
Accelerating the Classification of NOVA Food Processing Levels Using a Fine-Tuned Language Model: A Multi-Country Study



Abstract
:1. Introduction
2. Materials and Methods
2.1. Food Composition Databases
2.2. NOVA Food Classification System
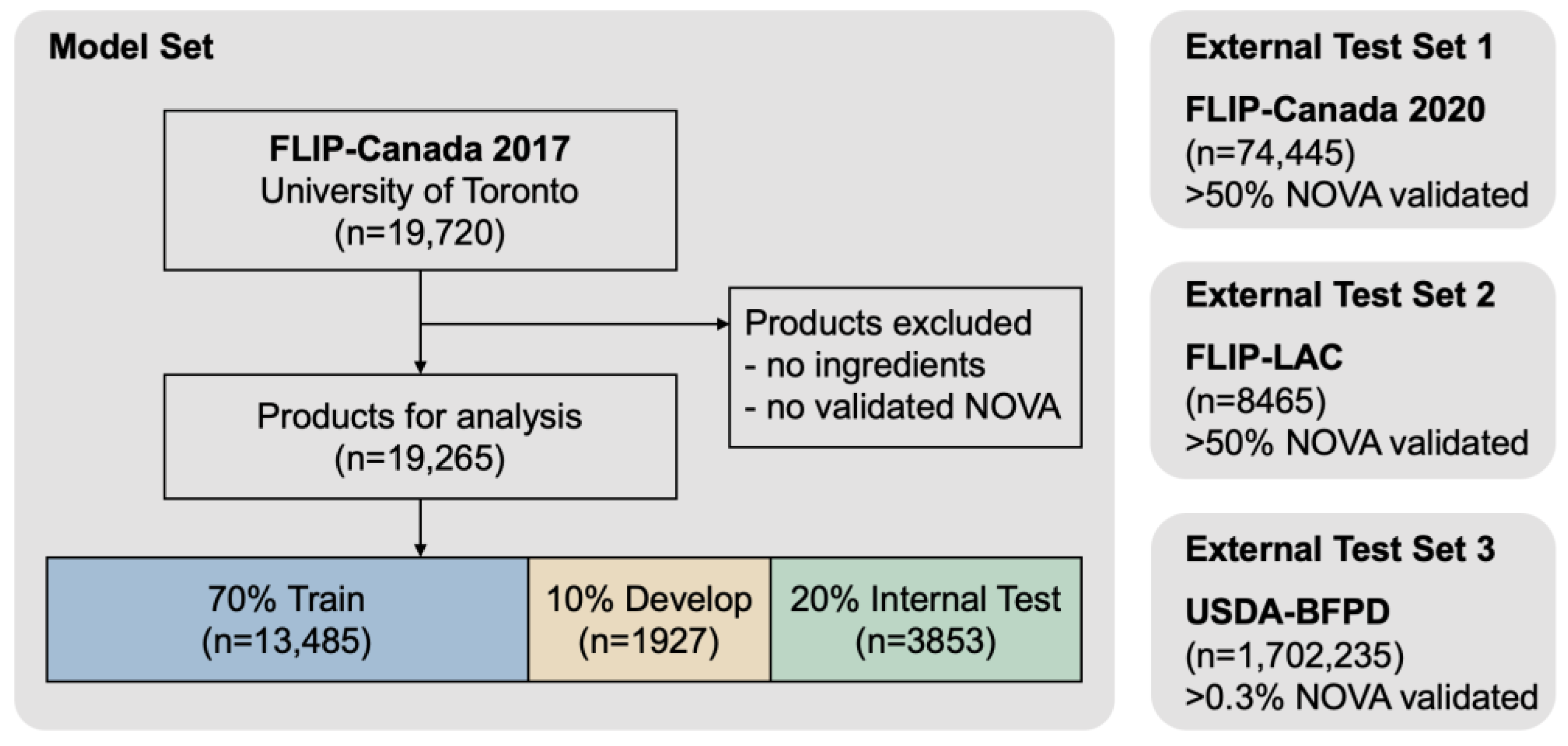
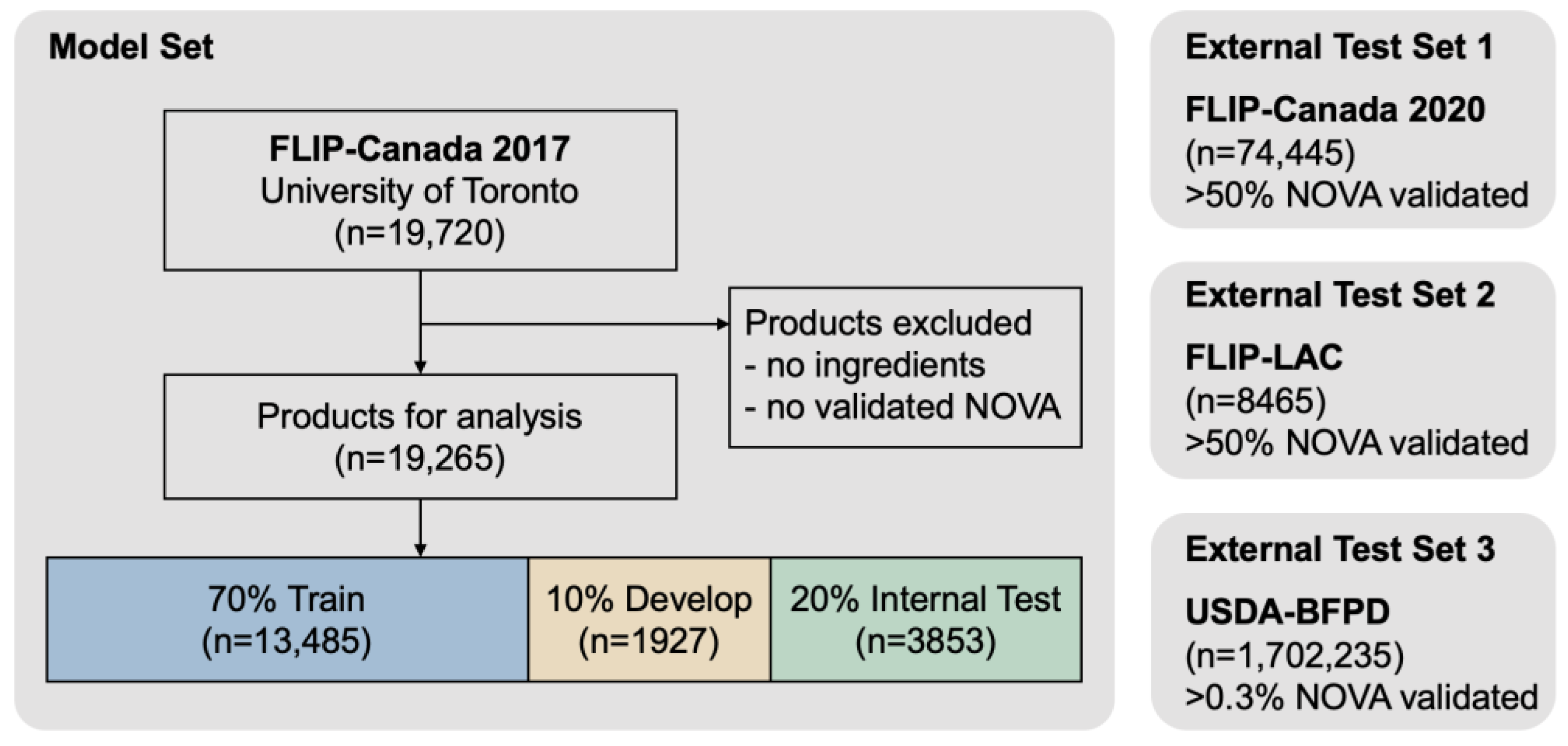
2.3. Data Preparation
2.4. Food Representations
2.5. Fine-Tuning Language Model
2.6. Statistical Analyses
3. Results
3.1. Different Machine Learning Algorithms Reached Moderate to High Accuracy in NOVA Food Processing Levels Classification
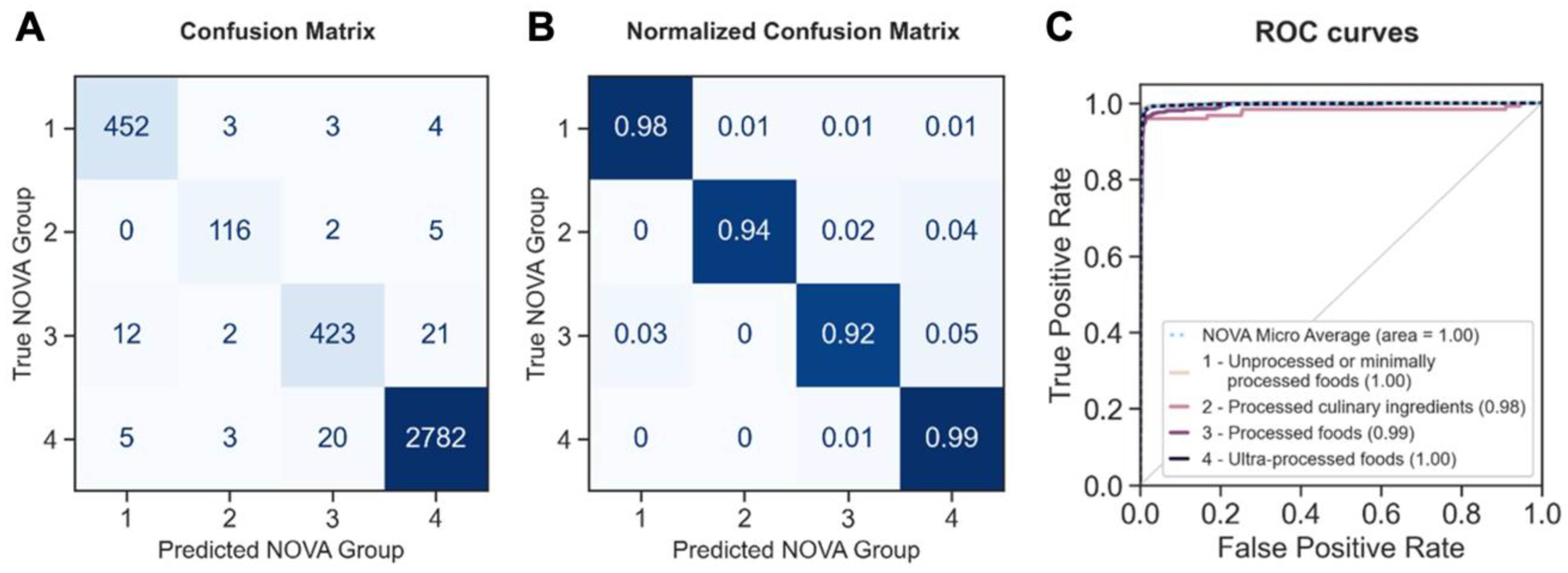
3.2. Fine-Tuned Language Model Performed Well in NOVA Food Processing Levels Classification
3.3. The Generalization Ability of the Fine-Tuned Language Model in NOVA Food Processing Levels Classification
