
Classification of Mobile-Based Oral Cancer Images Using the Vision Transformer and the Swin Transformer


 ,
,
Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
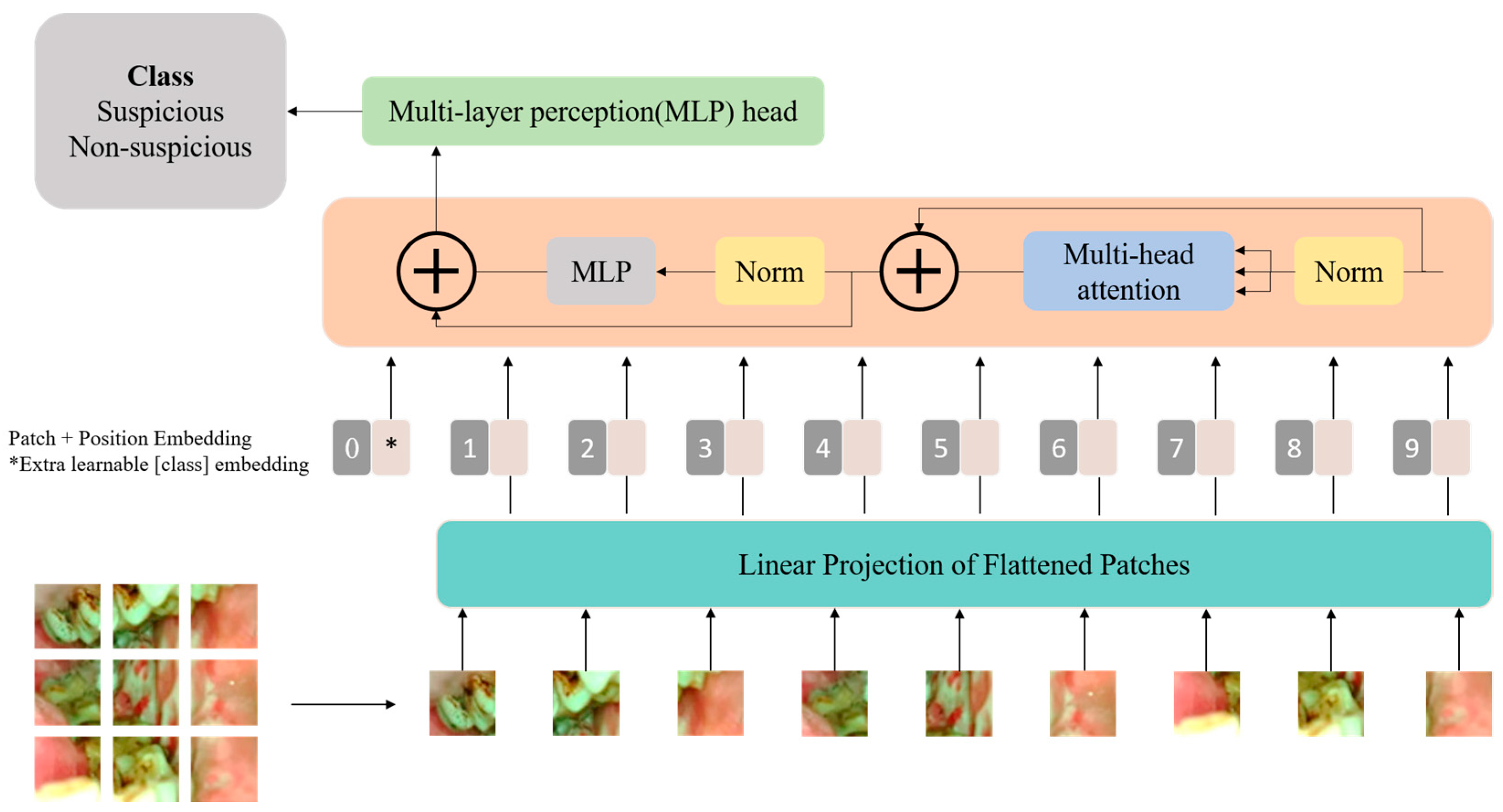
2.1. The Vision Transformer
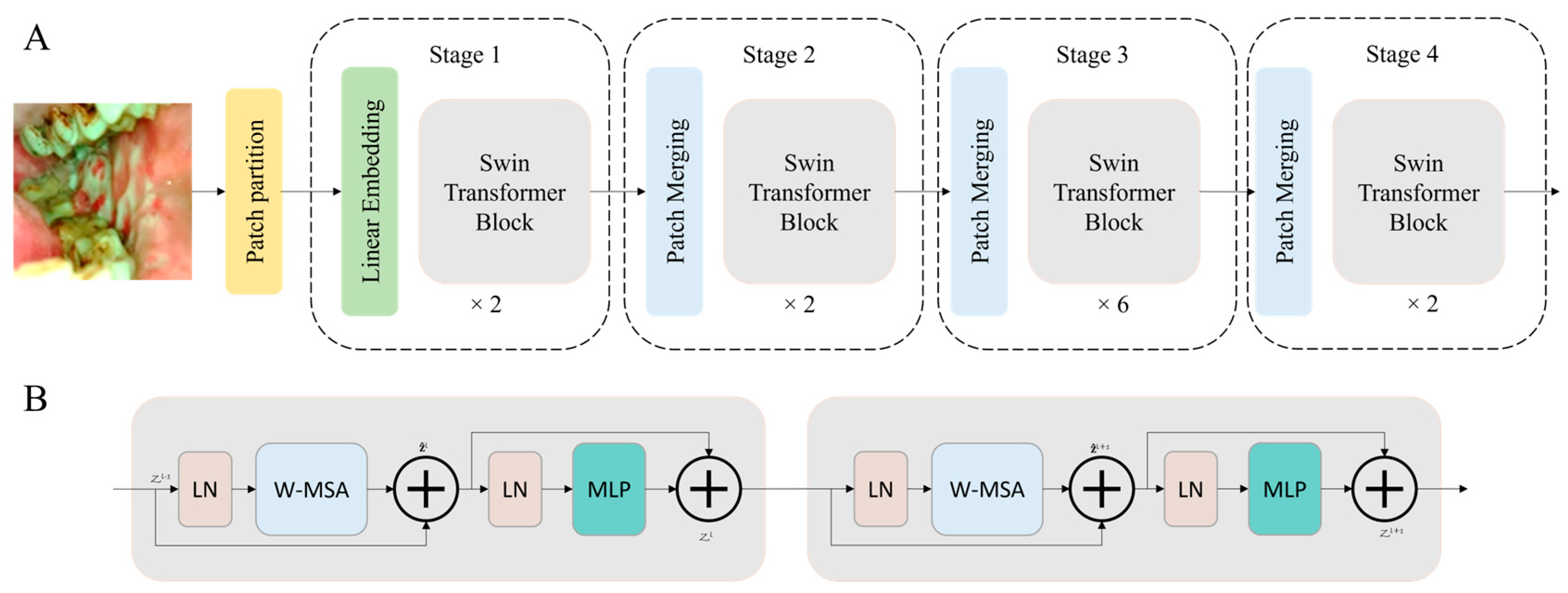
2.2. The Swin Transformer
2.3. CNN Models for Comparison
3. Experiments and Results
3.1. The Dataset
3.2. Data Augumentation
3.3. Pre-Training
3.4. Experiments Setup
3.5. The Experiments Results
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO Mortality Database. Available online: https://platform.who.int/mortality/themes/theme-details/topics/indicator-groups/indicators/indicator-details/MDB/a-lip-and-oral-cavity-cancers (accessed on 1 December 2023).
