1. Introduction
The microscopic morphology of a workpiece surface plays a crucial role in determining its wear resistance, corrosion resistance, and tribological behavior, which affect the operational life and reliability of the product. Surface roughness is often considered a key indicator of the surface morphology and quality of a machined workpiece [
1]. However, traditional roughness measurement methods often require significant time and resources in real-world manufacturing environments. As a result, they are inefficient for large-scale or high-precision production [
2]. Therefore, balancing high measurement accuracy with reduced inspection time and costs remains a key challenge in advanced manufacturing [
3].
With the rapid advancement of artificial intelligence technology, data-driven approaches have found successful applications across various fields. In the manufacturing industry, an increasing number of researchers are exploring AI algorithm-based data-driven methods to tackle the challenges of surface roughness prediction. Current AI-based prediction techniques are primarily divided into traditional machine learning approaches and deep learning-based [
4].
Machine learning-based surface roughness modeling approaches typically use machining parameters as decision variables [
5]. By extracting key features and using them as model inputs, traditional machine learning algorithms, such as linear regression, Support Vector Machine (SVM), etc., are used for predicting surface roughness. Çaydaş et al. [
6] designed three distinct SVM algorithms for surface roughness prediction in stainless steel turning. They compared their performance with that of artificial neural networks (ANNs). The experimental results demonstrated that all three SVM algorithms significantly outperformed ANN in terms of prediction accuracy. Pimenov et al. [
7] employed various machine learning algorithms to assess the influence of maximum wear, machining time, and cutting power on surface roughness prediction. The results indicated that the Random Forest and Regression Tree models achieved higher prediction accuracy for surface roughness. Siyambas et al. [
8] utilized the XGBoost algorithm to predict the surface roughness of titanium alloys, aiming to optimize coolant selection for achieving the required product quality at minimal cost. Zhang et al. [
9], considering industrial application demands such as applicability, implementation simplicity, and cost-effectiveness, developed a Gaussian Process Regression model to predict surface roughness in the turning process of brass.
Deep learning-based surface roughness prediction methods leverage end-to-end neural networks to automatically extract complex high-dimensional features through multi-layer structures. Such methods have also been widely used in industrial fields, including aerospace, automotive manufacturing, and precision parts machining [
10,
11]. For example, Pan et al. [
12] utilized vibration signals as input for a Convolutional Neural Network (CNN) to develop a surface roughness prediction model. Guo et al. [
13] implemented a Long Short-Term Memory (LSTM) network as the prediction framework, incorporating grinding force, vibration, and acoustic emission signals as inputs, achieving superior predictive performance. Lin et al. [
14] proposed a surface roughness prediction framework that integrates three models: Fast Fourier Transform Deep Neural Network (FFT-DNN), Fast Fourier Transform Long Short-Term Memory Network (FFT-LSTM), and one-dimensional Convolutional Neural Network (1-D CNN). In this framework, FFT-DNN and 1-D CNN are used for feature extraction, and FFT-LSTM serves as the prediction model, yielding highly accurate surface roughness predictions.
In recent years, swarm intelligence algorithms have been increasingly combined with machine learning and deep learning to develop smarter and more efficient manufacturing solutions, aiming to optimize processes, improve prediction accuracy, and enhance decision-making. For instance, researchers have employed Grey Wolf Optimization (GWO) to fine-tune support vector machine (SVM) parameters [
15], combined quantum-behaved particle swarm optimization (QPSO) with machine learning for surface defect prediction [
16], and utilized genetic algorithm (GA)-optimized artificial neural networks (ANNs) to analyze machining effects on material surfaces [
17]. Additionally, gradient-boosting regression trees (GBRTs) coupled with GA have been used to model process parameters and optimize predictive performance [
18].
Both traditional machine learning and deep learning heavily rely on the quantity and quality of samples. However, real-world production often presents challenges such as high data collection costs, long cycle times, and complex and variable working conditions, making it difficult to obtain large-scale, high-quality data. Optimizing the representation of the feature space based on limited data and constructing high-accuracy prediction models with greater generalization capability are key issues in few-shot learning research. Virtual Sample Generation (VSG) is a primary solution in this field, which can generate new samples and expand the training dataset. Studies have shown that incorporating synthetic data can significantly improve the prediction accuracy and generalization ability of models [
19]. This approach effectively addresses the issue of insufficient samples in environments with data imbalance or small-sized datasets, with particularly notable effects in tasks involving fewer samples [
20]. In the field of surface roughness prediction, most existing studies focus on generating synthetic samples using deep learning methods or linear interpolation techniques. Wen et al. [
21] proposed a local linear estimator for point-wise prediction in end milling, incorporating a pseudo-data generator to improve the fully interpolated local linear estimation performance. However, linear interpolation-based virtual sample generation methods can only create new samples among existing data points, restricting them to the range of known data distributions. Several studies have employed the adversarial training mechanism between generators and discriminators in Generative Adversarial Networks (GANs) to generate realistic synthetic data for training dataset augmentation, thereby enhancing model generalization capability. Wang et al. [
22] introduced a data augmentation approach for surface roughness prediction based on a GAN, which enhanced vibration signal data and significantly improved prediction accuracy. Cooper et al. [
23] designed a Conditional GAN to generate power signals associated with different process parameter combinations, effectively enhancing CNN-based surface roughness prediction accuracy.
