Abstract
Cases of a new emergent infectious disease caused by mutations in the coronavirus family, called “COVID-19,” have spiked recently, affecting millions of people, and this has been classified as a global pandemic due to the wide spread of the virus. Epidemiologically, humans are the targeted hosts of COVID-19, whereby indirect/direct transmission pathways are mitigated by social/spatial distancing. People naturally exist in dynamically cascading networks of social/spatial interactions. Their rational actions and interactions have huge uncertainties in regard to common social contagions with rapid network proliferations on a daily basis. Different parameters play big roles in minimizing such uncertainties by shaping the understanding of such contagions to include cultures, beliefs, norms, values, ethics, etc. Thus, this work is directed toward investigating and predicting the viral spread of the current wave of COVID-19 based on human socio-behavioral analyses in various community settings with unknown structural patterns. We examine the spreading and social contagions in unstructured networks by proposing a model that should be able to (1) reorganize and synthesize infected clusters of any networked agents, (2) clarify any noteworthy members of the population through a series of analyses of their behavioral and cognitive capabilities, (3) predict where the direction is heading with any possible outcomes, and (4) propose applicable intervention tactics that can be helpful in creating strategies to mitigate the spread. Such properties are essential in managing the rate of spread of viral infections. Furthermore, a novel spectra-based methodology that leverages configuration models as a reference network is proposed to quantify spreading in a given candidate network. We derive mathematical formulations to demonstrate the viral spread in the network structures.
1. Introduction
COVID-19 has recently been classified as a global pandemic by the World Health Organization (WHO) [1]. Since the spark of the pandemic, there has been a strong continues international tendency to understand its spread and the fast pace of social contagions. In general, the epidemiological triad is considered when studying infectious diseases: (a) the virus itself to consider less virulent strains and the impact throughout the genetic mutations within its lifecycle, (b) the environment where the virus propagates and transmits—e.g., wind, heat, humidity, etc.—and (c) the host, as our primary focus, which refers to any being in which the virus survives and flourishes. Viruses are able to naturally mutate to spread and infect other hosts of different species ranging from insects to humans. Unfortunately, COVID-19 has already reached humans and now is able to quickly transmit from one human host to another. Different mediums of transfer are applicable to different viruses that target suitable host systems with immunity deficiencies. The immune system may be compromised due to pre-existing health conditions, some of which are chronic diseases such as hypertension, diabetes, heart problems, etc. Studies on COVID-19 have reported possible infection routes that are similar to those that have been observed for the seasonal flu, i.e., transmission through contaminated services or through the air in the case that the infected individual is at a close distance to others [2]. Thus, local and international agencies, i.e., the WHO and CDC [3], as well as governments have recommended social distancing and self-quarantine to mitigate the spread of the virus. While the novel character and contagiousness of COVID-19 are questionable, the current study is highlighted in Figure 1 [4].
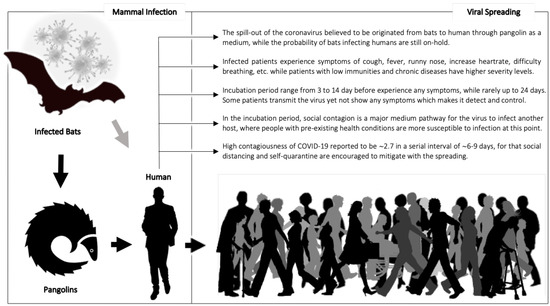
Figure 1.
A general overview of the COVID-19 infection process and viral spreading.
Social contagions have changed the functioning of societies from physical spaces to a more socially networked nature [5]. This requires understanding the social fabric and values of predefined social networks amongst society members. However, data generated from social interactions are not well defined or measured, and simple straightforward analysis along with the unavailability of proper tools and models to recognize such spreading have been reported [6]. Hence, it becomes necessary to explore alternative methods to achieve the best possible understanding of the spread of the virus. One of these methods is the utilization of artificial intelligence and network science techniques to understand current societal mobility and to suggest new applicable intervention tactics that can be helpful to determine strategies to mitigate the spread [7]. The proposed system architecture—outlined in Table 1—models the effects of social proliferation that result from agents’ opportunistic explorations and exploitations via the fast interconnectivity to better understand the current wave of the emergent network-centric spreading. The success of the proposed system, which measures and predicts the viral spread to identify possible interventions and reduce the mortality of infected patients, is demonstrated through succinct evaluations of the effectiveness of modeling human individuals generically and cognitively as intelligent agents and mapping their current social behaviors as an open multiagent system while taking into account cultures, beliefs, norms, values, ethics, etc.

Table 1.
An outline of the three stages to be addressed in the proposed system.
Hence, we aim to propose a system as an intelligent socio-behavioral analyzer using date science and artificial intelligence techniques. The system encapsulates two segments: (a) the intelligent socio-behavioral analysis part, which theoretically models the current social behaviors of an individual and population as intelligent agents and multiagent systems for precise evaluations of spreading and contagion, as well as for a better prediction of the future trajectories; (b) the data science and artificial intelligence part, which takes the multiagent systems as the inputs and analyzes the data to predict viral spread and infection routes as early as possible. This novel system should be able to (1) reorganize and synthesize infected clusters of any networked agents, (2) clarify any noteworthy members of the population through a series of analyses of their behavioral and cognitive capabilities, (3) predict where the direction is heading with any possible outcomes, and (4) propose applicable intervention tactics that can be helpful in creating strategies to mitigate the spread. Such properties are essential in managing the rate of spread of viral infections [4]. The system architecture should answer the following main questions: How can we model the viral spreading and predict social contingency in the time of a pandemic peak? (a) How can human individuals be modeled generically and cognitively as intelligent agents and their current social behaviors be mapped as an open multiagent system while taking into account cultures, beliefs, norms, values, ethics, etc.? (b) How do we understand and predict the trajectory of the viral spreading and possible infected regions in order to help with orienting social contingencies and strategizing with the spreading?
