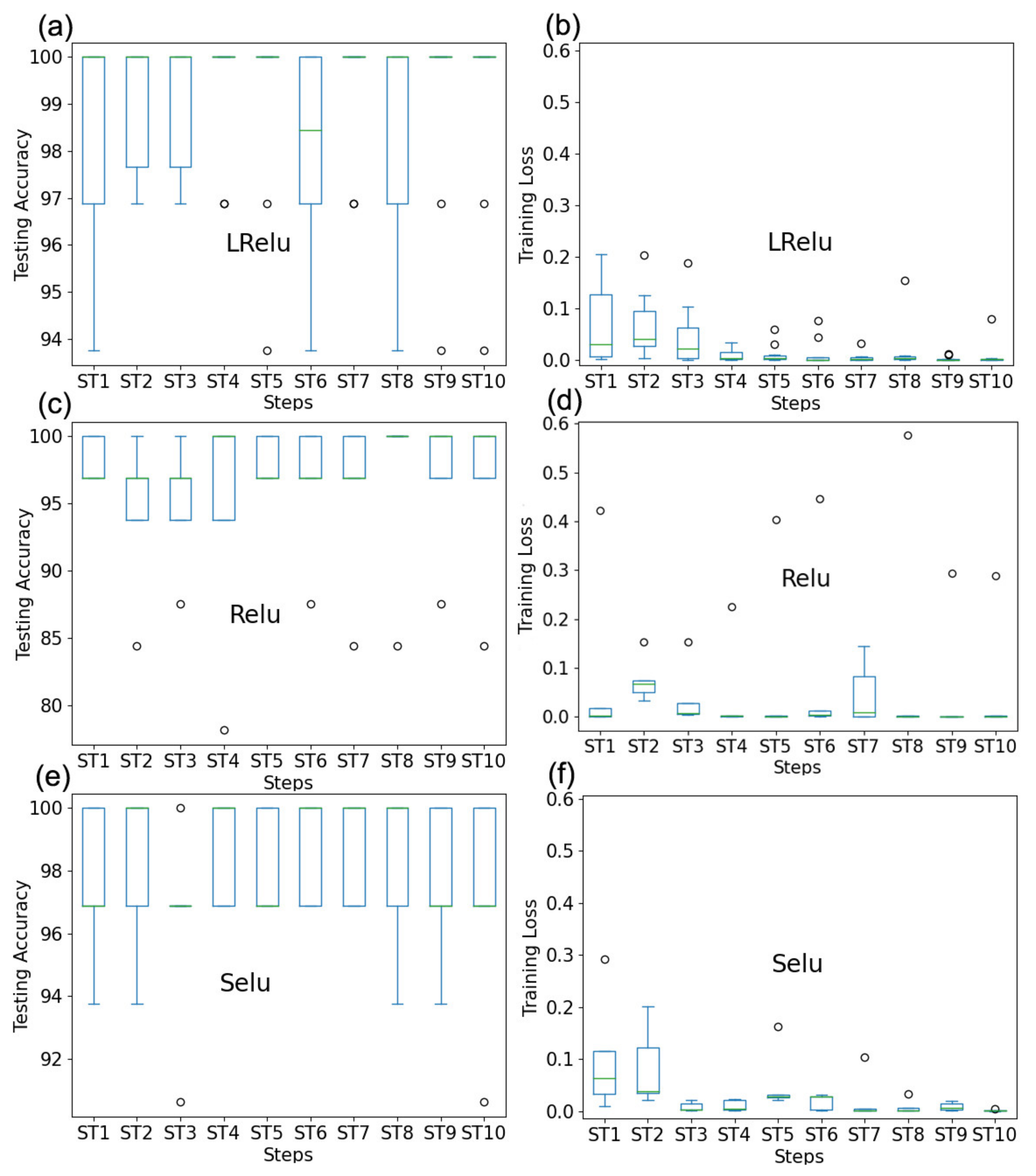
5.4. Experiment and Analysis Based on Single Parameter Optimization
- (A)
On the q
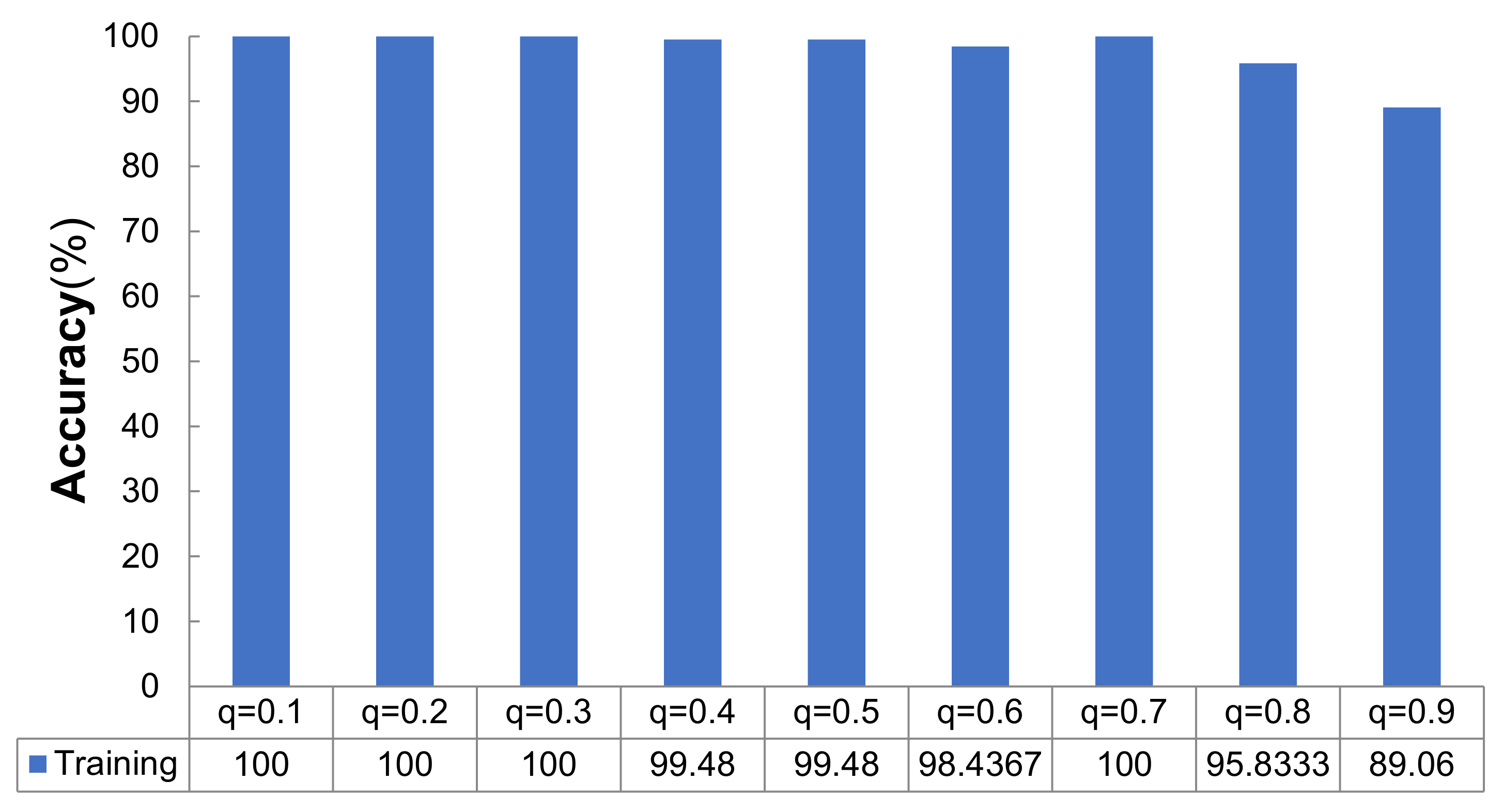
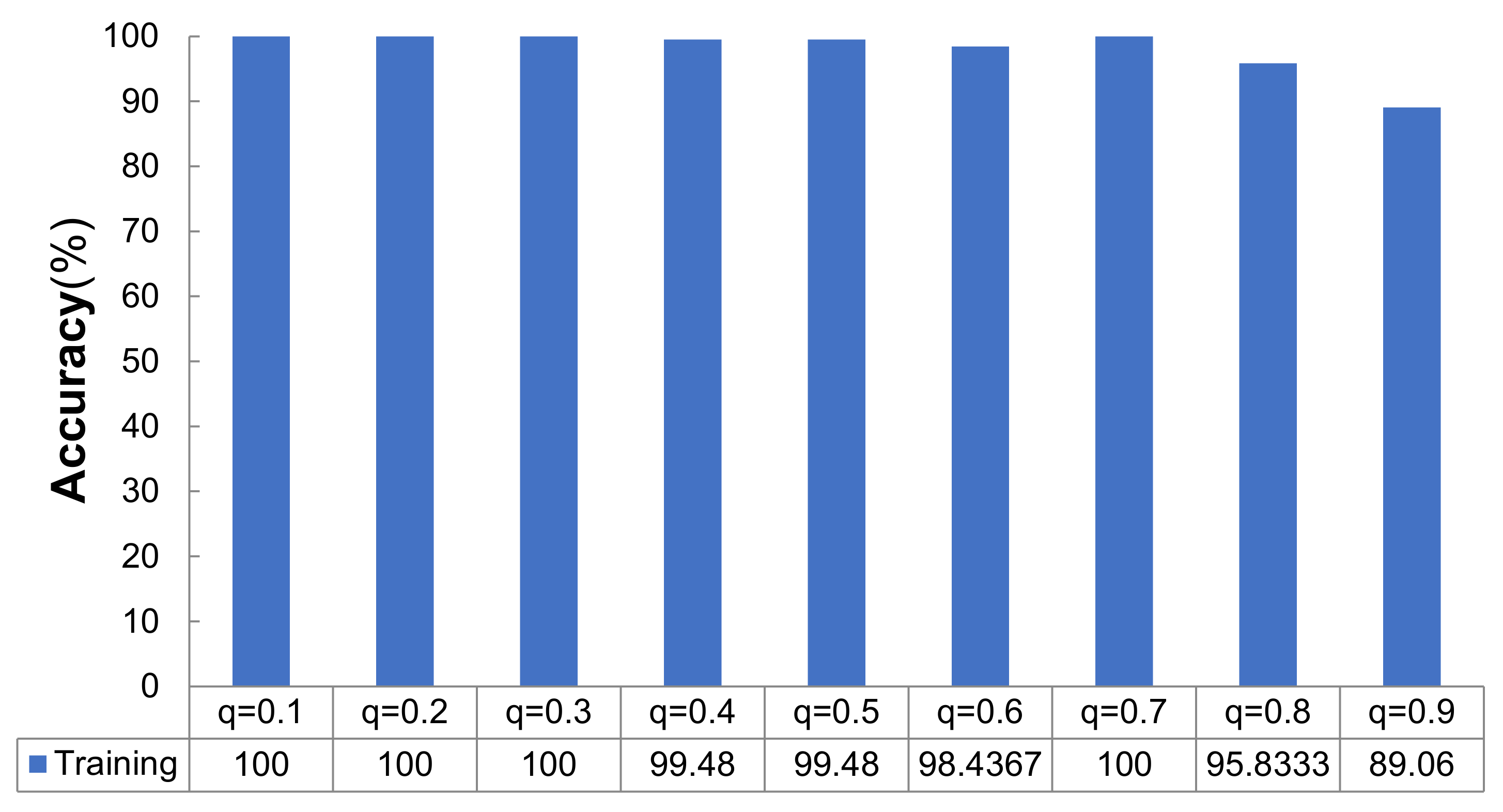
To study the effect of the dropout rate on the examined deep learning model, we set different settings as q = {0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}, and the other three parameters were m = 64, ke = 5, and lr = 1 × 10−4.
According to
Figure 1, the training accuracy of the network model varied with different dropout rates as follows: when
q = {0.1, 0.2, 0.3, 0.7}, the training accuracy was 100%; when
q = {0.4, 0.5, 0.6, 0.8, 0.9}, the training accuracies were 99.48%, 99.48%, 98.44%, 95.83%, and 89.06%, respectively. It can be concluded that the average accuracy did not change when the dropout rate was between 0.1–0.3 in the training stage. Then, when
