

Dynamic Image Difficulty-Aware DNN Pruning


Abstract
1. Introduction
- Utilizes difficulty metrics that incorporate human observations as well as image quality scores to build a prediction model that can predict the difficulty of an image at run-time;
- Introduces a lightweight exploration loop for pruning combinations; and
- Adaptively prunes DNNs during inference time based on the predicted image difficulty scores.
2. Methodology
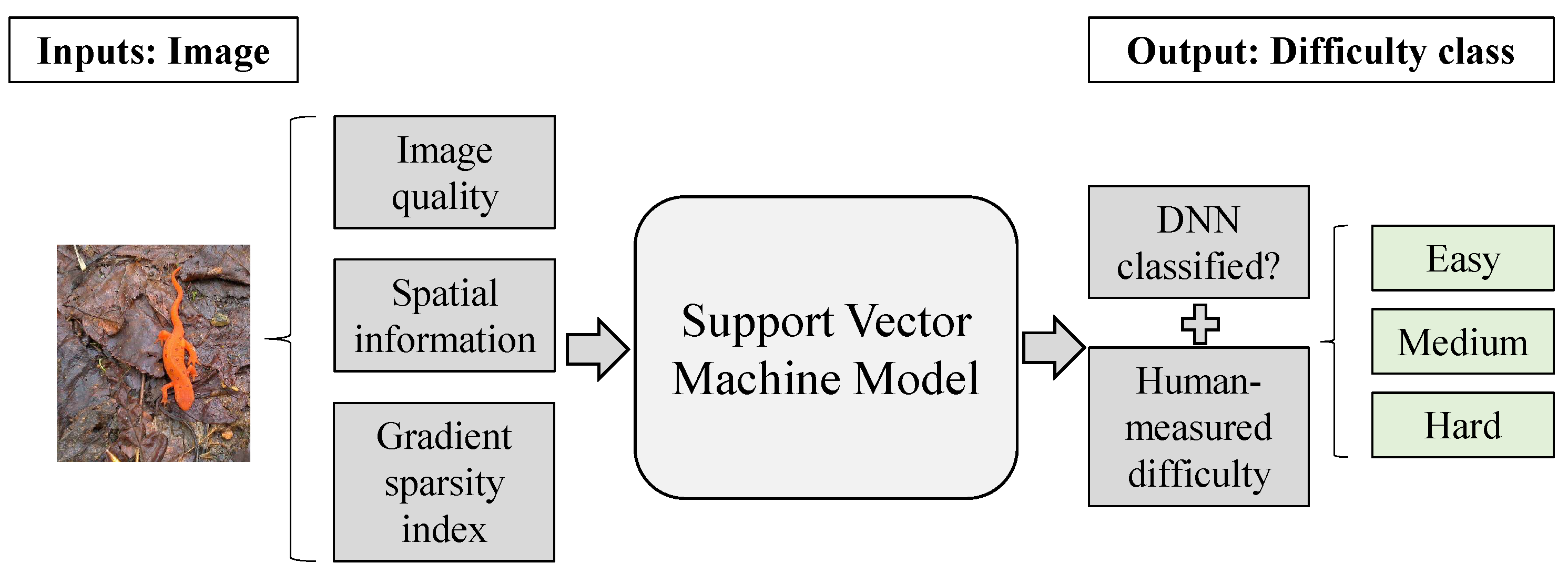
2.1. Quantifying and Classifying Image Difficulty
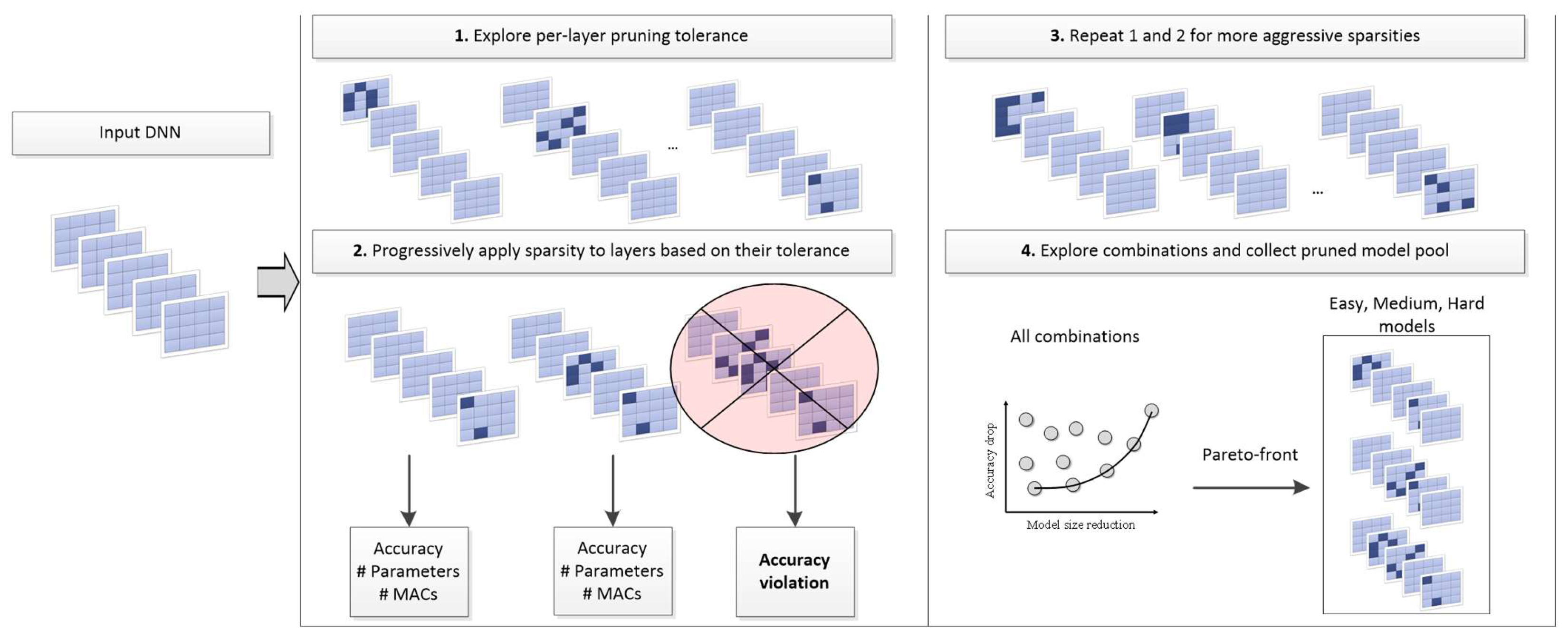
2.2. DNN Pruning Tolerance
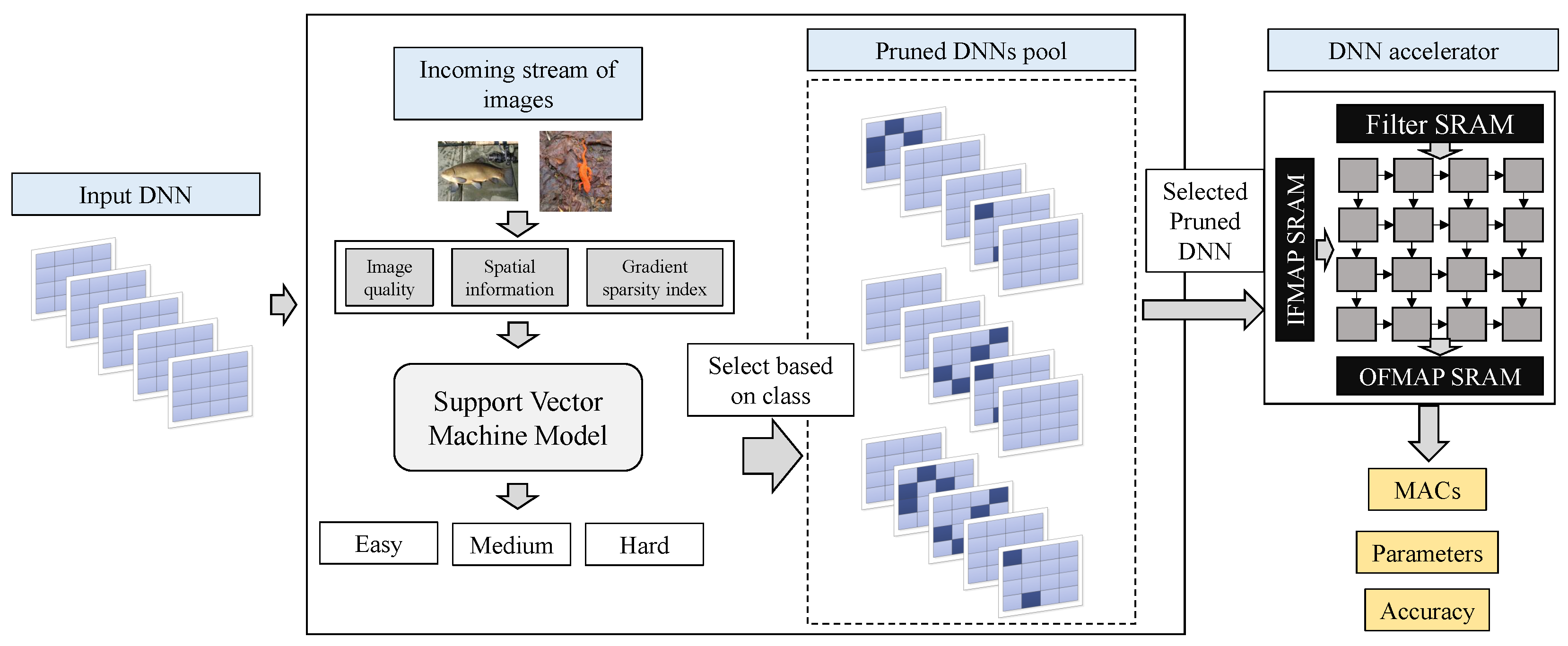
2.3. Bringing It All Together: Run-Time Pruning Based on Image Difficulty
3. Evaluation
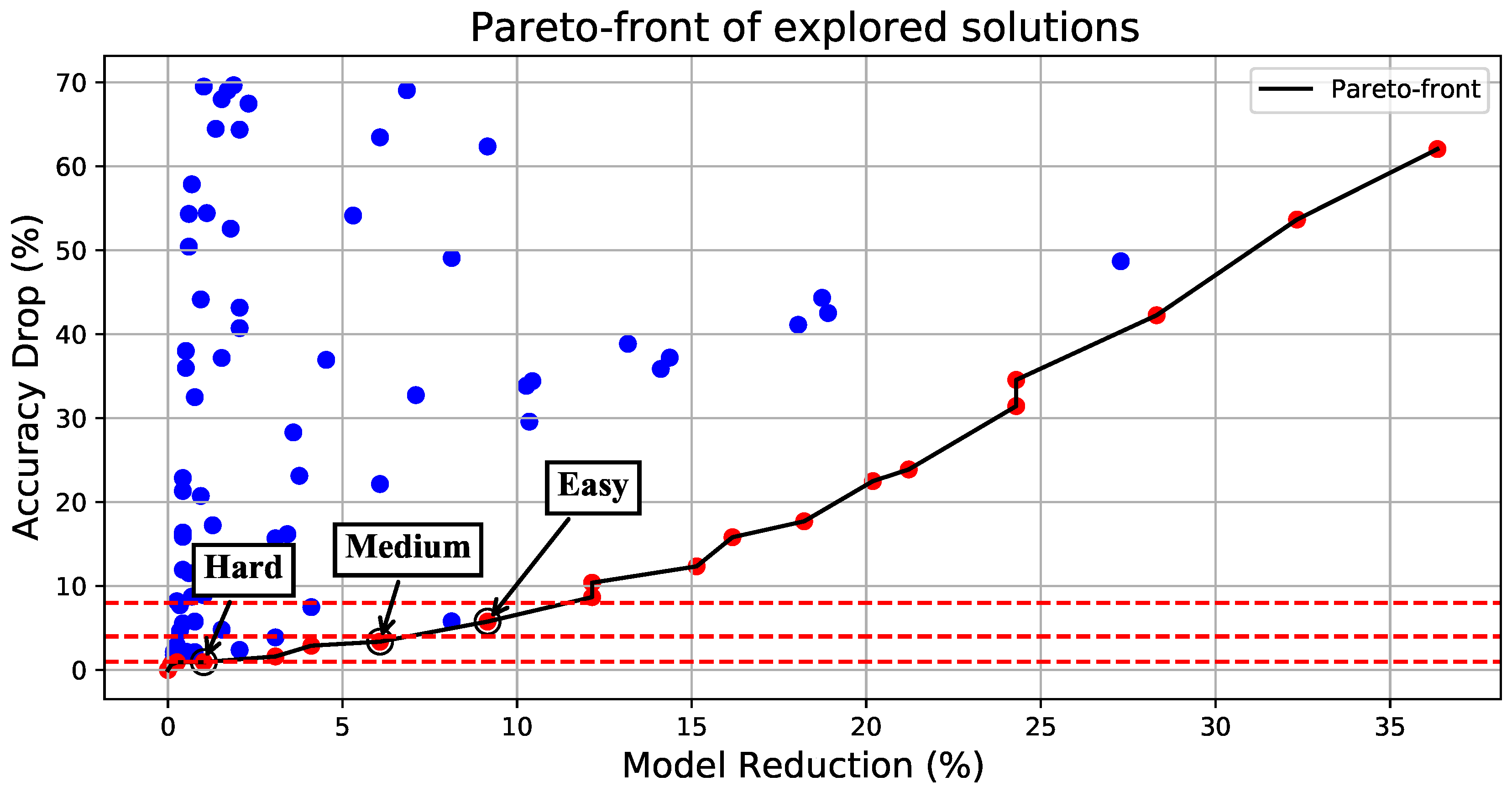
- The ResNet models: The ResNet models are overall more tolerant to pruning, allowing for significant speedups and a reduction in MAC operations and model size. Both of the examined ResNets comprise multiple convolutional layers, allowing for more pruning combinations to be explored. An illustrative example on the ResNet-18 specifically is shown in Figure 4. For all the combinations, we only consider solutions that lie on the Pareto front, and we select three different accuracy drop thresholds of increasing aggressiveness to select the Hard, Medium, and Easy DNNs: 1%, 4% and 8%, respectively. This way, we aim to have an overall average accuracy that does not fall more than 4% below the baseline accuracy on average. As shown in Table 1, we manage to stay below a 2% drop in accuracy for all DNNs considered in this work due to the adaptive nature of the framework at run-time.
