1. Introduction
The implementation of artificial intelligence (AI) and machine learning (ML) in clinical laboratory settings has demonstrated significant potential to improve laboratory efficiency, reduce subjectivity, and standardize complex analytical processes. In the field of flow cytometry, particularly for the detection of minimal/measurable residual disease (MRD), deep neural networks (DNNs) offer a promising approach to enhance the reliability and consistency of data analysis while reducing the considerable time burden on laboratory staff [
1].
MRD status in patients with chronic lymphocytic leukemia (CLL) has become increasingly important as it is not only a powerful independent predictor of survival but also plays a potential role in MRD-directed therapies [
1,
2,
3,
4,
5]. Flow cytometric (FC) immunophenotyping is critical in detecting MRD in CLL patients, but traditional flow cytometric analysis is complex, time-consuming, and prone to subjectivity [
6,
7,
8,
9,
10,
11]. The analysis of multi-parameter flow cytometry data for MRD detection represents a significant bottleneck in the laboratory workflow, typically requiring 10–15 min per case for manual analysis by experienced technologists [
8]. The integration of AI-assisted analysis offers the potential to dramatically reduce this time while maintaining or potentially improving analytical performance.
Clinical implementation of AI-assisted flow cytometry analysis requires a two-phase approach: rigorous clinical validation before deployment followed by continuous performance monitoring after implementation. For clinical validation, comprehensive assessment of method comparison, precision, and analytical sensitivity is essential to ensure the AI-assisted approach meets or exceeds the performance of current manual analysis by a trained human. This includes quantitative comparison against expert manual analysis (manual reference method), verification of precision across multiple operators and instruments, and confirmation of analytical sensitivity at clinically relevant MRD levels as specified in the Clinical Laboratory Improvement Amendments (CLIA) [
12]. Only through such thorough validation can we establish confidence in the AI-assisted approach for clinical use.
However, successful validation represents only the beginning of quality assurance for AI/ML systems in clinical laboratories. As highlighted in recent publications addressing AI implementation in healthcare, without consistent and rigorous performance monitoring, the benefits of AI/ML could be overshadowed by inaccuracies, inefficiencies, and potential patient harm [
13,
14]. AI models, being inherently data-driven, are susceptible to performance degradation over time due to factors, such as covariate shift (changes in input data distribution) or concept drift (changes in the relationship between input data and target output) [
15,
16].
For an AI-assisted flow cytometry approach to CLL MRD detection, potential sources of covariate shift include variations in instrument performance, reagent lots, sample preparation procedures, and patient-specific differences. Such shifts can lead to deteriorating model performance if not detected and addressed promptly. Therefore, comprehensive performance monitoring strategies—including daily electronic quality control, input data drift detection, real-time error analysis, and statistical acceptance sampling—are essential for maintaining confidence in the AI-assisted approach over time and ensuring compliance with regulatory requirements, such as those specified by CLIA [
12,
17].
