
Using Single-Voxel Magnetic Resonance Spectroscopy Data Acquired at 1.5T to Classify Multivoxel Data at 3T: A Proof-of-Concept Study

 ,
,  ,
,  ,
, 
Abstract
Simple Summary
Abstract

1. Introduction
2. Materials and Methods
2.1. Datasets
- The MV is stored as a valid experiment in the eTDB (not marked as test case).
- Acquisition was done using PRESS or semi-Laser sequences.
- Echo time (TE) is short TE (30–32 ms).
- The diagnosis of the case is mm, gb, me, lgg (a2, od or oa).
- The MRI study must be fully loaded into the eTDB, i.e., the whole set of images must be uploaded; therefore, the number of MRI slices could not be lower than the number of MRS slices.
- For multi-slice MV acquisitions, the number of MRS slices had to be the same as the available MRI slices.
- The data format should allow for the extraction of the parameters for MV grid localization over the corresponding MRI slice.
2.2. MRI Processing of the eTDB Data
2.3. MV Voxel Labelling
2.4. Quality Control
2.5. Classification Tasks
- 4-class task: mm vs. lgg vs. agg vs. no
- 3-class task: mm vs. agg vs. no.
2.6. Feature Selection
2.7. Classification
2.8. Classifier Evaluation
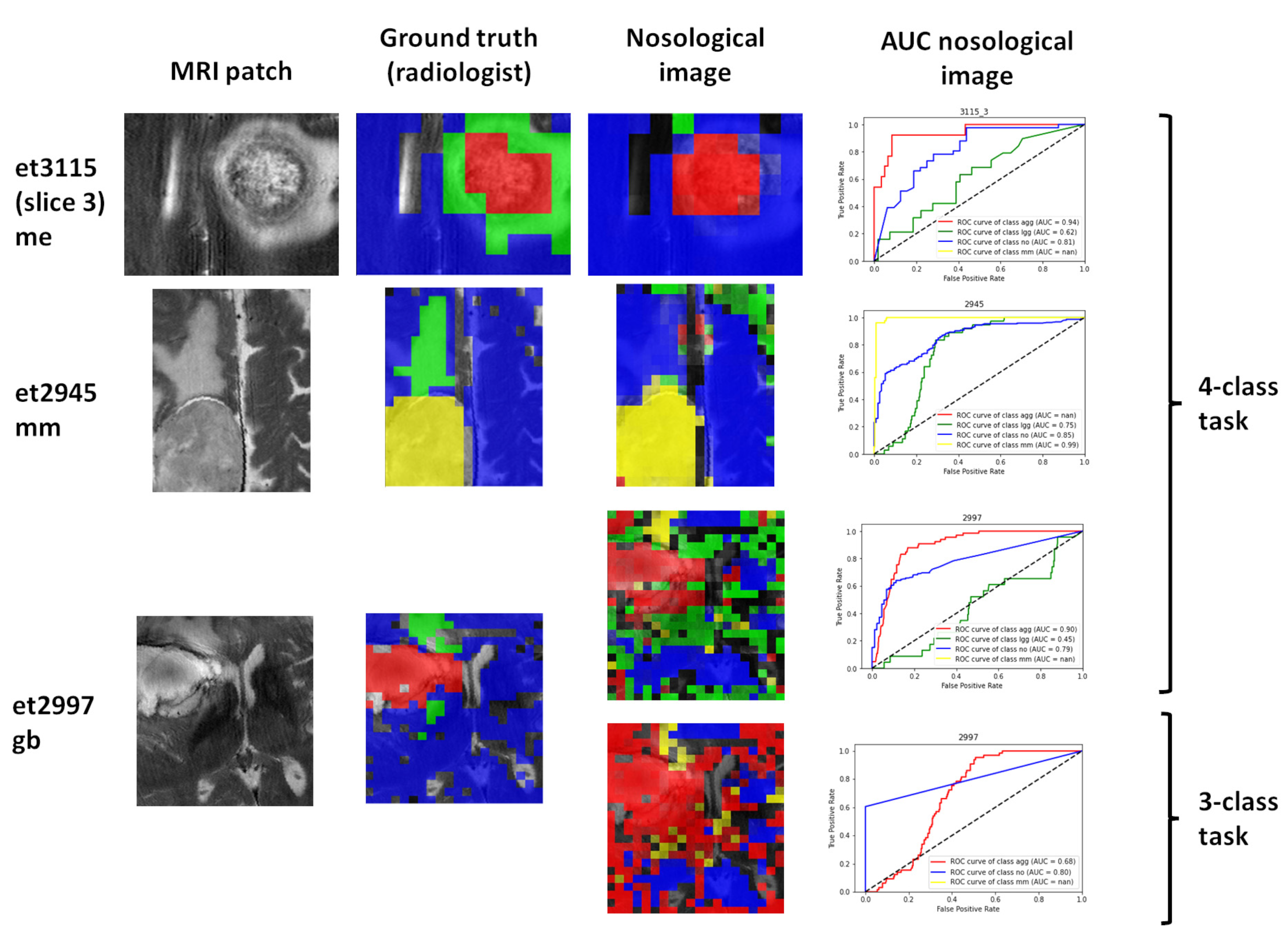
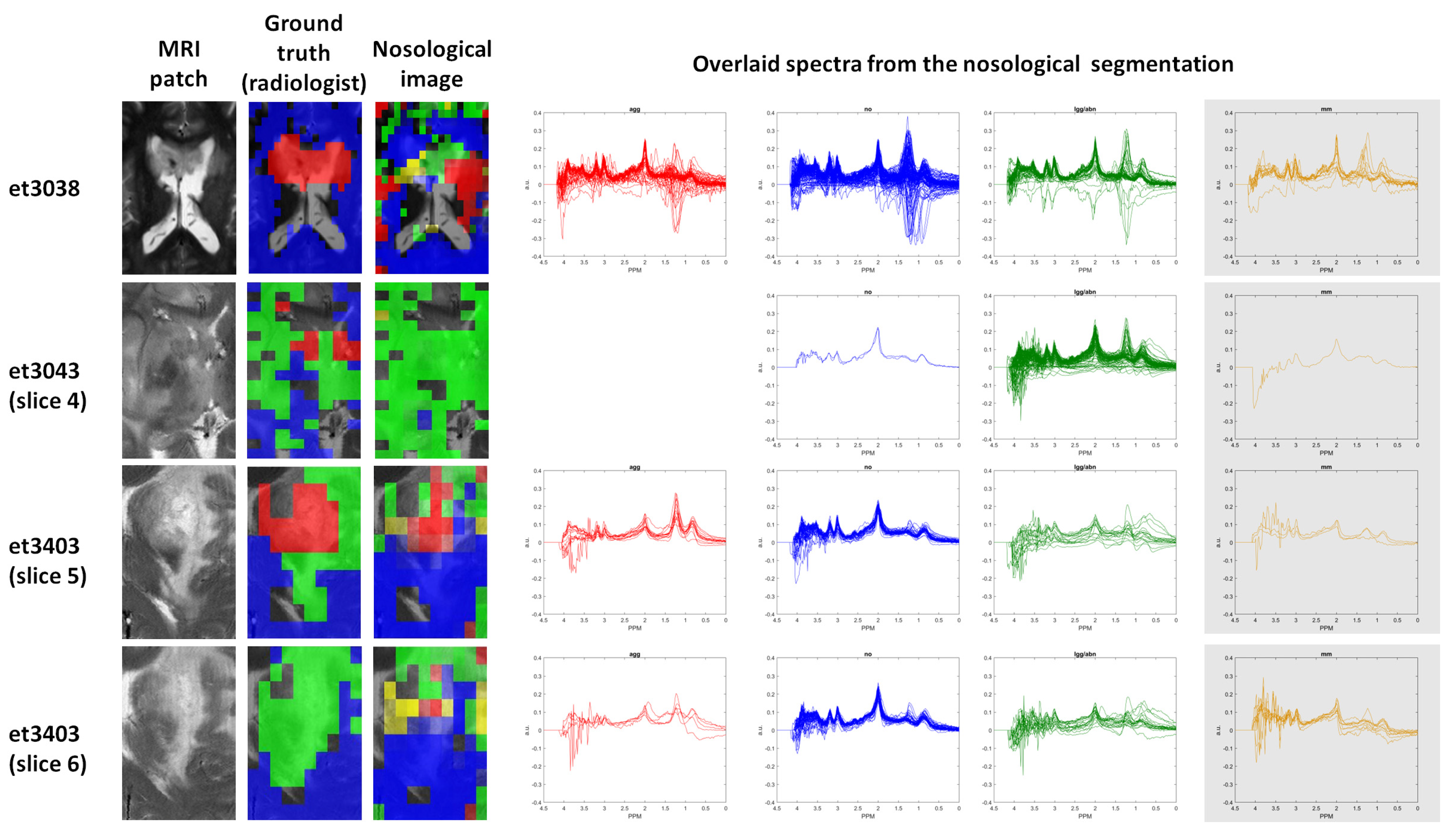
2.9. Visualization of the Test Set Classification: Nosological Maps
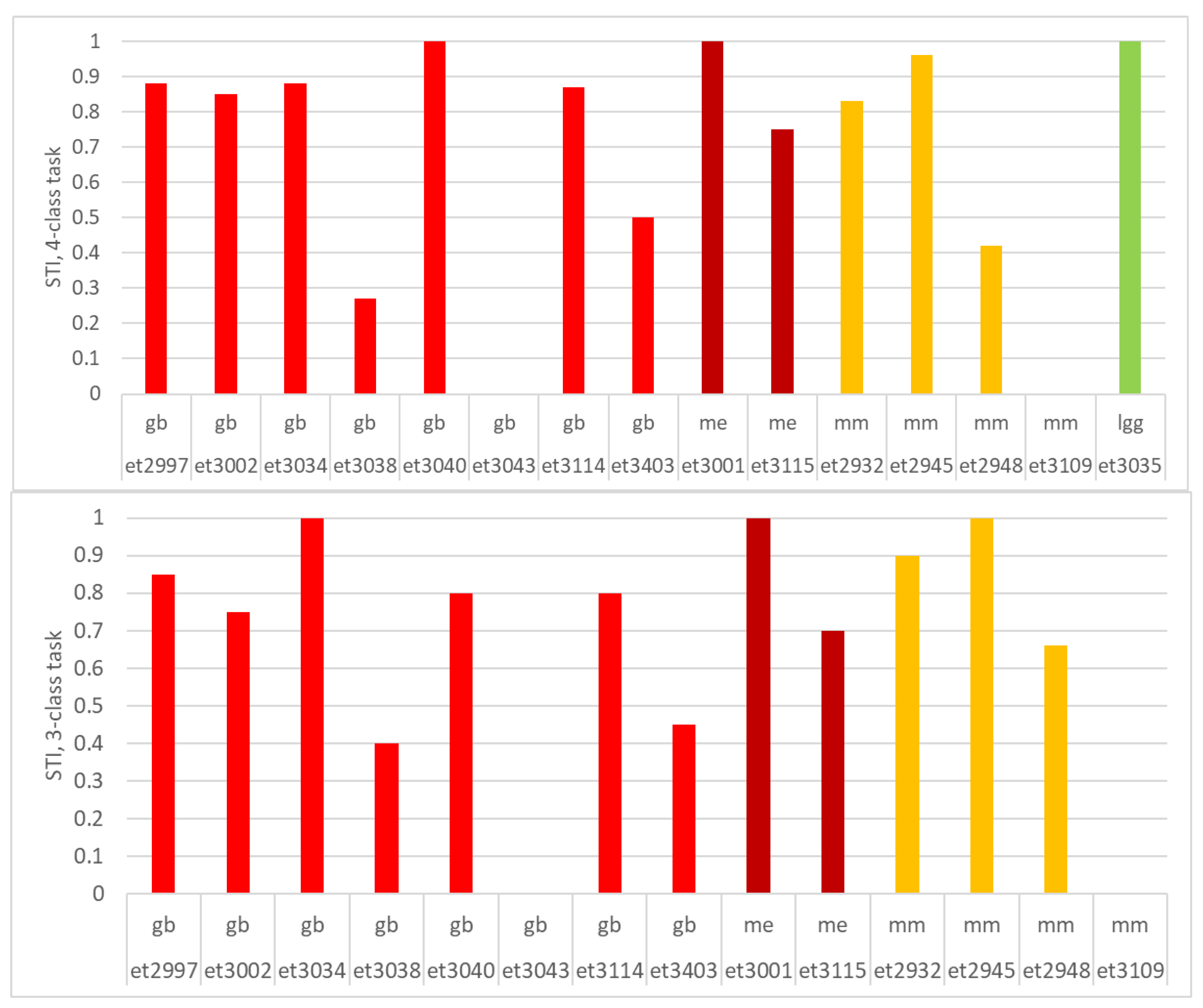
2.10. Nosological Image Evaluation
- Whether the class of the solid tumor region corresponded to the diagnosis of the patient.
