1. Introduction
Breast cancer (BC) is the most common cause of cancer death in women, with 1 in 8 cancer cases, and its incidence has increased significantly despite the preventive and curative approaches utilized in recent years [
1,
2]. In 2020, the International Agency for Research on Cancer (IARC) and World Health Organization (WHO) reported 2.26 million new BC cases and 684,996 global cases of BC mortality in females, surpassing lung cancer with 2.20 million new cases. Further, the diagnosis of new cases and BC death by 2040 is predicted to increase to over 3 million and 1 million, respectively [
3,
4]. BC is a heterogeneous disease and the symptoms may include a bump, skin dimpling, nipple discharge, scaly hair patch and flaky skin around the nipple, and thickness/swelling in some parts of the breast [
5]. BC survival rates were found to be variable, at ~80%, ~60%, and ~40% in high-, mid-, and low-income countries, respectively.
An accurate diagnosis is key for the optimal treatment of cancer patients. At present, cancer classification and diagnosis heavily depend on the subjective evaluation of physical examination, clinical/pathological test, radiological scan, and histopathological information, but they are subject to human errors [
6]. Surprisingly, medical error is the third leading cause of death, even in the most advanced countries such as the USA [
7]. Additionally, in some instances, (i) incomplete or misleading clinical information, (ii) complicated radiological images, and (iii) variable, atypical, or lack of morphologic features in histological information may result in diagnostic confusion, and thus affect patient care [
2].
Molecular diagnostics offer precise, fair, and efficient breast cancer classification, but are not widely applied in clinical settings. Microarray-platform-based assays, including the Affymetrix GeneChip Human Genome U133 Plus 2.0 array (Affymetrix, Santa Clara, CA, USA), have the ability to measure thousands of gene expressions simultaneously for each data point (sample) [
8,
9]. Expression profiling to check for variability in gene expression is an important factor influencing the precision and accuracy of clinical decisions in the diagnosis of BC [
1,
8,
10,
11,
12,
13]. Despite the large-scale, high-dimensional, and highly redundant type of microarray data, with numerous tools to identify genes that are differentially expressed across cancer/disease phenotypes, the interpretation of results and follow-up analysis are quite challenging. DNA-microarray-based gene expression profiling is promising for BC diagnosis and prognosis [
12,
14], but limitations such as small sample size, biased case vs. control distribution, multiple BC subtypes, variable populations, and different platforms, complicate the analysis, and the identification of gene signatures remains an issue [
15,
16,
17,
18,
19].
In 1999, the first gene expression signature was identified to classify leukemia into acute myeloid leukemia (AML) and acute lymphoblastic leukemia (ALL). Since then, a series of gene expression signatures have been reported for various cancers to classify tumors, tumor types, tumor stages, and predict the disease prognosis [
20,
21].
BC is a very heterogeneous disease and is categorized into five molecular subtypes: HER2+, basal (ER−/HER2−/PR−), luminal A (ER+/HER2, with a low-proliferative phenotype), luminal B (ER+/HER2, with a high-proliferative phenotype), and normal BC [
17]. Each subtype exhibits distinct transcriptomics patterns, and finding unified BC biomarkers or the gene signature applicable to all molecular subtypes remains a challenge [
13,
22]. Hence, multiple datasets need to be integrated to find universal diagnostic/prognostic biomarkers broadly applicable to all BC subtypes.
A stringent filtration condition drastically reduces the number of DEGs, but filters out many biologically relevant genes as well, whereas a lenient cutoff allows for many genes to pass through, and a follow-up issue arises in selecting the most interesting genes. Although conducting gene ontology and pathway enrichment analysis is useful in predicting biological processes, cellular components, molecular function, networks, and canonical pathways for the detected DEGs, the selection of the most relevant genes, a diagnostic and/or prognostic biomarker, in cancer remains a challenge. Machine learning methods and different evaluation techniques such as the Kaplan–Meier (KM) estimator might be useful in identifying the biologically relevant genes from a long DEG list, without any obvious selection way [
8,
11].
Another problem in high-throughput gene expression profiling is reducing the extremely high dimensionality of irrelevant or redundant gene features responsible for cancer classification accuracy. Feature selection methods have been used to select key genes from thousands of expressed genes, but the large numbers of microarray genes used in most existing methods for cancer classification often hamper the model outcomes. For an efficient diagnostic model for BC, machine-learning-based feature selection methods were applied to a smaller number of differentially expressed genes passing the standard statistical cutoff of p < 0.5 and log2folds change > 2 in BC.