Our group previously developed a DNN-assisted approach for automated CLL MRD detection using a 10-color flow cytometry panel from 202 consecutive CLL patients who had completed therapy, collected between February 2020 and May 2021 [
8]. This development cohort comprised 142 CLL MRD-positive and 60 CLL MRD-negative samples, with more than 256 million total events analyzed in an 80:10:10% ratio for training, validation, and testing, respectively. The DNN was trained on uncompensated data from a single-tube panel consisting of CD5-BV480, CD19-PE-Cy7, CD20-APC-H7, CD22-APC, CD38-APC-R700, CD43-BV605, CD45-PerCP-Cy5.5, CD200-BV421, Kappa-FITC, and Lambda-PE. The 10-color panel has been extensively validated for its robustness and reliability of detecting CLL MRD. Our initial work demonstrated high accuracy in detecting CLL MRD and potential for significant workflow improvements, based on an average DNN inference time of 12 s to process 1 million events per case through the model. In the current study, we describe the comprehensive clinical laboratory validation and post-implementation performance monitoring of the DNN-assisted human-in-the-loop workflow for CLL MRD detection by flow cytometry (
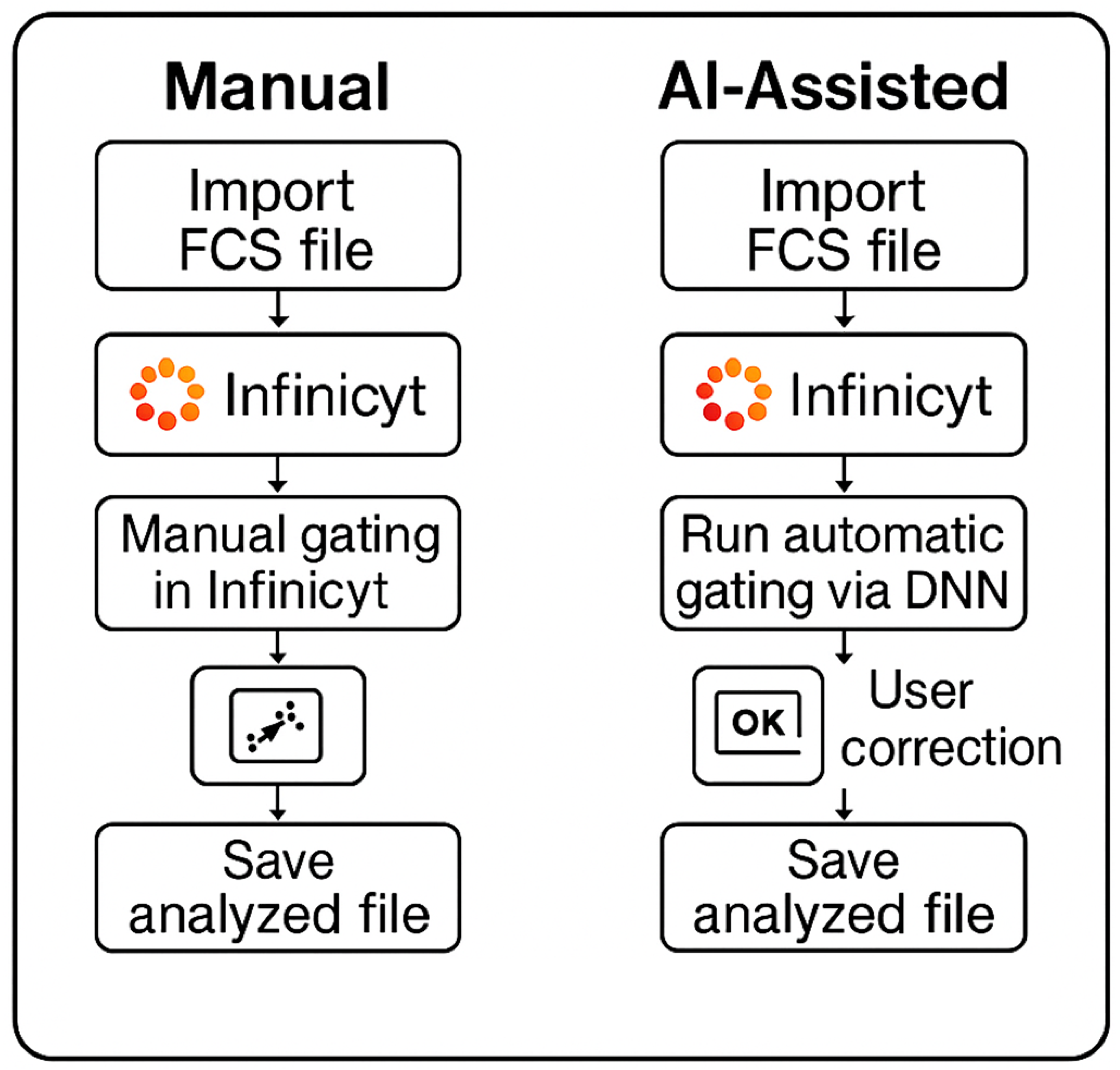
Figure 1), ensuring that the benefits of AI integration are realized without compromising patient care.
2. Methods
2.1. Method Comparison
A method comparison study was conducted to evaluate the performance of DNN-assisted human-in-the-loop analysis for CLL MRD detection (DNN + 2nd review) compared to the manual reference method. The sample size was calculated based on both binary classification parameters (minimum tolerable accuracy of 97.5%, alpha of 5% representing type I error rate, beta of 20% representing type II error rate or a statistical power of 80%) and quantitative method comparison via Deming regression (expected correlation coefficient of 0.95, tolerable slope deviation of ±0.05), yielding a minimum requirement of 240 consecutive clinical samples based on the quantitative approach. The sample set included both MRD-positive and MRD-negative specimens, with at least 30% in each category, and with MRD-positive samples spanning the analytical range.
Ground truth for each case was established at both the qualitative level (positive vs. negative) and quantitative level (percentage of clonal events) by an on-bench technologist and secondary review by a member of the development team using the current validated manual reference approach in Infinicyt software (v 2.1) [Cytognos, Spain]. For the DNN approach, a hybrid workflow was implemented using both a full-cohort DNN (F-DNN) for initial analysis of all cases and a low-count DNN (L-DNN) specifically for cases with predicted low event counts (<1000 events) as described by Salama et al. [
8].
The acceptance criteria for the primary analysis were as follows: (1) observed accuracy for binary classification not significantly lower than the minimum tolerable accuracy of 97.5% (alpha = 5%) with negative predictive value (NPV) above 97.5%; and (2) observed regression slope deviation not significantly higher than 0.05.
2.2. Precision
2.2.1. Quantitative Precision
To verify the precision of the DNN + 2nd review method, raw flow cytometry standard (FCS) files from the original method evaluation study were reanalyzed. Six samples representing clinically relevant CLL MRD levels (5 CLL MRD-positive bone marrow and 1 CLL MRD-positive peripheral blood sample, all with <1% clonal events) were included in the analysis. No new sample processing or acquisition was performed, as this precision verification study aimed to verify that the human-in-the-loop AI model maintains the precision claims established in the original method evaluation.