- Ferlay, J.; Colombet, M.; Soerjomataram, I.; Parkin, D.M.; Piñeros, M.; Znaor, A.; Bray, F. Cancer statistics for the year 2020: An overview. Int. J. Cancer 2021, 149, 778–789. [Google Scholar] [CrossRef]
- Thomas, A.; Manchella, S.; Koo, K.; Tiong, A.; Nastri, A.; Wiesenfeld, D.; Surgery, M. The impact of delayed diagnosis on the outcomes of oral cancer patients: A retrospective cohort study. Int. J. Oral Maxillofac. Surg. 2021, 50, 585–590. [Google Scholar] [CrossRef]
- Sujir, N.; Ahmed, J.; Pai, K.; Denny, C.; Shenoy, N. Challenges in early diagnosis of oral cancer: Cases series. Acta Stomatol. Croat. 2019, 53, 174. [Google Scholar] [CrossRef]
- Uthoff, R.D.; Song, B.; Sunny, S.; Patrick, S.; Suresh, A.; Kolur, T.; Keerthi, G.; Spires, O.; Anbarani, A.; Wilder-Smith, P.; et al. Point-of-care, smartphone-based, dual-modality, dual-view, oral cancer screening device with neural network classification for low-resource communities. PLoS ONE 2018, 13, e0207493. [Google Scholar] [CrossRef]
- Resteghini, C.; Trama, A.; Borgonovi, E.; Hosni, H.; Corrao, G.; Orlandi, E.; Calareso, G.; De Cecco, L.; Piazza, C.; Mainardi, L. Big data in head and neck cancer. Curr. Treat. Options Oncol. 2018, 19, 62. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Chen, E.; Banerjee, O.; Topol, E.J. AI in health and medicine. Nat. Med. 2022, 28, 31–38. [Google Scholar] [CrossRef]
- Hamet, P.; Tremblay, J.J.M. Artificial intelligence in medicine. Metabolism 2017, 69, S36–S40. [Google Scholar] [CrossRef]
- Chan, H.-P.; Samala, R.K.; Hadjiiski, L.M.; Zhou, C. Applications. Deep Learning in Medical Image Analysis; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–21. [Google Scholar]
- Song, B.; Sunny, S.; Uthoff, R.D.; Patrick, S.; Suresh, A.; Kolur, T.; Keerthi, G.; Anbarani, A.; Wilder-Smith, P.; Kuriakose, M.A. Automatic classification of dual-modalilty, smartphone-based oral dysplasia and malignancy images using deep learning. Biomed. Opt. Express 2018, 9, 5318–5329. [Google Scholar] [CrossRef]
- Song, B.; Li, S.; Sunny, S.; Gurushanth, K.; Mendonca, P.; Mukhia, N.; Patrick, S.; Gurudath, S.; Raghavan, S.; Tsusennaro, I. Classification of imbalanced oral cancer image data from high-risk population. J. Biomed. Opt. 2021, 26, 105001. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 280–296. [Google Scholar]
- Thisanke, H.; Deshan, C.; Chamith, K.; Seneviratne, S.; Vidanaarachchi, R.; Herath, D. Semantic segmentation using Vision Transformers: A survey. Eng. Appl. Artif. Intell. 2023, 126, 106669. [Google Scholar] [CrossRef]
- Lee, S.; Jung, Y.J. Hint-Based Image Colorization Based on Hierarchical Vision Transformer. Sensors 2022, 22, 7419. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Costa, G.S.S.; Paiva, A.C.; Junior, G.B.; Ferreira, M.M. COVID-19 automatic diagnosis with ct images using the novel transformer architecture. In Anais do XXI Simpósio Brasileiro de Computação Aplicada à Saúde; Sociedade Brasileira de Computação: Porto Alegre, Brazil, 2021; pp. 293–301. [Google Scholar]
- Tanzi, L.; Audisio, A.; Cirrincione, G.; Aprato, A.; Vezzetti, E.J.I. Vision transformer for femur fracture classification. Injury 2022, 53, 2625–2634. [Google Scholar] [CrossRef]
- Gheflati, B.; Rivaz, H. Vision transformers for classification of breast ultrasound images. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; pp. 480–483. [Google Scholar]
