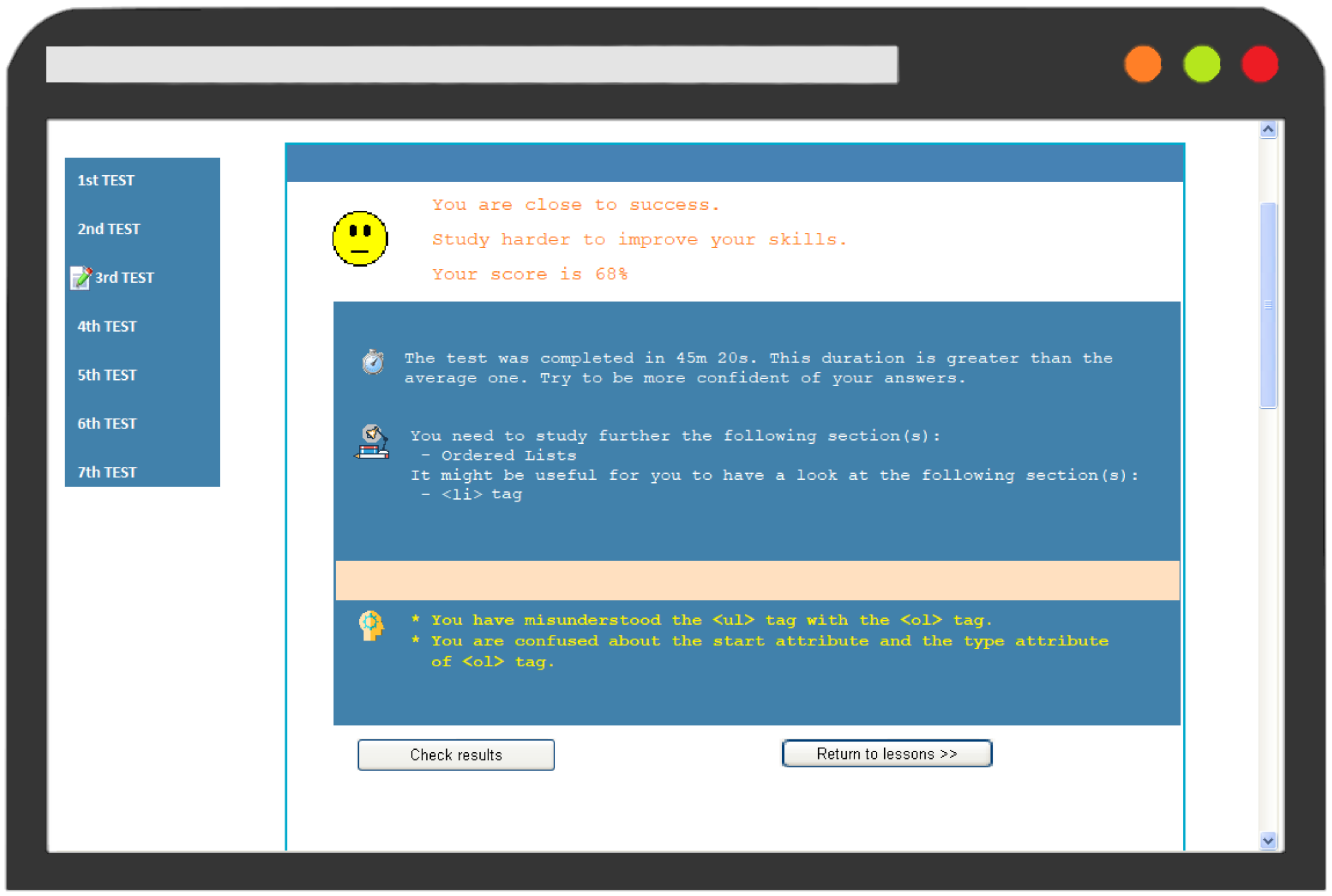
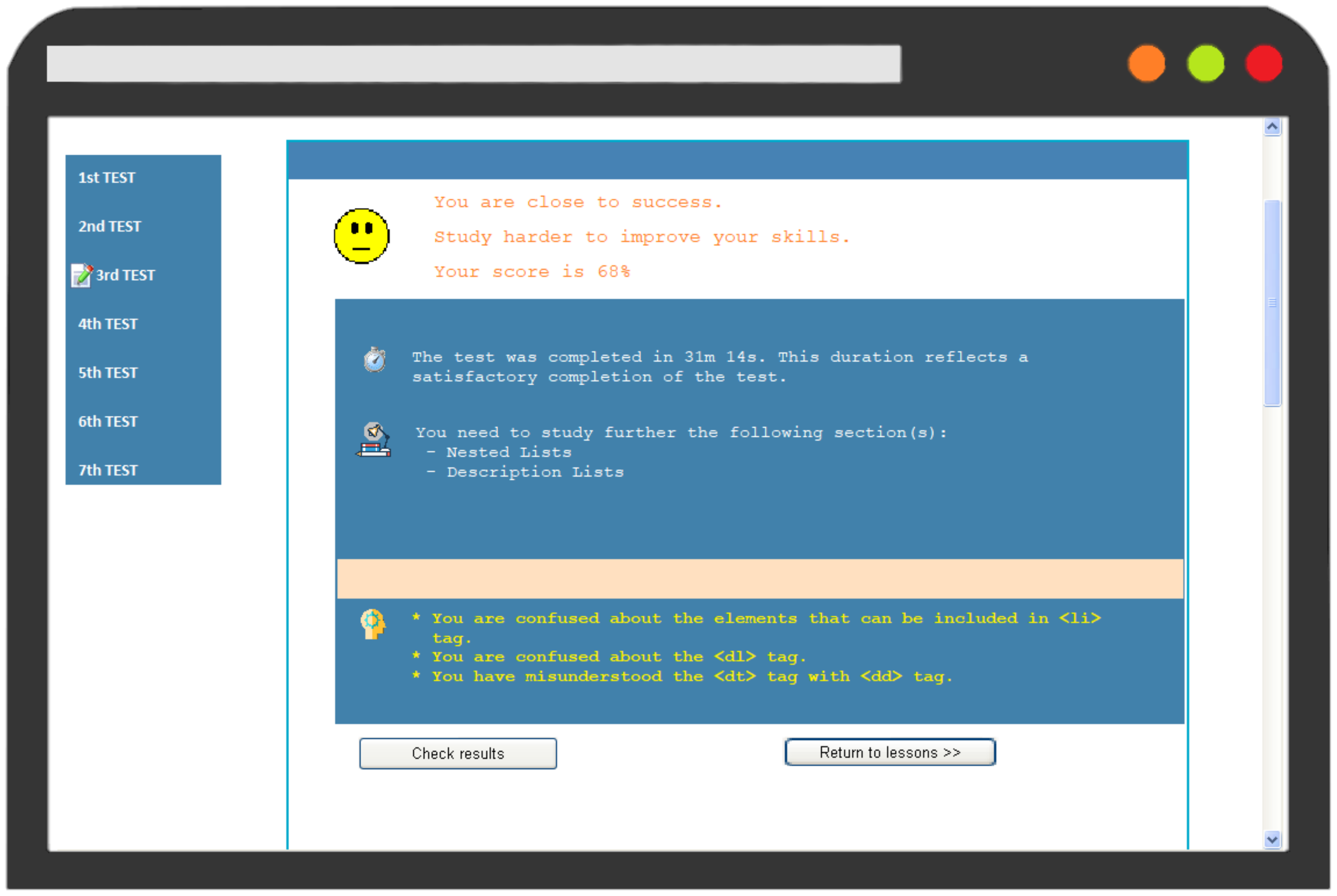
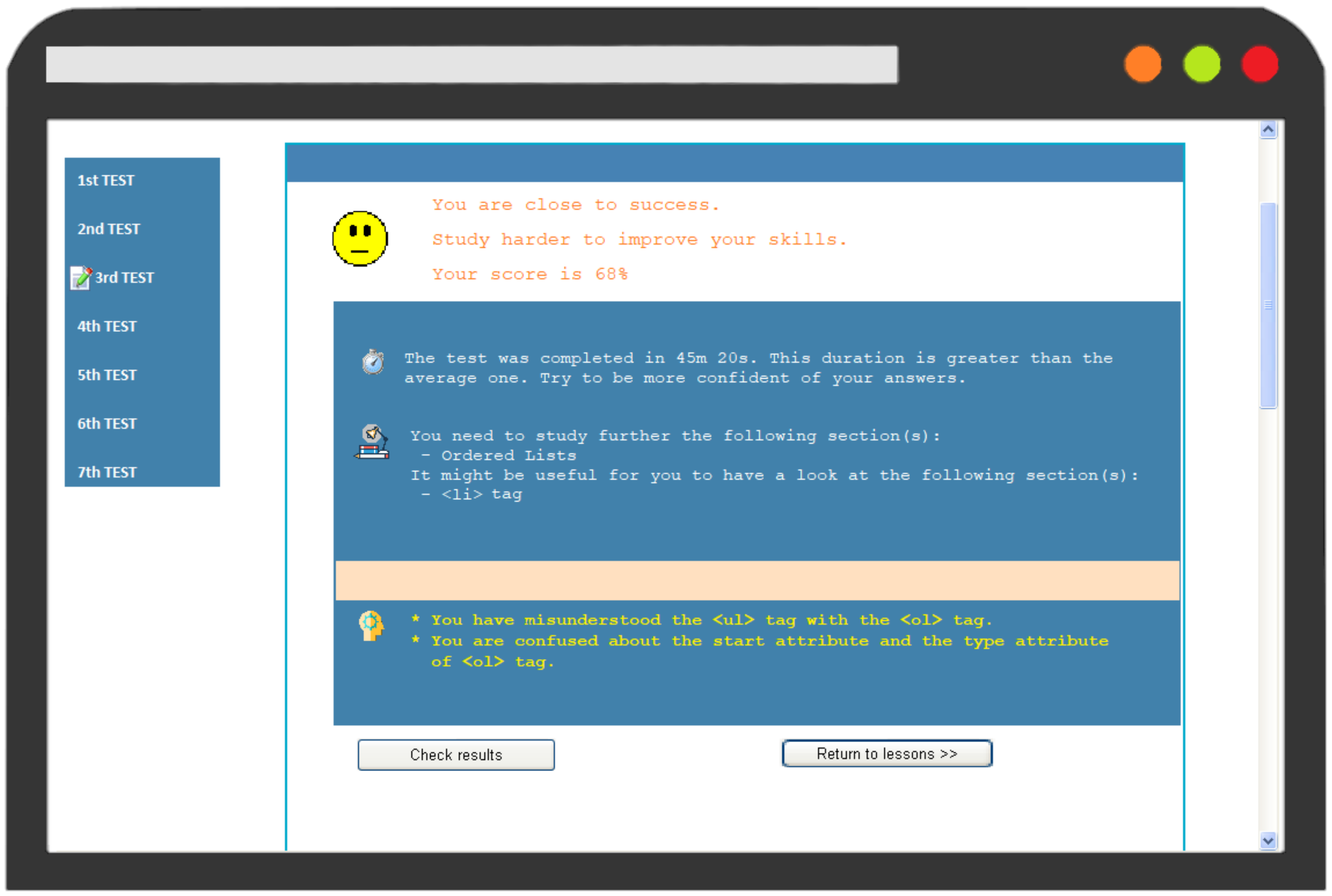
- Success rate on the test, giving a corresponding motivation message.
- Time taken for completing the test, which is compared to the average time all students needed to fill in the test.
- Concepts in which the student had made a mistake that indicated a misconception.
- The misconceptions detected by the diagnostic mechanism.
