
An FPGA-Based High-Performance Stateful Packet Processing Method

Abstract
:1. Introduction
1.1. Motivations
1.2. Limitations of Prior Art
1.3. Proposed Approach
- A match-action table that supports both stateful and stateless packet processing and can process 200 M PHV per second.
- A series of RISC-like instruction sets and corresponding hardware structure designed based on basic packet processing requirements.
- A hardware implementation method for PHV dynamic scheduling that is capable of achieving high-performance packet processing, flow state consistency, and maintaining the sequence of PHV input and output.
2. Related Works
3. System Design
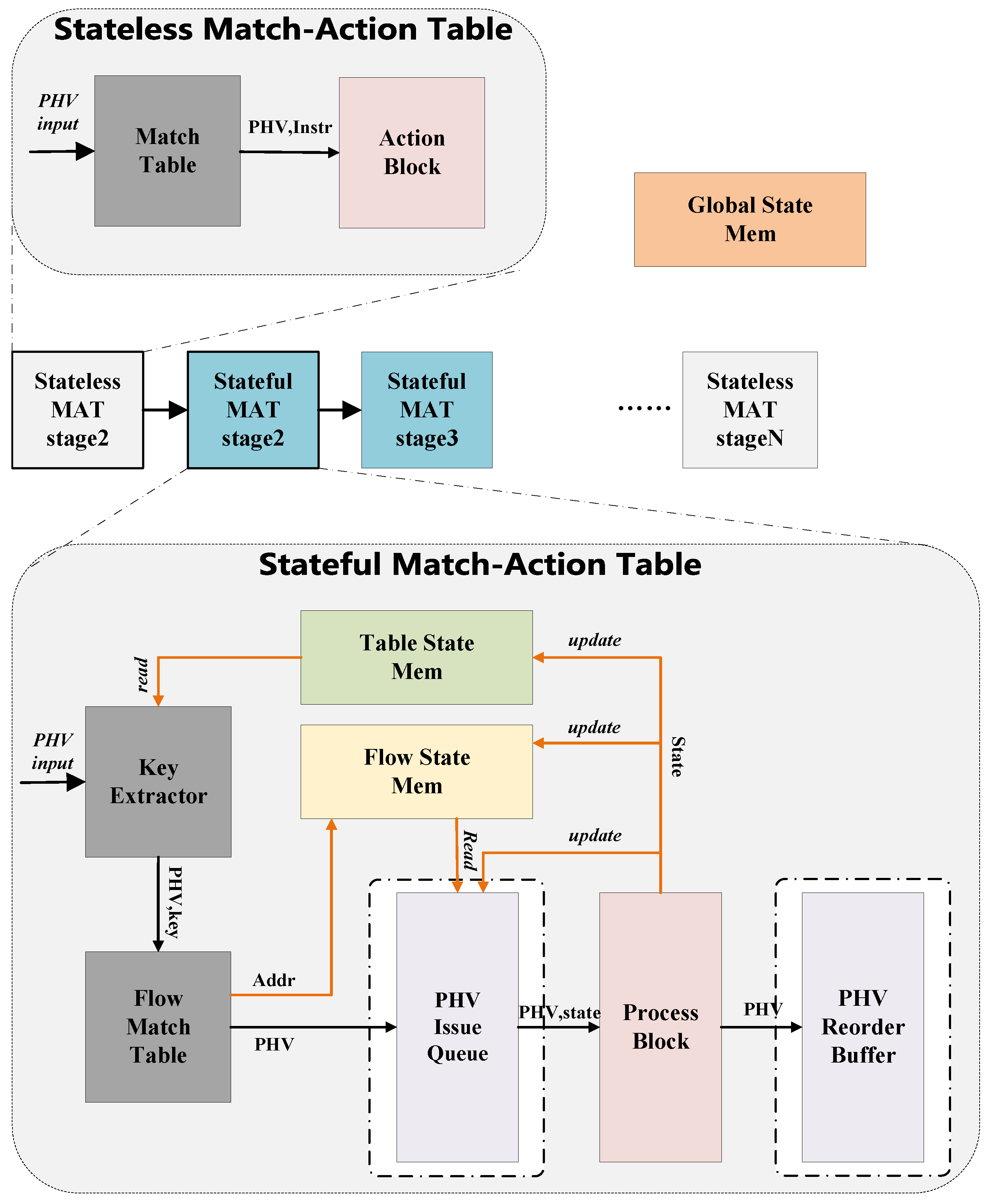
3.1. System Overview
- The global state is shared by all packets entering the switch.
- The table state is shared by packets entering the same match-action table.
- The flow state is shared by packets matching the same table entry.
- The per-packet state is used by an individual data packet to pass information between different match-action tables.
- In Section 3.2, we describe the hardware implementation of PHV dynamic scheduling.
- In Section 3.3, we describe the PHV process block that supports VLIW (Very Long Instruction Word) and its corresponding hardware structure.