q increased from 0.4 to 0.7, the accuracy range was very small, but when
q increased from 0.7 to 0.9, the training accuracy decreased sharply. The convergence of the accuracy rate is shown in
Figure 2. As shown in
Figure 2a, the fastest convergence rate on the training set was achieved when
q = {0.5, 0.4, 0.3}.
Figure 2b shows that the convergence rate was relatively fast for the test set when
q = {0.5, 0.4, 0.3}.
Table 1 shows that the variation in time consumption could be divided into three distinct stages: in the first stage, when
q < 0.4, the time consumption increased with the increase in the dropout value; in the second stage, when 0.4 ≤
q ≤ 0.6, the time taken for
q = 0.4 decreased relative to that required for
q = 0.3, but when the dropout increases from 0.4 to 0.6, the time increased with the increase in the dropout value. Stage 3: when
q = 0.6 increased to
q = 0.8, the time decreased as the dropout value increased. However, when
q = 0.8 and
q = 0.9, there was no significant change in the time consumption of the operation.
Considering the convergence of the accuracy and cross-entropy loss values during model training, the convergence of the accuracy during testing and the time consumption incurred when going through the same steps, the experiment showed that the best performance obtained by the deep neural network model using dropout occurred when the dropout rate was set as q = {0.3, 0.4, 0.5}.
