3.1. One-Pixel Attack
Considering that the original image could be represented by an
n-dimensional array
,
f is the model we chose to attack. The input of model
f is the original image
x, from which the confidence level of what category
x is could be obtained, which is
f(x). The adversarial image is generated by perturbing a pixel in the original image
x. Here, the perturbed pixel is defined as
and the limit of the perturbation length is specified as
L. Supposing that the class set in the dataset is
the original image belongs to class
cori, and we want to change it into an adversarial class
cadv.
cadv and
cori C, hence this can be done using the following equation:
In a one-pixel attack scenario, since we only want to change one pixel, the value of L is set to 1. The most direct way to find the best solution is an exhaustive search, which involves trying every different pixel in the image. For a RGB image, there will be as many as possibilities. As a result, a more effective way to simulate adversarial attacks is a differential evolution.
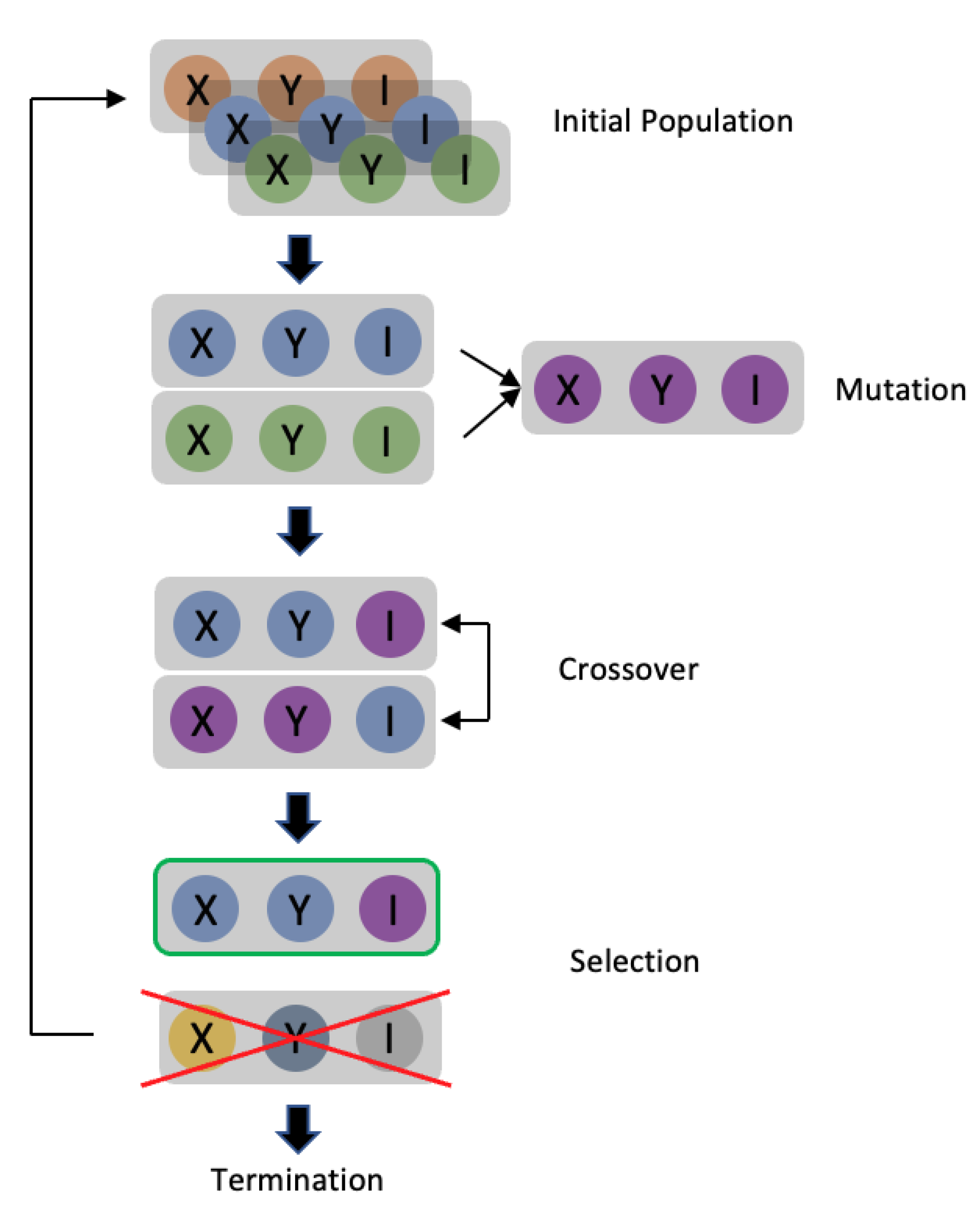
3.2. Differential Evolution
A differential evolution (DE) [
13] is a branch of an evolution strategy (ES) [
14]. The algorithm is developed by mimicking the natural breeding process. The DE process is shown in
Figure 1 with each stage described as follows:
- (1)
Initial populations
The process starts with the generation of possible solutions to the issue to be solved. Each potential solution is called a “gene”. A set of solutions is produced in each “generation”, which is the process of a specific run of the ES. This set of solutions is called a “population”. As mentioned above, f is the model to be attacked for the base image x. In a one-pixel attack, the solution is in the form of (X, Y, R, G, B) array if the base image is colored, or the form of (X, Y, I) array if the image is a greyscale one. X denotes the value of the x-coordinate, Y denotes the value of the y-coordinate, and I denotes the value of the grey level. The solution for the two-pixel attacks and three-pixel attacks is (X1, Y1, I1, X2, Y2, I2) and (X1, Y1, I1, X2, Y2, I2, X3, Y3, I3), respectively (greyscale image). The population size is set to 100, meaning that there will be 100 adversarial arrays in each generation of the DE. The initial population will be developed randomly, after which a set of parental adversarial arrays will be set The superscript indicates the number of generations, and the subscript indicates the index.
- (2)
Mutation
The following formula was used to generate new genes in the mutation process:
means that this is the j generation array with index i, and the apostrophe means that this is the offspring population. r is a random number ranging between 1 and the size of the parent population. F is the mutant factor that ranges from 0 to 1 and decides the strength of the mutation. According to the above formula, the mutant gene firstly comprises a random parental gene , and secondly, the difference between the two parental genes . The mutant factor decides how much the difference between the two random parental genes will affect the “base gene” . The offspring population is generated by repeating the above equation 100 times. Assuming that this is generation j in the DE process, the generated offspring population is denoted as .
