
Optimization of a Spin-Orbit Torque Switching Scheme Based on Micromagnetic Simulations and Reinforcement Learning

 , ,
, ,  and
and 
Abstract
1. Introduction
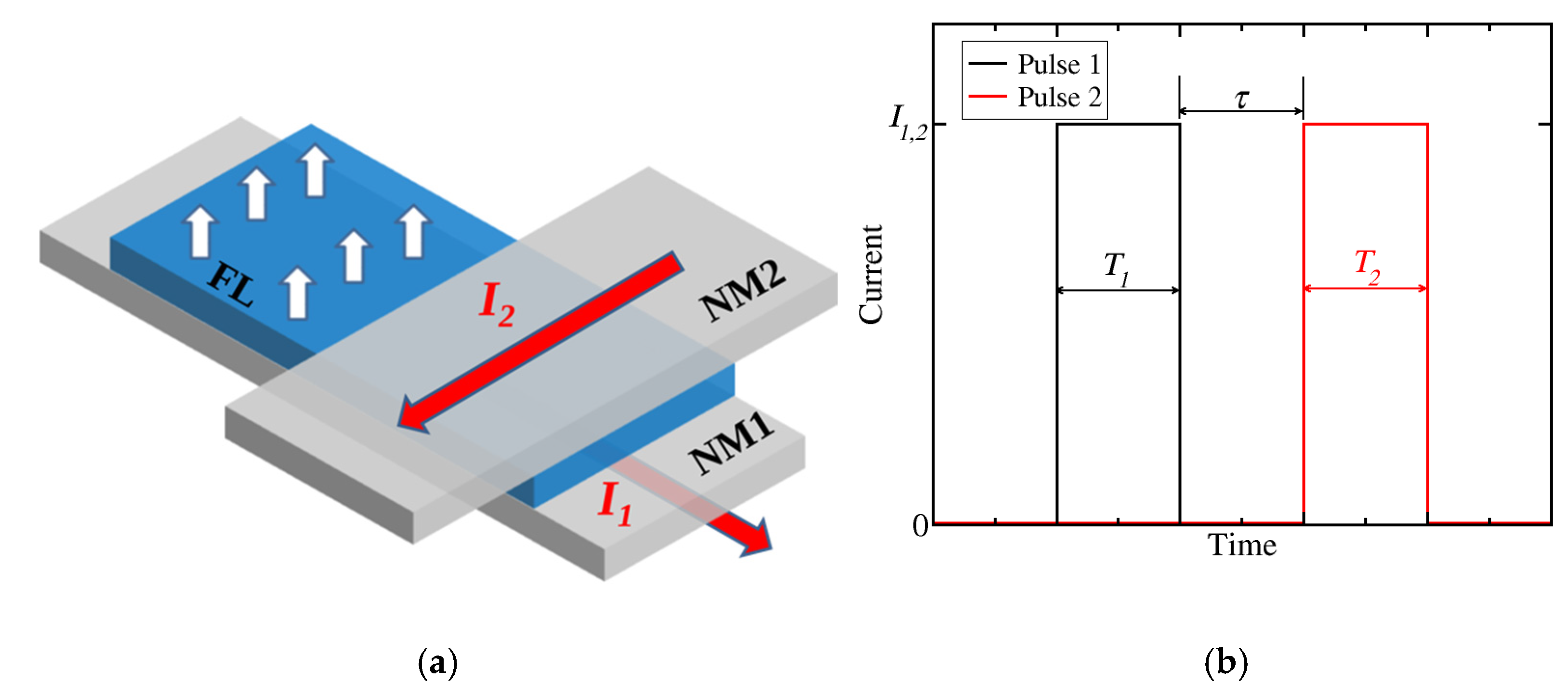
2. Spin-Orbit Torque Memory Cell and Switching Dynamics
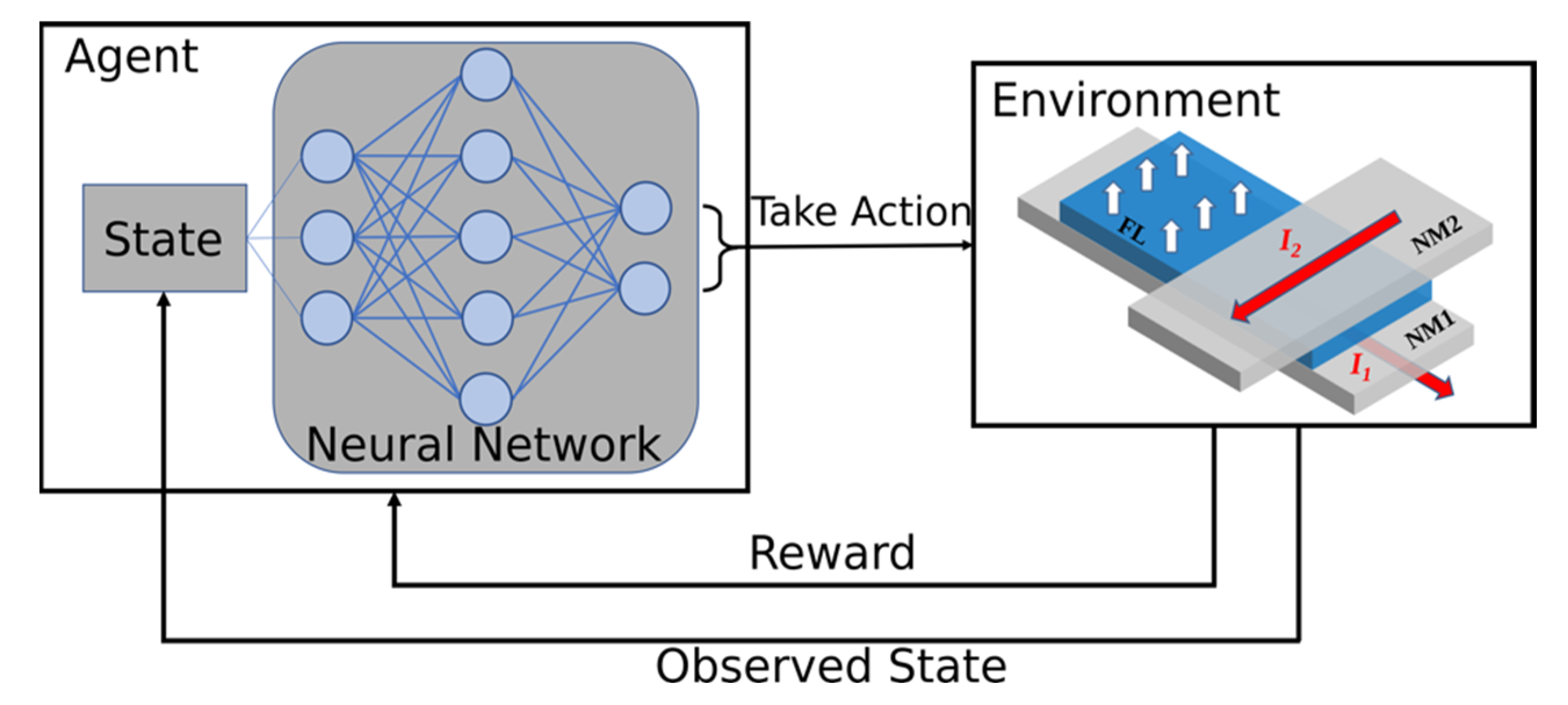
3. Reinforcement Learning for the Two-Pulse Spin-Orbit Torque Switching
4. Results and Discussion
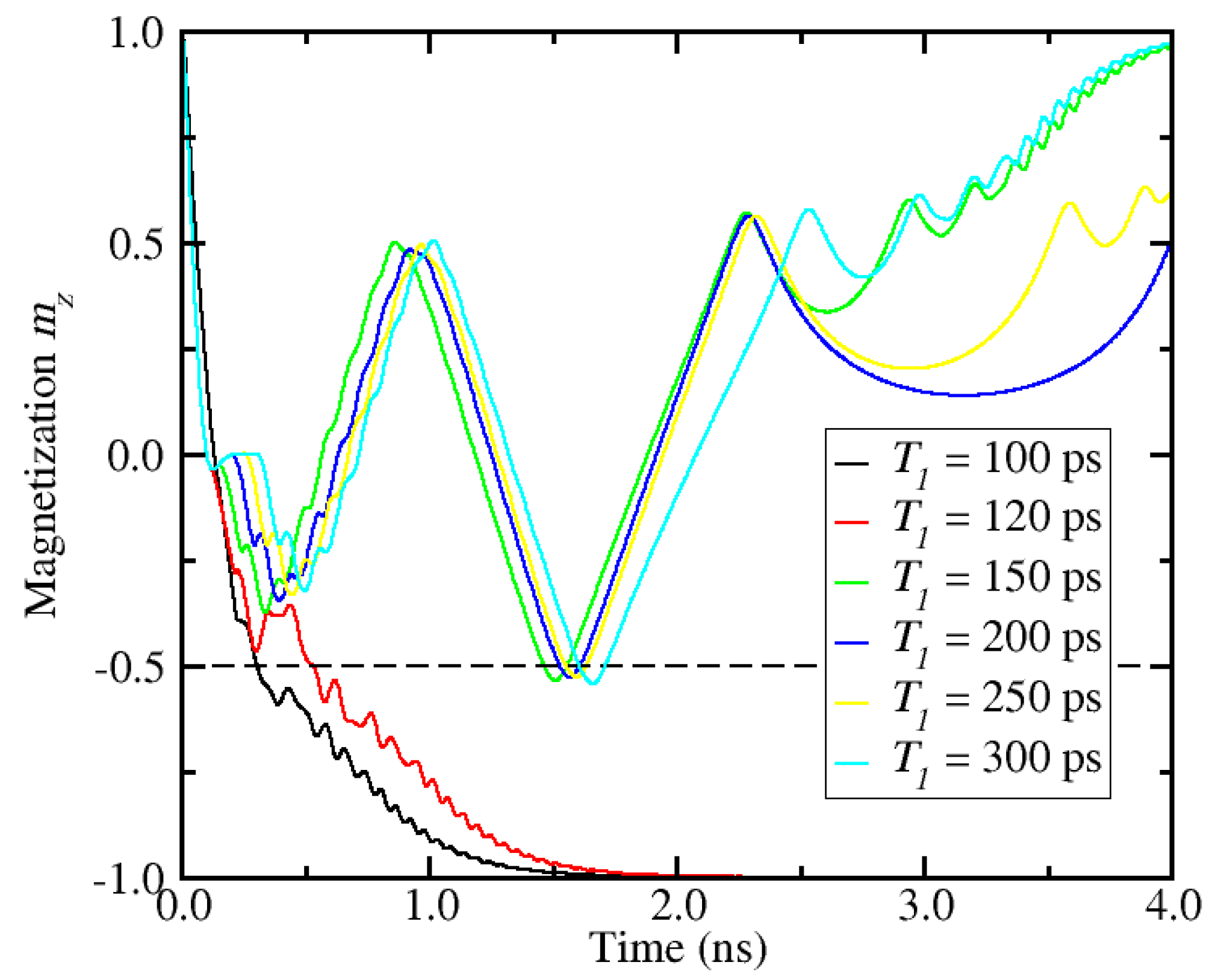
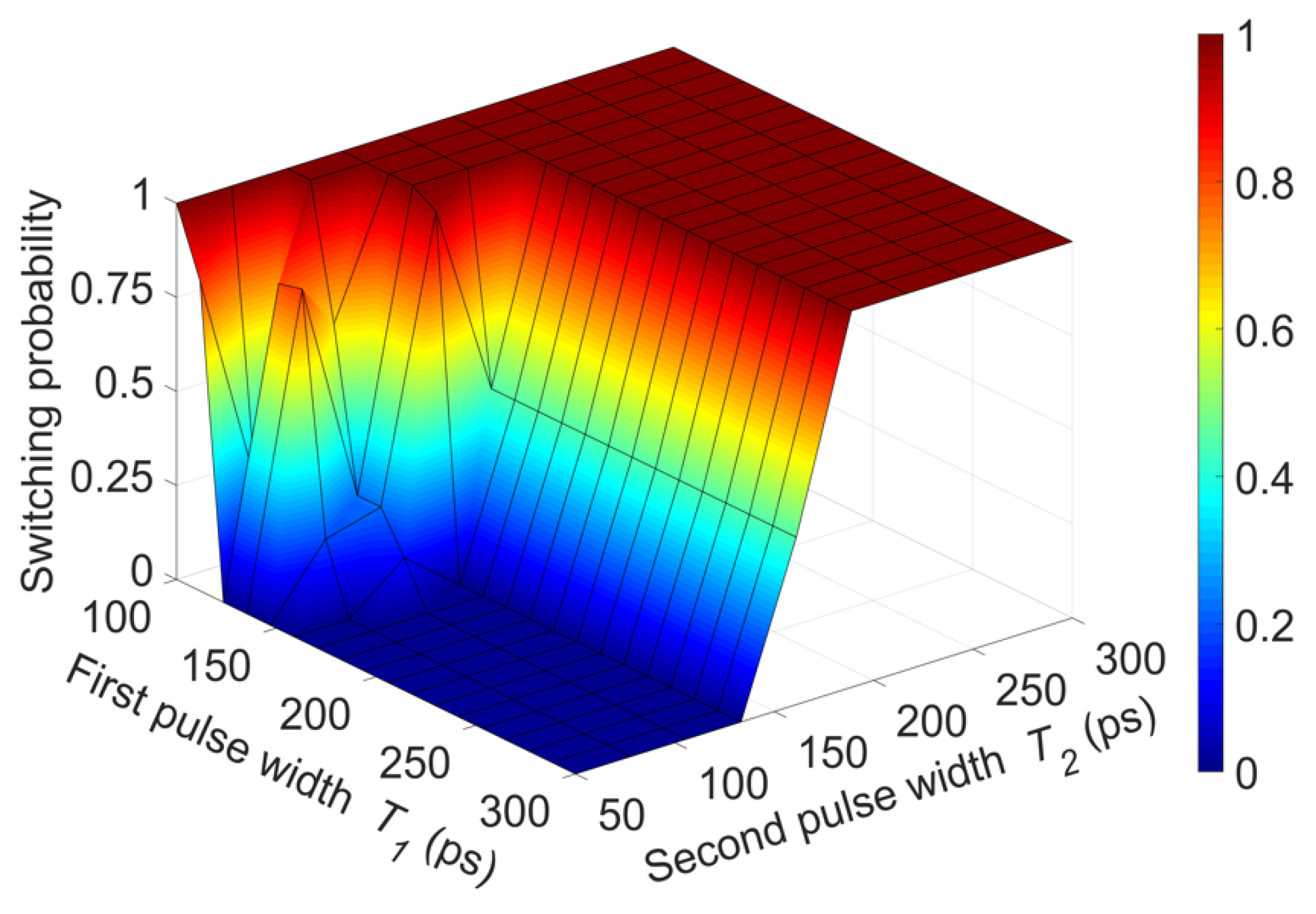
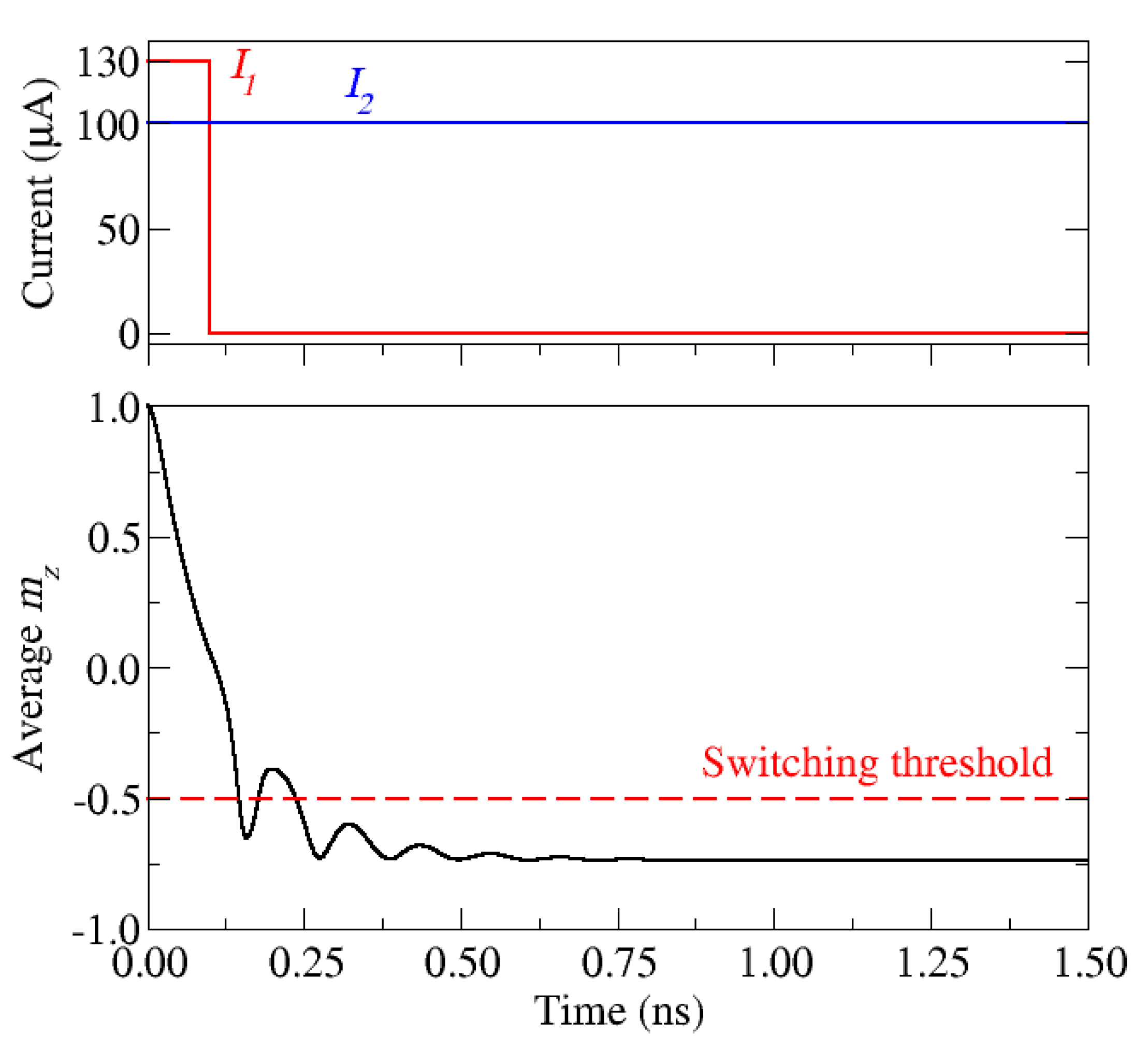
4.1. Numerical Simulations
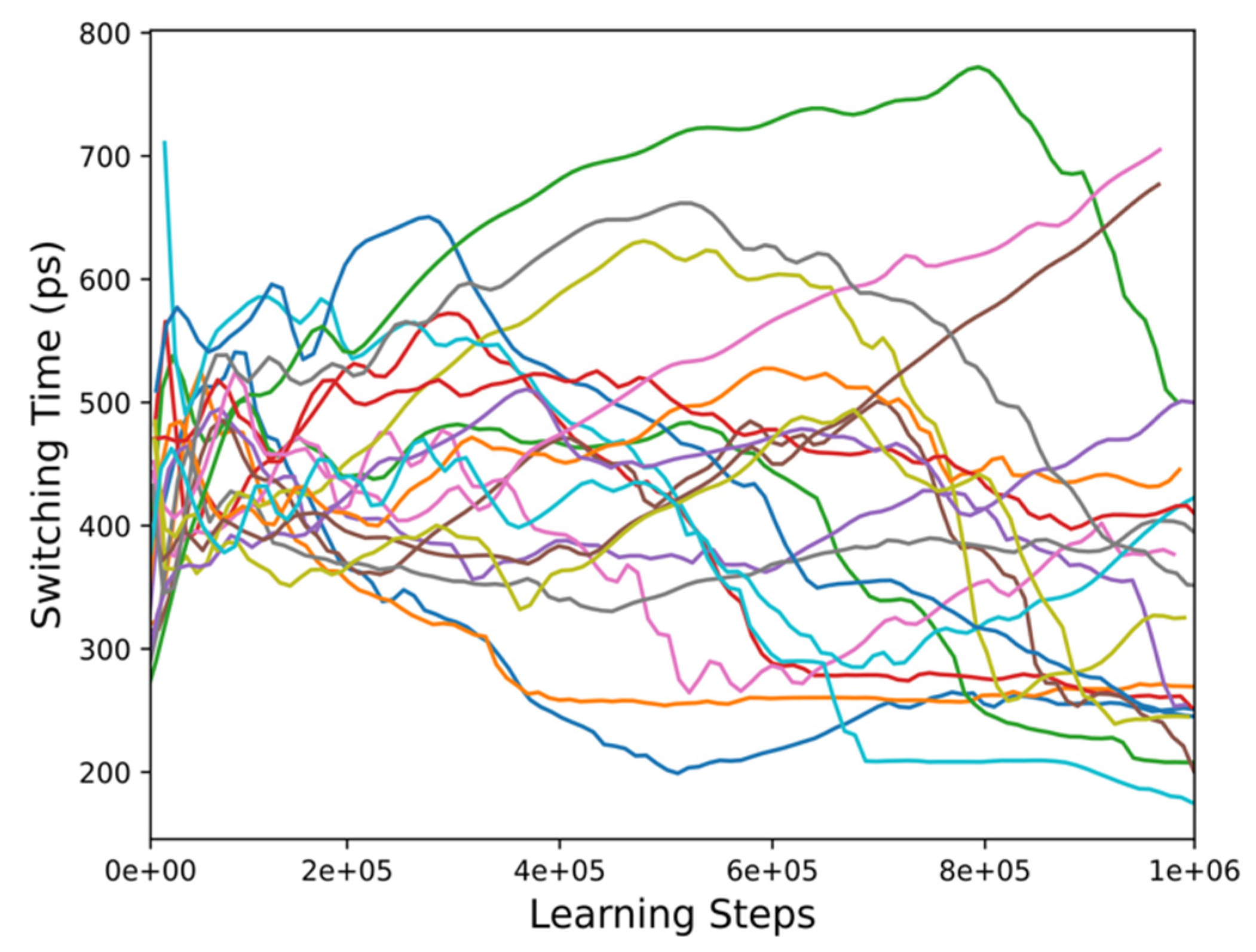
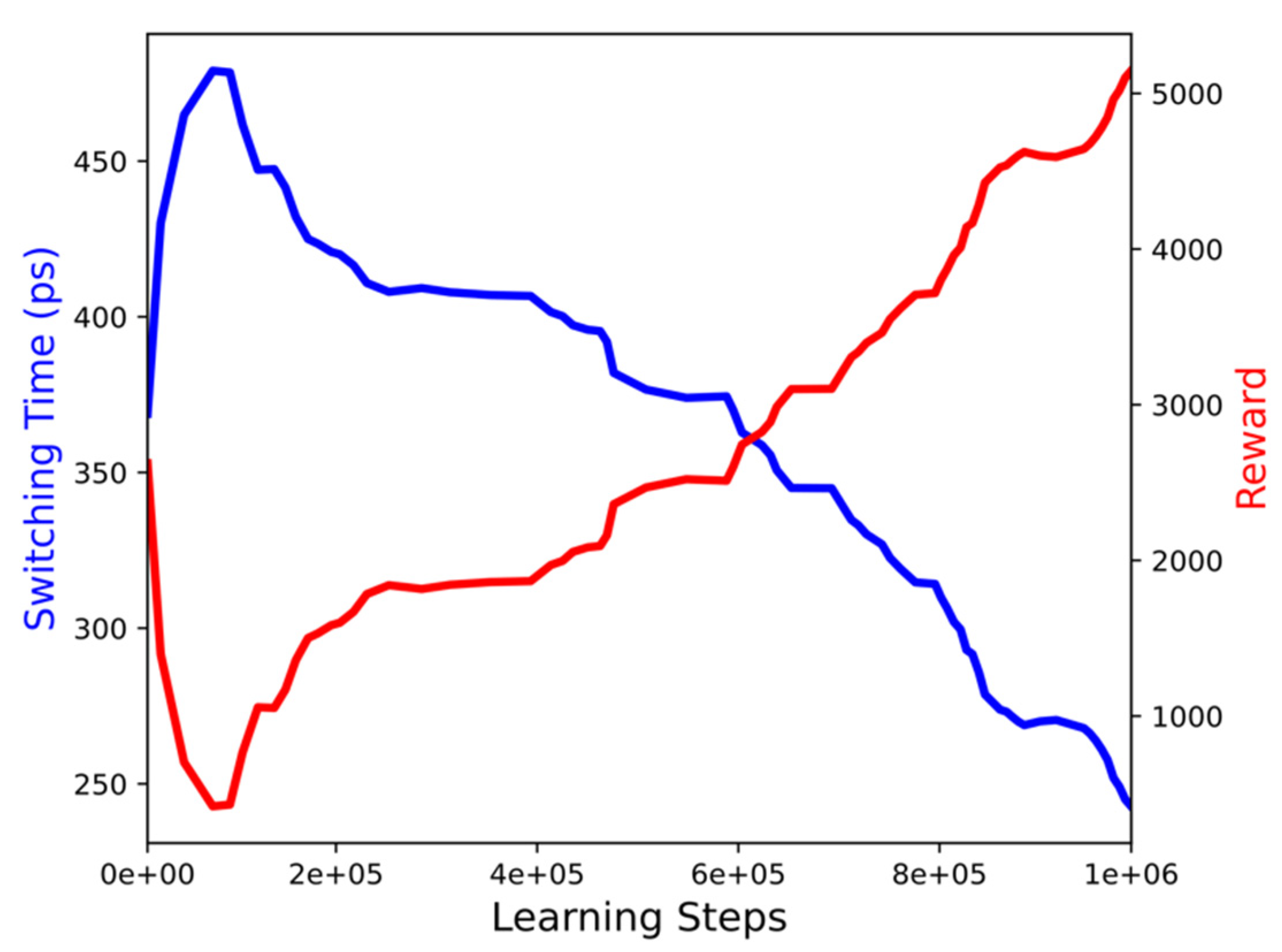
4.2. Reinforcement Learning Experiments
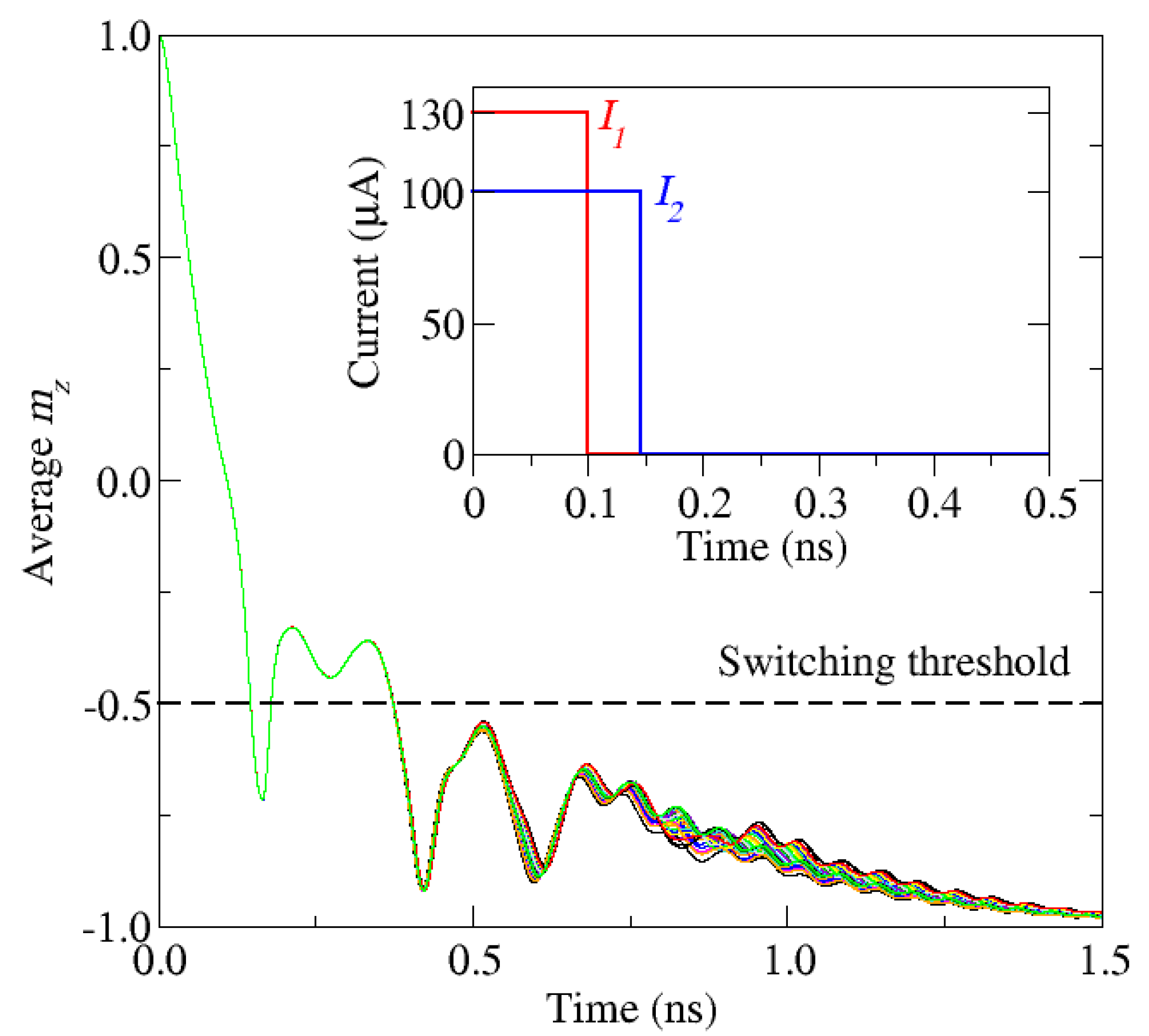
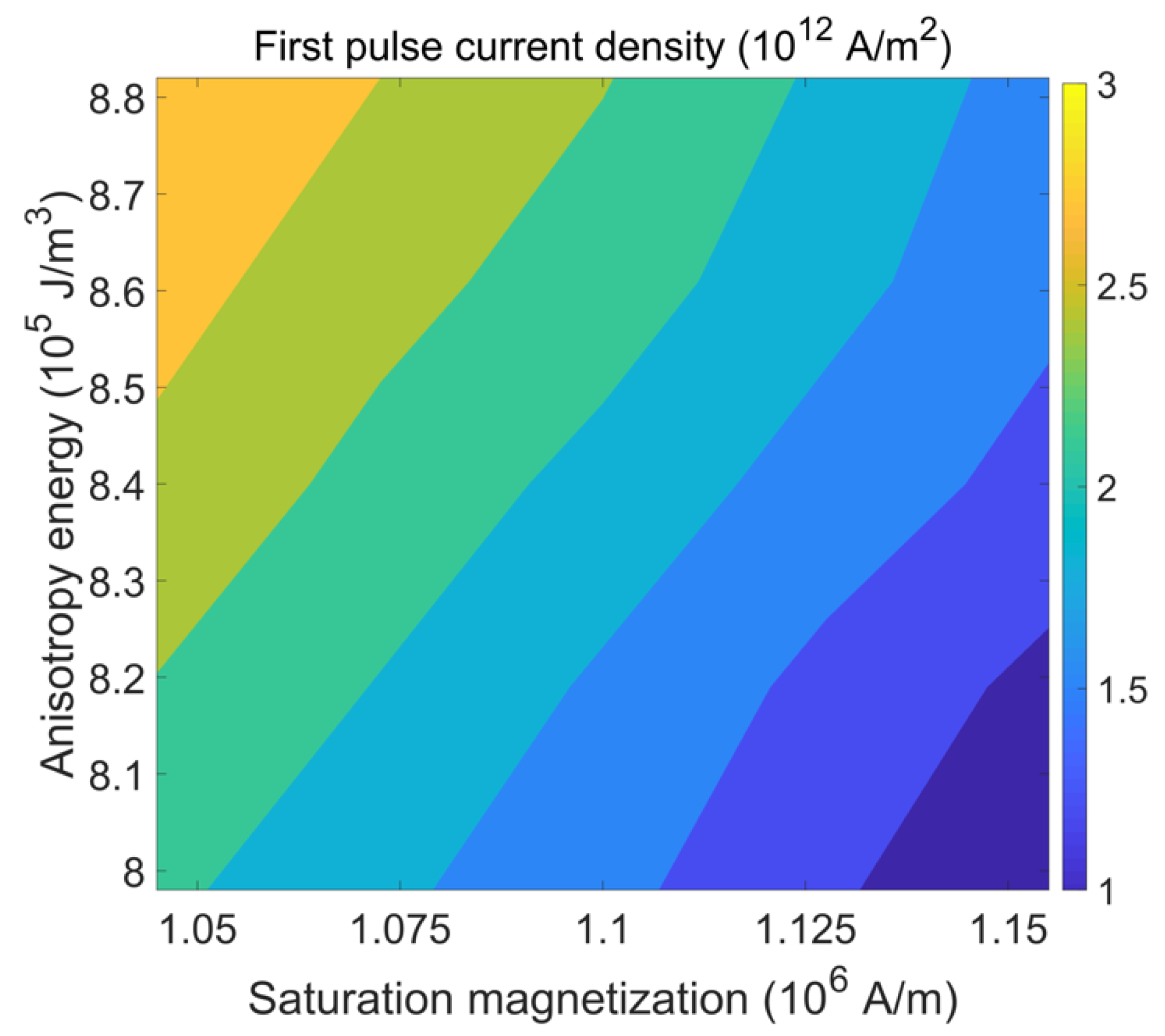
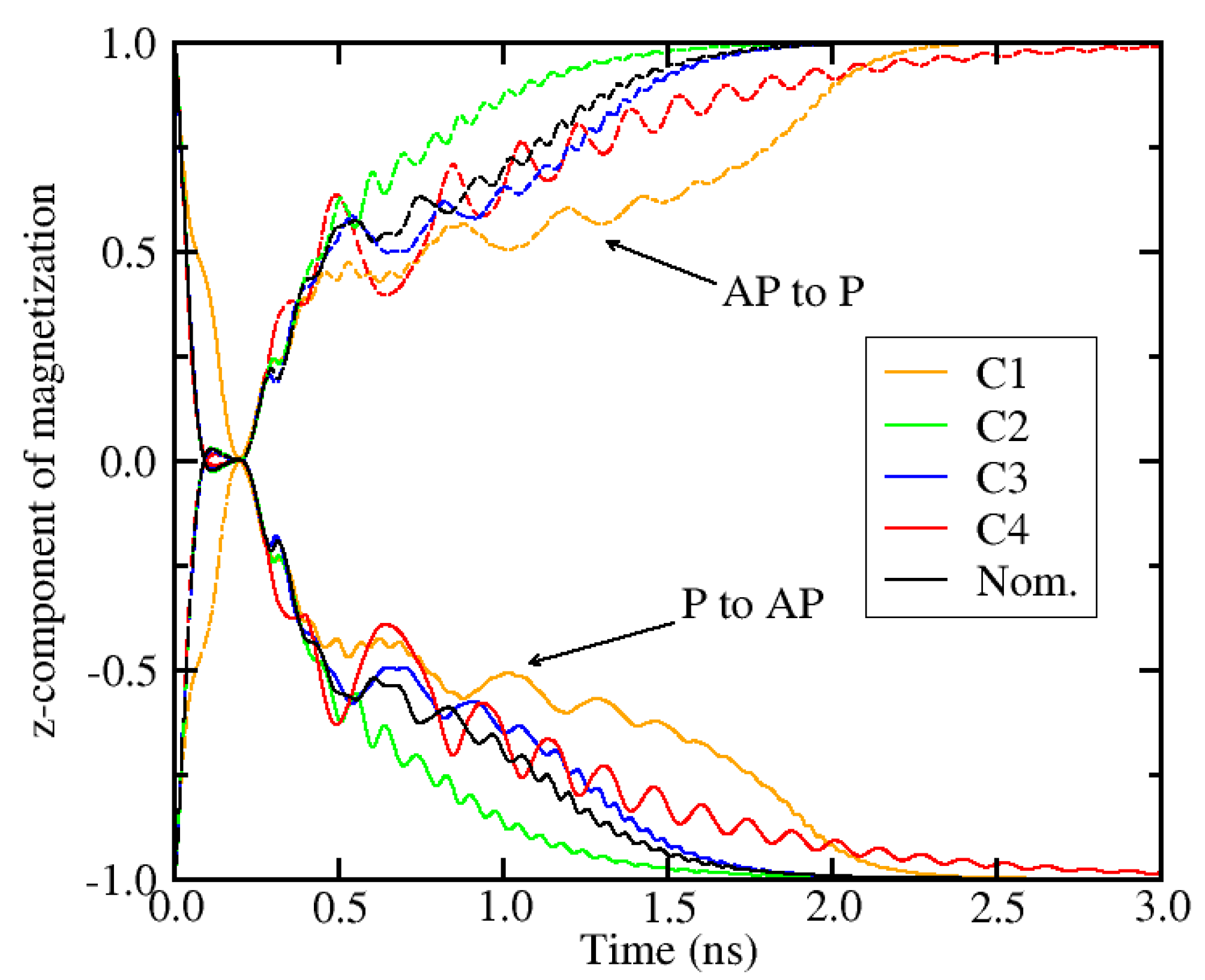
4.3. Impact of Parameter Variations
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jew, T. MRAM in Microcontroller and Microprocessor Product Applications. In Proceedings of the 2020 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020; pp. 11.1.1–11.1.4. [Google Scholar]
- Han, S.; Lee, J.; Shin, H.; Lee, J.; Suh, K.; Nam, K.; Kwon, B.; Cho, M.; Lee, J.; Jeong, J.; et al. 28-nm 0.08mm2/Mb Embedded MRAM for Frame Buffer Memory. In Proceedings of the 2020 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020; pp. 11.2.1–11.2.4. [Google Scholar]