To address these challenges, we integrated eleven GEO oligonucleotide microarray datasets to create a gene expression database of 701 samples (356 breast tumors and 345 normal breast tissues) and applied different R packages and machine learning methods on gene expression data for the molecular classification, accurate diagnosis, and prognostic evaluation of the identified gene signatures in BC. A larger sample size gave greater analysis power because it constricted the distribution of the test statistic. Further, an almost equal group (3356 vs. 3345) reduced the biases in machine-learning-based data analysis, and increases the accuracy of the model and predicted biomarkers. We also demonstrated that the combined use of molecular pathway analysis, expression analysis, feature selection methods, and survival analysis was helpful in selecting gene signatures with high confidence.
2. Materials and Methods
2.1. Data Sets and Patients
The raw gene expression data, a set of binary files in a CEL format, of BC from eleven datasets, including GSE61304, GSE42568, GSE7904, GSE3744, GSE29431, GSE26910, GSE31138, GSE71053, GSE10780, GSE30010, and GSE111662, were retrieved from the Gene Expression Omnibus (GEO) database using “GEOquery” library of the R program (
https://www.ncbi.nlm.nih.gov/geo/, accessed on 2 January 2023). We selected only the human breast tumor samples to eliminate differential genetic interference in different BC cell lines. Clinicopathological information from the original studies was used for analysis. The ratio of breast tumors to normal breast was biased in the majority of the deposited GEO datasets, including GSE61304, GSE42568, GSE7904, GSE3744, and GSE26910. Thus, we included additional normal breast cases (GSE30010 and GSE111662) to balance the data (n = 701, 356 = BT vs. 345 = NB) for a better outcome, while identifying DEGs or applying ML methods to develop a diagnostic model (
Table 1). This study was approved by the university’s CEGMR bioethical committee (16-CEGMR-bioeth-2022), dated 13 October 2022, and we recruited patients for the validation of potential biomarkers after obtaining their consent.
2.2. Preprocessing and Differential Expression Analysis
The median expression values of less than 5.55 intensity on the log2 scale of each probe, indicating the failure of true hybridization, were filtered out. We also excluded the probes expressed in less than two samples. We merged all the raw CEL files (n = 701) and applied the RMA method for the normalization of expression values, and generated box plots using the “oligo” package from R software. Principal component analysis (PCA) was performed using “prcomp function”, and hierarchical clustering was carried out using the “pheatmap” R package to correlate the samples with the probes.
We used linear models for the microarray “Limma” package of R to identify differentially expressed genes (DEGs), using an empirical Bayesian method to assess the differences in gene expression. Wang et al. (2021) conducted a study demonstrating the superior performance of the moderated
t-test when the sample size was ≥40. [
23,
24]. Our study, with a sample size of 701, comprising 356 breast tumors and 345 normal breast samples, exceeds the required 95% power of the test, and the nearly equal representation of the test (tumor) and control (normal) groups mitigates biases in machine-learning-based data analysis, and enhances the accuracy of the model and predicted biomarkers. The “decideTests” function was used to differentiate between the altered (up or down) and normal expression. The “topTable” function from R was applied with a cut-off-adjusted
p-value (Benjamini–Hochberg-corrected false discovery rate) < 0.05 and log2 fold change > ±2 to detect the most significant DEGs in BC compared with normal samples. Unannotated probes, not representing genes, were removed, and duplicate probes, representing single genes, were averaged for expression values to get a unique set of DEGs.
2.3. Functional Pathway and Gene Set Enrichment Analysis
We used a comprehensive set of functional annotation tools, such as the QIAGEN Ingenuity Pathway Analysis (IPA knowledgebase v84978992, QIAGEN, USA) and WEB-based Gene SeT AnaLysis Toolkit (WebGestalt 2019,
https://www.webgestalt.org/, accessed on 2 January 2023), to investigate and understand the biological meaning of long-list significant DEGs [
1,
25,
26]. We explored gene ontologies, enriched and canonical pathways, upstream regulators, disease and functions, and the networks associated with BC. Over-representation (or enrichment) analysis (ORA), a statistical method, was used to determine the presence of known genes in pre-defined sets, as well as in dataset/DEGs.
2.4. Machine Learning and Feature Selection Methods
We applied machine learning methods to BC transcriptomics data and considered performance measurements such as classification accuracy, specificity, sensitivity, and AUC, to identify the most informative features. To determine the effectiveness of a classification model, a set of performance metrics was used for assessment, such as measuring the model’s ability to accurately classify instances into the correct categories. We used the confusion matrix to compute the accuracy, precision, recall, and F1 score, as shown in Equations (1)–(4).