- Jiang, Z.; Dong, Z.; Wang, L.; Jiang, W. Neuroscience. Method for diagnosis of acute lymphoblastic leukemia based on ViT-CNN ensemble model. Comput. Intell. Neurosci. 2021, 2021, 7529893. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Chen, J.; He, Y.; Frey, E.C.; Li, Y.; Du, Y. Vit-v-net: Vision transformer for unsupervised volumetric medical image registration. arXiv 2021, arXiv:2104.06468. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Zhang, L.; Wen, Y. MIA-COV19D: A transformer-based framework for COVID19 classification in chest CTs. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 513–518. [Google Scholar]
- Xie, J.; Wu, Z.; Zhu, R.; Zhu, H. Melanoma detection based on swin transformer and SimAM. In Proceedings of the 2021 IEEE 5th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Xi’an, China, 15–17 October 2021; pp. 1517–1521. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; pp. 272–284. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Uthoff, R.D.; Song, B.; Sunny, S.; Patrick, S.; Suresh, A.; Kolur, T.; Gurushanth, K.; Wooten, K.; Gupta, V.; Platek, M.E.J.J.o.b.o. Small form factor, flexible, dual-modality handheld probe for smartphone-based, point-of-care oral and oropharyngeal cancer screening. J. Biomed. Opt. 2019, 24, 106003. [Google Scholar] [CrossRef] [PubMed]
- Birur, N.P.; Song, B.; Sunny, S.P.; Mendonca, P.; Mukhia, N.; Li, S.; Patrick, S.; AR, S.; Imchen, T.; Leivon, S.T.; et al. Field validation of deep learning based Point-of-Care device for early detection of oral malignant and potentially malignant disorders. Sci. Rep. 2022, 12, 14283. [Google Scholar] [CrossRef] [PubMed]
- Uthoff, R.D.; Song, B.; Birur, P.; Kuriakose, M.A.; Sunny, S.; Suresh, A.; Patrick, S.; Anbarani, A.; Spires, O.; Wilder-Smith, P. Development of a dual-modality, dual-view smartphone-based imaging system for oral cancer detection. In Proceedings of the Design and Quality for Biomedical Technologies XI, San Francisco, CA, USA, 27–28 January 2018; pp. 106–112. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Gao, Y.; Zhou, M.; Metaxas, D.N. UTNet: A hybrid transformer architecture for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part III 24. Springer: Berlin/Heidelberg, Germany, 2021; pp. 61–71. [Google Scholar]
- Bhojanapalli, S.; Chakrabarti, A.; Glasner, D.; Li, D.; Unterthiner, T.; Veit, A. Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10231–10241. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]



{kind=link}
{kind=link}
| 5-Fold Cross-Validation Results | Sensitivity | Specificity | PPV | NPV | Accuracy |
|---|---|---|---|---|---|
| VGG19 | 0.864 | 0.841 | 0.839 | 0.866 | 0.852 |
| ResNet50 | 0.848 | 0.842 | 0.838 | 0.853 | 0.845 |
| ViT | 0.872 | 0.856 | 0.853 | 0.875 | 0.864 |
| Swin Transformer | 0.905 | 0.870 | 0.870 | 0.905 | 0.887 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, B.; KC, D.R.; Yang, R.Y.; Li, S.; Zhang, C.; Liang, R. Classification of Mobile-Based Oral Cancer Images Using the Vision Transformer and the Swin Transformer. Cancers 2024, 16, 987. https://doi.org/10.3390/cancers16050987
Song B, KC DR, Yang RY, Li S, Zhang C, Liang R. Classification of Mobile-Based Oral Cancer Images Using the Vision Transformer and the Swin Transformer. Cancers. 2024; 16(5):987. https://doi.org/10.3390/cancers16050987
Chicago/Turabian StyleSong, Bofan, Dharma Raj KC, Rubin Yuchan Yang, Shaobai Li, Chicheng Zhang, and Rongguang Liang. 2024. "Classification of Mobile-Based Oral Cancer Images Using the Vision Transformer and the Swin Transformer" Cancers 16, no. 5: 987. https://doi.org/10.3390/cancers16050987
APA StyleSong, B., KC, D. R., Yang, R. Y., Li, S., Zhang, C., & Liang, R. (2024). Classification of Mobile-Based Oral Cancer Images Using the Vision Transformer and the Swin Transformer. Cancers, 16(5), 987. https://doi.org/10.3390/cancers16050987