- Whether the localization of the solid tumor region agreed with the MRI segmentation performed by the radiologist.
- Whether it agreed with the MRI segmentation (in cases where the radiologist marked a surrounding, abnormal area).
3. Results
3.1. Available Data
3.2. Feature Selection and Classification Results
3.3. Visualization Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Negendank, W. Studies of human tumors by MRS: A review. NMR Biomed. 1992, 5, 303–324. [Google Scholar] [CrossRef]
- Preul, M.C.; Caramanos, Z.; Collins, D.L.; Villemure, J.G.; Leblanc, R.; Olivier, A.; Pokrupa, R.; Arnold, D.L. Accurate, noninvasive diagnosis of human brain tumors by using proton magnetic resonance spectroscopy. Nat. Med. 1996, 2, 323–325. [Google Scholar] [CrossRef] [PubMed]
- Arias-Mendoza, F.; Payne, G.S.; Zakian, K.L.; Schwarz, A.J.; Stubbs, M.; Stoyanova, R.; Ballon, D.; Howe, F.A.; Koutcher, J.A.; Leach, M.O.; et al. In vivo 31P MR spectral patterns and reproducibility in cancer patients studied in a multi-institutional trial. NMR Biomed. 2006, 19, 504–512. [Google Scholar] [CrossRef] [PubMed]
- Tate, A.R.; Griffiths, J.R.; Martinez-Perez, I.; Moreno, A.; Barba, I.; Cabanas, M.E.; Watson, D.; Alonso, J.; Bartumeus, F.; Isamat, F.; et al. Towards a method for automated classification of 1H MRS spectra from brain tumours. NMR Biomed. 1998, 11, 177–191. [Google Scholar] [CrossRef]
- McKnight, T.R.; von dem Bussche, M.H.; Vigneron, D.B.; Lu, Y.; Berger, M.S.; McDermott, M.W.; Dillon, W.P.; Graves, E.E.; Pirzkall, A.; Nelson, S.J. Histopathological validation of a three-dimensional magnetic resonance spectroscopy index as a predictor of tumor presence. J. Neurosurg. 2002, 97, 794–802. [Google Scholar] [CrossRef] [PubMed]
- De Vos, M.; Laudadio, T.; Simonetti, A.W.; Heerschap, A.; Van Huffel, S.; Laudadio, T.; Heerschap, A.; De Vos, M.; Laudadio, T.; Simonetti, A.W.; et al. Fast nosologic imaging of the brain. J. Magn. Reson. 2007, 184, 292–301. [Google Scholar] [CrossRef]
- Simonetti, A.W.; Melsse, W.J.; van der Graaf, M.; Heerschap, A.; Buydens, L.M.C.; Melssen, W.J.; van der Graaf, M.; Postma, G.J.; Heerschap, A.; Buydens, L.M.C. A new chemometric approach for brain tumor classification using magnetic resonance imaging ad spectroscopy. Anal. Chem. 2003, 75, 5352–5361. [Google Scholar] [CrossRef]
- Hangel, G.; Cadrien, C.; Lazen, P.; Furtner, J.; Lipka, A.; Hečková, E.; Hingerl, L.; Motyka, S.; Gruber, S.; Strasser, B.; et al. High-resolution metabolic imaging of high-grade gliomas using 7T-CRT-FID-MRSI. Neuroimage Clin. 2020, 28, 102433. [Google Scholar] [CrossRef]
- Majos, C.; Bruna, J.; Julia-Sape, M.; Cos, M.; Camins, A.; Gil, M.; Acebes, J.J.J.; Aguilera, C.; Arus, C.; Majós, C.; et al. Proton MR spectroscopy provides relevant prognostic information in high-grade astrocytomas. Am. J. Neuroradiol. 2011, 32, 74–80. [Google Scholar] [CrossRef]
- Li, X.; Jin, H.; Lu, Y.; Oh, J.; Chang, S.; Nelson, S.J. Identification of MRI and 1H MRSI parameters that may predict survival for patients with malignant gliomas. NMR Biomed. 2004, 17, 10–20. [Google Scholar] [CrossRef]
- Hattingen, E.; Raab, P.; Franz, K.; Lanfermann, H.; Setzer, M.; Gerlach, R.; Zanella, F.; Pilatus, U. Prognostic value of choline and creatine in WHO grade II gliomas. Neuroradiology 2008, 50, 759–767. [Google Scholar] [CrossRef]
- Wilson, M.; Andronesi, O.; Barker, P.B.; Bartha, R.; Bizzi, A.; Bolan, P.J.; Brindle, K.M.; Choi, I.-Y.; Cudalbu, C.; Dydak, U.; et al. Methodological consensus on clinical proton MRS of the brain: Review and recommendations. Magn. Reson. Med. 2019, 82, 527–550. [Google Scholar] [CrossRef]
- Tkáč, I.; Deelchand, D.; Dreher, W.; Hetherington, H.; Kreis, R.; Kumaragamage, C.; Považan, M.; Spielman, D.M.; Strasser, B.; de Graaf, R.A. Water and lipid suppression techniques for advanced 1H MRS and MRSI of the human brain: Experts’ consensus recommendations. NMR Biomed. 2021, 34, e4459. [Google Scholar] [CrossRef] [PubMed]
- Kreis, R.; Boer, V.; Choi, I.-Y.; Cudalbu, C.; de Graaf, R.A.; Gasparovic, C.; Heerschap, A.; Krššák, M.; Lanz, B.; Maudsley, A.A.; et al. Terminology and concepts for the characterization of in vivo MR spectroscopy methods and MR spectra: Background and experts’ consensus recommendations. NMR Biomed. 2021, 34, e4347. [Google Scholar] [CrossRef] [PubMed]
- Öz, G.; Deelchand, D.K.; Wijnen, J.P.; Mlynárik, V.; Xin, L.; Mekle, R.; Noeske, R.; Scheenen, T.W.J.; Tkáč, I.; Andronesi, O.; et al. Advanced single voxel 1H magnetic resonance spectroscopy techniques in humans: Experts’ consensus recommendations. NMR Biomed. 2021, 34, e4236. [Google Scholar] [CrossRef] [PubMed]
- Oeltzschner, G. MRSHub. Available online: https://mrshub.netlify.com/ (accessed on 20 July 2023).
