A Time Delay Neural Network Based Technique for Nonlinear Microwave Device Modeling


 and
and
Abstract
:1. Introduction
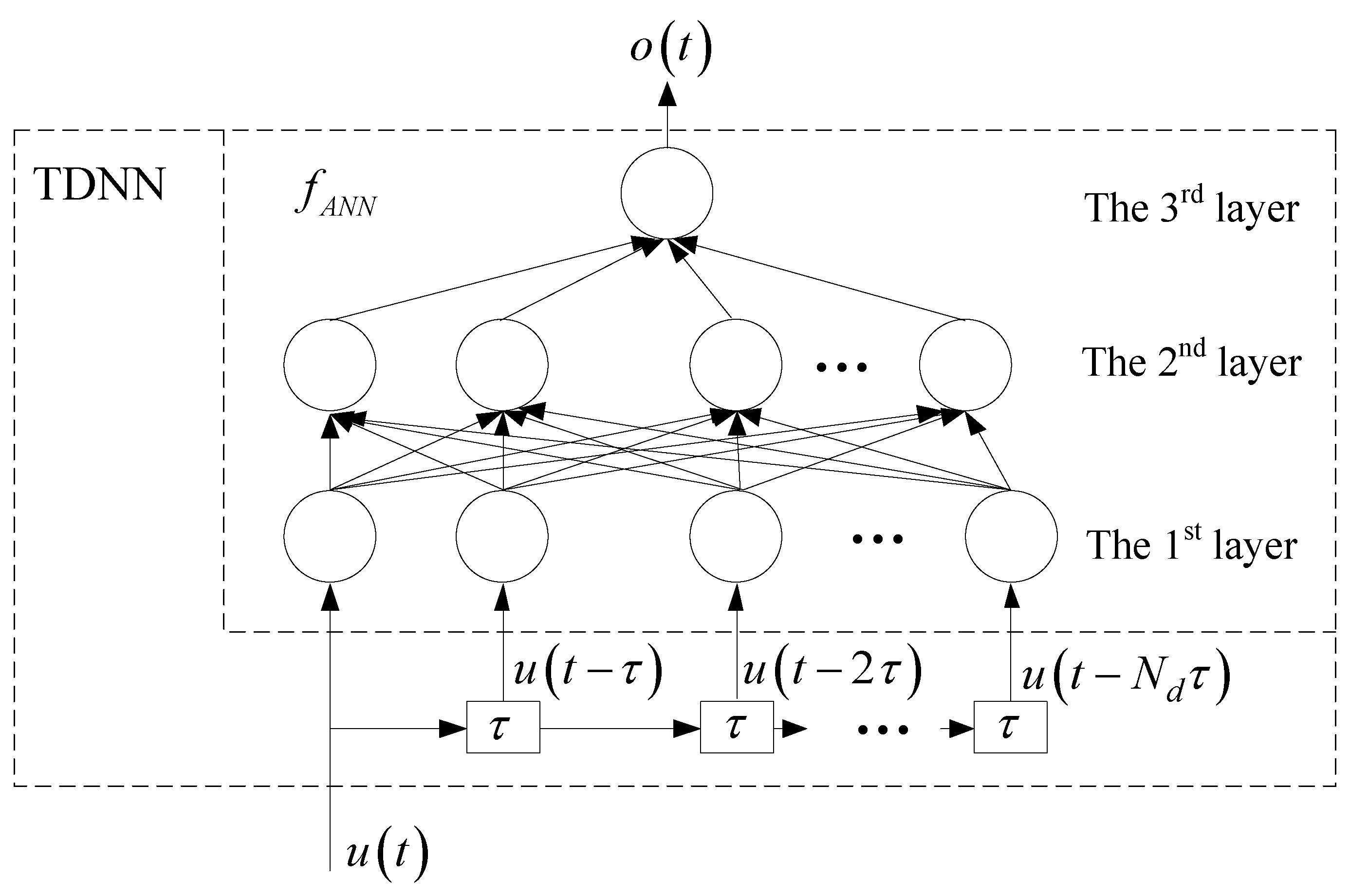
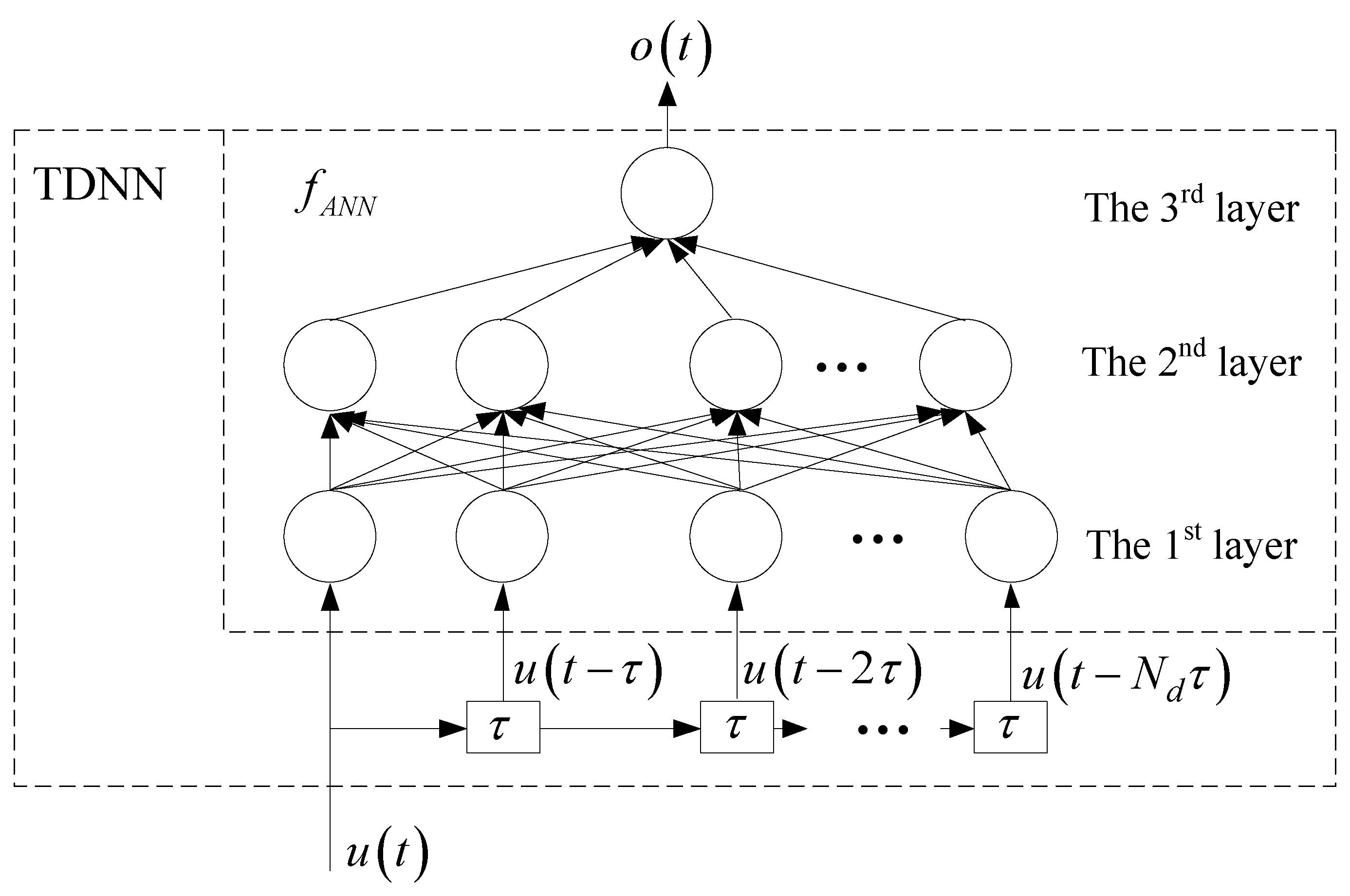
2. Formulations of the Proposed Time Delay Neural Network (TDNN) Model
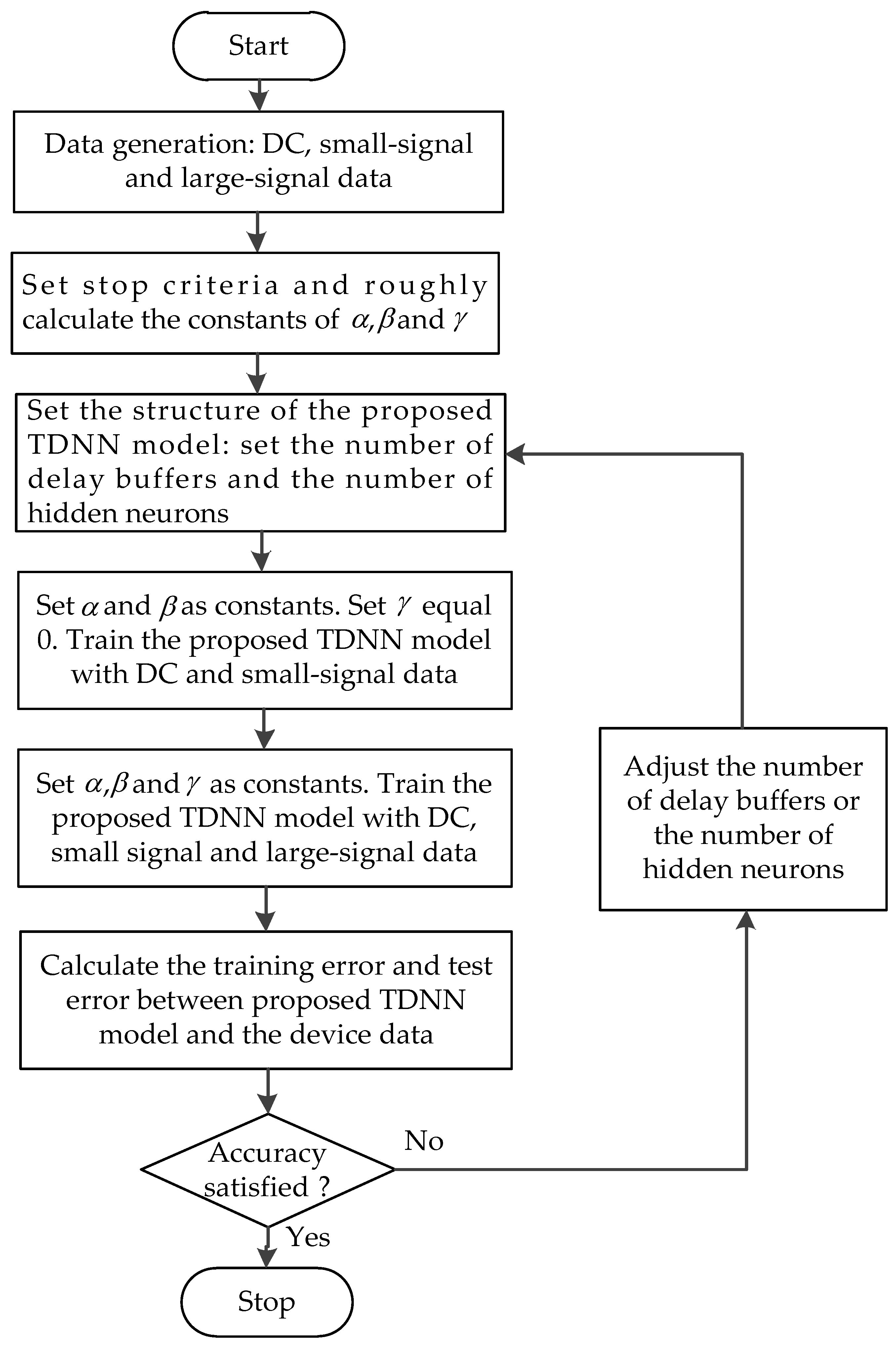
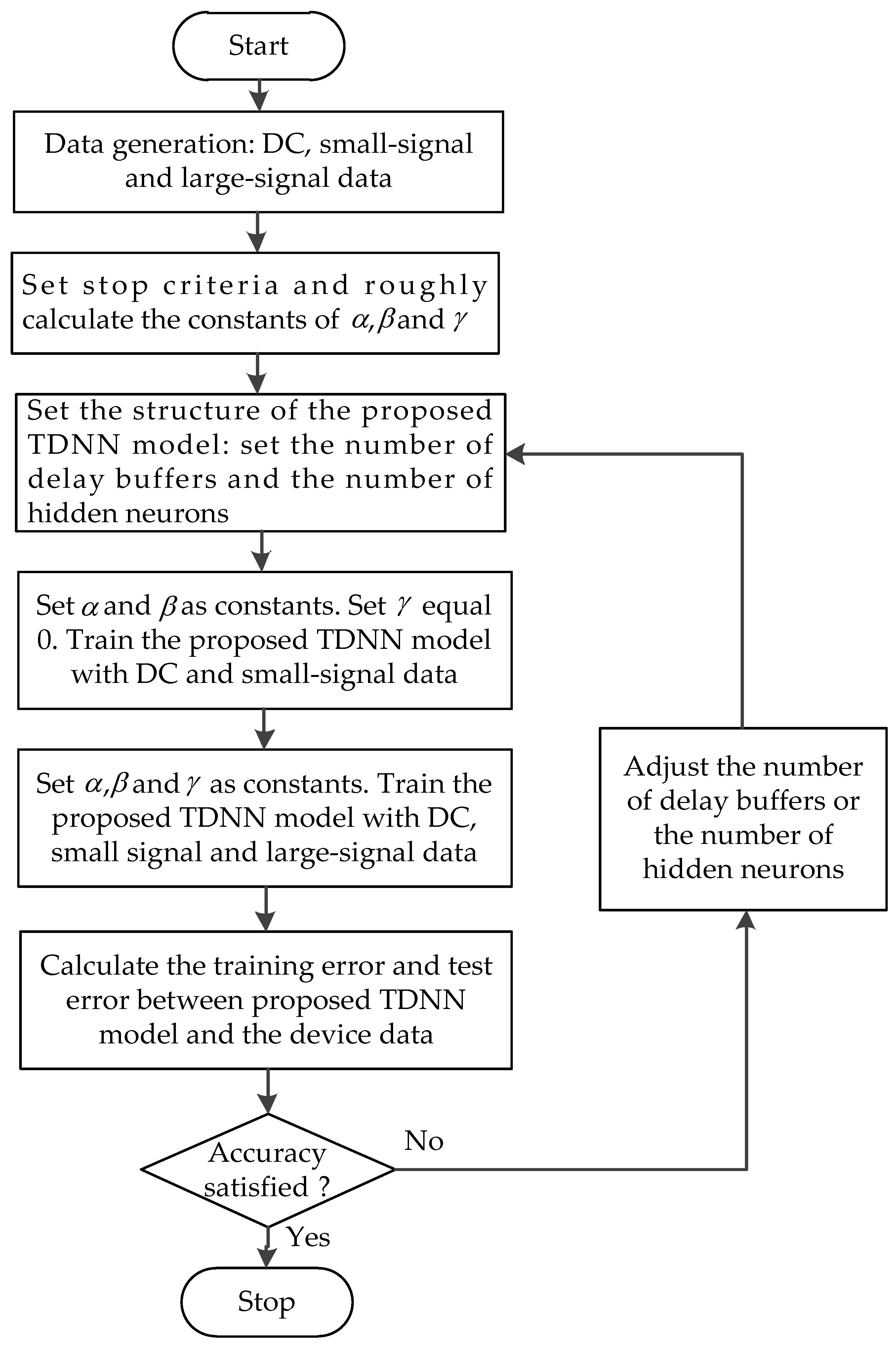
3. An Algorithm for Training the Proposed TDNN Model
4. Examples
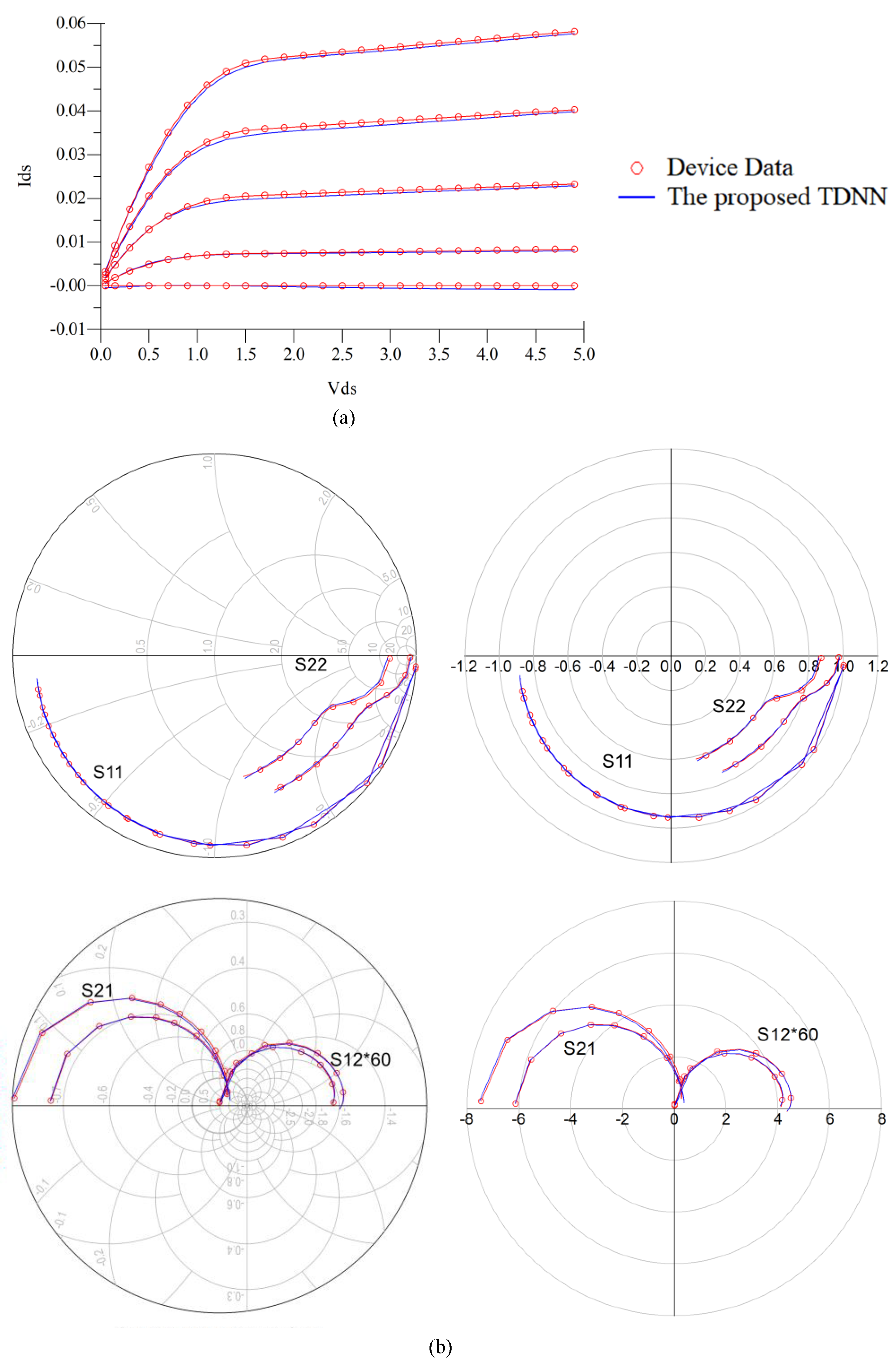
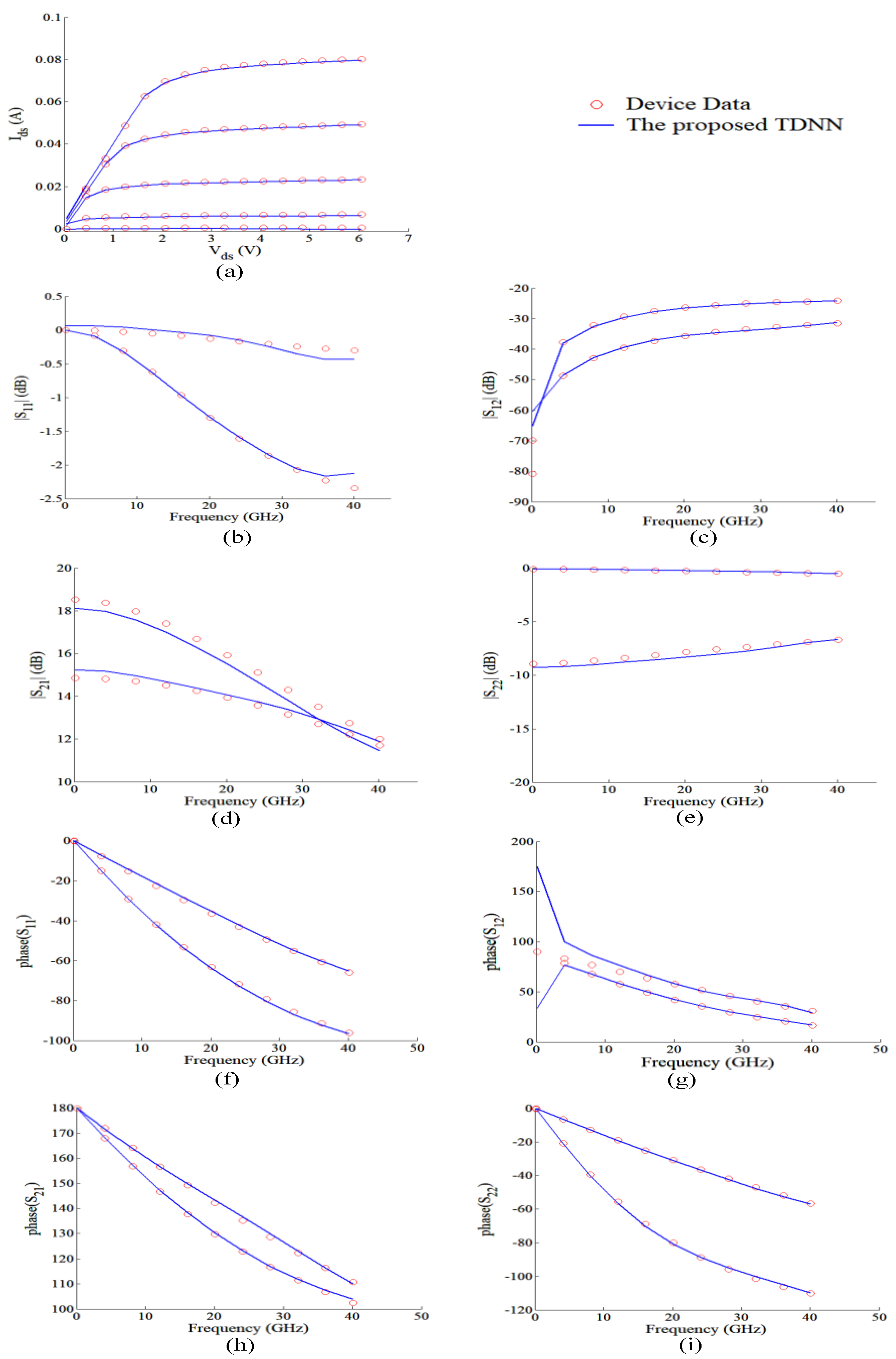
4.1. GaAs Metal-Semiconductor-Field-Effect Transistor (MESFET)
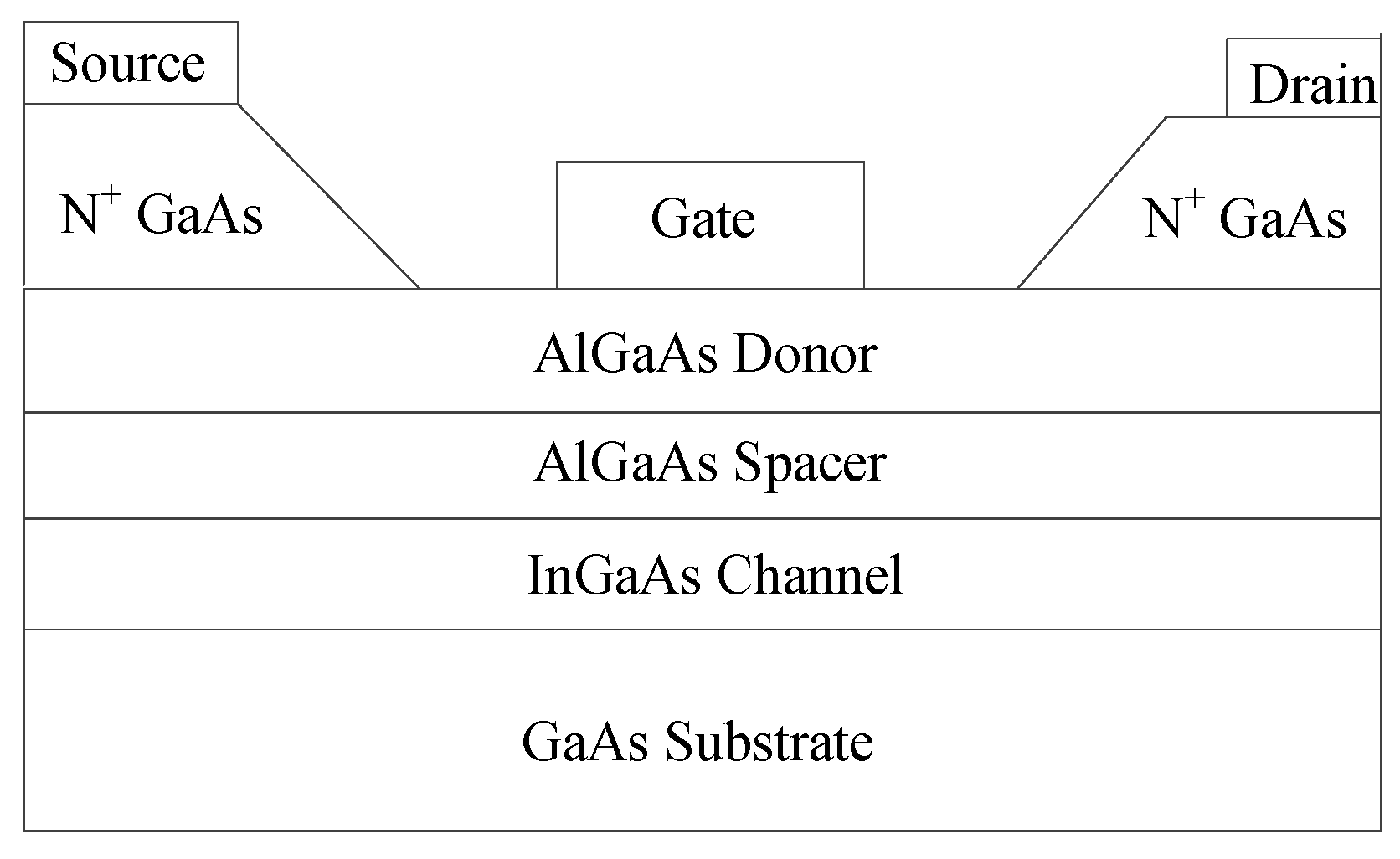
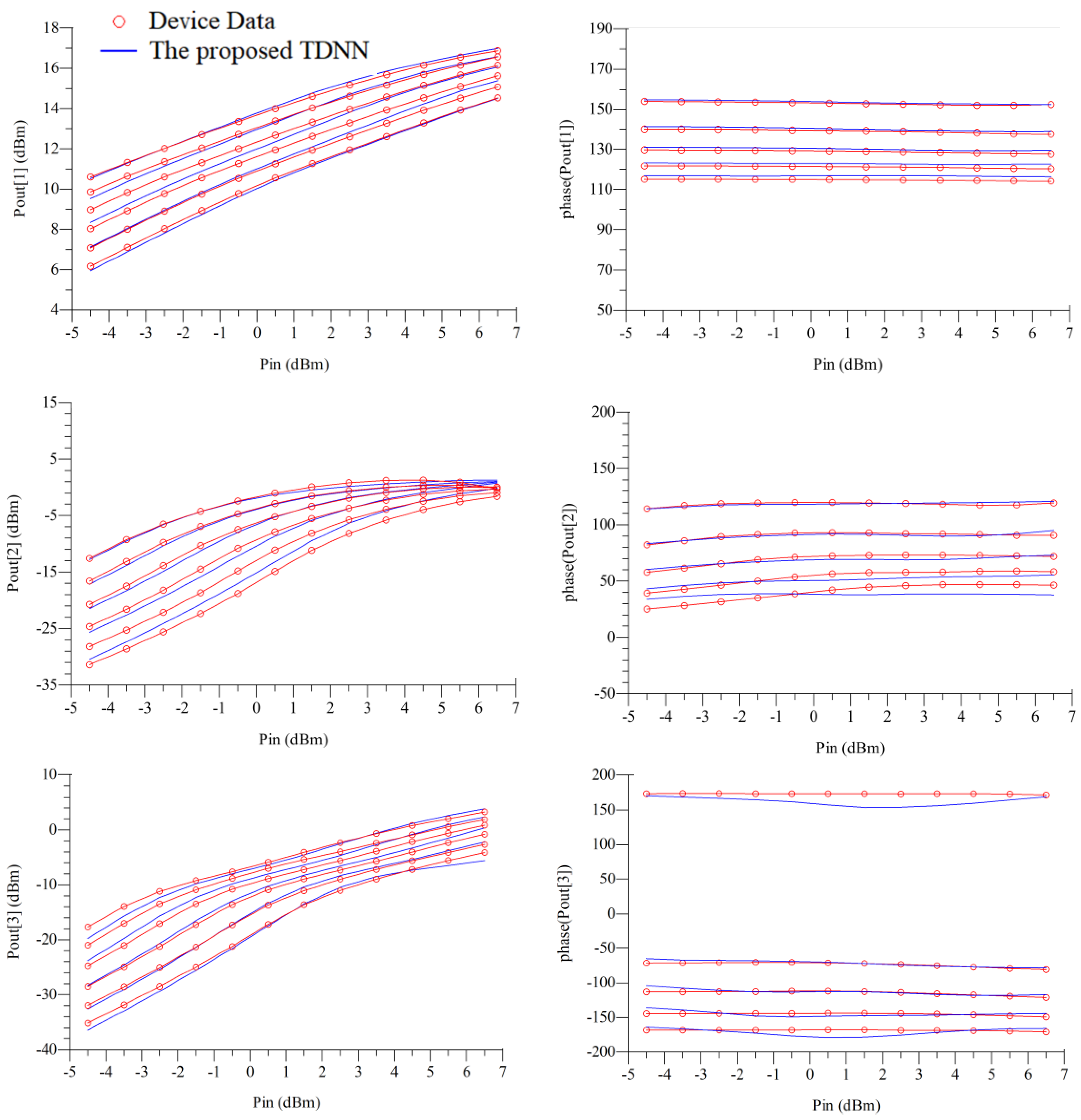
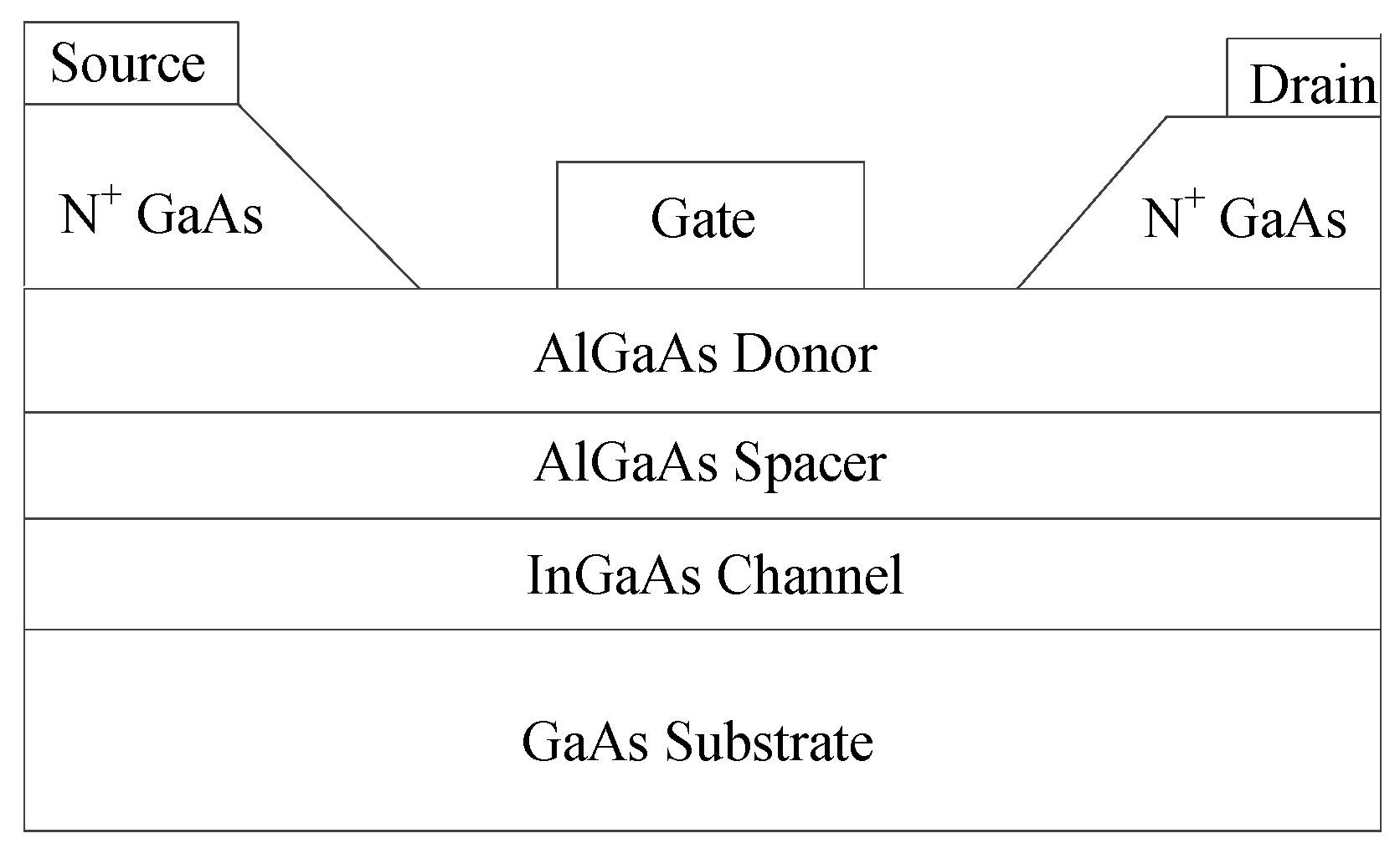
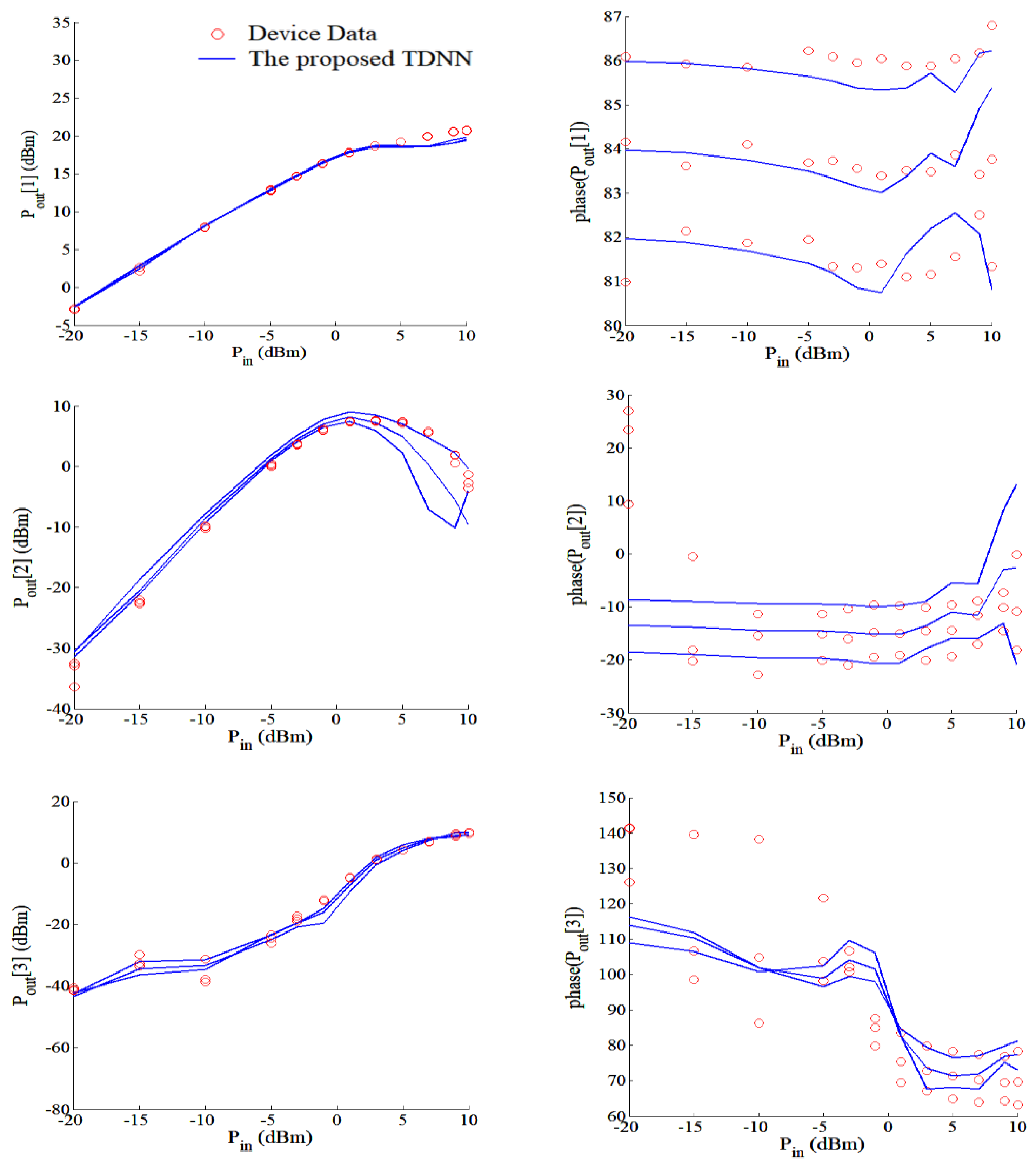
4.2. GaAs High-Electron Mobility Transistor (HEMT)
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, Q.J.; Gupta, K.C.; Devabhaktuni, V.K. Artificial neural networks for RF and microwave design—from theory to practice. IEEE Trans. Microw. Theory Tech. 2003, 51, 1339–1350. [Google Scholar] [CrossRef]