In addition, the model’s performance was evaluated by plotting the receiver operating characteristic curve (ROC) and the area under the ROC (AUC), which is a metric used to measure the model’s effectiveness. Models with larger AUCs are considered to have higher performance.
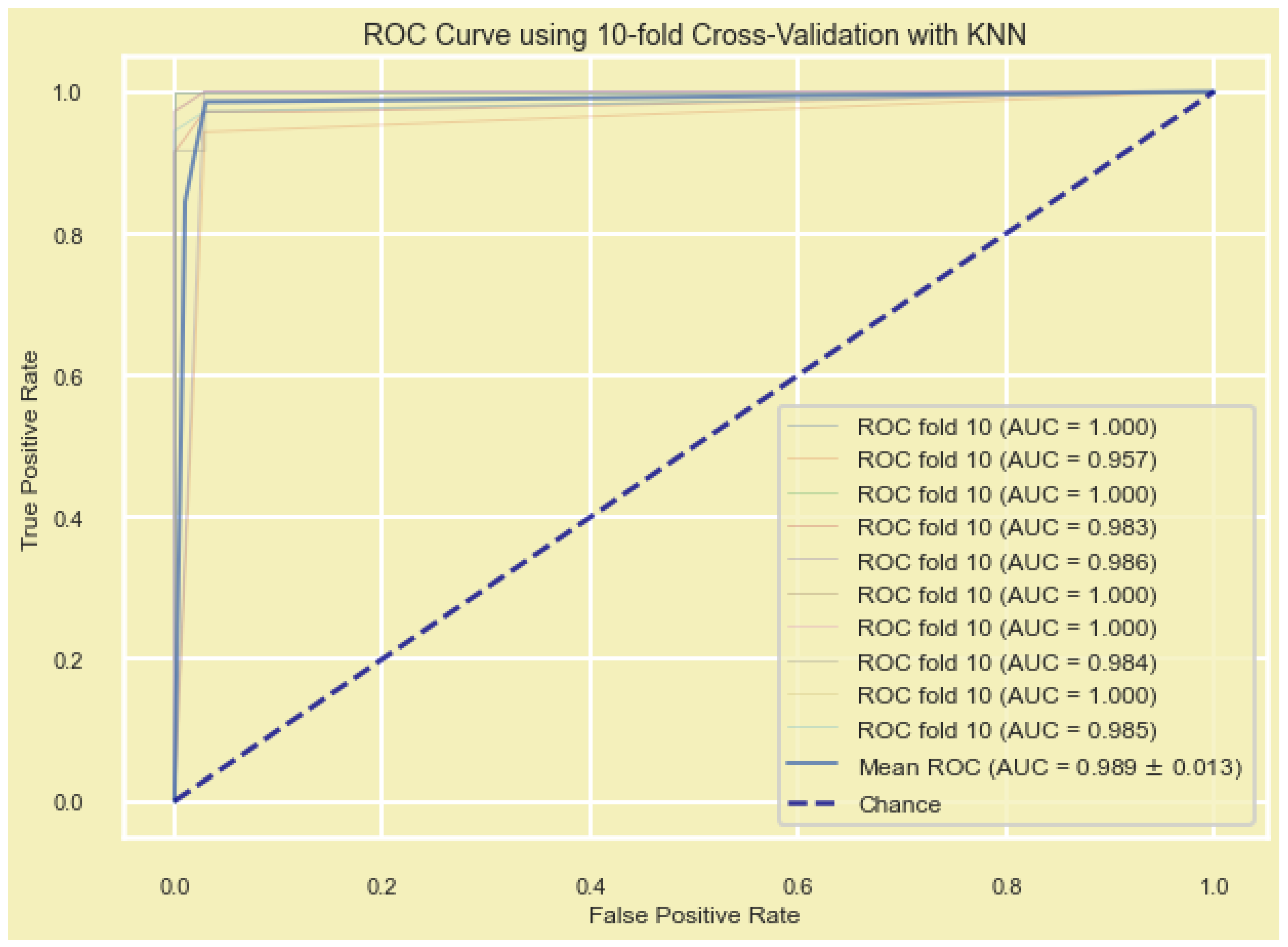
The Scikit-learn (sklearn) in python platform was used to build the ROC curves of the DEGs and measure the AUC to compare the diagnostic value of the DEGs, and to predict the accuracy of the detected DEGs. The ROC curve, reflecting the relationship between sensitivity and specificity, and AUC were used to determine the diagnostic value of a factor in a specific disease, with AUC values between 0.5 and 1 representing low and high authenticity, respectively.