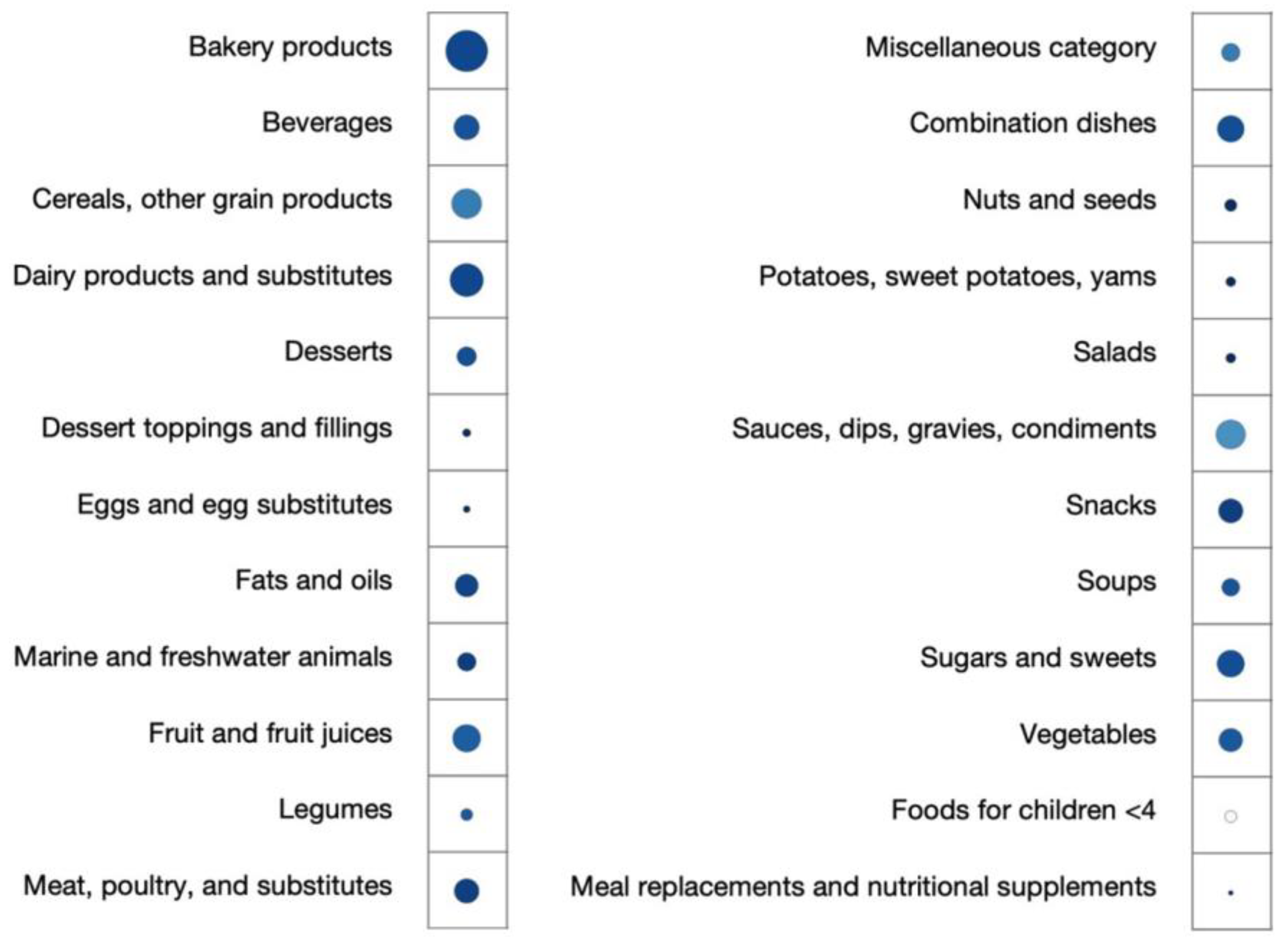
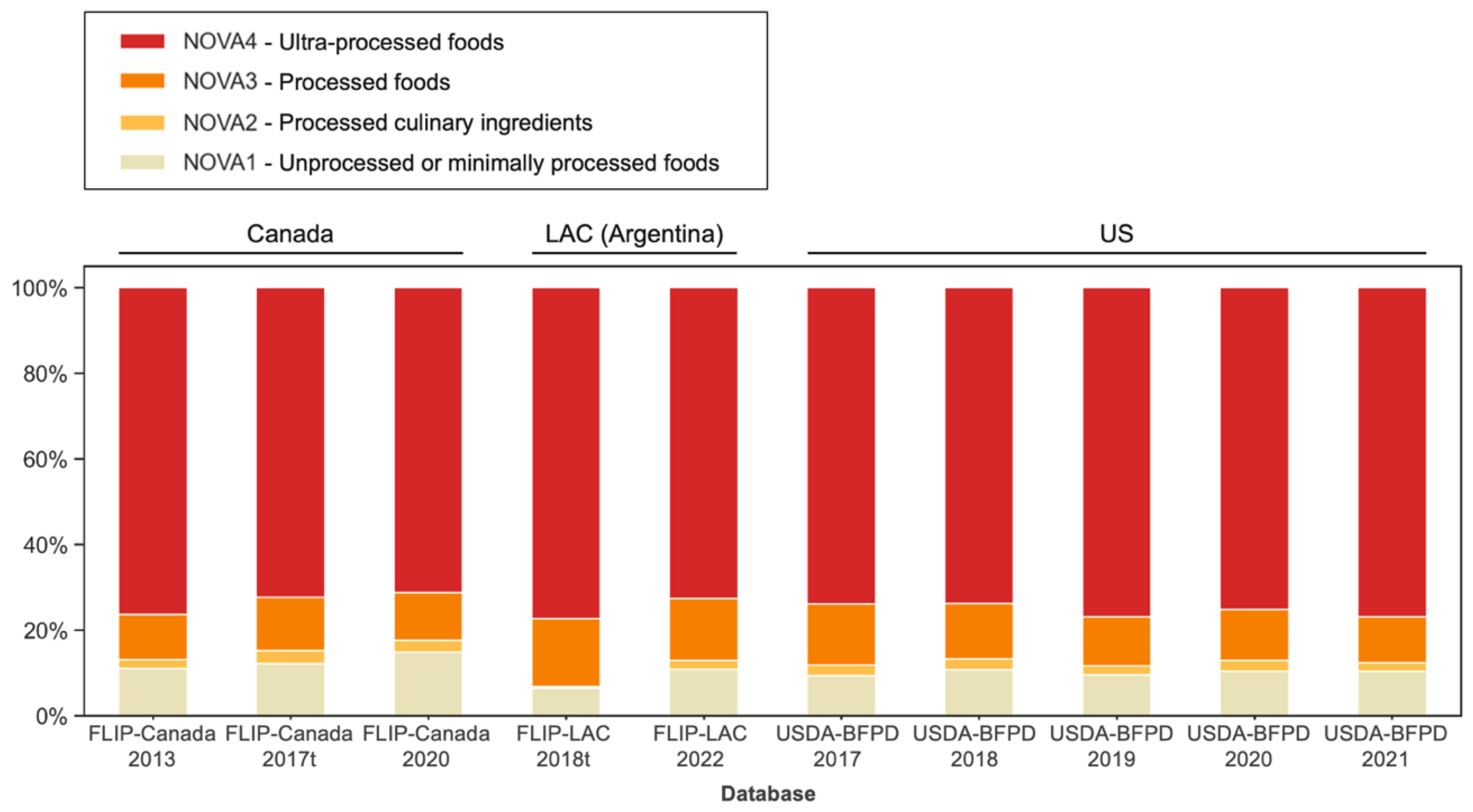
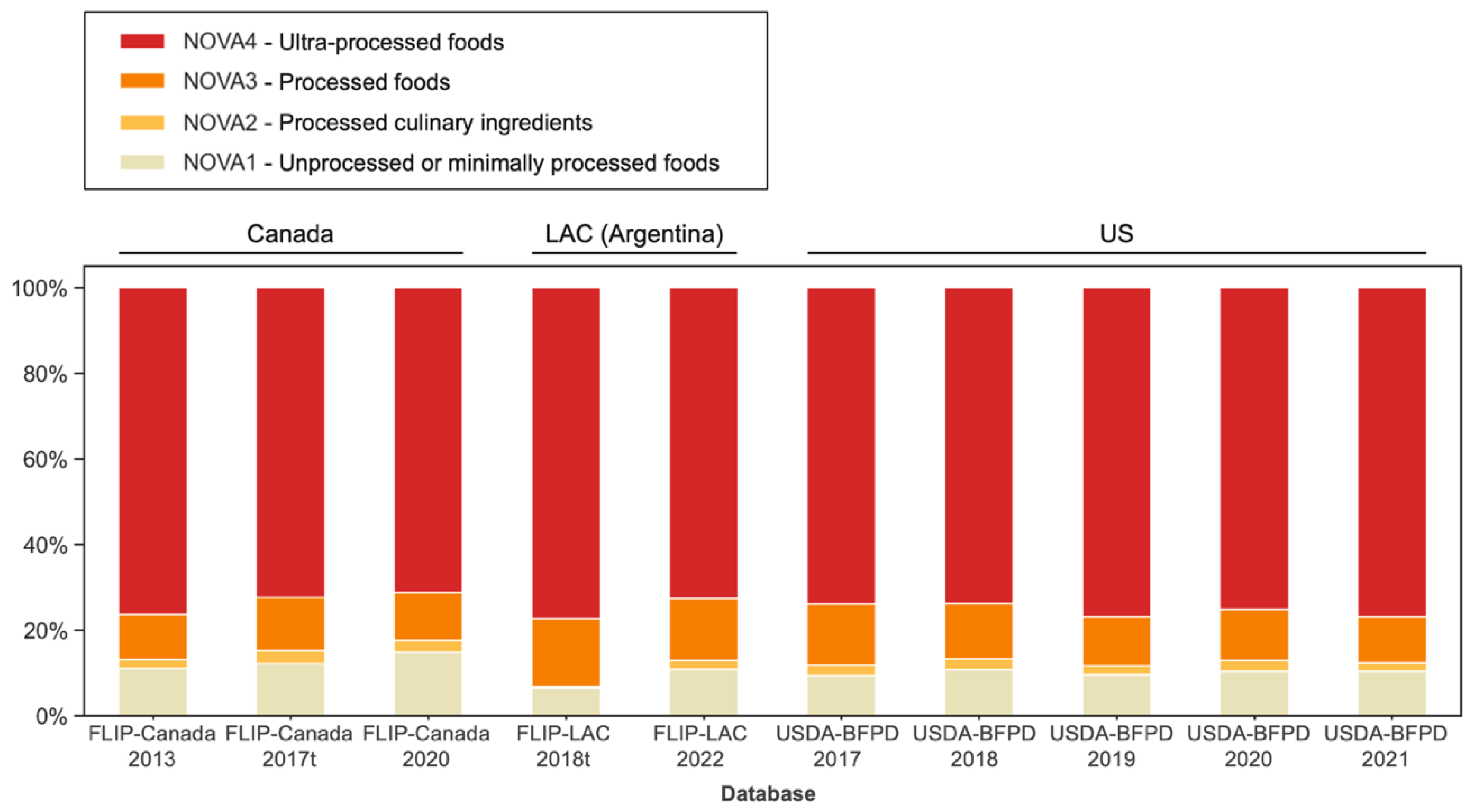
3.4. Using Fine-Tuned Language Model to Estimate NOVA Food Processing Levels in the Food Supply across Different Countries
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Monteiro, C.A.; Moubarac, J.C.; Cannon, G.; Ng, S.W.; Popkin, B. Ultra-processed products are becoming dominant in the global food system. Obes. Rev. 2013, 14, 21–28. [Google Scholar] [CrossRef] [PubMed]
- Marino, M.; Puppo, F.; Del Bo’, C.; Vinelli, V.; Riso, P.; Porrini, M.; Martini, D. A systematic review of worldwide consumption of ultra-processed foods: Findings and criticisms. Nutrients 2021, 13, 2778. [Google Scholar] [CrossRef] [PubMed]