- Naik, V.B.; Yamane, K.; Lee, T.Y.; Kwon, J.H.; Chao, R.; Lim, J.; Chung, N.L.; Behin-Aein, B.; Hau, L.Y.; Zeng, D.; et al. JEDEC-Qualified Highly Reliable 22nm FD-SOI Embedded MRAM For Low-Power Industrial-Grade, and Extended Performance Towards Automotive-Grade-1 Applications. In Proceedings of the 2020 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020; pp. 11.3.1–11.3.4. [Google Scholar]
- Shih, Y.C.; Lee, C.F.; Chang, Y.A.; Lee, P.H.; Lin, H.J.; Chen, Y.L.; Lo, C.-P.; Lin, K.F.; Chiang, T.W.; Lee, Y.J.; et al. A Reflow-Capable, Embedded 8Mb STT-MRAM Macro with 9ns Read Access Time in 16nm FinFet Logic CMOS Process. In Proceedings of the 2020 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020; pp. 11.4.1–11.4.4. [Google Scholar]
- Edelstein, D.; Rizzolo, M.; Sil, D.; Dutta, A.; DeBrosse, J.; Wordeman, M.; Arceo, A.; Chu, I.C.; Demarest, J.; Edwards, E.R.J.; et al. A 14 nm Embedded STT-MRAM CMOS Technology. In Proceedings of the 2020 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020; pp. 11.5.1–11.5.4. [Google Scholar]
- Lee, T.Y.; Yamane, K.; Otani, Y.; Zeng, D.; Kwon, J.; Lim, J.H.; Naik, V.B.; Hau, L.Y.; Chao, R.; Chung, N.L.; et al. Advanced MTJ Stack Engineering of STT-MRAM to Realize High Speed Applications. In Proceedings of the 2020 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020; pp. 11.6.1–11.6.4. [Google Scholar]
- Apalkov, D.; Dieny, B.; Slaughter, J.M. Magnetoresistive Random Access Memory. Proc. IEEE 2016, 104, 1796–1830. [Google Scholar] [CrossRef]