Each sample was assayed in triplicate on two different instruments, and analyses were performed by two operators using the DNN + 2nd review method, generating a total of 12 replicates per sample (3 replicates × 2 instruments × 2 operators). Each operator analyzed 36 FCS files (3 replicates × 2 instruments × 6 samples).
The acceptance criteria required verification of precision estimates (repeatability and within-laboratory SD) from the original method evaluation study, with specific upper verification limits established for each sample as shown in the
Supplementary Material, Table S1.
2.2.2. Qualitative Precision
To verify the qualitative precision of the DNN + 2nd review method across multiple operators, we designed a blinded study using a set of historical cases. Ten CLL MRD-positive samples representing a mixture of clonal percentages and four CLL MRD-negative samples were selected for analysis. Each file was replicated four times, and the files were de-identified and renamed to aid with blinding. This created a set of 56 blinded FCS files (14 samples × 4 replicates) that were randomly sorted and then analyzed by four trained technologists over a period of two weeks to reduce the possibility of recall for the four replicates per case. The qualitative precision data files were interspersed with the method comparison study to further aid with blinding.
The total number of analyses performed was 224 (14 samples × 4 replicates × 4 technologists). For each sample, we assessed the level of agreement among the four technologists by calculating accordance, concordance, and concordance odds ratio as described by Langton et al. [
18]. Additionally, a test of equal sensitivities and specificities across all four raters was performed following the methodology described by Wilrich [
19].
The acceptance criterion for this study was that there should be no significant difference in sensitivity and specificity of identifying CLL MRD levels across the four technologists when using the DNN + 2nd review method (alpha = 0.05).
2.3. Analytical Sensitivity (Method Detection Limit)
The lower level of quantitation (LLOQ) of the assay is 0.002% (2 × 10
−5) based on 1,000,000 total events analyzed and an abnormal cell immunophenotype detected in a cluster of at least 20 cells. The limit of detection (LOD) is 0.001% (1 × 10
−5). The assay sensitivity meets or exceeds the 0.01–0.001% (10
−4–10
−5) level of detection by flow cytometry, as recommended by the NCCN and iwCLL guidelines for MRD analysis in CLL [
20,
21]. Results between the LOD and LLOQ may be reported as suspicious or equivocal.
To verify the limit of detection and quantification, the raw FCS files from the original LLOQ evaluation study were reanalyzed. Two CLL MRD-positive bone marrow specimens and one CLL MRD-positive peripheral blood specimen, previously diluted to targeted clonal percentages of 0.02% (1 replicate each), 0.002% (3 replicates each), and 0.001% (3 replicates each), were included in this assessment. No new sample processing or acquisition was performed, as this verification study aimed to confirm that the human-in-the-loop AI model achieves the precision claims from the original method evaluation study at the LLOQ.
One technologist evaluated each FCS file from the original LLOQ study using the DNN + 2nd review method. The acceptance criteria specified that the calculated intra-assay CV for each targeted 0.002% MRD triplicate should be <30% to verify the LLOQ claims.
2.4. Real-Time Performance Monitoring
Following the implementation of the DNN-assisted analysis pipeline for CLL MRD detection, we established a comprehensive monitoring system to ensure continuous quality assessment. This system operates in four main ways: daily electronic quality control, input data drift detection, error analysis monitoring, and attribute acceptance sampling for negative cases.
2.4.1. Daily Electronic Quality Control
At the beginning of each user’s shift, a prepared test file undergoes complete processing through both stage 1 (generate event-level DNN-inferences) and stage 2 (human review and saving of corrected event-level classifications). The system verifies that the workflow is functioning correctly by comparing the hashed file contents against reference values established during validation. This provides immediate confirmation that the DNN script is being executed as expected for that specific user’s workstation and the local Infinicyt software configuration. Any deviations from expected hash values trigger alerts, allowing for immediate troubleshooting before clinical sample analysis begins.