- Feng, F.; Na, W.; Liu, W.; Yan, S.; Zhu, L.; Ma, J.; Zhang, Q.-J. Multifeature-assisted neuro-transfer function surrogate-based EM optimization exploiting trust-region algorithms for microwave filter design. IEEE Trans. Microw. Theory Tech. 2020, 68, 531–542. [Google Scholar] [CrossRef]
- Na, W.; Liu, W.; Zhu, L.; Feng, F.; Ma, J.; Zhang, Q.J. Advanced extrapolation technique for neural-based microwave modeling and design. IEEE Trans. Microw. Theory Tech. 2018, 66, 4397–4418. [Google Scholar] [CrossRef]
- Kabir, H.; Zhang, L.; Kim, K. Automatic parametric model development technique for RFIC inductors with large modeling space. In Proceedings of the 2017 IEEE MTT-S International Microwave Symposium (IMS), Honololu, HI, USA, 4–9 June 2017; pp. 551–554. [Google Scholar]
- Jin, J.; Zhang, C.; Feng, F.; Na, W.; Ma, J.; Zhang, Q. Deep Neural Network Technique for High-Dimensional Microwave Modeling and Applications to Parameter Extraction of Microwave Filters. IEEE Trans. Microw. Theory Tech. 2018, 67, 4140–4155. [Google Scholar] [CrossRef]
- Du, X.; Helaoui, M.; Jarndal, A.; Liu, T.; Hu, B.; Hu, X.; Ghannouchi, F.M. ANN-based large-signal model of AlGaN/GaN HEMTs with accurate buffer-related trapping effects characterization. IEEE Trans. Microw. Theory Tech. 2020, 68, 3090–3099. [Google Scholar] [CrossRef]