- Askari, M.; Heshmati, J.; Shahinfar, H.; Tripathi, N.; Daneshzad, E. Ultra-processed food and the risk of overweight and obesity: A systematic review and meta-analysis of observational studies. Int. J. Obes. 2020, 44, 2080–2091. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhang, Z.; Yang, H.; Qiu, P.; Wang, H.; Wang, F.; Zhao, Q.; Fang, J.; Nie, J. Consumption of ultra-processed foods and health outcomes: A systematic review of epidemiological studies. Nutr. J. 2020, 19, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Elizabeth, L.; Machado, P.; Zinöcker, M.; Baker, P.; Lawrence, M. Ultra-processed foods and health outcomes: A narrative review. Nutrients 2020, 12, 1955. [Google Scholar] [CrossRef]
- Lane, M.M.; Davis, J.A.; Beattie, S.; Gómez-Donoso, C.; Loughman, A.; O’Neil, A.; Jacka, F.; Berk, M.; Page, R.; Marx, W. Ultraprocessed food and chronic noncommunicable diseases: A systematic review and meta-analysis of 43 observational studies. Obes. Rev. 2021, 22, e13146. [Google Scholar] [CrossRef]
- Delpino, F.M.; Figueiredo, L.M.; Bielemann, R.M.; da Silva, B.G.C.; Dos Santos, F.S.; Mintem, G.C.; Flores, T.R.; Arcêncio, R.A.; Nunes, B.P. Ultra-processed food and risk of type 2 diabetes: A systematic review and meta-analysis of longitudinal studies. Int. J. Epidemiol. 2021, 51, 1120–1141. [Google Scholar] [CrossRef]
- Suksatan, W.; Moradi, S.; Naeini, F.; Bagheri, R.; Mohammadi, H.; Talebi, S.; Mehrabani, S.; Hojjati Kermani, M.a.; Suzuki, K. Ultra-processed