- (B)
On the m
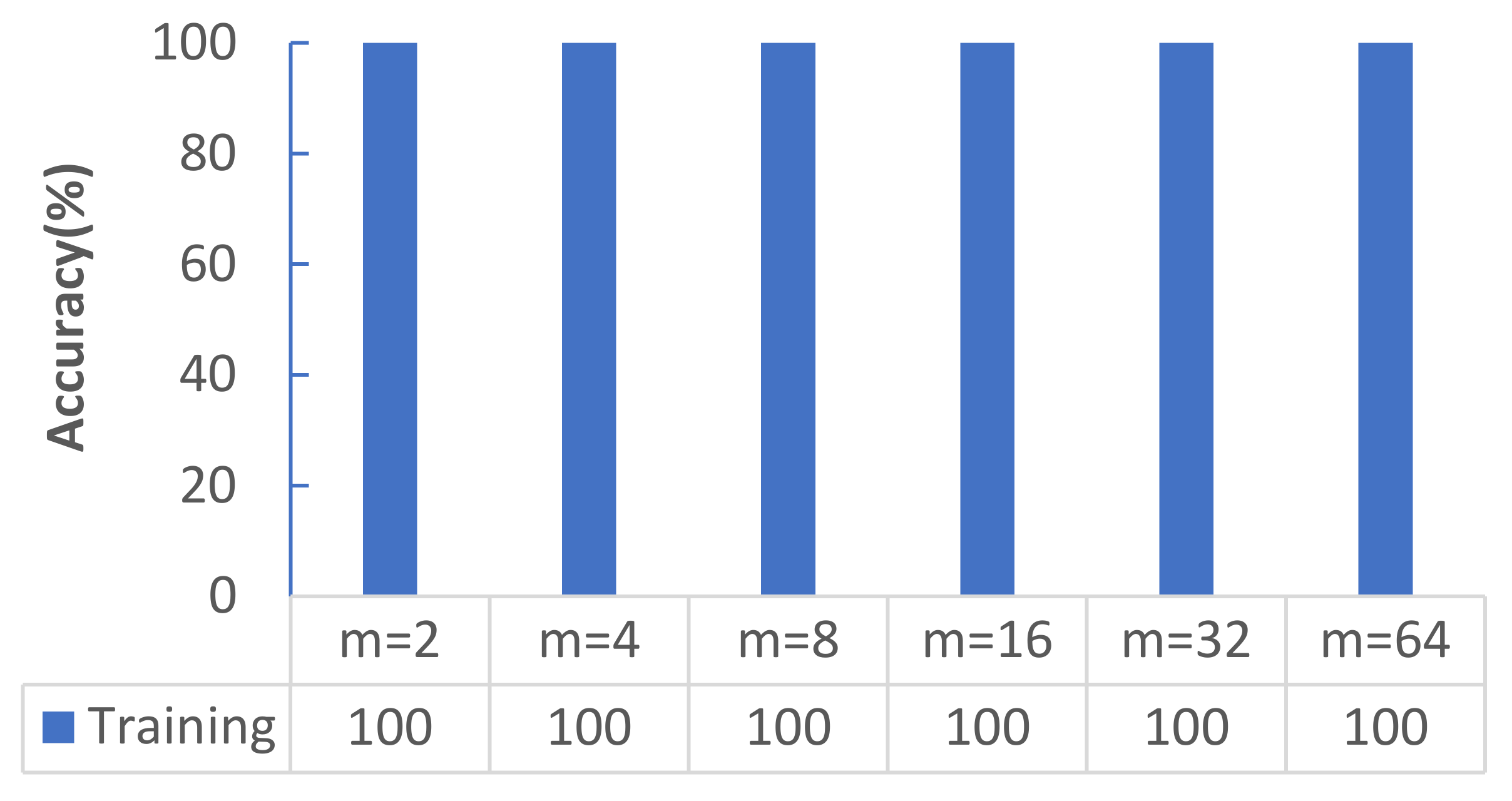
The m is an important parameter in machine learning that is set in a reasonable range; it can improve the memory utilization rate of the computer, improve its processing speed with the same amount of data, and reduce the training shock caused by the decline in memory. To observe the changes in the performance of the multilayer CNN model when the batch size was set to different values, we designed an experiment in this section. The parameter variable of this experiment was the batch size value; i.e., the other parameters were held constant: q = 0.5, lr = 1 × 10−4, and ke = 5.
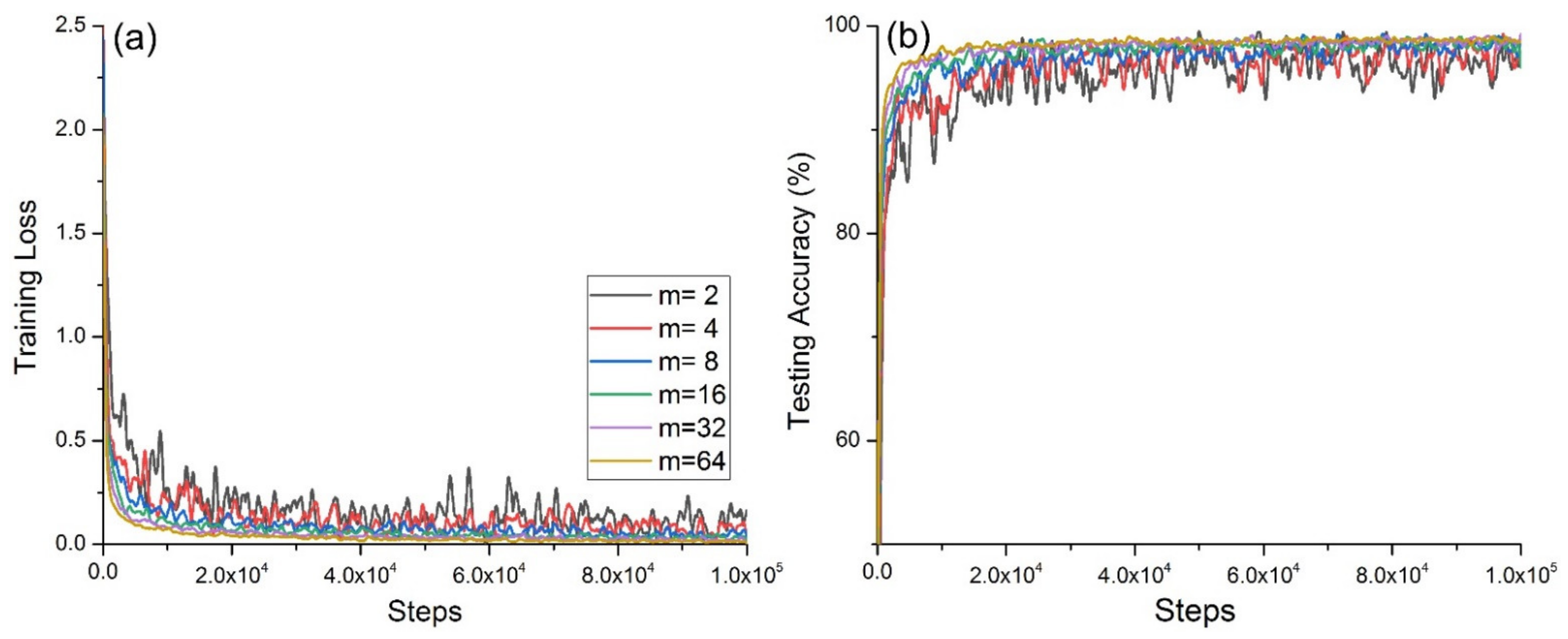
Figure 3 shows that with increasing
m, the average accuracy rate did not change and reached 100%.