- Zhao, P.; Wu, K. Homotopy optimization of microwave and millimeter-wave filters based on neural network model. IEEE Trans. Microw. Theory Tech. 2020, 68, 1390–1400. [Google Scholar] [CrossRef]
- Xiao, L.; Shao, W.; Jin, F.; Wang, B.; Joines, W.T.; Liu, Q.H. Semisupervised radial basis function neural network with an effective sampling strategy. IEEE Trans. Microw. Theory Tech. 2020, 68, 1260–1269. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y.; Yu, M.; Panariello, A. Efficient modeling of Ku-band high power dielectric resonator filter with applications of neural networks. IEEE Trans. Microw. Theory Tech. 2019, 67, 3427–3435. [Google Scholar] [CrossRef]
- Feng, F.; Gongal, V.M.R.; Zhang, C.; Ma, J.G.; Zhang, Q.J. Parametric modeling of microwave components using adjoint neural networks and pole-residue transfer functions with EM sensitivity analysis. IEEE Trans. Microw. Theory Tech. 2017, 65, 1955–1975. [Google Scholar] [CrossRef]
- Zhang, W.; Feng, F.; Gongal, V.M.R.; Zhang, J.; Yan, S.; Ma, J.; Zhang, Q.-J. Space Mapping Approach to Electromagnetic Centric Multiphysics Parametric Modeling of Microwave Components. IEEE Trans. Microw. Theory. Tech. 2018, 66, 3169–3185. [Google Scholar] [CrossRef]