The remainder of the article is organized as follows: Section 2 highlights some of the recent developments in the literature with a slightly similar focus. Section 3 presents two artificial intelligence perspectives that complement each other to encapsulate a system that understands the viral spreading of the current pandemic. Section 4 summarizes and sheds light on possible future directions that are still to be explored to understand the current pandemic.
2. Literature Review
A virus is a microscopic agent that can multiply only in living cells of animals, plants, or bacteria [8]. A virus particle is formed of a genetic element, or genome, hosted inside a protein shell. When some disease-causing viruses enter host cells, they begin producing new copies of themselves instantly, often outpacing the immune system’s production of protective antibodies. This progressive and rapid (re-)production can result in cell death and the transformation of the virus to nearby ones. Some viruses may cause worse scenarios by replicating themselves and invading the host cell genome, leading to permanent illness or harmful transformation and cancer [9]. While research shows that some of the viruses that infect bacteria, plants, and animals (including humans), such as those of the bacteriophage type, do not cause disease, many of them do. Of those viruses that cause illness, they can be categorized into two main groups in terms of their time, short-term (acute) diseases, and long-term (chronic) diseases. Human poliovirus and similar picornaviruses are instances of severe infections that lock the protein structure in the host cell. Unfortunately, the infected cell dies within hours of the attack. Another example includes the Vesicular Stomatitis Virus (VSV) of the family Rhabdoviridae. On the other hand, some other viruses appear to be less harmful in comparison to the above ones, but can still cause long-term sickness, although the risk of severe illness may be different for everyone. Examples of this type include the influenza viruses of the family Orthomyxoviridae, the Poxviruses, Reoviruses, Togaviruses, Adenoviruses, and Herpesviruses. Some viruses’ danger comes from their ability to distribute widely [10].
Close to the end of 2019, a new strain of viruses was discovered in Wuhan City, Hubei, China, and it is referred to by the WHO as SARS-CoV-2 or 2019 Corona Virus Disease (“COVID-19”). As a family of RiboNucleic Acid (RNA) viruses, Coronaviruses (CoVs) cause sicknesses ranging from common cold symptoms to serious critical diseases and even death—e.g., reports on Middle East Respiratory Syndrome (MERS-CoV) and Severe Acute Respiratory Syndrome (SARS-CoV) [8]. The source(s) of SARS-CoV-2 transmission is still unknown. Yet, available genetic and epidemiological data suggest that COVID-19 is a zoonotic pathogen with potential spillover directly from wildlife or via intermediate animal hosts or their products. Continued human-to-human transmission has been confirmed where many healthcare workers have been infected in clinical environments with clear clinical sickness and fatalities [11]. Although most of the cases were reported in China at that time, COVID-19 has expanded to more than 200 countries and territories around the globe. As of 10 April, there have been more than 1,677,000 reported cases, 22% among them having recovered, while more than 101,000 are reported dead [12]. Most of the reported infected cases are associated with fever and respiratory symptoms (coughing, shortness of breath, and pneumonia). However, there is not much information about SARS-CoV-2 to draw precise conclusions about the transmission mode, clinical presentation, or the degree and extent to which it has spread [13].
The utilization of artificial intelligence can help in observing the trends in COVID-19 at the national and global level, by analyzing the daily collected data, classifying them, and predicting the next potential wave of the spread [6]. AI would also be a useful tool in providing a rapid detection of new cases in countries where the virus is not circulating and to monitor cases in countries where the virus has started to circulate [14]. Nonetheless, AI can accelerate the processes of getting epidemiological data and information to conduct risk assessments at the national, regional, and global levels. Thus, it helps to present epidemiological information to guide preparation and response measures [15]. Since the beginning of this pandemic, several research papers discussing COVID-19 from the AI point of view have been published [16,17]. The work in [15] proposed a simple mathematical model for an early prediction of the outbreak in Mainland China based on limited epidemiological data. The authors considered finding what they called “unreasonable data”, which they tried to rule out to come up with a clearer prediction model. The daily statistics showed that the study succeeded in predicting the cases range in Mainland China as it was about 80,778 cases as of 10 March. However, it focused on the early state of the virus spread and did not take into account the long-term changes and waves. Another work that discussed and predicted the spreading in Mainland China was [18]. To do so, the study used five statistical methods with the well-known Chinese search engine, Baidu, to analyze a dataset of social media search indexes for words including fever, dry cough, chest distress, coronavirus, and pneumonia. Results showed that the new suspected case numbers were associated significantly with the lagged series of social media search indexes.
The work in [19] offered an analysis and data mining for social media public opinion related to COVID-19 in China. It used another dataset of related virus keyword from Baidu with a greater concentration on some provinces. Similar to the previous one, it only studied the reaction of the public to the virus spread, where there was no true effect of the virus contagion or spread. The study in [20] offered an overview of the potential area of research and digital technologies with their possible impact on public health strategies. It discussed the capability of using the Internet of Things, big data, AI, and blockchain whether directly related to COVID-19 as in monitoring, surveillance, detection, and prevention of COVID-19 on the one hand or indirectly by analyzing the collected data to mitigate the impact of the virus. Yet, the study provided no particular method nor model, rather offering a likely field to examine. Reference [21] provided a mathematical model for calculating the transmissibility of COVID-19 in South Korea. It presented a simulation and statistical analysis with the assumption of the probable infection source as a bat, to an unknown host, to a seafood market reservoir, until it reached humans. However, the authors admitted that the accuracy of the mathematical model needs more investigation and verification since the study was conducted based on limited available data.