2.4.2. Input Data Drift and Out-of-Distribution Detection
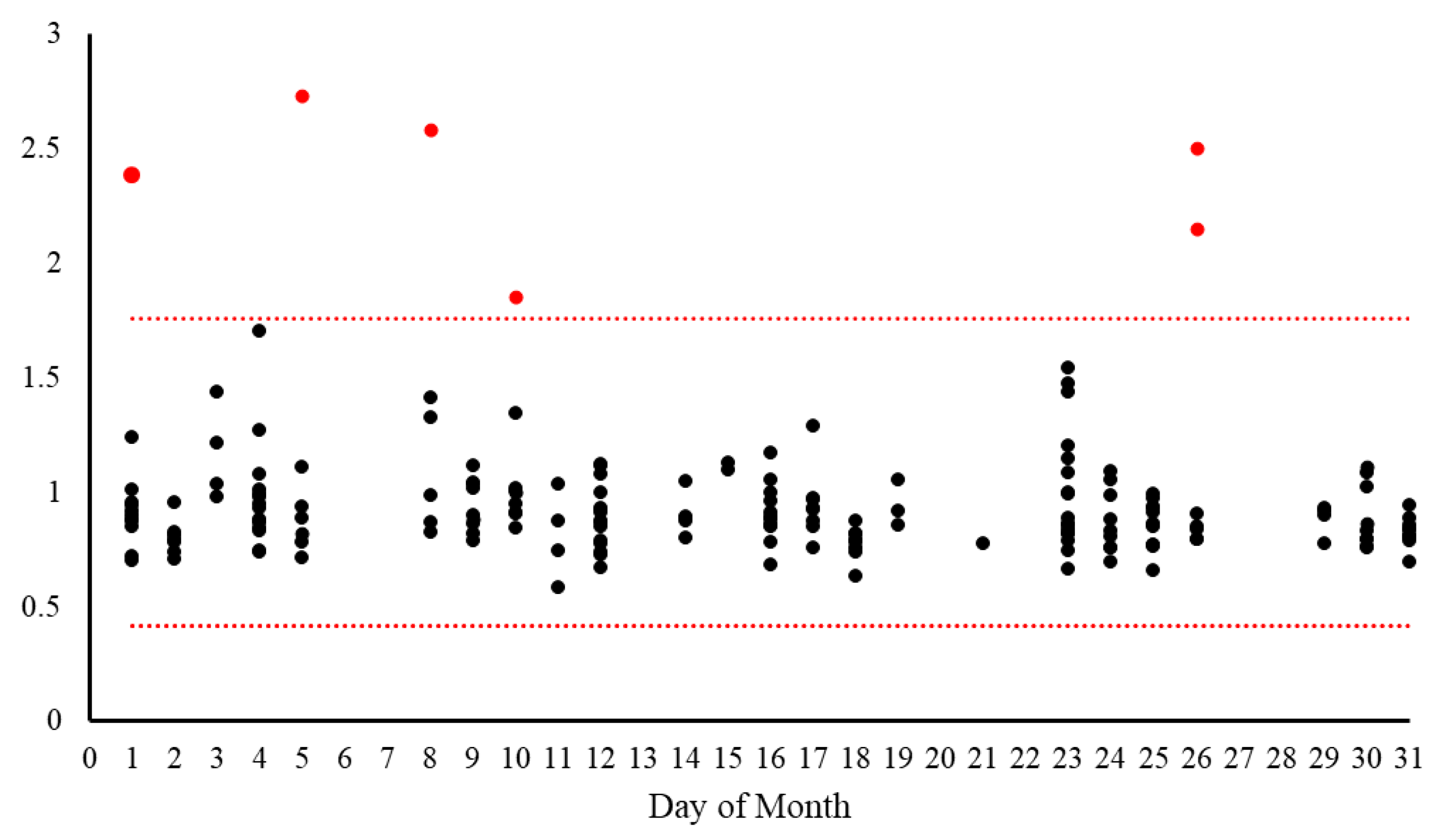
To identify potential changes in the characteristics of input data that could impact DNN performance, we implemented a drift detection system based on a data reconstruction approach using Principal Component Analysis (PCA) to identify subtle distributional changes not apparent at the individual feature level. The three-step process begins with data preparation (missing value imputation, frequency encoding, and standardization), followed by dimensionality reduction where PCA captures approximately 65% of variance from the training cohort, creating a compressed latent space representation. Finally, data are reconstructed using inverse PCA transformation, and Euclidean distances between original and reconstructed data points are calculated to produce a reconstruction error metric. Significant deviations in this error (exceeding three standard deviations from the reference mean) indicate potential drift, allowing detection of complex, multivariate shifts that might adversely affect model performance even when individual features appear stable. The metric can also be used for out-of-distribution detection to identify new samples that are different from the training distribution.
For each analyzed specimen, a random subset of 10,000 events was extracted and compared against a reference data distribution derived from the training dataset. The system calculates upper and lower threshold boundaries based on the training set distribution (mean ± 3 standard deviations). Each analyzed sample receives a quantitative drift score and an alert status (True/False) indicating whether the sample falls outside the expected range. These values are logged to a database and visualized on a monitoring dashboard, allowing laboratory staff to identify trends or sudden shifts in data characteristics that might require investigation or model recalibration. Input data drift is formally defined as an occurrence when 5 or more samples processed on the same calendar day exhibit reconstruction error values that consistently deviate from the expected reference range in the same direction. Specifically, all deviating samples must fall either exclusively above the upper threshold or exclusively below the lower threshold to be considered a true drift event, rather than random variation.
2.4.3. Error Analysis Monitoring
For ongoing performance verification, the laboratory monitors the concordance between the classification of individual events from the DNN output (prior to human review) against the final corrected classifications (DNN + 2nd review). Each event is categorized as:
- •
True Positive (TP): Correctly classified as clonal event by DNN and verified by technologist
- •
True Negative (TN): Correctly classified as non-clonal event by DNN and verified by technologist
- •
False Positive (FP): Incorrectly classified as clonal event by DNN but corrected by technologist
- •
False Negative (FN): Incorrectly classified as non-clonal event by DNN but corrected by technologist
The system calculates key performance metrics: accuracy, sensitivity, specificity, positive predictive value (PPV) and negative predictive value (NPV) for the clonal event population versus other events. These metrics are logged to a relational database and displayed graphically on a real-time dashboard. While no specific cutoff values are established for corrective action at this time, this monitoring system enables identification of performance trends and potential degradation over time, particularly with changes in reagent lots, instrument calibration, or sample preparation protocols.