- Feng, F.; Na, W.; Liu, W.; Yan, S.; Zhu, L.; Zhang, Q. Parallel gradient-based EM optimization for microwave components using adjoint-sensitivity-based neuro-transfer function surrogate. IEEE Trans. Microw. Theory Tech. 2020. [Google Scholar] [CrossRef]
- Zhang, C.; Feng, F.; Gongal-Reddy, V.-M.-R.; Zhang, Q.J.; Bandler, J.W. Cognition-driven formulation of space mapping for equal-ripple optimization of microwave filters. IEEE Trans. Microw. Theory Tech. 2015, 63, 2154–2165. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, C.; Feng, F.; Zhang, W.; Ma, J.; Zhang, Q. Polynomial Chaos-based approach to yield-driven EM optimization. IEEE Trans. Microw. Theory Tech. 2018, 66, 3186–3199. [Google Scholar] [CrossRef]
- Sen, P.; Woods, W.H.; Sarkar, S.; Pratap, R.J.; Dufrene, B.M.; Mukhopadhyay, R.; Lee, C.; Mina, E.F.; Laskar, J. Neural-network-based parasitic modeling and extraction verification for RF/millimeter-wave integrated circuit design. IEEE Trans. Microw. Theory Tech. 2006, 54, 2604–2614. [Google Scholar] [CrossRef]
