In-DRAM Cache Management for Low Latency and Low Power 3D-Stacked DRAMs


Abstract
:1. Introduction
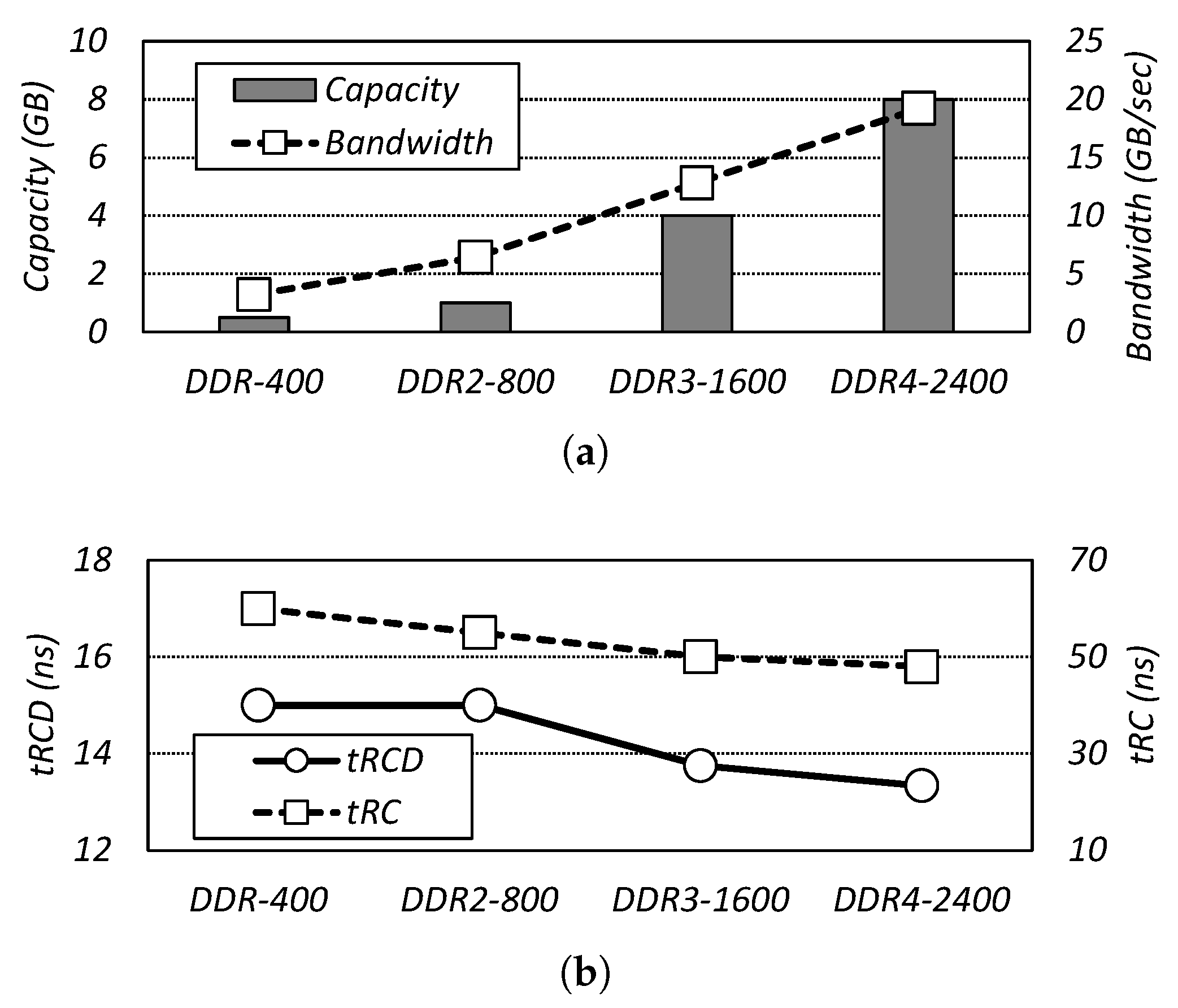
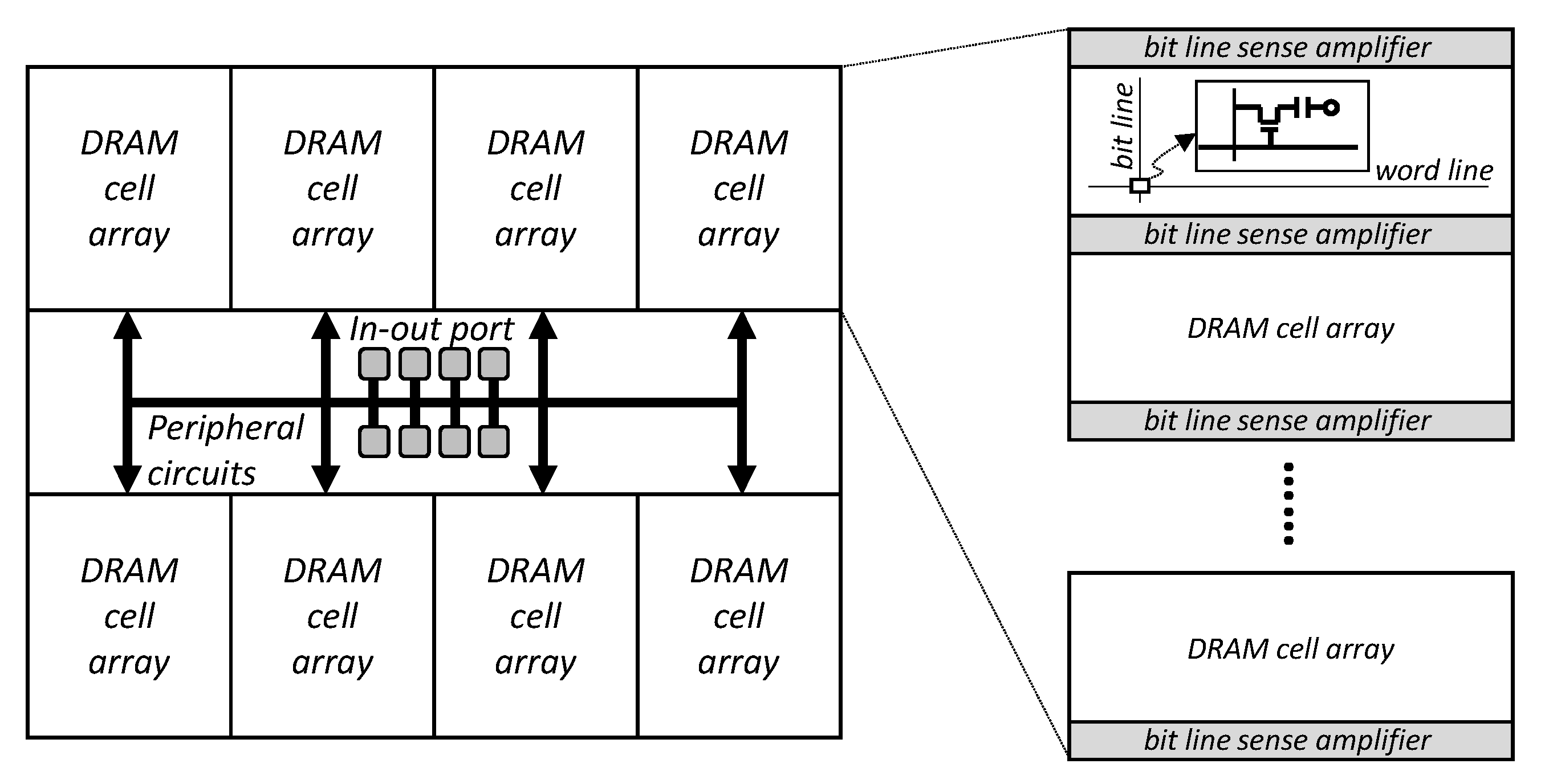
2. Background and In-Dynamic Random Access Memory (DRAM) Cache Architecture
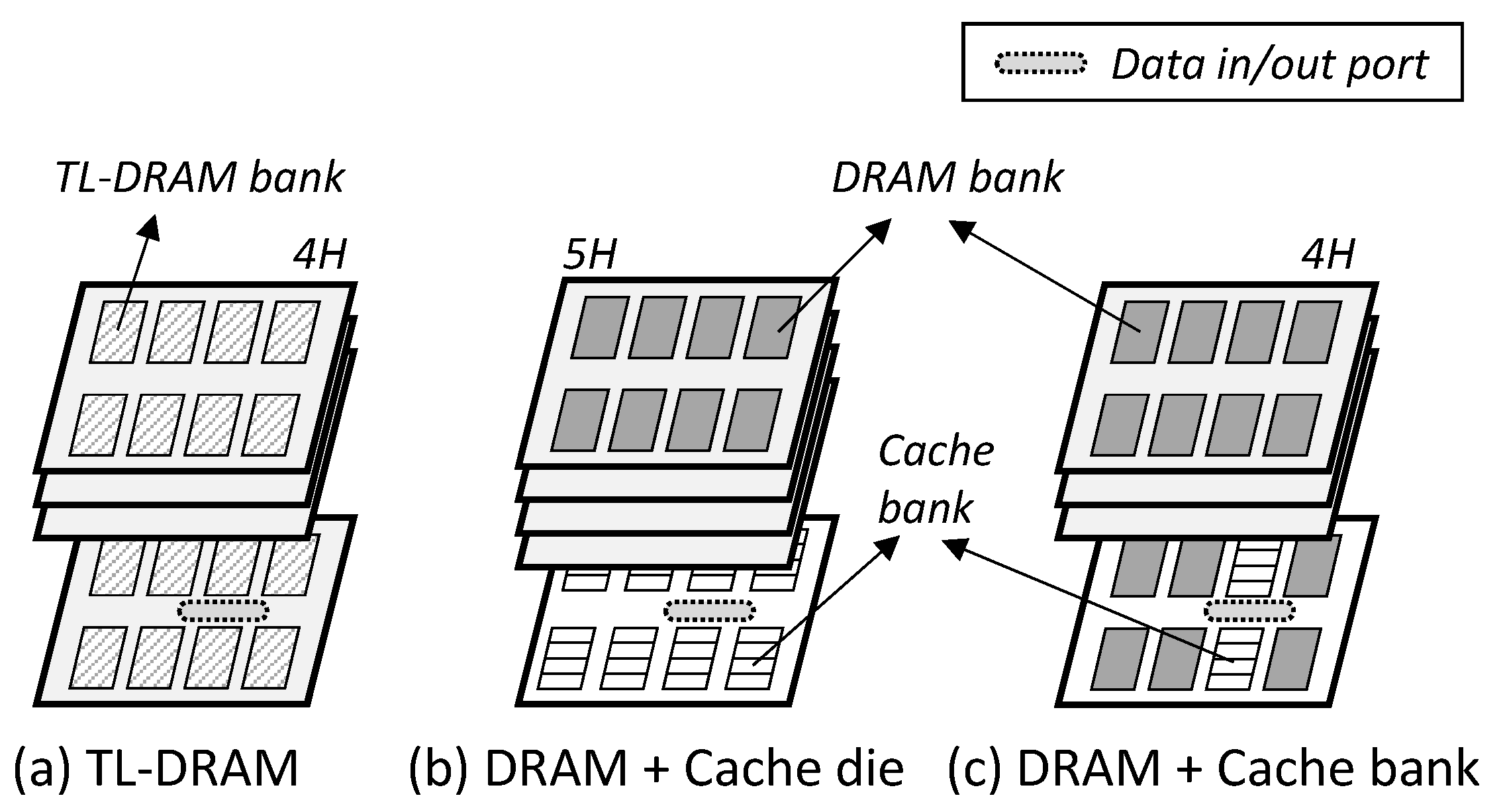
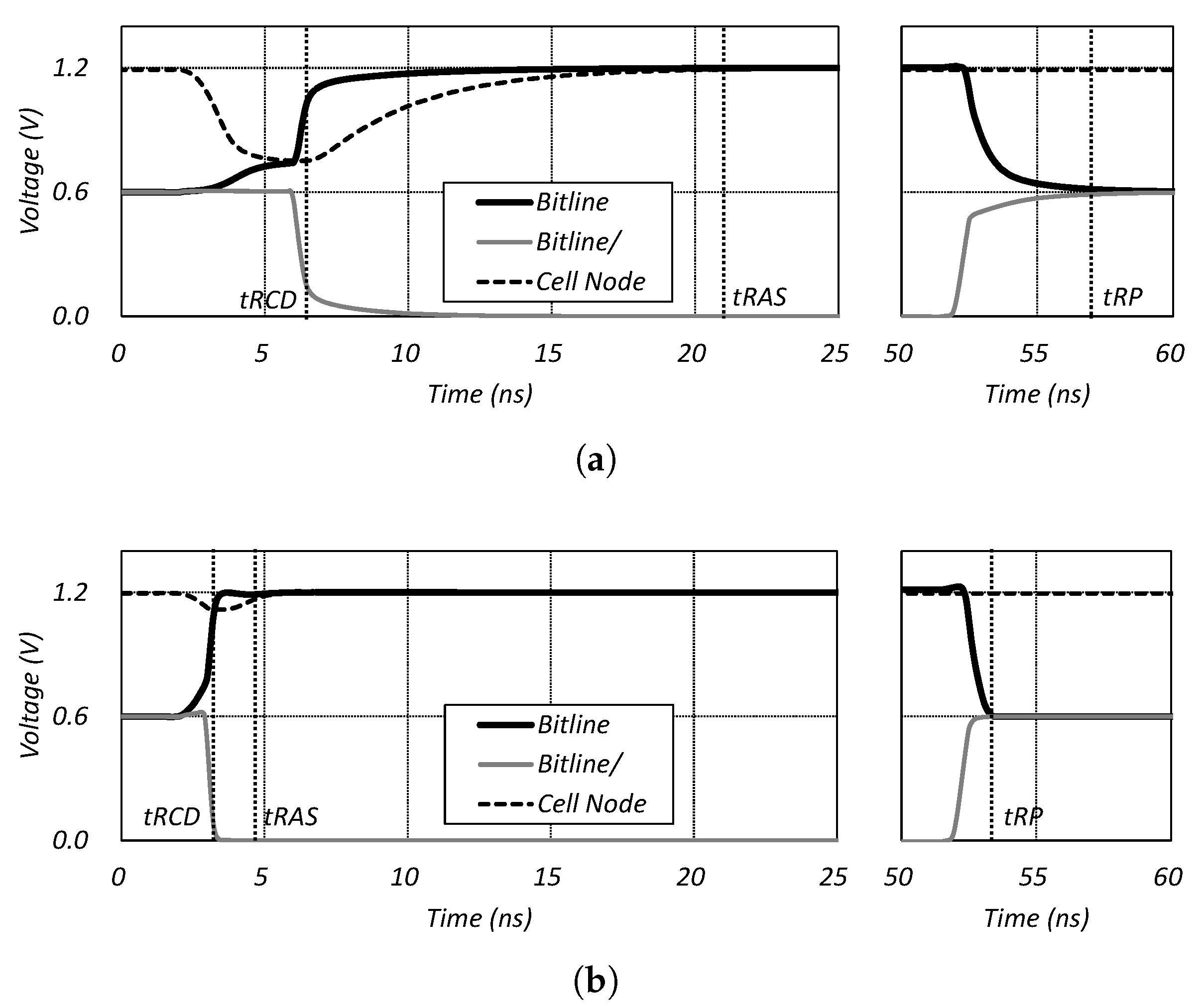
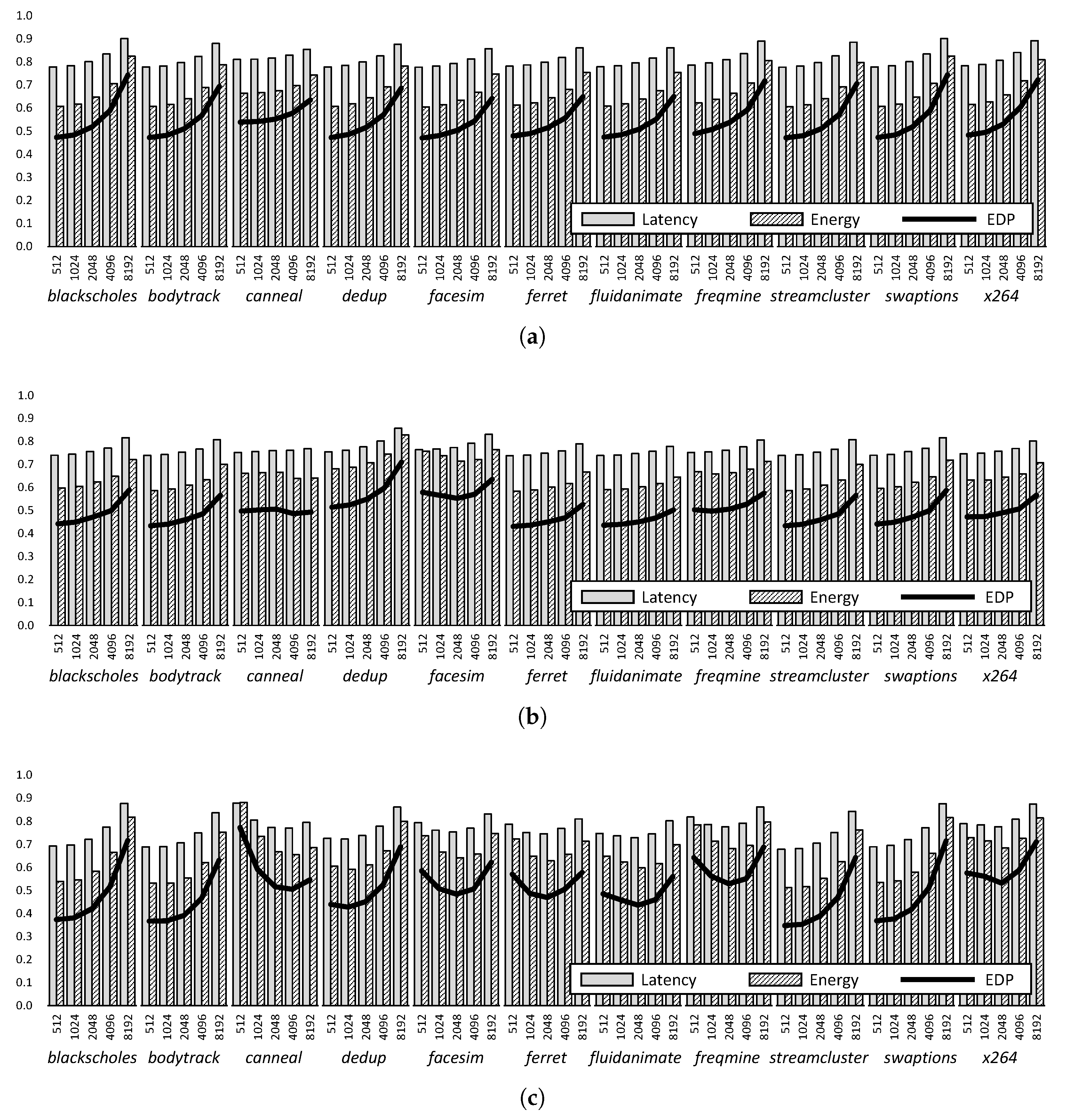
- TL-DRAM: This divides the bit line of the DRAM array into two segments and uses the long one as the DRAM memory, and the short one as the in-DRAM cache [19,21]. Here, the TL-DRAM exploits the characteristic that the short bit line improves the sensing and the pre-charge speed, and uses it as a cache memory. Figure 3a shows the TL-DRAM architecture, which is the same in terms of the overall DRAM structure. However, the DRAM array belonging to one bank is different from the conventional one.
- Cache-die: This utilizes a single die among the 3D-stacked dies as the cache (Figure 3b). The in-DRAM cache can be implemented as SRAM or DRAM, but only the DRAM is covered in this paper. This architecture has the advantage of being able to implement a significant amount of cache capacity, but it has the disadvantage of requiring a large area overhead.
- Cache-bank: This is similar to the CHARM structure [20]. Some DRAM banks are used as low-latency DRAM caches, and this paper calls them cache banks (Figure 3c). It has a smaller cache capacity than the cache die, but it can significantly reduce the latency because the cache banks are close to the input/output interfaces of the DRAM.