2.4.4. Attribute Acceptance Sampling for Negative Cases
Ready identification of false-positive AI classifications is possible in a human-in-the-loop workflow, since human reviewers can pay special attention to events classified as clonal. However, identification of false-negative AI classifications is more challenging, since the clonal events could be classified as any of the remaining normal classes. To provide additional quality assurance focused specifically on the critical performance characteristic of false negative results, we implemented a periodic review process based on attribute acceptance sampling principles. This approach focuses on confirming the reliability of negative case determinations from the DNN + 2nd review workflow through targeted expert review.
Based on our laboratory’s average volume of approximately 74 negative cases per month (determined by DNN + 2nd review), we established a semi-annual quality control review cycle covering approximately 444 negative cases per 6-month period. Using the hypergeometric distribution, we calculated that to achieve 95% confidence that at least 95% of reported “negative” cases are truly negative, a random sample of 84 “negative” cases must be drawn from each 6-month period, with an acceptance criterion of no more than 1 allowable failure in the sample.
To distribute this workload evenly, 14 randomly selected negative cases undergo additional expert review each month. The results of these reviews are documented and analyzed at the end of each 6-month cycle. If more than one false negative is identified within the 84-case sample, a comprehensive investigation is initiated, potentially leading to workflow adjustments or consideration of model re-verification or retraining.
2.5. Analysis Time Reduction Study
To evaluate the long-term impact of the DNN + 2nd review workflow on laboratory efficiency, we conducted a timing study across multiple laboratory technologists during routine clinical operations. This study was designed to quantify real-world time savings in comparison to our pre-implementation baseline measurements and to assess the consistency of these efficiency gains over time.
Five laboratory technologists with varying levels of experience participated in the timing study over a one-month period. For each case analyzed using the DNN + 2nd review method, technologists recorded the total analysis time from initiation of review to completion of the final report. The start time was defined as the moment when the technologist began reviewing the DNN-classified events, and the end time was recorded when the technologist finalized their review and classification.
No specific case selection criteria were applied; all consecutive clinical samples received during the study period were included, representing the typical case mix encountered in routine practice. The recorded times were compared against two reference points: (1) pre-implementation baseline measurements of manual analysis time collected before the DNN-assisted workflow was deployed, and (2) the initial post-implementation measurements. For statistical analysis, we calculated the mean, standard deviation, minimum, and maximum analysis times for the overall dataset and for each individual technologist. The percentage reduction in analysis time compared to pre-implementation baseline was calculated to quantify the workflow efficiency gain.
4. Discussion
The results of our comprehensive validation and post-implementation monitoring demonstrate that the DNN-assisted human-in-the-loop approach for CLL MRD detection provides accurate, precise, and reliable results while dramatically reducing analysis time compared to traditional manual methods. Our findings validate the approach described by Salama et al. [