3. Examples of Operation
4. System Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Somyürek, S. The new trends in adaptive educational hypermedia systems. Int. Rev. Res. Open Distrib. Learn. 2015, 16. [Google Scholar] [CrossRef]
- Somyürek, S.; Brusilovsky, P.; Guerra, J. Supporting knowledge monitoring ability: Open learner modeling vs. open social learner modeling. Res. Pract. Technol. Enhanc. Learn. 2020, 15, 1–24. [Google Scholar] [CrossRef]
- Troussas, C.; Krouska, A.; Sgouropoulou, C. Collaboration and fuzzy-modeled personalization for mobile game-based learning in higher education. Comput. Educ. 2020, 144, 103698. [Google Scholar] [CrossRef]
- Cuong, B.C.; Lich, N.T.; Ha, D.T. Combining Fuzzy Set—Simple Additive Weight and Comparing with Grey Relational Analysis For Student’s Competency Assessment in the Industrial 4.0. In Proceedings of the 2018 10th International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 1–3 November 2018; pp. 294–299. [Google Scholar]
- Saad, M.B.; Jackowska-Strumillo, L.; Bieniecki, W. ANN Based Evaluation of Student’s Answers in E-tests. In Proceedings of the 2018 11th International Conference on Human System Interaction (HSI), Gdansk, Poland, 4–6 July 2018; pp. 155–161. [Google Scholar]
- Troussas, C.; Krouska, A.; Virvou, M. A multilayer inference engine for individualized tutoring model: Adapting learning material and its granularity. Neural Comput. Appl. 2021, 1–15. [Google Scholar] [CrossRef]
- Troussas, C.; Krouska, A.; Sgouropoulou, C. Improving Learner-Computer Interaction through Intelligent Learning Material Delivery Using Instructional Design Modeling. Entropy 2021, 23, 668. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.-M.; Hsieh, M.Y.; Usak, M. A Multi-Criteria Study of Decision-Making Proficiency in Student’s Employability for Multidisciplinary Curriculums. Mathematics 2020, 8, 897. [Google Scholar] [CrossRef]
- Stansfield, J.C.; Carr, B.; Goldstein, I.P. Wumpus Advisor I: A First Implementation of a Program that Tutors Logical and Probabilistic Reasoning Skills; Massachusetts Institute of Technology: Cambridge, MA, USA, 1976. [Google Scholar]
- Martins, A.C.; Faria, L.; de Carvalho, C.V.; Carrapatoso, E. User modeling in adaptive hypermedia educational systems. Educ. Technol. Soc. 2008, 11, 194–207. [Google Scholar]
- Liu, Z.; Wang, H. A Modeling Method Based on Bayesian Networks in Intelligent Tutoring System. In Proceedings of the 2007 11th International Conference on Computer Supported Cooperative Work in Design, Melbourne, Australia, 26–28 April 2007; pp. 967–972. [Google Scholar]
- Qodad, A.; Benyoussef, A.; El Kenz, A.; Elyadari, M. Toward an Adaptive Educational Hypermedia System (AEHS-JS) based on the Overlay Modeling and Felder and Silverman’s Learning Styles Model for Job Seekers. Int. J. Emerg. Technol. Learn. 2020, 15, 235–254. [Google Scholar] [CrossRef]
- Zhao, J.; Li, M.; Liu, W.; Li, S.; Lin, Z. Detection of Chinese Grammatical Errors with Context Representation. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018; pp. 25–29. [Google Scholar]