- Hu, G.; Nowak, J.J.; Gottwald, M.G.; Brown, S.L.; Doris, B.; D’Emic, C.P.; Hashemi, P.; Houssameddine, D.; He, Q.; Kim, D.; et al. Spin-Transfer Torque MRAM with Reliable 2 ns Writing for Last Level Cache Applications. In Proceedings of the 2019 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; pp. 2.6.1–2.6.4. [Google Scholar]
- Alzate, J.G.; Arslan, U.; Bai, P.; Brockman, J.; Chen, Y.J.; Das, N.; Fischer, K.; Ghani, T.; Heil, P.; Hentges, P.; et al. 2 MB Array-Level Demonstration of STT-MRAM Process and Performance Towards L4 Cache Applications. In Proceedings of the 2019 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; pp. 2.4.1–2.4.4. [Google Scholar]
- Sakhare, S.; Perumkunnil, M.; Bao, T.H.; Rao, S.; Kim, W.; Crotti, D.; Yasin, F.; Couet, S.; Swerts, J.; Kundu, S.; et al. Enablement of STT-MRAM as Last Level Cache for the High Performance Computing Domain at the 5nm Node. In Proceedings of the 2018 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 1–5 December 2018; pp. 18.3.1–18.3.4. [Google Scholar]
- Aggarwal, S.; Almasi, H.; DeHerrera, M.; Hughes, B.; Ikegawa, S.; Janesky, J.; Lee, H.K.; Lu, H.; Mancoff, B.; Nagel, K.; et al. Demonstration of a Reliable 1Gb Standalone Spin-Transfer Torque MRAM for Industrial Applications. In Proceedings of the 2019 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; pp. 2.1.1–2.1.4. [Google Scholar]
