
Chronic Lymphocytic Leukemia Progression Diagnosis with Intrinsic Cellular Patterns via Unsupervised Clustering

 ,
,  ,
,  , , ,
, , ,  and
and 
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Patient Cohort and Data Collection
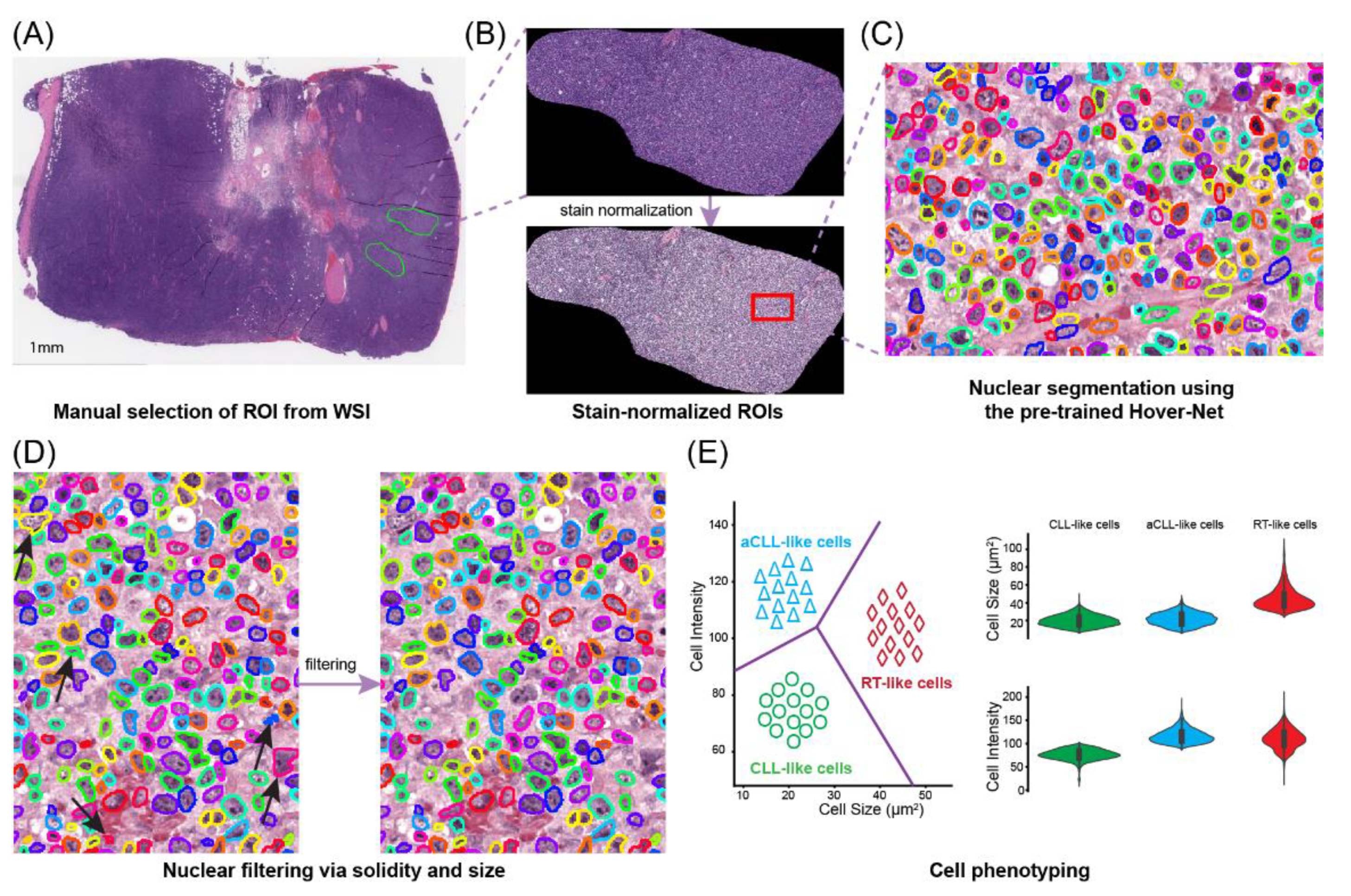
2.2. Region of Interest (ROI) Selection
2.3. Cell Segmentation and Filtering
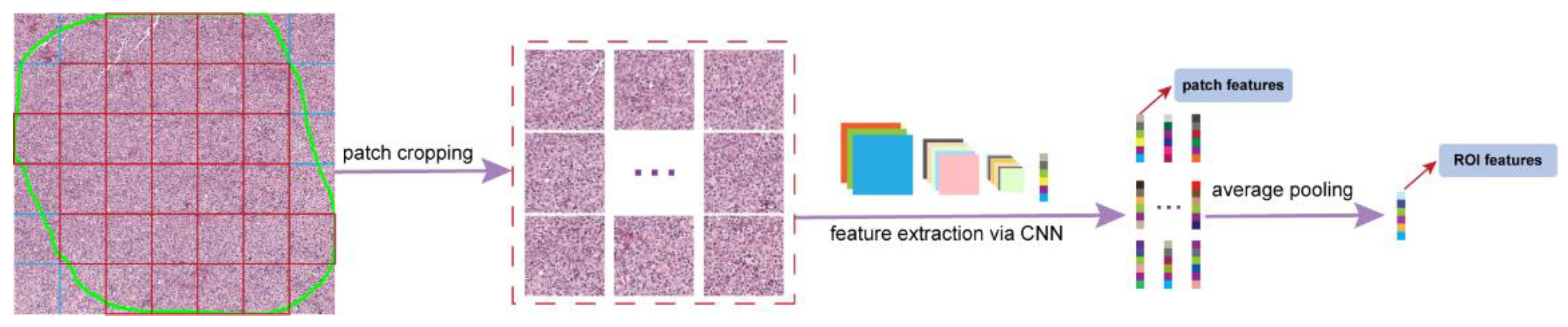
2.4. Pathomics Feature Extraction
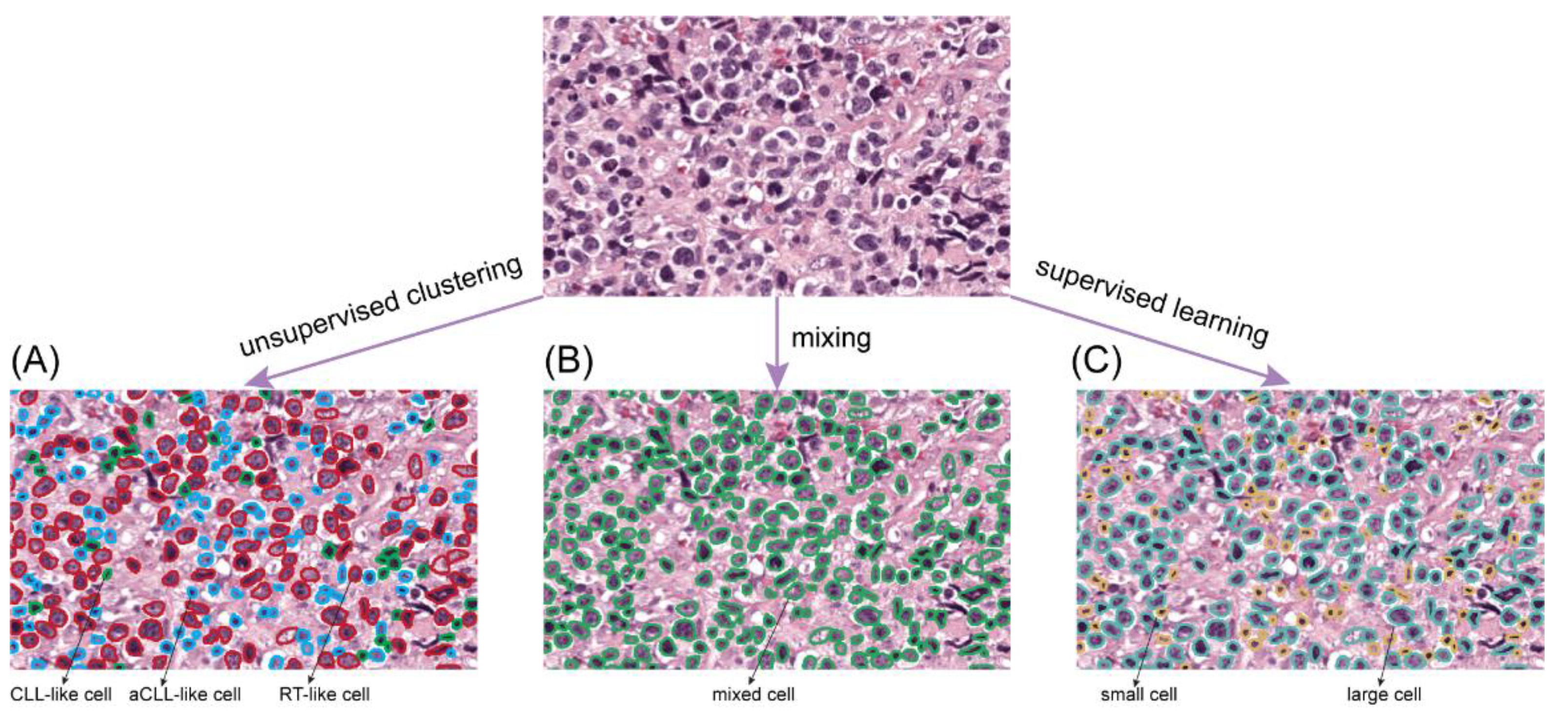
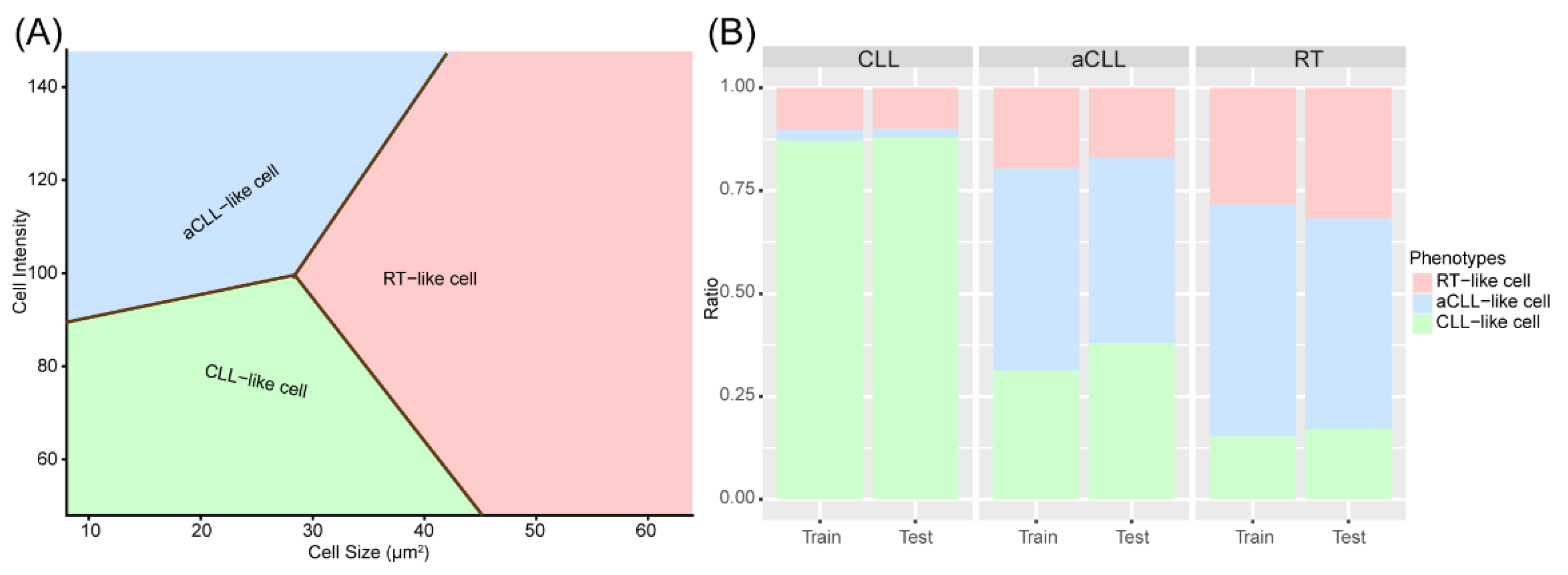
2.4.1. Newly Proposed Unsupervised Clustering for Cell Phenotyping
2.4.2. Comparison to Alternative Ways of Cell Profiling
Feature Extraction via Mixed Cells
Feature Extraction via Supervised Learning
2.5. Machine Learning Models for Disease Progression Prediction
2.5.1. Cellular Feature-Based Diagnosis Models
2.5.2. Comparison to the Convolutional Neural Network (CNN)
2.5.3. Generalizability Evaluation via Repeated Splitting
2.6. Statistical Analysis
3. Results
3.1. Discovery and Validation of Three Cellular Subtypes
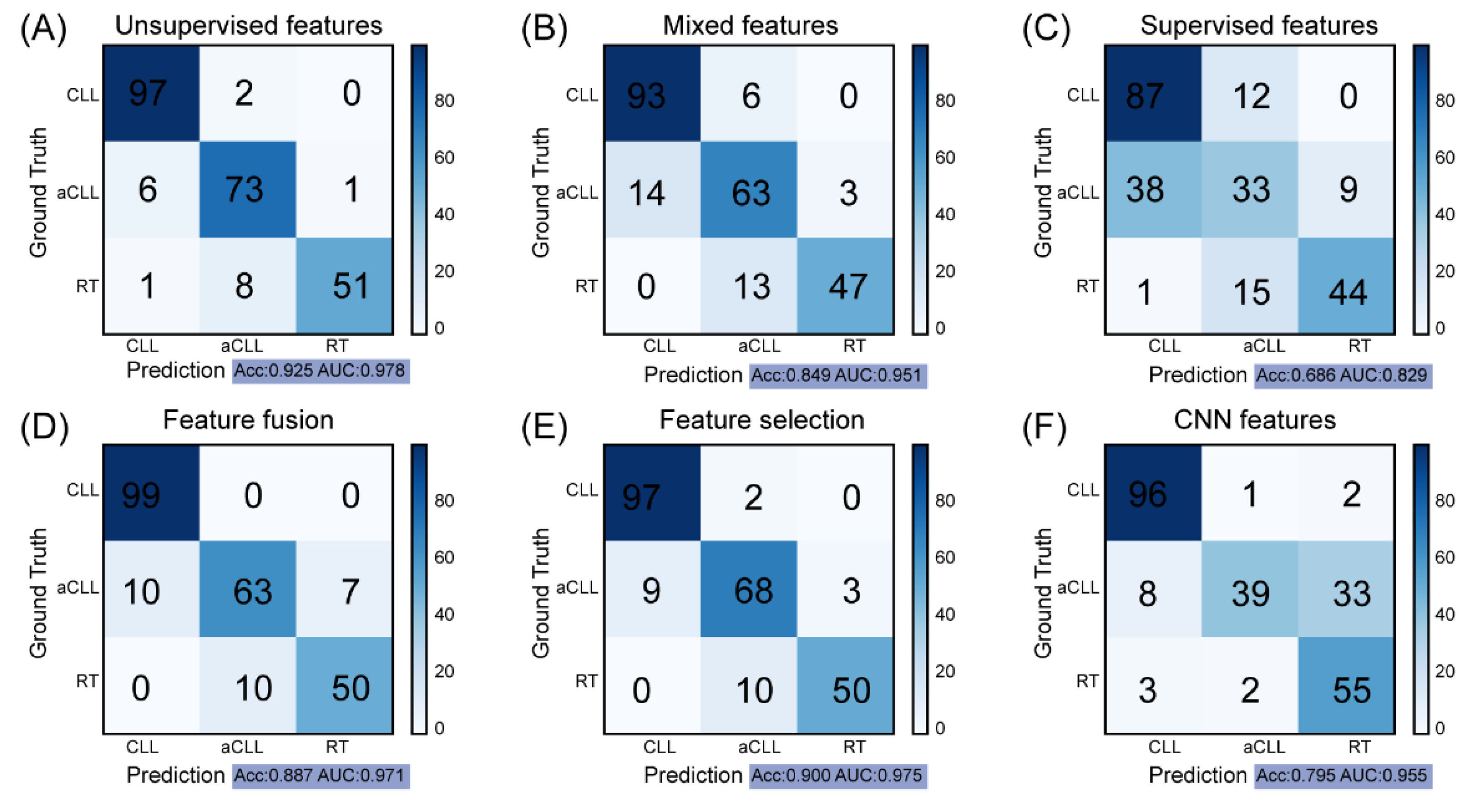
3.2. Clustering-Based Model Obtains the Best Performance for Disease Progression Prediction
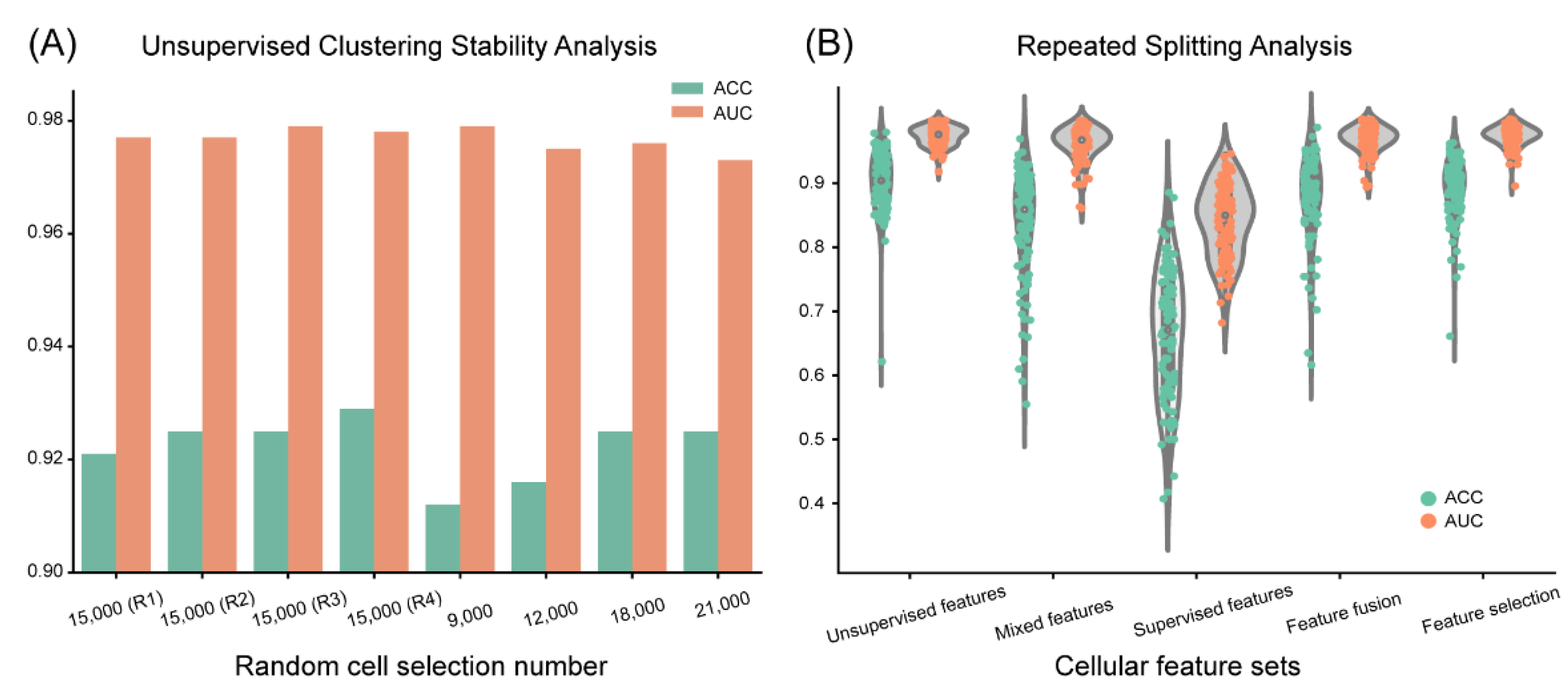
3.3. Clustering-Based Model Shows High Reproducibility and Robustness
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wierda, W.G.; Byrd, J.C.; Abramson, J.S.; Bilgrami, S.F.; Bociek, G.; Brander, D.; Brown, J.; Chanan-Khan, A.A.; Chavez, J.C.; Coutre, S.E.; et al. NCCN Guidelines Insights: Chronic Lymphocytic Leukemia/Small Lymphocytic Lymphoma, Version 2.2019. J. Natl. Compr. Cancer Netw. 2019, 17, 12–20. [Google Scholar] [CrossRef] [Green Version]
- Gine, E.; Martinez, A.; Villamor, N.; Lopez-Guillermo, A.; Camos, M.; Martinez, D.; Esteve, J.; Calvo, X.; Muntanola, A.; Abrisqueta, P.; et al. Expanded and highly active proliferation centers identify a histological subtype of chronic lymphocytic leukemia (“accelerated” chronic lymphocytic leukemia) with aggressive clinical behavior. Haematologica 2010, 95, 1526–1533. [Google Scholar] [CrossRef]
- Gupta, R.; Kurc, T.; Sharma, A.; Almeida, J.S.; Saltz, J. The Emergence of Pathomics. Curr. Pathobiol. Rep. 2019, 7, 73–84. [Google Scholar] [CrossRef] [Green Version]