3. Exploration of in-DRAM Cache Management
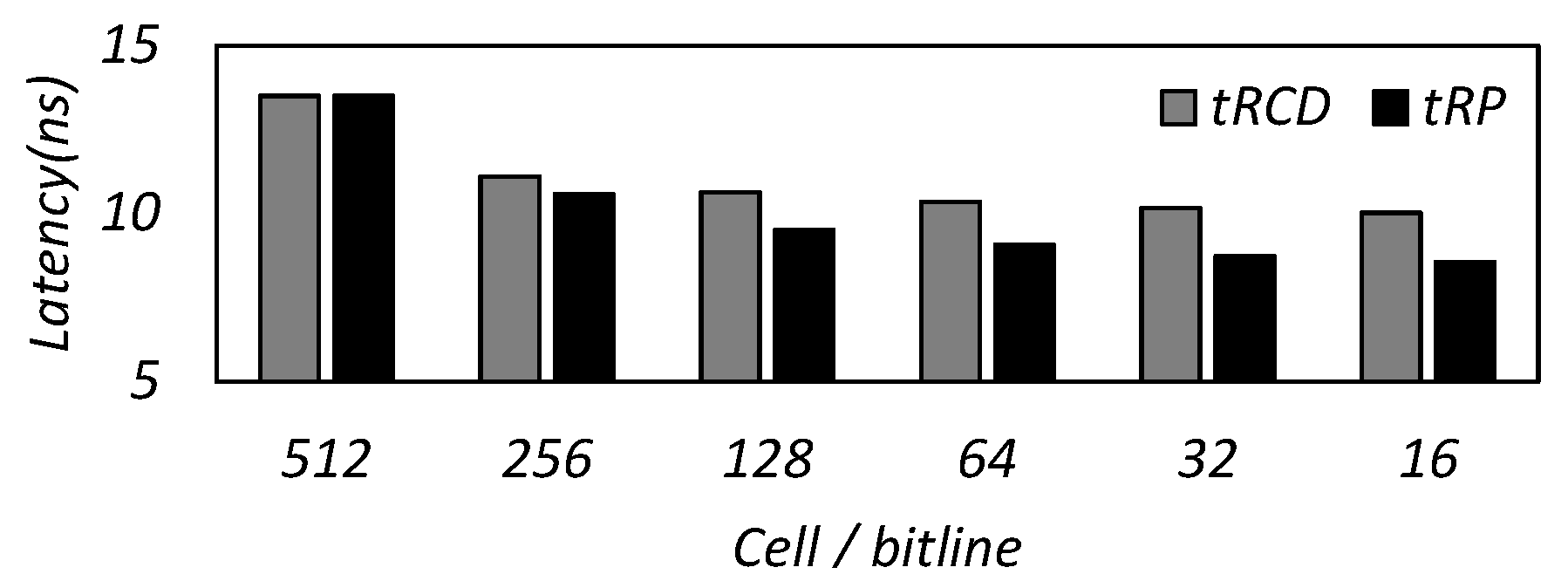
3.1. Trade-Off between Capacity and Latency
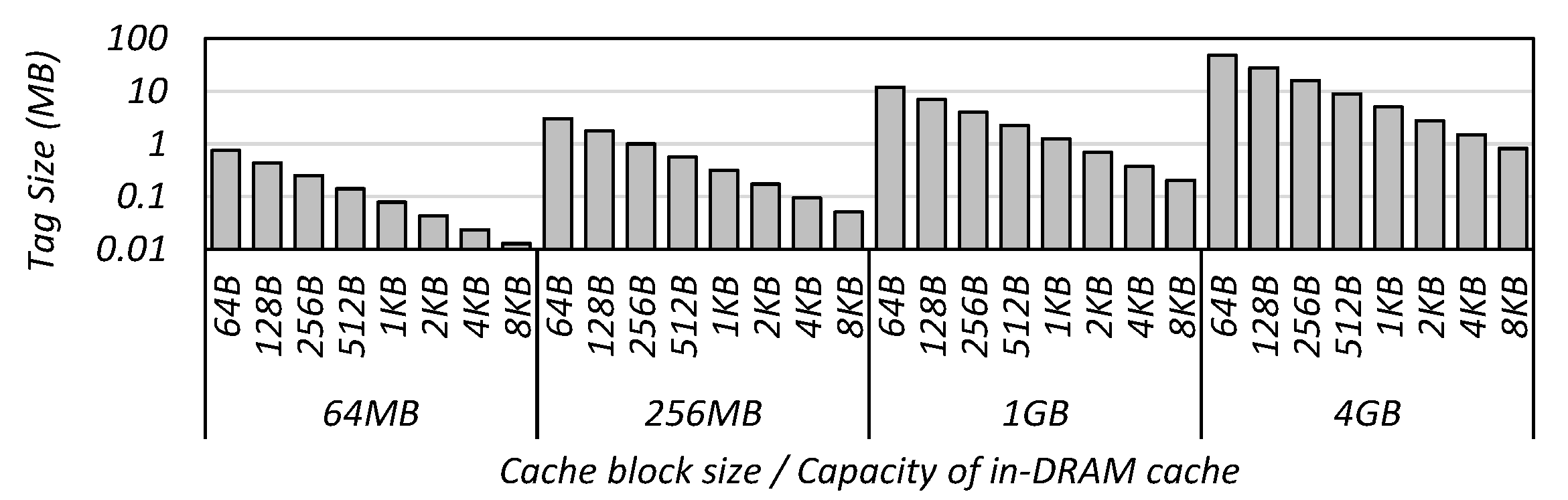
3.2. Trade-Off between Tag Size and Power Consumption
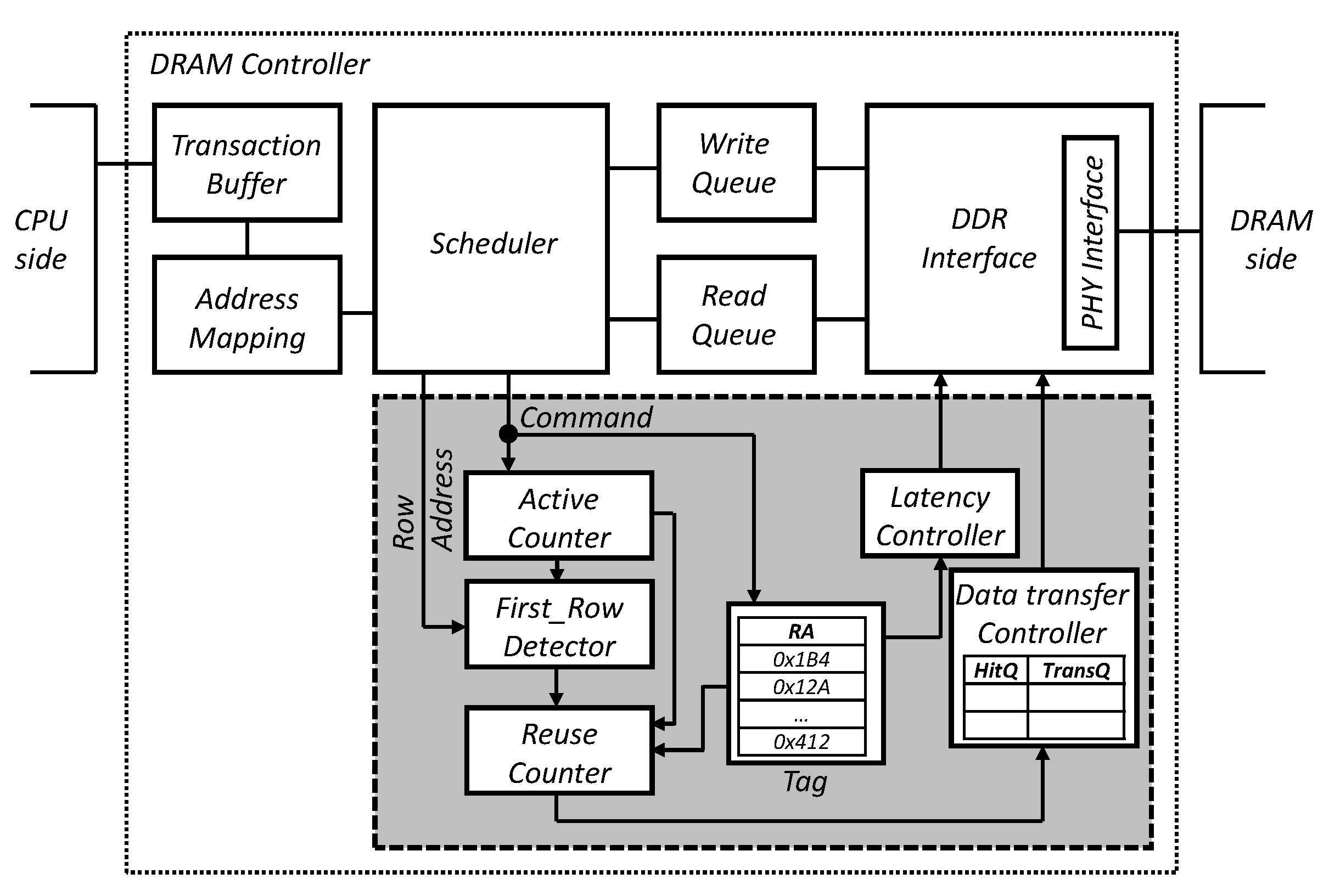