We used seven machine learning algorithms, including (i) recursive feature elimination with cross validation (RFECV) with logistic regression, (ii) RFECV with support vector machine (SVM), (iii) Lasso regularization (L1) with logistic regression, (iv) Lasso regularization (L1) with support vector classification (SVC-L1), (v) random forest (RF) classifier, (vi) extremely randomized trees (extra trees) classifier, and (vii) genetic algorisms (GA), to find the most significantly expressed genes in all samples (n = 701, 356BT + 345NB) and construct the diagnostic model from candidate DEGs. To validate the constructed diagnostic and prognostic models, we used five additional ML methods, including (i) adaptive boosting (AdaBoost), (ii) gradient-boosted decision trees (GBDT), (iii) K-nearest neighbors (KNN), (iv) multilayer perceptron (MLP), and (v) the extreme gradient boosting (XGBoost).
2.4.1. RFECV with Logistic Regression or with SVM
We used RFECV with logistic regression and SVM in Python using the RFECV class from the scikit-learn library. The RFECV with logistic regression or SVM is a method of feature selection in machine learning. It is a combination of two techniques: recursive feature elimination (RFE) and cross validation (CV). RFE is a backward selection algorithm that starts with all the features and removes the weakest feature until a specified number of features is left. CV, on the other hand, is a technique used to evaluate the performance of a model by dividing the data into several folds and training the model on different folds, while testing it on one fold at a time. In RFECV with logistic regression or SVM, the RFE algorithm is combined with CV to eliminate features, while also evaluating the performance of the logistic regression model. This helps determine the optimal number of features that provide the best performance, while avoiding overfitting. By combining these two techniques, RFECV with logistic regression or SVM ensures that the final feature set is not only informative, but also generalizable to new data.
2.4.2. LASSO Regularization (L1) Using Logistic Regression or Support Vector Classification
We used L1 with logistic regression and SVM from the scikit-learn library to identify the most significant genes [
27]. LASSO regularization is a technique used to reduce the number of features in a model and prevent overfitting. The technique shrinks the magnitude of the coefficients using a penalty term proportional to the absolute value of the coefficients, resulting in some coefficients becoming zero. It helps select the most relevant features, while reducing the impact of irrelevant or noisy features on the model’s performance. L1 regularization is particularly useful when dealing with a large number of features or highly correlated features. The loss function of Lasso regression is defined as shown in (5):
where lambda is the regularization parameter that controls the strength of the penalty term.
In logistic regression with LASSO regularization, the L1 penalty term helps reduce the impact of irrelevant or noisy features on the model’s performance by shrinking their coefficients toward zero. This can improve the model’s interpretability and reduce the risk of overfitting, especially when dealing with high-dimensional data.
In SVM, LASSO regularization is implemented by adding a penalty term to the objective function that minimizes the classification error. The penalty term is dependent on the magnitude of the coefficients of the features, so larger coefficients receive a larger penalty. This ensures that features with a large impact on the classification result receive a smaller penalty and are more likely to be included in the final model.
2.4.3. Random Forest
The random forest classifier is a machine learning algorithm used for both classification and regression problems [
28]. It is an ensemble of decision trees, where each tree is trained on a random subset of data. The final prediction is made by taking the average of all the trees’ predictions. In feature selection, a random forest classifier is used to select the most important features in the dataset. The algorithm calculates the importance of each feature by measuring the average decrease in impurity for that feature. The higher the average decrease, the more important the feature is considered.
2.4.4. Extra Trees Classifier
The extra trees classifier is an ensemble machine learning algorithm that can be used for feature selection in Python [
29]. It is a type of random forest classifier where multiple decision trees are grown and combined to make a prediction. The algorithm works by randomly selecting a subset of features at each split in the tree and determining the most important features based on their impact on the final prediction. By aggregating the feature importance scores across all trees, the extra trees classifier can provide a ranking of the most important features for a given dataset. This can be useful in identifying the most relevant features for building a predictive model and reducing the dimensionality of the data.
2.4.5. Genetic Algorithm
This algorithm uses principles of evolution and natural selection to find the optimal combination of features that result in the best model performance. The algorithm starts with a random set of features and uses a fitness function to evaluate the performance of each combination. The best performing combinations are then recombined and mutated to create a new generation of features, and the process continues until a satisfactory set of features is found [
30].
2.4.6. XGBoost
This algorithm is an ensemble learning method that works by combining multiple weak models into a strong one [
31]. It uses gradient boosting, which is a method of iteratively training decision trees on residuals to improve the model performance. It provides faster computation and parallelization of training, which is useful when working with large datasets. It also has built-in regularization techniques to reduce overfitting, which is a common problem in machine learning.