In addition, most of the current research focuses on simple feature generation or the combination of existing features, which fails to adequately capture the deeper interactions between different variables. The exploration of systematic feature construction techniques remains insufficient.
Wang et al. employed a quadratic polynomial approach to expand machining parameter features [
24]. While this method offers certain advantages, such as simplicity in form and computational efficiency, its fundamental limitation lies in its insufficient capability to represent nonlinear process features. Ruan et al. extended the machining parameter features using higher-order polynomials and introduced a variational autoencoder (VAE) to generate virtual samples to alleviate the issue of data scarcity [
25]. Although higher-order polynomials enhance the expressive power compared to quadratic ones, they are still constrained by fixed functional forms, lack adaptability to feature structures, and suffer from an exponential increase in computational complexity with the order of the polynomial. Moreover, VAEs require large datasets to learn the true data distribution effectively, and under small-sample conditions, they tend to generate low-diversity or unrealistic samples, such as repeated or overly similar data. Chen et al. employed three different types of generative adversarial networks (GANs) to augment 1030 original machining data samples [
26], but they still failed to adequately capture the true data distribution. Similarly, Brock et al. pointed out that the performance of GANs significantly degrades when trained on limited data [
27]. Yu et al. attempted to mitigate overfitting under data scarcity by regularizing the discriminator in the GAN framework, but the generator remained unconstrained [
28], which could result in the generation of samples that do not conform to process principles. In contrast, virtual sample generation shows greater potential under small-sample scenarios.
Therefore, using more advanced VSG-based feature construction strategies is essential in small-sample scenarios. These strategies help uncover additional useful information to improve the accuracy of surface roughness prediction. To address these existing challenges, further exploration of efficient and flexible methods for data generation and feature mining is necessary. On one hand, more tailored virtual sample generation strategies should be designed for different working conditions and data distribution characteristics to maximize the enrichment of the sample space. On the other hand, a more systematic feature expansion approach should be devised, focusing on deep variable correlations and nonlinear features, to fully explore the intrinsic mechanisms of the processing process and potential information. This will provide stronger support for predicting roughness in small-sample conditions.
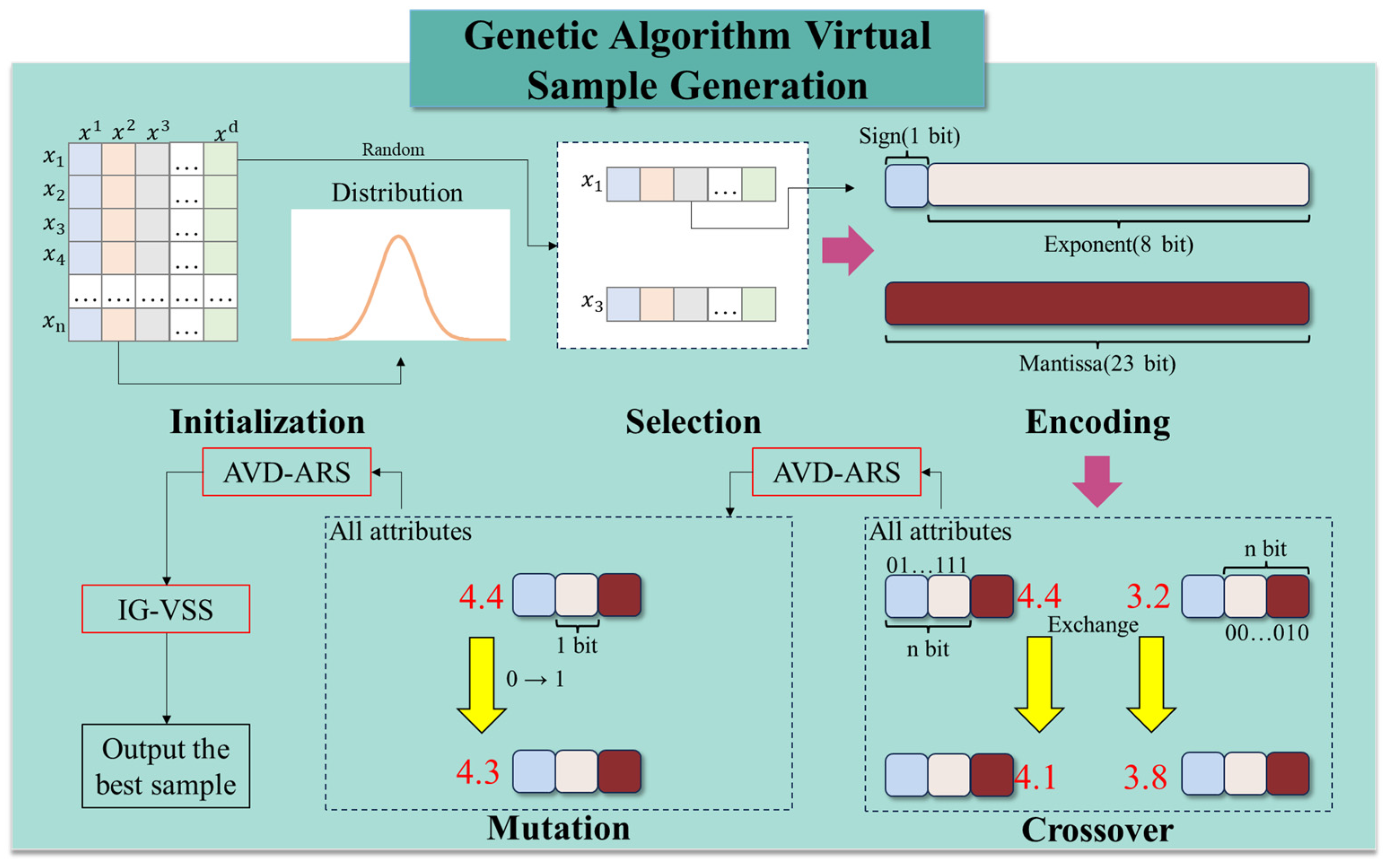
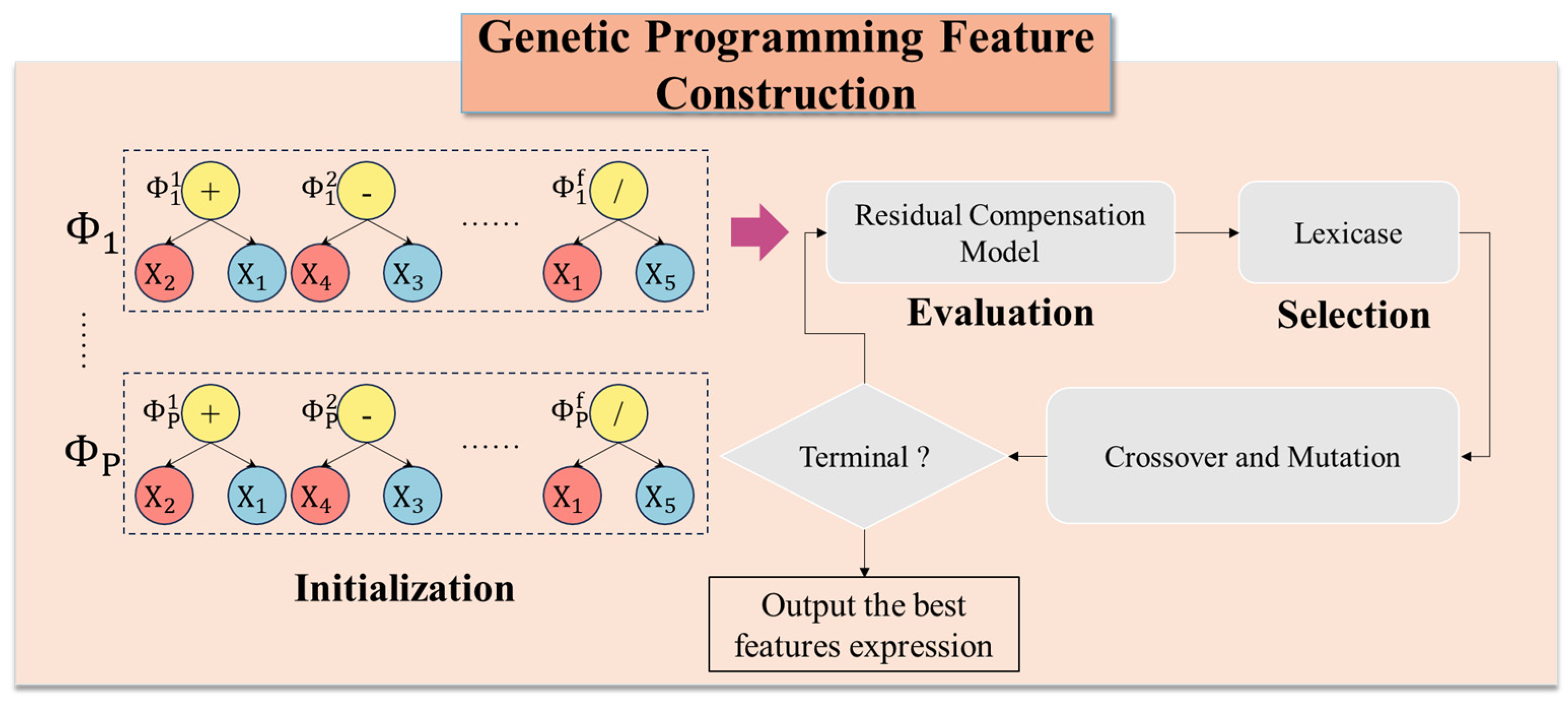
To address the challenges mentioned above, this paper presents a novel data augmentation method, i.e., a Genetic Algorithm-based Virtual Sample Generation (GA-VSG) and a Genetic Programming-based Feature Construction (GP-FC) approach, for predicting surface roughness, which applies swarm intelligence algorithms to optimize the feature space for data enhancement.