The impromptu formations, adaptations, and functioning of human-based networks have been scientifically impacted by the underlining social interactions [22]. Spatial agents’ interactions evaluate the viral flow of infections to enable, constrain, or limit the transmission [23]. Beneficence and trust are some of the common social traits in homologous structures formed from continuous cooperative interactions to construct cohesive societies [24]. Interactions within a cluster/a society are, on the one hand, intra-societal communications as bonding measures to consider the operations of frequent changes in the social and economic landscape. On the other hand, inter-societal interactions as bridging measures are common in traditional societies in order to strengthen social communications across different clusters for agile adaptations and access to critical resources available in the social environment [25,26,27]. Both views of interactions allow the society to synthesize and recognize social and information demands, i.e., internally or externally, to plastically adapt to those changes, which in turn influence its members [28].
Socio-behavioral formations are influenced by continues patterns of interactions led by agents performing complex activities [29], which may affect the individual, as well as the society’s performance features [30,31,32]. Interaction protocols characterize working structures to include hierarchies, holarchies, coalitions, teams, etc. [33]. Those arrangement patterns define the operation segments of a society since they exhibit very limited explicit abstract features [34]. Network-centric design stimulates the oversight of operations through self-integrating coordination, as well as asynchronous temporal freedom, e.g., US-DDF embraced this paradigm to accommodate collaboration and resource sharing across work units [35]. The literature guides us to model a society at a generalized level to permit arrangements of command and control by cutting across domains without functionally altering internal operations [36,37]. The model should be applicable to understand other systems besides the spreading of infectious diseases [38], e.g., factory cells, river dam control, organized labor unions, electrical power grids, and traffic control. In the area of crowd management, current researchers face difficulty in crowd control and in proposing efficient algorithms to manage movements and directions [39]. Thus, we embark on modeling artificial, agent-based networks that possess the features of human counterparts by exploring and exploiting significant advancements in current deep learning algorithms and in the field of multiagent systems, which have shown promising results in overcoming the limitations in strategizing with the crowd [40,41]. The proposed artificial model may lack long-term temporal history when used to address certain problems in contrast with the benefit of collective memories and temporal resilience in dynamic human societies.
Recently, we have been witnessing an increasing interest of scientific research to tackle COVID-19 from different perspectives, ranging from micro-analysis of the virus itself and how the hosts react internally to it to more generic ways of understanding infections and transmissions [42]. Some related works discussed in this section set aside the rapid release of scientific pieces of evidences contributing to the body of knowledge, which has been estimated to be close to scientific peer-reviewed papers each week. To keep up with such a rapid pace, this section focused on the systematic reviews of relevant studies to contribute to our system by assessing, synthesizing, and interpreting the findings with an impartial summary. Although research discussing the COVID-19 pandemic has been proposed recently, the number of research works that employ effective AI models is still low. Even with the existing AI related papers on the virus, those models face many challenges to be addressed and solved such as limited data resources and a thorough analysis of the still emergent virus. For such reasons, we aim to study the COVID-19 virus from different perspectives to overcome the gap in the literature and provide an efficient and reliable systematic model that can reflect humans and their rapid social behaviors for better and quicker analysis, studying the factors that may have an impact on the social spreading of the virus, and proposing an accurate and effective understanding of the viral spreading of the COVID-19 pandemic.
3. The Underlying Intelligent Socio-Behavioral Architecture
We have observed the need for an intelligent system that analyzes the social activities of people on a daily basis. This system plays the role of an intelligent socio-behavioral analyzer that utilizes date science and artificial intelligence techniques to encapsulate two segments:
- A.
- The intelligent socio-behavioral analysis part, which maps the current social behaviors of an individual and population to intelligent agents and multiagent systems for precise evaluations of spreading and contagions, as well as for a better prediction of the streams’ future trajectories.
- B.
- The prediction model part, which takes the multiagent systems as inputs and analyzes the data to predict viral spreading and infection streams as early as possible.
The encapsulation of those two segments will lead us to form an intelligent system that helps to understand the spreading of the virus and to predict its future trajectory as early as possible. The features of the system include adaptiveness, smartness, responsiveness, and accuracy. The system should assist a non-medical/health specialist to understand the viral spreading of the virus.
3.1. Segment A: The Socio-Behavioral MAS Model
COVID-19, as stated in the literature, is mainly aerosolized and transmitted from one host to another [43]. Social distancing has been encouraged to overcome mass infection and to stabilize the curve of new cases. Here, socio-behavioral analysis comes to a place where the social activities of the population are the main focus. The aim is to model the current population as a multiagent system taking into consideration their values, norms, culture, and beliefs. The field of agents and multiagent systems has proven its efficacy in modeling human behavior and social interactions ranging from individual entities to crowd evacuation, control, and management. Different stages are considered for this objective to generally include,
- Formally modeling individual human beings as rational agents with properties essential for building collective intelligence. Such intelligent agents are aware of their surroundings and are able to socialize with their peers, as well as act upon climate/societal changes.
- Modeling societies as intelligent multiagent systems while taking into consideration the social engagement factors. This is obvious from the literature, and possibly due to our limited knowledge, some cultures have been overlooked when modeling societies, yet many existing models may not applicable in real life.
- Those models will ease the understanding of the socio-behavioral system within the society in focus besides other useful aspects in analysis and predictions. Multiple factors are to be considered in the modeling of a social system including links-prediction, social-structure/-topology, organizations/team formation, etc. Figure 2 depicts a generic social multilayered model of a society in progressive motion.
