
Multi-Modal Graph Neural Networks for Colposcopy Data Classification and Visualization

 ,
, 
Simple Summary
Abstract
1. Introduction
- (1)
- Multi-Modal Graph Integration: We propose a GNN-based framework integrating colposcopy images, DeepLabv3-generated segmentation masks, and structural graph representations for enhanced cervical lesion classification.
- (2)
- Feature-Driven Segmentation: Lesion features such as area, perimeter, eccentricity, and GLCM-based textures are extracted to support discriminative graph construction and clinically interpretable outputs.
- (3)
- Graph-Based Reasoning: Graphs are constructed using Euclidean similarity-weighted edges, capturing lesion topology and improving decision consistency across subtle morphological variations.
- (4)
- Robust Validation and Optimization: The framework employs five-fold cross-validation and grid search to ensure high reliability and mitigate overfitting.
- (5)
- Cross-Domain Adaptability: Evaluations on brain tumor MRI, eye_disease, and Malhari colposcopy datasets demonstrate the model’s generalizability to other medical imaging tasks.
- (6)
- Clinically Interpretable Outputs: The system generates segmentation overlays, graph structures, and LIME visualizations with metrics and class predictions, aiding clinician trust and decision support.
2. Literature Review
- 1.
- Graph-Based Medical Image Classification Methods
- 2.
- Multi-Modal Data Integration
- 3.
- Validation and Hyperparameter Optimization
- 4.
- Classification Models without Segmentation
3. Materials and Methods
3.1. Methods
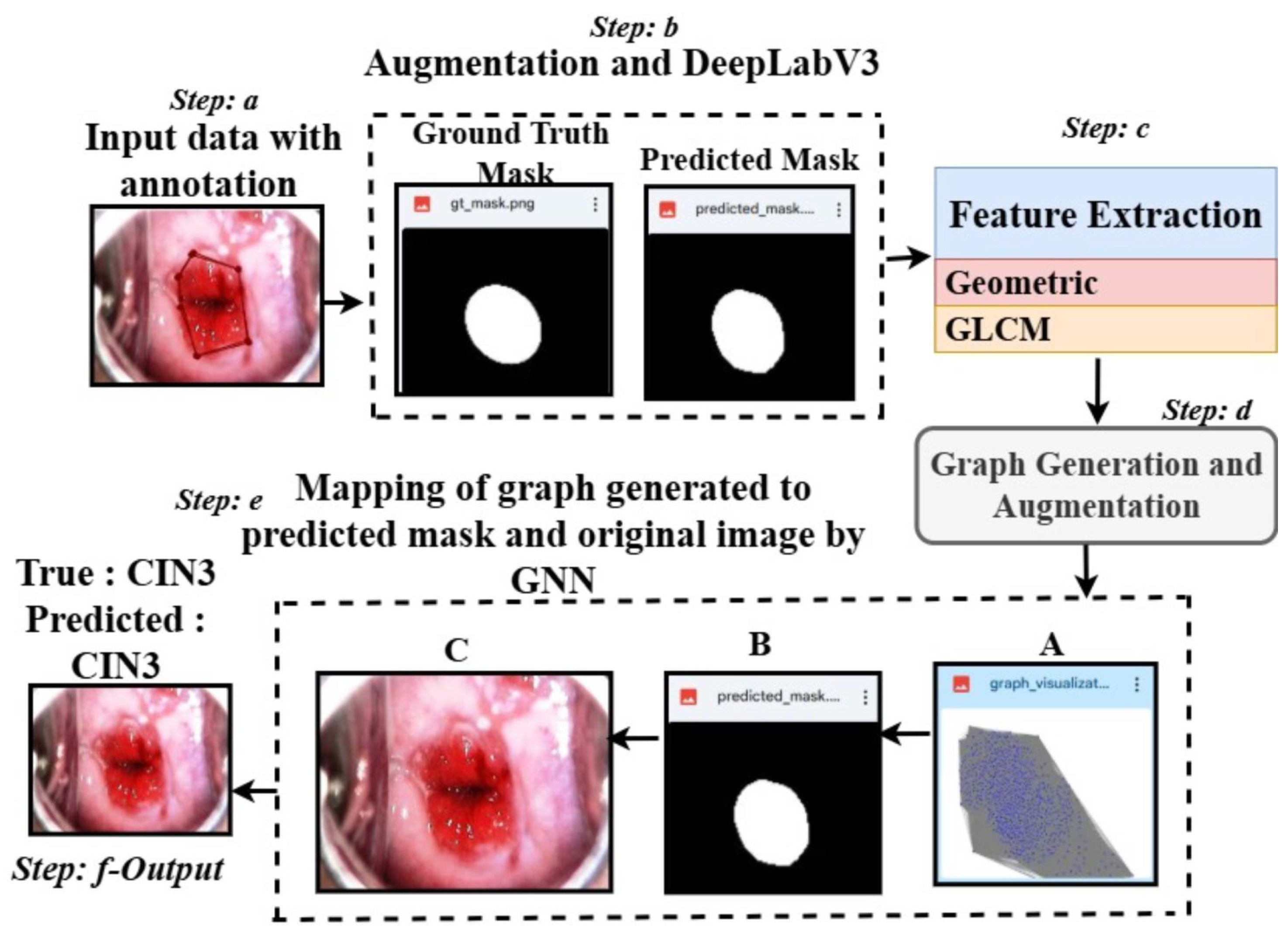
3.1.1. Framework Overview
- 1.
- Overall Architecture: The framework takes segmentation masks, extracts region-specific features (e.g., area, perimeter, texture), and constructs graphs where nodes represent regions and edges capture spatial relationships. These graphs, along with their associated labels, are fed into a GNN for classification. Our pipeline ensures robust generalization by performing K-fold cross-validation and leveraging grid search for hyperparameter tuning.
- 1.
- A batch of graphs is loaded along with their labels.
- 2.
- The GNN processes node features and edge weights to generate predictions.
- 3.
- A cross-entropy loss function is computed between the predictions and true labels.
- 4.
- Gradients are computed and used to update model parameters via backpropagation.
- 2.
- Mathematical Formulation
Loss Function
Graph Construction
- –
- Nodes represent segmented regions, with features such as area, perimeter, eccentricity, etc., denoted as for the i-th node.
- –
- Edges capture spatial or feature-based relationships between regions. The edge weight between nodes i and j is computed using Equation (2):
Graph Neural Network
K-Fold Cross-Validation
- –
- folds are used for training, and the remaining fold is used for testing.
- –
- Results are averaged across folds to compute performance metrics such as F1-score and AUC.
Hyperparameter Optimization
- –
- Hidden dimension ().
- –
- Learning rate ().
- –
- Number of training epochs (epochs).
3.2. Masking and Feature Extraction
- Geometric Features: These included area, perimeter, eccentricity, solidity, major and minor axis lengths, aspect ratio, compactness, and circularity.
- Texture Features: These were derived using the GLCM (Gray-Level Co-Occurrence Matrix) and included contrast, correlation, energy, and homogeneity [66].
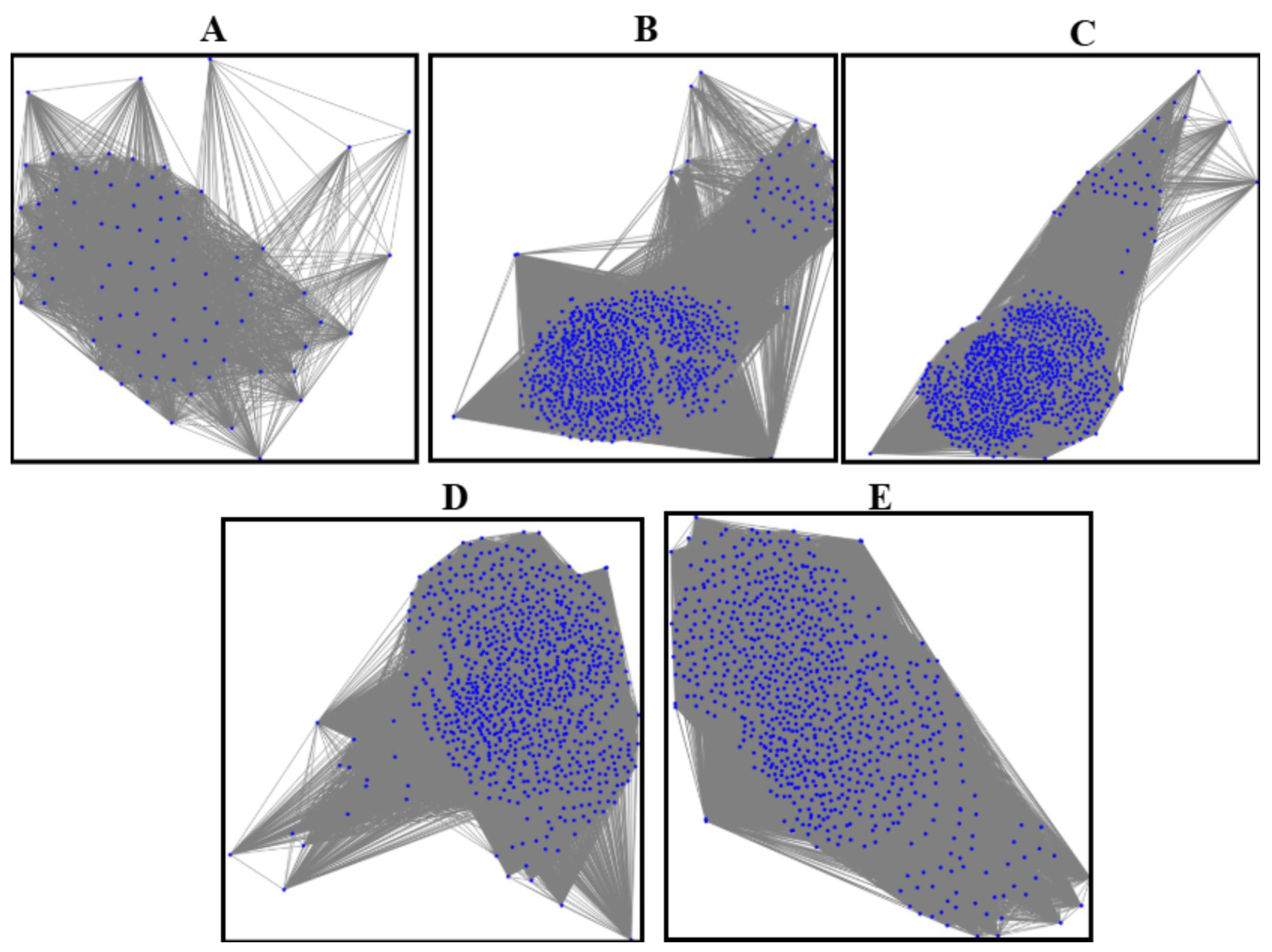
3.3. Graph Generation and Augmentation
3.4. GNN (Graph Neural Network) for Final Mapping and Classification with K-Fold Cross-Validation and Hyperparameter Fine-Tuning
3.4.1. Graph Neural Networks (GNNs)
3.4.2. Graph-to-Mask-to-Image Mapping
3.4.3. K-Fold Cross-Validation
- Training set: .