- Scheenen, T.J.; Heerschap, A.; Klomp, D.J. Towards 1H-MRSI of the human brain at 7T with slice-selective adiabatic refocusing pulses. Magn. Reason. Mater. Phys. 2008, 21, 95–101. [Google Scholar] [CrossRef] [PubMed]
- Zarinabad, N.; Wilson, M.; Gill, S.K.; Manias, K.A.; Davies, N.P.; Peet, A.C. Multiclass imbalance learning: Improving classification of pediatric brain tumors from magnetic resonance spectroscopy. Magn. Reson. Med. 2017, 77, 2114–2124. [Google Scholar] [CrossRef]
- Shamaei, A.; Starcukova, J.; Pavlova, I.; Starcuk, Z. Model-informed unsupervised deep learning approaches to frequency and phase correction of MRS signals. Magn. Reason. Med. 2023, 89, 1221–1236. [Google Scholar] [CrossRef]
- Kyathanahally, S.P.; Döring, A.; Kreis, R. Deep learning approaches for detection and removal of ghosting artifacts in MR spectroscopy. Magn. Reson. Med. 2018, 80, 851–863. [Google Scholar] [CrossRef]
- Tate, A.R.; Underwood, J.; Acosta, D.M.; Julia-Sape, M.; Majos, C.; Moreno-Torres, A.; Howe, F.A.; van der Graaf, M.; Lefournier, V.; Murphy, M.M.; et al. Development of a decision support system for diagnosis and grading of brain tumours using in vivo magnetic resonance single voxel spectra. NMR Biomed. 2006, 19, 411–434. [Google Scholar] [CrossRef]
- Julià-Sapé, M.; Acosta, D.; Mier, M.; Arùs, C.; Watson, D. A multi-centre, web-accessible and quality control-checked database of in vivo MR spectra of brain tumour patients. Magn. Reson. Mater. Phys. Biol. Med. 2006, 19, 22–33. [Google Scholar] [CrossRef] [PubMed]
- Julià-Sapé, M.; Lurgi, M.; Mier, M.; Estanyol, F.; Rafael, X.; Candiota, A.P.; Barceló, A.; García, A.; Martínez-Bisbal, M.C.; Ferrer-Luna, R.; et al. Strategies for annotation and curation of translational databases: The eTUMOUR project. Database J. Biol. Databases Curation 2012, 2012, bas035. [Google Scholar] [CrossRef] [PubMed]
- Julià-Sapé, M.; Griffiths, J.R.; Tate, R.A.; Howe, F.A.; Acosta, D.; Postma, G.; Underwood, J.; Majós, C.; Arús, C. Classification of brain tumours from MR spectra: The INTERPRET collaboration and its outcomes. NMR Biomed. 2015, 28, 1772–1787. [Google Scholar] [CrossRef] [PubMed]
- Kleihues, P.; Cavenee, W.K. Pathology and Genetics of Tumours of the Nervous System, New ed.; IARC Press: Lyon, France, 2000. [Google Scholar]
- Kleihues, P.; Louis, D.N.; Scheithauer, B.W.; Rorke, L.B.; Reifenberger, G.; Burger, P.C.; Cavenee, W.K. The WHO Classification of Tumors of the Nervous System. J. Neuropathol. Exp. Neurol. 2002, 61, 215–225. [Google Scholar] [CrossRef]
- Ortega-Martorell, S.; Julia-Sapé, M.; Lisboa, P.; Arús, C. Pattern recognition analysis of MR spectra. eMagRes 2016, 5, 945–958. [Google Scholar] [CrossRef]
- Ortega-Martorell, S.; Olier, I.; Julià-Sapé, M.; Arús, C. SpectraClassifier 1.0: A user friendly, automated MRS-based classifier-development system. BMC Bioinform. 2010, 11, 106. [Google Scholar] [CrossRef]
- Ortega-Martorell, S.; Lisboa, P.J.G.; Vellido, A.; Julià-Sapé, M.; Arús, C. Non-negative matrix factorisation methods for the spectral decomposition of MRS data from human brain tumours. BMC Bioinform. 2012, 13, 38. [Google Scholar] [CrossRef]
- Vellido, A.; Romero, E.; Julià-Sapé, M.; Majós, C.; Moreno-Torres, À.; Pujol, J.; Arús, C. Robust discrimination of glioblastomas from metastatic brain tumors on the basis of single-voxel 1H MRS. NMR Biomed. 2012, 25, 819–828. [Google Scholar] [CrossRef]
- Vellido, A.; Romero, E.; González-Navarro, F.F.; Belanche-Muñoz, L.A.; Juliá-Sapé, M.; Arús, C. Outlier exploration and diagnostic classification of a multi-centre 1H-MRS brain tumour database. Neurocomputing 2009, 72, 3085–3097. [Google Scholar] [CrossRef]
- Fuster-Garcia, E.; Tortajada, S.; Vicente, J.; Robles, M.; García-Gómez, J.M. Extracting MRS discriminant functional features of brain tumors. NMR Biomed. 2013, 26, 578–592. [Google Scholar] [CrossRef]
- Tortajada, S.; Fuster-Garcia, E.; Vicente, J.; Wesseling, P.; Howe, F.A.; Julia-Sape, M.; Candiota, A.P.A.-P.P.; Monleon, D.; Moreno-Torres, A.; Pujol, J.; et al. Incremental Gaussian Discriminant Analysis based on Graybill and Deal weighted combination of estimators for brain tumour diagnosis. J. Biomed. Inform. 2011, 44, 677–687. [Google Scholar] [CrossRef] [PubMed]
