
Single RGB Image 6D Object Grasping System Using Pixel-Wise Voting Network

Abstract
:1. Introduction
- By reprojecting the object model into the pose estimation space, we improve the performance of the pixel-wise voting network (PV-net) so that PV-net can operate properly under a real working scene of lighting interference and low resolution. In addition, PV-net is only in the theoretical stage so far, whereas we apply this pose estimation network in a real robotic system.
- Based on the RGB image as the network input, it is difficult to tell the difference between the object and its photo. The native sensor of the robotic arm platform hardly meets the requirement of the RGB-D deep learning network training. To overcome this shortage, a fast and stable method is proposed to judge whether the detected object from PV-net is real or not by analyzing the point cloud captured from the depth sensor.
- By combining the methods described above, an autonomous 6 dimensional (6D) grasping system is implemented to accomplish real-time grasping tasks in industrial packaging logistics environments where the real object is mixed with its wrapping paper photos. This stable and robust grasping system is potentially applicable to large-scale production pipelines.
2. Previous Research and Relative Approaches
2.1. Pose Estimation Approaches
2.1.1. Correspondence Approaches
2.1.2. Template Approaches
2.1.3. Regression Approaches
2.1.4. Voting Approaches
2.2. Robotic Grasping
3. Materials and Methods
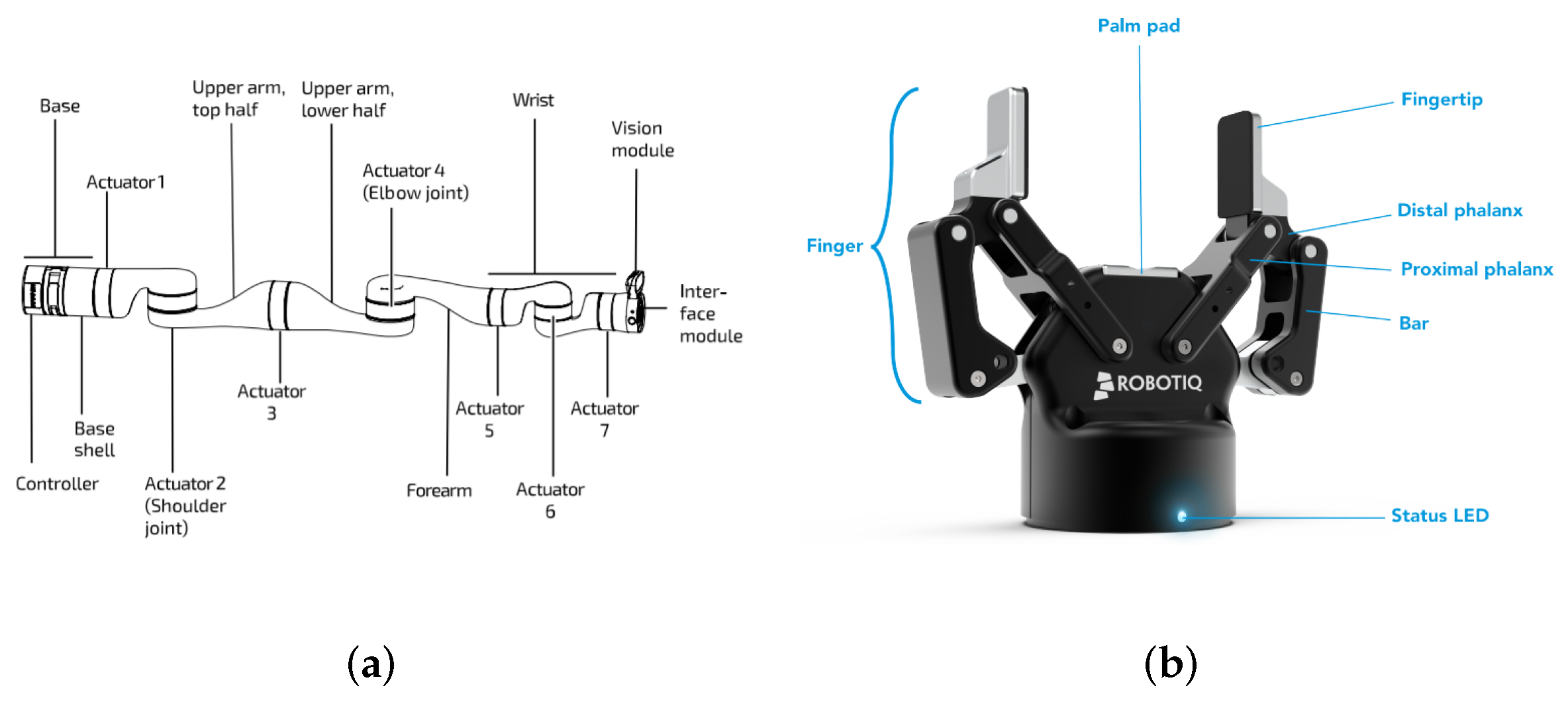
3.1. Robot Model and Perception Hardware
3.2. 6DOF Pose Estimation Based on PV-net
3.3. Reprojection Judgment in Point Cloud
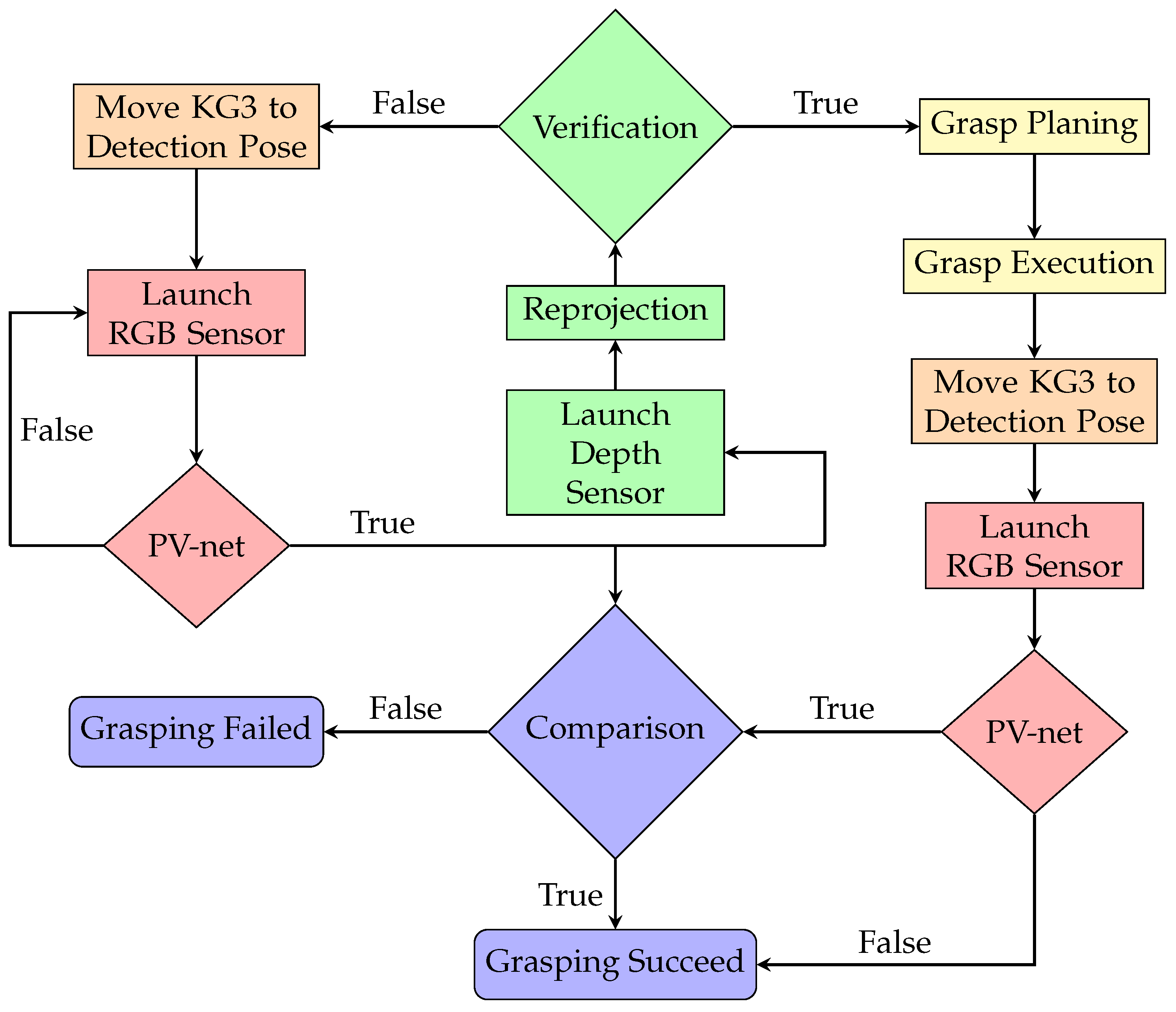
3.4. System Implementation
- Move the KG3 to a preset pose which is prepared for detection.
