
A Lightweight Hybrid Model with Location-Preserving ViT for Efficient Food Recognition

 ,
,  ,
,
Abstract
1. Introduction
- A ViT module LP–ViT (Location-Preserving Vision Transformer) Block that effectively extracts global features of food images is designed and implemented. LP–ViT directly obtains the correlation between all pixels while maintaining the original spatial structure of the image through a series of reversible operations, thereby achieving more efficient fusion with the local features extracted by CNN.
- The HBlock (Hybrid Block) based on the series structure of LP–ViT block and CNN is designed and used as the backbone to establish a neural network Efficient Hybrid Food Recognition Net (EHFR–Net) that effectively recognizes food images.
- In view of the characteristics of the LP–ViT block, which starts to extract global features at the shallow layer of the network, an adapted neural network hierarchical layout structure is designed to effectively reduce the number of parameters and calculations and further achieve lightweight.
- We conduct extensive experiments on three open-source food image recognition datasets. Results demonstrate the effectiveness of our method, surpassing state-of-the-art CNN-based, ViT-based, and hybrid lightweight models with simple training recipes.
2. Related Works
2.1. Lightweight CNNs, ViTs, and Hybrid Models
2.2. Lightweight Food Recognition
3. Materials and Methods
3.1. Datasets and Training Settings
3.2. Overview of EHFR–Net
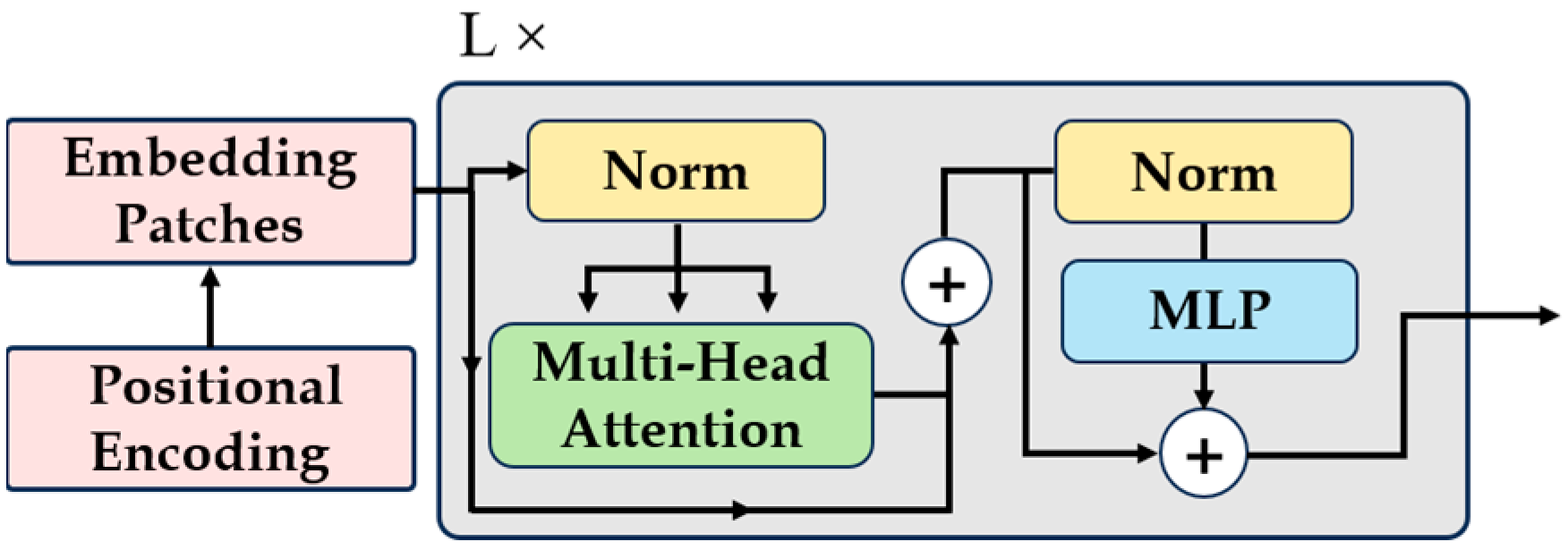
3.3. LP–ViT
3.4. HBlock and Overall Network Architecture
3.4.1. HBlock
3.4.2. Overall Structure of EHFR–Net
4. Results
4.1. Results on ETHZ Food–101
4.2. Results on Vireo Food–172
4.3. Results on UEC Food256
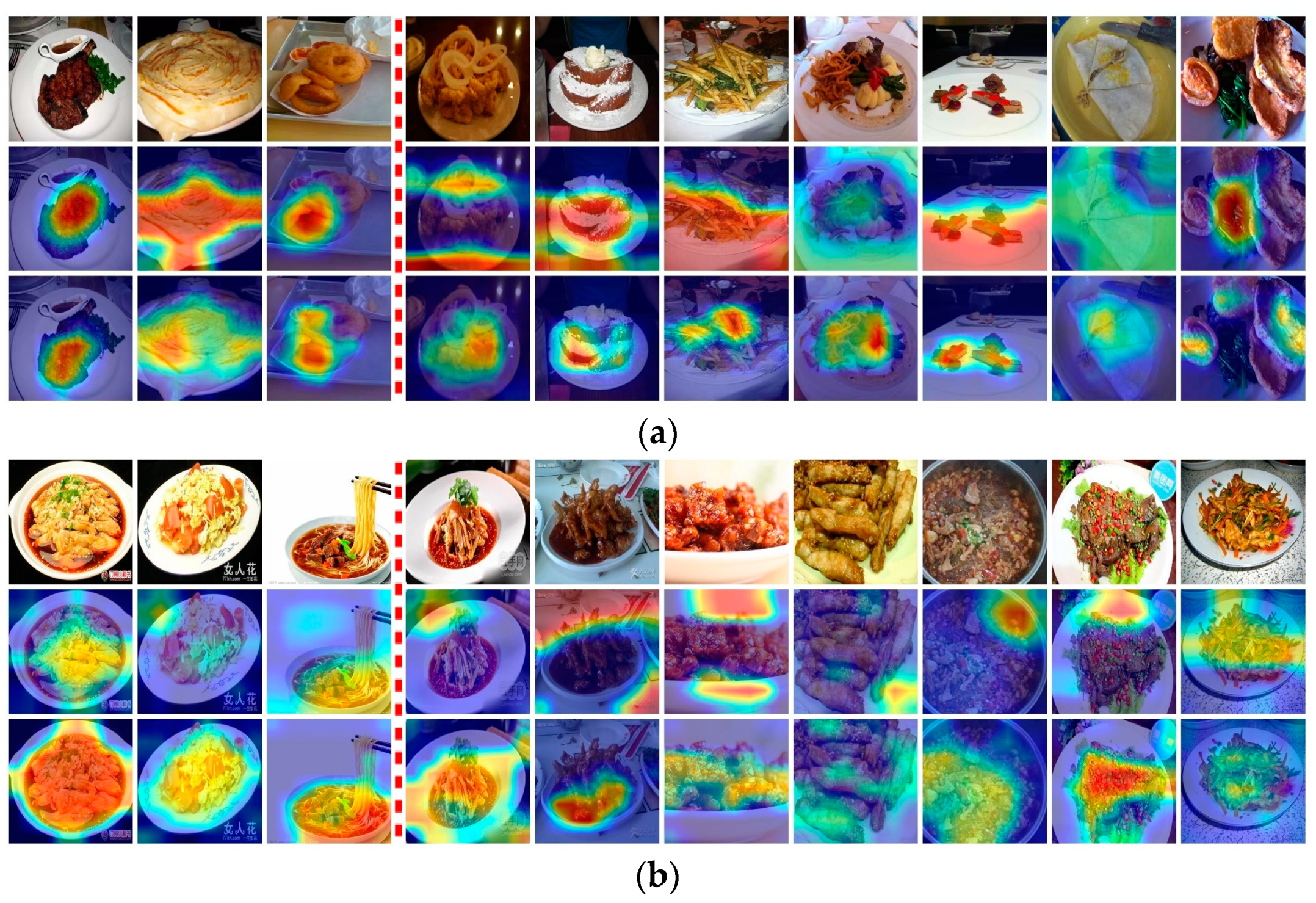
4.4. Qualitative Analysis and Visualization
4.5. Ablation Study
- Effectiveness of LP–ViT. We first present an ablation study to verify the efficiency of the proposed LP–ViT design by replacing the LP-ViT block with the original Multi-Head Attention (MHA) block. Compared with the ViT model using the ordinary MHA, the EHFR–Net using LP–ViT achieved the highest Top-1 accuracy with significantly reduced calculation and fewer parameters: 90.67% versus 88.80% (Food–101), 91.38% versus 89.66% (Food–172), 71.30% versus 69.28% (Food256). The computational effort is only about one-sixth that of the MHA. This shows that LP–ViT can extract global features from food images more efficiently, thereby improving the accuracy and efficiency of the model.