2.4.7. GBDT
This is a machine learning algorithm that works by building an ensemble of decision trees in a way that each subsequent tree focuses on the errors made by the previous trees [
32]. This iterative process results in a model that can learn complex non-linear relationships in data. It has the ability to handle large datasets, handle missing data, and provide accurate predictions with high interpretability.
2.4.8. MLP
This is a type of feedforward artificial neural network that consists of multiple layers of nodes that process information from the input layer to the output layer through a series of nonlinear transformations [
33]. The nodes in each layer are connected to the nodes in the previous and next layers, and each node applies an activation function to the weighted sum of its inputs. The goal of training the MLP is to minimize this cost function by adjusting the weights and biases in the network using an optimization algorithm such as gradient descent. This allows the model to learn the best set of weights that can accurately predict the binary classification labels for unseen data. The cost function in the binary classification of MLP uses the binary cross-entropy loss of function and is defined as shown in (6):
where
N is the number of samples,
is the actual outcome,
is the probability of the tumor class, and
is the probability of the normal class.
2.4.9. AdaBoost
This is an ensemble learning algorithm that combines several weak learners to create a strong learner [
34]. It works by repeatedly fitting a weak learner to the data, and adjusting the weights of the training samples to focus on the misclassified ones. The algorithm then combines these weak learners to form a strong learner that is capable of accurately predicting the target variable.
2.4.10. KNN
The K-nearest neighbors (KNN) is a popular machine learning algorithm belonging to the family of instance-based or lazy learning algorithms, which means that it does not attempt to learn a function from the training data [
35]. Instead, KNN stores all the training data, and classifies new data based on the similarity of its features to those in the training set. The number of nearest neighbors (K) is a hyperparameter that can be tuned to improve performance.
2.5. Survival Analysis Using the Kaplan–Meier Estimator
The KM estimator, a statistical technique tool (available at
https://kmplot.com/analysis/, accessed on 10 February 2023) was used for calculating survival probability functions to investigate the overall and relapse-free survival of prognostic genes for breast cancer patients. It is assumed that the occurrence of the event is fixed in time, and both the censored observations and data points have an equal chance of survival [
8,
36].
The mathematical expression of KM is expressed as shown in (7):
stands for survival function.
In this context,
refers to the count of individuals at risk at a specific time
tᵢ, and
is the count of events that happen at the same time,
tᵢ. The survival curve remains unchanging between the two events or times, i.e., between
tᵢ and
tᵢ + 1 [
36].
This analysis was conducted for mRNA (gene chip) microarray data for the relapse-free and overall survival. The KM analysis was performed with a confidence interval and log rank p-value cut-off of >95% and ≤0.05, respectively. We proceeded to further check the mRNA (RNA seq) datasets for overall survival for genes which were significant in both microarray data for relapse-free survival and overall survival. Finally, we established eight gene hubs (four upregulated and four downregulated) for prognostic importance.
The web-based KMplot tool incorporates three databases in the background: TCGA, EGA, and GEO [
37]. The Kaplan–Meier method is a strong non-parametric statistical approach used for predicting the likelihood of survival. The KM analysis was performed with a confidence interval and log rank
p-value cut-off of >95% and ≤0.05, respectively.
2.6. RNA Isolation and qRT-PCR
Trizol was used to lyse the cells, and chloroform and isopropanol were used to extract RNA. After determining the RNA concentration, the cDNA (complimentary deoxyribonucleic acid) was reverse-transcribed. The primer sets were designed for the identified gene signature using Primer-3 software (V.0.4.0). ABI 7500 instruments were used for real-time quantitative PCR. Endogenous GAPDH gene expression was measured as the internal control to determine the relative expression of the detected genes. The reaction was run in a final volume of 10 μL, comprising 5 μL SYBR-Green qPCR master mix (KAPA Biosystems, Wilmington, MA, USA), 10 pmol of each primer, and 20 ng genomic DNA. PCR was performed in triplicate using the SYBR-Green qPCR master mix (KAPA Biosystems, USA) in a 96-well plate. Raw data were generated through the use of StepOne Plus™ Real-Time PCR Systems and Data Assist software. qPCR data were analyzed by ∆∆CT or the Livak method, and the GraphPad PRISM software was used for presentation.
2.7. Statistical Analysis
All statistical analyses were conducted using R software (version v.4.2.2) (R core team 2021). R was also used for the picture generation. The chi-squared test was used to compare categorical variables of patient characteristics. The Wilcoxon rank sum test was used to compare the expression signature. The p-values were adjusted for multiple comparisons using the Benjamini–Hochberg method, and the default value <0.05 was considered statistically significant, otherwise specified. Cox regression analysis (univariate and/or multivariate) was used to assess the contribution of all parameters, such as evaluating the independent predictive OS performance of different clinical factors and the detected biomarkers. The KM curve and time-dependent ROC curve were drawn by the R package “survminer” and “survivalROC”, respectively.