- Test set: .
3.4.4. Hyperparameter Fine-Tuning
3.4.5. Final Classification
- K-Fold Cross-Validation Phase (1–100 epochs): The macro-average F1-score () and macro-average validation accuracy () are computed to provide an overall evaluation of the model’s performance across all classes during the initial training phase.
- Fine-Tuning Phase (101–151 epochs): The macro-average F1-score () and macro-average validation accuracy () are calculated post fine-tuning to reflect the improvement in the model’s classification performance.
- Layer 1: Node features are linearly transformed and aggregated using the normalized adjacency matrix to produce embeddings .
- Layer 2: The embeddings are further transformed and aggregated to produce .
- Pooling: Node embeddings are aggregated (mean pooling) into a graph-level embedding .
- Classification: A fully connected layer maps to class logits , which are passed through softmax to obtain class probabilities. The final predicted label is the class with the highest probability.
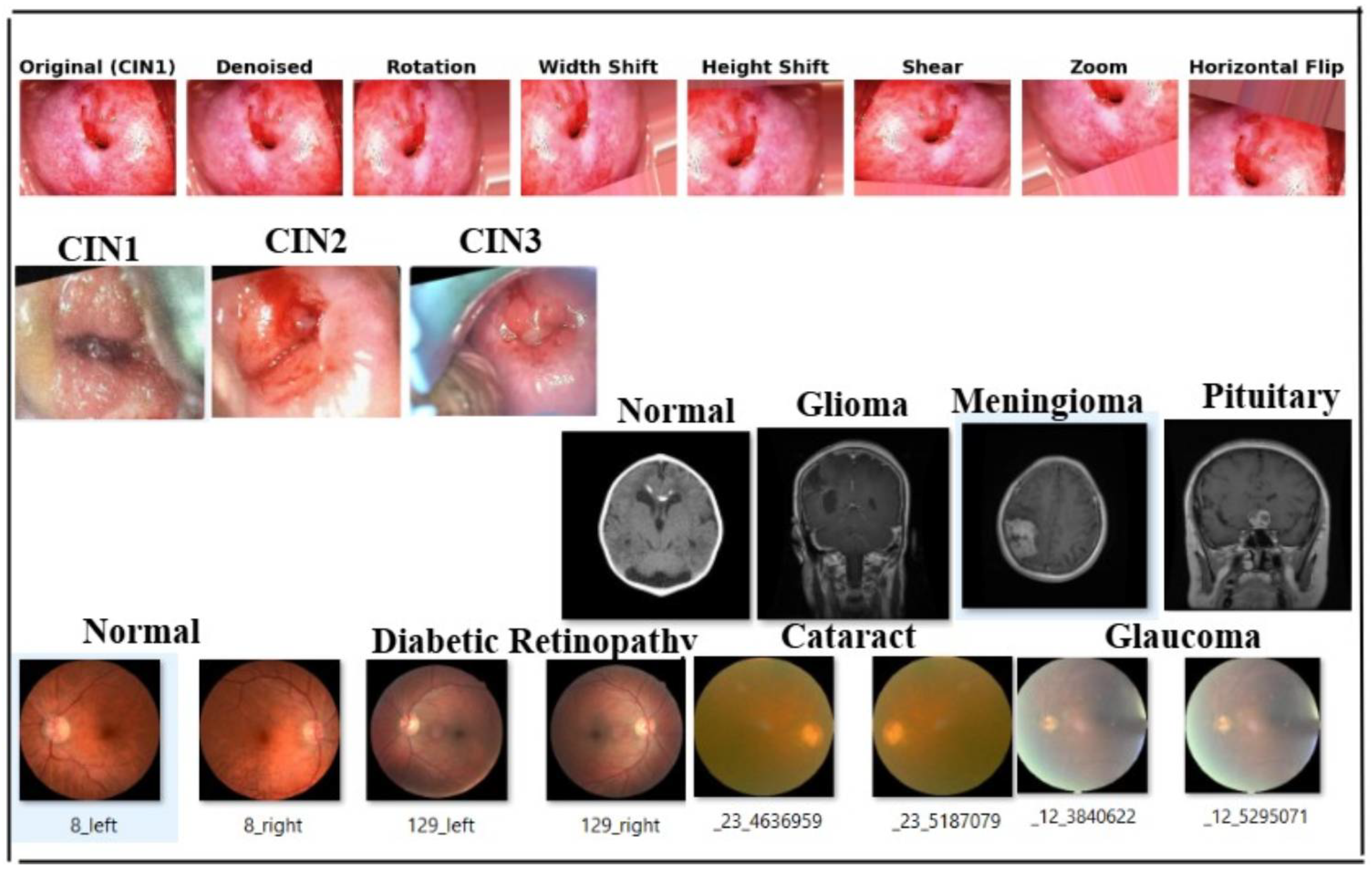
3.5. Datasets and Handling of Class Imbalance
3.6. Data Availability and Ethical Considerations
- IARC [69]: This colposcopy dataset was personally provided to the author via email communication by the respective custodians of the IARC colposcopy data bank. The dataset includes separate metadata files in .csv format. It was utilized in this research solely for academic purposes. As the dataset was shared directly for research use, and no specific licensing terms were provided, it was used in accordance with standard academic research practices.
- Malhari [70]: This dataset is publicly available on the Kaggle platform; however, no explicit licensing information was provided by the dataset uploader. In accordance with best academic practices, the dataset was used solely for non-commercial academic research purposes. No modifications were made to the original data, and no redistribution of the dataset was performed. Furthermore, no patient-identifiable information was included or processed. This use complies with fair research practices for publicly available datasets lacking explicit licensing terms.
- eye_disease dataset [71]: The secondary dataset was obtained under the Open Data Commons Open Database License (ODbL) v1.0. In accordance with the license, proper attribution has been provided, and the dataset was used exclusively for non-commercial academic research purposes.
- Brain tumor MRI dataset [72]: This dataset is available under the Creative Commons CC0 1.0 Universal (Public Domain Dedication) license. It can be freely used, modified, and distributed without restriction. In this study, the dataset was utilized strictly for academic research purposes. Although attribution is not legally required under CC0, appropriate credit has been provided to acknowledge the source.
4. Results
4.1. Evaluation Metrics and Implementation Details
4.1.1. Metrics
- Dice Coefficient:
- Intersection over Union (IoU):
- Precision:
- Recall:
- Binary Cross-Entropy Loss:
4.1.2. Training Details
- Training Set: 80% of the data four folds).
- Validation Set: A subset of the training set, used for hyperparameter tuning (grid search).
- Test Set: 20% of the data one fold), used for final evaluation.
4.1.3. Hyperparameter Tuning
- Hidden Dimension: [32, 64];
- Learning Rate: [0.001, 0.01];
- Epochs: 100;
- Early Stopping: Yes.
4.1.4. Execution Environment
- Operating System: Windows 10 Home Single Language;
- Python Version: 3.10.12 (main, 6 November 2024, 20:22:13) [GCC 11.4.0];
- TensorFlow Version: 2.15.0;
- Keras Version: 2.15.0;
- Hardware Accelerator: Colab Pro, v2-8 TPU;
- CPU: Intel(R) Core(TM) i5-1035G1 CPU @ 1.00 GHz, 1.19 GHz;
- Installed RAM: 16.0 GB (15.8 GB usable).