- (3)
Crossover
Since the original one-pixel attack did not include a crossover, it was not used in this work.
- (4)
Selection
Unlike many other evolution strategies that enable the next generation of top performance genes to survive, DE uses a pairwise survival strategy to select the group of genes that will survive. The selection process will be applied to each parent and offspring pair. There will now be two sets of arrays in our work: and , each of which contains 100 arrays in the form of (X, Y, I) (for the one-pixel attack on a grayscale image). Each array will generate a corresponding adversarial image modified from the original image. Hence, the algorithm will now have two groups of adversarial images and . These images will then be input to trained model f to generate two sets of confidence level arrays, and . The performance of the adversarial images can be evaluated based on the confidence level. Supposing that the class set in the dataset and the original image belongs to class cori., the confidence level arrays that are generated can be denoted as . Each element of each confidence level array corresponds to the confidence level of the class. is how confident the model is that the image belongs to class ck. The groups of adversarial arrays that survive will then be selected when the algorithm pairs the confidence level arrays in an equation. It will compare each group of confidence levels, which means it will compare on the kth position of the confidence level array. Supposing that ck is the target class, the target attack experiment aims to maximize the fitness score. This means that the confidence level with the higher value should be reserved. For instance, the parental gene will perform better if . Notably, the algorithm will preserve the parental gene when the performance of both genes is similar. This group of preserved genes is then passed to the next step.
- (5)
Termination
An early-stop mechanism is established to determine if the performance is good enough. Based on the above selection process, the algorithm has 100 adversarial arrays corresponding to 100 adversarial images, each belonging to a specific class in class set C. In a non-target attack, the process will be terminated if one image has a class that is different from the original image. On the other hand, the process will be terminated in a targeted attack if one image has the same class as the target class; otherwise, the preserved group of genes will become the new parental initial population, and the DE process will be re-run. The process will also be terminated when the maximum iteration is reached.