- Launch the RGB camera to send the 640 × 480 resolution image to the PV-net server via the Ethernet at a speed of 30 frames per second for object recognition, segmentation and pose estimation. KG3 continues to wait until the object is detected.
- Launch the depth sensor after receiving the 6D pose value and judge whether the object is real in the scene captured by the depth sensor. If the judgment is rejected, move KG3 back to step 1.
- Calculate and execute the grasping plan after the judgment is passed. After grasping the object and placing it to the designated location, move KG3 back to the preset object detection pose.
- Launch the RGB camera and detect the object via PV-net again. If PV-net cannot detect the object, it means that there is no object in the scene. Otherwise, compare the previous 6D estimated pose with the current 6D estimated pose to judge whether this grasping is successful or not.
4. Results
4.1. The Performance of PV-net Perception
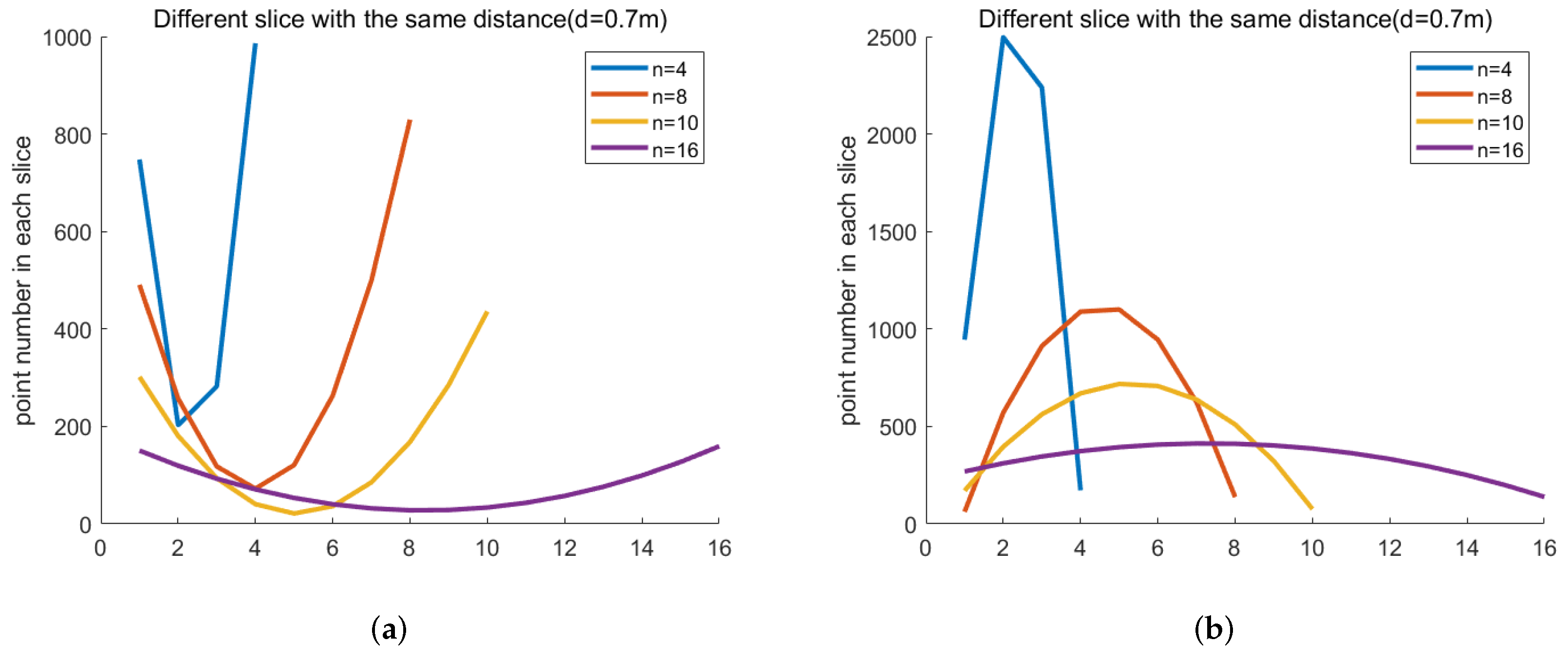
4.2. The Performance of Reprojection Judgment in Point Cloud
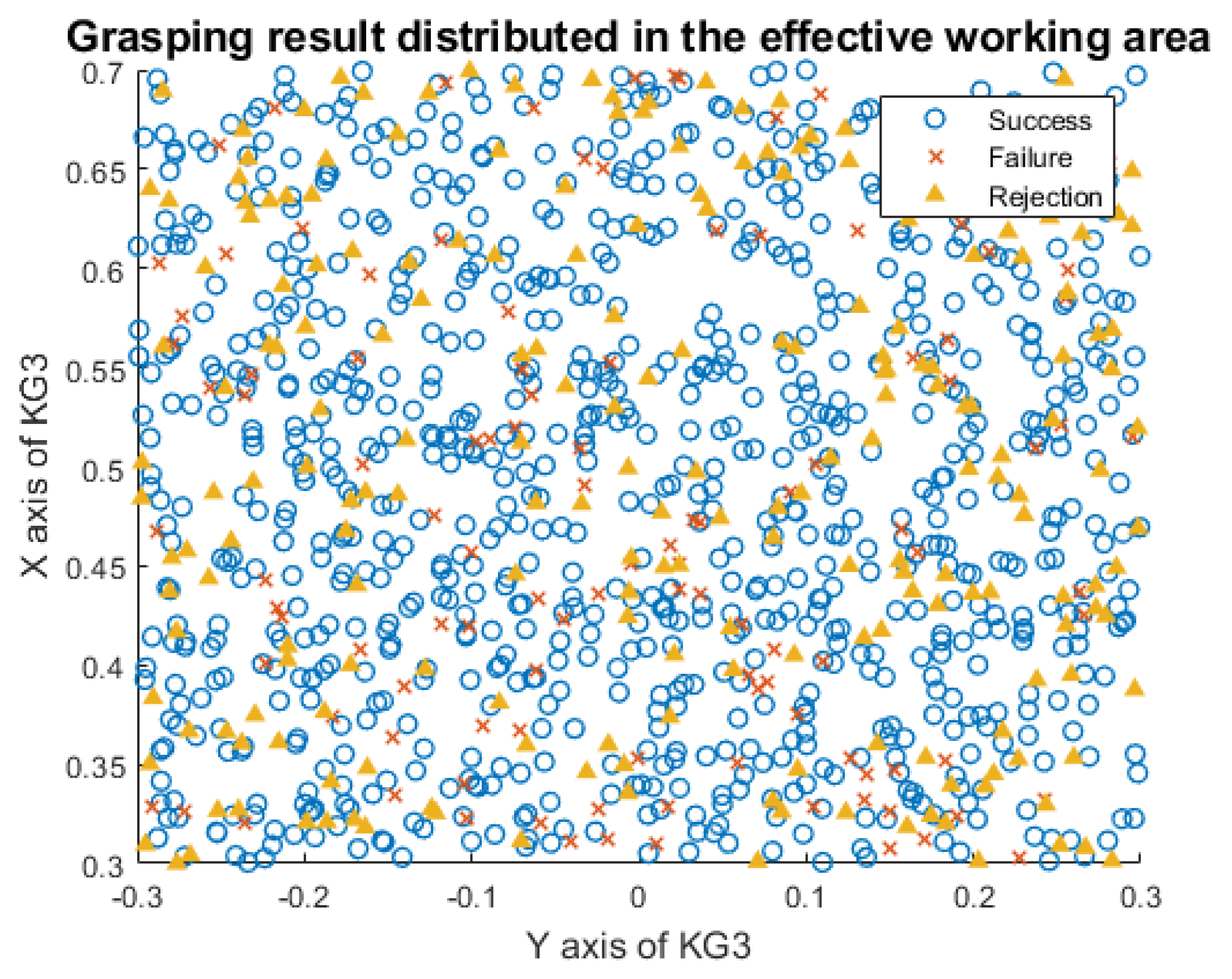
4.3. Entire System Performance
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Du, G.; Wang, K.; Lian, S. Vision-based robotic grasping from object localization, pose estimation, grasp detection to motion planning: A review. arXiv 2019, arXiv:1905.06658. [Google Scholar]
- Lowe, D. Local feature view clustering for 3D object recognition. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar] [CrossRef] [Green Version]
- Rothganger, F.; Lazebnik, S.; Schmid, C.; Ponce, J. 3D Object Modeling and Recognition Using Local Affine-Invariant Image Descriptors and Multi-View Spatial Constraints. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 231–259. [Google Scholar]