4.2. Result of Execution of the Proposed Model on the Primary Augmented Dataset
4.2.1. Inference Time per Image, Computational Complexity, and Real-Time Feasibility
4.2.2. FLOPs and TPU and GPU Memory Usage During Training
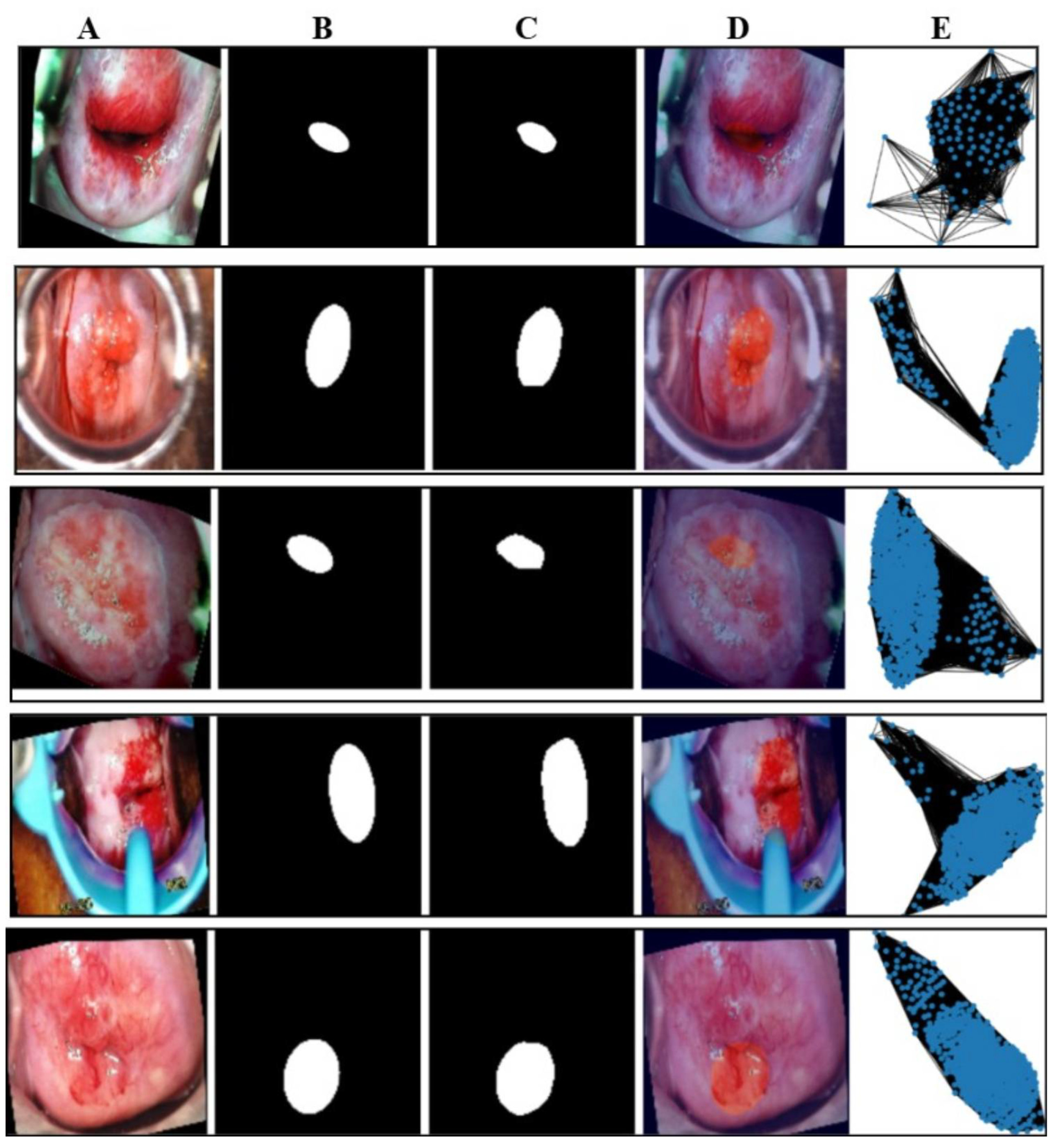
4.2.3. Masking
Qualitative Results
Quantitative Results
4.2.4. Results of Feature Extraction and Analysis
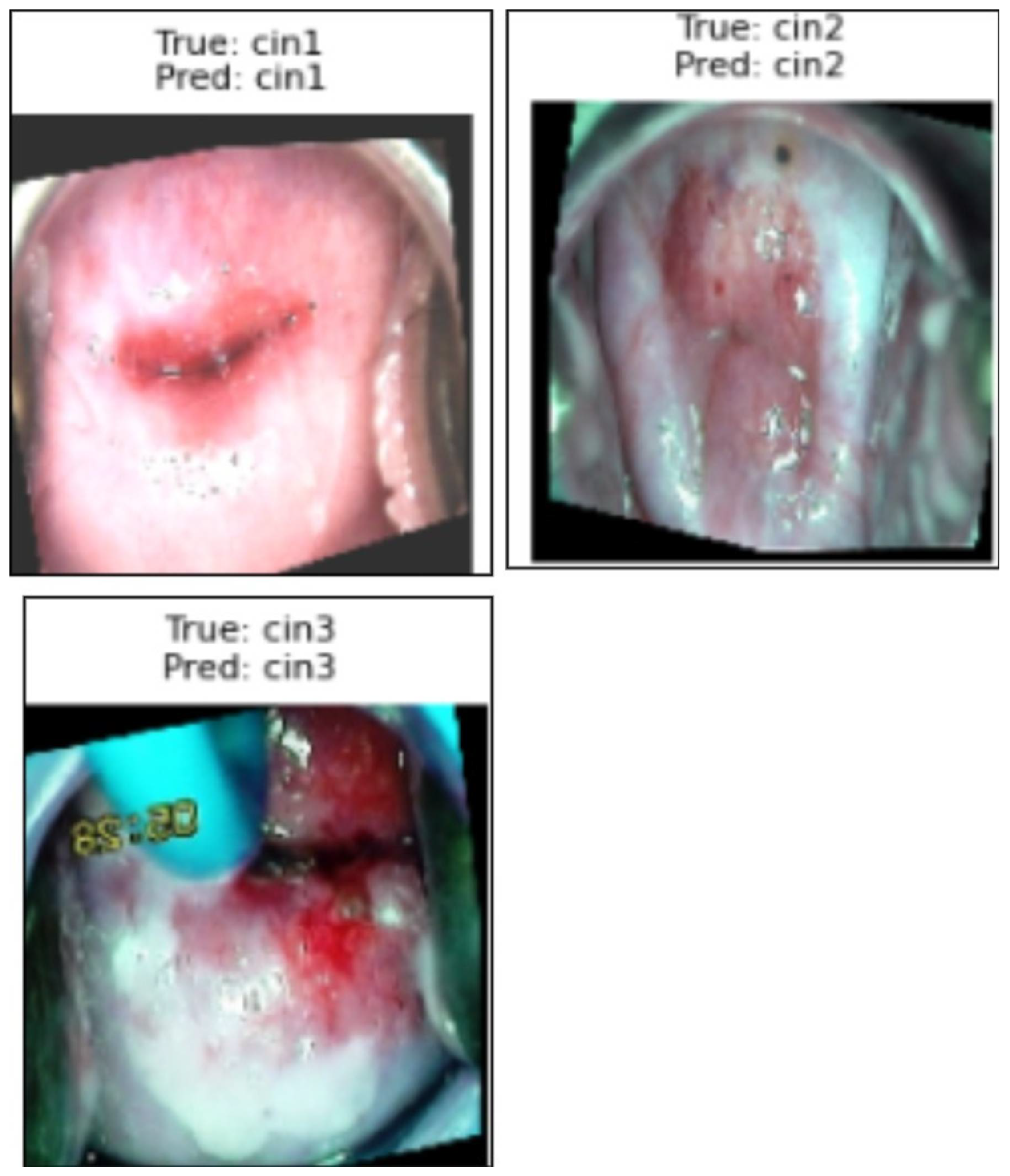
4.2.5. Results and Analysis of the Proposed Graph Neural Network on the Primary Dataset
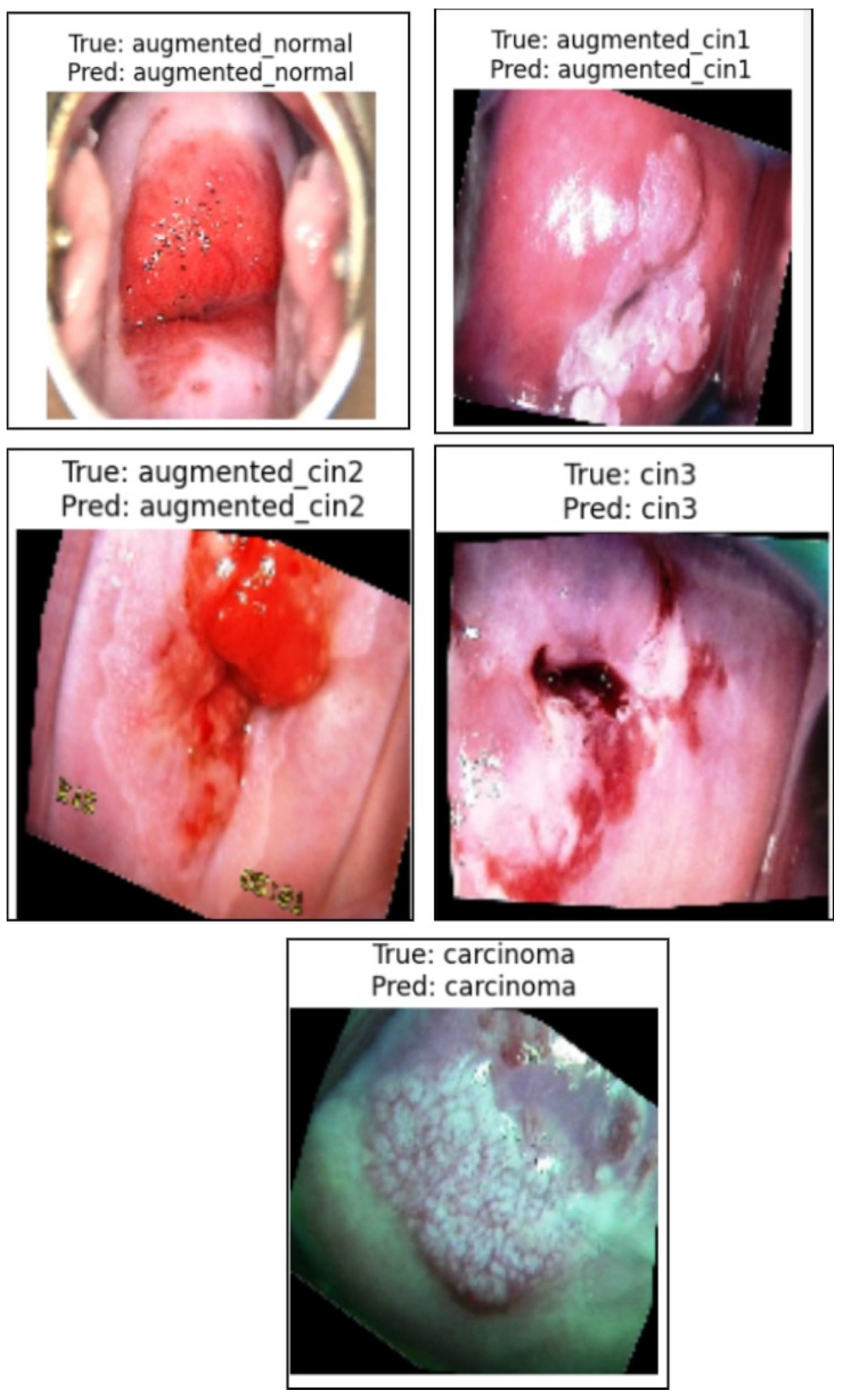
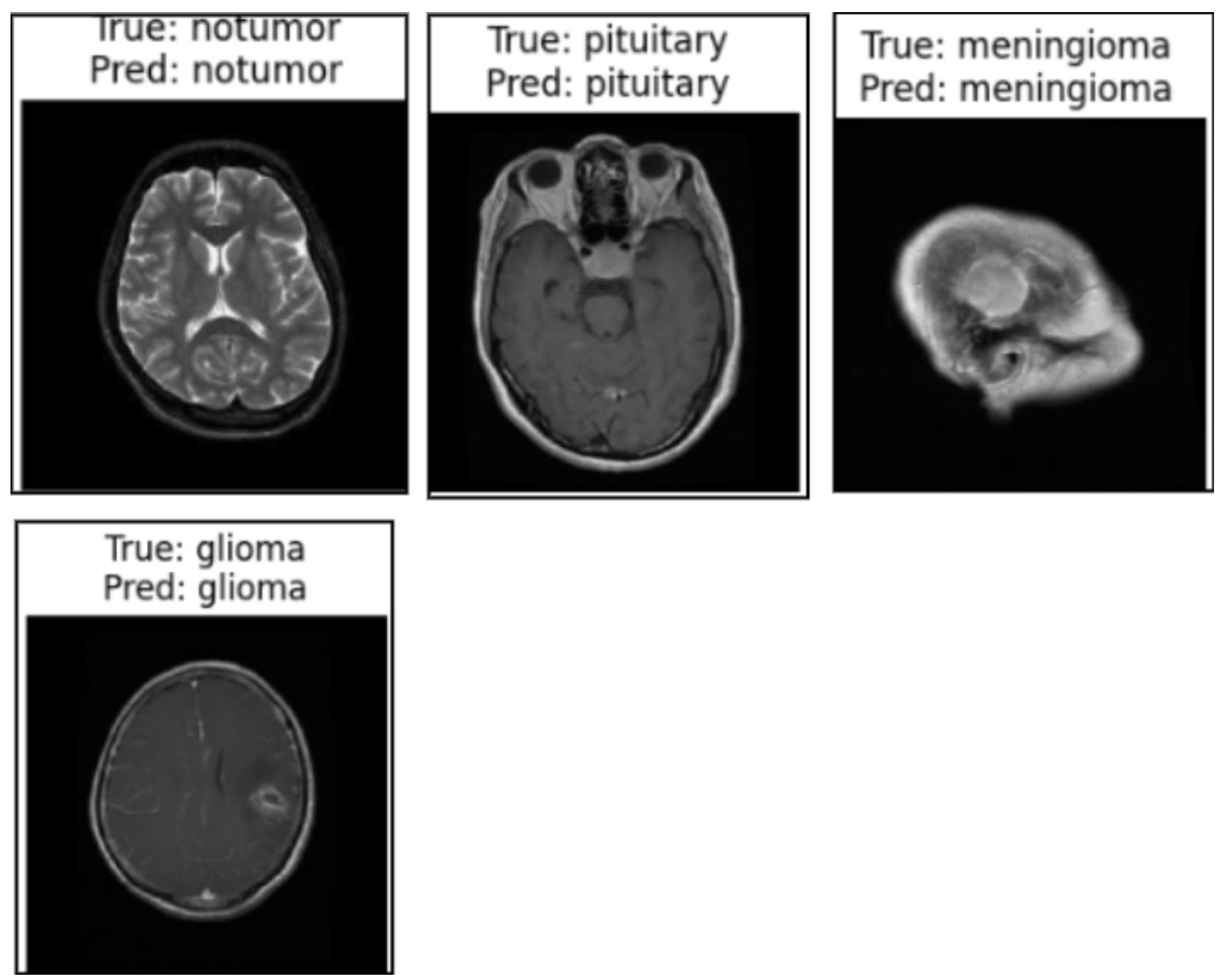
Qualitative Results in the Validation Dataset
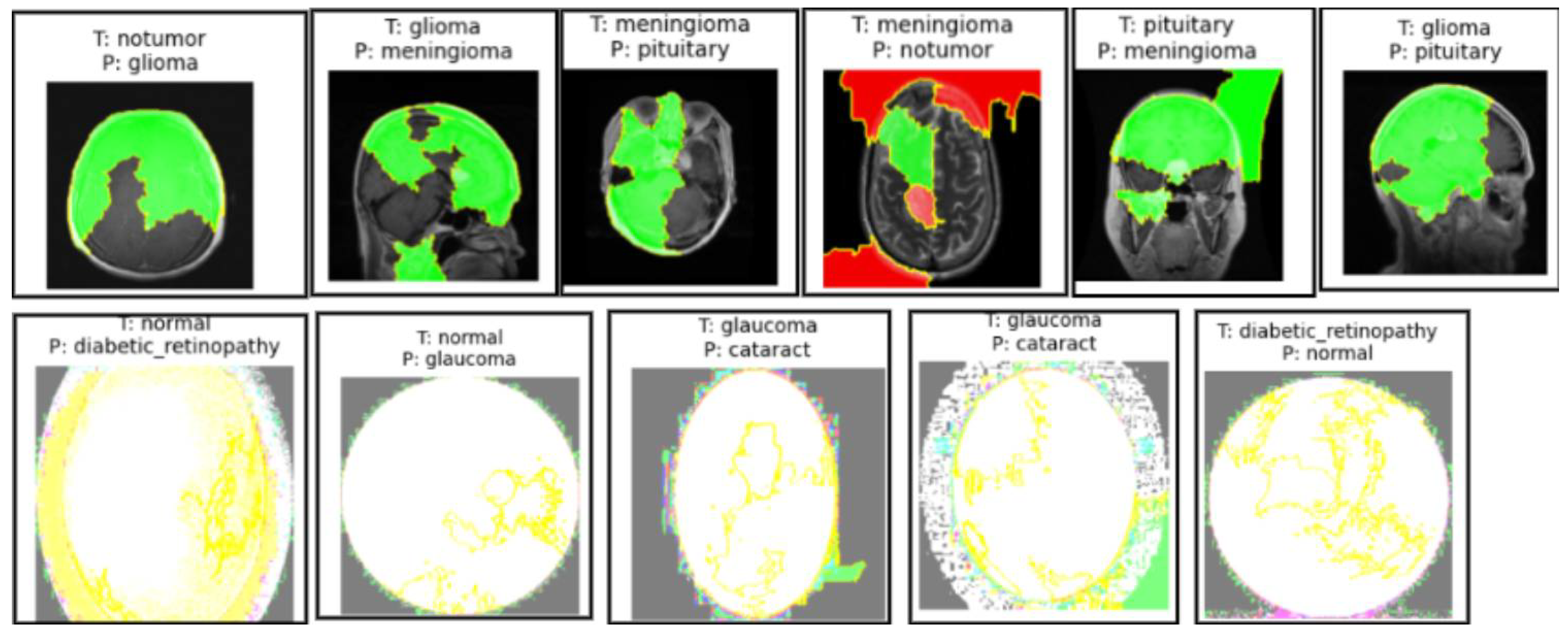
Analysis of False Positives and False Negatives
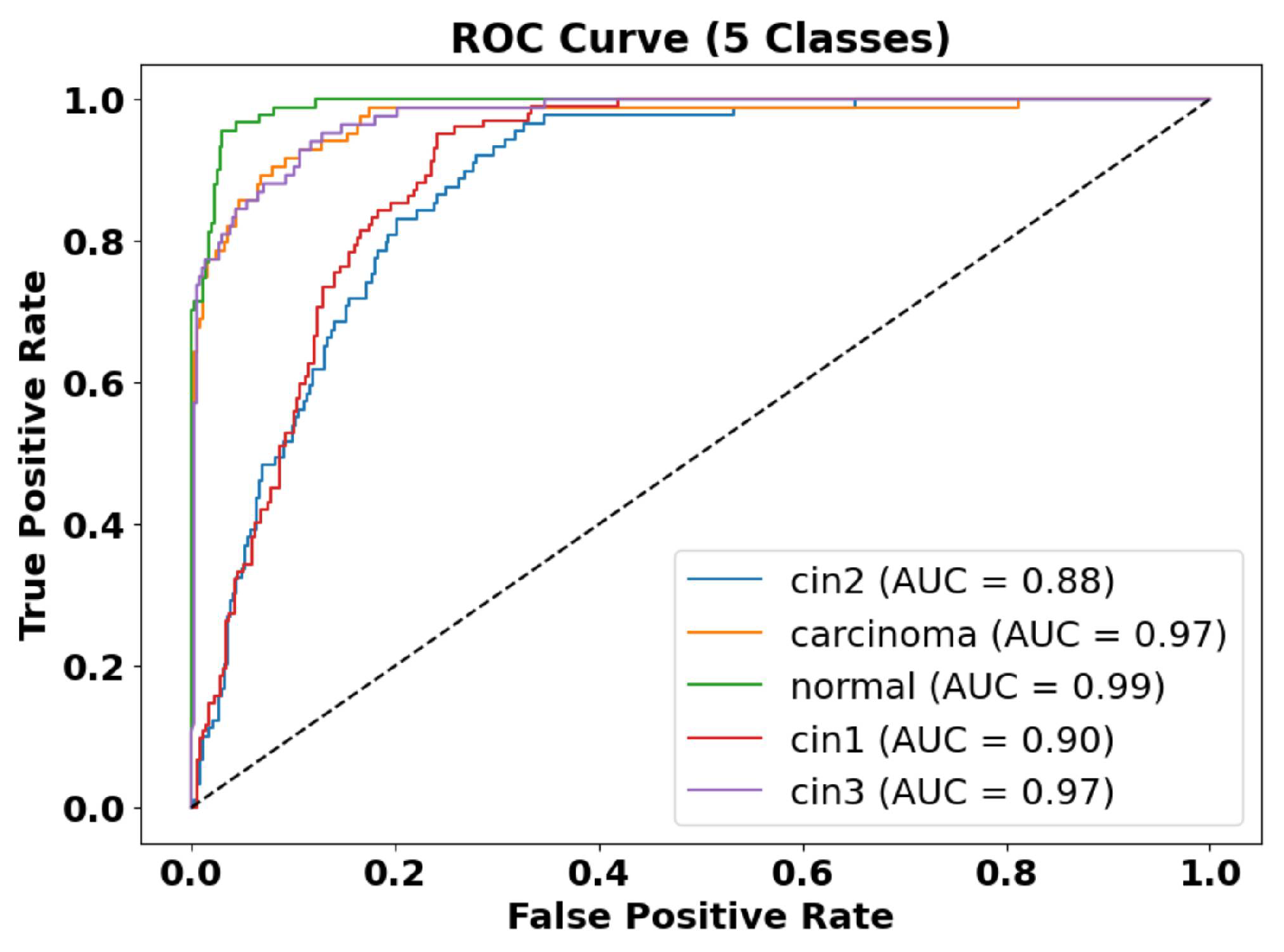
Quantitative Results in the Validation Dataset
4.2.6. Proposed Model Explainability by LIME
Misclassifications by the Model of the Brain MRI Dataset and Eye_Disease Dataset Explained by LIME
4.2.7. Ablation Studies
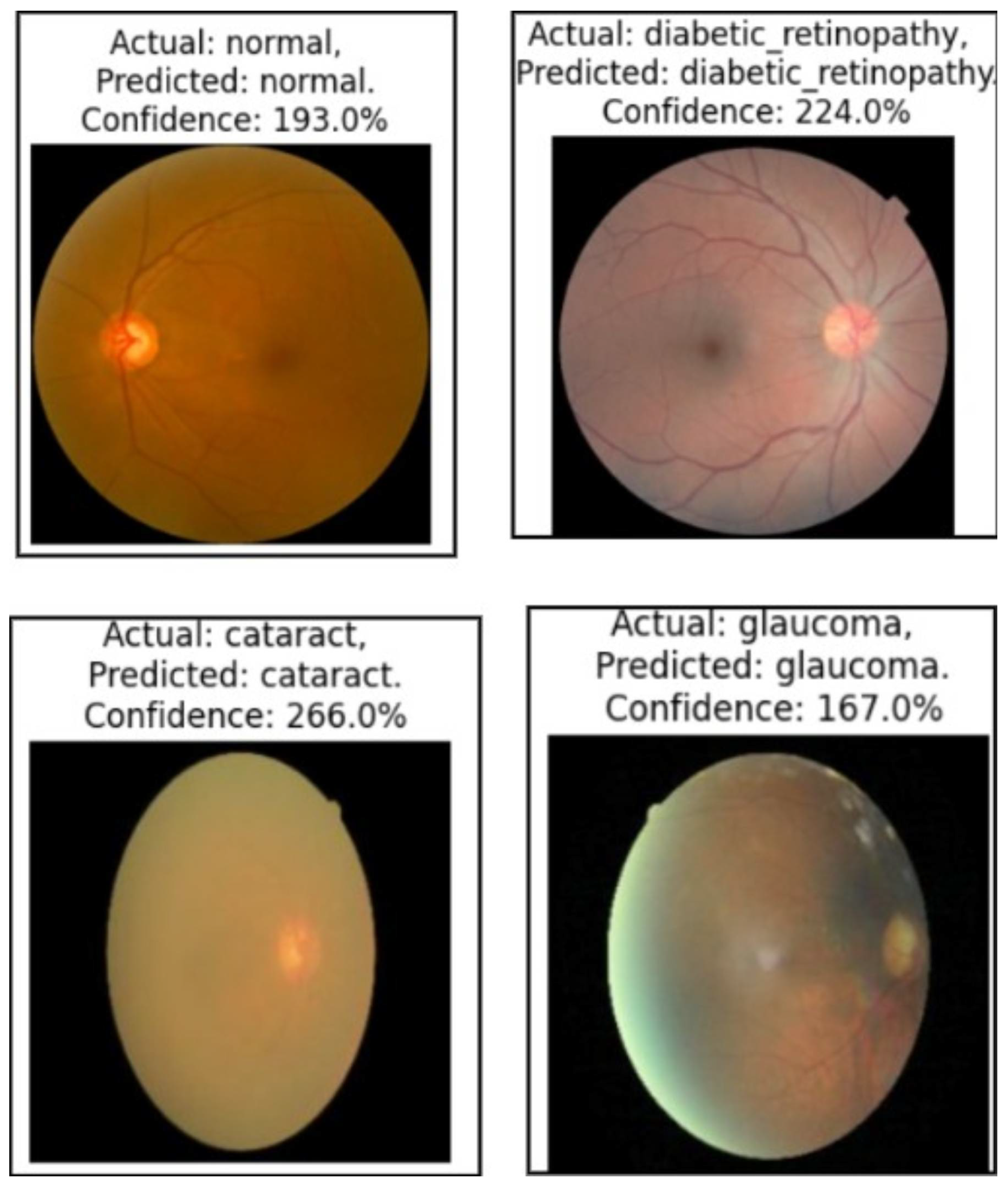
Model Generalization on Brain Tumor MRI Dataset, the Malhari Dataset and the Eye_Disease Dataset Without Augmentation
Comparative Analysis of Fixed Graph Weights, Focal Loss, and the Proposed Augmented Adaptive Graph Learning Framework
5. Discussion
6. Limitations and Future Research
7. Conclusions
7.1. Clinical Application
7.2. Analysis of Performance on Real-World Clinical Data
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GCN | Graph Convolutional Network |
| LIME | Local Interpretable Model-Agnostic Explanations |
| CIN | Cervical Intraepithelial Neoplasia |
References
- SEER. Cancer Stat Facts: Cervix Uteri Cancer. Surveillance, Epidemiology, and End Results Program (SEER). 2024. Available online: https://seer.cancer.gov/statfacts/html/cervix.html (accessed on 8 March 2024).
- Prasla, S.; Moore-Palhares, D.; Dicenzo, D.; Osapoetra, L.; Dasgupta, A.; Leung, E.; Barnes, E.; Hwang, A.; Taggar, A.S.; Czarnota, G.J. Predicting Tumor Progression in Patients with Cervical Cancer Using Computer Tomography Radiomic Features. Radiation 2024, 4, 355–368. [Google Scholar] [CrossRef]
- de Sousa, C.; Eksteen, C.; Riedemann, J.; Engelbrecht, A.M. Highlighting the Role of CD44 in Cervical Cancer Progression: Immunotherapy’s Potential in Inhibiting Metastasis and Chemoresistance. Immunol. Res. 2024, in press. [Google Scholar] [CrossRef]
- Gomes, M.L.D.S.; Moura, N.D.S.; Magalhães, L.D.C.; Silva, R.R.D.; Silva, B.G.S.; Rodrigues, I.R.; Sales, L.B.; Oriá, M.O. Systematic Literature Review of Primary and Secondary Cervical Cancer Prevention Programs in South America. Rev. Panam. Salud Pública 2023, 47, e96. [Google Scholar] [CrossRef]
- Soares, L.; Dantas, S.A. Cervical Cancer and Quality of Life: Systematic Review. Clin. J. Obstet. Gynecol. 2024, 7, 17–24. [Google Scholar]
- Wubineh, B.Z.; Rusiecki, A.; Halawa, K. Segmentation and Classification Techniques for Pap Smear Images in Detecting Cervical Cancer: A Systematic Review. IEEE Access 2024, 12, 118195–118213. [Google Scholar] [CrossRef]
- Nour, M.K.; Issaoui, I.; Edris, A.; Mahmud, A.; Assiri, M.; Ibrahim, S.S. Computer-Aided Cervical Cancer Diagnosis Using Gazelle Optimization Algorithm with Deep Learning Model. IEEE Access 2024, 12, 13046–13054. [Google Scholar] [CrossRef]
- Bappi, J.O.; Rony, M.A.T.; Islam, M.S.; Alshathri, S.; El-Shafai, W. A Novel Deep Learning Approach for Accurate Cancer Type and Subtype Identification. IEEE Access 2024, 12, 94116–94134. [Google Scholar] [CrossRef]
- Li, X.; Xu, Z.; Shen, X.; Zhou, Y.; Xiao, B.; Li, T.Q. Detection of Cervical Cancer Cells in Whole Slide Images Using Deformable and Global Context Aware Faster RCNN-FPN. Curr. Oncol. 2021, 28, 3585–3601. [Google Scholar] [CrossRef]
- de Lima, C.R.; Khan, S.G.; Shah, S.H.; Ferri, L. Mask Region-Based CNNs for Cervical Cancer Progression Diagnosis on Pap Smear Examinations. Heliyon 2023, 9, e21388. [Google Scholar]
- Baba, T.; Miah, A.S.M.; Shin, J.; Hasan, M.A.M. Cervical Cancer Detection Using Multi-Branch Deep Learning Model. arXiv 2024, arXiv:2408.10498. [Google Scholar]