- Fuster-Garcia, E.; Navarro, C.; Vicente, J.; Tortajada, S.; García-Gómez, J.M.; Sáez, C.; Calvar, J.; Griffiths, J.; Julià-Sapé, M.; Howe, F.A.; et al. Compatibility between 3T 1H SV-MRS data and automatic brain tumour diagnosis support systems based on databases of 1.5T 1H SV-MRS spectra. Magn. Reson. Mater. Phys. Biol. Med. 2011, 24, 35–42. [Google Scholar] [CrossRef] [PubMed]
- García-Gómez, J.M.; Luts, J.; Julià-Sapé, M.; Krooshof, P.; Tortajada, S.; Robledo, J.V.; Melssen, W.; Fuster-García, E.; Olier, I.; Postma, G.; et al. Multiproject-multicenter evaluation of automatic brain tumor classification by magnetic resonance spectroscopy. Magn. Reson. Mater. Phys. Biol. Med. 2009, 22, 5–18. [Google Scholar] [CrossRef]
- García-Gómez, J.M.; Tortajada, S.; Vidal, C.; Julià-Sape, M.; Luts, J.; Moreno-Torres, A.; Van Huffel, S.; Arús, C.; Robles, M. The effect of combining two echo times in automatic brain tumor classification by MRS. NMR Biomed. 2008, 21, 1112–1125. [Google Scholar] [CrossRef] [PubMed]
- Zandt, H.I.; van Der Graaf, M.; Heerschap, A. Common processing of in vivo MR spectra. NMR Biomed. 2001, 14, 224–232. [Google Scholar] [CrossRef]
- Julia-Sape, M.; Arias-Mendoza, F.; Griffiths, J.R. Clinical trials of MRS methods. eMagRes 2015, 4, 779–788. [Google Scholar] [CrossRef]
- Pérez-Ruiz, A.; Julià-Sapé, M.; Mercadal, G.; Olier, I.; Majós, C.; Arús, C. The INTERPRET Decision-Support System version 3.0 for evaluation of Magnetic Resonance Spectroscopy data from human brain tumours and other abnormal brain masses. BMC Bioinform. 2010, 11, 581. [Google Scholar] [CrossRef]
- Mocioiu, V.; Ortega-Martorell, S.; Olier, I.; Jablonski, M.; Starcukova, J.; Lisboa, P.; Arús, C.; Julià-Sapé, M. From raw data to data-analysis for magnetic resonance spectroscopy—The missing link: jMRUI2XML. BMC Bioinform. 2015, 16, 378. [Google Scholar] [CrossRef]
- Stefan, D.; Cesare, F.D.; Andrasescu, A.; Popa, E.; Lazariev, A.; Vescovo, E.; Strbak, O.; Williams, S.; Starcuk, Z.; Cabanas, M.; et al. Quantitation of magnetic resonance spectroscopy signals: The jMRUI software package. Meas. Sci. Technol. 2009, 20, 104035. [Google Scholar] [CrossRef]
- Edden, R.A.E.; Puts, N.A.J.; Harris, A.D.; Barker, P.B.; Evans, C.J. Gannet: A batch-processing tool for the quantitative analysis of gamma-aminobutyric acid–edited MR spectroscopy spectra. J. Magn. Reson. Imaging 2014, 40, 1445–1452. [Google Scholar] [CrossRef]
- Hernández-Villegas, Y.; Ortega-Martorell, S.; Arús, C.; Vellido, A.; Julià-Sapé, M. Extraction of artefactual MRS patterns from a large database using non-negative matrix factorization. NMR Biomed. 2022, 35, e4193. [Google Scholar] [CrossRef] [PubMed]
- Sklearn.Feature_Selection.chi2—Scikit-Learn 1.2.0 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.chi2.html (accessed on 12 July 2023).
- Sklearn.Feature_Selection.SequentialFeatureSelector, Scikit-Learn. Available online: https://scikit-learn/stable/modules/generated/sklearn.feature_selection.SequentialFeatureSelector.html (accessed on 12 July 2023).
- Boruta · PyPI. Available online: https://pypi.org/project/Boruta/ (accessed on 12 July 2023).
- Sklearn.Feature_Selection.SelectKBest, Scikit-Learn. Available online: https://scikit-learn/stable/modules/generated/sklearn.feature_selection.SelectKBest.html (accessed on 12 July 2023).
- Sklearn.Linear_Model.Lasso, Scikit-Learn. Available online: https://scikit-learn/stable/modules/generated/sklearn.linear_model.Lasso.html (accessed on 20 July 2023).
- Numpy.Corrcoef—NumPy v1.24 Manual. Available online: https://numpy.org/doc/stable/reference/generated/numpy.corrcoef.html (accessed on 12 July 2023).
- Gillies, S.; van der Wel, C.; Van den Bossche, J.; Taves, M.W.; Arnott, J.; Ward, B.C.; others. Shapely; GitHub: San Francisco, CA, USA, 2022. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; IEEE Computer Society: Washington, DC, USA, 1995; Volume 1, p. 278. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Scheenen, T.W.; Klomp, D.W.; Wijnen, J.P.; Heerschap, A. Short echo time 1H-MRSI of the human brain at 3T with minimal chemical shift displacement errors using adiabatic refocusing pulses. Magn. Reason. Med. 2008, 59, 1–6. [Google Scholar] [CrossRef]
- Wijnen, J.P.; Idema, A.J.S.; Stawicki, M.; Lagemaat, M.W.; Wesseling, P.; Wright, A.J.; Scheenen, T.W.J.; Heerschap, A. Quantitative short echo time 1H MRSI of the peripheral edematous region of human brain tumors in the differentiation between glioblastoma, metastasis, and meningioma. J. Magn. Reson. Imaging 2012, 36, 1072–1082. [Google Scholar] [CrossRef] [PubMed]