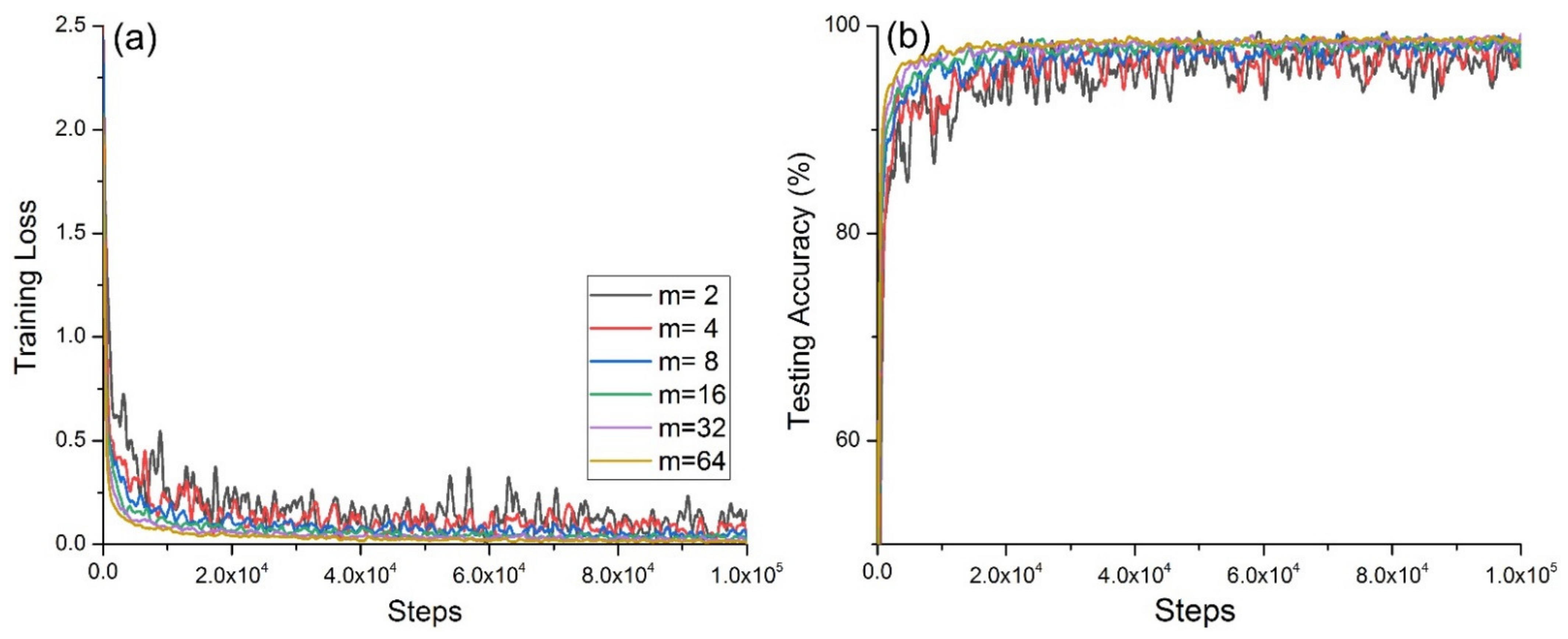
Figure 4a shows the change in the cross-entropy loss with the same number of steps for the network model on the training set at different
m values, and
Figure 4b shows the accuracy of the network model on the test set with different
m.
Figure 4a shows that when
m = 2, the convergence was slowest and exhibited strong oscillation; when
m = 4, the convergence and oscillation were second only to those in the case when
m = 2; when
m = 64 and
m = 32, the convergence was fast and the oscillation was small.