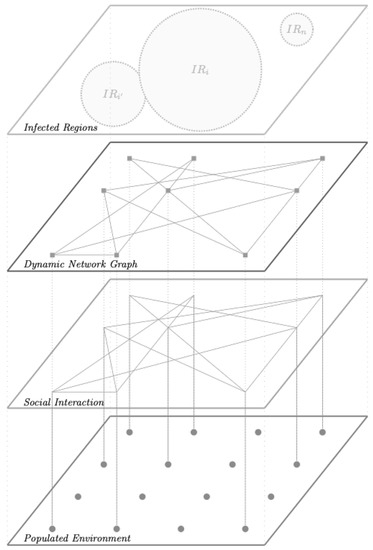 Figure 2. Generic multilayered model of a society in progressive motion.
Figure 2. Generic multilayered model of a society in progressive motion.
To formally model human society in a progressive motion of changing topologies, three main dimensions are considered. In general, agents reflect entities within a society who live on or are a part of some sort of invisible/implicit networked fabric that intertwines them together even though they may not be aware of it. Such a substrate allows entities/nodes to link up in any form with each other, when possible, forming a network that is not fully connected naturally. Different connections will form different networks, and each network has its own properties that distinguish it from others. Major properties should naturally be noticeable in their to-be-defined profiles in order to allow different agents in the open system to easily navigate through the network. The network generically forms a graph of nodes as agents and edges that link them together. The number of edges will change as a result of changes in the connections graph. Edges may richly or weakly capture ties among individuals because ties are most likely to appear when a mutual event occurs. Networks should be aware of major changes in their structures so that they maintain updated profiles with the important essence of their existence (e.g., agents and links). Important concepts of the network profile are presented in Definition 1.
Definition 1.
A network structure of continuous social interaction presents a tuple of , where:
- is a set of every being involved in the societal graph that is a reflection of a set of agents in the MAS. An agent profile that is is presented in 2.
- reflects the social topologies of the network that connects agents together.
- is a set of rules to govern members’ activities, which include and may be superseded by more specific norms, rules, and roles.
- defines the current range and orientation for the area of focus to help in the control and perhaps in providing a better reflection of the spreading.
As a part of the network, agents have various parameters and qualities that identify and differentiate them from others. Those parameters may change over time based on previous experiences that agents may acquire through their existence (i.e., life-cycle). When it comes to competing activities, such parameters play an important role in the final determination. Agents provide their parameters publicly in order to participate or to join mutual activities with others. Since agents’ parameters will envision their expected actions, we describe them as profiles. Thus, each agent will have a public profile that contains all pertinent agent attributes including their allegiances, capabilities, fitness, etc. This profile is presented in Definition 2.
Definition 2.
Every member agent within a societal graph (i.e., ) possesses a profile that is a tuple of ⟨⟩, where:
- is a set of relations that an agent has previously formed with other agents or organizations, e.g., wife/husband, household members, coworkers, etc.
- is the set of agent’s initial fitness values for different types of actions based on previous experiences.
- is an agent’s ordered preference for certain activities while avoiding others. It takes into consideration the individual initial state of norms, values, roles, and ethics.
- is the autonomy level at which an agent can perform actions independently of others. A highly autonomous agent works more independently while another with a lower autonomy seeks joint actions with others.
- refers to the preexisting health conditions and possibly inherited and yet hidden ones.
- presents a current location and a possible orientation considering close relations and preferences.
The agent profile presented in Definition 2 is not static. Agents should update their profiles continuously to include possible improvements of gain or loss while performing actions. Agents may include more information in their profiles that may not fall into any of the parameters listed above; however, those parameters are only highlights of the most common requirements for possible interactions. Profiling daily activities to ease possible interactions is revealed next.
There are many reasons that compel agents to socially interact with each other. The most pertinent reason for our formulation is to gather for a common activity. The size of an activity is based on the action that agents aim to pursue. Each distinct action will correspond to a distinct associated activity profile that is used in selecting best-fit agents to perform certain activities. An activity profile must contain action decomposition details that provide precedence and coordination requirements. With enough details, a plan can be retrieved from the storage of prior plans. If no plans match, a new plan is conceived. Most often, activities will have corresponding procedures/plans that will be retrieved from a case history. We have a set of actions that represent different activities’ profiles, where every activity profile is based on one action (i.e., ). Definition 3 shows the components required for each activity profile.
Definition 3.
An activity profile for a member agent that performs persistent actions is considered to be a tuple of , , , , where:
- stands for controlling participants and available positions (i.e., roles).
- is a vector of coordination rules for each agent or an agent group based on an agent profile.
- is the action for which the activity profile exists, which includes a set of tasks and a set of plans that should be followed to achieve this action. More details about are presented in Definition 4.
- is the precedence of the activity domain compared with others. That is, the priority level of this activity, to be addressed next, must be less than or equal to one, where one is the highest priority.
- stands for the independence of in the activity-profile from other competing actions that can be executed at the same time.
There exists an action profile for each activity to be assigned that differentiates it from other competing activities. Such a profile allows an agent to prioritize actions considering the eagerness and duration. When an activity is chosen, the action profile must identify different components presented in Definition 4.
Definition 4.
Each action, i.e., , is a tuple: , where:
- {Procedure} is a set of structured steps needed for achieving the . It should lead to the easiest and most safe way to complete an action in the least execution time possible.
- is a set of sub-actions that agents need to handle for executing a procedure, which is a set of consecutive sub-actions , and m is a unique independent number of sub-actions. Each sub-action will have its own , which is the temporal order of this sub-action among all other sub-actions in the next set of sub-actions to be assigned to agents, and reflects the level-of-dependency that indicates which sub-action can be achieved alone without any other requirement of prior sub-actions or in overlapping completion times.
- {Externality} is the set of external events upon which an agent generates reactions in order to address certain internal events with the .