- Kounelakis, M.G.; Dimou, I.N.; Zervakis, M.E.; Tsougos, I.; Tsolaki, E.; Kousi, E.; Kapsalaki, E.; Theodorou, K. Strengths and Weaknesses of 1.5T and 3T MRS Data in Brain Glioma Classification. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 647–654. [Google Scholar] [CrossRef] [PubMed]
- Louis, D.N.; Perry, A.; Wesseling, P.; Brat, D.J.; Cree, I.A.; Figarella-Branger, D.; Hawkins, C.; Ng, H.K.; Pfister, S.M.; Reifenberger, G.; et al. The 2021 WHO Classification of Tumors of the Central Nervous System: A summary. Neuro-Oncology 2021, 23, 1231–1251. [Google Scholar] [CrossRef] [PubMed]
- Acquarelli, J.; van Laarhoven, T.; Postma, G.J.; Jansen, J.J.; Rijpma, A.; van Asten, S.; Heerschap, A.; Buydens, L.M.C.; Marchiori, E. Convolutional neural networks to predict brain tumor grades and Alzheimer’s disease with MR spectroscopic imaging data. PLoS ONE 2022, 17, e0268881. [Google Scholar] [CrossRef] [PubMed]
- Zarinabad, N.; Abernethy, L.J.; Avula, S.; Davies, N.P.; Rodriguez Gutierrez, D.; Jaspan, T.; MacPherson, L.; Mitra, D.; Rose, H.E.L.; Wilson, M.; et al. Application of pattern recognition techniques for classification of pediatric brain tumors by in vivo 3T 1H-MR spectroscopy—A multi-center study. Magn. Reson. Med. 2018, 79, 2359–2366. [Google Scholar] [CrossRef]
- Zhao, D.; Grist, J.T.; Rose, H.E.L.; Davies, N.P.; Wilson, M.; MacPherson, L.; Abernethy, L.J.; Avula, S.; Pizer, B.; Gutierrez, D.R.; et al. Metabolite selection for machine learning in childhood brain tumour classification. NMR Biomed. 2022, 35, e4673. [Google Scholar] [CrossRef]
- Tsolaki, E.; Svolos, P.; Kousi, E.; Kapsalaki, E.; Fountas, K.; Theodorou, K.; Tsougos, I. Automated differentiation of glioblastomas from intracranial metastases using 3T MR spectroscopic and perfusion data. Int. J. Comput. Assist. Radiol. Surg. 2013, 8, 751–761. [Google Scholar] [CrossRef]
- De Barros, N.P.; Meier, R.; Pletscher, M.; Stettler, S.; Knecht, U.; Reyes, M.; Gralla, J.; Wiest, R.; Slotboom, J. Analysis of metabolic abnormalities in high-grade glioma using MRSI and convex NMF. NMR Biomed. 2019, 32, e4109. [Google Scholar] [CrossRef] [PubMed]
- De Barros, N.P.; McKinley, R.; Knecht, U.; Wiest, R.; Slotboom, J. Automatic quality control in clinical 1H MRSI of brain cancer. NMR Biomed. 2016, 29, 563–575. [Google Scholar] [CrossRef] [PubMed]
- Raschke, F.; Fuster-Garcia, E.; Opstad, K.S.; Howe, F.A. Classification of single-voxel 1H spectra of brain tumours using LCModel. NMR Biomed. 2012, 25, 322–331. [Google Scholar] [CrossRef] [PubMed]
- Kirasich, K.; Smith, T.; Sadler, B. Random Forest vs. Logistic Regression: Binary Classification for Heterogeneous Datasets. SMU Data Sci. Rev. 2018, 1, 9. Available online: https://scholar.smu.edu/datasciencereview/vol1/iss3/9 (accessed on 12 July 2023).
- Emir, U.E.; Larkin, S.J.; de Pennington, N.; Voets, N.; Plaha, P.; Stacey, R.; Al-Qahtani, K.; Mccullagh, J.; Schofield, C.J.; Clare, S.; et al. Non-invasive quantification of 2-hydroxyglutarate in human gliomas with IDH1 and IDH2 mutations. Cancer Res 2016, 76, 43–49. [Google Scholar] [CrossRef]
- Near, J.; Harris, A.D.; Juchem, C.; Kreis, R.; Marjańska, M.; Öz, G.; Slotboom, J.; Wilson, M.; Gasparovic, C. Preprocessing, analysis and quantification in single-voxel magnetic resonance spectroscopy: Experts’ consensus recommendations. NMR Biomed. 2021, 34, e4257. [Google Scholar] [CrossRef]
- Maudsley, A.A.; Andronesi, O.C.; Barker, P.B.; Bizzi, A.; Bogner, W.; Henning, A.; Nelson, S.J.; Posse, S.; Shungu, D.C.; Soher, B.J. Advanced magnetic resonance spectroscopic neuroimaging: Experts’ consensus recommendations. NMR Biomed. 2021, 34, e4309. [Google Scholar] [CrossRef]
- Gurbani, S.S.; Schreibmann, E.; Maudsley, A.A.; Cordova, J.S.; Soher, B.J.; Poptani, H.; Verma, G.; Barker, P.B.; Shim, H.; Cooper, L.A.D. A convolutional neural network to filter artifacts in spectroscopic MRI. Magn. Reson. Med. 2018, 80, 1765–1775. [Google Scholar] [CrossRef]
- Yuan, Y.; Yu, Y.; Guo, Y.; Chu, Y.; Chang, J.; Hsu, Y.; Liebig, P.A.; Xiong, J.; Yu, W.; Feng, D.; et al. Noninvasive Delineation of Glioma Infiltration with Combined 7T Chemical Exchange Saturation Transfer Imaging and MR Spectroscopy: A Diagnostic Accuracy Study. Metabolites 2022, 12, 901. [Google Scholar] [CrossRef]