- Lin, X.; Ge, S.; Song, R. Error analysis of Chinese-English machine translation on the clause-complex level. In Proceedings of the 2017 International Conference on Asian Language Processing (IALP), Singapore, 5–7 December 2017; pp. 185–188. [Google Scholar]
- Lee, L.-H.; Chang, L.-P.; Tseng, Y.-H. Developing learner corpus annotation for Chinese grammatical errors. In Proceedings of the 2016 International Conference on Asian Language Processing (IALP), Tainan, Taiwan, 21–23 November 2016; pp. 254–257. [Google Scholar]
- Haridas, M.; Vasudevan, N.; Nair, G.J.; Gutjahr, G.; Raman, R.; Nedungadi, P. Spelling Errors by Normal and Poor Readers in a Bilingual Malayalam-English Dyslexia Screening Test. In Proceedings of the 2018 IEEE 18th International Conference on Advanced Learning Technologies (ICALT), Mumbai, India, 9–13 July 2018; pp. 340–344. [Google Scholar]
- Troussas, C.; Chrysafiadi, K.; Virvou, M. Machine Learning and Fuzzy Logic Techniques for Personalized Tutoring of Foreign Languages. In Proceedings of the International Conference on Artificial Intelligence in Education, London, UK, 27–30 June 2018; pp. 358–362. [Google Scholar]
- Khodeir, N.A. Constraint-based and Fuzzy Logic Student Modeling for Arabic Grammar. Int. J. Comput. Sci. Inf. Technol. 2020, 12, 35–53. [Google Scholar] [CrossRef]
- Li, S.; Zhao, J.; Shi, G.; Tan, Y.; Xu, H.; Chen, G.; Lan, H.; Lin, Z. Chinese Grammatical Error Correction Based on Convolutional Sequence to Sequence Model. IEEE Access 2019, 7, 72905–72913. [Google Scholar] [CrossRef]
- Henley, A.Z.; Ball, J.; Klein, B.; Rutter, A.; Lee, D. An Inquisitive Code Editor for Addressing Novice Programmers’ Misconceptions of Program Behavior. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering Education and Training (ICSE-SEET), Madrid, Spain, 25–28 May 2021; pp. 165–170. [Google Scholar]
- Lai, A.F.; Wu, T.T.; Lee, G.Y.; Lai, H.Y. Developing a web-based simulation-based learning system for enhancing concepts of linked-list structures in data structures curriculum. In Proceedings of the 2015 3rd International Conference on Artificial Intelligence, Modelling and Simulation (AIMS), Kota Kinabalu, Malaysia, 2–4 December 2015; pp. 185–188. [Google Scholar]
- Chang, J.-C.; Li, S.-C.; Chang, A.; Chang, M. A SCORM/IMS Compliance Online Test and Diagnosis System. In Proceedings of the 2006 7th International Conference on Information Technology Based Higher Education and Training, Ultimo, Australia, 10–13 July 2006; pp. 343–352. [Google Scholar]
- Barker, S.; Douglas, P. An intelligent tutoring system for program semantics. In Proceedings of the International Conference on Information Technology: Coding and Computing (ITCC’05), Las Vegas, NV, USA, 4–6 April 2005; Volume 1, pp. 482–487. [Google Scholar]
- Khalife, J. Threshold for the introduction of programming: Providing learners with a simple computer model. In Proceedings of the 28th International Conference on Information Technology Interfaces, Cavtat, Croatia, 19–22 June 2006; pp. 71–76. [Google Scholar]
- Troussas, C.; Krouska, A.; Virvou, M. Injecting intelligence into learning management systems: The case of adaptive grain-size instruction. In Proceedings of the 2019 10th International Conference on Information, Intelligence, Systems and Applications (IISA), Patras, Greece, 15–17 July 2019; pp. 1–6. [Google Scholar]