- Lewis, J.S., Jr.; Ali, S.; Luo, J.; Thorstad, W.L.; Madabhushi, A. A quantitative histomorphometric classifier (QuHbIC) identifies aggressive versus indolent p16-positive oropharyngeal squamous cell carcinoma. Am. J. Surg. Pathol. 2014, 38, 128–137. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.H.; Chen, P.J.; McGough, M.; Xing, F.Y.; Wang, C.B.; Bui, M.; Xie, Y.P.; Sapkota, M.; Cui, L.; Dhillon, J.; et al. Pathologist-level interpretable whole-slide cancer diagnosis with deep learning (vol 1, pg 236, 2019). Nat. Mach. Intell. 2019, 1, 384. [Google Scholar] [CrossRef]
- Chen, P.J.; Liang, Y.; Shi, X.S.; Yang, L.; Gader, P. Automatic whole slide pathology image diagnosis framework via unit stochastic selection and attention fusion. Neurocomputing 2021, 453, 312–325. [Google Scholar] [CrossRef]
- Wang, H.; Cruz-Roa, A.; Basavanhally, A.; Gilmore, H.; Shih, N.; Feldman, M.; Tomaszewski, J.; Gonzalez, F.; Madabhushi, A. Mitosis detection in breast cancer pathology images by combining handcrafted and convolutional neural network features. J. Med. Imaging 2014, 1, 034003. [Google Scholar] [CrossRef]
- Rueckert, D.; Schnabel, J.A. Model-Based and Data-Driven Strategies in Medical Image Computing. Proc. IEEE 2020, 108, 110–124. [Google Scholar] [CrossRef] [Green Version]
- d’Humieres, T.; Savale, L.; Inamo, J.; Deux, J.F.; Deswarte, S.; Lionnet, F.; Loko, G.; Chantalat, C.; Damy, T.; Guillet, H.; et al. Cardiovascular phenotypes predict clinical outcomes in sickle cell disease: An echocardiography-based cluster analysis. Am. J. Hematol. 2021, 96, 1166–1175. [Google Scholar] [CrossRef]
- Syrykh, C.; Abreu, A.; Amara, N.; Siegfried, A.; Maisongrosse, V.; Frenois, F.X.; Martin, L.; Rossi, C.; Laurent, C.; Brousset, P. Accurate diagnosis of lymphoma on whole-slide histopathology images using deep learning. NPJ Digit. Med. 2020, 3, 63. [Google Scholar] [CrossRef]
- Li, D.; Bledsoe, J.R.; Zeng, Y.; Liu, W.; Hu, Y.; Bi, K.; Liang, A.; Li, S. A deep learning diagnostic platform for diffuse large B-cell lymphoma with high accuracy across multiple hospitals. Nat. Commun. 2020, 11, 6004. [Google Scholar] [CrossRef] [PubMed]
- Miyoshi, H.; Sato, K.; Kabeya, Y.; Yonezawa, S.; Nakano, H.; Takeuchi, Y.; Ozawa, I.; Higo, S.; Yanagida, E.; Yamada, K.; et al. Deep learning shows the capability of high-level computer-aided diagnosis in malignant lymphoma. Lab. Investig. 2020, 100, 1300–1310. [Google Scholar] [CrossRef] [PubMed]