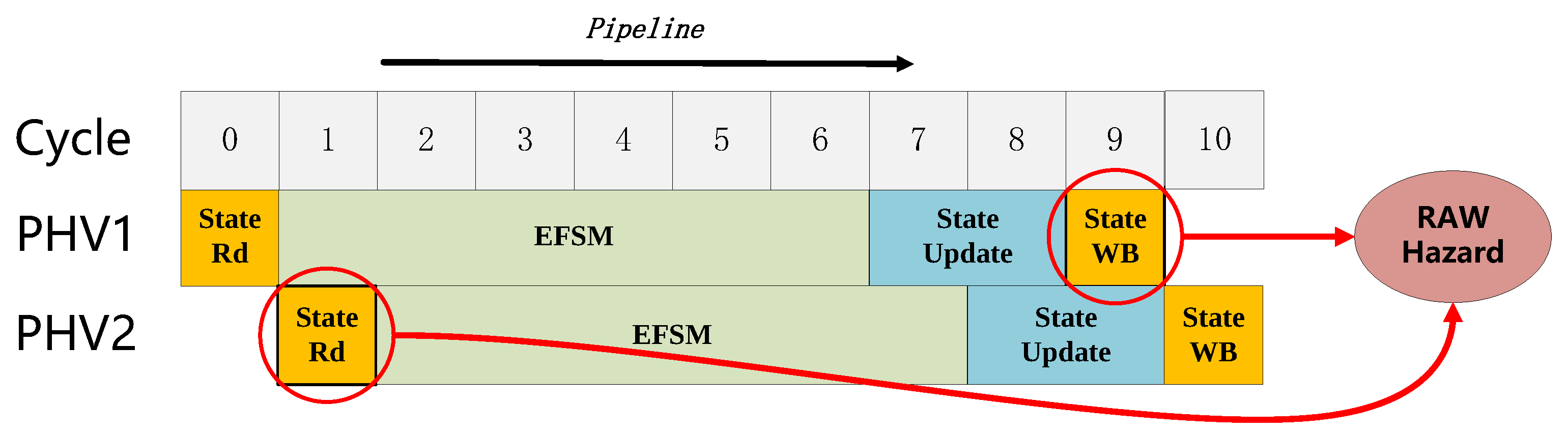
3.2. PHV Out-of-Order Scheduling
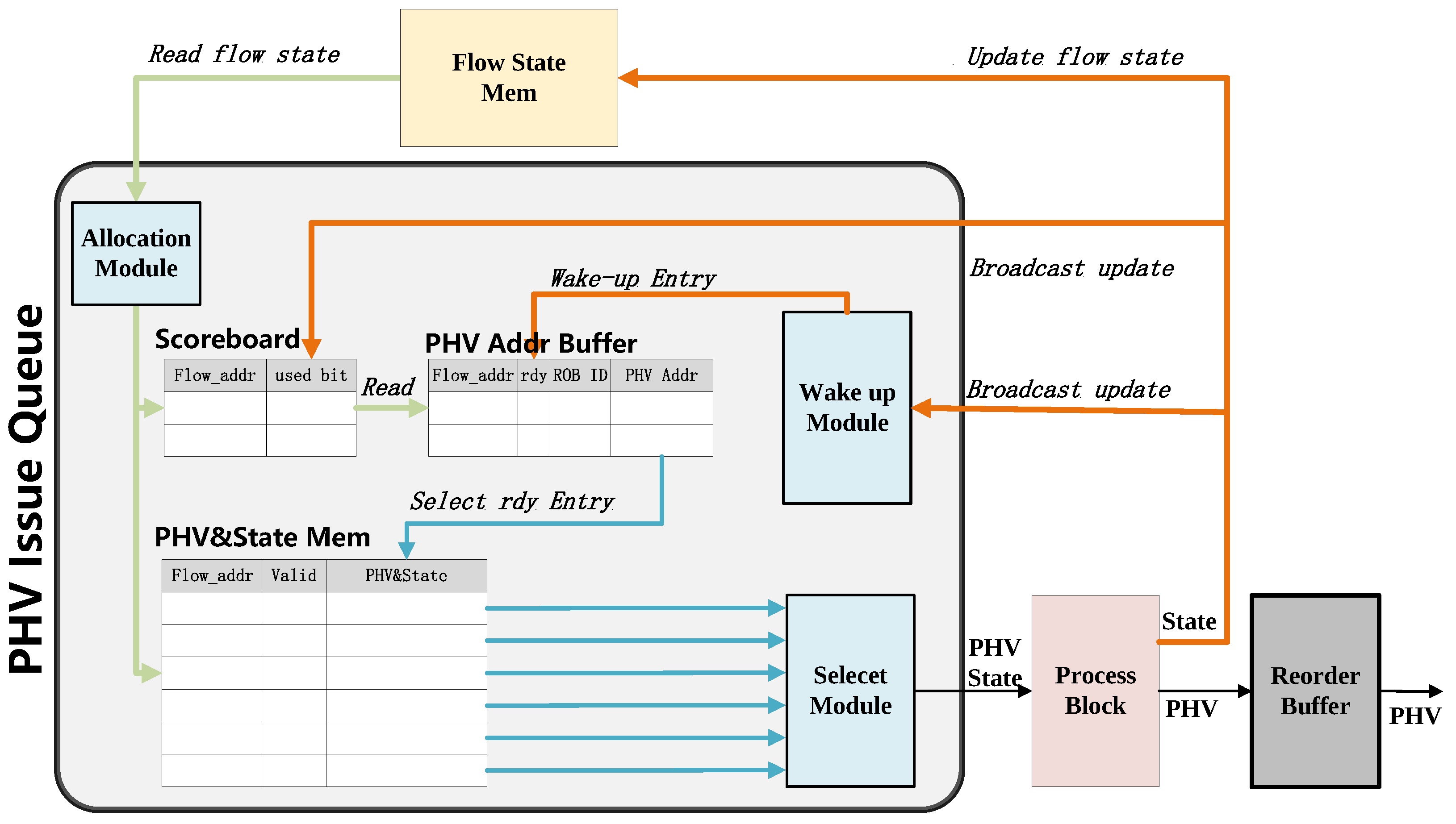
3.2.1. PHV Issue Queue
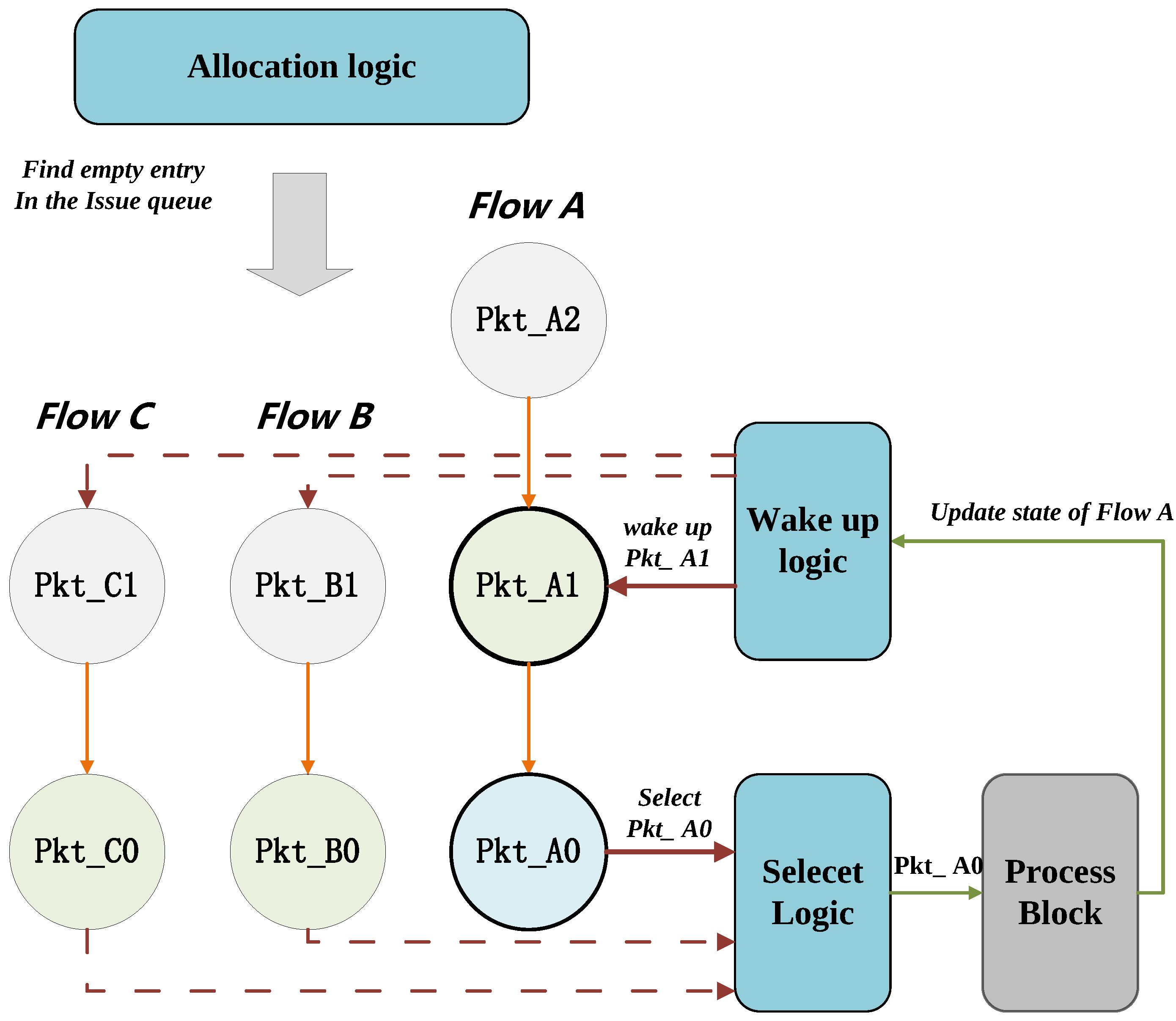
- Allocation Module: This module finds the free entry with the lowest address in the PHV Address Buffer and the free entry of PHV&State Mem. If no free entry is left, it will block the input data stream.