food consumption and adult mortality risk: A systematic review and dose–response meta-analysis of 207,291 participants. Nutrients 2021, 14, 174. [Google Scholar] [CrossRef]
- Koios, D.; Machado, P.; Lacy-Nichols, J. Representations of ultra-processed foods: A global analysis of how dietary guidelines refer to levels of food processing. Int. J. Health Policy Manag. 2022, 11, 2588. [Google Scholar] [CrossRef]
- Guías Alimentarias Para Chile. Ministerio de Salud-Chile. 2022. Available online: https://www.minsal.cl/wp-content/uploads/2022/12/guias_alimentarias_2022_2ed.pdf (accessed on 1 February 2022).
- Malaysian Dietary Guidelines 2020. National Coordinating Committee on Food and Nutrition. Ministry of Health Malaysia. 2021. Available online: https://hq.moh.gov.my/nutrition/wp-content/uploads/2021/07/Web%20MDG.pdf (accessed on 1 May 2021).
- Guias Alimentarias 2023 Para La Poblacion Mexicana. Gobierno de Mexico. 2023. Available online: https://www.gob.mx/promosalud/articulos/que-son-las-guias-alimentarias?idiom=es (accessed on 19 May 2023).
- Proposed Scientific Questions to Inform the Development of the Dietary Guidelines for Americans 2025–2030. Food and Nutrition Service. U.S. Department of Agriculture. 2023. Available online: https://www.fns.usda.gov/news-item/usda-0081.22 (accessed on 4 April 2022).
- Work Under Way—Scientific Questions. Dietary Guidelines for Americans. 2023. Available online: https://www.dietaryguidelines.gov/scientific-questions (accessed on 1 August 2023).