- Sato, H.; Honjo, H.; Watanabe, T.; Niwa, M.; Koike, H.; Miura, S.; Saito, T.; Inoue, H.; Nasuno, T.; Tanigawa, T.; et al. 14ns Write Speed 128Mb Density Embedded STT-MRAM with Endurance > 1010 and 10yrs Retention 85 °C Using Novel Low Damage MTJ Integration Process. In Proceedings of the 2018 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 1–5 December 2018; pp. 27.2.1–27.2.4. [Google Scholar]
- Golonzka, O.; Alzate, J.G.; Arslan, U.; Bohr, M.; Bai, P.; Brockman, J.; Buford, B.; Connor, C.; Das, N.; Doyle, B.; et al. MRAM as Embedded Non-Volatile Memory Solution for 22FFL FinFet Technology. In Proceedings of the 2018 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 1–5 December 2018; pp. 18.1.1–18.1.4. [Google Scholar]
- Miron, I.M.; Gaudin, G.; Auffret, S.; Rodmacq, B.; Schuhl, A.; Pizzini, S.; Vogel, J.; Gambardella, P. Current-Driven Spin Torque Induced by the Rashba Effect in a Ferromagnetic Metal Layer. Nat. Mater. 2010, 9, 230–234. [Google Scholar] [CrossRef] [PubMed]
- Honjo, H.; Nguyen, T.V.A.; Watanabe, T.; Nasuno, T.; Zhang, C.; Tanigawa, T.; Miura, S.; Inoue, H.; Niwa, M.; Yoshiduka, T.; et al. First Demonstration of Field-Free SOT-MRAM with 0.35ns Write Speed and 70 Thermal Stability under 400 °C Thermal Tolerance by Canted SOT Structure and its Advanced Patterning/SOT Channel Technology. In Proceedings of the 2019 IEEE Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; pp. 28.5.1–28.5.4. [Google Scholar]