Figure 4b shows that when
m = 2, the convergence was slowest, and exhibited strong oscillation; when
m = 4, its convergence and oscillation were second only to those in the case when
m = 2; when
m = 64 and
m = 32, its convergence was fast, and the oscillation was small.
When m = {2,4,8,16}, the accuracy was high, but the training cross-entropy loss value and test accuracy oscillated greatly, and the convergence was poor. The reason for this was that the number of samples fed each time was too small, which led to overfitting during the model training process.
Table 2 shows that as
m continued to increase, the running time for model also increased.
The above experimental results were in line with Equations (25) and (26). The m is one of the main hyperparameters that affects the learning performance of the deep model, and directly affects the parameter update of the cross-entropy loss function of the deep learning model.
Considering the convergence of the accuracy and cross-entropy loss during model training, the convergence of the accuracy during testing, and the running time incurred during the same steps, the experiment proved that when m = 32 was used, the performance of the deep neural network model reached its maximum.
- (C)
On the lr
The lr has a key impact on the performance of the model. Too large an lr causes the model to fail to converge, while a small rate causes the model to converge very slowly or fail to learn. To study the effects of different lr on the performance of a multilayer CNN, the parameter variables were lr = {1 × 10−2, 1 × 10−3, 1 × 10−4, 1 × 10−5, 1 × 10−6, 1 × 10−7}, while the other three parameters were held constant: q = 0.5, m = 32, and ke = 5.
It can be seen from
Figure 5 that when the learning rate was in the range {1 × 10
−2, 1 × 10
−3}, the average accuracy rate increased with a decreasing learning rate; and when
lr = 1 × 10
−4 and
lr = 1e-5, the average accuracy rate reached 100%. When
lr < 1 × 10
−5, the average accuracy dropped sharply, first to 90.6267%, and finally to 58.3367%.
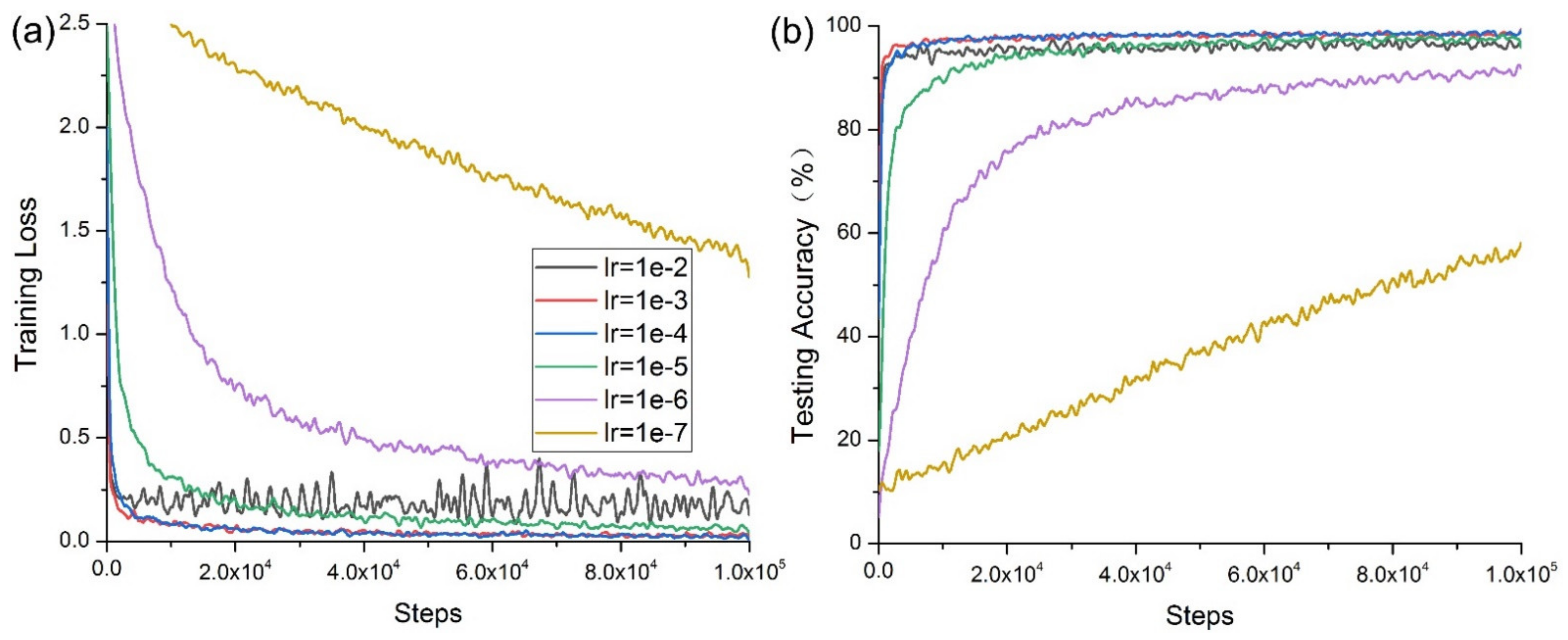
Figure 6 shows that when
lr =1 × 10
−7, both the training loss and testing accuracy failed to converge due to the low learning rate. When
lr =1 × 10
−6, the convergence rate of the model was slow, and was only faster than that obtained when
lr =1 × 10
−7. This experimental result is described in Equations (25) and (27); the learning rate is one of the main hyperparameters that affects the learning performance of the deep model and directly affects the parameter update of the cross-entropy loss function of the deep learning model.