- Ma, D.; Liu, J.; Li, J.; Zhou, Y. Cervical Cancer Detection in Cervical Smear Images Using Deep Pyramid Inference with Refinement and Spatial-Aware Booster. IET Image Process. 2020, 14, 4717–4725. [Google Scholar] [CrossRef]
- Ahmed, R.; Dahmani, N.; Dahy, G.; Darwish, A.; Hassanien, A.E. Early Detection and Categorization of Cervical Cancer Cells Using Smoothing Cross Entropy-Based Multi-Deep Transfer Learning. IEEE Access 2024, 12, 157838–157853. [Google Scholar] [CrossRef]
- Ileberi, E.; Sun, Y. Machine Learning-Assisted Cervical Cancer Prediction Using Particle Swarm Optimization for Improved Feature Selection and Prediction. IEEE Access 2024, 12, 152684–152695. [Google Scholar] [CrossRef]
- Al Qathrady, M.; Shaf, A.; Ali, T.; Farooq, U.; Rehman, A.; Alqhtani, S.M.; Alshehri, M.S.; Almakdi, S.; Irfan, M.; Rahman, S. A novel web framework for cervical cancer detection system: A machine learning breakthrough. IEEE Access 2024, 12, 41542–41556. [Google Scholar] [CrossRef]
- Zhang, Z.; Yao, P.; Chen, M.; Zeng, L.; Shao, P.; Shen, S.; Xu, R.X. SCAC: A Semi-Supervised Learning Approach for Cervical Abnormal Cell Detection. IEEE J. Biomed. Health Inform. 2024, 28, 3501–3512. [Google Scholar] [CrossRef]
- Ramwala, O.A.; Lowry, K.P.; Cross, N.M. Establishing a Validation Infrastructure for Imaging-Based Artificial Intelligence Algorithms Before Clinical Implementation. J. Am. Coll. Radiol. 2024, 21, 1569–1574. [Google Scholar] [CrossRef]
- Huang, S.C.; Pareek, A.; Jensen, M.; Lungren, M.P.; Yeung, S.; Chaudhari, A.S. Self-Supervised Learning for Medical Image Classification: A Systematic Review and Implementation Guidelines. NPJ Digit. Med. 2023, 6, 74. [Google Scholar] [CrossRef]
- Uddin, K.M.; Mamun, A.; Chakrabarti, A.; Mostafiz, R.; Dey, S. Ensemble Machine Learning-Based Approach to Predict Cervical Cancer Using Hybrid Feature Selection. Neurosci. Inform. 2024, 4, 100169. [Google Scholar] [CrossRef]
- Ramírez, A.T.; Valls, J.; Baena, A.; Rojas, F.D.; Ramírez, K.; Álvarez, R. Performance of Cervical Cytology and HPV Testing for Primary Cervical Cancer Screening in Latin America: An Analysis Within the ESTAMPA Study. Lancet Reg. Health–Am. 2023, 26, 100593. [Google Scholar] [CrossRef]
- Huang, J.; Ji, Y.; Qin, Z.; Yang, Y.; Shen, H.T. Dominant Single-Modal Supplementary Fusion (SIMSUF) for Multimodal Sentiment Analysis. IEEE Trans. Multimed. 2023, 26, 8383–8394. [Google Scholar] [CrossRef]
- Lan, S.; Li, X.; Guo, Z. An Adaptive Region-Based Transformer for Nonrigid Medical Image Registration with a Self-Constructing Latent Graph. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 16409–16423. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Ren, L.; Song, B.; Guo, Y.; Lu, J.; Liu, X.; Gong, G.; Li, D. Hypergraph-based numerical neural-like P systems for medical image segmentation. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 1202–1214. [Google Scholar] [CrossRef]
- Tang, Z.; Sun, Z.H.; Wu, E.Q.; Wei, C.F.; Ming, D.; Chen, S.D. MRCG: A MRI Retrieval Framework with Convolutional and Graph Neural Networks for Secure and Private IoMT. IEEE J. Biomed. Health Inform. 2021, 27, 814–822. [Google Scholar] [CrossRef]
- Singh, A.; Van De Ven, P.; Eising, C.; Denny, P. Dynamic Filter Application in Graph Convolutional Networks for Enhanced Spectral Feature Analysis and Class Discrimination in Medical Imaging. IEEE Access 2024, 12, 113259–113274. [Google Scholar] [CrossRef]
- Zhuang, Z.; Si, L.; Wang, S.; Xuan, K.; Ouyang, X.; Zhan, Y.; Xue, Z.; Zhang, L.; Shen, D.; Yao, W. Knee cartilage defect assessment by graph representation and surface convolution. IEEE Trans. Med. Imaging 2022, 42, 368–379. [Google Scholar] [CrossRef]
- Wang, H.; Huang, G.; Zhao, Z.; Cheng, L.; Juncker-Jensen, A.; Nagy, M.L.; Lu, X.; Zhang, X.; Chen, D.Z. Ccf-gnn: A unified model aggregating appearance, microenvironment, and topology for pathology image classification. IEEE Trans. Med. Imaging 2023, 42, 3179–3193. [Google Scholar] [CrossRef]
- Chang, J.; Lai, T.; Yang, L.; Fang, C.; Li, Z.; Fujita, H. FV-DGNN: A Distance-Based Graph Neural Network for Finger Vein Recognition. IEEE Trans. Instrum. Meas. 2023, 72, 2523011. [Google Scholar] [CrossRef]