- Effectiveness of HBlock integrated with CNN and LP–ViT. We designed a module HBlock that combines the CNN and ViT in series as the basic module of the model. Compared with models that only use CNN and models that only use ViT, EHFR–Net’s Top-1 recognition rate has significant advantages: 90.67% versus 88.37%, 87.81% (Food–101), 91.38% versus 90.05%, 89.86% (Food–172), 71.30% versus 68.27%, 68.19% (Food256). The results show that the fusion CNN and ViT strategy designed by HBlock based on the characteristics of food images can effectively extract local and global features to achieve better recognition results.
- Effectiveness of adjusted network architecture. Based on the characteristics of the food-image recognition task, we designed a new architecture that is different from the traditional hybrid model network structure. This structure allows our model to achieve higher accuracy while further achieving lightweight. Compared with networks using the same modules but traditional structures, EHFR–Net achieves higher accuracy in a smaller size: (2.82 M, 90.67%) versus (4.52 M, 87.95%) (Food–101), (2.84 M, 91.38%) versus (4.55 M, 89.36%) (Food–172), (2.87 M, 71.30%) versus (4.57 M, 67.26%) (Food256).
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Min, W.; Jiang, S.; Liu, L.; Rui, Y.; Jain, R.C. A Survey on Food Computing. ACM Comput. Surv. 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Allegra, D.; Battiato, S.; Ortis, A.; Urso, S.; Polosa, R. A review on food recognition technology for health applications. Health Psychol. Res. 2020, 8, 172–187. [Google Scholar] [CrossRef] [PubMed]
- Rostami, A.; Nagesh, N.; Rahmani, A.; Jain, R.C. World Food Atlas for Food Navigation. In Proceedings of the 7th International Workshop on Multimedia Assisted Dietary Management on Multimedia Assisted Dietary Management, ACM, Lisbon, Portugal, 10 October 2022; pp. 39–47. [Google Scholar]
- Rostami, A.; Pandey, V.; Nag, N.; Wang, V.; Jain, R.C. Personal Food Model. In Proceedings of the MM ’20: The 28th ACM International Conference on Multimedia, ACM, Virtual Event, 12–16 October 2020; pp. 4416–4424. [Google Scholar]
- Ishino, A.; Yamakata, Y.; Karasawa, H.; Aizawa, K. RecipeLog: Recipe Authoring App for Accurate Food Recording. In Proceedings of the MM’21: The 29th ACM Multimedia Conference, ACM, Virtual Event, 20–24 October 2021; pp. 2798–2800. [Google Scholar]
- Wang, W.; Min, W.; Li, T.; Dong, X.; Li, H.; Jiang, S. A review on vision-based analysis for automatic dietary assessment. Trends Food Sci. Technol. 2022, 122, 223–237. [Google Scholar] [CrossRef]
- Vasiloglou, M.F.; Marcano, I.; Lizama, S.; Papathanail, I.; Spanakis, E.K.; Mougiakakou, S. Multimedia data-based mobile applications for dietary assessment. J. Diabetes Sci. Technol. 2023, 17, 1056–1065. [Google Scholar] [CrossRef] [PubMed]
- Yamakata, Y.; Ishino, A.; Sunto, A.; Amano, S.; Aizawa, K. Recipe-oriented Food Logging for Nutritional Management. In Proceedings of the MM’22: The 30th ACM International Conference on Multimedia, ACM, Lisbon, Portugal, 10–14 October 2022; pp. 6898–6904. [Google Scholar]
- Nakamoto, K.; Amano, S.; Karasawa, H.; Yamakata, Y.; Aizawa, K. Prediction of Mental State from Food Images. In Proceedings of the 1st International Workshop on Multimedia for Cooking, Eating, and related APPlications, Lisbon, Portugal, 10 October 2022; pp. 21–28. [Google Scholar]
- Kawano, Y.; Yanai, K. FoodCam: A real-time food recognition system on a smartphone. Multim. Tools Appl. 2015, 74, 5263–5287. [Google Scholar] [CrossRef]
- Ródenas, J.; Nagarajan, B.; Bolaños, M.; Radeva, P. Learning Multi-Subset of Classes for Fine-Grained Food Recognition. In Proceedings of the 7th International Workshop on Multimedia Assisted Dietary Management, Lisbon, Portugal, 10 October 2022; pp. 17–26. [Google Scholar]
- Martinel, N.; Foresti, G.L.; Micheloni, C. Wide-Slice Residual Networks for Food Recognition. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; IEEE Computer Society: New York, NY, USA; pp. 567–576. [Google Scholar]