- Achi, H.E.; Belousova, T.; Chen, L.; Wahed, A.; Wang, I.; Hu, Z.; Kanaan, Z.; Rios, A.; Nguyen, A.N.D. Automated Diagnosis of Lymphoma with Digital Pathology Images Using Deep Learning. Ann. Clin. Lab. Sci. 2019, 49, 153–160. [Google Scholar]
- Mohlman, J.S.; Leventhal, S.D.; Hansen, T.; Kohan, J.; Pascucci, V.; Salama, M.E. Improving Augmented Human Intelligence to Distinguish Burkitt Lymphoma From Diffuse Large B-Cell Lymphoma Cases. Am. J. Clin. Pathol. 2020, 153, 743–759. [Google Scholar] [CrossRef]
- El Achi, H.; Khoury, J.D. Artificial Intelligence and Digital Microscopy Applications in Diagnostic Hematopathology. Cancers 2020, 12, 797. [Google Scholar] [CrossRef] [Green Version]
- Irshaid, L.; Bleiberg, J.; Weinberger, E.; Garritano, J.; Shallis, R.M.; Patsenker, J.; Lindenbaum, O.; Kluger, Y.; Katz, S.G.; Xu, M.L. Histopathologic and Machine Deep Learning Criteria to Predict Lymphoma Transformation in Bone Marrow Biopsies. Arch. Pathol. Lab. Med. 2021, 146, 182–193. [Google Scholar] [CrossRef]
- El Hussein, S.; Chen, P.; Medeiros, L.J.; Jaffray, D.; Wu, J.; Khoury, J.D. Artificial intelligence strategy integrating morphologic and architectural biomarkers provides robust diagnostic accuracy for disease progression in Chronic Lymphocytic Leukemia. J. Pathol. 2021, 256, 4–14. [Google Scholar] [CrossRef]
- Zhang, N.; Liang, R.; Gensheimer, M.F.; Guo, M.; Zhu, H.; Yu, J.; Diehn, M.; Loo, B.W., Jr.; Li, R.; Wu, J. Early response evaluation using primary tumor and nodal imaging features to predict progression-free survival of locally advanced non-small cell lung cancer. Theranostics 2020, 10, 11707–11718. [Google Scholar] [CrossRef]
- Austin, P.C. A critical appraisal of propensity-score matching in the medical literature between 1996 and 2003. Stat. Med. 2008, 27, 2037–2049. [Google Scholar] [CrossRef]
- Tizhoosh, H.R.; Pantanowitz, L. Artificial Intelligence and Digital Pathology: Challenges and Opportunities. J. Pathol. Inform. 2018, 9, 38. [Google Scholar] [CrossRef]
- Mercan, E.; Aksoy, S.; Shapiro, L.G.; Weaver, D.L.; Brunye, T.T.; Elmore, J.G. Localization of Diagnostically Relevant Regions of Interest in Whole Slide Images: A Comparative Study. J. Digit. Imaging 2016, 29, 496–506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peikari, M.; Gangeh, M.J.; Zubovits, J.; Clarke, G.; Martel, A.L. Triaging Diagnostically Relevant Regions from Pathology Whole Slides of Breast Cancer: A Texture Based Approach. IEEE Trans. Med. Imaging 2016, 35, 307–315. [Google Scholar] [CrossRef] [PubMed]