- AlexNet and GoogLeNet: Both of these models have very different structures. AlexNet has a small amount of convolution layers (just 8 in total), but its model requires tens of millions of parameters (61.1M) as opposed to the GoogLeNet model that has 22 convolution layers but requires just 6.62M parameters. The parameter amount for each DNN was calculated through [17]. Even though different in structure, convolution layers and parameters, they exhibit the same behavior, which is fairly conservative: they do not tolerate pruning as well, and the acceptable solutions found by the proposed framework led to lower reductions in MAC operations and parameters, which however came with a lower drop in the average accuracy.
Cost Efficiency Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Spantidi, O.; Zervakis, G.; Anagnostopoulos, I.; Amrouch, H.; Henkel, J. Positive/negative approximate multipliers for DNN accelerators. In Proceedings of the IEEE/ACM International Conference On Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; pp. 1–9. [Google Scholar]
- Spantidi, O.; Anagnostopoulos, I. How much is too much error? Analyzing the impact of approximate multipliers on DNNs. In Proceedings of the 23rd International Symposium on Quality Electronic Design (ISQED), Virtual Event, 6–7 April 2022; pp. 1–6. [Google Scholar]
- Amrouch, H.; Zervakis, G.; Salamin, S.; Kattan, H.; Anagnostopoulos, I.; Henkel, J. NPU Thermal Management. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 3842–3855. [Google Scholar] [CrossRef]
- Yang, H.; Gui, S.; Zhu, Y.; Liu, J. Automatic neural network compression by sparsity-quantization joint learning: A constrained optimization-based approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 14–19 June 2020; pp. 2178–2188. [Google Scholar]
- Han, S.; Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning structured sparsity in deep neural networks. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- He, Y.; Lin, J.; Liu, Z.; Wang, H.; Li, L.J.; Han, S. Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–800. [Google Scholar]
- Banner, R.; Nahshan, Y.; Soudry, D. Post training 4-bit quantization of convolutional networks for rapid-deployment. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Spantidi, O.; Zervakis, G.; Alsalamin, S.; Roman-Ballesteros, I.; Henkel, J.; Amrouch, H.; Anagnostopoulos, I. Targeting DNN Inference via Efficient Utilization of Heterogeneous Precision DNN Accelerators. IEEE Trans. Emerg. Top. Comput. 2022, 11, 112–125. [Google Scholar] [CrossRef]
- Tudor Ionescu, R.; Alexe, B.; Leordeanu, M.; Popescu, M.; Papadopoulos, D.P.; Ferrari, V. How hard can it be? Estimating the difficulty of visual search in an image. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2157–2166. [Google Scholar]