- Scoreboard: This module is a memory of flip flops that stores the status of the per-flow state and keeps track of per-flow state read and write operations. So, the number of flip flops is equal to the number of the flows. The scoreboard will be updated by the broadcast buses at every positive edge of the clock. So, this module is capable of detecting RAW hazards between the PHV’s corresponding flow states. The fields of used bits in the scoreboard indicate the validity of the input PHV’s flow state. Every time a new PHV enters, the system will check if the used bit is busy or not and read in the corresponding flow state. This module also checks the broadcast buses if there is a conflict in broadcast line and reads the line of the same flow address.
- PHV&State Mem: This module stores input PHV and its corresponding state information in the address of the memory given by the Allocation Module.
- PHV Addr Buffer: This module stores the address of the input PHV and its corresponding state in the lowest address free entry of the buffer given by the Allocation Module. Every entry includes the following fields: PHV&flow addr together with its ready bit (used to indicate whether the PHV has a dependency relationship), ROB (Reorder Buffer) ID. To maintain the old-first order in this buffer, bubble entry resulting from out-of-order dispatch needs to be considered. By shifting down the entries above the bubble entry, the issue queue could maintain the old-first rule. Additionally, this module associates an increasing ROB ID to each input PHV within the out-of-order window (size equal to the reorder buffer), which is used for PHV reordering.
- Select Module: In each clock cycle, the Select module will choose the lowest-address valid entry in the PHV Addr buffer, which is marked as ready to be dispatched. Then, this module dispatches the selected entry to the subsequent process block pipeline.
- Wake-up Module: This module continuously monitors the broadcast buses. Whenever the executed flow state address broadcasted matches the PHV Addr buffer’s entry, the corresponding flow state will be updated and marked as ready. If multiple entries match the broadcasted address, only the oldest one will be chosen as ready.
3.2.2. Reorder Buffer
3.2.3. Necessity of Old-First Rule
3.3. PHV Process Block
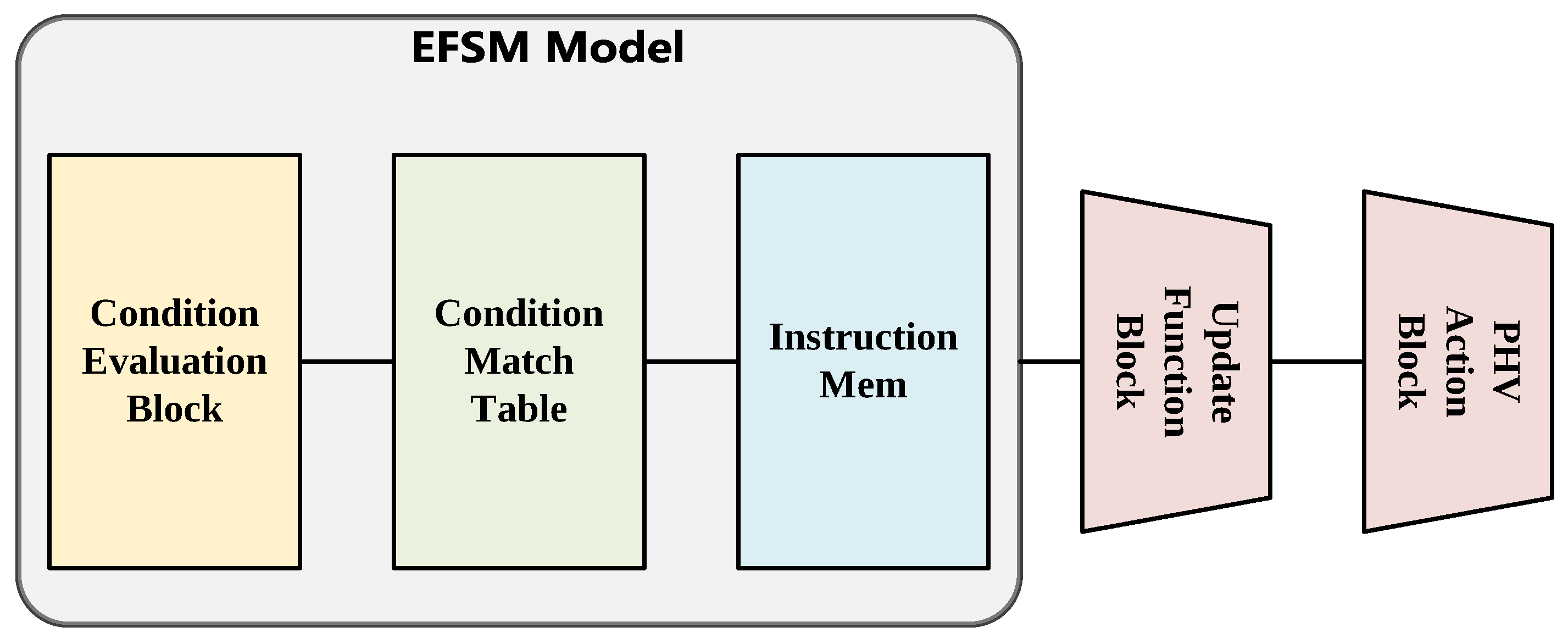
- EFSM Model: Based on the configured VLIW, the EFSM model calculates the vector-form condition evaluation results. The condition results and state information are used as input for the EFSM table, which could determine the address of the corresponding instructions for the processing strategy. The instructions will be fetched from the instruction RAM.