- Vahadane, A.; Peng, T.; Sethi, A.; Albarqouni, S.; Wang, L.; Baust, M.; Steiger, K.; Schlitter, A.M.; Esposito, I.; Navab, N. Structure-Preserving Color Normalization and Sparse Stain Separation for Histological Images. IEEE Trans. Med. Imaging 2016, 35, 1962–1971. [Google Scholar] [CrossRef] [PubMed]
- Jaume, G.; Pati, P.; Anklin, V.; Foncubierta, A.; Gabrani, M. HistoCartography: A Toolkit for Graph Analytics in Digital Pathology. In Proceedings of the MICCAI Workshop on Computational Pathology, Strasbourg, France, 27 September 2021; pp. 117–128. [Google Scholar]
- Graham, S.; Vu, Q.D.; Raza, S.E.A.; Azam, A.; Tsang, Y.W.; Kwak, J.T.; Rajpoot, N. Hover-Net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Med. Image Anal. 2019, 58, 101563. [Google Scholar] [CrossRef] [Green Version]
- Gamper, J.; Koohbanani, N.A.; Benet, K.; Khuram, A.; Rajpoot, N. Pannuke: An open pan-cancer histology dataset for nuclei instance segmentation and classification. In Proceedings of the European Congress on Digital Pathology, Warwick, UK, 10–13 April 2019; pp. 11–19. [Google Scholar]
- Kumar, N.; Verma, R.; Sharma, S.; Bhargava, S.; Vahadane, A.; Sethi, A. A Dataset and a Technique for Generalized Nuclear Segmentation for Computational Pathology. IEEE Trans. Med. Imaging 2017, 36, 1550–1560. [Google Scholar] [CrossRef]
- Vu, Q.D.; Graham, S.; Kurc, T.; To, M.N.N.; Shaban, M.; Qaiser, T.; Koohbanani, N.A.; Khurram, S.A.; Kalpathy-Cramer, J.; Zhao, T.; et al. Methods for Segmentation and Classification of Digital Microscopy Tissue Images. Front. Bioeng. Biotechnol. 2019, 7, 53. [Google Scholar] [CrossRef]
- Xing, F.; Yang, L. Robust Nucleus/Cell Detection and Segmentation in Digital Pathology and Microscopy Images: A Comprehensive Review. IEEE Rev. Biomed. Eng. 2016, 9, 234–263. [Google Scholar] [CrossRef]
- Filippone, M.; Camastra, F.; Masulli, F.; Rovetta, S. A survey of kernel and spectral methods for clustering. Patt. Recogn. 2008, 41, 176–190. [Google Scholar] [CrossRef] [Green Version]
- Bradski, G. The OpenCV library. J. Softw. Tools 2000, 25, 120–125. [Google Scholar]