4. Proposed In-DRAM Cache Management Algorithms
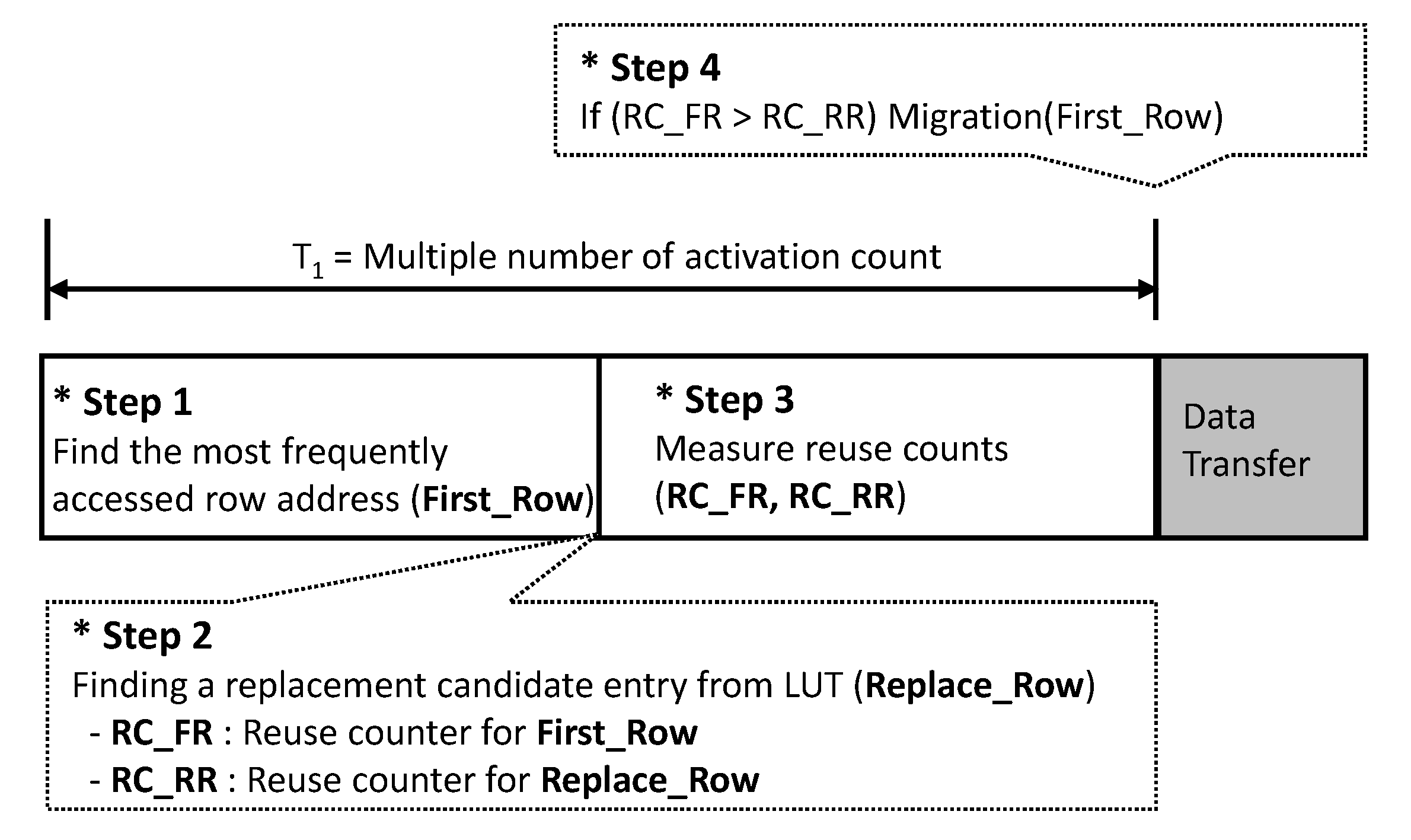
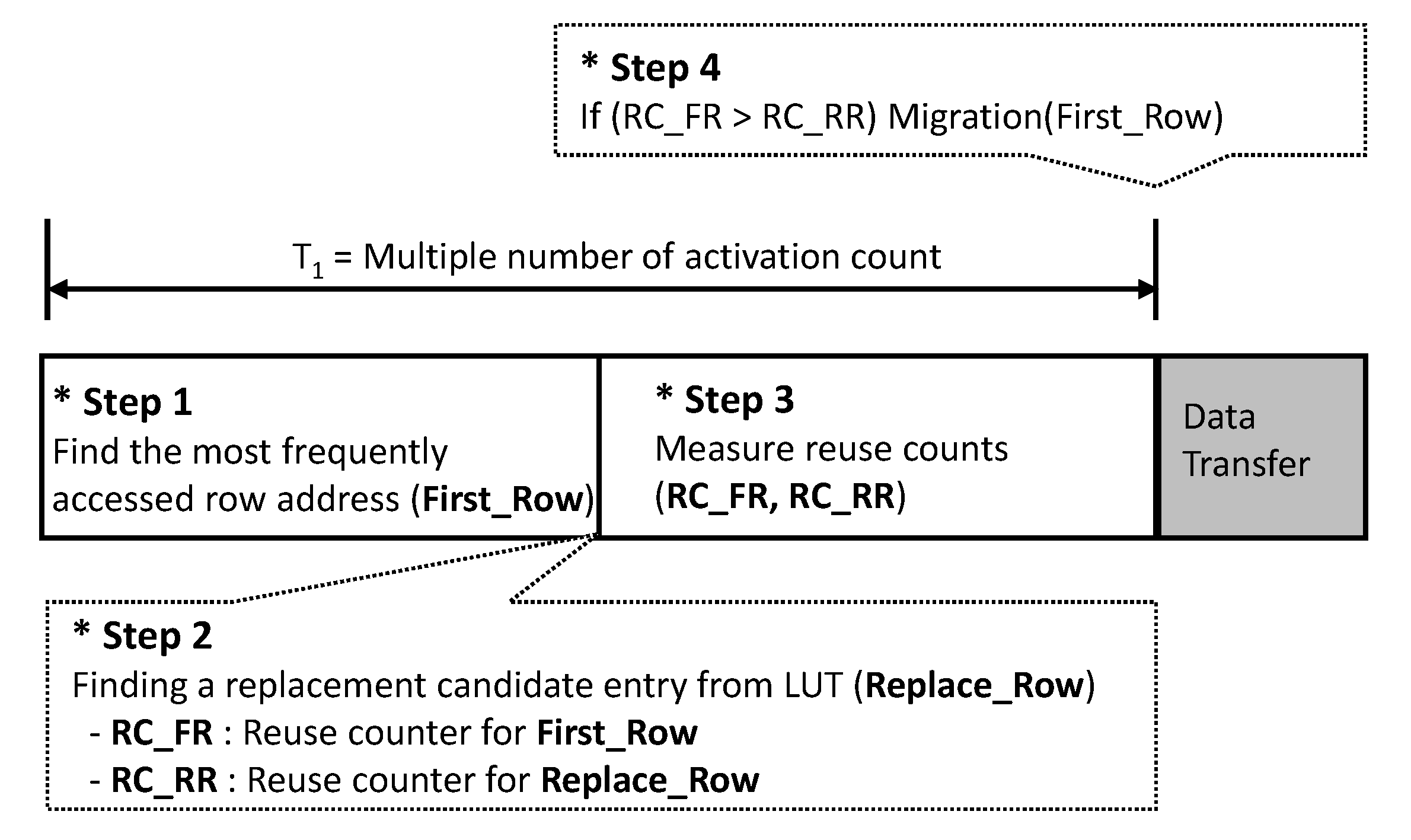
4.1. Critical Data Detection and Evaluation Scheme
- Step 1: The algorithm finds the most frequently accessed row address (First_Row).