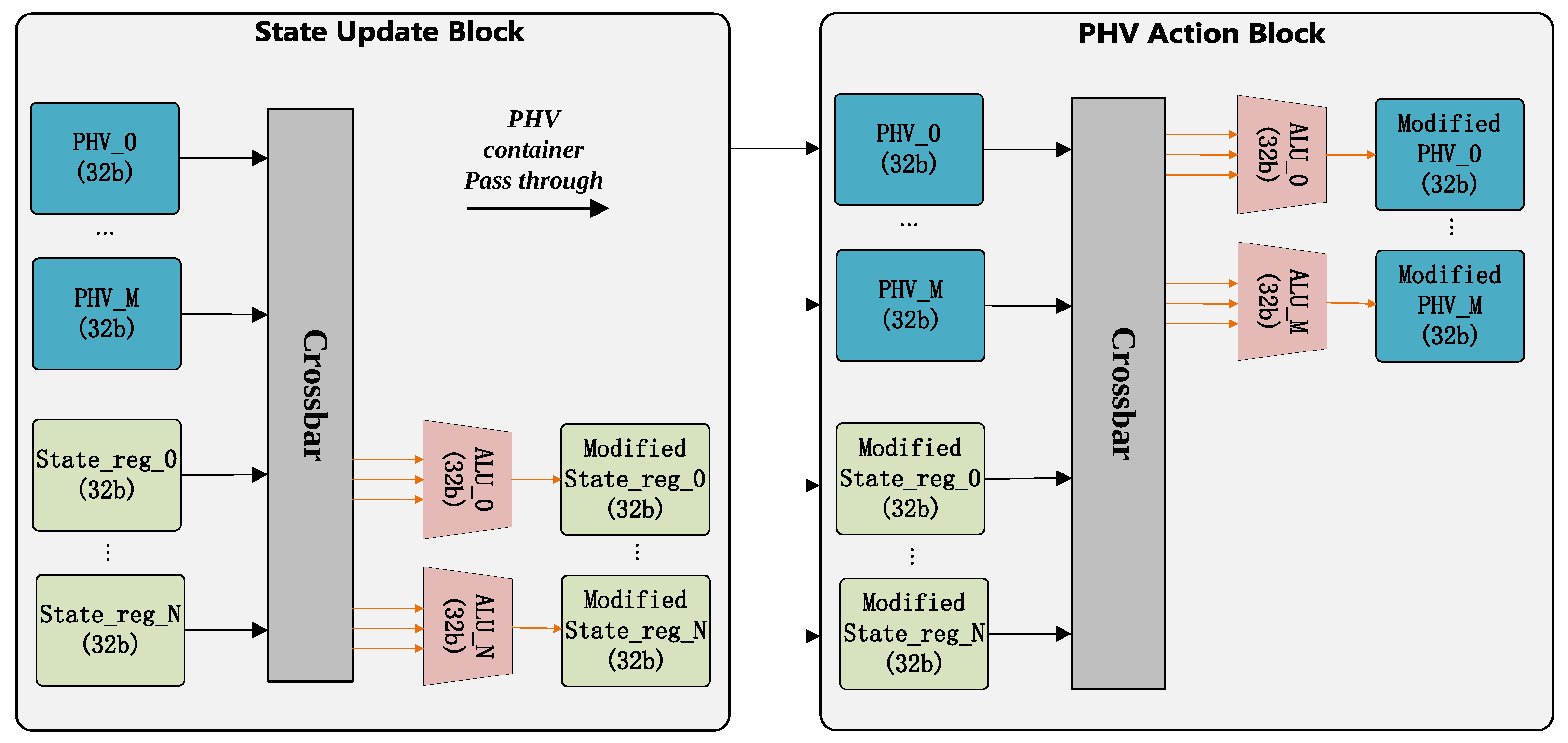
- State Update Block: Based on the input VLIW, the state update block performs the necessary operations to update the state.