- Peyre, R. Comparison between W-2 Distance and H-1 Norm, and Localization of Wasserstein Distance. Esaim Contr. Optim. Cal. Variat. 2018, 24, 1489–1501. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.Q.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the Kdd’16: The 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Hamerla, G.; Meyer, H.J.; Schob, S.; Ginat, D.T.; Altman, A.; Lim, T.; Gihr, G.A.; Horvath-Rizea, D.; Hoffmann, K.T.; Surov, A. Comparison of machine learning classifiers for differentiation of grade 1 from higher gradings in meningioma: A multicenter radiomics study. Magn. Reson. Imaging 2019, 63, 244–249. [Google Scholar] [CrossRef] [PubMed]
- Sasaki, K.; Jabbour, E.J.; Ravandi, F.; Konopleva, M.; Borthakur, G.; Wierda, W.G.; Daver, N.; Takahashi, K.; Naqvi, K.; DiNardo, C.; et al. The LEukemia Artificial Intelligence Program (LEAP) in chronic myeloid leukemia in chronic phase: A model to improve patient outcomes. Am. J. Hematol. 2021, 96, 241–250. [Google Scholar] [CrossRef] [PubMed]
- Deng, H.T.; Runger, G. Feature Selection via Regularized Trees. In Proceedings of the 2012 International Joint Conference on Neural Networks (Ijcnn), Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- Hou, L.; Samaras, D.; Kurc, T.M.; Gao, Y.; Davis, J.E.; Saltz, J.H. Patch-based Convolutional Neural Network for Whole Slide Tissue Image Classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 2016; pp. 2424–2433. [Google Scholar] [CrossRef] [Green Version]
- Coudray, N.; Ocampo, P.S.; Sakellaropoulos, T.; Narula, N.; Snuderl, M.; Fenyo, D.; Moreira, A.L.; Razavian, N.; Tsirigos, A. Classification and mutation prediction from non-small cell lung cancer histopathology images using deep learning. Nat. Med. 2018, 24, 1559–1567. [Google Scholar] [CrossRef] [PubMed]
- Manescu, P.; Shaw, M.J.; Elmi, M.; Neary-Zajiczek, L.; Claveau, R.; Pawar, V.; Kokkinos, I.; Oyinloye, G.; Bendkowski, C.; Oladejo, O.A.; et al. Expert-level automated malaria diagnosis on routine blood films with deep neural networks. Am. J. Hematol. 2020, 95, 883–891. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.; Shi, X.; Liang, Y.; Li, Y.; Yang, L.; Gader, P.D. Interactive thyroid whole slide image diagnostic system using deep representation. Comput. Methods Program. Biomed. 2020, 195, 105630. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; Volume 1–4, pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Agbay, R.L.; Jain, N.; Loghavi, S.; Medeiros, L.J.; Khoury, J.D. Histologic transformation of chronic lymphocytic leukemia/small lymphocytic lymphoma. Am. J. Hematol. 2016, 91, 1036–1043. [Google Scholar] [CrossRef]