- Zhong, Y.; Pei, Y.; Nie, K.; Zhang, Y.; Xu, T.; Zha, H. Bi-Graph Reasoning for Masticatory Muscle Segmentation from Cone-Beam Computed Tomography. IEEE Trans. Med. Imaging 2023, 42, 3690–3701. [Google Scholar] [CrossRef]
- Zhao, G.; Liang, K.; Pan, C.; Zhang, F.; Wu, X.; Hu, X.; Yu, Y. Graph Convolution-Based Cross-Network Multiscale Feature Fusion for Deep Vessel Segmentation. IEEE Trans. Med. Imaging 2022, 42, 183–195. [Google Scholar] [CrossRef]
- Fan, C.C.; Yang, H.; Zhang, C.; Peng, L.; Zhou, X.; Liu, S.; Chen, S.; Hou, Z.G. Graph reasoning module for Alzheimer’s disease diagnosis: A plug-and-play method. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 4773–4780. [Google Scholar] [CrossRef]
- Zhao, M.; Barati, M. Substation Safety Awareness Intelligent Model: Fast Personal Protective Equipment Detection Using GNN Approach. IEEE Trans. Ind. Appl. 2023, 59, 3142–3150. [Google Scholar] [CrossRef]
- Li, P.; Pei, Y.; Li, J.; Xie, H. Medical Image Recognition Using a Novel Neural Network Construction Controlled by a Kernel Method Encoder. IEEE Access 2024, 12, 146807–146817. [Google Scholar] [CrossRef]
- Hu, L.; Zhou, D.; Xu, J.; Lu, C.; Han, C.; Shi, Z.; Zhu, Q.; Gao, X.; Wang, N.; Liu, Z. Protecting prostate cancer classification from rectal artifacts via targeted adversarial training. IEEE J. Biomed. Health Inform. 2024, 28, 3997–4009. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, S.; Anastasio, M.A. A Test Statistic Estimation-Based Approach for Establishing Self-Interpretable CNN-Based Binary Classifiers. IEEE Trans. Med. Imaging 2024, 43, 1753–1765. [Google Scholar] [CrossRef]
- Mohsen, S.; Ali, A.M.; El-Rabaie, E.S.M.; ElKaseer, A.; Scholz, S.G.; Hassan, A.M.A. Brain Tumor Classification Using Hybrid Single Image Super-Resolution Technique with ResNext101_32×8d and VGG19 Pre-Trained Models. IEEE Access 2023, 11, 55582–55595. [Google Scholar] [CrossRef]
- Xing, Y.; Meyer, B.J.; Harandi, M.; Drummond, T.; Ge, Z. Multimorbidity Content-Based Medical Image Retrieval and Disease Recognition Using Multi-Label Proxy Metric Learning. IEEE Access 2023, 11, 50165–50179. [Google Scholar] [CrossRef]
- Ding, W.; Zhou, T.; Huang, J.; Jiang, S.; Hou, T.; Lin, C.T. FMDNN: A Fuzzy-Guided Multi-Granular Deep Neural Network for Histopathological Image Classification. IEEE Trans. Fuzzy Syst. 2024, 32, 4709–4723. [Google Scholar] [CrossRef]
- Zhang, Y.; Peng, C.; Wang, Q.; Song, D.; Li, K.; Zhou, S.K. Unified Multi-Modal Image Synthesis for Missing Modality Imputation. IEEE Trans. Med. Imaging 2025, 44, 4–18. [Google Scholar] [CrossRef]
- Huang, J.; Li, X.; Tan, H.; Cheng, X. Generative Adversarial Network for Trimodal Medical Image Fusion Using Primitive Relationship Reasoning. IEEE J. Biomed. Health Inform. 2024, 28, 5729–5741. [Google Scholar] [CrossRef]
- Owais, M.; Cho, S.W.; Park, K.R. Volumetric Model Genesis in Medical Domain for the Analysis of Multimodality 2-D/3-D Data Based on the Aggregation of Multilevel Features. IEEE Trans. Ind. Inform. 2023, 19, 11809–11822. [Google Scholar] [CrossRef]
- Pavarut, S.; Preedanan, W.; Kumazawa, I.; Suzuki, K.; Kobayashi, M.; Tanaka, H.; Ishioka, J.; Matsuoka, Y.; Fuji, Y. Improving Kidney Tumor Classification with Multi-Modal Medical Images Recovered Partially by Conditional CycleGAN. IEEE Access 2023, 11, 146250–146261. [Google Scholar] [CrossRef]
- Ling, Y.; Wang, Y.; Dai, W.; Yu, J.; Liang, P.; Kong, D. MTANet: Multi-Task Attention Network for Automatic Medical Image Segmentation and Classification. IEEE Trans. Med. Imaging 2023, 43, 674–685. [Google Scholar] [CrossRef] [PubMed]
- Ashwath, V.A.; Sikha, O.K.; Benitez, R. TS-CNN: A Three-Tier Self-Interpretable CNN for Multi-Region Medical Image Classification. IEEE Access 2023, 11, 78402–78418. [Google Scholar] [CrossRef]
- Zeng, Q.; Xie, Y.; Lu, Z.; Lu, M.; Zhang, J.; Zhou, Y.; Xia, Y. Consistency-Guided Differential Decoding for Enhancing Semi-Supervised Medical Image Segmentation. IEEE Trans. Med. Imaging 2025, 44, 44–56. [Google Scholar] [CrossRef]