- Garello, K.; Yasin, F.; Hody, H.; Couet, S.; Souriau, L.; Sharifi, S.H.; Swerts, J.; Carpenter, R.; Rao, S.; Kim, W.; et al. Manufacturable 300 mm Platform Solution for Field-Free Switching SOT-MRAM. In Proceedings of the 2019 IEEE Symposium on VLSI Circuits, Kyoto, Japan, 9–14 June 2019; pp. T194–T195. [Google Scholar]
- Garello, K.; Yasin, F.; Couet, S.; Souriau, L.; Swerts, J.; Rao, S.; Van Beek, S.; Kim, W.; Liu, E.; Kundu, S.; et al. SOT-MRAM 300 mm Integration for Low Power and Ultrafast Embedded Memories. In Proceedings of the 2018 IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 18–22 June 2018; pp. 81–82. [Google Scholar]
- Fukami, S.; Anekawa, T.; Zhang, C.; Ohno, H. A Spin-Orbit Torque Switching Scheme with Collinear Magnetic Easy Axis and Current Configuration. Nat. Nanotechnol. 2016, 11, 621–626. [Google Scholar] [CrossRef] [PubMed]
- Fukami, S.; Zhang, C.; DuttaGupta, S.; Kurenkov, A.; Ohno, H. Magnetization Switching by Spin-Orbit Torque in an Antiferromagnet-Ferromagnet Bilayer System. Nat. Mater. 2016, 15, 535–541. [Google Scholar] [CrossRef] [PubMed]
- Oh, Y.W.; Baek, S.H.C.; Kim, Y.M.; Lee, H.Y.; Lee, K.D.; Yang, C.G.; Park, E.S.; Lee, K.S.; Kim, K.W.; Go, G.; et al. Field-Free Switching of Perpendicular Magnetization through Spin-Orbit Torque in Antiferromagnet/Ferromagnet/Oxide Structures. Nat. Nanotechnol. 2016, 11, 878–884. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Razavi, S.A.; Shao, Q.; Li, X.; Wong, K.L.; Liu, Y.; Yin, G.; Wang, K.L. Spin-Orbit Torque from a Ferromagnetic Metal. Phys. Rev. B 2019, 99, 184403. [Google Scholar] [CrossRef]