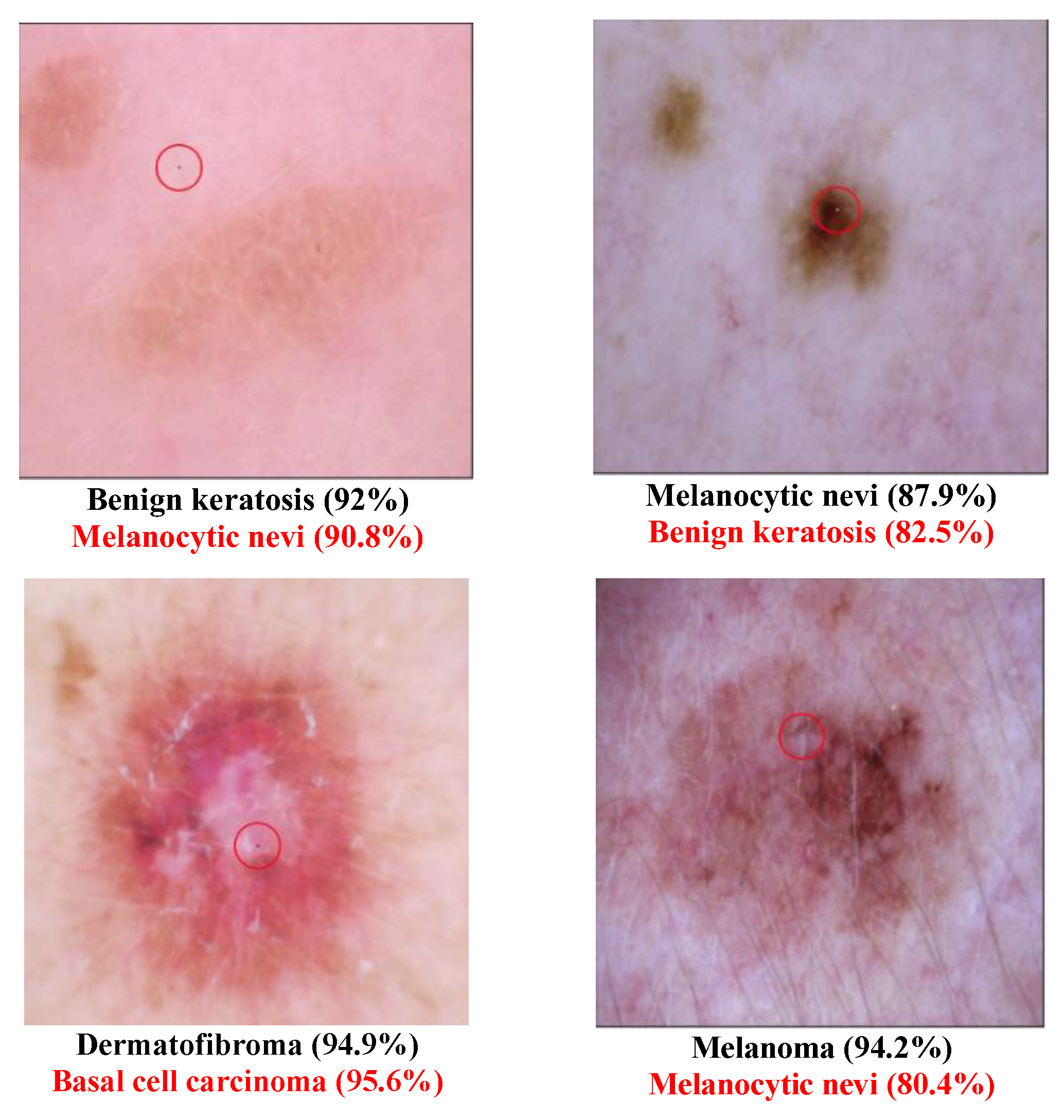
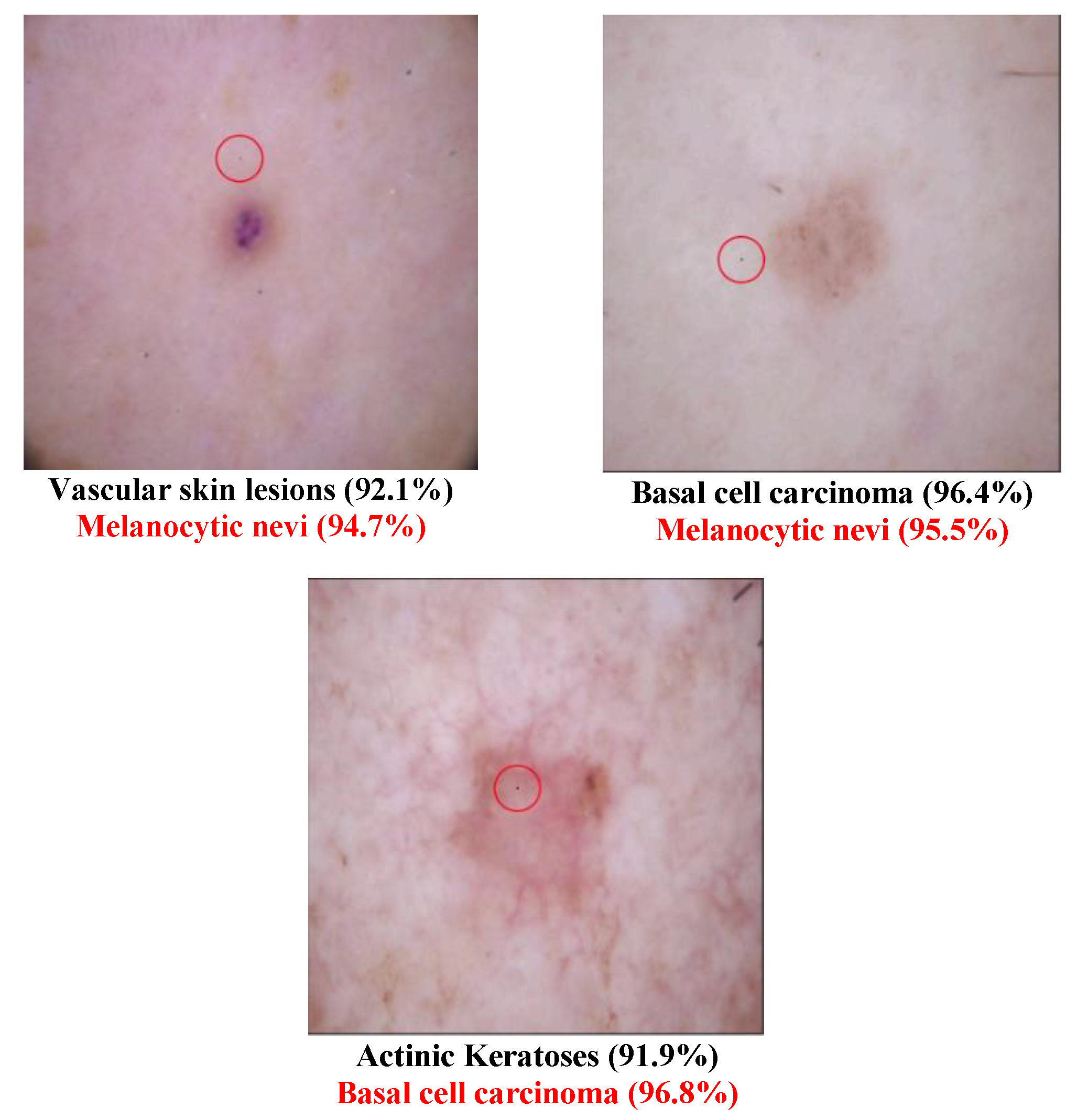
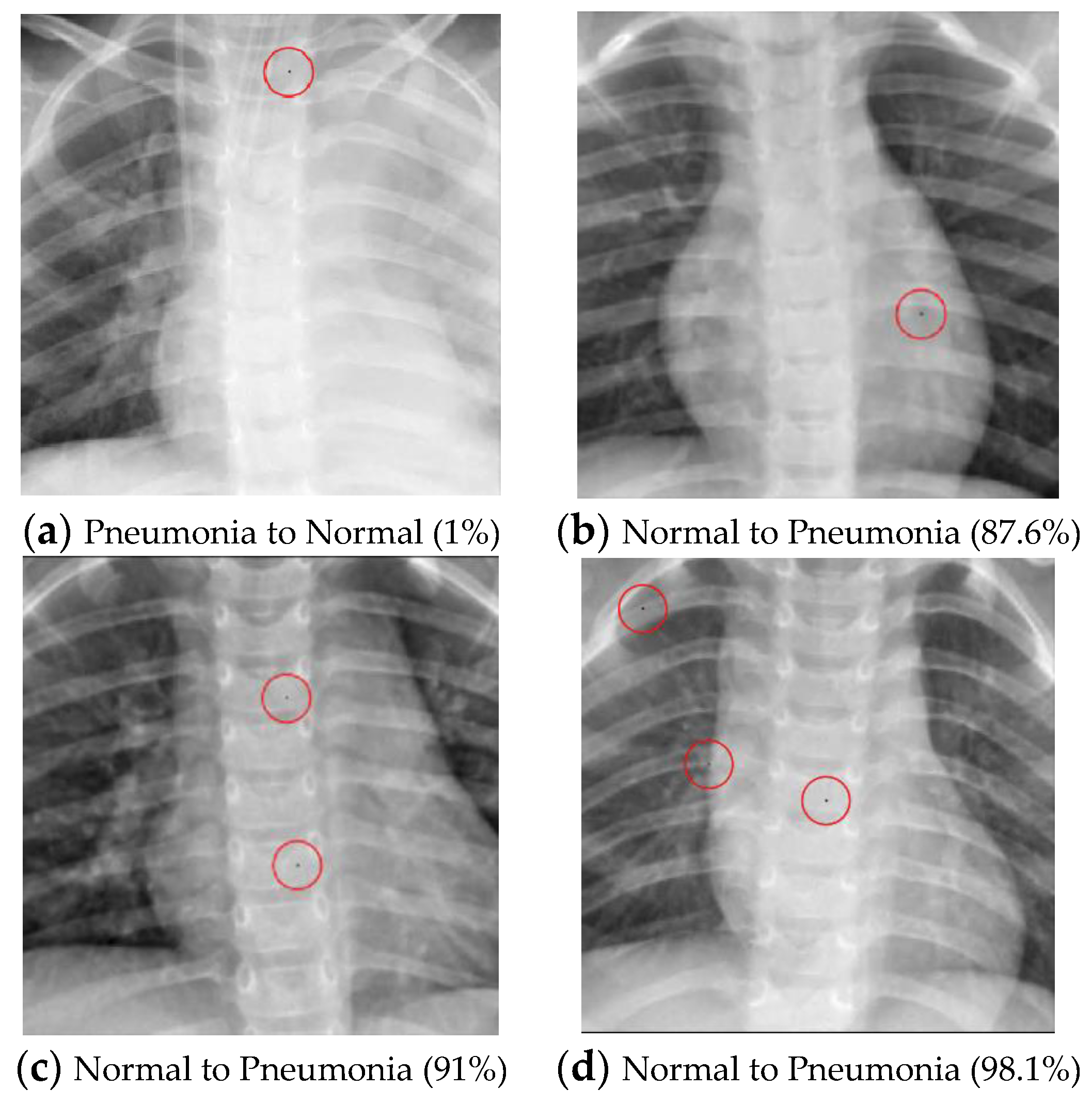
3.3. One-Pixel Attack Fitness Score Setting on a Multiclass Dataset and Multi-Label Dataset
Only multiclass datasets were used in the original one-pixel attack paper, but in medical images one image could contain multiple diseases, making a multi-label classification problem. The classifier not only needs to determine whether the image is diseased or not, but it also needs to identify all the diseases in the image. Recalling that a one-pixel attack uses DE to generate the adversarial images, and DE requires a fitness score to assess the performance of the generated images, the target or original class confidence level was used as the fitness score in the original one-pixel attack study. Suppose that the class set in the dataset is
, and the original image belongs to the class
.
, hence when this image is processed by the classifier it will generate a confidence interval vector