By combining acceptance–rejection sampling with the crossover and mutation operations of the genetic algorithm, the method ensures that the generated samples maintain a distribution consistent with the original data at the feature level. Then, incorporating the principle of minimizing absolute information gain, the approach iteratively selects the optimal offspring samples, guaranteeing the authenticity of generated samples at the sample level. Subsequently, the GP approach is employed to conduct deep feature extraction from both original and virtual samples. By adaptively combining and transforming existing features, the method constructs more representative composite variables and preserves key information from the machining process. It also compensates for nonlinear residuals that are hard to capture in conventional feature spaces, thereby enhancing the accuracy and robustness of surface roughness prediction. Finally, an Extreme Random Trees Regressor (ET) model is used for the final prediction.
The key contributions of this paper are summarized as follows:
- (1)
We validate the authenticity of virtual samples in surface roughness prediction at both the sample and feature levels. Extensive experiments demonstrate the contribution of virtual samples in enhancing the generalization ability of the predictive model;
- (2)
Based on a residual compensation model, we adaptively construct features to extract deeper information from the data. This process generates more representative composite variables, effectively capturing nonlinear residuals and addressing the limitations of traditional machining parameter-based feature spaces;
- (3)
Using the SHAP (Shapley Additive Explanations) framework, we provide consistent and intuitive explanations for model predictions. We also identified the average total contribution of key features affecting surface roughness in AWJP and MJP.
The remainder of this paper is organized as follows. The Methods section introduces the proposed approach in detail. The Experimental Setup section describes the datasets and algorithm parameters. The Results and Discussion section presents a comprehensive analysis of the experimental results, demonstrating the effectiveness and robustness of the proposed method. Finally, the Conclusion section summarizes the key contributions of this work and discusses future research directions in interpretability and feature construction, offering insights for further improving the intelligence and accuracy of surface roughness prediction.
3. Results and Discussion
3.1. Validation of the GA-VSG Method
The MSE of different machine learning models on the two original experimental datasets was first compared. The results are presented in the Base column of
Table 6. On AWJP, Random Forest (RF) delivers the best performance with an MSE of 0.1509, significantly outperforming the other models. ET and XGB follow closely behind with MSEs of 0.1522 and 0.1674, respectively, underscoring the effectiveness of ensemble learning methods on this dataset. On MJP, GBM achieves the best performance, with an MSE of 0.0011, demonstrating its strong capability in capturing fine-grained data patterns. XGB and RF also perform well, both with an MSE of 0.0014, further confirming the superiority of ensemble learning methods on complex datasets. The experimental results from both datasets indicate that ensemble learning methods consistently outperform single models in terms of MSE. This suggests that ensemble methods effectively capture complex nonlinear relationships and interaction features by aggregating predictions from multiple weak learners. Additionally, the performance of the same machine learning method varies slightly across different datasets. This variation may stem from intrinsic dataset characteristics and differences in data processing methods.
Then, the MSE of different machine learning models on the two experimental datasets was compared, which were augmented with data generated by the GA-VSG method. The arrow ↑ indicates an increase in MSE, ↓ indicates a decrease in MSE. After applying GA-VSG, the MSE of most machine learning methods on AWJP significantly decreases, with an average decrease of 0.0374, indicating that GA-VSG effectively expands the training set by generating virtual samples and enhancing model generalization. Notably, KNN’s MSE decreases by 11.59% and ET by 3.35%. DT, RF, and XGB experience a slight increase in MSE, likely because the virtual samples generated by GA-VSG alter the original data distribution. On MJP, GA-VSG increases the MSE of CAT and DT, while the MSE of other machine learning methods either decreases or remains unchanged, with an average decrease of 0.0068. This further demonstrates that the effectiveness of virtual sample generation highly depends on both the characteristics of the machine learning method and the dataset. For instance, CAT and DT may be more sensitive to noise or distribution shifts introduced by virtual samples, whereas other methods can better leverage the expanded dataset, improving or maintaining their performance.
Overall, GA-VSG proves effective for most machine learning methods, as the generated virtual samples successfully enhance model generalization. GA-VSG generates virtual samples through crossover and mutation operations of genetic algorithms, which essentially perform reasonable interpolation within high-density regions of the original data distribution. This difference explains why KNN (which relies on local similarity) and ET (which mitigates overfitting through additional randomness) exhibit improved performance, while DT-based models show increased sensitivity due to their rigid splitting rules. The accuracy improvement observed with GA-VSG in both AWJP and MJP suggests that the data in these domains possess smooth and continuous characteristics, making them suitable for interpolation-based augmentation.
3.2. Comparison with Other Virtual Sample Generation Methods
As shown in
Table 7, bold indicates the method with the greatest reduction in MSE. The GA-VSG method is compared with two other state-of-the-art virtual sample generation methods: GAN and VAE. Across both datasets, GA-VSG significantly reduces the MSE of most machine learning methods, indicating that its generated virtual samples effectively expand the training set and enhance model generalization. Overall, GA-VSG outperforms both GAN and VAE on both datasets, particularly in improving model generalization and reducing MSE. Therefore, GA-VSG proves to be a more effective virtual sample generation method, making it well-suited for various machine learning tasks.