- MacNeill, D.; Stiehl, G.M.; Guimaraes, M.H.D.; Buhrman, R.A.; Park, J.; Ralph, D.C. Control of Spin-Orbit Torques through Crystal Symmetry in WTe2/Ferromagnet Bilayers. Nat. Phys. 2016, 13, 300–305. [Google Scholar] [CrossRef]
- Yu, G.; Upadhyaya, P.; Fan, Y.; Alzate, J.G.; Jiang, W.; Wong, K.L.; Takei, S.; Bender, S.A.; Chang, L.T.; Jiang, Y.; et al. Switching of Perpendicular Magnetization by Spin-Orbit Torques in the Absence of External Magnetic Fields. Nat. Nanotechnol. 2014, 9, 548–554. [Google Scholar] [CrossRef] [PubMed]
- Sverdlov, V.; Makarov, A.; Selberherr, S. Two-Pulse Sub-ns Switching Scheme for Advanced Spin-Orbit Torque MRAM. Solid-State Electron. 2019, 155, 49–56. [Google Scholar] [CrossRef]
- de Orio, R.L.; Ender, J.; Fiorentini, S.; Goes, W.; Selberherr, S.; Sverdlov, V. Numerical Analysis of Deterministic Switching of a Perpendicularly Magnetized Spin-Orbit Torque Memory Cell. IEEE J. Electron Devices Soc. 2021, 9, 61–67. [Google Scholar] [CrossRef]
- Mehta, P.; Bukov, M.; Wang, C.H.; Day, A.G.; Richardson, C.; Fisher, C.K.; Schwab, D.J. A High-Bias, Low-Variance Introduction to Machine Learning for Physicists. Phys. Rep. 2019, 810, 1–124. [Google Scholar] [CrossRef] [PubMed]
- Kovacs, A.; Fischbacher, J.; Oezelt, H.; Gusenbauer, M.; Exl, L.; Bruckner, F.; Suess, D.; Schrefl, T. Learning Magnetization Dynamics. J. Magn. Magn. Mater. 2019, 491, 165588. [Google Scholar] [CrossRef]