, and
will denote the confidence level of the original class.
. If the experiment involves conducting a non-target attack, the goal will be to minimize
. If the experiment involves conducting a targeted attack and the adversarial images need to become class
(
), the goal will be to maximize the confidence level of class
.
. The same technique will be used for the multiclass datasets in this study [
8], but for the multi-label datasets the algorithm may not look at just one specific class. It will look at multiple class confidence levels at once. Supposing that the class set in the dataset is
the image label can be constructed with an array
.
. Each
corresponds to each class
in the class set
and the value will be 0 or 1. If the value is 0, the image does not contain this class, but if the value is 1 it does. The image can be considered to be a multi-dimensional array
, and the classifier can be represented by
. When the image
is input to the classifier
,
will produce a set of confidence levels
. Threshold
can be set with a range from 0 to 1, where, if
, the algorithm will consider it to contain a class
disease. Therefore, if all
, the image is of a normal patient with no disease. Suppose that an image
that we want to attack is found with the original class set
.
is a subset of
and has a label form
.
is a subset of
. By inputting the image
into the classifier it becomes
, and the classifier has successfully predicted the image and produced confidence level
. Because all the elements in the
needed to be considered at once, cosine similarity is used in this study to construct the fitness score. The generated adversarial image
will be input into the classifier and become
hence producing an adversarial confidence level
. If this is a non-target attack, the formula will be as follows:
is a very small number that prevents the denominator from becoming 0. The goal is to minimize the above formula.