8] and extend our laboratory’s work by establishing a robust framework for ongoing performance monitoring that ensures the continued safety and effectiveness of this AI-assisted workflow in routine clinical practice.
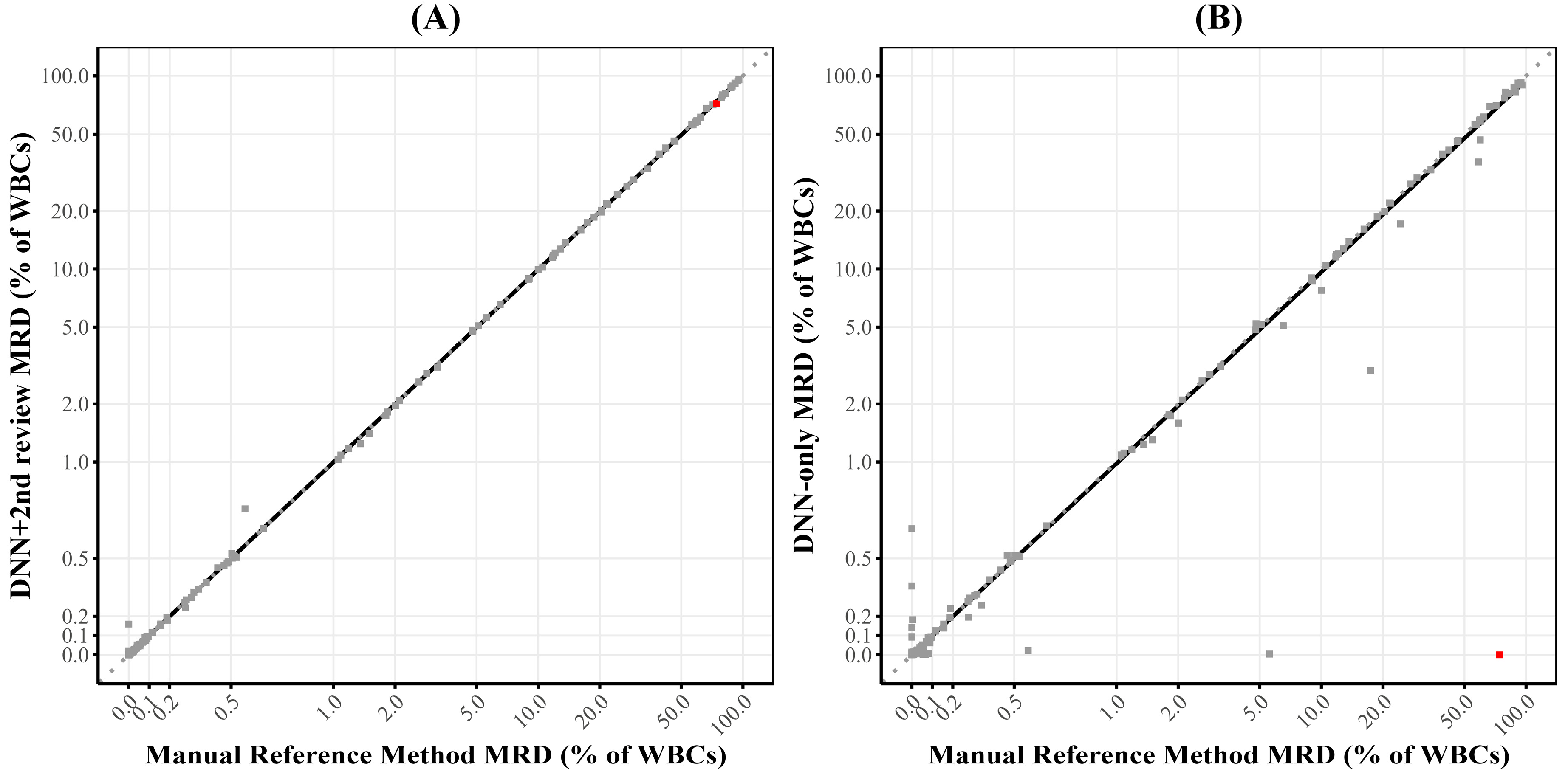
The method comparison study demonstrated excellent concordance between the DNN + 2nd review approach and the manual reference method relying on expert analysis, with 97.5% overall accuracy for qualitative determination and a correlation coefficient of 0.99 for quantitative assessment. The quantitative comparison showed no significant systematic bias, with a Deming regression slope of 0.99, well within our predefined acceptance criteria. These findings indicate that the DNN-assisted approach provides essentially equivalent diagnostic information to the current gold standard method while significantly improving laboratory workflow efficiency.
This efficiency improvement is clearly demonstrated by the timing study, which showed a consistent reduction in analysis time of approximately 60% compared to manual analysis (4.2 ± 2.3 min versus 10.5 ± 5.8 min), even after accounting for the additional quality assurance steps implemented to monitor for performance drift or shift over time. The persistence of this time reduction over a one-year period confirms that the efficiency gains are sustainable in routine clinical practice, not merely a short-term benefit during initial implementation. With an average time savings of 6.33 min per case and our laboratory’s annual volume of approximately 1500 CLL MRD cases, this translates to approximately 158 h of technologist time saved per year. This substantial efficiency improvement allows for better resource allocation, potentially reducing turnaround times and increasing laboratory capacity without requiring additional staffing. Similar efficiency improvements have been reported by other groups implementing AI-assisted workflows in clinical laboratory settings [
22], suggesting that this benefit is a consistent feature of successful AI integration rather than an isolated finding.
Our precision studies confirmed that the DNN + 2nd review method maintains the high level of precision established in the original validation, with excellent repeatability and within-laboratory precision for both qualitative and quantitative assessments. The qualitative precision study demonstrated no significant differences in sensitivity or specificity across multiple technologists, with near-perfect accordance and concordance statistics. The quantitative precision study showed that standard deviations for repeatability and within-laboratory precision were below the established upper verification limits for all but one sample, confirming that the DNN-assisted method achieves precision comparable to the original manual method. These findings align with previous studies demonstrating that AI-assisted approaches can reduce inter-operator variability in complex diagnostic tasks [
23,
24].
The analytical sensitivity verification confirmed the method’s ability to reliably detect and quantify CLL MRD at levels as low as 0.002%, consistent with the clinical requirements for MRD monitoring in CLL patients following therapy. This level of sensitivity is essential for early detection of disease recurrence and for evaluating treatment efficacy, particularly with the advent of novel targeted therapies that can achieve deep molecular responses [
25]. The importance of high analytical sensitivity in MRD detection has been emphasized by consensus guidelines and is critical for optimal patient management [
20].