- PHV Action Block: Based on the input VLIW, the PHV action block performs the necessary operations to modify the PHV.
| Algorithm 1: Calculate the Number of TCP Retransmission Packets |
|
3.3.1. Structure
3.3.2. VLIW
4. Hardware Implementation
4.1. Hardware Resources
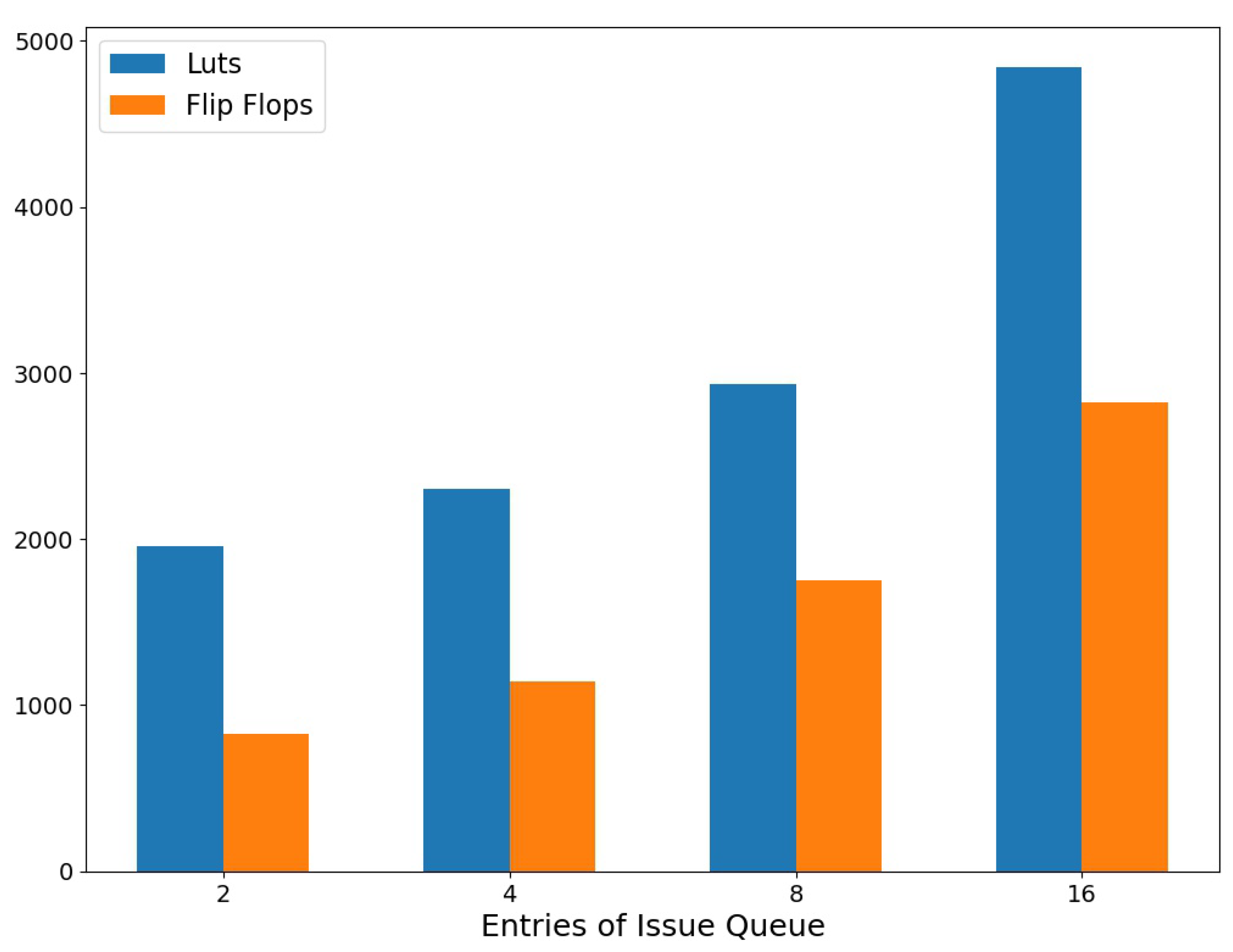
4.2. Issue Queue Parameters Analysis
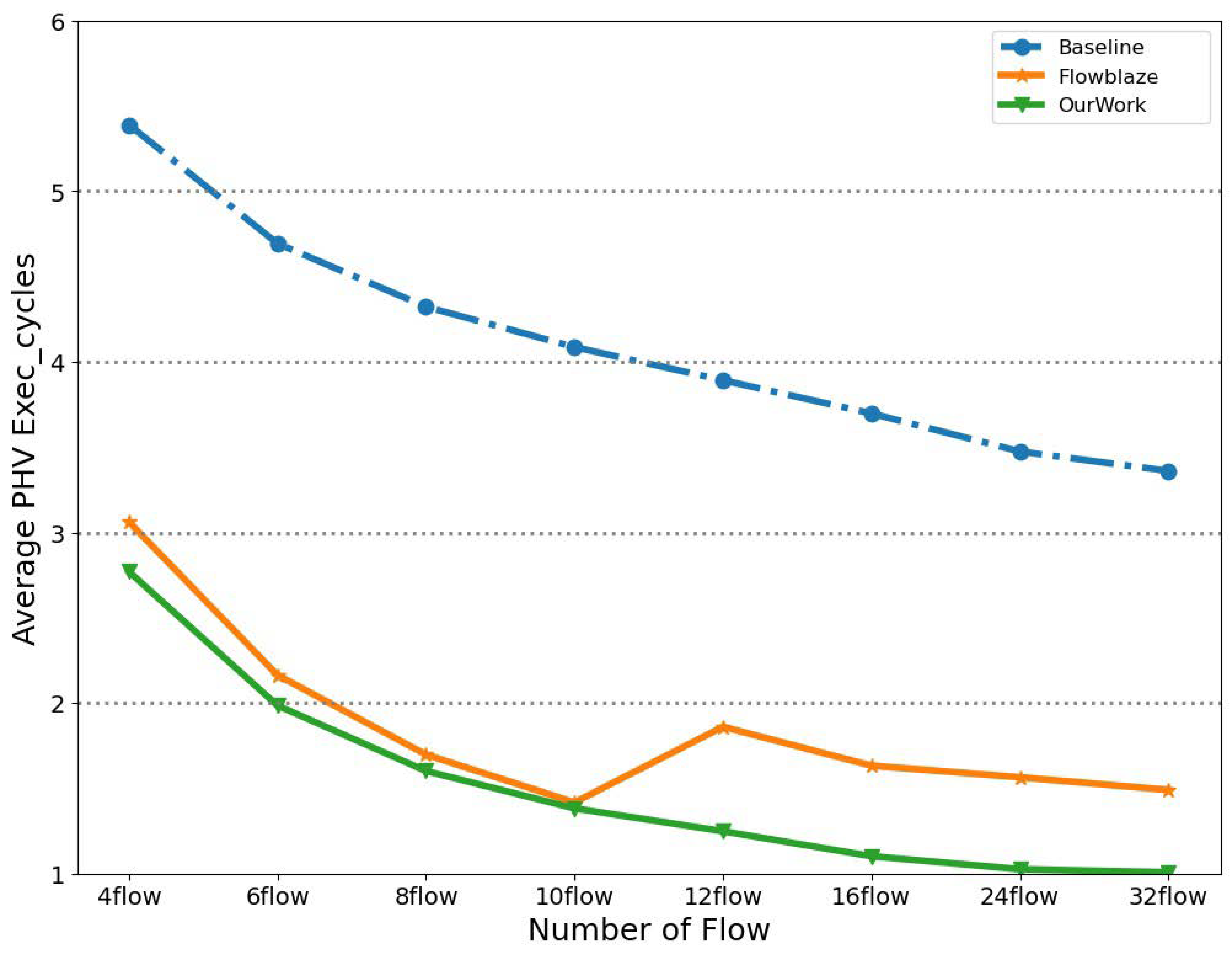
4.3. Method Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, X.; Cui, L.; Wei, K.; Tso, F.P.; Ji, Y.; Jia, W. A survey on stateful data plane in software defined networks. Comput. Netw. 2021, 184, 107597. [Google Scholar] [CrossRef]
- Li, J.; Jiang, H.; Jiang, W.; Wu, J.; Du, W. SDN-based stateful firewall for cloud. In Proceedings of the 2020 IEEE 6th International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), Baltimore, MD, USA, 25–27 May 2020; pp. 157–161. [Google Scholar]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Ibanez, S.; Brebner, G.; McKeown, N.; Zilberman, N. The p4-> netfpga workflow for line-rate packet processing. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 1–9. [Google Scholar]
- Wang, H.; Soulé, R.; Dang, H.T.; Lee, K.S.; Shrivastav, V.; Foster, N.; Weatherspoon, H. P4fpga: A rapid prototyping framework for p4. In Proceedings of the Symposium on SDN Research, Santa Clara, CA, USA, 3–4 April 2017; pp. 122–135. [Google Scholar]
- Bianchi, G.; Bonola, M.; Capone, A.; Cascone, C. Openstate: Programming platform-independent stateful openflow applications inside the switch. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 44–51. [Google Scholar] [CrossRef]
- Sivaraman, A.; Cheung, A.; Budiu, M.; Kim, C.; Alizadeh, M.; Balakrishnan, H.; Varghese, G.; McKeown, N.; Licking, S. Packet transactions: High-level programming for line-rate switches. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianópolis, Brazil, 22–26 August 2016; pp. 15–28. [Google Scholar]
- Moro, D.; Sanvito, D.; Capone, A. FlowBlaze. p4: A library for quick prototyping of stateful SDN applications in P4. In Proceedings of the 2020 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Leganes, Spain, 10–12 November 2020; pp. 95–99. [Google Scholar]