4. Discussion
In recent years, multiple molecular diagnostic prognostic and predictive biomarkers have been proposed, and despite the availability of few molecular tests, traditional pathological factors such as the number of lymph node metastases, tumor size, and tumor grade, continue to be mandatory for clinical decisions [
38]. However, in the era of personalized treatment, these factors alone are inadequate and require molecular/genomic assistance, as cancer occurs via genetic alterations that transform normal cells into tumor cells. Although significant knowledge exists related to carcinogenesis, a complete understanding of cancer development mechanisms is still required. In recent years, genomics and proteomics have played a vital part in the development of different biomarkers for breast cancer [
39,
40]. Gene expression profiling can detect genetic alterations in the origin, growth, proliferation, and metastasis of tumors, and classify them accordingly. Gene expression signatures, derived from DEGs, specifically correlate these genetic alterations with clinical variables such as the diagnosis and prognosis [
20,
41]. A correct and timely diagnosis is the starting point of treatment and determination of prognosis is the most immediate challenge in patient management. This can be best achieved through a combination of traditional clinicopathological prognostic factors, molecular biomarkers such as single-gene tests (ER, PR, HER2) and specific multigene tests (gene signatures).
Among the 355 DEGs identified in a combined BC cohort,
COL11A1, TOP2A, S100P, COL10A1, and
RRM2 were the most upregulated, while
ADH1B, ADIPOQ, PLIN1, LEP, and
LPL were the most downregulated DEGs in BC. The pathway and enrichment analyses of DEGs revealed activation of the kinetochore metaphase signaling pathway, PTEN pathway, HOTAIR regulatory pathway, etc., and suppression of the senescence pathway and phagosome formation pathways in BC. The most significantly enriched molecular processes were the extracellular matrix, cell division, mitotic cell cycle process, cell migration, and regulation of cell proliferation. First, to verify the reliability of our method of screening for biomarkers, we confirmed our finding of DEGs, pathways, and gene ontologies using literature mining and verification. Matching our results with previous findings was good evidence that they are indeed involved in the development and progression of BC [
42,
43,
44,
45,
46].
Kinetochore architecture and its functional regulation is one of the most fascinating multi-protein machineries in a cell [
47]. The kinetochore metaphase signaling is essential for chromosome segregation in mitosis and meiosis [
48]. The critical regulators of alignment and segregation of chromosomes during mitosis, aurora B kinase (AURKB), dual specificity protein kinase TTK (Mps1), and kinetochore protein NDC80 homolog (NDC80) previously reported were significant in our study too [
49]. Another essential pathway that was significantly upregulated in our study was PTEN/PI3K/AKT. This controls the signaling of numerous biological processes, including apoptosis, cell proliferation, cell growth, and metabolism. Phosphatase and tensin homolog deleted on chromosome 10 (PTEN) is a dual protein/lipid phosphatase, of which the main substrate is phosphatidyl-inositol,3,4,5 triphosphate (PIP3), the product of PI3K [
50,
51]. The PTEN tumor suppressor is the chief brake of the PI3K-Akt pathway and a common target for inactivation in somatic cancers [
52]. PTEN activity is frequently lost in several metastatic human cancers due to mutations, deletions, or promoter methylation silencing [
50]. Senescence is associated with mitochondrial metabolic activities such as the tricarboxylic acid cycle, oxidative phosphorylation, and glycolytic pathways. The old senescent cells die during aging or apoptosis. The senescence pathway promotes cell cycle arrest triggered in response to stress with increased AMP/ADP:ATP and NAD
+/NADH ratios, and activating AMPK, p53, p16, KRAS, etc. [
53,
54,
55]. The in vitro demonstration of oncogene-induced senescence establishes senescence as a vital tumor-suppressive mechanism, in addition to apoptosis. Senescence not only stops the proliferation of premalignant cells (tumorigenesis), but also eases the clearance of affected cells through the immunosurveillance [
56]. In vivo studies showed that suppression of the senescence pathway can also promote mammary tumorigenesis [
57].