3.3. Validation of VSG-FC Effectiveness
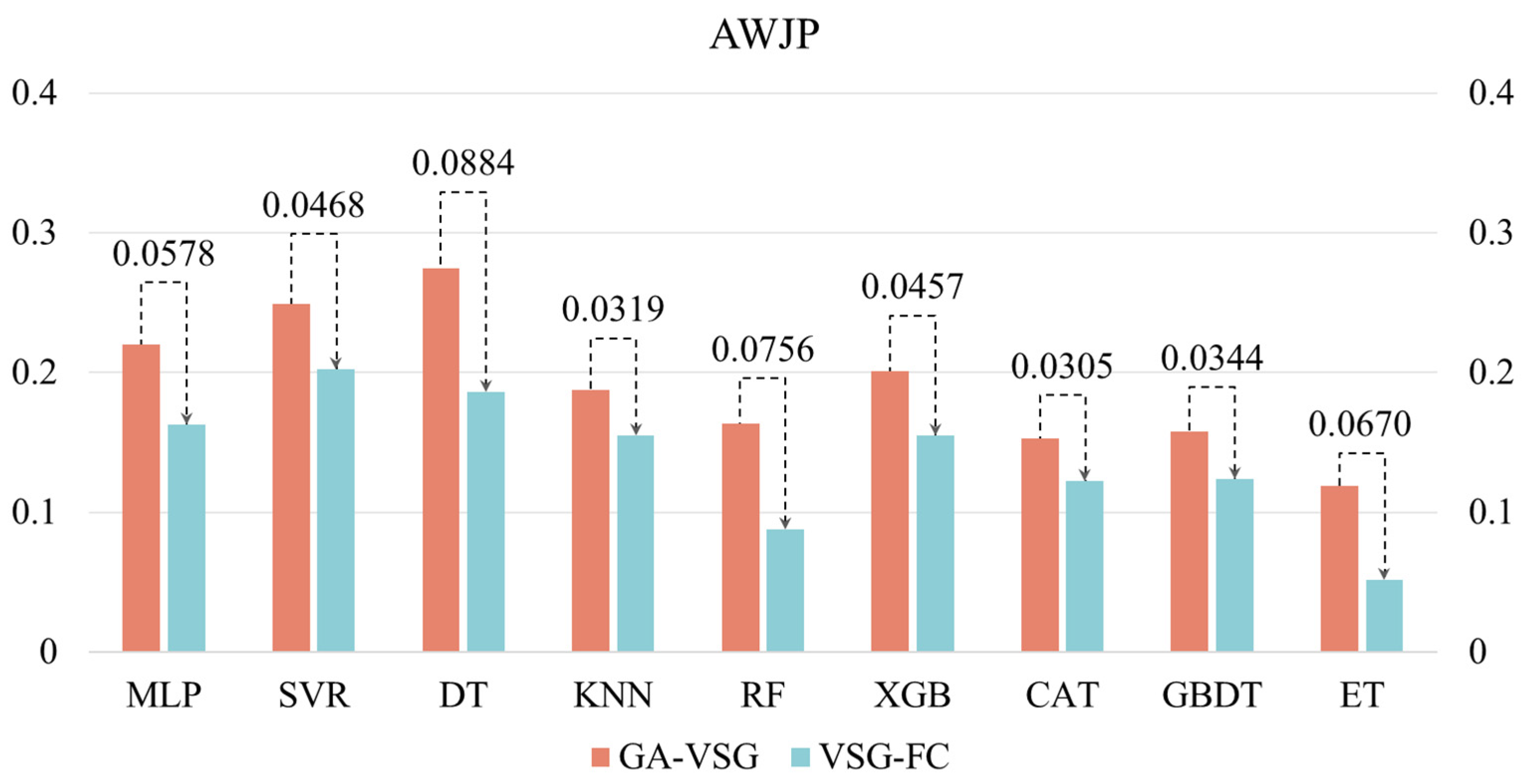
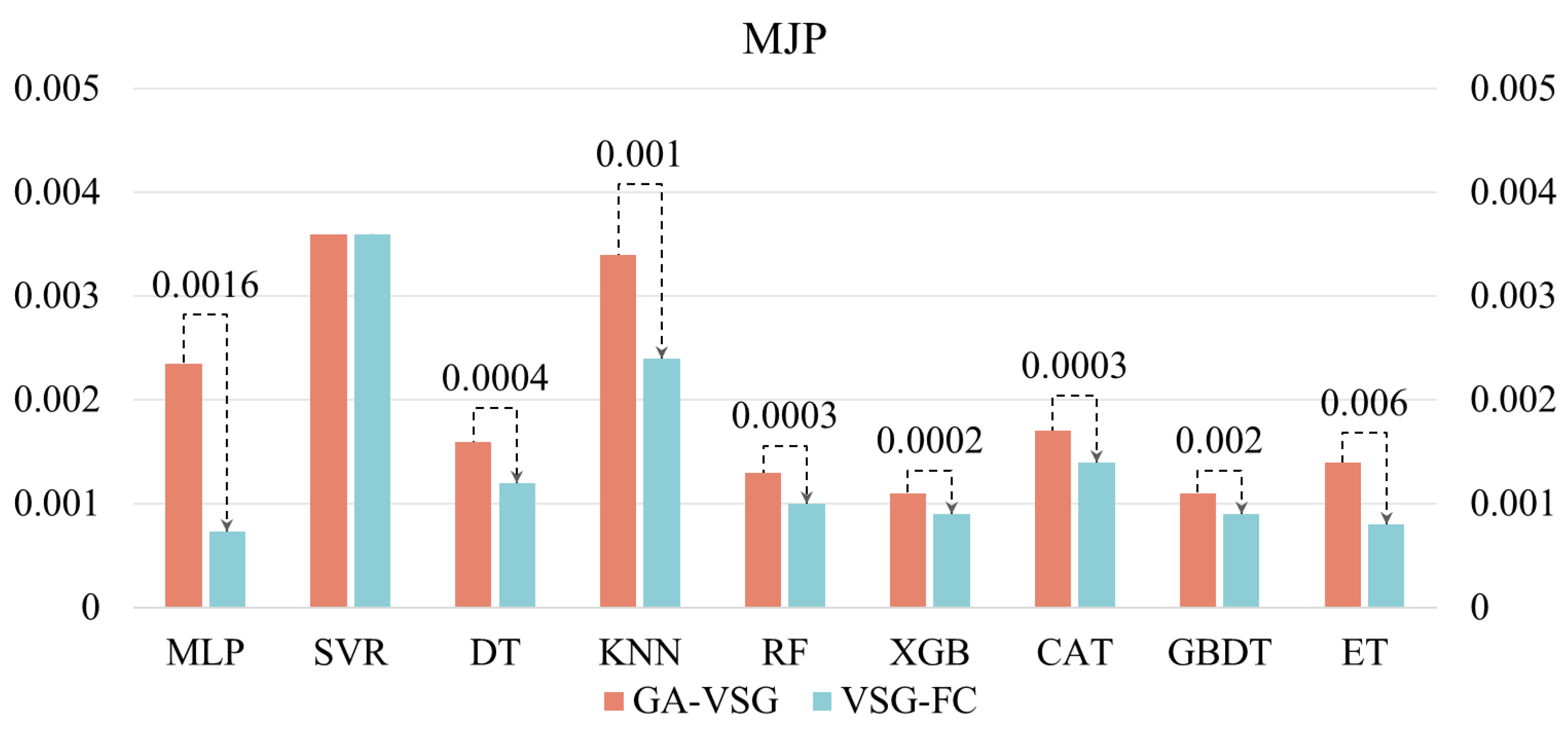
After generating virtual samples using the GA-VSG method, the feature space representation of the data is further enhanced through the GP-FC feature construction approach. To evaluate the effectiveness of GP-based feature construction, the performance of different machine learning methods before and after applying the GP-FC method was compared. The experimental results shown in
Figure 5 and
Figure 6 indicate that VSG-FC consistently outperforms GA-VSG across all datasets and models. On AWJP, VSG-FC significantly reduces MSE for all models compared to GA-VSG (to facilitate a clearer and more intuitive performance comparison of VSG-FC, all MLP values in
Figure 6 have been uniformly scaled by a factor of 10
2). For example, in MLP, MSE decreases from 0.2204 to 0.1626, a reduction of 26.2%. In ET, MSE drops from 0.1188 to 0.0518, reducing by 56.4%. These results demonstrate that VSG-FC provides substantial performance improvements, especially for complex datasets. On MJP, VSG-FC also delivers strong results. While the MSE of SVR remains unchanged at 0.0036, all other models show reductions in MSE. For example, in DT, MSE decreases from 0.0016 to 0.0012, a reduction of 25%, and in ET, MSE drops from 0.0014 to 0.0008, a reduction of 42.9%. These results suggest that VSG-FC is highly adaptable across different types of datasets.
While GA-VSG improves model generalization through virtual sample generation, its performance gains are limited. In contrast, VSG-FC further optimizes the model through feature construction, leading to a more substantial performance improvement. Different models