- Nelson, S.J.; Graves, E.; Pirzkall, A.; Li, X.; Antiniw Chan, A.; Vigneron, D.B.; McKnight, T.R. In vivo molecular imaging for planning radiation therapy of gliomas: An application of 1H MRSI. J. Magn. Reason. Imaging 2002, 16, 464–476. [Google Scholar] [CrossRef]
- Raschke, F.; Barrick, T.R.; Jones, T.L.; Yang, G.; Ye, X.; Howe, F.A. Tissue-type mapping of gliomas. NeuroImage Clin. 2019, 21, 101648. [Google Scholar] [CrossRef] [PubMed]
- Maudsley, A.A.; Gupta, R.K.; Stoyanova, R.; Parra, N.A.; Roy, B.; Sheriff, S.; Hussain, N.; Behari, S. Mapping of Glycine Distributions in Gliomas. Am. J. Neuroradiol. 2014, 35, S31–S36. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Sima, D.M.; Cauter, S.V.; Croitor Sava, A.R.; Himmelreich, U.; Pi, Y.; Van Huffel, S. Hierarchical non-negative matrix factorization (hNMF): A tissue pattern differentiation method for glioblastoma multiforme diagnosis using MRSI. NMR Biomed. 2013, 26, 307–319. [Google Scholar] [CrossRef] [PubMed]
- Maudsley, A.A.; Domenig, C.; Sheriff, S. Reproducibility of serial whole-brain MR spectroscopic imaging. NMR Biomed. 2010, 23, 251–256. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | SV STEAM | SV PRESS |
|---|---|---|
| Magnetic field | 1.5T | 1.5T |
| TE | 20–32 ms | 30–32 ms |
| TR | 1600–2000 ms | 1600–2000 ms |
| Volume | 4–8 cm3 | 4–8 cm3 |
| N averages metabolites | 256 | 192–128 |
| N averages water | 8–32 | 8–16 |
| N points | 512 (Philips) | 512 (Philips) |
| 1024 (Siemens) | 1024 (Siemens) | |
| 2048 (GE) | 2048 (GE) | |
| Bandwidth | 1000 Hz (Philips) | 1000 Hz (Philips) |
| 1000 Hz (Siemens) | 1000 Hz (Siemens) | |
| 2500 Hz (GE) | 2500 Hz (GE) | |
| Dummy scans | 4 | 4 |
| Parameter | Value |
|---|---|
| Magnetic field | 3T |
| Sequence | Semi-Laser |
| Model and scanner brand | TrioTim Siemens |
| Software version | Syngo MR B13 4VB13A |
| TE | 30 ms |
| TR | 1000 ms |
| FOV | 16 × 16 × 8/32 × 16 × 8/ 32 × 32 × 1 |
| VOI | 8 × 18 × 8/10 × 6 × 8/10 × 8 × 8/10 × 10 × 8/18 × 14 × 1/18 × 15 × 1/18 × 20 × 1/18 × 21 × 1/20 × 14 × 1/20 × 16 × 1/20 × 20 × 1/20 × 24 × 1/22 × 20 × 1/25 × 16 × 1 |
| Hanning filter | 100% |
| Slice thickness | 10 mm |
| N averages metabolites | 1–3 |
| N averages water | 1 |
| N points | 1024 or 4096 |
| Bandwidth | 2404 or 4000 Hz |
| Training Set | Number of Features | ||||||||||||||
| Feature Selection Method | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 50 Drop | 60 Drop | 70 Drop | 80 Drop | 90 Drop | Full | Classifier |
| SFFS | 0.12 | 0.10 | 0.10 | 0.10 | 0.10 | 0.08 | 0.08 | 0.06 | LDA | ||||||
| SFFS | 0.38 | 0.28 | 0.30 | 0.65 | 0.20 | 0.37 | 0.39 | 0.36 | SVM | ||||||
| SFFS | 0.09 | 0.08 | 0.04 | 0.04 | 0.03 | 0.04 | 0.02 | 0.03 | RF | ||||||
| Chi | 0.24 | 0.17 | 0.13 | 0.54 | 0.53 | 0.49 | 0.06 | 0.51 | LDA | ||||||
| Chi | 0.21 | 0.17 | 0.11 | 0.45 | 0.47 | 0.46 | 0.07 | 0.49 | SVM | ||||||
| Chi | 0.14 | 0.12 | 0.10 | 0.36 | 0.39 | 0.38 | 0.07 | 0.11 | RF | ||||||
| K-best | 0.34 | 0.20 | 0.17 | 0.19 | 0.14 | 0.11 | 0.14 | 0.11 | LDA | ||||||
| K-best | 0.40 | 0.12 | 0.12 | 0.09 | 0.11 | 0.09 | 0.10 | 0.11 | SVM | ||||||
| K-best | 0.05 | 0.05 | 0.06 | 0.04 | 0.11 | 0.09 | 0.10 | 0.11 | RF | ||||||
| Lasso | 0.17 | 0.11 | 0.08 | 0.12 | 0.09 | 0.08 | 0.08 | 0.16 | LDA | ||||||
| Lasso | 0.15 | 0.11 | 0.08 | 0.10 | 0.09 | 0.08 | 0.08 | 0.10 | SVM | ||||||
| Lasso | 0.13 | 0.10 | 0.08 | 0.10 | 0.10 | 0.10 | 0.10 | 0.11 | RF | ||||||
| Boruta | 0.09 | 0.09 | 0.09 | 0.14 | 0.16 | 0.07 | LDA | ||||||||
| Boruta | 0.06 | 0.07 | 0.06 | 0.07 | 0.05 | 0.06 | SVM | ||||||||
| Boruta | 0.03 | 0.01 | 0.02 | 0.03 | 0.03 | 0.01 | RF | ||||||||
| Test Set | Number of Features | ||||||||||||||
| Feature Selection Method | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 50 Drop | 60 Drop | 70 Drop | 80 Drop | 90 Drop | Full | Classifier |
| SFFS | 0.38 | 0.34 | 0.35 | 0.34 | 0.33 | 0.27 | 0.33 | 0.41 | LDA | ||||||
| SFFS | 0.68 | 0.60 | 0.60 | 0.39 | 0.64 | 0.64 | 0.64 | 0.40 | SVM | ||||||
| SFFS | 0.53 | 0.42 | 0.46 | 0.59 | 0.56 | 0.57 | 0.44 | 0.47 | RF | ||||||
| Chi | 0.71 | 0.68 | 0.31 | 0.66 | 0.68 | 0.68 | 0.49 | 0.66 | LDA | ||||||
| Chi | 0.69 | 0.66 | 0.56 | 0.65 | 0.68 | 0.69 | 0.55 | 0.69 | SVM | ||||||
| Chi | 0.68 | 0.67 | 0.55 | 0.63 | 0.64 | 0.70 | 0.56 | 0.70 | RF | ||||||
| K-best | 0.43 | 0.43 | 0.43 | 0.34 | 0.23 | 0.21 | 0.36 | 0.23 | LDA | ||||||
| K-best | 0.64 | 0.48 | 0.50 | 0.59 | 0.57 | 0.58 | 0.54 | 0.59 | SVM | ||||||