- Krugel, J.; Hubwieser, P.; Goedicke, M.; Striewe, M.; Talbot, M.; Olbricht, C.; Schypula, M.; Zettler, S. Automated Measurement of Competencies and Generation of Feedback in Object-Oriented Programming Courses. In Proceedings of the 2020 IEEE Global Engineering Education Conference (EDUCON), Porto, Portugal, 27–30 April 2020; pp. 329–338. [Google Scholar]
- Almeda, M. Predicting Student Participation in STEM Careers: The Role of Affect and Engagement during Middle School. J. Educ. Data Min. 2020, 12, 33–47. [Google Scholar]
- Sumartini, T.S.; Priatna, N. Identify student mathematical understanding ability through direct learning model. J. Phys. Conf. Ser. 2018, 1132, 012043. [Google Scholar] [CrossRef]
- Troussas, C.; Krouska, A.; Sgouropoulou, C. A Novel Teaching Strategy Through Adaptive Learning Activities for Computer Programming. IEEE Trans. Educ. 2021, 64, 103–109. [Google Scholar] [CrossRef]
- Brown, J.; VanLehn, K. Repair Theory: A Generative Theory of Bugs in Procedural Skills. Cogn. Sci. 1980, 4, 379–426. [Google Scholar] [CrossRef]
- Brown, J.S.; Burton, R.R. Diagnostic models for procedural bugs in basic mathematical skills. Cogn. Sci. 1978, 2, 155–192. [Google Scholar] [CrossRef]
- Rashid, T.; Asghar, H.M. Technology use, self-directed learning, student engagement and academic performance: Examining the interrelations. Comput. Hum. Behav. 2016, 63, 604–612. [Google Scholar] [CrossRef]
- Krouska, A.; Troussas, C.; Sgouropoulou, C. Fuzzy Logic for Refining the Evaluation of Learners’ Performance in Online Engineering Education. Eur. J. Eng. Res. Sci. 2019, 4, 50–56. [Google Scholar] [CrossRef] [Green Version]
- Alepis, E.; Troussas, C. M-learning programming platform: Evaluation in elementary schools. Informatica 2017, 41, 471–478. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Score Feedback | Score < 50% | 50% ≤ Score < 70% | 70% ≤ Score < 85% | Score ≥ 85% |
|---|---|---|---|---|
| Icon |  |  |  |  |
| Motivation message on the score | You have made many mistakes. You must study the lesson again from scratch to be better prepared for the test. Your score is xx% | You are close to success. Study harder to improve your skills. Your score is xx% | Bravo! You are very good. Keep up the good work. Your score is xx% | Congratulations! Excellent job. Continue like this. Your score is xx% |
| Comment on test duration | Average duration of all student to complete the test < Completion time of the student: | |||
| The test was completed in Xm Xs. This duration is greater than the average one. Try to be more confident of your answers. | ||||
| Average duration of all student to complete the test ≥ Completion time of the student: | ||||
| The test was completed in Xm Xs. This duration reflects a satisfactory completion of the test. | ||||
| Lesson’s Concepts | The system recommends to student to study again the sub-units of the lesson where was detected a bug. | |||
| Student Bugs | The systems delivers the detected misconceptions according to the buggy rule library. | |||
| Buggy Rules | |
|---|---|
| 1 | You have misunderstood the tag “<” with “#”. |