- ξ is a mapping function to perceive the relevance of an external event to multiple internal ones, e.g., where is an external event of the set and and are random internal events within the set that have been affected by the external one. It helps an agent to decide on which reaction it should perform as a result of a certain outside action.
- {Internality} is the set of internal planned statuses to be achieved for the sub-action’ completion. Internal event-based actions and interactions result in social effects such as synergies and social capitals, which are of importance to new link generation, i.e., collaboration and adaptation of emergent formations.
A general consideration of the procedure is to be built of And-Or graphs of actions. Naturally, behavior dependency is a factor since mutual actions may sometimes have overlapping durations. Some actions are dependent on the completion of others or to be completed in parallel with them both internally or externally. Both internality and externality play major roles in agents’ current and future social engagements, which may help in the prediction of future social behaviors and possibly link formation and interactions. At this stage, it becomes very obvious that modeling human society as an open multiagent system helps in the understanding of the current wave of the pandemic affecting human populations. We introduced four profiles that when modularly combined will better reflect a society in an abstract form in order to help us follow where the current wave is right now and where the stream is heading. The following subsection proposes generic steps to predict the trajectories of the streams and introduces a novel spectra-based process that allows us to mirror what happens in one population or another without a baseline spark of the infection stream.
3.2. Segment B: Prediction and Orientation
The second stage of the system is to utilize state-of-the-art deep learning methodologies in order to take advantage of the modeled data to predict possible infected individuals and the trajectory of the spreading stream. The inputs will be replicated and distributed to four modules for further analysis. The four modules are as follows:
- The first module is a social behavior analysis module where suitable AI algorithms are modified to detect direct social engagements and predict the level of contact taking into account the distortion that may occur. The algorithm aims to measure how long a person has stayed in the radius of approximately less that two meters of an infected person as a means of getting infected.
- The second module is the immunity detection module where the second AI algorithm detects and predicts the preexisting health conditions of a patient. The algorithm should measure and analyze the patients’ recent medical tests and reports. The aim of this algorithm is to measure the estimated immunity level of a patient based on his/her medical records. Multiple clinical conditions have been reported to be contributing to the severity of infection including hypertension, heart problems, diabetes, cancer, etc. For simplicity, one of them can be considered as the most common chronic disease, e.g., diabetes, throughout the evaluation process.
- The third module is a close network analyzer module as an additional module for the sole purpose of looking at the immunity aspect of a patient. It is a simple algorithm that analyzes the patient’s household members and close social networks. The close nets analysis algorithm looks at answers from a fixed set of questions provided by the patients or their medical records.
- The last module is the severity time stamp analyzer module. IT is a simple algorithm that analyzes the current severity of infections within a predefined radius. Due to COVID-19’s transition range and period, patients with higher intensity areas are at higher risk of being infected than those in rural areas.
The output from these four modules is forwarded to an artificial classifier module. This module implements a fusion classifier algorithm, where the inputs from the four modules are fused first based on some weightings, and then, a pre-trained classifier model can decide and provide the probability of whether the person has been infected or not. Figure 3 highlights the process of Segment B of the system from receiving inputs to the predictive outcomes.
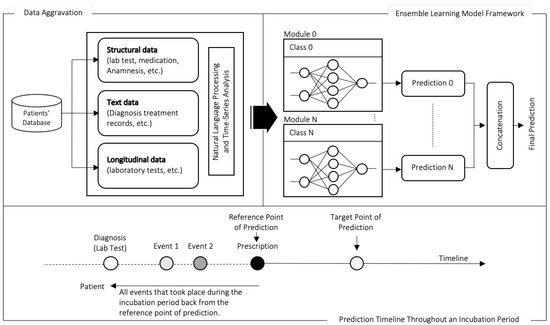
Figure 3.
A simplified framework that depicts the process of feature extractions up to predictions.
The implementation of the above theoretical framework in an expert software system is through the following five modules.
- The first one is responsible for performing standard pre-processing to the input data to minimize bias reporting.
- The second module is a specific output generator module as a reference for a few of the algorithms implemented as part of the proposed AI theoretical detection framework.
- The third module is an intelligent prediction module in which the proposed theoretical framework is implemented.
- The fourth and most important module for clinicians and health professional would be the reporting module. Upon receiving the output decision from the intelligent prediction module, it extracts data from various sources such as the social contacts, immunity levels, close nets, and severity time stamp. The generated report is meant also to give some insights on how the decision making was made.
- The last module incorporated into the system is a database of records including the input and output, i.e., reports. The multi-sensory data captured are used to provide quantitative support for the diagnosis, care, and treatment, replacing the current labor-intensive techniques.
At this point, member agents, as well as their social behavioral activities have been modeled as a complex open multiagent system. We also introduced a prediction methodology that utilizes state-of-the-art deep learning methods to predict the trajectory of the viral spreading. Next, we observe the possibility of mirroring the current modeling on a different segment of the population to reflect the possibility of upcoming trajectories and future intervention tactics beforehand.
3.3. Mirroring and Prediction
In order to understand the spreading within a social complex network, the consideration in this study is of two small segments of networks: (a) a candidate network graph represented as a finite matrix and (b) a sampled network graph of the same size reflecting the current wave of spreading. The purpose is to understand the extent to which a candidate network reflects the current spreading of the already infected network. We benefit form graph-spectra-based formulations. Therefore, to model a small segment of a network, we consider a graph , with a set of vertices as network members and edges to reflect interactions among these member entities. The adjacency matrix for the graph G that includes n members is described as follows:
where i.e., “1” if the two members have a relationship and “0” otherwise. The term “spectra” refers to the eigenvalues of A with standard notations denoted by in descending order, respectively, i.e., .