- Monteiro, C.A.; Cannon, G.; Levy, R.B.; Moubarac, J.-C.; Louzada, M.L.; Rauber, F.; Khandpur, N.; Cediel, G.; Neri, D.; Martinez-Steele, E. Ultra-processed foods: What they are and how to identify them. Public Health Nutr. 2019, 22, 936–941. [Google Scholar] [CrossRef]
- Monteiro, C.A.; Cannon, G.; Moubarac, J.-C.; Levy, R.B.; Louzada, M.L.C.; Jaime, P.C. The UN Decade of Nutrition, the NOVA food classification and the trouble with ultra-processing. Public Health Nutr. 2018, 21, 5–17. [Google Scholar] [CrossRef] [PubMed]
- Ardisson Korat, A.V.; Willett, W.C.; Hu, F.B. Diet, lifestyle, and genetic risk factors for type 2 diabetes: A review from the Nurses’ Health Study, Nurses’ Health Study 2, and Health Professionals’ Follow-up Study. Curr. Nutr. Rep. 2014, 3, 345–354. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.; Schermel, A.; Lee, J.; Weippert, M.; Franco-Arellano, B.; L’Abbé, M. Development of the Food Label Information Program: A Comprehensive Canadian Branded Food Composition Database. Front. Nutr. 2022, 8, 825050. [Google Scholar] [CrossRef] [PubMed]
- Ma, P.; Li, A.; Yu, N.; Li, Y.; Bahadur, R.; Wang, Q.; Ahuja, J.K. Application of machine learning for estimating label nutrients using USDA Global Branded Food Products Database (BFPD). J. Food Compos. Anal. 2021, 100, 103857. [Google Scholar] [CrossRef]
- Menichetti, G.; Ravandi, B.; Mozaffarian, D.; Barabási, A.-L. Machine learning prediction of the degree of food processing. Nat. Commun. 2023, 14, 2312. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Xie, Q.; Pei, J.; Chen, Z.; Tiwari, P.; Li, Z.; Fu, J. Pre-trained language models in biomedical domain: A systematic survey. ACM Comput. Surv. 2023. Available online: https://dl.acm.org/doi/pdf/10.1145/3611651 (accessed on 1 August 2023). [CrossRef]
- Ziems, C.; Held, W.; Shaikh, O.; Chen, J.; Zhang, Z.; Yang, D. Can Large Language Models Transform Computational Social Science? arXiv 2023, arXiv:2305.03514. Available online: https://arxiv.org/pdf/2305.03514.pdf (accessed on 12 April 2023).
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A pretrained language model for scientific text. arXiv 2019, arXiv:1903.10676. Available online: https://arxiv.org/pdf/1903.10676.pdf (accessed on 10 September 2019).
- Hu, G.; Ahmed, M.; L’Abbé, M.R. Natural language processing and machine learning approaches for food categorization and nutrition quality prediction compared to traditional methods. Am. J. Clin. Nutr. 2023, 117, 553–563. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. Available online: https://arxiv.org/pdf/1810.04805.pdf (accessed on 24 May 2019).
- U.S. Department of Agriculture (USDA), A.R.S. FoodData Central: USDA Global Branded Food Products Database. 2023. Available online: https://data.nal.usda.gov/dataset/usda-branded-food-products-database (accessed on 3 February 2023).
- Franco-Arellano, B.; Arcand, J.; Kim, M.A.; Schermel, A.; L’Abbé, M.R. Progress towards eliminating industrially produced trans-fatty acids in the Canadian marketplace, 2013–2017. Public Health Nutr. 2020, 23, 2257–2267. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Steele, E.; Khandpur, N.; Batis, C.; Bes-Rastrollo, M.; Bonaccio, M.; Cediel, G.; Huybrechts, I.; Juul, F.; Levy, R.B.; da Costa Louzada, M.L. Best practices for applying the Nova food classification system. Nat. Food 2023, 4, 445–448. [Google Scholar] [CrossRef] [PubMed]
- Vergeer, L.; Veira, P.; Bernstein, J.T.; Weippert, M.; L’Abbé, M.R. The Calorie and Nutrient Density of More-Versus Less-Processed Packaged Food and Beverage Products in the Canadian Food Supply. Nutrients 2019, 11, 2782. [Google Scholar] [CrossRef]
- Qasim, R.; Bangyal, W.H.; Alqarni, M.A.; Ali Almazroi, A. A fine-tuned BERT-based transfer learning approach for text classification. J. Healthc. Eng. 2022, 2022, 3498123. [Google Scholar] [CrossRef] [PubMed]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. Available online: https://arxiv.org/pdf/2008.05756.pdf (accessed on 13 August 2020).