- Buczak, A.L.; Babin, S.; Moniz, L. Data-driven approach for creating synthetic electronic medical records. BMC Med. Inform. Decis Mak. 2010, 10, 59. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.Y.; Wang, F.; Hu, J.Y.; Ye, J.P. From Micro to Macro: Data Driven Phenotyping by Densification of Longitudinal Electronic Medical Records. In Proceedings of the 20th Acm Sigkdd International Conference on Knowledge Discovery and Data Mining (Kdd’14), New York, NY, USA, 24–27 August 2014; pp. 135–144. [Google Scholar] [CrossRef]
- Haddi, Z.; Ananou, B.; Trardi, Y.; Pons, J.F.; Delliaux, S.; Ouladsine, M.; Deharo, J.C. Relevance Vector Machine as Data-Driven Method for Medical Decision Making. In Proceedings of the 18th European Control Conference (Ecc), Naples, Italy, 25–28 June 2019; pp. 1011–1016. [Google Scholar]
- Liang, Z.; Oba, S.; Ishii, S. An unsupervised EEG decoding system for human emotion recognition. Neural Netw. 2019, 116, 257–268. [Google Scholar] [CrossRef]
- Chen, P.J.; Fan, X.; Liu, R.Y.; Tang, X.X.; Cheng, H. Fiber Segmentation Using a Density-Peaks Clustering Algorithm. In Proceedings of the 2015 IEEE International Symposium on Biomedical Imaging, New York, NY, USA, 16–19 April 2015; pp. 633–637. [Google Scholar]
- Sirinukunwattana, K.; Aberdeen, A.; Theissen, H.; Sousos, N.; Psaila, B.; Mead, A.J.; Turner, G.D.H.; Rees, G.; Rittscher, J.; Royston, D. Artificial intelligence-based morphological fingerprinting of megakaryocytes: A new tool for assessing disease in MPN patients. Blood Adv. 2020, 4, 3284–3294. [Google Scholar] [CrossRef]
- Uzunova, H.; Schultz, S.; Handels, H.; Ehrhardt, J. Unsupervised pathology detection in medical images using conditional variational autoencoders. Int. J. Comput. Ass. Rad. 2019, 14, 451–461. [Google Scholar] [CrossRef]
- Sari, C.T.; Gunduz-Demir, C. Unsupervised Feature Extraction via Deep Learning for Histopathological Classification of Colon Tissue Images. IEEE Trans. Med. Imaging 2019, 38, 1139–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McAlpine, E.D.; Michelow, P.; Celik, T. The Utility of Unsupervised Machine Learning in Anatomic Pathology. Am. J. Clin. Pathol. 2021, 157, 5–14. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Li, C.; Gensheimer, M.; Padda, S.; Kato, F.; Shirato, H.; Wei, Y.; Schönlieb, C.-B.; Price, S.J.; Jaffray, D. Radiological tumour classification across imaging modality and histology. Nat. Mach. Intell. 2021, 3, 787–798. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Lect. Notes Comput. Sci. 2015, 9351, 234–241. [Google Scholar] [CrossRef] [Green Version]