Spectra have been studied before in the literature [44]. The authors in [44] compiled several signatures of the underlining network structures, e.g., triad for scale-free networks. In a similar perspective, the diffusion dynamics is governed by the largest eigenvalue, and the initial spectra reflect the threshold of diffusion [45]. Other parameters related to the spectra of a network are volumes, degrees, chromatics, cliques, cycles, and diameters [46]. Besides the adjacency matrix, spectral analysis of a graph Laplacian () of a network is another important matrix to analyze the structure of the underlining network; readers are advised to see [47]. As we focus on the adjacency matrix, the Laplacian in short subtracts the adjacency matrix from the diagonal degree matrix (diag) of each node, i.e., the node has a degree that is {diag in some non-negative tuples .
We compare the ideal network with the infected one in order to model an infected segment overlaying the defined network. We take advantage of the configuration model, which generates random networks from a given degree sequence. The degree sequence is not restricted to having a specific degree distribution and prompts choosing any desired one. Interested readers are referred to [48].
Consider the network graph G and the corresponding configuration model network as . Let represent the spectra of G in the descending order of values. Similarly, represents the spectra of in the descending order of values. The possible spreading of G is measured by:
where is the number of small sets presented in the candidate network of graph G.
At this point, we consider the modularity of the graph. Therefore, let there be a new matrix (B) that excludes the configuration model matrix from the adjacency matrix, i.e., let where A and C correspond to the adjacency matrix of G and , respectively. The expectation of matrix C is denoted by another matrix S, where the th entry of matrix S is , and and are the degree of node members i and j, respectively, and m is the total number of edges/relationships in the network graph G. In our consideration of a given network G, while the adjacency matrix (A) is a constant matrix, the following equality holds for the expectation of a matrix:
where matrix is modularity matrix corresponding to A with [49].
Let be the unit eigenvector for the adjacency matrix A and . Let be the associated eigenvalue, then:
Let and be eigenvectors/unit-vectors corresponding to matrices and S, respectively, and the corresponding eigenvalues are and . Consider . The above equation results in:
After performing standard linear algebraic operations, we have the following:
The modularity in spreading is stated in Equation 1, where we have the following:
- contributes to an expected spreading of the given network G.
- corresponds to the contribution of modularity in determining the matching trajectory of the spreading.
- signifies the change in the membership of nodes in different groups if clustering is performed using the eigenvectors of the modularity matrix against the eigenvectors of the adjacency matrix.
- signifies the change in the membership of nodes in different groups if clustering is performed using the eigenvectors of the S (expected partitioning under the configuration model) matrix against the eigenvectors of the adjacency matrix.
- signifies the number of self-loops generated in the configuration model corresponding to the given network, and it includes the effect of the higher growth rate of the maximum degree node in the network.
- corresponds to the contribution of the re-distribution of edges while partitioning is done using the modularity matrix.
- corresponds to the contribution of the re-distribution of edges while partitioning is done using the S matrix.
To this end, we observed the current behavior of the viral spreading from two perspectives: (a) from a micro-perspective by modeling an individual as a single intelligent cognitive agent entity, and any future collective intelligence it entails is considered an open multiagent system; and (b) from a macro-perspective by observing the population as a system of nested systems, where the macro-entities are agents’ societies with rational behaviors and slightly complex uncertainties—examples surpass micro-organisms going through the crowd like behaviors to discuss complex adaptive systems. In future work, several empirical evaluations will be conducted throughout the construction process going to the validation of the proposed system using statistically collected real-life data from datasets available online, as well as extracted specialized data.
4. Summary and Future Work
The disruptive nature of the COVID-19 pandemic, observed recently, demands rapid deployments of effective interventions. In the time of a pandemic, traditional approaches such as experimental testing, iterative development, and clinical validation are not feasible. A more realistic strategy relies on contagion control, requiring us to identify spreading strategies in order to manage the transmission of the virus. The fields of network science and artificial intelligence have developed and validated a series of computational tools to identify and strategize the spreading of infections. Here, we step across the domains to propose an intelligent system that not only understands the current nascent collective human behaviors in comparison with the spreading, but further to predict the stream of infections, which will hopefully prevent the spreading by providing detailed strategies and tactics applicable for each specific scenario.
The future work should validate the effectiveness of the proposed system through a series of empirical evaluations using real-life data in comparison with current state-of-the-art methodologies. Empirical evaluation is simply an examination and proof of a theory by experimental observation. The core to a suitable empirical evaluation is the precise design, planning, and implementation of the experiments in a way that the specified factors to be examined can be simply distinguished from other unrelated ones. As a global pandemic, there have been multiple releases of real-life open source data for researchers to validate their proposed methodologies on them. As this article considers a more generic design, future work should take advantage of such available data to evaluate and validate the effectiveness of the model and see if such a model is applicable to different regions, cultures, or groups. Data analysis can be carried out using regression analysis or another proper statistical method to test the hypotheses proposed in this study and to compare the findings with the available results. This will help to further understand how precise the proposed system is and to what extent it can be applied.
Moreover, state-of-the-art epidemiological studies can be considered in order to evaluate the proposed system through the study of what has caused the spreading and where the stream is heading. Different types of epidemiological studies are still open to be implemented for data collection using suitable analysis for later interpretations. Different phases of the research can also run on different validation methodologies in that cross-sectional (prevalence) studies, on one side of the spectrum, can be used for the first stage of development to understand the representative cluster at a specific time due to the wider coverage of information with an inexpensive and quick implementation. On the other side of the spectrum, randomized control trials are suitable in the second section of the system where the prediction takes place since this interventional study will highlight and compare changes in the symptoms and vitality rate. In general, targeted testing for COVID-19 should begin for a predetermined period of time and involve people who are more susceptible to being infected due to recent travel to high risk countries or have been in contact with infected patients.