- Pontarelli, S.; Bifulco, R.; Bonola, M.; Cascone, C.; Spaziani, M.; Bruschi, V.; Sanvito, D.; Siracusano, G.; Capone, A.; Honda, M.; et al. FlowBlaze: Stateful Packet Processing in Hardware. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), Boston, MA, USA, 26–28 February 2019; pp. 531–548. [Google Scholar]
- Luo, S.; Yu, H.; Vanbever, L. Swing state: Consistent updates for stateful and programmable data planes. In Proceedings of the Symposium on SDN Research, Santa Clara, CA, USA, 3–4 April 2017; pp. 115–121. [Google Scholar]
- Shukla, A.; Fathalli, S.; Zinner, T.; Hecker, A.; Schmid, S. P4consist: Toward consistent p4 sdns. IEEE J. Sel. Areas Commun. 2020, 38, 1293–1307. [Google Scholar] [CrossRef]
- Komajwar, S.; Korkmaz, T. Challenges and solutions to consistent data plane update in software defined networks. Comput. Commun. 2018, 130, 50–59. [Google Scholar] [CrossRef]
- Sviridov, G.; Bonola, M.; Tulumello, A.; Giaccone, P.; Bianco, A.; Bianchi, G. LODGE: LOcal Decisions on Global statEs in programmable data planes. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; pp. 257–261. [Google Scholar]
- Arashloo, M.T.; Koral, Y.; Greenberg, M.; Rexford, J.; Walker, D. SNAP: Stateful network-wide abstractions for packet processing. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianópolis, Brazil, 22–26 August 2016; pp. 29–43. [Google Scholar]
- Bianchi, G.; Bonola, M.; Pontarelli, S.; Sanvito, D.; Capone, A.; Cascone, C. Open Packet Processor: A programmable architecture for wire speed platform-independent stateful in-network processing. arXiv 2016, arXiv:1605.01977. [Google Scholar]
- Zhu, S.; Bi, J.; Sun, C.; Wu, C.; Hu, H. Sdpa: Enhancing stateful forwarding for software-defined networking. In Proceedings of the 2015 IEEE 23rd International Conference on Network Protocols (ICNP), San Francisco, CA, USA, 10–13 November 2015; pp. 323–333. [Google Scholar]
- Michel, O.; Bifulco, R.; Retvari, G.; Schmid, S. The programmable data plane: Abstractions, architectures, algorithms, and applications. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Sha, M.; Guo, Z.; Song, M. A Review of FPGA’s Application in High-speed Network Processing. J. Netw. New Media 2021, 10, 1–11. [Google Scholar]