- Jiang, S.; Min, W.; Liu, L.; Luo, Z. Multi-Scale Multi-View Deep Feature Aggregation for Food Recognition. IEEE Trans. Image Process. 2020, 29, 265–276. [Google Scholar] [CrossRef]
- Kawano, Y.; Yanai, K. Real-Time Mobile Food Recognition System. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR Workshops, Portland, OR, USA, 23–28 June 2013; IEEE Computer Society: New York, NY, USA, 2013; pp. 1–7. [Google Scholar]
- Pouladzadeh, P.; Shirmohammadi, S. Mobile Multi-Food Recognition Using Deep Learning. ACM Trans. Multim. Comput. Commun. Appl. 2017, 13, 36:1–36:21. [Google Scholar] [CrossRef]
- Tan, R.Z.; Chew, X.; Khaw, K.W. Neural architecture search for lightweight neural network in food recognition. Mathematics 2021, 9, 1245. [Google Scholar] [CrossRef]
- Sheng, G.; Sun, S.; Liu, C.; Yang, Y. Food recognition via an efficient neural network with transformer grouping. Int. J. Intell. Syst. 2022, 37, 11465–11481. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE Computer Society: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision-ECCV-15th European Conference, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 11218, pp. 122–138. [Google Scholar]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. Espnetv2: A light-weight, power efficient, and general purpose convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–17 June 2019; pp. 9190–9200. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML, PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–23 June 2018; Computer Vision Foundation/IEEE Computer Society: New York, NY, USA, 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–23 June 2018; Computer Vision Foundation/IEEE Computer Society: New York, NY, USA, 2018; pp. 7132–7141. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR, Virtual Event, Austria, 3–7 May 2021; Available online: https://openreview.net (accessed on 23 June 2021).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. Efficientformer: Vision transformers at mobilenet speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar]
- Huang, T.; Huang, L.; You, S.; Wang, F.; Qian, C.; Xu, C. LightViT: Towards Light-Weight Convolution-Free Vision Transformers. arXiv 2022, arXiv:2207.05557. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Vancouver, BC, Canada, 20–22 June 2023; pp. 14420–14430. [Google Scholar]
- Zhang, J.; Peng, H.; Wu, K.; Liu, M.; Xiao, B.; Fu, J.; Yuan, L. MiniViT: Compressing Vision Transformers with Weight Multiplexing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 12135–12144. [Google Scholar]
- Wu, K.; Zhang, J.; Peng, H.; Liu, M.; Xiao, B.; Fu, J.; Yuan, L. Tinyvit: Fast pretraining distillation for small vision transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 68–85. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-Former: Bridging MobileNet and Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 5260–5269. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. CMT: Convolutional Neural Networks Meet Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 12165–12175. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV, Montreal, BC, Canada, 10–17 October; IEEE: New York, NY, USA, 2021; pp. 22–31. [Google Scholar]
- Srinivas, A.; Lin, T.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Nashville, TN, USA, 20–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 16519–16529. [Google Scholar]
- Li, J.; Xia, X.; Li, W.; Li, H.; Wang, X.; Xiao, X.; Wang, R.; Zheng, M.; Pan, X. Next-vit: Next generation vision transformer for efficient deployment in realistic industrial scenarios. arXiv 2022, arXiv:2207.05501. [Google Scholar]
- Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Tzimiropoulos, G.; Martinez, B. Edgevits: Competing light-weight cnns on mobile devices with vision transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 294–311. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. In Proceedings of the Tenth International Conference on Learning Representations, ICLR, Virtual Event, 25–29 April 2022; Available online: https://openreview.net (accessed on 23 June 2021).