- Mobadersany, P.; Yousefi, S.; Amgad, M.; Gutman, D.A.; Barnholtz-Sloan, J.S.; Velazquez Vega, J.E.; Brat, D.J.; Cooper, L.A.D. Predicting cancer outcomes from histology and genomics using convolutional networks. Proc. Natl. Acad. Sci. USA 2018, 115, E2970–E2979. [Google Scholar] [CrossRef] [Green Version]
- Abels, E.; Pantanowitz, L.; Aeffner, F.; Zarella, M.D.; van der Laak, J.; Bui, M.M.; Vemuri, V.N.; Parwani, A.V.; Gibbs, J.; Agosto-Arroyo, E.; et al. Computational pathology definitions, best practices, and recommendations for regulatory guidance: A white paper from the Digital Pathology Association. J. Pathol. 2019, 249, 286–294. [Google Scholar] [CrossRef]
- Morrison, L.E.; Lefever, M.R.; Behman, L.J.; Leibold, T.; Roberts, E.A.; Horchner, U.B.; Bauer, D.R. Brightfield multiplex immunohistochemistry with multispectral imaging. Lab. Investig. 2020, 100, 1124–1136. [Google Scholar] [CrossRef]
- Schulz, D.; Zanotelli, V.R.T.; Fischer, J.R.; Schapiro, D.; Engler, S.; Lun, X.K.; Jackson, H.W.; Bodenmiller, B. Simultaneous Multiplexed Imaging of mRNA and Proteins with Subcellular Resolution in Breast Cancer Tissue Samples by Mass Cytometry. Cell Syst. 2018, 6, 25–36. [Google Scholar] [CrossRef] [Green Version]
- Lewis, S.M.; Asselin-Labat, M.L.; Nguyen, Q.; Berthelet, J.; Tan, X.; Wimmer, V.C.; Merino, D.; Rogers, K.L.; Naik, S.H. Spatial omics and multiplexed imaging to explore cancer biology. Nat. Methods 2021, 18, 997–1012. [Google Scholar] [CrossRef] [PubMed]
- Jackson, H.W.; Fischer, J.R.; Zanotelli, V.R.T.; Ali, H.R.; Mechera, R.; Soysal, S.D.; Moch, H.; Muenst, S.; Varga, Z.; Weber, W.P.; et al. The single-cell pathology landscape of breast cancer. Nature 2020, 578, 615–620. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Training Cohort (n = 67) | Testing Cohort (n = 68) | |||||
|---|---|---|---|---|---|---|---|
| CLL (22) | aCLL (17) | RT (28) | CLL (22) | aCLL (17) | RT (29) | ||
| Gender | Male | 15 | 11 | 17 | 14 | 13 | 18 |
| Female | 7 | 6 | 11 | 8 | 4 | 11 | |
| Age (years) | ≥60 | 9 | 10 | 15 | 9 | 7 | 15 |
| <60 | 13 | 7 | 13 | 13 | 10 | 14 | |