- Root, D.E. Future device modeling trends. IEEE Microw. Mag. 2012, 13, 45–59. [Google Scholar] [CrossRef]
- Liu, W.; Na, W.; Zhu, L.; Zhang, Q.J. A review of neural network based techniques for microwave device modeling. In Proceedings of the IEEE MTT-S International Conference Numerical Electromagnetic and Multiphysics Modeling and Optimization (NEMO), Beijing, China, 27–29 July 2016; pp. 1–2. [Google Scholar]
- Zhao, Z.; Zhang, L.; Feng, F.; Zhang, W.; Zhang, Q. Space mapping technique using decomposed mappings for GaN HEMT modeling. IEEE Trans. Microw. Theory Tech. 2020, 68, 3318–3341. [Google Scholar] [CrossRef]
- Rizzoli, V.; Costanzo, A.; Masotti, D.; Lipparini, A.; Mastri, F. Computer-aided optimization of nonlinear microwave circuits with the aid of electromagnetic simulation. IEEE Trans. Microw. Theory Tech. 2004, 52, 362–377. [Google Scholar] [CrossRef]
- Xu, J.J.; Yagoub, M.C.E.; Ding, R.T.; Zhang, Q.J. Neural based dynamic modeling of nonlinear microwave circuits. IEEE Trans. Microw. Theory Tech. 2002, 59, 913–923. [Google Scholar]
- Liu, T.; Boumaiza, S.; Ghannouchi, F.M. Dynamic behavioral modeling of 3G power amplifier using real-valued time-delay neural networks. IEEE Trans. Microw. Theory Tech. 2004, 52, 1025–1033. [Google Scholar] [CrossRef]