- Zhang, L.; Qiao, Z.; Li, L. An Evolutionary Deep Learning Method Based on Improved Heap-Based Optimization for Medical Image Classification and Diagnosis. IEEE Access 2024, 12, 102745–102773. [Google Scholar] [CrossRef]
- Yue, G.; Wei, P.; Zhou, T.; Song, Y.; Zhao, C.; Wang, T.; Lei, B. Specificity-Aware Federated Learning with Dynamic Feature Fusion Network for Imbalanced Medical Image Classification. IEEE J. Biomed. Health Inform. 2023, 28, 6373–6383. [Google Scholar] [CrossRef]
- Du, J.; Guan, K.; Zhou, Y.; Li, Y.; Wang, T. Parameter-Free Similarity-Aware Attention Module for Medical Image Classification and Segmentation. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 845–857. [Google Scholar] [CrossRef]
- Abdar, M.; Fahami, M.A.; Rundo, L.; Radeva, P.; Frangi, A.F.; Acharya, U.R.; Khosravi, A.; Lam, H.K.; Jung, A.; Nahavandi, S. Hercules: Deep hierarchical attentive multilevel fusion model with uncertainty quantification for medical image classification. IEEE Trans. Ind. Inform. 2022, 19, 274–285. [Google Scholar] [CrossRef]
- Showrov, A.A.; Aziz, M.T.; Nabil, H.R.; Jim, J.R.; Kabir, M.M.; Mridha, M.F.; Asai, N.; Shin, J. Generative Adversarial Networks (GANs) in Medical Imaging: Advancements, Applications and Challenges. IEEE Access 2024, 12, 35728–35753. [Google Scholar]
- Hou, Q.; Wang, Y.; Cao, P.; Cheng, S.; Lan, L.; Yang, J.; Liu, X.; Zaiane, O.R. A Collaborative Self-Supervised Domain Adaptation for Low-Quality Medical Image Enhancement. IEEE Trans. Med. Imaging 2024, 43, 2479–2494. [Google Scholar] [CrossRef]
- Dao, H.N.; Nguyen, T.; Mugisha, C.; Paik, I. A Multimodal Transfer Learning Approach Using PubMedCLIP for Medical Image Classification. IEEE Access 2024, 12, 75496–75507. [Google Scholar] [CrossRef]
- Liu, L.; Aviles-Rivero, A.I.; Schönlieb, C.B. Contrastive Registration for Unsupervised Medical Image Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2023, in press. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Xiao, Z.; Ma, J.; Wu, X.; Zhao, J.; Zhang, S.; Liu, J. Adaptive Dual-Axis Style-Based Recalibration Network with Class-Wise Statistics Loss for Imbalanced Medical Image Classification. IEEE Trans. Image Process. 2025, in press. [Google Scholar] [CrossRef]
- Guan, C.; Wang, W.; Ai, H.; Singh, R.P. A White-Box Module for Medical Image Multi-Classification via Bias Dendrite Net. IEEE Trans. Instrum. Meas. 2025, in press. [Google Scholar] [CrossRef]
- Li, S.; Kou, P.; Ma, M.; Yang, H.; Huang, S.; Yang, Z. Application of Semi-Supervised Learning in Image Classification: Research on Fusion of Labeled and Unlabeled Data. IEEE Access 2024, 12, 27331–27343. [Google Scholar] [CrossRef]
- Bayasi, N.; Hamarneh, G.; Garbi, R. GC2: Generalizable Continual Classification of Medical Images. IEEE Trans. Med. Imaging 2024, 43, 3767–3779. [Google Scholar] [CrossRef]
- Varughese, D.A.; Sridevi, S. DFPT-CNN: A Dual Feature Extraction and Pretrained CNN Synergy for Minimal Computational Overhead and Enhanced Accuracy in Multi-Class Medical Image Classification. IEEE Access 2024, 12, 58573–58585. [Google Scholar] [CrossRef]
- Qu, A.; Wu, Q.; Wang, J.; Yu, L.; Li, J.; Liu, J. TNCB: Tri-Net with Cross-Balanced Pseudo Supervision for Class Imbalanced Medical Image Classification. IEEE J. Biomed. Health Inform. 2024, 28, 2187–2198. [Google Scholar] [CrossRef]
- Penso, C.; Frenkel, L.; Goldberger, J. Confidence Calibration of a Medical Imaging Classification System That Is Robust to Label Noise. IEEE Trans. Med. Imaging 2024, 43, 2050–2060. [Google Scholar] [CrossRef]
- Liu, C.; Sun, C. A Fusion Deep Learning Model of ResNet and Vision Transformer for 3D CT Images. IEEE Access 2024, 12, 93389–93397. [Google Scholar] [CrossRef]
- Chen, T.; Wang, C.; Chen, Z.; Lei, Y.; Shan, H. HiDiff: Hybrid Diffusion Framework for Medical Image Segmentation. IEEE Trans. Med. Imaging 2024, 43, 3570–3583. [Google Scholar] [CrossRef] [PubMed]
- Wada, K. Labelme: Image Polygonal Annotation with Python. GitHub Repository. Available online: https://github.com/wkentaro/labelme (accessed on 8 March 2024).