AI and ML techniques based on automated medical diagnosis are increasing gradually for clinical, pathological, and radiological reports. The fusion of multiple techniques in different types of data processing for cancer study must be a further instrument to obtain successful results. An earlier convolution neural network approach had been applied for image processing in medical diagnosis [
58]. However, using AI and ML in the evaluation of high-throughput genomics data from patients in diagnostic decision-making is still a bottle neck in healthcare [
59,
60,
61]. Typically, microarray data have thousands of features (genes/probes), but only a few samples (in tens or hundreds). For ML classification, it is better to have a large cohort with fewer features. Eleven BC datasets from different studies were integrated to increase the cohort size. Transcriptomics profiling resulted in 355 DEGs associated with BC, but this number was technically too big to recommend for gene signature biomarkers for diagnostic or prognostic tests. However, AI and ML have the potential to filter out genes with the best diagnostic and prognostic importance. Thus, for BC diagnosis via binary classification (whether or not BC), we used seven ML and feature selection methods (RFECV-LR, RFECV-SVM, RF, extra trees, LASSO, SVM-L1, SVM-L2, and GA) for gene reduction, and found high accuracy in the models. We identified a hub of 28 genes predicted by at least three ML methods and present in at least four BC datasets. RFECV-LR and RFECV-SVM improved the classification accuracy of logistic regression by selecting the most relevant features for the model and helped reduce overfitting by removing irrelevant or redundant features. Recursive feature elimination was utilized to rank the genes, with a random forest classifier used to evaluate gene fitness through five-fold cross-validation [
62]. The extra trees method was versatile, less prone to overfitting, computationally efficient, robust to noise, and could handle missing data [
29,
63]. LASSO had advantages in its ability to handle multicollinearity, and provided a sparse solution for both variable selection and shrinkage problems [
64,
65]. SVM models were frequently used for classification and regression tasks using L1 and L2 regularization [
66]. L1 regularization had improved the interpretability of the model and reduced overfitting by encouraging sparsity and selecting only the most relevant features for the classification task. GA utilized the concept of survival of the fittest and was based on a population-based search approach for a robust and efficient search [
67].
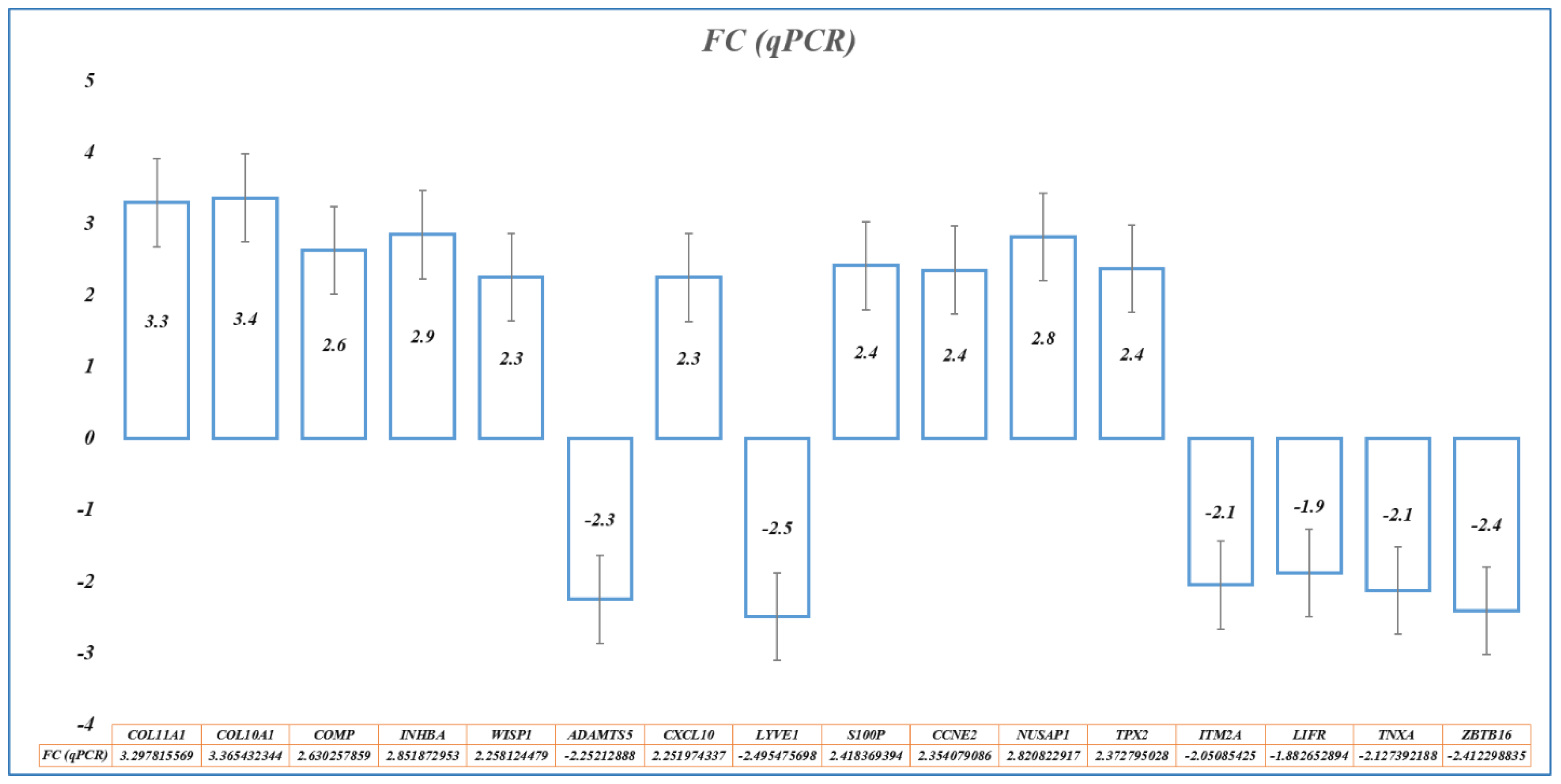
Based on the importance of the 28 hub genes in BC and using stringent filter conditions such as the genes predicted to be diagnostically important by at least five ML methods and present in at least seven BC datasets, a novel nine-gene signature (
COL10A,
S100P,
ADAMTS5,
WISP1,
COMP,
CXCL10,
LYVE1,
COL11A1, and
INHBA) was identified. Similarly, by evaluating 28 hub genes using RFS and OS analyses by KM plot, a novel prognostic model consisting of an eight-gene signature (
CCNE2,
NUSAP1,
TPX2,
S100P,
ITM2A,
LIFR,