Figure 6b shows that the convergence rate of the deep CNN increased with an increasing learning rate. However, when
lr = 1 × 10
−2, its convergence worsened, and its oscillation increased. When going through the same steps, the time required by the model differed little, as shown in
Table 3.
Experiments proved that the depth of the initial vector on CNN models had an impact on the performance, and when lr = 1 × 10−3 and lr =1 × 10−4, the depth of the neural network model attained the best performance condition.
- (D)
On the ke
The convolution process multiplies the elements in the convolution kernel and the corresponding pixels in the image successively, and sums them as the new pixel value after convolution. Then, the convolution kernel is shifted along the original image, and new pixel values are calculated until the whole image is covered. This process can produce many different effects according to different image convolution results.
In this section, experiments were designed to test the effects of different kernel sizes on the performance of the multilayer CNN. This set of experimental kernel sizes was used as a variable parameter, and its value was ke = {1,2,3,4,5,6,7}. The other three parameters were held constant: q = 0.5, m = 32, and lr =1 × 10−4.
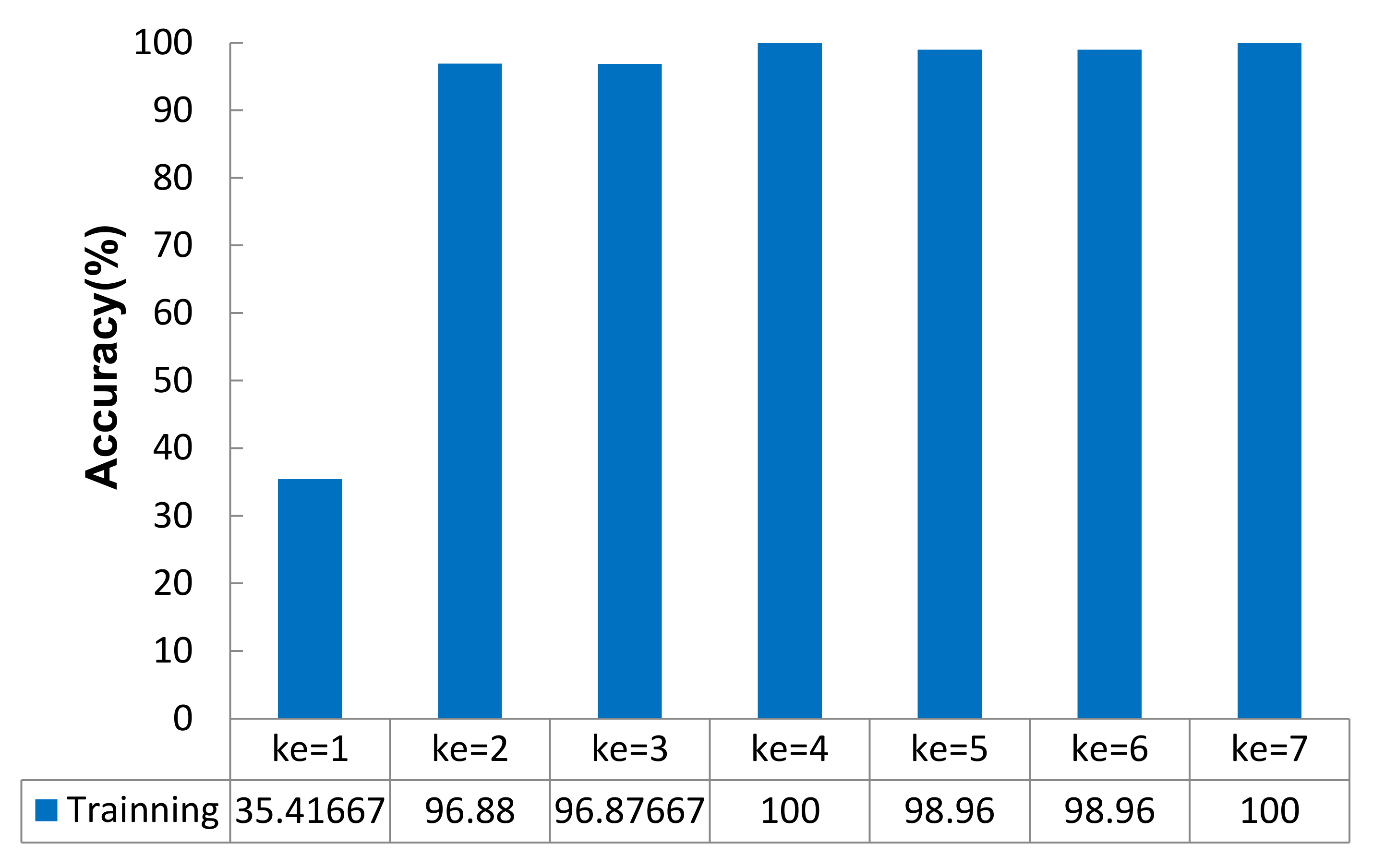
When the other parameters of the network model remained unchanged, the accuracy value of the model changed in two stages with increasing kernel size:
ke = {1,2,3,4} (stage 1) and
ke = {5,6,7} (stage 2). The change trends in the two stages showed that the accuracy rate of the model increased with increasing kernel size, as shown in
Figure 7.