- Mayo, D.; Cummings, J.; Lin, X.; Gutfreund, D.; Katz, B.; Barbu, A. How hard are computer vision datasets? Calibrating dataset difficulty to viewing time. In Proceedings of the 36th Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Winkler, S. Image complexity and spatial information. In Proceedings of the 5th International Workshop on Quality of Multimedia Experience (QoMEX), Klagenfurt am Worthersee, Austria, 3–5 July 2013; pp. 12–17. [Google Scholar]
- Li, L.; Cai, H.; Zhang, Y.; Lin, W.; Kot, A.C.; Sun, X. Sparse representation-based image quality index with adaptive sub-dictionaries. IEEE Trans. Image Process. 2016, 25, 3775–3786. [Google Scholar] [CrossRef] [PubMed]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. DepGraph: Towards Any Structural Pruning. arXiv 2023, arXiv:2301.12900. [Google Scholar]
- Spantidi, O.; Zervakis, G.; Anagnostopoulos, I.; Henkel, J. Energy-Efficient DNN Inference on Approximate Accelerators through Formal Property Exploration. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2022, 41, 3838–3849. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Samajdar, A.; Zhu, Y.; Whatmough, P.; Mattina, M.; Krishna, T. Scale-sim: Systolic cnn accelerator simulator. arXiv 2018, arXiv:1811.02883. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef]