TNXA, and
ZBTB16) was identified. Many gene expression signatures have been proposed for BC diagnosis and prognosis in recent years; few are under trial and five of them succeeded to get FDA approval for commercial and clinical application, including OncotypeDX (21-gene signature), MammaPrint (70-gene signature), Prosigna (58-gene signature), EndoPredict (12-gene signature), and Breast Cancer Index (7-gene signature) [
68,
69].
Gene signature validation was crucial before recommendation for further analysis and clinical trials. We used 10-fold-cross validation by five ML methods including KNN, GBDT, AdaBoost, XGBoost, and MLP. Several studies have reported successful applications of these ML methods in BC gene hub/signature validation [
70,
71,
72,
73,
74,
75]. KNN-based validation was used to classify genes based on their expression profiles, and identify the gene clusters associated with cancer metastasis [
72,
73]. GBDT and AdaBoost were used to identify the key genes and pathways associated with breast cancer metastasis [
72,
74,
76]. In addition, to identify disease-associated genes and pathways, XGBoost predicted cancer recurrence based on gene expression data [
71,
73]. The MLP method predicted gene clusters from expression data that were functionally related and associated with BC [
70,
72].
CCNE2 (Cyclin E2), involved in cell cycle regulation, can serve as an individual indicator of the likely outcome for BC patients. It is upregulated in tumor tissues and has the potential to function as a biomarker and linked to worse metastasis-free survival (MFS) outcomes and a poor overall survival [
77,
78]. NUSAP1 (nucleolar and spindle-associated protein 1) playing a critical role in cell division and being a useful prognostic marker, has been implicated in various types of cancer, including BC [
79]. The TPX2 (targeting protein for xenopus kinesin-like protein 2), a microtubule-associated protein involved in spindle formation and cell division, is highly expressed in various cancers, including BC [
80]. A high expression of TPX2 can reduce the survival time of HER2-positive patients, as well as triple negative BC [
81]. S100P, a calcium-binding protein, is involved in cell proliferation, differentiation, and apoptosis. An overexpression of S100P in BC cells makes it more aggressive, and hence it has the potential as a prognostic and therapeutic biomarker [
8]. ITM2A (integral membrane protein 2A) regulates cellular growth and survival, and its low expression may play a role in the progression of BC, especially at advanced stages and higher grades of triple-negative breast cancer [
82]. A decreased expression of LIFR (leukemia inhibitory factor receptor) may be a marker for a poorer prognosis and reduced survival in BC [
83]. TNXA (tenascin XA) is an extracellular matrix protein involved in cell adhesion and migration. The survival analysis of abnormally expressed TNXA in breast tissue indicates poor prognosis [
84]. A low expression of ZBTB16 (zinc finger and BTB domain-containing protein 16) in BC has been associated with a poor prognosis and an increased risk of metastasis [
85,
86].


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}