| Source | In | 11 | 9 | 19 | 6 | 8 | 20 |
| Outside | 11 | 8 | 9 | 16 | 9 | 9 | |
| Biopsy technique | EB | 11 | 7 | 8 | 12 | 7 | 10 |
| CNB | 11 | 10 | 20 | 9 | 10 | 19 | |
| OS (M) | Longer | 9 | 7 | 12 | 9 | 7 | 13 |
| Shorter | 13 | 10 | 16 | 13 | 10 | 16 | |
| Unsupervised Features | Mixed Features | Supervised Features |
|---|---|---|
| 1. CLL-like cell ratio | 7. mean cell size | 11. large cell ratio |
| 2. aCLL-like cell ratio | 8. mean cell intensity | 12. S/L cell intensity correlation |
| 3. RT-like cell ratio | 9. mean cell distance | 13. S/L cell intensity chi-square |
| 4. CLL-like cell density | 10. cell density | 14. S/L cell intensity Wasserstein distance |
| 5. aCLL-like cell density | 15. small cell density | |
| 6. RT-like cell density | 16. large cell density | |
| 17. mean small to small cell distance | ||
| 18. mean small to large cell distance | ||
| 19. mean large to small cell distance | ||
| 20. mean large to large clel distance |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; El Hussein, S.; Xing, F.; Aminu, M.; Kannapiran, A.; Hazle, J.D.; Medeiros, L.J.; Wistuba, I.I.; Jaffray, D.; Khoury, J.D.; et al. Chronic Lymphocytic Leukemia Progression Diagnosis with Intrinsic Cellular Patterns via Unsupervised Clustering. Cancers 2022, 14, 2398. https://doi.org/10.3390/cancers14102398
Chen P, El Hussein S, Xing F, Aminu M, Kannapiran A, Hazle JD, Medeiros LJ, Wistuba II, Jaffray D, Khoury JD, et al. Chronic Lymphocytic Leukemia Progression Diagnosis with Intrinsic Cellular Patterns via Unsupervised Clustering. Cancers. 2022; 14(10):2398. https://doi.org/10.3390/cancers14102398
Chicago/Turabian StyleChen, Pingjun, Siba El Hussein, Fuyong Xing, Muhammad Aminu, Aparajith Kannapiran, John D. Hazle, L. Jeffrey Medeiros, Ignacio I. Wistuba, David Jaffray, Joseph D. Khoury, and et al. 2022. "Chronic Lymphocytic Leukemia Progression Diagnosis with Intrinsic Cellular Patterns via Unsupervised Clustering" Cancers 14, no. 10: 2398. https://doi.org/10.3390/cancers14102398
APA StyleChen, P., El Hussein, S., Xing, F., Aminu, M., Kannapiran, A., Hazle, J. D., Medeiros, L. J., Wistuba, I. I., Jaffray, D., Khoury, J. D., & Wu, J. (2022). Chronic Lymphocytic Leukemia Progression Diagnosis with Intrinsic Cellular Patterns via Unsupervised Clustering. Cancers, 14(10), 2398. https://doi.org/10.3390/cancers14102398