- Mehta, S.; Rastegari, M. Separable Self-attention for Mobile Vision Transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar]
- Yang, S.; Chen, M.; Pomerleau, D.; Sukthankar, R. Food recognition using statistics of pairwise local features. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR, San Francisco, CA, USA, 13–18 June 2010; IEEE Computer Society: New York, NY, USA, 2010; pp. 2249–2256. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Gool, L.V. Food-101-Mining Discriminative Components with Random Forests. In Proceedings of the Computer Vision-ECCV 2014–13th European Conference, Zurich, Switzerland, 6–12 September 2014; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2014; Volume 8694, pp. 446–461. [Google Scholar]
- Yanai, K.; Kawano, Y. Food image recognition using deep convolutional network with pre-training and fine-tuning. In Proceedings of the 2015 IEEE International Conference on Multimedia & ExpoWorkshops, ICMEWorkshops, Turin, Italy, 29 June–3 July 2015; IEEE Computer Society: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Min, W.; Liu, L.; Luo, Z.; Jiang, S. Ingredient-Guided Cascaded Multi-Attention Network for Food Recognition. In Proceedings of the 27th ACM International Conference on Multimedia, MM. ACM, Nice, France, 21–25 October 2019; pp. 1331–1339. [Google Scholar]
- Kagaya, H.; Aizawa, K.; Ogawa, M. Food Detection and Recognition Using Convolutional Neural Network. In Proceedings of the ACM International Conference on Multimedia, MM. ACM, Orlando, FL, USA, 7 November 2014; pp. 1085–1088. [Google Scholar]
- Horiguchi, S.; Amano, S.; Ogawa, M.; Aizawa, K. Personalized Classifier for Food Image Recognition. IEEE Trans. Multim. 2018, 20, 2836–2848. [Google Scholar] [CrossRef]
- Min, W.; Wang, Z.; Liu, Y.; Luo, M.; Kang, L.; Wei, X.; Wei, X.; Jiang, S. Large Scale Visual Food Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9932–9949. [Google Scholar] [CrossRef] [PubMed]
- Klasson, M.; Zhang, C.; Kjellström, H. A Hierarchical Grocery Store Image Dataset With Visual and Semantic Labels. In Proceedings of the IEEEWinter Conference on Applications of Computer Vision, WACV, Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: New York, NY, USA, 2019; pp. 491–500. [Google Scholar]
- Kawano, Y.; Yanai, K. FoodCam-256: A Large-scale Real-time Mobile Food RecognitionSystem employing High-Dimensional Features and Compression of Classifier Weights. In Proceedings of the ACM International Conference on Multimedia, MM. ACM, Orlando, FL, USA, 7 November 2014; pp. 761–762. [Google Scholar]
- Loshchilov, I.; Hutter, F. DecoupledWeight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019; Available online: https://openreview.net (accessed on 23 June 2021).