- Exl, L.; Fischbacher, J.; Kovacs, A.; Oezelt, H.; Gusenbauer, M.; Yokota, K.; Shoji, T.; Hrkac, G.; Schrefl, T. Magnetic Microstructure Machine Learning Analysis. J. Phys. Mater. 2019, 2, 014001. [Google Scholar] [CrossRef]
- Dai, M.; Hu, J.-M. Field-Free Spin-Orbit Torque Perpendicular Magnetization Switching in Ultrathin Nanostructures. NPJ Comput. Mater. 2020, 6, 78. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd. ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; Petersen, S.; et al. Human-Level Control Through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and Go Through Self-Play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- de Orio, R.L.; Makarov, A.; Goes, W.; Ender, J.; Fiorentini, S.; Sverdlov, V. Two-Pulse Magnetic Field-Free Switching Scheme for Perpendicular SOT-MRAM with a Symmetric Square Free Layer. Phys. B Condens. Matter 2020, 578, 411743. [Google Scholar] [CrossRef]
- Makarov, A. Modeling of Emerging Resistive Switching Based Memory Cells. Ph.D. Thesis, Institute for Microelectronics, TU Wien, Austria, 2014. Available online: https://www.iue.tuwien.ac.at/phd/makarov/ (accessed on 12 March 2021).
- Raffin, A.; Hill, A.; Ernestus, M.; Gleave, A.; Kanervisto, A.; Dormann, N. Stable Baselines 3. Available online: https://github.com/DLR-RM/stable-baselines3 (accessed on 12 March 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Saturation magnetization, MS | 1.1 × 106 A/m |