- Cao, Y.; Zhang, Q.J. A New Training Approach for robust recurrent neural-network modeling of nonlinear circuits. IEEE Trans. Microw. Theory Tech. 2009, 57, 1539–1553. [Google Scholar] [CrossRef]
- Schreurs, D.; Droma, M.O.; Goacher, A.A.; Gadringer, M. RF Power Amplifier Behavioral Modeling; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Yan, S.; Zhang, C.; Zhang, Q.J. Recurrent neural network technique for behavioral modeling of power amplifier with memory effects. Int. J. RF Microw. Comput.-Aided Eng. 2015, 25, 289–298. [Google Scholar] [CrossRef]
- Mkadem, F.; Boumaiza, S. Physically inspired neural network model for RF power amplifier behavioral modeling and digital predistortion. IEEE Trans. Microw. Theory Tech. 2011, 52, 2274–2284. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, Q.J.; Liu, K.; Ma, Y.; Peng, B.; Yan, S. A Novel dynamic neuro-space mapping approach for nonlinear microwave device modeling. IEEE Microw. Wirel. Compon. Lett. 2016, 26, 131–133. [Google Scholar] [CrossRef]
- Xu, J.J.; Yagoub, M.C.E.; Ding, R.T.; Zhang, Q.J. Exact adjoint sensitivity for neural based microwave modeling and design. IEEE Trans. Microw. Theory Tech. 2003, 51, 226–237. [Google Scholar]
- Long, Y.S.; Guo, Y.X.; Zhong, Z. A 3-D table-based method for non-quasi-static microwave FET devices modeling. IEEE Trans. Microw. Theory Tech. 2012, 60, 3088–3095. [Google Scholar] [CrossRef]
- Homayouni, S.M.; Schreurs, D.M.M.-P.; Crupi, G.; Nauwelaers, B.K.J.C. Technology-independent non-quasi-static table-based nonlinear model generation. IEEE Trans. Microw. Theory Tech. 2009, 57, 2845–2852. [Google Scholar] [CrossRef]
- Zhang, L.; Rueda, H.; Kim, K.; Aaen, P. Non-quasi-static large-signal model for RF LDMOS power transistors. In Proceedings of the 2018 IEEE MTT-S International Microwave Symposium, Philadelphia, PA, USA, 10–15 June 2018. [Google Scholar]
- Crupi, G.; Schreurs, D.M.M.-P.; Caddemi, A.; Raffo, A.; Vannini, G. Investigation on the non-quasi-static effect implementation for millimeter-wave FET models. Int. J. RF Microw. Comput.-Aided Eng. 2010, 20, 87–93. [Google Scholar] [CrossRef]
- Advanced Design System (ADS), 2013.06; Keysight Technologies: Santa Rosa, CA, USA, 2013.