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetV2: Enhance Cheap Operation with Long-Range Attention. In Proceedings of the NeurIPS, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Input | Operator | Exp Ratio | Patch Size | Output Channel | Stride |
|---|---|---|---|---|---|---|
| Head | Conv2D | - | - | 2 | ||
| Block Group 1 | Inverted Residual | 1 | - | 2 | ||
| Inverted Residual | 1 | - | 1 | |||
| LP-ViT | - | - | ||||
| Block Group 2 | Inverted Residual | 1 | - | 2 | ||
| Inverted Residual | 1 | - | 1 | |||
| Inverted Residual | 3 | - | 1 | |||
| LP-ViT | - | - | ||||
| LP-ViT | - | - | ||||
| Block Group 3 | Inverted Residual | 3 | - | 2 | ||
| Inverted Residual | 3 | - | 1 | |||
| Inverted Residual | 3 | - | 1 | |||
| LP-ViT | - | - | ||||
| LP-ViT | - | - | ||||
| LP-ViT | - | - | ||||
| Block Group 4 | Inverted Residual | 6 | - | 2 | ||
| Inverted Residual | 2.5 | - | 1 | |||
| Inverted Residual | 2.5 | - | 1 | |||
| LP-ViT | - | - | ||||
| LP-ViT | - | - | ||||
| Block Group 5 | Inverted Residual | 6 | - | 2 | ||
| LP-ViT | - | - |
| Method | Top-1 Acc. | #Params | #FLOPs |
|---|---|---|---|
| ShuffleNetV2-0.5 [19] | 74.3% | 0.5 M | 41.6 M |
| EHFR–Net-0.5 | 89.4% | 0.8 M | 428.3 M |
| MobileViTv2-0.5 [39] | 87.0% | 1.1 M | 480.2 M |
| ShuffleNetV2-1.0 [19] | 78.0% | 1.4 M | 148.8 M |
| MobileNetV3-0.5 [23] | 82.4% | 1.5 M | 73.3 M |
| GhostNetV2-0.5 [50] | 81.2% | 1.7 M | 54.0 M |
| EHFR–Net-0.75 | 90.4% | 1.8 M | 981.9 M |
| MobileViTv2-0.75 [39] | 87.2% | 2.5 M | 1051.4 M |
| ShuffleNetV2-1.5 [19] | 80.3% | 2.6 M | 303.6 M |
| MobileNetV3-0.75 [23] | 85.5% | 2.8 M | 161.9 M |
| EHFR–Net-1.0 | 90.7% | 2.8 M | 1238.5 M |
| MobileNetV3-1.0 [23] | 86.2% | 4.3 M | 218.9 M |
| MobileViTv2-1.0 [39] | 87.6% | 4.4 M | 1843.4 M |
| EHFR–Net-1.25 | 91.1% | 4.5 M | 2104.5 M |
| EfficientNeT B0 [21] | 85.2% | 4.7 M | 566.9 M |
| GhostNetV2-1.0 [50] | 83.6% | 5.0 M | 176.9 M |
| ShuffleNetV2-2.0 [19] | 82.0% | 5.6 M | 596.4 M |
| MobileNetV3-1.25 [23] | 86.2% | 6.4 M | 366.8 M |
| EHFR–Net-1.0 | 91.3% | 6.4 M | 2985.5 M |
| MobileViTv2-1.25 [39] | 88.3% | 6.9 M | 2856.0 M |
| GhostNetV2-1.3 [50] | 84.8% | 7.8 M | 282.5 M |
| MobileNetV3-1.5 [23] | 86.5% | 8.6 M | 500.4 M |
| MobileViTv2-1.5 [39] | 88.6% | 9.9 M | 4089.3 M |
| EHFR–Net-2.0 | 91.5% | 11.1 M | 4787.4 M |
| GhostNetV2-1.6 [50] | 85.5% | 11.2 M | 415.0 M |
| MobileViTv2-1.75 [39] | 88.9% | 13.4 M | 5543.5 M |
| GhostNetV2-1.9 [50] | 85.7% | 15.3 M | 572.8 M |