| Exchange constant, A | 1.0 × 10−11 J/m |
| Perpendicular anisotropy, K | 8.4 × 105 J/m3 |
| Gilbert damping factor, α | 0.035 |
| Spin Hall angle, θSH | 0.3 |
| Thermal stability factor, Δ | 45 |
| Free layer dimensions | 40 nm × 20 nm × 1.2 nm |
| NM1: w1 × l | 20 nm × 3 nm |
| NM2: w2 × l | 20 nm × 3 nm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Orio, R.L.; Ender, J.; Fiorentini, S.; Goes, W.; Selberherr, S.; Sverdlov, V. Optimization of a Spin-Orbit Torque Switching Scheme Based on Micromagnetic Simulations and Reinforcement Learning. Micromachines 2021, 12, 443. https://doi.org/10.3390/mi12040443
de Orio RL, Ender J, Fiorentini S, Goes W, Selberherr S, Sverdlov V. Optimization of a Spin-Orbit Torque Switching Scheme Based on Micromagnetic Simulations and Reinforcement Learning. Micromachines. 2021; 12(4):443. https://doi.org/10.3390/mi12040443
Chicago/Turabian Stylede Orio, Roberto L., Johannes Ender, Simone Fiorentini, Wolfgang Goes, Siegfried Selberherr, and Viktor Sverdlov. 2021. "Optimization of a Spin-Orbit Torque Switching Scheme Based on Micromagnetic Simulations and Reinforcement Learning" Micromachines 12, no. 4: 443. https://doi.org/10.3390/mi12040443
APA Stylede Orio, R. L., Ender, J., Fiorentini, S., Goes, W., Selberherr, S., & Sverdlov, V. (2021). Optimization of a Spin-Orbit Torque Switching Scheme Based on Micromagnetic Simulations and Reinforcement Learning. Micromachines, 12(4), 443. https://doi.org/10.3390/mi12040443