Funding
This work was funded by the Deanship of Scientific Research at Albaha University, Saudi Arabia (Grant number: 1441/10). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of the Deanship of Scientific Research or Albaha University.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The author would like to thank Abdullah Alomari for his valuable inputs and comments on an early version of this manuscript, as well as Ghanim Alghamdi for his consultancy on the biological perspective of the pandemic at an early stage.
Conflicts of Interest
The author declares no conflict of interest.
References
- World Health Organization: Geneva, Switzerland. 2020. Available online: https://www.who.int/about (accessed on 20 March 2020).
- Krug, R.M. The Influenza Viruses; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Centers for Disease Control and Prevention, Atlanta, GA, USA. Available online: https://www.cdc.gov/ (accessed on 11 May 2020).
- Del Fava, E.; Cimentada, J.; Perrotta, D.; Grow, A.; Rampazzo, F.; Gil-Clavel, S.; Zagheni, E. The differential impact of physical distancing strategies on social contacts relevant for the spread of COVID-19. medRxiv 2020. [Google Scholar] [CrossRef]
- Cirillo, P.; Taleb, N.N. Tail risk of contagious diseases. Nat. Phys. 2020, 16, 606–613. [Google Scholar] [CrossRef]
- Allam, Z.; Dey, G.; Jones, D.S. Artificial Intelligence (AI) Provided Early Detection of the Coronavirus (COVID-19) in China and Will Influence Future Urban Health Policy Internationally. AI 2020, 1, 156–165. [Google Scholar] [CrossRef]
- Gysi, D.M.; Valle, Í.D.; Zitnik, M.; Ameli, A.; Gan, X.; Varol, O.; Sanchez, H.; Baron, R.M.; Ghiassian, D.; Loscalzo, J.; et al. Network Medicine Framework for Identifying Drug Repurposing Opportunities for COVID-19. arXiv 2020, arXiv:2004.07229. [Google Scholar]
- Xu, Z.; Shi, L.; Wang, Y.; Zhang, J.; Huang, L.; Zhang, C.; Liu, S.; Zhao, P.; Liu, H.; Zhu, L.; et al. Pathological findings of COVID-19 associated with acute respiratory distress syndrome. Lancet Respir. Med. 2020, 8, 420–422. [Google Scholar] [CrossRef]
- Wagner, R.R.; Krug, R.M. Virus. Encyclopaedia Britannica. 2020. Available online: https://www.britannica.com/science/virus (accessed on 16 June 2020).
- Walls, A.C.; Park, Y.J.; Tortorici, M.A.; Wall, A.; McGuire, A.T.; Veesler, D. Structure, function, and antigenicity of the SARS-CoV-2 spike glycoprotein. Cell 2020, 181, 281–292. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Yu, T.; Du, R.; Fan, G.; Liu, Y.; Liu, Z.; Xiang, J.; Wang, Y.; Song, B.; Gu, X.; et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: A retrospective cohort study. Lancet 2020, 395, 1054–1062. [Google Scholar] [CrossRef]
- World Health Organization. Coronavirus Disease 2019 (COVID-19): Situation Report; World Health Organization: Geneva, Switzerland, 2020; Volume 70. [Google Scholar]
- Malanson, G.P. COVID-19, zoonoses, and physical geography. SAGR J. 2020, 44. [Google Scholar] [CrossRef]
- La, V.P.; Pham, T.H.; Ho, M.T.; Nguyen, M.H.; P Nguyen, K.L.; Vuong, T.T.; Tran, T.; Khuc, Q.; Ho, M.T.; Vuong, Q.H.; et al. Policy Response, Social Media and Science Journalism for the Sustainability of the Public Health System Amid the COVID-19 Outbreak: The Vietnam Lessons. Sustainability 2020, 12, 2931. [Google Scholar] [CrossRef]
- Zhong, L.; Mu, L.; Li, J.; Wang, J.; Yin, Z.; Liu, D. Early Prediction of the 2019 Novel Coronavirus Outbreak in the Mainland China Based on Simple Mathematical Model. IEEE Access 2020, 8, 51761–51769. [Google Scholar] [CrossRef]
- Mashamba-Thompson, T.P.; Crayton, E.D. Blockchain and Artificial Intelligence Technology for Novel Coronavirus Disease-19 Self-Testing. Diagnostics 2020, 10, 198. [Google Scholar] [CrossRef] [PubMed]
- Cho, H.; Ippolito, D.; Yu, Y.W. Contact Tracing Mobile Apps for COVID-19: Privacy Considerations and Related Trade-offs. arXiv 2020, arXiv:2003.11511. [Google Scholar]
- Qin, L.; Sun, Q.; Wang, Y.; Wu, K.F.; Chen, M.; Shia, B.C.; Wu, S.Y. Prediction of Number of Cases of 2019 Novel Coronavirus (COVID-19) Using Social Media Search Index. Int. J. Environ. Res. Public Health 2020, 17, 2365. [Google Scholar] [CrossRef] [PubMed]
- Han, X.; Wang, J.; Zhang, M.; Wang, X. Using Social Media to Mine and Analyze Public Opinion Related to COVID-19 in China. Int. J. Environ. Res. Public Health 2020, 17, 2788. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Carin, L.; Dzau, V.; Wong, T.Y. Digital technology and COVID-19. Nat. Med. 2020, 26, 459–461. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.M.; Rui, J.; Wang, Q.P.; Zhao, Z.Y.; Cui, J.A.; Yin, L. A mathematical model for simulating the phase-based transmissibility of a novel coronavirus. Infect. Dis. Poverty 2020, 9, 1–8. [Google Scholar] [CrossRef]