respond to VSG-FC with varying degrees of improvement. For instance, on AWJP, ET achieves the largest MSE reduction of 56.40%, whereas on MJP, MLP shows the most significant improvement (MSE reduction of 68.63%). This suggests that the optimization effect of VSG-FC varies across models, likely due to differences in model structure and learning capacity. Its core idea is to capture underlying patterns in the data by constructing new features, thereby compensating for the limitations of the original features. By comparing the MSE of GA-VSG and VSG-FC across different datasets and models, the experiment results validate the effectiveness of VSG-FC in reducing MSE across different datasets and models.
3.4. Shapley-Based Interpretability Analysis
Shapley theory [
44] is used for fairly distributing contributions among participants in cooperative games. In machine learning, Shapley theory is widely applied in model interpretability analysis, particularly through the SHAP (Shapley Additive Explanations) framework, which calculates SHAP values to provide consistent and intuitive explanations for model predictions [
45]. In this study, the Shapley method is employed to visualize the contributions of different features in influencing the prediction of surface roughness, providing a theoretical reference for subsequent experiments.
Figure 7 presents the average total contribution of four key features affecting the surface roughness in AWJP and MJP. The second and fourth most influential features in both datasets are Pressure and Tool set, respectively. This difference may be attributed to variations in process conditions, machining environments, or differences in the distribution of input features across datasets.