- Albumentations Team. Albumentations: Fast and Flexible Image Augmentations. GitHub Repository. Available online: https://github.com/albumentations-team/albumentations (accessed on 8 March 2024).
- Chai, T.; Xiao, Z.; Shen, X.; Liu, Q.; Li, N.; Guan, T.; Tian, J. TransDeep: Transformer-Integrated DeepLabV3+ for Image Semantic Segmentation. IEEE Access 2025, 13, 6277–6291. [Google Scholar] [CrossRef]
- Shao, L.; He, J.; Lu, X.; Hei, B.; Qu, J.; Liu, W. Aircraft Skin Damage Detection and Assessment From UAV Images Using GLCM and Cloud Model. IEEE Trans. Intell. Transp. Syst. 2023, 25, 3191–3200. [Google Scholar] [CrossRef]
- Li, S.; Zhu, Q.; Guan, D.; Shen, B.; Zhang, L.; Ji, Y.; Zhang, D. Long-Interval Spatio-Temporal Graph Convolution for Brain Disease Diagnosis. IEEE Trans. Instrum. Meas. 2025, in press. [Google Scholar] [CrossRef]
- Hossain, S.; Chakrabarty, A.; Gadekallu, T.R.; Alazab, M.; Piran, M.J. Vision Transformers, Ensemble Model, and Transfer Learning Leveraging Explainable AI for Brain Tumor Detection and Classification. IEEE J. Biomed. Health Inform. 2023, 28, 1261–1272. [Google Scholar] [CrossRef]
- International Agency for Research on Cancer. Cervical Cancer. IARC. Available online: https://www.iarc.who.int/cancer-type/cervical-cancer/ (accessed on 8 March 2024).
- Shovit, S. Malhari Colposcopy Dataset. Kaggle. Available online: https://www.kaggle.com/datasets/srijanshovit/malhari-colposcopy-dataset (accessed on 8 March 2024).
- Doddi, G. Eye Diseases Classification. Kaggle. 2022. Available online: https://www.kaggle.com/datasets/gunavenkatdoddi/eye-diseases-classification (accessed on 8 March 2024).
- Nickparvar, M. Brain Tumor MRI Dataset. Kaggle. Available online: https://www.kaggle.com/datasets/masoudnickparvar/brain-tumor-mri-dataset (accessed on 8 March 2024).
- Singh, R.; Gupta, S.; Bharany, S.; Almogren, A.; Altameem, A.; Rehman, A.U. Ensemble Deep Learning Models for Enhanced Brain Tumor Classification by Leveraging ResNet50 and EfficientNet-B7 on High-Resolution MRI Images. IEEE Access 2024, 12, 178623–178641. [Google Scholar] [CrossRef]
- Huang, N.Y.; Liu, C.X. Efficient Tumor Detection and Classification Model Based on ViT in an End-to-End Architecture. IEEE Access 2024, 12, 106096–106106. [Google Scholar] [CrossRef]
- Ge, P.; Yan, T.; Wong, P.K.; Li, Z.; Chan, I.N.; Yu, H.H.; Gao, S. Simultaneous Segmentation and Classification of Esophageal Lesions Using Attention Gating Pyramid Vision Transformer. IEEE Trans. Emerg. Top. Comput. Intell. 2024, in press. [Google Scholar] [CrossRef]
- Zhu, Y.; Fu, C.; Du, J.; Jin, Y.; Du, S.; Zhao, F. Prediction of Cervical Cancer Lymph Node Metastasis via a Multimodal Transfer Learning Approach. Br. J. Hosp. Med. 2024, 85, 1–14. [Google Scholar] [CrossRef]
- Sha, Y.; Zhang, Q.; Zhai, X.; Hou, M.; Lu, J.; Meng, W.; Wang, Y.; Li, K.; Ma, J. CerviFusionNet: A Multi-Modal, Hybrid CNN-Transformer-GRU Model for Enhanced Cervical Lesion Multi-Classification. iScience 2024, 27, 111313. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Swavaf, M.; Elharrouss, O.; Abd-Alrazaq, A.; Damseh, R. Evaluating Segment Anything Model (SAM) on MRI Scans of Brain Tumors. Sci. Rep. 2024, 14, 21659. [Google Scholar] [CrossRef] [PubMed]
- Chauhan, N.K.; Singh, K.; Kumar, A.; Kolambakar, S.B. HDFCN: A Robust Hybrid Deep Network Based on Feature Concatenation for Cervical Cancer Diagnosis on WSI Pap Smear Slides. Biomed Res. Int. 2023, 2023, 4214817. [Google Scholar] [CrossRef] [PubMed]
- Vrahatis, A.G.; Lazaros, K.; Kotsiantis, S. Graph Attention Networks: A Comprehensive Review of Methods and Applications. Future Internet 2024, 16, 318. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, Y.; Shi, H.; Liu, Y.; Hong, C. Graph Triple Attention Network: A Decoupled Perspective. arXiv 2024, arXiv:2408.07654. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Image Dimensions | 128 × 128 pixels |
| Batch Size | 8 |
| Epochs | 100 |
| Learning Rate | 1 × 10−4 |
| Loss Function | Binary Cross-Entropy |
| Metrics | Dice Coefficient, IoU, Precision, Recall |
| Training Dataset Split | 64% |
| Validation Dataset Split | 16% |
| Test Dataset Split | 20% |
| Stage | Description |
|---|---|
| Feature Extraction | Extracted geometric and texture features from segmented masks for five classes (normal, CIN1, CIN2, CIN3, carcinoma). |
| Initial Graph Construction | Created one graph per class using original features. Nodes represent segmented regions, edges are based on Euclidean distances between feature vectors, and edge weights are the inverse of distances. |
| Feature Augmentation | Applied Gaussian noise to features (area, perimeter, eccentricity, mean intensity, and contrast) with noise level defined as a fraction of the standard deviation. |
| Augmented Graph Construction | Generated 500 graphs per class using augmented features. Threshold for edge creation was randomized, and edge weights were computed using the inverse-distance formula. |
| Graph Storage | Saved graphs in GML format and visualized graphs using a spring layout. |
| Name of the Dataset | Sample Size |
|---|---|
| Primary dataset (as received from IARC) | Normal: 136, CIN1: 278, CIN2: 286, CIN3: 296, carcinoma: 200. |
| After augmentation (using Albumentations library [64]) | Augmented to 900 images and 900 masks per class. |
| Graphs for classification (augmented dataset) | 500 graphs per class considered for performing classification. |
| Final classification (on augmented primary dataset) | 900 images, 900 masks per class, and 500 graphs per class considered. |
| Model generalization using secondary datasets | Malhari dataset: 900 CIN1 images, 930 CIN2 images, 960 CIN3 images. |
| Brain MRI dataset: 1595 no tumor, 1457 pituitary, 1339 meningioma, 1321 glioma images. | |
| eye_disease dataset: 1038 cataract, 1098 diabetic retinopathy, 1007 glaucoma, and 1074 normal images. |
| Model | Inference Time (TPU) | Inference Time (GPU) | FLOPs (Training) | Peak GPU Memory Usage |
|---|---|---|---|---|
| DeepLabV3 | 30 ms per image | 50 ms per image | ∼40 GFLOPs | 5.8 GB |
| GCN | 20 ms per graph | 30 ms per graph | ∼2.5 GFLOPs | 2.1 GB |
| Class | Dice Coefficient (%) | IoU (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|
| Normal | 90.5 | 82.1 | 91.0 | 90.0 |
| CIN1 | 92.4 | 85.4 | 93.1 | 91.7 |
| CIN2 | 91.8 | 84.7 | 92.5 | 91.0 |
| CIN3 | 93.01 | 86.8 | 94.0 | 92.5 |
| Carcinoma | 92.56 | 86.1 | 93.7 | 91.8 |
| Feature | Class | ||||
|---|---|---|---|---|---|
| Normal | CIN1 | CIN2 | CIN3 | Carcinoma | |
| Perimeter | 150.2 | 120.3 | 130.6 | 140.4 | 155.8 |
| Area | 1800.4 | 900.5 | 1100.7 | 1500.9 | 1750.6 |