| MobileViTv2-2.0 [39] | 89.5% | 17.5 M | 7218.3 M |
| LNAS–NET [16] | 75.9% | 1.8 M | - |
| LTBDNN(TD–192) [17] | 76.8% | 12.2 M | - |
| EHFR–Net-1.0 | 90.7% | 2.8 M | 1238.5 M |
| Method | Top-1 Acc. | #Params | #FLOPs |
|---|---|---|---|
| ShuffleNetV2-0.5 [19] | 74.3% | 0.5 M | 41.6 M |
| EHFR–Net-0.5 | 89.4% | 0.8 M | 428.3 M |
| MobileViTv2-0.5 [39] | 87.3% | 1.2 M | 480.2 M |
| ShuffleNetV2-1.0 [19] | 81.0% | 1.4 M | 148.9 M |
| MobileNetV3-0.5 [23] | 83.0% | 1.6 M | 73.4 M |
| GhostNetV2-0.5 [50] | 81.8% | 1.8 M | 54.1 M |
| EHFR–Net-0.75 | 91.0% | 1.8 M | 956.0 M |
| MobileViTv2-0.75 [39] | 88.0% | 2.5 M | 1051.4 M |
| ShuffleNetV2-1.5 [19] | 82.4% | 2.7 M | 303.7 M |
| EHFR–Net-1.0 | 91.3% | 2.8 M | 1210.3 M |
| MobileNetV3-0.75 [23] | 85.9% | 2.9 M | 162.0 M |
| MobileNetV3-1.0 [23] | 86.7% | 4.4 M | 219.0 M |
| EHFR–Net-1.25 | 91.7% | 4.5 M | 2066.5 M |
| MobileViTv2-1.0 [39] | 88.2% | 4.5 M | 1843.4 M |
| EfficientNeT B0 [21] | 83.6% | 4.8 M | 567.0 M |
| GhostNetV2-1.0 [50] | 84.7% | 5.1 M | 117.0 M |
| ShuffleNetV2-2.0 [19] | 83.8% | 5.7 M | 596.6 M |
| EHFR–Net-1.5 | 91.8% | 6.5 M | 2985.5 M |
| MobileNetV3-1.25 [23] | 86.9% | 6.5 M | 366.9 M |
| MobileViTv2-1.25 [39] | 87.9% | 6.9 M | 2856.1 M |
| GhostNetV2-1.3 [50] | 85.7% | 7.9 M | 282.5 M |
| MobileNetV3-1.5 [23] | 86.5% | 8.7 M | 500.4 M |
| EHFR–Net-1.75 | 91.7% | 8.8 M | 3891.4 M |
| MobileViTv2-1.5 [39] | 88.6% | 10 M | 4089.4 M |
| EHFR–Net-2.0 | 91.9% | 11.1 M | 4787.5 M |
| GhostNetV2-1.6 [50] | 86.2% | 11.3 M | 415.1 M |
| MobileViTv2-1.75 [39] | 89.1% | 13.5 M | 5543.5 M |
| GhostNetV2-1.9 [50] | 86.0% | 15.4 M | 572.9 M |
| MobileViTv2-2.0 [39] | 89.4% | 17.6 M | 7218.4 M |
| Method | Top-1 Acc. | #Params | #FLOPs |
|---|---|---|---|
| ShuffleNetV2-0.5 [19] | 74.3% | 0.5 M | 41.6 M |
| EHFR–Net-0.5 | 89.4% | 0.8 M | 428.3 M |
| MobileViTv2-0.5 [39] | 69.1% | 1.2 M | 465.9 M |
| ShuffleNetV2-1.0 [19] | 55.2% | 1.5 M | 149.0 M |
| MobileNetV3-0.5 [23] | 62.1% | 1.7 M | 73.5 M |
| EHFR–Net-0.75 | 71.5% | 1.8 M | 956.0 M |
| GhostNetV2-0.5 [50] | 61.1% | 1.9 M | 54.2 M |
| MobileViTv2-0.75 [39] | 69.8% | 2.6 M | 1051.5 M |
| ShuffleNetV2-1.5 [19] | 57.5% | 2.7 M | 303.7 M |
| EHFR–Net-1.0 | 71.6% | 2.9 M | 1210.4 M |
| MobileNetV3-0.75 [23] | 64.9% | 3.0 M | 162.1 M |
| MobileNetV3-1.0 [23] | 65.5% | 4.5 M | 219.0 M |
| MobileViTv2-1.0 [39] | 70.0% | 4.5 M | 1843.4 M |
| EHFR–Net-1.25 | 71.9% | 4.6 M | 2066.6 M |
| EfficientNet B0 [21] | 64.0% | 4.9 M | 567.1 M |