If this is the target attack and the target class set is
,
is a subset of
and has a label form
,
is a subset of
, the formula will be as follows:
The goal is to maximize the above formula. The algorithm transformed the label and confidence level range from [0, 1] to [−1, 1] as a reminder to calculate the cosine similarity. This is because if the label is all zeroes, the cosine similarity will always be zero, causing the fitness function to fail.




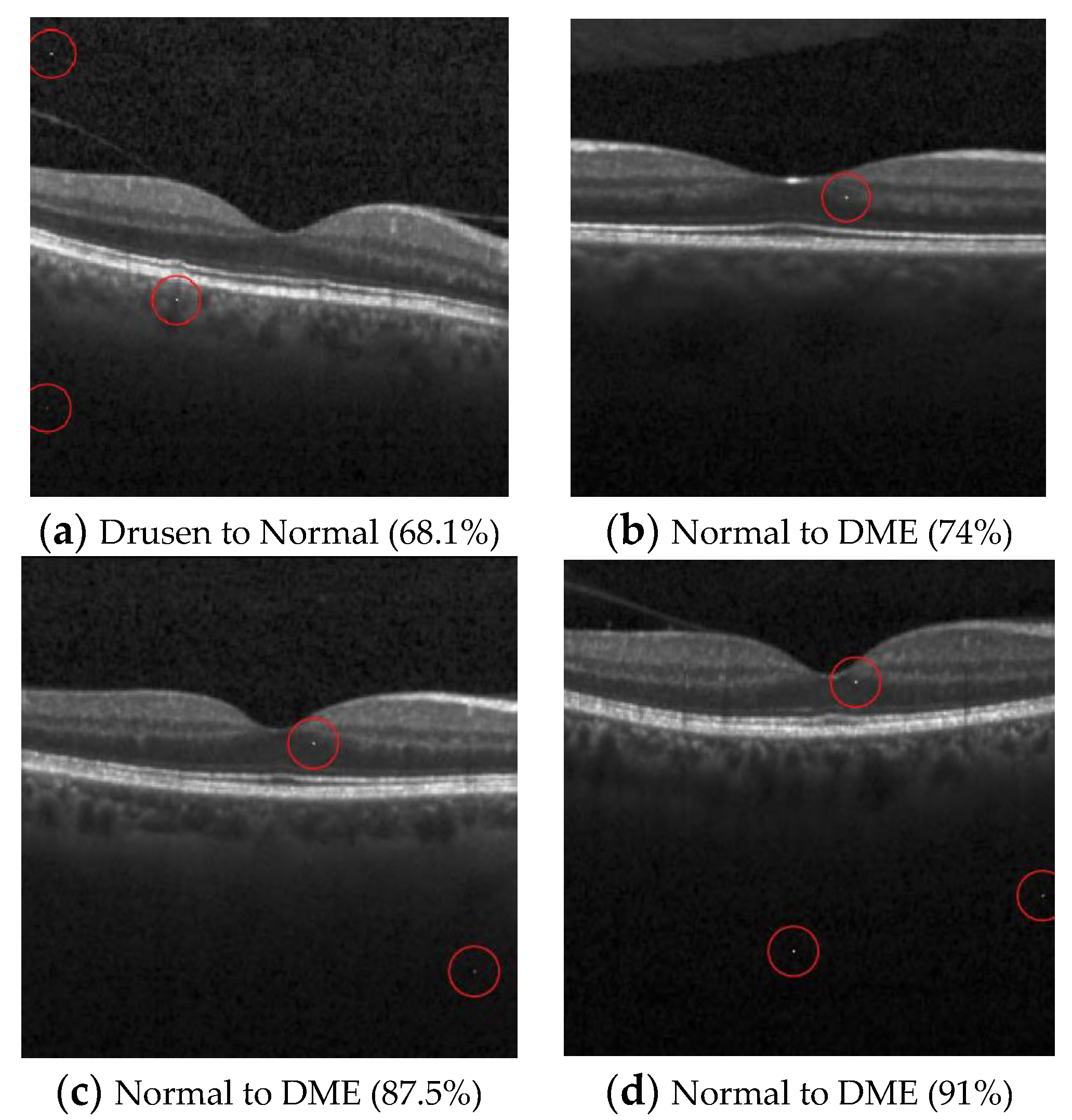






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}