- Statz, H.; Newman, P.; Smith, I.W.; Pucel, R.A.; Haus, H.A. GaAs FET device and circuit simulation in SPICE. IEEE Trans. Electron. Device 1987, 34, 160–169. [Google Scholar] [CrossRef]
- Zhang, Q.J. NeuroModelerPlus_V2.1E; Carleton University: Ottawa, ON, Canada, 2008. [Google Scholar]
- Medici 2013. 12-0; Synopsys Inc.: Mountain View, CA, USA, 2013.
- Chang, C.Y.; Kai, F. GaAs High-Speed Devices: Physics, Technology, and Circuit Applications; Wiley: New York, NY, USA, 1994. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Vaule | Parameter Name | Vaule |
|---|---|---|---|
| Cgs (F) | 9.581 × 1013 | Lambda (1/V) | 0.05 |
| Cgd (F) | 7.598 × 1014 | Alpha (1/V) | 3.0 |
| Cds (F) | 1 × 1014 | B (none) | 3.0 |
| Crf (F) | 1 × 1014 | Rgd (Ohm) | 3 |
| Vto (V) | 0.5 | Rg (Ohm) | 1 |
| Beta (A/V2) | 0.310 | Rd (Ohm) | 5 |
| Vbi (V) | 0.9 | Rs (Ohm) | 2 |
| Data Type | Parameter Name | Training Data | Test Data | ||||
|---|---|---|---|---|---|---|---|
| Min | Max | Step | Min | Max | Step | ||
| DC data | Vg (V) | −0.6 | 0.4 | 0.2 | −0.5 | 0.3 | 0.2 |
| Vd (V) | 0 0.4 | 0.2 5 | 0.1 0.2 | 0.05 0.3 | 0.15 4.9 | 0.1 0.2 | |
| Small-signal data | Vg (V) | −0.6 | 0.4 | 0.2 | −0.5 | 0.3 | 0.2 |
| Vd (V) | 0 0.4 2.6 | 0.2 2.2 5 | 0.1 0.2 0.4 | 0.05 0.3 2.4 | 0.15 2.1 4.8 | 0.1 0.2 0.4 | |
| f (GHz) | 0.1 | 40.1 | 1 | 0.1 | 40.1 | 1 | |
| Large-signal data | Vg (V) | −0.2 | −0.1 | 0.1 | −0.15 | −0.15 | 0 |
| Vd (V) | 3.0 | 3.2 | 0.2 | 3.1 | 3.1 | 0 | |
| Pin (dBm) | −5 | 7 | 1 | −4.5 | 6.5 | 1 | |
| freq (GHz) | 1 | 6 | 1 | 1.5 | 5.5 | 1 | |
| Load (Ohm) | 40 | 60 | 10 | 45 | 55 | 10 | |
| Approach | Training | Test |
|---|---|---|
| MLP | 53.99% | 51.14% |
| TDNN (Nd = 1) | 6.16% | 6.22% |
| TDNN (Nd = 2) | 3.59% | 2.75% |
| TDNN (Nd = 3) | 2.95% | 2.11% |
| TDNN (Nd = 4) | 2.38% | 1.88% |
| Parameter Name | Value (um) | |
|---|---|---|
| Gate Length (um) | 0.2 | |
| Gate Width (um) | 100 | |
| Thickness (um) | AlGaAs Donor Layer | 0.025 |
| AlGaAs Spacer Layer | 0.01 | |
| InGaAs Channel Layer | 0.01 | |
| GaAs Substrate | 0.045 | |
| Doping Density (1/cm3) | AlGaAs Donor Layer | 1 × 1018 |
| InGaAs Channel Layer | 1 × 102 | |
| Source N+ | 2 × 1020 | |
| Drain N+ | 2 × 1020 | |
| Data Type | Parameter Name | Training Data | Test Data | ||||
|---|---|---|---|---|---|---|---|
| Min | Max | Step | Min | Max | Step | ||
| DC data | Vg (V) | −0.2 | 0.8 | 0.2 | −0.1 | 0.7 | 0.2 |
| Vd (V) | 0 | 6.2 | 0.1 | 0.05 | 6.15 | 0.1 | |
| Small-signal data | Vg (V) | −0.2 | 0.8 | 0.2 | −0.1 | 0.7 | 0.2 |
| Vd (V) | 0 0.4 2.6 | 0.2 2.2 6.2 | 0.1 0.2 0.4 | 0.05 0.3 2.4 | 0.15 2.1 6.0 | 0.1 0.2 0.4 | |
| f (GHz) | 0.1 | 40.1 | 1 | 0.1 | 40.1 | 1 | |
| Large-signal data | Pin (dBm) | −20 −3 | −5 9 | 5 2 | −20 −3 | −5 9 | 5 2 |
| freq (GHz) | 2 | 5 | 1 | 2.5 | 4.5 | 1 | |
| Approach | 30 Hidden Neurons | 40 Hidden Neurons | ||
|---|---|---|---|---|
| Training Error | Test Error | Training Error | Test Error | |
| MLP | 31.13% | 33.98% | 33.07% | 34.11% |
| TDNN (Nd = 1) | 6.41% | 6.58% | 6.24% | 6.48% |
| TDNN (Nd = 3) | 3.10% | 3.32% | 2.68% | 2.88% |
| TDNN (Nd = 5) | 2.44% | 2.51% | 2.16% | 2.24% |
| TDNN (Nd = 7) | 1.49% | 1.86% | 1.15% | 1.9% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Zhu, L.; Feng, F.; Zhang, W.; Zhang, Q.-J.; Lin, Q.; Liu, G. A Time Delay Neural Network Based Technique for Nonlinear Microwave Device Modeling. Micromachines 2020, 11, 831. https://doi.org/10.3390/mi11090831
Liu W, Zhu L, Feng F, Zhang W, Zhang Q-J, Lin Q, Liu G. A Time Delay Neural Network Based Technique for Nonlinear Microwave Device Modeling. Micromachines. 2020; 11(9):831. https://doi.org/10.3390/mi11090831
Chicago/Turabian StyleLiu, Wenyuan, Lin Zhu, Feng Feng, Wei Zhang, Qi-Jun Zhang, Qian Lin, and Gaohua Liu. 2020. "A Time Delay Neural Network Based Technique for Nonlinear Microwave Device Modeling" Micromachines 11, no. 9: 831. https://doi.org/10.3390/mi11090831
APA StyleLiu, W., Zhu, L., Feng, F., Zhang, W., Zhang, Q.-J., Lin, Q., & Liu, G. (2020). A Time Delay Neural Network Based Technique for Nonlinear Microwave Device Modeling. Micromachines, 11(9), 831. https://doi.org/10.3390/mi11090831