| GhostNetV2-1.0 [50] | 63.9% | 5.2 M | 177.1 M |
| ShuffleNetV2-2.0 [19] | 60.1% | 5.9 M | 596.7 M |
| EHFR–Net-1.5 | 72.3% | 6.5 M | 2941.3 M |
| MobileNetV3-1.25 [23] | 65.7% | 6.6 M | 367.0 M |
| MobileViTv2-1.25 [39] | 71.2% | 7.0 M | 2856.1 M |
| GhostNetV2-1.3 [50] | 65.0% | 8.0 M | 282.7 M |
| EHFR–Net-1.75 | 72.6% | 8.8 M | 3840.2 M |
| MobileNetV3-1.5 [23] | 67.1% | 8.8 M | 500.5 M |
| MobileViTv2-1.5 [39] | 71.2% | 10.0 M | 4089.5 M |
| EHFR–Net-2.0 | 72.7% | 11.2 M | 4731.2 M |
| GhostNetV2-1.6 [50] | 65.5% | 11.4 M | 415.2 M |
| MobileViTv2-1.75 [39] | 71.4% | 13.6 M | 5543.6 M |
| GhostNetV2-1.9 [50] | 66.1% | 15.5 M | 573.0 M |
| MobileViTv2-2.0 [39] | 71.5% | 17.7 M | 7218.5 M |
| Dataset | Ablation | Top-1 Acc. | #Params | #FLOPs |
|---|---|---|---|---|
| Food-101 | EHFR–Net-1.0 | 90.67% | 2.82 M | 1210.31 M |
| LP–ViT → MHA | 88.80% | 3.67 M | 6292.49 M | |
| w/o LP–ViT | 88.37% | 3.19 M | 1082.62 M | |
| w/o CNN | 87.81% | 2.89 M | 1667.64 M | |
| ANS → TNS | 87.95% | 4.52 M | 842.1 M | |
| Food-172 | EHFR–Net-1.0 | 91.38% | 2.84 M | 1210.33 M |
| LP–ViT → MHA | 89.66% | 3.70 M | 6292.51 M | |
| w/o LP–ViT | 90.05% | 3.21 M | 1082.64 M | |
| w/o CNN | 89.86% | 2.91 M | 1667.67 M | |
| ANS → TNS | 89.36% | 4.55 M | 842.15 M | |
| Food256 | EHFR–Net-1.0 | 71.30% | 2.87 M | 1210.36 M |
| LP–ViT → MHA | 69.28% | 3.72 M | 6292.54 M | |
| w/o LP–ViT | 68.27% | 3.24 M | 1082.67 M | |
| w/o CNN | 68.19% | 2.94 M | 1667.69 M | |
| ANS → TNS | 67.26% | 4.57 M | 842.18 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, G.; Min, W.; Zhu, X.; Xu, L.; Sun, Q.; Yang, Y.; Wang, L.; Jiang, S. A Lightweight Hybrid Model with Location-Preserving ViT for Efficient Food Recognition. Nutrients 2024, 16, 200. https://doi.org/10.3390/nu16020200
Sheng G, Min W, Zhu X, Xu L, Sun Q, Yang Y, Wang L, Jiang S. A Lightweight Hybrid Model with Location-Preserving ViT for Efficient Food Recognition. Nutrients. 2024; 16(2):200. https://doi.org/10.3390/nu16020200
Chicago/Turabian StyleSheng, Guorui, Weiqing Min, Xiangyi Zhu, Liang Xu, Qingshuo Sun, Yancun Yang, Lili Wang, and Shuqiang Jiang. 2024. "A Lightweight Hybrid Model with Location-Preserving ViT for Efficient Food Recognition" Nutrients 16, no. 2: 200. https://doi.org/10.3390/nu16020200
APA StyleSheng, G., Min, W., Zhu, X., Xu, L., Sun, Q., Yang, Y., Wang, L., & Jiang, S. (2024). A Lightweight Hybrid Model with Location-Preserving ViT for Efficient Food Recognition. Nutrients, 16(2), 200. https://doi.org/10.3390/nu16020200