- Nister, D.; Stewenius, H. Scalable Recognition with a Vocabulary Tree. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2161–2168. [Google Scholar] [CrossRef]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Li, Y.; Snavely, N.; Huttenlocher, D.; Fua, P. Worldwide pose estimation using 3d point clouds. In European Conference On Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 15–29. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Chan, A.; Derpanis, K.; Daniilidis, K. 6-dof object pose from semantic keypoints. In Proceedings of the 2017 IEEE International Conference On Robotics And Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-time seamless single shot 6d object pose prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 292–301. [Google Scholar]
- Zhou, X.; Karpur, A.; Luo, L.; Huang, Q. Starmap for category-agnostic keypoint and viewpoint estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 318–334. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes. In Computer Vision—ACCV 2012; Lee, K.M., Matsushita, Y., Rehg, J.M., Hu, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 548–562. [Google Scholar]
- Zhu, M.; Derpanis, K.G.; Yang, Y.; Brahmbhatt, S.; Zhang, M.; Phillips, C.; Lecce, M.; Daniilidis, K. Single image 3D object detection and pose estimation for grasping. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient Response Maps for Real-Time Detection of Textureless Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Acharya, D.; Khoshelham, K.; Winter, S. BIM-PoseNet: Indoor camera localisation using a 3D indoor model and deep learning from synthetic images. ISPRS J. Photogramm. Remote. Sens. 2019, 150, 245–258. [Google Scholar] [CrossRef]
- Acharya, D.; Singha Roy, S.; Khoshelham, K.; Winter, S. A recurrent deep network for estimating the pose of real indoor images from synthetic image sequences. Sensors 2020, 20, 5492. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, S.; Liu, D.; Lu, W. Indoor camera pose estimation via style-transfer 3D models. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 335–353. [Google Scholar] [CrossRef]