- Step 2: The in-DRAM cache manager selects a candidate entry (Replace_Row) to be replaced in the tag, where the replacement policy can be the least recently used (LRU) or first-in first-out (FIFO) that are similar to the legacy replacement policy [1]. In this paper, we use the FIFO, which can minimize the time delay for the candidate selection.
- Step 3: It measures the reuse counts for the First_Row and Replace_Row, called RC_FR and RC_RR, respectively, to define the more valuable one in terms of reuse.
- Step 4: The manager compares RC_FR and RC_RR and starts the transfer if RC_FR is larger than RC_RR.
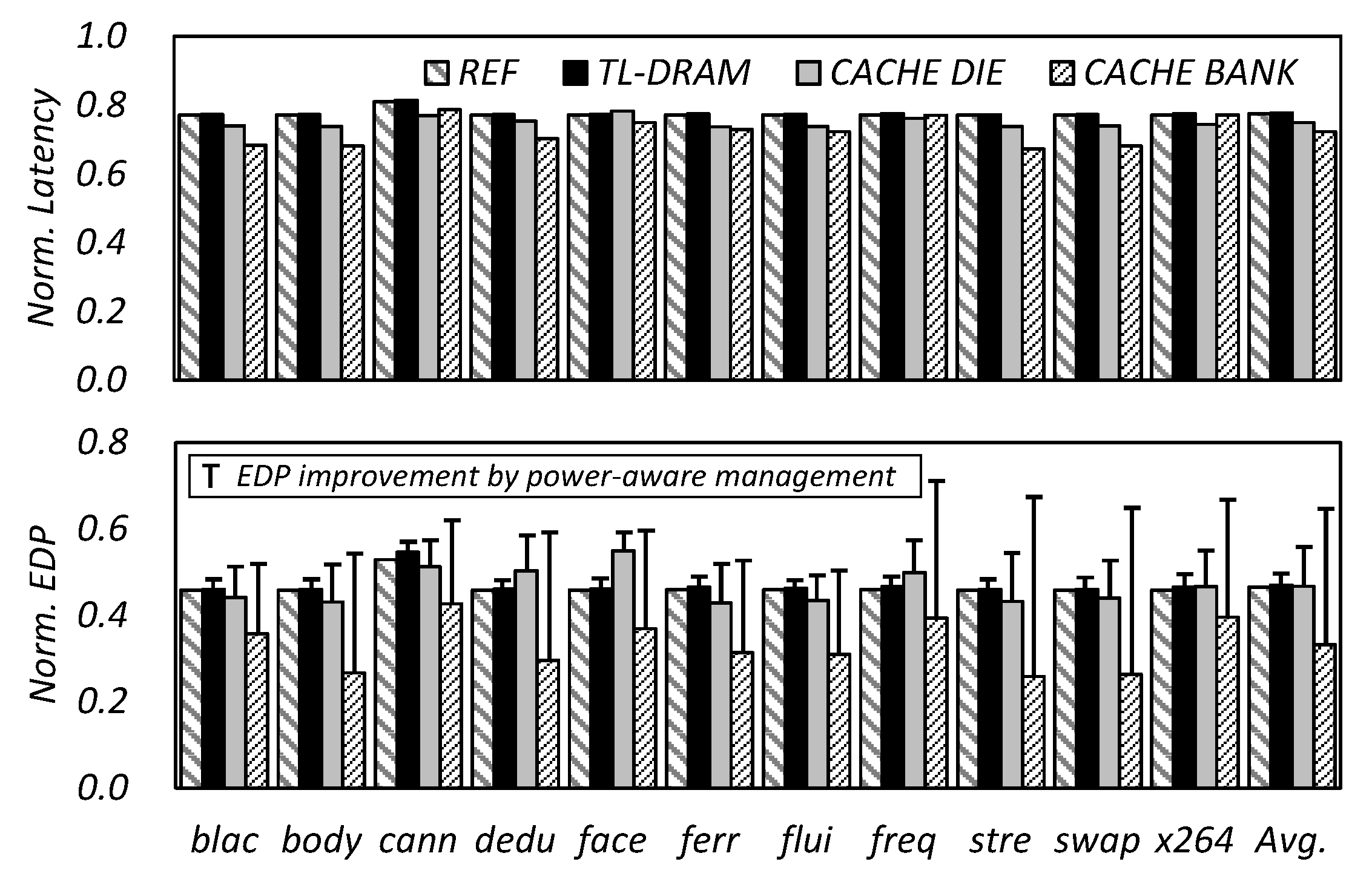
4.2. Power-Aware in-DRAM Cache Management Algorithm
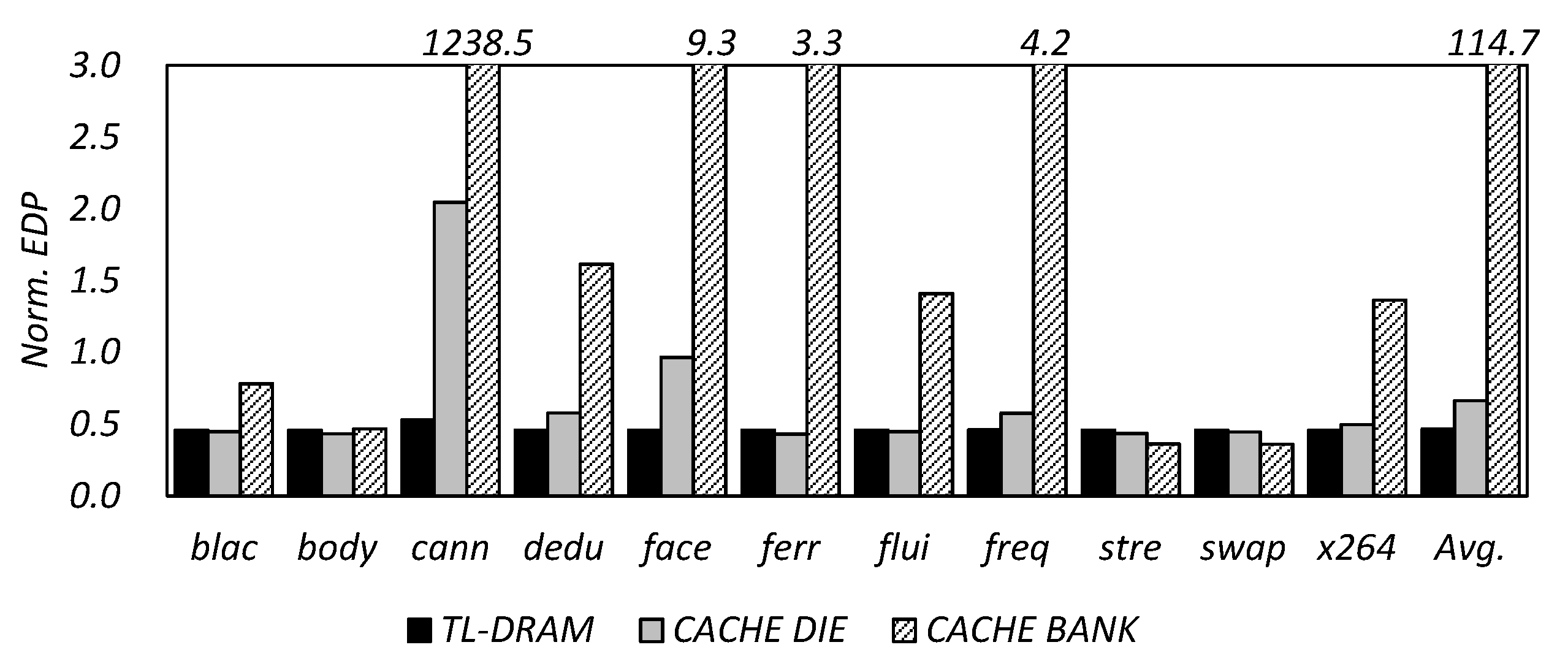
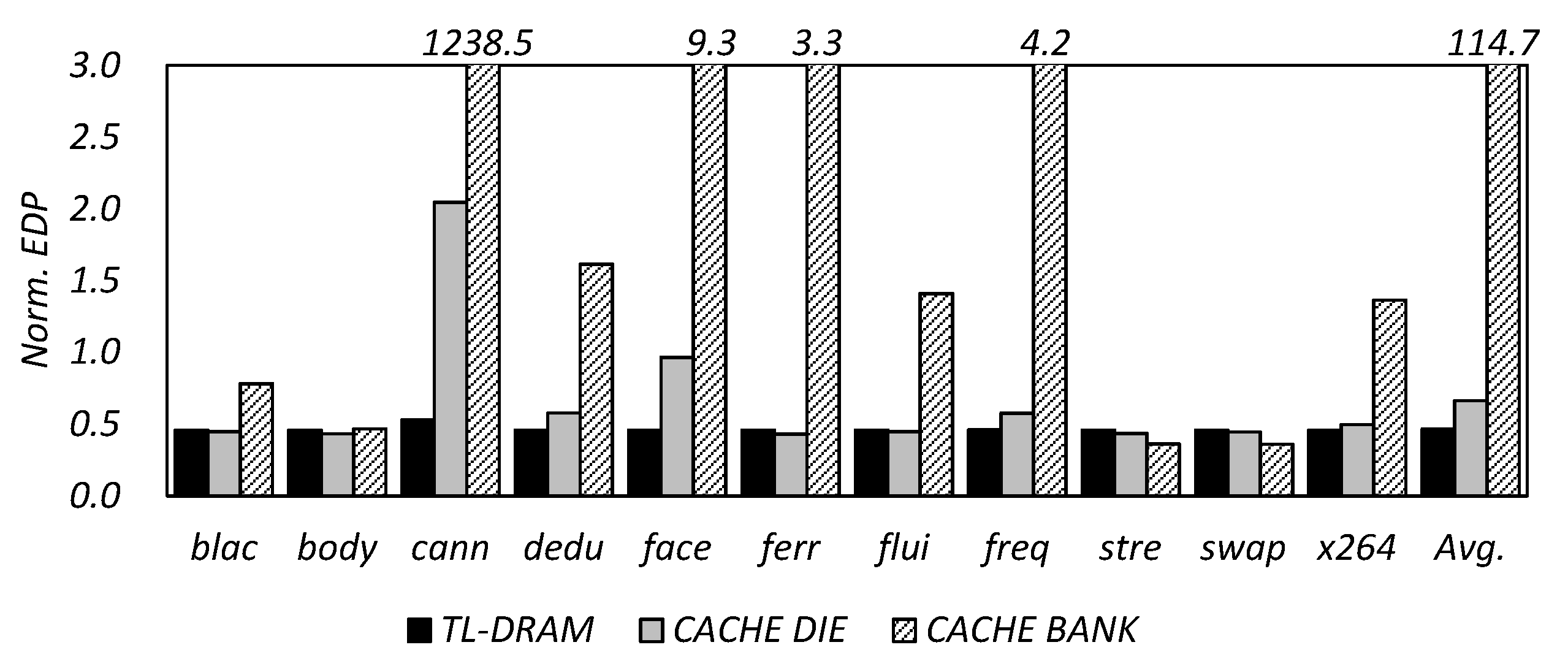
5. Experimental Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DRAM | dynamic random access memory |
| OLTP | on-line transaction processing |
| TSV | through silicon via |
| HBM | high-bandwidth memory |
| HMC | hybrid memory cube |
| SRAM | static random access memory |
| CDDE | critical data detection and evaluation |
| LRU | least recently used |
| FIFO | first-in first-out |
| EDP | energy delay product |
References
- Jacob, B.; Ng, S.; Wang, D. Memory Systems: Cache, DRAM, Disk; Morgan Kaufmann Publishers: Burlington, MA, USA, 2010. [Google Scholar]
- Wulf, W.A.; McKee, S.A. Hitting the Memory Wall: Implications of the Obvious. SIGARCH Comput. Archit. News 1995, 23, 20–24. [Google Scholar] [CrossRef]
- Wilkes, M.V. The Memory Gap and the Future of High Performance Memories. SIGARCH Comput. Archit. News 2001, 29, 2–7. [Google Scholar] [CrossRef]
- JEDEC. DDR SDRAM STANDARD; JEDEC: Arlington, VA, USA, 2008. [Google Scholar]
- JEDEC. DDR2 SDRAM STANDARD; JEDEC: Arlington, VA, USA, 2009. [Google Scholar]
- JEDEC. DDR3 SDRAM STANDARD; JEDEC: Arlington, VA, USA, 2012. [Google Scholar]
- JEDEC. DDR4 SDRAM STANDARD; JEDEC: Arlington, VA, USA, 2017. [Google Scholar]
- Clapp, R.; Dimitrov, M.; Kumar, K.; Viswanathan, V.; Willhalm, T. A Simple Model to Quantify the Impact of Memory Latency and Bandwidth on Performance. In Proceedings of the 2015 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, Portland, OR, USA, 15–19 June 2015; ACM: New York, NY, USA, 2015; pp. 471–472. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, G.; Ooi, B.C.; Tan, K.L.; Zhang, M. In-Memory Big Data Management and Processing: A Survey. IEEE Trans. Knowl. Data Eng. 2015, 27, 1920–1948. [Google Scholar] [CrossRef]
- Xie, Y.; Loh, G.H.; Black, B.; Bernstein, K. Design space exploration for 3D architectures. ACM J. Emerg. Technol. Comput. Syst. (JETC) 2006, 2, 65–103. [Google Scholar] [CrossRef]