| Circularity | 0.86 | 0.82 | 0.00 | 0.89 | 0.00 |
| Eccentricity | 0.85 | 0.42 | 0.92 | 0.88 | 0.90 |
| Contrast | 310.6 | 400.8 | 450.9 | 520.5 | 600.3 |
| Mean Intensity | 0.65 | 0.68 | 0.55 | 0.58 | 0.50 |
| Metric | Class | Before FT () | After FT () | Noisy | Low Contrast | Epochs Trained |
|---|---|---|---|---|---|---|
| Training Accuracy () | Normal | 91.2 | 97.6 | – | – | 100/51 |
| CIN1 | 89.8 | 96.3 | – | – | ||
| CIN2 | 90.5 | 96.8 | – | – | ||
| CIN3 | 89.9 | 96.7 | – | – | ||
| Carcinoma | 90.1 | 96.9 | – | – | ||
| Training Loss () | Normal | 0.158 | 0.070 | – | – | 100/51 |
| CIN1 | 0.170 | 0.073 | – | – | ||
| CIN2 | 0.165 | 0.068 | – | – | ||
| CIN3 | 0.162 | 0.069 | – | – | ||
| Carcinoma | 0.160 | 0.067 | – | – | ||
| Precision () | Normal | 89.7 | 95.5 | – | – | |
| CIN1 | 88.5 | 94.1 | – | – | ||
| CIN2 | 89.0 | 94.7 | – | – | ||
| CIN3 | 89.6 | 95.2 | – | – | ||
| Carcinoma | 90.2 | 95.8 | – | – | ||
| Recall () | Normal | 90.1 | 95.8 | – | – | |
| CIN1 | 88.7 | 94.3 | – | – | ||
| CIN2 | 89.3 | 95.0 | – | – | ||
| CIN3 | 89.8 | 95.5 | – | – | ||
| Carcinoma | 90.5 | 96.0 | – | – | ||
| F1-Score () | Normal | 89.9 | 95.6 | 91.1 | 89.4 | 100/51 |
| CIN1 | 88.6 | 94.2 | 89.5 | 88.1 | ||
| CIN2 | 89.2 | 94.8 | 90.2 | 88.7 | ||
| CIN3 | 89.7 | 95.3 | 90.8 | 89.5 | ||
| Carcinoma | 90.3 | 95.9 | 91.5 | 90.3 | ||
| Validation Accuracy () | Normal | 92.3 | 99.1 | 94.2 | 91.6 | 100/51 |
| CIN1 | 91.5 | 98.8 | 92.3 | 90.8 | ||
| CIN2 | 92.0 | 99.0 | 93.1 | 91.4 | ||
| CIN3 | 91.8 | 98.9 | 93.7 | 91.9 | ||
| Carcinoma | 92.4 | 99.2 | 94.5 | 92.3 | ||
| Validation Loss () | Normal | 0.152 | 0.050 | 0.125 | 0.149 | 100/51 |
| CIN1 | 0.160 | 0.052 | 0.131 | 0.150 | ||
| CIN2 | 0.155 | 0.051 | 0.118 | 0.143 | ||
| CIN3 | 0.158 | 0.050 | 0.120 | 0.140 | ||
| Carcinoma | 0.151 | 0.049 | 0.115 | 0.139 | ||
| Macro-Average F1-Score () | All Classes | 89.4 | 94.56 | 90.6 | 89.2 | 100/51 |
| Macro-Average Validation Accuracy () | All Classes | 92.1 | 98.98 | 93.6 | 91.6 | |
| Early Stopping Applied? | All Classes | No | Yes (No imp. for 3 epochs) | – | – |
| Class | Fidelity Score (%) | Stability Score (%) | Local Accuracy (%) |
|---|---|---|---|
| Normal | 91.2 | 89.8 | 92.6 |
| CIN1 | 89.4 | 87.9 | 91.0 |
| CIN2 | 90.5 | 88.5 | 92.3 |
| CIN3 | 91.8 | 90.1 | 93.7 |
| Carcinoma | 92.1 | 89.4 | 94.2 |
| Average | 91.0 | 89.1 | 92.8 |
| Dataset | Metric | Solution/Class | Label | Value |
|---|---|---|---|---|
| Segmentation Performance | ||||
| Malhari | Dice Coeff. (%) | Lugol’s iodine | CIN1, CIN2, CIN3 | 84.2, 85.8, 86.1 |
| Dice Coeff. (%) | Acetic acid | CIN1, CIN2, CIN3 | 85.9, 86.5, 86.98 | |
| Dice Coeff. (%) | Normal saline | CIN1, CIN2, CIN3 | 83.5, 84.0, 85.6 | |
| IoU (%) | Lugol’s iodine | CIN1, CIN2, CIN3 | 84.5, 85.1, 85.6 | |
| IoU (%) | Acetic acid | CIN1, CIN2, CIN3 | 84.0, 84.6, 85.2 | |
| IoU (%) | Normal saline | CIN1, CIN2, CIN3 | 83.8, 84.2, 84.7 | |
| Brain MRI | Dice Coeff (%) | – | No Tumor, Glioma, Meningioma, Pituitary | 90.5, 91.8, 92.1, 92.56 |
| IoU (%) | – | No Tumor, Glioma, Meningioma, Pituitary | 82.1, 84.7, 86.8, 86.1 | |
| Eye Disease | Dice Coeff (%) | – | Normal, DR, Cataract, Glaucoma | 91.8, 92.3, 92.8, 93.56 |
| IoU (%) | – | Normal, DR, Cataract, Glaucoma | 90.1, 90.7, 91.8, 92.1 | |
| Classification Performance (Before and After Fine-Tuning) | ||||
| Malhari | Macro F1 (%) | All | All CIN | B: 89.4, A: 90.56 |
| Val. Acc. (%) | All | All CIN | B: 89.88, A: 91.02 | |
| Epochs Trained | All | All CIN | B: 100, A: 51 | |
| Early Stopping? | All | All CIN | No → Yes | |
| Brain MRI | Macro F1 (%) | All | All MRI | B: 88.4, A: 91.56 |
| Val. Acc. (%) | All | All MRI | B: 90.1, A: 91.98 | |
| Epochs Trained | All | All MRI | B: 100, A: 51 | |
| Early Stopping? | All | All MRI | No → Yes | |
| Eye Disease | Macro F1 (%) | All | All Eye | B: 89.4, A: 90.56 |
| Val. Acc. (%) | All | All Eye | B: 92.1, A: 94.98 | |
| Epochs Trained | All | All Eye | B: 100, A: 51 | |
| Early Stopping? | All | All Eye | No → Yes | |
| Metric | Graph with Fixed Weights | Focal Loss (No Augmentation) | Proposed Model (Augmented) |
|---|---|---|---|
| Macro-Average F1-Score (%) | 86.5 | 88.9 | 94.56 |
| Validation Accuracy (%) | 88.2 | 91.3 | 98.98 |
| Epochs Trained (Before Fine-Tuning) | 100 | 100 | 100 |
| Epochs Trained (After Fine-Tuning) | 100 | 72 | 51 |
| Early Stopping Applied? | No | Yes (Patience: 5 epochs) | Yes (No improvement for 3 epochs) |
| Metric | EfficientNet | ViT | ResNet50 | Ours |
|---|---|---|---|---|
| M1 | 87.4/93.86 | 88.9/94.1 | 86.3/92.9 | 89.4/94.56 |
| M2 | 90.23/97.68 | 90.89/98.5 | 90.3/96.2 | 92.1/98.98 |
| Epochs Trained | 100/50 | 100/50 | 100/50 | 100/50 |
| Early Stopping? | No | No | No | Yes |
| (No improvement for 3 epochs) |
| Method | M1: Macro-Average F1-Score | M2: Macro-Average Validation Accuracy | Epochs Trained |
|---|---|---|---|
| Segmentation-Based Approaches | |||
| MTANet [75] | 88.9/93.7 | 90.5/96.2 | 100/50 |
| Segment Anything Model (SAM) [78] | 87.5/93.0 | 89.8/95.5 | 100/50 |
| Feature-Extraction-Based Approaches | |||
| Deep Learning Model for Cervical Cancer Prediction [76] | 87.6/92.1 | 89.8/95.4 | 100/50 |
| Hybrid Deep Feature Extraction [79] | 88.1/93.4 | 90.2/96.1 | 100/50 |
| Graph-Based Learning Approaches | |||
| Graph Attention Networks (GAT) [80] | 89.0/94.2 | 91.0/97.1 | 100/50 |
| Graph Transformer Networks (GTN) [81] | 89.4/94.5 | 91.3/97.4 | 100/50 |
| K-Nearest Neighbour [8] | 86.9/89.8 | 89.3/91.5 | 100/50 |
| Hybrid Models for Classification | |||
| CerviFusionNet [77] | 89.2/94.0 | 91.2/96.8 | 100/50 |
| Our Proposed Approach | 89.4/94.56 | 92.1/98.98 | 100/51 (Early Stopping) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatterjee, P.; Siddiqui, S.; Kareem, R.S.A.; Rao, S.R. Multi-Modal Graph Neural Networks for Colposcopy Data Classification and Visualization. Cancers 2025, 17, 1521. https://doi.org/10.3390/cancers17091521
Chatterjee P, Siddiqui S, Kareem RSA, Rao SR. Multi-Modal Graph Neural Networks for Colposcopy Data Classification and Visualization. Cancers. 2025; 17(9):1521. https://doi.org/10.3390/cancers17091521
Chicago/Turabian StyleChatterjee, Priyadarshini, Shadab Siddiqui, Razia Sulthana Abdul Kareem, and Srikanth R. Rao. 2025. "Multi-Modal Graph Neural Networks for Colposcopy Data Classification and Visualization" Cancers 17, no. 9: 1521. https://doi.org/10.3390/cancers17091521
APA StyleChatterjee, P., Siddiqui, S., Kareem, R. S. A., & Rao, S. R. (2025). Multi-Modal Graph Neural Networks for Colposcopy Data Classification and Visualization. Cancers, 17(9), 1521. https://doi.org/10.3390/cancers17091521