- Chen, J.; Li, S.; Lu, W. Align to locate: Registering photogrammetric point clouds to BIM for robust indoor localization. Build. Environ. 2022, 209, 108675. [Google Scholar] [CrossRef]
- Chen, J.; Lu, W.; Yuan, L.; Wu, Y.; Xue, F. Estimating construction waste truck payload volume using monocular vision. Resour. Conserv. Recycl. 2022, 177, 106013. [Google Scholar] [CrossRef]
- Bueno, M.; Bosché, F.; González-Jorge, H.; Martıénez-Sánchez, J.; Arias, P. 4-Plane congruent sets for automatic registration of as-is 3D point clouds with 3D BIM models. Autom. Constr. 2018, 89, 120–134. [Google Scholar] [CrossRef]
- Vidal, J.; Lin, C.; Martıé, R. 6D pose estimation using an improved method based on point pair features. In Proceedings of the 2018 4th International Conference On Control, Automation And Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 405–409. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martıén-Martıén, R.; Lu, C.; Fei-Fei, L.; Savarese, S. Densefusion: 6D object pose estimation by iterative dense fusion. In Proceedings of the IEEE/CVF Conference On Computer Vision And Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- Mao, Z.; Iizuka, T.; Maeda, S. Bidirectional electrohydrodynamic pump with high symmetrical performance and its application to a tube actuator. Sens. Actuators Phys. 2021, 332, 113168. [Google Scholar] [CrossRef]
- Lin, H.Y.; Liang, S.C.; Chen, Y.K. Robotic Grasping With Multi-View Image Acquisition and Model-Based Pose Estimation. IEEE Sens. J. 2020, 21, 11870–11878. [Google Scholar] [CrossRef]
- James, S.; Davison, A.J.; Johns, E. Transferring end-to-end visuomotor control from simulation to real world for a multi-stage task. arXiv 2017, arXiv:1707.02267. [Google Scholar]