- Kang, U.; Chung, H.J.; Heo, S.; Ahn, S.H.; Lee, H.; Cha, S.H.; Ahn, J.; Kwon, D.; Kim, J.H.; Lee, J.W.; et al. 8Gb 3D DDR3 DRAM using through-silicon-via technology. In Proceedings of the 2009 IEEE International Solid-State Circuits Conference—Digest of Technical Papers, San Francisco, CA, USA, 8–12 February 2009; pp. 130–131. [Google Scholar] [CrossRef]
- Oh, R.; Lee, B.; Shin, S.W.; Bae, W.; Choi, H.; Song, I.; Lee, Y.S.; Choi, J.H.; Kim, C.W.; Jang, S.J.; et al. Design technologies for a 1.2V 2.4Gb/s/pin high capacity DDR4 SDRAM with TSVs. In Proceedings of the 2014 Symposium on VLSI Circuits Digest of Technical Papers, Honolulu, HI, USA, 10–13 June 2014; pp. 1–2. [Google Scholar] [CrossRef]
- JEDEC. HIGH BANDWIDTH MEMORY (HBM) DRAM; JEDEC: Arlington, VA, USA, 2012. [Google Scholar]
- Pawlowski, J.T. Hybrid Memory Cube (HMC). In Proceedings of the 2011 IEEE Hot Chips 23 Symposium (HCS), Stanford, CA, USA, 17–19 August 2011. [Google Scholar]
- Zhang, Z.; Zhu, Z.; Zhang, X. Cached DRAM for ILP processor memory access latency reduction. IEEE Micro 2001, 21, 22–32. [Google Scholar] [CrossRef]
- Kimuta, T.; Takeda, K.; Aimoto, Y.; Nakamura, N.; Iwasaki, T.; Nakazawa, Y.; Toyoshima, H.; Hamada, M.; Togo, M.; Nobusawa, H.; et al. 64 Mb 6.8 ns random ROW access DRAM macro for ASICs. In Proceedings of the 1999 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 17 February 1999; pp. 416–417. [Google Scholar] [CrossRef]
- Micron Technology. RLDRAM 2 and 3 Specifications; Micron Technology: Boise, ID, USA, 2004. [Google Scholar]
- Sharroush, S.M.; Abdalla, Y.S.; Dessouki, A.A.; El-Badawy, E.S.A. Dynamic random-access memories without sense amplifiers. e i Elektrotechnik und Informationstechnik 2012, 129, 88–101. [Google Scholar] [CrossRef]
- Lee, D.; Kim, Y.; Seshadri, V.; Liu, J.; Subramanian, L.; Mutlu, O. Tiered-latency DRAM: A low latency and low cost DRAM architecture. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 615–626. [Google Scholar] [CrossRef]
- Son, Y.H.; Seongil, O.; Ro, Y.; Lee, J.W.; Ahn, J.H. Reducing Memory Access Latency with Asymmetric DRAM Bank Organizations. In Proceedings of the 40th Annual International Symposium on Computer Architecture, Tel-Aviv, Israel, 23–27 June 2013; ACM: New York, NY, USA, 2013; pp. 380–391. [Google Scholar] [CrossRef]
- Kim, Y.; Seshadri, V.; Lee, D.; Liu, J.; Mutlu, O. A case for exploiting subarray-level parallelism (SALP) in DRAM. In Proceedings of the 2012 39th Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 9–13 June 2012; pp. 368–379. [Google Scholar] [CrossRef]