- Braesco, V.; Souchon, I.; Sauvant, P.; Haurogné, T.; Maillot, M.; Féart, C.; Darmon, N. Ultra-processed foods: How functional is the NOVA system? Eur. J. Clin. Nutr. 2022, 76, 1245–1253. [Google Scholar] [CrossRef]
- Petrus, R.R.; do Amaral Sobral, P.J.; Tadini, C.C.; Gonçalves, C.B. The NOVA classification system: A critical perspective in food science. Trends Food Sci. Technol. 2021, 116, 603–608. [Google Scholar] [CrossRef]
- Baldridge, A.S.; Huffman, M.D.; Taylor, F.; Xavier, D.; Bright, B.; Van Horn, L.V.; Neal, B.; Dunford, E. The healthfulness of the US packaged food and beverage supply: A cross-sectional study. Nutrients 2019, 11, 1704. [Google Scholar] [CrossRef]
- Pagliai, G.; Dinu, M.; Madarena, M.; Bonaccio, M.; Iacoviello, L.; Sofi, F. Consumption of ultra-processed foods and health status: A systematic review and meta-analysis. Br. J. Nutr. 2021, 125, 308–318. [Google Scholar] [CrossRef]
- Polsky, J.Y.; Moubarac, J.-C.; Garriguet, D. Consumption of ultra-processed foods in Canada. Health Rep. 2020, 31, 3–15. [Google Scholar]
- Hamel, V.; Nardocci, M.; Flexner, N.; Bernstein, J.; L’Abbé, M.R.; Moubarac, J.-C. Consumption of Ultra-Processed Foods Is Associated with Free Sugars Intake in the Canadian Population. Nutrients 2022, 14, 708. [Google Scholar] [CrossRef] [PubMed]
- Juul, F.; Parekh, N.; Martinez-Steele, E.; Monteiro, C.A.; Chang, V.W. Ultra-processed food consumption among US adults from 2001 to 2018. Am. J. Clin. Nutr. 2022, 115, 211–221. [Google Scholar] [CrossRef] [PubMed]
- Zapata, M.E.; Cediel, G.; Arrieta, E.; Rovirosa, A.; Carmuega, E.; Monteiro, C.A. Ultra-processed foods consumption and diet quality among preschool children and women of reproductive age from Argentina. Public Health Nutr. 2022, 1–10. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature * | Model † | NOVA Classification Performance | ||
|---|---|---|---|---|
| Accuracy | Balanced Accuracy | F1 Score | ||
| Structured data | XGBoost | 0.890 | 0.797 | 0.882 |
| Bag-of-words | XGBoost | 0.970 | 0.938 | 0.970 |
| Pre-trained embeddings | XGBoost | 0.940 | 0.882 | 0.940 |
| Fine-tuned language models | BERT-Base | 0.978 | 0.955 | 0.978 |
| DistilBERT-Base | 0.979 | 0.958 | 0.979 | |
| MPNet-Base | 0.979 | 0.954 | 0.979 | |
| all-MiniLM-L6 | 0.979 | 0.956 | 0.979 | |
| multi-qa-MiniLM-L6-cos | 0.979 | 0.959 | 0.979 | |
| Method * | Database † | NOVA Classification Performance | ||
|---|---|---|---|---|
| Accuracy | Balanced Accuracy | F1 Score | ||
| Structured data | FLIP-Canada | 0.872 | 0.737 | 0.862 |
| Bag-of-words | FLIP-Canada | 0.937 | 0.870 | 0.936 |
| Pre-trained embedding | FLIP-Canada | 0.921 | 0.831 | 0.917 |
| Fine-tuned model | FLIP-Canada | 0.941 | 0.896 | 0.940 |
| Structured data | FLIP-LAC | 0.857 | 0.726 | 0.850 |
| Bag-of-words | FLIP-LAC | 0.863 | 0.681 | 0.858 |
| Pre-trained embedding | FLIP-LAC | 0.825 | 0.567 | 0.808 |
| Fine-tuned model | FLIP-LAC | 0.891 | 0.654 | 0.889 |
| Structured data | USDA-BFPD | 0.806 | 0.647 | 0.788 |
| Bag-of-words | USDA-BFPD | 0.919 | 0.832 | 0.918 |
| Pre-trained embedding | USDA-BFPD | 0.900 | 0.766 | 0.892 |
| Fine-tuned model | USDA-BFPD | 0.948 | 0.881 | 0.947 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, G.; Flexner, N.; Tiscornia, M.V.; L’Abbé, M.R. Accelerating the Classification of NOVA Food Processing Levels Using a Fine-Tuned Language Model: A Multi-Country Study. Nutrients 2023, 15, 4167. https://doi.org/10.3390/nu15194167
Hu G, Flexner N, Tiscornia MV, L’Abbé MR. Accelerating the Classification of NOVA Food Processing Levels Using a Fine-Tuned Language Model: A Multi-Country Study. Nutrients. 2023; 15(19):4167. https://doi.org/10.3390/nu15194167
Chicago/Turabian StyleHu, Guanlan, Nadia Flexner, María Victoria Tiscornia, and Mary R. L’Abbé. 2023. "Accelerating the Classification of NOVA Food Processing Levels Using a Fine-Tuned Language Model: A Multi-Country Study" Nutrients 15, no. 19: 4167. https://doi.org/10.3390/nu15194167
APA StyleHu, G., Flexner, N., Tiscornia, M. V., & L’Abbé, M. R. (2023). Accelerating the Classification of NOVA Food Processing Levels Using a Fine-Tuned Language Model: A Multi-Country Study. Nutrients, 15(19), 4167. https://doi.org/10.3390/nu15194167