In AWJP, the SHAP value of Feed Rate is significantly higher than that of other features, indicating its dominant influence on surface roughness prediction. Feed Rate directly affects the material removal rate and the contact time between the tool and the workpiece during machining. A higher Feed Rate may lead to increased cutting forces and intensified vibrations, resulting in a rougher surface. Conversely, a lower Feed Rate may cause extended friction time, leading to heat accumulation, which can also deteriorate surface quality. Processing pressure may influence the contact between the tool and the workpiece. Insufficient pressure can result in incomplete cutting, reducing machining efficiency, while excessive pressure can accelerate tool wear, indirectly degrading surface quality.
In MJP, the SHAP value of Step dominates, indicating that Step is the key control parameter for surface roughness. Step-over determines the overlap ratio of adjacent machining paths. A larger step-over may leave unprocessed areas (e.g., tool marks in milling), directly increasing surface roughness, while a smaller step-over may lead to material hardening or tool wear due to repeated cutting.
The average surface roughness in MJP is lower than that in AWJP, which may be a key factor contributing to the difference in feature importance. This suggests that for workpieces with higher surface roughness, Feed Rate should be the primary focus, whereas for those with lower roughness, Step is more critical.
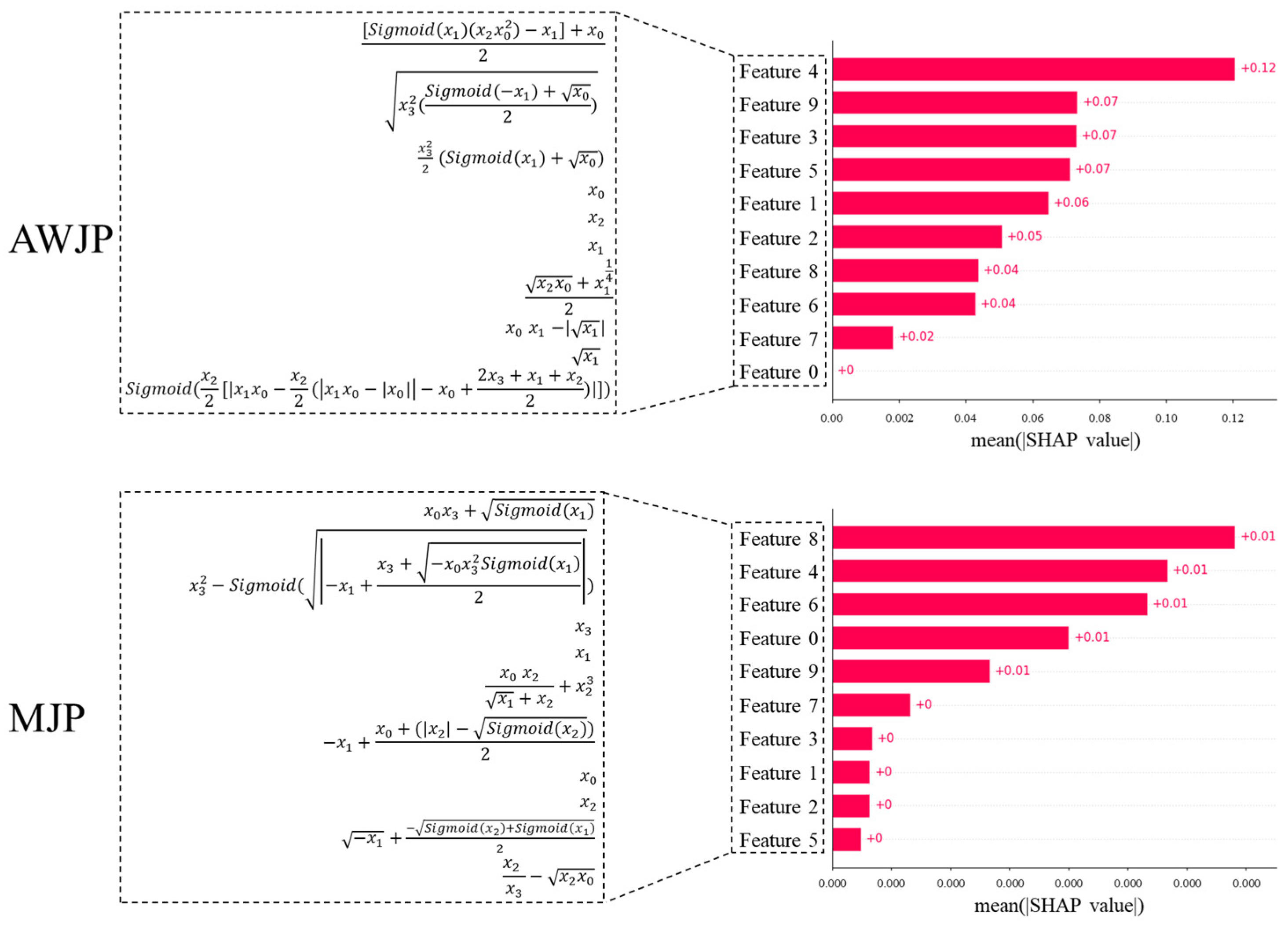
Additionally,
Figure 8 illustrates the contributions of the VSG-FC features in AWJP and MJP, where
,
,
, and
represent Feed Rate, Pressure, Tool Set, and Step, respectively. VSG-FC constructs different feature expressions across the two datasets to represent surface roughness prediction. Compared to the original machining parameters, the features constructed by VSG-FC exhibit superior predictive performance. In the AWJP dataset,
: Feed Rate remains the dominant feature in forming higher-order features, which aligns with the SHAP values calculated from the original features. Similarly, in the MJP dataset,
, Step is the leading feature.