- Zmora, N.; Jacob, G.; Zlotnik, L.; Elharar, B.; Novik, G. Neural Network Distiller: A Python Package For DNN Compression Research. arXiv 2019, arXiv:1910.12232. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy Drop (%) | MAC Reduction (%) | Parameter Reduction (%) | Speedup | |
|---|---|---|---|---|
| ResNet-18 | 1.84 | 12.11 | 9.65 | ×1.28 |
| ResNet-34 | 1.75 | 11.53 | 9.41 | ×1.36 |
| ResNet-50 | 1.79 | 11 | 9.32 | ×1.35 |
| AlexNet | 0.58 | 5.61 | 4.23 | ×1.1 |
| GoogLeNet | 0.78 | 7.88 | 5.82 | ×1.15 |
| Accuracy Drop (%) | MAC Reduction (%) | Parameter Reduction (%) | Speedup | |
|---|---|---|---|---|
| VGG11 (10% PR) | 3.25 | 8.4 | 6.6 | ×1.22 |
| VGG16 (10% PR) | 4.13 | 9.1 | 8.91 | ×1.26 |
| VGG11 (5% PR) | 1.61 | 6.67 | 3.5 | ×1.08 |
| VGG16 (5% PR) | 1.42 | 7.32 | 6.68 | ×1.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pentsos, V.; Spantidi, O.; Anagnostopoulos, I. Dynamic Image Difficulty-Aware DNN Pruning. Micromachines 2023, 14, 908. https://doi.org/10.3390/mi14050908
Pentsos V, Spantidi O, Anagnostopoulos I. Dynamic Image Difficulty-Aware DNN Pruning. Micromachines. 2023; 14(5):908. https://doi.org/10.3390/mi14050908
Chicago/Turabian StylePentsos, Vasileios, Ourania Spantidi, and Iraklis Anagnostopoulos. 2023. "Dynamic Image Difficulty-Aware DNN Pruning" Micromachines 14, no. 5: 908. https://doi.org/10.3390/mi14050908
APA StylePentsos, V., Spantidi, O., & Anagnostopoulos, I. (2023). Dynamic Image Difficulty-Aware DNN Pruning. Micromachines, 14(5), 908. https://doi.org/10.3390/mi14050908