- Jing, L.; Wang, J.; Chen, X. Research on Key Technologies of SDN Switch Supporting State Programmability; The Institute of Acoustics of the Chinese Academy of Sciences: Beijing, China, 2022; CSTR:35001.37.01.33142.20220037. [Google Scholar]
- Abella Ferrer, J.; Canal Corretger, R.; González Colás, A.M. Power-and complexity-aware issue queue designs. IEEE Micro 2003, 23, 50–58. [Google Scholar] [CrossRef]
- Smith, J.E.; Sohi, G.S. The microarchitecture of superscalar processors. Proc. IEEE 1995, 83, 1609–1624. [Google Scholar] [CrossRef]
- Forencich, A.; Snoeren, A.C.; Porter, G.; Papen, G. Corundum: An open-source 100-gbps nic. In Proceedings of the 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Fayetteville, AR, USA, 3–6 May 2020; pp. 38–46. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | Parameters | Description |
|---|---|---|
| Global state mem | 64 b × 8 | width and entry num |
| Table state mem | 64 b × 8 | width and entry num |
| Flow state mem | 128 b × 4 K | width and entry num |
| Pkt state reg | 64 b | width |
| Condition Block | 8 | ALU num |
| Update Block | 10 | ALU num |
| Action Block | 22 | ALU num |
| Issue Queue | 8 | entry num |
| Reorder Buffer | 32 | depth |
| Our Work | FlowBlaze [10] | |
|---|---|---|
| Luts | 60,871 (12%) | 71,712 (14%) |
| Flip Flops | 35,898 (3%) | Unknown |
| Our Work | Software [20] | |
|---|---|---|
| latency/us | 2.9 | 13.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, R.; Guo, Z. An FPGA-Based High-Performance Stateful Packet Processing Method. Micromachines 2023, 14, 2074. https://doi.org/10.3390/mi14112074
Lu R, Guo Z. An FPGA-Based High-Performance Stateful Packet Processing Method. Micromachines. 2023; 14(11):2074. https://doi.org/10.3390/mi14112074
Chicago/Turabian StyleLu, Rui, and Zhichuan Guo. 2023. "An FPGA-Based High-Performance Stateful Packet Processing Method" Micromachines 14, no. 11: 2074. https://doi.org/10.3390/mi14112074
APA StyleLu, R., & Guo, Z. (2023). An FPGA-Based High-Performance Stateful Packet Processing Method. Micromachines, 14(11), 2074. https://doi.org/10.3390/mi14112074