Beyond the initial validation, our implementation of a multi-faceted performance monitoring system has provided valuable insights into the real-world performance of the AI-assisted workflow and established a model for continuous quality assurance of AI applications in clinical laboratories. The input data drift detection system identified a small percentage of cases (2.97%) that fall outside the expected distribution, primarily high-burden CLL cases and non-CLL neoplasms with distinct immunophenotypes. This finding highlights the importance of understanding the limitations of AI models trained on specific disease entities and the value of automated mechanisms for identifying cases that may challenge the model’s classification capabilities, i.e., out-of-distribution examples [
15,
26,
27].
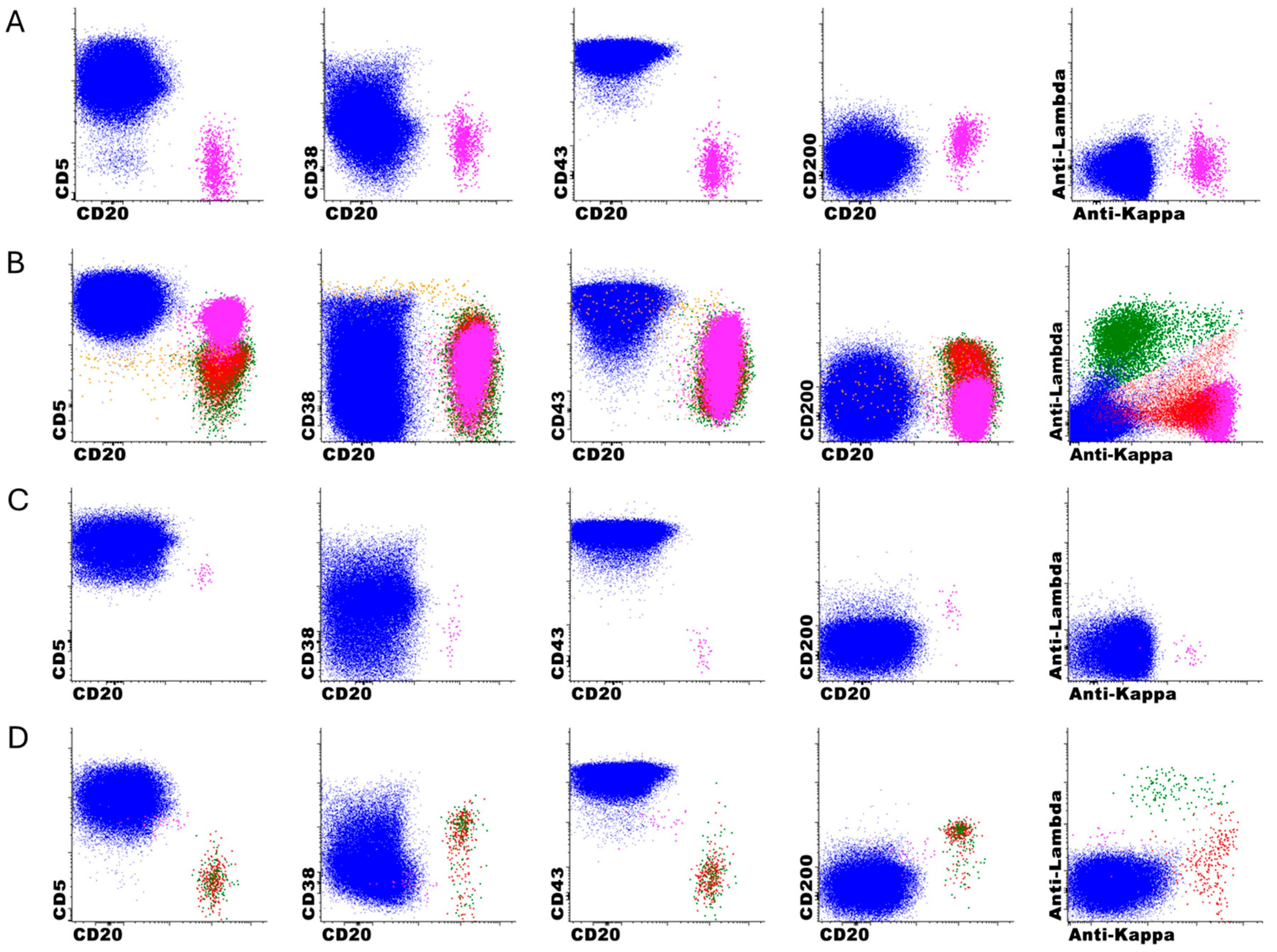
The error analysis monitoring revealed specific patterns in the performance of the DNN-only, with a high sensitivity (97%) but more modest specificity (59%) when compared DNN + 2nd review, which is expected since the DNN was optimized for high negative predictive value. It is important to clarify that this specificity concern primarily relates to the DNN-only analysis rather than the DNN + 2nd review approach, which demonstrated excellent performance in clinical validation (97.5% accuracy, 100% sensitivity, 94.6% specificity). Our approach intentionally prioritizes high sensitivity and NPV, as false-positive classifications can be readily corrected during expert review, whereas false-negatives are extremely difficult to detect among millions of events. To improve specificity while maintaining sensitivity, we are exploring several strategies, including gradient boosting methods, uncertainty quantification techniques, class weightings, and focal loss functions. It is also possible that the incorporation of other markers, such as CD79b or T cell markers, could improve the performance of the model. The analysis of missed cases identified specific immunophenotypic features that challenge the DNN’s classification abilities, particularly CD5-negative B-cell neoplasms (5/13) and lymphoproliferative disorders with atypical immunophenotypes (7/13), with only one classic CLL case missed due to low event counts just below our threshold. This information is valuable for both targeted education of laboratory staff and potential future refinements of the DNN model to improve its performance on these challenging edge cases. Similar error pattern analyses have been proposed to maintain patient safety at the forefront of AI development and facilitate safe clinical deployment [
28].