- Muralimanohar, N.; Balasubramonian, R.; Jouppi, N.P. CACTI 6.0: A Tool to Model Large Caches. In Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture, Chicago, IL, USA, 1–5 December 2007. [Google Scholar]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The Gem5 Simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Rosenfeld, P.; Cooper-Balis, E.; Jacob, B. DRAMSim2: A Cycle Accurate Memory System Simulator. IEEE Comput. Archit. Lett. 2011, 10, 16–19. [Google Scholar] [CrossRef]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The PARSEC benchmark suite: Characterization and architectural implications. In Proceedings of the 2008 International Conference on Parallel Architectures and Compilation Techniques (PACT), Toronto, ON, Canada, 25–29 October 2008; pp. 72–81. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU Frequency | 2 GHz |
| DRAM Types | DDR3 1600 (800 MHz) |
| DRAM Capacity | 2 GB |
| in-DRAM Cache Capacity | TL-DRAM: 256 MB Cache-die: 512 MB Cache-bank: 128 MB |
| Cache Block Size | 256 KB |
| Tag Size (DRAM controller) | TL-DRAM: 2.25 KB Cache-die: 4.5 KB Cache-bank: 1.125 KB |
| Row Buffer Policy | Adaptive Open Page |
| DRAM cells per a bit line | 512 (DRAM) 64 (in-DRAM cache) |
| DRAM cells per a word line | 1024 |
| Refresh Rate | 64 ms |
| Bit line array structure | Open bit-line |
| Transfer time per a row | 128 * tCCD (5 ns) = 640 ns |
| Paramter | Symbol | Normal DRAM | in-DRAM Cache |
|---|---|---|---|
| Clock cycle | tCK | 1.25 ns | 1.25 ns |
| ACT to internal RD or WR delay | tRCD | 13.75 ns | 8.75 ns |
| PRE command period | tRP | 13.75 ns | 8.75 ns |
| ACT-to-PRE command period | tRAS | 35.0 ns | 15.0 ns |
| ACT-to-ACT command period | tRC | 48.75 ns | 23.75 ns |
| Internal RD command to data | tAA | 13.75 ns | 8.75 ns |
| Write recovery time | tWR | 15.0 ns | 10.0 ns |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.H.; Chung, E.-Y. In-DRAM Cache Management for Low Latency and Low Power 3D-Stacked DRAMs. Micromachines 2019, 10, 124. https://doi.org/10.3390/mi10020124
Shin HH, Chung E-Y. In-DRAM Cache Management for Low Latency and Low Power 3D-Stacked DRAMs. Micromachines. 2019; 10(2):124. https://doi.org/10.3390/mi10020124
Chicago/Turabian StyleShin, Ho Hyun, and Eui-Young Chung. 2019. "In-DRAM Cache Management for Low Latency and Low Power 3D-Stacked DRAMs" Micromachines 10, no. 2: 124. https://doi.org/10.3390/mi10020124
APA StyleShin, H. H., & Chung, E.-Y. (2019). In-DRAM Cache Management for Low Latency and Low Power 3D-Stacked DRAMs. Micromachines, 10(2), 124. https://doi.org/10.3390/mi10020124