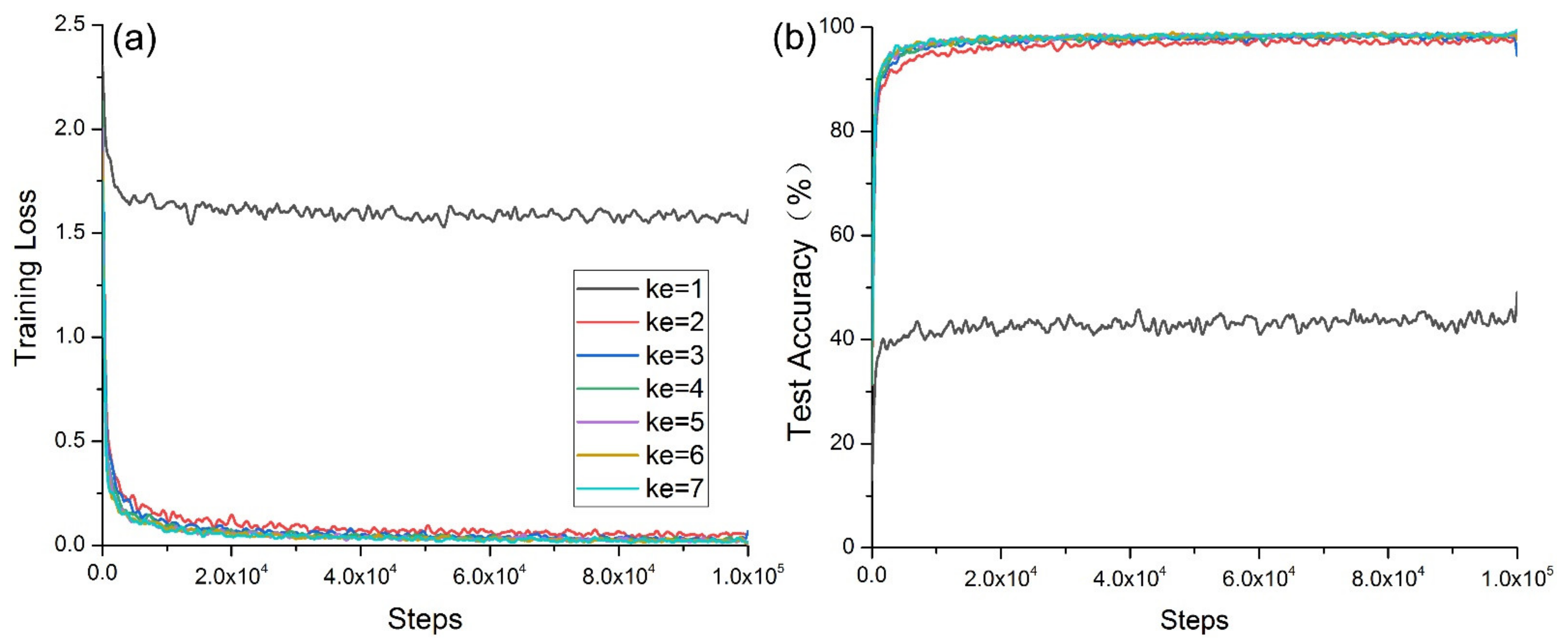
In
Figure 8a, when
ke = 1, the convergence was slowest and exhibited strong oscillation. When
ke = 2, the oscillation was second only to those obtained when
ke = 1. When
ke > 3, its convergence was good, and there were no obvious changes in the kernel size. In
Figure 8b, when
ke = 1, the convergence was slowest and exhibited strong oscillation. When
ke = 2, the convergence and oscillation were second only to those obtained when
ke = 1. When
ke > 3, the convergence was good, and there were no obvious changes in the
ke value.
With an increasing
ke value, the time consumed by the model for learning could be divided into two stages, as shown in
Table 4. The time consumption at
ke = 2 was 654 s lower than that at
ke = 1. The time consumption at
ke = 3 was 621 s lower than that at
ke = 2. The time consumption at
ke = 4 was 143 s higher than that at
ke = 3. The time consumption at
ke = 5 was 241 s higher than that at
ke = 6. The time consumption at
ke = 7 was 151 s higher than that at
ke = 6.
According to the four indicators of model training accuracy, cross-entropy loss value convergence, test accuracy convergence, and the time spent during the same step, the experiments showed that ke had an impact on the performance of the deep CNN model. The optimal value range of the kernel size was ke = {4, 5}, and when ke = 4, the performance of the deep CNN model reached the best state.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}