The attribute acceptance sampling program provided statistical verification that at least 95% of reported negative cases are true negatives (with 95% confidence), further validating the reliability of the DNN + 2nd review workflow for making negative determinations in routine clinical practice. This approach offers an efficient mechanism for ongoing verification of this critical performance characteristic without requiring exhaustive manual review of all negative cases, adapting established quality control techniques from manufacturing to the clinical laboratory setting [
29].
Together, these monitoring components form a comprehensive quality assurance framework that addresses the unique challenges of maintaining AI performance in clinical settings. AI models are inherently data-driven and susceptible to performance degradation over time due to factors, such as covariate shift or concept drift. Our monitoring framework directly addresses these challenges by incorporating mechanisms for detecting input data drift, tracking error patterns, and statistically verifying critical performance characteristics over time.
Bazinet et al. recently published their experience using DeepFlow, a commercially available AI-assisted FC analysis software for CLL MRD detection. They reported overall concordance of 96% between their AI-assisted analysis and expert manual gating, but a lower correlation for quantitative results of 0.865 compared to our workflow [
30]. Interestingly, they encountered similar challenges in cases with atypical immunophenotypes, particularly CLL with trisomy 12, which showed higher expression of B cell markers and lower CD43 expression that made AI classification more difficult. While the DeepFlow software offers a user-friendly graphical interface and rapid processing speed (3 s for ~1 million events), our DNN-assisted approach offers several advantages. Our model was specifically designed for implementation within existing clinical laboratory workflows, with complete integration into the Infinicyt software platform widely used in flow cytometry laboratories. Additionally, our comprehensive post-implementation monitoring system—including daily electronic quality control, input data drift detection, error analysis monitoring, and attribute acceptance sampling—provides ongoing safeguards that are essential for maintaining reliable performance in routine clinical use. Both studies highlight the potential of AI to dramatically improve laboratory efficiency while maintaining diagnostic accuracy, with each approach offering different advantages for implementation based on a laboratory’s specific needs and existing infrastructure. The human-in-the-loop design of both workflows represents a balanced approach to AI integration in clinical laboratories, leveraging the efficiency and standardization benefits of automation while maintaining expert oversight for cases that may challenge the AI model. This aligns with emerging best practices for clinical AI applications, which recognize that human expertise and AI capabilities are often complementary rather than competitive.
The limitations of our study include its focus on a specific disease entity (CLL) and flow cytometry panel at a single institution, which limits the generalizability of our findings to other applications and laboratories. Due to the inherent pre-analytical and analytical variability associated with instrument–reagent combinations and panel design, we expect that each laboratory would need to train and validate their own AI model with local data to account for site-specific variables, including instruments, reagents, and pre-analytic factors. Additionally, while our post-implementation monitoring has extended over several months, longer-term follow-up will be needed to fully assess the stability of the DNN model’s performance over time and across changing clinical and laboratory conditions. Whether model retraining can address performance degradation over time is also an unresolved question. Our DNN model was trained on post-treatment samples, enabling effective recognition of common treatment-induced immunophenotypic changes, such as CD20 negativity and dim CD23 expression. Error analysis revealed that missed cases were primarily attributable to atypical baseline immunophenotypes, rather than treatment-related changes. While our current model handles typical post-treatment modifications well, emerging therapies, such as CAR T-cell therapy, could introduce new challenges for flow cytometric CLL MRD detection.
Future work should focus on the development of more sophisticated drift detection algorithms that can differentiate between different types of drift (e.g., covariate shift versus concept drift), which could further refine our monitoring approach and provide more targeted guidance for model maintenance and updating [
31]. A promising avenue also involves the integration of uncertainty quantification methods to improve the detection and handling of atypical immunophenotypes. By implementing techniques, such as Monte Carlo dropout, deep ensembles, or Bayesian neural networks, we could quantify the model’s epistemic uncertainty (uncertainty due to limited knowledge) for each analyzed event and case [
32,
33,
34,
35]. High uncertainty values would automatically flag cases with unusual or ambiguous immunophenotypic features for closer expert review, potentially improving the detection of CD5-negative lymphoproliferative disorders and other non-CLL neoplasms that currently challenge the DNN. This technique would further enhance the human-in-the-loop workflow by focusing expert attention on the most challenging cases while allowing the DNN to operate independently on typical cases with high confidence, potentially driving additional efficiency improvements while maintaining or enhancing diagnostic accuracy.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}