VSG-FC not only significantly enhances prediction performance through feature construction but also generates structured and interpretable expressions that hold greater value for industrial research. Unlike traditional black-box feature construction methods, this approach outputs explicit mathematical forms that can be directly linked to physical machining mechanisms, thereby providing a traceable analytical path for process optimization. These symbolic features offer triple potentials: (1) a tool for discovering process knowledge, enabling the extraction of latent physical laws from data; (2) to build a general feature library across different processes, reducing the cost of repeated modeling; (3) to support causal inference studies, by enabling reverse analysis of key process parameter relationships through the expressions.
3.5. Discussion
We have systematically evaluated the performance of various machine learning models on AWJP and MJP datasets, with an in-depth investigation into how virtual sample generation and feature engineering methods affect model generalization capabilities. Experimental results demonstrated that ensemble learning methods exhibit significant advantages in both tasks, validating their effectiveness in capturing complex data features through multi-learner collaborative mechanisms. Notably, the models showed clear task-dependent performance characteristics. For instance, RF achieved optimal performance on AWJP data while GBM outperformed on MJP data.
Regarding data augmentation, the proposed GA-VSG method employs a genetic algorithm-driven intelligent interpolation strategy to effectively expand training samples while preserving original data distribution characteristics. Compared with generative approaches like GAN and VAE, GA-VSG demonstrates more stable performance improvements, particularly showing significant gains with KNN and ET models, thereby offering new insights for addressing small-sample learning challenges. However, the sensitivity of decision tree-based models to virtual samples also reveals limitations of data augmentation techniques, indicating their effectiveness is constrained by both model structural robustness and data distribution smoothness. The further developed VSG-FC feature construction method, which optimizes feature space through GP, outperformed GA-VSG across all tested models, confirming the synergistic effects between feature engineering and data augmentation.
By analyzing the Shapley values of features computed based on model predictions, the varying importance of process parameters within the model was revealed, providing a theoretical foundation for understanding quality control mechanisms under different machining conditions. The dominant influence of feed rate in AWJP versus the crucial role of step parameters in MJP reflects differential impact patterns of distinct machining mechanisms on surface morphology. These findings not only validate expectations from traditional machining theory but also provide a quantitative basis for feature selection in intelligent process optimization systems.
4. Conclusions
In the field of machining, surface roughness prediction plays a crucial role in optimizing manufacturing processes, improving product quality, reducing production costs, and ensuring that components meet specific functional and assembly requirements. In this study, we propose the VSG-FC framework, a surface roughness prediction model that integrates GA-VSG and GP-FC. This framework enhances the data space from two perspectives—sample augmentation and feature construction—to improve model prediction accuracy and generalization capability. The GA-VSG method is first used to generate high-quality virtual samples, significantly expanding the training dataset and addressing the issue of data scarcity in industrial polishing processes. Then, the GP-FC method enhances the model’s learning capacity by automatically constructing discriminative feature combinations. Specifically, the GA-VSG approach overcomes the limitation of deep learning models that rely heavily on large-scale real-world datasets. By leveraging evolutionary search, it effectively enriches the data distribution and reduces dependence on physical data collection. In addition, GP-FC automatically searches for optimal feature combinations, reducing the reliance on domain-specific knowledge for manual feature engineering and enabling end-to-end feature optimization.
The effectiveness of the VSG-FC framework is validated on two real-world polishing process datasets. Experimental results demonstrate that GA-VSG substantially improves the performance of most machine learning models, reducing MSE by an average of 0.0374 on the AWJP dataset and by 0.0068 on the MJP dataset, confirming the effectiveness of evolutionary-based data augmentation. Furthermore, GA-VSG outperforms generative models such as GAN and VAE in enhancing predictive performance and generalization, as its virtual samples lead to more accurate and robust model outputs. When GA-VSG is combined with GP-FC, the resulting VSG-FC model shows a significant performance boost—on the AWJP dataset, the ET model achieved a maximum MSE reduction of 56.40%, while on the MJP dataset, the MLP exhibited the most notable improvement with a 68.63% reduction in MSE. Additionally, Shapley value-based analysis identifies key features that drive surface roughness in different datasets and reveals their underlying mechanisms. This comparative analysis not only supports the theoretical influence of process parameters but also provides a basis for targeted optimization.
Future work will focus on two directions: algorithm optimization and application extension. On the algorithmic side, future efforts will introduce mechanisms such as expression compression, evolution strategies guided by regularization, or complexity penalty terms to encourage GP to construct feature expressions that are structurally simpler and semantically clearer, thereby enhancing model interpretability. On the application side, we plan to extend the proposed framework to other machining scenarios in order to comprehensively assess its generalization capability.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}