| K-best | 0.52 | 0.47 | 0.55 | 0.59 | 0.57 | 0.58 | 0.54 | 0.59 | RF | ||||||
| Lasso | 0.53 | 0.48 | 0.55 | 0.51 | 0.50 | 0.47 | 0.47 | 0.50 | LDA | ||||||
| Lasso | 0.54 | 0.53 | 0.51 | 0.53 | 0.57 | 0.49 | 0.49 | 0.59 | SVM | ||||||
| Lasso | 0.53 | 0.48 | 0.52 | 0.55 | 0.57 | 0.58 | 0.58 | 0.59 | RF | ||||||
| Boruta | 0.42 | 0.33 | 0.24 | 0.20 | 0.27 | 0.30 | LDA | ||||||||
| Boruta | 0.45 | 0.47 | 0.46 | 0.46 | 0.48 | 0.44 | SVM | ||||||||
| Boruta | 0.47 | 0.48 | 0.48 | 0.47 | 0.48 | 0.45 | RF | ||||||||
| Training Set | Number of Features | |||||||||||
| Feature Selection Method | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 80 Drop | 90 Drop | Full | Classifier |
| SFFS | 0.07 | 0.07 | 0.07 | 0.07 | 0.07 | 0.07 | 0.05 | 0.05 | LDA | |||
| SFFS | 0.23 | 0.20 | 0.19 | 0.06 | 0.06 | 0.06 | 0.05 | 0.06 | SVM | |||
| SFFS | 0.40 | 0.33 | 0.35 | 0.10 | 0.08 | 0.15 | 0.10 | 0.11 | RF | |||
| Chi | 0.12 | 0.12 | 0.39 | 0.05 | 0.06 | 0.07 | 0.07 | 0.09 | LDA | |||
| Chi | 0.10 | 0.11 | 0.36 | 0.05 | 0.05 | 0.06 | 0.05 | 0.07 | SVM | |||
| Chi | 0.09 | 0.08 | 0.49 | 0.06 | 0.07 | 0.05 | 0.05 | 0.06 | RF | |||
| K-best | 0.13 | 0.17 | 0.07 | 0.04 | 0.08 | 0.13 | 0.12 | 0.12 | LDA | |||
| K-best | 0.15 | 0.12 | 0.10 | 0.07 | 0.06 | 0.11 | 0.10 | 0.10 | SVM | |||
| K-best | 0.23 | 0.16 | 0.11 | 0.11 | 0.10 | 0.14 | 0.12 | 0.13 | RF | |||
| Lasso | 0.08 | 0.08 | 0.05 | 0.05 | 0.05 | 0.05 | 0.03 | 0.04 | LDA | |||
| Lasso | 0.09 | 0.04 | 0.06 | 0.08 | 0.07 | 0.06 | 0.06 | 0.03 | SVM | |||
| Lasso | 0.08 | 0.06 | 0.07 | 0.06 | 0.07 | 0.06 | 0.07 | 0.06 | RF | |||
| Boruta | 0.23 | 0.10 | 0.06 | LDA | ||||||||
| Boruta | 0.09 | 0.12 | 0.10 | SVM | ||||||||
| Boruta | 0.09 | 0.10 | 0.04 | RF | ||||||||
| Test Set | Number of Features | |||||||||||
| Feature Selection Method | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 80 Drop | 90 Drop | Full | Classifier |
| SFFS | 0.25 | 0.25 | 0.26 | 0.26 | 0.27 | 0.26 | 0.19 | 0.25 | LDA | |||
| SFFS | 0.38 | 0.38 | 0.38 | 0.27 | 0.29 | 0.28 | 0.32 | 0.33 | SVM | |||
| SFFS | 0.44 | 0.44 | 0.43 | 0.33 | 0.32 | 0.35 | 0.33 | 0.33 | RF | |||
| Chi | 0.42 | 0.41 | 0.61 | 0.32 | 0.33 | 0.33 | 0.32 | 0.45 | LDA | |||
| Chi | 0.39 | 0.39 | 0.58 | 0.35 | 0.35 | 0.36 | 0.35 | 0.44 | SVM | |||
| Chi | 0.39 | 0.41 | 0.67 | 0.33 | 0.34 | 0.36 | 0.34 | 0.40 | RF | |||
| K-best | 0.50 | 0.40 | 0.40 | 0.35 | 0.30 | 0.38 | 0.32 | 0.27 | LDA | |||
| K-best | 0.48 | 0.58 | 0.41 | 0.43 | 0.46 | 0.48 | 0.47 | 0.46 | SVM | |||
| K-best | 0.44 | 0.53 | 0.38 | 0.41 | 0.44 | 0.50 | 0.48 | 0.48 | RF | |||
| Lasso | 0.39 | 0.27 | 0.28 | 0.28 | 0.26 | 0.28 | 0.33 | 0.29 | LDA | |||
| Lasso | 0.36 | 0.35 | 0.28 | 0.35 | 0.33 | 0.32 | 0.32 | 0.44 | SVM | |||
| Lasso | 0.31 | 0.24 | 0.32 | 0.33 | 0.34 | 0.35 | 0.35 | 0.34 | RF | |||
| Boruta | 0.39 | 0.32 | 0.27 | LDA | ||||||||
| Boruta | 0.49 | 0.43 | 0.44 | SVM | ||||||||
| Boruta | 0.46 | 0.44 | 0.51 | RF | ||||||||
| AUC | |||||
|---|---|---|---|---|---|
| Set | mm | agg | lgg | no | |
| 4-class task | SV train | 0.99 | 0.97 | 0.98 | 0.99 |
| MV test | 0.95 | 0.89 | 0.82 | 0.82 | |
| 3-class task | SV train | 0.99 | 0.98 | - | 1.00 |
| MV test | 0.90 | 0.83 | - | 0.82 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ungan, G.; Pons-Escoda, A.; Ulinic, D.; Arús, C.; Vellido, A.; Julià-Sapé, M. Using Single-Voxel Magnetic Resonance Spectroscopy Data Acquired at 1.5T to Classify Multivoxel Data at 3T: A Proof-of-Concept Study. Cancers 2023, 15, 3709. https://doi.org/10.3390/cancers15143709
Ungan G, Pons-Escoda A, Ulinic D, Arús C, Vellido A, Julià-Sapé M. Using Single-Voxel Magnetic Resonance Spectroscopy Data Acquired at 1.5T to Classify Multivoxel Data at 3T: A Proof-of-Concept Study. Cancers. 2023; 15(14):3709. https://doi.org/10.3390/cancers15143709
Chicago/Turabian StyleUngan, Gülnur, Albert Pons-Escoda, Daniel Ulinic, Carles Arús, Alfredo Vellido, and Margarida Julià-Sapé. 2023. "Using Single-Voxel Magnetic Resonance Spectroscopy Data Acquired at 1.5T to Classify Multivoxel Data at 3T: A Proof-of-Concept Study" Cancers 15, no. 14: 3709. https://doi.org/10.3390/cancers15143709
APA StyleUngan, G., Pons-Escoda, A., Ulinic, D., Arús, C., Vellido, A., & Julià-Sapé, M. (2023). Using Single-Voxel Magnetic Resonance Spectroscopy Data Acquired at 1.5T to Classify Multivoxel Data at 3T: A Proof-of-Concept Study. Cancers, 15(14), 3709. https://doi.org/10.3390/cancers15143709