- Tremblay, J.; To, T.; Sundaralingam, B.; Xiang, Y.; Fox, D.; Birchfield, S. Deep object pose estimation for semantic robotic grasping of household objects. arXiv 2018, arXiv:1809.10790. [Google Scholar]
- Wan, W.; Harada, K.; Nagata, K. Assembly sequence planning for motion planning. Assem. Autom. 2018, 38, 195–206. [Google Scholar] [CrossRef] [Green Version]
- Stevšić, S.; Christen, S.; Hilliges, O. Learning to Assemble: Estimating 6D Poses for Robotic Object-Object Manipulation. IEEE Robot. Autom. Lett. 2020, 5, 1159–1166. [Google Scholar] [CrossRef]
- Peng, S.; Zhou, X.; Liu, Y.; Lin, H.; Huang, Q.; Bao, H. Pvnet: Pixel-wise voting network for 6dof object pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 2020. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slice (n) | Accurate Rate (%) | Distance (d) | Accuracy Rate (%) | ||||
|---|---|---|---|---|---|---|---|
| Object | Photo | Average | Object | Photo | Average | ||
| 4 | 82.91 | 86.63 | 84.77 | 0.4 m | 92.48 | 93.80 | 93.14 |
| 8 | 88.09 | 85.27 | 86.68 | 0.5 m | 93.14 | 95.42 | 94.28 |
| 10 | 93.54 | 98.95 | 96.26 | 0.6 m | 91.97 | 93.95 | 92.96 |
| 16 | 85.96 | 89.15 | 87.56 | 0.7 m | 93.54 | 98.95 | 96.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Zhou, C.; Koike, Y.; Li, J. Single RGB Image 6D Object Grasping System Using Pixel-Wise Voting Network. Micromachines 2022, 13, 293. https://doi.org/10.3390/mi13020293
Zhang Z, Zhou C, Koike Y, Li J. Single RGB Image 6D Object Grasping System Using Pixel-Wise Voting Network. Micromachines. 2022; 13(2):293. https://doi.org/10.3390/mi13020293
Chicago/Turabian StyleZhang, Zhongjie, Chengzhe Zhou, Yasuharu Koike, and Jiamao Li. 2022. "Single RGB Image 6D Object Grasping System Using Pixel-Wise Voting Network" Micromachines 13, no. 2: 293. https://doi.org/10.3390/mi13020293
APA StyleZhang, Z., Zhou, C., Koike, Y., & Li, J. (2022). Single RGB Image 6D Object Grasping System Using Pixel-Wise Voting Network. Micromachines, 13(2), 293. https://doi.org/10.3390/mi13020293