| 2 | You have confused the body section with the head section. |
| 3 | You are confused about the i tag and the b tag. |
| 4 | You have misunderstood the attribute face of font tag. |
| 5 | You have confused the p tag with the paragraph tag. |
| 6 | You have confused the <ol> tag with the <ul> tag. |
| 7 | You are confused about the start attribute and the type attribute of <ol> tag. |
| 8 | You are confused about the <ul> tag. |
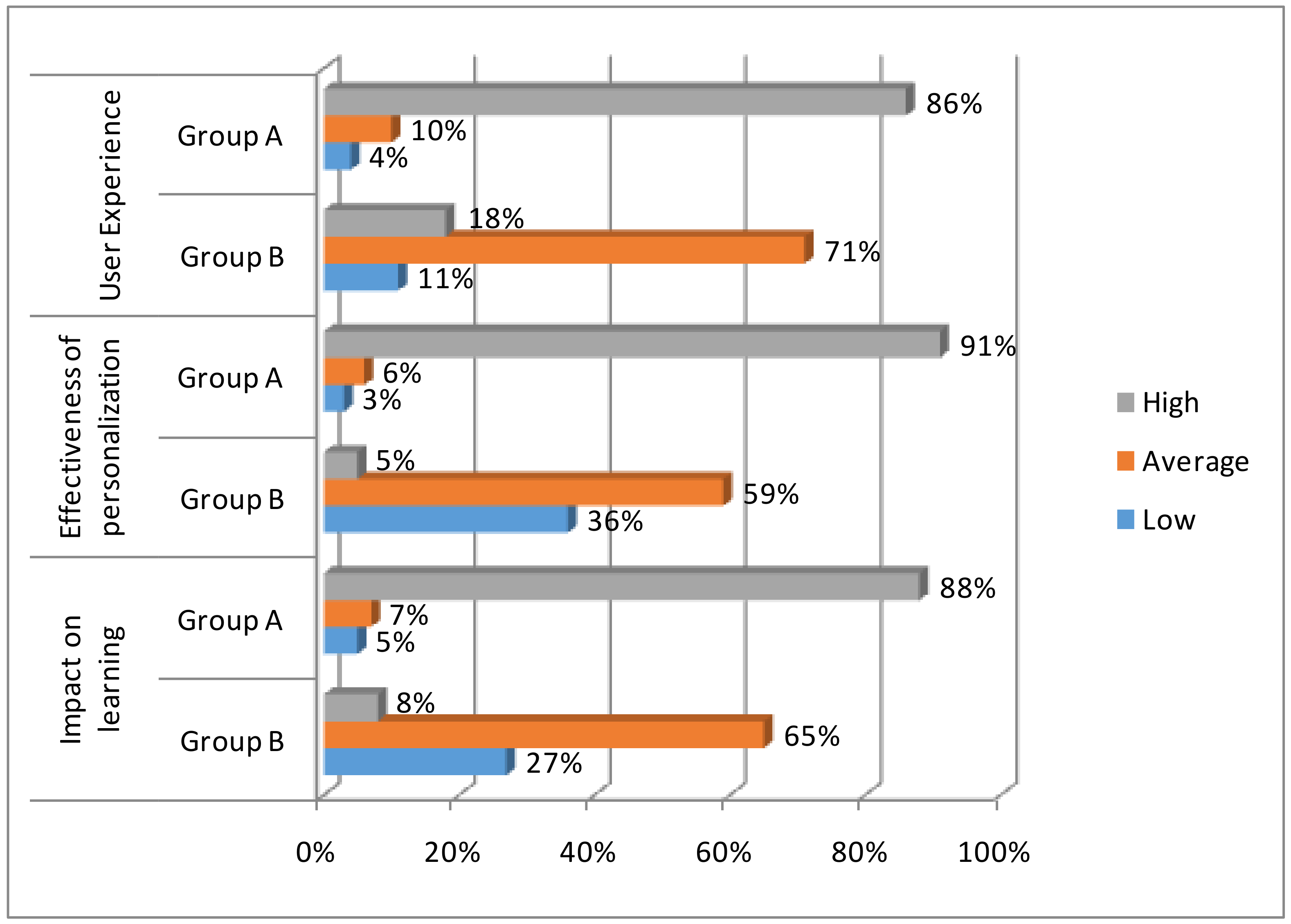
| Dimension | Questions | |
|---|---|---|
| User Experience | 1 | Rate the user interface of the system. (1–10) |
| 2 | Rate your learning experience. (1–10) | |
| 3 | Did you like the interaction with the system? (1–10) | |
| Effectiveness of personalization | 4 | Did the system detect appropriately your misconceptions? (1–10) |
| 5 | Rate the way the personalized guidance was presented. (1–10) | |
| 6 | Rate the learning content relevance to your personal profile. (1–10) | |
| Impact on Learning | 7 | Would you like to use this platform in other courses as well? (1–10) |
| 8 | Did you find the software helpful for your lesson? (1–10) | |
| 9 | Would you suggest the software to your friends to use it? (1–10) | |
| 10 | Rate the easiness in interacting with the software. (1–10) |
| Q4 | Q5 | Q6 | ||||
|---|---|---|---|---|---|---|
| Group A | Group B | Group A | Group B | Group A | Group B | |
| Mean | 8.65 | 5.23 | 8.73 | 5.45 | 8.48 | 5.6 |
| Variance | 3.36 | 2.18 | 2.72 | 1.38 | 3.18 | 1.89 |
| Observations | 40 | 40 | 40 | 40 | 40 | 40 |
| Pooled Variance | 0.69 | 0.11 | 0.46 | |||
| Hypothesized Mean Difference | 0 | 0 | 0 | |||
| Degree of Freedom | 39 | 39 | 39 | |||
| t Stat | 16.19 | 10.78 | 10.81 | |||
| P(T ≤ t) two-tail | 6.58 × 10−19 | 2.92 × 10−13 | 2.7 × 10−13 | |||
| t Critical two-tail | 2.023 | 2.023 | 2.023 | |||
| Learning Outcomes | ||
|---|---|---|
| Group A | Group B | |
| Mean | 82.45 | 70.05 |
| Variance | 167.99 | 170.05 |
| Observations | 40 | 40 |
| Pooled Variance | 169.02 | |
| Hypothesized Mean Difference | 0 | |
| Degree of freedom | 78 | |
| t Stat | 4.27 | |
| P(T ≤ t) two-tail | 5.55 × 10−5 | |
| t Critical two-tail | 1.99 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krouska, A.; Troussas, C.; Sgouropoulou, C. A Cognitive Diagnostic Module Based on the Repair Theory for a Personalized User Experience in E-Learning Software. Computers 2021, 10, 140. https://doi.org/10.3390/computers10110140
Krouska A, Troussas C, Sgouropoulou C. A Cognitive Diagnostic Module Based on the Repair Theory for a Personalized User Experience in E-Learning Software. Computers. 2021; 10(11):140. https://doi.org/10.3390/computers10110140
Chicago/Turabian StyleKrouska, Akrivi, Christos Troussas, and Cleo Sgouropoulou. 2021. "A Cognitive Diagnostic Module Based on the Repair Theory for a Personalized User Experience in E-Learning Software" Computers 10, no. 11: 140. https://doi.org/10.3390/computers10110140
APA StyleKrouska, A., Troussas, C., & Sgouropoulou, C. (2021). A Cognitive Diagnostic Module Based on the Repair Theory for a Personalized User Experience in E-Learning Software. Computers, 10(11), 140. https://doi.org/10.3390/computers10110140