- Michalska-Smith, M.J.; Allesina, S. Telling ecological networks apart by their structure: A computational challenge. PLoS Comput. Biol. 2019, 15, e1007076. [Google Scholar] [CrossRef]
- Kissler, S.M.; Tedijanto, C.; Goldstein, E.; Grad, Y.H.; Lipsitch, M. Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period. Science 2020, 368, 860–868. [Google Scholar] [CrossRef]
- Borgatti, S.P.; Foster, P.C. The network paradigm in organizational research: A review and typology. J. Manag. 2003, 29, 991–1013. [Google Scholar]
- Van Alstyne, M. The state of network organization: A survey in three frameworks. J. Organ. Comput. Electron. Commer. 1997, 7, 83–151. [Google Scholar] [CrossRef]
- Ekbia, H.R.; Kling, R. Network organizations: Symmetric cooperation or multivalent negotiation? Inf. Soc. 2005, 21, 155–168. [Google Scholar] [CrossRef]
- Hovorka, D.S.; Larsen, K.R. Enabling agile adoption practices through network organizations. Eur. J. Inf. Syst. 2006, 15, 159–168. [Google Scholar] [CrossRef]
- Sussman, S.W.; Siegal, W.S. Informational influence in organizations: An integrated approach to knowledge adoption. Inf. Syst. Res. 2003, 14, 47–65. [Google Scholar] [CrossRef]
- Snow, C.; Fjeldstad, Ø. Network Paradigm: Applications in Organizational Science. In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Wright, J.D., Ed.; Elsevier: Oxford, UK, 2015; Volume 16, pp. 546–550. [Google Scholar]
- Barabási, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Watts, D.J. The “new” science of networks. Annu. Rev. Sociol. 2004, 30, 243–270. [Google Scholar] [CrossRef]
- Zhou, W.; Duan, W.; Piramuthu, S. A social network matrix for implicit and explicit social network plates. Decis. Support Syst. 2014, 68, 89–97. [Google Scholar] [CrossRef]
- Horling, B.; Lesser, V. A survey of multi-agent organizational paradigms. Knowl. Eng. Rev. 2004, 19, 281–316. [Google Scholar] [CrossRef]
- Sheridan, P.; Onodera, T. A Preferential Attachment Paradox: How Preferential Attachment Combines with Growth to Produce Networks with Log-normal In-degree Distributions. Sci. Rep. 2018, 8, 1–11. [Google Scholar] [CrossRef]
- Alberts, D.S.; Hayes, R.E. Power to the Edge: Command, Control, in the Information Age; Technical Report; Office of the Assistant Secretary of Defense Washington DC Command and Control: Washington, DC, USA, 2003.
- Gross, T.; D’Lima, C.J.D.; Blasius, B. Epidemic dynamics on an adaptive network. Phys. Rev. Lett. 2006, 96, 208701. [Google Scholar] [CrossRef]
- St-Onge, G.; Thibeault, V.; Allard, A.; Dubé, L.J.; Hébert-Dufresne, L. School closures, event cancellations, and the mesoscopic localization of epidemics in networks with higher-order structure. arXiv 2020, arXiv:2003.05924. [Google Scholar]
- Burgio, G.; Arenas, A.; Gómez, S.; Matamalas, J.T. Network clique cover approximation to analyze complex contagions through group interactions. arXiv 2021, arXiv:2101.03618. [Google Scholar]
- Loke, S.W. Crowd-Powered Mobile Computing and Smart Things; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Zhan, B.; Monekosso, D.N.; Remagnino, P.; Velastin, S.A.; Xu, L.Q. Crowd analysis: A survey. Mach. Vis. Appl. 2008, 19, 345–357. [Google Scholar] [CrossRef]
- Shin, S.K.; Kook, W. Can knowledge be more accessible in a virtual network?: Collective dynamics of knowledge transfer in a virtual knowledge organization network. Decis. Support Syst. 2014, 59, 180–189. [Google Scholar] [CrossRef]
- Perra, N. Non-pharmaceutical interventions during the COVID-19 pandemic: A rapid review. arXiv 2021, arXiv:2012.15230. [Google Scholar]
- Allard, A.; Moore, C.; Scarpino, S.V.; Althouse, B.M.; Hébert-Dufresne, L. The role of directionality, heterogeneity and correlations in epidemic risk and spread. arXiv 2020, arXiv:2005.11283. [Google Scholar]
- Cvetkovic, D.M.; Doob, M.; Sachs, H. Spectra of Graphs; Academic Press: New York, NY, USA, 1980; Volume 10. [Google Scholar]
- Wang, Y.; Chakrabarti, D.; Wang, C.; Faloutsos, C. Epidemic spreading in real networks: An eigenvalue viewpoint. In Proceedings of the 22nd International Symposium on Reliable Distributed Systems, Florence, Italy, 6–8 October 2003; IEEE: New York, NY, USA; 2003; pp. 25–34. [Google Scholar]
- Seary, A.J.; Richards, W.D. Spectral Methods for Analyzing and Visualizing Networks: An Introduction. In Dynamic Social Network Modeling and Analysis; Breiger, R., Carley, K.M., Pattison, P., Eds.; National Academies Press: Washington, DC, USA, 2003; pp. 209–228. [Google Scholar]
- Huang, L.; Li, R.; Chen, H.; Gu, X.; Wen, K.; Li, Y. Detecting network communities using regularized spectral clustering algorithm. Artif. Intell. Rev. 2014, 41, 579–594. [Google Scholar] [CrossRef]
- Albert, R.; Jeong, H.; Barabási, A.L. Error and attack tolerance of complex networks. Nature 2000, 406, 378–382. [Google Scholar] [CrossRef]
- Newman, M.E. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).